Order Now
- Home
- About Us
-
Services
-
Assignment Writing
-
Academic Writing Services
- HND Assignment Help
- SPSS Assignment Help
- College Assignment Help
- Writing Assignment for University
- Urgent Assignment Help
- Architecture Assignment Help
- Total Assignment Help
- All Assignment Help
- My Assignment Help
- Student Assignment Help
- Instant Assignment Help
- Cheap Assignment Help
- Global Assignment Help
- Write My Assignment
- Do My Assignment
- Solve My Assignment
- Make My Assignment
- Pay for Assignment Help
-
Management
- Management Assignment Help
- Business Management Assignment Help
- Financial Management Assignment Help
- Project Management Assignment Help
- Supply Chain Management Assignment Help
- Operations Management Assignment Help
- Risk Management Assignment Help
- Strategic Management Assignment Help
- Logistics Management Assignment Help
- Global Business Strategy Assignment Help
- Consumer Behavior Assignment Help
- MBA Assignment Help
- Portfolio Management Assignment Help
- Change Management Assignment Help
- Hospitality Management Assignment Help
- Healthcare Management Assignment Help
- Investment Management Assignment Help
- Market Analysis Assignment Help
- Corporate Strategy Assignment Help
- Conflict Management Assignment Help
- Marketing Management Assignment Help
- Strategic Marketing Assignment Help
- CRM Assignment Help
- Marketing Research Assignment Help
- Human Resource Assignment Help
- Business Assignment Help
- Business Development Assignment Help
- Business Statistics Assignment Help
- Business Ethics Assignment Help
- 4p of Marketing Assignment Help
- Pricing Strategy Assignment Help
- Nursing
-
Finance
- Finance Assignment Help
- Do My Finance Assignment For Me
- Financial Accounting Assignment Help
- Behavioral Finance Assignment Help
- Finance Planning Assignment Help
- Personal Finance Assignment Help
- Financial Services Assignment Help
- Forex Assignment Help
- Financial Statement Analysis Assignment Help
- Capital Budgeting Assignment Help
- Financial Reporting Assignment Help
- International Finance Assignment Help
- Business Finance Assignment Help
- Corporate Finance Assignment Help
-
Accounting
- Accounting Assignment Help
- Managerial Accounting Assignment Help
- Taxation Accounting Assignment Help
- Perdisco Assignment Help
- Solve My Accounting Paper
- Business Accounting Assignment Help
- Cost Accounting Assignment Help
- Taxation Assignment Help
- Activity Based Accounting Assignment Help
- Tax Accounting Assignment Help
- Financial Accounting Theory Assignment Help
-
Computer Science and IT
- Operating System Assignment Help
- Data mining Assignment Help
- Robotics Assignment Help
- Computer Network Assignment Help
- Database Assignment Help
- IT Management Assignment Help
- Network Topology Assignment Help
- Data Structure Assignment Help
- Business Intelligence Assignment Help
- Data Flow Diagram Assignment Help
- UML Diagram Assignment Help
- R Studio Assignment Help
-
Law
- Law Assignment Help
- Business Law Assignment Help
- Contract Law Assignment Help
- Tort Law Assignment Help
- Social Media Law Assignment Help
- Criminal Law Assignment Help
- Employment Law Assignment Help
- Taxation Law Assignment Help
- Commercial Law Assignment Help
- Constitutional Law Assignment Help
- Corporate Governance Law Assignment Help
- Environmental Law Assignment Help
- Criminology Assignment Help
- Company Law Assignment Help
- Human Rights Law Assignment Help
- Evidence Law Assignment Help
- Administrative Law Assignment Help
- Enterprise Law Assignment Help
- Migration Law Assignment Help
- Communication Law Assignment Help
- Law and Ethics Assignment Help
- Consumer Law Assignment Help
- Science
- Biology
- Engineering
-
Humanities
- Humanities Assignment Help
- Sociology Assignment Help
- Philosophy Assignment Help
- English Assignment Help
- Geography Assignment Help
- Agroecology Assignment Help
- Psychology Assignment Help
- Social Science Assignment Help
- Public Relations Assignment Help
- Political Science Assignment Help
- Mass Communication Assignment Help
- History Assignment Help
- Cookery Assignment Help
- Auditing
- Mathematics
-
Economics
- Economics Assignment Help
- Managerial Economics Assignment Help
- Econometrics Assignment Help
- Microeconomics Assignment Help
