STAT6000 Statistics for Public Health Assignment Help
Assignment Brief
Length 2000
Learning Outcomes:
This assessment addresses the following learning outcomes:
1. Understand key concepts in statistics and the way in which both descriptive and inferential statistics are used to measure, describe and predict health and illness and the effects of interventions.
2. Apply key terms and concepts of statistics for assignment help including; sampling, hypothesis testing, validity and reliability, statistical significance and effect size.
3. Interpret the results of commonly used statistical tests presented in published literature.
Submission Due Sunday following the end of Module 4 at 11:55pm AEST/AEDT*
Weighting - 30%
Total Marks - 100 marks
Instructions:
This assessment requires you to read two articles and answer a series of questions in no more than 2000 words. Most public health and wider health science journals report some form of statistics. The ability to understand and extract meaning from journal articles, and the ability to critically evaluate the statistics reported in research papers are fundamental skills in public health.
Read the Riordan, Flett, Hunter, Scarf and Conner (2015) research article and answer the following
questions:
1. This paper presents two hypotheses. State the null and alternative hypothesis for each one, and describe the independent and dependent variables for each hypothesis.
2. What kind of sampling method did they use, and what are the advantages and disadvantages of recruiting participants in this way?
3. What are the demographic characteristics of the people in the sample? Explain by referring to the descriptive statistics reported in the paper.
4. What inferential statistics were used to analyze data in this study, and why?
5. Regarding the relationship between FoMO scores, weekly drinks, drinking frequency, drinking quantity, and BYAACQ. Answer the following questions;
a) Which variable had the weakest association with FoMO score?
b) Which variable had the strongest association?
c) Was the association (weakest and strongest) statistically significant?
d) What are the correlation coefficients for both associations (weakest and strongest)?
e) State how much variation in weekly drinks, drinking frequency, drinking quantity, and BYAAC is attributed toFoMO scores.
f) What variables are controlled in the correlation analysis test?
6. How representative do you think the sample is of the wider population of college students in New Zealand? Explain why.
Paper 2: Wong, M. C., S., Leung, M. C., M., Tsang, C. S., H., . . . Griffiths, S. M. (2013). The rising tide
of diabetes mellitus in a Chinese population: A population-based household survey on 121,895
persons. International Journal of Public Health, 58(2), 269-276. Retrieved from:
http://dx.doi.org.ezproxy.laureate.net.au/10.1007/s00038-012-0364-y
Read the Wong et. al. (2014) paper and answer the following questions:
1. Describe the aims of the study. Can either aim be restated in terms of null and alternative hypotheses? Describe these where possible.
2. What are the demographic characteristics of the people in the sample? Explain by referring to the descriptive statistics reported in the paper.
3. What inferential statistics were used to analyze data in this paper, and why?
4. What did the researchers find when they adjusted the prevalence rates of diabetes for age and sex?
5. Interpret the odds ratios for self-reported diabetes diagnosis to explain who is at the greatest risk of diabetes.
6. What impact do the limitations described by the researchers have on the extent to which the results can be trusted, and why?
Assessment Criteria
• Knowledge of sampling methods, and research and statistical concepts 20%
• Interpretation of research concepts, statistical concepts and reported results, demonstrating applied knowledge and understanding 40 %
• Critical analysis of research elements including sampling, results and limitations 30%
• Academic writing (clarity of expression, correct grammar and punctuation, correct word use) and accurate use of APA referencing style 10%
Solution
Riordan, Flett, Hunter, Scarf and Conner (2015) research article answers:

Answer:
Hypothesis 1:
Null hypothesis: H0: Students’ alcohol consumption frequency was not dependent on FoMO score.
Alternate hypothesis: HA: Students’ with higher FoMO scores consumed increased amount of alcohol compared to those with lower FoMO scores.
Independent Variable: Alcohol consumption frequency of the participants of the study was considered assignment writing-point psychometric scale FoMO (“Fear of missing out”) was considered as the dependent variable. A variation between prevalent apprehensions of the participants regarding engagement in social engagements was measured using the FoMO.
Hypothesis 2:
Null hypothesis: H0: There was no relation between FoMO score and alcohol-related consequences.
Alternate hypothesis: HA: Students with higher FoMO score will come across more alcohol-related consequences compared to those with lower in FoMO.
Independent Variable: Alcohol related consequences measured using B-YAACQ scale, which assessed negative impacts of alcohol drinking for last three months.
Dependent Variable: The 10-point psychometric scale FoMO (“Fear of missing out”) was considered as the dependent variable.

Answer:
Sampling Technique: The research analyzed two studies where data was collected from the University of Otago, Dunedin. The first study was a cross sectional study where data from 182 students was collected in a convenience sampling methodology. Study 2 had a research methodology of ‘daily diary study’, where 262 participants were recruited from psychology classes.
Advantage: Convenience samples are an economical way of collecting data. It doesn't take much effort and money for initiate a convenience sampling methodology. As, in the present study survey link was posted on a departmental page where students can vote online. Therefore, it is one of the most economical options for the collection of data in the study that also saves time while gathering information. This is also useful as an intervention to collect feedback from hesitant participants as one can contact people about specific questions related to the study within minutes while using this method. Surveys can get partners to help provide more information about a person's demographic profile so that normalization can be created in a large group in the future.
Disadvantage: Information received from the study using convenient sampling may not represent characteristics of the general population. Therefore, conclusions based on the collected data may not provide information about the entire Otage population. Moreover, it was difficult to know whether some participants provided incorrect information or not. In future studies, it also becomes difficult to replicate the results due to nature of the collected data from the convenience sampling. Again, such data collected fails to show differences that may exist between multiple subgroups is one of the limitations of the present study which fails to differentiate between FoMO scores of men and women.

Answer:
Age, gender, and ethnicity are the three demographic characteristic details available in the paper. Explanation: Among 182 participants in the study 1, 78.6% were female participants. All of the study subjects were aged between 18-25 years with an average age of 19.4 years and a standard deviation of 1.4 years. Ethnicity wise categorization revealed that the sample was predominantly New Zealand European origin with presence of 80.8%. Rest of them was Asian (3.8%), Maori or Pacific Islander (6.0%), or belonged to other (7.7%) ethnic groups. A larger sample of 262 students participated in study 2, where 75.3% were female. The age bracket was 18-25 years with average of 19.6 years and a standard deviation of 1.6 years. Predominant presence of New Zealand European descent was noted (76%), where 12.2% were Asian, 7.2% were Maori or Pacific Islander, and 4.6% from other ethnicities.

Answer:
Inferential Tests: Two inferential statistics were used for testing the hypotheses. An independent t-test was administered to compare frequency of alcohol consumption between men and women. Alongside, Pearson’s correlation test was used to assess the relation between FoMO scores, alcohol consumption frequency and negative effects of alcohol consumption measured with B-YAACQ scale.
Reason of Use: An independent t-test was used to compare average drinking frequencies between male and female students by comparing their average drinking frequencies together with the standard deviations.
Pearson’s correlation coefficient was used to find the pairwise relation between FoMOs mean, weekly frequency of drinks, drinking quantity, drinking frequency, and B-YAACQ scale (Riordan et al., 2015).

Answer:
In study 1, weekly drinks had the weakest relation with FoMO score. In study 2, drinking frequency had the weakest relation with FoMO score.

Answer:
In both the studies, B-YAACQ scale score had the strongest relationship with FoMO score.
Answer:
The weakest associations were not statistically significant, whereas the strongest relationship between B-YAACQ scale score and FoMO score was statistically significant.

Answer:
Study 1:
The correlation coefficient between Weekly drinks with FoMO score was -0.014 (weakest)
The correlation coefficient between B-YAACQ scale score and FoMO score was 0.249 (strongest)
Study 2:
The correlation coefficient between drinking frequency with FoMO score was 0.092 (weakest)
The correlation coefficient between B-YAACQ scale score and FoMO score was 0.301(strongest)

Answer:
Overall, FoMOs score was not associated to the amount and frequency of weekly consumption of alcohol. In Study 1, there was no link between the average amount of FoMOs and alcohol. However, in study 2, there was a significant association between drinking session quantity and the FoMOs scores. FoMO scores impacted drinking session quantity with a 2.8% variance in Study 2, corresponding to Cohen's d ("small" effect) of 0.339. In addition, in both studies, association of FoMOs with alcohol-related higher number of severe negative consequences over the past three months is also a major concern. In both the studies, the amount negative alcohol outcomes varied by 6.2% and 9.1% was due to FoMOs, corresponding to 0.514 and 0.631 Cohen d (moderate effects).

