COMP1702 Big Data Assignment Sample
coursework Learning Outcomes:
1 Explain the concept of Big Data and its importance in a modern economy
2 Explain the core architecture and algorithms underpinning big data processing
3 Analyze and visualize large data sets using a range of statistical and big data technologies
4 Critically evaluate, select and employ appropriate tools and technologies for the development of big data applications
All material copied or amended from any source (e.g. internet, books) must be referenced correctly according to the reference style you are using.
Your work will be submitted for plagiarism checking. Any attempt to bypass our plagiarism detection systems will be treated as a severe Assessment Offence.
Coursework Submission Requirements
• An electronic copy of your work for this coursework must be fully uploaded on the Deadline Date of 29th Mar 2021 using the link on the coursework Moodle page for COMP1702.
• For this coursework submit all in PDF format. In general, any text in the document must not be an image (i.e. must not be scanned) and would normally be generated from other documents (e.g. MS Office using "Save As ... PDF"). An exception to this is handwritten mathematical notation, but when scanning do ensure the file size is not excessive.
• There are limits on the file size (see the relevant course Moodle page).
• Make sure that any files you upload are virus-free and not protected by a password or corrupted otherwise they will be treated as null submissions.
• Your work will not be printed in colour. Please ensure that any pages with colour are acceptable when printed in Black and White.
• You must NOT submit a paper copy of this coursework.
• All course works must be submitted as above. Under no circumstances can they be accepted by academic staff
The University website has details of the current Coursework Regulations, including details of penalties for late submission, procedures for Extenuating Circumstances, and penalties for Assessment Offences. See http://www2.gre.ac.uk/current- students/regs
Detailed Specification
You are expected to work individually and complete a coursework that addresses the following tasks. Note: You need to cite all sources you rely on with in-text style. References should be in Harvard format. You may include material discussed in the lectures or labs, but additional credit will be given for independent research.
PART A: Map Reduce Programming [300 words ±10% excluding java codes] (30 marks)
There is a text file (“papers.txt” is uploaded in Moodle) about computer science bibliography. Each line of this file describes the details of one paper in the following format: Authors|Title|Conference|Year. The different fields are separated by the “|” character, and the list of authors are separated by commas (“,”). An example line is given below: D Zhang, J Wang, D Cai, J Lu|Self-Taught Hashing for Fast Similarity Search|SIGIR|2010
You can assume that there are no duplicate records, and each distinct author or conference as a different name.
PART B: Big Data Project Analysis [2000 words ±10% excluding references] (70 marks)
Precision agriculture (PA) is the science of improving crop yields and assisting management decisions using high technology sensor and analysis tools. The AgrBIG company is a leading provider of agronomy services, technology and strategic advice. They plan to develop a big data system. The users can be farmers, research laboratories, policy makers, public administration, consulting or logistic companies, etc. The sources of data will be from various Sensors, Satellites, Drones, Social media, Market data, Online news feed, Logistic Corporate data, etc.
You need to design a big data project by solving the following tasks for the AgrBIG company:
Task1 (25 marks): Produce a Big Data Architecture for the AgrBIG company with the following components in detail for assignment help
- Data sources,
- Data extraction and cleaning,
- Data storage,
- Batch processing,
- Real time message ingestion,
- Analytical Data store
For each of the above, discuss various options and produce your recommendation which best meets the business requirement.
Task2 (10 marks): The AgrBIG company needs to store a large collection of plants, corps, diseases, symptoms, pests and their relationships. They also want to facilitate queries such as: "find all corn diseases which are directly or indirectly caused by Zinc deficiency". Please recommend a data store for that purpose and justify your choice.
Task3 (10 marks): MapReduce has become the standard for performing batch processing on big data analysis tasks. However, data analysists and researchers in the AgrBIG company found that MapReduce coding can be quite challenging to them for data analysis tasks. Please recommend an alternative way for those people who are more familiar with SQL language to do the data analysis tasks or business intelligence tasks on big data and justify your recommendation.
Task 4 (15 marks): The AgrBIG company needs near real time performance for some services such as soil moisture prediction service. It has been suggested the parallel distributed processing on a cluster should use MapReduce to process this requirement. Provide a detailed assessment of whether MapReduce is optimal to meet this requirement and If not, what would be the best approach.
Task 5 (10 marks): Design a detailed hosting strategy for this Big Data project and how this will meet the scalability, high availability requirements for this global business.
Assessment criteria
For a distinction (mark 70-79) the following is required:
1. An excellent/very good implementation of the coding task, all components are working and provide a very good result.
2. An excellent/very good research demonstrating a very good/ excellent understanding of big data concepts and techniques.
Note: In order to be eligible for a very high mark (80 and over) you will need to have:
Solution
Part A:
As the Map Reduce system in Hadoop mainly works on distributed server environment which helps in parallel execution of different processes and handle the communications among the different systems.
The model is a unique methodology of split-apply-join technique which helps in information retrieval. Mapping of the data is finished by the Mapper class and lessens the assignment is finished by Reducer class. On the other hand, MapReduce comprises of two stages – Map and Reduce.
As the name MapReduce recommends, the reducer stage happens after the mapper stage has been finished. Thus, the first is the guide work, where huge amount of data is perused and prepared to create key-value sets as middle of the results.
The yield of a Mapper or guide work (key-value sets for the process) is contribution to the Reducer. The reducer gets the key- value pair from different guide occupations.
At that point, the reducer totals those moderate information tuples (middle key-esteem pair) into a more modest arrangement of tuples or key-esteem sets which is the last yield. MapReduce expands on the perception that numerous data preparing errands have a similar essential construction: a calculation is applied over an enormous number of records (e.g., Web pages) to produce incomplete outcomes, which are then collected in some style. Normally, the per-record calculation and total capacity differ as per task, however the fundamental design stays fixed. Taking motivation from higher-request capacities in utilitarian programming, MapReduce gives a deliberation at the place of these two activities.
Following is the algorithm used for the program;
For Mapper
Input: ((word, datafilename), ( N,n, m))
consider D is known ()
Output ((word, datafilename), TF*IDF)
For Reducer
Just the considered identity function
Part B:
Task 1
Big Data Architecture is used by AgrBIG company in order to manage the business and the data related to the business can be analysed effectively. The architecture framework comes with different infrastructure solution for data storage, providing an opportunity to a business to hold a large amount of information and data (Ponsard et al., 2017). Data analytical tools are used in order to fetch the required result from a big set of data using the various components of big data architecture.
Data Sources
In order to ensure the effective running of the business and acquiring the desired outputs and profits, the company has to ensure that all the data that is to be operated or processed must be available to the company in time of requirement. The company has thus used different sources for utilising different data. The data sources come in different form from the company. Application data stores are used by the company in order to store the relational databases about different information about vendors and clients as well as the employees (Lai and Leu, 2017). Static files are produced by the company in order to run the applications, such as the server files, files associated with the website handling. Real-time data sources are also used by the company like devices which uses the technology of the Internet of Things.
Data extraction and Cleaning
Tokuç, Uran and Tekin (2019) discussed, the system has to include all data cleaning features in order to clear the junk data from the system for an effective running of the data tools that has been used by the management of the company. The company has to think of different approaches to ensure the cleaning of data is undertaken where the junk data has no requirement in the database. The data can be extracted from the system using any query language. Here, the company is dependent on NoSQL database for extracting information regarding different requirements of the business and associated stakeholders.
Data storage
For the process of data storage, the data is typically stored by AgrBIG company contains a huge number of information that is stored in the form of distributed files which contain a large volume of files and data that is stored in different formats. This huge volume of data can be stored in the storage called data lake. The data lake is considered to be the storage area used by the company in order to storage the vital information associated to the company and can be implemented for use anytime (Grover et al., 2018). The company is using Azure Data Lake Store for the storage of big data.
Batch Processing
As opined by Kim (2019), since the data used by the company comes in huge volume, they require to be provided with a solution of big data processing in order to filter the data and extracted in the time of requirement. Typically, long-running batch jobs are used to process the data files stored in big data. These data can be then prepared for the analysis of different jobs. The jobs related to analysis can include sourcing of files. processing the files and writing any new outputs on the files. U-SQL jobs is used in combination with Azure Data Lake Analytics in order to extract the required information. The company has also approached Map Reduce job for clustering the data using Java program.
Real-Time message ingestion
The solution of the data which is being extracted by the company if consists of real-time data sources then it has to implement the real-time message ingestion system in order to make the data for stream process. This is a way of simple storage of data where the incoming messages are handled and dropped into the folder which will be used for further processing. Different solution needs message ingestion according to eh requirements in order to act as buffer for the message an support the delivery of the message on forming semantics with queue.
Analytical Data store
Different kind of big data solution re now being prepared and used for analysis of data and the tools serves the data for processing in a sematic and structured format. Various analytic tools have been implemented in order to bring out the analysis through queries form the relation data warehouse. NoSQL technology or Hive database has been used for providing metadata abstraction features over the data files in the distributed storage of the system. The most traditional system being used by the business intelligence to implement the analytical storage of data through Azure Synapse analytics which is largely used by the company in order to provide a managed service in big data handling (Govindan et al., 2018). garbage company also uses cloud-based data warehousing for supporting interactive database management in order to serve the purpose of data analysis.
Task 2
garbage company has decided to implement large storage of bid data using a NoSQL database. This approach has been used by the company in order to handle a large volume of data which can be effectively extracted and used in higher speed and the scalability of the architecture being high (Eybers and Hattingh, 2017). In order to implement a scale-out architecture, NoSQL databases has been used by the company in order to communicate the queries even with cloud computing technologies. Moreover, it enables to process the data in large clusters and thus increases the capacity of the computers when added to the clusters.
Another reason for using the NoSQL database is to store the every unstructured and structured data with the help of some predefined schemas., These schemas can be easily used to transform into the data and can be loaded into the database. Few transformations are required in order to store retrieve information. In addition to that, the preference of choosing the NoSQL database by the AgrBIG company is that the database has the flexibility feature in order to be easily controlled by the developers and can be adaptable to holds different forms of data.
This technology has also features to update the data of the database easily by making transformation in the structure of the data. The value for rows and columns in the database can be updated with new values without disrupting the existing structure. The database comes with developer-friendly characteristics, which enables the developer to keep the control of the system and its associated structures of the data (Ekambaram et al., 2018). It thus helps to store the data where it can be closely observed when used in different application by the company. Moreover, the data in and data out is useful and easier though this technology used by the business.
Task 3
There are different methods that the company can use for data analysis tasks. The company has found that MapReduce is through an effective technology for the data analysis requirements of AgrBIG company, but the technology is posing different challenges in implementation. MapReduce uses different stages for the extraction of the data requirements. Though the technology is highly approached and effective in mapping a large set of data into cluster and creating several small elements of data by breaking them into tuples. Yet, the company prefers to use some other technology in order to implement the data processing. Hive can be used by AgrBIG company in order to run the parallel distributed system along with being familiar with the SQL language. This can be implemented by the company to run in parallel with MapReduce in order to distribute the data and sending these, mapper programs to the required location, locating the failures for handling. Hive is an alternative to MapReduce in order to reduce the line of the codes and making it easier to understand.