- Business Economics Assignment Help
- Marketing Plan Assignment Help
- Demand Supply Assignment Help
- Comparative Analysis Assignment Help
- Health Economics Assignment Help
- Macroeconomics Assignment Help
- Political Economics Assignment Help
- International Economics Assignments Help
-
Academic Writing Services
-
Essay Writing
- Essay Help
- Essay Writing Help
- Essay Help Online
- Online Custom Essay Help
- Descriptive Essay Help
- Help With MBA Essays
- Essay Writing Service
- Essay Writer For Australia
- Essay Outline Help
- illustration Essay Help
- Response Essay Writing Help
- Professional Essay Writers
- Custom Essay Help
- English Essay Writing Help
- Essay Homework Help
- Literature Essay Help
- Scholarship Essay Help
- Research Essay Help
- History Essay Help
- MBA Essay Help
- Plagiarism Free Essays
- Writing Essay Papers
- Write My Essay Help
- Need Help Writing Essay
- Help Writing Scholarship Essay
- Help Writing a Narrative Essay
- Best Essay Writing Service Canada
-
Dissertation
- Biology Dissertation Help
- Academic Dissertation Help
- Nursing Dissertation Help
- Dissertation Help Online
- MATLAB Dissertation Help
- Doctoral Dissertation Help
- Geography Dissertation Help
- Architecture Dissertation Help
- Statistics Dissertation Help
- Sociology Dissertation Help
- English Dissertation Help
- Law Dissertation Help
- Dissertation Proofreading Services
- Cheap Dissertation Help
- Dissertation Writing Help
- Marketing Dissertation Help
- Programming
-
Case Study
- Write Case Study For Me
- Business Law Case Study Help
- Civil Law Case Study Help
- Marketing Case Study Help
- Nursing Case Study Help
- Case Study Writing Services
- History Case Study help
- Amazon Case Study Help
- Apple Case Study Help
- Case Study Assignment Help
- ZARA Case Study Assignment Help
- IKEA Case Study Assignment Help
- Zappos Case Study Assignment Help
- Tesla Case Study Assignment Help
- Flipkart Case Study Assignment Help
- Contract Law Case Study Assignments Help
- Business Ethics Case Study Assignment Help
- Nike SWOT Analysis Case Study Assignment Help
- Coursework
- Thesis Writing
- CDR
- Research
-
Assignment Writing
-
Resources
- Referencing Guidelines
-
Universities
-
Australia
- Asia Pacific International College Assignment Help
- Macquarie University Assignment Help
- Rhodes College Assignment Help
- APIC University Assignment Help
- Torrens University Assignment Help
- Kaplan University Assignment Help
- Holmes University Assignment Help
- Griffith University Assignment Help
- VIT University Assignment Help
- CQ University Assignment Help
-
Australia
- Experts
- Free Sample
- Testimonial
BDA601 Big Data and Analytics Report Sample
Task Summary
Customer churn, also known as customer attrition, refers to the movement of customers from one service provider to another. It is well known that attracting new customers costs significantly more than retaining existing customers. Additionally, long-term customers are found to be less costly to serve and less sensitive to competitors’ marketing activities. Thus, predicting customer churn is valuable to telecommunication industries, utility service providers, paid television channels, insurance companies and other business organisations providing subscription-based services. Customer-churn prediction allows for targeted retention planning.
In this Assessment, you will build a machine learning (ML) model to predict customer churn using the principles of ML and big data tools.
As part of this Assessment, you will write a 1,000-word report that will include the following:
a) A predictive model from a given dataset that follows data mining principles and techniques;
b) Explanations as to how to handle missing values in a dataset; and
c) An interpretation of the outcomes of the customer churn analysis.
Please refer to the Task Instructions (below) for details on how to complete this task.
Task Instructions
1. Dataset Construction
Kaggle telco churn dataset is a sample dataset from IBM, containing 21 attributes of approximately 7,043 telecommunication customers. In this Assessment, you are required to work with a modified version of this dataset (the dataset can be found at the URL provided below). Modify the dataset by removing the following attributes: MonthlyCharges, OnlineSecurity, StreamingTV, InternetService and Partner.
