DHI401 STAT6001 Digital Health and Informatics Assignment Sample
Question
Task Instructions
You will write a journal based on weekly learning from the subject that records weekly personal and professional reflections on the current status of digital health applications in Australia. This online custom essay help is expected to enhance your knowledge of digital health applications in Australia, as it applies both professionally and personally. You may be a health practitioner or working in the health-related sector. Assessment 2 assignment help seeks to follow your experiential journey through the subject and map your enhanced awareness and knowledge regarding digital health and informatics.
Step 1: Go to this link for Reachout.com: https://au.reachout.com/tools-and-apps
You will find a series of mobile apps and tools for health and well-being in the Australian context.
Step 2: Select TWO of the interventions that are active for your evaluation.
Step 3: Conduct an evaluation for each tool/intervention using these guiding questions:
a. What is the primary objective behind this intervention?
b. How long has it been active, and are there any apparent results (For example, user feedback, public reviews and so on)? What do these say? Review the qualitative feedback.
c. Who is the infrastructure provider/host for the solution? (For example, the solution may be hosted on Microsoft or AWS cloud servers. This would indicate the extent to which the solution is stable and secure.)
d. Demographic – Who seems to be using the solution in the past 12 months? Is the solution catering to the socio-cultural requirements in the Australian context? (For example, are the interfaces applicable to indigenous communities, culturally and linguistically diverse communities and so on?)
e. What are the privacy measures apparent from the solution?
f. Consider the ethical, legal and regulatory principles, best practices and laws related to the solution in the Australian context. From a scale of 1 to 10 (with 10 being the highest), evaluate the compliance based on the information available.
g. Has the solution been actively taken up by the proposed users? What may be the deterrents?
h. From a wider global research, are there any comparative solutions available that can be better used instead of this solution? Can these be used in the Australian context?
i. From your professional point of view, would the solution help in your work or at a personal level?
i. If yes, explain the applicability of the solution in your professional and personal context (if applicable).
ii. If no, explain the gaps and provide recommendations on improvement.
Structure:
1. Introduction
Introduce each of the two selected digital tools or interventions and its background information.
What is the primary objective of this tool? What are the secondary objectives?
2. Evaluative Discussion:
Classify the challenges for each tool/intervention according to the following subheadings:
• Infrastructure/environment (200 words per tool – total 400 words)
• Legal/Regulatory (200 words per tool – total 400 words)
• Ethical/Socio-cultural issues (200 words per tool – total 400 words)
3. Conclusion and Recommendations:
Provide actionable and practical recommendations, with guidelines for implementation.
Link your conclusion back to your introduction.
4. Reference List
APA 7th edition referencing must be followed.
Please refer to the rubric at the end of this document for the assessment criteria.
Answer
Introduction
Digitalization has reached a stage that defines that in today's competitive world, technology would solve most of the problems in the easiest form. The fact that can be defined is that most health organizations are implementing technological resources to solve the most critical issues within a short period.
Concerning this, the two tools that can be selected for health are Headspace and Daylio. Both the applications have both the primary and the secondary objectives which further would be productive. Considering the primary objective of daily it can be substantiated that it is used for tracking the moods, activities including the goals and objectives of the individuals (Ughetto et al., 2021). It is so that with keeping information about the daily routine, it easy to keep a possible track of everything in the easiest format. Relating to the secondary objective of the application, the purpose of the device is also to track the mood of the small children, and thereby if any kind of problem arises in the future it can automatically be solved within a period.
In a similar pattern, the goal and objective of headspace are that it collaborates to design and thus deliver innovative ways to work with those young people to strengthen the mental health and wellbeing of the individuals. At this phase of the period, it is substantial that mental check-up is one of the required notions which has to be kept intact and thus to improve the overall health set up, technological boost is very much needed to make the individual feel better in some way or the other. As such that, the selected applications in a way or the other proves to be beneficial or advantageous in the long run respectively. It is that for maintaining a kind of stability in the system it is such that both applications are required to enhance the mental stability of the persons who are suffering from health issues within a period.
As such it can be defined that both the selected applications in some of the other prove to be beneficial at some point of the time. It is so that with the help of the following applications, the health issues at once would be solved within a short period in the long run.
Evaluation Discussion
Infrastructure Environment
Headspace
The primary objective behind the tool is to help individuals in mental health traumatic situations within a period. As such that the public has a proper review regarding the device. The reason is that most of the patients who have used the application got some helpful results in the long run (Zhang et al., 2018). Statistics have shown that headspace as being used by individuals has provided the most advantageous benefits to persons who are suffering from different types of ailments. The objective of the application is that it is a kind of tool that has the probability to substantiate a different form on an overall process respectively.
With the implementation of the following protocol or the application, one can achieve a beneficial notion respectively. Thus, the assurance that can be generated is that it can very well be helpful to procure a beneficial aspect in the mere future by helping to provide a curative method to the people who require some peace within a period. For the time being, it can be evaluated that the following application proves to be helpful on certain grounds and such that it is helpful in the long run.
Daylio
In taking into consideration of the following application, it can well be stated that the selected one acts as a kind of tracking device by which the individuals can very well track the daily schedules or the routines and thereby the moods and the activities which are on a going process can relatively be understood.
The feedback that has been received for the following application is that with the help of the following element, the individuals would be able to keep a proper tracking record and thus accordingly work to it (Lee et al., 2015). In due course of time, the device was originated to gain positive insights.
It can thus be evaluated that the daily collection of the moods and the activities in a statistical order or to some extent can probably be beneficial to a certain extent respectively (Chaudhry, 2016). Therefore, it is such that for curing the mental problems which are present within an individual it is that the selected one has proved to be the best in due course of time. So, the fact or the statement that can be enumerated is that with the help of the following object, the health problems which are lurking back would disappear.
Legal
The legal principles that can be generated with the following application are that daily has certain of the compliances which are based on procedural notions. In comparison to the headspace which can bring mindfulness into the individuals, on a similar basis, daily in a similar way does so however following certain of the interventions in the long run.
Ranging on a scale it is at a range of 6, which again defines that some improvements are required to be made concerning the following application so that in the future, the device could be able to provide a productive notion (PW & I, 2016). In other words, the fact that can again be foretold is that with the help of the following object, the individuals who are not healthy or are in a traumatic situation would be helpful to a certain limit respectively. As such on an overall process, it can be helpful to state that the following device to a certain limit of the time, would prove advantageous to a certain degree of importance in the long run.
The implication that can henceforth be stated is that with the help of the following device the individuals had been able to make a curable practice in the future.
Privacy policy
The ‘privacy policy’ is the legal document that reveals the ways a user collects, utilizes, reveals and manages the client’s data. This personal information can be used to identify a person. These policies set out how people should collect and manage the personal information and steps people should take to protect these information. These privacy policies do not affect the confidentiality of the clients (Chaudhry, 2016).
HeadSpace: The “headspace National Youth Mental Health Foundation Ltd” (headspace) is responsible for protecting user’s privacy. When a user uses the headspace app it indicates that the user accepts all the privacy policies along with approving the collection and disclosure by the headspace app according to the conditions. The headspace app does not reveal any personal information to a third party without the consent of the user, unless it is required by law.
