Character Embedded Based Deep Learning Approach For Malicious Url Detection
Learning Outcomes
The aim of this research is to enable you to undertake a sizeable piece of individual academic work in an area of your own interest relevant to, and to demonstrate technical skills acquired in, your programme of study.
This postgraduate work will include an advanced level of research, analysis, design, implementation and critical evaluation of your solution.
You must cover the following topics in practice by applying them to your chosen research project:
• Identification of a suitable research topic,
• Research methods,
• Literature surveys, searches and reviews, Dissertation
• Plagiarism and referencing,
• Effectively engaging with academic research both on a theoretical and practical point of view,
• Academic writing and presentation skills for matlab dissertation help
• The development and documentation, to a master level standard, of a large, non-trivial and genuine research project aligned with your Master of Science programme.
At the end of this module, you will be able to:
Knowledge
1. Demonstrate an advanced knowledge of one chosen and highly specific area within the scope of your Master of Science programme and to communicate this knowledge through both a written report (dissertation) and an oral assessment,
2. Demonstrate the knowledge of research methods appropriate for a master level course and to communicate this knowledge through both a written report (dissertation) and an oral assessment
The Contents of your Dissertation
It must include the following sections:
• Title page showing the title, student number, programme, year and semester of submission,
• Contents page(s),
• Acknowledgements (if you wish to acknowledge people that have helped you),
• Abstract,
• Body of the dissertation,
• List of references,
• Appendices (including implementation code).
Observe the following guidelines when writing your dissertation:
• Your dissertation must be word-processed. In particular, hand written submissions will NOT be accepted. You are also encouraged to use LATEX typesetting, which is best for producing high quality, well-formatted scientific publications. Overleaf (www.overleaf.com) is an online LATEX editor.
• Pages must be numbered but you will find paragraph numbers easier for cross referencing.
• Appendices should only contain supporting documentation which is relevant to the report in which they are included. Their size should be kept to a minimum.
• Material must be accurate and presented in a structured manner.
• The information contained within your dissertation should be presented in such a way as to allow both staff and students in the future to read, understand and learn from you.
• The word limit should be adhered to (see Section 21.). Indeed, this limit is set to force you to synthesize your thoughts. This ability is very important in industry as you must convey to your colleagues and managers the key ideas about your work in a clear and concise way. However, I point out that massively moving content from the body of your report to appendices is not a substitute for writing concisely.
• The code of your implementation must be submitted as appendices. It does NOT count towards the word limit.
This is a 60-credit course and its assessment is based on two elements:
• The writing of a 15,000-word dissertation (with a tolerance of ± 10% for the length of the final document),
• A presentation of the research work. This presentation will be in the form of a viva-voce where you will be required to present and defend your work.
Solution
Chapter 1
1.1 Introduction
Malicious URLs are the purpose of promoting scams as well as frauds and attacks. The infected URLs are actually detected by the antiviruses. There are various approaches to detecting malicious URLs which are mainly categorized by four parts such as classification based on contents, blacklists, classification based on URLs, and approach of feature engineering. Several linear and non-linear space transformations are used for the detection of malicious URLs; this actually improves the performance as well as support. The Internet is the basic part of daily life and the Uniform resource locator (URLs) are the main infrastructure for the entire online activities and discriminate the malware from benign problems. URL involves some of the complicated tasks such as data collection in a constant manner and feature extraction and pre-processing of data as well as classification. The online systems which are specialized and draw a huge amount of data are always challenging the traditional malware detection methods. The malicious URLs are now frequently used by criminals for several illegal activities such as phishing, financial activities, fake shopping, gaming, and gambling. Omnipresence smartphones are also the cause of illegal activities stimulated by the code of Quick response (QR) and encode the fake URLs in order to deceive the senior people. Detection of malicious URLs is focused on the improvement of the classifiers. The feature extraction and the feature selection process improves the efficiency of classifiers and integrates non-linear and linear space transformation processes in order to handle the large-scale URL dataset.
Deep learning embedded Data Analysis is in effect progressively utilized in digital protection issues and discovered to be helpful in situations where information volumes and heterogeneity make it bulky for manual appraisal by security specialists. In useful network protection situations including information-driven examination, acquiring information with comments (for example ground-truth names) is a difficult and known restricting component for some administered security examination tasks. Huge parts of the huge datasets commonly stay unlabeled, as the assignment of comment is broadly manual and requires an enormous measure of master mediation. In this paper, we propose a viable dynamic learning approach that can proficiently address this limit in a reasonable network protection issue of Phishing classification, whereby we utilize a human-machine community-oriented way to deal with plan a semi-regulated arrangement. An underlying classifier is learned on a limited quantity of the explained information which in an iterative way, is then slowly refreshed by shortlisting just important examples from the enormous pool of unlabeled information that is destined to impact the classifier execution quickly. Focused on Active Learning shows a critical guarantee to accomplish quicker intermingling regarding the grouping execution in a cluster learning structure and in this manner requiring much lesser exertion for a human explanation.
1.2 Background
The Malicious URLs are used by cybercriminals by some unsolicited scams, malware advertisements, and phishing methods. Detecting malicious URLs includes the approaches of signature matching and regular expression as well as blacklisting. The classic system of machine learning systems is actually used for the detection of malicious URLs. The state of art is used to evaluate and from the architectures and the features are essential for the embedding methods of malware URL detection. URLDetect or DURLD is used to encode the embedding which is done at the character level. In order to capture the different types of information encoded in the URL, use the architectures of deep learning in order to extract the features at the character level and estimate the URL probability. Currently, malicious features are not extracted appropriately and the current detection methods are currently based on the DCNN network in order to solve the problems. On the multilayer original network, another new folding layer is added and the pooling layer is being replaced by the K-max layer of pooling and using the dynamic convolution algorithm the middle layer in the feature mapping width. The internet users are actually tricked by using phishing techniques and spam by the hackers and the spammers. They are also using the Trojans and malware URLs to leak the sensitive information of the victims. In the traditional method, the detection of malicious URLs is adopted using methods based on the blacklist. This method actually has some of the advantages such as it improves the high data speed and reduces the rate of false positives and this is very easy for the realization. In recent times, the algorithm of domain generation for detecting the different malicious domains in order to detect the blacklist method of traditional methods (Cui et al. 2018, p. 23).
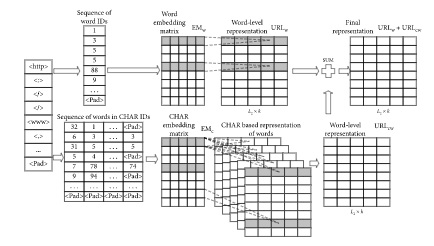
Figure 1: Method of word embedding
(Source: Verma and Das, 2017, p. 12)
The machine learning process is used to detect the model based on prediction and the statistical properties are classified as the benign URL. According to the model of vector embedding, the URL sequence is imputed in the proper vector and the subsequent process is being facilitated. This process is being initialized in a normal manner and the appropriate expression of the vector is being used for the training process. The advanced word embedding method is being used for character embedding. This data is extracted the phase information from the Unique resource locator and the extracted information is being extracted for the subsequent training process in order to obtain the proper expression vector and this is provided in the subsequent layer of convulsion. According to the method of dynamic conclusion, the input data is gathered from the extracted features. The procedure of this system includes folding, convulsion, and dynamic pooling which is suggested by the DCNN parameters for the current layer of convulsion. According to the DCNN training the output of the upper layer is being inputted in the next layer of the networks in order to convert the expression of the suitable vector. According to the method of the block extraction, the name of the domain, as well as the subdomain name, actually encodes the branch of the second data. In the embedding layer, the unique resource locator is actually used at the top level of the management (Patgiri et al. 2019, p. 21).
The powerlessness of the end client framework to recognize and eliminate the noxious URLs can place the real client in weak condition. Besides, the use of noxious URLs may prompt ill-conceived admittance to the client information by foe (Tekerek, 2021). The fundamental thought process in vindictive URL recognition is that they give an assault surface to the foe. It is essential to counter these exercises through some new approaches. In writing, there have been many separating components to identify the noxious URLs. Some of them are Black-Listing, Heuristic Classification, and so on These conventional instruments depend on catchphrase coordinating and URL linguistic structure coordinating. Subsequently, these traditional systems can't successfully manage the consistently advancing innovations and web-access methods. Besides, these methodologies additionally miss the mark in recognizing the advanced URLs like short URLs, dull web URLs. In this paper, we propose a novel characterization technique to address the difficulties looked at by the customary components in vindictive URL recognition. The proposed arrangement model is based on modern AI techniques that not just take care of the linguistic idea of the URL, yet in addition the semantic and lexical importance of these powerfully evolving URLs. The proposed approach is required to beat the current methods.
1.3 Problems analysis
In this section, the domain names, as well as the subdomain names, are extracted from the Unique resource locator and each URL has a fixed length which is actually being flattened in the flattened layer where the domain names, as well as subdomain names, are being marked. The common users need to use the advantages of the word embedding process which effectively express the rare words. The rare words can be represented accurately by the word embedding system in the URL. This method actually diminishes the scale of the present embedded matrix and thus memory space is also being reduced. This process is also converting the words which are new and the accurate vectors are not existing in the training sets and this helps to extract the character information. The attackers and the hackers are actually communicate using a control center through the DGA names which are malicious in nature and the structure of the network actually select a large amount of the URL data sets and the subdomains and domains in the top level are included at the dataset division (Sahoo et al. 2017, p. 23).
The deeply embedded learning process has been the most efficient way in determining the malicious websites causing potential threats to the users. These sites do not only contain damage-causing elements, but they can also get into a system and steal the data of a user and outsource it on the internet. If you notice at the address bar while using certain websites, they have very long URLs. These long texts indicate the subsidiary file directory of the file where it is present, clearly stating the parent folders and file name in the text. This deep learning process is easy to apply on such websites having long texts in the URL as it covers the maximum amount of data that the URL holds. But providing the same kind of security with short text URLs gets difficult (Cui, He, Yaoand Shi, 2018). These websites are more open to getting affected by such malicious websites. Therefore, the leaked data is mostly from websites having short URLs as the technology does not secure the subsidiary files and folders. Hence, the algorithm and working of the deeply embedded learning process need to modify in such a way that it covers each type of website with the best protocols.
1.4 Aim and Objectives
Aim
The preliminary aim of this research is to investigate character embedded-based deep learning approaches for malicious URL detection.
Objectives
- To determine the effects of multi-layer perception for determining malicious URL
- To determine the effects of artificial neural networks for determining malicious URL
- To determine the process of the deep embedded learning process for reducing malicious activities
- To recommend strategies for the machine learning process for eliminating malicious activities
1.5 Research Questions
- How to determine the effects of multi-layer perception for determining malicious URLs?
- How to determine the effects of artificial neural networks for determining malicious URLs?
- How to determine the process of deep embedded learning to reduce malicious activities?
- What are the recommended strategies for the machine learning process for eliminating malicious activities?
1.6 Rationale
Malicious URL is a well-known throat that is continuously surrounding the territory of cybersecurity. These URLs act as an effective tool that attackers use for propagating viruses and other types of malicious online codes. Reportedly, Malicious URLs are responsible for almost 60% of the cyber-attacks that take place in the modern-day (Bu and Cho, 2021). The constant attacks through malicious URLs are a burning issue that causes almost millions of losses for organizations and personal data losses for individuals. These malicious URLs can easily be delivered through text messages (Le et al. 2018). Email links, browsers and their pop-ups, online advertisement pages, etc. In most cases of cybersecurity casualties, these malicious URLs are directly linked with a shady website that has some downloadable embedded. These processes of downloads and downloaded materials can be viruses, spy-wares, worms, key-loggers, etc. which eventually corrupts the systems and sucks most of the important data out of it (Saxe and Berlin, 2017).
Nowadays, it has become a significant challenge for app developers and cyber security defenders to deal with these unwanted malicious viruses and mitigate them properly in order to protect the privacy of individuals and organizations. Previously the security protectors have significantly tried to use URL blacklisting and signature blacklisting in order to detect and defend the spread of malicious URLs (Vinayakumar et al. 2018). Although with the advancement of technology attackers have implemented new tools that can spread malicious URLs and it has become a constant huddle for cybersecurity professionals to deal with these problems. In order to improve the abstraction and timelessness of the malicious URL detection methods, professionals are developing python based machine learning techniques that can deal with this issue automatically by recognizing the malicious threats beforehand.
The issue of malicious URLs is becoming the most talked-about threat nowadays because on a daily basis worldwide companies and individuals are facing unwanted attacks from malicious attackers via malicious URLs. Reports from the FBI states that almost 3.5 billion records of data were lost in 2019 due to malicious attacks on their server. Also, according to some research, almost 84% of the worldwide email traffic is spam (Yang, Zhao, and Zeng, 2019). Some of the research work from IBM has confirmed that almost 14% of the malicious breaches surprisingly involve the process of phishing. Some of the related research has pointed out that almost 94% of the security attacks involve the process of malicious URLs and injecting malware through email (Yang, Zuo and Cui, 2019). Most of the common scams that involve malicious URLs generally involve phishing and spam. Phishing is a process of fraud that criminals generally use in order to deceive the victims by impersonating trusted people or organizations. The work process of Phishing involves receiving a malicious URL via email from a trusted individual or organization and after clicking on that particular URL most of the important data is hacked and compromised by the attackers. Nowadays it has become a process of spoofing some known addresses or names of individuals.
The emerging risk of malicious URLs and security casualties due to it has become a massive issue in today’s digital world. Security professionals face constant huddles dealing with this issue at the present time. In this scenario, developers need to take the process of a deep learning-based approach in order to mitigate the issues with these malicious URLs. In order to detect malicious URLs professionals can take character embedded-based deep learning approaches. Developing an effective machine learning system programmed with Python can be an efficient step for the developers in order to mitigate the issue of security attacks through Malicious URLs.
The research regarding the credibility of character embedded-based deep learning to detect malicious URLs can guide further researchers towards the way they should form their research. Additionally, this research can provide a wide range of scenarios that can efficiently describe multiple circumstances and parables of malicious URL attacks. The increase in the scam rates in recent years needs to be resolved with python-based embedded deep learning and this research attempts to identify the loophole in the existing system and tries to point out the issues regarding the harmful effect of malicious URLs.
1.7 Summary
The different sections of the introductory chapter provide the basics of the research efficiently where it introduces the credentials of malicious URLs and their extensive effect on the everyday security struggle of individuals and organizations. It efficiently points out the main aims and objectives of the research and clarifies what range will be covered by the researchers in the whole research paper. It also discusses the emerging issues of malicious URLs and how python based deep learning techniques can be fruitful and efficient to mitigate the security casualties caused by malicious URLs. Through the different parts of the introduction chapter, the researchers provide an insight into the whole territory that the research will cover and it also ensures that the issues with malicious URLs are resolved with an effective character embedded-based deep learning approach.
Chapter 2: Literature Review
2.1 Introduction
This literature part introduces the main detection control process based upon the blacklist. Hackers use spam or phishing for tricking customers into pressing on malicious URLs, which will be affected and implanted on any victims’ system or computers, and these victims’ personal sensitive data information would be hacked or leaked on social platforms. This type of malicious technology URLs detection could help each user to identify the malicious URLs and can prevent the users directly from attack by the malicious URLs. Traditionally, this research upon malicious URLs detection has adopted blacklist-based control methods for detecting malicious URLs. These methods have many unique benefits. The literature review has to point out which attackers could generate several malicious related domains as names by a simple seed for effectively evading the previous traditional system to detect this. Hence, nowadays, a domain control generation regarding algorithms or DGA could generate thousands of several malicious URL domain user names per day that could not be properly detected by the traditional method of blacklist-based effectively.
2.2 Conceptual framework
(Sources: Self-created)
2.3 Multilayer perceptron
Web-based applications are highly popular nowadays, be it online shopping, education, or web-based discussion forums. The organizations have vastly benefited from the employment of these applications. Also, most website developers rely on Content Management System (CMS) to build a website, which in turn uses lots of third-party plug-ins which have a lack of control. These CMS were created with a motive for people with less knowledge of computer programming, graphics imaging to build their website. However, they are patched for security threats, which becomes an easy way for hackers to steal valuable information from the website. This in turn exposes the website to cybersecurity risks such as Uniform Resource Locator (URL). These can lead to various risky activities like doing illegal activities on the client-side, further embedding malicious scripts into the web pages thereby exploiting the vulnerabilities at the end of the user. The study focuses on measuring the effective nature of identifying malicious URLs by using the multilayer Perception Technique. With the study, the researchers are trying to create a safe option for web developers to further improve the security of web-based applications.
Living with the 21st century, the world is moving towards obtaining so many technologies. The countries are at their best to produce and innovate the best of the technology to set up a benchmark in the entire world, and so does the UK. It is considered one of the most developed in terms of technology and is a civilized country. Since the developers have taken the country to a technological upfront, this makes the people much aware now of the innovated technologies and information systems. Modern or advanced technologies are developed to make the working of humans easier. People use modern technology to ease their work but there are people who try to deceive others and make fake and fraudulent technologies that are disguised as the real ones (SHOID, 2018). They do so with the intention to steal other’s personal data. This research is conducted with the objective to learn the approach for malicious URL detection. URL is termed as Uniform Resource Locator; it is an address of a given unique resource on the Web. So, what happens is that the people with wrong intentions or hackers try to create a malicious URL. This technique is termed mimicking websites.
The study lists the various artificial intelligence (AI) techniques used in the detection of malicious URLs that come in Decision Tree, Support Vector Machines, etc. The main reason for choosing Multilayer Perceptron (MLP) technique is because it is a "feed-forward artificial neural network model", primarily effective in identifying malicious URLs when the networks have a large dataset (Kumar, et al. 2017). Also, many others have stressed on the MLP technique having a high accuracy rate. The study has an elaborative explanation of the various techniques to identify malicious URLs, also giving an overview of studies on the particular topic. The research methodology consisted of the collection of 2.4 million URLs, where the data was pre-processed and divided into subsets. The result of the experiment was measured on the number of looping/epochs that are produced by the MLP system. Where the best performing URLs will be shown by a smaller number of looping/epochs and the bad ones by a greater number of looping/epochs. The dataset has been further divided into Matlab three smaller datasets which are the training dataset, validation dataset, and testing dataset. The training dataset trains the neural network by adjusting the weight and bias during the training stage. The validation dataset estimates how well the neural network model has been trained (Sahoo, Liu and Hoi, 2017).
After being trained and validated, the testing dataset evaluates the neural network. With the examples of figures, the study delineates the performance of training, validation, and testing in terms of mean squared error, where the iteration (epochs) moves forward. The study, however, seemed skeptical on suggesting the fastest training algorithm, as the training algorithm is influenced by many factors that include the complexity of the problem, the count of weights, the error goal, the number of data points in the training set. The vulnerabilities identified in Web applications; the most recognized ones are the problems caused by unchecked input. The attackers have to inject malicious data into web applications and manipulate applications using malicious data to exploit unchecked input. The study provided an extensive review on various techniques Naive Bayes, Random Forest, K-nearest neighbors, LogitBoost.The study used the Levenberg-Marquardt Algorithm (trainlm) as it was the fastest training function based on feedforward artificial neural network and the default training function as well. With the validation and test curves being quite similar, it meant that the neural network can predict the minimum error if compared with the real data training.
The study has however proved on the MLP system being able to detect, analyze and validate the malicious URLs, where the accuracy was found to be 90-99%. Achieving the objective and scope of the study by using data mining techniques in the detection and prediction of malicious URLs. Despite producing successful data, the study highlights the improvements: Gathering more information from experts for increasing accuracy leading to better reliability within the system (Le, et al. 2018). Further development of the system by enhancing knowledge in data mining along with improving neural network engines in the system.
For better accuracy, the system can be improved by using a hybrid technique where the study suggested combining the system with the Bayesian technique, decision tree, or support vector techniques.
The detection of malicious URLs has been addressed as a binary classification problem. The paper studies the performance of prominent classifiers, which includes Support Vector Machines, Multi-Layer Perceptrons, Decision Trees, Na¨?ve Bayes, Random Forest, and k-Nearest Neighbors. The study also adopted a public dataset that consisted of 2.4 million URLs as examples along with 3.2 million features. The study concluded that most of the classification methods have attained considerable, acceptable prediction rates without any domain expert, or advanced feature selection techniques as shown by the numerical simulations. Out of all the methods, the highest accuracy was attained by Multi-Layer Perceptron, and Random Forest, in particular, attained the highest accuracy. Highest scores for Random Forest in precision and recall. They indicate not only the production of the results in a balanced and unbiased prediction manner but also give out credibility. It enhances the method's ability to increase the identification of malicious URLs within reasonable boundaries. When only numerical features are used for training, the results of this paper indicate that for URL classification the classification methods must achieve competitive prediction accuracy rates (Wejinya and Bhatia, 2021).
2.4 Artificial neural network (ANN)
The study approaches the convolutional neural network algorithm for classification of URL, Logistic regression (LR), Support Vector Machine (SVM). The study, at first, gathered data, collected websites offering malicious links via browsing, and crawled on several malicious links from other websites. The Convolutional neural network algorithm was first used to detect malicious URLs as it was fast and quick. It also approached the blacklisting technique followed by features extraction with word2vec features and Term frequency-inverse document frequency features. The experiment could identify 75643 malicious URLs out of 344821 URLs. The algorithm has been able to attain an accuracy rate of about 96% in detecting malicious URLs. There is no doubt as to the importance of malicious URL detection for the safety of cyberspace. The study stresses deep learning as a probable and promising solution in the detection of malicious URLs for cybersecurity applications. The study compared the support vector machine algorithm on Term frequency-inverse document frequency along with the word vac feature based on the CNN algorithm and the logistic regression algorithm. While comparing the three aspects (precision, recall, fl-score) of Support Vector Machines (SVM),
Convolutional Neural Network (CNN), and Logical Regression (LR):
Term frequency-inverse document frequency of SVM can be used with the logical regression method, as the SVM of the aspects is higher than that of the logical regression algorithm. On the other hand, the convolution neural network (CNN) proved consistent on both Word2vac and on Term frequency-inverse document frequency.
Following the success of CNN in showing exemplar performance for text classification in many applications, be it speech recognition, natural language processing, speech recognition, etc., the study utilized CNN to learn a URL embedding for malicious URL detection (Joshi, et al. 2019). The URLNet understands a URL string as input applying CNNs to a URL's characters and words. The study also describes the approaches like blacklisting possessing limitations as they are highly exhaustive. The paper proposed a CNN-based neural network, URLNet for malicious URL detection. The study also stressed the various approaches adopted by other studies that had critical limitations, like the use of features with the added inability to detect sequential concepts in a URL string (Zhang, et al. 2020). The use of features further requires manual feature engineering, thereby leaving us unable to manage unseen features in test URLs, which seems to alleviate by the URLNet solution proposed by the study. The study applied Character CNNs and Word CNNs and optimized the network. The advanced word-embedding techniques, proposed by the study are supposed to help in dealing with rare words, a problem often encountered in malicious URL Detection tasks. This allowed URL Net in learning to embed and utilize sub word information from hidden words at test time and hence worked overall without the need for expert features.
The study's goal is to investigate the efficacy of the given URL attributes, demonstrating the utility of lexical analysis in detecting and classifying malicious URLs, with a focus on practicality in an industrial environment. This experimental study was primarily concerned with the identification and classification of different forms of URLs using lexical analysis through binary and multiclass classification, with a focus on comparing common deep learning models to conventional machine learning algorithms. Overall, the results of the two experiments showed improved output precision, with an improvement of 8-10% on average across all models, and the other showing a lower level of efficiency, with average accuracy. The study concludes that deep neural networks are somewhat less efficient than Random Forest while collecting the training and prediction times, concurring feature analysis. The less efficiency was concluded based on higher variance, feature count to match RF's performance, complexity, and time taken to train and predict at the time of deployment (Lakshmi and Thomas, 2019). An RF model can be employed to minimize the effort, as deploying the RF model can reduce the feature set to 5-10 features, is cost-effective, and will display efficient performance.
Whereas on the other side, despite being popular DNN frameworks, the employment of Keras-TensorFlow and Fast.ai over RF would require the need for more resources. The resources can be utilized in others domains within any organization. In a summary, it is quite succinct from the study that for any organization, in case of considering an alternation or a choice for its detection system, Random Forest is the most promising and efficient model for deployment.
The deep neural network models' findings suggest that further work is needed to explicitly demonstrate one's dominance over another (Naveen, Manamohana and Verma, 2019). A preference for one DNN model over the other in the current work will suggest the model's priorities: Fast-AI is superior in terms of accuracy at the expense of time, while the Keras-TensorFlow model is superior in terms of latency at the expense of accuracy. The feature analysis of the lexical-based ISCXURL-2016 dataset, as the work's final contribution, demonstrates the significance of the basic characteristics of these malicious URLs. The key conclusion drawn from this portion of the work is that the multiclassification problem needs more features than the binary classification problem.
Furthermore, the basic lexical features found inside URLs could be used to reduce the overhead cost of a deployed model, according to this analysis. Some of the study's limitations could spur further research. The paper suggests that it did not exhaustively investigate all of the network configurations and hyperparameters available for DNNs that could potentially boost their efficiency. While these enhancements can increase the recorded accuracy of succeeding RFs, they affect training and testing times, as well as the additional disadvantage of overfitting models, which reduces their real-world generalizability. The study further leaves a gap in its research as it did not deploy and examine the efficacy of the models with additional experiments; leaving it for future studies. The research paper believes that more research is required on this front to help bridge the gap between academic research and industrial implementations, to reduce the negative economic impacts of malicious URLs on businesses of all types.
2.5 Embedded learning process
The paper suggests the use of feature engineering and feature representation to be used and reformed to manage the URL variants. The study proposes DUD where raw URLs get encoded using character-level embedding. This paper presents a comparative analysis of deep learning-based character level embedding models for Malicious URL detection. The study took around 5 models, two on CNN, two on RNN, and the last one being the hybrid of CNN and LSTM. All the architectures of deep learning have a marginal difference if seen from the purview of accuracy. Coming to the models, where each model performed well and displayed a 93-98% Malicious URL detection rate. The experiment had a false positive rate of 0.001. This also means that out of 970 malicious URLs detected by deep learning-based character level embedding models, the model label only one good URL as malicious. The study suggests enhancing DeepURLDetect (DUD) by adding auxiliary modules which include registration services, website content, file paths, registry keys, and network reputation.
The paper performed the malicious URL detection approach on different deep neural network architectures. The study used Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) to differentiate Malicious and benign URLs. The training and evolution of the models were done on the ISCX-URL-2016 dataset. The results of the experiment showed the CNN model performing well having an acceptable rate of accuracy for the identification of Malicious URLs. The study mentions plan to bring up a hybrid deep learning model for the detection of Malicious URLs. A multi-spatial Convolutional Neural network was proposed by the study for an efficient detection sensor. After extensive evaluations, the detection rate achieved 86 .63% accuracy. A prototype, Raspberry Pi was used for enabling real-time detection.
2.6 Machine learning process
Many organizations with collaborations, bet it Google, Facebook and many start - ups work together in creating a safe system, preventing the users from falling into the trap of malicious URLs. Even though these organizations use exhaustive databases and manually refining a large number of URL sets regularly. However, this is not a feasible solution, as, despite high accuracy, human intervention is one of the major limitations. So, the study introduces the use of sophisticated machine learning techniques. The novel approach can be availed as a common platform for many internet users. The study shows the ability of a machine in judging the URLs based on the feature set. The feature set will be used to classify the URLs. The study claims its proposed method to bring improved results when traditional approaches get short in identifying Malicious URLs. The study further suggests improving the machine learning algorithm, which will give better results using the feature set. However, the features set will undergo evolution over time, hence effort is being made in creating robust features set in handling a large number of URLs. The study introduces the feature sets, composed of 18 features token count, largest path, average path token, largest token, etc. along with a generic framework. Using the framework at the network edge can help to protect the users of the digital space against cyber-attacks. The feature sets can be used with Support Vector Machine (SVM) for malicious URL detection.
The study focuses on using machine learning algorithms in the classification of URLs based on features and behavior (Astorino, et al. 2018). Algorithms like Support Vector Machine (SVM) and Random Forest (RF) are the supervisors in the detection of Malicious URLs. The extraction of features is done from static and dynamic which is claimed as new to the literature. The prime contribution to the research is of the newly proposed features. The study doesn't use special attributes nor does it create huge datasets for accuracy. The study concludes on application and implementation of the result in informing security technologies in information security systems, along with building a free tool for detection of Malicious URLs in web browsers.
The study combines attributes that are easy to calculate and big data processing technologies in ensuring the balance of two factors; which are the system's accuracy and processing time. The study suggests on the proposed system be comprehended as a friendly and optimized solution for Malicious URL detection. As per the study, going by statistics, URLs that increase the attacks are malicious URLs, phishing URLs, and botnet URLs. Some of the techniques that attack the system by using Malicious URLs are - Phishing, Social engineering, spam, and Drive-by Download.
The paper takes a machine learning solution combining URL lexical features, JavaScript source features along payload size. The study aims to create a real-time malware classifier in blocking out malicious URLs. For doing so, the study focusses on three sub-categories of web attacks: drive-by downloads, where the users unknowingly download malware; next comes Phishing where the intruders come up with websites posing it to be legitimate to steal user information while exploiting from JavaScript code that is generally found in the website source code. The paper could conduct a successful study whereby the construction of the SVM was taken to for the classification of malicious URLs. The study further proposes that testing, in the case of malicious URLs could be done on a wider array inculcating a sophisticated JavaScript feature extractor along with more of diving into network features. The study also mentioned using trained SVM, where Malicious URLs can be detected without any browsing device. Overall, it gives machine learning a potential approach for discovering cyber-attacks, attackers as wells as any malware URLs. The threat can also be mitigated by automatic URL detection by using a trained SVM. With it, a user can check the credibility of the URLs before using it for a real-time service, a pre-emptive service without creating an impact on the mobile experience.
URLs mostly malicious are generated on a day-to-day basis, and many of the techniques are used by researchers for detecting the malicious ones promptly. The most famous is the Blacklist method, often used for the easy identification of malicious URLs. The traditional method derives some limitations due to which identification of new ones becomes a bit difficult. Whereas Heuristic, an advanced technique, cannot be used for all types of attacks. Whereas the machine learning techniques undergo several phases and attain a considerate amount of accuracy in the detection of Malicious URLs. The paper gives a piece of extensive information, lists out the main methods which include blacklist, heuristic, and machine learning. The paper also discusses the Batch learning algorithm and online learning algorithm in the case of algorithms and phases for Malicious URL detection. The study describes the Feature extraction and representation phase as well. The study performs a detailed study of the various processes involved in the detection of malicious URLs. Increasing cybercrime cases have led to the weakening of cyberspace security and various ways are used in the detection of such kinds of attacks. Out of all the techniques, the machine learning technique is the most sought-after technique for such attacks. This particular paper intends to outline the various methods for malicious URL detection along with mentioning the pros and cons of machine learning over others.
2.7 malicious Web sites' URLs and others
Malicious Web pages are a key component of online illegal activity. Because of the risks of these pages, end-users have demanded protections to prevent them from visiting them. The lexical and host-based features of malicious Web sites' URLs are investigated in this report. The study demonstrates that this problem is well-suited to modern online learning algorithms. Online algorithms not only process large numbers of URLs faster than batch algorithms, but they also adapt to new features in the constantly changing distribution of malicious URLs more quickly. The paper created a real-time framework for collecting URL features, which we pair with a feed of labeled URLs on a real-time basis from a large Web mail provider.
Malicious Web pages continue to be a plague on the Internet, despite current defenses. The study mentions that by training an online classifier using the features and labels, detection of malicious Web pages can give 99 percent accuracy over a healthy dataset. The study also mentioned on organizations try to detect suspicious URLs by examining their lexical and host-based features to prevent end-users from accessing these pages.URL classifiers face a unique challenge in this domain because they must work in a complex environment where criminals are actively developing new tactics to counter our defenses. To win this competition, the need of algorithms is required that can adapt to new examples and features on the fly. The paper tested various methods for detecting malicious URLs to eventually implement a real-time system.
Experiments with a live feed of labeled examples exposed batch algorithms' shortcomings in this domain. Their precision tends to be constrained by the stored number of training examples in memory. The study looked into the issue of URL classification in an online environment after seeing this weakness in practice. On a balanced dataset, the paper discovered that the online algorithm performing the best (such as CW) produces highly accurate classifiers with error rates of about 1% (Kumi, Lim and Lee, 2021). The good performance of these classifiers, according to our findings, is in the face of new features through continuous retraining. The paper however hopes that this research will serve as a model for other machine learning applications in the future in the domain of computer security and digital space protection.
The digital space is often thought to be an efficient space to constantly become a threat, as it delivers attacks that include malware, phishing, and spamming. The study to block such attacks has delivered a machine learning method for the identification of malicious URLs and their attack types. The SVM detected malicious URLs while the attack types were recognized by the RAkEL and ML-kNN. A list of discriminative features namely link popularity, malicious SLD hit ratio, malicious link ratios, and malicious ASN ratios are attained from lexical, DNS, DNS fluxiness, network, webpage, link popularity properties of the associated URLs, which are highly effective as per the experiments. It is also efficient in identification and detection tasks. Achieving 98% accuracy in detecting malicious URLs and identifying the attack types, the paper further studies the effectiveness of each group on detection and identification discussing the discriminative features.
Feature engineering is a crucial step in detecting malicious URLs. In this paper, five space transformation models are used to create new features that free the linear and non-linear communications between points in malicious URLs data (decomposition on singular value, distance metric learning, Nyström methods, DML-NYS, and NYS-DML).
The proposed feature engineering models are successful and can dramatically boost the performance of certain classifiers in identifying malicious URLs, with experiments using 331,622 URL instances. The paper aims to identify malicious URLs, which require continuous data collection, feature collection and extraction, and model training. The integrated models combined the benefits of nonlinear, linear, unsupervised, and supervised models to concentrate on one aspect of space revision. The study mentions the future research path to look at how classifiers can be improved in terms of training time and accuracy based on URL characteristics.
Because of its widespread use, except for Naïve Bayes, the classifiers' highest TPR on the two textual-content datasets was 42.43 percent, while the highest TPR on the URL-based dataset was 86.40 percent (Patil and Patil, 2018). The detection rate of malicious URLs using a content-based approach was significantly lower than the URL-based approach used in this analysis. These findings indicate that separating malicious from benign websites solely based on their content is difficult, if not impossible. While transformer-based deep neural networks such as Bidirectional Encoder Representations from Transformers (BERT) and Net have made significant progress in recent years and be very effective on a variety of text mining tasks, they do not always apply well to the detection of malicious websites.
2.8 Summary
In the last part of the literature review, the basic summary of this branch to process data information is to expand the main input of this detection method. This paper proposes a malicious URL detection model based on a DCNN. It often adopts the word to embed based upon the basic character control embedding system for extracting features not manually or automatically with learning outcomes of the URL expression. Finally, they verify validity in that model through a proper series of contrast control experiments.
Chapter 3: Research Methodology
3.1 Introduction
Nowadays, the main methods to detect malicious URLs could be easily divided by the traditional controldetection drive method based upon blacklist with detection capacity methods based upon machine learning technique. Although the methods are efficient and simple, it could not properly detect any newly complex generated control malicious URLs, and also has been severed limitations. The malicious URLs detection methodology models are based upon the neural convolutional networks. Therefore, construction in the method mainly involves three main modules as vector convolution module, blockage extraction control module, and dynamic embedding module. The URLs are inputted directly into these embedding layers, or they utilize as word control embedding that is based upon characteristics embedding for transforming the basic URL from the vector embedding expression. Hence, this URL would be often input in the cover-up CNN just for the feature detection extraction.
3.2 Justification philosophy
The basic URL detection control process is justified by these sections. Firstly, domain user name, then subdomain device name with domain suffix name is often sequentially able to be extracted directly from the URL. Therefore, in this primary branch related to this detection method, it pads every URL to a particular length that each word is remarked within a significant number.
Justification
These whole URLs are represented by the sequence in numbers (Hain et al. 2017, p.161). Secondly, the main sequence is inputted to their embedding control layer to train together within a layer. This sequence would learn a specific vector convention expression process during their training control process. This overall data information stream output from embedding covered layers is subsequently outputted into the CNN. However, output control passes by the convolution detection layer, the folding purposes, and the pooling device layer of three successive rounds over the process.
3.3 Research approach
When it is trained in a totally connected URL layer, these features of the computer are often extracted by a neural convolutional network automatically and to extract artificially directly from an URL work field.
Justification
This detection methodology could effectively use critical data information of the named URL, including the top-level names domain and the domain of the national name, for achieving higher profile accuracy to recall (Bu, S.J. and Cho 2021, p.2689). Through the output of the SVM analysis, it can be analysed and understand that by predicting the test data set parameters. The malicious URLs detection methodology models are based upon the neural convolutional networks. Hence, accuracy is important, especially to the detection processes, because when the main accuracy is very low, nominal websites and pages might be estimated classified by malicious web and would be relocked.
Researchers of this thesis have to use proper machine learning tools and techniques for identifying malicious URLs. Therefore, these systems also require extracting the control of the main features manually, or attackers could design the features for avoiding identifying them.
Justification
It often has the highest speed, in a lower false-positive cyber rate, that’s it is too easy for users (Hamad et al. 2019, p. 4258). However, nowadays, a domain control generation regarding algorithms or DGA could generate thousands of several malicious URL domain user names per day that could not be properly detected by the traditional method of blacklist-based effectively. Faced with these issues in the recent complex networking environment, to design a more powerful and effective URL malicious detection model for becoming the research review focus.
The importance of gathering relevant data for or learning this specific methodology is predictable by the fact that its analysis will deliver fruitful information. There could be multiple aspects of taking the interviews but the most primary objective of carrying out an interview for such a thing is comprehensive and descriptive answers. The prospect of conducting a descriptive and comprehensive interview will deliver an influential amount of data for qualitative analysis. The qualitative analysis will consist of multiple elements and different angles of which the interviewer has not thought of. This will allow the analyst to segment the whole collected information in the comprehensive and market them in categories. Such kind of demarcation is extremely influential to identify what needs to be done and how it needs to be done. The interview will consist of a set of questions for getting the most appropriate methodology.
The participants of this interview can be analysts or cybersecurity experts who have substantial expertise and knowledge in this domain. There can be a set of questions that will dwell deeper into their experience with malicious URLs. The questions can be like telling about the experience with different kinds of malicious threats and how it is being carried out. In what ways the whole network in the digital market can be divided and which segment is most vulnerable. The types of tools analysts have incorporated previously to battle with such kinds of threats. Their familiarity with machine learning and how it can deliver this security. The current period of threat intelligence is associated with malicious URLs and their extent and what is the feature proposition in this arena. All the answers collected from more than 40 participants must be analysed strictly and finalized categorically.
The proposition of the Focus group is to identify a certain kind of group which has something in common and is largely affected by such kind of malicious activities. There is no denying the effects of malicious URLs in every possible domain of the digital world. But it is important to identify who are the most valuable domains and what are the intricacies associated with their domain and how they can be protected or resolved. The division of Focus groups can be parametrically decided based on the usage or exposure of the individuals. One focus group can be youth who are most largely influenced by E-Commerce activities. Another Focus group can be made on the basis of the age range in which the elderly people are most vulnerable.
Another Focus group can be an influential or well-known personality who is always on the verge of such threats. Under Focus groups can be individuals of the technical domain to identify what you think about such kinds of URLs and how they count them. All these focus groups must go through a group discussion for our individual campaign to curate the most suitable and appropriate pattern among their visualization and experience. In this methodology, there can be a couple of assignments such as a qualitative interview or quantitative survey which will provide the information in the form of experience or facts that can be used for other analyses of every domain of malicious URLs. These Focus groups provide a generalized view of malicious URLs and they are expected to not have much of technical background. The objective of the Focus group is to get collective information in a generalized way so that emotional, as well as psychological angles, can be comprehended.
There are so many case studies across the globe over the course of the last three decades where a particular scenario has been showcased. The powerful element of a case study is that it represents some kind of storyline or psychological processing of the fraud or criminal carrying out the particle malicious activity. These case studies provide a sense of generalized view in a multidimensional way which is to be comprehended by seeking the acquired or necessary information. Any type of information or processed facts can be utilized to define a new kind of angle in a particle attack. The case studies have built credibility based upon describing the whole scenario in a descriptive and sophisticated way.
The effectiveness of conducting research with a case study is that it is based on real-life scenarios and the most important element is it delivers the process of conducting the malicious activity (Story). The identification of the process and its psychological background is another challenge that has to be analysed so that a comprehensive and multidimensional campaign can be conducted to prevent these things from happening in the future. Case studies also portray the type of vulnerability possessed by the one who got adversely affected due to malicious attacks. The collected information from case studies and sorting information contained in it is further analysed to develop a quantitative parameter and predictable patterns. This is more of a profound approach in having things for developing documentation that contains a set of processes in a descriptive as well as instructive manner. The role of machine learning in this is to find keywords and collect them for testing them in a dataset.
This is more of an academic and theoretical perception of identifying and battling with unethical activities associated with malicious URLs. The association of keeping records goes beyond collecting data and information. It is meant to store the information in a very sophisticated and profound manner by documenting all the elements categorically and specifically. There can be multiple categories in which the collected information for malicious activities can be divided and stored. The process of doing so is also a matter of research to identify certain threats. The importance of record-keeping methodology is to build a strong case hold of identifying the intricate elements of URL characters and a certain pattern to identify the malicious content in it. Keeping recording is a responsibility that must be carried out with diligence so that none of the information can go to waste.
The importance of record-keeping research methodology is done to implement the positive effects of sharing and promoting research for the elements so that ethics can be maintained. There is much research that has already been conducted on character identification or you are a letter to vacation for and define its malicious content. All these research papers have been stored in a sophisticated manner which can be utilized through a partial window in order to get a strong base point for this research. The main proposition of methodology is to incorporate ethics and moral conduct in the research which is essentially required here for cybersecurity issues. It is meant to provide support for data analytics whenever required during technical analysis. There should be a keeper for looks after this and device information whenever necessary.
The process of observation begins with identifying the objective of the research which is here to identify the URL for its malicious content. Then the recording method is identified which can be anything here from the URL text to its landing page description or title, etc. All disconnected records based on human conduct of identifying the malicious content are recorded and questions are developed or in other ways, statements are being identified. This process is continued with every other encounter by observing all the elements and answering the questions specified before conducting this research. This methodology is completely based on human observation skills for or having intuition regarding any threat and approach being carried out to analyse and identify it. This process is slow and yet powerful because of its implications.
There can be many researchers across the domains who would adopt conducting observation for this research we identify malicious activities based on human skills. Incorporated questions allow the human mind to seek the attributes of whole digital information present before them. The process of observation in taking notes is the activity that is carried out in a sorted manner. These collected notes are analysed for behavioural elements of the malicious activities along with inferences associated with them. This behavioural analysis can be done by finding a set of patterns either directly or through data analysis. Every type of research comes to one point where it has a set of data that can be further that quickly as well as actually portrayed so that software based on the algorithm of probabilistic theory can find something which the human mind has missed.
3.10 Ethnographic research
The positional element of ethnography is associated with a behavioural analogy that can be aligned with the interaction of humans. In this case, the concept of economic geography can be related to an online culture where people are indulged in promotional and camping activities to cover their prospect of phishing and spamming. The conceptual and theoretical element in this kind of research is that it battles with the norms of technicality held by intellectuals. This means that a person with profound knowledge of online activities as well as the science of science opts to utilize it for delivering harm to normal people to get money or some kind of benefit. Since this kind of research can be changed across various domains but here it is specifically oriented with a psychological aspect.
The main question or objective behind this methodology is to identify the patterns of activities being carried out in the name of cover activities (Bhattacharjee, et al. 2019). The cover activities can include promotional campaigns or largely free gifts to the people. The method incorporated to analyse these is based upon seeking what kind of activities are going around in the market as well as how free stuff excites people to look over them. This also portrays a fact that certain kinds of malicious threats can be prevented by identifying such elements of attraction across different types of websites. Considering from the perspective of embedded learning and deep learning is that the backlinks as well as source code of certain web pages can be analysed to identify URLs that have targeted malicious activity. In this way, ethnographic research can facilitate a unique way of repression against malicious threats.
3.11 Summary
This could be quantified through the study that the different outputs based upon the heat maps work towards providing a better workspace and adhering to the laws and regulations. This could and needs to be inferred through the heat map that the different data septets of the map structure act towards providing a certain point of observation. The overall address needs to be confirmed through a proper guideline that works towards mitigating the different random parameters. The URL length and other parameters could be plotted in order to Number towards addressing the different parameters in relation to the respective variables and order. Through the random forecast, it can be addressed and identified by the different structural analyses. This needs to be addressed through a proper order of discussions. The output and random forecast classification work towards addressing the dataset that contains scattered data and determining the different classification of the overall data sets as addressed through the different parameters. Through the output of the SVM analysis, it can be analysed and understood that by predicting the test data set parameters could be set properly.
Chapter 4: Discussion
4.1 Phishing
Phishing is one of the types of cybercrime that adopts the way of contract to the target through emails. The objective of this crime is to get access to sensitive and confidential information of the targeted user by showcasing oneself as a reliable or legitimate individual or organization. Thus, collected information can cause harm to multiple levels such as loss of money, credible information, private details, identity theft, etc. It has a set of hyperlinks that takes the users to some other landing page or website whose sole purpose is to get more from the users. Such emails also contain some attachment that is sometimes senseless or contains a virus in it (Yuan, Chen, Tian and Pei, 2021). The primary identification of phishing is done by an unusual sender. The section of hyperlinks here is malicious URLs that are used to facilitate more harm to the user. The concept of phishing goes hand in hand with malicious URLs which is yet another objective to be analysed through data analysis.
4.2 Spamming
Spamming is another method of transmitting information from a criminal to the victim through lucrative offers. The proposition in spamming is the same as phishing. The only difference is an approach that varies for this one. There are various elements that spam can contain in terms of information and demanding economic data of the individual. The most effective element of phishing is that it contains graphics whereas spamming is mostly texts. The concept of spamming has also begun with mails but was generally used for text messages which were later broadened. The difference between phishing and spamming is that phishing demands the user’s information whereas spamming allures the person to visit a site to avail of some kind of information or offer. The intricacy of machine learning in this is to analyse the contents of the mail to identify the pattern for declaring it spam. There has been huge research on this by Google where they employed machine learning algorithms to declare a particular message as spam.
4.3 Malicious Content Detection
Malicious websites consider being a significant element in cyber-attacks found today. These harmful websites attack their host in two ways. The first one is the involvement of crafted content that exploits browser software vulnerabilities to achieve the users' files and use them accordingly for malicious ends, and the second one involves phishing that tricks users giving permissions to the attackers for the destruction. Both of these are discussed in detail before. These attacks are increasing very rapidly in today's world. Many peoples are getting attacked and end up losing their files, specifications, and businesses.
Detection of malicious content and blocking them involves multiple challenges. Firstly, the detection of such URLs must perform very quickly on the commodity hardware that operates in endpoints and firewalls of the user, so they cannot slow down the browsing experience of the user during the complete process. Secondly, the approaches made must be flexible to changes in syntactic and semiotic changes in malicious web content such that techniques of adversarial evasion like JavaScript obfuscation do not come under the detection radar. Finally, the detection approach must identify the small pieces of code and some specific characters in the URL that indicate the website is potentially dangerous. It is the most crucial point as many attackers enter via ad networks and comment feeds as tiny components into the users' computer. This paper will be focusing on the method of the methods in which the above-discussed steps can execute.
The methodology in the detection of malicious URLs using deep learning works in various ways. These ways are below:
Inspiration and Design Principles
The following intuitions listed below are involved in the building of the model for detecting harmful websites.
1) Malicious websites have a small portion of malicious code that infects the user. These small snippets are mainly JavaScript coded and embedded in a variable amount of Benign content (Vinayakumar, Soman and Poornachandran, 2018). For identifying the given document for threats, the program must examine the entire record at multiple spatial levels. It needs to scan because the size and range of this snippet are small, the length variance of the HTML document is large enough, which means that the document portion representing the malicious content is variable among the examples. It concludes that the identification of malicious URLs needs multiple repetitions as such small codes being variable need not detects in the first scan.
2) Specific parsing of the HTML documents, in reality, is the collection of HTML, CSS, JavaScript, and raw data is unacceptable as it complicates the implementation of the system, requires high computational overhead, and creates a hole in the detector. Attackers can breach to get into it and exploit the heart of the system.
3) JavaScript emulation, static analysis, or symbolic execution within HTML documents is undesirable. It is so because of the imposition of computational overhead and also because of the attacking hole; it opens up within the detector for the attackers.
From these ideas, the program must have the following design decisions that will help to resolve the maximum of the problems encountered.
1) Rather than parsing in detail, static analysis, graphic execution, or emulation of HTML document contents, the program can design to store a simple block of words. These words tokenize with the documents to perform minimal run tests for their assumptions. Every malicious URL contains a specific set of letters that links it to its original website. The program function is to search those keywords then the overall execution time can get decreased.
2) Instead of using the simple block of words representation declared over the entire document, the program can capture the multiple spatial scales locality that represents different levels of localization and aggregation, helping the program to find malicious contents in the URL at a very minute level where the overall might fail.
Approach for the method
The approach for this method involves a feature extraction process. It checks a series of characters in the HTML document and a Neural Network Model (NNM), which makes the classification decisions of the data within the webpage based on a shared-weight examination. The classification occurs at the hierarchical level of aggregation. The neural network contains two logical components for the execution of the program (Vanitha and Vinodhini, 2019).
• The first component: termed an inspector, aggregates information in the document to 1024 length by applying weights at spatial scales hierarchy.
• The second component: termed a master, uses the inspector outputs to make final decisions for the classification.
Backpropagation is used for optimizing the components of inspector and master in the network. Furthermore, the paper will focus on describing the function of these models in the overall functioning of the program.
4.4 Feature Extraction
The functioning of the program begins with the extraction of token words from the HTML webpage. The target webpage or document is tokenized using expression: ([A \xO 0- \x7F] + 1\ w+) that splits no alphanumeric words in the document. Then, the token divides into chunks of equal length 16 in a sequence. Here the word length defines as some tokens that include the last chunk gets fewer tokens if the document does not divide by 16.
Next, to create a bag of each chunk, a modified version of each chunk is used with 1024 bins. A technique is used to change the bin placement in the program that helps to feature both token and hash length. It results in a workflow where the files tokenize and divide into 16 equal length chunks of the token and then features the hash of each token multiplied by 1024 (number of bins). The 16*1024 quantity represents the texts extracted from the webpage divided into chunks, and each element in this chunk represents an aggregation over every 1/16 of the input document.
4.5 Inspector
When a feature representation is set for an HTML document, the design gets its input in the neural network. The first step is to create a hierarchical diagram of the sequential token of chunks in the computational flow. Here the sixteen token groups collapse into eight sequential token bags, eight token groups collapse into four groups, four collapses to two, and two token group collapses to one. The process helps to obtain multiple tokens groups representation that captures token occurrences at various spatial scales. The collapsing process occurs by averaging the windows of length two and step size two over the 16 token groups formed first. This process occurs repetitively until a single group of the token comes. Note, while averaging, the norm of each representation level in the token group is kept the same within the document. This is the reason why averaging is preferred over summing, as in summing, this norm will be changing each time the group changes.
When the hierarchical representation has been formed by the inspector, it starts hitting each node in the aggregation tree and computes an output vector with it (Bo, et al. 2021). The inspector has two fully connected layers with 1024 RELU units and considers a feed forwards neural network. The inspector regulates through layer normalization so that to guard against dropouts and vanishing gradients. The dropout rate used here is 0.2.
After visiting each node, for computing the inspector’s output of 1024-dimension, across the 31 outputs produced by 31 distinct chunks and each output containing 1024 output neurons, the maximum of each is taken. It results in the maximum output from each neuron in the final output layer of the inspector that gets all of its activations over the node in the hierarchy. Hence, this will make the output vector capture the patterns that will help to match the template of the malicious URLs features. Moreover, whenever they appear on the HTML webpage, it will help to point out such contents.
4.6 Master
After the computation of 1024-dimensional output by the inspector over the HTML webpage, these outputs are inputs into the master component. Like the inspector, the master is also a feed-forward neural network in design. But the master is with two layers of the logical fully-connected block. Here also, each fully connected layer precedes by the dropout and normalization of a layer. The dropout rate of the master is at 0.2. The overall construction of the master is similar to the construction of the inspector, with a difference that the output vector of the inspector is input for the master.
4.7 Summary
The final layer of the model is a composition of 26 sigmoid units that corresponds to 26 detection decisions the program makes for the malicious contents about the HTML webpage. Here, one sigmoid member is valuable in deciding whether the target HTML webpage is malicious or benign (Khan, 2019). The rest 25 sigmoid help determine other tags like whether the webpage is using a phishing document or exploitation for an instance. For training the models, each sigmoid output applies with binary cross-entropy loss and then the output of resulting parameters averages to calculate the parameter updates. Each of the sigmoid doesn't need to be helpful for the model. Many sigmoid in these results as bad for the model and are useless. The sole purpose of the model is to distinguish between the malicious content and the valuable content that serves at the end of the execution of this system.
Chapter 5: Analysis
5.1 Introduction
With the change in the centuries, new innovations have been witnessed in the world. People are getting advanced day by day by adapting the trends, and so does computers. The features of these machines are getting advanced after every innovation. If we go back to hundred years, the computer was just an electronic device used for storing and processing data. It was used for fast calculations. But as the grew, in 1959, machine learning was originated by Arthur Samuel, who was an American pioneer in the field of computer gaming and artificial intelligence. So, machine learning can be defined as the study of computer algorithms that gets improved automatically through experiences and by the use of data. In simple words, we can say that machine learning or MI is an application of artificial intelligence which provides the computer system an ability to learn automatically from experiences and also improve with every time without being specially programmed (Do Xuan, Nguyen and Nikolaevich). It can be seen as artificial intelligence but artificial intelligence or AI is a machine technology that behaves like humans, whereas machine learning or MI is a part or subset of artificial intelligence that allows the machine to learn something new from every experience. Here, computer algorithms mean steps or procedures taught to the machine which enable it to solve logical problems and mathematical problems. It is a well-defined sequence of instructions to be implemented in computers to solve the class of typical problems.
Among the mentioned uses of MI, machine learning or the embedded deep learning are best used for the detection of malicious content in Uniform Resource Locator or URL. Uniform Resource Locator or URL is defined as a unique locator or identifier used to locate a resource on the internet. It is referred to as a web address. A Uniform Resource Locator or URL consists of three parts, namely, Protocol, Domain, and Path. For example, if we assume ‘https://example.com/homepage’ this particular web address of a popular blogging site. In this, ‘https://’ is a protocol, ‘example.com’ is a domain and ‘homepage’ is a path. Thus, these three contents are together called URL or Uniform Resource Locator.
These URLs have made the work on the computer and internet easy for the users but with the positive side, it also consists of the negative side. These URLs become malicious by hackers which are not so easy to recognize. What happens is that the hackers create almost the same-looking websites or web addresses which have a very minute difference. The people who are not much aware of the malicious content fail to recognize the disguised website and share their true details with them. Thus, the hackers behind the disguised web address get the access to information of the user. They use it to steal data and to do illegal works or scams. For example, assume ‘https://favourite.com’ is a website of a photo-sharing site and the malicious website is made by the hacker like ‘https://fav0urite.com.’ These two websites are look-like and are difficult to predict. Thus, to predict the malicious content in Uniform Resource Locator the embedded deep learning plays a crucial role (Srinivasan, et al. 2021).
The detection of malicious Uniform Resource Locator contains the following stages or phases. These phases are:
1. Collection Stage: This is the first stage in the detection process of malicious Uniform Resource Locators with the help of MI or Machine Learning. So, in this stage, the collections, as well as the study of clean and malicious URLs, are done. After the collection of the URLs, labelling is done correctly and is then proceeded to attribute extractions.
2. Attribute Extraction Stage: Under this stage, the URL attribute extraction and selection are done in three following ways:
• Lexical Stage or features: This includes the length of the domain, the length of URL, the maximum token length, the length of the path, and the average token in the domain.
• Host-based Stage or features: Under this feature, the extraction is done from the host characteristics of Uniform Resource Locators. These indicate the location of malicious URLs and also identify the malicious servers.
• Content-based Stage or features: Under this, the extraction is acquired when the web page is downloaded. This feature works more than the other two features. The workload is heavy since a lot of extraction needs to be done at this stage.
3. Detection Stage: After the attribute extraction stage, the URLs are put to the classifier to classify whether the Uniform Resource Locator is clean or malicious.
Thus, the embedded deep learning or machine learning is best used to detect the malicious Uniform Resource Locators. It enhances the security against spam, malicious, and fraud websites.
5.2 Single type Detection
AI has been utilized in a few ways to deal with group malicious URLs. To recognize spam site pages through content examination. They utilized site-dependent heuristics, for example, words utilized in a page or title, what's more, part of the apparent substance. A process created a spam signature age structure called AutoRE to identify botnet-based spam messages. AutoRE utilizes URLs in messages as info and yields normal articulation marks that can identify botnet spam. This utilized measurable techniques to order phishing messages. They utilized a huge openly accessible corpus of genuine and phishing messages. Their classifiers analyze ten unique highlights, for example, the number of URLs in an email, the number of spaces, and the number of dabs in these URLs. It broke down the maliciousness of a huge assortment of website pages utilizing an AI calculation as a per-channel for VM-based examination. They embraced content-based highlights including the presence of muddled JavaScript and adventure locales pointing iframes. A method proposed a finder of malicious Web content utilizing AI. Specifically, we acquire a few page substance highlights from their highlights. This method proposed a phishing site classifier to refresh Google's phishing boycott naturally. They utilized a few highlights acquired from area data and page substance.
5.3 Multiple type Detection
The order model can distinguish spam and phishing URLs. They portrayed a strategy for URL order utilizing measurable techniques on lexical and host-based properties of malevolent URLs. Their strategy recognizes both spam and phishing yet can't recognize these two sorts of assault. Existing AI-based methodologies typically zero in on a solitary sort of malevolent conduct. They all use AI to tune their characterization models. Our strategy is likewise founded on AI, yet another also, more remarkable, and proficient grouping model is utilized. Also, our technique can recognize assault types of malicious URLs. These developments add to the predominant execution and capacity of our strategy. Other related work. Web spam or spamdexing points at acquiring an uncalled for high position from an inquiry motor by impacting the result of the web search tool's positioning calculations. Connection-based positioning calculations, which our connection prominence is like, are broadly utilized via web crawlers. Connection ranches are ordinarily utilized in Web spam to influence connect-based positioning calculations of web indexes, which can likewise influence our connection ubiquity (Jiang, et al. 2017). Investigates have proposed strategies to identify Web spams by utilizing proliferating trust or doubt through joins, identifying explosions of connecting movement as a dubious sign, coordinating connection and substance highlights, or different connection-based highlights including changed PageRank scores. A considerable lot of their procedures can be acquired to impede sidestepping join ubiquity highlights in our locator through interface ranches.
Unprotected Web applications are weak spots for programmers to assault an association's organization. Measurements show that 42% of Web applications are presented to dangers and programmers. Web demands that Web clients demand from Web applications are controlled by programmers to control Web workers. Web questions are identified to forestall controls of programmer assaults. Web assault discovery is amazingly fundamental in data conveyance over the previous many years. Peculiarity techniques dependent on AI are liked in Web application security. This current examination is expected to propose a peculiarity - based Web assault identification engineering in a Web application utilizing profound learning strategies. Many web applications experience the ill effects of different web assaults because of the absence of mindfulness concerning security. Hence, it is important to improve the unwavering quality of web applications by precisely recognizing malevolent URLs. In past investigations, watchword coordinating has consistently been utilized to identify malevolent URLs, however, this strategy isn't versatile. In this paper, factual investigations dependent on angle learning and highlight extraction utilizing a sigmoidal limit level are consolidated to propose another identification approach dependent on AI methods. In addition, the credulous Bayes, choice tree, and SVM classifiers are utilized to approve the exactness and proficiency of this technique. At last, the trial results show that this strategy has a decent recognition execution, with an exactness rate above 98.7%. In functional use, this framework has been sent on the web and is being utilized in huge scope discovery, breaking down roughly 2 TB of information consistently (Verma, and Das, 2017). The malicious URLs location is treated as a parallel arrangement issue and execution of a few notable classifiers are tried with test information. The calculations of Random Forests and backing Vector Machine (SVM) are concentrated specifically which accomplish a high precision. These calculations are utilized for preparing the dataset for the characterization of good and awful URLs. The dataset of URLs is separated into preparing and test information in 60:40, 70:30, and 80:20 proportions. The precision of Random Forests and SVMs is determined for a few emphases for each split proportion. As per the outcomes, the split proportion 80:20 is seen as a more precise split and the normal exactness of Random Forests is more than SVMs. SVM is seen to be more fluctuating than Random Forests in precision.
5.4 Data description
Figure 1: Code for data display
(Source: Self-created)
The panda’s package is used to develop the different python programming techniques. The data display is the first step to obtain the columns of the respective dataset which are analyzed. The dataset.csv dataset is used here to analyze the malicious URL detection using machine learning techniques.
Figure 2: Output of data display
(Source: Self-created)
The output of the data display shows the variables of the dataset.csv dataset which represents the information regarding the malicious URLs which are to be detected (Rakotoasimbahoakaet al., 2019, p.469). The head command is used to show the attributes of the dataset in the python programming language. Therefore, the user can access the information of the dataset using the above-developed codes.
5.5 Histogram