The coding approach of Hadoop comes with difficult functionality making it more complex for the business as it is time consuming. According to Bilal and Oyedele (2020), for advanced programming interfaces, the AgrBIG company can use Hive for the handling any large data. the technology also comes with special tools for the execution of data and manipulation of data. Hive also comprise of such technology which comes with different processing concepts for the selection, filtering and ordering of data according to provided syntax and has the flexibility to make conceptual adjustments Thus in most cases those who are familiar with SQL language prefers to have Hive over MapReduce as the data analysis tool for big data.
Task 4
Garbage company is concerned about implementing a scalable architecture that has the capacity to handle a large amount of distributed data in different servers across the cloud. The large data sets can be effectively handles and can be operated in parallel technology using MapReduce. Thus, this is chosen as the one of the best and optimal solution to the requirement of the business, which can handle the data effectively and process the huge amount of data at a very cost-effective solution. For real-time processing of data, the cost-effective approach used by MapReduce helps to meet the requirements of the business effectively as the technology allows the storage of data and processing of the data at a very affordable cost (Becker, 2017). The business of AgrBIG company has found that the programming through MapReduce has made an effective access to different sources of the data which helps to generate and extract values according to the requirements and thus flexible for the data processing and storage.
The business has also got advantages by MapReduce programming as it supports faster access to the distributed file system, which uses different mapping structure in order to locate data that is stored in clusters. The tools that MapReduce offers allows faster processing of big data. The essential feature for using MapReduce in order to recommend the technology as the optimal solution for the requirement of the business is the security which is the vital aspect of this application. Only approved users can gain the access to the data storage of the system and processing of the data.
MapReduce enables the AgrBIG company to provide the feature of parallel distributed processing through which the tasks can be divided in an effective manner and the execution can be done in parallel techniques. The parallel processing technique for the programming ensure the use of multiple process which can effectively handle the tasks by diving them and the programs can be computed and executed in faster approach (Walls and Barnard, 2020). Moreover, the data availability using this application is secured as the data is being forwarded to various node in the network. In case of failure of any of the node, data can be processed from other node which has the access of the data. This is offered by the fault tolerance feature of the application, which is very vital to meet the requirements of the business and make it more sustainable.
Task 5
Defining a big data strategy for hosting the requirements of the business it requires to synchronize the data for handling the objectives of the business in order to implement for big data. The strategy should be implemented in such a way that it can aligning the quality of the organisation long with approaching the performance goals focusing on different measurable outcomes. The strategy should be implemented with high scalability so that it possesses the decision making using data resources. Moreover, the data increases its volume with the expansion of the organisation, so it is required to choose the right data in order to find the solution to the various problems of the business. In the next approach, effective tools for handling the big data must be used by AgrBIG company in order to address the problems of the business. As stated by Ajah and Nek (2019), the Hadoop is being extensively used for an efficient handling of unstructured and structured data of the company. For the optimisation of the data, different analytical tools can be used by the company to meet the requirements and make the predictions based on the assumption of consumer behaviour. The entire process can ensure high availability of the information to meet the requirements of the business globally by synchronizing the entire flow of data with the help of public and private cloud provision which also comes with the feature of backups and data security. Thus, a hosting strategy for implementing Big Data project can ensure the management of organisation with the minimisation of risks and helps the project team to discover unexpected outcomes and examine the effects of the analysis.
Reference List
Ajah, I.A. and Nweke, H.F., (2019). Big data and business analytics: Trends, platforms, success factors and applications. Big Data and Cognitive Computing, 3(2), p.32. https://www.mdpi.com/2504-2289/3/2/32/pdf
Becker, D.K., (2017, December). Predicting outcomes for big data projects: Big Data Project Dynamics (BDPD): Research in progress. In 2017 IEEE International Conference on Big Data (Big Data) (pp. 2320-2330). IEEE. https://ieeexplore.ieee.org/abstract/document/8258186/
Bilal, M. and Oyedele, L.O., (2020). Big Data with deep learning for benchmarking profitability performance in project tendering. Expert Systems with Applications, 147, p.113194. https://uwe-repository.worktribe.com/preview/5307484/Manuscript.pdf
Ekambaram, A., Sørensen, A.Ø., Bull-Berg, H. and Olsson, N.O., (2018). The role of big data and knowledge management in improving projects and project-based organizations. Procedia computer science, 138, pp.851-858. https://www.sciencedirect.com/science/article/pii/S1877050918317587/pdf?md5=fb25e51566ae00860fc3831ce4088ce0&pid=1-s2.0-S1877050918317587-main.pdf
Eybers, S. and Hattingh, M.J., (2017, May). Critical success factor categories for big data: A preliminary analysis of the current academic landscape. In 2017 IST-Africa Week Conference (IST-Africa) (pp. 1-11). IEEE. https://www.academia.edu/download/55821724/Miolo_RBGN_ING-20-1_Art7.pdf
Govindan, K., Cheng, T.E., Mishra, N. and Shukla, N., (2018). Big data analytics and application for logistics and supply chain management. https://core.ac.uk/download/pdf/188718529.pdf
Grover, V., Chiang, R.H., Liang, T.P. and Zhang, D., (2018). Creating strategic business value from big data analytics: A research framework. Journal of Management Information Systems, 35(2), pp.388-423. https://files.transtutors.com/cdn/uploadassignments/2868103_1_bda-2018.pdf
Kim, S.H., (2019). Risk Factors Identification and Priority Analysis of Bigdata Project. The Journal of the Institute of Internet, Broadcasting and Communication, 19(2), pp.25-40. https://www.koreascience.or.kr/article/JAKO201914260900587.pdf
Lai, S.T. and Leu, F.Y., (2017, July). An iterative and incremental data preprocessing procedure for improving the risk of big data project. In International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing (pp. 483-492). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-319-61542-4_46
Ponsard, C., Majchrowski, A., Mouton, S. and Touzani, M., (2017). Process Guidance for the Successful Deployment of a Big Data Project: Lessons Learned from Industrial Cases. In IoTBDS (pp. 350-355). https://www.scitepress.org/papers/2017/63574/63574.pdf
Tokuç, A.A., Uran, Z.E. and Tekin, A.T., (2019). Management of Big Data Projects: PMI Approach for Success. In Agile Approaches for Successfully Managing and Executing Projects in the Fourth Industrial Revolution (pp. 279-293). IGI Global. https://www.researchgate.net/profile/Ahmet_Tekin7/publication/331079533_Management_of_Big_Data_Projects/links/5c86857ba6fdcc068187e918/Management-of-Big-Data-Projects.pdf
Walls, C. and Barnard, B., (2020). Success Factors of Big Data to Achieve Organisational Performance: Theoretical Perspectives. Expert Journal of Business and Management, 8(1). https://business.expertjournals.com/23446781-801/
DS7003 Advanced Decision Making: Predictive Analytics & Machine Learning Assignment Sample
Essential information
Welcome to this M-Level module on Advanced Decision Making. The module forms part of the MSc in Data Science and the Professional Doctorate in Data Science. This guide provides details of scheduled meetings, aims and learning outcomes, approaches to learning and teaching, assessment requirements, and recommended reading for this module. You will need to refer to it throughout the module. Further material may be distributed during the course of the module via Moodle (https://moodle.uel.ac.uk/).
You should consult the relevant Programme Handbook for details of the regulations governing your program.
The Data Science curriculum, for practical reasons, segments the learning process and preparing for research into a number of modules, and those modules into sessions. These sessions will necessarily overlap as their content can be treated from different perspectives and positions. Their content should be treated holistically rather than piecemeal.
Aims and learning outcomes
This module aims to develop a deep understanding of ways of making decisions that are based strongly on data and information. Particular focus will be on mathematical decision-making models including some use of computer-based support. Various case studies will be examined.
Learning outcomes for the module are for students for assignment help
1. Understand the design of decision-making models.
2. Understand the mathematical logic basis of decision-making.
3. Understand how to assign probabilities to uncertain events; assign utilities to possible consequences and make decisions that maximize expected utility.
4. Use of software-based decision-making tools.
5. Critically evaluate alternative decision models.
6. Conduct decision-making exercises.
7. Critically evaluate and analyze data.
8. Compose decision-making based reports.
The definitive description of the module is given in Annex 1.
Approaches to learning and teaching
This module is structured around 10 on-campus sessions over the one-week block.
This module employs a variety of approaches to learning and teaching, which include staff-led presentations, class and small-group discussions, debates, reflection, group exercises, journal-keeping and independent study. You are expected to spend time outside classes preparing for sessions by reading, thinking and engaging in other on- line activities as advised.
Important transferable skills for students intending to undertake or make a career in research include time management, communication skills and evaluation skills. This module places emphasis on developing these skills within the framework of completing the assignment. Strong emphasis is placed on your learning from experience. You must bring a laptop to each class for the practical exercises.
Reading
You are expected to read widely as part of your work for this module, and to spend approximately 15 hours per week in independent study and preparation for assessment. An indicative reading list is given in the Unit Specification Form in Annex 1 of this Guide and additional resources are made available through Moodle. These resources do have considerable overlap between the topics and in some cases repeat some of the knowledge. That is inevitable when looking at a rich literature. You are expected to identify further resources relevant to your particular interests and to the assignment through the Library’s on-line databases and from current affairs materials as Decision Making is very topical.
Attendance
Attendance at sessions is monitored. You should use your student ID card to touch in at the beginning of each session. You do not need to touch out.
Assessment
The assessment for this Module consists of one item: an analysis and review of decision-making using data set(s) of the student’s choosing using machine learning in R for classification, regression or time series of 5,000 words equivalence.
The piece of coursework should be submitted on-line using Moodle. Your work should first be submitted to Turnitin to guard against plagiarism and you can re- submit corrected work up to the due date and time that is specified for each piece of coursework. It is the student’s responsibility to ensure that coursework has been properly submitted on-line to the designated Moodle drop box. Late work may not have accepted for marking and could be treated as a non-submission. If there are justified extenuating circumstances, then these should be submitted on the requisite form according to the general academic regulations. The minimum pass mark for the module is 50%. Students who are unsuccessful in any M-level assessment can be re-assessed once without attendance and should they not be successful on the second take must re-take the module with attendance.
Solution
Introduction
Datasets these days offer several hidden useful information. Data mining is the field of extracting useful data with the help of different algorithms and techniques that covers classification, association, regression and association. It is noteworthy that health care industries have been majorly dependent on data mining tools and techniques. The patients’ risk factors can be predicted if a genuine dataset is examined over these data mining methods. Other than heart diseases, data mining is extensively used to predict other health conditions such as asthma, diabetes, breast cancer, etc. Many well-known studies have been published that proves the efficiency of algorithms such as support vector machine, logistic regression, naïve Bayesian classifier, neural networks and decision trees. The health care research in direction to predict underlying disease is widely in practice since few decades now (Jabbar, 2016).
