Character Embedded Based Deep Learning Approach For Malicious Url Detection
Learning Outcomes
The aim of this research is to enable you to undertake a sizeable piece of individual academic work in an area of your own interest relevant to, and to demonstrate technical skills acquired in, your programme of study.
This postgraduate work will include an advanced level of research, analysis, design, implementation and critical evaluation of your solution.
You must cover the following topics in practice by applying them to your chosen research project:
• Identification of a suitable research topic,
• Research methods,
• Literature surveys, searches and reviews, Dissertation
• Plagiarism and referencing,
• Effectively engaging with academic research both on a theoretical and practical point of view,
• Academic writing and presentation skills for matlab dissertation help
• The development and documentation, to a master level standard, of a large, non-trivial and genuine research project aligned with your Master of Science programme.
At the end of this module, you will be able to:
Knowledge
1. Demonstrate an advanced knowledge of one chosen and highly specific area within the scope of your Master of Science programme and to communicate this knowledge through both a written report (dissertation) and an oral assessment,
2. Demonstrate the knowledge of research methods appropriate for a master level course and to communicate this knowledge through both a written report (dissertation) and an oral assessment
The Contents of your Dissertation
It must include the following sections:
• Title page showing the title, student number, programme, year and semester of submission,
• Contents page(s),
• Acknowledgements (if you wish to acknowledge people that have helped you),
• Abstract,
• Body of the dissertation,
• List of references,
• Appendices (including implementation code).
Observe the following guidelines when writing your dissertation:
• Your dissertation must be word-processed. In particular, hand written submissions will NOT be accepted. You are also encouraged to use LATEX typesetting, which is best for producing high quality, well-formatted scientific publications. Overleaf (www.overleaf.com) is an online LATEX editor.
• Pages must be numbered but you will find paragraph numbers easier for cross referencing.
• Appendices should only contain supporting documentation which is relevant to the report in which they are included. Their size should be kept to a minimum.
• Material must be accurate and presented in a structured manner.
• The information contained within your dissertation should be presented in such a way as to allow both staff and students in the future to read, understand and learn from you.
• The word limit should be adhered to (see Section 21.). Indeed, this limit is set to force you to synthesize your thoughts. This ability is very important in industry as you must convey to your colleagues and managers the key ideas about your work in a clear and concise way. However, I point out that massively moving content from the body of your report to appendices is not a substitute for writing concisely.
• The code of your implementation must be submitted as appendices. It does NOT count towards the word limit.
This is a 60-credit course and its assessment is based on two elements:
• The writing of a 15,000-word dissertation (with a tolerance of ± 10% for the length of the final document),
• A presentation of the research work. This presentation will be in the form of a viva-voce where you will be required to present and defend your work.
Solution
Chapter 1
1.1 Introduction
Malicious URLs are the purpose of promoting scams as well as frauds and attacks. The infected URLs are actually detected by the antiviruses. There are various approaches to detecting malicious URLs which are mainly categorized by four parts such as classification based on contents, blacklists, classification based on URLs, and approach of feature engineering. Several linear and non-linear space transformations are used for the detection of malicious URLs; this actually improves the performance as well as support. The Internet is the basic part of daily life and the Uniform resource locator (URLs) are the main infrastructure for the entire online activities and discriminate the malware from benign problems. URL involves some of the complicated tasks such as data collection in a constant manner and feature extraction and pre-processing of data as well as classification. The online systems which are specialized and draw a huge amount of data are always challenging the traditional malware detection methods. The malicious URLs are now frequently used by criminals for several illegal activities such as phishing, financial activities, fake shopping, gaming, and gambling. Omnipresence smartphones are also the cause of illegal activities stimulated by the code of Quick response (QR) and encode the fake URLs in order to deceive the senior people. Detection of malicious URLs is focused on the improvement of the classifiers. The feature extraction and the feature selection process improves the efficiency of classifiers and integrates non-linear and linear space transformation processes in order to handle the large-scale URL dataset.
Deep learning embedded Data Analysis is in effect progressively utilized in digital protection issues and discovered to be helpful in situations where information volumes and heterogeneity make it bulky for manual appraisal by security specialists. In useful network protection situations including information-driven examination, acquiring information with comments (for example ground-truth names) is a difficult and known restricting component for some administered security examination tasks. Huge parts of the huge datasets commonly stay unlabeled, as the assignment of comment is broadly manual and requires an enormous measure of master mediation. In this paper, we propose a viable dynamic learning approach that can proficiently address this limit in a reasonable network protection issue of Phishing classification, whereby we utilize a human-machine community-oriented way to deal with plan a semi-regulated arrangement. An underlying classifier is learned on a limited quantity of the explained information which in an iterative way, is then slowly refreshed by shortlisting just important examples from the enormous pool of unlabeled information that is destined to impact the classifier execution quickly. Focused on Active Learning shows a critical guarantee to accomplish quicker intermingling regarding the grouping execution in a cluster learning structure and in this manner requiring much lesser exertion for a human explanation.
1.2 Background
The Malicious URLs are used by cybercriminals by some unsolicited scams, malware advertisements, and phishing methods. Detecting malicious URLs includes the approaches of signature matching and regular expression as well as blacklisting. The classic system of machine learning systems is actually used for the detection of malicious URLs. The state of art is used to evaluate and from the architectures and the features are essential for the embedding methods of malware URL detection. URLDetect or DURLD is used to encode the embedding which is done at the character level. In order to capture the different types of information encoded in the URL, use the architectures of deep learning in order to extract the features at the character level and estimate the URL probability. Currently, malicious features are not extracted appropriately and the current detection methods are currently based on the DCNN network in order to solve the problems. On the multilayer original network, another new folding layer is added and the pooling layer is being replaced by the K-max layer of pooling and using the dynamic convolution algorithm the middle layer in the feature mapping width. The internet users are actually tricked by using phishing techniques and spam by the hackers and the spammers. They are also using the Trojans and malware URLs to leak the sensitive information of the victims. In the traditional method, the detection of malicious URLs is adopted using methods based on the blacklist. This method actually has some of the advantages such as it improves the high data speed and reduces the rate of false positives and this is very easy for the realization. In recent times, the algorithm of domain generation for detecting the different malicious domains in order to detect the blacklist method of traditional methods (Cui et al. 2018, p. 23).
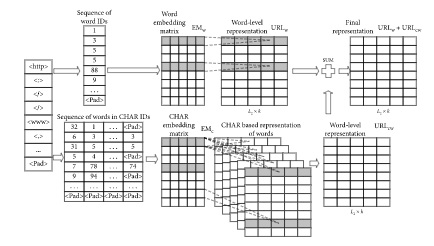
Figure 1: Method of word embedding
(Source: Verma and Das, 2017, p. 12)
The machine learning process is used to detect the model based on prediction and the statistical properties are classified as the benign URL. According to the model of vector embedding, the URL sequence is imputed in the proper vector and the subsequent process is being facilitated. This process is being initialized in a normal manner and the appropriate expression of the vector is being used for the training process. The advanced word embedding method is being used for character embedding. This data is extracted the phase information from the Unique resource locator and the extracted information is being extracted for the subsequent training process in order to obtain the proper expression vector and this is provided in the subsequent layer of convulsion. According to the method of dynamic conclusion, the input data is gathered from the extracted features. The procedure of this system includes folding, convulsion, and dynamic pooling which is suggested by the DCNN parameters for the current layer of convulsion. According to the DCNN training the output of the upper layer is being inputted in the next layer of the networks in order to convert the expression of the suitable vector. According to the method of the block extraction, the name of the domain, as well as the subdomain name, actually encodes the branch of the second data. In the embedding layer, the unique resource locator is actually used at the top level of the management (Patgiri et al. 2019, p. 21).
The powerlessness of the end client framework to recognize and eliminate the noxious URLs can place the real client in weak condition. Besides, the use of noxious URLs may prompt ill-conceived admittance to the client information by foe (Tekerek, 2021). The fundamental thought process in vindictive URL recognition is that they give an assault surface to the foe. It is essential to counter these exercises through some new approaches. In writing, there have been many separating components to identify the noxious URLs. Some of them are Black-Listing, Heuristic Classification, and so on These conventional instruments depend on catchphrase coordinating and URL linguistic structure coordinating. Subsequently, these traditional systems can't successfully manage the consistently advancing innovations and web-access methods. Besides, these methodologies additionally miss the mark in recognizing the advanced URLs like short URLs, dull web URLs. In this paper, we propose a novel characterization technique to address the difficulties looked at by the customary components in vindictive URL recognition. The proposed arrangement model is based on modern AI techniques that not just take care of the linguistic idea of the URL, yet in addition the semantic and lexical importance of these powerfully evolving URLs. The proposed approach is required to beat the current methods.
1.3 Problems analysis
In this section, the domain names, as well as the subdomain names, are extracted from the Unique resource locator and each URL has a fixed length which is actually being flattened in the flattened layer where the domain names, as well as subdomain names, are being marked. The common users need to use the advantages of the word embedding process which effectively express the rare words. The rare words can be represented accurately by the word embedding system in the URL. This method actually diminishes the scale of the present embedded matrix and thus memory space is also being reduced. This process is also converting the words which are new and the accurate vectors are not existing in the training sets and this helps to extract the character information. The attackers and the hackers are actually communicate using a control center through the DGA names which are malicious in nature and the structure of the network actually select a large amount of the URL data sets and the subdomains and domains in the top level are included at the dataset division (Sahoo et al. 2017, p. 23).
The deeply embedded learning process has been the most efficient way in determining the malicious websites causing potential threats to the users. These sites do not only contain damage-causing elements, but they can also get into a system and steal the data of a user and outsource it on the internet. If you notice at the address bar while using certain websites, they have very long URLs. These long texts indicate the subsidiary file directory of the file where it is present, clearly stating the parent folders and file name in the text. This deep learning process is easy to apply on such websites having long texts in the URL as it covers the maximum amount of data that the URL holds. But providing the same kind of security with short text URLs gets difficult (Cui, He, Yaoand Shi, 2018). These websites are more open to getting affected by such malicious websites. Therefore, the leaked data is mostly from websites having short URLs as the technology does not secure the subsidiary files and folders. Hence, the algorithm and working of the deeply embedded learning process need to modify in such a way that it covers each type of website with the best protocols.
1.4 Aim and Objectives
Aim
The preliminary aim of this research is to investigate character embedded-based deep learning approaches for malicious URL detection.
Objectives
- To determine the effects of multi-layer perception for determining malicious URL
- To determine the effects of artificial neural networks for determining malicious URL
- To determine the process of the deep embedded learning process for reducing malicious activities
- To recommend strategies for the machine learning process for eliminating malicious activities
1.5 Research Questions
- How to determine the effects of multi-layer perception for determining malicious URLs?
- How to determine the effects of artificial neural networks for determining malicious URLs?
- How to determine the process of deep embedded learning to reduce malicious activities?
- What are the recommended strategies for the machine learning process for eliminating malicious activities?
1.6 Rationale
Malicious URL is a well-known throat that is continuously surrounding the territory of cybersecurity. These URLs act as an effective tool that attackers use for propagating viruses and other types of malicious online codes. Reportedly, Malicious URLs are responsible for almost 60% of the cyber-attacks that take place in the modern-day (Bu and Cho, 2021). The constant attacks through malicious URLs are a burning issue that causes almost millions of losses for organizations and personal data losses for individuals. These malicious URLs can easily be delivered through text messages (Le et al. 2018). Email links, browsers and their pop-ups, online advertisement pages, etc. In most cases of cybersecurity casualties, these malicious URLs are directly linked with a shady website that has some downloadable embedded. These processes of downloads and downloaded materials can be viruses, spy-wares, worms, key-loggers, etc. which eventually corrupts the systems and sucks most of the important data out of it (Saxe and Berlin, 2017).