Answer:
Age and gender of the participants were the two controlled variables in the correlation analysis.

Answer:
All the participants belonged to the age group of 18-25 years that indeed can represent wider undergraduate population of New Zealand universities. However, the age group seems inadequate to represent graduate students from universities.
Reason:
The experimental data were collected from undergraduate college students of the University of Otago, Dunedin (New Zealand). The first study used cross-sectional study with convenience sampling to include 182 students as participants, and the second study went with daily diary study including 262 participants. The convenience sampling technique used to collect data also indicates possible presence of falsified data. Hence, sample of the present study is representative of wider undergraduate population of colleges in New Zealand. However, the wider representation of all the students from the entire nation seems not possible using the sample of this study.
Wong et al (2013) research article answers:

Answer:
Primary objective of the studied paper was to assess the generality of results found from analysing the effect of age, household income, and sex on diabetes prevalence among 121,895 participants representing entire Hong Kong population. The survey was conducted in 2001, 2002, 2005, and 2008 to evaluate results across a period of 8 years. The entire sample was stratified in two strata based on gender of the participants (Wong et al., 2013).
First Objective was to assess the effect of increase in age on diabetes prevalence among the participants.
Null hypothesis: H0: There existed no association between increase in age and diabetes prevalence.
Alternate hypothesis: H0: There existed statistically significant association between increase in age and diabetes prevalence (0-39 was referent age group).
Second Objective was to assess the effect of low household income on diabetes prevalence among the participants.
Null hypothesis: H0: There existed no association between low household income and diabetes prevalence.
Alternate hypothesis: H0: There existed statistically significant association between low household income and diabetes prevalence (participants earning above $ 50,000 referent income group).

Answer:
Diabetes prevalence of 121,895 people across 2001, 2002, 2005, and 2008 was collected with demographic information regarding their age, household income, and gender. The sample consisted of 103,367 adult participants with age of 15 years and more. The average age of participants in the sample was calculated to be 38.2 years.
Information on gender of 121,895 participants revealed a balances presence of both the genders with females (N = 61, 831, 50.2%) being just greater in number. Household income (HK dollars) of sample participants was categorised in four categories (≥ 50,000, 25,000-49,999, 10,000-24,999, and ≤ 9,999). Presence of 10,000-24,999 income group of participants was the highest (N = 50,648, 42.4%), followed by 10,000-24,999 income group (N = 32,748, 27.4%), ≤ 9,999 (N = 23,578, 19.7%), and ≥ 50,000 (N = 12,452, 10.4%).
Sample was categorized according to age (years) in eight groups (< 15, 15-24, 25-34, 35-44, 45-54, 55-64, 65-74, and ≥ 75). Among 103,367 adult participants (≥ 15), 13.8% (N = 16, 834) belonged to age group of 15-24, 14.6% (N = 17,751) to age group of 25-34, 18.2% (N = 22,206) to age group of 35-44, 16.4% (N = 20,033) to age group of 15-24, 9.2% (N = 11,179) to age group of 15-24, and a total of 12.6% (N = 15,364) belonged to age groups of 65-74, and ≥ 75.

