Reports
HI5030 System Analysis and Design Report Sample
This assessment relates to the unit learning outcomes as in the Unit of Study Guide. This assessment is designed to give students skills to explore the latest system analysis and design trends, challenges, and future directions.
In this individual research paper, you will explore a contemporary issue in systems analysis and design, integrating academic research with practical application. The assignment is designed to deepen your understanding of the selected issue and its real-world impact on business information systems. You will critically analyse the issue, apply relevant methodologies to a real-world or hypothetical scenario, and propose solutions to address the challenges it presents.
1. Issue Selection:
- What You’ll Do: Choose a contemporary issue from the list provided by the unit coordinator. Some examples of issues you might consider include:
o Agile vs. Waterfall Methodologies: The challenges and benefits of agile methodologies compared to traditional waterfall approaches in system development.
o Data Privacy and Security: How emerging privacy regulations, such as GDPR, impact system design and the challenges of ensuring compliance while maintaining system efficiency.
o Integration of AI in System Design: The opportunities and challenges of incorporating artificial intelligence into business information systems, including issues related to data quality, bias, and explainability.
o Cloud-Based Systems vs. On-Premises Systems: The considerations and trade-offs involved in choosing cloud-based solutions over traditional on-premises systems, including security, cost, and scalability.
o User-Centred Design: The importance of user experience (UX) in systems analysis and design, and the challenges of balancing user needs with technical requirements.
2. Research and Practical Application:
- What You’ll Do: Start by conducting a literature review on your chosen issue. Look for academic articles, industry reports, and case studies that discuss the issue in depth. Then, apply the insights from your research to a practical scenario. For example:
o Agile vs. Waterfall Methodologies: After reviewing the strengths and weaknesses of both approaches, you could apply them to a project management scenario in a software development company. You might create a prototype or design document showing how an agile approach could be adapted to a traditionally waterfall project, highlighting the potential benefits and challenges.
o Data Privacy and Security: If your issue is data privacy, you could apply your research to a company that needs to redesign its information systems to comply with GDPR. This could involve proposing specific changes to data storage and processing practices and demonstrating how these changes would be implemented.
3. Impact and Solution Analysis:
• What You’ll Do: Analyse how the selected issue impacts the design and implementation of business 1 information systems in your scenario. Discuss how the issue affects system functionality, data management, and the communication of requirements to stakeholders. Then, propose practical solutions or methodologies that could address these challenges. For example:
o Agile vs. Waterfall Methodologies: Your analysis might reveal that while agile offers greater flexibility, it may be less effective in highly regulated industries where detailed documentation is required. You could propose a hybrid approach that incorporates the flexibility of agile with the structure of waterfall.
o Integration of AI in System Design: You might identify that the use of AI introduces new challenges in data quality and bias. To address this, you could propose a framework for regular audits of AI systems to ensure they are fair and transparent.
4. Documentation and Communication:
• What You’ll Do: Compile your findings, analysis, and proposed solutions into a well-organized research paper. Your paper should clearly articulate both the theoretical research and the practical application. Ensure your writing is accessible to both technical and non-technical audiences, using clear explanations and supporting your arguments with evidence from your research and application.
Solution
Introduction
Background
The rapid expansion in digital platforms has forced data security and privacy to become integral in modern-day processes. With private information becoming an asset, governments and regulating bodies have formulated strong policies such as GDPR in an attempt to secure information regarding users from misuse, unauthorized access, and information leakages. GDPR compels a strong collection of requirements such as transparency in processing, granting users high levels of information control, and having strong security controls in place (Sharma, 2019, p5-33). Organizations must re-engineer system approaches in compliance with such requirements in a manner that maintains efficiency in the system intact.
Purpose
This report for the Assignment Help aims to examine how GDPR affects system design, such as its challenge for organizations in achieving compliance at a cost not incurring a loss in system performance. It involves an in-depth analysis of methodologies and approaches companies can use in harmonizing information systems with GDPR compliance at a level not compromise operational agility.
Scope
The study addresses information systems in financial services and in e-commerce whose operations entail working with sensitive information regarding users at a fundamental level. Analysis entails compliance issues, impact on system structures, and proposed solutions in terms of using privacy-preserving technology and automation.
Structure
The report is organized into key sections, beginning with an analysis of GDPR and similar legislation, followed by a careful analysis of compliance barriers and ramifications for commercial infrastructure, and then a real-world application case study to present actual compliance methodologies, culminating in proposed methodologies and an implementation schedule for enhancing security for information and compliance with legislation.
Literature Review
Theoretical Background
Major GDPR compliance concepts are privacy-by-design, data minimization, encryption, and lawful processing of data. Privacy-by-design ensures that data protective measures are included in system development at an early stage and not appended later. Data minimization entails collecting data that is pertinent to a certain purpose, reducing exposure to security threats. Encryption secures stored and in-transit data, and access to them in an unauthorized way is difficult. Lawful processing of data ensures openness in processing an individual's data and for a certain purpose defined under GDPR. Kamocki and Witt, (2020) state that compliance is enhanced through privacy-by-design principles, through inclusion of security in system architecture, and reducing security breaches (Kamocki, and Witt, 2020, p3423-3427). Daniel, 2022 further identifies that secure processing and encryption are vital considerations in the protection of users' information, and in reducing exposure to cybersecurity threats (Daniel, 2022, p33-43).
Current Research
Recent studies have concentrated specifically on GDPR's function in redefining information security architectures. Research identifies added expenses and complexity, particularly for SMEs, with compliance. Most companies have a problem with interpreting GDPR requirements, and therefore, have an ad hoc form of compliance. According to studies, GDPR encourages increased trust in consumers, but full compliance is challenging with changing requirements and technological development. Höglund, (2019) believes that blockchain technology can deliver secure, unalterable transaction logs in supporting GDPR compliance, particularly in terms of controlling data (Höglund, 2019, p12-32). Carroll et al., in 2023 refer to using AI for compliance automation, with companies being capable of tracking and controlling user information and reducing human intervention and mistakes (Carroll et al., 2023, p1-19).
Relevance to Business Information Systems
Compliance needs to shape business systems through an impact on database structure, access controls, and authentication processes for users. GDPR necessitates that companies implement strong access controls in a move to stop unauthorized access to sensitive information. Companies must also maintain thorough logs of processing activity, and therefore, must modify database administration systems. Rules for the right to be forgotten and data portability require companies to implement processes through which users can request deletion of information or move information to new service providers. Business information systems must also include real-time tracking tools to detect information breaches and honor GDPR’s 72-hour breach reporting requirement. According to MBULA, (2019), companies that fail to comply with these requirements face significant penalties, and compliance is a key concern for system architects (MBULA, 2019, p1-7). In addition, studies conducted by Höglund (2019) have determined that GDPR compliance is driving companies to redesign their system architectures with enhanced security capabilities, including biometric authentication and sophisticated algorithms for encryptions (Höglund, 2019, p12-32).
Analysis of the Issue
Description of the Issue
GDPR compliance involves several technical, operational, and legal complexities. Organizations must maintain security for information, manage consent, and have effective breach response processes in position. Having to maintain compliance and yet preserve efficiency in the system involves additional complications. Organizations must redesign systems in a way that incorporates privacy-related controls in a manner that doesn't affect operations. Regulatory bodies have severe penalties for non-compliance, and compliance is, therefore, significant in terms of financial and reputational loss avoidance. Besides, GDPR involves proactive security for information, with continuous updating and tracking in terms of emerging vulnerabilities and changing legislation and laws (Tamburri, 2020, p1-14).
Impact on Business Information Systems
Companies must re-engineer information systems to:
- Implement encrypted data and secure access protocols in compliance with GDPR security standards, such as end-to-end encryption, secure key management, and complex authentication processes to resist unauthorized access to information (Pookandy, 2020, p19-32).
- Ensure compliance with the rights of users over information, such as erasure and portability. Organizations must have processes in place through which deletion and moving of information can be requested in terms of GDPR’s principle of right-to-be-forgotten.
- Develop real-time auditing capabilities in a manner that will enable companies to monitor and log all processing activity for data, for transparency and for compliance with regulators to verify compliance.
- Introduce role-based access controls to limit access to sensitive information based on job roles. Individual datasets can only have access for approved staff, and through this, security and data vulnerabilities will be reduced to a minimum.
- Conduct regular compliance audits and risk assessments to assess potential vulnerabilities in business information systems and apply corrective actions in anticipation of breaches taking place.
Comparison of Methodologies/Approaches
- Traditional security methodologies focus first and foremost on perimeter security, such as anti-malware and firewalls, but lack in GDPR compliance through an insufficiency of deeper security processes for safeguarding information. Traditional methodologies provide a baseline level of security, but not one capable of supporting modern compliance frameworks with a focus on safeguarding information at all processing stages.
- Privacy-enhancing technologies (e.g., homomorphic encryption) allow for increased compliance through computations over encrypted data, not in its plaintext state. In such a way, private information is preserved even during processing, but such techniques require high computational powers, with increased operational costs and system overheads (Hall, 2024, p39-46).
- Hybrid approaches integrate AI-facilitated compliance monitoring with traditional security methods. AI-facilitated compliance tools can monitor compliance with policies, detect outliers, and manage risks with effectiveness. Hybrid approaches, through a combination of traditional security methodologies and emerging techniques for protecting privacy, integrate compliance and system performance harmoniously. Organizations can utilize AI-facilitated auditing tools to scan high volumes of information in real time, and compliance can be guaranteed with reduced intervention.
Practical Application
Scenario Description
A multinational e-commerce retailer will have to re-engineer its information management system in compliance with GDPR legislation. The retailer processes enormous amounts of information about its customers, including payment details, individual identifiers, and web browsing behavior. GDPR compliance will require significant changes in collecting, storing, and accessing information in a way that doesn't affect operational efficiency in any manner. Embedding security controls in a way that doesn't impair user experience will challenge the retailer, and a careful balancing act between compliance and agility in operations will be a necessity.
The introduction of new technology such as artificial intelligence (AI) and machine learning (ML) brings opportunity and challenge together. AI not only will enhance security for information but will require a high level of governance for ethics compliance. Cross-border transmissions of information will have to be handled, and with them, additional legal requirements will become applicable. In this case study, an optimized compliance path with GDPR and at the same time not compromising efficiency in operations will be exhibited.
Application of Methodologies
Automated Consent Management Systems: Implementing automated consent management tools keeps users in control of collecting and processing information about them. Automated consent management tools make it easier for users to opt in and withdraw consent at any stage, in compliance with GDPR requirements. Automated tracking of consent reduces administration and lessens the risk of non-compliance through having a current record of a user's preference (Chhetri et al., 2022, p.2763(5)).
Multi-Factor Authentication (MFA): The adoption of multi-factor authentication (MFA) fortifies security for information through a multi-step access-granting verification process. By utilizing biometric authentication, one-time passwords (OTPs), and hardware tokens, MFA reduces unauthorized access with high-security protocols in position for safeguarding sensitive information about a user in case of future hacks and cyber attacks (Lawson, 2023, p1-13).
Data Retention Policies: Developing robust data retention policies assists in deleting unnecessary and outdated information automatically in a manner that adheres to GDPR requirements. Having an automatic mechanism for deleting information lessens vulnerability to over-storage of information, and subsequently lessens vulnerability to a data breach. Policies also allow companies to have effective use of storage and compliance with requirements for minimizing information under legislation.
Real-Time Compliance Monitoring: Integrating real-time compliance tracking tools helps companies monitor processing activity and label suspected violations in real-time. AI-powered analysis tells companies about processing activity for specific users, and companies can actively correct compliance failures in real-time even when no failure actually occurred.
Incident Response and Breach Notification Protocols: Establishing structured incident reporting and breach notification processes helps in minimizing loss in case of a breach. GDPR mandates organisations to report to regulators in 72 hours when a breach is discovered. Automated incident reporting and incident resolution processes enable rapid incident identification, containment, resolution, compliance, and trust with stakeholders (Obanla and Sapozhnikov, 2019, p12-20).
Outcome
The redesigned system vastly improves security for the data, with increased compliance with GDPR and operational effectiveness for the organization. Automated consent management enables transparency and trust with the users, and multi-factor authentication strengthens access controls. Data retention policies minimize unnecessary storing of data, safeguarding against future legal repercussions. Real-time compliance checking reduces compliance-related danger, with ongoing compliance with developing standards. AI and ML integration fortifies security for the data and enables real-time danger detection and response. Automated reporting processes streamline GDPR compliance audits, with reduced administration involved.
By balancing security, compliance, and operational efficiency, the organization achieves an expandable and flexible information management infrastructure. In the long-term, the enhanced system enables a safer, user-centric information environment for both the organisation and its clients. Implementation of AI-powered security and compliance tools not only ensures GDPR compliance but puts the organization at an edge in terms of ethical information processing and cybersecurity solidity.
Proposed Solutions
Solution Description
To address GDPR compliance in an effective manner, companies must undertake a multi-faceted approach comprising encryption, governance, and compliance automation.
Encryption and access controls: Secure information at rest and in transit with robust encryption algorithms like AES-256. Implement multi-dimensional authentication processes, such as biometric and multi-factor authentication (MFA), to safeguard access (Iavich et al., 2024, p70-78).
Data Governance Framework: Adopt a documented data governance model with role-based access controls (RBAC), real-time activity logging, and automated audit trails for compliance with GDPR transparency and accountability requirements (Nookala, 2024, p2-18).
Automated Compliance Monitoring: Install AI-based compliance monitoring software that periodically audits system logs and data transactions for suspected compliance failures. Automated software can detect unapproved access, label non-compliant data storage, and generate real-time alerts for security professionals
Justification
Implementing these solutions strengthens security for data and ensures efficiency in the system. Encryption keeps even unauthorized access at bay, and yet, keeps the information in an uninterpretable and secure state. Having a strong data governance model reduces the chance of any kind of human errors, and with that, helps companies comply with regulatory requirements with ease. Automated compliance checking reduces the burden of constant checking, allowing companies to detect and correct any compliance-related issues.
Implementation Plan
- Assessment: Conduct a complete GDPR compliance review to detect security and governance vulnerabilities, evaluate processing risks for your data, and confirm compliance with applicable regulations.
- Development: Modify system infrastructure with strengthened encryption techniques, role-based access controls (RBAC), and compliance tools for securing information.
- Testing: Perform in-depth security tests, including penetration testing, system audits, and acceptance tests, to validate protective controls
- Deployment: Implement compliance in phased phases, with a minimum level of operational disruption and opportunity for iterative refinement and system optimizations.
- Monitoring: Establish continuous compliance tracking with AI-facilitated analysis, conduct regular audits, and apply real-time risk management methodologies to assure GDPR compliance and system integrity.
Conclusion
GDPR has initiated a new era in system development with its imposition of strong data protection and prioritization of anonymity for users. Organizations must operate in an environment with a complex scheme of regulation that will require them to integrate privacy-by-design methodologies, secure information processing, and real-time transactional observation for compliance. Compliance poses such challenges as implementation complexity, uncertainty in legislation, and performance compromises, but proactive techniques such as encryption, role-based access controls, and governance automation can harmonize system efficiency with compliance requirements effectively. Besides, companies have to review security and compliance methodologies in a continuous manner regularly in an ongoing search for countering new emerging threats and changing compliance requirements in a long-term basis.
As businesses increasingly depend on digital infrastructure, security for information has become a part of system planning. Organizations must integrate privacy as a principle in planning, such that security controls have no impact on operational efficiency. Trends in technology enriched with privacy, AI-powered compliance tracking, and blockchain-powered tracking of information can make GDPR compliance easier to manage. With these emerging trends, frameworks for safeguarding information can become efficient and allow companies to maintain agility and responsiveness at the same time. As awareness regarding information privacy keeps growing, companies prioritizing compliance can gain a competitive edge through trust and a demonstration of a desire to safeguard individual information. Overall proactive and meticulous compliance will not only allow companies to manage risks but will make them overall cybersecurity strong.
Recommendations
Actionable Steps
To ensure long-term GDPR compliance and future emerging legislation regarding data privacy, companies must act in anticipation in fortifying security frameworks:
- Regularly update security policies in accordance with developing laws and legislation, with a view to revising them every six months and including best practice in the field.
- Implement privacy-enhancing techniques such as homomorphic encryption and differential privacy in an effort to mitigate vulnerabilities in data exposure and maintain usability for operations and analysis.
- Conduct periodic audits, both internal and external, to detect vulnerabilities and evaluate system resilience.
- Employ automated compliance tools for real-time deviation in policies and taking immediate corrective actions.
Best Practices
- Adopt a security-first development at every stage of software and system development, with security controls incorporated at each stage
- Establish transparent data processing policies to inform users about how their information is collected, stored, and processed, in a manner that will instill trust in regulators
- Train employees in GDPR compliance and best practice, instilling a culture of awareness and accountability.
Reference
.png)

Reports
HI5033 Database Design Report Sample
Assignment Description
This assessment requires individual completion. Students are expected to complete a critique and conduct a literature review to discuss a contemporary issue relating to Database Systems and identify appropriate approaches to address this issue. The topic is “Evaluating the Impact of Indexing Techniques on Query Performance in Relational Databases”.
Each student is required to search the literature and find a minimum of ten (10) academic research papers (references) related to this topic. Subsequently, the student must critically analyse the selected references and provide an in-depth discussion on how they reflect the topic. This assessment is worth 40% of the unit’s grade and is a major assessment. Students are advised to begin working on this assessment as soon as possible.
Deliverable Description
You need to submit the final version of your assignment in Week 12. The structure of the final report should include a cover page and 5 sections as follows:
1. Introduction
State the purpose and objectives of the report, present an overview of the topic, and outline the scope of your analysis.
2. Literature Review
Summarize key findings from at least ten academic papers, highlighting relevant theories, methodologies, and results. Identify major trends, gaps, and areas of consensus or disagreement within the literature.
3. Discussion
Critically analyse the references reviewed in the literature review. Discuss how these sources contribute to the understanding of database optimisation, examining their relevance, strengths, and limitations.
4. Conclusion
Summarize your findings, emphasizing key insights from the literature review and discussion.
5. References
Provide a comprehensive list of all references cited in your report, formatted according to the Adapted Harvard Referencing style.
Solution
Introduction
The purpose of the report is to understand the perceptions in the existing literature related to the impact of the indexing technique and query performance in a relational. The main objective of this review is to understand the concept in detail and to know the implications of different aspects, techniques, models, and theories related to indexing and query that are associated with database performance and advancement. Indexing technique and query performance are a significant part of relation and database because they choose the effectiveness and feasibility of different databases for the Assignment Help in responding to challenges and advancement areas. In this respect, the nature of changes in indexing and query performance shows the evolution of databases. The scope of the analysis of literature will show different areas of query management as well as indexing techniques that are focused on the database application as well as developed by different researchers as well as real-time implementations. The scope is also to understand those areas that create advancement in the different databases.
Literature Review
Gadde (2021) opines that artificial intelligence helps reduce downtime and increase the accuracy of relational databases. The discussion shows an investigation of the understanding of leveraging artificial intelligence for improvement and enhancement of efficiency by minimising down time in relational database systems. It is seen that alignment of both traditional and modern proactive theoretical solutions of maintenance seems effective in providing the result. Historical data were reviewed on certain metrics, leading to the understanding that a random forest-based predictive model accuracy in maintenance and performance. It is there for the fact that the AI-driven predictive model as a trend enhances the database management system is gaining momentum.
Ali et al. (2022) argue that techniques like compact data structure and multi-query Optimisation are seen to be effective in enhancing data quality performance within the system. That discussion shows a review of techniques and systems that help contribute to the RDF query graph. The focus is on identifying the growth of RDF in terms of graph-based models that provide a theoretical understanding of challenges and KPIs. In terms of gaining efficiency graph partitioning in distributed systems shows more accuracy than local systems in scalability. The discussion is based on reviewing and examining the results of 135 RDF/SPARQL engines and 12 benchmarks. The discussion shows Limited knowledge about scalability in RDF and multi-query Optimisation as a concept.
Han et al. (2021) highlight that ML-based methods help to enhance the performance of the traditional query execution process. The discussion creates an understanding of the role of different estimation cardinality estimation methods to improve the functioning of the Quadri Optimisation in relational databases. The research focuses on understanding a model with respect to theoretical approaches of DBMS that helps in comparing traditional methods with modern machine learning-based approaches. The study shows different new aspects in the machine learning data driven method like P-error instead of E error that helps in improving the functionalities and feasibility of a system. The methods include the establishment of new benchmarks for real-world databases and the evaluation of multiple cardinality estimation methods. The finding shows that machine learning will create a modernised trend of shifting from traditional to modern query Optimisation models. There is inadequate information about the concept of the real world in this context.
Kossmann, Papenbrock, and Naumann (2022) view that dependence on data improves query optimisation. The discussion provides results of the survey in which different types of data-dependent processes are reviewed in query Optimisation in a relational database system. Rule-based and cost-based Optimisation approaches are considered for the review of the model in terms of theoretical understanding. Findings show that refinement of the execution plan, computation reduction and enhancement of indexing strategies showed improvement in enquiry Optimisation who data dependencies. A review of the survey is adopted as a methodology to gain insights. Trends indicate that there is increased research on the advanced metadata for query Optimisation. The low implementation rate of data-dependent processes in real practice limits knowledge and focus in the discussion.
Hosen et al. (2024) highlight that a new model or query language can enhance the abilities of the query. The discussion focuses on creating a new query language and a model for temporal graph data to understand its effectiveness in creating efficiency. Graph database principles are considered to identify the utilisation and features of the model. The finding shows that the model is capable of increasing the feasibility and efficiency of both real-world and synthetic data sets. The discussion indicates a significant growing interest in temporal data graphs and progressive query language. There is limited historical data about the temporal paragraph in the existing query model that can be compared through the discussion.
Pan, Wang, & Li (2024) argue that vector data management shows challenges in indexing and hybrid query execution. The discussion shows in-depth research on vector database management systems to outline its key challenges and future scope in research and techniques. Theoretical concepts like embedding-based retrieval, data management principles and similarities search are focused on and considered for gaining relevant insights. The finding highlights different categories and emerging techniques of vector database management systems including all its visible challenges. Models with unstructured data or large databases are growing rapidly facilitating the need for an advanced approach of vector database management in the coming time. Gaps in studies of hybrid query or Optimisation techniques are found within the discussion.
Wang et al. (2021) opine that Milvus is a vector-based data management system capable of managing high-dimensional data. Discussion highlights a specific with the database management model to show its competence and effectiveness in responding to high dimensional data of Artificial Intelligence and databased applications. Theoretical attributes and principles of system architecture have been focused on understanding the need for this model in data query management. The results indicate that Milvus is looking to outperform an existing database system by offering advanced functionalities. An extensive benchmark is set for evaluation of the specific vector database management system to compare it with multiple other database systems. Future trend shows increasing use of Artificial Intelligence and data science facilitates the need for a high performance vector database management system. Limitations of studies are seen in understanding hybrid data query processing.
Liu et al. (2021) view that error reduction and logical operation show effective query execution on knowledge graphs. The purpose of the discussion is to identify ways through which the execution in the knowledge graph can be enhanced. The mention of neutral embedding-based methods is done to identify gaps in the traditional approaches. The finding reveals that the proposed method is seen to enhance accuracy and efficiency in the query management of a knowledge graph. The methodology involves proposing a modern that can address embedding entities and queries in a vector space. The trend highlighted is a shift from rule based model to deep learning approaches. Limitation of discussion is seen in identifying the management of complex queries associated with various nodes.
Trummer et al. (2021) point out that the neural approach improves performances in various software analysis applications. The discussion sheds light on neural software analysis, in which approaches are exploded to enhance the efficiency and performance of systems. Finding show that neural approaches are effective in creating systematic functioning of analysis software Complex code patterns leading to enhancement of the existing process. The methods involve conducting training on the neural networks on large codebases. A major trend is seen in the adoption of machine learning in software engineering for code analysis. Gaps in the study are found in understanding the consequences of integrating modern neural analysis with traditional ones in terms of efficiency and flexibility.
Wang et al. (2022) opine that V-chain+ is an effective model that improves query performance more than existing systems. The study aims to explore the Boolean range of queries and their effectiveness in the blockchain database. Findings show that the proposed model in the research has significantly addressed mitigating gaps in the existing system and increasing efficiency enquiry performance within the database. A sliding window accumulator and an objective registration index are designed as part of the method to conduct this research. The trend shows that there is increasing integration of index techniques with the blockchain for data retrieval. Gaps of knowledge are seen in inefficiency and prayer solutions to the challenges used to Complex query management.
Khan et al. (2023) point out that a NoSQL database is better than SQL in managing large volumes of unstructured data. The discussion focuses on a comparative assessment of two types of data: NoSQL and SQL. The outcome shows that NoSQL by Scheme with less structure and horizontal scalability, responds effectively and better than SQL databases to manage Complex data. The methodology adopted for this purpose is a systematic review of literature With a definite number of sample data. The growing trend is seen in the adoption of NoSQL databases for big data applications and Systems. The study shows a gap in providing effective solutions to issues like interoperability and data portability.
Cao et al. (2021) state that a native cloud-based database is capable of quick responses to adverse situations or failures. The study aims to explore in native cloud-based database in terms of its application for aggravated data centres to improve efficiency, availability and performance. Resource disaggregation theory provides a strong theoretical framework to identify aspects related to the New database designing. The finding suggests that the specific database is helpful in failure recovery faster in practice. Methods like optimistic locking, index-aware prefetching, etc, are used for creating the design of the proposed model. Trends show growing interest in serverless and aggravated databases to respond to scalability and cost-effectiveness. An understanding of the scalability gap is found in studies within the traditional and existing databases.
Fotache et al. (2023) opine that data masking has minimal impact on query improvement. The discussion explored the role of performance penalty in dynamic data masking in SQL databases focusing on Oracle. Privacy by design model and security theories are considered to identify different principles and aspects related to data masking in SQL databases. The results show that dynamic determine asking has a weak influence on query management in an SQL database. Methods include query analysis, machine learning models, etc. The future growing interest in the alignment of security and compliance in databases holds a significant part in the discussion. The discussion provides less focus on the Cost performance of dynamic data masking in Real-world scenarios.
Panda, Dash & Jena, (2021) highlights that Particle Swarm Optimisation increases efficiency of the query execution. The purpose of the study is to optimise the query response time of blockchain by applying evolutionary algorithms. Blockchain indexing, cryptographic security theories helps to understand the framework more dominantly and significantly. Finding show that PSO reduce computational costs within systems. The adoption of artificial intelligence in the optimisation of blockchain databases is a major trend. The limitations of the study are seen in identifying the role of artificial intelligence in the centralised system in terms of query response management.
Wu & Cong (2021) state that deep autoregressive models provide better accuracy and improve cardinality estimation in databases. The discussion provides a new proposed model for improving estimation cardinality in a database. Gumbel Software trick and deep learning techniques provide a theoretical framework for understanding the requirement of the proposed database. The results show a reduction in error and an improvement in efficiency in workload shifts. The study is done using a hybrid training model. Trends in the discussion is seen in growing AI Adoption in cardinality estimation within a database. The gap is seen in identifying further Optimisation techniques.
Discussion
Considering the literature review, one of the major aspects that is considered as a strength focus on advancement related to query execution or management is the adoption of artificial intelligence. In most of the review of discussion artificial intelligence is found to be effective in handsome database system by reduction of error down time and and enhancement of scalability efficiency and performance. Artificial intelligence enhances the performance of a query in a database system proficiently (Panda et al., 2021). In terms of understanding future scope, it is also seen that the growing interest and adoption of artificial intelligence is the need for more advanced and data-driven models for queries and indexing. This growing interest also has led to different new model proposals, as seen in the existing literature. The second positive aspect that comes out of the literature review is the focus on creating models that reflect the alignment of both the traditional and modern forms, focusing on that theoretical foundation and creating a progressive approach for relational database query management. Deep learning-based models are seen to Breach the gap between data-driven and query-driven approaches. It simply means that all of the focus in proposing new models and techniques identifies strengths of the traditional approaches and modern technology in terms of mitigating the gaps and challenges. This shows are very potential nature of Advanced indexing techniques as well as query management in relational databases.
Major weakness or gaps seen in the existing model is limitations of knowledge related to advanced Optimisation or Technology implementation for making a traditional database efficient. Specific models are seen to be proposed for mitigating only specifications like blockchain. There is a Limited number of knowledge in identifying a specific solution that can address multiple databases and their challenges. In this respect, there is a need for more future research on areas right real-time analysis of computational cost neural network, etc, to understand the appearance of relational database query management in the coming time. Despite growing demand, the discussion shows certain limitations of AI in indexing and query management. There is less focus on real-time query Optimisation, which reflects the scalability of a database. It is to be noted that artificial intelligence means more explanation in terms of application to real-world scenarios. Database complexities are also growing with time and creating different unrecognisable patterns of data constructed data that create obstacles for the user to perform efficiently. In this respect, future research on AI applications in the area of query analysis and indexing needs to be focused more on real business case studies.
The sources used for the literature review collectively show that database Optimisation is a significant part of adjusting for future challenges and opportunities. Performance enhancement is the primary purpose for this Optimisation, for which integration with artificial intelligence hybrid or cloud-based approaches and security management needs to be focused and prioritised.
Conclusion
To conclude, it can be said that query Optimisation is one of the significant aspects that continuously changes with the advancement of Technology and the changing nature of the different database systems. So, most of the articles provide an understanding of square Optimisation and different models and techniques that are relevant to creating a positive impact on performance. It is also to be noted that the discussion shows an inclination to our artificial intelligence as one of the potential technology that addresses the need for database indexing and query management over a long time. That discussion highlights different types of proposed models and theoretical approaches that enhance the dimension of knowledge related to the current implications of relational databases as well as query performance and indexing approaches. This is significant in identifying the potential of the database development areas.
References
.png)

Assignment
CSE5CRM Cyber Security Risk Management Program Assignment Sample
Assessment Components
Component 1: Asset Evaluation and Classification
Objective: Demonstrate the ability to identify and classify organizational assets for risk assessments.
Tasks:
1. Asset Inventory Creation:
Develop a comprehensive inventory of an organization's assets (hardware, software, data, human resources). Provide a detailed description of each asset.
2. Asset Categorization:
Categorize each asset into groups (e.g., critical, sensitive, non-critical).
Justify the categorization based on the asset's role and importance to the organization.
3. CIA Triad Evaluation:
Assess each asset based on confidentiality, integrity, and availability requirements.
Assign a classification level (e.g., high, medium, low) and justify the classification.
4. Business Impact Analysis:
Conduct a Business Impact Analysis (BIA) to determine the potential impact of asset compromise on business operations.
Classify assets according to their impact on business continuity.
5. Data Sensitivity and Value Assessment:
Evaluate the sensitivity and value of data handled by each asset.
Classify assets based on the data they manage and provide justification.
Deliverable: A report documenting the asset inventory, categorization, CIA triad evaluation, business impact analysis, and data sensitivity and value assessment.
Assessment Criteria:
- Completeness and accuracy of the asset inventory.
- Justification for asset categorization and classification.
- Depth of analysis in the BIA and data sensitivity assessment.
- Clarity and organization of the report.
Component 2: Developing Methods for Evaluating and Monitoring Cyber Risk Management
Objective: Develop and apply methods for evaluating and monitoring cyber risk management.
Tasks:
1. Qualitative Risk Assessment:
Utilize qualitative methods (e.g., expert judgment, scenario analysis) to evaluate cyber risks.
Document the process and findings.
2. Quantitative Risk Assessment:
Apply quantitative methods (e.g., Annual Loss Expectancy, Monte Carlo simulations) to quantify cyber risks.
Present the results and explain the methodology used.
3. Key Risk Indicators (KRIs):
Develop a set of KRIs to monitor the organization's risk landscape.
Explain how these KRIs will be measured and monitored.
4. Continuous Monitoring Plan:
Design a plan for continuous monitoring of cyber threats, including tools and techniques to be used (e.g., SIEM, IDS, EDR).
Explain how the monitoring plan will be implemented and maintained.
5. Periodic Risk Assessment Plan:
Develop a schedule and methodology for conducting regular risk assessments.
Outline the steps for updating the risk assessment based on new threats and vulnerabilities.
Deliverable: A comprehensive document detailing the qualitative and quantitative risk assessments, KRIs, continuous monitoring plan, and periodic risk assessment plan.
Assessment Criteria:
- Appropriateness and thoroughness of the risk assessment methods.
- Justification for the selection of KRIs.
- Feasibility and effectiveness of the continuous monitoring and periodic risk assessment plans.
- Clarity and professionalism of the document.
Component 3: Determining Cost-effective Treatments to Manage Cyber Risk
Objective: Identify and justify cost-effective treatments to manage cyber risk.
Tasks:
1. Risk Treatment Options Analysis:
Identify and analyze risk treatment options (e.g., risk avoidance, risk reduction, risk transfer, risk acceptance).
Provide examples and justifications for each option.
2. Prioritization of Security Controls:
Prioritize security controls based on their effectiveness and cost.
Use the results from the risk assessments to guide prioritization.
3. Cost-benefit Analysis:
Conduct a cost-benefit analysis for each proposed security control.
Include calculations for Return on Security Investment (ROSI) and Total Cost of Ownership (TCO).
4. Implementation Plan:
Develop a plan for implementing selected security controls.
Outline the steps, resources required, and timeline for implementation.
5. Cost-effective Security Metrics:
Propose metrics to measure the cost-effectiveness of implemented security controls.
Explain how these metrics will be monitored and reported.
Solution
Component 1: Asset Evaluation and Classification
1.1 Asset Inventory Creation
.png)
.png)
Table 1: Assets inventory
(Source: Self-created)
1.2 Asset Categorization
Critical
- Web Server
- Firewall
- ERP System
Non-critical
- Workstations
Sensitive
- CRM System
- Customer Database
1.3 CIA Triad Evaluation
.png)
Table 2: CIA Triad Evaluation
(Source: Self-created)
Justification
The risk classification levels, therefore, depend on the significance of the asset to the operations, security, and data of the organization. The firewall, IT administrator, and customer database are highly classified because their loss or compromise impacts confidentiality, integrity, and availability severely by breaching customer data, shutting down operations, and attracting penalties. Enterprise resource planning and customer relationship management, as are the systems under discussion, are considered high in importance (Fraser et al. 2021).
1.4 Business Impact Analysis
Business impact analysis (BIA) is the assessment for the Assignment Help of the effect that adverse events will have on an organization’s operations in the event of the compromise of assets. In the case of the web server, firewall, CRM system, and ERP system, if compromised, it is very devastating to business continuity. For example, the web server responsible for hosting customer applications means the absence of this resource will result in a lack of access to services, loss of trust, and consequently low revenues. It safeguards the whole network and the failure of a firewall means that the organization is vulnerable to cyber-attacks and all the other systems would be at risk (Ghadge et al. 2020).
.png)
Figure 1: Risk Assessment and Business Impact Analysis
(Source: Linkedin.com, 2024)
Also, highly sensitive assets such as the customer database and financial records will cause severe legal and financial penalties as a result of data privacy laws such as GDPR. The opportunity loss would mean the inability to make sales, customer inconvenience, and delay in responding to their needs and demand but the harm is not severe as it will entail loss in potential revenue. Despite the definite usefulness of data analysts, their non-attendance does not necessarily lead to a stop of activities (Crumpler, and Lewis, 2022).
Classification
.png)
Table 3: Assets classification
(Source: Self-created)
1.5 Data Sensitivity and Value Assessment
.png)
Table 4: Data Sensitivity and Value Assessment
(Source: Self-created)
Component 2: Developing Methods for Evaluating and Monitoring Cyber Risk Management
2.1 Qualitative Risk Assessment
The qualitative risk assessment process of the anticipated scenario opened quite valuable information for the organization’s cybersecurity risks. The analysis of possible phishing attacks showed one important conclusion, though such attacks are progressing in real-world scenarios. For instance, the recent attack, the Twitter hack of the year 2020, where the attackers used phishing techniques to gain control over the executives’ accounts, indicates the risks involving negligence when it comes to the aspect of employee training on how to identify the threats (Li, and Liu, 2021). The investigation of insider threats provided more understanding of problems related to frustrated personnel becoming criminals and exploiting their privileges. Prominent examples like the Edward Snowden case of 2016 show that insider threats can have severe consequences for organizational reputation and customer loyalty.
2.2 Quantitative Risk Assessment
Annual Loss Expectancy (ALE)
The Annual Loss Expectancy (ALE) assessment enables the measurement of loss from identified threats in the assets. First, one specifies the assets and the threats that they face, for example, loss of data, or ransomware attacks. Next, every asset is given a dollar amount attached to it. There are three main types of threats, and the threat frequency, which is expressed as the Annual Rate of Occurrence (ARO), is calculated using statistical data (Kamiya et al. 2021).
“SLE=Asset Value * Exposure Factor”
“ALE= SLE * ARO”
Findings
.png)
Table 5: Findings from quantitative analysis
(Source: Self-created)
2.3 Key Risk Indicators
Key Risk Indicators (KRIs)
- Number of Security Incidents: This KRI measures the overall cumulative count of security incidents which can be within a month or within a quarter. An increasing rate of occurrence may also point to weaknesses that may require prompt action to be taken.
- Phishing Attack Rate: This represents the number of employees who have failed the phishing simulation tests. A higher rate indicates the need for enhancing the security training and awareness programs within their organizations (Zwilling et al. 2022).
- User Access Violations: This one measures the number of attempts made by unauthorized individuals to access restricted data or information systems. In user group wise use of physical access controls, an increase in violations could be from potential insiders or lack of access control (Sarker et al. 2021).
Measurement and Monitoring of KRIs
- Data Collection: Implement organizational structures for acquiring key data for each KRI. For instance, the Security Information and Event Management (SIEM) tool logs security incidents and access attempts.
- Regular Reporting: Develop KPIs and KRIs and locate or build the respective trending charts into the systems, to provide capabilities to track changes over time. In cases of monthly or quarterly reporting, there will be improved recognition of new trends and risks (Gupta et al. 2023).
- Continuous Review: Ensure that KRIs are dynamic while conducting routine reviews on such factors in relation to changes in the risk environment and business direction. This ensures that the indicators are still meaningful and in tune with the objectives that the organization seeks to put forward (Khinvasara et al. 2023).
2.4 Continuous Monitoring Plan
.png)
Table 6: Continuous Monitoring Plan
(Source: Self-created)
2.5 Periodic Risk Assessment Plan
.png)
.png)
Table 7: Continuous Monitoring Plan
(Source: Self-created)
The process of the newly updated risk assessment has included several steps that still need to be followed to ensure cybersecurity is still adequate. First, the organizations have to gather threat intelligence by either purchasing, or getting a feed that alerts them to threats, the second part is that they have to read and be aware of different industry reports and trends.
Component 3: Determining Cost-effective Treatments to Manage Cyber Risk
3.1 Risk Treatment Options Analysis
Risk Avoidance
Risk avoidance gives direction in the disposal of do in order to erase each activity that has the possibility to put the organization at risk. For example, if relatives are aware of vulnerabilities of a certain software application that cannot be fixed to a reasonable extent, they might decide not to use it in the organization.
.png)
Figure 2: Risk treatment options
(Source: Researchgate.net, 2024)
Risk Reduction
Risk minimization is centered on achieving the lowest probabilities of occurrence of risks and their severity. For instance, an organization may employ more and sophisticated firewalls and intrusion detection systems, to strengthen a network security standard (Zeadally et al. 2020). Training common employees on cybersecurity can also reduce the instances of errors which are common causes of cyber threats.
Risk Transfer
Risk transfer means the transferring of responsibility of a risk to a third party usually through contracts and or insurance. For example, an organization may invest in cyber liability insurance for protection from losses that may occur due to hacking. The said approach enables the organization to cap its resources liability while at the same time making sure that resources for dealing with such are available.
3.2 Prioritization of Security Controls
Risk control is helpful for organizations because it assists in efforts to prioritize security controls and allocate resources in a way that will be most effective in diminishing risk. Considering security controls, it is also possible to describe a risk-based approach that takes into account not only the effectiveness of the particular control but also the costs for its implementation.
.png)
Figure 3: How to implement the types of security controls
(Source: sprinto.com, 2024)
Also, the cost of controls should also be taken into consideration by organizations. It is not reasonable to use high-cost controls at workplaces when low-cost can offer almost the same level of protection.
3.3 Cost-Benefit Analysis
Firewall
- Initial Cost: $20,000
- Annual Maintenance Cost: $3,000
- Lifespan: 5 years
Total Cost (TCO) = 20,000 + (3,000*5)
=35,000
Risk Reduced (Annual Savings) = $100,000
ROSI = 10000/3500 * 100
= 285.71%
Intrusion Detection System
- Initial Cost: $15,000
- Annual Maintenance Cost: $2,500
- Lifespan: 5 years
- Risk Reduced (Annual Savings): $75,000
Total Cost (TCO) = 15000 + 2500*5
= 27500
ROSI = 75000 / 27500 * 100
= 272.73%
Employee Training
- Initial Cost: $5,000
- Annual Maintenance Cost: $1,000
- Lifespan: 3 years
- Risk Reduced (Annual Savings): $25,000
Total Cost (TCO) = 5000 + 3*1000
= 8000
ROSI = 25000/8000 *100
= 312.5%
Based on the cost-benefit analysis, the three proposed security controls have high ROSI, and the most beneficial security control is the employee training program.
3.4 Implementation Plan
.png)
.png)
Table 8: Implementation plan
(Source: Self-created)
3.5 Cost-effective Security Metrics
Proposed Metrics to Measure
Thus, the effectiveness of the security controls implemented in an organization can be represented by a set of metrics that are listed below, which can give a proper understanding of the organization’s security. One of these is Return on Security Investment (ROSI) which measures security investment dollar returns against the dollars invested.
Monitoring and Reporting of Metrics
In order to make these metrics more effective, the organization should incorporate a proper monitoring and reporting technique in order to ensure that security controls are evaluated consistently. This serves as a basis for making the correct evaluations concerning the prevailing security situation (Khando et al. 2021).
References
Reports
MCRIT010 Innovation and Commercialisation in IT Report 3 Sample
This is a case study of a well-known international brand. Students will apply the knowledge and skills on Innovation and Commercialisation in IT, from the weekly topics to the four questions based on the case study provided.
Word Length: 2,000 words (+/- 10%)
There are four questions. Each question is of equal value that is 7 1/2% each. Therefore, the word length for each question should be approximately 500 words each, to ensure the depth of answer to each question.
Formatting: Use Arial or Calibri 12 point font. Single or 1 1⁄2 spacing. The structure of the case study report is a title page, the questions as headings and answer the questions, then a reference list page.
Questions
Question 1) Disruptive Innovation
The case study refers to After Pay as a Disruptive Innovation in the finance industry.
(a) Do you agree with the analysis, why or why not?
(b) In your answer provide a definition and description of Christiansen’s Disruptive Innovation.
(c) How might traditional banks have used Disruptive Innovation to innovate their own fintech products?
Question 2) Timing of Entry
The case identifies Pay’s first mover status in the Australian buy now pay later (BNPL) market.
(a) How was After Pay different to previous buy now pay later products in Australia, to be called a first mover?
(b) What are the advantages for After Pay to be a first mover, what are the disadvantages?
(c) Is After Pay able to maintain its competitive advantage from fast followers or do fast followers have an advantage over After Pay?
Question 3) Innovation Strategic Direction
(a) Evaluate After Pay’s strategic direction in the BNPL later fintech industry using Porter’s Five Forces.
(b) Apply the Blue Ocean Strategy Eliminate Reduce Raise Create (ERRC) grid to After Pay, to evaluate their Blue Ocean Strategy. Use this ERRC grid to draw the Strategic Canvas for After Pay with the competitors as the traditional credit card companies.
Question 4) Future of After Pay
(a) This case study is the situation for After Pay in 2020. Provide an update of After Pay’s since 2020, referring to how they performed during and after COVID-19 lockdowns in Australia.
(b) What has been the impact of recent regulation changes to the BNPL industry on After Pay?
(c) How have they continued to innovate since 2020?
Solution
Question 1 Disruptive Innovation
A) AfterPay growing as disruptive Innovation in the Finance Industry
- The case study has referred to after-pay as a disruptive innovation in the finance industry, being one of the fastest-growing innovations commercially in today's business. Definitely, the disruptive innovation in the finance industry has transformative growth in recent times also analysed in case study review informatively. Pay Touch Group has integrated new digital platforms into the Fintech Sphere allowing consumers to experience fast services (Kamuangu, 2024). The new consumer centric approach used in business has shaped constant growth of new millennial shopping preferences.
- AfterPay as a disruptive innovation in the finance industry, claims to solve key problems with highly disruptive innovation for businesses growth domains.
Disruptive innovation has constantly risen in recent times due to highly flexible demands, leading wider vision productively on constant business work parameters. AfterPay has a huge competitive profits scope with usage and implementation of disruptive innovation growth and inclusion of sustained change parameters.
B) Christensen's theory of disruptive innovation
- Christenson’s theory for The Assignment Helpline of disruptive innovation signifies process by which products or services take root in creative applications in market. The theory determines bringing less expensive and more accessible in terms of technology brings new moves upmarket displacing established competitors' pace. It signifies relentless growth with stages: disruption of incumbent, dynamic and new rapid linear evolution, appealing convergence, and complete imagination within systems rise functionally (Christensen, 2015).
- Disruptive technology in the finance industry has shaped constant growth goals technically and enlarged varied goals for businesses today. Also, the theory states untapped new constant changes with the usage of disruptive technology growth rise, wider strengths through online systems, and disruptive innovation expansion (Christensen, 2015). The BPNL segment has risen 8% within e-commerce payment, by around a three-fold increase, and the international market expecting a rise by around 22% over five years to approx. $33 billion.
C) Traditional banks have used Disruptive Innovation to innovate their own Fintech services.
- Traditional banks have used Disruptive innovation to work within their own Fintech products, as the Fintech boom is a global phenomenon with 40% of investments rising in recent times. Fintech hubs globally including Australia's new markets have emerged specifically, bringing sustained constant growth among commercial usage. The BPNL Fintech segment within Australia expanded in 2020, with high-scale innovation and new demand-oriented investments by companies specifically (Ahmed et al., 2024).
- AfterPay has become a global Fintech giant, with a clear market leader in a rising competitive segment in recent times diversely. Customers can make purchases and pay with four equal payments, which has increased rapid demand for technology-oriented systems. AfterPay slogan “There’s nothing to pay" has dragged in a varied rise in new consumers today, stating the significance of the drastic strength rise in flexible technology systems.
Question 2 Timing of entry
A) AfterPay reason for first mover advantage
- AfterPay offers many unique features in its services from other player sin fintech business within Australia, focusing on sustainable growth market criteria and delivering best competent services. It has expanded around 50% of Australian market, requiring higher customers’ ability to have their purchase now and pay later option. It also focuses on segment, that customers without high traditional interest credit are able to make new purchases and can further have four equal payment systems (Güleç et al., 2024).
- The business model of AfterPay has flipped economies of credit cards innovatively by leading constant change, incorporating new systems of credit cards with high consumer oriented strengths. Also, through this simple product offering, AfterPay is attractive to consumers as it offers one repayment reschedule and also flat fee structure on missed payment dates.
B) Advantages and disadvantages of AfterPay first mover advantage
- The advantages of AfterPay to be the first mover are many, as company has focused on providing best user experience for people who like to spend more. It can be also highlighted that consumers with more purchasing power have been major target market, with inclusion of free credit and retailers should pay more in returns to their larger transactions.
- Advantages of AfterPay are that it is a multi-sided platform business connects to larger range of consumers, millennial using credit cards within growing market scenarios. Millennials in Australia are the most competitively growing strong market, that are rising with new purchasing power for receiving goods (Wang et al., 2024). The company boasts of new 86 million consumers and a network of 200000 merchants, rising commercial goodwill.
- However, some disadvantages are there such as AfterPay 20% of revenue comes from its late fees, signifying the company earns more from reprocessing which increases dependability. Pay shares faced a decline of 4.7% major per cent in share value after the governance firm, which has brought enlarged change dynamically. There is an error in technology, which has led to a rise in concerns regarding changing access to new pay later debts criteria dynamically.
C) AfterPay maintaining competitive advantage
- AfterPay is unable to maintain a competitive advantage from fast followers, as there is a build-up of headwinds for the company. There has been a recent striking deal with us retail giants in 2021, leading to a resurgence of share prices and varied change substantially. The company is making substantial losses, with the average revenue ratio hovering around 50 and, the technical valuation of the share price being overpriced (Ferraro et al., 2024).
- Also, AfterPay has rumours of regulation, dampening its future prospects. There are also rising global competitors entering the market all the time, thus increasing external risks for business. Investors have been impatient with lowered returns from company revenue levels, thus being highly risk for future business goals. The company has intensely disrupted the accuracy and validity of data, sidestepping credit obligations and wider loopholes raising financial stress and potentially causing losses.
Question 3 Innovative Strategic Direction
A) Porter Five Forces model
Analysis of in BNPL Later Fintech industry forces impacting AfterPay using the Porter Five Forces model will focus on identifying the company's further new business goals competitively. The major factors of the five models are as follows:
- Competitive rivalry within the industry: The BNPL market has been found to be valued at USD 30.38 billion in 2023 analysis, the market is projected to grow to rise of 37.38 in 2024 and a CAGR of 20.7% during the recent period. There is a high threat for AfterPay Company, as new fintech companies are raising revenue within BPNL for expanding best standards in consumer spending habits (W. Van Alstyne, 2016).
- Threat of new entrants: There is also a high threat of new entrants for the company, as Klama Swedish BNPL Company backed by Alibaba provides high competition within the lucrative European market. The Karma solutions company has been rising among consumers, merchants with new lucrative growing opportunities within market systematically. The entry of PayPal in 2020 has also been a threat to rapid expansion in the US within three months, raising business challenges for AfterPay.
- Threat of substitutes: BPNL players are rising today with new creative business models and higher interest towards faster consumer services exponentially. Consumers have new substitutes, thus there is medium threat of this factor for AfterPay business.
- Threat of suppliers’ power: There is less threat of suppliers, as automation and fast supply chain management sustainable factors are focused by company (Vynogradova et al., 2024).
- Threat of consumers’ power: Medium threats to this factor, as consumers have a preference for AfterPay services due to highly innovative and dynamic services.
Also consumers today further have many new choices too, which increases competition for businesses to largely focus on wider dimensions.
Therefore, a review has been informative regarding changing BNPL market domains competitively growing in market scenarios. It has also integrated new channels extensively, ideally focused on core mechanisms stating constant innovation with fintech.
B) ERRC model of blue ocean strategy
The ERRC model of Blue Ocean's strategy will focus on reducing AfterPay and will evaluate company performance with competitors as traditional credit card companies. Eliminate- reduce-raise-create grid is an essential innovative matrix tool driving companies to focus on eliminating errors and creating new blue ocean development.
.png)
.png)
Figure 1: ERRC graph, 2024
The ERRC graph has focused on identifying major dimensions on new growing and fluctuating changes rising in business of After Play, it has presented major values on larger values towards diverse changing market perceptions. ERRC graphical representation has also established focus on range, complexity, and changing demands.
- Interest rates and fees will be eliminated by company
- Traditional credit checks in reduce section, as it will curb down old technical flaws and loopholes in system
- Merchant benefits and customer convenience in raise section, are major parameters that will be raised and developed
- Instalment payment in create section, important for After pay to install new changes
There has to be a focus developed on eliminating unnecessary complexity in payment schedules, and standardized payment systems at After Play. The new online consumer engagement, digital quality promotions, and new digital quality features have to rise with higher levels of investments (Kumari et al., 2023).
Question 4 Future of After-pay
A) AfterPay conditions since 2020, performance during and after the COVID-19 lockdown in Australia
- After play platform business is highly competitive advantage turning credit traditional into new debit business, changing regulation of banks aspects variedly.
The company has charged commissions from retailers worth 6% of transaction value, charging drops of risk and price of customers providing new superior value levels functionally.
- The company has become Fintech Giant worth over $30 billion within market capitalization in 2020, signifying major new demands rising in business levels (Hughes, 2018). The After-pay condition post-COVID economic downturn can be analysed with the threat of economic downturn, being a major threat to the company's booming success levels. The company has faced high competition from various new entrants in business-changing market scenarios; consumers are highly trusting AfterPay commercial services.
- There is also attention on fact that merchants will be benefiting in recession, with excess inventory and risen consumers retailers engagement in BNPL system commercially (Powell et al., 2023). However, some major players like PayPal and Alibaba Kalma are some major stiff competitors of After Play which are rising in demand in the BPNL industry.
B) Analysis of recent regulation changes impacting business of AfterPay
- AfterPay has turned traditional credit card system into new debit appraisal service, escaping new regulations at banks that to be further abided by. Instead of receiving interest from consumers, the brand has focused on specifically leading change into charging commission from retailers of around 6% within new transaction values (Financial Review. 2018)
- The recent regulation changes in the BPNL industry on AfterPay have led to change drops in risk and price for consumers focused on providing new superior value propositions successively on wider standards. After play slogan “There’s nothing to pay” led rise to hundreds and thousands of millennial, consumers in Australia purchasing goods with high flexibility.
C) Innovation since 2020
- The company's striking new commercial deal with one of the most prominent US retail giant in the middle of year 202, that has grown to be wider resurge on share price value within market scenarios.
- AfterPay like most competitors aims to reduce losses, the average price/ revenue ratio hovering around new 50 forms within rising technical changes within rising share price. Playing a multi-sided platform business, within a new marketplace enhances attention on aversion to credit cards and grows in an ecosystem (CHOICE, 2018).
- After the Play model has been flipping economies of credit cards, a business model is highly creative technically for incorporating new submission levels. This simple product offering is highly attractive, as repayment rescheduling is based on a flat fee structure for missed payments.
References
Reports
BUS5DWR Data Wrangling and R Report 2 Sample
Assignment Details
Objective:
The main goal of this assignment is to perform a comprehensive analysis of the Dubai Real Estate Transactions of first six months in 2023 using R. Through careful data wrangling and analytical techniques, you will extract meaningful insights about the Dubai Real Estate market.
Your analysis will focus on:
- Identify trends in the types and volumes of real estate transactions.
- Highlight price trends across different property types and neighborhoods.
- Assess market activity over time, analyzing transaction fluctuations.
- Provide strategic recommendations based on your findings that can help guide real estate investment and development decisions.
Part 1: Data Wrangling & Exploration
1.1 As a data analyst, write a brief description (1 paragraph) on your initial approach to extracting meaningful insights from the Dubai Real Estate Transaction dataset. What challenges might arise during the early stages of analysis?