Nowadays, it has become a significant challenge for app developers and cyber security defenders to deal with these unwanted malicious viruses and mitigate them properly in order to protect the privacy of individuals and organizations. Previously the security protectors have significantly tried to use URL blacklisting and signature blacklisting in order to detect and defend the spread of malicious URLs (Vinayakumar et al. 2018). Although with the advancement of technology attackers have implemented new tools that can spread malicious URLs and it has become a constant huddle for cybersecurity professionals to deal with these problems. In order to improve the abstraction and timelessness of the malicious URL detection methods, professionals are developing python based machine learning techniques that can deal with this issue automatically by recognizing the malicious threats beforehand.
The issue of malicious URLs is becoming the most talked-about threat nowadays because on a daily basis worldwide companies and individuals are facing unwanted attacks from malicious attackers via malicious URLs. Reports from the FBI states that almost 3.5 billion records of data were lost in 2019 due to malicious attacks on their server. Also, according to some research, almost 84% of the worldwide email traffic is spam (Yang, Zhao, and Zeng, 2019). Some of the research work from IBM has confirmed that almost 14% of the malicious breaches surprisingly involve the process of phishing. Some of the related research has pointed out that almost 94% of the security attacks involve the process of malicious URLs and injecting malware through email (Yang, Zuo and Cui, 2019). Most of the common scams that involve malicious URLs generally involve phishing and spam. Phishing is a process of fraud that criminals generally use in order to deceive the victims by impersonating trusted people or organizations. The work process of Phishing involves receiving a malicious URL via email from a trusted individual or organization and after clicking on that particular URL most of the important data is hacked and compromised by the attackers. Nowadays it has become a process of spoofing some known addresses or names of individuals.
The emerging risk of malicious URLs and security casualties due to it has become a massive issue in today’s digital world. Security professionals face constant huddles dealing with this issue at the present time. In this scenario, developers need to take the process of a deep learning-based approach in order to mitigate the issues with these malicious URLs. In order to detect malicious URLs professionals can take character embedded-based deep learning approaches. Developing an effective machine learning system programmed with Python can be an efficient step for the developers in order to mitigate the issue of security attacks through Malicious URLs.
The research regarding the credibility of character embedded-based deep learning to detect malicious URLs can guide further researchers towards the way they should form their research. Additionally, this research can provide a wide range of scenarios that can efficiently describe multiple circumstances and parables of malicious URL attacks. The increase in the scam rates in recent years needs to be resolved with python-based embedded deep learning and this research attempts to identify the loophole in the existing system and tries to point out the issues regarding the harmful effect of malicious URLs.
1.7 Summary
The different sections of the introductory chapter provide the basics of the research efficiently where it introduces the credentials of malicious URLs and their extensive effect on the everyday security struggle of individuals and organizations. It efficiently points out the main aims and objectives of the research and clarifies what range will be covered by the researchers in the whole research paper. It also discusses the emerging issues of malicious URLs and how python based deep learning techniques can be fruitful and efficient to mitigate the security casualties caused by malicious URLs. Through the different parts of the introduction chapter, the researchers provide an insight into the whole territory that the research will cover and it also ensures that the issues with malicious URLs are resolved with an effective character embedded-based deep learning approach.
Chapter 2: Literature Review
2.1 Introduction
This literature part introduces the main detection control process based upon the blacklist. Hackers use spam or phishing for tricking customers into pressing on malicious URLs, which will be affected and implanted on any victims’ system or computers, and these victims’ personal sensitive data information would be hacked or leaked on social platforms. This type of malicious technology URLs detection could help each user to identify the malicious URLs and can prevent the users directly from attack by the malicious URLs. Traditionally, this research upon malicious URLs detection has adopted blacklist-based control methods for detecting malicious URLs. These methods have many unique benefits. The literature review has to point out which attackers could generate several malicious related domains as names by a simple seed for effectively evading the previous traditional system to detect this. Hence, nowadays, a domain control generation regarding algorithms or DGA could generate thousands of several malicious URL domain user names per day that could not be properly detected by the traditional method of blacklist-based effectively.
2.2 Conceptual framework
(Sources: Self-created)
2.3 Multilayer perceptron
Web-based applications are highly popular nowadays, be it online shopping, education, or web-based discussion forums. The organizations have vastly benefited from the employment of these applications. Also, most website developers rely on Content Management System (CMS) to build a website, which in turn uses lots of third-party plug-ins which have a lack of control. These CMS were created with a motive for people with less knowledge of computer programming, graphics imaging to build their website. However, they are patched for security threats, which becomes an easy way for hackers to steal valuable information from the website. This in turn exposes the website to cybersecurity risks such as Uniform Resource Locator (URL). These can lead to various risky activities like doing illegal activities on the client-side, further embedding malicious scripts into the web pages thereby exploiting the vulnerabilities at the end of the user. The study focuses on measuring the effective nature of identifying malicious URLs by using the multilayer Perception Technique. With the study, the researchers are trying to create a safe option for web developers to further improve the security of web-based applications.
Living with the 21st century, the world is moving towards obtaining so many technologies. The countries are at their best to produce and innovate the best of the technology to set up a benchmark in the entire world, and so does the UK. It is considered one of the most developed in terms of technology and is a civilized country. Since the developers have taken the country to a technological upfront, this makes the people much aware now of the innovated technologies and information systems. Modern or advanced technologies are developed to make the working of humans easier. People use modern technology to ease their work but there are people who try to deceive others and make fake and fraudulent technologies that are disguised as the real ones (SHOID, 2018). They do so with the intention to steal other’s personal data. This research is conducted with the objective to learn the approach for malicious URL detection. URL is termed as Uniform Resource Locator; it is an address of a given unique resource on the Web. So, what happens is that the people with wrong intentions or hackers try to create a malicious URL. This technique is termed mimicking websites.
The study lists the various artificial intelligence (AI) techniques used in the detection of malicious URLs that come in Decision Tree, Support Vector Machines, etc. The main reason for choosing Multilayer Perceptron (MLP) technique is because it is a "feed-forward artificial neural network model", primarily effective in identifying malicious URLs when the networks have a large dataset (Kumar, et al. 2017). Also, many others have stressed on the MLP technique having a high accuracy rate. The study has an elaborative explanation of the various techniques to identify malicious URLs, also giving an overview of studies on the particular topic. The research methodology consisted of the collection of 2.4 million URLs, where the data was pre-processed and divided into subsets. The result of the experiment was measured on the number of looping/epochs that are produced by the MLP system. Where the best performing URLs will be shown by a smaller number of looping/epochs and the bad ones by a greater number of looping/epochs. The dataset has been further divided into Matlab three smaller datasets which are the training dataset, validation dataset, and testing dataset. The training dataset trains the neural network by adjusting the weight and bias during the training stage. The validation dataset estimates how well the neural network model has been trained (Sahoo, Liu and Hoi, 2017).
After being trained and validated, the testing dataset evaluates the neural network. With the examples of figures, the study delineates the performance of training, validation, and testing in terms of mean squared error, where the iteration (epochs) moves forward. The study, however, seemed skeptical on suggesting the fastest training algorithm, as the training algorithm is influenced by many factors that include the complexity of the problem, the count of weights, the error goal, the number of data points in the training set. The vulnerabilities identified in Web applications; the most recognized ones are the problems caused by unchecked input. The attackers have to inject malicious data into web applications and manipulate applications using malicious data to exploit unchecked input. The study provided an extensive review on various techniques Naive Bayes, Random Forest, K-nearest neighbors, LogitBoost.The study used the Levenberg-Marquardt Algorithm (trainlm) as it was the fastest training function based on feedforward artificial neural network and the default training function as well. With the validation and test curves being quite similar, it meant that the neural network can predict the minimum error if compared with the real data training.
The study has however proved on the MLP system being able to detect, analyze and validate the malicious URLs, where the accuracy was found to be 90-99%. Achieving the objective and scope of the study by using data mining techniques in the detection and prediction of malicious URLs. Despite producing successful data, the study highlights the improvements: Gathering more information from experts for increasing accuracy leading to better reliability within the system (Le, et al. 2018). Further development of the system by enhancing knowledge in data mining along with improving neural network engines in the system.
For better accuracy, the system can be improved by using a hybrid technique where the study suggested combining the system with the Bayesian technique, decision tree, or support vector techniques.
The detection of malicious URLs has been addressed as a binary classification problem. The paper studies the performance of prominent classifiers, which includes Support Vector Machines, Multi-Layer Perceptrons, Decision Trees, Na¨?ve Bayes, Random Forest, and k-Nearest Neighbors. The study also adopted a public dataset that consisted of 2.4 million URLs as examples along with 3.2 million features. The study concluded that most of the classification methods have attained considerable, acceptable prediction rates without any domain expert, or advanced feature selection techniques as shown by the numerical simulations. Out of all the methods, the highest accuracy was attained by Multi-Layer Perceptron, and Random Forest, in particular, attained the highest accuracy. Highest scores for Random Forest in precision and recall. They indicate not only the production of the results in a balanced and unbiased prediction manner but also give out credibility. It enhances the method's ability to increase the identification of malicious URLs within reasonable boundaries. When only numerical features are used for training, the results of this paper indicate that for URL classification the classification methods must achieve competitive prediction accuracy rates (Wejinya and Bhatia, 2021).
2.4 Artificial neural network (ANN)
The study approaches the convolutional neural network algorithm for classification of URL, Logistic regression (LR), Support Vector Machine (SVM). The study, at first, gathered data, collected websites offering malicious links via browsing, and crawled on several malicious links from other websites. The Convolutional neural network algorithm was first used to detect malicious URLs as it was fast and quick. It also approached the blacklisting technique followed by features extraction with word2vec features and Term frequency-inverse document frequency features. The experiment could identify 75643 malicious URLs out of 344821 URLs. The algorithm has been able to attain an accuracy rate of about 96% in detecting malicious URLs. There is no doubt as to the importance of malicious URL detection for the safety of cyberspace. The study stresses deep learning as a probable and promising solution in the detection of malicious URLs for cybersecurity applications. The study compared the support vector machine algorithm on Term frequency-inverse document frequency along with the word vac feature based on the CNN algorithm and the logistic regression algorithm. While comparing the three aspects (precision, recall, fl-score) of Support Vector Machines (SVM),
Convolutional Neural Network (CNN), and Logical Regression (LR):
Term frequency-inverse document frequency of SVM can be used with the logical regression method, as the SVM of the aspects is higher than that of the logical regression algorithm. On the other hand, the convolution neural network (CNN) proved consistent on both Word2vac and on Term frequency-inverse document frequency.
Following the success of CNN in showing exemplar performance for text classification in many applications, be it speech recognition, natural language processing, speech recognition, etc., the study utilized CNN to learn a URL embedding for malicious URL detection (Joshi, et al. 2019). The URLNet understands a URL string as input applying CNNs to a URL's characters and words. The study also describes the approaches like blacklisting possessing limitations as they are highly exhaustive. The paper proposed a CNN-based neural network, URLNet for malicious URL detection. The study also stressed the various approaches adopted by other studies that had critical limitations, like the use of features with the added inability to detect sequential concepts in a URL string (Zhang, et al. 2020). The use of features further requires manual feature engineering, thereby leaving us unable to manage unseen features in test URLs, which seems to alleviate by the URLNet solution proposed by the study. The study applied Character CNNs and Word CNNs and optimized the network. The advanced word-embedding techniques, proposed by the study are supposed to help in dealing with rare words, a problem often encountered in malicious URL Detection tasks. This allowed URL Net in learning to embed and utilize sub word information from hidden words at test time and hence worked overall without the need for expert features.