Headspace operates in metro, rural and regional areas of Australia. Headspace is responsible to eliminate all forms of discrimination and welcome diversity in health services. The app welcomes all persons irrespective of lifestyle, gender identity and choice.
Daylio: The ‘Daylio’ app offers the facility of maintaining a journal without actually writing it. This is a very quick responding app. The activity logs and the mood chart allow a user to link between the activity and mental state, which promotes the overall health of a person (Haradji et al., 2021). The Daylio app does not disclose these information to any other person. The terms and conditions are accepted by the user when he starts using the app.
Rating the applications it can be substantiated that the headspace is within a range of 1 to 6 and daylio is in a margin of 7. This adequately states that both the applications are to some extent helpful to a certain degree of importance in the long run respectively. This is related to the fact that in respect of health perspective, the fact is that both the applications have the capability to induce a differentiated form in the long run.
Ethical
Codes of ethics
People are getting inspired across the world throughout the pandemic by the leadership of the app. The authenticity and visibility of the headspace app are lifting up the people and organizations during this difficult time. Now the world needs this. The app headspace and Daylio both particularly offer,
• Honest and authentic relationship with the followers.
• Value to the experience of the employees and the users.
• The environment where the employees and the users know that their contribution and opinions matter.
• Illustration the code of ethics in a proper way.
Communication with the users and the employees about the ethical policies of the app is important.
Information About Stakeholders
People join the mental health pledges, by being influenced by the commitment of these apps. But benefits in the business are the matter of concern also. The headspace app obeys that, “happy employee leads the healthy business”. Helping the people in this field requires some intense research on the people. The objectives are tbhe policies taken by them that , are beneficial for the users as well as for the reputation of the business. Their research shows,
• Nearly 40% of the people take a day off due to stress and depression.
• Nearly 30% of the people think that they suffer from depression.
The organization thinks business benefits lie in the employee engagement and sentiment. The level of anxiety and demand define the attitude of work, productivity level, accuracy and efficiency of an employee. It the organization takes care of the wholeness of a person then it contributes in the overall well-being of both the company and the user.
Consistent and Clear Information
Uncertainty leaves room for contradiction and inaccurate information. It is always important to provide with clear, frequent and reliable information. For example, the headspace app and their ‘people operations team’ collects weekly updates and verified information and set a fresh action plan accordingly. The managers should also be empowered by proper training that supports their team and further educate them.
Enforcement of the ethical policies
The implementation of the policies is more important than the making of policies. One headspace research showed that nearly 51% of the worker’s experience stress in their workplace over their personal lives. The another survey showed nearly 90% of the employees think their organization should present the mental health benefits to their dependents (PW & I, S, 2016).
So in this scenario the apps successfully offer the users a better service tio take care of the mental health. This considers the burnout problem, wellness stressors and invest in the mental health of the employees.
Activities according to the pledge
The headspace app hopes to make an impact on the mental health of the employees. The headspace research shows that almost 5 out of 10 employees are not happy about the mental health benefits their company offers them. The objective of the Daylio app is to help them find the proper resources they need (Lee et al., 2015). Some of the procedures the app follow to make them grow are,
- They publically and visibly announce their pledge to their customers.
- They share their plans to address the problems related to mental health internally.
- They highlight the benefits and amplify the voice of their employees in the mental health concerns
- They are able to set an example through their previous actions to handle mental health problem
- Their activities encourage the outsiders to join their programs.
Conclusion and recommendations
There are still some questions about whether the users clearly understand the privacy policies and those policies help the users to get informed or not. A report published in 2002 showed that, the visual designs always have more influence than the privacy policies of the apps. Another report stated that when the privacy information are not prominent then the users prefer to use other applications. The privacy policies assure that, when a site or app hold those policies they will not share data with the third party without the consent. Critics also have the questions if the users even read the policies before using the app. A study showed that only 2% of the users carefully read the privacy policies.
Recommendations
In this critical time, when the whole world is suffering from a crisis and the pandemic is contributing positively to that, these two apps are contributing for the wellbeing of the people by helping them staying mentally fit. This is needed more in this time.
These apps should be more user friendly and the privacy policies should be clearer and easy to understand for the user. That would contribute positively in the customer experience and business benefit both.
References
Chaudhry, B. (2016). Daylio: mood-quantification for a less stressful you. Health, 2, 34-34. https://doi.org/10.21037/mhealth.2016.08.04
Lee, C., Lee, Y., Lee, J., & Buglass, A. (2015). Improving the extraction of headspace volatile compounds: development of a headspace multi-temperature solid-phase micro-extraction-single shot-gas chromatography/mass spectrometry (mT-HS-SPME-ss-GC/MS) method and application to characterization of ground coffee aroma. Analytical Methods, 7(8), 3521-3536. https://doi.org/10.1039/c4ay03034f
PW, A., & I, S. (2016). Application of Technology 4-Axis CNC Milling for Manufacturing Artistic Ring. Advances In Automobile Engineering, 01(S1). https://doi.org/10.4172/2167-7670.s1-007
Ughetto, P., Bourmaud, G., & Haradji, Y. (2021). Analyser les mutations des espaces et des temps à l’ère de la digitalisation. Activites, (18-2). https://doi.org/10.4000/activites.6459
Zhang, X., LIU, W., LU, Y., & LÜ, Y. (2018). Recent advances in the application of headspace gas chromatography-mass spectrometry. Chinese Journal Of Chromatography, 36(10), 962. https://doi.org/10.3724/sp.j.1123.2018.05013
STAT6200 Statistics for Public Health Assignment Help
Assignment Brief
Individual/Group - Individual
Length - 1,200 words (+/- 10%)
Learning Outcomes
This assessment addresses the following learning outcomes:
a) Critically apply the theories on key concepts in descriptive and inferential statistics
b) Analyze survey design and sampling methods to collect valid and reliable data and appraise methodologies
c) Assess the data and determine the appropriate parametric and non-parametric statistical tests, and how to control for confounding variables
d) Evaluate types of inferential statistics and interpret the results of these analyses using theoretical examples or as presented in published literature
e) Apply key concepts of statistics, including: sampling, hypothesis testing, distribution of data, validity and reliability, statistical significance and effect size
Submission Due Sunday following the end of Module 8 at 11:55pm
Weighting - 40%
Total Marks - 100 marks
Instructions:
This assessment requires you to read excerpts from four articles and answer a series of questions in no more than 1,200 words (+/- 10%).
Most public health and wider health science journals report some form of statistics. The ability to understand and extract meaning from journal articles, and the ability to critically evaluate the statistics reported in research papers are fundamental skills in public health. This type of assessment demonstrates how students can apply the skills that they learn in this course to real-world scenarios wherein they might need to interpret/review articles for public health use.
After reading published research articles, you will be asked to interpret, describe and report the following types of statistics for assignment help:
o State the null and alternative hypothesis
o Detail the demographic characteristics of the people in a sample
o Report summary descriptive and inferential statistics reported in the paper
o Describe what inferential statistics were used for the analysis of data in a study and why
o Interpret the odds ratios or hazard ratios for reported outcomes
o Evaluate the impact design limitations described by the researchers have on study or the extent to which results can be generalized to the population
Paper Excerpts for Interpretation
Paper 1:
1. What was the purpose of the research?
2. What kind of data was used, and what statistical analysis was performed on the data?
3. Refer to Table 2. Describe the correlation between overweight, obesity, BMI and HDI for both men and women.
4. What inferential statistics were used for analysis of the data summarized in Table 2, and why?
5. What was the conclusion of the study?
Paper 2:
1. Describe the research design of the study.
2. What demographic characteristics were considered for the people in the sample? Explain by referring to the descriptive statistics reported in the paper.