1.3 Identify columns with missing values. Instead of removing rows, explain two methods you would use to handle missing data related to the columns you identified and apply one method to fill in missing values for one selected column and show the dataframe.
1.4 In real-world datasets, inconsistencies in data are common and need to be addressed. The room column appears to have some inconsistencies. Analyze the data and fix the inconsistencies.
1.5 You are interested in counting the number of sales matches the below criteria:
1.6 Identify potential outliers in the amount column. Choose and apply an appropriate method for dealing with these outliers. Explain why you chose this method. (2 marks)
1.7 Create two new columns that extract the day, month from the transaction date
1.8 Define a function in R that takes the property size in square meters (property size sqm) as input and categorizes properties into three categories:
1.9 Group the data by property type and calculate the average property size sqm for each property type. Provide a brief insight based on the results. (3 marks)
1.10 Calculate the average propety sale price categorized by property subtype and present the results in descending order. What insights can be derived from this analysis?
Part 2: Market Trend Analysis & Strategic Insights
2.1 Use a histogram to analyze the distribution of the amount (property sale price) .
(a) Use a histogram to visualize the distribution of property sale amounts. Ensure the bins are appropriately adjusted to highlight key patterns in the data.
(b) Based on the histogram, provide insights into the distribution of property sale amounts. Are there any noticeable patterns or trends?
2.2 Using appropriate visualization (i.e bar graph), analyze transaction count based on room types.
(a) Create an appropriate visualization to view the transaction count based on room types (e.g., 1 B/R, 2 B/R, studio). Ensure the graph clearly shows the transaction count for different room types.
(b) Analyze the visualization and discuss the insights based on visualisation. 2.3 Using appropriate visualisation/s, analyze transaction count for the top 10 areas.
2.3 You are interested in analyzing whether the nearest landmark has a significant impact on the amount (property sale price) and the subtype of properties (i.e Flat, villas) sold in these areas.
(a) Using appropriate visualisation/s, compare property sale prices based on different nearest landmarks. Ensure the visualization clearly displays any patterns or differences.
(b) Is the dominant property subtype consistent across all landmarks, or does it vary depending on the proximity to different landmarks? (Displaying the data of dominant property subtype is sufficient)
2.4 You are interested in analyzing the monthly sales of top 10 property subtypes (e.g., flats, villas, townhouses) to discover insights. Using the new month column created from transaction_date, visualize the total number of property sales per month, based on top 10 property subtypes.
(a) Using appropriate analytic and visualization techniques analyse monthly sales grouped by property subtypes.
(b) Based on the visualizations, discuss any noticeable trends or insights you can extract.
Solution
Introduction
The Dubai real estate market, which has grown and developed swiftly and includes various transactions, calls for insights based on existing research. This case study is based on a transactional analysis of data gathered on the property market within the first half of 2023. Knowledge of these mechanisms is essential for making correct investment choices and forecasting a perspective evolution of quotes.
Objectives
- To assess patterns of transactions and define trends in the Dubai real estate market.
- To compare the sales prices of the different types of properties and to measure the changes that happen in the market at different periods.
- To support investment decisions regarding the promotion of business initiatives with clear growth strategies and statistics.
Dataset
The dataset sample size is more than 81000, and the data specifies the real estate sales in Dubai within the 1st half of 2023. Some of the rich fields that it contains include “transaction number”, “date of transaction”, “type of property”, “size”, “amount of transaction”, and “location”. Further specifications with the “number of rooms”, “parking”, “close metro”, and “mall” facilities help in the elaborative study of market transactions. The implication of this particular dataset of transaction frequency, price fluctuation and investment potential by type of property and neighbourhood is a unique resource that enables strategic decision-making at a time of significant market volatility.
Part 1: Data Wrangling and Exploration
1.1
The first stage in dealing with the Dubai Real Estate Transaction dataset is data preprocessing and visualization. This involves dealing with cases of missing data; cleaning up errors; and managing variables such as property size and transaction value (Piryonesi and El-Diraby, 2020). Some of the difficulties include handling missing values, peculiarities in the variance of goods’ values, and variations in categorical variables such as property type, or room numbers for the assignment helpline Besides, the required accuracy of the data especially when dealing with many transactions can interfere with the analysis process (Hu et al. 2021). All these early-stage issues need to be sorted out to obtain clear and valuable data helpful in investment decisions.
1.2
.png)
Figure 1: Summary of Data
(Source: R Studio)
The dataset has in total of 81,601 records and the attributes of the dataset include among others, transaction number, amount, and size of property in terms of square meters. All but “amount” and “property size sqm” are categorical while these two are quantitative with very high variability. For example, the transaction amount varies from 57 to more than 3.8 billion and therefore, it also contains outliers. Moreover, there is have missing value in the “property size sqm” column. The diversity of this data set creates many possibilities for studying pricing and room categorization as well as area specificities to make market-oriented decisions.
1.3
![]()
Figure 2: Removing Null Values
(Source: R Studio)
Two typical strategies for dealing with missing data are to replace numerical “imputing to the median” because it is not sensitive to outliers and to “apply the mode to categories”. From the dataset, missing values in property_size_sqm were imputed by the median since dropping some of the observations might in essence distort the result set.
1.4
.png)
Figure 3: Unique Value and Fixing Consistency
(Source: R Studio)
The image illustrates the cleaning of room column where raw observations include “1 bedroom” and “3 bedroom” are standardised to “1 B/R” and “3 B/R” respectively Non-residential values are excluded including “Shop” and “Office”. This makes it easier to maintain consistency in the representation of data hence enhancing the accuracy of analysis regarding room types and characteristics of any given property.
1.5
a)
.png)
Figure 4: Countling the Sales
(Source: R Studio)
The image shows filtering of property transactions that are located in the area containing “bay” (CASE INSENSITIVE) and gave 5482 hits. This depicts sales of a high number in bay related areas suggesting the need or probably popularity of such developments in such areas.
b)
.png)
Figure 5: Countling the Sales
(Source: R Studio)
The attached image displays the filter of property sale located either in an area that includes the words Jumeirah and/or Marina with a sale size exceeding 100 sqm. The study also revealed that there were 8,051 transactions in these areas, showing their activerx market, especially for properties of this size. Perhaps these regions are considered to be either prime or high usage areas.
1.6
.png)
Figure 6: Outliers using Box plot and removal of outliers
(Source: R Studio)
This is evidenced by the boxplot for property sale amount that shows potential outliers in these values and values that may go up to 4 billion or more. The code uses the IQR to outliers and filters with bounds for amounts beyond this context, which came from the interquartile range. This improves the generalisability of the data set because analyses are conducted on standard or average transactions that are not distorted by outliers.
1.7
.png)
Figure 7: Mutating Date Column
(Source: R Studio)
The code is used to change the type of transaction date column into date format and also make two new columns day and month. It can be used to analyze the transaction cross-section over one day and month to establish the potential transition of transaction surge period or property sales on a seasonal basis.
1.8
.png)
Figure 8: Categorising and Function
(Source: R Studio)
The code assigns a function that partitions properties into three categories Small if they measure less than or equal to 500 square meters, Medium if they are more than 500 square meters but less than or equal to 1500 square meters, and Large if they are more than 1500 square meters. The function is used on the dataset by creating a new column named “property size category”. The first five rows ensure modification of the data for analysis of the size of the properties; together with the insights for the investors interested in specific property types.
1.9
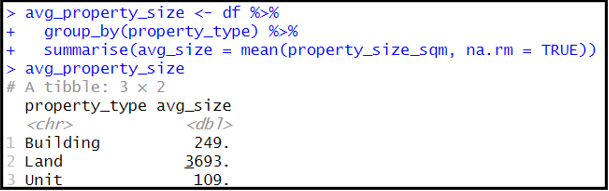
Figure 9: Average Property Size
(Source: R Studio)
The code ideally splits the data according to the property_type where it computes the Mean property size for each property type. The study found that land properties possess the largest average size of 3693 sqm while buildings with 249 sqm and units of 109 sqm. This analysis reveals the variation in size of different property types, which is useful in identifying property investment opportunities depending on space.
1.10
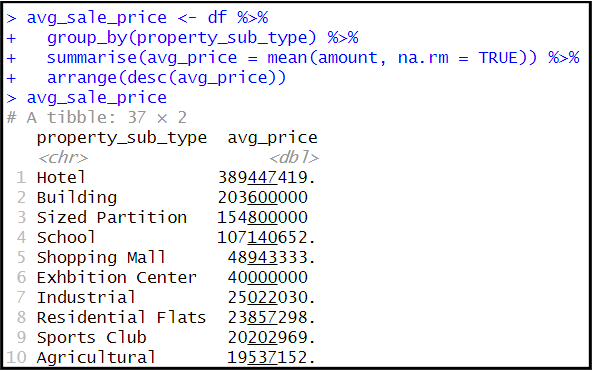
Figure 10: Average Sale Price
(Source: R Studio)
The code then computes the average of the sale prices for each property subtype arranged in a descending manner. Hotels have the largest number on average price at 389.4 million, again followed by buildings and partitioned properties. This can be seen from the significant differences in the property values for subtypes, using the example of commercial and specialized properties that are more expensive than residences, including flats and agricultural land.
1.11
![]()
Figure 11: Filtering
(Source: R Studio)
The code searches through properties in the Jumeirah which are FLATs and cost not more than 2000000, of 2 bedroom and freehold tenure. This selection focuses on investing in mid-ranked assets in the best area for those investors who are searching for stable and cheap properties. Such criteria increase the chances of consistent revenues because Jumeirah’s market value is high and the need for residential flats continues to rise.
Part 2: Market Trend Analysis & Strategic Insights
2.1
a)
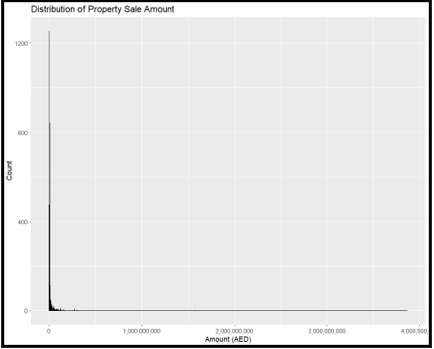
Figure 12: Distribution of Property Sale Amount
(Source: R Studio)
The histogram provided below displays the amounts of property sales in Dubai and it is quite clear that there are a large number of sales that occurred in comparatively less amount and as we go to higher amounts, there is a drastic decrease in the number of transactions. The market of properties can be considered quite active, as most of the properties being sold are of values below 1 billion. Approximately 3.9 billion are made up of a small number of very large or luxury items, including commercial transactions. These skew the distribution, pointing to the fact that the market is diverse, as shown in the figure above.
b)
This indicates a dichotomy in the market a large number of lower-priced or middle-range properties that are affordable by a large pool of potential consumers with a relatively smaller number of high-value deals for luxury consumers. To stakeholders, these extremes are beneficial when planning for investment solutions, where market solutions are continuously liquid and are differentiated from luxury that deals with high-end individuals. Such analysis is important in providing a prognosis of the best investment strategies for the returns to be realized in a volatile market.
2.2
a)
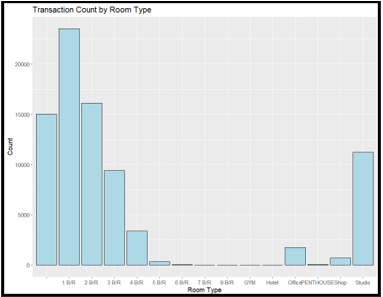
Figure 13: Count of Room Type
(Source: R Studio)
The bar chart depicting the transaction given by the room type depicts that there are much higher transactions than 2 B/R (two-bedroom) than 1 B/R and studio apartment. The number of transactions of properties with three or more bedrooms is relatively lower. While analyzing the results the respondents’ preferences for studio apartments are evident and can probably be attributed by it has higher demand due to cost and demand for rentals (Asquith et al. 2023).
b)
Notably, there are few transactions for luxury items like; the penthouses, huge flats with five or more bedrooms, and commercial structures like offices and retail shops. The higher stock percentage for smaller residential units includes 1 B/R, 2 B/R and Studio because Dubai continues to experience increasing demand in mid-segment and affordable housing more so by the expatriates and young people. This insight informs the finding that investors who focus on smaller properties have higher liquidity and demand whereas the premium, large properties are likely to be sold to speciality buyers or long-term investors who wish to make high-value gains.
2.3
a)
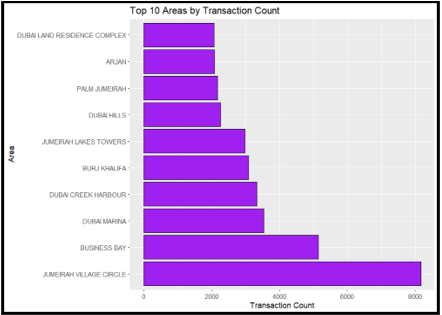
Figure 14: Transaction Count
(Source: R Studio)
The bars in the chart represent the 10 regions in Dubai with the highest count of transactions; Jumeirah Village Circle has the most transactions followed by Business Bay and Dubai Marina. These areas are generally characterized by integrated use and have been the most affordable and competitive for investors as well as buyers.
b)
Business Bay and Dubai Marina have also recorded market activities due to their business-friendly locations and lifestyle properties. However, locations such as Burj Khalifa and Palm Jumeirah record relatively low numbers of transactions mainly because they are on the high end and property prices are relatively expensive (Al-Kodmany, 2024). This implies that though there are luxury properties which are good investment tools there are mostly ‘mid-market’ stocks in well-located, easily accessible areas which drive the market. This insight is so comforting to investors targeting sectors of the market that attract most transactions, hence greater liquidity, and thus safer investment options that yield quick results.
2.4
a)
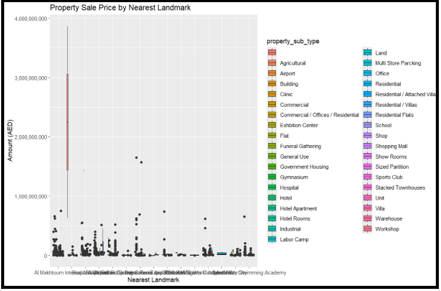
Figure 15: Property Sale Price by Landmark
(Source: R Studio)
b)
The subtype of property most dominant is not the same depending on how close it is to different structures. A number of commercial properties like offices and hotels are available close to special landmarks like airports whereas a large number of residential flats are available close to general like malls. It shows that location plays an important role in determining the kinds of properties and market forces in any given market.
c)
Location plays a major role in the revaluation, and properties closer to such attractions attract higher prices than those located in industrial or residential areas which contain airports and business accommodations respectively. On the other hand, residential flats close to general landmarks such as malls have moderate pricing implicating a different trend between the type of a landmark and the price of a property.
2.5
a)
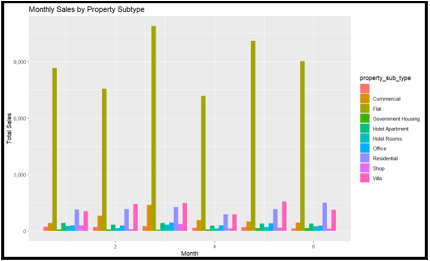
Figure 16: Monthly Sales By Property Subtype
(Source: R Studio)
The bar chart illustrating monthly sales distribution by property subtype reveals that the category of flats stands as the most popular one each month and this signifies that the market for residential flats remained active the entire year. Other subtypes like villa, commercial and residential properties are also much less volatile but show comparatively less variation.
b)
This means that flats are more popular as the property to rent or buy throughout the year thus closing more deals, commercial and residential properties have minimal and stable rates of sales, proving the fact that it is rather in greater demand than flats.
Conclusion
The examination of Dubai’s real estate also reveals that the demand for flats is high while other types have a limited market. The strategic view shows prices changing in proximity to landmarks and helps investors make more informed decisions for the greatest profitability.
References

Reports
ITW601 Information Technology – Work Integrated Learning Report 1 Sample
Assessment Task
As a group, write a 1,500-word (+/- 10%) project proposal to critically evaluate a potential project and devise an approach to deliver this project to market.
Please refer to the Task Instructions for details on how to complete this task.
A project proposal is a document that an IT engineer/manager, often working in a team, develops for business stakeholders in order to provide information about the proposed project and seek approval and funding.
A project proposal generally contains the title of the project, the methodology that will be adopted for the project and the expected outcomes of the proposed project. The project proposal should also discuss the benefits that the development of the proposed infrastructure/project will have for the business as well as describing the financials of the project and an estimated timeline for the successful completion of the project.
This assessment will help you to develop your problem solving, management and teamwork skills. You will need to demonstrate your ability to identify and communicate ideas to different stakeholders in order to gain their approval for your ICT-based project proposal.
Your group can come up with your own idea in IT/cybersecurity domain, but these are some suggestions which may assist you in formulating a project –
- Embedding COVID-19 infographics to an analytics website.
- Implementing a CI/CD pipeline for continuous delivery.
- Migrating in-house infrastructure to cloud platform (MS Azure/AWS).
- Setting up data pipelines for an AI-based project in cloud.
Proposal Structure
Your 1,500-word (+/- 10%) project proposal should contain the following:
1. Title of the proposed project
2. Description of the project (300 words)
- Describe the business stakeholders for the project
- Describe the project you are planning to undertake
- Start with a high-level overview of the project, then explain it in more detail
3. Proposed solution (500 words)
- Describe how your proposed solution is effective by comparing it with some other alternative approaches
- Describe the importance of your proposed solution in terms of business value.
4. Project plan (500 words)
- Discuss here the resources, cost and timelines of your project
Resources from Module 4 will help you write this section.
5. Conclusion (200 words)
- Provide a succinct summation of what has been addressed in your report.
You will need to develop and support your project proposal with industry specific and academic references and include a reference list in APA style.
Solution
Proposal
Description of the project
Stakeholders of the project
To ensure alignment with the company’s IT and cybersecurity strategy and manage the project effectively in an AI driven cybersecurity platform, the Chief Information Officer (CIO) or Chief Technology Officer (CTO) could oversee the adoption of the platform. Stakeholders are responsible for ensuring that the platform adheres to regulatory frameworks and data protection laws such as GDPR and HIPAA (Franke et al., 2024). Additionally, the IT operating team and risk management team could handle the integration of the new platform with existing infrastructure by ensuring seamless operations and minimal disruptions. Business unit leaders and employees can also enhance security measures on the platform's usability by providing feedback.
Planning of the project
In the initial phase, the project goal is to engage with stakeholders to determine technical and business requirements, such as system capabilities, compliance needs, integration points, and user preferences. The platform design phase includes network setup real-time analytics, and security features to complete the machine learning models and data analytics tools (Rehman et al., 2024). In the development phase, the integration of AI and machine learning models helps to detect threats with real-time monitoring of network traffic, user behaviour, and system logs. During the pilot testing, the project will gather user feedback on the functionality, usability, and efficiency of the platform. Based on pilot feedback the project will ensure data privacy protocols by including GDPR and HIPAA. Lastly, to improve threat detection and response capabilities, the project will continuously monitor the platform’s performance to ensure long-term effectiveness.
Overview of the project
The project of AI-driven cybersecurity focuses on building a robust, scalable, and user-friendly system that integrates AI capabilities for threat detection and response (Huyen et al., 2024). The project aims to develop an AI-driven cybersecurity platform by leveraging advanced machine learning algorithms to enhance real-time threat detection that improves the overall security posture of organizations. The project will also follow a structured development process to ensure the platform's scalability and effectiveness in evolving cyber landscapes. A user-friendly dashboard will automate incident response which allows security professionals to interact with the system using natural language commands.
Proposed solution
AI-based cybersecurity is one of the efficient, innovative and intelligent identification processes of cybersecurity threats. Effective utilisation of the threats can improve the overall protection mechanism. By using the machine learning approach, the platform can work with a large amount of data from distinct sources and define the possible security threats in the shortest time. It also offers predictions, intuitive design, the ability to become an integrated part of the existing tools, as well as mechanisms that enhance the refinement of detection and response in real-time for the assignment helpline.
Comparison with Alternative Approaches
One of the main alternatives to AI-driven platforms is rule-based security systems. The rule-based structure searches threats through pattern matching, and their configurations are set manually to target known weaknesses (Khraisat & Alazab, 2021). While these systems can effectively mitigate known threats, they perform worse when the threat involves unknown attacks. Furthermore, Rule Based Systems (RBS) are generally prone to higher False Positive (FP) rates which inundate security analysts thus hindering their response times (Fokas & Brovko, 2020). On the other hand, the proposed AI system can learn automatically from the threat data. This process helps to detect new patterns of attack, can eliminate the false positives and adapt to the changing environment. Without frequent updates, the AI-based system can able to get an improved outcome.
Another is Security Information and Event Management (SIEM) solutions, where disparate entities’ information is processed for continuous threat analysis (Dias & Correia, 2020). Despite its incredible ability of data aggregation, SIEM platforms rely on human intervention when detecting and responding to an attack, and this takes time. It features a data aggregation process like SIEM, but it goes a layer higher in automating the response to an incident without involving human intervention. A big plus for the AI platform is that all actions are performed automatically and the decision-making process is done much faster than with manual methods.
Business Value of the Proposed Solution
Great business value is achieved by this innovative system. Identification of capabilities and handling cyber threats can be done more effectively through this process. One organisation can use this system to get more stabilised and secure cyber protection. This improvement in the security posture minimises the chance of a data leak, which is financially and reputationally devastating (Bandari, 2023). The platform’s capability for predicting certain risks and adaptive learning mechanisms also protect organisations from evolving threats, giving organisations a preemptive cyberattack plan that reduces the number of possible weak points.
One of the essential business values is the automation functions of the platform. Incident management can be automated. The automated system ensures that the work of security specialists is not overloaded. This means that fewer man-hours are required in incident management (Fokas & Brovko, 2020). Therefore, assurance of savings in costs associated with operations is obtained. Also, cutting across response time of incidents enables organisations to handle or prevent impacts of cyber threats with minimal downtime and loss of business value.
The integration capability means that businesses can truly get the most out of earlier investments in cybersecurity tools. Instead of existing systems being replaced, they are enriched by an advanced AI-based layer that can integrate into the current framework of any organisation, so there is no need for them to redesign their security systems.
Project plan
.png)
.png)
.png)
.png)
.png)
Table 1: Project Plan
(Source: Self-created)
Analysis
The project plan for the AI-driven cybersecurity platform basically involves the total six important phases, each of them with specific resources, proper timelines, and expected costs (Reddy et al. 2020). In phase 1, all industrial experts and stakeholders consulted to gather the platform requirements to ensure the legal compliance with basic regulations such as HIPAA and GDPR, and involving a main cybersecurity expert team and other legal professionals ($100,000, 1 month). A legal team specializing in the main facts of data protection laws (e.g., GDPR, HIPAA) and it is an essential factor to review compliance, and addressing potential privacy issues and other regulatory requirements, and decreasing risks of legal breaches and fines.
Cybersecurity experts that would be hired to gather the detailed platform requirements, to ensure the platform meets organizational needs (Onih et al. 2024). In phase 2, the machine learning model development focuses on improving the advanced threat detection algorithms to user behavior analysis, use network data, and the system log (Goswami et al. 2024). Data scientists and machine learning engineers specifically build the real-time analytics models with access to large threat detection algorithms, user behavior analysis, and system logs.
Machine learning and data science engineers build the real-time analytics models, with access to the large threat datasets ($700,000 in the expected 3 months). In phase 3, platform development & integration, front-end developers, along with the cybersecurity experts will be properly hired to create the platform infrastructure to build APIs, and integration with associated tools such as design and SIEM, and design of user-friendly interfaces and other response workflows around $1,000,000 5 months. Pilot testing involves assessing the platform's optimization with the full development team. In this phase utilizes the cloud storage and other servers to ensure a smooth deployment (Lanka et al. 2024). In the phase of ongoing support & improvements, the platform navigates the continuous monitoring, bug fixing, and feature updating.
Conclusion
The AI-driven cybersecurity platform project offers a comprehensive approach to improving the posture of an organization. By leveraging advanced machine learning models with real-time threat detection the project automates incident response. The study elaborates the phases clearly to ensure scalability, adaptability, and user-friendly structure. The ability to analyze vast datasets, predict risks, and respond in real-time sets provides Security Information and Event Management (SIEM) solutions. However, rule-based systems struggle with high false-positive rates that delay responses. Also, Effective data aggregation of SIEM platforms heavily relies on manual intervention for decision-making which is also time-consuming. In a business perspective, the platform delivers significant value by leveraging threat detection and incident management. It also reduces reliance on human intervention that minimizes operational costs. The project complies with legal and regulatory frameworks for continuous improvements through feedback loops and adaptive learning mechanisms to respond to future cyber threats.
References
.png)