Answer:
Inferential analysis for evaluating the impact of age and income on diabetes prevalence across years was Binary Logistic Regression. In the constructed model age and groups were adjusted for better comparison. The age group of 0-39 years was the referent, whereas income group of ‘≥ 50,000’ was considered as the referent in the regression model. A multivariate regression model was also used to assess the independent association between diabetes prevalence and participants’ demographic details.
Initially, use of multivariate regression model indicated the causal relation and association between diabetes and demographic factors. Binary Logistic Regression models are generally used where the dependent variable has two categories. The linear regression model fails to assess the impact of predictors on two different categories of an outcome variable. The odd ratios in the Binary Logistic regression models display the exact relation with the predictor, especially with reference to age and income referent categories.
Answer:
The results in the Binary Logistic Regression model were statistically significant when age and sex were adjusted for measuring diabetes prevalence. Two separate regression models were constructed based on gender, and in each model age groups were reorganized to better comparison of diabetes prevalence. Importantly, the study also considered 2001 as base year or referent year to compare the results of 2005 and 2008.
Initially, females were noted to be (31.8%, 2005; 69.3%, 2008) have higher diabetes prevalence compared to that of the males (27.8%, 2005; 47.9%, 2008). But, when adjusted for sex no significant difference in diabetes prevalence was noted between male and females. Also, significantly increasing diabetes prevalence was noted for lower household income group when compared to highest income group.
Answer:
Adjusted Odd Ratio (AOR) for sex and age were evaluated from the Logistic Regression Model. Age adjusted groups comparison revealed that people aged between 40 and 65 years (AOR = 32.21, 95% CI 20.6–50.4, p < 0.001) were significantly at higher risk of diabetes prevalence compared to the referent age group of 0-39 years. Notably, people aged over 65 years were 120 times more associated (AOR = 120.1, 95% CI 76.6–188.3, p < 0.001) to diabetes compared to referent group.
Monthly household income category of 25,000-49,999 (AOR = 1.39, 95% CI 1.04-1.86, p < 0.05), 10,000-24,999 (AOR = 1.58, 95% CI 1.2-2.07, p < 0.001), and ≤ 9,999 (AOR = 2.19, 95% CI 1.66-2.88, p < 0.001) were all significantly at a higher risk of association with diabetes compared to highest income group (≥ 50,000), especially the lowest income group had almost two-fold chance of diabetes in such comparison.
Answer:
The coefficient of determination in the Binary Logistic Regression model was R2 = 0.198, implying that adjusted variables were able to explain 19.8% variation in diabetes prevalence. Hence, search of other predictors of diabetes prevalence, such as eating habit, family history, and affinity towards sugar and carb would have been beneficial.
Also, it has to be noted that the sample data was collected from self-reported survey of Chinese people. From previous literatures, it can be illustrated that most of the people in China are ignorant about preventive diabetes check-up (Yang et. al., 2010). Therefore, the self-reported data could have been erroneous and skewed. Generalization of the statistical analyses of the study could be a terrible mistake.
References
Riordan, B. C., Flett, J. A., Hunter, J. A., Scarf, D., & Conner, T. S. (2015). Fear of missing out (FoMO): The relationship between FoMO, alcohol use, and alcohol-related consequences in college students. Annals of Neuroscience and Psychology, 2(7), 1-7.
Wong, M. C., Leung, M. C., Tsang, C. S., Lo, S. V., & Griffiths, S. M. (2013). The rising tide of diabetes mellitus in a Chinese population: a population-based household survey on 121,895 persons. International journal of public health, 58(2), 269-276.
Yang, W., Lu, J., Weng, J., Jia, W., Ji, L., Xiao, J., ... & Zhu, D. (2010). Prevalence of diabetes among men and women in China. New England Journal of Medicine, 362(12), 1090-1101.
BEO1106 Business Statistics Assignment Sample
Introduction
The price of a property can be determined by a number of factors (in addition to the market
trend). These factors may include (but not the least): The location, the land size, the size of the built area, the building type, the property type, number of rooms, number of bathroom and toilets, swimming pool, tennis court and so on.
The sample data you collected for your assignment contain the following variables:
V1 = Region where property is located (1 = North, 2 = West, 3 = East, 4 = Central)
V2 = Property type (0 = Unit, 1 = House)
V3 = Sale result (1 = Sold at auction, 2 = Passed-in, 3 = Private sale, 4 = Sold before auction).
Note that a blank cell for this variable indicates that the property did not sell.
V4 = Building type (1 = Brick, 2 = Brick veneer, 3 = Weatherboard, 4 = Vacant land)
V5 = Number of rooms
V6 = Land size (Square meters)
V7 = Sold Price ($000s)
V8 = Advertised Price ($000s).
Requirement
In relation to the Simple Regression topic of Business Statistics, for this Case Study, you are
required to conduct a regression analysis to estimate the relation between Number of Rooms and Advertised Price of properties in Melbourne.
Instruction
You need to prepare a sample data using the Number of Rooms and the Advertised Price variables. You may find that V5 (Number of Rooms) variable has some missing observations in your sample. In order for Excel to estimate a regression equation, Excel requires a balanced data set. This means that both dependent variables and independent variables must have the same (balanced) number of observations in the data set. To balance the data set, we have to remove the observations which contain missing data. Refer to the steps in the Excel file Regression Estimation example for Case Study.xlsx to assist you to construct your balanced sample data set for the regression analysis.
Task 1
In the Answer Sheet provided, name the dependent variable (Y) and the independent variable (X). Provide a brief explanation for assignment help to support your choice.
Task 2
In a sentence, explain whether you expect a positive or a negative relation between the X and the Y variables.
Task 3
Use Excel to produce a scatterplot using the independent variable for the horizontal (X) axis and the dependent variable as the vertical (Y) axis. Copy and paste the scatterplot to the Answer Booklet.
Hint: Follow the graph presentation (in Step 5, Regression Estimation example for Case
Study.xlsx).
Note:Title of the scatterplot and the labels for axes will account for 0.5 mark for each.
Task 4
Follow the Excel procedure (select Data / Data Analysis / Regression) outlined on seminar note Slide 16, using the X variable and the Y variable you nominated in Task 1, generate regression estimation output tables. Copy the Regression Statistics and Coefficients tables (refer to Slide 27 and Slide 28) to the Answer Booklet.
Task 5
Refer to the Regression Statistics table in Task 4, briefly describe the strength of the correlation between X and Y variables. Ensure your statement is supported by the statistic figure from the table.
Task 6
Does the information shown in the Coefficients table agree with your expectation in Task 2?
Briefly explain the reasoning behind your answer.
Task 7
Refer to the Coefficients table, and follow the presentation on seminar note Slide 19, construct the least squares linear regression equation for the relationship between the independent variable and the dependent variable.
Task 8
Interpret the estimated intercept and the slope coefficients.
Task 9
Select one of the two following scenarios which describe your choice in Task 1.
• In Task 1, if you nominated Number of Rooms is the independent variable, then you are asked to estimate the Advertised Price (dependent variable) of a property given the number of rooms of the property is 5.
• In Task 1, if you nominated Advertised Price is the independent variable, then you are asked to estimate the Number of Rooms (dependent variable) of a property given the advertised price is $1.55 (million).
Task 10
With reference to the R Square value provided in the Regression Statistics table, explain whether you would trust your estimation in Task 9. Comment on whether your answer in Task10 agrees with the answer in Task 5 in terms of the strength of the linear relationship between X and Y.
Task 11
State, symbolically, the null and alternative hypotheses for testing whether there is a positive linear relationship between Number of Rooms and Advertised Price in the population.
Task 12
Use the Empirical Rule, state the z- value which is corresponding to 2.5% significant level.
Task 13
Use the p-value approach to decide, at a 2.5% level of significance, whether the null hypothesis of the test referred to in Task 11 can be rejected (or not). Make sure you provide a justification for your decision.
Task 14
Following the decision in Task13, provide a precise conclusion to the hypothesis test conducted in Task 13.
Task 15
From information provided in the Coefficients table, construct a 95% confidence interval estimate of the gradient of the population regression line. Is this interval consistent with the conclusion to the hypothesis test you arrived at in Task 14? Briefly explain the reasoning behind your answer
Solution
.png)
Statistical Analysis Assignment Sample
INSTRUCTIONS
Perform the required calculations using Excel (and PHStat where appropriate), present your findings (i.e., the relevant output), and prepare short written responses to the following questions. Please note that you must provide a clear interpretation and explanation of the results reported in your output. Please submit your answers in a single Word file.
Question 1 – Binomial Distribution (8 marks)
A university has found that 2.5% of its students withdraw without completing the introductory business analytics course. Assume that 100 students are registered for the course.
a) What is the probability that two or fewer students will withdraw?
b) What is the probability that exactly five students will withdraw?
c) What is the probability that more than three students will withdraw?
d) What is the expected number of withdrawals from this course?
Question 2 – Normal Distribution
Suppose that the return for a particular investment is normally distributed with a population mean of 10.1% and a population standard deviation of 5.4%.
a) What is the probability that the investment has a return of at least 20%?
b) What is the probability that the investment has a return of 10% or less?
A person must score in the upper 5% of the population on an IQ test to qualify for a particular occupation.
c) If IQ scores are normally distributed with a mean of 100 and a standard deviation of 15, what score must a person have to qualify for this occupation
Question 3 – Normal Distribution (4 marks)
According to a recent study, the average night’s sleep is 8 hours. Assume that the standard deviation is 1.1 hours and that the probability distribution is normal.
a) What is the probability that a randomly selected person sleeps for more than 8 hours?
b) Doctors suggest getting between 7 and 9 hours of sleep each night. What percentage of the population gets this much sleep?
Question 4 – Normal Distribution (10 marks)
The time needed to complete a final examination in a particular college course is normally distributed with a mean of 160 minutes and a standard deviation of 25 minutes. Answer the following questions:
a) What is the probability of completing the exam in 120 minutes or less?
b) What is the probability that a student will complete the exam in more than 120 minutes but less than 150 minutes?
c) What is the probability that a student will complete the exam in more than 100 minutes but less than 170 minutes?
d) Assume that the class has 120 students and that the examination period is 180 minutes in length. How many students do you expect will not complete the examination in the allotted time?
Solution
Question 1
Here, number of trials (n) = 100
Probability of success i.e. student withdrawing from course (p) = 0.025
The various probabilities have been computed using BINOMIST function in Excel.