3. Which reported statistic was common to Figures 2, 4 and 5 in this paper? Please describe the outcome variable and statistic.
4. Refer to Figure 2. What did the researchers find for the number of disease-free years from age 40 when they categorized the participants by BMI?
5. What type of descriptive statistic is illustrated in Figure 3? List the variables included.
Paper 3:
1. Describe the aim of the study. Based on the study design, can the aim be restated in terms of null and alternative hypotheses?
2. What type of statistical analysis was used to independently examine the effect of diabetes status and type on in-hospital death with COVID-19? Why?
3. Interpret and report the adjusted odds ratios for in-hospital COVID-19-related death associated with diabetes status.
4. How generalizable are the findings described by the researchers to the population, and why?
5. What was the main finding of the study?
Paper 4:
1. Describe the aims of the study. Based on the study design, can the aim be restated in terms of null and alternative hypotheses? If so, state the null and alternative hypothesis.
2. Which four primary outcomes were examined by the study? Refer to Figure 2 - interpret and report the statistical results of these four primary outcomes.
3. Examine Figure 3, what was the outcome for Diabetes? Please report the statistics.
4. What was the most likely explanation for the effect of the intervention described in the discussion?
5. What were the limitations of the study reported in the discussion?
Solution
Paper 1:
Previous researches have demonstrated that obesity is one of the known health threats that lead to serious non-communicable diseases like diabetes, cardiovascular disease, blood pressure and even cancer. Ataey et al. (2020), arguesin their study that Human Development Index (HDI) has significant impact on the prevalence of obesity. The study also assesses the degree to which HDI influence the prevalence of overweight and obesity.
In the analysis, Ataey et al. (2020) used secondary quantitative data and using the SPSS, descriptive and inferential statistical analysis has been used. To determine the association between prevalence of overweight and obesity with HDI based on gender, data for Eastern Mediterranean Region has been collected. UN resource for HDI data and WHO resource were used for gathering information regarding overweight, obesity and other non-communicable diseases.
The study has presented its finding in table 2 where correlation between HDI with overweight, obesity and BMI is presented. As per the correlation, for male HDI has significant impact on overweight, obesity and BMI as their p value is lower than 0.05. Correlation also demonstrates the HDI influence the overweight, obesity and BMI highly as correlation of .721, .714 and .549 shows, HDI can lead to change in overweight by 72.1%, 71.4% and 54.9% respectively (Ataey et al. 2020). When it comes to female, then the correlation is valid for overweight and obesity as their p value is lower than 0.05. Correlation of .615 and .617 demonstrates, HDI can change overweight by 61.5% and obesity by 61.7% respectively (Ataey et al. 2020). Hence, for as the inferential analysis, here correlation analysis has been used to summarise the outcome in table 2.
To conclude, the study stated that there is good level of significant association between HDI and obesity and overweight (Ataey et al. 2020). The study at last asks policymakers to consider HDI factors while making general health policy for controlling non-communicable diseases.
Paper 2:
Previous studies have demonstrated that obesity is one of the major factors that lead to risks of several chronic diseases. However, it is not yet discovered, to which extent obesity is connected with the loss of diseases free years in different socioeconomic groups. Thus, the study authored by Nyberg et al. (2018) has performed a comparative analysis to determine the number of free years from any non-communicable disease for people overweight and obese with people who are normal weight. To analyse the research aim, present study has used quantitative approach of data analysis. Using the deductive approach of study, here analysis has been done of the Body Mass Index (BMI) with risk free years based on gender. To perform the study, researcher here considered variables like BMI, gender and age.
As per the statistical analysis, it can be seen that mean age of the male is 44.6 years and it is 43.4 years for female. Out of total respondents, 60.8% were female respondents and 39.2% were male respondents (Nyberg et al. 2018). Average BMI is 25.7 kg/m2 for males, and BMI is 21.468 for normal weight and 14.93 kg/m2 for overweight males. On the other hand, for females, mean BMI is 24.5 kg/m2 with 44.760 for normal weight and 5.670 for overweight (Nyberg et al. 2018).
Coming to the finding of the analysis, it has been observed that figure 2, 4 and 5 demonstrates mean age of disease-free years. Also, all three figures demonstrate gender wise significance of the disease-free years. As per the figure 2, it can be seen that when participants were arranged based by BMI, then average men age free year is 69.3 years for normal weight and 65.3 years for obese level I (Nyberg et al. 2018). For women, risk free years is 69.4 years and it is 66.7 years for obese level I (Nyberg et al. 2018). Using the descriptive statistics, prevalence level of obesity, has been presented based on socioeconomic status and gender. Hence, here graphical presentation has been used as descriptive statistics. Variable that was included in the study were obesity level, smoking, physical inactivity, gender and socio-economic status.
Paper 3:
Various study has demonstrated that there is long standing debate that whether diabetes has association with morality related to covid19. To understand the phenomenon, analysis has been made to check how the relative risks for type 1 and type 2 diabetes impact the covid19 related mortality during march 1 2020 to May 11 2020 by (Barron et al. 2020). Underpinning the study design, the study aim can be restated as well like: how the mortality rate of covid19 is associated with the diabetes type 1 and type 2. To analyse the restated research aim, hypothesis can be developed as follows:
Null hypothesis (H0): Mortality rate of covid19 does not have association with type 1 and type 2 diabetes
Alternative hypothesis (H1): Mortality rate of covid19 have positive association with type 1 and type 2 diabetes
Using the actual research design, for analysing the effect of diabetes and the type of in-hospital death during covid19, odd ratio has been used and descriptive statistics were used to determine generic characteristics of the data. In figure 2, the study has presented adjusted odd ratios for demonstrating in-hospital covid19 related death for diabetes. As per the same, it can be seen that odd ratio is high for female and people who are ages more than 80 years and who have diabetes have odd ratio of 9.2 compared to control group. It has been further found that people who have diabetes type 1 are more prone to covid19 mortality and for type 2 diabetes people mortality rate is low (Barron et al. 2020). The finding of the study is valid for the England population who are having type 1 and type 2 diabetes. Thus, the study finding cannot be generalised for other part of the world where the factors like ethnicity, diabetes level, age benchmark changes. To conclude, the study found that there is independent association between the covid19 mortality and in hospital death for type 1 and type 2 diabetes.
Paper 4:
Previous studies have demonstrated that lifestyle intervention can slow down the type 2 diabetes glucose tolerance level; however, it is uncertain that whether it result in fewer complication or enhanced longevity under uncertainty. Thus, Gong et al. (2019) authored their study to determine how long-term effect of lifestyle intervention with impaired glucose tolerance level have implication on diabetes and mortality. Based on the study design, it can be restated as null and alternative hypothesis.