Figure 3: Code for histogram
(Source: Self-created)
The histogram represents the range of the specific variable which is present in a dataset. In this report, the histogram of the URL_LENGTH is developed using python programming. The different plots of the ranges of URL length are shown in the output of the histogram.
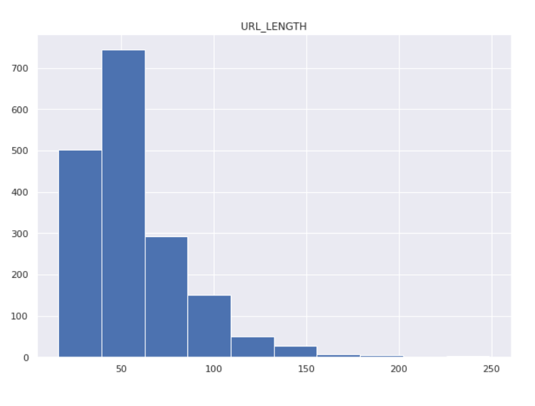
Figure 4: Output of Histogram
(Source: Self-created)
The output of the histogram shows the relation between the URL_LENGTH variable with the other variables in the dataset.csv dataset (Sahoo et al., 2017, p.158). The purpose of the histogram is to analyze the composition of the mentioned variable with different values as recorded in the dataset.
5.6 Heat map