Question 2
a) Mean = 10.1%
Standard deviation = 5.4%
The relevant output from Excel is shown below.
.png)
The z score is computed using the inputs provided. Using the NORMS.DIST(1.833) function, the probability of P(X<20%) has been determined. Finally, the probability that the return would be atleast 20% is 0.0334.
b) Mean = 10.1%
Standard deviation = 5.4%
The relevant output from Excel is shown below for assignment help
The z score is computed using the inputs provided. Using the NORMS.DIST(-0.0185) function, the probability of P(X<10%) has been determined. It can be concluded that there is a probability of 0.4926 that the given investment has a return of 10% or less.
c) The relevant output from Excel is shown below.
.png)
The requisite percentile score required is 95%. The corresponding Z value for this as determined using NORMS.INV has come out as 1.644854. This along with the mean and standard deviation has been used to derive the minimum qualification score as 124.67. Hence, to be in the top 5%, a candidate needs to score atleast 124.67 in the IQ test.
Question 3
a) The relevant output from Excel is shown below.
.png)
Using the mean, standard deviation and the X value, the Z score has been computed as zero. Using NORMS.DIST(0) function, the probability of P(X<=8) has come out as 0.5. Further, the probability of P(X>8) has been computed as 0.5. Hence, the probability that a randomly selected person sleeps more than 8 hours is 0.5.
b) The relevant output from Excel is shown below.
.png)
For X1 = 7 hours, the corresponding z score was computed followed by finding the P(X<7) using NORMS.DIST(-0.9091) function. For X2 = 9 hours, the corresponding z score was computed followed by finding the P(X<9) using NORMS.DIST(0.9091) function. The probability that people would be getting sleep between 7 and 9 hours is 0.6367. Thus, 63.67% of the population is getting sleep between the 7 and 9 hours each night.
Question 4
a) The relevant output from Excel is shown below.
.png)
For X =120, the corresponding z score was computed followed by finding the P(X<=120) using NORMS.DIST(-1.6) function. The probability of completing the exam in 120 minutes or lesser is 0.0548.
b) The relevant output from Excel is shown below.
.png)
For X1 = 120 minutes, the corresponding z score was computed followed by finding the P(X<120) using NORMS.DIST(-1.6) function. For X2 = 150 minutes, the corresponding z score was computed followed by finding the P(X< 150) using NORMS.DIST(-0.40) function. The probability that a student will complete the test in more than 120 minutes but less than 150 minutes is 0.2898.
c) The relevant output from Excel is shown below.
.png)
For X1 = 100 minutes, the corresponding z score was computed followed by finding the P(X<100) using NORMS.DIST(-2.4) function. For X2 = 170 minutes, the corresponding z score was computed followed by finding the P(X< 170) using NORMS.DIST(0.40) function. The probability that a student will complete the test in more than 100 minutes but less than 170 minutes is 0.6472.
d) The relevant output from Excel is shown below.
.png)
For the score of 180 minutes, the corresponding Z score is 0.8. Using NORMS.DIST(0.8), the P(X<180) is 0.7881. Hence, the probability of student taking more than 180 minutes or not finishing within the allotted 180 minutes is 0.2119. The total number of students given is 120. Thus, students not finishing within the allotted 180 minutes is 0.2119*120 = 25.42 or 26 students.
STATS7061 Statistical Analysis Assignment Sample
Prepare short written responses to the following questions. Please note that you must provide a clear interpretation and explanation of the results for assignment help reported in your output.
Question 1 – Binomial Distribution
A university has found that 2.5% of its students withdraw without completing the introductory business analytics course. Assume that 100 students are registered for the course.
a) What is the probability that two or fewer students will withdraw?
b) What is the probability that exactly five students will withdraw?
c) What is the probability that more than three students will withdraw?
d) What is the expected number of withdrawals from this course?
Question 1
Here, number of trials (n) = 100
Probability of success i.e. student withdrawing from course (p) = 0.025
The various probabilities have been computed using BINOMIST function in Excel.
a) P(X≤2) = BINOMDIST(2,100,0.025,True) = 0.5422
.png)
b) P(X=5) = BINOMDIST(5,100,0.025,False) = 0.0664
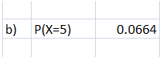
c) P(X>3) = 1- BINOMDIST(3,100,0.025,True) = 0.2410
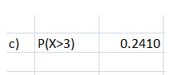
d) Expected withdrawals = 100*2.5% = 2.50 students
Question 2 – Normal Distribution
Suppose that the return for a particular investment is normally distributed with a population mean of 10.1% and a population standard deviation of 5.4%.
a) What is the probability that the investment has a return of at least 20%?
b) What is the probability that the investment has a return of 10% or less?
A person must score in the upper 5% of the population on an IQ test to qualify for a particular
occupation.
c) If IQ scores are normally distributed with a mean of 100 and a standard deviation of 15, what score must a person have to qualify for this occupation?
Question 2
a) Mean = 10.1%
Standard deviation = 5.4%
The relevant output from Excel is shown below.
.png)
The z score is computed using the inputs provided. Using the NORMS.DIST(1.833) function, the probability of P(X<20%) has been determined. Finally, the probability that the return would be atleast 20% is 0.0334.
b) Mean = 10.1%
Standard deviation = 5.4%
The relevant output from Excel is shown below.
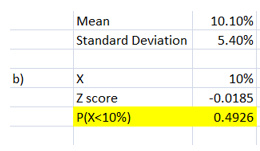
The z score is computed using the inputs provided. Using the NORMS.DIST(-0.0185) function, the probability of P(X<10%) has been determined. It can be concluded that there is a probability of 0.4926 that the given investment has a return of 10% or less.
c) The relevant output from Excel is shown below.
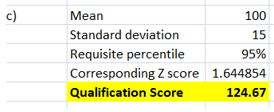
The requisite percentile score required is 95%. The corresponding Z value for this as determined using NORMS.INV has come out as 1.644854. This along with the mean and standard deviation has been used to derive the minimum qualification score as 124.67. Hence, to be in the top 5%, a candidate needs to score atleast 124.67 in the IQ test.
Question 3 – Normal Distribution
According to a recent study, the average night’s sleep is 8 hours. Assume that the standard deviation is 1.1 hours and that the probability distribution is normal.
a) What is the probability that a randomly selected person sleeps for more than 8 hours?
b) Doctors suggest getting between 7 and 9 hours of sleep each night. What percentage of the population gets this much sleep?
Question 3
a) The relevant output from Excel is shown below.
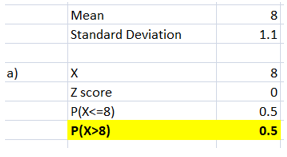
Using the mean, standard deviation and the X value, the Z score has been computed as zero. Using NORMS.DIST(0) function, the probability of P(X<=8) has come out as 0.5. Further, the probability of P(X>8) has been computed as 0.5. Hence, the probability that a randomly selected person sleeps more than 8 hours is 0.5.
b) The relevant output from Excel is shown below.
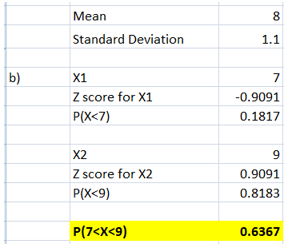
For X1 = 7 hours, the corresponding z score was computed followed by finding the P(X<7) using NORMS.DIST(-0.9091) function. For X2 = 9 hours, the corresponding z score was computed followed by finding the P(X<9) using NORMS.DIST(0.9091) function. The probability that people would be getting sleep between 7 and 9 hours is 0.6367. Thus, 63.67% of the population is getting sleep between the 7 and 9 hours each night.
Question 4 – Normal Distribution
The time needed to complete a final examination in a particular college course is normally distributed with a mean of 160 minutes and a standard deviation of 25 minutes. Answer the following questions:
a) What is the probability of completing the exam in 120 minutes or less?
b) What is the probability that a student will complete the exam in more than 120 minutes but less than 150 minutes?
c) What is the probability that a student will complete the exam in more than 100 minutes but less than 170 minutes?
d) Assume that the class has 120 students and that the examination period is 180 minutes in length. How many students do you expect will not complete the examination in the allotted time?
Question 4
a) The relevant output from Excel is shown below.
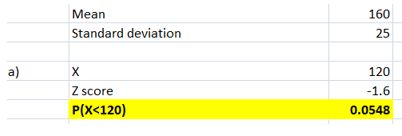
For X =120, the corresponding z score was computed followed by finding the P(X<=120) using NORMS.DIST(-1.6) function. The probability of completing the exam in 120 minutes or lesser is 0.0548.
b) The relevant output from Excel is shown below.

For X1 = 120 minutes, the corresponding z score was computed followed by finding the P(X<120) using NORMS.DIST(-1.6) function. For X2 = 150 minutes, the corresponding z score was computed followed by finding the P(X< 150) using NORMS.DIST(-0.40) function. The probability that a student will complete the test in more than 120 minutes but less than 150 minutes is 0.2898.
c) The relevant output from Excel is shown below.
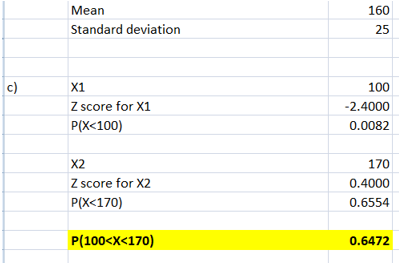
For X1 = 100 minutes, the corresponding z score was computed followed by finding the P(X<100) using NORMS.DIST(-2.4) function. For X2 = 170 minutes, the corresponding z score was computed followed by finding the P(X< 170) using NORMS.DIST(0.40) function. The probability that a student will complete the test in more than 100 minutes but less than 170 minutes is 0.6472.
d) The relevant output from Excel is shown below.