Null hypothesis: there is no significant influence of lifestyle intervention in people with impaired glucose tolerance level on diabetes and mortality
Alternative hypothesis: there is positive significant influence of lifestyle intervention in people with impaired glucose tolerance level on diabetes and mortality
To analyse the association, four major variables were considered, as presented in figure 2, which diabetes, cardiovascular disease (CVD) event, CVD deaths and Compositive microvascular disease. Figure 2 demonstrated the difference in diabetes and mortality effect on control and intervention group. The finding demonstrated that intervention group has media delays in diabetes by 3.96 years (Gong et al. 2019). CVD event and CVD deaths represented a 1.44-year growth in life expectancy. Figure 3 finding demonstrates that intervention group has better hazard ratio during follow up time and significance level was 0.001. For the CVD event, CVD death, Composite microvascular disease also, intervention group demonstrated better outcome. Though the finding was good, it was limited in terms of size of sample. Apart from this, there was irregularities in participation examination and the finding was limited for diabetes type 2 patients only.
Reference:
Ataey, A., Jafarvand, E., Adham, D., & Moradi-Asl, E. (2020). The relationship between obesity, overweight, and the human development index in world health organization eastern Mediterranean region countries. Journal of Preventive Medicine and Public Health, 53(2), 98. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7142010/
Barron, E., Bakhai, C., Kar, P., Weaver, A., Bradley, D., Ismail, H., ... & Valabhji, J. (2020). Associations of type 1 and type 2 diabetes with COVID-19-related mortality in England: a whole-population study. The lancet Diabetes & endocrinology, 8(10), 813-822. https://www.ncbi.nlm.nih.gov/pmc/articles/pmc7426088/
Gong, Q., Zhang, P., Wang, J., Ma, J., An, Y., Chen, Y., ... & Roglic, G. (2019). Morbidity and mortality after lifestyle intervention for people with impaired glucose tolerance: 30-year results of the Da Qing Diabetes Prevention Outcome Study. The lancet Diabetes & endocrinology, 7(6), 452-461. https://www.ncbi.nlm.nih.gov/pmc/articles/pmc8172050/
Nyberg, S. T., Batty, G. D., Pentti, J., Virtanen, M., Alfredsson, L., Fransson, E. I., ... & Kivimäki, M. (2018). Obesity and loss of disease-free years owing to major non-communicable diseases: a multicohort study. The lancet Public health, 3(10), e490-e497. https://www.sciencedirect.com/science/article/pii/S2468266718301397
HI6007 Statistics for Business Decisions Assignment Sample
Assignment Specifications
Purpose:
This assignment aims at assessing students’ understanding of different qualitative and quantitative research methodologies and techniques. Other purposes are:
1. Explain how statistical techniques can solve business problems
2. Identify and evaluate valid statistical techniques in a given scenario to solve business problems
3. Explain and justify the results of a statistical analysis in the context of critical reasoning for a business problem solving
4. Apply statistical knowledge to summarize data graphically and statistically, either manually or via a computer package
5. Justify and interpret statistical/analytical scenarios that best fit business solution
Instructions:
• Your assignment must be submitted in WORD format only.
• When answering questions, wherever required, you should copy/cut and paste the Excel output (e.g., plots, regression output etc.) to show your working/output. Otherwise, you will not receive the allocated marks. Moreover, you must attach your excel file which includes data, output etc.
• You are required to keep an electronic copy of your submitted assignment to re-submit, in case the original submission is failed and/or you are asked to resubmit.
• Please check your Holmes email prior to reporting your assignment mark regularly for possible communications due to failure in your submission.
Group Assignment Questions for Assignment Help
Assume your group is the team of data analytics in a renowned Australian company. The company offers their assistance to distinct group of clients including (not limited to), public listed companies, small businesses, educational institutions etc. Company has undertaken several data analysis projects and all the projects are based on multiple regression analysis.
Based on the above assumption, you are required to.
1. Develop a research question which can be addressed through multiple regression analysis.
2. Note: This should be a novel research question and you are not allowed to directly copy from internet.
3. Explain the target population and the expected sample size
4. Briefly describe the most appropriate sampling method.
5. Create a data set (in excel) which satisfy the following conditions. (You are required to upload the data file separately).
a. Minimum no of independent variables – 2 variables
b. Minimum no of observations – 30 observations
Note: You are required to provide information on whether you used primary or secondary data,
data collection source etc.
3. Perform descriptive statistical analysis and prepare a table with following descriptive measures for all the variables in your data set. Mean, median, mode, variance, standard deviation, skewness, kurtosis, coefficient of variation.
4. Briefly comment on the descriptive statistics in the part (5) and explain the nature of the distribution of those variables. Use graphs where necessary.
5. Derive suitable graph to represent the relationship between dependent variable and each independent variable in your data set. (ex: relationship between Y and X1, Y and X2 etc)
6. Based on the data set, perform a regression analysis and correlation analysis, and answer the questions given below.
a. Derive the multiple regression equation.
b. Interpret the meaning of all the coefficients in the regression equation.
c. Interpret the calculated coefficient of determination.
d. At 5% significance level, test the overall model significance.
e. At 5% significance level, assess the significance of independent variables in the model.
f. Based on the correlation coefficients in the correlation output, assess the correlation
between explanatory variables and check the possibility of multicollinearity.
Solution
Introduction:
Under the changing business scenario, firms are now concerned about making strategies with the factors that actually influence their market value. Though there are various factors that can influence the market value, core factors like profit, sales and asset value are considered to be major element that has direct impact on market value. There has been considered able amount of research that demonstrates association between market value and various core factors; however, there is very limited study that demonstrate the relation for the Indian companies. Hence, to demonstrate the association between market value with the profit, sales and asset from the perspective of the Indian public listed companies, present study has been done. To perform the study, here statistical analysis has been done using excel where descriptive statistics and inferential statistical analysis has been used.
Research Question:
Research question of the present study is as follows:
How the market value of the Indian public listed companies is influenced by the profit, sales value and asset value of the company?
Target population and sample size:
In the present study Indian public listed companies enlisted in the Forbes 2000 list has been considered (Forbes.com 2021). As per the list, there were total 50 Indian companies who have successfully endured during the pandemic and performed best to be in top 2000 companies in the world (Forbes.com 2021). Thus, the population size of the study is 50 and considering 95% confidence interval with 5% margin of error, 45 observation has been considered as the sample for final study dataset.
Sampling method:
In the contemporary research work, sampling has various approach and they can be classified into two major groups, probability sampling and non-probability sampling. If the sample size considered based on randomisation, then it is probability sampling, whereas, if the sample size is decided by the convenience of the researcher, then it is non probability sampling (Etikan and Babtope 2019, p1006(2-5)). In case of probability sampling, it can further be divided into four types, which are random sampling, systematic sampling, stratified sampling and cluster sampling. For the present study, researcher has considered sample based on the randomisation, hence, the probability sampling has been considered and as the researcher has selected data randomly, from the population, thus it can be mentioned that sampling method has followed random sampling approach. Choosing non-probability sampling would make the bias selection of the data by the researcher making validity of the finding invalid. On the other hand, choosing systematic, stratified or clustered sampling is not justified as researcher has not made any group for the purpose of analysis. Thus, random sampling is the justified option for choosing sample.