As the dataset is in .csv format, any spreadsheet application, such as Microsoft Excel or Open Office Calc, can be used to modify it. You will use your resulting dataset, which should comprise 7,043 observations and 16 attributes, to complete the subsequent tasks. The ‘Churn’ attribute (i.e., the last attribute in the dataset) is the target of your churn analysis. Kaggle.com. (2020). Telco customer churn—IBM sample data sets. Retrieved from https://www.kaggle.com/blastchar/telco-customer-churn [Accessed 05 August 2020].
2. Model Development
From the dataset constructed in the previous step, present appropriate data visualisation and descriptive statistics, then develop a ‘decision-tree’ model to predict customer churn. The model can be developed in Jupyter Notebook using Python and Spark’s Machine Learning Library (Pyspark MLlib). You can use any other platform if you find it more efficient. The notebook should include the following sections:
a) Problem Statement
In this section, briefly state the context and the problem you will solve in the notebook.
b) Exploratory Data Analysis
In this section, perform both a visual and statistical exploratory analysis to gain insights about the dataset.
c) Data Cleaning and Feature Selection
In this section, perform data pre-processing and feature selection for the model, which you will build in the next section.
d) Model Building
In this section, use the pre-processed data and the selected features to build a ‘decision-tree’ model to predict customer churn.
In the notebook, the code should be well documented, the graphs and charts should be neatly labelled, the narrative text should clearly state the objectives and a logical justification for each of the steps should be provided.
3. Handling Missing Values
The given dataset has very few missing values; however, in a real-world scenario, data- scientists often need to work with datasets with many missing values. If an attribute is important to build an effective model and have significant missing values, then the data-scientists need to come up with strategies to handle any missing values.
From the ‘decision-tree’ model, built in the previous step, identify the most important attribute. If a significant number of values were missing in the most important attribute column, implement a method to replace the missing values and describe that method in your
report.
4. Interpretation of Churn Analysis
Modelling churn is difficult because there is inherent uncertainty when measuring churn. Thus, it is important not only to understand any limitations associated with a churn analysis but also to be able to interpret the outcomes of a churn analysis.
In your report, interpret and describe the key findings that you were able to discover as part of your churn analysis. Describe the following facts with supporting details:
• The effectiveness of your churn analysis: What was the percentage of time at which your analysis was able to correctly identify the churn? Can this be considered a satisfactory outcome? Explain why or why not;
• Who is churning: Describe the attributes of the customers who are churning and explain what is driving the churn; and
• Improving the accuracy of your churn analysis: Describe the effects that your previous steps, model development and handling of missing values had on the outcome of your churn analysis and how the accuracy of your churn analysis could be improved.
Solution
INTRODUCTION
Customers are the important entities of any organization that help them to make business and profit. So, every organization should have an intention to attract more customers in order to gain more profit. For Assignment Help, If the customers will be satisfied with the service, they will be retained in the business of the organization otherwise attrition may be seen (Eduonix, 2018). This is called customer churning that defines whether the customer has been retained or attrited from the business. In this paper, customer attrition will be determined with the application of machine learning.
1 COLLECTION OF CUSTOMER CHURN DATA
The data has been collected from Kaggle regarding customer churn (BlastChar, 2017). The data contains the records of those customers who have left the company and for those also who have retained with the company by taking services and purchasing goods. The Data is shown below:
.png)
Fig-1: Customer Churn Dataset
Initially, after collecting the data, it has been seen that the data contains 7043 instances or rows and 21 features or columns. The number of rows and columns are shown below:
.png)
Fig-2: Initial Data Attributes
Now, five features namely Monthly Charges, Online Security, Streaming TV and Internet Service and Partner have been removed and the resulting dataset is now containing the following attributes:
.png)
Fig-3: Resulting Data Attributes
So, presently, the data contains 7043 instances and 16 columns.
1.1 INFORMATION FOR TELCO DATA
The descriptive statistics of the dataset has been checked and the following outcome has been achieved (Learning, 2018).
.png)
Fig-4: Data Description
After that, the information of the data has been checked and the following outcome has been obtained:
.png)
Fig-5: Data Information
From the information of the data, it has been seen that all features are now in the form of the object (categorical).