Figure 5: Code for heat map
(Source: Self-created)
The heatmap measures the values which represent the various shades of the same color for each value. The dark shades of the chart show the higher values and the lighter shaded areas contain the lower values which are obtained from the dataset.
.png)
Figure 6: Output of heat map
(Source: Self-created)
The output of the heat map defines the graphical representation of the data that are used to represent different values. The heat maps are used to discover the variables in the dataset.csv dataset (Khan et al., 2020, p.996). The heat map is developed here to represent the different columns of the dataset.csv dataset using the map structure.
5.7 Scatter Plot

Figure 7: Code for scatter plot
(Source: Self-created)
The scatter plot shows the relation between the dependent and independent variables of the dataset.csv dataset. The purpose of the scatter plot is used to represent the special characters in the URLs which contain malicious information.
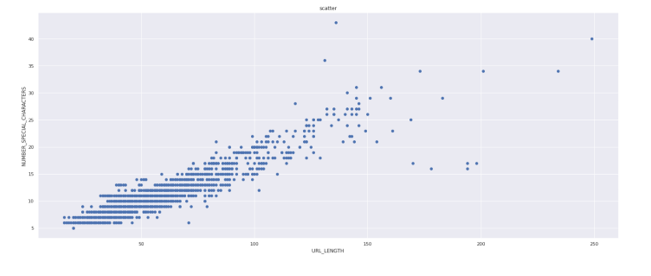
Figure 8: Output of scatter plot
(Source: Self-created)
The scatter plot observes the random variables in the malicious URL detection methods. The URL_LENGTH is plotted with respect to the NUMBER_SPECIAL_CAHARACTERS in the dataset.csv dataset. The scatter plot in the matplotlib library is used to sketch the scatter plot to determine the relationship between the two variables.
5.8 Random Forest

Figure 9: Code for random forest
(Source: Self-created)
The random forest is one kind of machine learning method which is used to measure the random variables present in the dataset (Kumar et al., 2017, p.98). The random forest is developed here to show the scatter plot based on all variables in the malicious URL detection dataset.
.png)
Figure 10: Output of random forest
(Source: Self-created)
The random forest classifier classifies the columns of the dataset using machine learning algorithms. The output of the random forest classification describes the sub-samples of the dataset which contains the scatters to determine the classification of the dataset.csv dataset.
5.9 SVM
.png)
Figure 11: Code for SVM
(Source: Self-created)
The support vector machine is a machine learning algorithm that measures the classification, regression, outlier detection based on the dataset. The support vector machine shows the expected scatter based on the variables of the malicious URL dataset (Joshi et al., 2019, p.889). The aim of SVM is to divide the dataset into different classes to perform the classification process.
.png)
Figure 12: Output of SVM
(Source: Self-created)
The output of the SVM analyses the trained and test samples of the dataset. The SVM classifies the predictors based on the variables of the dataset (Le et al., 2018, p.523). The scatter plot is developed by predicting the test set and then comparing the test set with the predicted value of the dataset.csv dataset.
5.10 Classification

Figure 13: Code for classification
(Source: Self-created)
The k classification is developed here to understand the number of nearest neighbors of the dataset.csv dataset. The number of nearest neighbors is the core deciding factor (Do Xuan et al., 2020, p.552). The k is the odd number that represents the number of classes in the neighbor clustering.
Figure 14: Output of classification
(Source: Self-created)
The output of the k classification shows the clustering of the different neighbors based on the dataset.csv dataset. The k nearest neighbors are used to measure the classification and regression analysis based on the given dataset. The
5.11 Support vector classifier

Figure 15: Code for SVM classifier
(Source: Self-created)
The support vector classifier determines the linear classifier with respect to a specific dataset. Therefore, the support vector classifier shows the model structure of the linear classification. The SVC is the command which is used to develop the support vector classifier using the malicious URL detection dataset. The support vector classifier improves the complexity of the classification which implements the generalization of the dataset variables.

Figure 16: Output of the svc
(Source: Self-created)
The output of SVM classification shows the size, weight of the dataset which is used here. The support vector classifier detects the malicious URL using the implementation of machine learning algorithms (Ferreira, 2019, p.114). Therefore, the support vector classifier represents the kernel trick to ensure the transformation of data using the transformation technology.
5.12 Support vector model

