Order Now
- Home
- About Us
-
Services
-
Assignment Writing
-
Academic Writing Services
- HND Assignment Help
- SPSS Assignment Help
- College Assignment Help
- Writing Assignment for University
- Urgent Assignment Help
- Architecture Assignment Help
- Total Assignment Help
- All Assignment Help
- My Assignment Help
- Student Assignment Help
- Instant Assignment Help
- Cheap Assignment Help
- Global Assignment Help
- Write My Assignment
- Do My Assignment
- Solve My Assignment
- Make My Assignment
- Pay for Assignment Help
-
Management
- Management Assignment Help
- Business Management Assignment Help
- Financial Management Assignment Help
- Project Management Assignment Help
- Supply Chain Management Assignment Help
- Operations Management Assignment Help
- Risk Management Assignment Help
- Strategic Management Assignment Help
- Logistics Management Assignment Help
- Global Business Strategy Assignment Help
- Consumer Behavior Assignment Help
- MBA Assignment Help
- Portfolio Management Assignment Help
- Change Management Assignment Help
- Hospitality Management Assignment Help
- Healthcare Management Assignment Help
- Investment Management Assignment Help
- Market Analysis Assignment Help
- Corporate Strategy Assignment Help
- Conflict Management Assignment Help
- Marketing Management Assignment Help
- Strategic Marketing Assignment Help
- CRM Assignment Help
- Marketing Research Assignment Help
- Human Resource Assignment Help
- Business Assignment Help
- Business Development Assignment Help
- Business Statistics Assignment Help
- Business Ethics Assignment Help
- 4p of Marketing Assignment Help
- Pricing Strategy Assignment Help
- Nursing
-
Finance
- Finance Assignment Help
- Do My Finance Assignment For Me
- Financial Accounting Assignment Help
- Behavioral Finance Assignment Help
- Finance Planning Assignment Help
- Personal Finance Assignment Help
- Financial Services Assignment Help
- Forex Assignment Help
- Financial Statement Analysis Assignment Help
- Capital Budgeting Assignment Help
- Financial Reporting Assignment Help
- International Finance Assignment Help
- Business Finance Assignment Help
- Corporate Finance Assignment Help
-
Accounting
- Accounting Assignment Help
- Managerial Accounting Assignment Help
- Taxation Accounting Assignment Help
- Perdisco Assignment Help
- Solve My Accounting Paper
- Business Accounting Assignment Help
- Cost Accounting Assignment Help
- Taxation Assignment Help
- Activity Based Accounting Assignment Help
- Tax Accounting Assignment Help
- Financial Accounting Theory Assignment Help
-
Computer Science and IT
- Operating System Assignment Help
- Data mining Assignment Help
- Robotics Assignment Help
- Computer Network Assignment Help
- Database Assignment Help
- IT Management Assignment Help
- Network Topology Assignment Help
- Data Structure Assignment Help
- Business Intelligence Assignment Help
- Data Flow Diagram Assignment Help
- UML Diagram Assignment Help
- R Studio Assignment Help
-
Law
- Law Assignment Help
- Business Law Assignment Help
- Contract Law Assignment Help
- Tort Law Assignment Help
- Social Media Law Assignment Help
- Criminal Law Assignment Help
- Employment Law Assignment Help
- Taxation Law Assignment Help
- Commercial Law Assignment Help
- Constitutional Law Assignment Help
- Corporate Governance Law Assignment Help
- Environmental Law Assignment Help
- Criminology Assignment Help
- Company Law Assignment Help
- Human Rights Law Assignment Help
- Evidence Law Assignment Help
- Administrative Law Assignment Help
- Enterprise Law Assignment Help
- Migration Law Assignment Help
- Communication Law Assignment Help
- Law and Ethics Assignment Help
- Consumer Law Assignment Help
- Science
- Biology
- Engineering
-
Humanities
- Humanities Assignment Help
- Sociology Assignment Help
- Philosophy Assignment Help
- English Assignment Help
- Geography Assignment Help
- Agroecology Assignment Help
- Psychology Assignment Help
- Social Science Assignment Help
- Public Relations Assignment Help
- Political Science Assignment Help
- Mass Communication Assignment Help
- History Assignment Help
- Cookery Assignment Help
- Auditing
- Mathematics
-
Economics
- Economics Assignment Help
- Managerial Economics Assignment Help
- Econometrics Assignment Help
- Microeconomics Assignment Help
- Business Economics Assignment Help
- Marketing Plan Assignment Help