For the score of 180 minutes, the corresponding Z score is 0.8. Using NORMS.DIST(0.8), the P(X<180) is 0.7881. Hence, the probability of student taking more than 180 minutes or not finishing within the allotted 180 minutes is 0.2119. The total number of students given is 120. Thus, students not finishing within the allotted 180 minutes is 0.2119*120 = 25.42 or 26 students.
STT500 Statistics for decision making Assignment 2 Sample
Description
The individual assignment must provide a 1500-word written report. This report for The Assignment Helpline will develop students' quantitative writing skills and test their ability to apply theoretical concepts covered from weeks 1-8. Please use Excel for statistical analysis in this assignment. Relevant Excel statistical output must be properly analysed and interpreted.
Assignment Data
The real estate markets present a fascinating opportunity for data analysts to analyse and predict property prices. Considering the data provided a large set of property sales records.
Attribute information:
PN: Property identification number • Price: Price of the property ($000) • Bedrooms: Number of bedrooms
• Bathrooms: Number of bathrooms
Lot size: Land size (in square meters)
The population property data from which you will select your sample data consists of 500 IDs each with an identifying property number (PN) ranging from 1 (or 001) to 500.
Your first task is to select 50 three-digit random (property) numbers ranging from 001 to 500 from the provided table of random numbers.
To select your 50 random property identification numbers, you will need to first go to a starting position row and column in the random number table. Defined by the last three digits of your Polytechnic Institute Australia student identification number. The last two digits of your PIA ID number identify the row, and the third last digit identifies the column of your (relatively) "unique" starting position.
You need to record these first three acceptable ID numbers into the first column of an Excel spreadsheet and then continue this process until fifty valid three-digit personal identification numbers are selected.
To select your sample data based on 50 randomly selected properties from the random number table, you will need to use these identification numbers to select properties from the Excel sheet of the population property data.
For the demonstration last three digits of 205, reading across row 05 from left to right starting at column 2 as instructed, you would encounter the following three-digit numbers.
04773 12032 51414 82384 38370 00249 80709 72605 67497
You need to record these first three acceptable ID numbers, 047, 120, 383 and 002 into the first column of an Excel spread-sheet and then continue this process until fifty valid three-digit personal identification numbers selected.
Students are required to use the generated data according to their student ID to answer the assessment questions.
Make sure the following questions are covered in the data analysis:
1) Create 50 randomly selected properties from the random number table based on your PIA ID number, you will need to use these identification numbers to select properties from the Excel sheet of the population property data. Use your data to answer questions 2-10.
2) Use Excel to create frequency distributions, Bar charts, and Pie charts for the number of bedrooms and bathrooms. Comment on the key findings.
3) What type of variable (Continuous, Discrete, Ordinal, or Nominal) is the number of bedrooms, and justify your answer.
4) Use Excel to create Histogram for the Price of the property and Land size (square ft lot). Also. Comment on the key findings.
5) Show descriptive summary statistics for the Price of the property in thousand dollars and Land size (square ft lot). Comment on the shape, canter, and spread of these two distributions.
6) Check the normality of the Price of the property data with three pieces of evidence.
7) Construct a 95% confidence interval for the population's average Price of the property, also Interpret the confidence interval.
8) Construct a 95% confidence interval for the population's average Land size (square ft lot) of the property, also Interpret the confidence interval.
9) Test whether the population's average Price of the property in thousand dollars is different from $530. Formulate the null and alternative hypotheses. State your statistical decision using the significant value (a) of 5%.
10) State your conclusion in context.
Solution
Task 1: Selecting Random Sample
1. Based on ID 20241288, last 3 digits are: 288, In my ID 88 identifies row and 2 identifies the
column in the random number table.
Data Table
Task 2: Use Excel to create frequency distributions
2. Frequency Distribution, Bar charts and Pie chart for number of Bedrooms and bathrooms
.png)
.png)
.png)
Task 2: Use Excel to Create Frequency Distributions
2. Frequency Distribution, Bar charts and Pie chart for number of Bedrooms and bathrooms
.png)
Table 1: Frequency Distribution
(Source: Ms Excel)
The key finding from the frequency distribution of bathrooms, therefore, is that number of bathrooms is an ordinal discrete variable, by which we mean that it is a ranked variable with defined, separate values (i. e. 1, 1. 5, 2 and so on). The bar chart shows the frequency and distribution of the number of bathrooms which is protracted to show the most frequently occurring bathroom count among the buildings. This aspect of the visualization is informative about how the bathroom availability is usually distributed in the properties and a way of giving an estimate of which bathroom count is more popular among the properties in the data set in helping to decipher the general pattern of these homes.
.png)
Figure 1: Bar chart of bedroom frequency Distribution
(Source: MS- EXCEL)
Interpretation: This bar chart relates to the distribution of the number of bedrooms in the properties. This bar advertises how many of them have a certain number of bedrooms. For instance if out of 100 properties the majority of them have 3 rooms, then the bar corresponding to 3 rooms shall be the highest. In particular, this visualization makes it easier to determine which frequency of bedrooms is typical of the sampled properties.
.png)
Figure 2: Barchart of Bathroom frequency Distribution
(Source: MS- EXCEL)
Key Findings: The key finding here is that the number of bathrooms is classified as an ordinal discrete variable because it represents a ranked order (from 1 to 4), and the values are discrete—indicating distinct, separate units without intermediate continuous values. Just as the frequency distribution of the bedroom, this bar chart shows the frequency distribution of the number of bathrooms in the properties. It will also show the range of the numbers of bathrooms most common among the households. This can be useful for comprehension of how the probability of access is divided with concern to the units in the data set.
3. Variable
The number of bathrooms is considered an ordinal discrete variable. This categorization is justified because the variable reflects a ranked order, where each value represents a meaningful progression or quantity of bathrooms. The numbers indicate a clear sequence, from fewer bathrooms to more, which inherently implies an order (ordinal). The values are discrete because they represent distinct, separate units—there are no fractional or continuous numbers between these specified values in this context. While 1.5 or 2.75 bathrooms are possible, the intervals between the listed values are specific and not continuous, further reinforcing the discrete nature of the variable.
4. Histogram of price of Property and land size
.png)
(Source : MS- EXCEL )
Key Findings :This histogram above illustrates the property prices and land sizes. By this, you are able to get a view of how these variables are distributed in that the height of the bars depict the number of properties in the given price or land size category. The shape of the histogram can also reveal whether the data is skewed, normally distributed and whether the data has some other special distribution. Here, the histogram effectively illustrates the distribution and dispersion of the data about property prices and land areas in order to detect the properties such as skewness, peak or any gaps.
5. Descriptive Summary Statistics
.png)
Table 2: Descriptive Summary Statistics of price of property
(Source : MS - Excel)
key Findings: The following table provides some of the property price summary measurements which include ‘mean’, ‘median’, ‘standard deviation’ and ‘range’. These measures provide essentials like the central tendencies and variability and also overall appearance of the distribution of property prices in the dataset. Average property price can be calculated using mean and median of the property prices and variability of the prices can be understood through, standard deviation. The range gives the variation of prices from the highest to the lowest, which shows the variation of the values.
.png)
Table 3: Descriptive Summary Statistics of Land Size
(Source : MS - Excel)
key Findings : In the same way as with price statistics, the following table gives an overview of some basic descriptive statistics of land size. They include such indicators as the arithmetic average, the median, and the standard deviation because they give a general idea of the size of the land within the established sample. The summary statistics of land size also assist in identifying the degree of dispersion of the land size proportional to properties being analyzed through the mean of the land size and the standard deviation.
6. Normality of the Price of Property Data with Three Pieces of Evidences
.png)
Figure 4 : Normality of the price of property Data with three pieces of evidences
(Source : MS EXCEL )
Key Findings:
This, most probably, represents a normality test – Q-Q plot, histogram, or a result of the Shapiro-Wilk test. The purpose is therefore to check the assumption that the property price data can be from a normal distribution. There will be three statistical measures to support or reject normality including histogram of the distribution, measuring the agreement of Q-Q plot and the p-value from a normality test. The condition is that data is normally distributed; it implies that a majority of house prices are exceptionally close to the average while very few prices are on the high or low end. If the data does not look like a normal distribution then further data transformation might be required or analyze the data using other statistical techniques.
7.
.png)
(Source : MS - Excel)
Interpretation :
This table gives the confidence interval of the average price of property. The confidence level is usually specified as 95% which means that the true population mean will, in all probability, lie within this range 95% of the time. This interval is important in determining the precision of the sample mean of the population mean. By using confidence intervals to generate hypotheses, it assists in estimating the population mean thus providing a range within which the mean property price lies.
8.
.png)
Table 5 : 95 % confidence interval for the population’s average Land Size
(Source : MS - Excel)
As is the case with the property price, this table shows the confidence interval for the average size of the land. It means the mean of the estimated average land size for the population has to be between that range with 95 percent confidence. A small interval provides more accuracy of the estimate as compared with the wide interval.
9.
.png)
Table 6: testing of population average price of property
(Source : MS - Excel)

