BDA601 Big Data and Analytics Assignment Sample
Task Summary
Critically analyse the online retail business case (see below) and write a 1,500-word online custom essay help report that: a) Identifies various sources of data to build an effective data pipeline; b) Identifies challenges in integrating the data from the sources and formulates a strategy to address those challenges; and c) Describes a design for a storage and retrieval system for the data lake that uses commercial and/or open-source big data tools. Please refer to the Task Instructions (below) for details on how to complete this task. Context A modern data-driven organisation must be able to collect and process large volumes of data and perform analytics at scale on that data. Thus, the establishment of a data pipeline is an essential first step in building a data-driven organisation. A data pipeline ingests data from various sources, integrates that data and stores that data in a ‘data lake’, making that data available to everyone in the organisation.
This Assessment prepares you to identify potential sources of data, address challenges in integrating data and design an efficient ‘data lake’ using the big data principles, practices and technologies covered in the learning materials. Case Study Big Retail is an online retail shop in Adelaide, Australia. Its website, at which its users can explore different products and promotions and place orders, has more than 100,000 visitors per month. During checkout, each customer has three options: 1) to login to an existing account; 2) to create a new account if they have not already registered; or 3) to checkout as a guest. Customers’ account information is maintained by both the sales and marketing departments in their separate databases. The sales department maintains records of the transactions in their database. The information technology (IT) department maintains the website. Every month, the marketing team releases a catalogue and promotions, which are made available on the website and emailed to the registered customers. The website is static; that is, all the customers see the same content, irrespective of their location, login status or purchase history. Recently, Big Retail has experienced a significant slump in sales, despite its having a cost advantage over its competitors. A significant reduction in the number of visitors to the website and the conversion rate (i.e., the percentage of visitors who ultimately buy something) has also been observed. To regain its market share and increase its sales, the management team at Big Retail has decided to adopt a data-driven strategy. Specifically, the management team wants to use big data analytics to enable a customised customer experience through targeted campaigns, a recommender system and product association. The first step in moving towards the data-driven approach is to establish a data pipeline. The essential purpose of the data pipeline is to ingest data from various sources, integrate the data and store the data in a ‘data lake’ that can be readily accessed by both the management team and the data scientists.
Task Instructions
Critically analyse the above case study and write a 1,500-word report. In your report, ensure that you:
• Identify the potential data sources that align with the objectives of the organisation’s datadriven strategy. You should consider both the internal and external data sources. For each data source identified, describe its characteristics. Make reasonable assumptions about the fields and format of the data for each of the sources;
• Identify the challenges that will arise in integrating the data from different sources and that must be resolved before the data are stored in the ‘data lake.’ Articulate the steps necessary to address these issues;
• Describe the ‘data lake’ that you designed to store the integrated data and make the data available for efficient retrieval by both the management team and data scientists. The system should be designed using a commercial and/or an open-source database, tools and frameworks. Demonstrate how the ‘data lake’ meets the big data storage and retrieval requirements; and Provide a schematic of the overall data pipeline. The schematic should clearly depict the data sources, data integration steps, the components of the ‘data lake’ and the interactions among all the entities.
Solution
Introduction
Retail industry has grown a lot in 2020-21, speciallyby the use of online store facility (Menidjel et al., 2021). Like the global retail market, Australian retail market has changed a lot. The market takes the online approach. Here customers are free to change their mind by simple mouse click. These makes this industry highly competitive.
Big Retail is a retail store situated in Adelaide,Australia. Historical data says, per month around 100000 customers visit their website and makes the purchases. The website is maintained by the IT department of Big Retail. The website is a static one. All the customers see the same content irrespective of their location and login status or purchase history. A visitor may login if he or she has an account,he or she can create an account or checkout as a guest user. These activities generate a huge amount of data every month. These raw data is unanalysed till now and a data-driven approach is not taken based on these collected data. Presently Big Retails are experiencing less sales and they are losing their revenue. Therefore, a data-driven approach has to be taken and a data pipeline needs to be made(Hussein& Kais,2021). By analysing the available dada, the possible solutions will come out and the revenue will reach its expected pick.