Reports
ICT710 ICT Professional Practice and Ethics Report 2 Sample
Assignment Details
Introduction
Students are required to use the findings of a needs analysis and usability test conducted on VitEat mobile app for the report. VitEat mobile app is a Mobile Food Delivery App. A mobile food delivery app that:
- connects customers with local restaurants
- offering a platform to browse menus
- place orders
- track deliveries.
The purpose of this report was to identify user needs, evaluate the product's usability, and provide recommendations for improvement.
Needs Analysis
To understand the needs and expectations of target users in relation to VitEat mobile app.
- Understanding user preferences for food types, cuisines, and dietary restrictions.
- Identifying pain points in the current food ordering process (e.g., long wait times, difficulty finding desired options).
- Assessing user expectations for delivery speed, accuracy, and customer service.
- Determining the importance of features like order customization, payment options, and loyalty programs.
Usability Testing
To evaluate the usability of VitEat mobile app and identify areas for improvement.
- Evaluating the ease of navigation within the app (e.g., finding restaurants, browsing menus, placing orders).
- Assessing the clarity and effectiveness of information displayed (e.g., menu items, pricing, delivery times).
- Testing the checkout process for efficiency and user-friendliness.
- Evaluating the order tracking experience and its usefulness to users.
- Assessing the overall user satisfaction with the app's design and functionality.
Below is the format for the report:
1. Executive Summary
2. Introduction
3. Methodology
3.1. Needs Analysis
3.2. Usability Testing
4. Findings
4.1. Needs Analysis
4.2. Usability Testing
5. Analysis and Discussion
6. Recommendations
7. Conclusion
8. Appendices
9. Visuals
Students need to use tool the following tools for this assessment:
1. Figma
2. MockFlow
3. Canva
4. Lucidchart
5. Visual Paradigm
Solution
1. Introduction
Popular as food ordering software, the VitEat is a mobile application system software that was developed to link consumers to eateries allowing consumers to search for everyday eateries, spot menus available, order for food and track delivery services. Success in a growing market of food delivery apps is highly depends on satisfaction of users and intuitive interface. In evaluating the VitEat app, this report undertakes a structured needs analysis and usability test in order to determine user preferences, and to identify usability problems and solutions that could aid in improving the performance and perceived satisfaction of the VitEat app by its users. In other words, the app’s functions should meet certain user expectations and satisfy users’ requirements.
2. Methodology
The research methodology includes two main approaches: require especially needs analysis and usability testing. These methods were used to find out the current position of the app and its effectiveness according to user experience for the assignment helpline.
2.1 Needs Analysis
To achieve the objectives of this study, an assessment of the preferences and the perceived pain associated with the VitEat app among the target users was done through the needs analysis. Again, the survey, and focus group discussion to the regular consumers of the delivery services mean that there is both the qualitative and quantitative information about the perceived consumer behavior.
.png)
Figure 1: Flowchart diagram
(Source: obtained from Lucidchart)
These areas were the choice of food, desire and necessity for specific food type, delivery time expectation and options like unique orders and loyalty programs.
2.2 Usability Testing
The first kind of test done was usability test with participants who used the application with different levels of experience, some of them used actual food delivery applications.
.png)
Figure 2: Usecase diagram
(Source: obtained from Lucidchart)
The participants were requested to use VitEat app interface with the various tasks that include; restaurant search, ordering of foods, and monitoring the delivery of the foods (Su et al., 2022). Navigation convenience, the readability of the data shown, the convenience of the checkout procedure, and the illustration design satisfaction rate were measured.
3.Findings
3.1 Needs Analysis
The needs analysis was useful in determining the likes of VitEat’s target clients and the challenges and expectations they have toward the use of VitEat. Through surveys and focus group discussions, several key themes emerged:
Food Preferences and Dietary Needs: People underlined their need for varied meals to be offered by restaurants that would meet all kinds of restrictions or preferences. Again there was special focus on Vegan/vegetarian, gluten free and low calorie meals available for consumption. Several participants emphasized their ability to quickly search for the menu items within the relevant dietary limits easily, stating that this would also help in identifying appropriate items on the screen (Belanche et al., 2020).
.png)
Figure 3: Home page
(Source: Self Created)
Order Customization: A considerable number of the respondents considered the facility to modify their orders to be important. This included changing or deleting the ingredients, selecting the portion size and inserting special requests (such as an allergy). Another option, which was considered to be the major one, is the possibility to change orders due to restricting diets and the personally chosen taste (Tong and Samsudin, 2022).
.png)
Figure 4: Menu page
(Source: Self Created)
Pain Points in the Ordering Process: The participants also highlighted issues concerning the length of time it takes to wait for a response, navigation within the app to order particular foods or restaurants, and timeliness and costs of deliveries. Participants’ reported that confusing or less pertinent labelling of food types itself presented considerable challenges when it came to finding easily for instance vegetarian or keto type of foods.
.png)
Figure 5: Checkout page
(Source: Self Created)
User Expectations for Delivery: Delivery speed was a crucial aspect that the users cared about since majority of the participants complained when delivery took more than 30–45 minute. Furthermore, users considered timeliness of product delivery, and expected increased clarity from restaurants in case of late delivery.
.png)
Figure 6: Order Tracking page
(Source: Self Created)
Payment and Loyalty Program: Payment options clients demanded are mobile wallets non-card based, credit cards and cash on delivery option. They also showed a good consensus in a proposed loyalty program that issues discounts, free delivery, or other unique promotions to users who frequently make orders. This feature was deemed crucial for customer loyalty as it was an area quite crucial for customers.
3.2 Usability Testing
Ease of Navigation: Studies have shown that users have a fairly good impression of the appearance of the app’s interface; however, significant difficulties are observed when it comes to choosing a restaurant (Joseph et al., 2021). In particular, there were no options for setting the type of cuisine the user was interested in, or the type of meal suitable for a particular diet. Close to half of the participants in the survey pointed out the general belief that the filter rules needed to be beefed up with enhanced categorization.
Clarity of Displayed Information: Many respondents stated that the information provided by the app, including information on the menu, prices for different dishes, or delivery time, is inaccurate or unclear. Some of the users gave examples that certain meals were described poorly, the type, quantity, or proportion of ingredients was not described well by the food and menu descriptions (Ling, 2024). While, estimates of the delivery time were either unclear or not well indicated.
Checkout Process: Based on the usability test done, the checkout process was noted to be one of the areas that users found to be most problematic. While useful, it was considered cumbersome, especially with regard to the many steps required to complete an order (Diri and Zainal, 2023). Users complained of inconvenience whenever they changed payment methods and asked for more convenience features including the one click payment or saving payment details for future use.
Order Tracking Experience: For convenience, some users had commended the development of delivery tracking feature; but the implementation of the feature was not optimal (Fauzan et al., 2022). The real-time tracking was not dependable, and the estimated time of arrival was not steady, or updated each time. This has simply created much needed confusion and frustration for the users who merely wished to have clearer updates about their delivery’s progress.
User Satisfaction with App Design: In general, users paid attention to the fact that the app looked good, but they left the app understanding that it was not as useful as they expected.
.png)
Figure 7: About page
(Source: Self Created)
Navigation was not very smooth, moreover, checkout was not very smooth, and tracking was not very clear, all these factors made the user experience a little boring. Some aspects highlighted include the fact that by counting down the core activities, the app could dramatically narrow its remit and make the quality of real time relevant information delivered to the customer the centerpiece of the ordering process.
4. Analysis and Discussion
Through the needs analysis and usability testing, the main ideas for the areas of improvement of the VitEat mobile app have been identified (Sungboonlue et al., 2022). First of all, one can note the necessity to attract users that are into dietary filters and the necessity of customization elements. Hence, in addition to diversification of assortments, users are looking for the flexibility to adjust orders, based on nutrition limitations and preferences: this means that the existing app proposal does not respond to these clients’ needs. Thus, the usability problems described by the users regarding navigation and information clarity mean that App interface is not highly clickable for straightforward browsing purposes. Insufficient filters combined with over-complicated menu descriptions increases the choice difficulty for users, frustrating them (Holanda Muniz et al., 2024). In addition, the flow at the check-out stage was considered to be complex, and this may demotivate users from making purchases. Though many users availed of the real time tracking system that was integrated, the updates they receive were not up to date, which hampers user satisfaction and minimizes the trust level on the delivery. These results indicate that despite the fact that the app serves its purpose, improvements should be made to address users’ concerns for prompt and effective response as well as ensure better personalisation measures. As one could probably imagine, concentrating on these areas would probably result in higher user satisfaction and consequently, retention.
5. Recommendations
The following changes are proposed in order to optimize the functionalities and make VitEat mobile app more comprehensible and user-friendly. First of all, further improvements should also be made to the navigation system: Adding greater number of easy-to-understand filters, for example, there should be filters like Vegan, Gluten-free or Low carb restaurants. This would make the process of categorizing the food quicker and more efficient for use by its clients. Also, the checkout process requires rationalization of the checkout process with reduced sequence stages so that it may take less time as compared to the current one.
Another simple improvement is clearer confirmation messages during the payment process, and such options as saving the payment information for the subsequent one-click payments for multiple orders. A major area that needs enhancement is the current tracking of delivery in live application. When the delivery time is estimated right, real time information relayed by the app, the satisfaction of users using the delivery service will improve. This would also encourage solutions ranging from mobile wallet possibilities, PayPal, to cash on delivery, which would also further extend the opportunity for customer satisfaction.
Conclusion
VitEat developed an efficient mobile application for the food delivery services that allow users to find the restaurants close to them and place and track the orders easily. Despite this, the needs analysis and usability testing have brought out several areas of strength that the current design is lacking in specifically concerning navigation, checkout and order tracking. The mentioned problems will be solved with the help of the recommendations given in this report, therefore increasing the likelihood of VitEat to succeed within fast-growing food delivery service market.
References
.png)
Case Study
BUS5VA Visual Analytics Case Study 2 Sample
Assignment Details
Case Study 1 - Bank Marketing Campaign for Intelligent Targeting
In this case study, envision yourself as a junior business analyst collaborating with the marketing team to analyse and determine the best campaign strategy for a bank aimed at attracting customers to open term deposits. Successful marketing campaigns are characterised by their focus on customer needs and overall satisfaction.
However, several variables play a pivotal role in determining the success of a marketing campaign. We must carefully consider the following variables when crafting a marketing campaign:
- Customer Segmentation: Identify the target population segment and justify your choice. This aspect is very important as it suggests which segment of the population is most likely to respond to the marketing campaign's message.
- Distribution Channels: Devise the most effective strategy for reaching customers. It is important to define the target population segment to address and select appropriate communication channels, such as telephones, TV, and social media, for disseminating the campaign's message.
- Pricing Strategy: Determine the optimal pricing strategy for potential clients. Note that in the context of the bank's marketing campaign, pricing may not be the primary concern, as the bank's primary objective is to encourage clients to open deposit accounts to support its operational activities.
- Promotional Strategy: Outline the strategy's execution and how potential clients will be engaged. This step should follow an in-depth analysis of past campaigns (if available) to gain insights from past mistakes and enhance the overall effectiveness of the marketing campaign.
Your task as a junior business analyst is to address the following questions from the marketing team by creating visualisations in Tableau:
Task 1.1 (5 Marks): Investigate whether there is a significant age distribution difference between clients who make a deposit and those who do not.
Task 1.2 (5 Marks): Analyse whether a client's job or career has an impact on their likelihood to make a deposit.
Task 1.3 (5 Marks): Explore how the duration of the last contact influences the campaign's success (i.e., the likelihood to make a deposit).
Task 1.4 (5 Marks): Identify at least four campaign strategies, such as who should be contacted, how to contact them, and when to contact them. Present your findings in the form of a dashboard in Tableau.
Case Study 2 - Sports Analytics for Informed Decision Making
In this case study, you will take on the role of an analyst consultant working closely with the manager of a soccer team. Your objective is to explore the Soccer Match Dataset (available on LMS) and help the team manager to make informed decisions. The Soccer Match Dataset is a comprehensive collection of spatio-temporal events that occur during an entire season of seven soccer competitions, including La Liga, Serie A, Bundesliga, Premier League, Ligue
1, FIFA World Cup 2018, and UEFA Euro Cup 2016. This dataset offers valuable insights into various aspects of soccer matches, such as passes, shots, fouls, and more, and contains information about position, time, outcome, player, and other characteristics. Your task is to conduct descriptive analytics on this dataset and create interactive Tableau visualisations to empower the team manager with insights into the datasets, enabling informed decision-making.
Task 2.1 (5 Marks): The manager is searching for a skilled goalkeeper to join the team. Generate visualisations ranking goalkeepers based on the number of save attempts they made and highlight the top 5 goalkeepers with the most save attempts. Your visualisations should enable users to access player attributes, including weight, height, full name, and nationality, by hovering over the players of interest.
Task 2.2 (5 Marks): Lionel Messi (wyId: 3359) and Cristiano Ronaldo (wyId: 3322) are two of the greatest soccer players. Compare the game performance (e.g., the number of shots and number of passes) and physical characteristics (e.g., height, weight, and dominant foot) of Lionel Messi and Cristiano Ronaldo, to aid the manager in deciding between the two legendary players for potential recruitment.
Task 2.3 (5 Marks): The manager is interested in the potential impact of players' physical characteristics on their game performance. Create visualisations to investigate the correlations between players' physical characteristics (e.g., height, weight, and dominant foot) and their game performance (e.g., the number of passes, number of shots, and number of free kick).
Task 2.4 (5 Marks): Develop a Tableau dashboard to be used by the manager for future reference. Your dashboard should enable the manager to (1) rank players based on a selected event type (focusing on Pass, Shot, Free Kick, Foul, Offside) and (2) compare game statistics between the first half (1H) and second half (2H) of matches, based on a selected event type (Pass, Shot, Free Kick, Foul, Offside).
Solution
Introduction
In today’s age of big data understanding and presenting data in an iterative manner is of essence is the ability that defines many analyses. Tableau is one of the most popular tools used for data visualization and it helps users to analyze data and create interactive visualizations for business intelligence. This report explores the application of Tableau in two distinct case studies: an advert produced by a bank that is in a marketing campaign that focuses on efficient promotions and sports statistical analysis focusing on soccer teams. Analyzing Tableau’s tools, the report shows that such visualizations enable discovering hidden patterns and characteristics, improve marketing and player performance strategies. Hypothesis targeting the age bracket of clients to be targeted based on job, impact of job to deposit like likelihood, goalkeeper performance analytic, and comparing icons soccer players will showcase how Tableau transforms data into insights. This exploration therefore emphasizes the centrality of data visualization in enabling strategic management and organizational performance.
Case 1: Bank Marketing Campaign for Intelligent Targeting
Task 1.1: Investigate Whether There Is a Significant Age Distribution Difference Between Clients
The first task sought to identify whether there is a skewed age difference between the clients who open the term deposit and those who did not (Mazlan, Sainan and Mohamed, 2023). To do this, a histogram with ages as the x-axis and frequency as the y-axis was made possible using Tableau with the option to segment results based on deposit status.
The findings of the Visualization indicated that the clients who are using term deposit were older than the other group who were not using the term deposit (Dewi, Nilawati. and Anandita, 2024). This was evident from the distribution where the age group of depositors ended up being dominated by older people (Park and Park, 2021). There is an apparent indication that trying to reach out to older clients might help in enhancing the probability of realizing future marketing initiatives. Additional quantization could entail splitting age into particular categories to capture niche markets more accurately.
.png)
Figure 1: Part of Significant age distribution difference between clients
(Source: Implemented by Tableau)
The shared visualization concerns a line graph that focuses on the distribution of clients by their age. The x axis is the age of the clients starting from 15 up to 95 while the y axis is the number of clients in that age group. The peak has arisen in the age group of 25-35, wherein the values are gradually decreasing with the increase in age for the assignment helpline.
Task 1.2: Analyse Whether a Client's Job or Career Has an Impact on Their Likelihood to Make a Deposit
To illustrate the correlation between job type and the propensity to make a deposit as observed from the client data, a bar chart was developed using Tableau as shown in Table 5. This chart made the degree of differentiation among job types and deposit rates comprehensible, as the number of deposit comparison has been established above. As the bar chart showed there were certain professions where higher deposit rates were found especially the management and technical jobs.
.png)
Figure 2: Bar Chart of Job Type on Deposit Likelihood
(Source: Implemented by Tableau)
This insight will be useful for the marketing team in the bank to know which job categories are likely to embrace deposit campaigns. They provide an avenue of targeting specific job categories eliminating the generality of marketing messages thus enhancing the prospects of achievement of campaign goals.
Task 1.3: Explore How the Duration of the Last Contact Influences the Campaign's Success
For this work, this visualization was created in Tableau, to analyze the connection between the length of the last interaction with the effectiveness of the campaign (Dent et al. 2021). The graph depicted contact duration on the amount of loan deposit with each dot or node referring to a particular client.
.png)
Figure 3: Visualization of the Duration of the Last Contact Influences the Campaign's Success
(Source: Implemented by Tableau)
The plot also unmasks an increasing trend of deposit rates with longer contact durations. This means that if the interaction with the clients is taken further, the likelihood of getting a deposit would be improved. This plot established this correlation further, to stress the necessity of extemporaneous communication at potential clients. From this insight, the marketing team may be in a position to modify its contact strategies with the view of enhancing the general impact of the campaigns.
Task 1.4: Dashboard Creation
The last activity entailed creating a dashboard in table of the results of the preceding tasks. Additionally, the dashboard included components that let users navigate to the content by applying various filters.
To synthesize, the dashboard united several components to offer an overall opinion about the marketing campaign. Firstly, it included the Age Distribution visualization that displayed the distribution of the number of clients by their ages and their deposit/ no deposit status. This element enabled the users to recognize relationships in the age segment with higher deposit ratio. Secondly, the Job Type Analysis component used a bar chart to show how likely a deposit was going to be made based on job type. This made it easy to identify which professions were more receptive to the marketing campaign hence helping in propagation efforts.
Figure 4: Dashboard Creation Part
(Source: Implemented by Tableau)
Finally, there was the Contact Duration Analysis which depicted the campaign success based on the duration of contact with the clients. This component helped to understand the positive effects of longer contact with clients by illustrating how deposit rates depended on contact duration. Altogether, such elements allowed considering various aspects of deposit behavior and identifying factors affecting them more carefully. Dynamic data visualization and its interactivity proved beneficial in gaining a broader perspective of how the campaign was performing and contributed to the fine-tuning of marketing efforts.
Case 2: Sports Analytics for Informed Decision Making
Task 2.1: Rank Goalkeepers Based on Save Attempts
This task aimed at defining and sorting a list of goalkeepers according to the number of save attempts. To compare the goalkeepers by the number of save attempts, a bar chart was created in Tableau with emphasis on the best performers.
The bar chart was very effective in displaying the save attempts for the five top goalkeepers, complete with tooltips that displayed the weight, height, full name, and nationality of each player.
Figure 5: The part of Identifying Goalkeepers based on Save Attempts
(Source: Implemented by Tableau)
On this account, this visualization is essential particularly for the team manager where they get to judge potential goalkeepers on their performance from a clear, comparative vantage. Because there is more information regarding hover one can make a better decision when selecting it.
Task 2.2: Compare Lionel Messi and Cristiano Ronaldo
To analyses the performance of the game and the body measurements between Lionel Messi and Cristiano Ronaldo, the following visualizations were developed (Stephens and Young, 2020). Two bar charts were used to track down their shots and passes and, on the other hand, a table contained the players physical characteristics like height, weight, and preferred foot.
.png)
Figure 6: Comparison Between Messi and Ronaldo using Bar Chart
(Source: Implemented by Tableau)
The bar charts above revealed that Cristiano Ronaldo made more shots than Messi did while Messi completed more passes. The table that was provided to me showed how they differ in height, weight and the preferred foot they use. This detailed comparison is beneficial for the manager to make the right decision about recruitment since it presents a clear view of every player’s qualities.
Task 2.3: Investigate Physical Characteristics and Game Performance
This task was to assess the correlation between the players physical properties and the performance on the game (Torres-Ronda and Curtis, 2022). In the context of data exploration affordances, charts was developed in Tableau to establish relationship patterns between height, weight and the side of the foot depending on various performance statistics including, the passes, the shots and the free kicks.
Figure 7: Visualization Part of Investigate Physical Characteristics and Game Performances
(Source: Implemented by Tableau)
The plots revealed that defensive effectiveness increased positively with height while weight was also positively and moderately associated with the number of shots attempted by the players. This information is crucial in analyzing how specific physical characteristics can somehow affect one’s performance on the game, and thus in assessment of players. For example, it will enable the team to know which player would be best suited for which role given his or her physical attributes of the team.
Task 2.4: Dashboard Creation
The last activity involved creating a detailed and all-encompassing dashboard that would help the manager in the assessment of players’ and match data. Some of the features were amusing and these included Player Ranking in which rankings for different event types were depicted and Half-Time Comparison in which comparison of game statistics between the first and the second half for selected event was depicted.
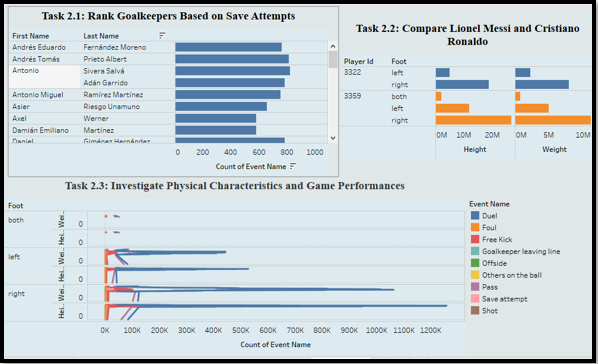
Figure 8: Dashboard Creation Part
(Source: Implemented by Tableau)
Some smaller elements like drop down menus and filter functionalities enabled the manager to select different event types and view statistics side-by-side. Thus, this dashboard can be used as a vital means that helps to control player performance and match characteristics for making better decisions.
Conclusion
The examples outlined above show how it is possible to use Tableau to analyze various sets of data and come up with useful information from the large chunks of information. In the case of bank marketing campaign, Tableau analysis pointed out important insights with regards to age, job type and contact duration which were rather helpful for fine tuning the existing and future marketing campaigns. In the sports analytics case, Tableau offered a clear comparison analysis between goalkeepers and famous players, and impact of physical attributes on the gamers. The use of interactive dashboards in both cases improved option for data and decisions Accent of the data and mechanics for the decisions. In general, Tableau has been of great help in transforming data into insights particularly in marketing and in managing sporting events.
References
.png)
Reports
ICT306 Advance Cybersecurity Report 2 Sample
Assignment Details
Case Study: Security Breach at TechCo Pty Ltd.
Background: TechCo Pty Ltd. is a multinational technology company that specializes in developingmcutting-edge software solutions for various industries. With a wide customer base and a strong reputation for innovation, TechCo Pty Ltd. has been at the forefront of the technology landscape for years. However, the company recently faced a major security breach that has had far-reaching consequences. The breach involved the compromise of sensitive customer data, including personally identifiable information (PII) and financial details. This incident has not only damaged the company’s reputation but has also raised serious concerns about the effectiveness of TechCo Pty Ltd cybersecurity measures.
Issue: During the investigation, it was discovered that the attackers utilized a combination of sophisticated techniques to gain unauthorized access to TechCo Pty Ltd’s systems. They began by conducting thorough footprinting, reconnaissance, and enumeration activities. Through publicly available information, online forums, and social media platforms, the attackers gained insights into TechCo Pty Ltd’s network infrastructure, identifying potential vulnerabilities and weaknesses. This detailed reconnaissance allowed them to map out the organization's systems and determine potential entry points for their attack.
Building upon their initial reconnaissance, the attackers proceeded to conduct scanning and sniffing activities. By using specialized tools and scanning techniques, they identified open ports, services, and protocols that were vulnerable to exploitation. Additionally, through network sniffing, the attackers were able to capture and analyze network traffic, seeking sensitive information such as usernames, passwords, and other credentials. This gave them a deeper understanding of TechCo Pty Ltd’s network architecture and allowed them to identify potential targets for their subsequent malicious activities.
Incident Details: In addition to technical methods, the attackers employed social engineering tactics to bypass TechCo Pty Ltd.'s security defences. They crafted sophisticated phishing emails that appeared to be legitimate and targeted specific employees within the organization. Through these deceptive emails, the attackers tricked employees into clicking on malicious links or opening infected attachments, thereby compromising their workstations and providing the attackers with unauthorized access. Furthermore, the attackers utilized phone calls posing as TechCo Pty Ltd. IT support personnel to manipulate unsuspecting employees into divulging sensitive information or unwittingly providing access credentials.
Once inside the network, the attackers launched a series of coordinated attacks, including denial of service (DoS) attacks, buffer overflow exploits, and system hacking/password cracking/privilege escalation techniques. These attacks disrupted TechCo Pty Ltds systems, causing significant
downtime and hampering the organization's ability to deliver products and services to its customers.
Result: The repercussions of this security breach have been extensive. In addition to financial losses and reputational damage, TechCo Pty Ltd. is now faced with the challenge of rebuilding customer trust and implementing robust security measures to prevent future incidents. The incident highlights the critical importance of comprehensive cybersecurity strategies that encompass not only technical safeguards but also employee education and awareness programs. Ethical issues and frameworks play a vital role in guiding organizations' cybersecurity practices, emphasizing the need for responsible and ethical handling of customer data.
Question 1
Describe the techniques used by the attackers for footprinting, reconnaissance, enumeration, scanning, and sniffing during the security breach. Discuss the implications of each technique on the organization’s security posture.
As part of executing penetration testing for the organization, include footprinting/reconnaissance (collect/gather information about the organization) using tools like Nmap or Zenmap.
Should scanning your selected organization prove unsuccessful, gather data on your virtual Windows 10 machine using tools like Nmap or Zenmap. This data should encompass the operating system, IP address, status of ports (whether they’re open, closed, or filtered), and the versions of those ports, among other details. Please make sure to include screenshots of your activities within the report. These will serve as proof of your experiment& execution.
Question 2
Explain the concept of social engineering and its relevance to the security breach. Identify and discuss at least three social engineering tactics that could have been employed by the attackers. Provide recommendations on how the organization can mitigate the risks associated with social engineering attacks.
You’ll be exploring the use of social engineering tools available in Kali Linux to understand how a User’s email address and password can be compromised. You will be tasked with setting up a simulated scenario using the Social-Engineer Toolkit (SET) to create a counterfeit Gmail login page. Demonstrate the process by which a user's email password might be captured when they unknowingly enter their details into the fraudulent website. Please make sure to include screenshots of your activities within the report. These will serve as proof of your experiment’s execution.
Question 3
Discuss the impact of the denial of service (DoS) attack on the organization’s systems and services. Identify the different types of DoS attacks that could have been used in this scenario and explain how they disrupt the availability of systems. Propose countermeasures to prevent or mitigate the impact of DoS attacks.
To demonstrating a denial of service (DoS) attack simulation, employ SYN Flooding with hping3 to launch a DoS attack against your virtual Windows 10 machine from your Kali Linux setup. During this experiment, utilize Wireshark to verify the effectiveness of the DoS attack on the Windows 10 machine. Ensure to capture and provide screenshots of the process. Please make sure to include screenshots of your activities within the report. These will serve as proof of your experiment’s execution.
Question 4
Explain the concept of buffer overflow and its potential exploitation by attackers. Discuss the consequences of a successful buffer overflow attack on the organization’s systems. Provide recommendations on how the organization can prevent buffer overflow vulnerabilities. Further, assess the organization's vulnerabilities using tools such as Nikto or OWASP ZAP. If evaluating your organization's vulnerabilities doesn’t pan out, shift your focus to analysing vulnerabilities on scanme.nmap.org using Nikto or OWASP ZAP. In both scenarios, it’s essential to document your process through screenshots. Please include snapshots of your efforts in footprinting both your organization and your Windows 10 machine, as well as in conducting a vulnerability assessment for both your organization and scanme.nmap.org.
Please make sure to include screenshots of your activities within the report. These will serve as proof of your experiment’s execution.
Question 5
Analyse the techniques used by the attackers to gain unauthorized access to the organization’s systems, including system hacking, password cracking, and privilege escalation. Discuss the potential risks associated with these attacks and propose effective countermeasures to enhance system security.
You’re tasked with setting up a new user on an FTP server running on your virtual Windows 10 machine.
Solution
Question 1:
.png)
The ipconfig command is used on the Windows 10 operating system, and the machine’s network configuration information is obtained. The output lists different types of addresses, including the so-called IPv4 address, with a value of 192. 168. 182. 116, which is the focus of the further network scan. Other network elements are also presented, such as a temporary IP address of 192. 168. 88. 220 and the link-local IPv6 address of FE80::5054: 64CF:F7CF: BA6. The temporary IPv6 address is 2001: 0: 5054: 64CF: F7CF: BA6: 2, and the default gateway address is 192. 168.1.0.
.png)
Figure 2: Result of “Nmap” scan of “192.168.182.116”
In Figure 2, the target machine IP address is 192. 168. 182. 116 is scanned using the Nmap tool in Kali Linux. The scan reveals that four ports are open such as Wbem, file and printer sharing services msrpc 135/TCP, NetBIOS 139/TCP, Microsoft 445/TCP, and wsdapi 5357/TCP. These ports relate to Microsoft services, which can probably be attacked if there are weaknesses or openings.
.png)
Figure 3: Port scanning of “192.168.182.116” IP address
Figure 3 shows a port scan (-p-) launched on the target IP (192. 168. 182. 116) through Nmap. This scan probes all 65,535 possible TCP ports and identifies six open ports. The other TCP numbers identified include 135, 139, 445, 5040, 5357, and 7680. There are supported several services msrpc and netbios-ssn, hence showing that several network services are running on the given machine. The extra open ports (5040 and 7680)contain an added chance to take benefit.
.png)
Figure 4: Aggressive scan of “192.168.182.116”
Figure 4 shows another scan done using the Nmap tool, a more aggressive scan marked by -A on the target IP 192. 168. 182. 116. Open ports and previously identified services are present in the scans, and it was discovered that the target machine is using either Windows 10 or Windows Server 2019. the assignment helpline It also indicates that the service running on port 5357 (http) gives the message of ‘service unavailable’.
.png)
Figure 5: Host-script result of aggressive scan
The host script that is obtained when attacking with an aggressive scan, probably with Nmap, offers plenty of information concerning the target system. It shows the NetBIOS name of the computer as DESKTOP-FWQ2QF1 and NetBIOS user. The smb2-time results suggest that message signing is on but not mandatory, which means a moderate level of security configuration, as displayed below. Also, the MAC address information ‘Oracle VirtualBox NIC’ points towards the fact that the system is in a virtual environment. From the traceroute details, one hop with the IP address of 192. 168. 182. 116, with a round trip time (RTT) of 2.05 ms.
.png)
Figure 6: Network packet capturing using “wireshark”
The figure below shows an example of a network packet capture with Wireshark, an application used to capture and analyze network traffic. The capture most probably targets the host and network service interaction. Wireshark depicts features including the source (Src) and destination (Dst) IP address, protocols (TCP, UDP), packet size and other features related to the transmission.
.png)
Figure 7: Another details of a network packet
This figure presents further particularities of a single network packet captured with the Wireshark tool. It demonstrates that specific protocols such as SSOP (Secure Socket Offloading Protocol) probably indicate secure traffic, providing metadata on different carrying information including TTL(times to live), packet size, and source and destination port numbers.
.png)
Figure 8: Information gathering using “dig” tool
This figure illustrates the result of using the dig tool, which is a powerful tool of Kali Linux for performing DNS querying and gathering information on a given domain. The command queries amazon. query com for any DNS records. This output shows different types of records being looked for, which include A (IPv4), AAAA (IPv6), and NS (Name servers), giving a view of the underlying Amazon infrastructure.
Question 2:
.png)
This figure illustrates the starting point of an actual social engineering attack using the widely known tool known as the Social-Engineer Toolkit (SET). The user gets a list of options, which are available to attack like Social-Engineering Attacks, Penetration Testing, Update SET configuration etc.
.png)
Figure 10: Selecting “Website attack vectors” option
In the SET, the user chooses the Website Attack Vectors from the list of options available on the terminal. This option allows the attacker to establish bogus Web sites aimed at ‘tricking’ users with the intention of capturing their username and password or by delivering malware through web-borne attacks like phishing and drive-by exploitation.
.png)
Figure 11: Choosing “Credential harvester attack method”
the user picks the Credential Harvester Attack Method from the Website Attack Vectors. This method mimics other genuine websites and logs into the usernames and passwords entered by unsuspecting users. Another thing that is targeted in phishing attacks is the theft of usernames, passwords or any other information.
.png)
Figure 12: Choosing “Web templates” option
The Web Templates is chosen by the user to launch a fake website with the help of several types of templates. This makes it easier for a hacker to set up the cloned website for capturing people’s log-in credentials. These templates are copies of real websites and thus they seem as real as possible, which in turn increases the probabilities of deceiving users.
.png)
Figure 13: Providing the target IP address
The last step is adding the target IP address for the operation, which is the credential harvester attack. The destination IP address is where the harvested credentials is delivered. In this case, the IP address 192. 168. 182. 209 is given here, which depicts the attacker’s system, which collect the credentials if the victim engages in the clone site.
.png)
Figure 14: Choosing the fake website template
This figure depicts the selection of a dummy website template in the Social-Engineer Toolkit, commonly referred to as the SET in Kali Linux. This tool assists its users in copying legitimate websites to make fake phishing pages. In this case, the user chooses template ‘2’, which is likely to be Google, Twitter, or another popular site that helps the attacker harvest the user credentials.
.png)
Figure 15: “Social engineering” attack is started
This figure shows how a valid website is copied to launch a social engineering attack. This is courtesy of the HTTP GET requests as the tool replicates the selected website. The cloned sitetrick the target into submission and supply sensitive data, such as login information, through what looks like a trusted interface.
.png)
Figure 16: Find the fake website in the target system “Windows 10”
This figure shows the fake phishing website launched on the target system having Windows 10. The actual page cloned from the Google sign-in page is also visible, where users are asked to put their log in details. After the victim has entered details, they are recorded by the attacker, thus making phishing attacks effective in social engineering.
Question 3:
.png)
This figure demonstrates the use of the hping3 tool in Kali Linux to perform a Distributed Denial of Service (DDoS) attack. The command hping3 -S—-flood -V 192. 168. 182. 116 initiates a flow of TCP SYN packets to the target IP address and thus contributes to high network loads. It is run in flood mode, and none of the packet replies are displayed.
.png)
Figure 18: High CPU usage of target system due to “DDoS” attack
This figure depicts the effect of the DDoS attack in resource utilization of the target system. The task manager shows that the CPU usage is at 97% and memory usage at 95% to show that the attack is overwhelming the system’s processing capability andslow it down.
.png)
Figure 19: Capturing the network packets after doing “DDoS” attack
This figure shows the use of a network monitoring tool such as Wireshark in capturing packets produced during the DDoS attack. The tool scans the excessive flow of SYN packets aimed at the target system, in order to analyze the characteristics of the traffic and check the efficiency of an attack.
.png)
Figure 20: Providing the information about a specific network packet
This figure provides information about a network packet captured during the performance of DDoS, which is given by this figure. Using the data presented in the picture, it is possible to identify the source and destination addresses of Ethernet, probably protocol (TCP), and the packet size. It emphasises the packet sequence numbers in an attempt to show the progress of the attack in addition to assisting in analysing the network traffic in the event of an attack.
Question 4:
.png)
In this figure, the user is browsing a sample vulnerability site to test the site for security. The IMAGE depicts the links to vulnerabilities, AJAX sampling, and areas of an insecure site without security headers. The content explains possible vulnerabilities that an intruder can take advantage of; it presents safety challenges in a web platform.
.png)
Figure 22: Find the details about the vulnerable website using “nikto” tool
The figure illustrates Nikto, a web server vulnerability scanner used to find problems on a target site. The tool highlights some of the HTTP security headers missing in web applications, including “X-Frame-Options” and “Content-Type-Options,” which help counter threats such as clickjacking and content spoofing, respectively. The output provides and exposes some of the defects in web security.
Question 5:
.png)
It captures the user in a Kali Linux terminal, where the user navigates the terminal and changes the working directory to /home/kali/Desktop. There are files of the directory listed to include ‘abcd. zip,’ ‘ddos. pcapng,’ and ‘password. txt.’ This command relieves a user's current location in the filesystem to show the existence of files frequently used by the cyber-security officer in activities like password cracking and a DoS analysis.
.png)
Figure 24: Performing password attack using “hydra” tool
This figure displays how a password attack is launched using the ‘Hydra’ tool, a network logon cracker. The command starts with 12 actions per server, all designed to perform login password cracking. The process involves the use of one password per task or in other words, the trial of one password.
.png)
Figure 25: The result of password attack
The figure shows a successful password attack on the target machine, which is 192. 168. 143. 116. The “Hydra” tool identifies the valid login credentials such as username as “admin” and password as “123. “ This shows that the system's security has been left vulnerable due to poor credentials, an aspect that attackers can use.
Bibliography
.png)
Reports
ICT80011 Research Method Report Sample
1. This is an individual assessment which is worthy of 60% of the total marks for this unit. Your submitted report must not have been submitted nor published elsewhere.
2. You can choose whatever topic as your wish. But, the topic must be within the disciplines of science, computing, engineering or technology.
3. Refer to Modules 6, 7 and 8 lectures on how to prepare this submission.
4. You must submit your report or proposal as a pdf file before the due date of 11:00pm Monday, September 23, 2024 to the appropriate submission system at Canvas.
5. Your submitted file must be named as FinalAssignment-YourStudentID-
YourFullName.pdf
6. Your submission must use single column, single spacing, 12 point font size on A4 papers. Your submission shall contain no more than six pages including, figures/tables/references and everything (around 2500 words).
7. On the first page of your report, you must state (a) title of your report with an indication whether it is a research proposal or a research report, (b) your full name, and (c) your student number.
8. The total mark for this assessment is 60, with the marking scheme as follows:
a. 20 marks – presentation, formatting, and compliance with the requirements as specified above
b. 20 marks – structure, organisation and consistency
c. 20 marks – readability, clarity and quality
9. Refer to the Unit Outline for late submission and plagiarism.
10. You are not allowed to use any AI (artificial intelligence) assistance or tool in this assignment.
Solution
1. Introduction
A. General Background for the Study
Concerning the efforts to mitigate climate change in the global benchmarks, the construction sector has been a challenge of addressing its carbon footprint. From the above illustration, it is clear that concrete, one of the most common construction materials, contributes to about 8% of carbon emissions.
.png)
Figure 1: Carbon emissions mitigation process for cement industry
(Source: Ige et al. 2024)
B. Purpose of the Study
The objective of this study for The Assignment helpline is to examine the possibility of using carbon negative concrete instead of normal concrete used in construction. It seeks to explore the strategies, tools and approaches used in generating such content, and impact made in addressing climate change issue. More broadly, so the career interest of the study is associated with the general advancement and utilization of the carbon negative concrete technology and its possibility to be implemented on a large scale within the construction sector in order to gain more sustainable environmental outcomes.
C. Guiding Questions
This study is guided by the following questions:
1. What are some of the necessary constancies as well as procedures necessary in the development of carbon negative concrete?
2. Which of them is more efficient in performance comparing to traditional concrete and what is the cost difference between the both types of concrete and environmental consequences of using the carbon negative concrete?
3. What are the implications and prospectus of embedding and materializing carbon negative concrete in the construction industry at macro level?
4.To what extent carbon-negative concrete can help the construction industry to deliver the concept of net zero emitters?
D. Delimitation and Limitations
Carbon negative concrete is the main area of concern in this research mainly in terms of technical and environmental impact. Although it briefly discusses the economic considerations of the material as well as its potential for expansion, this is not an exhaustive discussion of the financial viability of this material. Furthermore, the studys scope is restrained by published research and information available for carbon negative concrete, especially in advancement, trial stages, or newly emerging market areas. It also recognizes the weakness associated with long-term results since carbon negative concrete has not been employed on a large scale.
E. Importance of the Research
The implication and relevance of this study is the ability to add its weight to the struggle against climate change by encouraging the use of sustainable construction material. Carbon negative concrete is a revolutionary shift towards reduction of carbon emissions in the construction sector, and the uptake of this product might significantly contribute towards implementation of strategies such as the Paris Agreement on climate change (Estrada and Lee, 2023). This research is useful for policymakers, engineers, and construction firms in their endeavour to embrace environmentally sustainable construction practices and help in combating the enhanced global carbon emissions.
2. Methodology
A. Theoretical Framework

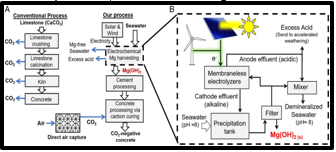
Figure 2: Carbon negative cement manufacturing
(Source: Palash Badjatya et al., 2022)
Life cycle assessment is employed to portray a comprehensive picture of carbon-negative concrete making from the stages of obtaining raw materials to concrete disposal. This makes it necessary to assess the energy used for the product manufacturing, transportation emissions, and use, and its CO 2 sequestration capability. LCA is necessary to check carbon-negative statements, which indicate the square material’s environmental benefit, total credit, and comparison with normal concrete.
B. Type of Design and Assumptions
The study design is both qualitative and quantitative in approach hence forming a mixed method design. This approach helps to examine all the necessary aspects to the subject due to qualitative results from interviews and questionnaires, juxtaposed with objective quantitative data from case and lab experiments.
.png)
Table 1: Carbon Absorption Capabilities of Carbon Negative Concrete (per cubic meter)
One of the most important presumptions of the study is that carbon-negative concrete can be used broadly in the construction industry if this material supplies costs compared to normal concrete and possesses similar characteristics. Another assumed premise is that carbon capturing techniques incorporated into construction materials will play a great role in the achievement of the Zero Carbon Emission regulatory standards as promulgated in the Paris accord.
C. Role of the Researcher
So as a civil engineering researcher interested in sustainability, the task of the researcher is to act as the middle-man between ideas and implementation. The role of the researcher involves undertaking of literature search and review, analysis and synthesis of the results in order to provide a bias free look at carbon negative concrete. Interviews with industry experts are also conducted by the researcher, survey data are combined and analyzed, as well as results of LCA studies, all the information is evaluated for its reliability and relevancy (Tiefenthaler, 2022). This reduces the possibility of bias in the research because the person conducting the research has the right knowledge to analyze construction materials that go into the construction of green buildings and the best practice in this area.
D. Site and participants selection
The research includes three test sites, Europe, and North America, that have incorporated carbon-negative concrete within their development projects. These site are chosen depending on the applicability of carbon negative concrete, size of the project and geographical location. Some of these buildings are a commercial office building in Norway, a housing project in Canada and a government building in the United Kingdom (Niveditha et al. 2020).
E. Data Collection Strategies
Data collection involves multiple strategies to ensure a comprehensive understanding of carbon negative concrete’s potential:
1. Interviews: Face to face interviews are carried out with 10 construction industry insiders: five who have used carbon negative concrete, five who have not, but have experienced similar low-carbon solutions.
2. Surveys: Questionnaire was given to more than 50 Construction professionals for collecting quantitative data about awareness level, challenges and preparations to take up the carbon negative concrete. Information collected from these surveys is utilized to recognize trends concerning use of specific material and expected performance.
.png)
Table 2: Comparison of Carbon Emissions for Different Types of Concrete

4. Lab Testing: Quantitative information is collected from the experiments performed on carbon negative concrete including its Compressive strength, Tensile strength &
Absorption capability. The preliminary investigations show that the material has the potential for comparable or better performance as typical current concrete with 35 MPa compressive strength or typical average strength of concrete used in building foundation.
F. Reliability of the study
Another method of increasing the reliability of the study is the method of triangulation-this is the use of multiple data sources to enhance validity of the study. Interviews conducted, survey results, laboratory results and case studies are compared to prevent findings from being made from one particular source. This is helpful to come up with a balanced vision on what is expected out of the material and what it cannot offer.
3. Findings
A. Relationship to Literature

.png)
C. Relationship to Practice
In use, the research establishes that carbon negativity of concrete offers performance characteristics that are similar to normal concrete in strength, durability, and flexism. But still, there is an issue on cost, on supply chain management, and on the acceptance of the industry. Nevertheless, several pilot projects have shown the possibility of using carbon negative concrete in large construction works and hence opening up the possibility of using such concretes in other big constructions.
4. Management Plan, Timeline, and Feasibility
A. Management Plan
The management plan has to have structure since carbon-negative concrete cannot be constructed through an unstructured approach. It entails stakeholder management; acquisition of licenses and permits, procurement of materials and management of transport and other services. It also demands the material scientist, engineers, and construction practitioners close working in order to deliver performance standards with the carbon negative concrete.
B. Timeline
The use of carbon negative concrete can be phased over a period of 3 to 5 years where the initial step is to undertake the pilot projects followed by notice projects, then the major projects. The first stage is that of experimentation and then construction starts on a small scale in order to assess its capacity. Often, the time line moves to the overall tests with material being used in pilot scale and in commercial and home constructions.
C. Feasibility
Success of carbon negative concrete is, however, predator on several factors which are cost of implementation, availability of the materials, level of support from the authorities and the customers or the construction industry. The material is now still more costly as compared to conventional concrete although the future trends towards the development of efficient technologies enhancing production to meet growing demand should help contain the costs. Also, adoption might be sparked by existing or expected financial incentives by federal authorities toward sustainable construction. In a nut shell, the study reveals that carbon negative concrete can be used effectively in the construction industry.
1. The problem of the study and its setting

Literature also covers the lifecycle assessment (LCA) of the proposed carbon-negative concrete and evaluates the impact differences between the even traditional concrete. Research indicates that carbon negative concrete has a lesser carbon inclusion from the life cycle of manufacturing Concrete through its disposal (Padnani, 2022). Nevertheless, with current knowledge, certain barriers persist, such as the issues of applicability of carbon capture technologies, incorporation of such materials into current building codes, and the feasibility of using such systems in larger-scale constructions at reasonable cost.
Also, current literature examines the possibility of an economic alternative by also highlighting how carbon negative concrete can provide an edge to traditional mediums. It can be further explained by the support of governmental policies and carbon credits; for instances, the policy briefs for Europe and US Green Building Council underline that low carbon materials are crucial for stepping up building activity in the future.
This is due to the fact that the data analyzed is qualitative and it is usually presented in the form of narratives or qualitative information The treatment of the data is as follows.
The study also uses lifecycle assessment (LCA) models to evaluate carbon negative concrete’s overall environmental impact. This data is critical for understanding how carbon negative concrete performs over time and across its full lifecycle, including factors such as transportation emissions and energy usage during production.
The researcher is a civil engineer with specialty in construction materials and life cycle assessment. This background will help to achieve an adequate understanding of both the technological processes of concrete production and environmental concerns of construction materials. Experimental research on low carbon building materials has been conducted by the same researcher in the past accompanied by work on the role of green technologies in minimizing carbon emissions.
Further, the researcher has practical experience in carbon capture technologies and has interacted with professionals from various construction companies and material science laboratory. This present study does not require the use of research assistants; however, engagement of construction engineers and sustainability professionals guarantees external benchmarking of the study’s data collection process.
5. Conclusion
In conclusion, carbon-negative concrete is one of the solutions of environmental protection in constructional industry that may potentially decrease the global amount of carbon emissions. Indeed, there are some challenges that are still present but it seems that a great focus in green building materials and climate change make the next generation carbon negative concrete crucial in the future construction process.
References
.png)
Reports
ICT5356 Principles of Artificial Intelligence Report Sample
You will create a white paper report (1000 words) on the future of AI technology in relation to your chosen organisation, outlining:
- What emerging AI technologies could be used by the organisation
- What kind of policies or guidelines the organisation will consider, to be responsible in its development or use of any future AI technologies
- What approach the organisation will use to develop or use these AI technologies
- What wider impact AI technology will have on the industry or field the organisation works in
Solution
Introduction
AI is rapidly gaining traction in various industries due to its qualities of boosting efficiency, innovation, and competitiveness (Javaid et al., 2021). Capgemini is a global consulting, technology services and digital transformation company. Capgemini is present in more than 50 countries and has over 300000 employees It aims to support organisations in today’s digital world (Capgemini, 2021). This white paper provides information on possible AI technologies that might be integrated at Capgemini, the policies and guidelines needed for the right development of AI technologies, how the above technologies may be integrated, and the effects of the deployment of AI technologies on the market.
Emerging AI Technologies for Capgemini
Capgemini can harness numerous emerging AI technologies to improve its offerings of service and operational efficiency:
.png)
Figure 1:Emerging AI Technologies
Source: (T, 2023)
- AI Driven Data Analytics: In the case of Capgemini, it remains possible to implement AI-based data analysis tools that enhance the effectiveness of decision-making (Proksch, Bielert & Paliwal, 2024). These tools can assist in deriving more value from large volumes of data which in turn could assist the company in providing improved solutions to clients.
- Natural Language Processing (NLP) and Conversational AI: The use of ConvAI and NLP can be employed towards the development of complex chatbots and Virtual personal assistants (Suta et al., 2020). These technologies can help the customer service by providing quick and contextually relevant responses, thus enhancing the level of client satisfaction.
- Machine Learning and Predictive Analytics: By implementing the technique of machine learning, Capgemini can produce models to predict the future of the market, actions of client, and risks. This would be useful in initial stages of the problem and would make it easier to direct to the best approach (Suta et al., 2020).
- AI in Cybersecurity: Applying AI in cybersecurity is useful to defend Capgemini’s infrastructure and clients’ data from attacks. AI can recognize threats within a small span of time, counter different threats on its own, and provide a comprehensive threat report (Soni et al., 2020).
Policies and Guidelines for Responsible AI Development
Since the company is gradually increasing the use of its operational activities with the help of AI technologies, it is crucial to establish certain norms that would define the employment of AI. One of them is to introduce an ethical initiative that would meet the standards of AI at the international level (Díaz-Rodríguez et al., 2023). This framework for The Assignment Helpline should guarantee that the integration of AI technologies is done in a way that is as transparent and as fair as possible to avoid creation of biased AI algorithm and to protect the users’ privacy and data.
To increase credibility of developed AI systems in Capgemini, it is suggested that it follows monitoring and auditing during development. Periodic checking and reviewing will assist to know whether the particular AI systems are performing well, or if they are compliant to ethical standards (Díaz-Rodríguez et al., 2023). All these measures are necessary to curb disputes that may occur when applying artificial intelligence and to reduce the risks associated with the use of artificial intelligence based solutions. This notion of AI should be answered by Capgemini pertaining to how much and what form of transparency and accountability should be afforded to it.
Approach to Developing and Using AI Technologies
Capgemini’s approach to AI development and deployment should be strategic, iterative, and focused on long-term benefits:
- Innovation Hubs and R&D: This means that innovation centres, partnering with research and development facilities of Capgemini should be established to harness the new possibilities of AI technology innovation (Toch, 2018). These hubs happen to contain the newer concepts or solutions that can be re applied to meet a certain need of the client.
- Strategic Partnerships and Collaborations: The company should involve existing AI start-ups, research organizations, and technology suppliers to obtain the newest advances in AI technology (Soni et al., 2020). This can also help explain why Capgemini will be a viable player in the current and future AI market.
- Agile Development and Implementation: By using AI, Capgemini will be capable to be more flexible when it arises to generating AI projects and augmenting the solutions in reaction to feedback while in the field. This will help to guarantee that the AI systems are appreciated and continue to improve the solution of client problems (Soni et al., 2020).
- AI Training and Skill Development: This is why Capgemini should encourage its employees to attend AI training so that it can be assured that they are equipped to apply AI technologies in the organization (Javaid et al., 2021). These training sessions will go a long way in ensuring that the company does not lag behind when it comes to development of artificial intelligence.
Wider Implications of AI Technology for the Industry
The adoption of AI technologies by Capgemini will have a significant impact on the consulting, technology services, and digital transformation industries:
- Increased Efficiency and Cost Savings: AI will complete several processes, which will signify that both Capgemini and its customers will see enhanced streamlining and cost savings. This will increase the adoption of AI across industries since organisations will do everything within their power to survive (Tomašev et al., 2020).
- Enhanced Decision-Making: Big data analysis and predictive behaviors that are integrated with AI will enable Capgemini and its clients to be able to make better decisions (Mantelero, 2018). This will lead to improved business performance and change in organizational practices from intuition to evidence-based.
- Evolution of Workforce Roles: While AI is applied to automate routine processes, the work of human employees will shift toward more creative and analytical activities (Mantelero, 2018). This change will lead to reinvention and elevation of the workforce, which will produce a new balance in the field.
- Ethical and Regulatory Challenges: The increased adoption of AI across industries will lead to new ethical and regulatory questions that Capgemini will have to address within the legal frameworks. To overcome these challenges, the industry will have to adopt standards and best practices (Tomašev et al., 2020).
Conclusion
With the development of AI technologies, Capgemini can become an example of how to implement AI solutions responsibly and as a pioneering company. Through the use of new AI technologies, the development of effective policies and guidelines, and the inclusion of AI as a strategic priority, Capgemini can not only improve its services but also influence the development of the industry. AI is set to revolutionize consulting, technology services and digital transformation and Capgemini sits well within this revolution.
References
.png)
Reports
DATA4200 Data Acquisition and Management Report 1 Sample
Assessment Description
Business Problem: Airbnb is a U.S. company which provides an online marketplace for short- term and/or holiday accommodation. Airbnb collect large volumes of data to gain insight into their clients and associated customers, such as review scores, host acceptance rate, ‘superhosts’, popular accommodation types and density of listings in particular location.
Data sets: We have obtained data on Airbnb listings in Melbourne with a variety of variables. Sampled datasets, the original data and data dictionary will be available from Week 4. See sections below.
Assessment Instructions
Analysis and Report
Use Microsoft Excel or Power BI or Tableau.
Recall the sampling methods below that you have learnt about in lectures.
• Non-probability sampling
• Probability sampling
A data dictionary file and the following datasets (as .csv files) that contain sample data generated using quota, systematic, simple random, and stratified sampling will be available from week 4, see section c. below. You will also have to access the original population dataset cleansed listings dec 18.csv from the source, see section a. and section e. below.
Create a report and include your response to the following questions:
a. Access the data file cleansed listings dec 18.csv, by going to the link provided on MyKBS under the Assessment 1 tab. You will initially be downloading a zip folder from the Melbourne Airbnb Open Data project on Kaggle. Extract all the files within the folder and then choose the file cleansed listings dec 18.csv. Browse over the columns and comment on which variables appear to be the most useful in terms of insights into current listings. Document that in your report.
b. List an advantage, possible disadvantage and limitations of each of the sampling methods.
c. Access the sampled data sets on MyKBS. Choose a number of different variables, as in part (a), then for each of the sampled datasets create summary statistics for each of those variables. That is, make sure that the selected variables are the same for each of the four datasets and document them in your report.
d. Interpret and compare the results of the summary stats across all four sample datasets. What conclusions can you draw from the comparison. Document your findings in your report.
e. Repeat the above for the original dataset cleansed listings dec 18.csv. Explain with statistical examples which sampling method summary stats (across all chosen variables) were nearest in value to the original dataset summary stats.
Explain the variations in your report and include the supporting data. Explain possible ethical issues that could occur from the use of sampled data.
Briefly evaluate the software that you have used to produce the summaries.
Solutions