2 DEVELOPMENT OF DECISION TREE MODEL
2.1 PROBLEM STATEMENT
In this paper, the problem statements have been prepared as follows:
1. What are the factors that are influencing customer churn?
2. How Decision Tree Classifier is helpful in determining the attrition of customers?
2.2 EXPLORATORY DATA ANALYSIS
The data analysis has been performed based on some of the features. First, the analysis has been done to visualize the customer attrition based on gender (Sosnovshchenko, 2018). It has been seen that Male customer has more tendency to be attrited compared to female customers.
.png)
Fig-6: Analysis of Gender
Nest, the analysis has been done to visualize whether Online backup is related to customer attrition. The outcome of the analysis is shown below:
.png)
Fig-7: Analysis of Online Backup
The analysis has been performed on the paperless billing of the purchased products. It has been seen that those customers have been attrited who have not received paperless billing.
.png)
Fig-8: Analysis of Paperless Billing
The analysis has been performed on the payment method for the purchased products. It has been seen that those customers have been attrited who have used the electronic check.
.png)
Fig-9: Analysis of Payment Method
2.3 DATA CLEANING AND FEATURE SELECTION
2.3.1 Data preprocessing and Cleaning
As seen earlier, the features of the data are categorical that cannot be fitted into machine learning (Learning, 2018). So, all the features have been preprocessed and converted to numerical data using data encoding as follows:
.png)
Fig-10: Data Preprocessing and Encoding
After preprocessing the data, the missing values have been found and it has been seen that there are no missing values in the data as follows:
.png)
Fig-11: Detecting Missing Values
So, there is no requirement for data cleaning as the data is already cleaned.
2.3.2 Feature Selection
Now, the correlation has been applied to check the relationship of the features with Churn. The outcome of the correlation is shown below in the form of a heatmap:
.png)
Fig-12: Correlation of Features
From the outcome of the correlation, the highly correlated features have been selected and shown below:
.png)
Fig-13: Finally Selected Features
So, these features will now be used as the final predictor features for the Decision Tree Classifier by retaining Churn as the target feature (Sosnovshchenko, 2018).
2.4 MODEL BUILDING
The predictor features have been selected from the correlation and the final dataset is shown below:
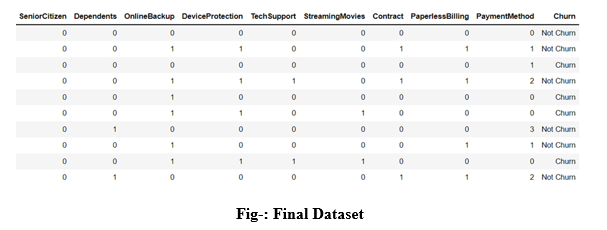
This data has been split into train and test sets as follows:
.png)
Fig-14: Data Splitting
The data splitting has been done using a 75-25 split ratio and the training dataset contains 5283 observations (through which the decision tree classifier will be trained) and the test set contains 1760 instances (through which the decision tree model will be tested) (Eduonix, 2018). In this test set, 1297 instances belong to “Not Churn” and 463 instances belongs to “Churn”. Now, the decision tree classifier has been applied with the following hyperparameter tuning and it has been trained with the training data:
• criterion='entropy'
• splitter='random'
• max_features='auto'
• random_state=10
After training the decision tree classifier, the model has been tested and the confusion matrix has been obtained as follows:
.png)
Fig-15: Confusion matrix
In this confusion matrix, It can be seen that 1110 instances out of 1297 instanced have been correctly classified as “Not Churn” and 302 instances out of 463 instances have been correctly classified as “Churn”. By considering the overall performances, 1412 instances have been correctly classified by attaining 80.23% accuracy, 81% precision, 80% recall and 80% f1-score. The performance overview is shown below in the form of a classification report (Lakshmanan, Robinson, & Munn, 2021).
.png)
Fig-16: Classification Report
3 FINDING AND CONCLUSION
The data has been selected from Kaggle regarding customer churn and analysed for the detection of customer attrition. In this context, the data has been preprocessed and the features have been selected. After preparing the data, it has been split into train and test sets and the decision tree classifier has been trained and tested accordingly and the performance of the classification has been achieved. The problem statements have been addressed as follows:
1. The features such as senior citizen, Dependents, online backup, DeviceProtection, TechSupport, StreamingMovies, Contract, PaperlessBilling, PaymentMethod have been seen to be the important features for the prediction of customer churn.