Dataset creation:
Present study has considered data from the Forbes 2000 list where top 2000 public listed companies from world has been presented (Forbes.com 2021). As the dataset has been collected from the online source, thus secondary data collection approach has been used for making the dataset (Olabode et al. 2019, p(28(2)). The complete dataset available in Forbes provides country and industry wise top public listed company names who has exceled during pandemic. From this online data source, dataset from present study has been considered where four major variables were present which are:
• Market value
• Profit
• Sales value
• Asset value
All the values of the chosen variables have been presented in the form of Billion $. For making the dataset, first all available Indian public listed companies in the Forbes 2000 list have been considered and then through the random sampling, 45 companies have been used for making final sample dataset (Forbes.com 2021). For the further analysis, market value has been marked as the dependent variable, and profit, sales value and asset value has been marked as independent variable.
Descriptive statistical analysis:
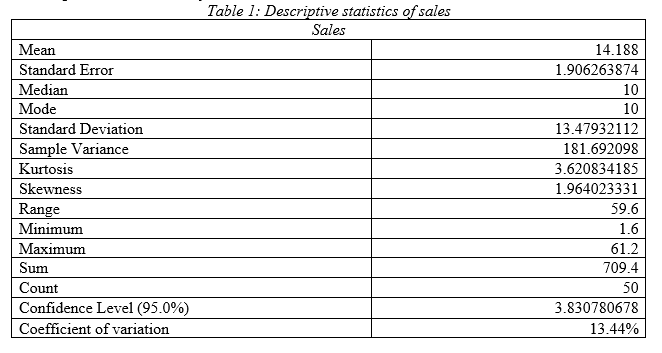
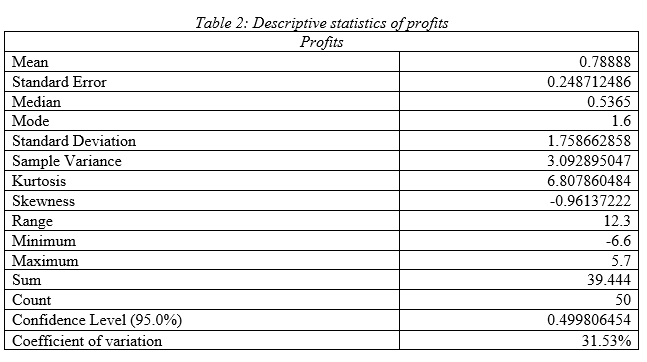
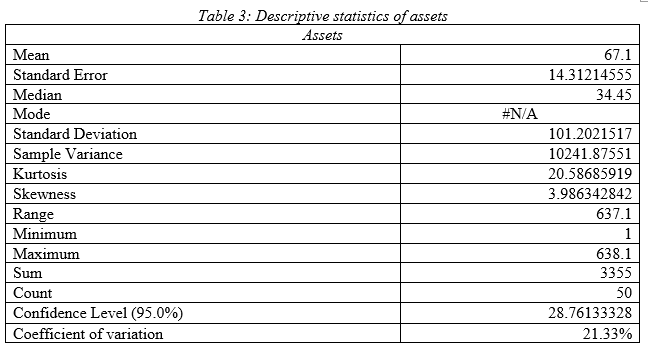
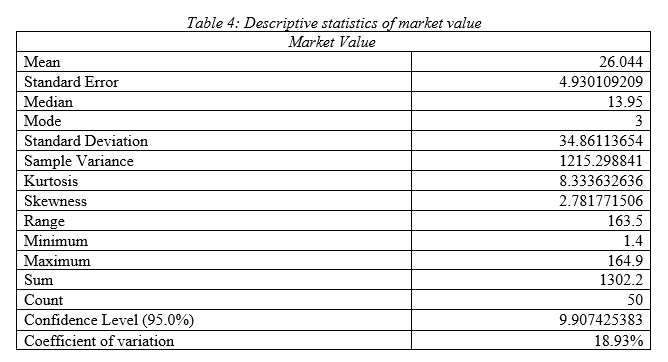
Comment on descriptive statistics:
As per the descriptive statistics of sales it can be seen that mean value of annual sales of the Indian public listed companies is 14.18 billion $ with standard deviation 13.47 and variance 181.69; hence, the Indian public listed firms have high variability in sales value (Acosta et al. 2020, p3(3)). Median is 10 and mode is 10; hence most of the firms have profit of 10 billion $. As per the kurtosis and skewness, it can be seen that data has outlier and there is right tail. High range of 59.6 demonstrates, upper and lower sales value has high difference that satisfies the fact that sales data has high variability in it. Comparing the coefficient of variation, it can be stated that it has lower variation in data compared to other variables.
As per the descriptive statistics of profits it can be seen that mean value of annual profit of the Indian public listed companies is .79 billion $ with standard deviation 1.75 and variance 3.09; hence, the Indian public listed firms have low variability in profit value. Median is .54 and mode is 1.6; hence most of the firms have profit of .536 billion $. As per the kurtosis and skewness, it can be seen that data has outlier and there is left tail. Moderate range of 12.3 demonstrates, upper and lower profit value has low difference that satisfies the fact that profit data has low variability in it. Comparing the coefficient of variation, it can be stated that it has highest variation in data compared to other variables.
As per the descriptive statistics of assets value it can be seen that mean value of annual asset value of the Indian public listed companies is 67.1 billion $ with standard deviation 101.20 and variance 10241.87; hence, the Indian public listed firms have very high variability in assets value. Median is 34.45; hence most of the firms have asset value of 34.45 billion $. As per the kurtosis and skewness, it can be seen that data has outlier and there is right tail. High range of 637.1 demonstrates, upper and lower asset value has very high difference that satisfies the fact that asset value data has high variability in it. Comparing the coefficient of variation, it can be stated that it has high variation in data compared to other variables.
As per the descriptive statistics of market value it can be seen that mean value of annual market value of the Indian public listed companies is 26.04 billion $ with standard deviation 34.86 and variance 1215.29; hence, the Indian public listed firms have high variability in market value. Median is 13.95 and mode is 3; hence most of the firms have market value of 10 billion $. As per the kurtosis and skewness, it can be seen that data has outlier and there is right tail. High range of 163.5 demonstrates, upper and lower market value has high difference that satisfies the fact that market value data has high variability in it. Comparing the coefficient of variation, it can be stated that it has moderate variation in data compared to other variables.
Graphical presentation of association between dependent and independent variable:
In order to represent the association between the dependent variable (market value) and independent variable (profit, assets and sales value), graphical presentation has been used.
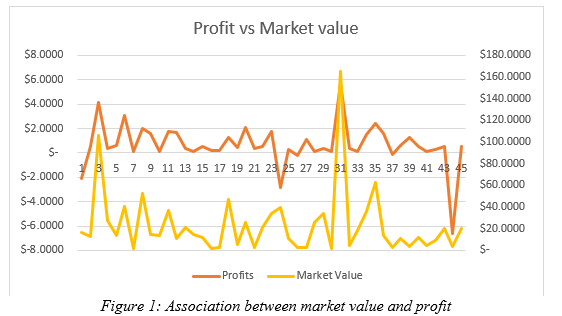
As per the figure 1, it can be seen that there is a good association between the market value and profit. As the profit of different firm changed, market value of the same has changed also. Major spikes can be seen for the 3rd, 31st and 43rd firm, where high change in the profit, and market value can be seen; however, the changes, is unidirectional. This means, overall change in the profit has resulted in change in market value in same direction.