- Demand Supply Assignment Help
- Comparative Analysis Assignment Help
- Health Economics Assignment Help
- Macroeconomics Assignment Help
- Political Economics Assignment Help
- International Economics Assignments Help
-
Academic Writing Services
-
Essay Writing
- Essay Help
- Essay Writing Help
- Essay Help Online
- Online Custom Essay Help
- Descriptive Essay Help
- Help With MBA Essays
- Essay Writing Service
- Essay Writer For Australia
- Essay Outline Help
- illustration Essay Help
- Response Essay Writing Help
- Professional Essay Writers
- Custom Essay Help
- English Essay Writing Help
- Essay Homework Help
- Literature Essay Help
- Scholarship Essay Help
- Research Essay Help
- History Essay Help
- MBA Essay Help
- Plagiarism Free Essays
- Writing Essay Papers
- Write My Essay Help
- Need Help Writing Essay
- Help Writing Scholarship Essay
- Help Writing a Narrative Essay
- Best Essay Writing Service Canada
-
Dissertation
- Biology Dissertation Help
- Academic Dissertation Help
- Nursing Dissertation Help
- Dissertation Help Online
- MATLAB Dissertation Help
- Doctoral Dissertation Help
- Geography Dissertation Help
- Architecture Dissertation Help
- Statistics Dissertation Help
- Sociology Dissertation Help
- English Dissertation Help
- Law Dissertation Help
- Dissertation Proofreading Services
- Cheap Dissertation Help
- Dissertation Writing Help
- Marketing Dissertation Help
- Programming
-
Case Study
- Write Case Study For Me
- Business Law Case Study Help
- Civil Law Case Study Help
- Marketing Case Study Help
- Nursing Case Study Help
- Case Study Writing Services
- History Case Study help
- Amazon Case Study Help
- Apple Case Study Help
- Case Study Assignment Help
- ZARA Case Study Assignment Help
- IKEA Case Study Assignment Help
- Zappos Case Study Assignment Help
- Tesla Case Study Assignment Help
- Flipkart Case Study Assignment Help
- Contract Law Case Study Assignments Help
- Business Ethics Case Study Assignment Help
- Nike SWOT Analysis Case Study Assignment Help
- Coursework
- Thesis Writing
- CDR
- Research
-
Assignment Writing
-
Resources
- Referencing Guidelines
-
Universities
-
Australia
- Asia Pacific International College Assignment Help
- Macquarie University Assignment Help
- Rhodes College Assignment Help
- APIC University Assignment Help
- Torrens University Assignment Help
- Kaplan University Assignment Help
- Holmes University Assignment Help
- Griffith University Assignment Help
- VIT University Assignment Help
- CQ University Assignment Help
-
Australia
- Experts
- Free Sample
- Testimonial
ITC573 Data Knowledge and Engineering Assignment Sample
Assignment Brief
Value: 20%
Group Assessment: No
Submission method options: Alternative submission method
TASK
For this task, you are required to download the Airlines dataset which is available in the Massive Online Analysis (MOA) framework. You will need to access the airlines. arff file. Moreover, you are required to download the MOA (https://sourceforge.net/projects/moa- data stream/) software for this task.
Answer the following short answer questions based on the given dataset.
Knowledge obtained through all topics from Topic 1 to Topic 9, particularly Topic 8 and Topic 9 can be useful for assignment help to answering the questions.
Q1. Data Pre-processing [10 marks]
1. Assume that the Airlines dataset has some missing values. Out of the missing value imputation techniques (i.e. Mean Imputation, EMI and DMI) discussed in this subject, which technique do you prefer to use for the Airlines dataset? Why? [5 marks]
2. Again assume that the Airlines dataset has some missing values and some corrupt values. Do you prefer to handle the missing values before handling the corrupt values? Why? [5 marks]
Q2. Incremental Learning [10 marks]
You are required to perform a data mining task to evaluate different incremental learning algorithms. Load the airlines. arff data set into MOA and compare the performance on this data set for the following algorithms:
• HoeffdingTree
• Adaptive Random Forest
• Hoeffding Adaptive Tree
• Leveraging Bagging
Write a response that shows the performance of the different algorithms and comment on their performance using the classification accuracy and other performance metrics used in MOA. In your report consider:
• Is there a difference in performance between the algorithms?