Cardiovascular diseases are now becoming more chronic in last few years. Every year millions of people including all age groups die of severe heart diseases. The disease might not be detected at early stage due to which people have been dying as soon as the disease is diagnosed. However, early detection of heart disease can save patients’ lives as their risk factors are known before the time has passed. This prediction at early stage may help in minimizing mortality rates. The heart diseases are of various kinds that includes coronary heart disease, cardio myopathy, hypertensive heard disease, heart failure, etc. These conditions are caused due to diabetic conditions, hypertensions, high cholesterol levels in body, obesity, etc.
Data mining methods and techniques can be fruitful in early prognosis of disease that can calculate high risk factors by analyzing existing dataset. The data mining tools and algorithms are proven to be accurate enough to predict right information (Gandhi, 2015). The dataset used in this research on which analysis is done is collected from Cleveland Heart Clinic; the database is popularly known as Cleveland Heart Disease Database (CHDD) used by many researchers. The information about its key attributes is discussed later in the chapter.
The research report is organized as follows. The next section offers machine learning insights and details of categories of algorithms prevalent in machine learning. Later, literature is presented towards the researches being conducted to predict cardiovascular diseases by other researchers. Then, methodology is discussed about the work conducted in this research. It provides detailed description of how diseases are predicted by support vector machine and logistic regression. Additionally, both the techniques are tested for their accuracy and hence compared. The objectives of this research are two-fold: First, finding how accurate these two selected methods are for predicting heart disease. Second, comparison of two methods based on their accuracy.
Traditionally, statistical techniques were used to develop intelligent applications. The predictions were simply based on interpolation formulae as learned in high schools. However, in today’s AI applications, traditional interpolation formulae could fail; hence, new techniques are successfully developed to fulfill current AI needs and requirements. Most popular methods in artificial intelligence and machine learning are regression, clustering, classification, probability and decision trees. These methods contain several different algorithms to suit different class of problems to solve complex problems (Babu, 2017). Machine learning is further categorized as in figure 1.
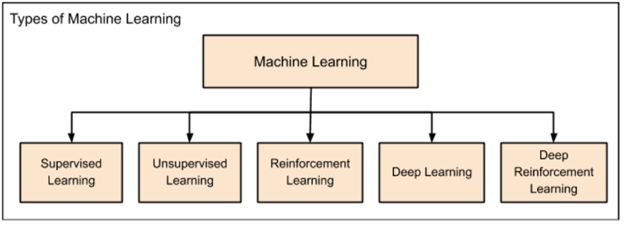
Figure 1 Categories of Machine Learning (Babu, 2017)
The categories of machine learning are:
Supervised Learning: The very first found machine learning technique used first to predict residential pricing. The supervised learning, as the name suggests, supervises entire application working. Just as child is taught to walk, by holding hands, the supervised learning algorithm monitors each and every step of application to achieve best results. Regression and Classification are kinds of methods used in supervised learning.
Regression: The machine is trained first by providing results for the input value. The machine then learns the relationship between input and output values. Once the machine learns it, the value of output is predicted for input provided based on empirical relationship between previous inputs and their respected outputs.
Classification: The classification problem efficiently categorizes the pool of data into predefined classes. For example, if a box contains blue, red and green balls; the classification algorithm can sort and find the number of balls of each color in the box. The classification algorithm classifies objects of same kind into one category whose label is previously named. This technique of machine learning falls under supervised learning where group names are already defined. Objects are classified as per nature described.
Unsupervised Learning: This method doesn’t require any other agent to supervise it. Completely opposite to supervised learning, unsupervised learning technique never allows machine to train itself on the basis of known outputs from certain inputs. Rather, the algorithm forces machine to find all possible values of the given input. This is achieved by identifying the features mostly appearing in input.
Reinforcement Learning: The idea is to reward the machine whenever it achieves desired results. Consider at an instance, when training a dog to fetch a ball. If a ball thrown is fetched by dog, it is rewarded by the master. This helps dog to understand how to do the commanded task. This type of learning is termed as reinforcement. This algorithm is usually applied in games. The application should analyze the possible next moves after each next step. If the predicted next step is correct, the machine is rewarded else it is punished or penalized. This will help algorithm to identify right and wrong moves; hence the machine will learn right moves as the game proceeds. Thus, the accuracy towards winning keeps on increasing.
Deep Learning: To aid in analyzing big data, deep learning was introduced so that applications can be designed as human brains that can create artificial neural network.
Deep Reinforcement Learning: Similar to reinforcement learning, when deep learning application or machine works the same as expected, it is rewarded in deep reinforcement learning.
These algorithms are founded as listed from supervised learning to deep reinforcement learning. With need to solve each new complex problem, new machine learning method was introduced.
Literature Review
Researchers have been trying since decades the accurate way to predict heart diseases so that lives of millions of people can be saved. Authors have developed a system to detect heart diseases accurately by monitoring heart rate data collected from a survey (Wijaya, 2013). The tools act as a data feeder and retriever in the survey which is a pitfall. In other words, if tool isn’t available, data cannot be read. However, the correct prediction of severity of heart disease could increase person’s life span by developing healthy lifestyle. The system developed by authors (Gavhane, 2018) is less accurate as results obtained. The other researchers (Ul Haq et al., 2018) developed a system which was comparatively reliable that included usage of classification technique. The back propagation algorithm was used to predict heart diseases; and the results were promising (Xing et al., 2007). Used feature selection for gaining more accurate results. The authors developed a system to find heart diseases, cancer and diabetes from the dataset.
Apart from usage of feature selection and back propagation few researchers have developed systems that made good use of other algorithms such as support vector machine, neural network, regression, decision trees and several classifiers such as naïve bayes. The datasets were different and common for few authors but the techniques were unique. The datasets used were collected all around the globe; the results were different and accuracies differed in many ways as use of techniques were different. Xing et al. collected dataset of thousand patients wherein different parameters were included such as hypertension, smoking habits, age, gender, diabetic or not, etc. The authors developed three algorithms: SVM, ANN and decision trees. The accuracies calculated were 92.1%, 91.0% and 89.6% respectively.
Chen et al. developed a system to predict heart diseases with the help of algorithms like SVM, neural network, Bayes Calssifier, decision trees and logistic regression. The most accurate of all is support vector machine (90.5%) whereas the accuracy of logistic regression was the least (73.9%). Neural network, Bayes classifier and decision trees had accuracies 88.9%, 82.2%, 77.9% respectively.
Many researchers have selected different attributes of dataset for several machine learning techniques. It was observed that it does not provide a justified basis to compare the techniques for their accuracy. With this thing in consideration, Soni et al. selected those attributes that can affect largely to heart of patients that consist of gender, obesity, hypertension, smoking habits, drinking habits, salt intake, cholesterol level, diabetes, family history of the same disease, no physical exercises, etc. Similarly, Shouman et al. identified blood pressure as another risk factor that can be considered while predicting heart disease. Cleveland Heart Disease database is highly considered by researchers as it is one of the most trusted dataset for analysis. The very first research on this dataset was conducted in 1989 by Detrano et al. where logistic regression was implemented and accuracy of 77% was attained. This is worth noting that accuracy of models after their evolution is dramatically increasing and it is found to be above 90%. Many researchers have used combination of machine learning techniques to attain accuracy as high as possible.
Other than SVM and logistic regression, k-means clustering and c4.5 decision trees were implemented by Manikanthan and Latha to predict heart disease. The accuracy of the system was 92% which was considered as a promising approach. Nor Heiman et al. studied methods in decision tree algorithm to minimize errors. Dota et al. used decision tree algorithm to compare accuracies to detect quality of water. Rajeshwari et al chose some attributes that can help patients to find the list of medical tests that are of no need. Lakshmi et al used many data mining techniques such as c4.5, k-means, decision trees etc. and found their specificity. It was observed that PLS-DA shown promising results in prediction of heart disease. Taneja used Naïve Bayes classifier to choose attributes from dataset. He proved that data mining techniques for feature selection are equally important as that of prediction or classification itself. Sudhakar and Manimekalai comparatively presented many data mining techniques as a survey research paper. Ahmed and Hamman performed data mining for cardiovascular predictions using support vector machine and clustering techniques. They also performed association rules mining for attribute selection. Sugumaran et al performed data mining for fault detection using svm and classification.
Methodology
The research concentrates on implementation of logistic regression and support vector machines on Cleveland heart disease dataset in order to find and compare their accuracies.
Support Vector Machine
A machine learning model that helps in finding known patterns for classification and regression. SVM is mostly applied when the data can be classified into two groups. The hyper plane generated by SVM can be useful in partitioning similar kind of objects with other quite efficiently. It is considered that the distance between two classes should be maximum to prove that the model is good. To solve real world problems SVM is highly considered since it is a pure mathematical model and may provide best results. It is also better to SVM when a dataset consists of many attributes. The foremost task, an SVM does is mapping data into kernel space. Selection of kernel space can be quite challenging with SVM.
Logistic Regression
Logistic regression can predict the outcome with limited group categorical value dependent on a variable. In CHDD, the outcome should be heart disease detected or not. The outcomes are usually binary in logistic regressions. With binary, it means having two values at maximum. The probability of success is largely measured by logistic regression.
The system flowchart is presented below in figure 2. The Cleveland heart disease dataset is used via its link. The next step is data exploration and pre-processing. To accomplish this, features are selected first, in this dataset important parameters are first identified and selected for further processing. Support Vector Machine model is first applied and its accuracy is stored in an array. Later, Logistic Regression model is also applied and its accuracy is again stored in the same array. Finally, the accuracy of both the models applied is compared and results are presented. The experimental analysis is presented in next section.
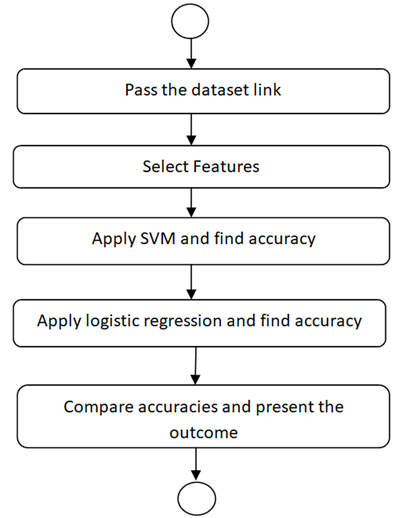
Figure 2 Flowchart of Proposed Research
Data Exploration using R
Data Exploration is the initial and the most important step of data mining process. It not only helps in finding uncovered aspects but also offers details of the data under observation. It helps in building a system that can be accurate to its peak.
Data Exploration is a stepping stone for analysts to visualize dataset by applying statistical methods on dataset. The data and its nature are well understood by data exploration step. The size, type of attributes, format of attributes plays important roles in data exploration. The manual and automated, both ways are widely used as per data analysts ease. This step helps them to visualize important graphs and hence find correlation between attributes. The outlier detection and distribution of values of attributes can be performed by data exploration tools much efficiently than that of manual efforts. The datasets collected by other researchers are raw data and to find few important insights, it is necessary to perform data exploration. The data collection is a pillar to data exploration. To select correct data for analysis is again an important task. While selecting a dataset analyst must know what are the important attribute types to lookup.