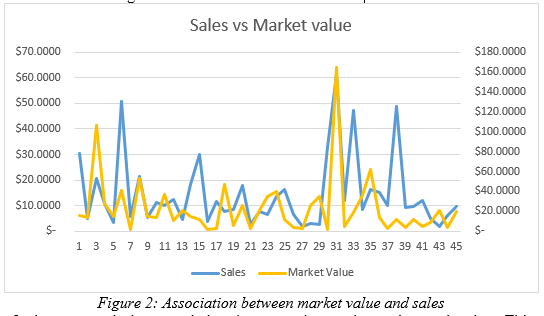
Figure 2 demonstrated the association between the market value and sales. This figure demonstrates a positive association between the dependent and independent variable. As the change occurred in sales value among the chosen Indian public listed companies, market value of the same has also changed. However, it is also important to mention that, there are some firms like 15th, 31st, 37th to 41st firm, where change in the sales value has not demonstrated identical change in market value. Thus, though the association between dependent and independent variable is positive, yet they are not very strong.
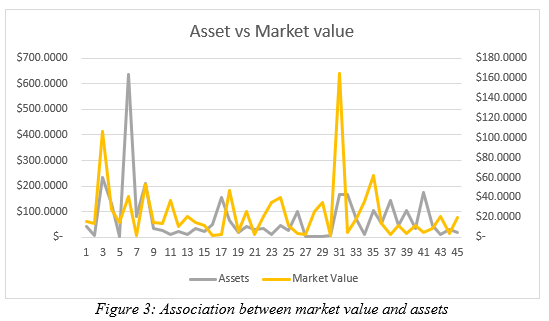
Figure 3 demonstrated association between the asset and market value. Here also change in asset price of the Indian public listed companies represent positive change in market value. However, it is also important to mention that there are certain companies like 5th, 31st, 21st to 25th, where change in asset price has been high, where as market value change has been very low. This demonstrates, though the association between asset price and market value is positive, yet it is not very strong.
Using the figure 3,
Regression analysis:
a.
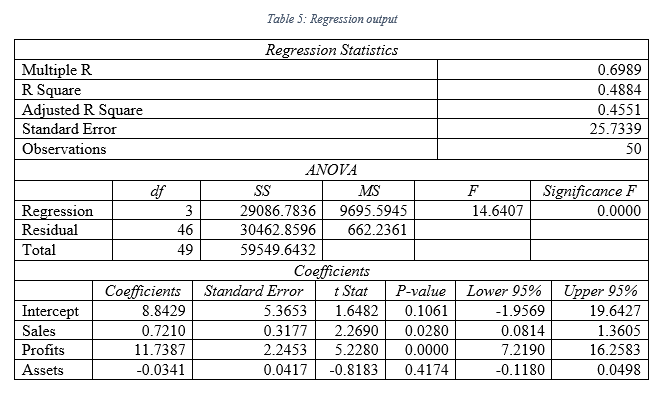
As per the regression output presented in table 5, following regression equation can be formed:
Y = 8.84 + 0.72x1 + 11.74x2 – 0.03x3
[Y represents the dependent variable market value, x1 is sales value, x2 is profit value and x3 is asset value]
b.
As per the outcome of the table 5, intercept term has been found to be 8.84; this means, even if the sales, profit and asset is nil, market value will be 8.84 billion $ for the Indian public listed companies. Sales coefficient demonstrates that, with change in each billion $ of sales, market value will be increased by .72 billion $. Coefficient of profits of 11.74 demonstrates, change in each billion $ of profit will lead to rise in market value of the Indian public listed companies by 11.74 billion $. Lastly, coefficient of -0.03 for assets, determines that change in each billion $ of assets can lead to change in market value by .03 billion dollars negatively; hence, if there is rise in asset, there will be fall in market value and vis-à-vis (Chicco et al., 2021, p6(2-3)).
c.
As per the table 5 outcome, coefficient of determination, which is R Square has been found to be 0.49. This defines that, independent variable in regression model developed can explain 56% of variability in the data of dependent variable (Kadim et al., 2020, p860(2)).
d.
At 5% level, F value significance has been found to be 0.00 and the F value is 14.64. Thus, the model is significant and a good fit model.
e.
At 5% significance level, independent variable can be considered to be significant, if the p value is lower than 0.05, which is critical value. As per the output in table 5, p value of sales has been 0.02, p value of profits has been 0.00 and p value of assets has been 0.41 respectively (Miko 2021, p2(3)). Hence, at 5% level of significance, sales and profit can significantly influence the market value as their p value is lower than 0.05.
f.
To check the multicollinearity, Variance Inflation Factors (VIF) has been used (Shrestha 2020, p39(2)).
VIF = 1/(1 – R Square) = 1/(1-.48) = 1/.52 = 1.92
As per the calculated VIF, it is lower than 5, hence there is multicollinearity.
Conclusion:
As per the analysis, it has been found that there is positive association between the market value and independent variables like sales, profit and asset value. Though the association between dependent and independent variables are positive, yet, the association for market value with sales and asset is weak. As per the regression analysis, it can also be seen that assets do not influence the market value significantly, whereas, profit and sales can influence the market value significantly.
Reference:
A Kadim, N Sunardi, T Husain (2020), The modeling firm's value based on financial ratios, intellectual capital and dividend policy, Accounting, 6(5), pp.859-870. http://m.growingscience.com/ac/Vol6/ac_2020_48.pdf
B Miko (2021), Assessment of flatness error by regression analysis, Measurement, 171, p.1 - 10. https://www.sciencedirect.com/science/article/pii/S0263224120312264
Chicco, D., Warrens, M.J. and Jurman, G., 2021. The coefficient of determination R-squared is more informative than SMAPE, MAE, MAPE, MSE and RMSE in regression analysis evaluation. PeerJ Computer Science, 7, p.e623. https://peerj.com/articles/cs-623/
Forbes.com 2021. GLOBAL 2000, The World's Largest Public Companies. Available at: https://www.forbes.com/global2000/#3f01c42f335d
I Etikan, O Babtope (2019), A basic approach in sampling methodology and sample size calculation, Med Life Clin, 1(2), p.1006. http://www.medtextpublications.com/open-access/a-basic-approach-in-sampling-methodology-and-sample-size-calculation-249.pdf
MN Acosta Montalvo, MA Andrade, E Vazquez, F Sanchez, F Gonzalez-Longatt, JL Rueda Torres (2020), Descriptive Statistical Analysis of Frequency control-related variables of Nordic Power System. https://openarchive.usn.no/usn-xmlui/bitstream/handle/11250/2758995/2020GonzalezLongattDescriptive_POSTPRINT.pdf?sequence=4&isAllowed=y
N Shrestha (2020), Detecting multicollinearity in regression analysis, American Journal of Applied Mathematics and Statistics, 8(2), pp.39-42. https://www.researchgate.net/profile/Noora-
Shrestha/publication/342413955_Detecting_Multicollinearity_in_Regression_Analysis/links/5eff2033458515505087a949/Detecting-Multicollinearity-in
-Regression-Analysis.pdf
SO Olabode, OI Olateju, AA Bakare (2019), An assessment of the reliability of secondary data in management science research, International Journal of Business and Management Review, 7(3), pp.27-43. https://www.researchgate.net/profile/Akeem Bakare 2/publication/344346438_AN_ASSESSMENT_OF_THE_RELIABILITY_OF_SECONDARY_DATA_IN_MANAGEMENT
_SCIENCE_RESEARCH/links/5f6a7ff0a6fdcc0086346109/
AN-ASSESSMENT-OF-THE-RELIABILITY-OF-SECONDARY-DATA-IN-MANAGEMENT-SCIENCE-RESEARCH
STA201 Business Statistics Assignment Sample
Assessment - Analytics Assignment
Individual/Group - Individual
Length - 1000 Words
Learning Outcomes - The Subject Learning Outcomes demonstrated by successful completion of the task below include:
a) Produce, analyse, and present data graphically and numerically, and perform statistical analysis of central tendency and variability.
b) Apply inferential statistics to draw conclusions about populations, including confidence levels, hypothesis testing, analysing variance and comparing with benchmarks in decision making processes.
c) Measure uncertainty, including continuous and discrete probability and sampling distributions to select appropriate methods of data analysis.
d) Apply parametric tests and analysis techniques to determine causation and forecasting to assist decision making.
e) Utilise technology to analyse and manipulate data and present findings to peers and other stakeholders.