Figure 17: Implementation of the support vector model
(Source: Self-created)
The support vector model shows the implementation of the machine learning algorithm which measures the classification and regression challenges based on the malicious URL dataset. The support vector array shows the array structure of the result of the support vector machine (Sahoo et al., 2017, p.158). The purpose of the modeling is to determine the decision boundary through which the data can be divided in n-dimensional space.
Chapter 6: Recommendation
In this paper, we propose a technique utilizing machines figuring out how to recognize malevolent URLs of all the well-known assault types including phishing, spamming, and malware contamination, and recognize the assault types malignant URLs endeavor to dispatch. We have embraced a huge arrangement of discriminative highlights identified with printed designs, interface structures, content organization, DNS data, and organization traffic. A large number of these highlights are novel and exceptionally successful. As portrayed later in our trial considers, connect prevalence and certain lexical and DNS highlights are exceptionally discriminative in not just distinguishing noxious URLs yet additionally distinguishing assault types. Likewise, our strategy is hearty against known avoidance strategies such as redirection, interface control, and quick motion facilitating.
The set of recommendations can be divided into two sets. One of them can be on the user level and the other on the developer level. The task at the user level is quite simple which is to report spam for any URL content that seems malicious or contains such type of data. The tasks at the developer end are quite large and comprehensive. A developer can look forward to developing certain kinds of methodologies or ways through which they can develop software or a tool that can be embedded in the URL detection mechanism to identify its malicious content. There are numerous ways through which it can be done. The concepts of Machine learning applicable to this scenario can be based on supervised learning or non – supervised learning. The supervised learning will involve training a model based on collected URLs with malicious content or resource. Unsupervised learning will deliver an option for identifying it on a trial and test basis (Ferreira, 2019). Unsupervised learning cannot be applied to this scenario whereas supervised one can be utilized. The algorithms of supervised learning will be used to develop a deep learning algorithm that will analyze the characters and identify the pattern in it to declare certain URLs to be malicious or not. The process of development will be backed by a huge amount of test data and that’s why web applications such DNS or HTTP or web browsers will have these tools to identify the URLs with certain context. The main proposition behind using these methodologies is to implement the comprehensive method of applying different machine learning algorithms at different places to find possibilities for developing a tool that can detect such malicious URLs. The whole process should be done so intricately that nothing is left out and at the same time, the tool should be in learning mode to gather new data and detection parameters.
Chapter 7: Conclusion
Cyber-attackers have expanded the quantity of contaminated has by diverting clients of traded off famous sites toward sites that abuse weaknesses of a program and its modules. To forestall harm, identifying tainted hosts dependent on intermediary logs, which are by and large recorded on big business organizations, is acquiring consideration as opposed to restriction-based sifting on the grounds that making boycotts has gotten troublesome because of the short lifetime of malicious spaces and camouflage of endeavor code. Since data extricated from one URL is restricted, we center around a succession of URLs that incorporates relics of vindictive redirections. We propose a framework for distinguishing malevolent URL arrangements from intermediary logs with a low bogus positive rate. To clarify a powerful methodology of noxious URL arrangement recognition, we analyzed three methodologies: individual-based methodology, convolutional neural organization (CNN), and our recently evolved occasion de-noising CNN (EDCNN).
Therefore, highlighting designing in AI-based arrangements needs to advance with the new malignant URLs. As of late, profound learning is the most talked about because of the critical outcomes in different man-made consciousness (AI) undertakings in the field of picture preparing, discourse handling, characteristic language handling, and numerous others. They have the capacity to remove includes naturally by taking the crude info messages. To use this and to change the viability of profound learning calculations to the assignment of pernicious URL's location. All weaknesses are distinguished in Web applications, issues brought about by unchecked information are perceived similar to the most widely recognized. To abuse unchecked info, the aggressors, need to accomplish two objectives which are Inject malicious information into Web applications and Manipulate applications utilizing malevolent information. Web Applications getting requesting furthermore, a famous wellspring of diversion, correspondence, work and instruction since making life more helpful and adaptable. Web administrations additionally become so broadly uncovered that any current security weaknesses will most likely be uncovered and misused by programmers.
The process of detecting malicious URLs is not an easy task and it requires comprehensive efforts on multiple ends. The primary domain that has been specifically covered in this paper is Machine Learning and character recognition. This paper has gone through multiple algorithms and methodologies that can be considered a part of Machine Learning which can be utilized to detect malicious URLs. The paper has established a fundamental and obvious set of risks associated with a malicious URL and the necessity to battle and curb it. The important analogy associated with malicious URLs is that their harmful effect is unprecedented and opens door to multiple such occurrences in the future. That’s why it is important to consider the processes of detection to intricately define an overall strategy to detect malicious URLs. The concept of detection and restricting malicious URLs is an ever-growing and developing process. The main reason behind this is that hackers and spammers are consistently looking for new methodologies to conduct harmful processes for the user to make them vulnerable. The paper has covered all the important aspects of the Machine Learning domain to prevent attacks of malicious URLs. The set of recommendations has laid to follow a certain set of tasks associated with URL detection such as reporting spam to any such website or mail that has the intention to deliver harmful content.
The paper went through all the important terminologies and methodologies of algorithms–based tools that can be used for identifying and blocking malicious URLs. The research methodology employed in this paper is the Delphi method and the use of several other research papers is highly detectable. The necessity of preventing malicious URLs is extremely important for the sake of data security and privacy issues. This must be administered seriously in continuance to sustain the integrity of online activity without losing any kind of credibility.
References
1. Shibahara, T., Yamanishi, K., Takata, Y., Chiba, D., Akiyama, M., Yagi, T., Ohsita, Y. and Murata, M., 2017, May. Malicious URL sequence detection using event de-noising convolutional neural network. In 2017 IEEE International Conference on Communications (ICC) (pp. 1-7). IEEE. https://ieeexplore.ieee.org/abstract/document/7996831/
2. SHOID, S.M., 2018. Malicious URL classification system using multi-layer perceptron technique. Journal of Theoretical and Applied Information Technology, 96(19). http://www.jatit.org/volumes/Vol96No19/15Vol96No19.pdf
3. Choi, H., Zhu, B.B. and Lee, H., 2011. Detecting Malicious Web Links and Identifying Their Attack Types. WebApps, 11(11), p.218. http://gauss.ececs.uc.edu/Courses/c5155/pdf/webapps.pdf
4. Tekerek, A., 2021. A novel architecture for web-based attack detection using convolutional neural network. Computers & Security, 100, p.102096. https://www.sciencedirect.com/science/article/pii/S0167404820303692
5. Cui, B., He, S., Yao, X. and Shi, P., 2018. Malicious URL detection with feature extraction based on machine learning. International Journal of High Performance Computing and Networking, 12(2), pp.166-178. https://www.inderscienceonline.com/doi/abs/10.1504/IJHPCN.2018.094367
6. Patgiri, R., Katari, H., Kumar, R. and Sharma, D., 2019, January. Empirical study on malicious URL detection using machine learning. In International Conference on Distributed Computing and Internet Technology (pp. 380-388). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-030-05366-6_31
7. Tan, G., Zhang, P., Liu, Q., Liu, X., Zhu, C. and Dou, F., 2018, August. Adaptive malicious URL detection: Learning in the presence of concept drifts. In 2018 17th IEEE International Conference On Trust, Security and Privacy in Computing And Communications/12th IEEE International Conference On Big Data Science And Engineering (TrustCom/BigDataSE) (pp. 737-743). IEEE. https://ieeexplore.ieee.org/abstract/document/8455975
8. Kumar, R., Zhang, X., Tariq, H.A. and Khan, R.U., 2017, December. Malicious url detection using multi-layer filtering model. In 2017 14th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP) (pp. 97-100). IEEE. https://ieeexplore.ieee.org/abstract/document/8301457
9. Sahoo, D., Liu, C. and Hoi, S.C., 2017. Malicious URL detection using machine learning: A survey. arXiv preprint arXiv:1701.07179. https://arxiv.org/abs/1701.07179
10. Le, H., Pham, Q., Sahoo, D. and Hoi, S.C., 2018. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv preprint arXiv:1802.03162. https://arxiv.org/abs/1802.03162
11. Wejinya, G. and Bhatia, S., 2021. Machine Learning for Malicious URL Detection. In ICT Systems and Sustainability (pp. 463-472). Springer, Singapore. https://link.springer.com/chapter/10.1007/978-981-15-8289-9_45
12. Joshi, A., Lloyd, L., Westin, P. and Seethapathy, S., 2019. Using Lexical Features for Malicious URL Detection--A Machine Learning Approach. arXiv preprint arXiv:1910.06277. https://arxiv.org/abs/1910.06277
13. Naveen, I.N.V.D., Manamohana, K. and Versa, R., 2019. Detection of malicious URLs using machine learning techniques. International Journal of Innovative Technology and Exploring Engineering, 8(4S2), pp.389-393. https://manipal.pure.elsevier.com/en/publications/detection-of-malicious-urls-using-machine-learning-techniques
14. Ferreira, M., 2019. Malicious URL detection using machine learning algorithms. In Digital Privacy and Security Conference (p. 114). https://privacyandsecurityconference.pt/proceedings/2019/DPSC2019-paper11.pdf
15. Verma, R. and Das, A., 2017, March. What's in a url: Fast feature extraction and malicious url detection. In Proceedings of the 3rd ACM on International Workshop on Security and Privacy Analytics (pp. 55-63). https://dl.acm.org/doi/abs/10.1145/3041008.3041016
16. Jiang, J., Chen, J., Choo, K.K.R., Liu, C., Liu, K., Yu, M. and Wang, Y., 2017, October. A deep learning based online malicious URL and DNS detection scheme. In International Conference on Security and Privacy in Communication Systems (pp. 438-448). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-319-78813-5_22
17. Srinivasan, S., Vinayakumar, R., Arunachalam, A., Alazab, M. and Soman, K.P., 2021. DURLD: Malicious URL Detection Using Deep Learning-Based Character Level Representations. In Malware Analysis Using Artificial Intelligence and Deep Learning (pp. 535-554). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-030-62582-5_21
18. Do Xuan, C., Nguyen, H.D. and Nikolaevich, T.V., Malicious URL Detection based on Machine Learning. https://pdfs.semanticscholar.org/2589/5814fe70d994f7d673b6a6e2cc49f7f8d3b9.pdf
19. Khan, H.M.J., 2019. A MACHINE LEARNING BASED WEB SERVICE FOR MALICIOUS URL DETECTION IN A BROWSER (Doctoral dissertation, Purdue University Graduate School). https://hammer.purdue.edu/articles/thesis/A_MACHINE_LEARNING_BASED_WEB_SERVICE_FOR_MALICIOUS_URL_DETECTION_IN_A_BROWSER/11359691/1
20. Bo, W., Fang, Z.B., Wei, L.X., Cheng, Z.F. and Hua, Z.X., 2021. Malicious URLs detection based on a novel optimization algorithm. IEICE TRANSACTIONS on Information and Systems, 104(4), pp.513-516. https://search.ieice.org/bin/summary.php?id=e104-d_4_513
21. Vanitha, N. and Vinodhini, V., 2019. Malicious-URL Detection using Logistic Regression Technique. International Journal of Engineering and Management Research (IJEMR), 9(6), pp.108-113. https://www.indianjournals.com/ijor.aspx?target=ijor:ijemr&volume=9&issue=6&article=018
22. Vinayakumar, R., Soman, K.P. and Poornachandran, P., 2018. Evaluating deep learning approaches to characterize and classify malicious URL’s. Journal of Intelligent & Fuzzy Systems, 34(3), pp.1333-1343. https://content.iospress.com/articles/journal-of-intelligent-and-fuzzy-systems/ifs169429
23. Yuan, J., Chen, G., Tian, S. and Pei, X., 2021. Malicious URL Detection Based on a Parallel Neural Joint Model. IEEE Access, 9, pp.9464-9472. https://ieeexplore.ieee.org/abstract/document/9316171
24. Bhattacharjee, S.D., Talukder, A., Al-Shaer, E. and Doshi, P., 2017, July. Prioritized active learning for malicious URL detection using weighted text-based features. In 2017 IEEE International Conference on Intelligence and Security Informatics (ISI) (pp. 107-112). IEEE. https://ieeexplore.ieee.org/abstract/document/8004883
25. Story, A.W.A.U.S., Malicious URL detection via machine learning. https://geoipify.whoisxmlapi.com/storiesFilesPDF/malicious.url.machine.learning.pdf
26. Astorino, A., Chiarello, A., Gaudioso, M. and Piccolo, A., 2017. Malicious URL detection via spherical classification. Neural Computing and Applications, 28(1), pp.699-705. https://link.springer.com/article/10.1007/s00521-016-2374-9
27. Kumi, S., Lim, C. and Lee, S.G., 2021. Malicious URL Detection Based on Associative Classification. Entropy, 23(2), p.182. https://www.mdpi.com/1099-4300/23/2/182
28. Zhang, S., Zhang, H., Cao, Y., Jin, Q. and Hou, R., 2020. Defense Against Adversarial Attack in Malicious URL Detection. International Core Journal of Engineering, 6(10), pp.357-366. https://www.airitilibrary.com/Publication/alDetailedMesh?docid=P20190813001-202010-202009240001-202009240001-357-366
29. Lekshmi, A.R. and Thomas, S., 2019. Detecting malicious urls using machine learning techniques: A comparative literature review. International Research Journal of Engineering and Technology (IRJET), 6(06). https://d1wqtxts1xzle7.cloudfront.net/60339160/IRJET-V6I65420190819-80896-40px67.pdf?1566278320=&response-content-disposition=inline%3B+filename%3DIRJET_DETECTING_MALICIOUS_URLS_USING_MAC.pdf&Expires=1620469335&Signature=ghgtkQboBA38~WCrAAjExLjT5L3ZDBSE2jpls6zh3jg49QqgCiAyVq7UK4O6wmjr5BYU9QYUSJchdzWkL8Ov6llROtE6r0z92NEEhQGqGt1MagVkDL4G1F14~krYHnqyhrxXXt5IqhIy9koq9w40mTVEATBGnGCtmNbmJyuXDDIPyCe2Rm9ovdNVkaEm8eJvhY49finxPF1b5E56Xxjd9lLRT-0M19~zcQYdZiNjWAsJrrJZBYo0~cUsJmpnJVG6d2Xg-1AzMLW27ltWpkorabTU5~1Ms~N5QRIXiYrt3HUeqX1GaEC8KcUulV9-PK5pJOLumVEBskg6wJSM~Hb-UQ__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA
30. Patil, D.R. and Patil, J.B., 2018. Feature-based Malicious URL and Attack Type Detection Using Multi-class Classification. ISeCure, 10(2). https://www.sid.ir/FileServer/JE/5070420180207
31. Bu, S.J. and Cho, S.B., 2021. Deep Character-Level Anomaly Detection Based on a Convolutional Autoencoder for Zero-Day Phishing URL Detection. Electronics, 10(12), p.1492. https://www.mdpi.com/1157690
32. Cui, B., He, S., Yao, X. and Shi, P., 2018. Malicious URL detection with feature extraction based on machine learning. International Journal of High Performance Computing and Networking, 12(2), pp.166-178.https://www.inderscienceonline.com/doi/abs/10.1504/IJHPCN.2018.094367
33. Le, H., Pham, Q., Sahoo, D. and Hoi, S.C., 2018. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv preprint arXiv:1802.03162.https://arxiv.org/abs/1802.03162
34. Le, H., Pham, Q., Sahoo, D. and Hoi, S.C., 2018. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv preprint arXiv:1802.03162. https://arxiv.org/abs/1802.03162
35. Patgiri, R., Katari, H., Kumar, R. and Sharma, D., 2019, January. Empirical study on malicious url detection using machine learning. In International Conference on Distributed Computing and Internet Technology (pp. 380-388). Springer, Cham.https://link.springer.com/content/pdf/10.1007/978-3-030-05366-6_31.pdf
36. Sahoo, D., Liu, C. and Hoi, S.C., 2017. Malicious URL detection using machine learning: A survey. arXiv preprint arXiv:1701.07179.https://arxiv.org/abs/1701.07179
37. Saxe, J. and Berlin, K., 2017. eXpose: A character-level convolutional neural network with embeddings for detecting malicious URLs, file paths and registry keys. arXiv preprint arXiv:1702.08568. https://arxiv.org/abs/1702.08568
38. Verma, R. and Das, A., 2017, March. What's in a url: Fast feature extraction and malicious url detection. In Proceedings of the 3rd ACM on International Workshop on Security and Privacy Analytics (pp. 55-63).https://dl.acm.org/doi/abs/10.1145/3041008.3041016
39. Vinayakumar, R., Soman, K.P. and Poornachandran, P., 2018. Evaluating deep learning approaches to characterize and classify malicious URL’s. Journal of Intelligent & Fuzzy Systems, 34(3), pp.1333-1343. https://content.iospress.com/articles/journal-of-intelligent-and-fuzzy-systems/ifs169429
40. Yang, P., Zhao, G. and Zeng, P., 2019. Phishing website detection based on multidimensional features driven by deep learning. IEEE Access, 7, pp.15196-15209. https://ieeexplore.ieee.org/abstract/document/8610190/
41. Yang, W., Zuo, W. and Cui, B., 2019. Detecting malicious URLs via a keyword-based convolutional gated-recurrent-unit neural network. IEEE Access, 7, pp.29891-29900. https://ieeexplore.ieee.org/abstract/document/8629082/
42. Sahoo, D., Liu, C. and Hoi, S.C., 2017. Malicious URL detection using machine learning: A survey. arXiv preprint arXiv:1701.07179.
https://arxiv.org/abs/1701.07179
43. Ferreira, M., 2019. Malicious URL detection using machine learning algorithms. In Proc. Digit. Privacy Security Conf. (pp. 114-122).
https://privacyandsecurityconference.pt/proceedings/2019/DPSC2019-paper11.pdf
44. Do Xuan, C., Nguyen, H.D. and Nikolaevich, T.V., 2020. Malicious url detection based on machine learning.
https://pdfs.semanticscholar.org/2589/5814fe70d994f7d673b6a6e2cc49f7f8d3b9.pdf
45. Le, H., Pham, Q., Sahoo, D. and Hoi, S.C., 2018. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv preprint arXiv:1802.03162.
https://arxiv.org/abs/1802.03162
46. Joshi, A., Lloyd, L., Westin, P. and Seethapathy, S., 2019. Using Lexical Features for Malicious URL Detection--A Machine Learning Approach. arXiv preprint arXiv:1910.06277.
https://arxiv.org/abs/1910.06277
47. Kumar, R., Zhang, X., Tariq, H.A. and Khan, R.U., 2017, December. Malicious URL detection using multi-layer filtering model. In 2017 14th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP) (pp. 97-100). IEEE.https://ieeexplore.ieee.org/abstract/document/8301457/
48. Khan, F., Ahamed, J., Kadry, S. and Ramasamy, L.K., 2020. Detecting malicious URLs using binary classification through addax boost algorithm. International Journal of Electrical & Computer Engineering (2088-8708), 10(1).
https://d1wqtxts1xzle7.cloudfront.net/64051690/44%2027sep%20%2029jun%2014apr%2019473%20ED%20%28edit%20lelli%20.pdf?1596070856=&response-content-disposition=inline%3B+filename%3DDetecting_malicious_URLs_using_binary_cl.pdf&Expires=1627026966&Signature=Fc86R-Fim4sTJXqv-T9~x76rKewY2Wz233XcezybbtWscGkvWzFU1iwJqXh0SVCdeDNVXiB0nFbzcg8kOsX3JnMBdR72Joh5AY6BiM5ttCfE5ExyOnMD7MBPKufRjvAkTpXDQ69oC78JIc1k5CQZjFPCZmU7PfuQ4P4M5zLWFHTBNZpZ3JMqDOghnvWCCjahLBU4DVqzFdDMjJX2dQU24zT0JCWQ2uRDm5jY3uZvhi0~whYNaAN0x0L7BBSpG-ruhXe8yQTyDccnlpLa6I89F9uDXSDkoOaPYmohrE7yRbOFr~G9Mx2EpbSkqWT8QLDHXtRldtFPzXEmfLuPirRuTA__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA
49. Rakotoasimbahoaka, A., Randria, I. and Razafindrakoto, N.R., 2019. Malicious URL Detection by Combining Machine Learning and Deep Learning Models. Artificial Intelligence for Internet of Things, 1.
https://vit.ac.in/AIIoT/pages/Proceedings_AIIOT2019_VIT.pdf#page=5
50. Bu, S.J. and Cho, S.B., 2021. Deep Character-Level Anomaly Detection Based on a Convolutional Autoencoder for Zero-Day Phishing URL Detection. Electronics, 10(12), p.1492. https://www.mdpi.com/1157690
51. Lee, W.Y., Saxe, J. and Harang, R., 2019. SeqDroid: Obfuscated Android malware detection using stacked convolutional and recurrent neural networks. In Deep learning applications for cyber security (pp. 197-210). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-030-13057-2_9
52. Wei, B., Hamad, R.A., Yang, L., He, X., Wang, H., Gao, B. and Woo, W.L., 2019. A deep-learning-driven light-weight phishing detection sensor. Sensors, 19(19), p.4258. https://www.mdpi.com/544856
53. Bu, S.J. and Cho, S.B., 2021, June. Integrating Deep Learning with First-Order Logic Programmed Constraints for Zero-Day Phishing Attack Detection. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2685-2689). IEEE. https://ieeexplore.ieee.org/abstract/document/9414850/
54. Hajian Nezhad, J., Vafaei Jahan, M., Tayarani-N, M. and Sadrnezhad, Z., 2017. Analyzing new features of infected web content in detection of malicious web pages. The ISC International Journal of Information Security, 9(2), pp.161-181. https://iranjournals.nlai.ir/handle/123456789/73428
Data science and Analytics Assignment Sample
Project Title - Investigating multiple imputations to handle missing data
Background: Multiple imputations are a commonly used approach to deal with missing values. In this approach an imputer repeatedly imputes the missing values by taking draws from the posterior predictive distribution for the missing values conditional on the observed values, and releases these completed data sets to analysts. With each completed data set the analyst performs the analysis of interest, treating the data as if it were fully observed. These analyses are then combined with standard combining rules, allowing the analyst to make appropriate inferences that incorporate the uncertainty present due to the missing data. In order to preserve the statistical properties present in the data, the imputer must use a plausible distribution to generate the imputed values. This can be challenging in many applications.
Objectives: The project will implement this approach and investigate its performance. Depending upon the student’s interest the project could include some of the following objectives:
1. Comparing multiple imputations with other approaches to deal with missing data in the literature.
2. Exploring the effect of Not Missing at Random data on inferences obtained from Multiple Imputation.
3. Explore the effect of a Missing at Random mechanism that is non-ignorable when using Multiple Imputation.
Approach: The project will illustrate performance of the methods being investigated through simulations to begin with. The methods could also potentially be applied to a data set measuring the survival times of patients after undergoing a kidney transplant or a relevant data set available from an online public repository.
Deliverables:
The main deliverable will be providing recommendations from the investigation of the area well as any indicating any limitations identified with the approach being considered. This will be evidenced with illustrations given through simulations as well as potentially using a real data example as well.
Key computing skills:
Knowledge of R or an equivalent programming language such as Python would be required. Knowledge of statistical computational techniques such as Monte Carlo Methods would be desirable.
Other key student competencies for assignments help
Knowledge of fundamental concepts of Statistical Inference and Modelling. An appreciation of Bayesian inference and methods would also be desirable.
Data availability:
Any data set we consider will be available to download from an online public repository such as the UK Data Service or made available to student via the Supervisor.
Any other comments:
Little RJA and Rubin DB (2002), Statistical Analysis with Missing data, Second Edition.
Instruction
1. Size limit of 10,000 words (excluding preamble, references, and appendices). Anything beyond this will not be read. In general, clear and concise writing will be rewarded.
2. Must include an Executive Summary (max 3 pages), which should be understandable by a non-specialist, explaining the problem(s) investigated, what you did and what you found, and what conclusions were drawn.
Written thesis
1. Times New Roman font size 12, with justification, should be used with 1.5 line spacing throughout. Pages should be numbered. Section headings and sub-headings should be numbered, and may be of a larger font size.
2. For references the Harvard scheme is preferred, e.g. Smith and Jones (2017)
3. Any appendices must be numbered
Solution
INVESTIGATING MULTIPLE IMPUTATIONS TO HANDLE MISSING DATA
Chapter 1: Introduction
1.1 Introduction
Multiple Imputation (MI) is referred to as a process that helps to complete missing research data. It is an effective way to deal with nonresponse bias and it can be taken into action when people fail to respond to a survey. Tools like ANOVA or T-Test make it easier for analysts to perform Multiple Imputations and retrieve missing data. It is also beneficial for extracting all sorts of data and leads to experimental design (Brady et al. 2015, p.2). However, the process of using single values raises questions regarding uncertainty about the values that need to be imputed; Multiple Imputation helps by narrowing the uncertainties about the missing values by calculating various different options. In this process, various versions of the same data set are created and combined in order to make the best values.
1.2 Background of the study
A multiple Imputation is a common approach made towards the missing data problem. The data analysis can only be possible if accurate information is procured (Alruhaymi and Kim, 2021, p.478). This process is commonly used in order to create some of the different imputed datasets that aim to properly combine results gained from each of the datasets. There are different stages involved in the process of Multiple Imputing in order to retrieve and fill in missing data. The primary stage is to create more than one copy of a particular dataset. Apart from that, there are different methods and stages that are involved in the actual process that determines the way of calculating missing data in a particular place by replacing the missing values with imputed values.
Gönülal, (2019, p.2) in his research paper “Missing Data Management Practices” pointed out that Multiple Imputation has the potential of improving the whole validity of research work. It requires a model of the distribution of each and every variable with their respective missing values from the user, in terms of the observed data. Gönülal has also said that Multiple Imputation might not be used as a complementary technique every time. It can be applied by specialists in order to obtain possible statistics.
1.3 background of the research
Managing and dealing with missing data is one of the biggest concerns that a company needs to manage whenever the overall management of the workforce is being managed by the company and its employees. Though the effectiveness of implementing an appropriate business and workplace model in practices missing data or data thief can lower its efficiency and effect6ivenes all over the workplaces. This also develops lots of difficulties regards with the elimination of personal biases where it becomes really difficult for the managers of business firms in acquiring an adequate research result. ITS or an interrupted time series are vastly utilized by hierarchies in business firms where they are capable of evaluating the potential effect of investigation over time due to utilization of real and long-term data. Both learnings on statistical analysis and missing data management can be beneficial for this type of sector where there is a balance among both population levels adapt and individual levels data (Bazo-Alvarez et al. 2021,m p.603). The non-responsive and unprocessed data mainly gets missed whenever the company deals with an activity it has been dealing with for a long time. Saving data in a systematic way requires a proper understanding of the ways data is being selectively simplified by effective deals. Gathering data, data analysis, and storing requires a proper understanding of the ways data can be managed in an organization.
As per the study of Izoninet al. (2021, p. 749), it can be said that managing and controlling missing data is amongst the most popular trends in this market. These are also considered smart systems which are utilized by large business firms which can help them in managing their assets, resources, and personal and professional business data. By mitigating missing data processes a huge number of business firms can be benefitted due to their ability in managing assets and conclude their tasks within the scheduled team. Different tools that are being used in research help to identify the missing data which has a great impact on the topic. Multiple imputations are one of the most crucial processes that help to gather or recover the data that are being used for a long time. Missing data needs to be recovering in selective time otherwise the data and its sources get lost in the wild cloud system (Haensch, 2021, p.111).
Developing a process by using different tools like ANOVA or t-test help to analyze the ways missing data got lost and also help to retrieve the missing data by maintaining a format is a process (Garciarena and Santana, 2017, p.65). Non-trivial methods to procure missing values are often adopted for using sophisticated algorithms. Known values are used to retrieve missing values from the database. This particular discussion on understanding the way huge data in cloud storage systems got lost and the ways this particular data that is highly needed for any company are retried are mentioned and elaborated in this study. Different data needs to be managed by the proper Data collection format and data storing systems. The proposed format of the research comprises different parts that have active involvement while providing a critical understanding of the missing data and data protection activities. The selected structure is being mentioned in the overall discussion that is maintained by the researcher while developing the research. In some cases, the data involves the process of critical information saving which got lost sometimes and for that using multiple inputting services the retrieve data and filling of lost data by using some other ones are also used and important ones. Also, this research provides a briefing about the "Missing Data Management Practice" which has an effective impact on the organizational function related to data safety and data security (Garciarena and Santana, 2017, p.65). Data security and data security-related other functions need a proper understanding of the ways the overall function of missing data-keeping targets are managed by the general approach of multiple imputations to serve the commonly used statistical understanding of the data. The uncertainty of the data and its combining results that are obtained from the critical understanding that helps to evaluate the representativeness of bias data packages are related to the values of the missing data. Missing information, different cases, statistical packages, and other things provide the knowledge which is related to the overall activity that is given importance by the organization and its other functions (Krause et al. 2020, p.112).
1.4 Problem statement
Missing data creates severe problems that eventually create a backlog for the organization or institute. The main problem of missing data and handling the exact ways of recovering those missing data presents the critical scenario of data management. The absence of data develops critical situations while dealing with research for a project because even the null hypothesis gets rejected while developing a test that has no such statistical power because of the missing data. The estimated parameters of the research outcome can cause biased outcomes because the data that are missing and also the misleading data from different sectors lower the task force as well. Also, the representative approach of the data samples got ruined by the missing one.
1.5 Rationale
The preliminary issue raised in this research is the implementation of Multiple Imputations in order to handle missing data.
This is an issue because it is an effective and helpful technique that helps in filling in missing data. Most of the time, important surveys are left incomplete because of less response from the people. Multiple Imputation helps in completing the surveys by gathering all the needed data after performing analysis of the whole data set (Grund et al. 2018, p.113).
It is an issue now because nowadays people are becoming ignorant about questionnaires and online surveys which is impacting the ultimate result of the survey. This method can help the completion of the surveys by filling in the missing data after replacing the missing data with imputed data.
This research can help in finding the best tools for performing Multiple Imputation methods to handle missing data.
1.6 Aim of the research
Aim
The primary aim of the research is to investigate Multiple Imputations in order to handle missing data.
1.7 Objectives of the research
Objectives
The main objectives of this research are:
? To investigate the factors that contribute to the process of Multiple Imputation that helps in handling missing data.
? To measure the capabilities of Multiple Imputations in handling missing data.
? To identify the challenges faced by the analysts while performing different Multiple Imputation techniques to fill in missing data.
? To identify the recommended strategy for mitigating the challenges faced while performing different Multiple Imputation techniques to fill in missing data.
1.8 Questions of the research
Question 1: what are the exact ways that help to contribute to the process of multiple imputations in order to handle the missing data in a systematic way?
Question 2: What are the exact ways that help to measure the capabilities of multiple imputations while handling different missing data?
Question 3: What exact challenges do the analysts face while mitigating data gaps by using multiple imputations techniques of filling the missing data?
Question 4: what are the exact recommended strategies that are provided for mitigating the challenges faced while performing different multiple imputation techniques to fill in missing data?
1.9 Proposed structure of the dissertation
1.10 Summary
This discussion comprises the overall concept of using multiple imputation techniques for retrieving missing data and restructuring is critically analyzed and mentioned for better understanding. The ways different data that have got lost somehow and still exist in the cloud bases of the data folder can be retrieved is the basic function of multiple imputations which is also mentioned in the discussion. The overall concept of the multiple imputations helps to reduce the place of losing data and keeping that data intact with the exact process for an organization are elaborately described in this study. In the above-discussed section, the complex multiple imputations which are used as a secondary tool for data analysis purposes are mentioned with integrity and transparency.
Chapter 2 Literature Review
2.1 Introduction
Multiple imputation is a process of managing data that are missing. The management of data can reduce the risks of losing a project for an organization or an institute. Through the differences in the data sets, the operational process of multiple imputations became complicated. Through this chapter, the researcher is going to describe the concept of multiple imputation processes in tackling missing data. A secondary tool of data analysis helps the researcher to gather all the information on the above-mentioned research topic. There is no scope of denying the fact that this chapter is one of the crucial parts of research as it works with the information of previous researchers on the same research topic. Through the analysis of the data of past researches, the possibility to complete research became possible.
A literature review helps the researcher to analyze the research topic from several sides. The characteristics of multiple imputation processes are going to be described in this chapter of the research. The areas that the process of multiple imputations covers have been described in this chapter. This chapter also consists of the negative as well as the positive impact of multiple imputation processes in managing missing data. This is one of the important chapters of research that provides information about the overall concept of the research.
2.2 Conceptual Framework
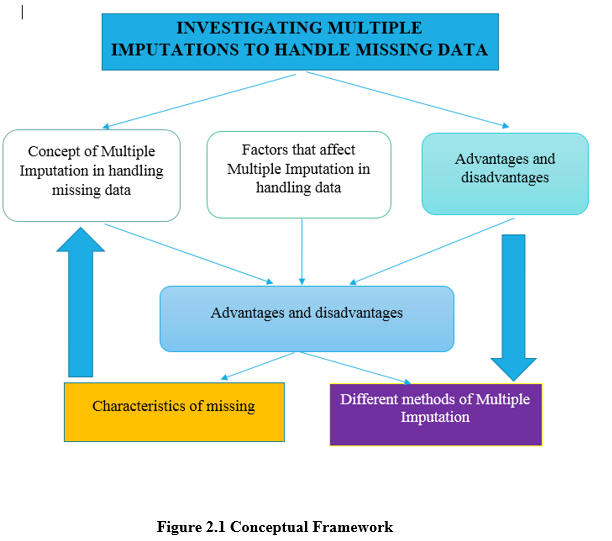
2.3 Concept of Multiple Imputation in handling missing data
Handling missing data is a quintessential aspect of analyzing bulk data and extracting results from it. It is a complex and difficult task to pull off for the professionals in this field. While optimizing the missing data and trying to retrieve it, professionals need to use effective strategies and technologies that can help them retrieve the lost or missing data and complete the overall report. Multiple Imputation is considered to be a straightforward procedure for handling and retrieving missing data. The common feature of Multiple Imputation was to prepare and convince these types of approaches in separate stages(Bazo-Alvarez et al. 2017, p.157). The first stage involves a data disseminator which calculatingly creates small numbers of the present dataset by filling in the lost or missing values with the collected samples from the imputation model. In the second stage data, analysts perform the computation process of their dataset by estimating it and combining it using simple methods in order to get pooled estimation of the dataset and the standard errors in the whole dataset.
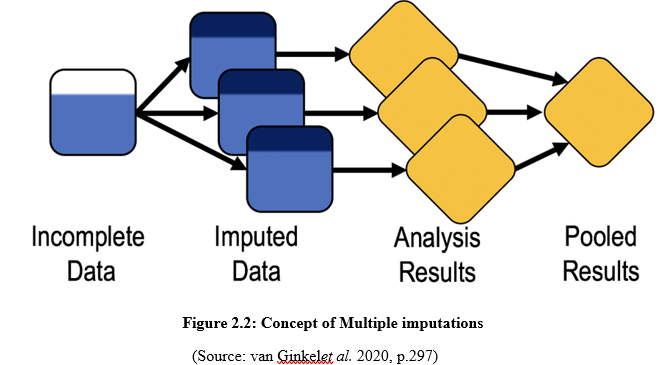
The process of Multiple Imputations was initially developed by statistical agencies and different data disseminators that provide several imputed datasets for repairing the problems and inconsistency in the dataset. MI can offer plenty of advantages to data analysts while handling or filling in missing data. Multiple Imputations replace the values of the missing sales with relevant data by analyzing the whole dataset and helps surveyors to complete a survey. The information filled in by the MI method is fully based on the information of the observed dataset. This process generates efficient inferences and provides unbiased and potentially realistic distribution of the missing data. The working structure of Multiple Imputation follows a series of steps which involves fitting the data into an appropriate model, estimating a missing point of the collected data, and then it repeats the first and the second step in order to fill in the missing values. After that, the process performs data analysis using T-Test or ANOVA which runs across all the missing data points (Nissen et al. 2019, p.20). Finally, it averages the values of the estimated parameters or standard errors acquired from the data model in order to provide a single-point estimation for the model. Sometimes calculating or approximating the missing values in a dataset is dynamic and surprisingly complex. In this scenario, MI involves two of the most competent and efficient methods to analyze the dataset. Those methods are Bayesian analysis and Resampling Methods. Nowadays data analysts use relevant computer software in order to fill in missing data by performing the Multiple Imputation process.
2.4: Different types of Multiple Imputation
Multiple Imputations is a simulation-based technique that helps in handling missing data. It has three different steps which involve the Imputation step, Completed-data analysis or estimation step, and pooling step. The imputation step generally represents one or multiple sets of plausible values for missing data (Nissen et al. 2019, p.24). While using the techniques of multiple imputations, the values that are missing are primarily identified and then a random plausible value replaces it with a sample of imputations. In the step of completed data analysis, the analysis is generally performed separately for each and every data set that is generated in the imputation step. Lastly, the pooling step involves the combination of completed data analyses. On the other hand, there are different types of Multiple Imputation in handling missing data. The three basic types of Multiple Imputation are Single Variable Regression Analysis, Monotonic Imputation, Markov Chain Monte Carlo (MCMC), or the Chained Equation method.