Data Source
The website of Big Retails is managed by the IT department of the company. Every day a large number of visitors comes in this website to see the product or to purchase. They provide their name, address, email id, phone number and other information. Customers follows a definite purchase pattern. Data are generated from this website every day.
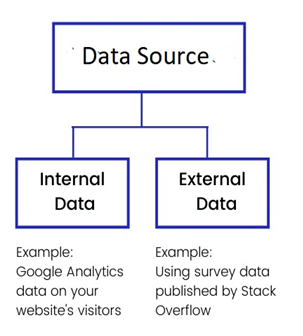
Figure 1: Data Source
Source: Created by Author
Internal Data Source
Every month around 100000 visitors visit Big Retails website. These huge number of website visitor generate a large amount of data. These website visitor data are internal data. Internal data is information which is generate within the organisation. The operations, maintenance, HR, finance, sales and marketing information within the company is also internal data (Feng, Fan & Bednarz,2019). Customer analysis, sales analysis report, cost analysis, marketing report, budget of Big Retail are internal data.
a) Internal data are reliable. These data are collected from the organisations own system. Therefore, during analysis,we can rely on these data.
b) Internal data or often unique and can be separated. Every data has unique meaning.
c) These data are operational data. Special DBMS operation is already done on these data.
d) Internal data are well defined data. The value, occurrence and event of these data are well defined. We know the exact value of each data.
External Data Source
External data are the data which is outside the current database. External data is collected from the outside source. Marketing department of Big Retail often make some market analysis and feedback collection campaign. Marketing department also does several surveys. Data which are collected from these campaign and surveys are external data.
Characteristics
a) These data are not reliable. These data are collected from external sources
b) Data operations are needed on external data.
c) We cannot use external data in DBMS.
d) External data are not well defined.
Structured data source
Structure data are those data which reside in a specific file or record. Structure data is stored in RDBMS (Anadiotis et al., 2021). In Big Retail, the data which are collected from the website visitors are identified and make unique. These data then store in a file. This file is the source of structure data.
Semi-Structured Data Source
Semi-structured data sources are emails,address of the customers who visited the website of Big Retail,XMLs,zipped files and web pages collected from different sources (Anadiotis et al., 2021).
Unstructured Data Source
Unstructured data sources are, Media information, audio and video files, surveillance data, geological data, weather data (Anadiotis et al., 2021). In Big Retail, audio and video message, email message collected form the customers are the source of unstructured data.
Challenge of Integrating Data from Different Sources
The website of Big Retail is a busy one. Everyday a large number of customers visits the website. There are internal analysis data as well. The survey data are also there. There ae structured and unstructured dada as well. Data are coming from different sources. Integrating such huge amountof data is a big challenge.
Challenges
The challenge of integrating data from different source are many. Big Retail is a large organisation. It has different types of data. All data are not structured. First challenge is to get a structured data. The integration challenge is, the data are not there where we need it(Gorji& Siami, 2020). Sometimes, the data are there but it is late. Getting data on right time, in right place itself is a challenge. The next challenge is getting an unformatted data or ill-formatted data. We get the data, but it is not formatted well i.e. the format of the data is not correct. Often the data quality is very poor. These data cannot be integrated. And again, there are duplicates of data. Throughout our pipeline, the data are duplicated (Zipkin et al., 2021). The data has to be clear. There is no clear understanding of data. These data cannot be integrated. Poor quality, duplicated and unclear data often make the situation tougher.
Solutions
The solutions of data integration problems are not many. But there are few effective solutions. We need to automate the data as much as possible. Manual data operation has to be avoided (Kalayci et al., 2021).We should opt for smallest integration first. It is advised to avoid large integration. The simplest way is to use a system integration software which will allow to integrate large amount of data from different sources. Some data integration softwareis Zapier, IFTTT, Dell Boomi etc.
Data lake
Data lake is a storage repository which stores a last amount of raw data it its own format until it is taken (Nargesian et al., 2020).