Submission Due by 11:55 pm AEST/AEDT Sunday end of Module 6.2 (Week 12).
Weighting - 30%
Assessment Tasks for assignment help
1. Prepare a summary statistics table and discuss the central tendency and variations for all variables.
2. Plot the dependent variable (house price), against each independent variable using scatter plot/dot function in Excel. Comment on the strength and the nature of the relationship between the dependent and the independent variables.
3. Generate a multiple regression summary output. Using the information on regression output, state the multiple regression equation.
4. Interpret the meaning of slope coefficients of independent variables.
5. Interpret the R 2 and adjusted R 2 of your model.
6. Conduct a test for significance of your overall multiple regression model at the 0.05 level of significance. You must state your null and alternative hypotheses.
7. At the 0.05 level of significance, determine whether each independent variable makes a significant contribution to the regression model. Based on these results, indicate the independent variables to include in this model.
8. Construct a 95% confidence interval estimate of population slope of house prices withproperty size. Interpret your results.
9. Construct a 95% confidence interval estimate of population slope of house prices with distance to nearest train station. Interpret your results.
10. Choose one of the houses currently advertised for sale in your chosen suburb (the one to collect the data of). Make sure to choose a house whose asking price is also advertised. Predict the price of the house using the regression equation you generated in part 3 and values of the independent variables as advertised. Compare the predicted price with the asking price.
Solution
Task 1: summary statistics:
As per the table 1 in appendix, it can be seen that mean value of sale price is $465542 with median $422500 and mode $420000. Hence, the average sales price is $465542, whereas most of the property price is $420000, thus the data is not normally distributed. Standard deviation is 141997.29 and sample variance is 20163229016.33. Thus, the housing sales price has very high variability in it. Kurtosis value of 3.09 signifies the fact that there are outliers and range of $790000 also demonstrates maximum and minimum housing price has very high difference in it (Bono et al., 2019). Mean value of bedroom is 3.78 with mode 4.
Average bedroom number is 3.78 whereas most of the property has 4 bedrooms. Standard deviation and sample variance is 0.51 and .26 respectively. Thus, the variation in data of bedroom is low. Kurtosis value is 2.42 that showcase there is low number of outliers with negative skewness that has right tail. Bathroom average count is 1.86 with mode 2. Thus, most of the houses has 2 bathrooms with average value of bathroom 1.86. Low standard deviation of 0.45 and sample variance of 0.20 showcase bathroom data has limited variability. Kurtosis value is 1.39 with range of 2 showcase there is low to moderate variability in the bathroom count data.
Property size has mean value of 791.40 m2 with mode752 m2 and median of 751 m2. Thus, most of the property size is 751 m2 with average value of 791.40 m2. Standard deviation and sample variance is very high that showcase property size has high variability. Kurtosis value of 34.49 and range of 3837 showcase there is very high variability in property size data. As per skewness of 5.37, data is highly skewed, and it has left tail. Average distance of property from metro station is .46 km, however, as per mode, most of the property has average distance of .43 km. Thus, the data is normally distributed, and it has low variability with standard deviation of .29 and sample variance of .08. Kurtosis of 4.05 demonstrates there is outliers and range signifies that the data has low variability in it.
Task 2: plotting dependent variables against independent variable:
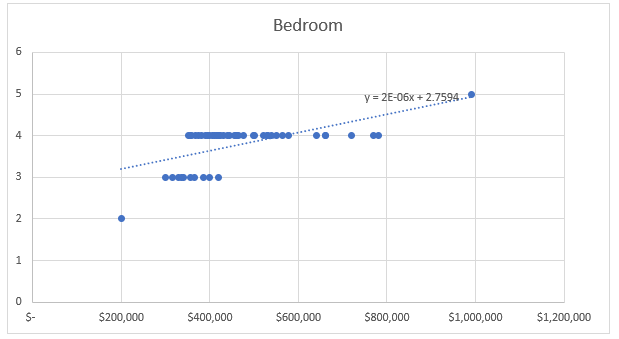
Figure 1: Association between number bedroom and property price
Figure 1 demonstrates the association between bedroom and property price. Though the plots did not showcase anything clearly, however, an upward sloping trend line demonstrated a positive association between the variables (Schober et al., 2018). Positive association demonstrates increase in number of bedrooms, increase the housing price.
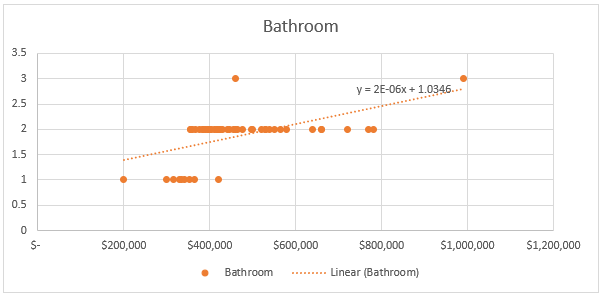
Figure 2: Association between bathroom number and property price
As per the figure 2 it can be seen that there is also an upward trend in price as the number of bathroom increases. Hence, the association is positive, however the degree of association is not clear from here.
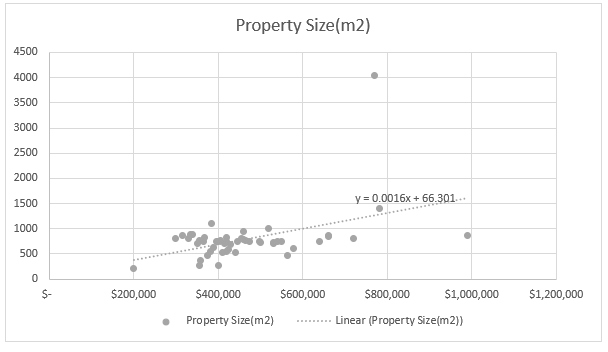
Figure 3: Association between property size and property price
Figure 3 demonstrated as the property size increase; price of property also increase. However, the plots are not scattered demonstrating, as the property size increase price of property does not increase moderately. Hence, though the trend line showcase a positive association between two values, yet the degree of association is not very high.