Single Variable Regression Analysis
The Single Variable Regression Analysis involves some dependent variables. It also uses a stratification variable for randomization. While using a dependent variable continuously, a base value of the dependent variable can be comprised in the process.
Monotonic Imputation
Monotonic Imputation can be generated by specifically mentioning the sequence of univariate methods. Then it gets followed by drawing sequentially synthetic observations under each and every method.
Markov Chain Monte Carlo or Chained Equation method
The basic process of Markov Chain Monte Carlo (MCMC) methods comprises a class of algorithms in order to sample from a profitability distribution. One can easily obtain a sample of the expected distribution by recording the different states from the chain (Stavsethet al. 2019, p.205). MCMC also has the expected distribution as its equilibrium distribution.
2.5: Factors that affect Multiple Imputation in handling data
Multiple imputation is a process that helps in managing data sets through missing values. The multiple imputation process works by providing a single value to every missing value through the set of plausible values. Single variable regression analysis, monotonous imputation, MCMC as well as Chained Equations are the factors that affect multiple imputation processes in managing missing data (van Ginkel et al. 2020, p.305). Multiple imputations are a process or technique that no doubt works by covering several areas to manage missing data. There are several steps like imputation, estimation and lastly pooling step in this data protection process. The process of collecting as well as saving data through the multiple imputation process is complicated as well as difficult. With the differences in the types of data, the process of managing missing data became difficult. The performance of the steps of multiple imputation processes is also different as all of them cover different kinds of data sets.
2.6: Advantages and disadvantages of using Multiple Imputation to handle missing data
Handling missing data is dynamic and complex yet an important task for surveys where some of the datasets are incomplete due to missing values. In those scenarios, data analysts use Multiple Imputation as an unbiased and efficient process in order to calculate the missing values and fill in those values properly in place. The process of Multiple Imputation expands the potential possibilities of various analyses that involve complicated models and will not converge given unbalanced data due to missingness (Stavsethet al. 2019, p.12). In such situations, the involved algorithms cannot estimate the parameters that are already involved in the process. These problems can be mitigated through Multiple Imputations as it can impute missing data by estimating the balanced data set and by doing an average of the parameters involved with it.
Multiple Imputations also create new avenues of analysis without collecting any further data, which eventually is a benefit for the process of imputation. Sometimes data analysts may determine their process of pursuing their objectives about handling missing data. Especially in complex and complicated datasets, performing imputations can be expensive. In this case, multiple imputation methods appear as a cost-beneficial procedure to handle missing data. As it is an unbiased process, it restricts unnecessary processes from entering the analysis (Takahashi, 2017, p.21). This also appears as a potential advantage of using Multiple Imputations. Apart from that, it provides an improved validity of the tests which eventually improves the accuracy of the results of the survey. Multiple Imputations is considered to be a precise process that indicates how different measurements are close to each other.
Although Multiple Imputation is an efficient process that helps in filling in missing values, it also has some drawbacks that can appear as potential problems for the researchers who are dealing with data. Initially, the problem begins while choosing the exact imputation method for handling missing data. Multiple Imputation is an extensive process that involves constant working with the imputed values, in some ways the process of working sometimes misbalances the congruence of the imputation method. Also, the accuracy of Multiple Imputations sometimes relies on the type of missing data in a project (Sim et al. 2019, p.17). Different types of missing data require different types of imputation and in this case, Multiple Imputation sometimes finds it difficult to compute the dataset and extract proper results out of it. Additionally, Multiple Imputations follow the dependent variables and those missing values consist of auxiliary values which are not identified. In this scenario, the complete analysis can be used as a primary analysis and there are no specific methods that can be used to handle missing data. But in this case, using multiple imputations can cause standard errors and it may increase these errors in the result as it encounters uncertainty introduced by the process of Multiple Imputation.
Multiple Imputations can have some effective advantages in filling in the missing data in a survey if used currently. Some advantages of Multiple Imputation (MI) are:
? It reduces the bias which eventually restricts unnecessary creeps from entering into an analysis.
? It improves the validity of a test which simply improves the accuracy of measuring the desired result of a survey. It is more appropriate while creating a test or questionnaire for a survey. It helps in addressing the specific ground of the survey which ultimately generates proper and effective results.
? MI also increases precision. Precision refers to the process which indicates how close two or more measurements are from each other. It provides the desired accuracy in the result by increasing precision in a survey.
? Multiple Imputations also result in robust statistics which outlines the extreme high or extreme low points of data. These statistics are also resistant to the outliers.
2.7: Challenges of Multiple Imputation process
There may be several challenges of multiple imputations at the time of handling missing data like-
Handling of different volumes of data
The operational process of the multiple imputation process is difficult as it works with the handling of missing data. The process of storing data that are in the database is simple, however, the possibility to recollect missing data is complicated. The process of multiple imputations takes the responsibility to complete a data set by managing as well as making plans related to the restoration process of missing data (Murray 2018, p.150). MI can work in several manners, moreover, it can be said that data argumentation is one of the most important parts of MI in controlling the loss of data. The operational process of multiple imputations is based on two individual equipment such as bayesian analysis and at the same time resampling analysis. Both methods are beneficial in managing the loss of data.
Time management
The challenge that multiple imputation processes face is related to the management of data sets no doubt. There may be the cause of missing a huge amount of data which creates a challenge for multiple imputations to complete the data set in minimum time. Moreover, this can be said that the multi-item scale of data makes the restoration process more complicated. Multiple imputations most of the time affect existing knowledge. Sometimes the restoration process takes a huge time which can cause the loss of a project. The amount of data matters at the time of collection of restoring data no doubt (Leyratet al. 2019, p.11). A small amount of missing data can be gathered at any time when a large amount of data takes much time to be restored. Though there are many advantages of multiple imputations, there is no scope of denying the fact that this process of missing data management is challenging at the time of its implementation.
Selection of the methods to manage missing data
The selection of the process of recollecting the data is also challenging as the management of the data set depends on the restoration of the same data that existed before. The selection method of the data restoration process depends on the quality of the data that are missing.
Different types of missing data
While considering the impact of missing data on a survey, the researchers should crucially consider the underlying reasons behind the missing data. In order to handle the missing data, they can be categorized into three different groups. These groups are Missing Completely At Random (MACR), missing At Random (MAR), and Missing Not At Random (MNAR). In the case of MACR, the data are missing independent of the unobserved or observed data. In this process of data, no difference that is systematic should not be there between the participants with the complete data and the missing data (Sullivan et al. 2018, p.2611). On the other hand, MAR refers to the type of missing data where the missing data is systematically related to the observed data but not related to the unobserved data. Lastly, in MNAR the missing data is related to both the unobserved data and observed data. In this type of missing data, the messiness is directly related to the factors or events that researchers do not measure.
2.8: Implementation of Multiple Imputation in handling missing data
Missing data can appear as a major restriction in surveys where the non-bias responses from people can cause an incomplete survey. In this scenario, researchers have to use some efficient statistical methods that can help in completing an incomplete survey. A variety of approaches can commonly be used by researchers in order to deal with the missing data. Primarily the most efficient technique that researchers use to deal with the missing data nowadays is the method of Multiple Imputations. At the initial stage, MI creates more than one copy of the dataset which contains especially the missing values replaced with imposed values. Most of the time these data are examined from the predictive distribution based on the observed data. Multiple Imputations involve the Bayesian approach and it should account fully for all the uncertainties to predict the values that are missing, by injecting the proper variability into the multiple times imputed values (Tiemeyer, 2018, p.145). Many researchers have found the multiple imputation techniques to be the most precise and effective technique in terms of handling missing data.
2.9: Capabilities of Multiple Imputation
Multiple imputation process is an effective process of handling the datasets that are missing due to lack of storing process of data. The cause behind the loss of data is the negligence of people in providing value to that data that was once beneficial for the operational process. There are some capabilities of multiple imputations like-
Protection of missing data
Protection of the data that are missing is one of the important parts of the operational process of multiple imputations. During deleting the unnecessary creeps, the opportunity of losing useful data is common. The process of deleting data is easy; however, the restoration process can be difficult. The negligence or the lack of carefulness of people at the time of managing data can be considered as the cause behind this losing data. There may be several cases when excessive data is lost by the management of an organization at the time of handling creep or useless data (Audigieret al. 2018, p.180). Sometimes the restoration process takes more time than expected which may cause the loss of a huge amount of projects for the management of an organization.
Managing the operational process
The management of the operational process is one of the important capabilities of multiple imputation processes. Through the management of data, the possibility to manage the loss of a project became less. It also helps to improve the validity related to a test that improves the aspired result. The test is completed through questionnaires as well as tests that develop the authenticity of data. This testing helps in the improvement of the operational process of an organization.
Increasing precision
This process refers to the closeness of one or more than one measurement with each other. The multiple imputation process is also related to robust statistics that outline a high as well as low volume of data. The size of data matters in the process of collection of restoring data no doubt. A small size of missing data can be gathered at any time, on the other hand, a large amount of data takes much time to be restored (Grund et al. 2018, p.140). There is no scope of denying the fact that this process of missing data management is challenging at the time of its implementation.
2.10: Characteristics of missing data and its protection processes
Missing data can be also recognized as data that is not stored perfectly. Missing data can provide several problems in the operational process of an organization. The absence of data can decrease the balance in the operational process of an organization or an institute. There are several types of missing data such as-
Missing completely by random
This missing data is related to negligence in managing data which causes the absence of data. This kind of missing data is not acceptable as it can reduce the reputation of an organization in the market. The operational power may be lost due to Missing data completely by random, however, the parameters which are estimated are not lost due to the missing of the data (Jakobsen et al. 2017, p.9).
Missing by random
This kind of data refers to the absences of the response of people. This type of missing data reflects that most of the time absence of data does not create big problems. This does not reflect that absence of data is beneficial or can be ignored easily.
No missing at random
This kind of missing data reflects the problems that missing data can cause. This missing data type provides the information of the negligence of people in handling or storing data. Missing values can be considered as the medium of this missing data. Moreover, it can be said that perfect planning related to storing data can reduce the risks of missing data (Enders 2017, p.15).
The operational process of the multiple imputation process is difficult as it works through the handling of missing data. The process of storing data which is in the database is simple; however, the possibility to recollect missing data is complicated. The process of deleting data is easy; however, the restoration process can be difficult. The negligence or the lack of carefulness of people at the time of managing data can be considered as the cause behind this losing data. There may be several cases when excessive data is lost by the management of an organization at the time of handling creep or useless data (Brand et al. 2019, p.215). There is no scope of denying the fact that the adobe mentioned types of missing data are difficult to be handled as losing data is easy and restoring data is difficult.

2.11: Different methods of Multiple Imputation to handle missing data
Multiple Imputation is a straightforward process that helps in filling in the missing values in a dataset. There are different methods involved in performing Multiple Imputations. The methods of MI sometimes vary due to the work structure and missing data type. In general, there are three types of Multiple Imputation and according to the complexity; these methods are taken into action by the data analysts (Huqueet al. 20108, p.16). These three types are 1) Single Value Regression Analysis, 2) Monotonic Imputation, and 3) Markov Chain Monte Carlo (MCMC) method. These methods are generally used by professionals while using Multiple Imputation in handling missing data. On the other hand, there are some different MI methods that data analysts use especially in imputing longitudinal data (Sullivan et al. 2018, p.2610). Some of the longitudinal methods are allowed to follow the subject-specific variance of error in order to produce stable results within random intercepts. Apart from that, there are different studies that professionals use while conducting the Multiple Imputation process.
Single Value Regression Analysis
This analysis process is generally concerned with the relationship between one independent numeric variable and a single dependent numeric variable. And in this analysis, the single dependent variable relies upon the independent variable in order to get things done. Also, these variables include an indicator in case the trial is multi-center and there is usually more than one variable with the prognostic information which are generally correlated with the outcomes. While using a dependent variable continuously, a general baseline value of those dependent variables might also be included in the process of analysis.
Monotonic Imputation
The imputation of missing data can be generated with a specific sequence of some univariate processes in the monotone imputation. This process follows the sequential synthetic observations under different methods. In the missing data, the method of monotone imputation is ordered into a specific pattern that follows monotone imputation. On the other hand, if the missing data is not monotone, the process of Multiple Imputation is conducted through the MCMC method which is a potential method for conducting Multiple Imputations to handle missing data.
Markov Chain Monte Carlo
MCMC is a probabilistic model that provides a wide range of algorithms for random sampling from the high-dimensional distribution of probability. This method is eligible for drawing independent samples from the actual distribution in order to perform the process of imputation. In this process, a sample is drawn where the first sample is always dependent on the existing sample. This process of dependability is called the Markov Chain. This process generally allows the actual algorithms to narrow down the quantity that is approximated from the process of distribution. It can also perform a process if a large number of variables are present there.
2.12: Practical Implication of Multiple Imputation in handling missing data
Multiple Imputation is a credible process that is generally implemented by professionals of the statistical field in order to generate the missing values within a statistical survey. The preliminary goal of Multiple Imputation is to calculate the uncertainty in a dataset because of the missing values that are present in subsequent inference. The practical implication is a bit different from the gothic objectives of Multiple Imputation (Haensch, 2021, p.21). The implication of MI in the revival of missing values is generally attained through simpler means. The working process of Multiple Imputation is similar to the task of constructing predictive and valid intervals with a single regression model. In this case, the Bayesian imputation models are the most competent method in order to perform the imputation process properly and achieve the approximate proper imputations that are generally needed for handling the uncertainties of the chosen model. The Bayesian imputation process is a reliable natural mechanism that helps in accounting for the different models with uncertainty.
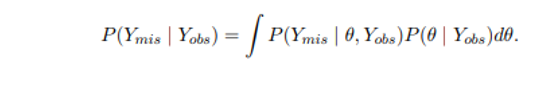
Figure 2.7: Bayesian analysis
(Source: Choi et al. 2019, p.24)
In the analysis, the imputations are generated from the assumed value where 0 is a parameter that is indexing the model for Y. In order to show the uncertainties in the model, compositionally the imputations can be sampled. Here in this formula, the uncertainty of the model is represented with P and the intrinsic uncertainties of the missing values are represented with PY here. In both cases, the worth of Bayesian imputation is proven where the influence of the technique is proved as useful here. Also, the Bayesian bootstrap for a proper hot-deck imputation is a relevant example of the practical implication of Multiple Imputations in handling missing data.
2.13: Literature Gap
Different imputation-related inputs have been discussed under the different areas of discussion. Utmost effort is made of the different factors, Advantages in order to strengthen the concepts. Different important elements like Hot Deck, Cold Deck, and Mean Substitutions have been created here. This could and needs to be identified that a basic frame could act towards catering to the different sections of the analysis. This could have been discussed while understanding and analyzing the different mean values and biases. Notwithstanding different aspects to it, there are certain areas where flaws and frailties could arise (Choi et al. 2018, p.34). The Gap areas included different analyses like Non-Negative Matrix Factorization, Regression analysis, and so on. Even the different analyses like Bootstrapping, Censoring (Statistics), and others. Taking all these into consideration this could be opined that the overall literature Review contains the divergent aspects of MMC and other models and most recent and generic discussions. Although the researchers have tried to provide a clear insight of the factors that are generally used in Multiple Imputation to handle missing data, there are some limitations that were there while preparing the literature for the research. Firstly, the outbreak of COVID-19 has appeared as a drawback for the researchers to collect relevant data for the research. Apart from that, the literature of this research tries to explain the different methods used by the data analysts while performing Multiple Imputations for different purposes. Some of the grounds of Multiple Imputation were not available to the researchers because of the restricted allotted budget. Although, after all these constraints, the literature attempts to provide a fair insight into how Multiple Imputations can be useful in handling missing data.
Chapter 3: Methodology
3.1 Introduction
In order to develop this particular research tools and strategies have been implicated that have a vigorous impact on the overall research outcome. The methodology is one of the tools that help to evaluate the understanding of the ways effective strategies shape the research with proper aspects and additional understanding (Andrade, 2018). In this particular research, a conflicting understanding about the missing data and critical implication of Multiple Imputations (MI) are mentioned throughout that help to judge the ways missing data are creating complications while dealing with the project formation and strategies.
3.2 Research Philosophy
Research philosophy can be referred to as a belief that states the ways in which research should be conducted. It also states the justified and proper watts of collecting and analyzing data. In order to research around the implementation of Multiple Imputation in handling missing data, the researchers will use the Positivism Philosophy. The positivism philosophy is a philosophy that adheres to the point of view of the factual knowledge gained through several observations while conducting the whole research (Umer, 2021, p.365). This chapter represents the estimation of parameters of exponential distribution along with the assistance of the likelihood of estimator under both censored and general data.
Justification
Using positivism philosophy for this research can be justified because it helps in interpreting the research findings in an objective way. It also helps the researchers to collect precise and effective data for the research which eventually helps in conducting the research with minimum casualties.
3.3 Research Approach
The researchers will use the Deductive Approach for this research as it is completely focused on developing hypotheses based on the deductive theory. It also helps in designing a particular research strategy in order to check the credibility of the hypotheses made regarding the research topic (van Ginkel et al. 2020, p.298). Choosing the deductive approach for this research project will expectedly act positively for the researchers as it will allow them to research extensively on the application of Multiple Imputation in order to handle missing data. A deductive approach may help the researchers to figure out the causal links between the different methods of Multiple Imputation in order to handle missing data.
3.4 Research design
For this research development, the researcher has chosen a descriptive and exploratory research design. Descriptive research design helps to investigate the variables with a wide variety and also so the outcome which has an impression on the research topic is evaluated by this particular research design. The descriptive research design helps to analyze the topic with proper investigation ideas and provides an outcome with justified notations. Exploratory design helps to conduct research on the basis of previously done studies and on earlier outcomes (Eden and Ackermann, 2018). While developing this research and finding out the ways missing data evaluate the overall project structure are also mentioned with proper understanding and justification.
3.5 Research Method
In order to develop this research, the researcher has used both qualitative and quantitative research methods for a systematic project development formation. Both primary and secondary data sources have been used for this research structure development. Qualitative data help to develop research by implicating the outcomes which have previously been confirmed by some other researchers who have dealt with the topic (Cuervo et al. 2017). Critical matters related to missing data and its functions are measured by the quantitative research method implication on the other hand the qualitative research method helped the quantitative outcome to come to a conclusion.
3.6 Data Collection and Analysis Method
Collecting and analyzing data is the most important aspect of research. In this case, the researchers need to collect their needed data efficiently in order to conduct their research regarding using Multiple Imputations to handle missing data. Most importantly, the researchers need to use both primary and secondary sources to collect data. Also, they need to use procedures like ANOVA and T-test in order to analyze their collected data (Wang and Johnson, 2019, p.81). The software for analyzing the data should be based on R studio and Stata in order to generate accurate results. Also, the researchers will be using primary data sources like questionnaires and interviews of the professionals in order to gather their needed information regarding this technique. Additionally, the researchers can use datasets available online. Journals and scholarly articles regarding this topic will be helpful for the research especially the journals from the professionals can provide the researchers with extensive exposure to the implication of the Multiple Imputation process in managing missing data.
3.7 Research strategy
For this particular study development research has you step-by-step research strategy for gathering information to direct the action of the research with effort. Enabling research with systematic development criteria is all about developing the course that has the power to evaluate the result at once (Rosendaal and Pirkle, 2017). In this research, the development researcher has used the systematic action-oriented research strategy for its strong core development.
3.8 Data Sources
For the research methodology part, the researcher has used different kinds of primary and secondary sources of data to develop an analysis of the missing data and its activities. Previously done researches have helped the course of the topic related to deal with the conception of the missing data and retrieving the data by using the Multiple Imputation technique. The overall understanding also provides an idea that the data sources that have been used while developing the research have helped to manage the overall course of the ideal research development. With previous existing files, an R studio and Stata have been conducted as well to generate the result also the ANOVA and T-TEST have been conducted as well to gather the data for the resulting outcome.
3.9 Sampling technique
Sampling is very important in conducting and formulating the methodology of any research. By the sampling method, the information about the selected population is being inferred by the researcher. Various sampling techniques are there that are being used in formulating the methodology of research such as simple random sampling, systematic sampling, and stratified sampling. In this research of handling the missing data by the investigation of multiple imputations, a simple random sampling technique is to be used in which every member of the population has an equal chance and probability of getting selected effectively (Kalu et al. 2020). Moreover, by the simple random sampling technique, the error can be calculated in selecting and handling the missing data by which the selection bias can be reduced effectively which is good for the conduction of the research effectively. By this sampling technique, the missing data that is to be handled can be selected appropriately and they can be sampled effectively. Thus, by the implementation of the sampling technique properly, the research can be conducted and accomplished appropriately.
3.10 Ethical issue
Several ethical issues are being associated with the conduction of this research of handling the missing data by the investigation of multiple imputations. In handling the missing data, if there becomes any mishandling by the researcher or if there is an error in the data collection and data analysis, the occurrence of mishandling of the data can be done. As a consequence of this mishandling of the data, those data can be leaked or can be hacked by which the privacy of the data can be in danger. Moreover, those data can have important and personal information about different human beings or different organizations. By mishandling the data, they can be leaked or hacked effectively. Thus, this is a serious ethical issue that is being associated with the conduction of the research and this issue is to be mitigated appropriately for the proper conduction of the research effectively. All these ethical issues are going to manage by the following legislation from the Data Protection Act (Legislation.gov.uk, 2021).
3.11 Timetable
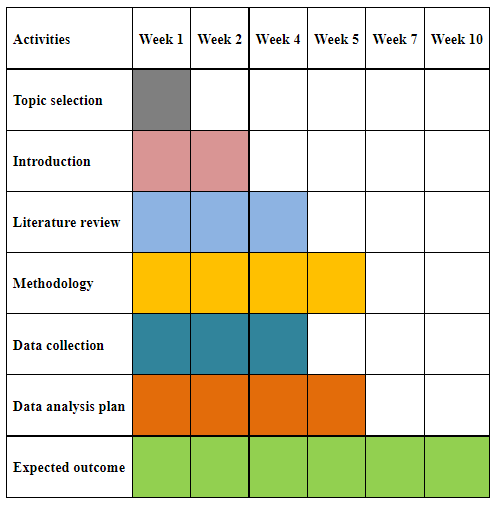
Table 3.1: Timetable of the research
(Source: Self-created)
3.12 Research limitation
Time: Though the research is being conducted very well, it does not complete in the given time and exceeds the time that is being conceded for accomplishing this research. Thus, this is a limitation in the accomplishment of the research that needs to be given more concern in the future.
Cost: The cost that was being estimated for the conduction of the research has been exceeded its value which is a limitation of conducting this research.
Data handling: Some of the missing data could not be handled well in the conduction of the research by which there is a chance of leaking data which is a big limitation in the conduction of the research.
3.13 Summary
Conclusively, it can be said that the methodology part is very important in the proper conduction of the research as by selecting the proper aspects of the methodology and formulating the methodology properly, the research can be accomplished appropriately. Moreover, the research philosophy, approach, research design, data collection, sampling technique, ethical issues, and timetable of the research are being formulated and discussed that is applicable to the conduction of the research. In addition to this, there are some limitations in the research that is also being discussed in this section effectively. These limitations need to be mitigated for the proper accomplishment of the research appropriately.
Chapter 4: Findings and Analysis
After analyzing the collected data regarding the implications of Multiple Imputations in order to handle missing data an extensive result can be extracted from the observed dataset. Researchers can yield the results after removing the rows that contain the missing values in an incomplete survey. The researchers can use a combination of different approaches in order to yield the best results. Additionally, the analysis process can follow the TDD where every method must be tested empirically. Also, the use of the ANOVA method in order to fill in the missing data stands out to be the most effective aspect of using Multiple Imputation techniques for dealing with missing data (Wulff, and Jeppesen, 2017, p.41). The research has also aimed to find out the working process of MI technology and how it replaces the missing number with the imputation value. Another finding can be extracted from the research that the MI method is the easiest method to implement and it is not computationally intensive in order to fill in missing data. Within the replaced missing values the researchers can evaluate the efficiency of the various data handling techniques along with Multiple Imputation techniques (Xie and Meng, 2017, p.1486). These processes have now moved to machine learning technologies where it is now conducted with software based on Python coding and technologies like ANOVA and T-Test have made it easier for the researchers to find out the missing values with the Multiple Imputation technique.
4.2 Quantitative data analysis
The quantitative data analysis includes the statistical data analysis that also includes the mathematical data such that the analysis has been shown using the Stata software. This also includes the representation of the mathematical results such that all the data is acquired from the Stata software. This different data analysis includes the survey data that has been shown using the data set such that the wlh has been shown. The quantitative data analysis includes the numerical data that has been shown using the Stata software. R Studio software has been utilized along with the STATA software to show the visualization and analysis such that the Linear regression, T-test, Histogram, and other visualization has been shown using the STATA software.
Thus, the assessment has also shown the different results that have been acquired from the conducted analysis that has been shown using the Stata software. The main aim of the quantitative analysis includes the determination of the correlation between the attributes that are present in the data set. Thus, from the different data visualization process the R studio and the STATA software the data visualization and different algorithm has been shown using the R studio software such as this includes the Z test, T-test and the Annova test that has been performed by the assessment using the R studio software such that this also includes the execution of the specific codes that has been implemented using the R studio software.
Figure 4.2.1: Reflects the data set in Stata
(Source: Self-created)
This figure reflects the data set that has been shown using the Stata software such that this shows the different variables that are present in the data set. In this research report, the assessment has been shown using the R studio and the Stata software. According to Girdler-Brown et al., (2019, p.180), the R Studio software has been used to show the Anova Test T-test upon the data set such that the complete report has been reflected using the two different software such as the R studio and the Stata.
This placed figure reflects the data set that has been imported by the assessment such that the codes to view helped to reflect the data set using the R studio software.

This figure reflects the mean and standard deviation using the Stata such as this reflects the mean and standard deviation has been extracted upon the PID column. This figure also reflects the value that shows that the standard deviation has been extracted with a value of 2560230 and the mean value has been extracted as 1.47 from the observation such as 178639.

This placed figure reflects the Anova test that has been performed by the assessment using the Stat software upon the Payment column such that the value of variance has been observed as 402.4137.

This placed figure reflects the T-test that has been performed by the assessment using the Stata software such that the degree of freedom has been extracted between two columns such “paygu” and “paynu”.
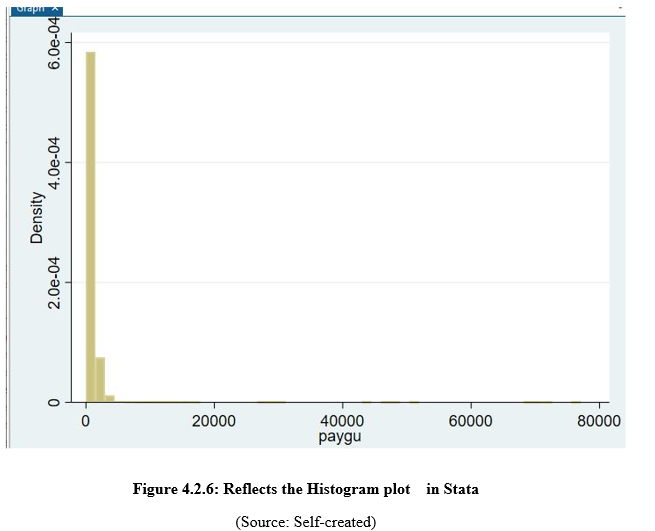
This placed figure reflects the Histogram plot that has been plotted between the payments of the employees and the density.
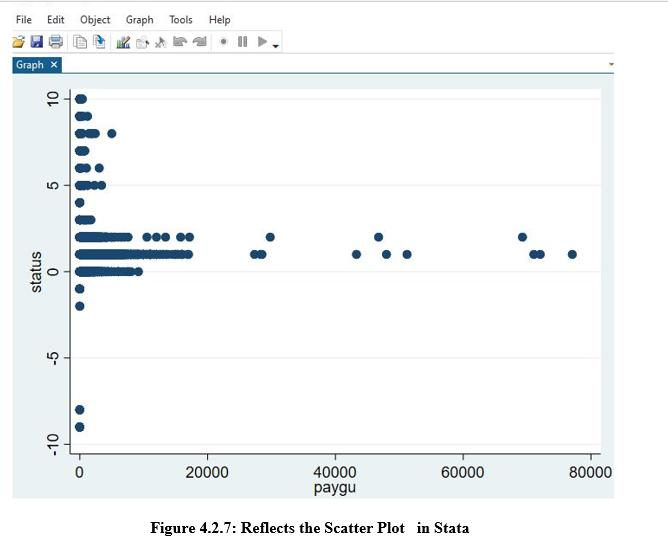
This placed figure reflects the Scatter plot that has been plotted between the payment of employees and the status of the employees with the help of the Stata software to determine the correlation between and closeness between the attributes.
This figure reflects the bhps information that has been shown using the Stata software such that the assessment has reflected the information from the given do files. This BHPS information has been implemented such that this has been extracted using the

This placed figure reflects the R studio codes such that this R studio includes the installation of packages such that this also includes the summary and other different types of data analysis such as the T-test, Z-test such as the assessment.
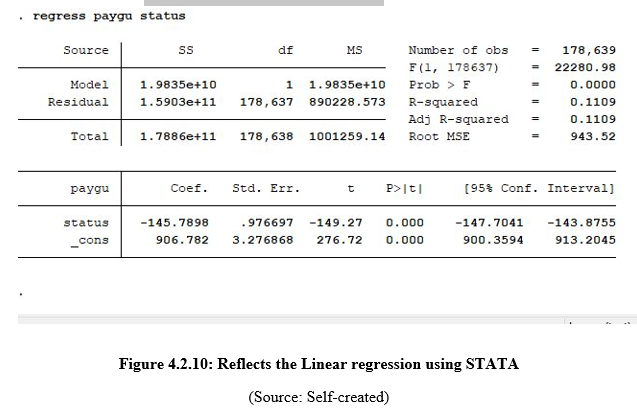
This figure reflects the result of linear regression that has been performed by the assessment using the STATA software. This figure reflects that the F1 score has been obtained from the R studio software such that this includes the 22280.98.
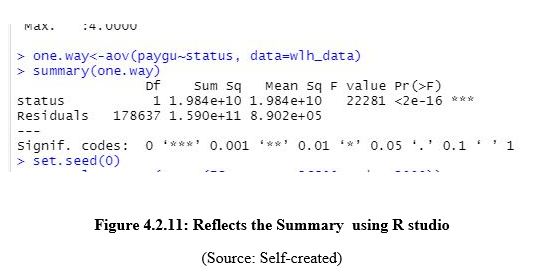
This figure reflects the summary report that was extracted by the assessment using the R studio software such that this Mean and other parameters have been extracted using the software.