The study's goal is to investigate the efficacy of the given URL attributes, demonstrating the utility of lexical analysis in detecting and classifying malicious URLs, with a focus on practicality in an industrial environment. This experimental study was primarily concerned with the identification and classification of different forms of URLs using lexical analysis through binary and multiclass classification, with a focus on comparing common deep learning models to conventional machine learning algorithms. Overall, the results of the two experiments showed improved output precision, with an improvement of 8-10% on average across all models, and the other showing a lower level of efficiency, with average accuracy. The study concludes that deep neural networks are somewhat less efficient than Random Forest while collecting the training and prediction times, concurring feature analysis. The less efficiency was concluded based on higher variance, feature count to match RF's performance, complexity, and time taken to train and predict at the time of deployment (Lakshmi and Thomas, 2019). An RF model can be employed to minimize the effort, as deploying the RF model can reduce the feature set to 5-10 features, is cost-effective, and will display efficient performance.
Whereas on the other side, despite being popular DNN frameworks, the employment of Keras-TensorFlow and Fast.ai over RF would require the need for more resources. The resources can be utilized in others domains within any organization. In a summary, it is quite succinct from the study that for any organization, in case of considering an alternation or a choice for its detection system, Random Forest is the most promising and efficient model for deployment.
The deep neural network models' findings suggest that further work is needed to explicitly demonstrate one's dominance over another (Naveen, Manamohana and Verma, 2019). A preference for one DNN model over the other in the current work will suggest the model's priorities: Fast-AI is superior in terms of accuracy at the expense of time, while the Keras-TensorFlow model is superior in terms of latency at the expense of accuracy. The feature analysis of the lexical-based ISCXURL-2016 dataset, as the work's final contribution, demonstrates the significance of the basic characteristics of these malicious URLs. The key conclusion drawn from this portion of the work is that the multiclassification problem needs more features than the binary classification problem.
Furthermore, the basic lexical features found inside URLs could be used to reduce the overhead cost of a deployed model, according to this analysis. Some of the study's limitations could spur further research. The paper suggests that it did not exhaustively investigate all of the network configurations and hyperparameters available for DNNs that could potentially boost their efficiency. While these enhancements can increase the recorded accuracy of succeeding RFs, they affect training and testing times, as well as the additional disadvantage of overfitting models, which reduces their real-world generalizability. The study further leaves a gap in its research as it did not deploy and examine the efficacy of the models with additional experiments; leaving it for future studies. The research paper believes that more research is required on this front to help bridge the gap between academic research and industrial implementations, to reduce the negative economic impacts of malicious URLs on businesses of all types.
2.5 Embedded learning process
The paper suggests the use of feature engineering and feature representation to be used and reformed to manage the URL variants. The study proposes DUD where raw URLs get encoded using character-level embedding. This paper presents a comparative analysis of deep learning-based character level embedding models for Malicious URL detection. The study took around 5 models, two on CNN, two on RNN, and the last one being the hybrid of CNN and LSTM. All the architectures of deep learning have a marginal difference if seen from the purview of accuracy. Coming to the models, where each model performed well and displayed a 93-98% Malicious URL detection rate. The experiment had a false positive rate of 0.001. This also means that out of 970 malicious URLs detected by deep learning-based character level embedding models, the model label only one good URL as malicious. The study suggests enhancing DeepURLDetect (DUD) by adding auxiliary modules which include registration services, website content, file paths, registry keys, and network reputation.
The paper performed the malicious URL detection approach on different deep neural network architectures. The study used Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) to differentiate Malicious and benign URLs. The training and evolution of the models were done on the ISCX-URL-2016 dataset. The results of the experiment showed the CNN model performing well having an acceptable rate of accuracy for the identification of Malicious URLs. The study mentions plan to bring up a hybrid deep learning model for the detection of Malicious URLs. A multi-spatial Convolutional Neural network was proposed by the study for an efficient detection sensor. After extensive evaluations, the detection rate achieved 86 .63% accuracy. A prototype, Raspberry Pi was used for enabling real-time detection.
2.6 Machine learning process
Many organizations with collaborations, bet it Google, Facebook and many start - ups work together in creating a safe system, preventing the users from falling into the trap of malicious URLs. Even though these organizations use exhaustive databases and manually refining a large number of URL sets regularly. However, this is not a feasible solution, as, despite high accuracy, human intervention is one of the major limitations. So, the study introduces the use of sophisticated machine learning techniques. The novel approach can be availed as a common platform for many internet users. The study shows the ability of a machine in judging the URLs based on the feature set. The feature set will be used to classify the URLs. The study claims its proposed method to bring improved results when traditional approaches get short in identifying Malicious URLs. The study further suggests improving the machine learning algorithm, which will give better results using the feature set. However, the features set will undergo evolution over time, hence effort is being made in creating robust features set in handling a large number of URLs. The study introduces the feature sets, composed of 18 features token count, largest path, average path token, largest token, etc. along with a generic framework. Using the framework at the network edge can help to protect the users of the digital space against cyber-attacks. The feature sets can be used with Support Vector Machine (SVM) for malicious URL detection.
The study focuses on using machine learning algorithms in the classification of URLs based on features and behavior (Astorino, et al. 2018). Algorithms like Support Vector Machine (SVM) and Random Forest (RF) are the supervisors in the detection of Malicious URLs. The extraction of features is done from static and dynamic which is claimed as new to the literature. The prime contribution to the research is of the newly proposed features. The study doesn't use special attributes nor does it create huge datasets for accuracy. The study concludes on application and implementation of the result in informing security technologies in information security systems, along with building a free tool for detection of Malicious URLs in web browsers.
The study combines attributes that are easy to calculate and big data processing technologies in ensuring the balance of two factors; which are the system's accuracy and processing time. The study suggests on the proposed system be comprehended as a friendly and optimized solution for Malicious URL detection. As per the study, going by statistics, URLs that increase the attacks are malicious URLs, phishing URLs, and botnet URLs. Some of the techniques that attack the system by using Malicious URLs are - Phishing, Social engineering, spam, and Drive-by Download.
The paper takes a machine learning solution combining URL lexical features, JavaScript source features along payload size. The study aims to create a real-time malware classifier in blocking out malicious URLs. For doing so, the study focusses on three sub-categories of web attacks: drive-by downloads, where the users unknowingly download malware; next comes Phishing where the intruders come up with websites posing it to be legitimate to steal user information while exploiting from JavaScript code that is generally found in the website source code. The paper could conduct a successful study whereby the construction of the SVM was taken to for the classification of malicious URLs. The study further proposes that testing, in the case of malicious URLs could be done on a wider array inculcating a sophisticated JavaScript feature extractor along with more of diving into network features. The study also mentioned using trained SVM, where Malicious URLs can be detected without any browsing device. Overall, it gives machine learning a potential approach for discovering cyber-attacks, attackers as wells as any malware URLs. The threat can also be mitigated by automatic URL detection by using a trained SVM. With it, a user can check the credibility of the URLs before using it for a real-time service, a pre-emptive service without creating an impact on the mobile experience.
URLs mostly malicious are generated on a day-to-day basis, and many of the techniques are used by researchers for detecting the malicious ones promptly. The most famous is the Blacklist method, often used for the easy identification of malicious URLs. The traditional method derives some limitations due to which identification of new ones becomes a bit difficult. Whereas Heuristic, an advanced technique, cannot be used for all types of attacks. Whereas the machine learning techniques undergo several phases and attain a considerate amount of accuracy in the detection of Malicious URLs. The paper gives a piece of extensive information, lists out the main methods which include blacklist, heuristic, and machine learning. The paper also discusses the Batch learning algorithm and online learning algorithm in the case of algorithms and phases for Malicious URL detection. The study describes the Feature extraction and representation phase as well. The study performs a detailed study of the various processes involved in the detection of malicious URLs. Increasing cybercrime cases have led to the weakening of cyberspace security and various ways are used in the detection of such kinds of attacks. Out of all the techniques, the machine learning technique is the most sought-after technique for such attacks. This particular paper intends to outline the various methods for malicious URL detection along with mentioning the pros and cons of machine learning over others.
2.7 malicious Web sites' URLs and others
Malicious Web pages are a key component of online illegal activity. Because of the risks of these pages, end-users have demanded protections to prevent them from visiting them. The lexical and host-based features of malicious Web sites' URLs are investigated in this report. The study demonstrates that this problem is well-suited to modern online learning algorithms. Online algorithms not only process large numbers of URLs faster than batch algorithms, but they also adapt to new features in the constantly changing distribution of malicious URLs more quickly. The paper created a real-time framework for collecting URL features, which we pair with a feed of labeled URLs on a real-time basis from a large Web mail provider.
Malicious Web pages continue to be a plague on the Internet, despite current defenses. The study mentions that by training an online classifier using the features and labels, detection of malicious Web pages can give 99 percent accuracy over a healthy dataset. The study also mentioned on organizations try to detect suspicious URLs by examining their lexical and host-based features to prevent end-users from accessing these pages.URL classifiers face a unique challenge in this domain because they must work in a complex environment where criminals are actively developing new tactics to counter our defenses. To win this competition, the need of algorithms is required that can adapt to new examples and features on the fly. The paper tested various methods for detecting malicious URLs to eventually implement a real-time system.
Experiments with a live feed of labeled examples exposed batch algorithms' shortcomings in this domain. Their precision tends to be constrained by the stored number of training examples in memory. The study looked into the issue of URL classification in an online environment after seeing this weakness in practice. On a balanced dataset, the paper discovered that the online algorithm performing the best (such as CW) produces highly accurate classifiers with error rates of about 1% (Kumi, Lim and Lee, 2021). The good performance of these classifiers, according to our findings, is in the face of new features through continuous retraining. The paper however hopes that this research will serve as a model for other machine learning applications in the future in the domain of computer security and digital space protection.
The digital space is often thought to be an efficient space to constantly become a threat, as it delivers attacks that include malware, phishing, and spamming. The study to block such attacks has delivered a machine learning method for the identification of malicious URLs and their attack types. The SVM detected malicious URLs while the attack types were recognized by the RAkEL and ML-kNN. A list of discriminative features namely link popularity, malicious SLD hit ratio, malicious link ratios, and malicious ASN ratios are attained from lexical, DNS, DNS fluxiness, network, webpage, link popularity properties of the associated URLs, which are highly effective as per the experiments. It is also efficient in identification and detection tasks. Achieving 98% accuracy in detecting malicious URLs and identifying the attack types, the paper further studies the effectiveness of each group on detection and identification discussing the discriminative features.
Feature engineering is a crucial step in detecting malicious URLs. In this paper, five space transformation models are used to create new features that free the linear and non-linear communications between points in malicious URLs data (decomposition on singular value, distance metric learning, Nyström methods, DML-NYS, and NYS-DML).
The proposed feature engineering models are successful and can dramatically boost the performance of certain classifiers in identifying malicious URLs, with experiments using 331,622 URL instances. The paper aims to identify malicious URLs, which require continuous data collection, feature collection and extraction, and model training. The integrated models combined the benefits of nonlinear, linear, unsupervised, and supervised models to concentrate on one aspect of space revision. The study mentions the future research path to look at how classifiers can be improved in terms of training time and accuracy based on URL characteristics.