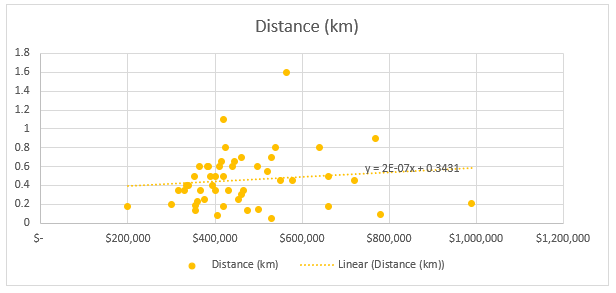
Figure 4: Association between distance from metro and property price
Figure 4 demonstrates a positive association between the distance from metro and property price. Hence, with rise in distance of property from metro, price tends to rise. However, as the distance increase, housing price does not increase proportionately as per plot demonstrating a weak association.
Task 3: Multiple regression:
To develop model that can predict the housing price based on independent variables, multiple regression has been done here. As per table 2 in appendix, following regression model can be mentioned:
Y = -169462.44 + 104230.45 * X1 + 80772.80 * X2 + 100.18 * X3 + 25196.60 * X4 [Where, Y is property price, X1 is bedroom number, X2 is bathroom number, X3 is property size and X4 is distance from metro]
Task 4: Slope coefficient interpretation:
As per table 2, slope coefficient of bedroom is 104230.45 which mean, change in 1 unit of bedroom can lead the property price to increase by $104230.45. Slope coefficient of bathroom demonstrates 1 unit of bathroom addition can lead to rise in house price by $80772.80. As per property size slope coefficient, 1 m2 rise in property size increase the property price by $100.18. Distance slope coefficient, 1 km rise in distance can increase the housing price by $25196.60.
Task 5: R2 and adjusted R2 model:
R square value of the model is 0.53, which mean independent variables can explain 53% of variability of the data in dependent variable. Adjusted R Square demonstrates how additional independent variable can change the predictability of the model for dependent variable (Sharma et al., 2021). Adjusted R Square value of 0.49, means addition of exploratory variables can actually fails to make the model more significant in predicting variability of data.
Task 6: Test of significance of model:
Null hypothesis: H0: Fit of intercept only model is equal to predicted model
Alternative hypothesis: H1: Fit of intercept only model is significantly reduced compared to predicted model
As per the ANOVA in table, F value is 0.00, which is lower than critical value of 0.05. Hence, the model is a good fit model and null hypothesis is accepted here.
Task 7: Test of significance of independent variable:
At 0.05 level of significance, as per table 2, only bedroom and property size seems to significantly influence the property price as their p value is 0.02 and 0.00 respectively. For other exploratory variables, p value is 0.1 (for bathroom) and 0.62 (for distance) which is higher than critical value of 0.05. Thus, bathroom and distance cannot significantly influence the property price.
Considering the significance of bedroom and property size, these factors can only be included in the regression model; thus, the revised regression model is as follows:
Y = -169462.44 + 104230.45 * X1 + 100.18 * X3
Task 8: 95% confidence interval of property size:
Confidence interval = b1 ± t(1-α)/2, n-2 * se(b1)
At 95% confidence interval, t(1-α)/2, n-2 = 2.011
b1 = 100.18
se(b1) = 28.92
Confidence interval = 100.18 ± 2.011 * 28.92 = 58.13
Confidence interval = 100.18 ± 58.13 = 158.13, 42.05
So, with 95% confidence interval, one m2 change in property size change the housing price between $158.13 and $42.05.
Task 9: 95% Confidence interval of distance:
Confidence interval = b1 ± t(1-α)/2, n-2 * se(b1)
At 95% confidence interval, t(1-α)/2, n-2 = 2.011
b1 = 25196.60
se(b1) = 51167.47
Confidence interval = 25196.60 ± 2.011 * 51167.47 = 128094.38, -77701.18
So, with 95% confidence interval it can be said that with 1 km change in distance, housing price change between $128094.38 and -$77701.18.
Task 10: Estimation of House Price:
House price at Clayton with 3-bedroom, 1 bathroom, 191 m2 property size and .5 km distance to metro:
Y = -169462.44 + 104230.45 * 3 + 100.18 * 191 = $162363.61
Hence, the estimated property price at Clayton would be $162363.31
Reference:


- Assignment - Child Care
- Assignment - Mathematics
- Assignment - Accounting
- Assignment - Auditing
- Assignment - Biology
- Assignment - Law
- Assignment - Management
- Assignment - Nursing
- Assignment - Finance
- Assignment - Computer Science and IT
- Assignment - Humanities
- Assignment - Economics
- Assignment - Statistics
- Assignment - Architecture
- Assignment - Engineering
- Assignment - cookery
- Assignment - Marketing
- Case Study - Chemistry
- Case Study - Accounting
- Case Study - Law
- Case Study - Management
- Case Study - Nursing
- Case Study - Finance
- Case Study - Computer Science and IT
- Case Study - Engineering
- Case Study - Economics
- Case Study - Biology
- Case Study - Auditing
- Case Study - Marketing
- Case Study - Project Management
- Coursework - Diploma
- Coursework - Accounting
- Coursework - Auditing
- Coursework - Biology
- Coursework - Management
- Coursework - Nursing
- Coursework - Finance
- Coursework - Computer Science and IT
- Coursework - Engineering
- Coursework - Humanities
- Coursework - Child Care
- Coursework - Project Management
- Coursework - Economics
- Coursework - Cookery
- Coursework - Law
- Dissertation - Accounting
- Dissertation - Auditing
- Dissertation - Biology
- Dissertation - Law
- Dissertation - Management
- Dissertation - Nursing
- Dissertation - Finance
- Dissertation - Computer Science and IT
- Dissertation - Humanities
- Dissertation - Economics
- Essay - Politics
- Essay - Childcare
- Essay - Accounting
- Essay - Biology
- Essay - Law
- Essay - Management
- Essay - Nursing
- Essay - Computer Science and IT
- Essay - Humanities
- Essay - Economics
- Essay - Auditing
- Essay - Engineering
- Essay - Architecture
- Essay - Finance
- Essay - Science
- Essay - Marketing
- Programming - Computer Science and IT
- Reports - Management
- Reports - Computer Science and IT
- Reports - Project Management
- Reports - Marketing
- Reports - Nursing
- Reports - Engineering
- Reports - Accounting
- Reports - Humanities
- Reports - Finance
- Reports - Architecture
- Reports - Biology
- Reports - Economics
- Reports - Childcare
- Reports - Law
- Research - Accounting
- Research - Auditing
- Research - Biology
- Research - Law
- Research - Management
- Research - Nursing
- Research - Finance
- Research - Computer Science and IT
- Research - Science
- Research - Engineering
- Research - Humanities
- Research - Economics
- Research - Project Management
- Research - Statistics
- Research - Architecture
- Research - Marketing
- Thesis Writing - Computer Science and IT
- Thesis Writing - Engineering
- Thesis Writing - Biology
- Thesis Writing - Finance
- Thesis Writing - Humanities
- Thesis Writing - Auditing
- Thesis Writing - Economics
- Thesis Writing - Law
- Thesis Writing - Nursing
- Thesis Writing - Accounting
- Thesis Writing - Architecture


.png)
~5.png)
.png)
~1.png)























































.png)