Statistical Decision:
Interpretation: The following table will have the information of whether the null hypothesis should be rejected or not at a significance level (alpha) of 5% using the test statistic and p value. Most often, the p value is determined alongside the lower bound and if the p value gets less than 0. 05, the null hypothesis is being turned down which makes it clear that the average price of the property is significantly different from the set value.
10. Conclusion
This analysis gave a detailed description of property characteristics such as the distribution of the number of bedrooms and bathrooms, the price of the property and land area. These distributions described how frequent a particular combination of bedrooms and bathrooms were and in the analysis, bathrooms was determined to be an ordinal discrete variable because of the ranked and distinct values. Histograms of property prices and size of the land, represented the spread of the corresponding variable and can give an indication of the skewness of the variables. Descriptive statistics yielded measures of central tendency and variability which are important in the assessment of the overall frequency distribution of property prices and sizes of land. The results of the normality tests on property prices indicated that, even though data seemed more or less normally distributed, it was still necessary to conduct additional tests or transformations. The 95% confidence intervals were also employed to estimate the population means of property prices as well as land sizes to show the preciseness of the samples that were taken. Finally, hypothesis testing was used to ascertain whether the mean property price deviated by a statistically significant margin from a given value, in the overall population. Collectively, these analyses provide properties characteristics’ important information and provide practical references for real estate related industries.
SIT741 Statistical Data Analysis Assignment Sample
Q1: Car accident dataset (10 points)
Q1.1: How many rows and columns are in the data? Provide the output from your R Studio
Q1.1: What data types are in the data? Use data type selection tree and provide detailed explanation. (2 points for data types, 2 points for explanation)
Q1.3: How many regions are in the data? What time period does the data cover? Provide the output from your R Studio
Q1.4: What do the variables FATAL and SERIOUS represent? What’s the difference between them?
Q2: Tidy Data
Q2.1 Cleaning up columns. You may notice that the road traffic accidents csv file has two rows of heading. This is quite common in data generated by BI reporting tools. Let’s clean up the column names. Use the code below and print out a list of regions in the data set.
Q2.2 Tidying data
a) Now we have a data frame. Answer the following questions for this data frame.
- Does each variable have its own column? (1 point)
- Does each observation have its own row? (1 point)
- Does each value have its own cell? (1 point)
b) Use spreading and/or gathering (or their pivot_wider and pivot_longer new equivalents) to transform the data frame into tidy data. The key is to put data from the same measurement source in a column and to put each observation in a row. Then, answer the following questions.
I. How many spreading (or pivot_wider) operations do you need?
II. How many gathering (or pivot_longer) operations do you need?
III. Explain the steps in detail.
IV. Provide/print the head of the dataset.
c) Are the variables having the expected variable types in R? Clean up the data types and print the head of the dataset.
d) Are there any missing values? Fix the missing data. Justify your actions.
Q3: Fitting Distributions
In this question, we will fit a couple of distributions to the “TOTAL_ACCIDENTS” data.
Q3.1: Fit a Poisson distribution and a negative binomial distribution on TOTAL_ACCIDENTS. You may use functions provided by the package fitdistrplus.
Q3.2: Compare the log-likelihood of two fitted distributions. Which distribution fits the data better? Why?
Q3.3 (Research Question): Try one more distribution. Try to fit all 3 distributions to two different accident types. Combine your results in the table below, analyse and explain the results with a short report.
Q4: Source Weather Data
Above you have processed data for the road accidents of different types in a given region of Victoria. We still need to find local weather data from the same period. You are encouraged to find weather data online.
Besides the NOAA data, you may also use data from the Bureau of Meteorology historical weather observations and statistics. (The NOAA Climate Data might be easier to process, also a full list of weather stations is provided here: https://www.ncei.noaa.gov/pub/data/ghcn/daily/ghcnd-stations.txt )
Answer the following questions:
Q4.1: Which data source do you plan to use? Justify your decision. (4 points)
Q4.2: From the data source identified, download daily temperature and precipitation data for the region during the relevant time period. (Hint: If you download data from NOAA https://www.ncdc.noaa.gov/cdo-web/, you need to request an NOAA web service token for accessing
the data.)
Q4.3: Answer the following questions (Provide the output from your R Studio):
- How many rows are in your local weather data?
- What time period does the data cover?
Q5 Heatwaves, Precipitation and Road Traffic Accidents
The connection between weather and the road traffic accidents is widely reported. In this task, you will try to measure the heatwave and assess its impact on the road accident statistics. Accordingly, you will be using the car_accidents_victoria dataset together with the local weather data.
Q5.1. John Nairn and Robert Fawcett from the Australian Bureau of Meteorology have proposed a measure for the heatwave, called the excess heat factor (EHF). Read the following article and summarise your understanding in terms of the definition of the EHF. https://dx.doi.org/10.3390%2Fijerph120100227
Q5.2: Use the NOAA data to calculate the daily EHF values for the area you chose during the relevant time period. Plot the daily EHF values.
Q6: Model Planning
Careful planning is essential for a successful modelling effort. Please answer the following planning questions.
Q6.1. Model planning:
a) What is the main goal of your model, how it will be used?
b) How it will be relevant to the emergency services demand?
c) Who are the potential users of your model?
Q6.2. Relationship and data:
a) What relationship do you plan to model or what do you want to predict?
b) What is the response variable?
c) What are the predictor variables?
d) Will the variables in your model be routinely collected and made available soon enough for prediction?
e) As you are likely to build your model on historical data, will the data in the future have similar characteristics?
Q6.3. What statistical method(s) will be applied to generate the model? Why?
Q7: Model The Number of Road Traffic Accidents
In this question you will build a model to predict the number of road traffic accidents. You will use the car_accidents_victoria dataset and the weather data. We can start with simple models and gradually makemthem more complex and improve them. For example, you can use the EHF as an additional predictor to augment the model. Let’s denote by Y the road traffic accident variable.
Randomly pick a region from the road traffic accidents data.
Q7.1 Which region do you pick?
Q7.2 Fit a linear model for Y according to your model(s) above. Plot the fitted values and the residuals. Assess the model fit. Is a linear function sufficient for modelling the trend of Y? Support your conclusion with plots.
Q7.3 As we are not interested in the trend itself, relax the linearity assumption by fitting a generalised additive model (GAM). Assess the model fit. Do you see patterns in the residuals indicating insufficient model fit?
Q7.4 Compare the models using the Akaike information criterion (AIC). Report the best-fitted model through coefficient estimates and/or plots.
Q7.5 Analyse the residuals. Do you see any correlation patterns among the residuals?
Q7.6 Does the predictor EHF improve the model fit?
Q7.7 Is EHF a good predictor for road traffic accidents? Can you think of extra weather features that may be more predictive of road traffic accident numbers? Try incorporating your feature into the model and see if it improves the model fit. Use AIC to prove your point.
Q8: Reflection
In the form of a short report answer the following questions (no more than 3 pages for all questions):
Q8.1: We used some historical data to fit regression models. What additional data could be used to improve your model?
Q8.2: Overall, have your analyses answered the objective/question that you set out to answer?
Q8.3: Missing value [10 marks]. If the data had some with missing values, what methods would you use to address this issue? (Provide 1-3 relevant references)
Q8.4. Overfitting [10 marks]. In Q7.4 we used the Akaike information criterion (AIC) to compare the models. How would you tackle the overfitting problem in terms of the number of explanatory variables that you could face in building the model? (Provide 1-3 relevant references)
Solution
Q1. Car Accident Dataset
Q1.1 Dataset description
![]()
Figure 1: Dimension of Dataset
(Source: R Studio)
The Dataset contains 1644 Rows and 29 Columns which are generated using the “dim” code.
Q1.2 Data type identification
.png)
Figure 2: Type of Dataset
(Source: R Studio)
The Dataset is based on the character datatype which means every data in the dataset contains one byte character.
.png)
Figure 3: Selection Tree Code
(Source: R Studio)
The code sets each column of the `car_accidents” dataset and identifies and prints the data type of each column used in this dataset. The type function for The Assignment Helpline determines whether the column is of “numeric”, “character”, “factor” or “date” and returns the type. It has proved to be useful for the identification of the structure of the datasets necessary for further steps of data preprocessing and analysis in the research.
Q1.3 Identification of the regions in dataset
.png)
Figure 4: Number of Regions
(Source: R Studio)
In the Dataset, there are a total of 7 regions available which are generated using the given codes.
.png)
Figure 5: Date Range
(Source: R Studio)
The Dataset covers the date range between 1st January 2016 to 30th June 2020.
Q1.4 Representation of FATAL and SERIOUS variables
The variables FATAL and SERIOUS are measures of the number of road traffic accidents by area of the world in which they occurred. FATAL shows the total, fatal pedestrian accidents and SERIOUS, indicates the number of severe, but not fatal, injuries. The critical difference lies in the outcome: fatalities refer to loss of lives while serious injuries point towards possible long-term health complications (Jiang et al. 2024). This is particularly important in terms of evaluation of the level of acuity and hence, of resource use in emergency services treatment.
Q2. Tidy Data
Q2.1 Cleaning up columns.
.png)
Figure 6: Cleaning up Columns
(Source: R Studio)
The code removes some unwanted characters and spaces from the column names of car accident data which are available in the car_accidents_victoria.csv file data set, In this file there are two rows of headers. The first two rows are read separately, various double underscores are used to generate different names for the columns, and the number ‘0’ is added to certain columns. The column named daily_acccidents is then taken from the cleaned dataset after omitting the first two rows of the Excel file and the column headers are given standard names for further use. This makes certain data manipulation to be correct and makes subsequent modelling to be clear.
Q2.2 Tidying data
a
![]()
Figure 7: Column Identification
(Source: R Studio)
The code then demonstrates whether each variable in the daily_accidents dataset is properly indexed in its column by using the is.atomic function. The output reproduced this with the value of `TRUE’ signifying that the data was well formatted for analysis.