Because of its widespread use, except for Naïve Bayes, the classifiers' highest TPR on the two textual-content datasets was 42.43 percent, while the highest TPR on the URL-based dataset was 86.40 percent (Patil and Patil, 2018). The detection rate of malicious URLs using a content-based approach was significantly lower than the URL-based approach used in this analysis. These findings indicate that separating malicious from benign websites solely based on their content is difficult, if not impossible. While transformer-based deep neural networks such as Bidirectional Encoder Representations from Transformers (BERT) and Net have made significant progress in recent years and be very effective on a variety of text mining tasks, they do not always apply well to the detection of malicious websites.
2.8 Summary
In the last part of the literature review, the basic summary of this branch to process data information is to expand the main input of this detection method. This paper proposes a malicious URL detection model based on a DCNN. It often adopts the word to embed based upon the basic character control embedding system for extracting features not manually or automatically with learning outcomes of the URL expression. Finally, they verify validity in that model through a proper series of contrast control experiments.
Chapter 3: Research Methodology
3.1 Introduction
Nowadays, the main methods to detect malicious URLs could be easily divided by the traditional controldetection drive method based upon blacklist with detection capacity methods based upon machine learning technique. Although the methods are efficient and simple, it could not properly detect any newly complex generated control malicious URLs, and also has been severed limitations. The malicious URLs detection methodology models are based upon the neural convolutional networks. Therefore, construction in the method mainly involves three main modules as vector convolution module, blockage extraction control module, and dynamic embedding module. The URLs are inputted directly into these embedding layers, or they utilize as word control embedding that is based upon characteristics embedding for transforming the basic URL from the vector embedding expression. Hence, this URL would be often input in the cover-up CNN just for the feature detection extraction.
3.2 Justification philosophy
The basic URL detection control process is justified by these sections. Firstly, domain user name, then subdomain device name with domain suffix name is often sequentially able to be extracted directly from the URL. Therefore, in this primary branch related to this detection method, it pads every URL to a particular length that each word is remarked within a significant number.
Justification
These whole URLs are represented by the sequence in numbers (Hain et al. 2017, p.161). Secondly, the main sequence is inputted to their embedding control layer to train together within a layer. This sequence would learn a specific vector convention expression process during their training control process. This overall data information stream output from embedding covered layers is subsequently outputted into the CNN. However, output control passes by the convolution detection layer, the folding purposes, and the pooling device layer of three successive rounds over the process.
3.3 Research approach
When it is trained in a totally connected URL layer, these features of the computer are often extracted by a neural convolutional network automatically and to extract artificially directly from an URL work field.
Justification
This detection methodology could effectively use critical data information of the named URL, including the top-level names domain and the domain of the national name, for achieving higher profile accuracy to recall (Bu, S.J. and Cho 2021, p.2689). Through the output of the SVM analysis, it can be analysed and understand that by predicting the test data set parameters. The malicious URLs detection methodology models are based upon the neural convolutional networks. Hence, accuracy is important, especially to the detection processes, because when the main accuracy is very low, nominal websites and pages might be estimated classified by malicious web and would be relocked.
Researchers of this thesis have to use proper machine learning tools and techniques for identifying malicious URLs. Therefore, these systems also require extracting the control of the main features manually, or attackers could design the features for avoiding identifying them.
Justification
It often has the highest speed, in a lower false-positive cyber rate, that’s it is too easy for users (Hamad et al. 2019, p. 4258). However, nowadays, a domain control generation regarding algorithms or DGA could generate thousands of several malicious URL domain user names per day that could not be properly detected by the traditional method of blacklist-based effectively. Faced with these issues in the recent complex networking environment, to design a more powerful and effective URL malicious detection model for becoming the research review focus.
The importance of gathering relevant data for or learning this specific methodology is predictable by the fact that its analysis will deliver fruitful information. There could be multiple aspects of taking the interviews but the most primary objective of carrying out an interview for such a thing is comprehensive and descriptive answers. The prospect of conducting a descriptive and comprehensive interview will deliver an influential amount of data for qualitative analysis. The qualitative analysis will consist of multiple elements and different angles of which the interviewer has not thought of. This will allow the analyst to segment the whole collected information in the comprehensive and market them in categories. Such kind of demarcation is extremely influential to identify what needs to be done and how it needs to be done. The interview will consist of a set of questions for getting the most appropriate methodology.
The participants of this interview can be analysts or cybersecurity experts who have substantial expertise and knowledge in this domain. There can be a set of questions that will dwell deeper into their experience with malicious URLs. The questions can be like telling about the experience with different kinds of malicious threats and how it is being carried out. In what ways the whole network in the digital market can be divided and which segment is most vulnerable. The types of tools analysts have incorporated previously to battle with such kinds of threats. Their familiarity with machine learning and how it can deliver this security. The current period of threat intelligence is associated with malicious URLs and their extent and what is the feature proposition in this arena. All the answers collected from more than 40 participants must be analysed strictly and finalized categorically.
The proposition of the Focus group is to identify a certain kind of group which has something in common and is largely affected by such kind of malicious activities. There is no denying the effects of malicious URLs in every possible domain of the digital world. But it is important to identify who are the most valuable domains and what are the intricacies associated with their domain and how they can be protected or resolved. The division of Focus groups can be parametrically decided based on the usage or exposure of the individuals. One focus group can be youth who are most largely influenced by E-Commerce activities. Another Focus group can be made on the basis of the age range in which the elderly people are most vulnerable.
Another Focus group can be an influential or well-known personality who is always on the verge of such threats. Under Focus groups can be individuals of the technical domain to identify what you think about such kinds of URLs and how they count them. All these focus groups must go through a group discussion for our individual campaign to curate the most suitable and appropriate pattern among their visualization and experience. In this methodology, there can be a couple of assignments such as a qualitative interview or quantitative survey which will provide the information in the form of experience or facts that can be used for other analyses of every domain of malicious URLs. These Focus groups provide a generalized view of malicious URLs and they are expected to not have much of technical background. The objective of the Focus group is to get collective information in a generalized way so that emotional, as well as psychological angles, can be comprehended.
There are so many case studies across the globe over the course of the last three decades where a particular scenario has been showcased. The powerful element of a case study is that it represents some kind of storyline or psychological processing of the fraud or criminal carrying out the particle malicious activity. These case studies provide a sense of generalized view in a multidimensional way which is to be comprehended by seeking the acquired or necessary information. Any type of information or processed facts can be utilized to define a new kind of angle in a particle attack. The case studies have built credibility based upon describing the whole scenario in a descriptive and sophisticated way.
The effectiveness of conducting research with a case study is that it is based on real-life scenarios and the most important element is it delivers the process of conducting the malicious activity (Story). The identification of the process and its psychological background is another challenge that has to be analysed so that a comprehensive and multidimensional campaign can be conducted to prevent these things from happening in the future. Case studies also portray the type of vulnerability possessed by the one who got adversely affected due to malicious attacks. The collected information from case studies and sorting information contained in it is further analysed to develop a quantitative parameter and predictable patterns. This is more of a profound approach in having things for developing documentation that contains a set of processes in a descriptive as well as instructive manner. The role of machine learning in this is to find keywords and collect them for testing them in a dataset.
This is more of an academic and theoretical perception of identifying and battling with unethical activities associated with malicious URLs. The association of keeping records goes beyond collecting data and information. It is meant to store the information in a very sophisticated and profound manner by documenting all the elements categorically and specifically. There can be multiple categories in which the collected information for malicious activities can be divided and stored. The process of doing so is also a matter of research to identify certain threats. The importance of record-keeping methodology is to build a strong case hold of identifying the intricate elements of URL characters and a certain pattern to identify the malicious content in it. Keeping recording is a responsibility that must be carried out with diligence so that none of the information can go to waste.
The importance of record-keeping research methodology is done to implement the positive effects of sharing and promoting research for the elements so that ethics can be maintained. There is much research that has already been conducted on character identification or you are a letter to vacation for and define its malicious content. All these research papers have been stored in a sophisticated manner which can be utilized through a partial window in order to get a strong base point for this research. The main proposition of methodology is to incorporate ethics and moral conduct in the research which is essentially required here for cybersecurity issues. It is meant to provide support for data analytics whenever required during technical analysis. There should be a keeper for looks after this and device information whenever necessary.
The process of observation begins with identifying the objective of the research which is here to identify the URL for its malicious content. Then the recording method is identified which can be anything here from the URL text to its landing page description or title, etc. All disconnected records based on human conduct of identifying the malicious content are recorded and questions are developed or in other ways, statements are being identified. This process is continued with every other encounter by observing all the elements and answering the questions specified before conducting this research. This methodology is completely based on human observation skills for or having intuition regarding any threat and approach being carried out to analyse and identify it. This process is slow and yet powerful because of its implications.
There can be many researchers across the domains who would adopt conducting observation for this research we identify malicious activities based on human skills. Incorporated questions allow the human mind to seek the attributes of whole digital information present before them. The process of observation in taking notes is the activity that is carried out in a sorted manner. These collected notes are analysed for behavioural elements of the malicious activities along with inferences associated with them. This behavioural analysis can be done by finding a set of patterns either directly or through data analysis. Every type of research comes to one point where it has a set of data that can be further that quickly as well as actually portrayed so that software based on the algorithm of probabilistic theory can find something which the human mind has missed.
3.10 Ethnographic research
The positional element of ethnography is associated with a behavioural analogy that can be aligned with the interaction of humans. In this case, the concept of economic geography can be related to an online culture where people are indulged in promotional and camping activities to cover their prospect of phishing and spamming. The conceptual and theoretical element in this kind of research is that it battles with the norms of technicality held by intellectuals. This means that a person with profound knowledge of online activities as well as the science of science opts to utilize it for delivering harm to normal people to get money or some kind of benefit. Since this kind of research can be changed across various domains but here it is specifically oriented with a psychological aspect.
The main question or objective behind this methodology is to identify the patterns of activities being carried out in the name of cover activities (Bhattacharjee, et al. 2019). The cover activities can include promotional campaigns or largely free gifts to the people. The method incorporated to analyse these is based upon seeking what kind of activities are going around in the market as well as how free stuff excites people to look over them. This also portrays a fact that certain kinds of malicious threats can be prevented by identifying such elements of attraction across different types of websites. Considering from the perspective of embedded learning and deep learning is that the backlinks as well as source code of certain web pages can be analysed to identify URLs that have targeted malicious activity. In this way, ethnographic research can facilitate a unique way of repression against malicious threats.
3.11 Summary
This could be quantified through the study that the different outputs based upon the heat maps work towards providing a better workspace and adhering to the laws and regulations. This could and needs to be inferred through the heat map that the different data septets of the map structure act towards providing a certain point of observation. The overall address needs to be confirmed through a proper guideline that works towards mitigating the different random parameters. The URL length and other parameters could be plotted in order to Number towards addressing the different parameters in relation to the respective variables and order. Through the random forecast, it can be addressed and identified by the different structural analyses. This needs to be addressed through a proper order of discussions. The output and random forecast classification work towards addressing the dataset that contains scattered data and determining the different classification of the overall data sets as addressed through the different parameters. Through the output of the SVM analysis, it can be analysed and understood that by predicting the test data set parameters could be set properly.