This figure reflects the T-test hypothesis that has been extracted by the assessment using the R studio software such that this shows the mean of x such as this includes the 36447.49. This summary has been extracted by the assessment using the STATA software such that this reflects the Anova test that has been implemented upon the R studio software such that this includes the 95% of the confidence level that has been implemented using the specific R studio codes that have been shown in the above figures (Nguyen et al., 2019, p.154). Here the detailed application of the ‘ggplot’ and ‘tidyverse’ helps to create the statistical test implementation. The collections of the above R studio packages help to develop the data representation. The application of those artifacts is able to present the evaluation of ANOVA and T-test. The application of the ggplot package inj the software interface of R helps to present the final visualization outcomes of the statistical data analysis method. Here is the correlation between different columns.
This different kind of data visualization and the data analysis using the two different methods such that this implemented different analysis has helped to extract the data and the data visualization(Baker, 2020, p.187). From the different data visualization, the correlation between the attributes has been shown in this research report with results of implemented analysis and visualization. Thus, The main aim of the quantitative analysis includes the determination of the correlation between the attributes that are present in the data set.
This complete section reflects the Quantitative analysis and within this quantitative analysis the results that have been extracted have been shown such as the WHl data set has been imported in both the software platforms. quantitative data analysis includes the numerical data that has been shown using the Stata software. R Studio software has been utilized along with the STATA software to show the visualization and analysis such that the Linear regression, T-test, Histogram, and other visualization has been shown using the STATA software. Thus, the assessment has also shown the different results that have been acquired from the conducted analysis that has been shown using the Stata software (Dvorak et al., 2018, p.120). This complete process involves deep research using the different methods that have been acquired using the software.
Finding 1: The effect of missing data is extremely hazardous
The effect of missing data is one of the most critical complications that different organizations face when it comes to managing and saving data for organizational function purposes. In order to manage organizational function, a company needs to gather previous data that provide knowledge about the way a company has maintained its function helps to evaluate the future therefore losing some of this data causes a tremendous hazard. Losing data has critical importance in the method of handling the overall structure of the workforce that has been implicated in an organization. Managing data is like connecting dots which needs to be in a systematic formation to provide the outcome in a formative way (Garciarena and Santana, 2017, p.65). Data science provides an understanding that missing data tends to slip through cracks from the appropriate form of data.
Handling missing data and dealing with the havocs requires proper management skills and understanding of the length of the data. It has been seen that how much bigger the dataset is the chances of losing some data has a tremendous chance. Retrieving missing data from a small data set is quite easy but as soon as the length of the data set got bigger the problem got bigger as well. The proliferation of data and understanding its values related to invertible missing scenarios related to the behavioral sciences as well (Choi et al. 2019, p.36). The academic, organization or any functional activities required to save the previously done dataset to understand the ways critical complications are already have been managed in otherwise in the past and also the way things can be managed in future depends on the way previously done. Missing data creates confusion and difficulty to conclude when it comes to making decisions.
Finding 2: There is a connection between missing data type and imputation method
There is an interconnection between the type of missing data and the imputation techniques being used to recover those datasets. The different missing data types are missing completely at random (MCAR), missing at random (MAR), missing not at random (MNAR), missing depending on the value itself (MIV) (Ginkelet al. 2020, p.308). All these data types are identified by the way they got lost and the variety of reasons behind the loss can be considered as the most formally distributed data set experiences of loss. Implicating imputation methods by understanding the ways they have got lost are considered as the full feeling part which can be executed by the differences of the consideration of the data loss. The quality of the data and the importance and method are interrelated because the classification of the problems and supervising those classifications needs to implicate proper algorithms which only can be possible if the right way of lost data type can come to light. The classification and multiple imputations depend on the way things are being managed by learning classifiers with proper supervised ways that depend on the performance and the missing data type as well. The improper choice of using multiple imputations also creates problems when it comes to dealing with lost data sets. Therefore identifying the type of the data set comes as the priority while using multiple imputations to find out the data that an institution exactly needs.
Finding 3: Multiple Imputations has a huge contribution when it comes to retrieving missing data
In order to achieve an unbiased estimate of the data outcome implicating multiple imputations turns out to be one of the most effective and satisfying ways of retrieving missing data. Using multiple imputations has severe results and its outcome helps to build the understanding with standard statistical software implication results and its interpretation is highly needed when it comes to managing organizational function. Multiple imputations work in four different stages: first, the case deletion is the primary target of this system, choosing the substitution of the missing cells is managed by this one as well, statistical imputation is the core of this function, and at last, it deals with a sensitivity analysis (Grund et al. 2018, p.149). Multiple imputations have the primary task to manage the consequences of the missing data which addresses the individual outcomes which has a vigorous impact on the workforce function. The flexibility of the data and the way statistical analysis of the data is being managed semi- routinely to make sure the potential of the result validity may not get any biased decision. The potential pitfalls of the understanding and the application of multiple imputations depend on the way statistical methods are used by using the concept of the data types which are being missed from the data set (Kwak and Kim, 2017, p.407). Replacing missing values or retrieving The lost one depends on the way statistical imputation is working. The sensitivity of the analysis that can vary the estimated range of the missing value turned out to be both good and bad and the missing number which is quite moderate helps to provide the sensitive outcome based on different circumstances.
Finding 4: Increasing traffic flow speed is also dependent on multiple data imputation
Managing a website depends on different data sets which stock the previously identified data which has a vigorous impact on the overall work function. Increasing website traffic flow depends on the way the data which has been lost is retrieved and properly implicated in website modification. The overall concept also comprises the critical analysis of the findings that are gathered while using multiple imputations whenever a traffic jam created in a website depends on the way data is being handled by the management team. Website and its function is a cloud-based portal that is managed through proper data integration understandings which eventually evolved the course of data implication in a website. Managing website flow in order to reach the customer and also to manage the organizational function flow having the sense of dealing with critical postures related to the data set provides an understanding regarding the ways data can be managed (Enders, 2017, p.18).
4.4 Conclusion
This part of the project can be concluded on the basis of the above observations and their expected outcomes. Data analysis is amongst the most essential segments in any kind of research which have the capability of summarizing acquired research data. This process is associated with the interpretation of acquired data which are acquired through the utilization of specific analytical and logical reasoning tools which play an essential role in determining different patterns, trends, and relations. This also helps researchers in evaluating the researched data as per their understanding of researched topics and materials. It also provides an insight into research and how the researchers derived their entire data and understanding of personal interpretation. In this part of the research, the researchers are able to conduct both quantitative and qualitative data analytical methods in concluding their research objectives. In this research in maintaining the optimum standards and quality of research, the researchers have utilized several Python-based algorithms including T-Test and Supportive vector mechanisms along with multiple imputation techniques. Moreover, they are also able to implement machine learning mechanisms and ANOVA in their practices which helps them in acquiring the research data they have desired to deliver before the commencement of the research and able to acquire an adequate research result.
Chapter 5: Conclusion and Recommendation
5.1 Conclusion
Handling missing values with the help of multiple imputation techniques is dependent on many methods and practices. These methods are distinctive and fruitful in their own aspect of work. Also, it can be extracted from the research that the size of the dataset, computational cost, number of missing values acts as a prior factor behind the implication of Multiple Imputation in handling missing data. Also, multiple imputations can be an effective procedure in order to validate the missing data and refill the left data. The results validity of Multiple Imputation is dependent on the data modeling and researchers should not implement it in incompetent scenarios.
The Multiple imputation process is considered to be an effective tool in order to handle missing data although, it should not be implemented everywhere. Researchers should use the MI technique particularly in the research works where the survey is incomplete but consists of some relevant data beforehand. The working process of Multiple Imputation involves analyzing the previous data and concluding according to it. Also, researchers should use three of the different methods of MI technique according to the situations given. If the messiness is not monotone, researchers should use the MCMC method in order to achieve maximum accuracy in their results.
The research work has been particularly focused upon developing the concept prior to analyzing the dataset to understand the dataset and make the necessary analysis of data using different strategies. The following research work has used different statistical tools like T-test and Anova in understanding the pattern of missing information from the data set. Missing data is a very common problem while handling big data sets, multiple imputation strategy is very commonly used. Missing pieces of information creates a backlog for any organization requiring additional resources to fulfill them in an unbiased manner. Execution of the analysis clarified the different challenges that are faced while extracting data and understanding the gaps that are present. Missing data management practice has been identified with its subsequent effects and impacts it can have on particular business activity.
During the process of handling data, there can be multiple points of imputation, in analyzing this information the system is required to collect necessary samples from the imputed model and consecutively combine them in the data set aligning it to standard error. Resampling Methods and Bayesian analysis being the two of the commonly used strategies to analyze imputed data have been utilized for constructing the research work. Missing data can be broadly classified under different categories based on the nature and type of data missing from the data set. Complete random missing of data, the random missing of data, and no random missing of data are the broad categories of missing data. The different characteristics of missing data have been investigated in this research work along with the processes that can be applied to protect the necessary information. Missing data can be handled through different methods. MCMC method, Monotonic imputation, and single value regression constitute some of the models that can be used by professions in the identification of missing data. During the imputation process, 0 is taken as a parameter for indexing the model.
5.2 Linking with objective
Linking with objective 1
The research work has included the usage of different statistical tools along with a comprehensive and extensive study of different kinds of literature. Information gathered from different academic sources has been exceptionally beneficial in understanding the different factors which are involved and consecutively contribute to the process of handling missing data. The application of multiple imputation processes has proven to be an advantageous stage towards finding missing data in the data set that has been used for analysis. The combination of results of several imputed data sets has assisted in linking with the fiesta research objective.
Linking with objective 2
The presence of multiple imputations in a particular set of data makes allowance for researchers to obtain multiple unbiased estimates for different parameters used in the sampling method. These missing data, therefore, have allowed the researcher to gain good estimates over the standard errors. Replacement of identified missing values with plausible values has allowed variation in parameter estimates.
Linking with objective 3
Multiple imputations of missing data information present themselves in a very challenging manner. Through practical application of the analysis process, the challenges have been realized in a more constructive manner. The literature review of existing studies had proved to be a repository of information allowing the researcher to identify appropriate variables to be included along with random stratification and allocation of values. Diverse strategies applied to gain information regarding the methods to fill out missing values and appropriate application in the analysis process has assisted in linking with the third objective of the research work
Linking with objective 4
Identification of a recommended strategy that is going to prove beneficial in mitigating the diverse challenges faced during filling up of missing data in data imputation techniques required gaining detailed knowledge on the topic itself. Moreover, hands-on analysis assisted in the consolidation of the theoretical knowledge into a practical manner allowing the researcher to view the challenges from a detailed perspective. Through the appropriate application of prior knowledge gained through the literature review section and its consecutive application in mitigating the different challenges faced, the fourth objective has been met.
5.3 Recommendations:
Though the effectiveness of multiple imputations in handling missing data also has some of its own critiques. Amongst these, its similarities with likelihood techniques and limitations in assuming missing data at random are amongst its capabilities. In this section, the researchers are able to provide recommendations by which individuals can enhance their capabilities in handling missing data and which can help them in acquiring adequate results. These include-
Recommendation 1: Train individuals in improving their understandings of patterns and prevalence of missing data