• Which algorithm performs the best?
Your response should include the necessary screenshots, tables, graphs, etc. to make your report understandable to the reader. The recommended word length for the report is 700 to 1000 words.
SUBJECT LEARNING OUTCOMES
This assessment task will assess the following learning outcome/s:
1. be able to compare and critique various data pre-processing techniques.
2. be able to evaluate the usefulness of data cleansing and pre-processing in discovering useful knowledge necessary for critical business decision.
3. be able to evaluate and compare time series data mining approaches for business decision making.
You MUST prepare and present all text answers to the above tasks in a single document file. All images must also be embedded into the document. All files such as your response to the assignment tasks and Turnitin reports will all be in a single directory, identified by your name.
REQUIREMENTS
Your response to each of the questions such as Q1. a and Q1. b should be no longer than 500 words (excluding figures, tables and graphs). Administrative sections of your assessment such as headings, table of contents, reference list and other diagrams and figures are not included in the word count. In text citations are included as part of your word count. Please note that the length of an answer is not very important. The quality and completeness of an answer is important.
For this assessment you’re required to use APA7 referencing to acknowledge the sources that you have used in preparing your assessment. Please visit Referencing at CSU for guidance. In addition, a very useful tool for you to use that demonstrates how to correctly use in-text referencing and the correct way to cite the reference in your reference list is the Academic Referencing Tool (ART).
This assignment must be uploaded to Turnitin. Students will need to download the Turnitin report and submit it via Turnitin along with the assignment. More information on using Turnitin at CSU can be found at https://www.csu.edu.au/current-students/learning-resources/information- planning/assignments/plagiarism-checking
Solution
Introduction
The paper aims to evaluate the data mining models in incremental learning using Massive Online Analysis or MOA tool. In this context, the Airline data has been selected on which the data mining algorithms will be applied after preprocessing it.
Data Pre-processing
Primarily, the discussion about the data pre-processing will be done in this section. One of the most important data preprocessing is the missing data handling without which the data mining algorithm will not respond properly (Tahir & Loo, 2020).
Computation on Missing Values
The data has been collected in ARFF (Attribute Relational File Format) and loaded in MOA. It has not been seen that there are any missing values. However, if the data will contain missing values, there are three ways to handle this and those are as follows:
1. Replace missing values by mean
2. Replace missing values with EMI
3. Replace missing values with DMI
When the EMI (Expected Maximization Imputation) is applied to the data, the missing data will be replaced by the most occurred values in the feature. If this will be done, the central tendency of the data may be changed and for the continuous variable, it will not work properly as the mode is not a valid computation for continuous variables. On the other hand, Decision Tree-Based EMI method is used to replace the missing values by creating the decision tree model and signifying the value at each node (Beaulac & Rosenthal, 2018). So, the DMI method is time-consuming for large datasets. When the missing data is replaced by the mean value of the features, the central tendency is maintained. However, replacing missing values for categorical or nominal features, mean will not work. As airline data contain both the continuous and nominal features, both mean values (for continuous) and the EMI method (for nominal) will have to be used (Islam, 2011).
Corrupt values are not similar to missing values. In most cases, corrupt values come in the form of special characters such as “?” etc. Those characters are not traced when missing values is found as those are not the missing values and rather treated as the valid member of those features with wrong values (Zhu & Wu, 2020). If those values are not replaced, those values will produce the wrong outcome of the data analysis and finally in the application of data mining algorithms. So, those corrupt values in the data need to be removed to make the dataset cleaned and without any kind of the wrong valuation. So, before missing value treatment, the corrupt values need to be converted to missing values or NaN values so that those will be traced at the time of finding the missing values (Ghalib Ahmed Tahir, 2020). So, finally, it will be easier to trace all the missing values and can be replaced by a suitable method.
So, in view of the thought, the corrupt values need to be converted to missing values first and then the imputation of missing values should be done.
Incremental Learning
In this section, the incremental learning methods will be applied to the airline data and the performances will be observed.