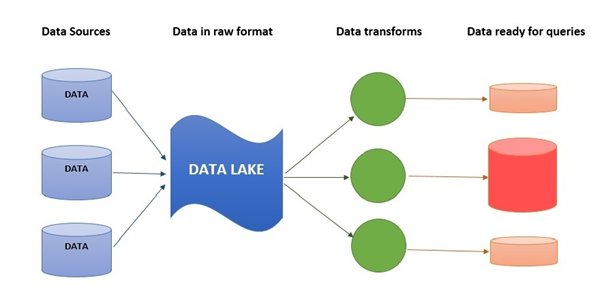
Figure 2: Data Lake
Source: Created by Author
Data lake does not use file or folder to store data, it stores data is its own flat architecture. Data lake is often a Hadoop oriented object storage. Data is first loaded in the Hadoop platform. After that, business analytics and data mining tools are used to get these data. Just like physical lake, it is a huge storage of data. The format of data is not a problem here.
Here, in Big Retail, data are coming from
1. website visitors,
2. active customers,
3. buyers,
4. feedback givers,
5. survey report,
6. sales reports
7. internal analytics report etc.
These data are structured as well as unstructured data. These data have different format. Some are integers, some are characters, some are binary data. These data are stores in data lake. Through the data pipeline these data cometothe data lake. Whenever the database administration of data scientist needs the data, some operations are done on that data and make the data available for use.
Schematic of the Overall Data Pipeline
The data pipeline is a set of actions that happen to the raw data to make them usable for the analytics purpose. There are series of data processing elements which are to be used on raw data.
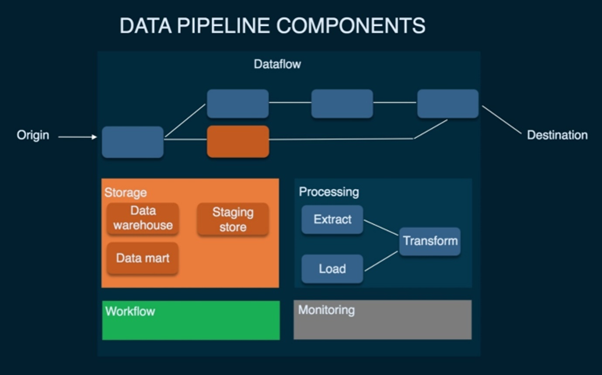
Figure 3: Data Pipeline Components
Source: (Giebler et al, 2019)
Big Retail business generate a massive amount of data which needs to be analysed to get the perfect business value and opt a business discission. Analysing data withing the system is not a wise idea. Moving data between systems requires many steps. Collecting data from one source, copping that data, upload the data to the cloud, reformatting the data, different operations on data and then joins it to other systems. This is a complex procedure. Data pipeline is the summation of all these above steps (Giebler et al, 2019).
Data from different source of Big Retails are collected first. Next part is uploading the data to the cloud. The using different software tool formatting of data is happening. Here the data goes to the data lake of Big Retail. In data lake, these data are received first and irrespective of its original format, it is stored in flat format(Quemy, 2019).
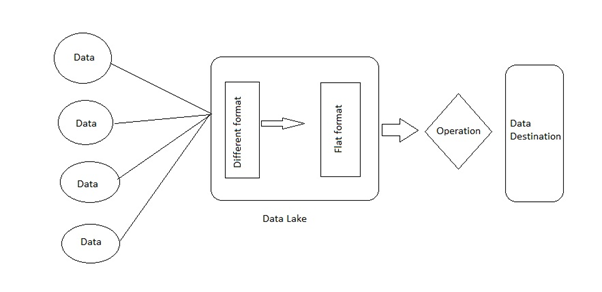
Figure 4: Data Pipeline
Source: Created by Author
Conclusion
The business scenario of today’s world is changing. Like other industry, retail in also facing a huge change due to the advancement of technology (Komagan, 2021). Big Retail of Adelaide, Australia needs to build this above-mentioned data pipeline and data lake. Being an online store, it is highly depending upon data and e-technology. It has been found that the data pipeline can help the store to get the data effectively. The proposed data lake will help to store data and can provide it when necessary. Using analytics tools, data analyst and data scientist can predict the business scenario and advice the management of Big Retail to take the necessary actions.