Recommendation 2: Implementation of machine learning methods in handling missing data
Deductive, mean median mode regression
Recommendation 3: Stochastic regression imputation in handling missing data
Table 5.3: Recommendation 3
(Source: Self-Created)
Recommendation 4: Deletion method in handling missing data
Table 5.4: Recommendation 4
(Source: Self-Created)
Recommendation 5: Technological implementation in handling missing data
Table 5.5: Recommendation 5
(Source: Self-Created)
Recommendation 6: Alternative methods in handling missing data
Table 5.6: Recommendation 6
(Source: Self-Created)
5.4 Limitation
One of the main disadvantages of using multiple imputation methods for the identification of missing data is that the process fails to preserve the relationship amongst variables. Therefore, in the future perspective, mean imputation can be incorporated in analyzing data so that the sample size remains similar providing unbiased results even if the data sets are missing out at random. Instances when large amounts of data are considered instances of missing information hampers the research work and simultaneously reduces the standard of information in a system. In this regard, different data sets present easily across the public platform need to be assessed so that efficient procedural planning can be executed to understand the relationship amongst the variables even better.
5.5 Future research
There has been a growing interest in the field of synthetic data attracting attention from different statistical agencies. In contrast to traditional sets of data synthetic data possesses the capabilities of optimal modification of inferential methods so that scalar quantity interval estimates can be performed for larger data sets. These strategies are also beneficial in the analysis of complex data, factor analysis, cluster analysis, and different hierarchical models. Therefore, in the future, these synthetic design strategies can be incorporated into the research work so that a better allocation of resources can be obtained.
Missing data or information has the statistical capability to lead towards great loss in different business sectors, ranging from healthcare, transport, agriculture, education, construction, and telecommunication, therefore necessary approaches need to be applied so that technology can be developed to predict missing values which do not disrupt the primary data set. Considering sets of data from different countries the models can be trained better to identify the missing information and fit them significantly eliminating the challenges brought with it. Moreover, the adoption of these approaches through future research has the benefit of developing efficient resource planning strategies.
References
.png)
.png)
.png)
MSc Computer Science Project Proposal Sample
Section 1: Academic
This section helps Academic staff assess the viability of your project. It also helps identify the most appropriate supervisor for your proposed research. This proposal will be referred to as a point of discussion by your supervisor in seminar sessions.
Briefly Describe Your Field Of Study
For organizations making the change to the cloud, strong cloud security is basic. Security dangers are continually advancing and getting more modern, and distributed computing is no less in danger than an on premise climate. Therefore, it is crucial to work with a cloud supplier that offers top tier security that has been redone for your foundation.
WHAT QUESTION DOES YOUR PROJECT SEEK TO ANSWER?
1. What is data security issues in cloud computing?
2. What techniques are recommended for cloud-based data security
3. Which is the superlative cloud-based data security techniques?
4. What is the cloud-based storage security technique?
5. Which is the superlative cloud- based data security techniques?
6. What is existing security algorithm in cloud computing?
WHAT HYPOTHESIS ARE YOU SEEKING TO TEST?
Now a days, every companies are using cloud based system and these systems are not more secure because very easy to hack that cloud based system and the stolen personal information.
WHAT ARE THE PROBABLE PROJECT OUTCOMES?
• More improve Native integration into cloud management and security systems
• Develop more Security automation
• Data collection on cloud improve more secure and faster
Section 2: Technical
This section is designed to help the technical team ensure the appropriate equipment to support each project has been ordered. It also exists to help you fully ascertain the technical requirements of your proposed project. In filling out this section please note that we do not ‘buy’ major items of equipment for student projects. However, if a piece of equipment has a use to the department beyond the scope of a single project, we will consider purchasing it. Though purchasing equipment through the university is often is a slow process.
Solution
Chapter 1: Introduction
1.1 Introduction
The cloud-based security system consists of a surveillance system that streams the network directly to the cloud with the advantage of being able to view it. The challenging tasks can be done to improve the security system and efficiency and this wireless security system presents drawbacks. Some types of cloud computing systems like private clouds, public clouds, hybrid clouds, and multi-clouds. For Assignment Help, Cloud computing is a new model of computing developed through on-grid computing. This refers to applications delivered as services over the internet and hardware and software system in the data center that gives from services. This service is used for utilizing computer systems and referring to internal centers of data and the term private cloud is used for the internal data centers that have to fulfill the requirement of the business (Al-Shqeerat et al. 2017, p.22).
1.2 Background of the study
Cloud-based security is an advanced and very new concept that known as cloud computing. Cloud security has various advanced level techniques that help deliver crucial data or information in various places or remote zones. It also analysis cloud security which is related to an algorithm in cloud computing. Cloud computing techniques have various a patterns of rules, controls, advanced technologies, and processes. These work as a protector that secures the systems, which are cloud-based. This cloud-based security has a fine structure that holds all data or information and protects it. Cloud computing system delivers data or information with the help of the internet, a very basic medium nowadays. Moreover, cloud-based security has maintained a protocol of cyber security that boosts to secure the whole data or information with help of cloud computing systems. The main features of cloud security are to keep all data secure and private It also maintains online-based information or data, an application which uses increased day by day. Cloud computing works a delivery medium via the internet. It helps to distribute data or information everywhere especially the remote area. It is mainly good secure systems of the remote areas to communicate in various sectors. Various IT-based companies invest capital to develop cloud computing systems and various technologies that describe the algorithms part in cloud computing systems.
1.3 Problem statement
People get access to open the pool of the sources like apps, servers, services, computer networks, etc. This has the possibility of using the privately-owned cloud and improves the way data is accessed and removes the updates of the system. Cloud computing ensures that the data security system increases the flexibility of the employees and organizations. The organization has the capacity for making good decisions to grow the scale of the product or services. Cloud computing system is implemented through the advantages of the business that is moving continuously for adopting new technology and trends. There are multiple challenges of cloud computing services that face the business like security, password security, cost management, lack of expertise, control, compliance, multiple cloud management, performance, etc. the main concern for investing the cloud-based security system is issues because of the data that is store and process by the third party (Velliangiri et al. 2021, p. 405).
People access the accounts that become vulnerable and know the password in the cloud to access the information of the security system. This cloud computing enables access to the application of software over the internet connection and saves for investing the cost of the computer hardware, management, and maintenance. The workload is increasing rapidly through technology, improving the tools of the cloud system, and managing the difficulties of this system and demand for the trained workforces that deal with the tools and services of the organization. This system is mainly based on the high-speed internet connection and incurs a vast business losses for the downtime of the internet (Chiregi et al. 2017, p.1).
1.5 Aim and objectives
The aim of the study is determining techniques and algorithms of cloud-based security systems.
Objectives:
- To determine the techniques of cloud-based security system
- To describe the security algorithm that is helpful for cloud computing
- To access the data sources of cloud security system
- To examine the proper security algorithm for this system
1.6 Research questions
Research questions of this research are illustrated below:
- What are the different techniques associated with cloud-based security?
- How can security algorithms be beneficial for cloud computing?
- How can data source be accessed in cloud security system?
- What are the ways of managing security algorithms in this system?
1.7 Significance of the research
Research Rational
Cloud computing is mainly used for sharing data from one place to another place so that it needs various protection to secure the data. Mainly, sometimes there have some important or private data that needs to secure using the cloud computing systems. It has various advanced-level techniques that help to develop the algorithm parts of cloud computing. It is majorly used in the methods of the internet so that there have high risks in cloud computing systems. The most common issue of cloud-based security systems are data or information visibility and stealing data from cloud computing security. For that reason, consumers are worried about using cloud-computing systems (Mollah et al. 2017, p. 38).
The cloud computing system works as a service provider, which provides services to hold data as backup. This is an essential part because every company or consumer uses cloud systems as internal storage. For this purpose, it needs to secure and maintain proper protocol so that recover the issues of cloud computing systems. It covers up the old traditional patterns that use people so secure the cloud computing system is mandatory. Cloud computing systems are internet-based system. There has a high risk to create various issues nowadays. Mainly, protecting privacy is the main motive of cloud-based computing systems (Spanaki and Sklavos, 2018, p. 539).
In the current days, cloud-computing systems are the topmost security service provider so that it has various issues that increase day by day. Lacks of resources, internet issues are major reasons so that cloud-computing systems are affected very much. Data stealing is a very common way so that creates issues in cloud computing systems only for using the internet to use cloud-based security technologies (Pai and Aithal, 2017, p. 33).
According to the researcher's opinion, the cloud computing system is one of the most popular systems used in various sectors worldwide to progress the entire system. The user mainly faces data security issues, password-related issues, connection issues of the internet, cost management of using cloud computing systems, various management issues, and data control issues. These all issues are increased very much in current conditions. Sometimes it crosses its limitation and joins with various kinds of unethical issues, which are sometimes reaching out, to controls to manage. The researcher also notices that various technical issues are based on the cloud computing systems and affect the management sectors of cloud computing systems. It is difficult for a user who uses a cloud computing system to identify the location where access their services (Malhotra et al. 2021, p. 213).
This study observes a higher level of significance as cloud security is one of the most effective technologies that are considered by the business. This study is important for developing the infrastructure of the business, and it offers data protection to different organizations. Cloud security is identified to be a proven security technique, and that it helps in offering identity and authenticity of different data information. It also ensures the individual with overall control and encryption of the presented data information. Furthermore, this study is to present empowerment to individuals so that activities of data masking and managing integration in the obtained data can be managed (Elzamly et al. 2017). This study ensures a significant enhancement in the application of cloud computing, as the data activities tend to observe encryption in developing data security features. The organization is known for developing cloud-based security systems as it offers individuals backups, and it offers individuals with redundant storage. It is also known for developing the visibility and compliance level of the entire security system, and individuals are known for managing effective computer-based security. The entire organizational process observes enhancement in the overall computer-based security system, and it helps in managing an effective network protection system.
This research is to focus on developing the encryption level of the study, and that it is necessary for individuals in managing effective cloud provider services. Information has also been offered regarding the process of developing the enhancing overall infrastructure security, as the major areas are physical security, software security and infrastructure security. Moreover, this study is likely to ensure that the data cannot get leaked and it also helps in reducing the chances of data theft and it helps in ensuring protection to customer details, it is also important for offering security to the assets of the business (Chiregi and Navimipour, 2017). Cloud security is also important for developing the overall competitive advantage level of the business. The cloud security system is observing higher demand in the competitive market, as it ensures the users with around the clock axis, and it ensures teh users with higher availability of data information. This system is also known for managing higher protection of DDoS attacks and it ensures the individuals with a higher level of regulatory compliance.
1.8 Summary
This paper describes the technology and algorithms of cloud-based data and how this help the security system. This part holds the introduction of the given topic and many of the technique names. The problem statement, aims, and objectives are also described here through the researcher. Many of the challenges are to have a brief discussion on this part of the paper. This section of the study has clearly described the background of the study, as it has offered data regarding the necessary elements of cloud security. This section has further described the research questions of the study that are to be met in the course of the research. Information has further been presented regarding the significance of the research, as it has highlighted the growing demand for cloud security usage in the competitive market.
Chapter 2: Literature Review
2.1 Introduction
Data protection is one of the major concerns in these present days. Without it, it would be impossible for organizations to transfer private datasets. Magnitude is one of the main reasons that keep the datasets safe and they have to build some proven security techniques so they can protect all the datasets present in the cloud. Authentication and identity, encryption, secure deletion, data masking, and access control are some of the major data protection methods that show some credibility and effectiveness in cloud computing. Basic data encryption should not be the only solution when it comes to being based on this matter; developers need to focus more on the other functions also (Alrawi et al. 2019, p. 551).
In this case, it can be said that the public and private clouds lay in a secure environment but it is not impossible to attack all the datasets present in the cloud system. Every organization has the responsibility to protect their datasets via implementing various algorithms in their security system. Cloud security involves some procedures and technologies that help to secure the cloud-computing environment to fight against internal and external cybersecurity threats. It helps deliver information about the technologies that provide services in the entire internet system. It has become a must thing to do because it has helped the government and the organizations to work collaboratively. It has accelerated the process of innovations in organizations (Chang and V. 2017, p. 29).
Cloud computing security refers to the idea of technical disciplines and processes which have helped IT-based organizations to build a secure infrastructure for their cloud system. With the help of a cloud service provider, those organizations can work through every aspect of the technology. They can show their effectiveness in networking, servers, storage, operating systems, middleware, data and applications and runtime.
2.2 Background of the study
Cloud computing is not a new concept; it is an old method that has helped in delivering information and services in remote areas. It has helped those areas by creating some analogous ways for electricity, water and other utilities so the customers can lead a life with no worries. Cloud computing services have been delivered with the help of the network and the most common of them is the internet. As the days keep passing by the technologies have started to get implemented in the cloud computing services. The electric grid, water delivery systems, or other distribution infrastructure are some of the most common services provided by the cloud computing service in remote areas (Chenthara et al. 2019, p. 74361).
In the urban areas, it has shown some of its services and helps the customers to get satisfied with it. It can be said that in some ways cloud computing has become the new way of computing services and has become more powerful and flexible to achieve their key functions. There have been some reasons that caused ambiguity in cloud computing so it can be said that people can become uncertain because of those ambiguities. The National Institute of Standards and Technology has thought that it would be better if they start to develop standardized language so they can help people to understand the main aim of cloud computing and clear up all those ambiguities that caused the uncertainties (Chiregi et al. 2017, p. 1)
Since the year 2009, the federal government has tried to shift their data storage so they can enjoy the cloud-based services and created bin-house data centers. They have intended to achieve two specific goals while doing this and one of them is to reduce the level of the total investment that has been made by the federal government in IT-based organizations. The second objective is to understand the whole plot of advantages that can be caused by cloud adoption. However, the challenges stayed the same while the organizations have made changes in their cloud-shifting procedures. According to the recent surveys it can be seen that they have tried to state the advantages of cloud computing services (Cogo et al. 2019, p. 19).
Those advantages are efficiency, accessibility, and collaboration, rapidity of innovation, reliability, and security. The federal IT managers have stated that they are very concerned about the security of the cloud environments but they cannot immediately eliminate those threats. They need some time so they can implement betterment in their services. Some qualities that can be seen only in this service are that it is easier for the users to get access to its services when it is very necessary. They can easily get access to the capabilities of this service and they can change the analogy from one source to another (Geeta et al. 2018, p. 8).
The broad network access is available in this service and that is one of the finest qualities this service has because it can be impossible for the users if they got tied into one location to access their services. In addition, it can measure the amount of their provided services so it can become easier for the users.
2.3 Types of Cloud Computing
There are mainly 4 variants of cloud computing private clouds, hybrid clouds, public clouds, and multi-clouds.
Private clouds
Private clouds are generally explained as cloud environments that provide full dedication for a group or single-end user. It mainly happens where the environment takes participation from the back of the user or firewall of the group. A cloud are explainable as a private cloud when the bottom line infrastructures of the IT concentrate on a single customer and provide isolated access only to the user (Sadeeq et al. 2021, p.1).
However on-perm IT infrastructure resources are no longer required for the private clouds. These days’ organizations are implementing private clouds for their systems on rent. Vendor-owned data concentrates on the placed off-premises, which makes absolution for every location and every ownership of the users. This also leads to the private sub points that are:
(i) Managed private clouds
Customers establish and apply a private cloud that can be configured, deployed, and managed with the help of a third-party vendor. Managed private clouds can be a cloud option of delivery that guides enterprises with under skilled or understaffed teams of IT for providing better private cloud infrastructure and services to the user.
(ii) Dedicated clouds
It refers to an A cloud that is included in another cloud. A user can have a dedicated cloud depending on both a public cloud and a private cloud. As an example, a department of the accountant could have their personal dedication cloud included in the private cloud of the organization (Sadeeq et al. 2021, p.1).
Public Clouds
Public clouds are the typical environments of the clouds created through the infrastructure of IT, which is not owned by an end-user. Fee largest providers of the public clouds have consisted of Amazon Web Services (AWS), Alibaba Cloud, IBM Cloud, Google Cloud, and Microsoft Azure.
The classical form of the public clouds used to run off-premises, but the recent structures of the public clouds providers saturated offering the user or clients cloud services that are concentrated on the centre of on-premise data. The implementation of this has made distinctions of ownership and location obsolete.
When the environments were divided and redistributed for the different tenants all clouds become or act like public clouds. Fee structures characteristics now became less mandatory things for the providers of the public clouds as the providers started to provide access to the tenants to make the use of their clouds free of cost for their clients. An example of the tenants can be Massachusetts Open Cloud. The bare-metal infrastructure of IT used by the providers of public cloud is abstracted and can be sold in the form of IaaS or it can be improved involved in the cloud platform, which can be sold as PaaS (Uddin et al. 2021, p.2493).
Hybrid Clouds
A hybrid cloud can be explained as a single IT environment established through the help of the multiple environments that are linked with the help of the wide-area networks (WANs), virtual private networks (VPNs), local area networks (LANs), and APIs.
Multi clouds
Multi-clouds are the approach of the clouds, which is established for working with more than one service of the cloud. These services can be generated from more than one vendor of the clouds that are public or private. All hybrid clouds can be considered as multi-clouds but not all the multi-clouds can be considered as hybrid clouds. It takes actions like hybrid clouds when many clouds are linked through some integration form or orchestration.
An environment of multi-cloud can exist on purpose to control in a better way of the sensitive data or as storage space redundant for developed recovery of disaster or due to an accident; generally, it provides the outcome of the shadow IT. Implementation of multiple clouds has become a common process across all the enterprises throughout the entire world that are concentrating to develop their security system and performance with the help of an expanded environmental portfolio (Alam et al. 2021, p.108).
Figure 2.1: Types of Cloud Computing
(Source: self-created)
2.4 Types of cloud security
Several types of cloud security can be seen and they are Software-as-a-service (SaaS), Infrastructure-as-a-service (IaaS), and Platform-as-a-service (PaaS).
Software-as-a-service (SaaS)
It is a software distribution model that can provide cloud systems with host applications and makes them easily accessible to the users. It is one type of way out of delivering the applications with the help of internet services. It does not maintain and install software instead; it gives easy access to the users so they can understand the nature of complex software and hardware management. One of the main functions of this cloud security system is to allow the users to use cloud-based applications so they can get every service from the internet. The common examples of these functions are emails, calendars, and other official tools. It can provide the users with a proper software solution if they are facing troubles regarding that. It can be purchased as a purchased service to the users based on a subscription. There is no requirement for additional software to get installed in the system of the customers. The updates of this cloud security model can get done automatically without causing an intervention.
Figure 2.2: Software-as-a-service (SaaS)
(Source: researchgate.net, 2021)
Infrastructure-as-a-service (IaaS)
It is that kinds of model that offers services based on the computing system to the users. It can offer essential services that are important for the storage and networks of a device and become very useful to the users. It can deliver essential information by delivering virtualized computing resources over the entire internet connection. It is a highly automated service that can be easily owned by a resource provider and can give compliments to the storage and network capabilities of a devices. This cloud security system can host the main components of the entire infrastructure of the world in the on-premise data centre. This service model includes some major elements like servers, storage and networking hardware, virtualization which is also known as the hypervisor layer. In this mode, third party service providers can easily get access to the host hardware. In addition, they can get the services that have the ways to operate the system, server, storage system and several IT components that can help deliver a highly automated model (Singh et al. 2017, p. 1).
Figure 2.3: Infrastructure-as-a-service (IaaS)
(Source: diva-portal.org, 2021)
Platform-as-a-service (PaaS)
It is also a cloud-computing model that can provide several hardware and software tools to third-party service providers. A completely developed technology can improve the entire environment of a cloud system. It can enable all the resources in that system and by doing that it can deliver all the applications to third parties. It can provide a platform for the further development of software. As a platform, it can solve all the requirements for the third parties so they enjoy cloud-based tools for software and hardware. It has the opportunity to host an infrastructure that can be applied in the cloud system and works well than the in-house resources. It can virtualized other applications so the developers can help the organizations by creating a better environment for the cloud systems of the organizations.
Figure 2.3: Platform-as-a-service (PaaS)
(Source: ijert.org, 2021)
2.5 Areas of cloud security
Several key areas can be seen in this matter and they are
i) Identifying the access management system
It is the core point of the entire security system so it is very important to handle because if any datasets got leaked from this system then it would be harmful to the users or for tube organizations. They need to have some role-based principles so they can easily have some privileges to get access to the control implementation. It can handle some major key functions like password management, creating and disabling credentials, privileged account activity, segregation of environments and role-based access controls.
ii) Securing the information of the datasets present in the cloud system
For the purpose of securing all the present datasets in the cloud system, the developers must understand the vulnerabilities that the system has. They can implement the models so they can easily get access to the main system without getting into any kind of trouble in the network. They can have proper interactions with the resources and can collect valuable information about the cloud system.
iii) Securing the entire operating system
For the purpose of securing the datasets present in the cloud system, it is needed to be implemented in the cyber and networking system of the devices. It can support the providers by giving the proper configurations so they can easily handle all the algorithms in cloud computing.
iv) Giving protection to the network layers
This point is all about protecting the resources from unauthorized access in the system. It can become a challenging task so the developers need to be cautious so they can easily understand the connection between the resources and get a brief idea about their requirements.
v) Managing the key functions of the entire cybersecurity system
Without the help of a proper monitoring program, it would be impossible for the developers to understand the requirements of the entire cloud system. They cannot have the insights to identify the security ingredients of if anything is wrong in the cloud system without properly monitoring it. The implementation of a monitoring program is a crucial matter because it cannot get easily done and it needs the help of the operational sights to fulfil its functions. It can enable the notification system if anything suspicious occurs in the venture system and can send signals to the resources easily in that way (Riad et al. 2019, p. 86384).
Figure 2.5: Areas of cloud security
(Source: researchgate.net, 2021)
2.6 Pros of cloud security
Several advantages cloud security systems have in the matter of cloud computing and are, they can protect all the datasets from DDoS (Distributed denial of service attacks). As they have risen in this present situation, it has become necessary to stop the huge amount of incoming and outgoing traffic. So it is one of the best functions that cloud-computing systems have and it can protect all private information that way. In the increasing era of data breaches, it has become necessary to create some protocols so they can protect the sensitive information of the users and the organizations. Cloud computing can provide solutions so the users can easily understand that if it is time to turn up or down so many third parties would not be able to intervene when they are browsing anything on the internet. It can provide the system with high flexibility and availability that includes continuous monitoring over the entire system (Majumdar et al. 2018, p. 61).
2.7 Cons of cloud security
It has the major issue of data loss because sometimes if any natural disaster occurs then the system can lose its sensitive information. It has the major disadvantage in inside theft because if anyone would steal private data then it would not be able to check the identity of that person. Data breaching is also an issue in cloud computing services. The cloud computing system can lose its control over the system at any time so it is not impossible that if they have the responsibility of securing the entire network system but they can leak all the datasets at any moment (Punithavathi et al. 2019, p. 255).
2.8 Types of security algorithms
Several types of algorithms can be of help in this matter and they are: RSA algorithm, Blowfish Algorithm, Advanced Encryption Standard (AES), Digital Signature Algorithm
(DSA), Elliptic Curve Cryptography Algorithm, El Gamal encryption, Diffie Hellman Key Exchange, homomorphic algorithm and more
Figure 2.6: Types of security algorithms
(Source: slideshare.net, 2021)
2.8.1 RSA algorithm
The RSA algorithm can be referred to as an asymmetric cryptography algorithm that refers to the meaning applied by both public and private keys. These links are the two different mathematical linked keys. According to their name, public keys are sharable publicly while private keys maintain secrets and privacy. This key cannot be shared with everyone and needs authentication access. Only the authorized user can use this link for his or her own purpose.
2.8.2 Blowfish Algorithm
Blowfish is an initial symmetric encryption algorithm established by Bruce Schneier in 1993. Symmetric encryption applies a single encryption key for both decrypts along with encrypting data (Quilala et al. 2018, p. 1027). The sensitive information and the key of symmetric encryption can be utilized under an encryption algorithm for transforming sensitive data into ciphertext. Blowfish with the help of successor Twofish takes participation in the replacement process of Data Encryption Standard (DES). However, the process was failed because of the small size blocks. The block size of the Blowfish is 64, which can be considered without any security. Twofish takes participation in fixing this issue with the help of a 128-size block. In Comparison to the DES, Blowfish is much faster; however, it can be traded in its speed for providing security (Quilala et al. 2018, p. 1027).
2.8.3 Advanced Encryption Standard (AES)
The AES algorithm, which is also referable as the Rijndael algorithm works as an asymmetrical block cipher algorithm that works with plain texts, included in the block of 128 bits (Abdullah and A. 2017, p. 1). It helps to convert chase data to cipher text by applying the key of 128, 192, and 256 bits. Until the moment the AES algorithm has been considered as a secure application, application of it got popular on the standard spread worldwide (Nazal et al. 2019, p. 273).
2.8.5 Elliptic Curve Cryptography Algorithm
Elliptic Curve Cryptography is a technique that depends on the keys to encrypt data. ECC concentrates on the pairs of the private and public keys to encrypt and decrypt the web traffics. ECC is discussed frequently in the context of RSA Cryptography algorithms. It uses large prime numbers. It focuses on the elliptic curving theory that is applicable for creating smaller, faster and more Cryptography algorithms that provides more efficient keys (Gong et al. 2019, p. 169).
2.8.6 El Gamal encryption
The ElGamal encryption system included in cryptography, that is referable as an asymmetric key encryption applicable for public-key cryptography that concentrates on Diffie–Hellman key exchange. It focuses on the public key encryptions.
2.9 Characters of cloud computing
2.9.1 Cloud security storage
Cloud security is a set of technologies that protect the personal and professional data stored online. This applies the rigor of the premise’s data centers and secures the cloud infrastructure without the help of hardware. Cloud strong services and providers use the network for connecting the secure data centers to process and store the online data. There are four types of security storage like public, private, hybrid, and community.
Public clouds
Cloud resources as hardware, network devices, storage are operated through the thyroid party providers and delivered by the web. Public clouds are common and used for office apps, emails, and online storage (Mollah et al. 2017, p. 38).
Private clouds
The resources for the computing clouds are used especially for the organization and located in the premises data center or hosted by the providers of third-party cloud services. The infrastructure is maintained through the private network with the hardware and software.
Hybrid clouds
This implies the solution that combines private clouds and public clouds. Data and applications move through the private and public clouds for better flexibility and deployment options (Radwan et al. 2017, p. 158).
Community cloud
Through the use of groups who have the objectives share the infrastructure of multiple institutions and handle them by the mediator.
2.9.2 Security algorithm in cloud computing
There are five types of security algorithms like Hash Message Authentication Code (HMAC), Secure Hash Algorithm (SHA), Message Digest Version (MD5), Data Encryption Standard (DES), and Cipher Block Chaining (CBC). HMAC is a secret key algorithm that provides data integrity and authentication by the digital signature that keyed the functions of products. The MD5 algorithm is a hash function that produces a 128-bit value and SHA is a hash function that produces the bit value 160 and virtue of the growth of the value. This is secure but requires a longer processing time. DES is an encryption algorithm that the government is using to define as the official standards and breaks a message into the 64-bit cipher blocks. DES applies exclusive OR operation to each of the bit values with the previous cipher block before this key. The secure algorithm is used for the processing time of the required algorithms (Tabrizchi et al. 2020, p. 9493).
2.10 Benefits of cloud computing
2.10.1 Reduce cost
Cloud computing gives the facility to start a company with less initial costs and effort. These services are shared through multiple consumers all over the world. Its reduced cost of services through the huge numbers of consumers and chargers amount depends on the infrastructure, platform, and other services. It also helps the consumers to reduce the cost by proper requirements and easily increase or decrease the demand of the services and products for the performance of the company in the markets (Jyoti et al. 2020, p. 4785).
2.10.2 Flexibility
This cloud computing is assisting many companies to start the business by small set up and increase to the large conditions fairly rapidly and scale back. The flexibility of the cloud computing system allows the companies to use the resources at the proper time and enable them to satisfy the demand of the customers. This is ready to meet the peak time of requirements through setting the high capacity servers, storage, etc. This has the facilities that help the consumers to meet the types of requirements of the consumers of the size of the projects.
2. 10.3 Recovery and backup
All the data is stored in the cloud and backed up and restored the same which is easier than storing the physical devices. Many techniques are recovered from any type of disaster and efficient and new techniques are adopted by most cloud services providers to meet the type of disaster. The provider gets the type of technique and supports the faster than individuals set up the organization irrespective of the limitation in geography (Sun and P. 2020, p. 102642).
2. 10.4 Network access
These cloud services deliver an open network and can be accessible the services in any time and from anywhere in the world. The facilities can be accessed by different types of devices like laptops, phones, PDAs, etc through these services. Consumers can access their applications and files anytime from any place through their mobile phones. This also increases the rate of adaptation of technology of cloud-based computing systems (Singh et al. 2019, p. 1550).
2. 10.5 Multi-sharing
Cloud computing offers the services by sharing the application and architecture over the internet and this help multiple and single users by multi-tenancy and virtualization. The cloud is working in distribution and sharing the mode of multiple users and applications can work effectively with the reduction of cost at the time of sharing the infrastructure of the company.
2.10.6 Collaboration
Many applications are delivering the effort of multiple groups of people who are working together or together. This cloud computing gives the convenient oath to work with a group of people on a common project in a proper manner (Shen et al. 2018, p. 1998).
2.10.7 Deliver of new services
This cloud system gives the services of multinational companies like Amazon, IBM, Salesforce, Google, etc. These organizations easily deliver new products or services through the application of cloud-based security systems at release time. This helps the process of converting data into a proper form and using the key to choose the proper algorithm.
2.11 Challenges of Cloud computing security
Cloud computing security alliance was directly handled by the professionals that are applicable for the company. However, it is not a split thing and can provide many challenges at the time implementing these security services for an organization. These challenges are mentioned below:
(i) Data breaches
Responsibility of both cloud service providers and their clients breaches of the data and there are proving in the records of the previous year.
(ii) Inadequate and Miss-configurations control of change
If the setup of the assets was positioned incorrectly, they can create vulnerable attacks.
(iii) Lack of proper architecture and strategy of the cloud system
Jumping of multiple organizations in a cloud without having an accurate and proper strategy or architecture in the palace the application of cloud security can be difficult (Bharati et al. 2021, p.67).
(iv) Insufficient credential, access, identity, and key management
These are the major threats of cloud security it leads to identity and access management issues. The issues can be like protection of improper credentials, lack of cryptographic key, certificate and password relation that can be performed automatically, scalability challenges of IAM, weak passwords used by the clients, and the absence of the multifactor authentications of the users.
(v) Hijacking of Account
Account hijacking of the cloud is the disclosure, expose, and accidental leakage or other cloud account compositions that are difficult to operate, maintain or administrate the environment of the cloud.
(vi) Insider threats
Insider threats are linked with the employees and other working networks included in an organization can cause challenges like loss of essential data, downtime of the system, deduct the confidence level of the customers, and data breaches (Ibrahim et al. 2021, p.1041).
(vii) APIs and Insecure interfaces
Cloud service providers’ UIs and APIs help the customers for making interact with cloud services and some exposed continents of the cloud environment. Any cloud security system begins with the quality of the safeguarded and is responsible for both Cloud Service Providers and customers.
There are also other threads that can be happen in the implementation of the cloud security such as Weak controlling plane, Failures of Met structure and apply structure, Cloud usage visibility limitations, Abuse and nefarious applications of cloud services (Malhotra et al. 2021, p.213).
(viii) Risks of Denial service attacks
A denial of service (DoS) attack can be referred to as an attempt for making service delivery impossible for the providers. A DoS attack on the system when the system is also repeatedly attacking and a distributed denial-of-service or DDoS take participation on for attacking multiple systems that are performing attacks. Attacks of Advanced persistent denial of service or APDoS attacks set their target on the layer of an application. In this situation, the hackers got access to hit directly on the database or services. This can create negative impact on the customer handling of the company.
(ix) Risks of Malware
Malware mainly affects the cloud servers of the provider as it affects the on-perm systems. Entices of the attacker get access while a user clicks on a malicious attachment included in an email or the links of social media, as it enables access to the attackers for downloading encoded malware for bypassing design and detection for eavesdropping The attackers steal the storage of the data included in the cloud service applications. It compromises the security of the authentic data.
2.12 Mitigation Techniques
Cloud computing security implementation can cause many challenges for professionals and organizations. It can reduce the potentiality and the image value of the company to their potential clients. A professional can have many challenges however; here some of the mitigating techniques of some of the challenges are mentioned by the scholar. Mitigation of the previously mentioned risks can be done by following some practices that are different for each potential risk. These mitigating practices are mentioned below.
2.12.1 Mitigating the risk of Data breaches
Problems of the data breaches can be solved with the help of the below-mentioned aspects :
(i) The company needs to develop the usage and permission policies of a wide computing company cloud security (Thomas et al. 2017, p. 1421)
(ii) The company needs to add multi-factor authentication.
(iii) Governance implementation for data access
(iv) Centralized logging enables for creating easy access to the logs for the investigators during a specific incident
(v) Implementation of data discovery and classification
(vi) Giving access to the analysis of user behaviors
(vii) Establishments of data remediation workflows
(viii) Implementation of DLP in the system
(ix) Outsourcing of the breach detection by applying a cloud access security broker (CASB) for analyzing the outbound activities
2.12.2 Mitigating risk of Mis-configuration
The below-mentioned practices will help the professional to mitigate the mis-configuration risks:
(i) Configurations of establishing a baseline and configuration of regular conduct audit for observing to drift away gained from those baselines.
(ii) Application of continuous change observing for detecting suspicious modifications and investigating the modifications promptly it is important for the modifier to know the exact modified settings along with the questions of when and where it occurs apparently.
(iii) Keeping information on who is having access to which kind of data and continuous revision of all the effective access of the user. Require information owner’s assets that the permission is similar with the role of the employees and matches perfectly with it.
2.12.3 Mitigating the Risk of Insider Threats
Insider threats can be mitigated if the organization follows certain practices that are highlighted below:
(i) Immediately de-provision access to the resources whenever a person makes changes in the system (Safa et al. 2019, p. 587).
(ii) Implementing data discovery and modification of the technologies
(iii) Observing the privileges that users are having with separate accounts
(iv) Implementation of the user behavior analytics. It generates a profile for baseline behavior
2.12.4 Mitigating the risk of Account Hijacking
Account hijacking can create major issues for both professionals and users. This problem can be mitigated as follows
(i) Implementation of access and identity control
(ii) Application of multi-factor authentication
(iii) Requirements of the strong passwords
(iv) Observing the behavior of the user
(v) Revoking and recognizing the excessive external access for a piece of sensitive information.
(vi) Eliminations of the accounts that are still unused and credentials
(vii) Principle applications for the minimum amounts of privilege
(viii) Taking control of the outsider third party access
(ix) Providing training to the employees on the prevention process of account hijacking
2.12.5 Mitigating risk of Service attack denials
For mitigating this type of risk, the companies need to make a structure of network infrastructure through a web application firewall. It can be solved also with the implementation of the content filtration process. Application of the load balancing for recognizing the potential inconsistencies of traffic is very essential for mitigating the problem.
2.12.6 Mitigating risks of Malware
This type of risk can be seen most commonly Best practices for mitigating Malware risk included in the company system are highlighted below:
(i) Solutions of the antivirus
(ii) Regular backups of the comprehensive data
(iii) Providing training to the employees on safe browsing and making a healthy and authentic habit for downloading things
(iv) Implementation of the developed and advanced web application firewalls
(v) Monitoring the activities of the users constantly (Sen et al. 2018, p. 2563)
2. 13 Literature gap
The cloud computing system is one of the major and highly recommended systems that use various companies on daily basis to maintain their data or information. Sometimes, the data or information is personal and important and needs to be secure and secret so that various companies, as well as government portals, are also using cloud computing methods to secure information or data. The various types of cloud computing systems need to develop more so that control the hacking parts as well as reduce cybercrime and unethical data sharing. Cyber security systems are needed to develop and change some issues of techniques that use to analyze the algorithms in cyber computing. Cloud computing should increase its capabilities in features so that it does not create any issues in multi-tasking or multi-sharing. Moreover, it maintains the flexibility of the specification of cloud computing systems. According to the researcher, it highlights that the factors of cost reducing are crucial and important issues of using cloud-computing systems. The public should more concern about their personal data or information so that reducing the unethical factors in current days. It is highly needed to maintain the current crime due to the help of cloud computing systems.
2.14 Summary
Here the researcher describes the types, areas, pros, and cons of the cloud security system. The types of security algorithms are also described in this part of the paper. Characters of cloud computing systems and benefits of this are also described here. The costs reduce process, flexibility, recovery, and backup, access to a broad network is also described here. The effectiveness of this system and many techniques has to hold part of this paper. The advantages and disadvantages of this cloud-based security system are discussed here. Confidentiality is related to privacy and ensuring the data is visible to the users and has difficulties with tenancy properties for the consumers to share software and hardware.
In this area, the researcher discusses shortly the topic that is very much important in current conditions. The researcher discusses an introduction almond background of the introduction in this section. Various types of cloud computing systems are discussed here so that people gather more authentic pieces of knowledge about the topic. Therefore, that it helps to research on this topic in further time. Here, also discuss the benefits of cloud computing systems and the disadvantages of cloud computing systems. Various disadvantages of cloud computing systems affect the security of the data or information stored in the cloud. Types of security algorithms are also discussed here in detail. Cloud computing has various kinds of features that enhance entire systems for use. Therefore, there have several benefits of cloud computing that enhance entire systems. Moreover, it has several issues that need also solutions. The literature gap provides some recommendations that help for further research.
Chapter 3: Methodology
3.1 Introduction
The computer networking courses are commonly taught in a mixed mode of involvement of the practices in the session besides the theory. Teaching computing networks in schools, colleges and universities have become challenging for the development of the country. This has difficulties in motivating the students to learn about networking and many students think the presentation must be proper for learning. Here is the description of Cisco Networking that grows the demand of the global economy and supports the share of software and hardware. The network technology of Cisco teaches and learns the software packet tracer and plays a key part in opening up the words of possibility.
3.2 Explanation of methodological approaches
Many cloud providers are embracing the new flexible, secure, automated approaches to the infrastructure of cloud services. The fast approaches are designed to monetize and deliver cloud services and align with the requirements of the customers. This reduces the costs of the automated core process and creates new revenue for the opportunities of the service system. Many customers turn to cloud providers to help to grow the capacities for the business, want the advantages of the cloud system, and manage the infrastructure of the technical issues. Security and performance are the main concern of the company and gain the flexibility of the development of the workloads of the cloud system (online-journals.org, 2021).
The Internet of Everything (IoE) brings the people together and processes the data and makes them think of the network that connects the valuable and relevant and also creates the total set of the requirements of the distribution of global and highly secure clouds. This presents large opportunities for Cisco cloud providers. These providers have to meet the needs of the customers and set new opportunities for the development of the market growth of the products. Cisco launched the concept of partnership that helps shape the journey of the cloud. The internet grew the connection of the isolated network of cloud platforms for the internet that increased the choice of models of the services (cisco.com, 2021).
The cloud system of Cisco helps to design the services and products to meet the profit of goals through maximizing flexibility. It enhances the security system and helps to make sure of the way of the future of the company through the standards strategies. Cisco has a focus that enables the delivery and monetizes the services of the cloud systems that fulfill the requirement of the customers. Cisco is committed to partner-centric cloud approaches of the clouds providers for various services to meet the needs of the customers of the company. This represents the change of the ways of development of the customers of the company and turns the cloud providers to help them for the growth of the capacities of the business (aboutssl.org, 2021).
The demand of the ecosystem is emerging from the combination of public, private, and hybrid cloud services and is hugely shaped and driven by the types of economics that the organization consumes for the help of services to reach the goals. Cloud opens a variety of options that help the customers achieve the economic goals of the company. The economic system has provided a huge opportunities for the types of the sets of revenue services and develops the interest of the customers. The economic conditions are involved to build the new cloud services and increase the capacities of the models (arxiv.org, 2021).
3.3 Choice of methods
Cisco has a strategy for building a new platform for the Internet of Everything with the proper partner by connecting the world of many clouds to the inter clouds. These strategies enable the business and reduce the risk factors of the company by the use of security services. The ability to move the workload of private and public clouds is managed by the environment of the network and innovation for the reduction of the risks. This committed to taking the lead role of the building of the clouds and for the development; this is an efficiency of the security system. With the help of the cloud security system, the portfolio has an extensive partner and has the flexibility to deliver the types of cloud systems.
Multiple cloud systems meet the requirement of the common platform for operating the virtual, physical, and services features and integrating the infrastructure of the functions. The policy includes service management and enables the organization the application of the platform for the development of the security system. These services help move the workloads to the clouds and sign the inter clouds for enabling the assignment of the customers. Cisco power system keeps the resources and with the geographical barrier and provides the validation of the market with a solution of the needs of the customers. The market programs are designed to help for the achievement of the value of the customers for the better result of the services.
3.4 Research philosophy
Research philosophy is used to analyze the total integral part of the study and specify the choice of data that are collected to complete the study properly. Research philosophy helps to clear the ideas and problems of the subject and also help to identify the challenges and help to make the decision to mitigate those challenges. Besides, it helps to empathize with the development of a sense of cloud security and provide new direction and observation that is suggested by new hypotheses and questions, which are encountered during the research process. The answer all questions that will come during the research time the techniques that are shown used to complete successfully which help to show the critical analysis of the learning, interpretive and evaluate the skills that are used in the research period (Ragab et al. 2018). Moreover, research philosophy awareness of the major points of the study, increases the knowledge of past theories, and helps to learn up to date.
The methodology focuses on the positivism of the study so that readers assume the benefits of the cloud security system and facilities. In this positivism research philosophy, the study developer has tried to understand the topic requirements and importance. The ultimate focus here is to find out the involvement of the influences and the ways of cloud-based security techniques and analysis of security in the network system. Besides, the methodology enhances the cloud computing system in modern life and shows its movements in the computer system and support to others to increase cloud security programmes to protect from cyber threats.
3.5 Research Approach
The research approach is used to note a plan and procedure that is necessary to understand the steps of the research process to complete the research process. The inductive approach is used for inductive reasoning to understand the research observation and its beginnings. Besides, the theories that are involved in the study are symmetrically done in the research procedure and various thematic structures, regularities and patterns are assemblies to understand the suitable conclusions. This study paper has followed only the deductive approach because this deductive approach helps to know the exploration of the phenomenon and includes valid and logical paths that support the theory and hypothesis. By using the deductive approaches, the theories are based on cloud security and a research survey is conducted from the internet user to understand its popularity and advantages. Also, social media users help to conduct the survey time, all data collected from them that help to proceed with the research theory.
3.6 Research Design
The research design refers to understanding the gist of each research step so that readers can notify the major and minor points of the research to theories. Besides, it helps to provide all details in each step of the research part in a minute and the reader can utilize the value of the research and research conducting times (Abutabenjeh and Jaradat 2018). Three points are helped to conduct this research theory that is descriptive, explanatory and exploratory research design. This research has followed a descriptive design that involves describing and observing the particular behavior of the study. That design helps to explain the characteristics of the study and specify the major hypothesis that is long-range. The design is used to make the structure of the topic and so that readers can gain knowledge about cloud security importance and its advantages. This design is chosen to add new ideas during the research period, make the subject effective, and increase its efficiency.
3.7 Data collection method
Data collection methods refer to collecting the data and information that helps to the procedure the research being successful. Besides, the data are essentially needed to answer subject related questions and help to mitigate all problems and evaluate their outcome. Two categories are used in data collection methods primary and secondary. Here a secondary data collection method was used to successfully conducts the study. The secondary data was collected from the journal and other research topics of the subjects. The journal helps to identify the major points of the study that help the researcher to conduct their research perfectly. The articles are true and most valuable that are chosen for research and researchers use and take all-important documents for proper make of the study (Misnik et al. 2019). The secondary data collection is used in the study and this data helps to show the review of the national and international user feedback points that help to analyse the major and mirror points of the cloud securing system and for understanding public review social journals and theoretical articles help to inform the basic idea of the research theory.
3.8 Nature of data collection quantitative
There are two different parts of this research of the secondary data collection where the quantitative part has been chosen for this research and it has used to conduct the research process perfectly. The questionnaires and surveys are used during the research time (Ruggiano and Perry, 2019). The questions are come from during the research per survey and the survey answer is taken from the user to understand the behaviour of the cloud security. The questions and surveys have been used to help to understand user benefits and their problems and this information helps to make the structure of the subject. The questions that arise during the research time and researchers notice that question and try to find the preferable answer of the question. The survey helps to respond to user opinions and understand their user behaviour.
3.9 Data analysis techniques
The data is collected from the secondary data collection that helps to the thematic analysis of the study thematic so that reader can view, notice, and view the important points of the study. It is used to show the impact points of the cloud security system and enhance its necessities. Themes are made based on the objectives that help to understand the concept of cloud based security system and all about its system and techniques. The first theme is based on the techniques of cloud-based security system. The second theme determines the algorithm of a cloud computing system in the network world. The third theme focus on accessing the data sources of cloud security systems in the computer system. The fourth theme shows the importance of the proper algorithm for this system
3.10 Ethical considerations
The research is conducted with the help of the network security law, the law is the information technology Act 2020, and researchers follow this act and use proper documents in the study that is legal and ethical. No false statement and wrong document included in this research pare and no other false activities, articles, and comments are present in the study that will hamper on the reader mind (Molendijk et al. 2018). The document has no copyright and true-statements are used in the subject and thematic analysis to the subjects that help focuses on the impact of the cloud security systems and its advantages and processes. No force and unexpected activities occur during the research period and the questions that come from users are verified particularly for the making perfect research conduction.
3.11 Summary
In this part, the researcher describes the methods and strategies for the development of cloud services. Here is an explanation of the methods that are helpful for the growth of the cloud-based security system. The researcher is also given a discussion about the choice of methods for the needs of the customer. Here is the description of the methods of the Cisco Company. The method that they use for growth of the business and new technology and tools helps for the development of the company. The cloud providers help them to grow the capacities of the business and have advantages using the techniques. This part is holding the total explanation of the process to improve the quality of the services and meet the solution of the facing challenges. In this part of the study, the study developer has used some tools and techniques that help to properly complete the dissertation part successfully. With the help of these tools, study developers improve the Algorithm in cloud computing advantages and help to analyse the research method to the reader so that reader can understand the cloud base security system and identify its importance. To proceed with the methodology part, research philosophy, research design, data collection, nature of the data, and data analysis techniques are used and all data are collected by using a survey process that helps to properly complete the methodology study. Questions and survey process are help to complete the research perfectly in the study.
Chapter 4: Results
Theme 1: A systematic review of the issues for the cloud computing
This systematic review of the study is regarded to the security system of cloud computing and this also summarizes the vulnerabilities and threats of the topic. This review is identifying the currents of the state and importation of the security system for the cloud composition system. This also focuses for identify the relevant issues of cloud computing that consider the risks, threats, and solutions of the security system for cloud computing. These questions are related to the aim of the work and finding the vulnerabilities with the proper solution of the system. The proper criteria are evaluated based on the experiences of the researcher and consider the constraints that involve the resources of the data. This concept makes the questions for the review of the security system (jisajournal.springeropen.com, 2021).
The experts have refined the results and important works that recover the sources and update the work that takes into account the constraints as factors, journals, renowned authors, etc. the sources are defined and describe the process for the criteria for the study that must be evaluated. The issues of the system maintain the exclusion and inclusion criteria for the study. The build of the issues for the system is to describe the process of the computing system. These studies consider the security of cloud computing and manage the threats, countermeasures, and risks for the security system. This issue is defining the sources of the studies that evaluate the criteria of the security system. The search chain is set the relevant studies to filter the criteria of the system.
Theme 2: Segmentation of cloud security responsibilities
Many cloud providers create a secure system for the customers and the model of the business is prevents breaches of the system and manages the trust of the public and customers. These providers are avoiding issues of the services and controls the needs of the customers and adding data to access the policies. The customers are uses in the cyber security in cloud-based security systems with the configuration. The cloud providers share the various levels of the sources that are responsible for the security system. There are many services types like Software as a service (SaaS), Infrastructure as a service (IaaS), and platform as a service (Paas). This is included in the public cloud services and the customers are managing the requirements of the security system. Data security is a fundamental thing this helps to succeed the system and benefits the gaining of the cloud system.
There are some challenges that are stored the access to the internet and able to manage the cloud-based security system. Cloud system is accessing the external environments of the network and managing these services by IT. The system has the ability to see the services and make these services fully visible for the users as opposed to the traditional to monitor the network. The cloud services are gives the environments for the better performance of the system. The user of the system are applying the data over the internet and make the controls of the tradition that is based on the network and effective for the system (mcafee.com, 2021).
Theme 3: Impact of Cloud computing
Cloud computing has emerged as a prominent system in It services space. However clouds service users confront with the issue of trust and how it is defined in the context of cloud computing, is often raised among potential users. The wide adoption of cloud computing requires a careful evaluation o this particular parading. The issued evolved in recent times is concerned with how the customer, provider and the society, in general aim to establish the trust. The semantics of trust in the cloud space established its nature as something as earned rather than something provided with a written agreement. Trust include space is made sinuous with security and privacy (Bunkar and Rai, 2017, p. 28). Trust is complexional phenomenon which involves a trust or expecting a specific behaviour from the trustee, believes the expected behaviour to occur based on trustee’s competence and is ready to take risk based on the belief. According to Saed et al. 2018, the expectancy factor gives rise to two types of trust - one is trust formed based on performance of the trustee and the trust formed around the belief system of the trustee. Trust in belief is transitive in nature, however, trust in performance is intransitive in nature. So The tractor’s expectancy about the trustee is solely dependent on examples about trustee’s competence, integrity and goodwill (Narang, 2017, p. 178). This leads to formation of a logical pathway for the belief in evidence to get converted into the belief in expectancy.
Trust in the cloud competing space rest on reputation, verification and transparency. Reputation is earned and maintained by service providers over long period. Reputation enables making of trust based judgement in cloud computing. After establishing initial trust, it gets maintained through establishment of verification mechanism. Maintain standards and ensuring accountability, ACSP ensures upholding trust in the service.
Theme 4: Facilities of Cloud computing
Organisations presently are working with big data projects which is requiring huge infrastructure investment. Cloud healable organisations to save huge upfront cost in storing large data in warehouses and data servers. It is the feature of cloud technology to handle large volume of data which has enabled businesses to migrate to cloud. This faster scalability feature of cloud is luring businesses to adopt it sooner. Big data, both in structured and unstructured form require more storage and increased processing power. The cloud provides the necessary infrastructure along with its scalability to manage huge spikes in traffic. Ming of big data within the cloud has made analytics more fast and accurate. Cost related to system upgrade, facility management and maintenance can be readily saved while working with big data. Focus is more given on creating of edge providing insights (Saed et al. 2018, p. 4). The pay as our go model of cloud service is more efficient in utilisation of resources. The ability to cultivate the innovative mindset is readily possible with cloud computing. The creative way of using big data is provided by the cloud infrastructure. With more convenience in handling big data, organisations can look to boost operational efficiency and provide improved customer experience. With features of smart analytics and surveillance capability has made it an ideal option for business in present context. The ability of performing operations faster than a standard computing device has enabled it to work with large data sets. The power of big data lyrics to occur within a fraction of time within the cloud is getting improved with refinement in technology (Kaleeswari et al. 2018, p. 46). Since, big data is stored with a third party by following the internet route, security becomes a unique challenge in terms of visibility an monitoring.
Trusting the cloud service provider and their offerings is considered as one of the strongest driving forces:-
Trusting the provider of cloud services is based on certain characteristics such as integrity confidentiality security availability reliability etc. The offering of cloud services by the provider basically depends upon monitoring and tracking of data. Cloud computing is becoming an integral part of IT service in today's digital world. The IT service providers forecast huge potential in collaborating IT services with cloud services (Rizvi et al. 2018, p. 5774). It enhanced flexibility along with more efficient service delivery that helps to release some burden of work from the IT department and enable them to focus on innovation and creativity. The use of cloud services continues to grow but the main concern lies with lack of maturity and inability to align completely with IT, security and data privacy issues, cost associated with time and skill etc. Though some study reports suggest that the majority of CFOs lack trust in cloud computing. This study report reveals the fact that cloud service is still slow in gaining consumers confidence.
Trust is a key factor for any type of evolution. From the perspective of a good business, if relationships are based on trust, costs are lower, communication between parties are easier and simple ways of interaction can be figured out. Cloud computing is based on the paradox that companies with prior experience report more positive results. Those who are inexperienced are reluctant (Wei et al. 2017, p. 11907). There are several service providers who provide better technologies, capabilities and processes rather than internal IT systems, but business organisations are more comfortable about the fact that their data are handled and managed by their own employees. Their decisions regarding use of cloud computing is based on their assumptions rather than experience. Thus the factor of trust lacks in such a situation.
Chapter 5: Discussion
5.1 Introduction
This part is base on the discussion of the total paper that determines the cloud-based security system. This describes the process of data collection and helps to get the results for the security system. Most approaches are discussed for the identification of the threats that have focused on cloud computing. The discussion of the sites is relates to the security system as data security, trust and this manages many problems in the environments of the system.
5.2 Summary of findings
The researcher is finding some keys for the management of the cloud computing system and this agreement the environments of the cloud-based security system. Trust is evaluating the opinion of the leaders that are influencing the behavior of the leaders and make the trustworthy and valid of the characteristic of the system. Trolls are posting improper and unreal comments that affect the moves o the system. This paper evaluates the trust by considering the impact of the opinions of the leaders on the total cloud environments. Thrust value is determined as a parameter like reliability, identity, availability, data integrity, and capability. This proposes the method for the opinion of the members and trolls the identification of the uses of topological metrics.
The method is to examine the various situations that show the results of the proper removal of the effects of the troll from all advice of the leaders. A cloud service provider offers the components of cloud computing for the company and gives an infrastructure for the services. The cloud provider is using the data entry and resources for the platform of the services to fulfill the requirements of the customers. This service has priced the uses of the models of the system and this charges the resources for the consumers as an amount of the time services that are used for the storage of virtual; machines that are used in the system.
Cloud computing is a vast service that is included in the consumer’s services like Gmail through the services that allow the large enterprises for hosting the data and running the system smoothly in the cloud. This cloud computing system is a service that manages the business strategies and develops the system of the organization. This helps to establish the infrastructure of the cloud computing system for the traditional issues of the system on the workload is moves the cloud service that offer the people beer services of the system.
There are many benefits for adopting cloud computing in the significance of the barrier for the adaptation of the new technology. These issues follow the compliance, legal, and privacy matters for the system and represent the new computing system for the users of the services this is a great deal with the security system of the network that helps to grow the work levels of the network. This security is concerned with the risks as the external data storage and this depends on the public internet.
The segments of the system are responsible for the system and only they can develop the system for the users. The cloud-computing providers make the business model for the growth of the services in the market and are easy to use for the users. They avoid the issues and risks of the system that helps the system for increment the policies of the security services. The providers share the level of the responsibilities for the security system. The organization is considers the popularity of the Saas like Salesforce that needs the plan to share the responsibilities of the data protector in the cloud.
5.3 Discussion of LR
This part is base on the description of the literature of the study that holds some important points of the given topic. In the background, the researcher is described some new concepts and methods of the study this helps to create the area for the system. Management of the system is the concept of the security system of the environments that has threats. There are various types of cloud computing systems like private, public, and hybrid, multi-clouds. Private cloud is generates by the explanation of the environments of the providers for the group of users. This customer is applying the private clouds is manage the vendor (Riad et al. 2019, p. 86384).
Public clouds are the types of clouds that are created the infrastructure of the IT and users. The providers of the public clouds are consisted the Web services and use the premises of the users that concentrate the center of the services. In this part, the researcher describes the types of cloud security like SaaS, PaaS, IaaS. This model gives the way of the application in the system of the services. This develops the technology of the improvement and enables all the sources for the system. This has the opportunity of the system for the development of the system. Here are the areas of the cloud security system as if identifying the system management, the developer of the system understands the system, and fulfill the requirements of the system. This is monitoring the whole system of the cloud services and implementing the program for the growth of the matter (Singh et al. 2017, p. 1).
There are some pros of the security system and this protects the dataset and becomes essential for a large amount of out coming and outgoing traffic. The functions that manage the system is a protector of private information of the increasing the branches of the protector of the system. The cons of the cloud system are the issues for the disaster of the system that lose the information of the dataset. The cloud computing system is responsible for the security system and for the whole network (Riad et al. 2019, p. 86384). Cloud computing has wide applications in several fields which is helpful for this generation.
There are some types of security algorithm that are describe in the literature part like RSA algorithm, Blowfish Algorithm, Advanced Encryption Standard, etc. the cloud security system is set the technology that protects the information for the human and applies the data center approaches for the security system. Cloud resources are network devices that operate the providers and deliver the web for the people who use the services continuously. There are many types of algorithms that are uses in cloud computing and the benefits of the systems are discusses here. There are also challenges and ways of mitigation of the problems of the study (Singh et al. 2017, p. 1).
5.4 Limitation and weakness of the study
There are many limitations and weaknesses of the cloud system like loss of data, data leakage, services attacks, new technology, etc. many of the cloud service providers are implements the security standards for the certificates of the industry to make sure that the environments of the safe of the remaining part of the system. The data is collects and store by the centers of the potentially open risks for the development of the study. The security level of the services is maintained by the providers of the cloud system and makes sure that the providers are stable the reliable and offer the terms of the condition of the services.
The cloud is set the technology for the development of the system by mitigating the changes for the services. These events manage the business system and process of the business that damaged the business through the cloud system. The cloud services are giving to the providers for managing the system and monitoring the infrastructure of the cloud security system. This is minimizes the plan and impact of the services for the customers and continues the services for the business. These cloud providers are mange the system of the cloud services and the customers are controlling the application of the data.
Cloud computing is a normal concept for the technology that has the trends for the large range of the system and that is dependents on the internet to provide the users with the proper needs of the system. That system is uses in the services to support the process of business and describe the network in a cloud system. Many risk factors are uses in the services for protecting the system for the data and accessing the system with the machine for the development of the economy of the country.
5.5 Summary
In this part, the researcher describes the policies of the data security system that helps the system for adopting new technology. Here the researcher gives a brief discussion about the risks factors of the system and finds the key factors for the secondary analysis. Here is also the discussion of the literature parts as this holds some important points of the study. Here is also the limitation and weakness of the study that helps for the improvement of the security system.
Chapter 6: Conclusion
6.1 Conclusion
In this research paper, the researcher is going to discuss the cryptographic exchanges in cloud computing services. The main idea of cloud computing services is to deserve the entire idea of encryption and decryption that can demolish the complexities of the software. With the rapid development of distributed system technologies, it has become a challenge to face the uncertainties that lie under the datasets. Therefore, in this section, the researcher is going to derive the algorithms that are effective in this matter.
A Cloud computing system is a paradigm that gives various services on demand at a low cost. The main goal of this is to give fast and easy use data storage services. This is a modern computing model taught diverse sources for the demand and this mainly gives data storage services in the cloud environment. The computing world is dealing with the services and treats the risks that are faces for the development of the existing techniques and adopting new techniques. The security system of the services has many techniques and the primary factor of the data is managing the services in the cloud system.
The paper is base on the cloud-based security system and analyzes the algorithm of the system. In the introduction part, the researcher describes the aim and objectives of the topic and the background of the study. The rationale is base on the answer to some questions that is relates to the topic that is described in the introduction part. This paper also holds the literature and methodology part is data collection method of the given topic. The researcher also describes the results of the interview and survey. Types of cloud computing, areas of cloud computing, pros and cons of the security system, benefits of the system are also describes here.
6.2 Linking with Objectives
Linking Objective 1: To determine the techniques of cloud-based security system
Several techniques can work as a cloud-based security system so it can be said that it is important for this matter to determine all the techniques related to the cloud-based security system. Cloud security is a mode of protection that collects all the datasets from the online platforms so they can keep them safe in a secured environment from getting stolen, deleted or leaked. There are methods like Firewalls, Virtual Private Networks (VPN), penetration testing, tokenization and obfuscation. Maintaining the data sets secure is the main function of these methods so it can be said that the developers need to focus on implementing these methods in the network system so they can keep the datasets safe and secure.
The cloud-based security system is design to utilize the programs and control the other features, which help for protecting the data. The system and the servers also use security for controlling the data that moves forth and needs without the risk to people for the data system. The backup system has directly checked the system and has the manual format for the system. The user of the services is driving the services to help the system and support this so that the responsibility of the users is to help for the development of the services. The test of the system is making the differences and need for the better performance of the system.
The hackers are hiring this system to test the security system and activities to find the issues about the storage places. They also give the recommendation to take care of the concerns of the option for the test that is deep for the system. The redundant storage is included for the drives the store data as per requirements and helps the data as possible. This makes the system harder for the data for stolen or broken. Every bit of the data is accessible for the system and distributes the data at a time.
Linking Objective 2: To describe the algorithm that is helpful for cloud computing
Here the researcher is trying to say that according to his/her opinion they conclude that a homomorphic algorithm is the best algorithm that can help the entire services of cloud computing. It can create a secure computing environment so they can keep the datasets safe. It can also collect valuable information from the datasets and keep them in secured cloud storage and prevent them from being deleted or leaked in public. The main ability of this mentioned algorithm is it can perform encryption and enable a high-security system for those encrypted datasets. It can show more effectiveness than the other algorithms such as DSA and RSA.
The cloud stores many amounts of data that becomes in the machine learning algorithms. Many people use the cloud platforms to store data and present the opportunity to leverage that helps for learning and shift the paradigm from the computing system. The cognitive computing system is design with the tools of Artificial Intelligence and manages the process. The machine learning language and natural language are to process the cloud-based security system. Chatbot has taken the virtual assistants for businesses and individuals. The users are manages the limitation of the system and increase the capacity of the learners. IoT cloud platform is design for the process of generating the data and generating the connection of the services.
This cloud computing manages the business policies and becomes the service that increases intelligence. Cloud-based machine learning has benefits for business intelligence (BI) and algorithms can process the data for the solution of the finds. The algorithms help the business for gaining an understanding of the behavior of the customers and create a product that is developing the marketing strategies and development of sales. This machine learning has much significance for the experience of the customers and needs to satisfy the customers. Business management understands the behavior of the customers.
Linking Objective 3: To access the data sources of cloud security system
Rather than storing information in the cloud storage on the devices, it can be said that the cloud computing system stores the datasets on the internet. Information that is available on the websites can give proper credentials to this entire system. It can also give credentials to locations that have any kind of internet connection. Also, cloud data protection is essential in this matter because it is a practiced method where they try to secure all the important datasets of an organization.
Database security system refers to the tools, measures, and control of the design of the database. This is focuses on the main tools of the system and managing the data system. This system is a complex and challenge that involves the information of the system and helps the technology and practices of the cloud security system. There are some disadvantages of the system and failure in maintaining the dataset. The intellectual property is able to manage the competitive of the market for the product of the company. Customers are not want to buy the products and do not have the trust to protect the collected data for the company.
Much software has misused the result of the breaches and followed the common type of the dataset and attack the cause of the security system. The system also has many treated like malicious insiders, negligent, infiltrators. Dataset is access to the network and threat of the security system with the portion of the network infrastructure. The security of the system is the extent of the confines of the cloud-based security system. The server of the data set is located within the security environment of the data center and awareness of accessing the dataset.
Linking Objective 4: To examine the proper algorithm for this system
Several algorithms can help the entire system of cloud computing and one of them is RSA. Its main function is it can intervene when it comes to creating a suitable environment for the entire dataset. This is the method where the datasets do cryptographic exchange for creating an environment that is secure and safe. In this research paper, the researcher has already stated that according to the researcher the homomorphic algorithm is the most effective one in this case. RSA can only create a secured environment but it can keep all their datasets safe from being hacked in any way.
The important algorithm in the cloud-based security system is RSA and produces the output for the dataset. This proves the proper algorithm for the analysis and the proper algorithm is the RSA algorithm. This algorithm is uses as a private key and public key and the private key suggests the secret data or information of a person. The public key is to suggest the information that is suggests publicly. The idea of this algorithm is to make the difficulties at the time of integration. The public key is holding the “multiplication of prime numbers” and the private key is derives from the “same two prime numbers”. This RSA algorithm is the basis of the cryptosystem that is uses for the proper services and enables the key for securing the system. This algorithm manages the difficulties for the product of the prime numbers and generates the complexity of the algorithm.
6.3 Recommendation
6.3.1 Assessment on risks of Cloud computing
.png)
.png)
Table 6.1: SMART recommendation
(Sources: Self-created)
6.4 Limitation of the study
A data center is a proper environment is applies for the dedicated services that only apply for accessing the users of the servers. The cloud environment is automated and dynamic and pools the resources that support the application workload and access this anytime and anywhere from the device. The information for the security professional makes the cloud computing system attractive and runs smoothly to the network security system. The risks of the security system are a threat to the data center and network that has many changes for the application of cloud system and complete the migration through this the application is a move to remain on-premises.
The risks of the cloud-based security system are facing some problems at the time of moving to the cloud that also becomes significant. Many data center applications are uses in a large range of ports and measure the effectiveness of the application that easily moves to the cloud. Cybercrimes are creates attacks that are used in the many vectors for compromising the target or goals and hiding the plain sight for the common application and completing the mission of the development of the system. The information of the security system is dictates to the mission for application and separated the security system.
6.5 Future scope of the study
The paper predicts the scope of the cloud-based security system in the future for the growth of cloud computing. The organization needs to use some new technology in the system for the development of the cloud computing system. The members of management are needs to invest in the code standards that support the migration of the system into the cloud. This cloud computing is associated with the thinks of the human-like internet and stored the collected data in the cloud and become easy for making sure of the network. This also controls the performance, functionality, and security of the system. The limitation has the speed of the network and controls the pace that collected the data and processes this. The network is fast and uses cloud computing in any place.
References
.png)
.png)
.png)
.png)
.png)