Data exploration need is quite well justified. It is always observed that data in the form of pictures, graphs and any form of visualization is more easily grasped by viewers than that of numerical data in tabular form or in excel sheets. Hence, it is a tedious task for analysts to put millions of data rows and their corresponding attributes to frame in a graph so that it is well understood to the viewers.
Data visualization in R and its exploration is quite simple as it takes syntax to learn. It first starts with loading dataset chosen into allowable extensions such as csv, xlx, json and txt. The variables are converted into characters from numbers to aid the parsing in R. A dataset is then transposed from wide to narrow structure. Dataset is sorted accordingly and plots are created as per visualization requirements. Duplicate variables can be easily removed using R. Merging and joining dataset as well as count and sum functions are also easily available. Data Exploration in R is based on fixed syntax as presented next.
1. Reading a dataset

2. Transpose a dataset

3. Remove duplicate values

4. Create a histogram
The operations provided here are just few from the pool of operations in R studio. There are numerous libraries one can import and use different function already defined in it.
Data Source
Dataset: Heart Disease Dataset from UCI Repository
Link: https://archive.ics.uci.edu/ml/datasets/Heart+Disease
The heart disease dataset is a collection of 303 records identified by 76 attributes. Out of which, goal attribute identifies if there is presence of heart disease in the underlying patient. It is represented by an integer value, where 0 indicates no heart disease and presence of heart disease is classified as values 1 to 4; low to the scales of severe.
14. #58 (num) (the predicted attribute)
Complete attribute documentation:
1 id: patient identification number
2 ccf: social security number (I replaced this with a dummy value of 0)
3 age: age in years
4 sex: sex (1 = male; 0 = female)
5 painloc: chest pain location (1 = substernal; 0 = otherwise)
6 painexer (1 = provoked by exertion; 0 = otherwise)
7 relrest (1 = relieved after rest; 0 = otherwise)
8 pncaden (sum of 5, 6, and 7)
9 cp: chest pain type
-- Value 1: typical angina
-- Value 2: atypical angina
-- Value 3: non-anginal pain
-- Value 4: asymptomatic
10 trestbps: resting blood pressure (in mm Hg on admission to the hospital)
11 htn
12 chol: serum cholestoral in mg/dl
13 smoke: I believe this is 1 = yes; 0 = no (is or is not a smoker)
14 cigs (cigarettes per day)
15 years (number of years as a smoker)
16 fbs: (fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)
17 dm (1 = history of diabetes; 0 = no such history)
18 famhist: family history of coronary artery disease (1 = yes; 0 = no)
19 restecg: resting electrocardiographic results
-- Value 0: normal
-- Value 1: having ST-T wave abnormality (T wave inversions and/or ST elevation or depression of > 0.05 mV)
-- Value 2: showing probable or definite left ventricular hypertrophy by Estes' criteria
20 ekgmo (month of exercise ECG reading)
21 ekgday(day of exercise ECG reading)
22 ekgyr (year of exercise ECG reading)
23 dig (digitalis used furing exercise ECG: 1 = yes; 0 = no)
24 prop (Beta blocker used during exercise ECG: 1 = yes; 0 = no)
25 nitr (nitrates used during exercise ECG: 1 = yes; 0 = no)
26 pro (calcium channel blocker used during exercise ECG: 1 = yes; 0 = no)
27 diuretic (diuretic used used during exercise ECG: 1 = yes; 0 = no)
28 proto: exercise protocol
1 = Bruce
2 = Kottus
3 = McHenry
4 = fast Balke
5 = Balke
6 = Noughton
7 = bike 150 kpa min/min (Not sure if "kpa min/min" is what was written!)
8 = bike 125 kpa min/min
9 = bike 100 kpa min/min
10 = bike 75 kpa min/min
11 = bike 50 kpa min/min
12 = arm ergometer
29 thaldur: duration of exercise test in minutes
30 thaltime: time when ST measure depression was noted
31 met: mets achieved
32 thalach: maximum heart rate achieved
33 thalrest: resting heart rate
34 tpeakbps: peak exercise blood pressure (first of 2 parts)
35 tpeakbpd: peak exercise blood pressure (second of 2 parts)
36 dummy
37 trestbpd: resting blood pressure
38 exang: exercise induced angina (1 = yes; 0 = no)
39 xhypo: (1 = yes; 0 = no)
40 oldpeak = ST depression induced by exercise relative to rest
41 slope: the slope of the peak exercise ST segment
-- Value 1: upsloping
-- Value 2: flat
-- Value 3: downsloping
42 rldv5: height at rest
43 rldv5e: height at peak exercise
44 ca: number of major vessels (0-3) colored by flourosopy
45 restckm: irrelevant
46 exerckm: irrelevant
47 restef: rest raidonuclid (sp?) ejection fraction
48 restwm: rest wall (sp?) motion abnormality
0 = none
1 = mild or moderate
2 = moderate or severe
3 = akinesis or dyskmem (sp?)
49 exeref: exercise radinalid (sp?) ejection fraction
50 exerwm: exercise wall (sp?) motion
51 thal: 3 = normal; 6 = fixed defect; 7 = reversable defect
52 thalsev: not used
53 thalpul: not used
54 earlobe: not used
55 cmo: month of cardiac cath (sp?) (perhaps "call")
56 cday: day of cardiac cath (sp?)
57 cyr: year of cardiac cath (sp?)
58 num: diagnosis of heart disease (angiographic disease status)
-- Value 0: < 50% diameter narrowing
-- Value 1: > 50% diameter narrowing
(in any major vessel: attributes 59 through 68 are vessels)
59 lmt
60 ladprox
61 laddist
62 diag
63 cxmain
64 ramus
65 om1
66 om2
67 rcaprox
68 rcadist
69 lvx1: not used
70 lvx2: not used
71 lvx3: not used
72 lvx4: not used
73 lvf: not used
74 cathef: not used
75 junk: not used
76 name: last name of patient
Experimental Analysis
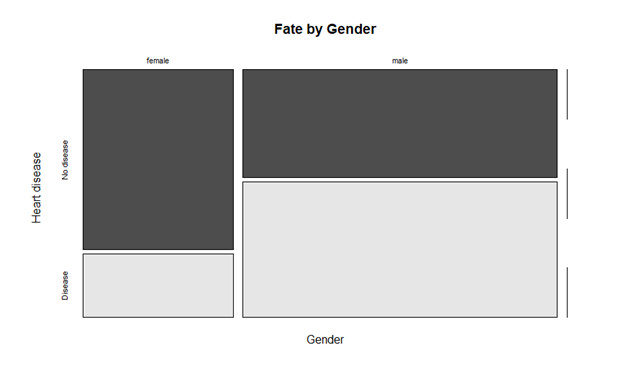
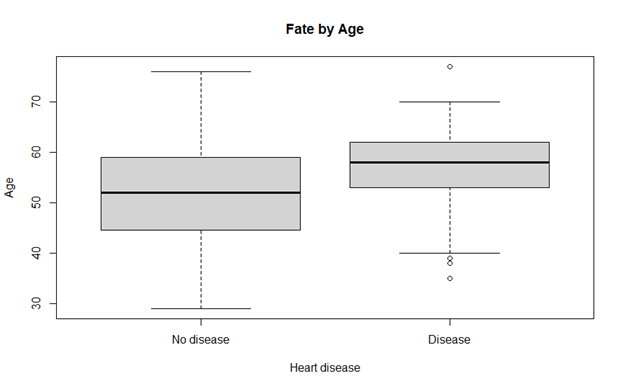
Comparisons
The metrics used to compare SVM and logistic regression is AUC and accuracy. As seen below, support vector machine performs better than logistic regression. Following is the snapshot of accuracy list of both the techniques used.
Some researchers have found that logistic regression performs better in most cases if selection of attribute is slightly different. However, in our prediction, support vector machine performed better. However, there is still need to finding another method that can provide better accuracy than SVM.
Conclusions
The research concentrated on mining data related to heart disease. The dataset is popular and hence highly trustworthy to conduct concrete research on. Only fourteen out of seventy-six attributes were selected to test models named support vector machine and logistic regression. This research explored data in R studio with the help of in built libraries for applying several models with utmost ease. Data mining has now gained huge importance due to curiosity of prediction for necessary information. Today’s world contains gigantic datasets built over the period of years. These datasets are future predictors for many hidden aspects. The models implemented in R shows that accuracy of support vector machine is better than logistic regression. However, the accuracy should be increased by implementing other data mining techniques such as decision trees or naïve bayes classifier, etc. The research report presents details related to machine learning domain along with data exploration in R. R studio is a user friendly platform with fixed syntax to explore data and find useful information from it.
References
Ahmed, A. & Hannan, S. (2012). Data mining techniques to find out heart diseases: An overview. International Journal of Innovative Technology and Exploring Engineering (IJITEE), Volume-1, Issue-4.
Babu, S. (2017). Heart disease diagnosis using data mining technique. International conference on electronics, communication and aerospace technology ICECA2017.
Chen, J. Xi, G. Xing, Y. Chen, J. & Wang, J. (2007). Predicting Syndrome by NEI Specifications: A Comparison of Five Data Mining Algorithms in Coronary Heart Disease. Life System Modeling and Simulation Lecture Notes in Computer Science, pp 129-135.
Detrano, R. Janosi, A. Steinbrunn, W. Pfisterer, M. Schmid, J. Sandhu, S. Guppy, K. Lee, S. & Froelicher, V. (1989). International application of a new probability algorithm for the diagnosis of coronary artery disease. The American Journal of Cardiology, pp 304-310.15.
Dota, M. Cugnasca, C. Savio, D. (2015). Comparative analysis of decision tree algorithms on quality of water contaminated with soil, Ciencia Rural, Santa Maria, v.45, n.2, p.267-273, ISSN 0103-8478.
Gandhi, M. (2015). Prediction in heart disease using techniques of data mining. International conference on futuristic trend in computational analysis and knowledge management (ABLAZE-2015).
Gavhane, A. (2018). Prediction of heart disease using machine learning, ISBN: 978-1-5386-0965-1.
Jabbar, M. (2016). Heart disease prediction system based on hidden Navie Bayes Classifier. International conference on circuits , controls, communications and computing (14C).
Lakshmi, K. Veera Krishna, M. and Prem Kumar, S. (2013). Performance Comparison of Data Mining Techniques for Predicting of Heart Disease Survivability. International Journal of Scientific and Research Publications, 3(6).
Mai Shouman, M. Turner, T. & Stocker, R. (2012). Using Data Mining Techniques In Heart Disease Diagnoses And Treatment. Electronics, Communications and Computers (JECECC), 2012 Japan-Egypt Conference March 2012, pp 173-177.
Manikantan, V. & Latha, S. (2013). Predicting the analysis of heart disease symptoms using medicinal data mining techniques. International Journal on Advanced Computer Theory and Engineering (IJACTE), ISSN (Print) : 2319 – 2526, 2(2).