These 34 variables will be used to form an organized and meaningful insight. The rest of variables will remain out of the scope for this analysis. The above variables will be used to identify Airbnb location, details of the host, what is the type of the property, number of rooms, bathrooms and bedrooms, so that the customer can have all details about the property before booking.
b. List an Advantage, Disadvantages and Limitations of the Sampling Methods
Non-Probability Sampling
Quota – Quota sampling is based on participant’s quotas or characteristics using some demographic factors like age or gender. The recruitment is done until each quota is met. The main advantage of quota sampling is saving of time as well as resources. This sampling is more straightforward and minimum resources are required to conduct this sampling.
Disadvantage – As the selection of participants is based on particular quota which is ease to access and low in cost, that results in sampling bias for the assignment helpline.
Limitations – As the sampling is not based on random selection, this may be a reason for research bias.
Convenience – This is the easiest and quick method for data sampling that are cost effective and easy to reach.
Disadvantage – This also cause sampling bias as this is based on unfair advantage to certain community.
Limitation – Accuracy of data is at stake as only easily contacted participants are reached to collect data.
Probability Sampling
Stratified – This sampling ensures that each stratum is represented accurately and also helps in minimizing sampling error as well as variability.
Disadvantages – This sampling can be difficult.
Limitations – Its difficult for researchers to confidently classify every participant into a subgroup.
Systematic – This technique of sampling can eliminate the clustered selection and also there are less chances of contamination of data.
Disadvantage – This sampling can provide inaccurate results because of unavailability of some data.
Limitations – This sampling may cause over or under representation of some particular pattern. Also, there is a greater risk of data manipulation.
c. Creation of Summary Statistics
We have selected two variables from the above list to develop the summary statistics. These variables are price and review score rating. Various statistics values are calculated using Tableau and MS Excel. Different types of functions are used to calculate all related statistic values. The average value of room price is 167.98 and the maximum price value is 162.67 whereas the minimum value is 14 for price variable. The similar stat values are calculated for review score rating.
Stratified Sampling
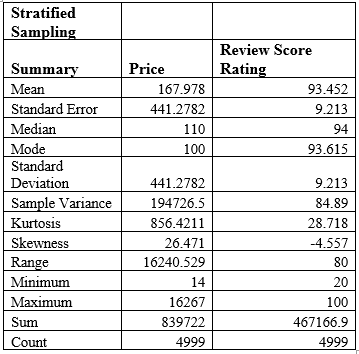
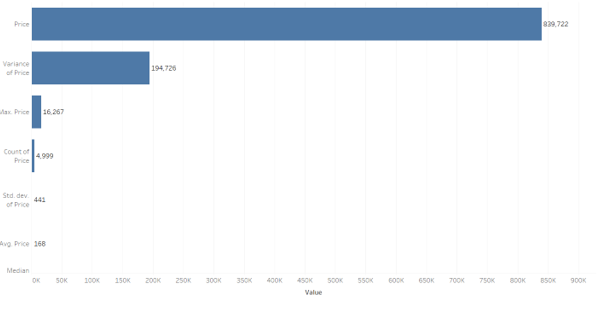
Quota Sampling
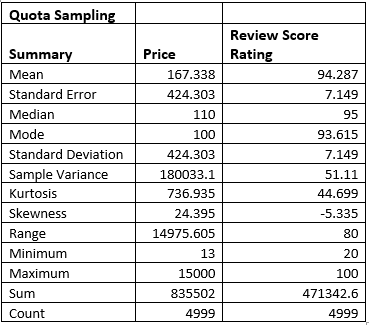
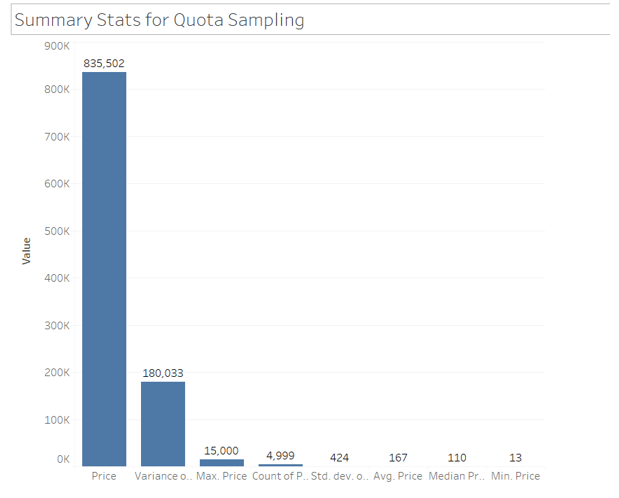
Random Sampling
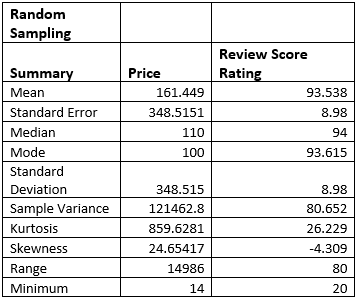
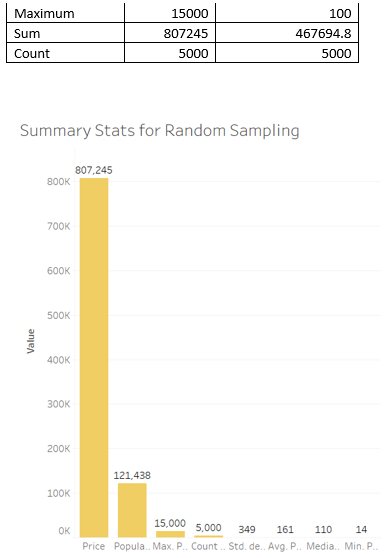
Systematic Sampling
.png)

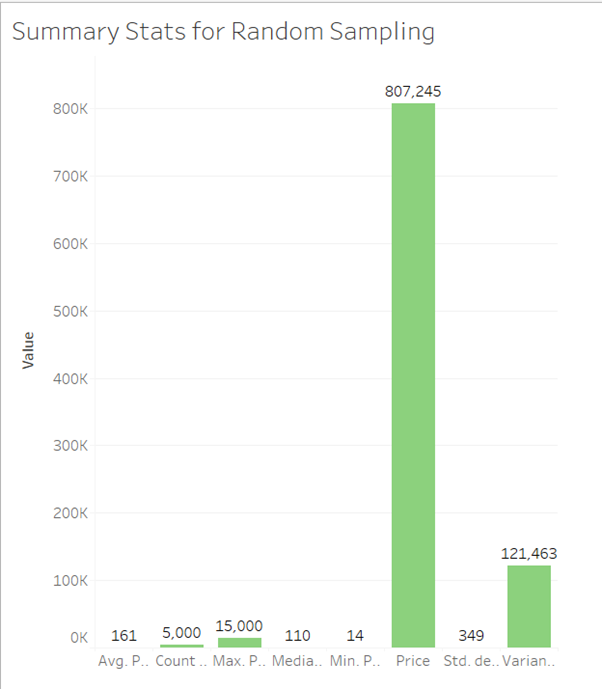
d. Comparison of all four sample data sets
Two variables have been considered to draw the comparison between given data sets. These four data sets include systematic, stratified, random and quota sampling techniques.
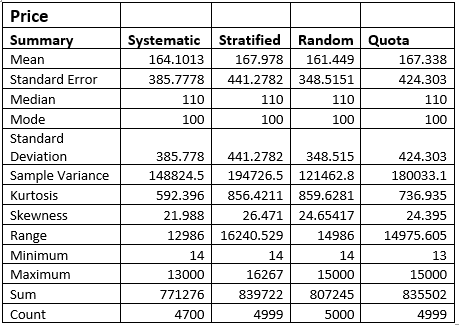
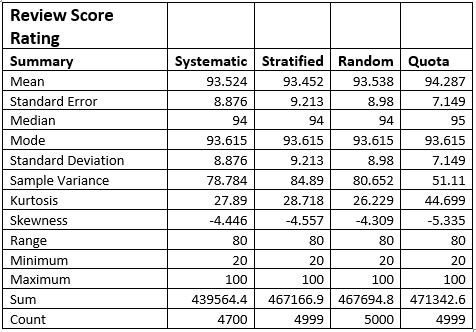
As we know that stratified sampling is more accurate as compared to other three, so average of price is strategically accurate in this sampling. On the other hand, standard error is mainly used to measure the efficiency and accuracy of the sample, but it has large value for stratified sampling. This implies that the stratified sampling dataset consist of discrepancy. There is no change in the values of median and mode. Standard deviation shows the measure of dispersion of data. From the comparison, it is clear that stratified data has maximum value, that indicates how wider the data is spread out. Hence, it signifies higher variability. Sample variation can be defined as a measure of dispersion of observations around the mean. Stratified sampling shows higher value of the variable that indicates the collected data can have higher variability. On the other hand, quota shows lower value of std deviation that indicates similar data collection.
Kurtosis defines the degree of peakedness whereas Skewness is degree of asymmetry of the distribution. Random data has higher value of kurtosis that shows greater probability of deviation from the mean. Stratified data is on second number. For all four data sets, distribution is positively skewed.
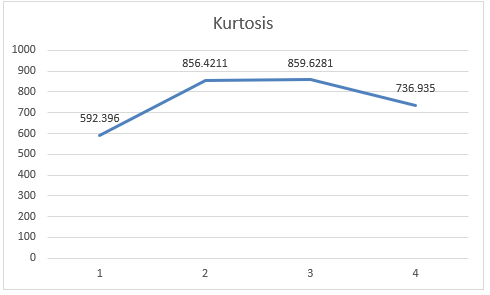
As the above curve is lower in peak, therefore, it is known as Platy_kurti. It shows that the chosen variable will be more stable as compared to other variables. For skewness, the curve is positively skewed.
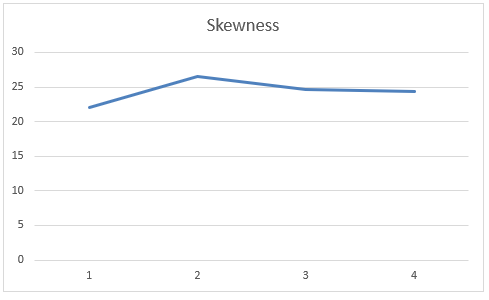
The second variable chosen for summary statistics is review score rating. Quota sampling shows maximum value for mean whereas standard error has largest value for stratified data sampling. Similarly, maximum value is derived for standard deviation statistics. Skewness is negative for all data sets which show data for this field is highly skewed.
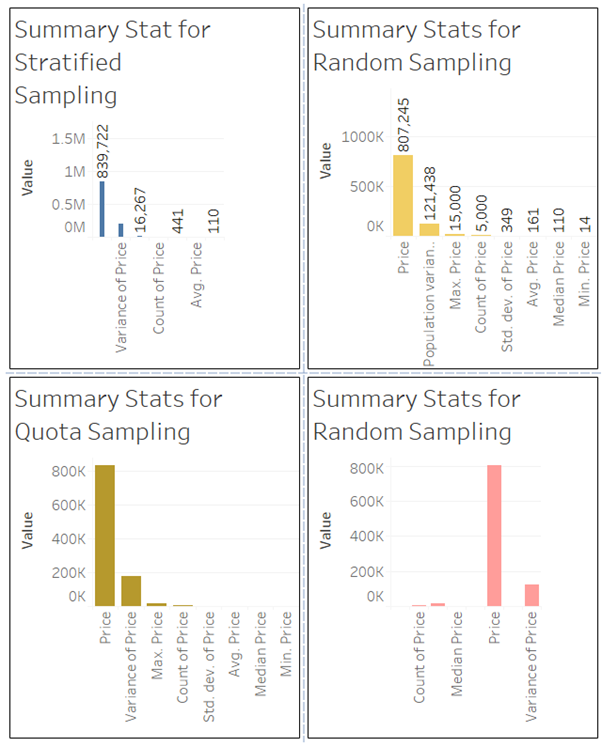
e. Using the Original Dataset
The same step is repeated for calculating summary statistics for cleansed listings dec 18.csv. All above data sets are merged into a single data set and then cleaned by removing null values and adding some values to the price field that consist of 0 values. All fields like Mean, standard error, median, mode, standard deviation, variance, kurtosis skewness and so on are calculated by using the same functions and by similar methods. The file consists of approximately 22000 data elements so its processing remains slow as compared to other data sheets. The average of price calculated is 148.07 which is in between of previous values. Standard error values is 210.84 which is still large, that indicates about discrepancy of the data set. Median and mode values are equivalent to the four data sets. Not much change has been notified in these values. Again standard deviation value comes to 210 showing the wider spread out of the data. This indicates that data is not limited to quota, systematic and random sampling. More data sampling means many more visualization can be possible and it leads to the perfect data analysis that may affect positive decision making by the company. Skewness is positive and its value is 26 which is a large value that indicates an excess of low values for the price field. High value of kurtosis shows distribution is more peaked. The summary statistics table for the price variable is shown below.
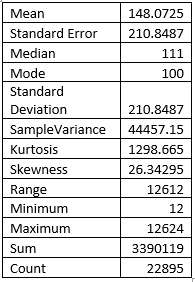
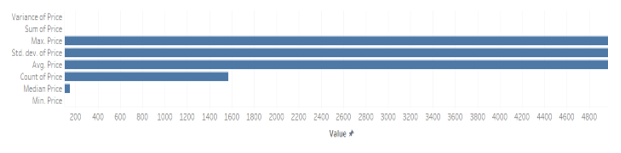
The summary stat calculations for review score rating variable is listed as following. According to the table, the average value of the merged field is 94.18 which lies in between the value calculated for all data sets. The discrepancy for this column is less because of small value of standard error. The calculated sample variance value for the field is 73.40 which is not much high and indicates less variability of the collected dataset. Again, kurtosis value is lower and the result of skewness calculated field is negative.
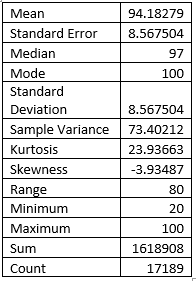
From the above discussion, by calculating summary stats for all four data set and the cleansed data set, it is clear that the value of that related field remains equivalent as both variables consists of similar values in all sheets. The only main difference lies in speed of processing of both types of data set.
Reports
EDES105 Indigenous History and Culture Report Sample
This unit has been designed to empower teachers to be better informed about Aboriginal and Torres Strait Islander Education. Critically analyse and reflect on one of the 6 key thematic areas of this unit listed below, examine the significance and relevance of your chosen theme to your future role as a teacher, and identify strategies to enhance your effectiveness in the classroom, particularly for Aboriginal and Torres Strait Islander students.
1. Country and Story.
2. Indigenous Knowledges.
3. Indigenous literacies and Aboriginal English/s.
4. Aboriginal Education Policies in NSW and Federally.
5. The stories being engaged in, within the Australian 'History Wars'
6. Incorporating and engaging Aboriginal perspectives in the teaching of a chosen curriculum area (Specify chosen focus). In this essay include the following:
1. Critical reflection and analysis of your perceived personal and individual role as future teachers.
2. Analysis and reflection of pedagogical components in quality Aboriginal and Torres Strait Islander education.
3. Critical analysis and personal reflections of the readings engaged in as they relate to your chosen thematic area.
Purpose: This assignment is designed to allow you to reflect on your experiences and learning journey and illustrate how you have furthered your understanding through an engagement with the perspectives and knowing shared by academic voices contained within the various readings provided, and other material and sources you have independently been researching. This final assignment is about the level of understanding and insight you have gained and can bring to your teaching as a synthesis of knowledge about your chosen theme.
Learning outcomes assessed: 1, 2, 3 & 4
Solution
Introduction
Efficient learning for Aboriginal students can be ensured by identifying specific needs and culturally appropriate practices. I have learnt various things for The Assignment Helpline throughout this unit which has helped me to understand the educational aspects of Aboriginal and Torres Strait Islanders. However, the main themes in this unit that attracted me the most are indigenous literacy and Aboriginal English. In the following discussion, I will explain how this theme can be significant for me to identify teaching strategies in the future and effectively foster an inclusive learning environment. The following reflection will include the insights that I have obtained from reading various articles and provided materials along with understanding from my independent research.
Personal Reflection and Critical Analysis
Australia currently has more than 250 indigenous languages along with 800 dialects (AIATSIS, 2023). This is why language is considered to be a living thing that is necessary to connect people to their ancestors, culture, and country. My knowledge regarding Aboriginal English and Indigenous literacies has developed effectively through learning from the provided readings. After going through all those readings, I have created an in-depth understanding of the importance of bilingual or multilingual practices to promote Indigenous literacies more effectively. Language is not just a means of communication for Indigenous people, rather it plays an important role in fostering a sense of identity among them. Although the Australian government ordered teachers to teach English for the first 4 hours of the day in remote schools in 2009, many schools such as Yirrkala School continued to teach “both ways” (Masters, 2021). While reading about the practice of these schools in my previous assignment, I have developed a detailed understanding that many students coming to remote schools do not have as much proficiency in English as they have in their first language. Thus, the students are more able to understand the topics taught in class if those are in both English and the student's native language. Thus, I comprehend that to promote indigenous literacies, a bilingual and multilingual environment is necessary. Moreover, from wider reading, I have identified this is also necessary for the survival of the language and cultural practices of the community. In many Indigenous communities, very few people have proficiency in their native language as more people are being educated in English (AIATSIS, 2023). For example, the Ngunnawal language has not been spoken fluently for nearly a century now. In many cases, only older people in the community have proficiency which I understand to be not suitable for maintaining the higher language diversity of the country. Thus, currently, the inclusion of elders from the community in the educational programs is necessary to revive the first languages of the indigenous communities for future generations. My understanding is that indigenous literacies are rooted in art, dance, song and oral traditions. Thus, it cannot be solely focused on conventional writing and reading methods. According to me, the preservation and promotion of Indigenous literacy are highly important and can be only ensured through integrating spatial, performative and visual elements that connect to the Indigenous culture effectively.
Argument and Examples
After reading various articles and comprehending learning from the provided materials, I have identified that colonization is one of the primary reasons that pressurized indigenous people to alter their language practices. Due to high pressure, many indigenous people started using colonizer languages which came at the expense of their ancestral language. However, in many countries such as Canada, the US and New Zealand multilingualism is currently highly promoted (Disbray et al., 2018). However, I have identified that the complexity in Australia to upscale multilingualism is more severe. As the Australian population as well as speaker communities of each language are limited in number, broad delivery of language reclamation and revitalisation programs is not possible (Disbray et al., 2018). My personal experience regarding this is that many people in the country speak more than one traditional language along with English. Although in remote areas, integrational transmission of language has been possible till now, the communities are facing physical, social and economic challenges. I have identified another argument in the article of Masters, (2021), bilingual curriculum for Indigenous people is efficient in increasing student engagement and attendance rates. I believe that enabling children to learn and play on the traditional lands is necessary to foster indigenous literacy effectively along with connecting the curriculum with the cultural aspects of the community. If integrated properly, people can even develop proficiency in Western numeracy without compromising their language. Schools like Yirrkala and Laynhapuy Homelands are the most significant examples that have been successful in their teaching strategies of aboriginal English along with promoting indigenous literacy. Previously many Aboriginal students used to drop out before completing year 12. However, Yirrkala is the first school in the community which has the first graduate year 12 by focusing on both aboriginal English and local language (Masters, 2021). The faculty members have also ensured that videos, books, apps and flashcards are developed in the local language. The case study has interested me significantly to understand that learning in a native language is more interesting to aboriginal students which helps them to connect with their culture more effectively. Apart from that, the remote schools are also strongly prioritizing the communities to enable them to make decisions regarding educational practices (Masters, 2021). However, one of the major challenges remaining in Australia is the funding of remote schools. The schools with poor attendance obtain lower funding which worsens the attendance more as the educators cannot access the necessary resources to increase engagement with the limited funds. Thus, I believe that a stronger analysis is required to be done by the federal government to ensure high literacy among the Aboriginal and Torres Strait Islanders.
Role as a Teacher
In the future, while practicing as a teacher, the above-discussed theme will have significance in bringing effectiveness to the classroom. The Aboriginal and Torres Strait Islander students require more engagement with their culture and first language to develop their knowledge efficiently. In this regard, the pedagogical model that I will incorporate into my teaching is Culturally Responsive Pedagogy to fulfill my role as a teacher efficiently. As per this pedagogy, teaching strategies need to emphasize the significance of the social situation and culture of students along with embedding it in the school's curriculum (Evans, Turner & Allen, 2020). Through this, I can demonstrate value and respect to the students and their culture to engage them more effectively in the learning process.
Moreover, I will consider these insights while teaching them. From my reading and learning, I have identified the ‘8 ways’ to be the most important pedagogical framework that can be incorporated into aboriginal teaching techniques. This framework was developed by Dr Martin Nakata and Dr Karen Martin and is focused on core curriculum content along with embedding Aboriginal perspectives for the students in every lesson (8 Ways, 2024). As a teacher, I can effectively engage with indigenous knowledge through this framework which is necessary to apply common ground in the classroom. The main focus of this framework is on a simple rule that everyone should put something back if they take something. To implement this rule effectively eight learning tools were mentioned in this framework such as storytelling, learning maps, land links and community links. Thus, while teaching aboriginal students, I will ensure that the curriculum incorporates these 8 tools. The ‘story sharing’ aspect of this framework must include cultural meaning-making and place-based significance which can be customized according to the particular culture of the Aboriginal students (Barkaskas & Gladwin, 2021). In the future, I will also consider using ‘learning maps’ to foster intellectual processes among aboriginal students by using metaphors which are grounded in the country and culture. In this regard, I will use diagrams, flowcharts and mind maps while teaching complex concepts to the students along with ensuring that they align with their indigenous culture. However, after evaluating various articles and readings, I have identified that language barriers remain a major challenge in creating inclusive learning environments. In this regard, the incorporation of ‘non-verbal’ techniques such as visual cues, gestures and body language will be highly suitable for bridging the language gap (8 Ways, 2024). Apart from that, I will also incorporate ‘images or symbols’ in the learning process while teaching which are identified to be the building blocks of learning in the framework. Through this, aboriginal students can learn new concepts more efficiently as visual elements are more effective in strengthening memory along with understanding the dynamic and cross-cultural meaning (Malcolm, Konigsberg & Collard, 2020). Land and environment are highly preferred in the indigenous curriculum. Thus, ‘land links’ will be incorporated while teaching the students more meaningfully about the concepts of ecology or geography. Outdoor learning will be a focused teaching strategy to connect lessons to the land.
‘Non-linear’ pedagogy is also widely accepted by practitioners to productively integrate School knowledge with communities. In this regard, project-based learning can enable aboriginal students to identify solutions for real-life problems innovatively and holistically (8 Ways, 2024). I will also incorporate this strategy while teaching to foster independent exploration of topics flexibly. Moreover, aboriginal scaffolding methodology will also be incorporated into my teaching strategy that aligns with the element of ‘deconstruct/reconstruct’ of the 8 ways framework. The Basic skill of the student can be built through this strategy which is effective for moving from familiar to familiar concepts. ‘Community Link' is the most important element of this framework and is aligned with my reading regarding the concept. While teaching aboriginal students, maintaining a connection with the community is necessary to ensure higher success (Santiago-Ortiz, 2019). Thus, I will consider inviting community members often, especially elders during classes. They can share their knowledge with the students through which community resources can be embedded efficiently in the curriculum. Through this, more respect can be shown to the community knowledge which can create a sense of belonging among the students.
Conclusion
From the above discussion, it can be concluded that the development of Indigenous literacy and Aboriginal English requires participation from the community members and strong curricular development. I have read various articles along with considering the provided learning materials to understand the concept in more depth. I have learned that using English as the main language in the curriculum is not the solution to improve educational outcomes among Aboriginal and Torres Strait Islander students. Schools are required to engage the community as well as focus on a bilingual and multilingual environment to ensure higher engagement among the students. In this regard, I will focus on culturally responsive pedagogy and 8 ways framework of my teaching strategy. As language remains a barrier to improving the learning environment for Aboriginal students, I will consider using visual elements, outdoor learning, project-based learning, and linking concepts with land and environment as core teaching strategies. Through this, the students can learn more effectively.
References
Reports
ICT103 Programming Report 2 Sample
ASSESSMENT DESCRIPTION
• In the group project, you will work in teams of 3-4 students.
• The assessment is divided into two components: Group report submission and mini-project demonstration.
• The details about the report structure are given below.
• The demonstration will include group demonstration of the implemented mini-project and followed by individual Q&A.
• The assessment must include object-oriented (OO) concepts like Class and Object, Encapsulation, Constructor, Inheritance, Getter and Setter methods, Method Overloading, and Association (multiple classes).
• Failing to use OO concepts will result in marks deduction as per the rubrics.
• The projects should be menu-based.
Report Structure:
The report should include the following sections:
1. Cover Page (provided by your lecturer): includes group member names, student ID and contribution.
2. Introduction: Brief description of the project and your assumptions about the project.
3. Flowchart and Class Diagram: Flow chart for the project logic and Class diagram for the identification of different classes, attributes and methods and any other OOP concepts implemented.
4. Implementation details: Mention the OOP concepts used. List the classes and methods and a short description of the purpose of the classes and methods.
5. Evaluation: Output screenshots for every menu item. The screenshots should show the system time and date.
6. Testing and Error Handling: Screenshots with incorrect input and the strategies you have applied to handle the errors or incorrect input scenarios. Validation of input can be a part of testing.
7. Contribution and Reflection: The section should include each team member’s contribution to the project development and their reflection on their learning experiences and project outcomes. It should mention individual’s roles, responsibilities, challenges faced, and insights gained throughout the project, emphasizing self-awareness and continuous improvement.
8. If you have implemented a Bonus feature, please mention that explicitly in the report and also emphasize that during the demonstration.
You can choose any project title
1 .Project Title - Library Management System
2. Project Title - Hotel Management System
3. Project Title - Employee Management System
4 . Project Title Student Management System
Solution
Introduction
The “Hotel Management System” is of console-based system which is a type of application software mainly used in the hotel to manage the main working areas. That is why this system is designed to help the hotel staff to improve efficiency and at the same time minimize the complexity of the work; this system allows the staff to control reservations, check-ins, and check-outs, and assign rooms without any difficulties. In real-time, application features such as room management and reservation for the room coupled with the secure management of the user’s account enhance operational efficiency. Some of the functions that may be assigned to an admin staff include the ability to check the guest details, record the room status, and perform other functions without interference or conflicts in case several events occur at the same time for the Assignment Helpline.
Flow Chart and Class Diagram
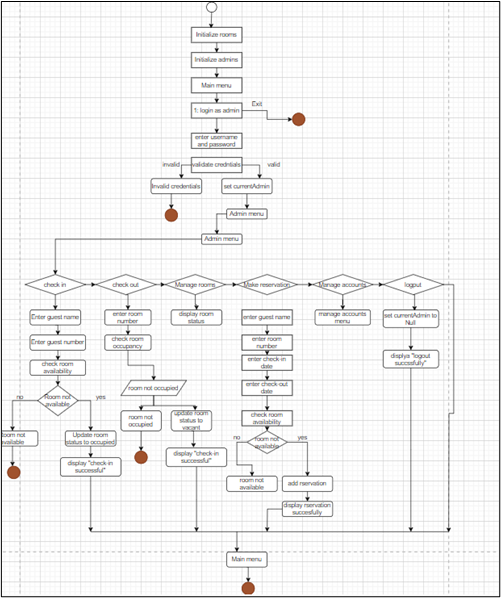
Figure 1: Flowchart
(Source: Self-created)
.png)
Figure 2: Class diagram
(Source: Self-created)
Implementation details
.png)
Figure 3: Use of encapsulation
(Source: Acquired from Netbeans ide)
The above figure shows the use of encapsulation which is acquired from the NetBeans ide. The above figure shows the Java code of encapsulation. It defines a class name room and the variables are guest name, room number, cheek-out date, and check-in date.
Evaluation
.png)
(Source: Acquired from Netbeans ide)
The above snip shows the check-in of the hotel booking which has been acquired from Netbeans Ide. It looks like this accompanies a hotel booking system since it contains options to input check-in and check-out dates for a hotel (Wang& Zhang, 2021). It leads to the selection of rooms, identification of room numbers, and check-in information. The format looks more like headings from checklists that a typical user is expected to follow when applying for a booking.
.png)
Figure 5: Check-out
(Source: Acquired from Netbeans ide)
The above-mentioned figure shows the check-out details. Available options are check-in, check-out, managing the rooms, making the reservation, managing the accounts, and logging off. The abstract user chooses the second option on the menu (Check Out) becomes room number (possibly ‘S’) and receives a message confirming the check-out.
.png)
Figure 6: Room management
(Source: Acquired from Netbeans ide)
The above figure represents the room management which and the entire code have been done in the Netbeans Ide. After entering the above code it asks the user to select a choice, probably about the status of the room, perhaps about its availability status, or check-out, or exiting from the program (Li et al., 2020). Here, the use of the word “Vacant” written twice and misspelled implies that you choose a room that is available or that you need to view the availability of rooms. The ultimate actions are to check out and log out.
.png)
Figure 7: Reservation system
(Source: Acquired from Netbeans ide)
The login by faculty can also be done in this console-based application as illustrated in the above figure. However, faculty can only manage the enrollment of courses and the grading system.
.png)
Figure 8: Managing account
(Source: Acquired from Netbeans ide)
The above-mentioned figure shows the managing account of the hotel. This figure elaborates a layout of a user interface to a hotel, probably to the part of the hotel that deals with admin responsibilities. The menu bar on the homepage contains options for check-in/check-out, making reservations, and managing accounts Yu, (2021). The user is then asked to enter their decision to choose the action that he or she would desire to take such as creating an admin account, viewing a list of all the admin accounts, and logging out.
Figure 9: Array creation to store data
(Source: Acquired from Netbeans ide)
The above snip shows the array creation to store data which is acquired from NetBeans ide. Some of them are: This seems to be a portion of a Java program on hotel management systems only (El et al., 2022). It carries the declaration of static fields: rooms and reservations, the creation of a scanner object to read the user’s inputs, and printing out choices.
Figure 10: Room availability
(Source: Acquired from Netbeans ide)
The above-mentioned snip represents the room availability where the guest name section and room number section have been created. However, after entering the room number it shows that the room is not available.
Figure 11: Exception handling
(Source: Acquired from Netbeans ide)
The above figure shows the exception handling which is acquired from Netbeans Ide. It is a concept where programming techniques are employed to manage those conditions and instances that are considered to be outside the normal operations of a program.
Testing and Error Handling:
(Source: Acquired from Netbeans ide)
The above snip represents the testing that has been acquired from the Netbeans platform. In the above figure, testLoginAdmin class has been created. This action has been verified if the username is correct or wrong.
Contribution
The “Hotel Management System” project has a collaborative effort by three team members, each contributing their unique expertise
â— The first person stated that she would mainly work on the shell of the program with the functionality of checking in, checking, out, and handling rooms. These are the general ideas only where she added the logic of real-time updates of the room status that the system has to support multi-operations.
â— The second person proceeded to manage the booked customers and interface. He designed a console-based interactive interface for the program and ensured the implementation of the major features of the reservations.
â— Third person in charge of account management and security duties”. She developed the processes for the creation and deletion of new accounts, integrated the access using credentials, and applied techniques to deal with exceptions.
Reflection
I believe that the overall work done in the framework of the “Hotel Management System” project was profitable for our team. We also experienced other difficulties and common problems like the management of the tasks, the synchronization of them, the integration of features, or the fixing of bugs. But due to the team efforts and proper planning we were able to develop a fully operational system that any user would agree is easy to navigate. In this journey, it is crucial to also learn the value of communication, planning, and proper strategies as tools in working around the challenges and getting ready for leveraging the accomplishments.
References
El Maghraoui, A., Hammouch, F. E., Ledmaoui, Y., & Chebak, A. (2022, June). Smart energy management system: a comparative study of energy consumption prediction algorithms for a hotel building. In 2022 4th Global Power, Energy and Communication Conference (GPECOM) (pp. 529-534). IEEE. DOI: 10.1109/GPECOM55404.2022.9815807.
Li, Q., Koo, C., Lu, L., & Han, J. (2020). A real-time management system for the indoor environmental quality and energy efficiency in a hotel guestroom. International Journal of RF Technologies, 11(2), 109-125. DOI: 10.3233/RFT-200263.
Wang, Q., & Zhang, B. (2021). Research and implementation of the customer-oriented modern hotel management system using fuzzy analytic hiererchical process (FAHP). Journal of Intelligent & Fuzzy Systems, 40(4), 8277-8285. DOI: 10.3233/JIFS-189650.
Yu, Y. (2021, April). Design and implementation of hotel network management information system in the era of big data. In Journal of Physics: Conference Series (Vol. 1881, No. 2, p. 022068). IOP Publishing. DOI 10.1088/1742-6596/1881/2/022068.
Reports
ICT501 Foundations of IT Report Sample
Assessment Details:
Choose one of the following areas to focus on for the consultation report. Assuming that you have received a request for consultation from an organization regarding one of these areas, you will conduct thorough research by consulting pertinent scholarly sources, including journal articles, conference papers, and textbooks. In this report you are required to review the developments, trends, opportunities and barriers for a chosen technological implementation or the concept, and then develop a consultation report with the recommendations and best practices.
Select one of these focus areas:
1. Machine Learning Applications in Healthcare
2. Quantum Computing and its Practical Applications
3. Cybersecurity in Internet of Things (IoT) Devices
4. Blockchain Technology for Secure Transactions
5. Augmented Reality (AR) and Virtual Reality (VR) in Education and Training
6. Data Privacy and Compliance in the Age of Big Data
7. Edge Computing and its Role in IoT and 5G Networks
8. Natural Language Processing (NLP) for Conversational Interfaces and Chatbots
9. Autonomous Vehicles and Intelligent Transportation Systems
10. Sustainable Computing and Green IT Practices
11. Wearable Technology and its Impact on Health and Wellness
12. 5G Networks and the Future of Wireless Communication
13. Smart Cities and Urban Informatics
14. Cloud Computing Security and Privacy Issues
15. Human-Computer Interaction (HCI) for Enhanced User Experience
Identify at least 10 recent scholarly articles related to your chosen focus area.
Assignment is of two parts. First section comprises of reviewing the findings and develop the consultation report. The second section requires to present a summary of your findings in a 3 min presentation.
Consultation report structure should be as follows:
1. Introduction (5 Mark)
In this section, you need to indicate a brief description of your chosen focus area. Discuss the objective of the consultation report and provide an outline of the structure of your document. Introduce the terminologies and definitions associated.
2. Technological Analysis (10 Mark)
Discuss the chosen technological implementation and its relevance to the modern Industry. Elaborate key features and capabilities of the technology you are analyzing. Further, document a comparison with alternative technologies.
3. Recent developments and trends (5 Marks)
Discuss the recent technological advancements, market trends and consumer preferences.
4. Opportunities and Challenges (5 Marks)
Discuss how the technology area of your choice creates opportunities to formulate effective business solutions for organizations. Also identify the challenges associated.
5. Ethical, privacy and governance concerns (5 Marks)
Discuss how the chosen technology impacts the ethical, privacy and governance concerns of the stakeholders.
6. Recommendations and best practices (5 Marks)
Summarize the recommendations and propose the best practices.
7. Documentation and References (5 Marks)
Provide all the in text citations and references in APA 7 format.
Solution
Introduction
With the rise of 5G networks, everyone has been informed that wireless communication technology will change in an unprecedented manner to offer high speeds, high reliability as well as efficiency. The purpose of this report is to establish an understanding of 5G and its impact on 5G including SME and recommend on strategies to be implemented in the same. This report for the Assignment Helpline adopted the following structure: overview and foundation of 5G technology, technological report, recent development and trends, opportunities, challenges, ethical, privacy, and governance issues, conclusion and recommendations, and best practices.
Technological Analysis
1.1 Technology implementation and its relevance to the modern Industry
5G Networks, the fifth generation of mobile network technology, are revolutionizing wireless communication by offering unprecedented speed, reduced latency, and enhanced connectivity. These advancements are pivotal in an era where the demand for seamless and rapid data transmission is escalating across industries. Unlike its predecessors, 5G provides significantly higher bandwidth, enabling faster data transfer rates that can reach up to 10 Gbps. This transformative capability is not just about speed; it also supports a massive number of devices, paving the way for the Internet of Things (IoT) to flourish (Salih et al., 2020).
In the modern industry, 5G is particularly relevant as it underpins the digital transformation initiatives essential for competitiveness and innovation. For instance, in the production sector, 5G enables the formation of such connected smart factories wherein machines can effectively communicate in real-time, and optimize production line, managing time for repairs, and increasing production efficiency. In the field of healthcare 5G allows for remote surgeries and detailed teleconferencing through services such as high definition video conferencing that requires low latency and dependable connections to be useful in important cases. The automotive industry too gains from 5G, for example, the implementation of self-driving cars : autonomous vehicles requires nearly real-time exchange of data with infrastructure and other vehicles (Vaigandla & Venu, 2021).
Moreover, 5G also possesses the merits of low latency and high reliability for the applications of next-generation immersive media technologies like Augmented Reality and Virtual Reality, which demands real-time processing of data to provide continuous user experience. These technologies are gradually implemented in different sectors depending on their needs in education, entertainment, or real estate by providing new concepts of perceiving digital content (Torres et al., 2020).
1.2 Key features and capabilities of the technology
The key features are-
- Enhanced Speed and Bandwidth: For the 5G networks and wireless communication, the data transfer speed is at least one order of magnitude higher and can reach up to 10 Gbps. This increased velocity includes increased streaming capability, fast downloading, and in general, affords better connectivity.
- Ultra-Low Latency Another area where 5G representatives do not propose communication speeds above certain numbers, but note that 5G networks stand out for their values of 1 ms or less. This is especially relevant for the context of demand-response systems, like self-driving cars, robotic operations performed remotely on the human body, internet video games (Fruehe, 2024).
- Massive Device Connectivity: 5G can support up to a million devices per square kilometer, facilitating the growth of the Internet of Things (IoT). This capability is essential for smart cities, where numerous sensors and connected devices operate simultaneously.
- Energy Efficiency: 5G technology is designed to be more energy-efficient, ensuring longer battery life for connected devices, which is particularly beneficial for IoT applications.
- Network Slicing: This feature allows the creation of virtual networks tailored to specific applications or industries. Network slicing ensures optimal performance and reliability for various use cases, from emergency services to entertainment.
- Improved Reliability and Security: Enhanced encryption and advanced security protocols in 5G ensure more secure data transmission, crucial for sensitive applications in finance, healthcare, and defense (Intel, 2024).
.png)
Figure 1: Key features and capabilities of the technology
(Source: ISRMAG, 2022)
1.3 Comparison with alternative technologies
.png)
.png)
Table 1: Comparison with alternative technologies
2 Recent developments and trends
2.1 Technological Advancements
- Enhanced Infrastructure and Deployment: Some of the latest innovations in 5G technology adoption include the fast progressing miniature cellular structures known as small cell networks which are additional to the extended macro cell stations. Small cells enhance spectrum density optimality, particularly in cities, so as to offer reliable high-speed data connection (Kaur et al., 2020). Also, pertaining to beamforming that has marked developments in amplifying the signal power and dependability, intensify 5G performance especially within crowded areas.
- Integration with Edge Computing: Thus, extending the integration of 5G with edge computing is a crucial advancement. An edge computing involves the processing of data closer to the source of the data collecting it allowing for faster rates of response. This is important for applications that need real time data processing for instance; self-driving automobile, the augmented reality, and the virtual reality.
- AI and Machine Learning: AI and machine learning are adopted in 5G network to enhance efficiency in networks, throughput, self-organizing networks, traffic control, and self-healing and self-organizing networks to avoid network challenges (Dangi et al., 2021). It also improves the quality and effectiveness of the 5G services through these technologies in transmitting information.
2.2 Market Trends
- 5G Infrastructure Investment: Operators continuing aggressive buildouts of 5G radio hardware and core network upgrades.
- Fixed Wireless Access (FWA): 5G FWA broadband is an alternative to cable/fiber, with Verizon, T-Mobile launching widespread residential/business offerings.
- Private 5G Networks: Enterprises deploying dedicated on-premises 5G for secure IIoT, robotics manufacturing use cases.
- Telco Cloud Platforms: Telecoms launching cloud platforms (e.g. AWS Wavelength, Azure for Operators) to monetize 5G+edge capabilities (Custom Market Insights, 2024).
2.3 Consumer Preferences
- 5G Mobile Data Demand: Rising mobile data usage (video, AR, cloud gaming) driving consumer demand for faster, low-latency 5G connections.
- 5G Phones: Over 1 billion 5G smartphone subscriptions globally in 2022 with continued growth as users upgrade devices.
- 5G Home Broadband: In underserved areas, 5G FWA seen as an affordable alternative to cable/fiber for fast home internet (Fact.MR, 2024).
Opportunities and Challenges
Opportunities
- Enhanced Connectivity and Productivity: This will be through providing organizations with a much-improved networking connectivity something that 5G technology and Wireless communication can bring to the business world today. For instance, the manufacturing firms can employ smart production lines through the help of the 5G technology to enhance the efficiency of the machines and the systems used by interconnecting them to perform the required actions in real time, for purposes of monitoring and maintaining the machines, as well as making production line enhancements. They increase efficiency and slice viable periods, boosting operation (Gustavsson et al., 2021).
- Innovative Business Models: 5G brings in high speed and low latency that can unlock new business models in organization. For example, a company in the telecommunication sector will be able to provide new services, such as streaming and cloud-based gaming, of even more enhanced and significantly higher quality with the particular frequency band. By using augmented reality (AR) technology and applications, the physical shops’ retailers can create engaging shopping experiences for consumers, and the extending of telemedicine services such as surgeries and constant patient tracking means reaching out for audiences that cannot be addressed across traditional manners at this point.
- Data-Driven Decision Making: Thus, throughputs of 5G, businesses can gather and process enormous amounts of data almost simultaneously. This capability enables business insight and data-driven decision-making through analytical and AI tools. For instance, logistics companies can leverage it to real-time analyzing to find the best strategies, cuts down expenses on logistics, and enhance customer satisfaction levels on their deliveries and fleet management (Mourtiz et al., 2021).
- Support for IoT and Smart Applications: It also underlines how 5G is an enabler of the Internet of Things and smart solutions. Cities can apply sophisticated physical structures such as bean network of traffic lights, smart networks, and leaders for environmental tracking, which improves urban life. E-commerce companies and original equipment manufacturers can leverage the IoT to develop better monitoring programs for assets, supply chains, and security systems to gain a competitive advantage in the market on the basis of efficiency of operations.
- Remote Work and Collaboration: Remote work proceeds due to the COVID-19 pandemics but will continue to develop even in the future. The implementation of 5G makes it convenient for organizations to conduct business remotely through high-quality video conferencing, virtual collaboration as well as high encrypted remote business applications (Rodriguez et al., 2021).
.png)
Figure 2: Opportunities of 5G Networks and the Future of Wireless Communication
(Source: Author, 2024)
Challenges
- High Deployment Costs: 5G deployment entails significant initial expenses as costs are incurred to install the necessary 5G infrastructure. The networks required for small cells, the upgrade of current infrastructure, and purchasing licenses for spectrum may result in high capital expenses, a challenge in particular for SMEs.
- Security Concerns: In combination with the integration of 5G technology, the opportunity for certain threatening cyber-attacks also do the same. While the multitude of interconnected devices helps security personnel to have more opportunities to penetrate the series of connected devices, it opens gates to dangerous threats also. It is imperative to establish strong security protocols but it is a daunting task as seen with the various and worsening attacks (Banker, 2024).
- Technological Integration: It’s relatively easy to apply new technologies to 5G on the existing foundations. Organizations have to check how suitable their existing systems and devices are with 5G networks. This may require create increases or replacements, the process of which may sometimes take a lot of time and money.
- Regulatory and Compliance Issues: The 5G technology is faced with some legal and compliance risks for its deployment is confined to specific regulations in different regions. Such regulations can be complex for organization to manage, especially those operating in two or more countries, each with different regulatory requirements and legal frameworks.
- Spectrum Availability: it can also state that it is one more factor that has to be taken into consideration. In some zones, spectrum availability is scant or closely contested, and this will hamper the rollout of 5G networks and adversely affect the pp prices that businesses would have to pay in order to adopt the new technology.
- Public Health and Environmental Concerns: There are ongoing public debates and concerns about the potential health effects of 5G radiation and its environmental impact. Addressing these concerns requires transparent communication and rigorous scientific research to reassure the public and policymakers (Banker, 2024).
.png)
Figure 3: Challenges of 5G Networks
(Source: Author, 2024)
3 Ethical, privacy and governance concern
.png)
.png)
.png)
.png)