- Assignment - Child Care
- Assignment - Mathematics
- Assignment - Accounting
- Assignment - Auditing
- Assignment - Biology
- Assignment - Law
- Assignment - Management
- Assignment - Nursing
- Assignment - Finance
- Assignment - Computer Science and IT
- Assignment - Humanities
- Assignment - Economics
- Assignment - Statistics
- Assignment - Architecture
- Assignment - Engineering
- Assignment - cookery
- Assignment - Marketing
- Case Study - Chemistry
- Case Study - Accounting
- Case Study - Law
- Case Study - Management
- Case Study - Nursing
- Case Study - Finance
- Case Study - Computer Science and IT
- Case Study - Engineering
- Case Study - Economics
- Case Study - Biology
- Case Study - Auditing
- Case Study - Marketing
- Case Study - Project Management
- Coursework - Diploma
- Coursework - Accounting
- Coursework - Auditing
- Coursework - Biology
- Coursework - Management
- Coursework - Nursing
- Coursework - Finance
- Coursework - Computer Science and IT
- Coursework - Engineering
- Coursework - Humanities
- Coursework - Child Care
- Coursework - Project Management
- Coursework - Economics
- Coursework - Cookery
- Coursework - Law
- Dissertation - Accounting
- Dissertation - Auditing
- Dissertation - Biology
- Dissertation - Law
- Dissertation - Management
- Dissertation - Nursing
- Dissertation - Finance
- Dissertation - Computer Science and IT
- Dissertation - Humanities
- Dissertation - Economics
- Essay - Politics
- Essay - Childcare
- Essay - Accounting
- Essay - Biology
- Essay - Law
- Essay - Management
- Essay - Nursing
- Essay - Computer Science and IT
- Essay - Humanities
- Essay - Economics
- Essay - Auditing
- Essay - Engineering
- Essay - Architecture
- Essay - Finance
- Essay - Science
- Essay - Marketing
- Programming - Computer Science and IT
- Reports - Management
- Reports - Computer Science and IT
- Reports - Project Management
- Reports - Marketing
- Reports - Nursing
- Reports - Engineering
- Reports - Accounting
- Reports - Humanities
- Reports - Finance
- Reports - Architecture
- Reports - Biology
- Reports - Economics
- Reports - Childcare
- Reports - Law
- Research - Accounting
- Research - Auditing
- Research - Biology
- Research - Law
- Research - Management
- Research - Nursing
- Research - Finance
- Research - Computer Science and IT
- Research - Science
- Research - Engineering
- Research - Humanities
- Research - Economics
- Research - Project Management
- Research - Statistics
- Research - Architecture
- Research - Marketing
- Thesis Writing - Computer Science and IT
- Thesis Writing - Engineering
- Thesis Writing - Biology
- Thesis Writing - Finance
- Thesis Writing - Humanities
- Thesis Writing - Auditing
- Thesis Writing - Economics
- Thesis Writing - Law
- Thesis Writing - Nursing
- Thesis Writing - Accounting
- Thesis Writing - Architecture


.png)
~5.png)
.png)
~1.png)























































.png)