Nor Haizan, W. Mohamed, M. & Omar, A. (2012). A comparative study of reduced error pruning method in decision tree algorithms. IEEE International conferance on control system, Computing and Engineering, 23 - 25, Penang, Malaysia.
Rajeswari, K. Vaithiyanathan, V & Pede, S. (2013). Feature Selection for Classification in Medical Data Mining. International Journal of emerging trends and technologies in Computer Science, 2(2).
Soni, J. Ansari, U. & Sharma, D. (2011). Predictive Data Mining for Medical Diagnosis: An
Overview of Heart Disease Prediction. International Journal of Computer Applications, doi 10.5120/2237-2860.
Sudhakar, K. and Manimekalai, M. (2014). Study of Heart Disease Prediction using Data Mining, International Journal of Advanced Research in Computer Science and Software Engineering, 4(1), ISSN: 2277 128X.
Sugumaran, V. Muralidharan, V. & Ramachandran, K. (2007). Feature selection using Decision Tree and classification through proximal support vector machine for fault diagnostics of roller bearing. mechanical systems and signal processing, 21 (2), Pages 930-942.
Taneja, A. (2013). Heart Disease Prediction System Using Data Mining Techniques. J. Comp. Sci. & Technol., 6(4), 457-466.
Ul Haq, A. Li, J. Memon, M. Nazir, S., & Sun, R. (2018). A Hybrid Intelligent System Framework for the Prediction of Heart Disease Using Machine Learning Algorithms.
Wijaya, R. (2013). Preliminary design of estimation heart disease by using machine learning ANN within one year. communication technology and electric vehicle technology , bandung-bali, Indonesia.
Xing, Y. Wang, J. & Gao, Z. (2007). Combination data mining methods with new medical data to predicting outcome of Coronary Heart Disease. Convergence Information Technology. International Conference November 2007, pp 868-872.
COMP1629 Penetration Testing Assignment Sample
Coursework Submission Requirements
• An electronic copy of your work for this coursework must be fully uploaded on the Deadline Date of Friday 13/03/2020 using the link on the coursework Moodle page for COMP1629.
• For this coursework you must submit a single PDF document. In general, any text in the document must not be an image (i.e. must not be scanned) and would normally be generated from other documents (e.g. MS Office using "Save As .. PDF"). An exception to this is hand written mathematical notation, but when scanning do ensure the file size is not excessive.
• There are limits on the file size (see the relevant course Moodle page).
• Make sure that any files you upload are virus-free for assignment help and not protected by a password or corrupted otherwise they will be treated as null submissions.
• Your work will not be printed in colour. Please ensure that any pages with colour are acceptable when printed in Black and White.
• You must NOT submit a paper copy of this coursework.
• All coursework must be submitted as above. Under no circumstances can they be accepted by academic staff
The University website has details of the current Coursework Regulations, including details of penalties for late submission, procedures for Extenuating Circumstances, and penalties for Assessment Offences. See http://www2.gre.ac.uk/current-students/regs
Coursework specification
Task 1 [15 marks]
Following a web application penetration testing engagement you have identified the following issues. You must complete the issue justification/explanation/CVEs/Vulnerability type as required and write appropriate recommendations for addressing each of the issues identified. You will need to conduct research on the nature and implications of these issues in order to complete the justification/explanation and recommendations. You must use the following issue templates provided. Assume that under “Results” section an actual screen capture or other evidence exists obtained during the assessment exists.

Task 2 [20 marks]
During a build review one of your colleagues acquired the following evidence but did not have time to write up the actual issues (there are two issues). Your task is to write up these issues using the template from Task 1. Hint: These are low rated issues.

Task 3 (65 marks)
As part of this engagement your lecturer will provide you with access to a group of systems (VM based or actual systems or both). You will have, depending on the scenario details, to assess the security of these systems within a given timeframe. There might be certain rules that you might need to follow during testing and these will be provided with the scenario details. An example of this might be” Perform a non-intrusive test” or “Keep bandwidth within or below a certain threshold”. Failing to adhere to any of these scenario rules will result to an automatic mark penalty, details of which will be provided with the scenario.
During the assessment period you will have to run various tools (as required), verify your results and gather all required evidence as needed (e.g. take screen captures, save the output of any tools used etc) so that later you can complete your report (a technical report with your findings using the template that you lecturer will provide). Automated tools such as Nessus, Quallys etc. should not be used for the reporting of the vulnerabilities.
Deliverables
Task 1,2 & 3: A completed professional technical report based on the template that will be provided by your lecturer.
Assessment criteria
Task 1 [15 Marks]
Task 2 [20 Marks]
Task 3 [65 Marks]
Marks may be deducted for:
Lack of technical depth, poor presentation, lack of tables, screen captures that do not provide adequate information or with relevant sections not highlighted as needed, screenshots that are not cropped appropriately, poor tool options, poor tool output explanation, poor recommendation, lack of professionalism in the answers provided, poor spelling/grammar, lack of integration/poor flow, poor references/appendices.
Marks will be awarded for:
Completeness, good technical content and depth and good report writing (including good use of English). Please make sure that you proofread your work. An appropriate professional report structure and presentation is expected.
Solution
1. Overview
The overview of the project describes the internet security of a banking organization carried out by a private firm. Several security testing tools will be used in the study. The test of penetration helps the organization in improving its cyber-security. Technically, these tests may not provide complete solutions of security for the organization but can reduce the probability of malicious attacks to systems.
1.1. Introduction
Cybersecurity penetration testing characteristically classifies the physical systems along with a particular goal that examines the available evidence and reveals the hidden information. For the situation of the XXX Bank network frameworks, the infiltration target is a grey box entrance test since it recognizes the change of the white box and black box. This is in the embodiment that the testing crew operations are from the comprehension of a trespasser who is outside to the business. Subsequently, the infiltration analyzer starts by distinguishing the organization map, the security apparatuses executed, the web confronting sites and administrations, among different angles.
1.2. Key Findings and Recommendations
Although, the source of such data is a lot significant for the analyzers to comprehend in the event that it began from metro bases or if the assailant is a disappointed laborer or ex-specialist who has the association's security data; for discovery testing. This is fundamental for XXX’s organization framework since it helps the testing team to examine the specific wellspring of spillage of the security data framework that is utilized by programmers. The white box testing is worried about interior applications that are predetermined for use by workers as it were (Yaqoob et al. 2017). For this situation, the testing bunch is furnished with all accessible objective data, counting the source code of the web utilization of the XXX Bank. Henceforth, examining and observation take a brief timeframe. Notwithstanding, the interface between the two testing boxes; the highly contrasting, is that since the XXX’s network framework is an inner application and given the security data of the framework is as it was controlled by the representatives. Accordingly, on the off chance that one representative is disappointed or terminated, the person in question may release the data to programmers. Subsequently, it is simple for them to pinpoint the shortcomings existing in the organization framework.
This establishes the grey box testing, which is fundamentally expected for testing site applications and is refined by assessing the laborer records to recognize how the assailant got access to the organization framework. The piece of the high contrast testing procedures will accordingly help the entrance analyzers effectively understand the objective framework, hence potentially uncover more generous susceptibilities; with not as a lot of exertion and cost. Since it syndicates the commitment of creators of the organization framework and the analyzers, consequently the item greatness of the framework is moderately overhauled (Furdek and Natalino 2020). Again, since less time is taken in acknowledgment of the specific wellspring of data for programmers, the originator, subsequently, has a ton of available energy to fix the imperfections.
1.3. Summary of Findings
In this experiment, several vulnerabilities that have been discovered through the finding of the study is Apache (Debian), X-XSS-Protection header, X-Content-Type-Options header, Uncommon header 'link' found with multiple values, Apache/2.4.10 appears to be outdated, No CGI Directories found, WordPress Akismet plugins. The followed findings are the coordination of the organization site that are broken down by design testing, to guarantee that the past security dangers or imperfections of the framework are checked on. In this way, the reasons for the earlier disappointment are recognized, and hence the experiments are proposed for discovering different discontents prior to striking creation. This guarantees the improved security of the information put away in that specific organization framework (Alzahrani 2018). Moreover, relapse testing of the product helps in guaranteeing that the recently presented highlights of the framework don't influence the security use of the framework, which may spill data to programmers.
2. 2. Task 1
2.1. CVE
Apache Debian: A vulnerability has been found in Apache HTTP Server 2.4.10 At the point when HTTP/2 was empowered for an HTTP: host or H2Upgrade was empowered for h2 on an HTTPS server (Seyyar, Çatak and Gül 2018). Therefore, having an Upgrade demand from http/1.1 to http/2 on XXX’s system server, has prompted a misconfiguration and cause a crash. The websites that never empowered the h2 convention or that solitary empowered it for HTTPS: and didn't set "H2Upgrade on" are not impacted by this problem.
X-XSS-Protection header: A missing X-XSS-Protection header has been found, which implies that XXX's website could be in danger of a Cross-webpage Scripting (XSS) assault. This issue is accounted for as extra data as it was. There is no immediate effect emerging from this issue.
X-Content-Type-Options header: A missing Content-Type header has been discovered, which implies that XXX's site could be in danger of a MIME-sniffing assault. The X-Content-Type-Options header is utilized to ensure against MIME sniffing risks (Petkova 2019). These risks have happened when the site permits clients to transfer the substance to a site anyway the client camouflages a specific document type as something different.
Apache/2.4.10 appears to be outdated: There are certain risks that have been found regarding Apache/2.4.10. The Apache HTTP Server 2.2.22 and its mod_headers module permits distant aggressors to sidestep unsetdirectives of RequestHeader by implementing a header in the trailer bit of sent information with partially moving code. A race condition in the mod_status module in the Apache HTTP Server 2.4.10 permits the remote aggressors to cause a rejection of administration, which is basically a stack-based support flood through a developed request that triggers inappropriate scoreboard taking care of inside the status_handler work in modules/generators/mod_status.c and the lua_ap_scoreboard_site in modules/lua/lua_request.c.
The Apache HTTP Server 2.4.10 and its mod_cgid module don't have a break component, and so it permits the distant attackers to cause a refusal of administration in XXX’s website by soliciting the CGI contents that don't peruse from its stdin document descriptor.
No CGI Directories found: A break in XXX's site results from feeble CGI contents can happen in an assortment of ways. This might be through accessing the source code of the content and discovering weaknesses contained in it, or by survey data showing registry structure, usernames, as well as passwords (Hamza et al. 2019). By controlling these contents, a programmer can adjust or see touchy information, or even shut down a worker so clients can't utilize the site. As a rule, the reason for poor CGI content can be followed back to the individual who composed the program. Notwithstanding, by following great coding rehearses, one can keep away from such issues and will actually want to utilize CGI programs without trading off the security of the site.