Hoeffding Tree
Primarily, the Hoeffding Tree has been applied to the airline data and classified to determine the flight delay (Guo, Wang, Fan, & Li, 2019). The screenshot of the application of this algorithm in MOA is shown below:
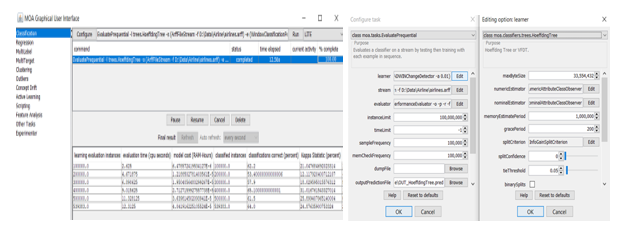
Fig-1: Application of Hoeffding Tree
After applying the algorithm, the following outcome has been obtained graphically as follows:
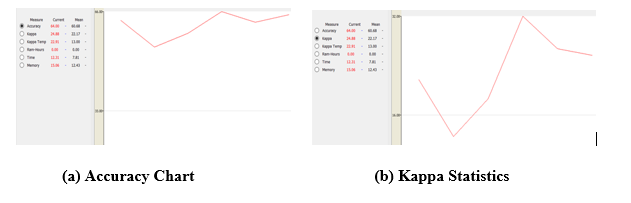
Fig-2: Visualization of Performance for Hoeffding Tree
After applying the Hoeffding Tree, the classification matrics have been stored and enlisted in the following table:
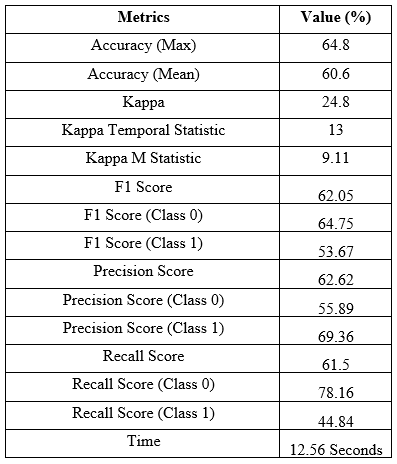
Table-1: Classification Metrics for Hoeffding Tree
Adaptive Random Forest
The Adaptive Random Forest has been applied to the airline data and classified to determine the flight delay. The screenshot of the application of this algorithm in MOA is shown below:
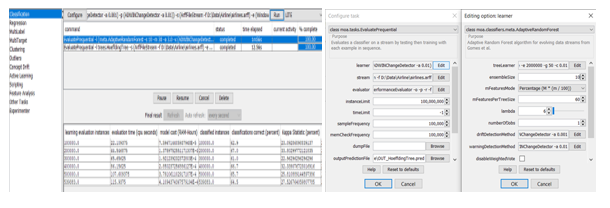
Fig-3: Application of Adaptive Random Forest
After applying the algorithm, the following outcome has been obtained graphically as follows:

Fig-4: Visualization of Performance for Adaptive Random Forest
After applying the Hoeffding Tree, the classification matrics have been stored and enlisted in the following table:
Table-2: Classification Metrics for Adaptive Random Forest
Hoeffding Adaptive Tree
The Hoeffding Adaptive Tree has been applied to the airline data and classified to determine the flight delay (Tahir & Loo, 2020). The screenshot of the application of this algorithm in MOA is shown below:
Fig-5: Application of Hoeffding Adaptive Tree
After applying the algorithm, the following outcome has been obtained graphically as follows:
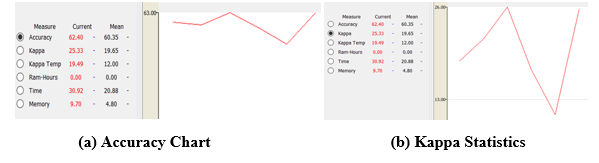
Fig-6: Visualization of Performance for Hoeffding Tree
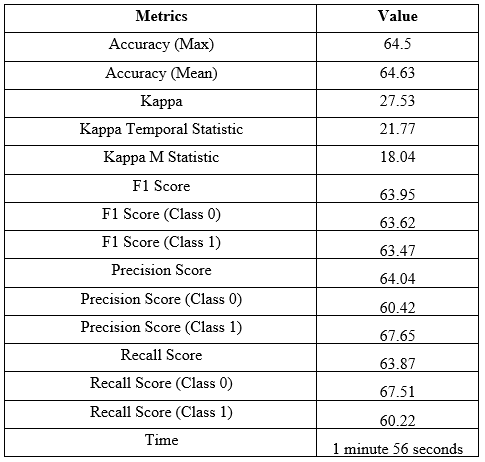
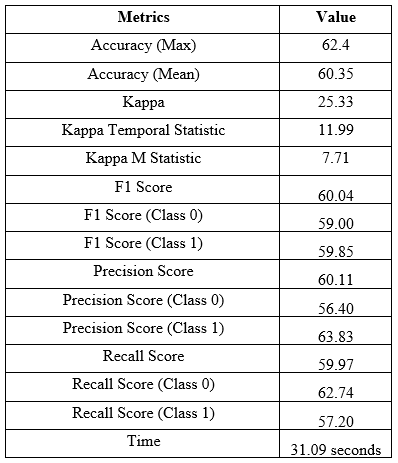
After applying the Hoeffding Tree, the classification matrics have been stored and enlisted in the following table:
Table-3: Classification Metrics for Hoeffding Adaptive Tree
Leveraging Bagging