2. Decision Tree Classifier can be used to classify and predict the customer churn with 80.23% accuracy, 81% precision, 80% recall and 80% f1-score.
4 REFERENCES
.png)

Download Samples PDF
Related Sample
- MBA652 Strategy and Leadership in Tourism and Hospitality
- GDECE101 Early Childhood Care and Education
- MGT600 Management People and Teams Report 3B
- ISYS5003 Principles of UX Design Assignment
- FIN201 Business Finance Case Study
- HI6008 Business Research Project Report 1
- MEM601 Engineering Sustainability Report 2
- HVAC System Design Assignment
- MBA Capstone Strategy Assessment
- EDUC9136 Education Policy Politics and Practice Assignment
- Mediation and Moderation of Sleep in Arthritis Fatigue Assignment
- LAW500 Business Law Assignment
- SAP102 Welfare Systems and Services in Australia 2B Essay
- BUECO5903 Assignment
- TECH5300 Bitcoin Case Study 1
- Cultural Differences Role in Marketing Strategies for MNCs
- BUS2004 Human Resource Management Assignment
- MBA506 Thinking Styles Negotiation and Conflict Management Report
- MKT60010 Marketing Management Assignment
- Dynamic Leadership Assignment

Assignment Services
-
Assignment Writing
-
Academic Writing Services
- HND Assignment Help
- SPSS Assignment Help
- College Assignment Help
- Writing Assignment for University
- Urgent Assignment Help
- Architecture Assignment Help
- Total Assignment Help
- All Assignment Help
- My Assignment Help
- Student Assignment Help
- Instant Assignment Help
- Cheap Assignment Help
- Global Assignment Help
- Write My Assignment
- Do My Assignment
- Solve My Assignment
- Make My Assignment
- Pay for Assignment Help
-
Management
- Management Assignment Help
- Business Management Assignment Help
- Financial Management Assignment Help
- Project Management Assignment Help
- Supply Chain Management Assignment Help
- Operations Management Assignment Help
- Risk Management Assignment Help
- Strategic Management Assignment Help
- Logistics Management Assignment Help
- Global Business Strategy Assignment Help
- Consumer Behavior Assignment Help
- MBA Assignment Help
- Portfolio Management Assignment Help
- Change Management Assignment Help
- Hospitality Management Assignment Help
- Healthcare Management Assignment Help
- Investment Management Assignment Help
- Market Analysis Assignment Help
- Corporate Strategy Assignment Help
- Conflict Management Assignment Help
- Marketing Management Assignment Help
- Strategic Marketing Assignment Help
- CRM Assignment Help
- Marketing Research Assignment Help
- Human Resource Assignment Help
- Business Assignment Help
- Business Development Assignment Help
- Business Statistics Assignment Help
- Business Ethics Assignment Help
- 4p of Marketing Assignment Help
- Pricing Strategy Assignment Help
- Nursing
-
Finance
- Finance Assignment Help
- Do My Finance Assignment For Me
- Financial Accounting Assignment Help
- Behavioral Finance Assignment Help
- Finance Planning Assignment Help
- Personal Finance Assignment Help
- Financial Services Assignment Help
- Forex Assignment Help
- Financial Statement Analysis Assignment Help
- Capital Budgeting Assignment Help
- Financial Reporting Assignment Help
- International Finance Assignment Help
- Business Finance Assignment Help
- Corporate Finance Assignment Help
-
Accounting
- Accounting Assignment Help
- Managerial Accounting Assignment Help
- Taxation Accounting Assignment Help
- Perdisco Assignment Help
- Solve My Accounting Paper
- Business Accounting Assignment Help
- Cost Accounting Assignment Help
- Taxation Assignment Help
- Activity Based Accounting Assignment Help
- Tax Accounting Assignment Help
- Financial Accounting Theory Assignment Help
-
Computer Science and IT
- Operating System Assignment Help
- Data mining Assignment Help
- Robotics Assignment Help
- Computer Network Assignment Help