WordPress Akismet plugins: From XXX's website frameworks, a basic XSS vulnerability has been found, which has been influencing Akismet, a mainstream WordPress module conveyed by a great many introduces. This weakness influences everybody utilizing Akismet form 3.1.4 in plain view" alternative empowered which is the situation as a matter of course on any new WordPress establishment (Currie and Walker 2019). The issue can be found in the manner Akismet manages hyperlinks present inside the site's remarks, which could permit an unauthenticated assailant with great information on WordPress internals to embed vindictive contents in the Comment part of the organization board. Doing this could prompt various abuse situations utilizing XSS
3. 3. Task 2
3.1. Issues
After analyzing the server of the organization various network vulnerabilities have been detected by the NTA Monitor Ltd. One of the essential vulnerabilities is found that is the Apache/2.4.10. In this type of vulnerability, various forms of malicious attacks and issues are associated with the network. Some of the issues are the SQL injection, Apache Ranger Security Bypass, and Authentication Bypass. SQL injection is the most common attacking factor that uses malicious SQL code to manipulate the database of the organization (Batista et al. 2019). Here, the database may include sensitive data information and customer details. If the SQL injection is successfully implemented on the server of the organization, then unauthorized access can be launched on the server of the organization by the external attackers. This type of attack may cause both financial and reputation loss for the organization. SQL language can execute commands, data retrieval, and updates on the organization server. There are three types of SQL injection that are In-band SQLi, Out-of-band SQLi, and Inferential SQLi. The same channel is used to launch the attack in the In-band SQLi and this is the simple and efficient type of attack.
While the security bypass is another major issue for the Apache Ranger. Security measures can be avoided by the Apache Ranger. However, a widely employed framework can be enabled by the Apache Ranger to monitor and access the network of the organization. On the other hand, user authentication can also be manipulated by the security threat.
Another malicious technique that is found on the company server is Clickjacking (Possemato et al. 2018). Using this type of attack, an attacker can hack the credentials of the customers who access the company website. The same interface is presented in front of the users. After clicking on the link, all the credentials of the customer are hacked by the hacker. In this type of attack, the X-Frame option does not return to the server. X-XSS-Protection is not defined in the header which is the feature of the modern web browser. This feature mainly protects websites from unprotected links and cyber threats.
Another issue that was raised during the security testing is the missing X-Content-Type-Option. This vulnerability can cause the MIME-sniffing from the declared content. On the other hand, some uncommon header links are found on the company server. This can create a disturbance on the network by initiating the attacking factors. However, the CGI directories are not found on the company server which is essential for configuring the webserver and files.
4. 4. Non-Intrusive Test
4.1. Tool Used
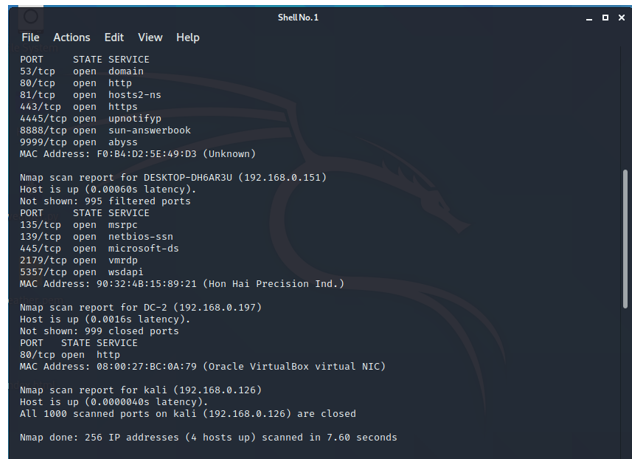
Nmap: Nmap, short for Network Mapper, is one kind of open source and free instrument for vulnerability checking and network revelation. Organization executives use Nmap to distinguish what gadgets are running on their frameworks, the finding has that are accessible and the administrations they offer, discovering open ports, and recognizing security chances. In this project, NMAP has been utilized to checking the vulnerability of the server (Rohrmann, Ercolani and Patton 2017). Nmap also can be utilized to screen single has just as huge administrations that include a large number of gadgets and large numbers of subnets. Despite the fact that Nmap has established during the long term and is incredibly adjustable, on an essential level it's a port-check instrument, collecting data by transfer crude parcels to framework ports. If the ports are open, then the security attack can be triggered on the server of the organization. It tunes in for reactions and decides if ports are open, shut, or sifted here and thereby, for instance, a firewall. Port checking can be identified by the number of the open ports.
Nmap scan
Nikto
Nikto is an open-source scanner where users can utilize it with any websites like Litespeed, OHS, HIS, Nginx, Apache, and others. It is an ideal internal mechanism for filtering websites (Kim 2017). It is fit for filtering for more than 6700 things to identify misconfiguration, unsafe records, and so forth and a portion of the highlights incorporate;
User can store the reports in CSV, XML and HTML formats
• It upholds Secure Socket Layer
• Sweep numerous ports on the sites
• Find subdomain
• Apache client identification
• Verifies for obsolete segments
• Identify stopping locales
There are numerous approaches to utilize Nikto.
• Utilizing binary on UNIX-based distro or Windows.
• Utilizing Kali Linux
• Docker compartment
• Nikto scan
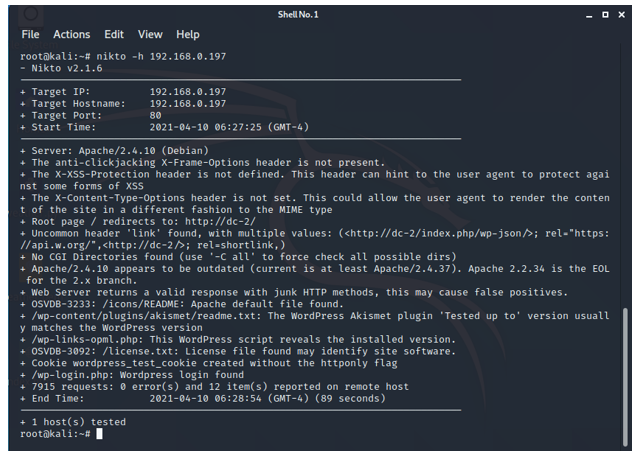
-Nikto v2.1.6
Nikto v2.1.6
---------------------------------------------------------------------------
+ Target IP: 192.168.0.197
+ Target Hostname: 192.168.0.197
+ Target Port: 80
+ Start Time: 2021-04-10 06:27:25 (GMT-4)
---------------------------------------------------------------------------
+ Server: Apache/2.4.10 (Debian)
+ The anti-clickjacking X-Frame-Options header is not present.
+ The X-XSS-Protection header is not defined. This header can hint to the user agent to protect against some forms of XSS
+ The X-Content-Type-Options header is not set. This could allow the user agent to render the content of the site in a different fashion to the MIME type
+ Root page / redirects to: http://dc-2/
+ Uncommon header 'link' found, with multiple values: (<http://dc-2/index.php/wp-json/>; rel="https://api.w.org/",<http://dc-2/>; rel=shortlink,)
+ No CGI Directories found (use '-C all' to force check all possible dirs)
+ Apache/2.4.10 appears to be outdated (current is at least Apache/2.4.37). Apache 2.2.34 is the EOL for the 2.x branch.
+ Web Server returns a valid response with junk HTTP methods, this may cause false positives.
+ OSVDB-3233: /icons/README: Apache default file found.
+ /wp-content/plugins/akismet/readme.txt: The WordPress Akismet plugin 'Tested up to' version usually matches the WordPress version
+ /wp-links-opml.php: This WordPress script reveals the installed version.
+ OSVDB-3092: /license.txt: License file found may identify site software.
+ Cookie wordpress_test_cookie created without the httponly flag
+ /wp-login.php: Wordpress login found
+ 7915 requests: 0 error(s) and 12 item(s) reported on remote host
+ End Time: 2021-04-10 06:28:54 (GMT-4) (89 seconds)
---------------------------------------------------------------------------
+ 1 host(s) tested
5. 5. Conclusion
In this report, a security testing has been illustrated on the server of the XXX bank by the NTA Monitor Ltd. After analyzing the server of the organization, various security vulnerabilities have been found that can damage the entire network of the organization. There are various types of vulnerabilities found that are Apache Ranger, anti-clickjacking, X-XSS-Protection, uncommon vulnerabilities, and word press. The organization needs to take some preventive actions in order to mitigate all the security threats on the server.
References
Alzahrani, M.E., 2018, March. Auditing Albaha University network security using in-house developed penetration tool. In Journal of Physics: Conference Series (Vol. 978, No. 1, p. 012093). IOP Publishing.
Batista, L.O., de Silva, G.A., Araújo, V.S., Araújo, V.J.S., Rezende, T.S., Guimarães, A.J. and Souza, P.V.D.C., 2019. Fuzzy neural networks to create an expert system for detecting attacks by sql injection. arXiv preprint arXiv:1901.02868.
Currie, J. and Walker, R., 2019. What do economists have to say about the Clean Air Act 50 years after the establishment of the Environmental Protection Agency?. Journal of Economic Perspectives, 33(4), pp.3-26.
Furdek, M. and Natalino, C., 2020, March. Machine learning for optical network security management. In 2020 Optical Fiber Communications Conference and Exhibition (OFC) (pp. 1-3). IEEE.
Hamza, M., Atique-ur-Rehman, M., Shafqat, H. and Khalid, S.B., 2019, January. CGI script and MJPG video streamer based surveillance robot using Raspberry Pi. In 2019 16th International Bhurban Conference on Applied Sciences and Technology (IBCAST) (pp. 947-951). IEEE.
Kim, B.H., 2017. Web Server Information Gathering and Analysis using Nikto. JOURNAL OF ADVANCED INFORMATION TECHNOLOGY AND CONVERGENCE, 7(1), pp.11-17.
Petkova, L., 2019. HTTP SECURITY HEADERS. Knowledge International Journal, 30(3), pp.701-706.
Possemato, A., Lanzi, A., Chung, S.P.H., Lee, W. and Fratantonio, Y., 2018, October. Clickshield: Are you hiding something? Towards eradicating clickjacking on Android. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (pp. 1120-1136).
Rohrmann, R.R., Ercolani, V.J. and Patton, M.W., 2017, July. Large scale port scanning through tor using parallel Nmap scans to scan large portions of the IPv4 range. In 2017 IEEE International Conference on Intelligence and Security Informatics (ISI) (pp. 185-187). IEEE.
Seyyar, M.B., Çatak, F.Ö. and Gül, E., 2018. Detection of attack-targeted scans from the Apache HTTP Server access logs. Applied computing and informatics, 14(1), pp.28-36.
Yaqoob, I., Hussain, S.A., Mamoon, S., Naseer, N., Akram, J. and ur Rehman, A., 2017. Penetration testing and vulnerability assessment. Journal of Network Communications and Emerging Technologies (JNCET) www. jncet.
CIS7030 Geospatial Analysis Assignment Sample
Task 1 – Descriptive explaining
a) Utilization of geospatial information are widely associates in social context with the support of different geospatial applications.
Discuss the following topics/techniques in conducting a geospatial data analysis.
1. Coordinate Reference Systems
2. Techniques for manipulating Geospatial Data
3. Proximity Analysis
Your answer should contain the following key points. (But not limited to those.)
An example describes real-world usage.
A code snippet/s that supports your answer.
b) The usages of geospatial technology are very minimal in Sri Lanka, comparative to other countries in the world.