Chapter 4: Discussion
4.1 Phishing
Phishing is one of the types of cybercrime that adopts the way of contract to the target through emails. The objective of this crime is to get access to sensitive and confidential information of the targeted user by showcasing oneself as a reliable or legitimate individual or organization. Thus, collected information can cause harm to multiple levels such as loss of money, credible information, private details, identity theft, etc. It has a set of hyperlinks that takes the users to some other landing page or website whose sole purpose is to get more from the users. Such emails also contain some attachment that is sometimes senseless or contains a virus in it (Yuan, Chen, Tian and Pei, 2021). The primary identification of phishing is done by an unusual sender. The section of hyperlinks here is malicious URLs that are used to facilitate more harm to the user. The concept of phishing goes hand in hand with malicious URLs which is yet another objective to be analysed through data analysis.
4.2 Spamming
Spamming is another method of transmitting information from a criminal to the victim through lucrative offers. The proposition in spamming is the same as phishing. The only difference is an approach that varies for this one. There are various elements that spam can contain in terms of information and demanding economic data of the individual. The most effective element of phishing is that it contains graphics whereas spamming is mostly texts. The concept of spamming has also begun with mails but was generally used for text messages which were later broadened. The difference between phishing and spamming is that phishing demands the user’s information whereas spamming allures the person to visit a site to avail of some kind of information or offer. The intricacy of machine learning in this is to analyse the contents of the mail to identify the pattern for declaring it spam. There has been huge research on this by Google where they employed machine learning algorithms to declare a particular message as spam.
4.3 Malicious Content Detection
Malicious websites consider being a significant element in cyber-attacks found today. These harmful websites attack their host in two ways. The first one is the involvement of crafted content that exploits browser software vulnerabilities to achieve the users' files and use them accordingly for malicious ends, and the second one involves phishing that tricks users giving permissions to the attackers for the destruction. Both of these are discussed in detail before. These attacks are increasing very rapidly in today's world. Many peoples are getting attacked and end up losing their files, specifications, and businesses.
Detection of malicious content and blocking them involves multiple challenges. Firstly, the detection of such URLs must perform very quickly on the commodity hardware that operates in endpoints and firewalls of the user, so they cannot slow down the browsing experience of the user during the complete process. Secondly, the approaches made must be flexible to changes in syntactic and semiotic changes in malicious web content such that techniques of adversarial evasion like JavaScript obfuscation do not come under the detection radar. Finally, the detection approach must identify the small pieces of code and some specific characters in the URL that indicate the website is potentially dangerous. It is the most crucial point as many attackers enter via ad networks and comment feeds as tiny components into the users' computer. This paper will be focusing on the method of the methods in which the above-discussed steps can execute.
The methodology in the detection of malicious URLs using deep learning works in various ways. These ways are below:
Inspiration and Design Principles
The following intuitions listed below are involved in the building of the model for detecting harmful websites.
1) Malicious websites have a small portion of malicious code that infects the user. These small snippets are mainly JavaScript coded and embedded in a variable amount of Benign content (Vinayakumar, Soman and Poornachandran, 2018). For identifying the given document for threats, the program must examine the entire record at multiple spatial levels. It needs to scan because the size and range of this snippet are small, the length variance of the HTML document is large enough, which means that the document portion representing the malicious content is variable among the examples. It concludes that the identification of malicious URLs needs multiple repetitions as such small codes being variable need not detects in the first scan.
2) Specific parsing of the HTML documents, in reality, is the collection of HTML, CSS, JavaScript, and raw data is unacceptable as it complicates the implementation of the system, requires high computational overhead, and creates a hole in the detector. Attackers can breach to get into it and exploit the heart of the system.
3) JavaScript emulation, static analysis, or symbolic execution within HTML documents is undesirable. It is so because of the imposition of computational overhead and also because of the attacking hole; it opens up within the detector for the attackers.
From these ideas, the program must have the following design decisions that will help to resolve the maximum of the problems encountered.
1) Rather than parsing in detail, static analysis, graphic execution, or emulation of HTML document contents, the program can design to store a simple block of words. These words tokenize with the documents to perform minimal run tests for their assumptions. Every malicious URL contains a specific set of letters that links it to its original website. The program function is to search those keywords then the overall execution time can get decreased.
2) Instead of using the simple block of words representation declared over the entire document, the program can capture the multiple spatial scales locality that represents different levels of localization and aggregation, helping the program to find malicious contents in the URL at a very minute level where the overall might fail.
Approach for the method
The approach for this method involves a feature extraction process. It checks a series of characters in the HTML document and a Neural Network Model (NNM), which makes the classification decisions of the data within the webpage based on a shared-weight examination. The classification occurs at the hierarchical level of aggregation. The neural network contains two logical components for the execution of the program (Vanitha and Vinodhini, 2019).
• The first component: termed an inspector, aggregates information in the document to 1024 length by applying weights at spatial scales hierarchy.
• The second component: termed a master, uses the inspector outputs to make final decisions for the classification.
Backpropagation is used for optimizing the components of inspector and master in the network. Furthermore, the paper will focus on describing the function of these models in the overall functioning of the program.
4.4 Feature Extraction
The functioning of the program begins with the extraction of token words from the HTML webpage. The target webpage or document is tokenized using expression: ([A \xO 0- \x7F] + 1\ w+) that splits no alphanumeric words in the document. Then, the token divides into chunks of equal length 16 in a sequence. Here the word length defines as some tokens that include the last chunk gets fewer tokens if the document does not divide by 16.
Next, to create a bag of each chunk, a modified version of each chunk is used with 1024 bins. A technique is used to change the bin placement in the program that helps to feature both token and hash length. It results in a workflow where the files tokenize and divide into 16 equal length chunks of the token and then features the hash of each token multiplied by 1024 (number of bins). The 16*1024 quantity represents the texts extracted from the webpage divided into chunks, and each element in this chunk represents an aggregation over every 1/16 of the input document.
4.5 Inspector
When a feature representation is set for an HTML document, the design gets its input in the neural network. The first step is to create a hierarchical diagram of the sequential token of chunks in the computational flow. Here the sixteen token groups collapse into eight sequential token bags, eight token groups collapse into four groups, four collapses to two, and two token group collapses to one. The process helps to obtain multiple tokens groups representation that captures token occurrences at various spatial scales. The collapsing process occurs by averaging the windows of length two and step size two over the 16 token groups formed first. This process occurs repetitively until a single group of the token comes. Note, while averaging, the norm of each representation level in the token group is kept the same within the document. This is the reason why averaging is preferred over summing, as in summing, this norm will be changing each time the group changes.
When the hierarchical representation has been formed by the inspector, it starts hitting each node in the aggregation tree and computes an output vector with it (Bo, et al. 2021). The inspector has two fully connected layers with 1024 RELU units and considers a feed forwards neural network. The inspector regulates through layer normalization so that to guard against dropouts and vanishing gradients. The dropout rate used here is 0.2.
After visiting each node, for computing the inspector’s output of 1024-dimension, across the 31 outputs produced by 31 distinct chunks and each output containing 1024 output neurons, the maximum of each is taken. It results in the maximum output from each neuron in the final output layer of the inspector that gets all of its activations over the node in the hierarchy. Hence, this will make the output vector capture the patterns that will help to match the template of the malicious URLs features. Moreover, whenever they appear on the HTML webpage, it will help to point out such contents.
4.6 Master
After the computation of 1024-dimensional output by the inspector over the HTML webpage, these outputs are inputs into the master component. Like the inspector, the master is also a feed-forward neural network in design. But the master is with two layers of the logical fully-connected block. Here also, each fully connected layer precedes by the dropout and normalization of a layer. The dropout rate of the master is at 0.2. The overall construction of the master is similar to the construction of the inspector, with a difference that the output vector of the inspector is input for the master.
4.7 Summary
The final layer of the model is a composition of 26 sigmoid units that corresponds to 26 detection decisions the program makes for the malicious contents about the HTML webpage. Here, one sigmoid member is valuable in deciding whether the target HTML webpage is malicious or benign (Khan, 2019). The rest 25 sigmoid help determine other tags like whether the webpage is using a phishing document or exploitation for an instance. For training the models, each sigmoid output applies with binary cross-entropy loss and then the output of resulting parameters averages to calculate the parameter updates. Each of the sigmoid doesn't need to be helpful for the model. Many sigmoid in these results as bad for the model and are useless. The sole purpose of the model is to distinguish between the malicious content and the valuable content that serves at the end of the execution of this system.
Chapter 5: Analysis
5.1 Introduction
With the change in the centuries, new innovations have been witnessed in the world. People are getting advanced day by day by adapting the trends, and so does computers. The features of these machines are getting advanced after every innovation. If we go back to hundred years, the computer was just an electronic device used for storing and processing data. It was used for fast calculations. But as the grew, in 1959, machine learning was originated by Arthur Samuel, who was an American pioneer in the field of computer gaming and artificial intelligence. So, machine learning can be defined as the study of computer algorithms that gets improved automatically through experiences and by the use of data. In simple words, we can say that machine learning or MI is an application of artificial intelligence which provides the computer system an ability to learn automatically from experiences and also improve with every time without being specially programmed (Do Xuan, Nguyen and Nikolaevich). It can be seen as artificial intelligence but artificial intelligence or AI is a machine technology that behaves like humans, whereas machine learning or MI is a part or subset of artificial intelligence that allows the machine to learn something new from every experience. Here, computer algorithms mean steps or procedures taught to the machine which enable it to solve logical problems and mathematical problems. It is a well-defined sequence of instructions to be implemented in computers to solve the class of typical problems.
Among the mentioned uses of MI, machine learning or the embedded deep learning are best used for the detection of malicious content in Uniform Resource Locator or URL. Uniform Resource Locator or URL is defined as a unique locator or identifier used to locate a resource on the internet. It is referred to as a web address. A Uniform Resource Locator or URL consists of three parts, namely, Protocol, Domain, and Path. For example, if we assume ‘https://example.com/homepage’ this particular web address of a popular blogging site. In this, ‘https://’ is a protocol, ‘example.com’ is a domain and ‘homepage’ is a path. Thus, these three contents are together called URL or Uniform Resource Locator.
These URLs have made the work on the computer and internet easy for the users but with the positive side, it also consists of the negative side. These URLs become malicious by hackers which are not so easy to recognize. What happens is that the hackers create almost the same-looking websites or web addresses which have a very minute difference. The people who are not much aware of the malicious content fail to recognize the disguised website and share their true details with them. Thus, the hackers behind the disguised web address get the access to information of the user. They use it to steal data and to do illegal works or scams. For example, assume ‘https://favourite.com’ is a website of a photo-sharing site and the malicious website is made by the hacker like ‘https://fav0urite.com.’ These two websites are look-like and are difficult to predict. Thus, to predict the malicious content in Uniform Resource Locator the embedded deep learning plays a crucial role (Srinivasan, et al. 2021).
The detection of malicious Uniform Resource Locator contains the following stages or phases. These phases are:
1. Collection Stage: This is the first stage in the detection process of malicious Uniform Resource Locators with the help of MI or Machine Learning. So, in this stage, the collections, as well as the study of clean and malicious URLs, are done. After the collection of the URLs, labelling is done correctly and is then proceeded to attribute extractions.
2. Attribute Extraction Stage: Under this stage, the URL attribute extraction and selection are done in three following ways:
• Lexical Stage or features: This includes the length of the domain, the length of URL, the maximum token length, the length of the path, and the average token in the domain.
• Host-based Stage or features: Under this feature, the extraction is done from the host characteristics of Uniform Resource Locators. These indicate the location of malicious URLs and also identify the malicious servers.
• Content-based Stage or features: Under this, the extraction is acquired when the web page is downloaded. This feature works more than the other two features. The workload is heavy since a lot of extraction needs to be done at this stage.