Figure 7: Row Identification
(Source: R Studio)
The code guarantees each observation in the daily_accidents has its row by way of checking to ensure no rows are repeated in the dataset while also ensuring the DATE column does not hold any missing values. The TRUE output as shown below also accredits the correct structuring of the data for analysis.
![]()
Figure 8: Cell Identification
(Source: R Studio)
It also confirms that each value in the daily_accidents dataset has its row by using is.na() to test that no value in this dataset is missing. To output FALSE, there is likely an information quality problem which is always common with data, that makes them improper for further analysis.
b
i)
.png)
Figure 9: Pivot Wider
(Source: R Studio)
A single `pivot_wider` transformation process is required to keep reshaping the dataset by widening different types of accidents, namely the accident type (FATAL, SERIOUS), which has to be categorized distinctly for every observation.
ii)
.png)
Figure 10; Pivot Longer
(Source: R Studio)
To merge multiple region-based columns into a single spread column while ensuring that all are under one variable to return the data to their tidy shape a double `pivot_longer` is needed.
iii)
The code begins with the `pivot_longer` function to transform multiple region-specific accident columns into one single column called `Region` which subsumes the types of accidents (FATAL, SERIOUS) under the column title `Accident_Type`. The `names_pattern` argument inputs the substring `Region` and `Accident_Type` out of column names because their matching is assumed to be most precise in the usage of regular expressions. Then the resulting long-format data is processed using `pivot_wider` and `Accident_Type` values are turned into variables. This extends the row of columns horizontally so that each type of accident is separated by its column, thus simplifying analysis between areas. The last `tidy_data’ format is convenient for the further analysis and modelling phase, visualisation and other statistical techniques (Pereira et al. 2019).
iv)
.png)
Figure 11: Head of Data
(Source: R Studio)
The code reshapes the ‘daily_accidents’ dataset so that it has a tidy form. The `long_data’ shows the same accident data as in the previous exercise but this data is in a long format with columns Region, Accident_Type, and their values. The `tidy_data` format then broadens these accident types into individual columns to make a clearer structure for counting accidents within regions over time.
c
.png)
Figure 12: Head Data
(Source: R Studio)
The various variables in the dataset might not be initially or automatically read in the expected form, for example, `DATE` may be read as a character `Date`(s), or accident counts as characters. For data type correction, there is a need to transform DATE to Date type while accident columns to numeric form of data. This improves the analysis of the data and also prevents a mistake made during data modelling from going unnoticed.
d
Yes, there are many cases of missing values in the dataset that lead to distortion of results. It is better to use the median or something called forwards filling because trends are weighed in such cases and they do not mislead in case some values are missing.
Q3. Fitting Distribution
Q3.1 Poisson distribution and a negative binomial distribution
.png)
Figure 13: Poisson Distribution
(Source: R Studio)
Poisson & Negative binomial distributions are then fitted on the `TOTAL_ACCIDENTS’ variable using the ‘fitdistrplus’ package. It can summarise and plot both models for easy comparison of goodness of distribution fit. This helps in its estimation to know which model best suits the prediction of variation in the accident count.
Q3.2 Comparison of the log-likelihood
![]()
Figure 14: LogLikelihood
(Source: R Studio)
The Negative Binomial model again is found to have a better fit with the data as its log-likelihood (-179060.2) is higher than that of Poisson ( -186547.4) while its AIC ( 358124.4) and BIC ( 358141.8) are comparatively lower to that of Poisson. This implies improved data modelling because the uncertainty in measurement is preserved as will be discussed later.
Q3.3 Research Question
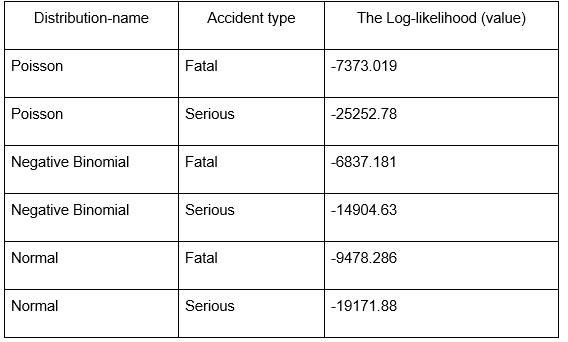
Table 1: Poisson Distribution
(Source: Self-Created)
According to the results, the Negative Binomial distribution has more log-likelihood values for Fatal and Serious types among all the analysed models, which means they are adjusted better than Poisson and Normal distributions. Negative Binomial is more appropriate where the variability of variance is high such as in accident modelling. The Poor fit of Poisson distribution indicates that it is inefficient for capturing the variability of the data, majority while the Moderate fit of the Normal distribution to the current data shows it is imprecise in estimation of count-based accident data. Therefore, the Negative Binomial model is suitable for this dataset in particular because of the effectiveness of its estimation in the case of overdispersion.
Q.4: Source Weather Data
Q.4.1 Data source justification
The historical weather observation data from the Bureau of Meteorology is chosen for its rich and accurate record of the environmental data, which is necessary for estimating the correlation between different weather conditions and traffic crash rates on the roads.
Q.4.2 Downloading dataset
Figure 14: Downloaded Dataset
(Source: EXCEL)
The Dataset is downloaded from the Bureau of Meteorology website.
Q.4.3 Answer the following questions (Provide the output from your R Studio):
.png)
Figure 15: Rows Identification
(Source: R Studio)
In the dataset there are 26115 rows are available.
.png)
Figure 16: Time Period
(Source: R Studio)
Time period is covered within 1st January 2016 to 30th December 2016.
Q.5: Heatwaves, precipitation and road traffic accidents
Q5.1 Summarization of the understanding
The Excess Heat Factor (EHF) measures heatwave intensity by analysing short-term and long-term heat anomalies. It compares the 30-day average to a three-day mean daily temperature above the 95th percentile. A high EHF indicates a severe heatwave, indicating health and environmental damage.
Q.5.2 Calculate the daily EHF values
.png)
Figure 17: EHF Factor
(Source: R Studio)
The graph shows January 2016–January 2017 daily Excess Heat Factor (EHF) data. The highest heat intensity was in April 2016. Summer EHF spikes are more frequent and intense, indicating heat stress. Heatwave severity decreases during cooler seasons.
Q.6: Model planning
Q.6.1 Model planning:
a)
The main goal is to predict road accidents using meteorological data for proactive traffic management and safety planning.
b)
Emergency services can disperse resources and reduce response times by predicting accident hotspots with the model.
c)
Traffic management, emergency services, urban planners, insurance companies, and public safety agencies can use it to improve road safety and resource allocation.
Q.6.2 Relationship and data
a)
Meteorological parameters like temperature, humidity, and EHF are linked to road accidents in different regions by the model. Accident probability and intensity are predicted based on meteorological conditions to aid prevention and resource allocation.
b)
Number of Road Accident will be the Response Variable from the car accident dataset.
c)
Temperature (temp), Humidity (humid), and Excess Heat Factor (EHF) are predictor variable from weather dataset
d)
Meteorological authorities collect and modify temperature, humidity, and EHF in real time to ensure accurate road accident predictions.
e)
In the absence of significant climatic alterations, meteorological patterns and vehicular accident trends are expected to adhere to seasonal fluctuations, rendering the model relevant for future forecasts.
Q.6.3 Application of the statistical model
Linear Regression will be employed for trend analysis, whereas Generalised Additive Models (GAM) will be utilised for non-linear relationships between weather and accident frequency. These methods enable the representation of smooth functions for variables such as temperature and humidity, which may not influence accidents linearly, to elucidate complex interconnections and improve forecasting precision.
Q.7 Model the Number of Road Traffic Accidents
Q.7.1 Region selection
Western Region is selected for the modelling.
Q.7.2 Fitting linear model
.png)
Figure 18: Linear Model
(Source: R Studio)
This graph compares the number of accidents in the WESTERN region (blue lines) to the linear model's predictions (red line). Despite increases in accident numbers, the linear model remains constant, failing to capture these oscillations. It appears that a linear model cannot accurately capture road accident trends. Systematic patterns in the residuals plot suggest that a Generalised Additive Model (GAM) might be better at capturing non-linear interactions. By showing that complex models improve predictions, this influences research.
Q.7.3 Fitting a generalised additive model
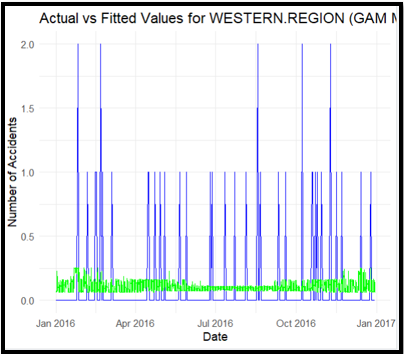
Figure 19: GAM Model
(Source: R Studio)
The graph illustrates the actual accident numbers (blue lines) in comparison to the fitted values using the GAM model (green line) for the WESTERN area. In contrast to the linear model, the GAM model accounts for local changes in accident patterns, demonstrating a superior match. Nonetheless, the increases in actual incidents remain inadequately reflected, indicating persistent patterns and possible underfitting. This suggests that the adaptable GAM is unable to properly encapsulate the non-linearities inherent in accident data, underscoring the necessity for more sophisticated models, including interaction terms or seasonal components.
Q.7.4 Comparison of the models
.png)
Figure 20: Comparison
(Source: R Studio)
AIC data show that the GAM model (AIC = 19103.07) matches better than the linear model (AIC = 19362.41). Non-linear patterns are better captured by the GAM model than the linear approach. GAM is better for accident analysis forecasts because meteorological variables and accident incidences are interconnected.
Q.7.5 Residual analysis
The GAM model residuals show patterns, indicating correlation. Clusters or patterns in residuals suggest model neglect of variability. Model efficacy may decrease due to time dependencies or omitted factors. This highlights the need for more advanced methods, such as time-series elements, to accurately depict accident dynamics and improve predictive precision.
Q7.6 Improvisation of predictor EHF
EHF quantifies the impact of severe heat on accident frequency, enhancing model fit and precision.
Q.7.7 Evaluation of EHF
EHF serves as a reliable predictor, as excessive heat can influence driver behaviour and vehicle performance, resulting in accidents. Nevertheless, supplementary meteorological variables such as precipitation, wind velocity, and visibility may possess greater forecasting capability. For example, precipitation can enhance road slipperiness, yet reduced sight can hinder driver reaction time. Incorporating precipitation into the model in conjunction with EHF allows us to evaluate whether it enhances model performance. An increase in model fit is suggested by a decrease in AIC with the inclusion of precipitation. This modification facilitates the capturing of a broader spectrum of meteorological factors impacting road safety, hence rendering the model more comprehensive for accident prediction.
Q.8 Reflection
Q.8.1 Recommendation of data
Additional data, including traffic density, road conditions, vehicle classifications, driver demographics, and accident severity, could substantially improve the model. Incorporating these characteristics would enhance the comprehension of accident causation, hence augmenting predictive efficacy and precision.
Q.8.2 Justification of the fulfilment of the research objectives
Indeed, my investigations have partially fulfilled the purpose by identifying critical meteorological variables influencing road accidents. Nevertheless, the models exhibit certain limits, suggesting that the inclusion of supplementary parameters could enhance prediction accuracy and reliability.
Q.8.3 Missing Value
In the presence of missing values, I would employ techniques such as mean or median imputed to provide continuous variables, mode imputation for categorical variables, or more sophisticated algorithms like KNN imputation and multiple imputation to maintain data integrity (Lee a& Yun, 2024).
Q.8.4 Overfitting
To address overfitting, I would employ approaches such as stepwise selection, regularisation methods (LASSO or Ridge regression), and cross-validation to minimise the number of explanatory variables, preserving just the most important predictors to enhance model generalisability (Laufer et al. 2023).
References
.png)