Resources management and Taxation are two (2) different geospatial applications, which can fulfill the current needs of Sri Lankans. Although, these applications can fulfill Sri Lankan needs, they are not being implemented in Sri Lanka, yet. Prepare a proposal to implement those applications in Sri Lanka. Following aspects should be incorporated in each proposal
- Need assessment
- Different types of data to be input
- Proposed functions / operations
- Expected output
Task 2 – Geospatial Application (25%)
Geospatial analysis can be applicable for the matters not only contexts in social, but also environmental, economic and political. The objective of this exercise is focused to select suitable spatial regions for hospitals at Vancouver, BC. When building a new hospital, there are criteria that should be followed in order to find the most appropriate location. These criteria consist of required proximities or distances from certain features, such as roads and public washrooms.
Thus, the required criteria are as follows,
At least 500m away from Existing Hospitals
Closer (within 100m) to the Residential Area (Dwellings)
Less than 100m away from Road
Less than 100m away from Street
Less than 100m away from Sub street
Less than 200m away from Metro
At least 500m away from Public Washrooms
Less than 500m away from Fire positions
Use the existing CRS (EPSG: 26910) as project CRS and prepare a map to present your result.
Task 3 – Geospatial Modeling through Programming
Use of python/R programming to analyze Geospatial data in social context.
You are provided all kinds of crime details during first six month of the year 2017 in Colombo Municipal Council area (1-15 divisions). Further details of schools and police stations are also provided. You may use graphs, charts or map, where necessary and explain your answer for following questions.
I. What are divisions having highest overall crime densities?
II. What is most occurring crime in each division?
III. Which month occurred the highest number of crimes in each division?
IV. Prove/disprove the statement – “Drug occurrence mostly occurs in the areas lesser than 150m from school”.
Solution
Introduction
The respective assessment research has been carried out in an extensive manner, in live of presenting contribution to the trending topic of Geospatial analysis. The respective report aims to achieve the fulfilment of providing a detailed comprehension regarding the aspect of Geospatial analysis along with recognising its utilisation throughout various sectors along with the benefits that it is capable of serving.
The respective research would comprise of a detailed and descriptive explanation towards the utilisation approaches of the Geospatial information along with shedding light upon the utilisation of Geospatial technology throughout the reason of Sri Lanka along with comparing the statistics with that of other countries throughout the world, concerning the implementation of Geospatial analysis along with the observed benefits throughout those respective Nations or regions, thus assisting the company of Novartis, Germany for fulfilling their goals.
Furthermore, a detailed explanation towards the applications of Geospatial technology would be described along with presenting a detailed map as a proposal for the using the respective technology for the detection of effective spatial regions regarding the hospitals throughout this state of Vancouver. Additionally, a detailed modelling of Geospatial technology and programming would also be presented through the medium of this report by the utilisation of python programming language to carry out the analysis of Geospatial data with respect to the social context.
Task 1 – Descriptive explaining
Coordinate Reference Systems
A coordinate references system, otherwise commonly referred as CRS indicates towards the approach throughout which the respective special data capable of representing the surface of the earth is flattened, so as to enable the drawing out of two-dimensional mapping of the respective surface. Still, it could be observed that each of these respective two-dimensional surfaces are utilising varied mathematical approaches towards carrying out the flattening process, which in turn a result in the differentiations throughout the coordinates system grids. These respective approaches for carrying out the flattening of given data have been particularly developed and designed towards implementing effective levels of optimisation throughout the accuracy of the respective information with regards to the length as well as the entire area.
In attempt towards putting a definition to the location of any given region, individuals could be observed for often utilising coordinate systems. This particular system comprises of the procedure which carries out operation upon the basis of the X as well as Y values located throughout a given 2 or more-dimensional space.
.png)
Figure 1 Coordinate system musing X, Y for defining location of objects
The above presented example displays the coordinate system comprising of a two-dimensional mapping and space, while it is well known that all the individuals a reside throughout a three-dimensional Earth, which also happens to be round in shape. Therefore, in attempt towards implementing definition of the various location of objects throughout the entire globe, it is necessary that a sophisticated coordinate system should be applied which has capabilities of adapting with the shape of the earth (Dissanayake et al., 2020).
.png)
Figure 2 CRS defines the translation between a location on the round earth and that same location.
The Components of a CRS
Any given respective coordinator reference system could be observed of being developed upon the basis of the below described key components:
Co-ordinate system: the utilisation of the variables X as well as Y throughout the great upon which the respective data is overlayed along with carrying out the procedure towards it defining the respective point of location throughout the space.
Horizontal as well as vertical units: these respective units are incorporated and utilised towards implementing a sophisticated and effective definition of the entire grid along with the variables of X Y as well as Z to be utilised like that of co-ordinate axes.
Datum: it could be defined like a modelled version of the entire shape of the earth capable of defining the specific origin to be utilised for implementing and placing the entire coordinates system throughout the space.
Project information: the respective mathematical equation which has been implemented and utilised towards flattening the various objects observed to be seen on around surface, so as to view these respective objects upon a flat surface (Piyathilake et al., 2021).
Importance of CRS
It is of imperative importance that the comprehension towards the co-ordinate system utilised by the data, particularly implements and works with varied and diverse range of data that is being store throughout various types of coordinate systems. If the individual possesses the data regarding the same exact location which is already stored throughout various other coordinate reference systems, they would not be capable of lining up throughout any type of GIS as well as other categories of programs, until the individual possesses a program like that of ArcGIS or QGIS capable of extending support to the "projection on the fly aspect".
Techniques for manipulating Geospatial Data for assignment help -
Zooming technique
Zooming upon a given respective model allows a given individual to move from a standard overview of a given respective object to that of a detailed one regarding some small part. Only the few major salient features required the necessity towards appearing throughout the generalized model, various other types of smaller details are there in deemed as in significant up till this point. As the viewer carries out the operation of zooming in, and increase within the clarity and accuracy of the details become more and more apparent. This could be better understood by a real-world example where one individual is capable of starting with a map of any given respective city like New York along with zoom in up on the region known as long Island and then further carry out the zooming process to efficiently view a given respect campus by the name of Stoney Brook at the end of the map.
This could be achieved by the implementation of sophisticated and adaptive hierarchical triangulation. This particular hierarchy could be identified to comprise of various categories of fixed levels comprising only of the least significant details that are already eliminated from the coarser levels (Seevarethnam et al., 2021).
Multi resolution views
It can be identified that an ideal terrain model regarding the real time simulation should indeed comprise of representations for:
A tree, throughout which each and every type of possible pruning can be identified as being the valid terrain model. It should also further be efficiently continuous throughout the entire surface regarding each and every pruning. Also, it should also be only single valued, implicating the formula of Z = f (x,y).
The multi resolution display, in similarity to zooming technique, show cases the capability of allowing the utilisation of much fewer and highly generalized triangles for the representation of areas which are identified as being further from the perspective of camera or being categorised as less important to the respective viewer. Dissimilar to the zooming technique, the multi resolution views could be further identify to poses the combination of varied levels of significant details throughout a given single seamless model. The multi resolution display is popularly utilised towards the rendering of various types of perspective views regarding a given scenario throughout which the entire 4 ground is capable of showcasing a great deal of details, as compared to the background (Somasiri et al., 2022).
Line of sight
The line-of-sight technique for the manipulation of Geospatial data is utilised for conducting effective levels of calculation for determining whether the given two points (p1, p2) in a space as well as an object model are capable of viewing each other or not, which would also be understood as whether or not their own respective views are getting obstructed by any given object.
In the most typical approach, the line of side can indeed be calculated by conducting the driver Singh of the entire path from a given respective point to that of another. Each of this respective surface patch could also be identified towards being encountered as well as tested regarding the aspect of obscuration.
Within a highly precise model, the entire number of patches to be examined could indeed be identified as being significantly large.
The line-of-sight calculation as well as the respective technique could also be identified as been the most significant analytic function to be carried out which also further comprises of merit study throughout the past.
Proximity Analysis
Proximity analysis can be defined as one of the approaches towards conducting a detailed analysis of various location regarding the features by conducting a measurement of the distance throughout them as well as various other features in the given respective area. Any given respective distance throughout a point A as well as point B, could indeed be measured by the medium of a straight line or by following a highly sophisticated networked path, like that of a street network.
This could be also further explained and comprehended in detail by the help of an example throughout which a site selection scenario could be taken, where the given prospect is highly interested towards building a large-scale manufacturing plant throughout and area known as the Daytona beach, further comprising of a significant consideration to be observed regarding the distance from the interstate as well as the airport (Wijesekara et al., 2021).
A given respective GIS user should indeed be capable towards simply clicking upon the point of locations representing the given respective site as well as the interstate exit Ramp or that of an airport to further gain the approximate measurement of the distance to be covered. After determining the entire distance, another significant information to be considered can be identified as the water as well as sewer availability along with considering the price per acre as well as the factor of availability regarding the labour to be analysed from the given respective database.
Feature-based proximity tools
Regarding the factor of feature data, various tools could be identified to be comprised within the proximity tool set along with having capabilities towards being implemented for the determination proximity relationships. These tools are also further capable of showcasing their prowess regarding the output information comprising of various buffer features or tables. Buffers could be further utilised for delineating the protected zones across the various features all to carry out the representation of various regions of influence. Further utilisations of the multiring buffer tool could be implemented for the classification of various areas across a given respective feature in to the upcoming year or moderate distance as well as the long-distance class, for conducting a sophisticated analysis (Mathanrajet al., 2019).
Usages of geospatial technology (Sri Lanka Case)
The respective section or rather the subsection focuses upon the utilisation of Geospatial technology throughout the case of Sri Lanka regarding the resource management as well as taxation related Geospatial application, capable of full feeling the needs of the respective nation according to its current on-going scenario. The respective section could be identified as a proposal towards the implementation of these respective applications throughout Sri Lanka, further comprising of the entire assessment of the scenario along with comprehension towards the various functions as well as operations along with the general overview of the expected output regarding the implementation of the Geospatial applications.
Assessment
It is a major fact that groundwater plays a highly significant role throughout several regions having high levels of population as well as irrigated agriculture along with having insufficient surface for utilising the water resources. In accordance to this, it would be identified that there are significant range of consequences regarding the over development of groundwater along with the predominant reduction of the entire bought table as well as the over exploitation and quality deterioration throughout the aquifers.
This could be specially observed to occur throughout the coastal regions where the intrusion of saline water into that of the coastal aquifer has indeed been identified to become a significant consequence, as a resultant of the unplanned exploitation of the groundwater. Therefore, it is highly imperative and essential to carry out the assessment of the different variations throughout the quality of groundwater as well as considering the factor of its availability towards identifying the risk zone of contamination throughout the aquifers, on that of a regional scale regarding the effective management of resources.
The geographical information system otherwise also commonly known as the GIS applications indeed pose a high level of significance with regards to the mapping as well as conducting administration and monitoring along with the modelling of the entire resource management, due to the fact that the entire procedure of data monitoring would be carried out at highly limited number of sites due to the reason of high cost of installation as well as maintenance, with concerns to money and time.