3.1 Mitigating Concerns
To address these ethical, privacy, and governance issues, stakeholders must adopt a multi-faceted approach:
- Equitable Deployment: Ensure that 5G infrastructure development is inclusive, providing access to underserved and rural communities to bridge the digital divide.
- Data Protection: Implement robust data protection policies and technologies to safeguard user privacy, including encryption and secure data storage.
- Regulatory Compliance: Maintain compliance with regional and international data protection and cybersecurity regulations, regularly updating practices to align with evolving laws.
- Public Engagement: Engage with the public to address health and environmental concerns transparently, providing clear communication and evidence-based information.
- Support for Workers: Develop programs to support workers displaced by automation, offering retraining and education opportunities to transition into new roles.
.png)
Figure 4: Mitigation strategies
(Source: Author, 2024)
Recommendations and best practices
3.2 Recommendations
- Inclusive Deployment: Invest in expanding 5G infrastructure to rural and underserved areas to bridge the digital divide and ensure equitable access to advanced technology.
- Regulatory Compliance: Ensure compliance with all relevant data protection and cybersecurity regulations across different regions, regularly updating practices to stay aligned with evolving laws.
- Workforce Transition Support: It also needs to develop training and education programs that will help workforce that has been rendered obsolete by automation and new technologies made possible by 5G to transition to new career paths (Aranda et al., 2021).
- Public Communication: Communicate with the public clearly regarding health and environmental risks and privacy issues associated with 5G to reduce misinformation.
3.3 Best Practices
- Collaborative Partnerships: Popular partnerships with local governments, businesses, and communities to promote inclusive 5G connectivity and respond to the region’s essential issues (Mourtzis et al., 2021).
- Proactive Risk Management: Carry out frequent risk analysis and take appropriate prevention steps to tackle possible cybersecurity and data privacy issues.
- Continuous Innovation: Equip 5G for the long-term competition and innovation by investing on research and development of enhanced technology and services.
- User Education: Engage the consumers and the businesses on the benefits, uses as well as the measures to be taken to prevent the misuse of 5G.
- Sustainable Practices: Assure the environment friendly deployment and functioning of 5G infrastructure to reduce the ecological footprint (Rodriguez et al., 2021).
4 References
.png)
.png)
Assignment
IFN552 System Analysis and Design Assignment 1 Sample
In this Assignment, you will take what you have learnt in weeks 1, 2 and 3 and apply this to a case. You will develop a list of questions that you would ask key stakeholders to elicit requirements, distil stakeholder needs into functional requirements in a Requirements Matrix, draw a Use Case Diagram and Activity Diagram. You will also justify your designs in short descriptions accompanying each of these outputs.
1. Read the Criterion-Referenced Assessment Rubric at the end of this document.
2. Read Case 1 (below) which pertains to all elements of this assignment.
3. Develop and document a list of questions for two of the key stakeholders to specifically gather functional requirements. Aim for approximately 10 key questions for each stakeholder type (you can also choose to add follow-up sub-questions if necessary).
4. Try out your questions on the Grower, Customer and Business chatbots (available by the end of Week 1) on Slack by entering a conversation with each under the “Apps” dropdown in the IFN552 Slack channel. Note the chatbots are there to provide you with an opportunity to practice asking stakeholder questions and to provide additional ‘bonus’ information about the case; they will not be able to answer all of your questions, but can help you explore and brainstorm some of the needs for the stakeholders. Please do not rely solely on these to develop your list of requirements.
5. Develop a Requirements Matrix to show the functional requirements of the new system. Aim for:
a) 15 Essential Functional Requirements
b) 5 Desirable Functional Requirements
c) 1 Optional Functional Requirement
You should include the suggested number for each priority of requirements, totalling around 21 Functional Requirements in your matrix. A small amount less or more may be ok depending on the quality of the ones you include, but you will need to stay around the number stated above. Whilst each will have certain priority, and the list may not be comprehensive, you need to ensure that all are relevant to the case and are concise, specific, measurable and actionable.
6. In 250 words or less, justify your choices (i.e. How/why did you decide to split the system into the modules you chose? How did you decide on priorities? Is there a particularly novel or unusual requirement that you have identified – if so, how does it meet the needs of your stakeholders? etc.).
7. Draw 1 (one) Use Case Diagram representing the new integrated system described in the case.
a) Aim to include around 15-20 Use Cases in your diagram (no more than 23). Ensure that the use cases you do include are important and relevant to the process being represented.
8. In 250 words or less also introduce your use case diagram (i.e. what is it describing? At which points do users interface with the system? What is outside the scope of your diagram? Etc.).
9. Draw an Activity Diagram, representing how a grower would order a kit on the website, monitor the growth of their produce, organize a swap for their grown produce with replenishment seeds/cuttings and
a customer eventually ordering some of that produce via the website.
You can start with the following assumptions:
a) Assume that the grower and customer are already in logged in states at the beginning of their processes (i.e., no need to include activities involved in login/register)
b) The delivery process is handled by an external company. There is therefore no need to include any activities associated with the delivery process other than those that involve the system being designed and/or other actors in the process
Remember to balance detail with clarity in your diagram. Take note of the following guidelines regarding scope:
a) Use around 2-3 swimlanes to differentiate system activities initiated by different actors. For activities performed by a subsystem with no interaction with an actor, you may use a separate “system” swimlane, however, ensure all other activities performed in actor swimlanes describe system interactions.
b) Use up to 60 shapes – ideally around 50 shapes – (shapes include boxes, decision nodes, fork and join, arrows, etc.) to show the process of user activities.
c) Use decision nodes two or three times and fork and join two or three times in your model.
d) Preferably, your activity diagram will be vertical, rather than horizontal (this will make it easier when merging it into the submission PDF).
10. Write a short description of your Activity Diagram in 250 words or less. Imagine you are presenting it to a set of stakeholders and you need to introduce concisely what it is showing (~1-2 sentences) and mention a few interesting/important activities or flows, as well as parts where you have made assumptions (~3-4 sentences).
Note that it’s important to practice this skill, as you will need to contextualise designs/diagrams when you create reports/presentations.
Solution
List of questions
Stakeholder #1: Growers
1. How frequently would you like to receive updates on the growth of your plants?
2. What kind of data would you like to see about the plants' growth? (e.g. temperature, humidity, light levels)
3. How would you prefer to receive updates on the growth of your plants? (e.g. email, SMS, app notifications)
4. What information would be helpful for you to know about the exchange process with delivery personnel?
5. Would you prefer to have the option to customize the seeds/cuttings you receive in your kit?
6. What would be your preferred method for providing feedback on the Grow Kit and the plants' growth?
7. How would you like to be paid for the produce you grow? (e.g. bank transfer, PayPal)
8. What kind of support would be helpful for you during the growing process? (e.g. online tutorials, live chat support)
9. How frequently would you like to receive new seeds/cuttings?
10. Would you be willing to provide additional information about your location and growing conditions to help improve the Grow Kit and plant growth?
Stakeholder #2: Website Users
1. What kind of user account management features would you like to see on the website?
2. How would you like to receive notifications about inventory levels and forecasts?
3. What kind of analytics would be helpful for you to have access to about plant growth and inventory management?
4. What kind of user data would be helpful for the website to collect to improve the user experience?
5. How would you like to be able to communicate with growers through the website? (e.g. messaging, chat)
6. What kind of security measures would you like to see implemented on the website?
7. What kind of payment processing system would be most convenient for you to use?
8. What kind of customer service features would be helpful for you to have access to on the website?
9. What kind of reporting features would be helpful for you to have access to on the website?
10. How frequently would you like to receive updates about the website's functionality and new features?
Requirement matrix
Requirements Matrix for Micro-Farming Start-Up
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
(Rodriguez et al., 2022)
The essential functional requirements are necessary for the system to function as intended. Without the sensor data collection, display, and algorithm integration, the business cannot accurately forecast produce availability and manage inventory levels. Produce collection and replenishment, along with the delivery driver booking system, are required to manage the exchange of produce and replenishment kits between the business and Growers. The integration of Grow Predict with the online store inventory management is essential to ensure accurate stock levels and provide customers with available produce. Lastly, Growers require the ability to select grow kit size and type of produce to grow, and to receive starter kits with all necessary components (Wang et al., 2020).
The desirable functional requirements, while not critical to the system, provide additional benefits to the stakeholders. Allowing customers to customize produce boxes and providing subscription-based discounts can increase sales and customer loyalty. Nutritional information can appeal to health-conscious customers, and feedback from Growers can improve the quality of the products. Alerts to Growers can help ensure healthy plant growth. The optional functional requirement enables Growers to sell excess produce to the online store, providing an additional revenue stream for Growers and increasing the variety of available produce for customers. However, this functionality is not essential to the system and may require additional resources to implement (Rodriguez et al., 2022).
The functional requirements for the assignment help have been prioritized based on the impact on the business and the needs of the stakeholders. The system has been divided into modules to ensure efficient development and management of each aspect.
Use case diagram
.png)
.png)
Figure 1 Use case Diagram.
The use case diagram describes the interactions between the actors and the system at the various touchpoints. Growers interact with the system through the Grower Portal, where they manage their Grow Kits and sell their produce. Customers interact with the system through the Online Store, where they browse and purchase produce boxes. The GrowPredict Algorithm interacts with the system to provide inventory forecasting based on the sensor data from the Grow Kits (AL-Msie'deen et al., 2022). Outside the scope of this diagram are the technical details of the system, such as the database and server infrastructure, and the specifics of the sensor data collection and analysis. The diagram shows the relationships between the actors and the system components and illustrates the flow of data and actions between them. It is important to note that the scope of the diagram does not include specific details about the sensors or the algorithm, but rather focuses on the high-level interactions between the actors and the system components (Arifin & Siahaan, 2020).
Activity diagram
.png)
Figure 2 Activity diagram.
The Activity Diagram is a visual representation of the steps involved in the Grower portal, from purchasing a kit to harvesting produce and replenishing it with new seeds/cuttings. The diagram shows the flow of activities, including the monitoring of plant growth, the notification system for harvest, and the scheduling of pickup/delivery times. It also includes assumptions, such as the delivery driver being booked automatically and the company paying for the products based on the weight of usable produce. An interesting flow is the integration of GrowPredict, which forecasts when certain products will be available and in what numbers, and how it helps connect the online store and the Grower portal (Bakar et al., 2020).
References
.png)
.png)
Reports
Introduction To Cyber Safety Report Sample
Scenario 1
Assume you and your group members are the owners of a small consultancy company located in Sydney. There are 20 employees working to support you and the external clients. Due to the COVID -19 pandemic, you have decided to allow the staff members to work from their home. They can take the work laptops to home or use their own devices instead. The staff members are required to use computer/laptop/mobile, smart board, Smart TV, and Multi-Functional Devices (e.g., printer, scanner). Often you organize the staff meeting using zoom or similar meeting tool e.g., MS Teams. The daily activities of the staff require them to use the computing devices for accessing and storing their files securely in their folders (individual works) and a shared folder (files required for all), as well as all the regular digital activities e.g., reading, writing, and sending emails, prepare reports using MS Office software and several other software applications, (for some, make financial transactions for the clients).
You are required to guide your staff members to follow the cyber safety practices while connecting to the internet from home using either their work or personal devices. To do so, you need to prepare safety instructions so that they are minimizing the risks.
Please prepare the guidelines for the staff members which may include but not limited to:
1. Identification of the digital assets of the organization.
2. How to secure the devices which connect to the internet.
3. Identify the risks and vulnerabilities they may face.
4. Safety practice measures to protect and safeguard devices and digital information etc.
Scenario 2
Investigate security and privacy features of 2 – 3 popular social media (e.g., Facebook, LinkedIn) platforms and make a recommendation of the preferred platform based on comparison of the security and privacy features available for their users. Furthermore, include a
- recommendation on strategies for protecting users on digital platforms
- guideline for young people to follow to keep themselves safe in their digital lives
Solution
Scenario – 1
There is a growing need to keep up with cybersecurity precautions to safeguard sensitive data as more workers choose to do their jobs from home. These are some precautions staff members may take to keep your electronics and data secure:
- Always make use of robust passwords when logging into any of the connected devices or software. All of these factors—upper- and lower-case letters, numbers, and symbols—make for a password that is both secure and easy to remember. Common terms, phrases, or information about the employee themselves should be avoided in passwords (Freedman 2023).
- Turn on two-factor authentication everywhere it is supported. By requiring a second authentication element, such a code given to the employee's mobile phone, two-factor authentication increases security (Freedman 2023).
- Always use the most recent updates for your programs. Old versions of programmes and software are a common target for hackers because of security holes they introduce. So, it is crucial to apply patches and updates to close the security holes (Kaspersky 2022).
- Make sure that the anti-virus software is up to date and in use. Devices protected by anti-virus software check for and prevent the installation of harmful software. Keeping it updated means it will be able to identify the latest dangers (Kaspersky 2022).
- Protect the data on the gadget by encrypting it. To prevent unauthorised access to private data, it may be encrypted and then decrypted using a special key. If the device is lost or stolen, the data will still be safe because of this precaution (Kaspersky 2022).
- Only connect to private Wi-Fi hotspots. In most cases, hackers may easily get access to and steal information from public Wi-Fi networks. Workers should connect only via a virtual private network (VPN) or their own private networks at home (Freedman 2023).
- Employees may reduce their exposure to cyber dangers when working from home by adhering to these safety procedures. Staff members must be taught to spot any unusual behaviour and notify the IT department promptly.
Scenario – 2
1.
LinkedIn and Facebook are two of the most popular social networking platforms globally. Both platforms for the assignment help have security and privacy features to safeguard their users' data. However, there are significant differences in the features offered by both platforms (Scroxton 2022).
LinkedIn primarily focuses on professional networking, and hence, it prioritizes the security and privacy of its users (Scroxton 2022). Some of the essential security and privacy features available on LinkedIn are:
- Two-Factor Authentication (2FA) - LinkedIn allows users to enable 2FA for their accounts, adding an extra layer of security.
- Privacy Settings - Users can control their privacy settings and determine who can see their profile and the information on it.
- Encrypted Communication - LinkedIn uses HTTPS to encrypt communication between the user's device and the server.
- Endorsement Control - Users can choose to accept or decline endorsements from other users.
- Data Download - Users can download their data, including their connections, messages, and other information, for backup purposes.
Facebook, on the other hand, is a platform for social networking, which means that users share personal information and data with their friends and family (Germain 2022). Some of the essential security and privacy features available on Facebook are:
- Two-Factor Authentication (2FA) - Facebook allows users to enable 2FA for their accounts, adding an extra layer of security.
- Privacy Settings - Users can control their privacy settings and determine who can see their profile and the information on it.
- Encrypted Communication - Facebook uses HTTPS to encrypt communication between the user's device and the server.
- Ad Preferences - Users can control the ads they see and the information used to show them.
- Data Download - Users can download their data, including their posts, messages, and other information, for backup purposes.
Based on the above security and privacy features, LinkedIn is the preferred platform for professional networking, while Facebook is suitable for social networking. However, users must also take additional measures, such as using strong passwords, avoiding clicking on suspicious links, and reporting any suspicious activities to the respective platform's support team (Germain 2022).
2.
It is vital to adhere to several techniques in order to secure users on LinkedIn and Facebook. Some of these strategies include:
• Using robust passwords and enabling two-factor authentication for all online accounts (Gerber 2019).
• When it comes to exchanging personal information and data online, use extreme caution (Gorton 2021).
• Make use of privacy settings to regulate who may see their profiles and information by restricting access to certain users or groups (Gorton 2021).
• Always use the most recent versions of your software and apps, and make sure you have anti-virus software installed (Gorton 2021).
• Immediately report any activities that you believe may be suspicious to the support personnel for the platform (Gerber 2019).
3.
Young people may protect themselves from potential dangers in their digital life by adhering to the following guidelines (Atamaniuk 2021):
- Users should not divulge any personal information online, including their complete name, address, phone number, or the name of your school (Atamaniuk 2021).
- Remember to use caution with any material that is to be uploaded online, such as images, videos, or comments (Atamaniuk 2021).
- Use extreme caution if interacting with unknown individuals online, particularly on social media sites (Newberry 2023).
- Make use of the privacy options so that users have control over who may see their profile and information (Newberry 2023).
- Users are required to report any instances of bullying, harassment, or suspicious actions to a responsible adult or a member of the support staff for the platform (Newberry 2023).
By adhering to these principles, young people may shield themselves from the dangers posed by the internet, including cyberbullying, harassment, identity theft, and other hazards. In addition, parents, individual and teachers have an important part to play in the process of teaching young people about online safety and monitoring the digital activities that their children engage in (Atamaniuk 2021).
References
Assignment
ICTCYS608 Perform cyber security risk Assignment 1 Sample
Assessment information
Information about how you should complete this assessment can be found in Appendix
A of the IT Works Student User Guide. Refer to the appendix for information on:
- Where this task should be completed
- The maximum time allowed for completing this assessment task
- Whether or not this task is open-book.
Note: You must complete and submit an assessment cover sheet with your work. A template is provided in Appendix C of the Student User Guide. However, if your RTO has provided you with an assessment cover sheet, please ensure that you use that.
Questions
Provide answers to all of the questions below:
1. Explain why it is important for an organisation to conduct a cyber security risk assessment.
2. List typical steps that would be followed to conduct and report on a cyber security risk assessment.
3. List three ways that could be used to measure risk culture and risk appetite in relation to cyber security.
4. Identify two sources of information that that could be used to find out about cyber security legislation.
Solution
1. Importance of Conducting a Cyber Security Risk Assessment for an Organization
Cyber security risk assessment identifies and assesses the probability and severity of potential threats to an organization's information assets (Ganin et al. 2020). It is a critical part of a comprehensive security program, as it allows organizations to anticipate and plan for possible risks and to develop appropriate countermeasures. Risk assessments provide the foundation for an effective security strategy by helping organizations identify, assess and reduce their vulnerabilities. Cyber security risk assessments allow organizations to understand the risk level, the potential consequences of an attack and the necessary steps to mitigate the threat. Organizations can ensure they adequately protect their digital assets and minimize risk exposure by regularly conducting cyber security risk assessments.
Organizations need to conduct a cyber security risk assessment because it enables them to identify vulnerabilities within their systems and provides them with a comprehensive picture of the threats posed by cybercriminals (Fraser, Quail, & Simkins, 2021). By conducting a risk assessment, organizations can understand their current cyber security posture and identify areas where they may need to invest in additional measures. It also helps organizations to identify and respond to potential cyber threats, allowing them to remain one step ahead of the hackers. Furthermore, it provides a framework for developing and implementing effective policies and procedures for mitigating risks associated with cyber security threats. This helps organizations protect their valuable data, networks, and systems from malicious actors. Any organization's cyber security risk assessment is essential to protect its sensitive data, networks, and systems.
2. The procedures for Performing and Documenting a Cyber Security Risk Evaluation
The process of finding, analyzing, and evaluating risk concerning cyber security is carried out step by step. Choosing cyber security measures compatible with the risks one encounter is always beneficial. Choosing the best cyber security without the risk assessment method would be a waste of time, effort, and resources. Information assets that a cyber-attack might impact are always identified in a cyber security risk evaluation. Typically, a risk calculation and analysis are done, and then controls are chosen to address the risks that have been found.
Determining the area of responsibility of the risk assessment: The risk assessment process for the assignment help always begins with choosing the assessment's scope (Pukala, Sira, & Vavrek, 2018). It is typically a significant and difficult procedure. Additionally, it is crucial to have the full backing of all parties whose actions fall under the purview of the assessment because understanding will depend on their contributions.
Identifying the risks - The second step in the risk assessment procedure is to identify the risks. There are three sections again in this place. It must first determine the properties. The next step is to determine the threats. Threats can be tactics, techniques, or even ways. The final step is to determine which portion of the risk is incorrect.
Analyzing the risks - The third stage is to correctly analyze the risks and determine the potential effects of the threats after they have been identified. The risk potential and possibility always provide a danger that is capable of leveraging a weakness in a cybersecurity risk assessment process (Eckhart, Brenner, Ekelhart, & Weippl, 2019).
Determining and prioritizing risks - Identifying and prioritizing the risks is the fourth stage in cyber security risk assessment. It might be accomplished using a risk grid. Eliminating a task might be the optimal course for proceeding if it means not being exposed to it if the risk exceeds the benefits.
Documentation of all risks - It is crucial to record all risks related to cyber security after analysis and determination. For management to remain informed of the risks associated with cybersecurity, it must also be reviewed and updated.
3. Three Ways That Could Be Used to Measure Risk Culture and Risk Appetite Concerning Cyber Security
When assessing the risk culture and risk appetite concerning cyber security, organizations can measure and understand the risks they face in three ways.
The first is to conduct a formal risk assessment, which can provide detailed information about the company’s current level of risk and identify areas for improvement. Conducting a formal risk assessment is a vital part of ensuring the security of a business (Bayar, Sezgin, Ozturk, & Sasmaz, 2020). It should be done systematically and thoroughly to provide detailed information about the current level of risk, identify areas of weakness and potential threats, and make recommendations for improvement. It can help the business evaluate its risk management strategies, assess the adequacy of its controls, identify areas where additional controls should be implemented, and identify potential opportunities to reduce its overall risk exposure.
The second is to survey employees and stakeholders to understand their attitudes and behaviours around cyber security. Surveying employees and stakeholders is a powerful tool for understanding how they perceive and interact with cyber security in their day to day activities. Through surveys, organizations can gain insight into the attitudes, behaviours and understanding of cyber security among their staff and stakeholders, allowing them to better assess their current cyber security stance and identify improvements.
Finally, organizations should review existing policies and procedures to align with industry best practices and organizational goals (Hubbard, 2020). Doing so will help organizations keep up with the changing needs of their industry, remain competitive, and achieve their desired outcomes. By implementing this process, organizations can identify any potential risks or opportunities to be capitalized on, allowing them to stay ahead of their competitors.
4. The Resources for Learning About Cyber Security Laws
The Security of Critical Infrastructure Act 2018 is the first piece of law about cyber security. This act generally imposes obligations on particular entities concerning communications and electricity (CISC AU, 2023). Financial services, stock markets, and data handling or storage are also included. The main goals of this SOCI Act amendment were to strengthen the security and resilience of the critical infrastructure by extending the range of industries and asset classes to which it applies and by introducing new responsibilities.
The Telecommunications (Interception and Access) Act 1979 is the second source of law about cyber security. In Australia, the TIA act is a broad regulatory framework for all Internet access, including data access (Home Affairs AU, 2023). The TIA act also allows access to communications to look into the process of requesting a warrant from a judge or tribunal. Applications for warrants must consistently adhere to all stringent Act requirements. When certain conditions arise, such as a crisis, the Agencies may also view the communications despite a warrant.
References
.png)
Reports
DATA4100 Data Visualisation Software Report 4 Sample
Your Task
This written report with a dashboard is to be created individually.
- Given a business problem and data, finalise visualisations and prepare a report for the Australian Department of Foreign Affairs and Trade.
- On Tuesday of week 13 at or before 23:55 AEST submit your written report as a Microsoft Word file with a snapshot of your dashboard via Turnitin.
This assessment covers Learning outcomes: LO2, LO3
Business Background:
Germany, Japan, South Korea, United States, France and China are amongst the main exporters of cars. Suppose that the Australian government is particularly interested in the products exported from Germany, as well as Australian products exported to Germany, in considering the possibility of a free trade agreement.
Suppose that you have been asked, as an analyst for the Australian Department of Foreign Affairs and Trade, to report on exports from Germany, and in particular, the types of products Germany exports to Australia. Likewise, analyse the products that Australia exports to Germany currently, based on your own research into available data sets.
Your written report (to be prepared in this assessment - in Assessment 4) will ultimately end up in the hands of the minister for trade and investment, so any final decisions made should be supported by data
In Assessment 4, you are to finish designing your visualisations, then prepare a report by interpreting the visualisations and integrating with theory from this subject.
Data set
- Use the data given to you in week 11
Assessment Instructions
- As an individual, finish the visualisations for your report.
- Write a structured report with appropriate sections, as follows:
- Introduce the business problem and content of your report.
- Interpret your charts, summaries, clustering and any other analyses you have done in the process of creating your visualisations, and link it back to the business problem of whether Australia should enter a free trade agreement with Germany?
- Justify the design of your visualisations in terms of what you have learnt about cognitive load and pre-attentive attributes and Tufte’s principles.
Solution
Introduction of Business Problem
The business problem is to gather information and analyse the trade between Germany and Australia in order to consider the possibility of (FTA) free trade agreement. Specifically, the Australian government taking interest in the products exported from Germany to Australia and the products exported from Australia to Germany. The analyst is tasked with collecting data and reporting on the current trade relationship between the two countries. So that decision can be made by the government based on visualization and analysis.
The analyst is working for Australian Department of Foreign Affairs and Trade and is expected to provide a comprehensive report on the trade relationship between Germany and Australia. The report should include information on the types of products that Germany exports to Australia and the types of products that Australia exports to Germany. The report will help the government in making informed decisions regarding a potential free trade agreement between the two countries.
Visualizations and Summary
This is an important issue for the Australian government because a free trade agreement with Germany could potentially bring economic benefits to both countries. By eliminating tariffs and other trade barriers, both Germany and Australia could increase their exports and grow their economies. However, the government must first understand the current trade relationship and the types of products being exchanged in order to determine if a free trade agreement is feasible and would be in the best interest of both countries.
This is the line and clustered column chart that represents the trade value of the sections and products. The highest product is available in section 6 and the highest trade value is in section 16.
Based on the line and clustered column chart showing the sum of trade value between Australia and Germany along with the count of products, several key insights and interpretations can be drawn:
Trade Value: The line chart shows the sum of trade value between Australia and Germany over time. This allows us to see the overall trend in the trade relationship between the two countries. If the line is trending upwards, it indicates an increase in the total trade value between the two countries. If the line is trending downwards, it indicates a decrease in the total trade value.
Product Count: The clustered column chart shows the count of products being traded between Australia and Germany. This allows us to see the variety of products being traded between the two countries and understand the composition of the trade relationship. If the count of products is increasing over time, it indicates a diversifying trade relationship. If the count of products is decreasing, it may indicate a more focused or specialized trade relationship.
.png)
This is the scatter chart that is divided into three clusters by using the auto clustering of power BI. the trade value per HS2 ID is represented in this chart.
.png)
This is the waterfall chart that represents the trade value per product and section. The products are divided into sections and that is shown in this chart. The car's trade value is highest that is up to 70bn.
.png)
This is the bar chart that represents the sum of a trade by using the section cluster that is done in the scatter chart. This will make the data and chart easier to understand.
Draft Dashboard
A visualization dashboard for the assignment help is an important tool for solving the business problem because it allows for a clear and concise representation of the trade data. Visualization dashboards provide a visual representation of the data, which can help the government quickly understand the key trends and patterns in the trade relationship between Germany and Australia. This can include visualizations such as bar charts, pie charts, and line graphs that clearly show the types and amounts of products being exported between the two countries.
Moreover, visualization dashboards can provide real-time updates to the data, allowing the government to track changes in the trade relationship over time. This can help the government identify any potential trade imbalances or changes in the trade relationship that may impact the feasibility of a free trade agreement.
Additionally, visualization dashboards can provide an interactive experience for the user, allowing them to explore the data in greater detail and uncover insights that may not be immediately apparent from a static report. This can help the government make more informed decisions based on a deeper understanding of the data.
Overall, a visualization dashboard is an important tool for solving the business problem of understanding the trade relationship between Germany and Australia because it provides a clear, concise, and interactive representation of the data that can help the government make informed decisions.
List of Dot Points
The visual information is provided in small chunks in the bar and scatter chart which is done by using the cognitive load. By putting much more information into each significant chunk of data and reducing the amount of them for a viewer to observe, one objective when developing visualization is to lessen the cognitive load.
The dot points for pre-attentive attributes
Color – Different colors are used in the charts to represent the different data which helps to understand the insights from the data.
Form – The type, shape, and size of the chart are selected to represent the meaningful information and the chart is clearly showing all the information (Nordlinder 2021).
An analysis and visualization report can help solve the business problem by providing a clear and concise representation of the trade relationship between Germany and Australia. The report can include visualizations such as bar charts, pie charts, and line graphs to clearly show the types and amounts of products being exported between the two countries. This information can help the government understand the current trade relationship and identify any potential trade imbalances.
Additionally, the report can use data analysis techniques such as trend analysis and regression analysis to identify any trends or patterns in the trade data over time. This information can help the government predict the potential impact of a free trade agreement and make informed decisions.
Finally, the report can highlight key insights and recommendations based on the data analysis. This information can be used by the government to make informed decisions regarding a potential free trade agreement with Germany. Overall, an analysis and visualization report can help the government make informed decisions by providing a comprehensive and clear understanding of the trade relationship between Germany and Australia.
Analysis of the trade relationship between Australia and Germany can provide valuable insights to inform decision making in several ways:
- Trade Opportunity: The analysis can reveal opportunities for expanding the trade relationship between Australia and Germany. For example, if there is a high demand for a particular type of product in Germany that is not being produced in Australia, this could provide an opportunity for Australian businesses to enter the German market.
- Market Trends: The analysis can also reveal trends in the trade relationship between Australia and Germany, such as changes in the demand for certain products or shifts in the composition of the trade relationship over time. This information can help businesses and government organizations make informed decisions about their trade strategies.
- Competitive Advantage: The analysis can reveal areas where Australia has a competitive advantage in the trade relationship with Germany. For example, if Australia is exporting a product that is in high demand in Germany, this could provide an opportunity for Australian businesses to increase their exports and gain a competitive advantage in the German market.
- Free Trade Agreement: The analysis can also provide valuable information to support the negotiation of a free trade agreement between Australia and Germany. For example, if the analysis reveals that there is significant potential for increased trade between the two countries, this could be used as a negotiating point to support the implementation of a free trade agreement.
Justification of Design
The visualizations is based on the principles of cognitive load and pre-attentive attributes and Tufte's principles of data visualization. These principles ensure that the visualizations are easily readable and provide the user with the most important information in an efficient manner.
In terms of cognitive load, the visualizations are designed to be simple and intuitive, with a minimal amount of clutter or distractions. This helps to reduce the cognitive load on the user, allowing them to quickly and easily understand the data. The use of colors and shapes that are easily distinguishable, as well as the use of clear and concise labels, help to make the data easily readable and reduce the cognitive load on the user.
In terms of pre-attentive attributes, the visualizations are designed to take advantage of the user's natural ability to quickly process visual information. This includes the use of colors to indicate different categories of data, as well as the use of shapes and patterns to quickly distinguish between different data points. These pre-attentive attributes help the user quickly understand the data, even before they have consciously processed it.
Finally, the visualizations are designed following Tufte's principles of data visualization, which emphasize the importance of maximizing the data-ink ratio. This means that the visualizations are designed to show only the most important information, without any unnecessary elements that may distract the user. This ensures that the visualizations are highly effective in conveying the data and providing insights into the trade relationship between Germany and Australia.
In addition, Tufte's principles also emphasize the importance of using clear and concise labelling, providing context to the data, and ensuring that the visualizations accurately represent the data. These principles help to ensure that the visualizations are not only aesthetically pleasing but also provide accurate and meaningful information to the user.
References
.png)
Reports
SIT763 Cyber Security Management Report Sample
Task 1: Cyber Security Risk Identification
Asset identification: Identify four assets, one of each type: information, knowledge, application, and business process. For each asset, determine is current worth (value), and the security requirements (confidentiality, integrity, and availability). Finally, prioritise the assets based on their level of criticality from highly critical to less critical.
.png)
Table I: Asset risk register
Record the name of the asset along its attributes on the table below.
Provide rational for the selection of the assets and their attributes as well as for the priority.
Threats and vulnerabilities identification: For each asset, identify two potential threats capable of causing harm to the asset and the corresponding vulnerabilities. Describe briefly the rational for the selection of the threats and vulnerabilities. Record the information on the table below.
.png)
Table II: Threat-vulnerability pair register
Task 2: Cyber Security Risk Assessment
In this section, you will rate the risk. You must justify and support your choice and show step by step your work and include all the formulas required to arrive at your answer.
Ranking vulnerabilities and threats: Rate the vulnerabilities and threats you identified in previous section. Record the result in the Table III.
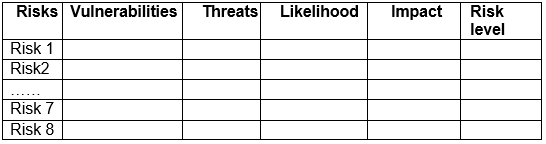
Table III: Inherent risk register
Compute the risk likelihood: Risk likelihood represents the likelihood that a threat will exploit a vulnerability assuming that there are no security controls in place. Record the result in the Table III.
Compute the risk impact: the risk likelihood represents the likelihood that a threat will exploit a vulnerability assuming that there are no security controls in place. Record the result in the Table III.
Compute the risk level: calculated risk level from the “likelihood” and “impact” and record the result in the Table III.
Task 3: Cyber Security Risk Evaluation
Existing Control: evaluate existing security control effectiveness to reduce the likelihood of a threat exploiting the vulnerability or the potential consequence arising from the vulnerability exploitation or both.
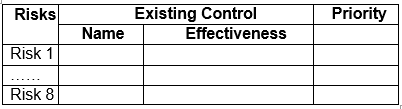
Table IV: Control and risk evaluation
Prioritise the risks: prioritise the risk to the asset based on the risk level. The risks are ordered from highest risk to lowest risk.
Task 4: Cyber Security Risk Treatment
Identify appropriate treatment option for mitigating the risk. Select and assess a range of security controls appropriate to remedy the risk. Provide rational and justification for the selection of the controls, treatment option and assessments.

Table V: Risk treatment
Solution
Introduction
Cybersecurity management is a strategic counterpart of an organization to protect their information resources and maintain a competitive advantage in spite of the evolving threat landscape [1]. It can be done by protecting sensitive data, personally identifiable information and intellectual property rights. This study has shed light on the cybersecurity management of XYZRG board by undertaking a broad cybersecurity risk assessment for The Assignment Help within their corporate setting.
Task 1: Cyber Security Risk Identification
1. Asset identification
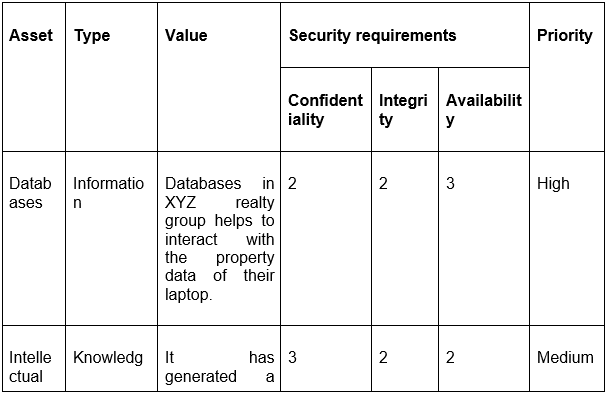
Table I: Asset risk register
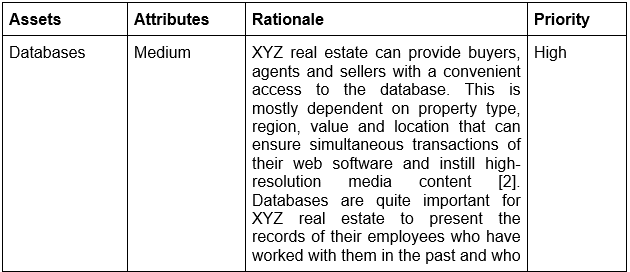
.png)

Table II: Assets and attributes pair register
2. Threats and vulnerabilities identification

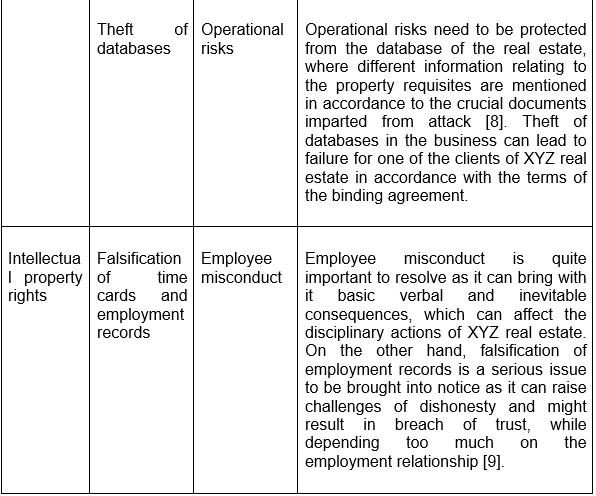
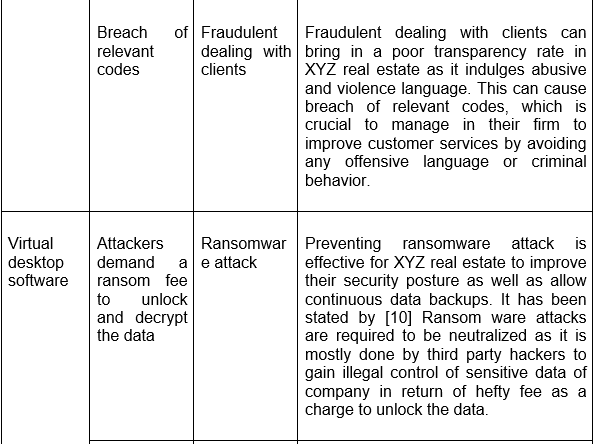
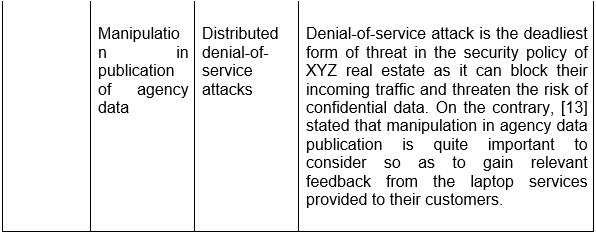
Table III: Threat-vulnerability pair register
Task 2: Cyber Security Risk Assessment
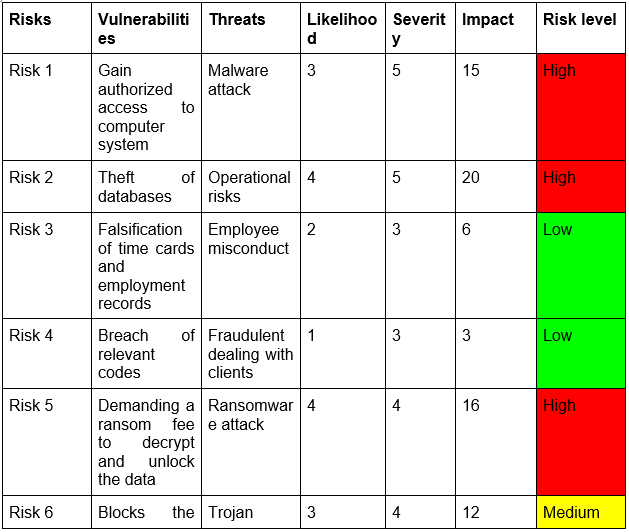
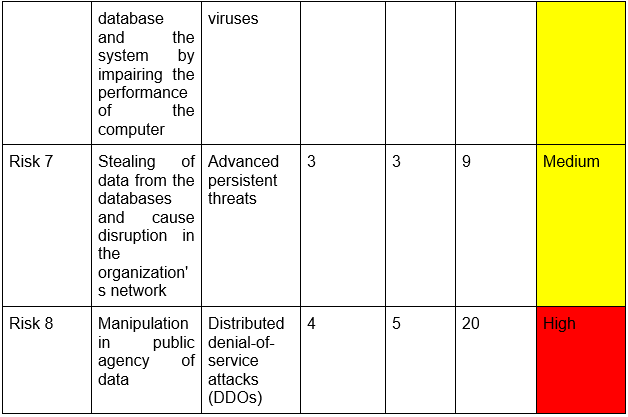
Table IV: Inherent risk register
It can be indicated from the cybersecurity risk assessment of XYZ real estate that they have an overall 8 types of risks that might devastate their employee productivity and business profitability. This might be due to the low-risk appetite of the organization in terms of brand reputation and loyalty as they have failed to pursue their long-term goals on the consideration of poor security policy and fraudulent dealing of their own pre-installed laptops to the respective clients [14]. There are four top-most and high risks of the real estate company such as malware attack, operational risks, ransomware attack and distributed denial-of-service attacks. XYZ real estate have failed to cover the warranty of their laptops through negligence including spilling liquids on the devices or dropping. It is due to such consideration that the organization is facing increased challenges of stolen databases as well as theft of laptops. This might instill a risk for the organization around their cybersecurity wall and damage the access control systems. It can be indicated from the likelihood and impact of these four risks that they are concerning XYZ real estate in terms of ensuring smooth connection with the clients due to the increase of unauthorized access to the computer system. It is quite important to get rid of malware attacks in the real estate company to achieve a baseline of cyber security by providing a safe compliance in their certification. This can assure the organization numerous benefits in terms of owning private productivity software and personal messaging apps on the laptop [15]. The benefits include improved customer confidence on investment, reduced insurance premiums and ability to tender their real estate services through a scheme of pre-requisite. Therefore, XYZ real estate needs to ensure strong memorable passwords and password-protected laptops to avoid the malware and DDOs attacks with a frequent check on the cybersecurity wall.
Task 3: Cyber Security Risk Evaluation
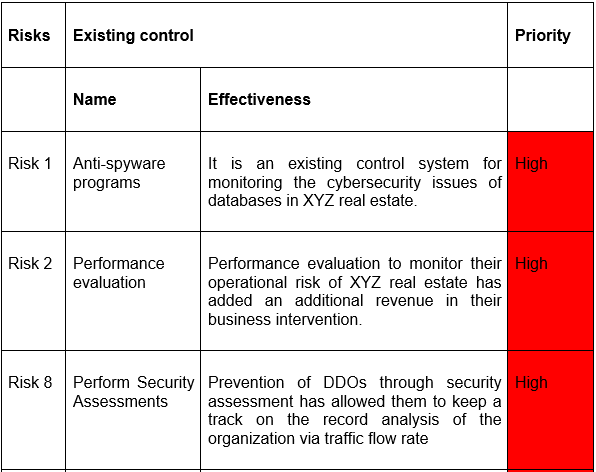

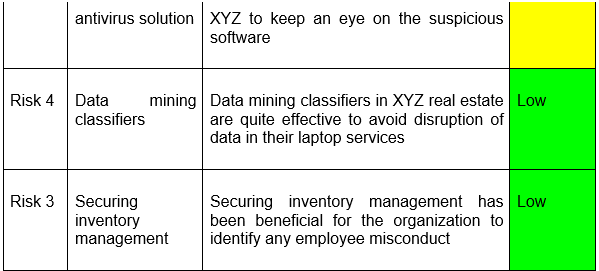
Table V: Control and risk evaluation
Task 4: Cyber Security Risk Treatment