- Assignment - Child Care
- Assignment - Mathematics
- Assignment - Accounting
- Assignment - Auditing
- Assignment - Biology
- Assignment - Law
- Assignment - Management
- Assignment - Nursing
- Assignment - Finance
- Assignment - Computer Science and IT
- Assignment - Humanities
- Assignment - Economics
- Assignment - Statistics
- Assignment - Architecture
- Assignment - Engineering
- Assignment - cookery
- Assignment - Marketing
- Case Study - Chemistry
- Case Study - Accounting
- Case Study - Law
- Case Study - Management
- Case Study - Nursing
- Case Study - Finance
- Case Study - Computer Science and IT
- Case Study - Engineering
- Case Study - Economics
- Case Study - Biology
- Case Study - Auditing
- Case Study - Marketing
- Case Study - Project Management
- Coursework - Diploma
- Coursework - Accounting
- Coursework - Auditing
- Coursework - Biology
- Coursework - Management
- Coursework - Nursing
- Coursework - Finance
- Coursework - Computer Science and IT
- Coursework - Engineering
- Coursework - Humanities
- Coursework - Child Care
- Coursework - Project Management
- Coursework - Economics
- Coursework - Cookery
- Coursework - Law
- Dissertation - Accounting
- Dissertation - Auditing
- Dissertation - Biology
- Dissertation - Law
- Dissertation - Management
- Dissertation - Nursing
- Dissertation - Finance
- Dissertation - Computer Science and IT
- Dissertation - Humanities
- Dissertation - Economics
- Essay - Politics
- Essay - Childcare
- Essay - Accounting
- Essay - Biology
- Essay - Law
- Essay - Management
- Essay - Nursing
- Essay - Computer Science and IT
- Essay - Humanities
- Essay - Economics
- Essay - Auditing
- Essay - Engineering
- Essay - Architecture
- Essay - Finance
- Essay - Science
- Essay - Marketing
- Programming - Computer Science and IT
- Reports - Management
- Reports - Computer Science and IT
- Reports - Project Management
- Reports - Marketing
- Reports - Nursing
- Reports - Engineering
- Reports - Accounting
- Reports - Humanities
- Reports - Finance
- Reports - Architecture
- Reports - Biology
- Reports - Economics
- Reports - Childcare
- Reports - Law
- Research - Accounting
- Research - Auditing
- Research - Biology
- Research - Law
- Research - Management
- Research - Nursing
- Research - Finance
- Research - Computer Science and IT
- Research - Science
- Research - Engineering
- Research - Humanities
- Research - Economics
- Research - Project Management
- Research - Statistics
- Research - Architecture
- Research - Marketing
- Thesis Writing - Computer Science and IT
- Thesis Writing - Engineering
- Thesis Writing - Biology
- Thesis Writing - Finance
- Thesis Writing - Humanities
- Thesis Writing - Auditing
- Thesis Writing - Economics
- Thesis Writing - Law
- Thesis Writing - Nursing
- Thesis Writing - Accounting
- Thesis Writing - Architecture


.png)
~5.png)
.png)
~1.png)























































.png)