References
Anadiotis, A. C., Balalau, O., Conceicao, C., Galhardas, H., Haddad, M. Y., Manolescu, I., ... & You, J. (2021). Graph integration of structured, semistructured and unstructured data for data journalism. Information Systems, 101846.https://www.sciencedirect.com/science/article/abs/pii/S0306437921000806
Feng, T., Fan, F., & Bednarz, T. (2019, November). A Data-Driven Optimisation Approach to Urban Multi-Site Selection for Public Services and Retails. In The 17th International Conference on Virtual-Reality Continuum and its Applications in Industry (pp. 1-9).https://dl.acm.org/doi/abs/10.1145/3359997.3365686
Giebler, C., Gröger, C., Hoos, E., Schwarz, H., & Mitschang, B. (2019, November). Modeling data lakes with data vault: practical experiences, assessment, and lessons learned. In International Conference on Conceptual Modeling (pp. 63-77). Springer, Cham.https://link.springer.com/chapter/10.1007/978-3-030-33223-5_7
Gorji, M., & Siami, S. (2020). How sales promotion display affects customer shopping intentions in retails. International Journal of Retail & Distribution Management.https://www.emerald.com/insight/content/doi/10.1108/IJRDM-12-2019-0407/full/html
Hussein, R. S., & Kais, A. (2021). Multichannel behaviour in the retail industry: evidence from an emerging market. International Journal of Logistics Research and Applications, 24(3), 242-260.https://www.tandfonline.com/doi/abs/10.1080/13675567.2020.1749248
Kalayci, T. E., Kalayci, E. G., Lechner, G., Neuhuber, N., Spitzer, M., Westermeier, E., & Stocker, A. (2021). Triangulated investigation of trust in automated driving: Challenges and solution approaches for data integration. Journal of Industrial Information Integration, 21, 100186.https://www.sciencedirect.com/science/article/abs/pii/S2452414X20300613
Komagan, M. L. (2021). Impact of Service Environment for effective consumer behavior in Retails Industry with reference to Heritage Super Market. Turkish Journal of Computer and Mathematics Education (TURCOMAT), 12(3), 4357-4364.https://turcomat.org/index.php/turkbilmat/article/view/1727
Menidjel, C., Bilgihan, A., & Benhabib, A. (2021). Exploring the impact of personality traits on perceived relationship investment, relationship quality, and loyalty in the retail industry. The International Review of Retail, Distribution and Consumer Research, 31(1), 106-129.https://www.tandfonline.com/doi/abs/10.1080/09593969.2020.1781228
Nargesian, F., Pu, K. Q., Zhu, E., Ghadiri Bashardoost, B., & Miller, R. J. (2020, June). Organizing data lakes for navigation. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (pp. 1939-1950).https://dl.acm.org/doi/abs/10.1145/3318464.3380605
Quemy, A. (2019). Data Pipeline Selection and Optimization. In DOLAP.https://www.aquemy.info/static/publications/quemy2019b.pdf
Zipkin, E. F., Zylstra, E. R., Wright, A. D., Saunders, S. P., Finley, A. O., Dietze, M. C., ... & Tingley, M. W. (2021). Addressing data integration challenges to link ecological processes across scales. Frontiers in Ecology and the Environment, 19(1), 30-38.https://esajournals.onlinelibrary.wiley.com/doi/full/10.1002/fee.2290

- Microservices Architecture Assignment
- MIS608 Agile Project Management
- MBA621 Healthcare Systems
- HCCSSD101 Case Management and Understanding Community Services
- MITS4004 IT Networking and Communication Assignment
- PROJ6000 Assignment 3
- BUMGT6973 Project Management Report 2
- LML6003 Migration Law Assignment
- PROG2008 Computational Thinking Assignment 3
- MIS500 Foundations of Information Systems Report 3
- LST2001 Introduction to Business and Company Law Assignment
- CPCCBC4012 Building and Construction Assignment
- BRH606 Business Research for Hoteliers
- ECO500 Economics for Business Assignment
- MGT302A Strategic Management Assignment
- Fluid Mosaic Model of Membrane Structure Assignment
- PHCA9521 Global Health and Development Assignment
- DATA4200 Data Acquisition and Management Report 1
- MIS610 Advanced Professional Practice
- LAW6001 Taxation Law Case Study


.png)
~5.png)
.png)
~1.png)























































.png)