- Database Assignment Help
- IT Management Assignment Help
- Network Topology Assignment Help
- Data Structure Assignment Help
- Business Intelligence Assignment Help
- Data Flow Diagram Assignment Help
- UML Diagram Assignment Help
- R Studio Assignment Help
-
Law
- Law Assignment Help
- Business Law Assignment Help
- Contract Law Assignment Help
- Tort Law Assignment Help
- Social Media Law Assignment Help
- Criminal Law Assignment Help
- Employment Law Assignment Help
- Taxation Law Assignment Help
- Commercial Law Assignment Help
- Constitutional Law Assignment Help
- Corporate Governance Law Assignment Help
- Environmental Law Assignment Help
- Criminology Assignment Help
- Company Law Assignment Help
- Human Rights Law Assignment Help
- Evidence Law Assignment Help
- Administrative Law Assignment Help
- Enterprise Law Assignment Help
- Migration Law Assignment Help
- Communication Law Assignment Help
- Law and Ethics Assignment Help
- Consumer Law Assignment Help
- Science
- Biology
- Engineering
-
Humanities
- Humanities Assignment Help
- Sociology Assignment Help
- Philosophy Assignment Help
- English Assignment Help
- Geography Assignment Help
- Agroecology Assignment Help
- Psychology Assignment Help
- Social Science Assignment Help
- Public Relations Assignment Help
- Political Science Assignment Help
- Mass Communication Assignment Help
- History Assignment Help
- Cookery Assignment Help
- Auditing
- Mathematics
-
Economics
- Economics Assignment Help
- Managerial Economics Assignment Help
- Econometrics Assignment Help
- Microeconomics Assignment Help
- Business Economics Assignment Help
- Marketing Plan Assignment Help
- Demand Supply Assignment Help
- Comparative Analysis Assignment Help
- Health Economics Assignment Help
- Macroeconomics Assignment Help
- Political Economics Assignment Help
- International Economics Assignments Help
-
Academic Writing Services
-
Essay Writing
- Essay Help
- Essay Writing Help
- Essay Help Online
- Online Custom Essay Help
- Descriptive Essay Help
- Help With MBA Essays
- Essay Writing Service
- Essay Writer For Australia
- Essay Outline Help
- illustration Essay Help
- Response Essay Writing Help
- Professional Essay Writers
- Custom Essay Help
- English Essay Writing Help
- Essay Homework Help
- Literature Essay Help
- Scholarship Essay Help
- Research Essay Help
- History Essay Help
- MBA Essay Help
- Plagiarism Free Essays
- Writing Essay Papers
- Write My Essay Help
- Need Help Writing Essay
- Help Writing Scholarship Essay
- Help Writing a Narrative Essay
- Best Essay Writing Service Canada
-
Dissertation
- Biology Dissertation Help
- Academic Dissertation Help
- Nursing Dissertation Help
- Dissertation Help Online
- MATLAB Dissertation Help
- Doctoral Dissertation Help
- Geography Dissertation Help
- Architecture Dissertation Help
- Statistics Dissertation Help
- Sociology Dissertation Help
- English Dissertation Help
- Law Dissertation Help
- Dissertation Proofreading Services
- Cheap Dissertation Help
- Dissertation Writing Help
- Marketing Dissertation Help
- Programming
-
Case Study
- Write Case Study For Me
- Business Law Case Study Help
- Civil Law Case Study Help
- Marketing Case Study Help
- Nursing Case Study Help
- Case Study Writing Services
- History Case Study help
- Amazon Case Study Help
- Apple Case Study Help
- Case Study Assignment Help
- ZARA Case Study Assignment Help
- IKEA Case Study Assignment Help
- Zappos Case Study Assignment Help
- Tesla Case Study Assignment Help
- Flipkart Case Study Assignment Help
- Contract Law Case Study Assignments Help
- Business Ethics Case Study Assignment Help
- Nike SWOT Analysis Case Study Assignment Help
- Coursework
- Thesis Writing
- CDR
- Research

.png)
~5.png)
.png)
~1.png)























































.png)