Furthermore, with considerations to the factor of taxation, the land valuation could be identified like that of art as well as science regarding the assessment of the values of any land property along with a determining the supplier as well as demand of the respective land property within the market. The entire factor of land parcel value is entirely dependent upon its geographical location, all the while considering a number of various physical as well as socio economic character traits, which could be identified to be internship to the respective area of land. The respective land owner holds the liability towards making payment of the rate until being exempted by the local government (Liyanage et al., 2022).
Therefore, the entire procedure regarding the valuation of a land could be described like that of the careful estimation and considerations to be presented regarding the calculation of the birth of any given respective land property upon the basis of the experience as well as judgement and the identification and assessment of the various characteristics regarding the given piece of land. The purpose to be fulfilled by conducting the process of valuation is to present the determination regarding the entire value of the respective area of land, along with presenting it in general terms as the market value or benefit value of it.
The various influence upon the given property or a land due to the aspect of location has been broadly regarded like that of the most significant factor to be considered, yet their incorporation throughout the methodology of valuation is indeed highly implicit. Due to the introduction of the GIS based value maps, individuals have obtained a medium towards showcasing the variations throughout the respective aspect of value, with regards to the level of individual properties. Furthermore, a diverse range of characteristics could be identified that make the entire process of valuation highly difficult as well as subjective and dependent upon the significant degree of experience as well as a local knowledge, like for example the entire aspect of heterogeneity throughout the interest as well as economic influences at that of the regional, local and national scale (Dissanayake et al., 2020). These respective characteristics are not capable of getting altered, thus making the entire procedure of valuation, a challenging profession. However, it could be made easier by the implementation or introduction of GIS based if applications which would make them seem prudent towards the minimalization of valuation as well as the factor of complexity by implementing improvements throughout the accessibility and dissemination of the respective data to be operated upon.
Different data to be input and Proposed functions and expected outputs.
Regarding the resource management through the utilisation of Geo special applications, the entire aspect of data to be utilised as input could be understood by taking an example of water resource management within Sri Lanka.
This would comprise of carrying out the process of gathering the information and data regarding the quality factor of the water samples as well as the assessment of the quantity levels. This would implicate the meaning that the identification of all the sampling points regarding the ordinary Wells which are dug at various locations should be identified along with the once which are in operational conditions as well as the ones which are not along with the ones which are utilised for agriculture and domestic purposes respectively.
The factor of electrical conductivity could also be measured throughout the situ, why the utilisation of CE470 (hack) conductivity metre.
Further data to be input wood comprise of the information and details regarding the quality of the water as well as the data regarding the availability assessment which was carried out along with carrying out the gradient analysis.
The gradient analysis is to be utilised for conducting the study of the entire spatial pattern throughout the EC as well as the DTW variation within the entire study.
In addition to this, another major factor should also be taken under consideration that is regarding the local indicators regarding the spatial auto correlations, also known as LISA. Has been the dimension regarding the spatial relationships, LISA is capable of allowing the individuals to carry out the detection of various clusters regarding the geographic parameters under the presented assumption that the entire spatial pattern is indeed non-random distribution.
With regards to the aspect of taxation as a Geo special application, it can be set that the integrated geographical buffering systems otherwise also known as the IGBS, is the highly effective as well as easy to understand procedure to be implemented along with possessing capabilities towards providing the individuals with quick as well as highly cheap technological platforms to be utilised like that of a base to conduct analysis. It also presents the individuals or users with the initial stage comprising of the spatial representation regarding the entire property information, to be utilised like that of a input, within the form of value maps(Pathmanandakumar et al., 2021). The capabilities to be demonstrated by the utilisation of the geographical information system could be observed as not only limited to the facilitation of organisations as well as conducting the management of the entire geographic data, but are also highly capable of unable in the researchers towards taking complete advantage of the information regarding locations which are comprised within the database so as to extend their support to the application of the spatial statistical as well as the special econometric tools.
With regards to the factor of complexity throughout the procedure of land valuation, property owners would indeed receive an approach which is highly easy to understand along with being highly capable for presenting explanation regarding how the respective property is being valued, does eliminating the continuous challenge post to the planners as well as assessors. The integrated geographical buffering system which would be operated upon the basis of the GIS as well as GPS is capable of completely full feeling the specified requirements regarding the taxation related procedures, as explained with the help of land valuation. Thus, the utilisation of different buffering modules along with that of a visual value model as well as the required valuation maps could indeed be easily created as well as extend effective levels of support to the individuals.
Task 2 – Geospatial Application
The respective section fulfils its objective of presenting a detailed exercise which drives the focus upon the discerning of suitable spatial regions for the development of hospitals throughout the city of Vancouver, BC. Several considerations have been taken as a concern for following the identification of the most appropriate allocation towards the development of hospitals.
.png)
Figure 3 Mapping for identification for location 500m away from existing hospitals
.png)
Figure 4 mapping for being in range of or away by 100m with various structures or entities.
Figure 5 mapping considerations for placing hospital 200mm away from Metro and 500m away from public Wash rooms and Fire Positions
Through the above presented screenshots representing the showcasing of various map results, it can be imperatively discerned that effective considerations have been presented towards the establishment of hospitals that are at least 500 m away from that of the existing ones. Furthermore, further considerations have also been presented towards selecting areas for establishing hospital which are closer to the residential area (within 100m of range), and effective considerations were also presented towards placing it away from the road Street as well as sub streets, by presenting a consideration of 100 m away. The results were also generated by basing the location upon being 200 m away from any metro, while also providing considerations for placing it away from various fire positions and public washrooms by providing a range of 500 m.
Task 3 – Geospatial Modelling through Programming
What are divisions having highest overall crime densities?
The respective results are generated with orientation towards the fulfilment of needs of Novartis, Germany, along with how the aspect Geospatial Analysis is capable of assisting the respective company.
.png)
Figure 6: Result for overall highest crime.
.png)
Figure 7: Count of overall highest crime
Grand Pass could be identified as the one having the highest overall crime density. But apart from this it can also be observed that the regions like, kollupitiya, Maradana, pettha, Modara and several other regions also present quite a high overall crime density value as they live throughout the range or count of 30 to 40.
What is most occurring crime in each division?
.png)
Figure 8: Most occurring crime
.png)
Figure 9: Count of crime based on type
It can be efficiently observed through the obtained results that the region of wellawatta has presented the most occurring crime as house breaking as well as theft within its respective division.
With regards to the division of Armour Street, it can be efficiently observed that the most occurring crime within this respective division is robbery
Which month occurred the highest number of crimes in each division?
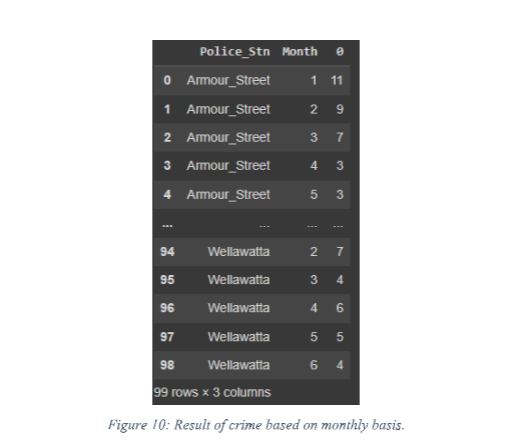
Figure 10: Result of crime based on monthly basis.
It can be efficiently observed through the obtained results that the region of wellawatta has presented the most occurring crime as house breaking as well as theft, on the months of April and July respectively, within its respective division.
.png)
Figure 11: Graphical representation of month count crime.
For Armour Street
The highest crime occurred in month of January.
For division Kurunduwaththa
.png)
Figure 12: Result for Kudurnduwaththa
.png)
Figure 13: In Krurnduwaththa
The highest crime occurred in month of January, march and may.
For division Modara
.png)
Figure 14: For Modara.
The highest crime occurred in month of February.
References
.png)

- Assignment - Child Care
- Assignment - Mathematics
- Assignment - Accounting
- Assignment - Auditing
- Assignment - Biology
- Assignment - Law
- Assignment - Management
- Assignment - Nursing
- Assignment - Finance
- Assignment - Computer Science and IT
- Assignment - Humanities
- Assignment - Economics
- Assignment - Statistics
- Assignment - Architecture
- Assignment - Engineering
- Assignment - cookery
- Assignment - Marketing
- Case Study - Chemistry
- Case Study - Accounting
- Case Study - Law
- Case Study - Management
- Case Study - Nursing
- Case Study - Finance
- Case Study - Computer Science and IT
- Case Study - Engineering
- Case Study - Economics
- Case Study - Biology
- Case Study - Auditing
- Case Study - Marketing
- Case Study - Project Management
- Coursework - Diploma
- Coursework - Accounting
- Coursework - Auditing
- Coursework - Biology
- Coursework - Management
- Coursework - Nursing
- Coursework - Finance
- Coursework - Computer Science and IT
- Coursework - Engineering
- Coursework - Humanities
- Coursework - Child Care
- Coursework - Project Management
- Coursework - Economics
- Coursework - Cookery
- Coursework - Law
- Dissertation - Accounting
- Dissertation - Auditing
- Dissertation - Biology
- Dissertation - Law
- Dissertation - Management
- Dissertation - Nursing
- Dissertation - Finance
- Dissertation - Computer Science and IT
- Dissertation - Humanities
- Dissertation - Economics
- Essay - Politics
- Essay - Childcare
- Essay - Accounting
- Essay - Biology
- Essay - Law
- Essay - Management
- Essay - Nursing
- Essay - Computer Science and IT
- Essay - Humanities
- Essay - Economics
- Essay - Auditing
- Essay - Engineering
- Essay - Architecture
- Essay - Finance
- Essay - Science
- Essay - Marketing
- Programming - Computer Science and IT
- Reports - Management
- Reports - Computer Science and IT
- Reports - Project Management
- Reports - Marketing
- Reports - Nursing
- Reports - Engineering
- Reports - Accounting
- Reports - Humanities
- Reports - Finance
- Reports - Architecture
- Reports - Biology
- Reports - Economics
- Reports - Childcare
- Reports - Law
- Research - Accounting
- Research - Auditing
- Research - Biology
- Research - Law
- Research - Management
- Research - Nursing
- Research - Finance
- Research - Computer Science and IT
- Research - Science
- Research - Engineering
- Research - Humanities
- Research - Economics
- Research - Project Management
- Research - Statistics
- Research - Architecture
- Research - Marketing
- Thesis Writing - Computer Science and IT
- Thesis Writing - Engineering
- Thesis Writing - Biology
- Thesis Writing - Finance
- Thesis Writing - Humanities
- Thesis Writing - Auditing
- Thesis Writing - Economics
- Thesis Writing - Law
- Thesis Writing - Nursing
- Thesis Writing - Accounting
- Thesis Writing - Architecture


.png)
~5.png)
.png)
~1.png)























































.png)