.png)
.png)
Table VI: Risk treatment
Conclusion
It can be concluded from the above that cybersecurity management for XYZRG board is crucial to protect their short-term and long-term resources. This can ensure them to stay safe from third-party attackers like malware, ransomware and DDOs, which might affect their brand reputation rate. Therefore, involving intrusion detection system and other security control measures are effective for the real estate agency to keep aloof their laptop services by improving customer service department and business productivity rate.
References
.png)
.png)
Reports
DATA4900 Innovation and creativity in business analytics Report 4 Sample
Assessment Description
In this assessment, you will be writing an individual report for the Assignment Helpline that encourages you to be creative with business analytics, whilst also developing a response to the UX, CX and Ethical innovation case study that you have selected.
Background:
In this assessment, you will be developing a response through application of the analytics concepts covered in weeks 10 & 11.
To do so, you will need to demonstrate:
1. How Design Thinking principles were applied in the development of your proposed innovation
2. Application of UX and CX principles during the development process
3. Acknowledgement and management of legal and ethical issues in the creation of your innovation.
4. Alignment to the customer journey for your nominated personas.
5. Utilisation of analytics tools.
Assessment Instructions
Select a case study brief from either Appendix A or Appendix B or a similar one of your own (select only one)
Apply UX and CX Design Thinking principles in delivering an analytics-based solution to this brief, taking into consideration UX, CX and ethical issues in developing this innovation.
Broad UX and CX steps are likely to include:
1. DISCOVER & DEFINE
• Problem statement
• Defining your target audience
• Creating Personas outcomes
• User journey mapping
2. DESIGN
• Lo-fi vs Hi-fi design
• Wireframes & prototypes
3. TEST + ITERATE
• How to capitalise on failure in rapid prototyping and fast loop iterations
In evaluating your proposed innovation from a UX and CX perspective,
- How feasible is the solution for implementation?
- How well does the solution meet the needs of the end-user
Solution
Introduction
This report is based on UK and CX ethical innovation for the case study of coffee machine. The background of this report is to propose innovation for coffee machine in order to create advanced coffee machine design that will provide additional features such as music while making coffee and add flavours. This report includes user persona based on the case study and user journey map based on thinking of the user in respect to the coffee machine application.
Problem Statement and solution
Tea and coffee machine
To make a tea and coffee machine more interesting
1. Music player integration: The machine could be linked to a music streaming service or a user's personal music library to play their favorite songs while making the drink.
2. Flavor customization: Allow customers to add flavors like mint, chili, or caramel to their drinks through the machine's interface or an app.
3. Visual displays: The machine could display different lights or animations while making the drink, or even mimic a game.
4. User app: An app could be created to interact with the beverage maker and improve the customer experience by allowing for easy customization, control, and monitoring of the machine.
5. Ease of use: Adding features to enhance customer ease of use such as a touch-screen interface, voice commands, and pre-set drink options.
Application of UX and CX principles during the development process
To apply UX and CX principles during the development process of the tea and coffee machine with light and music, consider the following steps:
• User research: Conduct user research to gather information on the target audience's needs, pain points, and behavior patterns in regards to making tea and coffee.
• Empathy mapping: Create empathy maps to understand the user's experience and emotions when making tea and coffee.
• Define problems: Identify the problems that users face when making tea and coffee and prioritize them based on their impact.
• Ideation: Generate a range of potential solutions to address the user problems, including the integration of light and music.
• Prototyping and Testing: Create prototypes of the most promising solutions and test them with a sample of users to gather feedback.
• Refinement: Based on the feedback, refine the solution to ensure it addresses the user needs and provides a seamless experience.
• CX Design: Ensure that the solution is designed with a focus on the customer experience, from the ease of use of the machine and app to the visual and sensory elements of the machine. Ensure that the integration of light and music enhances the user experience and adds to the overall enjoyment of making tea and coffee.
• Usability Testing: Test the machine's usability with a sample of users to ensure that it is user-friendly and meets their needs.
By following these steps, you can develop a tea and coffee machine that incorporates light and music in a way that enhances the user experience and provides a positive customer experience.
Acknowledgement and management of legal and ethical issues in the creation of your innovation.
When creating a UX and CX innovation, it is important to consider and manage the legal and ethical issues involved. This includes:
• Data privacy: Ensure that the user data collected through the application is stored securely and only used for the intended purpose, in compliance with relevant privacy laws.
• Intellectual property: Be aware of the intellectual property rights of others and ensure that any music, visual displays, or other content used in the innovation is legally obtained or licensed.
• Accessibility: Ensure that the application is accessible to users with disabilities, in compliance with relevant accessibility laws.
• User consent: Obtain user consent for the collection and use of their data, including clear and concise information on how their data will be used.
• Data security: Implement appropriate security measures to protect user data from unauthorized access, use, or disclosure.
• Responsibility: Ensure that the application is designed and developed in a way that minimizes potential harm to users, and that the company is held accountable for any issues that may arise.
By acknowledging and managing these legal and ethical issues, you can ensure that your UX and CX innovation is created in a responsible and sustainable manner, and that it meets the expectations of users and stakeholders.
User persona
Name: Melanie
Age: 30 years old
- Married/one child/Suburban
- Comfortable with tech
- Loves unusual flavours and trying new things
- Drinks a lot of coffee and various teas
- Leads a busy life
Customer journey map
Design thinking canvas
Utilisation of analytics tools.
Analytics tools can be useful throughout the UX and CX innovation process to gather insights and inform decision-making. Consider the following steps:
• Data collection: Use analytics tools to collect data on user behavior and feedback, including usage patterns, time spent on the application, and customer satisfaction scores.
• Data analysis: Analyze the data to identify patterns and trends that can inform decision-making, such as which features are being used most frequently, which areas of the application are causing the most frustration, and what customers are saying about the experience.
• User Testing: Use analytics tools to gather data on user testing, including how users interact with the application, what they like and dislike, and how they respond to different design elements.
• User Behavior Tracking: Use analytics tools to track user behavior over time, including the frequency and duration of usage, and any changes in behavior.
• Performance metrics: Use analytics tools to monitor the performance of the application, including load times, response times, and error rates, to identify areas for improvement.
By utilizing analytics tools throughout the UX and CX innovation process, you can gain valuable insights into user behaviour and customer experience, and make informed decisions that improve the overall quality of the application.
References
.png)
.png)
Research
COIT20251 Knowledge Audit for Business Analysis Report Sample
Task Description
In this assessment, you will demonstrate understanding of the core competencies and skills required for a Business Analyst. You will also demonstrate your knowledge in the use of tools and techniques for requirements elicitation and reporting.
The assessment has two parts – Part A: Reflections and Part B: Case Studies.
To construct this part of the assessment, you are required to a write a reflection on each of the three topics mentioned below.
1. The Business Analysis Maturity Model (BAMM)
2. Prototyping
3. Gap Analysis
In each reflection, you will provide a brief introduction of the topic (method/process/model), how the method/process/model works, stakeholders involved, inputs and outputs, how it helps business analysis and its benefits. You also need to include figures, diagrams and illustrations to improve the quality of presentation.
Each portfolio should contain approximately 400 words. You need to include at least three references (including at least two academic references) for each reflection. You also need to make sure that the references are cited in the text and the reflections are free from any grammatical and spelling errors.
Part B: Case Studies
In this part, you will analyse two short case studies and answer questions for The Assignment helpline given with each case study. The case studies will be made available on the Moodle unit website. The answer to each case study question should not contain more than 400 words.
You should include at least four references (including at least two academic references) in this part.
Solution
Part A: Reflections
1. The Business Analysis Maturity Model (BAMM)
The Business Analysis Maturity Model (BAMM) is a framework that helps organizations evaluate and improve their business analysis practices. It is based on the idea that organizations can progress through different levels of maturity in their business analysis practices, and that by understanding where they are currently, they can take steps to improve. BAMM is a process that allows organizations to measure and evaluate their current business analysis practices in order to identify areas for improvement and align their business analysis strategy with their overall organizational goals (Jayapalan, 2020).
Five levels of maturity:
BAMM consists of five levels of maturity: Initial, Managed, Defined, Quantitatively Managed, and Optimizing. Each level describes a different stage in the development of business analysis practices and includes specific characteristics and capabilities that organizations at that level are expected to possess (Nilsson & Dahlgren, 2019).
.png)
Figure 1 Characteristics of the maturity levels
(Source: Nilsson & Dahlgren, 2019)
- At the Initial level, business analysis is ad-hoc and reactive, with no clear processes or standards in place.
- At the Managed level, processes and standards are established, but they are not consistently followed.
- At the Defined level, processes and standards are consistently followed and there is a clear understanding of the business analysis role within the organization.
- At the Quantitatively Managed level, metrics are used to measure the effectiveness of business analysis practices.
- At the Optimizing level, business analysis practices are continuously improved (Nilsson & Dahlgren, 2019).
Stakeholders involved in BAMM and input and output to BAMM
The stakeholders involved in BAMM include business analysts, project managers, business leaders, and other stakeholders that are impacted by the business analysis process. The inputs to BAMM include data on the organization's current business analysis practices and the outputs are a report that describes the organization's level of maturity and recommendations for improvement (Terry Ramabulana et al., 2020).
The stakeholders involved in BAMM include business analysts, project managers, business leaders, and other stakeholders that are impacted by the business analysis process. The inputs to BAMM include data on the organization's current business analysis practices and the outputs are a report that describes the organization's level of maturity and recommendations for improvement (Terry Ramabulana et al., 2020).
BAMM process
The BAMM process typically includes the following steps:
• Define the scope of the assessment: Determine which business analysis practices will be evaluated and which stakeholders will be involved.
• Gather data: Collect data on the organization's current business analysis practices through interviews, surveys, and document reviews.
• Analyze data: Review the data and evaluate the organization's level of maturity in each of the five BAMM levels.
• Report results: Prepare a report that describes the organization's level of maturity and provides recommendations for improvement.
• Implement improvements: Develop and implement a plan to address any identified areas for improvement.
BAMM helps business analysis by providing a clear and objective way to assess the organization's current practices and identify areas for improvement. It also helps to align business analysis practices with the organization's overall strategy and goals. By using BAMM, organizations can improve the effectiveness and efficiency of their business analysis practices, which in turn can lead to better decision-making, improved project outcomes, and increased business value.
Benefits of BAMM:
• Provides a clear and objective way to assess the organization's current practices and identify areas for improvement.
• Helps to align business analysis practices with the organization's overall strategy and goals.
• Improves the effectiveness and efficiency of business analysis practices.
• Leads to better decision-making, improved project outcomes and increased business value
2. Prototyping
Prototyping is a process of creating a model or simulation of a system or product, which is used to test and evaluate the design before it is built. Prototyping is an iterative process, which means that the prototype is continually refined and improved until it meets the requirements of the stakeholders.
Prototyping is a process that involves creating a preliminary version of a product or system to test and evaluate its design and functionality. The prototype is typically a simplified version of the final product and is used to gather feedback and make improvements before the final product is developed. The process of prototyping allows stakeholders to test and evaluate the product or system's design and functionality before it is developed, which can help identify any problems or issues early on and ultimately save time and money in the long run.
Different types of prototypes
There are different types of prototypes, such as paper prototypes, wireframes, and functional prototypes. Paper prototypes are simple mockups of the product or system created using paper and pencil, while wireframes are digital mockups that show the layout and functionality of the product or system. Functional prototypes are more advanced and can be used to test the product or system's functionality (BA,2021).
.png)
Figure 2 Prototype
(Source: BA,2021)
Stakeholders involved in prototyping and input and output to prototyping
The stakeholders involved in prototyping include project managers, designers, developers, and users. The inputs to prototyping include the product or system's requirements, design, and any constraints. The outputs are the prototype itself, feedback from stakeholders and any improvements that need to be made (Lauff et al.,2020).
Process of prototyping
.png)
(Source: BA,2021)
The process of prototyping typically includes the following steps:
• Define the scope of the prototype: Determine the purpose of the prototype and what features and functionality need to be included.
• Create the prototype: Use various tools and techniques to create a preliminary version of the product or system.
• Test and evaluate the prototype: Gather feedback from stakeholders and use it to make improvements to the prototype.
• Refine and improve the prototype: Make any necessary changes to the prototype based on feedback and testing (BA,2021).
Prototyping in business analysis
Prototyping helps business analysis by allowing stakeholders to test and evaluate the product or system's design and functionality before it is developed. This can help to identify any problems or issues early on, which can save time and money in the long run. It also helps to ensure that the final product or system meets the user's needs and is fit for purpose (Baldassarre et al., 2020).
Benefits of prototyping
• Allows stakeholders to test and evaluate the product or system's design and functionality before it is developed (Lauff et al.,2020).
• Helps to identify problems or issues early on and save time and money in the long run.
• Ensures that the final product or system meets the user's needs and is fit for purpose.
3. Gap analysis
Gap analysis is a process that involves identifying the differences between the current state of an organization and its desired future state. It is used to identify areas where the organization needs to improve in order to achieve its goals and objectives. The process of gap analysis helps organizations to identify areas of weakness and prioritize areas for improvement (Robin, & Robin, 2021).
The process of gap analysis typically includes the following steps:
.png)
Figure 4 Gap Analysis Process
(Source: Santhosh & II MBA, n.d.))
• Define the scope of the gap analysis: Determine the goals and objectives of the organization and what areas will be evaluated.
• Collect data on the current state: Gather information on the organization's current processes, systems, and performance metrics.
• Define the desired future state: Identify the goals and objectives of the organization and what the desired state should be.
• Compare the current and desired states: Identify the differences between the current and desired states and document any gaps or areas of weakness.
• Prioritize the gaps: Determine which gaps have the most impact on the organization's goals and objectives and prioritize them for improvement.
• Develop recommendations: Develop a plan to address the identified gaps and improve the organization's processes and systems (Santhosh & II MBA, n.d.).
Stakeholders involved in gap analysis and input and output to gap analysis
The stakeholders involved in gap analysis include business analysts, project managers, business leaders, and other stakeholders that are impacted by the organization's goals and objectives. The inputs to gap analysis include data on the organization's current state, goals and objectives, and any constraints. The outputs are a report that describes the gap between the current and desired state, and recommendations for improvement (Suklan, 2019).
Gap analysis role in business analysis
Gap analysis helps business analysis by providing a clear and objective way to identify areas where the organization needs to improve in order to achieve its goals and objectives. It allows the organization to understand the gap between their current and desired state, and prioritize areas for improvement. By using gap analysis, organizations can improve their performance and achieve their goals more efficiently. It also allows organizations to identify the gap between the current state and desired state in the areas of operations, processes, systems, and performance, in order to make informed decisions about how to improve and move forward (Robin, & Robin, 2021).
Benefits of Gap Analysis:
• Provides a clear and objective way to identify areas where the organization needs to improve
• Helps organizations to understand the gap between their current and desired state
• Prioritize areas for improvement
• Improves the organization's performance and achieve their goals more efficiently.
• Allows to identify the gap between current state and desired state in the area of operations, processes, systems, and performance (Suklan, 2019).
Part-B
Case Study-1: A Manufacturing Company
1. Position of current users of the Case study organisation on the Power/Influence/Interest Diagram.
In the Power/Influence/Interest Diagram, the current users of the Case study organization would likely be located in the lower right quadrant, as they have minimal power and influence within the organization, but a high level of interest in the current system they are using. They are the ones who are directly impacted by the system and have a high level of interest in it, since they have been using it for a long time and are familiar with its capabilities and limitations. They have developed a sense of trust and comfort with the system, have established a workflow that is efficient for them and they don't want to change it (Reed, 2022).
.png)
Figure 5 Power/Influence/Interest Diagram
(Source: Paula, 2022)
The users may have some resistance to changing the system they are used to, and they do not want to spend time and effort learning a new system or dealing with the trauma of change that comes with it. They might not see the need for a new system, since the current one is working for them. They are not the problem owners, they are not the ones who have the problem with the old system, they are just the ones who have to work with it.
On the other hand, upper-level management is located in the upper left quadrant. They have the power and influence to make decisions for the organization, but their interest in the current system may not be as high as that of the users. They are concerned about the two people who are maintaining the system, and the potential consequences of not having anyone to maintain it. They are worried that the company will not be able to sell any new products if the system is not updated. They see the need for a new system written in a modern language with more modern technology (Mints & Kamyshnykova, 2019).
The Upper-level management are aware that the technology is outdated and that it is hard to find people who can maintain it. They are aware that the system is not meeting the current regulatory compliance standards, and they are worried that the company will be penalized if the system is not updated. They are the problem owners in this situation, they are the ones who have the problem with the old system and they are the ones who have to find a solution for it. Upper-level management is in a position of power and influence, and they have the responsibility to make decisions that will benefit the organization as a whole. They must weigh the concerns of the users with the needs of the organization, and find a solution that will work for both parties.
2. Strategies to effectively manage the stockholders in an "uncooperative users" situation
• Communicate the urgency and importance of the situation to upper management and gain their support in communicating the need for change to the users: The support of upper management is crucial to overcome resistance from the users. Upper management should be involved in the process of selecting and designing the new system, allowing them to provide input and feedback on how it will impact their work processes. They should be able to communicate the urgency of the situation and the potential risks if the system is not updated (Gupta et al., 2020).
• Involve the users in the process of selecting and designing the new system: By involving the users in the process, they will feel more invested in the new system, and their resistance to change may decrease. It is essential to understand their concerns and address them in the design of the new system. The users should be able to provide feedback on the system design and they should be able to test the new system before it is implemented. The users should be able to provide feedback on the system's ease of use and they should be able to provide feedback on the system's compliance with their workflow.
• Provide training and support for the new system: To mitigate the users' resistance to change, it is essential to provide training and support for the new system. This will help them understand how the new system works and how it will benefit them. The users should be able to attend training sessions and they should be able to receive support from the system's developers. The users should be able to receive support during the transition period and after the new system is implemented (Mints & Kamyshnykova, 2019).
• Communicate the benefits of the new system: It is essential to communicate the benefits of the new system to the users, such as increased efficiency, improved compliance, and better reporting capabilities. This will help the users understand why the new system is necessary and how it will improve their work processes. It is important to show the users how the new system will make their job easier, more efficient and how it will help them to meet the regulatory compliance (Gupta et al., 2020).
• Be flexible and open to feedback: It is essential to be flexible and open to feedback from the users throughout the process. The users should be able to provide feedback on the new system, and the system developers should be able to make changes based on the feedback. The system should be flexible enough to adapt to the users' needs.
• Have a plan in place for the transition: It is essential to have a plan in place for the transition from the old system to the new system. This will help ensure a smooth transition and minimize disruption to the users' work processes. The plan should include a timeline for the transition, a training schedule for the users, and a support plan for the users during and after the transition.
Case Study-2: Smart Solar Systems (3S)
1. Tangible and Intangible costs that would be involved in the business improvement options.
The business improvement options proposed for the 3S company that would involve both tangible and intangible costs.
Tangible costs
• Tangible costs include the cost of implementing cloud-based ERP and KM systems, as well as the cost of training front-line staff to become generalists (Chofreh et al., 2020).
• The cost of purchasing and implementing new software systems can be substantial, as well as the cost of training employees on how to use them.
• Additionally, there may be additional costs such as hardware upgrades or IT support that would need to be considered.
• These costs may include the purchase, installation and maintenance of the software, the cost of data migration, the cost of employee training, the cost of IT support and the cost of hardware upgrades (Velenturf & Jopson, 2019).
Intangible costs
• Intangible costs include the costs of changing the company organizational structure and culture. This may involve significant changes in how the company operates, which can be disruptive to employees and may require significant time and effort to implement.
Additionally, there may be a loss of experienced employees who are not comfortable with the new organizational structure or who may not possess the necessary skills to adapt to new roles. This can lead to a loss of institutional knowledge, which can be difficult to replace, and a loss of employee engagement, which can lead to a decrease in productivity (Andersson et al., 2019).
• Another intangible cost would be the time taken to implement these changes. The change process may take a while and might also face resistance from employees and managers who might be uncomfortable with the new ways of working.
This may lead to a decrease in productivity and may also lead to delays in completion of tasks and projects. This can also lead to a loss of customer trust and business opportunities (Carlsson Wall et al., 2022).
• Finally, the cost of flattening the organization hierarchy would be that managers may lose some of their decision-making power, and that front-line staff may not be prepared to take on more responsibility, which could lead to confusion and mistakes.
This may also lead to a loss of accountability and a lack of direction in the organization, which can lead to a lack of progress in achieving company goals (Andersson et al., 2019).
The business improvement options would involve significant tangible costs such as implementation of new software systems and training of employees, as well as intangible costs such as changes in organizational structure and culture, loss of experienced employees, and resistance from employees. Additionally, it can also lead to a loss of time and delay in achieving company goals
2. Tangible and Intangible benefits that business improvement options deliver once implemented successfully
The business improvement options proposed for the 3S company would deliver both tangible and intangible benefits once implemented successfully.
Tangible benefits
• Tangible benefits include improved efficiency and productivity, as well as cost savings resulting from the streamlined business processes. The implementation of cloud-based ERP and KM systems would allow for better collaboration, communication and sharing of knowledge among the teams, leading to improved workflow, faster decision making and reduced errors. This would lead to faster completion of projects, improved customer service and increased revenue for the company (Chofreh et al., 2020).
Flattening the organizational hierarchy would give front line staff more autonomy in decision making, which can lead to increased job satisfaction, higher employee engagement and improved performance. This can also lead to improved customer service as front line staff would be more empowered to make decisions that are in the best interest of the customer, which would lead to increased customer loyalty and repeat business (Andersson et al., 2019).
• Integrating business units would allow customer service, engineering & design, logistics, installation, marketing, and sales teams to collaborate and share information more easily without needing the approval of their managers. This would allow teams to work more efficiently and effectively, and would lead to faster completion of projects and increased customer satisfaction. This would also lead to increased revenue and improved company reputation (Velenturf & Jopson, 2019).
• Re skilling front line staff to become generalists would make them more versatile and adaptable to different roles, which would allow the company to respond more quickly to changing market conditions. This would also lead to better employee retention, as employees would be more likely to stay with the company if they were given the opportunity to learn new skills and take on new roles. This would lead to reduced recruitment and training costs for the company (Carlsson Wall et al., 2022).
Intangible benefits
Intangible benefits include improved company culture, increased employee engagement and improved customer satisfaction. A more collaborative and communicative culture would improve employee morale, and the ability to adapt to changing market conditions would lead to improved:
• Customer satisfaction
• Brand reputation and Customer loyalty.
• Employee engagement and motivation
• Performance and Productivity (Andersson et al., 2019).
The business improvement options would provide a range of tangible and intangible benefits once implemented successfully. These benefits include improved efficiency, productivity and cost savings, increased employee engagement and satisfaction, improved customer service and satisfaction, improved company culture and brand reputation, and the ability to adapt to changing market conditions. These improvements would ultimately lead to a more successful and profitable company.
The company will have better coordination, collaboration and information sharing among the teams across departments, leading to faster completion of projects and increased customer satisfaction. The company would be able to respond more quickly to changing market conditions, which would lead to increased revenue and improved company reputation. The company will also have reduced recruitment and training costs and improved employee retention, which would lead to improved performance and productivity.
References