3. Detection Stage: After the attribute extraction stage, the URLs are put to the classifier to classify whether the Uniform Resource Locator is clean or malicious.
Thus, the embedded deep learning or machine learning is best used to detect the malicious Uniform Resource Locators. It enhances the security against spam, malicious, and fraud websites.
5.2 Single type Detection
AI has been utilized in a few ways to deal with group malicious URLs. To recognize spam site pages through content examination. They utilized site-dependent heuristics, for example, words utilized in a page or title, what's more, part of the apparent substance. A process created a spam signature age structure called AutoRE to identify botnet-based spam messages. AutoRE utilizes URLs in messages as info and yields normal articulation marks that can identify botnet spam. This utilized measurable techniques to order phishing messages. They utilized a huge openly accessible corpus of genuine and phishing messages. Their classifiers analyze ten unique highlights, for example, the number of URLs in an email, the number of spaces, and the number of dabs in these URLs. It broke down the maliciousness of a huge assortment of website pages utilizing an AI calculation as a per-channel for VM-based examination. They embraced content-based highlights including the presence of muddled JavaScript and adventure locales pointing iframes. A method proposed a finder of malicious Web content utilizing AI. Specifically, we acquire a few page substance highlights from their highlights. This method proposed a phishing site classifier to refresh Google's phishing boycott naturally. They utilized a few highlights acquired from area data and page substance.
5.3 Multiple type Detection
The order model can distinguish spam and phishing URLs. They portrayed a strategy for URL order utilizing measurable techniques on lexical and host-based properties of malevolent URLs. Their strategy recognizes both spam and phishing yet can't recognize these two sorts of assault. Existing AI-based methodologies typically zero in on a solitary sort of malevolent conduct. They all use AI to tune their characterization models. Our strategy is likewise founded on AI, yet another also, more remarkable, and proficient grouping model is utilized. Also, our technique can recognize assault types of malicious URLs. These developments add to the predominant execution and capacity of our strategy. Other related work. Web spam or spamdexing points at acquiring an uncalled for high position from an inquiry motor by impacting the result of the web search tool's positioning calculations. Connection-based positioning calculations, which our connection prominence is like, are broadly utilized via web crawlers. Connection ranches are ordinarily utilized in Web spam to influence connect-based positioning calculations of web indexes, which can likewise influence our connection ubiquity (Jiang, et al. 2017). Investigates have proposed strategies to identify Web spams by utilizing proliferating trust or doubt through joins, identifying explosions of connecting movement as a dubious sign, coordinating connection and substance highlights, or different connection-based highlights including changed PageRank scores. A considerable lot of their procedures can be acquired to impede sidestepping join ubiquity highlights in our locator through interface ranches.
Unprotected Web applications are weak spots for programmers to assault an association's organization. Measurements show that 42% of Web applications are presented to dangers and programmers. Web demands that Web clients demand from Web applications are controlled by programmers to control Web workers. Web questions are identified to forestall controls of programmer assaults. Web assault discovery is amazingly fundamental in data conveyance over the previous many years. Peculiarity techniques dependent on AI are liked in Web application security. This current examination is expected to propose a peculiarity - based Web assault identification engineering in a Web application utilizing profound learning strategies. Many web applications experience the ill effects of different web assaults because of the absence of mindfulness concerning security. Hence, it is important to improve the unwavering quality of web applications by precisely recognizing malevolent URLs. In past investigations, watchword coordinating has consistently been utilized to identify malevolent URLs, however, this strategy isn't versatile. In this paper, factual investigations dependent on angle learning and highlight extraction utilizing a sigmoidal limit level are consolidated to propose another identification approach dependent on AI methods. In addition, the credulous Bayes, choice tree, and SVM classifiers are utilized to approve the exactness and proficiency of this technique. At last, the trial results show that this strategy has a decent recognition execution, with an exactness rate above 98.7%. In functional use, this framework has been sent on the web and is being utilized in huge scope discovery, breaking down roughly 2 TB of information consistently (Verma, and Das, 2017). The malicious URLs location is treated as a parallel arrangement issue and execution of a few notable classifiers are tried with test information. The calculations of Random Forests and backing Vector Machine (SVM) are concentrated specifically which accomplish a high precision. These calculations are utilized for preparing the dataset for the characterization of good and awful URLs. The dataset of URLs is separated into preparing and test information in 60:40, 70:30, and 80:20 proportions. The precision of Random Forests and SVMs is determined for a few emphases for each split proportion. As per the outcomes, the split proportion 80:20 is seen as a more precise split and the normal exactness of Random Forests is more than SVMs. SVM is seen to be more fluctuating than Random Forests in precision.
5.4 Data description
Figure 1: Code for data display
(Source: Self-created)
The panda’s package is used to develop the different python programming techniques. The data display is the first step to obtain the columns of the respective dataset which are analyzed. The dataset.csv dataset is used here to analyze the malicious URL detection using machine learning techniques.
Figure 2: Output of data display
(Source: Self-created)
The output of the data display shows the variables of the dataset.csv dataset which represents the information regarding the malicious URLs which are to be detected (Rakotoasimbahoakaet al., 2019, p.469). The head command is used to show the attributes of the dataset in the python programming language. Therefore, the user can access the information of the dataset using the above-developed codes.
5.5 Histogram

Figure 3: Code for histogram
(Source: Self-created)
The histogram represents the range of the specific variable which is present in a dataset. In this report, the histogram of the URL_LENGTH is developed using python programming. The different plots of the ranges of URL length are shown in the output of the histogram.
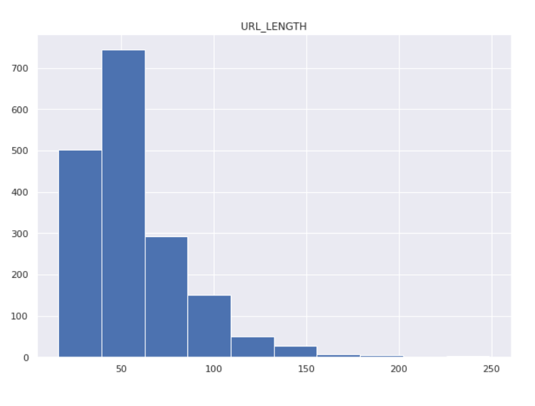
Figure 4: Output of Histogram
(Source: Self-created)
The output of the histogram shows the relation between the URL_LENGTH variable with the other variables in the dataset.csv dataset (Sahoo et al., 2017, p.158). The purpose of the histogram is to analyze the composition of the mentioned variable with different values as recorded in the dataset.
5.6 Heat map

Figure 5: Code for heat map
(Source: Self-created)
The heatmap measures the values which represent the various shades of the same color for each value. The dark shades of the chart show the higher values and the lighter shaded areas contain the lower values which are obtained from the dataset.
.png)
Figure 6: Output of heat map
(Source: Self-created)
The output of the heat map defines the graphical representation of the data that are used to represent different values. The heat maps are used to discover the variables in the dataset.csv dataset (Khan et al., 2020, p.996). The heat map is developed here to represent the different columns of the dataset.csv dataset using the map structure.
5.7 Scatter Plot

Figure 7: Code for scatter plot
(Source: Self-created)
The scatter plot shows the relation between the dependent and independent variables of the dataset.csv dataset. The purpose of the scatter plot is used to represent the special characters in the URLs which contain malicious information.
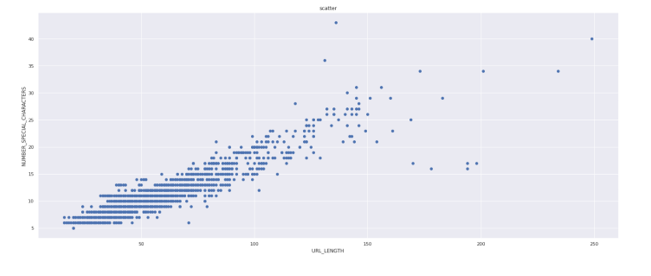
Figure 8: Output of scatter plot
(Source: Self-created)
The scatter plot observes the random variables in the malicious URL detection methods. The URL_LENGTH is plotted with respect to the NUMBER_SPECIAL_CAHARACTERS in the dataset.csv dataset. The scatter plot in the matplotlib library is used to sketch the scatter plot to determine the relationship between the two variables.
5.8 Random Forest

Figure 9: Code for random forest
(Source: Self-created)
The random forest is one kind of machine learning method which is used to measure the random variables present in the dataset (Kumar et al., 2017, p.98). The random forest is developed here to show the scatter plot based on all variables in the malicious URL detection dataset.
.png)
Figure 10: Output of random forest
(Source: Self-created)
The random forest classifier classifies the columns of the dataset using machine learning algorithms. The output of the random forest classification describes the sub-samples of the dataset which contains the scatters to determine the classification of the dataset.csv dataset.
5.9 SVM
.png)
Figure 11: Code for SVM
(Source: Self-created)
The support vector machine is a machine learning algorithm that measures the classification, regression, outlier detection based on the dataset. The support vector machine shows the expected scatter based on the variables of the malicious URL dataset (Joshi et al., 2019, p.889). The aim of SVM is to divide the dataset into different classes to perform the classification process.
.png)
Figure 12: Output of SVM
(Source: Self-created)
The output of the SVM analyses the trained and test samples of the dataset. The SVM classifies the predictors based on the variables of the dataset (Le et al., 2018, p.523). The scatter plot is developed by predicting the test set and then comparing the test set with the predicted value of the dataset.csv dataset.
5.10 Classification

Figure 13: Code for classification
(Source: Self-created)
The k classification is developed here to understand the number of nearest neighbors of the dataset.csv dataset. The number of nearest neighbors is the core deciding factor (Do Xuan et al., 2020, p.552). The k is the odd number that represents the number of classes in the neighbor clustering.
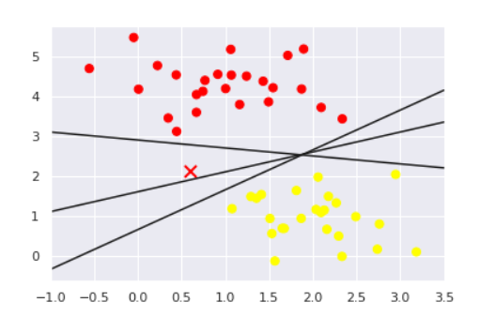
Figure 14: Output of classification
(Source: Self-created)
The output of the k classification shows the clustering of the different neighbors based on the dataset.csv dataset. The k nearest neighbors are used to measure the classification and regression analysis based on the given dataset. The
5.11 Support vector classifier

Figure 15: Code for SVM classifier
(Source: Self-created)
The support vector classifier determines the linear classifier with respect to a specific dataset. Therefore, the support vector classifier shows the model structure of the linear classification. The SVC is the command which is used to develop the support vector classifier using the malicious URL detection dataset. The support vector classifier improves the complexity of the classification which implements the generalization of the dataset variables.

Figure 16: Output of the svc
(Source: Self-created)
The output of SVM classification shows the size, weight of the dataset which is used here. The support vector classifier detects the malicious URL using the implementation of machine learning algorithms (Ferreira, 2019, p.114). Therefore, the support vector classifier represents the kernel trick to ensure the transformation of data using the transformation technology.
5.12 Support vector model

Figure 17: Implementation of the support vector model
(Source: Self-created)
The support vector model shows the implementation of the machine learning algorithm which measures the classification and regression challenges based on the malicious URL dataset. The support vector array shows the array structure of the result of the support vector machine (Sahoo et al., 2017, p.158). The purpose of the modeling is to determine the decision boundary through which the data can be divided in n-dimensional space.