The Leveraging Bagging has been applied to the airline data and classified to determine the flight delay. The screenshot of the application of this algorithm in MOA is shown below:
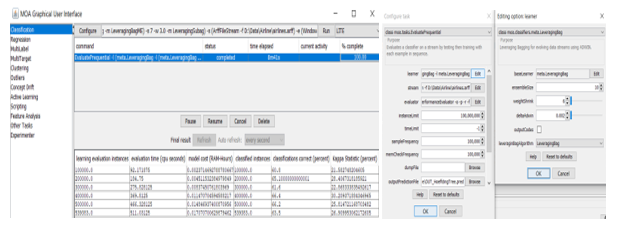
Fig-7: Application of Leveraging Bagging
After applying the algorithm, the following outcome has been obtained graphically as follows:
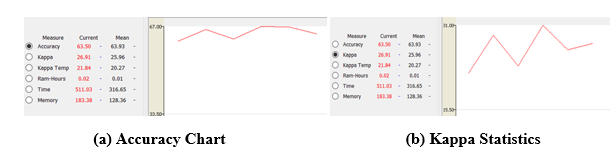
Fig-8: Visualization of Performance for Leveraging Bagging
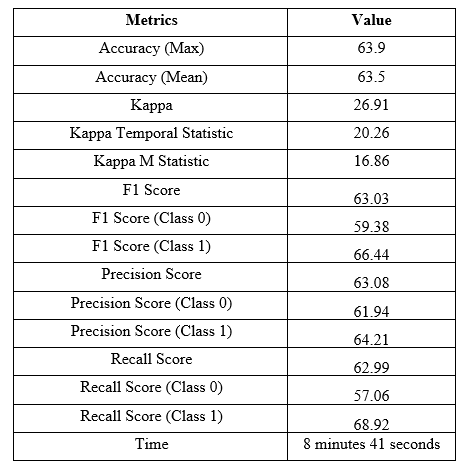
After applying the Hoeffding Tree, the classification matrics have been stored and enlisted in the following table:
Table-4: Classification Metrics for Leveraging Bagging
Finding and Conclusion
The algorithms have been applied to the airline data for the classification of flight delays. While applying the classifiers, the performance matrices have been recorded so that those can be compared to find the best one. From the overall experiment, the following finding has been obtained:
1. The performance of the chosen classifier differs from each other. The accuracy, precision, recall and f1-scores (Overall values and also by class) are different from each of the classifiers that prove the fact that the performances of classification are different from each other.
2. From the comparison of accuracy, it has been seen that the highest accuracy has been obtained from Adaptive Random Forest by 64.3% with the kappa value of 27.33% and precision by 64.04%. The execution time for Adaptive Random Forest (34 seconds) is also comparatively lower with higher accuracy.
References
Beaulac, C., & Rosenthal, J. S. (2018). BEST : A decision tree algorithm that handles missing values. University of Toronto, 1-22.
Ghalib Ahmed Tahir, C. K. (2020). Mitigating Catastrophic Forgetting In Adaptive Class Incremental Extreme Learning Machine Through Neuron Clustering. Systems Man and Cybernetics (SMC) 2020 IEEE International Conference, 3903-3910.
Guo, H., Wang, S., Fan, J., & Li, S. (2019). Learning Automata Based Incremental Learning Method for Deep Neural Networks. IEEE Access, 1-6.