Chapter 6: Recommendation
In this paper, we propose a technique utilizing machines figuring out how to recognize malevolent URLs of all the well-known assault types including phishing, spamming, and malware contamination, and recognize the assault types malignant URLs endeavor to dispatch. We have embraced a huge arrangement of discriminative highlights identified with printed designs, interface structures, content organization, DNS data, and organization traffic. A large number of these highlights are novel and exceptionally successful. As portrayed later in our trial considers, connect prevalence and certain lexical and DNS highlights are exceptionally discriminative in not just distinguishing noxious URLs yet additionally distinguishing assault types. Likewise, our strategy is hearty against known avoidance strategies such as redirection, interface control, and quick motion facilitating.
The set of recommendations can be divided into two sets. One of them can be on the user level and the other on the developer level. The task at the user level is quite simple which is to report spam for any URL content that seems malicious or contains such type of data. The tasks at the developer end are quite large and comprehensive. A developer can look forward to developing certain kinds of methodologies or ways through which they can develop software or a tool that can be embedded in the URL detection mechanism to identify its malicious content. There are numerous ways through which it can be done. The concepts of Machine learning applicable to this scenario can be based on supervised learning or non – supervised learning. The supervised learning will involve training a model based on collected URLs with malicious content or resource. Unsupervised learning will deliver an option for identifying it on a trial and test basis (Ferreira, 2019). Unsupervised learning cannot be applied to this scenario whereas supervised one can be utilized. The algorithms of supervised learning will be used to develop a deep learning algorithm that will analyze the characters and identify the pattern in it to declare certain URLs to be malicious or not. The process of development will be backed by a huge amount of test data and that’s why web applications such DNS or HTTP or web browsers will have these tools to identify the URLs with certain context. The main proposition behind using these methodologies is to implement the comprehensive method of applying different machine learning algorithms at different places to find possibilities for developing a tool that can detect such malicious URLs. The whole process should be done so intricately that nothing is left out and at the same time, the tool should be in learning mode to gather new data and detection parameters.
Chapter 7: Conclusion
Cyber-attackers have expanded the quantity of contaminated has by diverting clients of traded off famous sites toward sites that abuse weaknesses of a program and its modules. To forestall harm, identifying tainted hosts dependent on intermediary logs, which are by and large recorded on big business organizations, is acquiring consideration as opposed to restriction-based sifting on the grounds that making boycotts has gotten troublesome because of the short lifetime of malicious spaces and camouflage of endeavor code. Since data extricated from one URL is restricted, we center around a succession of URLs that incorporates relics of vindictive redirections. We propose a framework for distinguishing malevolent URL arrangements from intermediary logs with a low bogus positive rate. To clarify a powerful methodology of noxious URL arrangement recognition, we analyzed three methodologies: individual-based methodology, convolutional neural organization (CNN), and our recently evolved occasion de-noising CNN (EDCNN).
Therefore, highlighting designing in AI-based arrangements needs to advance with the new malignant URLs. As of late, profound learning is the most talked about because of the critical outcomes in different man-made consciousness (AI) undertakings in the field of picture preparing, discourse handling, characteristic language handling, and numerous others. They have the capacity to remove includes naturally by taking the crude info messages. To use this and to change the viability of profound learning calculations to the assignment of pernicious URL's location. All weaknesses are distinguished in Web applications, issues brought about by unchecked information are perceived similar to the most widely recognized. To abuse unchecked info, the aggressors, need to accomplish two objectives which are Inject malicious information into Web applications and Manipulate applications utilizing malevolent information. Web Applications getting requesting furthermore, a famous wellspring of diversion, correspondence, work and instruction since making life more helpful and adaptable. Web administrations additionally become so broadly uncovered that any current security weaknesses will most likely be uncovered and misused by programmers.
The process of detecting malicious URLs is not an easy task and it requires comprehensive efforts on multiple ends. The primary domain that has been specifically covered in this paper is Machine Learning and character recognition. This paper has gone through multiple algorithms and methodologies that can be considered a part of Machine Learning which can be utilized to detect malicious URLs. The paper has established a fundamental and obvious set of risks associated with a malicious URL and the necessity to battle and curb it. The important analogy associated with malicious URLs is that their harmful effect is unprecedented and opens door to multiple such occurrences in the future. That’s why it is important to consider the processes of detection to intricately define an overall strategy to detect malicious URLs. The concept of detection and restricting malicious URLs is an ever-growing and developing process. The main reason behind this is that hackers and spammers are consistently looking for new methodologies to conduct harmful processes for the user to make them vulnerable. The paper has covered all the important aspects of the Machine Learning domain to prevent attacks of malicious URLs. The set of recommendations has laid to follow a certain set of tasks associated with URL detection such as reporting spam to any such website or mail that has the intention to deliver harmful content.
The paper went through all the important terminologies and methodologies of algorithms–based tools that can be used for identifying and blocking malicious URLs. The research methodology employed in this paper is the Delphi method and the use of several other research papers is highly detectable. The necessity of preventing malicious URLs is extremely important for the sake of data security and privacy issues. This must be administered seriously in continuance to sustain the integrity of online activity without losing any kind of credibility.
References
1. Shibahara, T., Yamanishi, K., Takata, Y., Chiba, D., Akiyama, M., Yagi, T., Ohsita, Y. and Murata, M., 2017, May. Malicious URL sequence detection using event de-noising convolutional neural network. In 2017 IEEE International Conference on Communications (ICC) (pp. 1-7). IEEE. https://ieeexplore.ieee.org/abstract/document/7996831/
2. SHOID, S.M., 2018. Malicious URL classification system using multi-layer perceptron technique. Journal of Theoretical and Applied Information Technology, 96(19). http://www.jatit.org/volumes/Vol96No19/15Vol96No19.pdf
3. Choi, H., Zhu, B.B. and Lee, H., 2011. Detecting Malicious Web Links and Identifying Their Attack Types. WebApps, 11(11), p.218. http://gauss.ececs.uc.edu/Courses/c5155/pdf/webapps.pdf
4. Tekerek, A., 2021. A novel architecture for web-based attack detection using convolutional neural network. Computers & Security, 100, p.102096. https://www.sciencedirect.com/science/article/pii/S0167404820303692
5. Cui, B., He, S., Yao, X. and Shi, P., 2018. Malicious URL detection with feature extraction based on machine learning. International Journal of High Performance Computing and Networking, 12(2), pp.166-178. https://www.inderscienceonline.com/doi/abs/10.1504/IJHPCN.2018.094367
6. Patgiri, R., Katari, H., Kumar, R. and Sharma, D., 2019, January. Empirical study on malicious URL detection using machine learning. In International Conference on Distributed Computing and Internet Technology (pp. 380-388). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-030-05366-6_31
7. Tan, G., Zhang, P., Liu, Q., Liu, X., Zhu, C. and Dou, F., 2018, August. Adaptive malicious URL detection: Learning in the presence of concept drifts. In 2018 17th IEEE International Conference On Trust, Security and Privacy in Computing And Communications/12th IEEE International Conference On Big Data Science And Engineering (TrustCom/BigDataSE) (pp. 737-743). IEEE. https://ieeexplore.ieee.org/abstract/document/8455975
8. Kumar, R., Zhang, X., Tariq, H.A. and Khan, R.U., 2017, December. Malicious url detection using multi-layer filtering model. In 2017 14th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP) (pp. 97-100). IEEE. https://ieeexplore.ieee.org/abstract/document/8301457
9. Sahoo, D., Liu, C. and Hoi, S.C., 2017. Malicious URL detection using machine learning: A survey. arXiv preprint arXiv:1701.07179. https://arxiv.org/abs/1701.07179
10. Le, H., Pham, Q., Sahoo, D. and Hoi, S.C., 2018. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv preprint arXiv:1802.03162. https://arxiv.org/abs/1802.03162
11. Wejinya, G. and Bhatia, S., 2021. Machine Learning for Malicious URL Detection. In ICT Systems and Sustainability (pp. 463-472). Springer, Singapore. https://link.springer.com/chapter/10.1007/978-981-15-8289-9_45
12. Joshi, A., Lloyd, L., Westin, P. and Seethapathy, S., 2019. Using Lexical Features for Malicious URL Detection--A Machine Learning Approach. arXiv preprint arXiv:1910.06277. https://arxiv.org/abs/1910.06277
13. Naveen, I.N.V.D., Manamohana, K. and Versa, R., 2019. Detection of malicious URLs using machine learning techniques. International Journal of Innovative Technology and Exploring Engineering, 8(4S2), pp.389-393. https://manipal.pure.elsevier.com/en/publications/detection-of-malicious-urls-using-machine-learning-techniques
14. Ferreira, M., 2019. Malicious URL detection using machine learning algorithms. In Digital Privacy and Security Conference (p. 114). https://privacyandsecurityconference.pt/proceedings/2019/DPSC2019-paper11.pdf
15. Verma, R. and Das, A., 2017, March. What's in a url: Fast feature extraction and malicious url detection. In Proceedings of the 3rd ACM on International Workshop on Security and Privacy Analytics (pp. 55-63). https://dl.acm.org/doi/abs/10.1145/3041008.3041016
16. Jiang, J., Chen, J., Choo, K.K.R., Liu, C., Liu, K., Yu, M. and Wang, Y., 2017, October. A deep learning based online malicious URL and DNS detection scheme. In International Conference on Security and Privacy in Communication Systems (pp. 438-448). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-319-78813-5_22