Islam, M. G. (2011). A Decision Tree-based Missing Value Imputation Technique for Data Pre-processing. Proceedings of the 9-th Australasian Data Mining Confere, 41-50.
Tahir, G. A., & Loo, C. K. (2020). An Open-Ended Continual Learning for Food Recognition Using Class Incremental Extreme Learning Machines. IEEE Access, 82328 - 82346.
Zhu, H., & Wu, Y. (2020). Inverse-Free Incremental Learning Algorithms With Reduced Complexity for Regularized Extreme Learning Machine. Access IEEE, 177318-177328.

Download Samples PDF
Related Sample
- CRIM2024 Discipline of Criminology and Justice Assignment
- COIT20262 Advanced Network Security Assignment
- DAT7001 Data Handling and Decision Making
- BSBOPS502 Manage Business Operational Plan
- TBUS610 E Business Strategies Assignment
- HRMT20024 Human Resource Management Assignment
- CSM80017 Managing Quality and Safety in Construction Site Operations Report 2
- HI5030 System Analysis and Design Report
- MGT501 Business Environment Report 1
- Regenerative Architecture Assignment
- PUBH6206 Health Promotion and Community Health Assignment
- DS7003 Advanced Decision Making Predictive Analytics and Machine Learning
- LAW1507 Tort Law Assignment
- MMW226465 International Management Governance and Sustainability Assignment
- BSBLDR801 Lead Personal and Strategic Transformation Assignment
- BSBMGT515A Manage Operational Plan Assignment
- BUS2004 Human Resource Management Assignment
- MANU1381 Sustainable Engineering Systems and Environment Assignment
- COMP2003 Securing Networks Assignment
- MGT302A Strategic Management Assignment

Assignment Services
-
Assignment Writing
-
Academic Writing Services
- HND Assignment Help
- SPSS Assignment Help
- College Assignment Help
- Writing Assignment for University
- Urgent Assignment Help
- Architecture Assignment Help
- Total Assignment Help
- All Assignment Help
- My Assignment Help
- Student Assignment Help
- Instant Assignment Help
- Cheap Assignment Help
- Global Assignment Help
- Write My Assignment
- Do My Assignment
- Solve My Assignment
- Make My Assignment
- Pay for Assignment Help
-
Management
- Management Assignment Help
- Business Management Assignment Help
- Financial Management Assignment Help
- Project Management Assignment Help
- Supply Chain Management Assignment Help
- Operations Management Assignment Help
- Risk Management Assignment Help
- Strategic Management Assignment Help
- Logistics Management Assignment Help
- Global Business Strategy Assignment Help
- Consumer Behavior Assignment Help
- MBA Assignment Help
- Portfolio Management Assignment Help
- Change Management Assignment Help
- Hospitality Management Assignment Help
- Healthcare Management Assignment Help
- Investment Management Assignment Help
- Market Analysis Assignment Help
- Corporate Strategy Assignment Help
- Conflict Management Assignment Help
- Marketing Management Assignment Help
- Strategic Marketing Assignment Help
- CRM Assignment Help
- Marketing Research Assignment Help
- Human Resource Assignment Help
- Business Assignment Help
- Business Development Assignment Help
- Business Statistics Assignment Help
- Business Ethics Assignment Help
- 4p of Marketing Assignment Help
- Pricing Strategy Assignment Help
- Nursing
-
Finance
- Finance Assignment Help
- Do My Finance Assignment For Me
- Financial Accounting Assignment Help
- Behavioral Finance Assignment Help
- Finance Planning Assignment Help
- Personal Finance Assignment Help
- Financial Services Assignment Help
- Forex Assignment Help
- Financial Statement Analysis Assignment Help
- Capital Budgeting Assignment Help
- Financial Reporting Assignment Help
- International Finance Assignment Help
- Business Finance Assignment Help
- Corporate Finance Assignment Help
-
Accounting
- Accounting Assignment Help
- Managerial Accounting Assignment Help
- Taxation Accounting Assignment Help
- Perdisco Assignment Help
- Solve My Accounting Paper
- Business Accounting Assignment Help
- Cost Accounting Assignment Help
- Taxation Assignment Help
- Activity Based Accounting Assignment Help