17. Srinivasan, S., Vinayakumar, R., Arunachalam, A., Alazab, M. and Soman, K.P., 2021. DURLD: Malicious URL Detection Using Deep Learning-Based Character Level Representations. In Malware Analysis Using Artificial Intelligence and Deep Learning (pp. 535-554). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-030-62582-5_21
18. Do Xuan, C., Nguyen, H.D. and Nikolaevich, T.V., Malicious URL Detection based on Machine Learning. https://pdfs.semanticscholar.org/2589/5814fe70d994f7d673b6a6e2cc49f7f8d3b9.pdf
19. Khan, H.M.J., 2019. A MACHINE LEARNING BASED WEB SERVICE FOR MALICIOUS URL DETECTION IN A BROWSER (Doctoral dissertation, Purdue University Graduate School). https://hammer.purdue.edu/articles/thesis/A_MACHINE_LEARNING_BASED_WEB_SERVICE_FOR_MALICIOUS_URL_DETECTION_IN_A_BROWSER/11359691/1
20. Bo, W., Fang, Z.B., Wei, L.X., Cheng, Z.F. and Hua, Z.X., 2021. Malicious URLs detection based on a novel optimization algorithm. IEICE TRANSACTIONS on Information and Systems, 104(4), pp.513-516. https://search.ieice.org/bin/summary.php?id=e104-d_4_513
21. Vanitha, N. and Vinodhini, V., 2019. Malicious-URL Detection using Logistic Regression Technique. International Journal of Engineering and Management Research (IJEMR), 9(6), pp.108-113. https://www.indianjournals.com/ijor.aspx?target=ijor:ijemr&volume=9&issue=6&article=018
22. Vinayakumar, R., Soman, K.P. and Poornachandran, P., 2018. Evaluating deep learning approaches to characterize and classify malicious URL’s. Journal of Intelligent & Fuzzy Systems, 34(3), pp.1333-1343. https://content.iospress.com/articles/journal-of-intelligent-and-fuzzy-systems/ifs169429
23. Yuan, J., Chen, G., Tian, S. and Pei, X., 2021. Malicious URL Detection Based on a Parallel Neural Joint Model. IEEE Access, 9, pp.9464-9472. https://ieeexplore.ieee.org/abstract/document/9316171
24. Bhattacharjee, S.D., Talukder, A., Al-Shaer, E. and Doshi, P., 2017, July. Prioritized active learning for malicious URL detection using weighted text-based features. In 2017 IEEE International Conference on Intelligence and Security Informatics (ISI) (pp. 107-112). IEEE. https://ieeexplore.ieee.org/abstract/document/8004883
25. Story, A.W.A.U.S., Malicious URL detection via machine learning. https://geoipify.whoisxmlapi.com/storiesFilesPDF/malicious.url.machine.learning.pdf
26. Astorino, A., Chiarello, A., Gaudioso, M. and Piccolo, A., 2017. Malicious URL detection via spherical classification. Neural Computing and Applications, 28(1), pp.699-705. https://link.springer.com/article/10.1007/s00521-016-2374-9
27. Kumi, S., Lim, C. and Lee, S.G., 2021. Malicious URL Detection Based on Associative Classification. Entropy, 23(2), p.182. https://www.mdpi.com/1099-4300/23/2/182
28. Zhang, S., Zhang, H., Cao, Y., Jin, Q. and Hou, R., 2020. Defense Against Adversarial Attack in Malicious URL Detection. International Core Journal of Engineering, 6(10), pp.357-366. https://www.airitilibrary.com/Publication/alDetailedMesh?docid=P20190813001-202010-202009240001-202009240001-357-366
29. Lekshmi, A.R. and Thomas, S., 2019. Detecting malicious urls using machine learning techniques: A comparative literature review. International Research Journal of Engineering and Technology (IRJET), 6(06). https://d1wqtxts1xzle7.cloudfront.net/60339160/IRJET-V6I65420190819-80896-40px67.pdf?1566278320=&response-content-disposition=inline%3B+filename%3DIRJET_DETECTING_MALICIOUS_URLS_USING_MAC.pdf&Expires=1620469335&Signature=ghgtkQboBA38~WCrAAjExLjT5L3ZDBSE2jpls6zh3jg49QqgCiAyVq7UK4O6wmjr5BYU9QYUSJchdzWkL8Ov6llROtE6r0z92NEEhQGqGt1MagVkDL4G1F14~krYHnqyhrxXXt5IqhIy9koq9w40mTVEATBGnGCtmNbmJyuXDDIPyCe2Rm9ovdNVkaEm8eJvhY49finxPF1b5E56Xxjd9lLRT-0M19~zcQYdZiNjWAsJrrJZBYo0~cUsJmpnJVG6d2Xg-1AzMLW27ltWpkorabTU5~1Ms~N5QRIXiYrt3HUeqX1GaEC8KcUulV9-PK5pJOLumVEBskg6wJSM~Hb-UQ__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA
30. Patil, D.R. and Patil, J.B., 2018. Feature-based Malicious URL and Attack Type Detection Using Multi-class Classification. ISeCure, 10(2). https://www.sid.ir/FileServer/JE/5070420180207
31. Bu, S.J. and Cho, S.B., 2021. Deep Character-Level Anomaly Detection Based on a Convolutional Autoencoder for Zero-Day Phishing URL Detection. Electronics, 10(12), p.1492. https://www.mdpi.com/1157690
32. Cui, B., He, S., Yao, X. and Shi, P., 2018. Malicious URL detection with feature extraction based on machine learning. International Journal of High Performance Computing and Networking, 12(2), pp.166-178.https://www.inderscienceonline.com/doi/abs/10.1504/IJHPCN.2018.094367
33. Le, H., Pham, Q., Sahoo, D. and Hoi, S.C., 2018. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv preprint arXiv:1802.03162.https://arxiv.org/abs/1802.03162
34. Le, H., Pham, Q., Sahoo, D. and Hoi, S.C., 2018. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv preprint arXiv:1802.03162. https://arxiv.org/abs/1802.03162
35. Patgiri, R., Katari, H., Kumar, R. and Sharma, D., 2019, January. Empirical study on malicious url detection using machine learning. In International Conference on Distributed Computing and Internet Technology (pp. 380-388). Springer, Cham.https://link.springer.com/content/pdf/10.1007/978-3-030-05366-6_31.pdf
36. Sahoo, D., Liu, C. and Hoi, S.C., 2017. Malicious URL detection using machine learning: A survey. arXiv preprint arXiv:1701.07179.https://arxiv.org/abs/1701.07179
37. Saxe, J. and Berlin, K., 2017. eXpose: A character-level convolutional neural network with embeddings for detecting malicious URLs, file paths and registry keys. arXiv preprint arXiv:1702.08568. https://arxiv.org/abs/1702.08568
38. Verma, R. and Das, A., 2017, March. What's in a url: Fast feature extraction and malicious url detection. In Proceedings of the 3rd ACM on International Workshop on Security and Privacy Analytics (pp. 55-63).https://dl.acm.org/doi/abs/10.1145/3041008.3041016
39. Vinayakumar, R., Soman, K.P. and Poornachandran, P., 2018. Evaluating deep learning approaches to characterize and classify malicious URL’s. Journal of Intelligent & Fuzzy Systems, 34(3), pp.1333-1343. https://content.iospress.com/articles/journal-of-intelligent-and-fuzzy-systems/ifs169429
40. Yang, P., Zhao, G. and Zeng, P., 2019. Phishing website detection based on multidimensional features driven by deep learning. IEEE Access, 7, pp.15196-15209. https://ieeexplore.ieee.org/abstract/document/8610190/
41. Yang, W., Zuo, W. and Cui, B., 2019. Detecting malicious URLs via a keyword-based convolutional gated-recurrent-unit neural network. IEEE Access, 7, pp.29891-29900. https://ieeexplore.ieee.org/abstract/document/8629082/
42. Sahoo, D., Liu, C. and Hoi, S.C., 2017. Malicious URL detection using machine learning: A survey. arXiv preprint arXiv:1701.07179.
https://arxiv.org/abs/1701.07179
43. Ferreira, M., 2019. Malicious URL detection using machine learning algorithms. In Proc. Digit. Privacy Security Conf. (pp. 114-122).
https://privacyandsecurityconference.pt/proceedings/2019/DPSC2019-paper11.pdf
44. Do Xuan, C., Nguyen, H.D. and Nikolaevich, T.V., 2020. Malicious url detection based on machine learning.
https://pdfs.semanticscholar.org/2589/5814fe70d994f7d673b6a6e2cc49f7f8d3b9.pdf
45. Le, H., Pham, Q., Sahoo, D. and Hoi, S.C., 2018. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv preprint arXiv:1802.03162.
https://arxiv.org/abs/1802.03162
46. Joshi, A., Lloyd, L., Westin, P. and Seethapathy, S., 2019. Using Lexical Features for Malicious URL Detection--A Machine Learning Approach. arXiv preprint arXiv:1910.06277.
https://arxiv.org/abs/1910.06277
47. Kumar, R., Zhang, X., Tariq, H.A. and Khan, R.U., 2017, December. Malicious URL detection using multi-layer filtering model. In 2017 14th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP) (pp. 97-100). IEEE.https://ieeexplore.ieee.org/abstract/document/8301457/
48. Khan, F., Ahamed, J., Kadry, S. and Ramasamy, L.K., 2020. Detecting malicious URLs using binary classification through addax boost algorithm. International Journal of Electrical & Computer Engineering (2088-8708), 10(1).
https://d1wqtxts1xzle7.cloudfront.net/64051690/44%2027sep%20%2029jun%2014apr%2019473%20ED%20%28edit%20lelli%20.pdf?1596070856=&response-content-disposition=inline%3B+filename%3DDetecting_malicious_URLs_using_binary_cl.pdf&Expires=1627026966&Signature=Fc86R-Fim4sTJXqv-T9~x76rKewY2Wz233XcezybbtWscGkvWzFU1iwJqXh0SVCdeDNVXiB0nFbzcg8kOsX3JnMBdR72Joh5AY6BiM5ttCfE5ExyOnMD7MBPKufRjvAkTpXDQ69oC78JIc1k5CQZjFPCZmU7PfuQ4P4M5zLWFHTBNZpZ3JMqDOghnvWCCjahLBU4DVqzFdDMjJX2dQU24zT0JCWQ2uRDm5jY3uZvhi0~whYNaAN0x0L7BBSpG-ruhXe8yQTyDccnlpLa6I89F9uDXSDkoOaPYmohrE7yRbOFr~G9Mx2EpbSkqWT8QLDHXtRldtFPzXEmfLuPirRuTA__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA
49. Rakotoasimbahoaka, A., Randria, I. and Razafindrakoto, N.R., 2019. Malicious URL Detection by Combining Machine Learning and Deep Learning Models. Artificial Intelligence for Internet of Things, 1.
https://vit.ac.in/AIIoT/pages/Proceedings_AIIOT2019_VIT.pdf#page=5
50. Bu, S.J. and Cho, S.B., 2021. Deep Character-Level Anomaly Detection Based on a Convolutional Autoencoder for Zero-Day Phishing URL Detection. Electronics, 10(12), p.1492. https://www.mdpi.com/1157690
51. Lee, W.Y., Saxe, J. and Harang, R., 2019. SeqDroid: Obfuscated Android malware detection using stacked convolutional and recurrent neural networks. In Deep learning applications for cyber security (pp. 197-210). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-030-13057-2_9
52. Wei, B., Hamad, R.A., Yang, L., He, X., Wang, H., Gao, B. and Woo, W.L., 2019. A deep-learning-driven light-weight phishing detection sensor. Sensors, 19(19), p.4258. https://www.mdpi.com/544856
53. Bu, S.J. and Cho, S.B., 2021, June. Integrating Deep Learning with First-Order Logic Programmed Constraints for Zero-Day Phishing Attack Detection. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2685-2689). IEEE. https://ieeexplore.ieee.org/abstract/document/9414850/
54. Hajian Nezhad, J., Vafaei Jahan, M., Tayarani-N, M. and Sadrnezhad, Z., 2017. Analyzing new features of infected web content in detection of malicious web pages. The ISC International Journal of Information Security, 9(2), pp.161-181. https://iranjournals.nlai.ir/handle/123456789/73428

- PHCA9521 Global Health and Development Assignment
- The Effectiveness of Internal Audit and Internal Control Systems in Greek Bank
- HT5006 Childrens Language and Literacy Essay 2
- Project Management Coursework
- MBA652 Strategy and Leadership in Tourism and Hospitality Report 1
- EDU30064 Teaching Science Report 2
- MANU1381 Sustainable Engineering Systems and Environment Assignment
- NURBN1015 Introduction to Evidence Based Practice and Research Assignment
- MKTG10001 Principles of Marketing Assignment
- HDS310 Human Rights and Advocacy Assignment
- SAP103 Introduction to Welfare Law 3B Essay
- EAT80002 Professional Masters Industry Project Report
- ACCT6007 Financial Accounting Theory and Practice Report
- MBA402 Governance Ethics and Sustainability Case Study 2
- MBA631 Digital Marketing and Communication Assignment
- NURS3015 Health Variations 4 Assignment
- Cyberwar and International Law Assignment
- Public Relation Portfolio Assignment
- MBA643 Project Initiation Planning and Execution
- SYAD310 Systems Analysis and Design Assignment


.png)
~5.png)
.png)
~1.png)























































.png)