- Tax Accounting Assignment Help
- Financial Accounting Theory Assignment Help
-
Computer Science and IT
- Operating System Assignment Help
- Data mining Assignment Help
- Robotics Assignment Help
- Computer Network Assignment Help
- Database Assignment Help
- IT Management Assignment Help
- Network Topology Assignment Help
- Data Structure Assignment Help
- Business Intelligence Assignment Help
- Data Flow Diagram Assignment Help
- UML Diagram Assignment Help
- R Studio Assignment Help
-
Law
- Law Assignment Help
- Business Law Assignment Help
- Contract Law Assignment Help
- Tort Law Assignment Help
- Social Media Law Assignment Help
- Criminal Law Assignment Help
- Employment Law Assignment Help
- Taxation Law Assignment Help
- Commercial Law Assignment Help
- Constitutional Law Assignment Help
- Corporate Governance Law Assignment Help
- Environmental Law Assignment Help
- Criminology Assignment Help
- Company Law Assignment Help
- Human Rights Law Assignment Help
- Evidence Law Assignment Help
- Administrative Law Assignment Help
- Enterprise Law Assignment Help
- Migration Law Assignment Help
- Communication Law Assignment Help
- Law and Ethics Assignment Help
- Consumer Law Assignment Help
- Science
- Biology
- Engineering
-
Humanities
- Humanities Assignment Help
- Sociology Assignment Help
- Philosophy Assignment Help
- English Assignment Help
- Geography Assignment Help
- Agroecology Assignment Help
- Psychology Assignment Help
- Social Science Assignment Help
- Public Relations Assignment Help
- Political Science Assignment Help
- Mass Communication Assignment Help
- History Assignment Help
- Cookery Assignment Help
- Auditing
- Mathematics
-
Economics
- Economics Assignment Help
- Managerial Economics Assignment Help
- Econometrics Assignment Help
- Microeconomics Assignment Help
- Business Economics Assignment Help
- Marketing Plan Assignment Help
- Demand Supply Assignment Help
- Comparative Analysis Assignment Help
- Health Economics Assignment Help
- Macroeconomics Assignment Help
- Political Economics Assignment Help
- International Economics Assignments Help
-
Academic Writing Services
-
Essay Writing
- Essay Help
- Essay Writing Help
- Essay Help Online
- Online Custom Essay Help
- Descriptive Essay Help
- Help With MBA Essays
- Essay Writing Service
- Essay Writer For Australia
- Essay Outline Help
- illustration Essay Help
- Response Essay Writing Help
- Professional Essay Writers
- Custom Essay Help
- English Essay Writing Help
- Essay Homework Help
- Literature Essay Help
- Scholarship Essay Help
- Research Essay Help
- History Essay Help
- MBA Essay Help
- Plagiarism Free Essays
- Writing Essay Papers
- Write My Essay Help
- Need Help Writing Essay
- Help Writing Scholarship Essay
- Help Writing a Narrative Essay
- Best Essay Writing Service Canada
-
Dissertation
- Biology Dissertation Help
- Academic Dissertation Help
- Nursing Dissertation Help
- Dissertation Help Online
- MATLAB Dissertation Help
- Doctoral Dissertation Help
- Geography Dissertation Help
- Architecture Dissertation Help
- Statistics Dissertation Help
- Sociology Dissertation Help
- English Dissertation Help
- Law Dissertation Help
- Dissertation Proofreading Services
- Cheap Dissertation Help
- Dissertation Writing Help
- Marketing Dissertation Help
- Programming
-
Case Study
- Write Case Study For Me
- Business Law Case Study Help
- Civil Law Case Study Help
- Marketing Case Study Help
- Nursing Case Study Help
- Case Study Writing Services
- History Case Study help
- Amazon Case Study Help
- Apple Case Study Help
- Case Study Assignment Help
- ZARA Case Study Assignment Help
- IKEA Case Study Assignment Help
- Zappos Case Study Assignment Help
- Tesla Case Study Assignment Help
- Flipkart Case Study Assignment Help
- Contract Law Case Study Assignments Help
- Business Ethics Case Study Assignment Help
- Nike SWOT Analysis Case Study Assignment Help
- Coursework
- Thesis Writing
- CDR
- Research

.png)
~5.png)
.png)
~1.png)























































.png)