.png)
Case Study
TECH5300 Bitcoin Case Study 2 Sample
Your Task
This assessment is to be completed individually. In this assessment, you will evaluate the purpose, structure, and design of base layer 1 of the Bitcoin network, which provides the security layer.
Assessment Description
This assessment aims to evaluate your ability to analyse, evaluate, and critically assess the purpose, structure, and design of the base layer 1 of the Bitcoin network, which serves as the security layer. Additionally, you are required to explore the principles and significance of public-key cryptography in the context of Bitcoin transactions. By completing this assessment, you will demonstrate your proficiency in comprehending complex concepts, conducting in-depth research, and presenting well-structured arguments.
Case Study
Case Study Scenario: You have been appointed as a Bitcoin consultant for a financial institution seeking to explore the potential of utilising Bitcoin as part of their operations. Your task is to evaluate the purpose, structure, and design of the Bitcoin layer 1 network, with a particular focus on its security layer. Furthermore, you are required to analyse the role and impact of public-key cryptography in securing Bitcoin transactions.
Your Task: In this case study, you are required to prepare a detailed report addressing the following aspects:
1. Evaluation of the Purpose, Structure, and Design of Bitcoin Layer 1 Network:
a. Analyse the purpose and significance of the base layer 1 in the Bitcoin network, emphasising its role as the security layer.
b. Evaluate the structural components of the Bitcoin layer 1 network, including its decentralised nature, consensus mechanism, and transaction processing.
c. Assess the design principles and mechanisms employed within the Bitcoin layer 1 network to ensure security, immutability, and transaction verification.
2. Exploration of Public-Key Cryptography in Bitcoin Transactions:
a. Explain the fundamental principles of public-key cryptography and its relevance in securing Bitcoin transactions.
b. Analyse the mechanisms and algorithms used in public-key cryptography to ensure transaction verification, non-repudiation, and confidentiality in the Bitcoin network.
c. Evaluate the strengths and weaknesses of public-key cryptography within the context of Bitcoin transactions, considering factors such as key management, quantum resistance, and regulatory implications.
3. Evaluation of Security Challenges and Mitigation Strategies:
a. Identify and analyse the major security challenges and vulnerabilities associated with the Bitcoin layer 1 network, including potential attack vectors, double-spending, and transaction malleability.
b. Evaluate existing mitigation strategies and countermeasures employed to address these security challenges.
4. Future Outlook and Recommendations:
a. Discuss emerging trends, advancements, or potential challenges related to the Bitcoin layer 1 network and public-key cryptography.
b. Provide recommendations to the financial institution regarding the integration of the
Bitcoin layer 1 network and public-key cryptography into their operations, considering the benefits, risks, and potential mitigations.
Solution
Introduction
"The Security, Cryptography, and Future Outlook of the Bitcoin Layer 1 Network. This in depth examination explores the goal, composition, and architecture of the fundamental layer 1 network that underpins Bitcoin. For Assignment Help, It examines the use of public key cryptography for transaction security, assesses security risks, and suggests defences. While offering tactical suggestions for handling the shifting market, the conversation gives insights into new trends and developments.
1. Evaluation of the Purpose, Structure and Design of Bitcoin Layer 1 Network
a. Purpose and significance of the base layer 1 in the Bitcoin network
The network's core architecture, which is primarily concerned with security, is Bitcoin's base layer 1. The Proof of Work (PoW) consensus process, aims to enable safe and decentralised transactions (Akbar et al., 2021). In order to validate transactions and add them to the blockchain, miners compete to solve challenging mathematical puzzles. This creates a tamper resistant database. Due to its enormous processing capacity, this security mechanism has demonstrated resilience against threats, making Bitcoin very resistant to censorship and manipulation. Since its launch in 2009, the basic layer of Bitcoin has experienced uptime of over 99.98%, proving its reliability (Nguyen, 2019). The network's miners' dedication to network security is demonstrated by this astounding increase.
b. Structural components of the Bitcoin layer 1 network
Decentralisation, consensus through Proof of Work (PoW), and transaction processing are all embodied in the Layer 1 network of Bitcoin. Decentralisation is ensured via the dispersion of global nodes, which improves security and resilience. PoW requires miners to validate transactions by solving complex puzzles. Every 10 minutes, blocks are created for transaction processing, placing security over speed (Kenny, 2019). This methodical pace provides immutability while limiting throughput. Layer 2 solutions balance speed, trust, and security at Layer 1. Layer 1 of Bitcoin emphasises decentralisation, PoW consensus, and purposeful processing, reaffirming its leadership position in the cryptocurrency industry (Tatos et al., 2019).
c. Design principles and mechanisms
The layer 1 network for Bitcoin is carefully designed to provide security, immutability, and transaction verification. Decentralisation enhances security and prevents isolated failures. In order to add blocks, Proof of Work (PoW) uses difficult solutions (Jabbar et al., 2020). This collective effort maintains data accuracy by resisting retroactive alterations. The consensus of the nodes prevents unauthorised acts and double spending by verifying transactions before they are included in blocks. These ideas strengthen the first layer of Bitcoin, which is crucial to its function as a reliable store of value and digital money, encapsulating security, historical integrity, and reliable transaction validation (Jacobetty and Orton-Johnson, 2023).
2. Exploration of Public Key Cryptography in Bitcoin Transactions
a. Fundamental principles of public key cryptography
Asymmetric encryption and the generation of a public private key pair are the two underlying tenets of public key cryptography. In this system, a user creates two sets of keys: a public key that is widely disseminated and a private key that is kept secret (Aydar et al., 2019). Secure communication is made possible by the fact that messages encrypted with one key can only be decoded with the other. These concepts are essential for transaction security in the context of Bitcoin. Each user has their own set of keys. A transaction output is encrypted by the sender using the recipient's public key, the output can only be decrypted using the recipient's private key. This makes sure that the money can only be accessed by the legitimate owner. The private key must be kept secret at all times; if it is compromised, the related cash will also be lost (Rezaeighaleh and Zou, 2019).
b. Mechanisms and algorithms used in public key cryptography
The Bitcoin network uses a variety of techniques and algorithms, including public key cryptography, to guarantee transaction verification, non-repudiation, and secrecy.
Transaction Verification: Digital signatures and cryptographic hashes are used in Bitcoin. A transaction is signed with the sender's private key when a user starts it, yielding a distinctive digital signature (Krishnapriya and Sarath, 2020). The sender's public key is then used by nodes in the network to validate the signature. The transaction is regarded as confirmed and can be uploaded to the blockchain if the signature is legitimate.
Non-Repudiation: Non-repudiation is provided through digital signatures (Fang et al., 2020). A transaction can be authenticated using the associated public key once it has been signed with a private key. This improves accountability by preventing senders from downplaying their role in the transaction.
Confidentiality: Public keys used to generate Bitcoin addresses maintain secrecy. The names behind addresses are fictitious, despite the fact that transactions are recorded on a public blockchain (Bernabe et al., 2019). The money linked to an address can only be accessed by individuals possessing the private key, protecting ownership privacy.
c. Strengths and weaknesses of public key cryptography
- Strengths: With public-key cryptography, Bitcoin is more secure and private. It enables secure ownership verification and ensures confidentiality with digital signatures and bogus addresses (Guo and Yu, 2022). Without the need for a competent middleman, peer-to-peer transactions are also made easier. Furthermore, keys' cryptographic nature provides robust defence against brute-force attacks.
- Weaknesses: Key management is difficult because losing a private key means that money is lost forever. Furthermore, the security of public key cryptography depends on the complexity of certain mathematical puzzles, and potential future developments like quantum computers might undermine its security (Fernandez Carames and Fraga Lamas, 2020).
3. Evaluation of Security Challenges and Mitigation Strategies
a. Major security challenges and vulnerabilities
The Bitcoin network's first layer has security flaws and problems. When someone spends the same amount of Bitcoin twice, there is a danger of double-spending. Although the consensus system prevents it, a strong actor may launch a 51% assault, allowing for double spending (Hacken and Bartosz, 2023). Transaction malleability is a problem since it permits changes to IDs prior to confirmation, which might be confusing. It affects ID dependent processes even while security isn't immediately compromised. Attacks called Sybils take advantage of decentralisation by clogging the network with phoney nodes and upsetting stability. Eclipses control transactions and isolate nodes (Salman, Al Janabi and Sagheer, 2023). These difficulties highlight the necessity of constant attack detection, protocol improvements, and a variety of decentralised nodes to maintain the Layer 1 security and integrity of Bitcoin.
b. Existing mitigation strategies
In order to resolve the security issues in the Bitcoin layer 1 network, existing mitigation tactics and remedies are used (Tedeschi, Sciancalepore and Di Pietro, 2022). The decentralised consensus process prevents double spending by making such assaults prohibitively costly and necessitating a majority of honest miners. Furthermore, miners choose to confirm transactions with larger fees, decreasing the appeal of double spending. Segregated witness (SegWit) was introduced to address transaction malleability (Kedziora et al., 2023). SegWit increases block capacity and reduces vulnerability to malleability attacks by separating signature data from transactions.
Strong network topology and peer discovery techniques are used to defend against Sybil assaults, assuring connections with a variety of nodes rather than being dominated by a single party (Madhwal and Pouwelse, 2023). Eclipse attacks may be thwarted by selecting peers carefully, employing multiple points of connection, and monitoring network activity to look for malicious actors. In order to address these security issues, Bitcoin uses a mix of protocol upgrades, financial incentives, and network architecture, assuring the stability and dependability of its layer 1 network (Lin et al., 2022).
4. Future Outlook and Recommendations
a. Emerging trends, advancements, or potential challenges
New developments and trends in public-key cryptography and layer 1 of the Bitcoin network provide both opportunities and difficulties. Layer 2 scaling solutions like the Lightning Network seek to solve Bitcoin's scalability problems by enabling quicker, lower-cost off chain transactions while retaining the layer 1 network's security (Dasaklis and Malamas, 2023). On the other hand, the security of conventional public key cryptography is in danger from quantum computing, which may have an effect on Bitcoin. In order to address this danger and uphold the network's security, researchers are investigating quantum resistant cryptographic methods (Akter, 2023).
b. Recommendations
Opportunities exist for integrating public key cryptography and the Bitcoin layer 1 network into the operations of financial institutions, but this requires careful design. First, consider adopting Bitcoin for cross border payments to take advantage of its efficient and borderless nature. Public key cryptography may be used to improve security by assuring encrypted communication and safe transactions (Dijesh, Babu and Vijayalakshmi, 2020). Uncertain laws, volatile markets, and security concerns like key management are risks, nevertheless. For minimising these risks, use risk management strategies to cope with price changes, give solid key management processes top priority to prevent losing access to money, and do in depth due diligence on compliance requirements.
Consider introducing Bitcoin services gradually to reduce risks and stay current with market movements. Consult with compliance and blockchain experts if there are any issues. Overall, financial institutions may be prepared for success in the changing environment by developing a well thought-out plan that finds a balance between the benefits of Bitcoin, encryption, and risk reduction strategies (Ekstrand and Musial, 2022).
Conclusion
The study of Bitcoin's Layer 1 network concludes by highlighting the importance of this network for security, decentralisation, and transaction verification. Public key cryptography improves non repudiation and secrecy. Although security issues still exist, the network's integrity is supported by current mitigating techniques including consensus mechanisms and network architecture. Future developments like quantum resistant encryption and Layer 2 solutions present both possibilities and difficulties. Recommendations stress the integration of Bitcoin into financial institutions, led by strategic adoption and risk management, to ensure a strong basis for navigating the changing environment.
References
.png)
.png)
Case Study
TECH5300 Bitcoin Case Study 1 Sample
Your Task
This assessment is to be completed individually. In this assessment, you will evaluate the purpose, structure, and design of base layer 1 of the Bitcoin network, which provides the security layer.
Assessment Description
This assessment aims to evaluate your ability to analyse, evaluate, and critically assess the purpose, structure, and design of the base layer 1 of the Bitcoin network, which serves as the security layer. Additionally, you are required to explore the principles and significance of public-key cryptography in the context of Bitcoin transactions. By completing this assessment, you will demonstrate your proficiency in comprehending complex concepts, conducting in-depth research, and presenting well-structured arguments.
Case Study
Case Study Scenario: You have been appointed as a Bitcoin consultant for a financial institution seeking to explore the potential of utilising Bitcoin as part of their operations. Your task is to evaluate the purpose, structure, and design of the Bitcoin layer 1 network, with a particular focus on its security layer. Furthermore, you are required to analyse the role and impact of public-key cryptography in securing Bitcoin transactions.
Your Task: In this case study, you are required to prepare a detailed report addressing the following aspects:
1. Evaluation of the Purpose, Structure, and Design of Bitcoin Layer 1 Network:
a. Analyse the purpose and significance of the base layer 1 in the Bitcoin network, emphasising its role as the security layer.
b. Evaluate the structural components of the Bitcoin layer 1 network, including its decentralised nature, consensus mechanism, and transaction processing.
c. Assess the design principles and mechanisms employed within the Bitcoin layer 1 network to ensure security, immutability, and transaction verification.
2. Exploration of Public-Key Cryptography in Bitcoin Transactions:
a. Explain the fundamental principles of public-key cryptography and its relevance in securing Bitcoin transactions.
b. Analyse the mechanisms and algorithms used in public-key cryptography to ensure transaction verification, non-repudiation, and confidentiality in the Bitcoin network.
c. Evaluate the strengths and weaknesses of public-key cryptography within the context of Bitcoin transactions, considering factors such as key management, quantum resistance, and regulatory implications.
3. Evaluation of Security Challenges and Mitigation Strategies:
a. Identify and analyse the major security challenges and vulnerabilities associated with the Bitcoin layer 1 network, including potential attack vectors, double-spending, and transaction malleability.
b. Evaluate existing mitigation strategies and countermeasures employed to address these security challenges.
4. Future Outlook and Recommendations:
a. Discuss emerging trends, advancements, or potential challenges related to the Bitcoin layer 1 network and public-key cryptography.
b. Provide recommendations to the financial institution regarding the integration of the
Bitcoin layer 1 network and public-key cryptography into their operations, considering the benefits, risks, and potential mitigations.
Solution
Introduction
"The Security, Cryptography, and Future Outlook of the Bitcoin Layer 1 Network. This in-depth examination explores the goal, composition, and architecture of the fundamental layer 1 network that underpins Bitcoin. For Assignment Help, It examines the use of public-key cryptography for transaction security, assesses security risks, and suggests defences. While offering tactical suggestions for handling the shifting market, the conversation gives insights into new trends and developments.
1. Evaluation of the Purpose, Structure and Design of Bitcoin Layer 1 Network
a. Purpose and significance of the base layer 1 in the Bitcoin network
The network's core architecture, which is primarily concerned with security, is Bitcoin's base layer 1. The Proof of Work (PoW) consensus process, aims to enable safe and decentralised transactions (Akbar et al., 2021). In order to validate transactions and add them to the blockchain, miners compete to solve challenging mathematical puzzles. This creates a tamper-resistant database. Due to its enormous processing capacity, this security mechanism has demonstrated resilience against threats, making Bitcoin very resistant to censorship and manipulation. Since its launch in 2009, the basic layer of Bitcoin has experienced uptime of over 99.98%, proving its reliability (Nguyen, 2019). The network's miners' dedication to network security is demonstrated by this astounding increase.
b. Structural components of the Bitcoin layer 1 network
Decentralisation, consensus through Proof of Work (PoW), and transaction processing are all embodied in the Layer 1 network of Bitcoin. Decentralisation is ensured via
the dispersion of global nodes, which improves security and resilience. PoW requires miners to validate transactions by solving complex puzzles. Every 10 minutes, blocks are created for transaction processing, placing security over speed (Kenny, 2019). This methodical pace provides immutability while limiting throughput. Layer 2 solutions balance speed, trust, and security at Layer 1. Layer 1 of Bitcoin emphasises decentralisation, PoW consensus, and purposeful processing, reaffirming its leadership position in the cryptocurrency industry (Tatos et al., 2019).
c. Design principles and mechanisms
The layer 1 network for Bitcoin is carefully designed to provide security, immutability, and transaction verification. Decentralisation enhances security and prevents isolated failures. In order to add blocks, Proof of Work (PoW) uses difficult solutions (Jabbar et al., 2020). This collective effort maintains data accuracy by resisting retroactive alterations. The consensus of the nodes prevents unauthorised acts and double spending by verifying transactions before they are included in blocks. These ideas strengthen the first layer of Bitcoin, which is crucial to its function as a reliable store of value and digital money, encapsulating security, historical integrity, and reliable transaction validation (Jacobetty and Orton-Johnson, 2023).
2. Exploration of Public-Key Cryptography in Bitcoin Transactions
a. Fundamental principles of public-key cryptography
Asymmetric encryption and the generation of a public-private key pair are the two underlying tenets of public-key cryptography. In this system, a user creates two sets of keys: a public key that is widely disseminated and a private key that is kept secret (Aydar et al., 2019). Secure communication is made possible by the fact that messages encrypted with one key can only be decoded with the other. These concepts are essential for transaction security in the context of Bitcoin. Each user has their own set of keys. A transaction output is encrypted by the sender using the recipient's public key, the output can only be decrypted using the recipient's private key. This makes sure that the money can only be accessed by the legitimate owner. The private key must be kept secret at all times; if it is compromised, the related cash will also be lost (Rezaeighaleh and Zou, 2019).
b. Mechanisms and algorithms used in public-key cryptography
The Bitcoin network uses a variety of techniques and algorithms, including public key cryptography, to guarantee transaction verification, non-repudiation, and secrecy.
Transaction Verification: Digital signatures and cryptographic hashes are used in Bitcoin. A transaction is signed with the sender's private key when a user starts it, yielding a distinctive digital signature (Krishnapriya and Sarath, 2020). The sender's public key is then used by nodes in the network to validate the signature. The transaction is regarded as confirmed and can be uploaded to the blockchain if the signature is legitimate.
Non-Repudiation: Non-repudiation is provided through digital signatures (Fang et al., 2020). A transaction can be authenticated using the associated public key once it has been signed with a private key. This improves accountability by preventing senders from downplaying their role in the transaction.
Confidentiality: Public keys used to generate Bitcoin addresses maintain secrecy. The names behind addresses are fictitious, despite the fact that transactions are recorded on a public blockchain (Bernabe et al., 2019). The money linked to an address can only be accessed by individuals possessing the private key, protecting ownership privacy.
c. Strengths and weaknesses of public-key cryptography
- Strengths: With public-key cryptography, Bitcoin is more secure and private. It enables secure ownership verification and ensures confidentiality with digital signatures and bogus addresses (Guo and Yu, 2022). Without the need for a competent middleman, peer-to-peer transactions are also made easier. Furthermore, keys' cryptographic nature provides robust defence against brute-force attacks.
- Weaknesses: Key management is difficult because losing a private key means that money is lost forever. Furthermore, the security of public key cryptography depends on the complexity of certain mathematical puzzles, and potential future developments like quantum computers might undermine its security (Fernandez Carames and Fraga Lamas, 2020).
3. Evaluation of Security Challenges and Mitigation Strategies
a. Major security challenges and vulnerabilities
The Bitcoin network's first layer has security flaws and problems. When someone spends the same amount of Bitcoin twice, there is a danger of double-spending. Although the consensus system prevents it, a strong actor may launch a 51% assault, allowing for double spending (Hacken and Bartosz, 2023). Transaction malleability is a problem since it permits changes to IDs prior to confirmation, which might be confusing. It affects ID-dependent processes even while security isn't immediately compromised. Attacks called Sybils take advantage of decentralisation by clogging the network with phoney nodes and upsetting stability. Eclipses control transactions and isolate nodes (Salman, Al Janabi and Sagheer, 2023). These difficulties highlight the necessity of constant attack detection, protocol improvements, and a variety of decentralised nodes to maintain the Layer 1 security and integrity of Bitcoin.
b. Existing mitigation strategies
In order to resolve the security issues in the Bitcoin layer 1 network, existing mitigation tactics and remedies are used (Tedeschi, Sciancalepore and Di Pietro, 2022). The decentralised consensus process prevents double spending by making such assaults prohibitively costly and necessitating a majority of honest miners. Furthermore, miners choose to confirm transactions with larger fees, decreasing the appeal of double-spending. Segregated witness (SegWit) was introduced to address transaction malleability (Kedziora et al., 2023). SegWit increases block capacity and reduces vulnerability to malleability attacks by separating signature data from transactions.
Strong network topology and peer discovery techniques are used to defend against Sybil assaults, assuring connections with a variety of nodes rather than being dominated by a single party (Madhwal and Pouwelse, 2023). Eclipse attacks may be thwarted by selecting peers carefully, employing multiple points of connection, and monitoring network activity to look for malicious actors. In order to address these security issues, Bitcoin uses a mix of protocol upgrades, financial incentives, and network architecture, assuring the stability and dependability of its layer 1 network (Lin et al., 2022).
4. Future Outlook and Recommendations
a. Emerging trends, advancements, or potential challenges
New developments and trends in public-key cryptography and layer 1 of the Bitcoin network provide both opportunities and difficulties. Layer 2 scaling solutions like the Lightning Network seek to solve Bitcoin's scalability problems by enabling quicker, lower cost off-chain transactions while retaining the layer 1 network's security (Dasaklis and Malamas, 2023). On the other hand, the security of conventional public key cryptography is in danger from quantum computing, which may have an effect on Bitcoin. In order to address this danger and uphold the network's security, researchers are investigating quantum-resistant cryptographic methods (Akter, 2023).
b. Recommendations
Opportunities exist for integrating public-key cryptography and the Bitcoin layer 1 network into the operations of financial institutions, but this requires careful design. First, consider adopting Bitcoin for cross-border payments to take advantage of its efficient and borderless nature. Public key cryptography may be used to improve security by assuring encrypted communication and safe transactions (Dijesh, Babu and Vijayalakshmi, 2020). Uncertain laws, volatile markets, and security concerns like key management are risks, nevertheless. For minimising these risks, use risk management strategies to cope with price changes, give solid key management processes top priority to prevent losing access to money, and do in-depth due diligence on compliance requirements.
Consider introducing Bitcoin services gradually to reduce risks and stay current with market movements. Consult with compliance and blockchain experts if there are any issues. Overall, financial institutions may be prepared for success in the changing environment by developing a well-thought-out plan that finds a balance between the benefits of Bitcoin, encryption, and risk-reduction strategies (Ekstrand and Musial, 2022).
Conclusion
The study of Bitcoin's Layer 1 network concludes by highlighting the importance of this network for security, decentralisation, and transaction verification. Public-key cryptography improves non-repudiation and secrecy. Although security issues still exist, the network's integrity is supported by current mitigating techniques including consensus mechanisms and network architecture. Future developments like quantum-resistant encryption and Layer 2 solutions present both possibilities and difficulties. Recommendations stress the integration of Bitcoin into financial institutions, led by strategic adoption and risk management, to ensure a strong basis for navigating the changing environment.
References
.png)
.png)
Case Study
ICC104 Introduction to Cloud Computing Case Study 2 Sample
Context:
This assessment assesses student’s capabilities to identify key cloud characteristics, service models and deployment models.
During this assessment, students should go through the four case studies identified below and prepare a short report (250 words each) around the case studies as per the instructions.
Case Study 1: ExxonMobil moves to Cloud
“XTO Energy is a subsidiary of ExxonMobil and has major holdings in the Permian Basin, one of the world’s most important oil-producing regions. To overcome the challenges of monitoring and optimizing a vast number of widely dispersed field assets, XTO Energy has been digitalizing its Permian operations. By using Microsoft Azure IoT technologies to electronically collect data and then using Azure solutions to store and analyse it, XTO Energy gains new insights into good operations and future drilling possibilities”. (Microsoft, 2018)
Read the full Case study: https://customers.microsoft.com/en-us/story/exxonmobil-mining-oil-gasazure
Case Study 2: Autodesk Builds Unified Log Analytics Solution on AWS to Gain New Insights
“Autodesk, a leading provider of 3D design and engineering software, wants to do more than create and deliver software. It also wants to ensure its millions of global users have the best experience running that software. To make that happen, Autodesk needs to monitor and fix software problems as quickly as possible. Doing this was challenging, however, because the company’s previous application-data log solution struggled to keep up with the growing volume of data needing to be analyzed and stored.” (Amazon Web Services, n.d)
Read the full Case Study at https://aws.amazon.com/solutions/case-studies/autodesk-log analytics/
Case Study 3: ‘Pay by the Drink’ Flexibility Creates Major Efficiencies and Revenue for Coca-Cola’s
International Bottling Investments Group (BIG)
“BIG’s stated goal is to drive efficiencies, higher revenue, greater transparency and higher standards across all of its bottlers. But, the bottlers within BIG each faced very unique challenges inherent to their business and markets. Thus the challenge for the business was how to address the unique complexities and requirements of a very diverse group of bottlers with efficient infrastructure and standardized processes.” (Virtual Stream, n.d)
Read the full Case Study at https://www.virtustream.com/solutions/case-studies/coca-cola
Case Study 4: Rocketbots improves its systems availability in difficult regions while optimizing the cost.
“Since Rocketbots in its essence is a software solution built on the cloud, they needed the availability to give their customers their high-end solution at any time. For other providers giving Rocketbots the availability, they needed in Southeast Asia proved difficult. By leveraging Alibaba Cloud’s many data centers throughout Asia, Rocketbots was able to give their customers an optimized solution that would work well and more importantly was available when they needed it.“ (Alibaba Group, n.d)
Read the Complete Case Study: https://www.alibabacloud.com/customers/rocketbots
Instructions:
The assessment requires you to prepare a report based on the case studies mentioned above.
Report Instructions:
Start off with a short introduction (approximately 250 words) stating what the report is about and some basic information relevant to the case study. For example, you can provide background information including some context related to cloud computing. This section will be written in complete sentences and paragraphs. No tables, graphs, diagrams or dot points should be included.
The main body of the report should comprise of four different sections of 250 words each (one
section for each of the above mentioned case studies). With each section specifically addressing the following questions about the case study.
• Introduction of the case
• What was the challenge?
• How the challenge was solved?
• What were the different service models each utilized?
• What are the different deployment models each utilized?
• What services of public cloud providers each case study used?
• Reflection
Finally, write a conclusion (approximately 250 words) as a summary of your analysis of the case. This section brings together all of the information that you have presented in your report and should link to the purpose of the assessment as mentioned in the introduction. You can also discuss any areas which have been identified as requiring further investigation and how this will work to improve or change our understanding of the topic. This section does not introduce or discuss any new information specifically, and like the introduction, will be written in complete sentences and paragraphs. No tables, graphs, diagrams or dot points should be included.
Solutions
Introduction:
This report explores the transformative power of cloud computing through a compilation of four diverse case studies. Cloud computing has emerged as a technological game-changer, offering businesses access to scalable, flexible, and cost-effective solutions to various challenges. For Assignment Help, Public cloud providers, including Amazon Web Services (AWS), Microsoft Azure, Google Cloud, and Alibaba Cloud, have risen as industry leaders, offering various services to cater to businesses of all sizes and industries.
In the digital age, organisations face ever-increasing pressure to adapt and innovate to remain competitive. Cloud computing has driven this transformation, enabling businesses to modernise their IT infrastructure, improve operational efficiency, enhance data management and analytics, and deliver superior customer experiences.
Throughout the case studies, we will examine each company's unique challenges and how they utilised cloud solutions to overcome these obstacles. We will also explore each organisation's different service and deployment models and the specific cloud services provided by public cloud providers in each instance.
As we delve into the intricacies of each case, we will witness the diverse applications of cloud computing, from optimising mining operations and enhancing software development to modernising IT Infrastructure and streamlining customer engagement. These real-world examples will provide valuable insights into the potential of cloud technologies to drive innovation and shape the future of businesses across various sectors. In an ever-changing digital landscape, cloud computing is a strategic imperative for organisations seeking to thrive in the modern era.
Case Study 1:
• Introduction: ExxonMobil, a global oil and gas industry leader, faced a significant challenge in optimising its mining operations for increased efficiency and productivity. To tackle this issue, they sought a cutting-edge solution that could leverage modern technologies to streamline their processes and enhance their overall performance.
• Challenge: ExxonMobil's complex mining operations involved extensive data processing, analysis, and management. The vast amounts of data generated from their mining sites made it imperative to find a solution that could handle the volume, velocity, and variety of data while ensuring data security and compliance (Microsoft. 2018).
• Solution: Azure's advanced data analytics and machine learning tools enabled them to gain valuable insights from the data, facilitating better decision-making and predictive maintenance strategies.
• Service Models: ExxonMobil utilised various service models provided by Microsoft Azure to address different aspects of its mining operations. They leveraged Infrastructure as a Service (IaaS) for scalable and flexible computing resources to efficiently manage their mining data and applications. Platform as a Service (PaaS) was used to build and seamlessly deploy custom data analytics and machine learning solutions.
• Deployment Models: ExxonMobil employed a hybrid deployment model to ensure the best utilisation of resources and meet specific operational requirements.
• Public Cloud Services: In their collaboration with Microsoft Azure, ExxonMobil utilised various services, including Azure Virtual Machines, Azure Machine Learning, Azure Data Factory, and Azure Kubernetes Service.
• Reflection: ExxonMobil's adoption of Microsoft Azure's cloud services exemplifies how cutting-edge technologies can revolutionise traditional industries. By leveraging Azure's advanced tools and service models, ExxonMobil successfully tackled their challenges, improving operational efficiency and increasing its competitive advantage in the oil and gas sector.
Case Study 2:
• Introduction: Autodesk, a renowned software company specialising in 3D design, engineering, and entertainment software, faced a critical challenge in efficiently managing and analysing their vast amounts of log data.
• Challenge: Autodesk's diverse suite of software products generated a massive volume of log data from various sources. The challenge lay in processing, storing, and analysing this data in real time to identify and resolve issues, monitor application performance, and optimise software development.
• Solution: AWS provided Autodesk with an efficient and cost-effective solution to address its log analytics challenge. Autodesk could centralise and streamline its log data management by adopting AWS Cloud services. AWS offered highly scalable storage options and powerful data processing tools that allowed Autodesk to easily handle large volumes of log data (Amazon Web Services).
• Service Models: Autodesk utilised multiple service models provided by AWS to optimise their log analytics. They leveraged Infrastructure as a Service (IaaS) for scalable computing resources, enabling them to deploy log processing applications without managing underlying hardware.
• Deployment Models: To meet their specific requirements and ensure seamless integration, Autodesk employed a hybrid deployment model. They retained critical on-premises Infrastructure for certain sensitive data while migrating non-sensitive log data and analytics to the AWS cloud.
• Public Cloud Services: In their collaboration with AWS, Autodesk utilised a range of services, including Amazon S3 for cost-effective and scalable object storage, Amazon EC2 for resizable compute capacity, and Amazon CloudWatch for real-time monitoring and alerting of log data.
• Reflection: Autodesk's successful integration of AWS cloud services for log analytics exemplifies how public cloud solutions can revolutionise business data management and analysis. By adopting AWS's versatile service and deployment models, Autodesk overcame the challenges posed by the massive scale of log data and transformed its log analytics process. This case study illustrates the power of cloud-based solutions in enabling companies to harness the full potential of their data, make informed decisions, and enhance overall business performance.
Case Study 3:
• Introduction: Coca-Cola, the world-renowned beverage company, embarked on a transformative journey to migrate its IT Infrastructure to the cloud. To achieve this, they partnered with Amazon Web Services (AWS), a leading public cloud provider known for its robust and scalable solutions.
• Challenge: Coca-Cola faced the challenge of modernising its IT infrastructure to keep pace with rapidly evolving business needs. Their existing on-premises systems struggled to handle the increasing demands of data processing, storage, and global accessibility.
• Solution: AWS offered Coca-Cola a comprehensive cloud solution that addressed its challenges. By migrating to AWS Cloud, Coca-Cola could leverage various services to modernise its applications, streamline data management, and enhance overall agility.
• Service Models: Coca-Cola utilised various service models provided by AWS to meet its diverse requirements. They leveraged Infrastructure as a Service (IaaS) to flexibly manage their computing resources and storage needs (Atchison, 2020).
• Deployment Models: To ensure a smooth and secure migration, Coca-Cola adopted a hybrid deployment model. They moved some of their applications and workloads to the AWS cloud while retaining sensitive data and critical operations in their on-premises Infrastructure (AWS., 2014).
• Public Cloud Services: In their collaboration with AWS, Coca-Cola used a wide array of cloud services. These included Amazon EC2 for resizable compute capacity, Amazon S3 for secure and scalable object storage, Amazon RDS for managed relational databases, and Amazon Redshift for advanced data analytics.
• Reflection: Coca-Cola's successful migration to AWS Cloud showcases the potential of public cloud solutions in addressing modern business challenges. By embracing AWS's service and deployment models, Coca-Cola effectively modernised their IT infrastructure, gaining improved scalability, flexibility, and cost-efficiency. This case study is an excellent example of how cloud migration can empower businesses to stay competitive, foster innovation, and adapt to the ever-changing technological landscape.
Case Study 4:
• Introduction: Rocketbots, a leading customer engagement platform, faced a significant challenge in managing and analysing vast customer data while ensuring seamless interactions across various messaging channels.
• Challenge: Rocketbots needed to efficiently handle large volumes of customer data generated through multiple messaging platforms like WhatsApp, Facebook Messenger, and more.
• Solution: Alibaba Cloud provided Rocketbots with a powerful and scalable cloud infrastructure to address customer engagement needs. By leveraging Alibaba Cloud's robust computing resources and AI capabilities, Rocketbots could process and analyse customer data in real-time (Alibaba Group).
• Service Models: Rocketbots utilised various service models offered by Alibaba Cloud to bolster their customer engagement platform. They leveraged Infrastructure as a Service (IaaS) for scalable computing resources to efficiently handle data processing and analytics.
• Deployment Models: Rocketbots adopted a hybrid deployment model to cater to their specific requirements. They integrated Alibaba Cloud's services with their Infrastructure to maintain data privacy and compliance.
• Public Cloud Services: In their collaboration with Alibaba Cloud, Rocketbots utilised various services. These included Alibaba Cloud Elastic Compute Service (ECS) for flexible computing resources, Alibaba Cloud Machine Learning Platform for AI-driven insights, and Alibaba Cloud Object Storage Service (OSS) for secure and scalable data storage (Artificial Intelligence and Cloud Computing Conference 2018).
• Reflection: Rocketbots' successful partnership with Alibaba Cloud demonstrates the power of public cloud solutions in optimising customer engagement and data management. By embracing Alibaba Cloud's service and deployment models, Rocketbots achieved enhanced scalability, real-time data analytics, and personalised customer interactions.
Conclusion:
The case studies presented in this report highlight the significant impact of cloud computing on businesses across diverse industries. The transformative potential of cloud solutions is evident in the successful outcomes of ExxonMobil, Autodesk, Coca-Cola, and Rocketbots. By adopting cloud services, these companies improved operational efficiency, optimised data management, and enhanced customer engagement. The versatility and scalability of public cloud providers, such as AWS, Microsoft Azure, Google Cloud, and Alibaba Cloud, played a pivotal role in driving innovation and delivering exceptional results. As cloud computing continues to evolve, businesses must recognise its strategic importance and embrace this technology to stay competitive and thrive in the digital era. In the rapidly evolving digital landscape, cloud computing has emerged as a catalyst for business transformation. The case studies of ExxonMobil, Autodesk, Coca-Cola, and Rocketbots provide compelling evidence of how cloud solutions can revolutionize operations, data management, and customer engagement. These real-world examples demonstrate that cloud computing is no longer just a technological trend but a fundamental enabler of innovation and growth.
The scalability, flexibility, and cost-effectiveness offered by public cloud providers have empowered companies to modernize their IT infrastructure and optimize processes. The ability to harness massive amounts of data in real-time through cloud-based analytics and machine learning has allowed businesses to make data-driven decisions and gain a competitive edge. Moreover, the adoption of hybrid cloud models has enabled organizations to strike a balance between maintaining critical operations on-premises and leveraging the cloud's agility and scalability.
References
.png)
Reports
SRM751 Principles of Building Information Modelling Report 1 Sample
GENERAL INSTRUCTIONS
1. This document is to be read in conjunction with the Unit Guide for this unit.
2. It is the responsibility of each student to confirm submission requirements including dates, time, and format.
3. Extension or Special Consideration may be considered for late submission. It is the responsibility of eachstudent to understand Deakin regulations regarding late submission and Special Consideration for assessment.
4. You will be required to complete Assignments 1 and 2 individually, but Assignment 3 will be completed as a group. Further information regarding how groups are allocated is provided below.
5. All assignments, unless otherwise noted, must be submitted electronically through CloudDeakin. Assignments submitted in any other way will not be marked.
6. You may refer to publications, but you must write in your own “voice” and cite the references using the Author-Date (Harvard) system. It is essential for you to fully understand what you write and to be able to verify your source if you are requested to do so. The library and study support team provide workshops and advice on citations and referencing.
7. The University regards plagiarism as an extremely serious academic offence. Submission through CloudDeakin includes your declaration that the work submitted is entirely your own.
Please make full useof the ‘Check Your Work’ folder in the Dropbox tab on CloudDeakin. You can find all you need to know about citations, referencing and academic integrity at
https://www.deakin.edu.au/students/studying/study-support/referencing
8. Before starting your assignment, please read the University document, Study Support at
http://www.deakin.edu.au/students/study-support.
9. To prepare for your assignments, you should carefully read the references introduced in teaching sessions and on CloudDeakin, as well as consult websites and other relevant documents (for example, through searching databases).
10. Further details of assignments, including presentations will be provided in classes, seminars and through CloudDeakin.
PURPOSE OF ASSESSMENT TASK 1
The purpose of this assignment is to enable you to apply your knowledge of information management systems in the construction industry to provide a response to a real question. This assessment task addresses the following unit learning outcomes for this unit:
ULO1: Apply available methodologies for data and information creation, usage and sharing using innovative tools in the construction industry.
ASSESSMENT TASK 1 REQUIREMENTS
Each student must produce an individual report that demonstrates their understanding of the principles of BIM and the basic use of leading applications.
Solution
Reflection on the key lessons learned during the development process
During the BIM development process, I learned several valuable lessons that have helped me better understand the principles of BIM and its application in the construction industry. One of the key lessons I learned is the importance of collaboration and communication. BIM requires the involvement of various stakeholders, and effective communication is essential to ensure that everyone understands their roles and responsibilities. For Assignment Help, During the Revit Training, I realized that working collaboratively with other team members helped to improve the overall quality of the BIM model. Sharing ideas and feedback helped us to identify issues early in the process and find creative solutions. Collaboration and communication are crucial in the BIM development process (Tang et al., 2019). BIM requires collaboration between various stakeholders, and effective communication is essential to ensure that everyone understands their roles and responsibilities. Communication is essential in all phases of the BIM development process, from conceptualization to construction and maintenance. Collaborative and open communication channels enable project team members to share critical information, identify and address issues, and establish clear project goals and objectives.
Another lesson I learned during the BIM development process is the importance of data management. BIM models are data-rich, and it's essential to ensure that the data is accurate, complete, and consistent. During the Revit Training, I learned that data management involves data collection, verification, and validation. Effective data management ensures that all project team members have access to the most up-to-date and accurate data, which is crucial for making informed decisions (Hosseini and Taleai, 2021). Additionally, I learned the importance of organizing data in a standardized format to enable easy sharing and analysis across different stakeholders. BIM models are data-rich, and it's essential to ensure that the data is accurate, complete, and consistent. This requires a robust data management strategy that includes data collection, verification, and validation (Hardin and McCool, 2015). The data must be standardized and organized to enable easy sharing and analysis across different stakeholders. Effective data management processes help to ensure that all project team members have access to the most up-to-date and accurate data, which is crucial for making informed decisions.
Quality control and assurance are also crucial in the BIM development process. BIM models must be checked and verified regularly to ensure that they meet the required standards and specifications. I learned that quality control and assurance processes help to identify errors and omissions early in the process, reducing the risk of rework and increasing project efficiency. By using quality control and assurance processes, we were able to ensure that the BIM model was accurate, complete, and consistent. BIM models must be checked and verified regularly to ensure that they meet the required standards and specifications (Costin et al., 2018). This requires the use of quality control and assurance processes that ensure that the models are accurate, complete, and consistent. Quality control and assurance processes help to identify errors and omissions, thereby ensuring that issues are addressed early in the process. This, in turn, reduces the risk of rework and increases project efficiency.
Finally, I learned the importance of continuous improvement during the BIM development process. BIM models are continually evolving, and there is always room for improvement. During the Revit Training, I realized that incorporating feedback from stakeholders can help to enhance the overall quality of the BIM model and improve project outcomes. By using data analytics and performance metrics, we were able to identify areas for improvement and make changes that enhanced the BIM model. BIM models are continually evolving, and there is always room for improvement. Stakeholders must be open to feedback and willing to incorporate changes that improve the overall quality of the model and enhance project outcomes (Lu et al., 2017). Continuous improvement involves the use of data analytics and performance metrics to identify areas for improvement. It also involves stakeholder engagement to gather feedback and suggestions on how to enhance the BIM development process continually.
In conclusion, the BIM development process is a complex and iterative process that involves various stakeholders. Through the Revit Training, I learned several key lessons, including the importance of collaboration and communication, data management, quality control and assurance, and continuous improvement. Effective BIM development processes require a commitment to open and collaborative communication, effective data management, rigorous quality control and assurance, and a culture of continuous improvement. These principles are essential for stakeholders looking to use BIM models to optimize project outcomes, reduce risk, and increase efficiency. Incorporating these lessons into the BIM development process can help to improve the overall quality of BIM models and enhance project outcomes. As a future professional in the construction industry, I am now better equipped to apply these principles and achieve successful project outcomes through the use of BIM.
Report comparing the advantages and shortfalls of different BIM tools/tasks
Introduction
Building Information Modeling (BIM) is a digital representation of the physical and functional characteristics of a building (Lu et al., 2017). BIM software tools play a crucial role in the development and implementation of BIM processes (Bryde et al., 2013). This report aims to compare the advantages and shortfalls of different BIM tools and tasks.
BIM Tools
Autodesk Revit
Autodesk Revit is a popular BIM tool that provides architects, engineers, and construction professionals with a comprehensive platform for designing and managing building projects (Lu et al., 2017). The advantages of using Revit include its ability to integrate with other Autodesk software tools, such as AutoCAD, and its ability to support a wide range of file formats. The tool also allows for the creation of parametric models, which can be modified and updated easily (Bryde et al., 2013). However, Revit is known for its steep learning curve, which can be a shortcoming for new users. Additionally, Revit's file sizes can become quite large, which may cause performance issues on lower-end computers or when working on larger projects. Another potential shortcoming of Revit is its lack of flexibility in terms of customization, as users are limited to the features and tools provided by the software (Sacks et al., 2018). Furthermore, Revit's licensing can be expensive, which may be a barrier to smaller firms or individuals. The software also requires a powerful computer to run efficiently, which may add to the cost of adoption. Despite these potential drawbacks, Revit remains a popular BIM tool in the construction industry due to its robust features and integration capabilities.
SketchUp
SketchUp is a 3D modeling software tool that allows designers to create models quickly and efficiently. The tool has a user-friendly interface and allows for easy integration with other BIM software tools. SketchUp is also known for its extensive library of pre-built 3D models, which can be easily incorporated into designs. However, SketchUp is not suitable for large-scale projects and lacks some of the advanced features that other BIM tools offer. Furthermore, SketchUp's parametric modeling capabilities are limited, which can make it difficult to make complex changes to designs (Bryde et al., 2013). The tool also has limited capabilities when it comes to collaboration, which can be a drawback for teams working on large projects. Additionally, SketchUp's output capabilities are not as robust as other BIM tools, which may limit its usefulness for construction documentation and other project management tasks. Despite these limitations, SketchUp is a popular BIM tool for smaller-scale projects and for quick conceptual designs.
Navisworks
Navisworks is a BIM coordination tool that allows for the integration of multiple models and the detection of clashes between them. The tool provides users with real-time visualization of models and allows for the creation of detailed reports. Navisworks is also known for its ability to integrate with other BIM software tools, such as Revit and AutoCAD (Costin et al., 2018). However, Navisworks is not a comprehensive design tool and lacks some of the advanced features that other BIM tools offer.
BIM Tasks
Data Management
Data management is a critical task in the BIM process. The advantages of effective data management include accurate, complete, and consistent data, which is crucial for making informed decisions. Data management also enables easy sharing and analysis of data across different stakeholders (Lu et al., 2017). The shortfalls of poor data management include errors and omissions, which can lead to rework and increased project costs.
Collaboration and Communication
Collaboration and communication are essential tasks in the BIM process. The advantages of effective collaboration and communication include improved overall quality of the BIM model and enhanced project outcomes. Collaboration and communication also help to identify issues early in the process and find creative solutions. The shortfalls of poor collaboration and communication include misunderstandings, delays, and increased project costs.
Quality Control and Assurance
Quality control and assurance are critical tasks in the BIM process. The advantages of quality control and assurance processes include the identification of errors and omissions early in the process, reducing the risk of rework and increasing project efficiency (Eastman et al., 2011). Quality control and assurance also ensure that the BIM model is accurate, complete, and consistent (Lu et al., 2017). The shortfalls of poor quality control and assurance include errors and omissions, which can lead to rework and increased project costs.
Conclusion
In conclusion, BIM tools and tasks play a crucial role in the development and implementation of BIM processes. Different BIM tools have their advantages and shortfalls, and it is essential to select the appropriate tools for each project. Similarly, different BIM tasks have their advantages and shortfalls, and it is essential to prioritize tasks based on their impact on project outcomes. By effectively selecting and prioritizing BIM tools and tasks, stakeholders can improve the overall quality of BIM models and enhance project outcomes.
References
.png)
Reports
TECH1100 Professional Practice and Communication Report 1 Sample
Your Task
Your first assessment in this subject requires you to write an email which determines the factors of success for IT professionals that align with the expectations of diverse stakeholders, with an emphasis on stakeholder engagement.
Assessment Description
In this assessment task, you are required to demonstrate your understanding of the factors contributing to the success of IT professionals in stakeholder engagement, particularly those that align with the expectations of diverse stakeholders. You will write an email to your manager, summarising your research findings and providing recommendations for effective stakeholder engagement. The purpose of this email is to communicate your knowledge, insights, and recommendations in a professional context. This assessment aims to achieve the following subject learning outcomes:
LO1 - Determine the factors of success for IT professionals that align with the expectations of diverse stakeholders.
Assessment Instructions
For this assessment, you will need to submit a Word Document that emulates an email, with the following items that need to be covered in the assessment:
• Imagine you are an IT professional assigned to lead a project with diverse stakeholders.
• Write an email to your manager, summarising your research findings on the factors of success for IT professionals in stakeholder engagement.
• Provide a clear and concise overview of the key factors that contribute to successful stakeholder engagement, emphasizing their alignment with diverse stakeholder expectations.
• Include examples or case studies to support your points and illustrate the practical application of the identified success factors.
• Present well-supported recommendations for effective stakeholder engagement strategies that IT professionals can implement to meet diverse stakeholder expectations.
• Address any potential challenges or considerations associated with stakeholder engagement in the email.
• Use a professional and respectful tone throughout the email, ensuring clarity and coherence in your writing.
Solution
To
The Manager,
Date: 24/11/2023
Subject: Effective stakeholder engagements
As per the research undertaken to identify the key success factors for an IT professional in terms of the stakeholder's engagement. Three main factors have been identified: stakeholder management laden with social responsibilities, assessment of the stakeholders' expectations from the given project and an effective communication channel for the stakeholders. It has been found that ethics plays a crucial role in the management of the stakeholders with social responsibilities. Stakeholder management enhances the aspects of trust associated with the particular project. In other words, relational management significantly involves trust factors, which can be established with the help of an effective communication process. For Assignment Help, Societal stakeholders are the stakeholders who are engaged through different socio dynamic aspects. The examples of such stakeholders for the present IT project are the immediate communities, common masses, environment, NGOs (Non governmental organisations), media, trade unions and industry associations. The IT professionals must consider the impact of their actions on the social environment, which should not be adverse in the long run or with immediate effect (de Oliveira and Rabechini Jr, 2019, p. 132). It has been found that the Australian Computer Society provides effective guidelines regarding the ethical guidelines to be followed by a successful IT professional. The PMBOK (Project Management Body of Knowledge) can be used to understand project management and its associated processes and practices (Strous et al., 2020). The stakeholders' expectations from the project can be identified by implementing a few steps of processes by the IT professional. Transparency related to the various aspects of the undertaken project needs to be stated with utmost clarity, such as the proposed timeline for the project completion, the financial budget plan, and the risks and challenges associated with the project. After that, a successful assessment of the stakeholders can be conducted with the help of the knowledge gathered through suitable communication processes.
The main stakeholders identified for the present IT project include internal stakeholders such as employees, policymakers and investors. In contrast, the external stakeholders include customers, suppliers, and associated social or legal bodies. The adaptation of disruptive technologies in the IT field has necessitated the development of invisible interactions with the potential to deliver enhanced productivity. In the digitalised era, the disruptors include Blockchain, Digital Reality, and Cognitive technology. It is important for the IT professional to efficiently communicate the uses and resultant advantages of the disruptors to earn positive support from the stakeholders in the project. The stakeholders' major expectation is to complete the project within the proposed timeline while utilising the financial resources judiciously (Frizzo Barker et al., 2020, p. 54). The utility of quantum computing needs to be addressed in regular meetings to review the necessary decisions made regarding the given project. Therefore, the stakeholders can derive satisfaction by getting involved in the decision-making process for the particular project. Effective integrity settings are necessary to address the professional environment for an IT project. The aforementioned setting helps in encouraging the professional to gain more skill based activities, thereby increasing their expertise. On the other hand, professional societies help determine the professional level of professional aspiration by the individual employees (Tavani, 2015). The recognition for better performance is also suitably carried out by the aforementioned professional environment. It is stated that stakeholder mapping can be used to address the expectations of the individual stakeholders. It has been noted that factors such as impact, interest and influence are involved in the mapping process to address the diverse expectations of the various stakeholders suitably. Segmentation of the stakeholders can be utilised to make individual communications, which can help the professional understand each stakeholder's feedback related to a particular process of business (Tristancho, 2023). The data can help rectify and change the project's decisions with suitable strategies. The internal stakeholders, such as the employees, benefited from appropriate remunerations as per the evaluation of their work. The involvement of the external stakeholders has been identified as being instrumental in addressing the valuation of the project in terms of its functionality. The investors are focused on gaining profitability regarding the invested financial resources for the project's development. Effective planning and regular communication can deal with the diverse expectations of the stakeholders with ease and convenience.
The Apple iPhone development project and the Ford Pinto Design project have addressed the issues of stakeholder engagement suitably with the help of adequate success factors of project management (Dubey and Tiwari, 2020, p. 381). An effective communication channel was ensured to run parallelly with the project so that no miscommunication could hinder the development of the projects. Secrecy of the data was maintained up to the extent that the stakeholders did not feel left behind in the process.
The main challenge in stakeholder management is associated with effective decision making for a particular project. The stakeholders are of different opinion regarding a single task which shall be employed for the project. The different perspectives and expertise of the stakeholders make room for complex decision making processes within the project in the IT industry. The varying differences in the stakeholders' expectations can form considerable conflict in the priorities for the particular project. The stakeholders will use the resources to decide on the priorities to be addressed by the present project so that their expectations are suitably addressed. The differences in the priorities make the conflicting decisions involved in the project (Anicic and Buselic, 2020, p. 250). The ongoing project might face some considerable constraints regarding the available financial resources. The expertise in the technological aspect can also act as a constraint for an IT project development. Eventually, the limited resources fail to address all the expectations bestowed on the given project by various stakeholders. The accessibility to real time data regarding the ongoing project can make room for more chaos in the feedback and evaluation process. It is highly case for the IT project that most critical stakeholders are unaware of the technological knowledge involved. The resultant evaluative feedback from such stakeholders makes the project suffer adversely.
Enhancement of the collaboration and engagement values can be suitably addressed for effective stakeholder engagement in the IT project. The collaboration value will help enhance the actual valuation of the project for internal and external stakeholders. The adequate implementation of innovative and lucrative collaboration features for individual stakeholders will help motivate them to perform better in favour of the project. An example of an effective collaborative feature might be the opportunity to access the technological knowledge required to implement the project. Therefore, The knowledge can be utilised for more such projects so that the stakeholders are drawn towards the collaboration process. Value creation for the stakeholders can be addressed by identifying the necessary interest domains of the individual stakeholders. The announcement that the best employee will be provided with a salary hike effectively addresses the issue of engagement while enhancing the entire team's performance.
The concept of a Big Room can enhance the rapport between the internal and external stakeholders for an IT project. The Big Room can help enhance the community cohesiveness, which signifies the engagement of the stakeholders at a greater level. In other words, the Big Room can be regarded as a combined workplace for all the representatives of the identified stakeholders. The representatives can be physically present or remotely work on the project via appropriate digital mediums (Coates, 2019). The Big Room can help effectively communicate the issues faced while working on the project with the natural time effect. The overall impact of the introduction of the aforementioned concept can enhance the stakeholder's engagement effectively for an IT project. The IT project can be made to address all the relevant expectations of the stakeholders along with prioritising the need to reach its ultimate goal with the help of an efficient stakeholder’s management program. The aforementioned policies and strategies can be effectively implemented to meet the demands of the stakeholders both at the internal and external levels.
The SFIA can be used to develop the skills needed for an IT professional's successful career. Skill assessment is one of the different functions for which the public and private organisations extensively use the framework. Sourcing, supply management, relationship management, contract management and customer service support have been the framework's main features. Goal directed communication with the stakeholders can be learned with the help of the framework by the IT professionals to help communicate in the formal environment (Lehtinen and Aaltonen, 2020, p. 87). Risk management is also addressed with the help of the framework.
Emotional intelligence and effective communication strategies can ultimately act as instruments to manage stakeholders' engagement in the IT project. The temporal flexibility allowed for the different stakeholder's activities for the project to make room for enhanced performance and engagement. The nature of tasks undertaken by the different stakeholders is aptly technologically advanced; therefore, adequate rest on the part of the different stakeholders is necessary. In other words, creativity and intellectual capacity can be reflected as the mind is calm while a particular task is performed (Reynolds, 2018). The recommended temporal flexibility can be suitable for enhancing stakeholders' engagement.
Thanking you.
Regards and wishes,
Reference List:
.png)
Assignment
INFS5023 Information Systems for Business Assignment 2 Sample
OBJECTIVE
The objective of Part B of the assignment is to produce a written report addressing the question of how enterprises in the industry segment are using information and communication technologies (ICTs) to support business strategies, to seek competitive advantage (CA) or sustainable competitive advantage (SCA) and to identify opportunities for further use of these technologies by businesses in this industry segment to change or improve their businesses, or to gain CA and which of the strategies might be sustainable.
REQUIREMENT
Each group is required to:
Prepare and submit a written report on the group’s investigation to Learnonline. See below for details of the report requirements.
The report will have an executive summary.
An executive summary is a summary of a report made so that readers can rapidly become acquainted with a large body of material without having to read it all. It will usually contain a brief statement of the background information, concise analysis and main conclusions. The executive summary will be on a separate page directly before the main report and should be around half a page in length. The executive summary is in addition to the ten pages (maximum) of the main report. The report will have a title page and a contents page.
The report questions
The main written report will address the following questions/issues:
5. This part of your investigation focuses on business responses to the major forces identified in 4. (i.e. how they compete). Identify a range of the strategies that businesses have adopted to provide them with competitive advantage (CA) and which of these are sustainable competitive advantages (SCA) in response to these forces.
Your analysis should also consider issues such as cost leadership, innovation, differentiation, niche market and other strategies.
6. This part focuses on the internal arrangements within the individual businesses you have investigated — how they organise their businesses to implement their business strategies. Use Porter’s Value Chain Analysis Model to analyse organisations in the industry. The aim here is to explain how different businesses organise their processes to achieve their organisational objectives. You should choose to concentrate on at least two contrasting organisations in your segment to illustrate competitive responses. Justify your choice.
As this question requires some knowledge of internal processes, you may find it difficult to obtain specific information. Use whatever information is available to you to address this question as best you can.
7. Use Business Process Approach/ Model to identify how businesses in your industry segment are categorised as internal and external processes and how they enhance the organisation’s efficiency and effectiveness.
10. Explore the Internet and other sources to identify new and “trending” information and communication technologies, systems and applications that are becoming available or that will soon be available to businesses in this industry to assist them to gain a CA or SCA. Describe these new technologies, systems and applications..
11. Explain how the new information and communication technologies, systems, and applications identified in #10 above might be used to create a CA or SCA.
Your explanation should be in terms of some or all of the following:
effects on existing business models,
creating new business models,
supporting existing strategies,
creating new business strategies,
specific additions to a portfolio of information systems
improving the ability to compete in terms of the five forces analysis,
improving/creating new processes in terms of the value chain analysis,
improving customer relations.
12. How might these ICTs or applications create a competitive disadvantage?
13 Provide a critique of two of the analysis tools you have used. Evaluate how effective they are for exploring competitive advantage in the industry. Use a separate section with headings in your report for each analysis tool. Provide a supporting argument for your criticisms.
You are required to comment on how well they fulfil the purpose for which they were designed, not to just point to areas for which they were not designed.
Solution
Question no. 5
In response to the competitive forces in the milk segment of the dairy industry, businesses have adopted various strategies to attain a competitive advantage (CA) and sustainable competitive advantage (SCA). For Assignment Help -
1. Cost Leadership
Competitive Advantage (CA): Some companies seek to offer milk products at lower prices than their competitors to achieve economies of scale and operational efficiency (Kimiti, 2020). This can be a source of attraction for price-sensitive consumers.
Sustainable Competitive Advantage (SCA): If companies continue to invest in current technology, effective supply chain management, and maintain a robust cost control system, it may be possible to sustain the leadership of costs.
2. Product Differentiation
CA: Companies such as Nestle and Amul, aiming to create a distinct market presence and appeal to specific consumer segments, emphasize the different product characteristics of lactose-free or fortified milk.
SCA: Sustainable if the company continues to invest in research and development, introducing innovative milk products that meet changing consumer preferences and needs (Guiné et al., 2020).
3. Niche Market Focus
CA: Some companies are focused on particular niche markets, for example, organic or unique milk products that cater to a narrower but devoted customer base which will pay an additional premium in order to offer specialized services.
SCA: Sustainable if the company effectively meets the unique needs of the niche market and establishes strong brand loyalty within that segment.
4. Innovation and New Product Development
CA: Businesses invest in research and development to introduce novel dairy products or production methods, staying ahead of market trends and offering products that competitors do not.
SCA: Sustainable if the company maintains a culture of innovation, continually introduces successful new products, and adapts to changing consumer preferences.
5. Vertical Integration
CA: Vertical integration is a feature of companies like Amul, who own both dairy farms and processing facilities. This results in complete supply chain control, ensuring quality and cost advantages.
SCA: Sustainable if the company effectively manages and optimizes the integrated operations, achieving consistent quality and cost advantages over the long term.
6. Brand Equity and Recognition
CA: With solid brand recognition and consumer confidence, established brands such as Amul and Nestle can gain consumers' loyalty and market presence (Pandey et al., 2021).
SCA: Sustainable as long as the company maintains its brand reputation through consistent quality, marketing efforts, and customer satisfaction.
Question no. 6
The Porter value chain analysis model gives an overview of the internal activities that support a company's competitiveness. In the industry of dairy, firms like Amul, Nestle, and Saputo implement their business-related strategies through distinctive arrangements of value chains.
Amul
Amul, an Indian cooperative dairy firm, has a distinct value chain structure firmly ingrained in its collaborative concept (Pandey and Sahay, 2022). The joint venture includes millions of smaller milk manufacturers who share and control the company. In addition, these partnerships assist the Amul in getting the milk from the farmers directly and also ensure a steady supply of very high-quality raw materials.
Inbound Logistics: The tender procedure of Amul is exceptionally significant. They set up networks of collection points in remote areas, intending to ensure the availability of milk at a timely manner.
Operations: Amul maintains several processing factories around India. These facilities are focused on product diversification, with products ranging from milk to cheese, butter, yoghurt, and ice cream (JACKSON and JAYAPRAKASH, 2023). The cooperative concept promotes the ongoing advancement of processing technologies and procedures.
Outbound Logistics: Amul has a substantial distribution network, ensuring that its products efficiently extend urban and rural markets. However, this broad distribution extension permits them to cater towards a diverse base of customers.
Marketing and Sales: Amul is well-known for its aggressive marketing activities and has established a significant brand presence in India (Bapat, 2020). Their advertising frequently emphasises their goods' outstanding quality, low cost, and nutritious benefits.
Service: Amul places significant emphasis on customer satisfaction. They have established a robust customer service network that effectively handles inquiries, feedback, and complaints.
.png)
Figure 1: Value chain analysis model
(Source: Bruin, 2021)
Saputo
Compared to Amul, Saputo is a Canadian dairy corporation with a more centralised model. They have a global footprint with activities in many countries.
Inbound Logistics: Saputo's inbound logistics focus on procuring milk from various sources, including farms and external suppliers (Fernandes, 2021). They have established strong relationships with farmers and utilise advanced technology for milk collection.
Operations: Saputo maintains cutting-edge processing facilities outfitted with advanced technologies. In their manufacturing operations, they premium efficiency and quality control.
Outbound Logistics: Saputo has a well-organized logistics network for distributing dairy products across diverse markets. They leverage economies of scale to optimise distribution costs.
Marketing and Sales: Saputo employs a market-driven approach, tailoring their products to meet local preferences. They also engage in strategic acquisitions to expand their product portfolio and market reach.
Service: Saputo emphasises after-sales service by actively seeking customer feedback and adapting their products accordingly (Bonesteve, 2021).
Justification
A meaningful comparison in value chain strategies is provided with the analysis of Amul and Saputo. Amul's Cooperative Model also highlights the benefits of the centralised approach, and Saputo's worldwide operations show the importance of decentralised supply chains. The examination is intended to provide a detailed understanding of how different organisations organise processes to meet their objectives within the dairy sector.
Question no. 7
In the Dairy industry, businesses like Amul, Saputo, and Nestle utilise a Business Process Approach to enhance their efficiency and effectiveness through internal and external processes.
Internal Processes
Production and Processing: Amul, with over 70 processing plants in India, processes a staggering 38 million litres of milk daily (Singh, 2023). This internal operation transforms raw milk into a diverse range of dairy products.
Saputo operates 60+ manufacturing facilities globally, producing millions of pounds of dairy products yearly.
Quality Control: These companies implement rigorous quality control measures. For instance, Nestle conducts over 700,000 quality tests annually on their dairy products.
Product Development and Innovation: Amul and Nestle invest significantly in research and development. Amul's dedicated R&D centre and Nestle's global research network drive innovation and product diversification.
.png)
Figure 2: Business model of Amul
(Source: Ernie, 2019)
External Processes
Supply Chain Management: Amul's extensive network includes millions of farmers, ensuring a constant raw milk supply. Saputo balances procurement from owned farms and external sources, maintaining a flexible supply chain.
Distribution and Logistics: Amul's distribution network reaches over 3 million retail outlets in India. Saputo employs advanced logistics technology to distribute products globally (Gulati and Juneja, 2023).
Supplier Relationships: Amul's cooperative model establishes a direct and mutually beneficial connection with farmers. Nestle collaborates with a vast network of suppliers globally, ensuring a reliable supply of raw materials.
Efficiency and Effectiveness
Amul's cooperative approach reduces intermediate expenses, resulting in more cost-effective purchasing and a stronger position as India's largest dairy cooperative.
Saputo's global network and superior processing methods result in economies of scale, making it one of the world's top dairy processors.
Nestle's emphasis on innovation and product variety has enabled the company to create a significant position in the global dairy industry, boosting its overall efficacy (Kalyani and Shukla, 2022).
Question no. 10
In the dairy industry, several emerging technologies are poised to revolutionize operations and offer opportunities for competitive advantage (CA) and sustainable competitive advantage (SCA). Some significant trends are the following:
1. Internet of Things (IoT) in Dairy Farming: The Internet of Things refers to the incorporation of sensors and devices into dairy farms to monitor the health, behavioUr, and milk output of cows.
2. Block chain Technology for Traceability: The traceability of dairy products from farm to table is ensured through block chain technology (Khanna et al., 2022). Providing real-time information on the provenance and quality of dairy products will help to increase transparency and build consumer confidence.
3. Artificial Intelligence (AI) and Machine Learning for Data Analysis: In the dairy industry, AI and machine learning algorithms are used to analyze enormous data sets. They consider several facets of the dairy industry, including as milk quality, yield prediction, and resource allocation. It allows for data-driven decisions, which leads to improved product quality, resource management, and cost effectiveness.
4. Precision Agriculture for Feed Production: Precision agriculture makes use of data and technology to enhance dairy cow feed output (Monteiro, Santos and Gonçalves, 2021).
This technology has the potential to offer significant competitive advantages for enterprises like Amul, Saputo, or Nestle in the dairy sector. These companies may improve their efficiency, product quality, and sustainability through the use of these technologies within their operations to deliver both competitive advantage and long-term competitiveness.
.png)
Figure 3: Internet of Things (IoT) in Dairy Farming
(Source: Libelium, 2022)
Question no. 11
The identified information and communication technologies (ICTs) in the dairy industry can significantly impact a company's competitive advantage (CA) and sustainable competitive advantage (SCA) through various avenues:
1. Effects on Existing Business Models: ICTs like Block chain and IoT can transform existing business models by enhancing transparency and traceability. For example, Block chain can enable real-time tracking of dairy products, providing consumers with detailed information about their origin and quality (Casino et al., 2021).
2. Creating New Business Models: Robotic milking systems represent a potential shift in the dairy industry's business model. Automating milking processes increases efficiency and introduces a new paradigm in dairy farming, potentially leading to more sustainable practices.
3. Supporting Existing Strategies: AI and Machine Learning can augment existing data analysis strategies. For instance, they can optimize production schedules based on predictive analytics, aligning with cost leadership or efficiency strategies that companies may already have.
4. Creating New Business Strategies: Precision agriculture presents a new approach to feed production. This can lead to strategies focused on sustainable and efficient resource allocation, potentially reducing costs and enhancing product quality.
5. Specific Additions to Information Systems Portfolio: Implementing Blockchain and IoT systems require a specific addition to a company's information systems portfolio (Viriyasitavat et al., 2019). These technologies facilitate data collection, storage, and analysis, ensuring traceability and real-time monitoring.
6. Improving Ability to Compete (Five Forces Analysis): ICTs bolster a company's ability to compete in the five forces analysis. For instance, Block chain and IoT mitigate the threat of new entrants by establishing high barriers to entry through advanced technology adoption.
By incorporating these emerging information and communication technologies into their operation, dairy businesses can not only improve their efficiency but also distinguish themselves from the market to achieve a competitive advantage and a potential sustainable competitive advantage.
Question no. 12
Information and Communication Technologies (ICTs) and applications can potentially create a competitive disadvantage for businesses in the dairy industry if not implemented or managed effectively. In some cases, information and communication technologies may give rise to disadvantages:
1. Inadequate Data Security: If a dairy company fails to implement robust cybersecurity measures for its ICT systems, it becomes vulnerable to data breaches and cyberattacks. This may put at risk valuable confidential information, undermine customers' trust and have a significant economic and reputational impact.
2. Obsolete Technology: If the dairy business is not kept on top of technological developments, it will have a competitive disadvantage. Unupdated systems may result in inefficiencies, slow processes and an inability to satisfy customers' expectations of convenience and speed.
3. Poor Integration of Systems: ICT systems not seamlessly integrated across various departments and functions can result in data silos and inefficient workflows (Das, Gupta and Pal, 2023). This could lead to delays in decisions, reduced mobility and a lack of coherent customer experience.
4. Lack of Employee Training and Adoption: Productivity can be reduced, and available technology would be underutilised if employees do not receive adequate training on the practical application of ICT tools. This could lead to a lack of opportunities for automated processes, process optimisation and data-driven decision-making.
5. High Implementation and Maintenance Costs: Poorly planned or executed ICT projects can lead to budget overruns, tying up financial resources that could be better allocated elsewhere (Welde and Klakegg, 2022). It may result in financial strain, limiting the company's capacity to invest in others of its business.
Question no. 13
Critique of Porter’s Value Chain Analysis Model
Effectiveness for Exploring Competitive Advantage: Porter's Value Chain Analysis is an important tool to examine the internal business of a business to understand how different activities add value to its products and services (Dubey et al., 2020). It also gives information on the cost drivers and differentiators important to achieve a competitive advantage.
Strengths
Comprehensive Assessment: The model gives a formal framework for examining a company's core and support operations. This all-encompassing approach creates a clear grasp of how diverse functions contribute to the value-creation process.
Clear differentiation: It distinguishes between main activities and support activities. This distinction aids in identifying areas where a firm may have a competitive advantage or face obstacles.
Criticism
Static nature: Porter's approach is based on a static view of operations. Industries are continually changing due to technical advances, market developments, and shifting customer tastes. This approach may not represent dynamic changes in the industry landscape efficiently.
Limited Focus on External Factors: It generally focuses on internal procedures and may not sufficiently address external issues such as market developments, regulatory changes, or geopolitical effects. External variables can have a considerable influence on a company's competitive standing.
Critique of Business Process Approach/Model
Effectiveness for Exploring Competitive Advantage: The Business Process Approach takes a comprehensive look at a company's operations, focusing on the interaction of internal and external processes (Harmon, 2019). It helps find areas for efficiency and effectiveness improvement.
Strengths
Dynamic and adaptable: This strategy recognises the changing nature of industries and enterprises. It understands the necessity for processes to develop to meet shifting market needs and technology improvements.
Internal and external Process Integration: It successfully emphasises the relevance of both internal operations and exterior interactions (such as supply chain management and customer engagement) in gaining a competitive edge.
Criticism
Implementation Complexity: Implementing and administering a Business Process Approach may be time-consuming and difficult, especially for big firms (Fischer et al., 2020). It necessitates a thorough awareness of the entire value chain and practical cooperation between departments.
Data-Intensive Characteristics: This method is based on data-driven insights. Companies may struggle to obtain appropriate data or lack the requisite data management tools to effectively apply this method for competitive advantage.
References
.png)
.png)
Reports
MITS4002 Object-Oriented Software Development Report Sample
You will be marked based on your submitted zipped file on Moodle. You are most welcome to check your file with your lab tutor before your submission. No excuse will be accepted due to file corruption, absence from lecture or lab classes where details of lab requirements may be given. Please make sure that you attend Lecture EVERY WEEK as low attendance may result in academic penalty or failure of this unit.
This assessment item relates to the unit learning outcomes as in the unit descriptors.
This checks your understanding about object-oriented software development.
This assessment covers the following LOs.
LO1 Demonstrate understanding of classes, constructors, objects, data types and instantiation; Convert data types using wrapper methods and objects.
LO2 Independently analyse customer requirements and design object-oriented programs using scope, inheritance, and other design techniques; Create classes and objects that access variables and modifier keywords. Develop methods using parameters and return values.
LO3 Demonstrate adaptability in building control and loop structures in an object-oriented environment; Demonstrate use of user defined data structures and array manipulation.
Tank Circuit Program
Print your Student Name and Student Number.
1. Calculate the Capacitor with the input E, permittivity, A, cross-sectional area, d, separated distance.
2. Calculate the resonant frequency, f, of a tank circuit with the above C and input L.
C = EA and f= 1
d 2π√LC
Typical
Area = 5mm2 values: E =8.85×10−12F/m. (hardcode)
L = 1 μH Separated distances ~ 1mm (or less)
Round the Resonant frequency to two decimal places.
Here is a sample run:
Sample 1:
John Smith JS00001
Enter Capacitor Area (mm^2): 5
Enter Capacitor separated distance (mm): 0.5
Enter Inductance of the inductor (uH): 1
John Smith’s LC Tank Circuit Resonate Frequency: 16.92 MHz
Questions:
1. Did you store temporary values? Where and why?
2. How did you deal with errors? (Refer to the code/code snippet in your answer)
3. If the value E, permittivity was changed regularly, how would you change your code?
Submit the following items:
1. Submit this Word document with the following:
a. Copy of your code (screenshot – includes comments in your code)
b. Screenshot of the output of your code (3 times with expected values, 2 times with non-expected values – such as a zero as an input)
c. Your written response to the questions (Q1-3)
Solution
For Assignment Help
Screenshot of the Code as required:
.png)
Output 1:
Output 2:
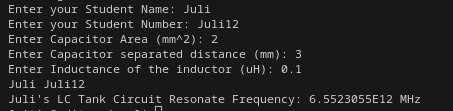
Output 3:
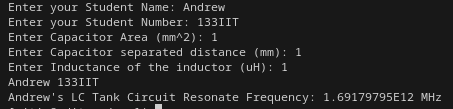
Output 4:
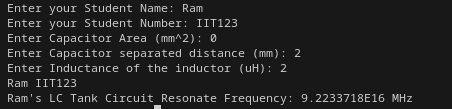
Output 5:
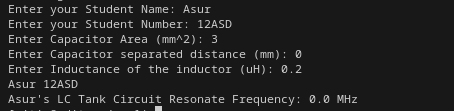
Questions and Answers:
1. Did you store temporary values? Where and why?
Temporary values are utilised in the provided Java code to store the computed capacitance (C) and resonant frequency (f). C and f are these ad hoc values. This is why they are employed:
The computed capacitance, which is an intermediate outcome obtained from user inputs and a formula (C = EA/d), is stored in the variable C.
The computed resonant frequency is another intermediate result obtained from user inputs and the formula (f = 1 / (2 * * sqrt(L * C)) and is stored in the variable f.
The storage of intermediate results for further processing and the user-friendly presentation of final results depend on these temporary variables (Chimanga et al., 2021).
2. How did you deal with errors? (Refer to the code/code snippet in your answer)
Error handling in the code is simple, and it is assumed that the user will input accurate numerical numbers. The code doesn't do much in the way of validation or error management. The user is implicitly expected to provide accurate values for the inputs (capacitor area, separation distance, and inductance), albeit this is not stated explicitly.
You can add extra validation tests to make sure the input values fall within acceptable ranges and are of the right data types in order to improve error handling and robustness. For instance, you can verify that the values are non-negative and fall within the acceptable ranges for this particular application.
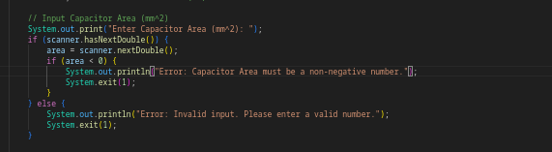
3. If the value E, permittivity was changed regularly, how would you change your code?
You can adjust the code to accept this number as an input from the user if the permittivity (E) value is prone to frequent changes. The code currently has a hardcoded value for E:
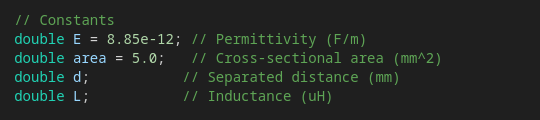
We can request the user to enter the permittivity value at runtime, exactly like other input values, rather than hardcoding this number. Here's an illustration of how we may change the code to accomplish that:

This update allows for flexibility when E needs to be modified frequently because the user can now input the permittivity value each time the programme is run (Saleh et al., 2021).
References:
.png)
Reports
ICT500 Emerging Technologies Report 3 Sample
Assessment Description and Instructions
Title: Explore emerging technologies in the field of AI and their potential impact on various industries
Background:
Artificial Intelligence (AI) is transforming the world at an unprecedented pace, impacting various fields, including healthcare, finance, education, and manufacturing, among others. Emerging technologies such as machine learning, natural language processing, computer vision, and robotics have significantly advanced the capabilities of AI systems. As these technologies continue to evolve, it is essential to explore the potential benefits and risks that come with their integration into various industries. Privacy and security are two critical aspects that must be considered as AI continues to shape our future.
Objectives:
• Explore emerging technologies in the field of AI and their potential impact on various industries.
• Investigate the ethical and legal implications of AI systems in terms of privacy and security.
• Analyse the potential benefits and risks of integrating AI systems in various industries from a privacy and security perspective.
• Develop recommendations on how organizations can manage the privacy and security risks associated with AI systems.
Tasks:
1. Choose one of these industries:
a. Healthcare
b. Finance
c. Education
d. Manufacturing
2. Provide an overview of emerging technologies in the field of AI, including machine learning, natural language processing, computer vision, and robotics. Discuss their potential impact on one of the above industries.
3. Investigate the ethical and legal implications of AI systems in terms of privacy and security. Consider aspects such as data protection, consent, transparency, and accountability. Analyze the current state of privacy and security regulations in your country or region and identify any gaps that need to be addressed.
4. Analyze the potential benefits and risks of integrating AI systems in various industries from a privacy and security perspective. Consider aspects such as data privacy, data security, cyber threats, and potential biases in AI systems. Provide examples of organizations that have successfully integrated AI systems while managing privacy and security risks.
5. Develop recommendations on how organizations can manage the privacy and security risks associated with AI systems. Consider aspects such as risk assessment, privacy by design, cybersecurity measures, and ethical considerations. Provide examples of best practices for organizations to follow.
Format:
• Introduction: Provide an overview of the topic and the objectives of the assignment.
• Literature Review: Discuss the emerging technologies in the field of AI and their potential impact on the chosen industry. Investigate the ethical and legal implications of AI systems in terms of privacy and security.
• Analysis: Analyse the potential benefits and risks of integrating AI systems in the chosen industry from a privacy and security perspective. Develop recommendations on how organizations can manage the privacy and security risks associated with AI systems.
• Conclusion: Summarize the key findings and provide recommendations for future research.
Solution
1. Abstract
This research began an exploratory trip into the emerging world of artificial intelligence (AI) technologies and its ethical and legal repercussions, with a strong emphasis on privacy and security, after AI's revolutionary influence on healthcare. For Assignment Help, A new era of healthcare opportunities has been brought about by the incorporation of AI technologies, such as robots, natural language processing, computer vision, and machine learning. It offers improved outcomes for patients and resource optimization via early illness identification, customized therapies, operational efficiency, and expedited medical research. But these incredible possibilities are matched with very difficult obstacles. Due to the importance and sheer quantity of information about patients involved, privacy and security considerations take on a significant amount of weight. Conscientious consent and openness are two ethical requirements that highlight the need for responsible AI implementation. Because AI algorithms are mysterious and often referred to as "black boxes," creative ways to ensure accountability and explicability are required. An analysis of the privacy and security legislation that is in place highlights the need for ongoing harmonization and adaptation by exposing a fragmented environment. The core of the study is its steadfast dedication to identifying these issues and making recommendations for fixes. It is morally required in the field of healthcare to consider privacy and security concerns while integrating AI. The suggestions made, which include strict security of information, informed approval, algorithm transparency, and compliance with regulations, set the path for a reliable AI ecosystem in the healthcare industry and guarantee improved care for patients and healthcare delivery going forward.
2. Introduction and objectives
Artificial Intelligence (AI) is a game-changing force that is transforming many different sectors. Its significant influence on the healthcare sector is especially remarkable. The impact of artificial intelligence (AI) is enormous in a society where technology is becoming more and more important. These technologies—which include robots, computer vision, natural language processing, and machine learning—have created previously unheard-of opportunities to improve patient outcomes, healthcare delivery, and medical research. In the end, it might bring in a new age of better medical care and more effective resource allocation by streamlining intricate diagnostic processes, treatment plans, and administrative duties. The use of AI in healthcare is now required; it is no longer an optional step. The need for quick, informed choices has never been higher as the demand for superior healthcare services keeps rising and health information becomes more complex. However, entering this AI-driven healthcare space requires careful consideration of cutting-edge AI technology. The critical analysis of the legal and moral ramifications that AI systems bring, especially with security and privacy, is equally important. It is essential, in this regard, to thoroughly evaluate these new technologies and any ethical and legal implications that may arise.
Objectives of the report:
• To Explore the emerging technology in the AI field and its potential effects on the healthcare industry
• To investigate the ethical and legal implications of the AI system in terms of privacy and safety.
• To analyze the potential advantages and risks of integration of AI systems in the healthcare industry from a privacy and security perspective
• To develop recommendations on how the organization can handle the privacy and safety risks associated with AI systems.
3. Background/Literature review
Artificial Intelligence (AI) is a disruptive force that has permanently changed a broad range of sectors [1]. Its widespread impact redefines how operations are carried out and cuts across all industries. With a special emphasis on its enormous influence on healthcare, this section explores the complex role that artificial intelligence plays across a range of sectors. In this case, the dynamic field of developing artificial intelligence technologies—which includes robots, computer vision, machine learning, and natural language processing—takes center stage. This investigation helps to clarify the significant changes that these breakthroughs bring to the field of healthcare. Additionally, this part provides insightful information on the possible advantages and associated hazards associated with the smooth integration of AI in the healthcare industry. AI's widespread use in current sectors shows its flexibility and innovative potential. Its impact on healthcare goes beyond augmentation to transformation. As AI advances, the provision of healthcare, outcomes for patients, and research in medicine will change. Benefits include better diagnosis and treatment, faster administrative procedures, resource allocation, and medical research. These exciting advancements have dangers including security, confidentiality, morality, and regulatory compliance [2]. This part prepares for a detailed discussion of AI's position in healthcare and its legal, moral, and practical ramifications.
AI's Pervasive Impact
Artificial Intelligence has a genuinely global influence, transforming a wide range of industries, including industry, banking, education, and more. Artificial Intelligence (AI) has shown its potency in enhancing productivity, enhancing decision-making procedures, and raising overall operational excellence in several sectors. However, the area of healthcare is where artificial intelligence is most noticeable. This industry is characterized by the confluence of three key factors: the need for precision medicine, an ever-growing pool of complicated medical data, and rising healthcare needs. Incorporation with artificial intelligence has become a necessary paradigm change in answer to these complex difficulties. Through improving diagnostic precision, refining treatment plans, simplifying administrative procedures, and accelerating medical research, it has the potential to completely transform the healthcare industry. The importance of AI in healthcare is highlighted in this context since it not only meets the industry's present demands but also opens the door to more efficient and patient-centered healthcare delivery in the future [3].
Emerge AI technology in healthcare
Healthcare and Machine Learning: With its invaluable skills, machine learning has emerged as a key component of healthcare. Clinical practice is changing as a result of its competence in tasks including medical picture interpretation, patient outcome prediction, and optimum treatment choice identification. Algorithms for machine learning adapt to the changing healthcare environment by continually learning from large datasets. This allows them to provide insightful information, support doctors in making data-driven choices, and enhance patient care. The capacity to identify nuanced patterns and trends in medical data gives medical personnel an invaluable tool for illness diagnosis and treatment, which in turn improves patient outcomes and streamlines healthcare delivery [4].
Healthcare and Natural Language Processing (NLP): When it comes to healthcare, Natural Language Processing (NLP) is revolutionary because it makes it possible for computers to understand and extract information from uncontrolled medical text data. With the use of this innovative technology, healthcare facilities can now automate clinical recording procedures, glean insightful information from large volumes of medical records, and quickly retrieve vital data. NLP's capacity to decipher intricate medical narratives improves administrative efficiency while also revealing important information concealed in healthcare data. This helps medical professionals give more accurate and knowledgeable treatment, which eventually improves patient outcomes [5].
Computer Vision's Role in Medical Imaging: By using AI-driven algorithms, computer vision is driving an upsurge in medical imaging. These advanced tools can identify abnormalities in medical pictures with an unprecedented level of precision. This revolutionary technology, especially in radiology and pathology, speeds up diagnostic and treatment choices. Computer vision algorithms help medical personnel identify anomalies quickly by quickly analyzing large datasets of pictures. This improves diagnostic accuracy and speeds up the beginning of suitable treatment procedures. Combining artificial intelligence with medical imaging allows for earlier detection and better results, which is a major advancement in patient care [6].
Healthcare Robotics: Robotics is becoming more versatile as a medical tool, moving beyond its traditional use in surgery. Robots with artificial intelligence (AI) capabilities are doing medical care, drug administration, and even precision surgery. These robots raise overall healthcare effectiveness, reduce the likelihood of human error, and enhance precision. It improves the quality of life for individuals with limited mobility by offering critical help to doctors during surgery with unparalleled accuracy. One excellent illustration of how AI may complement human abilities to deliver safer, more efficient, and patient-centered care is the integration of robotics into healthcare [7].
Potential benefits in healthcare industry
Numerous benefits arise from the use of AI in healthcare:
Better Early Diagnosis: Artificial Intelligence is used to detect diseases at an early stage, which enables timely interventions and personalized treatment plans.
Prediction: Via the identification of illness risk factors, AI systems allow humans to take preventive measures. Customized treatment plans based on each patient's unique genetic and health profile are possible because of AI-enabled precision medicine.
Streamlined Administrative Tasks: Artificial Intelligence (AI) lowers paperwork and boosts operational performance by automating administrative processes.
Resources allocating optimization: AI assists in ensuring that hospitals have the right resources accessible when they're required via resource allocation optimization.
Cost reduction: AI reduces healthcare expenses by increasing operational efficiency, which raises treatment accessibility and affordability.
Drug research is accelerated by artificial intelligence (AI), which analyses large datasets and may hasten the release of novel treatments.
Improved Clinical Trials: Artificial Intelligence (AI) enables clinical trials to be more precise and efficient, which accelerates the discovery of new therapies.
Patient Engagement: By providing individuals with tailored health information, AI-powered solutions enable patients to take an active role in their treatment.
Proactive Healthcare Management: By using AI-powered applications and gadgets to track their health, patients may improve their overall health and get early intervention.
Inherent risks and challenges
AI has a lot of potential for the healthcare industry, but integrating it also comes with a lot of dangers and difficulties that need to be carefully considered. The crucial concerns of security and privacy come first. To secure patient privacy and preserve data integrity, strict data protection mechanisms must be put in place for AI systems that handle enormous amounts of sensitive medical data. The ethical issues underlying AI-driven decision-making are also quite significant, particularly in situations where human lives are involved. It is crucial to guarantee AI algorithms' accountability, justice, and transparency to establish and preserve user confidence in these systems. Fair AI model development and bias correction are necessary for equal healthcare delivery. In addition, the constantly changing field of healthcare legislation demands careful adherence to standards to stay out of trouble legally and maintain moral principles. To move forward, the remainder of the report will provide a thorough analysis of the legal and moral ramifications of artificial intelligence (AI) in healthcare. It will do this by looking at the technology's possible advantages and inherent hazards through the lenses of security and confidentiality, as well as offer advice on how to responsibly navigate these complex issues [8].
4. Discussion /Analysis
Ethical and legal implications of AI in healthcare
The incorporation of AI systems in the constantly changing healthcare scene raises a complicated web of legal and moral problems, with a special emphasis on security and privacy. Strong patient data protection is essential to the moral use of AI in healthcare. To ensure confidentiality, integrity, and availability, strict data protection procedures are necessary due to the significant amounts of sensitive information handled. Respecting relevant data protection laws, such as the General Data Protection Regulation (GDPR) in the European Union or the Health Insurance Portability and Accountability Act (HIPAA) in the United States, becomes essential to protecting patient privacy. Informed patient permission is another area where ethical considerations are relevant. Here, openness in the use of data is emphasized, and patients are given the freedom to agree or disagree based on a thorough knowledge of how their information is gathered, processed, and used. Furthermore, the opaque character of certain AI algorithms—often referred to as "black boxes"—presents a problem for accountability and transparency. Therefore, it is essential to build procedures that inform patients and healthcare professionals about AI-driven judgments. This will foster confidence in technology and ensure accountability, particularly when AI systems have an impact on important medical decisions. Given the disparities in privacy and security laws throughout nations and areas, it is essential to evaluate the current legal environment in the context of the particular application. To guarantee that AI in healthcare complies with the strictest ethical guidelines and legal requirements, any holes and inconsistencies in the legal framework must be found. This discernment makes this possible.
Analysis of privacy and security Risks in the integration of AI:
Although the use of artificial intelligence in healthcare has enormous promise, certain privacy and security concerns should be carefully considered.
• Data privacy: There is a greater chance of data breaches, unauthorized access, or abuse due to the large volume of patient data that AI systems gather and analyze. It is critical to protect patient information via data anonymization, access limits, and encryption.
• Data Security: Maintaining patient confidentiality and preventing data breaches need to ensure the safety of healthcare data. AI integration requires strong cybersecurity protocols, such as frequent safety inspections and threat assessments.
• Cyberthreats: Malware and hacking assaults are two examples of cyber threats that AI systems are susceptible to. Because medical data has such value, fraudsters see the healthcare industry as a priority target. Strong cybersecurity defense and incident response procedures need to be invested in by organizations.
• Prejudices in AI Systems: When AI systems are trained on data that contains prejudices, they may unintentionally reinforce such biases. In particular, when AI impacts medical choices, healthcare organizations need to be very careful to identify and reduce biases to guarantee fair healthcare delivery.
• Effective Integrating Examples: Despite the difficulties, a large number of healthcare institutions have efficiently incorporated AI while controlling security and privacy issues. These illustrations highlight the best practices for implementing ethical AI, safeguarding data, and maintaining cybersecurity. They provide insightful case studies for anyone attempting to negotiate the challenging landscape of integrating artificial intelligence in healthcare.
.png)
Figure 1:Ethical and privacy issues in healthcare
Source: [9]
.png)
Figure 2:Success factors of implantation of AI in healthcare
Source: [10]
5. Conclusion
As a result, this thorough analysis has clarified the revolutionary possibilities for artificial intelligence (AI) in the healthcare sector, highlighting the critical role of cutting-edge AI technologies and thoughtfully tackling ethical and legal issues, especially those about security and privacy. The main conclusions highlight how artificial intelligence (AI), furled by innovations in robotics, computer vision, natural language processing, and machine learning, has brought about a period of unparalleled potential for the healthcare industry. It facilitates early illness detection, tailored therapy, operational effectiveness, and rapid medical research, which leads to improved patient outcomes and resource efficiency. It is abundantly obvious, nevertheless, that there are significant obstacles in the way of this potential trajectory. Considering the sensitivity and sheer amount of patient data at risk, security and privacy worries are major issues. Transparency and informed consent are two essential ethical requirements. Moreover, the 'black box' character of AI algorithms demands creative solutions for accountability and explainability. An analysis of the state of privacy and security laws today shows a disjointed environment, underscoring the need for constant adaptation and harmonization to keep up with the rapid advancement of artificial intelligence. This report's importance stems from its steadfast dedication to identifying these issues and outlining a solution. In healthcare, resolving privacy and security issues with AI adoption is not a choice; it is a moral must. A trustworthy artificial intelligence ecosystem in healthcare can only be shaped by implementing the principles made here, which include strict security of information, consent that is informed, computational transparency, and a dedication to regulatory compliance.
6. References
.png)
Reports
ICT102 Networking Report 3 Sample
Assessment Objective
The objective of this assessment is to evaluate student’s ability to design and configure a network using a network simulator for a given scenario and configuring routers, switches, firewalls, and other network components based on specific requirements.
ASSESSMENT DESCRIPTION:
This assignment is group-based. Each group will have 3-4 students. You can continue with the same group as for the previous assessment. In this assignment you will be designing and configuring a network for a university that has a Class B IP address of 148.23.0.0/16. There are two faculties and each faculty requires two separate subnets: one for staff and another for students. The faculty names and the number of hosts in each subnet are given below:
• Faculty of Arts: 400 students and 200 staff members
• Faculty of IT: 600 students and 300 staff members
Part 0
Declare team members contributions in the table below:
Part 1
Divide the allocated address space between department subnets as per requirements. Summarize the IP subnets and masks in a table like this:
Part 2
Construct the following network topology in GNS3 or Packet Tracer simulator. Ensure that all the hostnames and network addresses are well labelled.
Part 3
Configure the router using the assigned hostnames and IP address.
Part 4
Setup Virtual PC (VPC) in each of the four subnets as shown above. The virtual PC’s provide lightweight PC environment to execute tools such as ping, and trace route. For each faculty create two VPCs for students and two VPCs for staff. Each VPC should be able to ping the other VPC in the same subnet.
Part 5
Configure the access control list (ACL) on Router01 such that any traffic from Students’ subnets are blocked from entering the staff subnet. Traffic to and from other subnets should pass through. Pinging staff VPCs (in both faculties) from students’ VPCs should fail. In other words, student in each faculty should not be able to ping any staff computer in any faculty. Students can only ping students VPCs in any faculty. Staff members can ping any VPC (staff and students in any faculty).
Part 6
Configure DHCP services on Router01 such that all VPCs can get IP addresses dynamically assigned.
Part 7
Use the following checklist to ensure you network is configured correctly.
.png)
For each of your routers make sure to save your running configuration using the command write mem For the VPCs use the save filename command to save the configurations to a file.
Finally save the GNS3 (or Packet Tracer) project, i.e., the topology together with the startup configs. Zip the GNS3 (or Packet Tracer) project folder and submit it on Moodle with your report. Make sure your submission is complete and has all the necessary files to run the simulation.
Solution
Introduction
Dynamic host configuration protocol is the client-server protocol providing an internet protocol host with an IP address and other configuration information. DHCP protocol is applied in an open networking system to transfer information from one PC to another by using the stated IP address. For Assignment Help, This protocol applies to openly communicating with nodes but there needs permission from the local host. Using DGCP protocol, this is applicable to configure automatically configure all networking components by suppressing errors that occur in the network. This report will implement the application of the DHCP protocol in the university networking system The goal of the report is to implement the DHCP protocol to communicate between two departments Arts and IT.
Network configuration and Ping status
The network of the university is a three-layer network consisting of routers, switches, and virtual PCs. There is the configuration of routers as the host of the networks situated in the first layer of the network. The second layer consists of four different switches. The third layer consists of eight different PCs for connecting the people. There are the consists of the different IP addresses of the different devices. The condition of the networking is that IT students can not communicate with the staff of any of the departments. Overall network configurations are looking the same.
.png)
Figure 1: Network topology
(Source: Self-Created)
This is a three-layer network configuration containing the IP address of each of the component. The router provides internet connectivity to all of the respective nodes. Router C3725 has been placed in the system due to the availability of 10 different ethernet ports. The characteristics of this router are stated below.
.png)
Figure 2: Proposed router configuration
(Source: Self-created)
The router contains a MiB size of 128 and NVRAM contains 256 KiB. This also contains the size of the I/O memory is 5 % of the RAM. Input and output memory is liable for storing all of the IP addresses inside the router. The next layer contains four switches that provide the connectivity of the 8 different computers. There is the connectivity of the 8 computers to the four different departments. IT students, IT staff, Arts students and Arts staff are using two different computers each. The DNS of each of the systems is the same which is 255.255.255.0. There are four different branches containing four different subnet masks148.23.0.1, 148.23.2.1, 148.23.4.1, and148.23.8.1. There is the connectivity of eight different computers that contain IP addresses of the same domains. IT students are using the IP addresses of 0,1,2,3 domains respectively. The ping status is getting successful in the internal communication. Interestingly, the ping status has been damaged while communicating with the staff of IT. The overall ping status is looking like the same.
.png)
.png)
.png)

Figures: Successful ping status
(Source: Self-created)
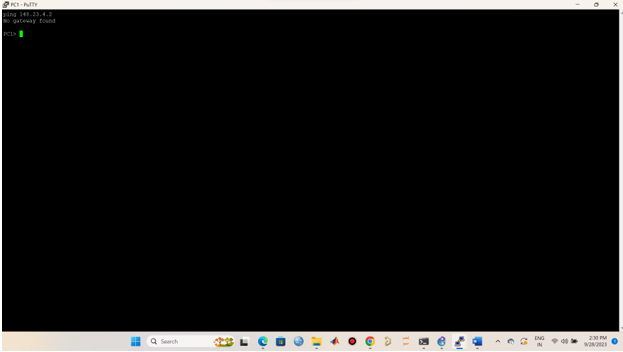
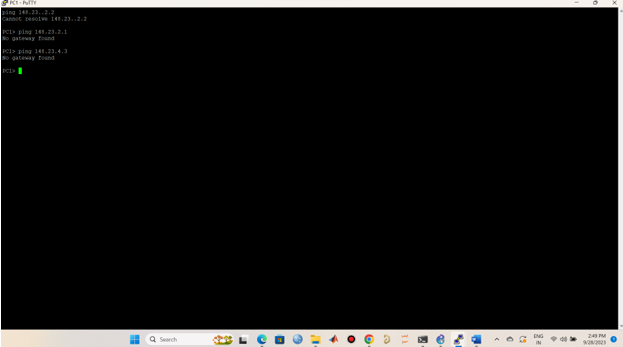
Figures: Unsuccessful ping status
(Source: Self-created)
Conclusion
This report concludes that the DHCP network protocol is widely accepted in automatic configurations. Applying the DHCP protocol the entire network traffic can be prohibited in a particular domain. The report has seen that using PC 1 one can send all the required information in nodes excluding IT staff.
Reference list
.png)
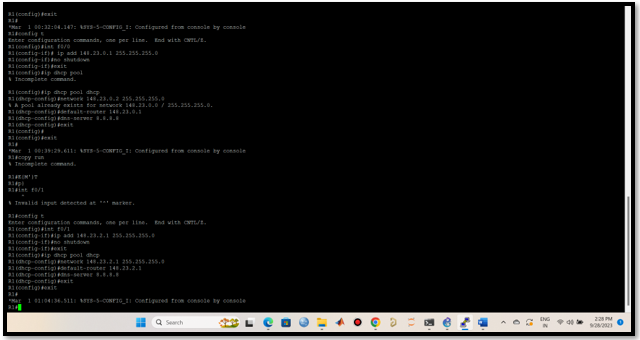
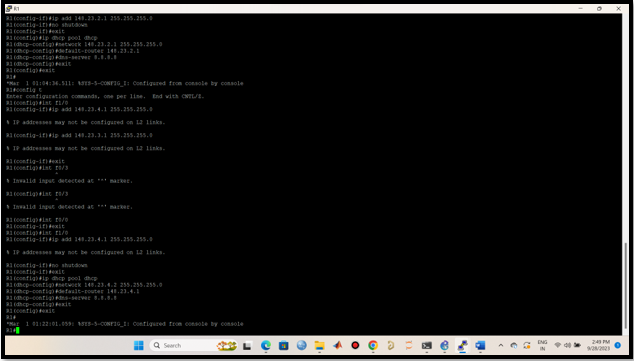
Reports
MITS5501 Software Quality, Change Management and Testing Report 2 Sample
This assessment related to the following Unit Learning Outcomes:
ULO1 Adopt specialized quality engineering and assurance procedures to improve the implementation quality and efficiency of software engineering projects using the advanced concepts and principles learnt throughout the unit.
ULO2 Independently develop clearly defined internal quality management approaches by addressing the quality factors and risks that may affect the resulting software development.
ULO3 Evolve peer review process using tools and techniques taught in the unit as well as carry out research on emerging techniques published in literature to further improve the peer review communication process
INSTRUCTIONS:
In this assessment students will work individually to develop Software Quality Assurance plan document. Carefully read the associated CASE STUDY for this assessment contained in the document MITS5501_CaseStudy_2023.pdf. From this Case Study you are to prepare the following:
1. Given the details in the Case Study, what are the software standards, practices, conventions, and metrics need to be used to improve the quality of the final product. You also need to identify the techniques to monitor the compliance of these standards.
2. Identify the tools and techniques used to perform peer reviews and the methods to reduce the risk of failure.
3. Develop a complete software quality assurance plan document based on the given case study. The document should have the following sections. However, you could add other topics based on your assumptions.
Quality Assurance Plan Document
a. Executive Summary
b. System Description
c. Management Section
d. Documentation Section
e. Standards, Practices, Conventions and Metrics
f. Peer reviews plan
g. Testing Methodology
h. Problem Reporting and Corrective action
i. QA Supporting Tools, Techniques and Methods
j. Software configuration management plan.
k. References
l. Appendices
Your report must include a Title Page with the title of the assessment and your name and ID number. A contents page showing page numbers and titles of all major sections of the report. All Figures included must have captions and Figure numbers and be referenced within the document. Captions for figures placed below the figure, captions for tables placed above the table. Include a footer with the page number. Your report should use 1.5 spacing with a 12-point Times New Roman font. Include references where appropriate. Citation of sources is mandatory and must be in the IEEE style.
Solution
Introduction
This study identifies the issues in the library management system and also help in proposing a solution through a digital library management system that can be created, implemented, and managed to fulfill the requirement of both staff and customers. For Assignment Help, This study includes different sections like the management section, documentation section, standard, practices, convention, and metrics section, review and inspection section, software configuration management plan, Quality Assurance, and testing.
Purpose Section
This section describes what software is included in the package and how it will be used, among other things. It also outlines the phases of each software product's life cycle that the SQA plan will cover. This section provides simple guidance for making sure the SQA strategy is appropriate for the program in question and its development and implementation stages [6].
Reference Document Section
All sources used to create the SQA plan are listed in detail in the Reference Documents section. This compiled document makes it simple to find resources that enhance and elaborate on the plan's primary text. Industry standards, project guidelines, process documentation, and other sources may be cited here to aid in the creation, execution, and assessment of the Software Quality Assurance strategy.
System Description
The Library Management System is an automation tool made for libraries of various sizes. This computerized system allows librarians to keep tabs on book sales, organize student information, and analyze collection depth. The system's central repository for books and member data helps avoid the kinds of problems that plague non-digital archives. In addition to improving library administration efficiency, the reporting module helps administrators with things like student enrolment, book lists, and issue/return data [5].
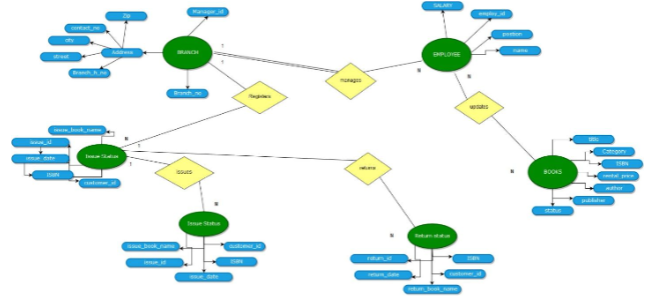
Figure 1 Entity Relationship Diagram of Library Management System
Management Section
There is a clear chain of command within the project's organizational structure. The Project Manager is responsible for directing the project and making sure it is completed on time, within scope, and budget. System design, coding, and database administration all fall under the purview of the development team, which consists of software developers and database administrators. The system's reliability and effectiveness are monitored by the Quality Assurance group. Feedback and user testing are provided by administrative and library employees.
Documentation Section
The software's governing documentation covers its whole lifespan, from development to maintenance. The Software Requirements Specification (SRS) is the document that first defines the parameters of the project. The project staff and interested parties check this document to make sure it covers everything. The SDD is a document that specifies the system's architecture, algorithms, and interfaces before, during, and after development. The SDD is evaluated by the development staff and domain specialists. The Test Plan and Test Cases papers outline the goals, methods, and anticipated results of the verification and validation processes. Peer evaluations and test execution outcomes are used to determine the level of sufficiency. The dependability and usefulness of the program rely on these papers, which are kept up-to-date by regular reviews, audits, and user feedback channels [1].
Standards, Practices, Conventions and Metrics Section
- Standards: This study will use conventional coding practices, such as those for file naming and commenting, as well as database best practices. Data encryption and privacy shall meet or exceed all applicable global requirements.
- Practices: Scrum, daily stand-ups, and continuous integration are just a few of the Agile development practices that will be used. Git will be used for version management, which will facilitate teamwork throughout development and help in tracking bugs.
- Conventions: We will require that all variables, functions, and database tables adhere to standard, human-readable names. Usability and accessibility guidelines will be taken into account throughout the UI design process.
- Metrics: Important performance indicators, such as system response times, error rates, and user satisfaction surveys, will be outlined. The quality of the code will be evaluated with the help of static analysis software [3].
Reviews and Inspections Section
At essential points in the planning and execution of the project, it will be reviewed and inspected by both technical and management personnel. Code quality and compliance with coding standards will be monitored by technical reviews, while project progress and resource allocation will be evaluated by management reviews. Reviews, walkthroughs, and inspections will be followed up with action items to remedy identified concerns, and approvals will be issued based on their successful completion to guarantee that the project continues to meet its quality goals and remains on schedule.
Software Configuration Management Section
Software configuration management (SCM) is an integral part of software development since it allows for the centralized management of all software and documentation revisions throughout a project's lifetime [4]. The SCMP focuses on the following topics:
1. Configuration Identification: This part of the SCMP defines how software and documentation configurations will be called and labeled. It details how CIs should be named, how versions should be numbered, and how their structure should look. It specifies who's responsible for what when it comes to creating and maintaining these identifiers.
2. Configuration Control: Software and documentation configuration management is outlined in the SCMP. There is a procedure for handling requests for modifications and putting them into effect.
3. Configuration Status Accounting: This section explains the methodology that will be used to track and report on the current state of setups. Specific sorts of status data, such as versioning, release notes, and baselines, are outlined. It also details how often and how to provide progress reports.
4. Configuration Audits: The SCMP specifies the steps to take while performing a configuration audit, whether it be an internal or external audit. It lays out the goals of an audit, the roles of the auditors conducting it, and the measures that should be taken in response to their findings.
5. Configuration Baselines: Sets the standards and methods for determining what constitutes a "configuration baseline," or a stable and officially sanctioned version of the program and documentation. It specifies how to choose, label, and file baselines.
6. Tools and Environment: The source control management (SCM) tools and environments that will be used throughout the project are covered in this section. Version control, bug tracking, and other configuration management technologies are described in depth.
7. Roles and Responsibilities: The SCMP establishes the tasks and functions of the SCM team members. The SCM manager, developers, testers, and other project participants fall under this category. It clarifies who is responsible for configuration identification, control, status accounting, audits, and baselining.
8. Training and Documentation: This document specifies the documentation and training needs of the SCM team. The SCMP, together with the process guidelines and SCM tool user manuals, are all part of the required paperwork.
9. Security and Access Control: This section deals with the topic of SCM-related security and access control. It specifies the rules for controlling access, encrypting data, and other security procedures to ensure the safety of configurations and associated data.
10. Continuous Improvement: Provisions for continuous process improvement are included in the SCMP. It specifies how the results of audits, reviews, and inspections will be included in the ongoing effort to improve SCM procedures.
Problem Reporting and Corrective Action
The program Configuration Management Plan (SCMP) for the project includes detailed instructions for tracking down and fixing bugs and other problems in the program and supporting documentation. The procedure for recording issues, particularly their severity and effect, as well as tracking and assigning them to be fixed, is outlined. It also details the processes involved in identifying problems, conducting investigations, and applying fixes.
Tools, Techniques, and Methodologies Section
Software tools, methods, and methodologies that aid Software Quality Assurance (SQA) are described in detail in the Tools, methods, and Methodologies section. Tools and processes such as Agile or Waterfall may be used for project management, along with other resources like testing frameworks, version systems of control, automated testing tools, peer review platforms, and more.
Code Control Section
Code Control describes the processes and tools used at each step of development to monitor and maintain the controlled versions of the designated program. Both software configuration management and the use of pre-existing code libraries are viable options. The integrity and traceability of software components are protected throughout the development lifecycle by this section's methodical version management of code.
Media Control Section
The Media Control section describes the processes and resources used to track down, organize, and secure the physical media that corresponds to each computer product and its documentation. This includes outlining how to back up and restore these media assets and taking precautions to prevent them from being stolen, lost, or damaged.
Supplier Control Section
In the Supplier Control section, we detail the procedures used to guarantee that third-party developers' code meets all of our expectations. Methods for ensuring that vendors obtain sufficient and thorough specifications are outlined. It specifies the measures to take to guarantee that previously generated software is compatible with the features addressed in the SQA strategy. If the software in question is still in the prototype phase, the provider in question must create and execute their own SQA plan according to the same criteria.
Records Collection, Maintenance, and Retention Section
In the section under "Records Collection, Maintenance, and Retention," the precise SQA records that will be kept are outlined. It specifies the retention period and details the processes and resources needed to create and maintain this record. Acquiring the necessary permissions and developing a strategy for execution are both key parts of putting the SQA plan into action. After the SQA plan has been implemented, an assessment of its efficacy may be performed, guaranteeing the orderly maintenance and storage of crucial documents throughout the project's lifespan.
Testing Methodology
The Testing Methodology section details the overall strategy, specific methods, and automated resources used during software testing. It specifies the various forms of testing (such as unit, integration, system, and acceptability testing) and the order in which they will be executed. Specific testing methods, such as black-box and white-box testing, as well as automated testing tools and frameworks, are described in this section. It assures that the software's functionality, reliability, and performance are tested in a systematic and well-organized manner [2].
References
.png)
Essay
CSIT985 Social Media for organization innovation Essay 2 Sample
Task Requirements
- Select a topic from the given list below and write an essay about the selected topic.
- Type of assessment: Individual work
- Word limit: 2000 words (+/- 10% excluding the bibliography)
- Referencing style: choose an appropriate style from here
- Due date and time: by 11 pm on Friday, 8 Sep 2023
- Turnintin check is required to avoid plagiarism. Plagiarism policies can be found from the link.
Essay topics
In both academic and grey literature, there is evidence of numerous ICT (Information and Communication Technology) initiatives that promise to deliver strategic advantage to companies and, sometimes, even countries. From the following list, choose one initiative as the focus of your analysis and define the ways in which this initiative is strategic.
Choose one initiative from the following list:
1) Communication and Collaboration Tools
2) Social media for organisation innovation
3) Software as a Service (SAAS) for corporations
4) Cloud services for corporations
5) Cloud services for developing countries
6) Digital Economy for developing countries
7) Heath Information Systems
8) Telecentres for developing countries
9) Open Source software for government in developing countries
10) Digital transformation for developing countries
11) E-learning and Digital Education for developing countries
12) Cloud services for e-government in developing countries
13) Data Privacy for corporations
14) Cyber Security for corporations
15) Network security for corporations
16) Zero-trust network for corporations
17) Automation in IT systems for corporations
Having established the strategic significance of the initiative goes on to describe the implications this initiative has for network design.
Solution
1. Introduction
Social media platforms have become an opportunity for organisations in order to create and develop online communities. Social media platforms have been significant for engaging customers in collaborative practices while creating value through product reviews, generating innovative ideas and even identifying all possible resources for innovation in an organisation. For Assignment Help, In this context, the role of social media in organisational innovation has been the main focus of this discussion. The implications of innovation for network design have also been a major part of this discussion. Moreover, the influence of communication with customers in turning organisational innovation has been also demonstrated in this essay.
2. Development of ideas
a. Define the way in which the selected initiative is strategic
According to Muninger, Hammedi, & Mahr, (2019), social media for organisational innovation can be referred to as a strategic approach that can transform the way businesses operate as well as compete in the contemporary world. On the contrary, it is opined by Chaffey, and Ellis-Chadwick (2019), that social media has emerged as a powerful tool for fostering collaboration, communication and creativity in organisations. The large number of presence of indvidauls in social media platform enble the orgnisation in the modern business world to use this platform as an strategic initiative. Following is the detailed illustration:
Enhanced communication: Social media platforms render a real-time and dynamic channel for communication in the organisation (Lee et al., 2022). They facilitate the instant sharing of information, feedback, and ideas among employees and help in breaking down traditional hierarchical communication issues. This ultimately fosters a more transparent and inclusive work environment thereby contributing to strategic advantage. One example that can be seen as social media as a great strategic initiative in the organisation is the Slack app. Slack app is utilised as a team communication platform which has transformed communication in the organisation (Montrief et al., 2021). It enables people in the organisation to share ideas, information and other documents easily, breaking down the barrier of hierarchical communication. Some of the organisations that use Slack and increase communication are IBM, shopify, and BuzzFeed (Patalay, 2022). They use the Slack app in social media to facilitate communication among their employees.
Increased creativity: Social media encourages idea-sharing and brainstorming aspects around geographies and departments (Nonthamand, 2020). This is in the form of virtual space. By creating a virtual space for the workforce to collaborate, it appears that the organisation is able to harness the collective creativity of its employees. Innovative thinking due to collaboration results to the development of new products and so social media can be referred to as strategic initiative. In the contemporary world where the evolving working landscape in at its peak, many organisations are able to increase creativity or it can be said due to strategic initiatives aspired by so, the organisation is able to head to innovation or create a new product. One of the initiatives that come under social media is the adobe’ Kickbox program (DEVECIYAN, 2021). It is an innovative initiative which encourages creativity in the organisation. This means employees are given a red box which contains resources involving a prepaid card in order to pursue its innovative ideas. It creates an online community as well as a social media platform for the workforce to share their progress at work, seek advice and collaborate with other departments or colleagues effectively. This kind of virtual space for collaboration contributes to the development of new products.
Improve customer engagement: Social media permits organisations to engage with customers directly and further collect valuable feedback (Manzoor et al., 2020). The real-time interaction provided by social media aids in understanding customer preferences and needs resulting in the development of customer-centric strategies. An organisation with the help of this is able to tailor their products and meet the demands of the customers effectively (Fachrurazi et al., 2022). Different organisations use social media as different means of initiative such as Starbucks which is a famous coffee retail chain and is well known for its active presence on social media channels like Instagram and Facebook (Linkedin.com, 2023). In this process, they encourage customers to share their thoughts, photos and feedback using the hashtag#Starbucks. Further, they respond to the customer's inquiries, understand their feedback and incorporate suggestions of the customers for improving its product according to the needs and tastes of the customers (Linkedin.com, 2023). This kind of direct engagement permits this organisation to maintain a strong connection with its large customer base and improvise its product offering thereby achieving higher profitability. This action can be viewed as a strategic action of Starbucks to sell its product and increase its profitability through social media. Social media is not only strategic to this organisation but it is also strategic for the famous vehicle firm Tesla. Elon Musk who is the CEO of Tesla has an active presence on the social media channel, Twitter (Liberto, 2023). He frequently interacted with enthusiasts to address their concerns and questions. It has been found that this particular firm has implemented software updates on the basis of customer suggestions gathered on the social media platform.
Global reach: Global reach generally means an organisation reaching a large number of people and many countries to sell its products and services. In this process, it cannot be denied that social media cannot be used as a strategic initiative. However, it is one of the effective means that prove or can be said to provide the organisation with the potentiality to reach globally by staying at one location. Social media channels have a vast number of users globally. Leveraging social media for innovation enables organisations to tap into a diverse talent pool and further expand their market reach worldwide (Nayak et al., 2020). This global perspective, therefore, can be regarded as a strategic advantage. One of the examples of the organisation can be viewed for Airbnb which is a lodging and travel experiences platform. It used social media as a strategic initiative to expand globally. The initiative was strategic because Airbnb encourages guests and hosts to share their travel photos, experiences and reviews on channels like Twitter and Instagram. This take of action not only helps in creating brand awareness among large consumers but it is also kind of able to do promotion for its products and services on a large scale. This has created the organisation to have global reach meaning consumers from worldwide would come and have great travel experiences through this organisation.
b. Describe the implications of this initiative for the network design
Analysing the present business's perspective, social media platforms provide an opportunity for all organisations to create an online community where users can engage 24 hours. Organisations adopt social media to generate ideas, product reviews, customer feedback and identify a new source of innovation. Implication for the network design for social media is a complex factor where organisations carefully manage to generate customers and increase revenue.
Increasing security: The online presence has created a threat for the organisation because the lack of cyber security fraudulent activity has created data leaks of customers (Muneer, Alvi & Farrakh 2023). Customer feedback on online orders and transaction processes on social media is needed to maintain the security of the organisation. Implementing proper security measures through network design helps customer engagement, which impacts trust and loyalty. The AI and machine learning algorithms are the preferable network design or the organisation that can protect consumer data.
Content moderation: Implement the social media platform through innovation and the organisation needs to moderate content for the safe data for the customers (Manzoor et al. 2020). The automated process can create threats for the customers and also organisations. In this regard, Google's content moderation approach on a daily basis focuses on effective content moderation strategies in social media to engage customers.
Increase scalability: Implemented network design for organisation innovation through social media the large amount of data needs to be protected in every way. Social media users are increasing on a daily basis and customers can get their preferred products and services. Without scalability, social media innovation strategy can create a lack of major organisations such as Google, Apple and IBM (Susanto et al. 2021).
Using audio-video content: Audio-video content is helpful for customers with new product features. Through audio-video methods, customers can select the right products and services. The audio-video content analysis can bind customers globally. Attractive social media content needs to be evaluated by fashion-based companies such as Zara, H&M and others (Sudirjo 2021). Additionally, through the process, sustainable initiative features can be shown by the organisation, which influence customers purchasing behaviour.
User authentication: During innovation organisations need to ensure effective authorised users to access the network. Organisations need to identify fake users through social media because fake users create confusion and customers' minds. Therefore, effective user authentication implements a strong presence before customers.
Implement training: Organisations need to provide training during the use of social media. Any innovative content is attractive to the customers but training-based employees can easily handle the innovation. Additionally, they can promote the best product strategy using social media, which eliminates risk and cyber threats.
Identify the target audience: Social media works as an ICT for customers (Shahbaznezhad Dolan & Rashidirad 2021). Customers can identify the content product, innovation and features through the medium. As a result, organisations can select existing customers who can prefer the product. However, in analysing customers' behaviour on social media platforms, the right application needs to be focused on influencing audience behaviour. Sometimes low-cost budget products are helpful to organisations. The cost management strategy ensures a proper network diagram for the organisation in innovation.
Social media has played a significant role in terms of allowing graphic design in terms of reaching a much wider customers as compared to ever before. Based on the huge engagement of customers with visual content on social media, the impact of social media initiatives has become profound and far-reaching through graphic design. In addition, social media has helped in building and increasing connections with target customers while creating a platform for sharing feedback and opinions of valuable customers. As per the social network theory, structural as well as cognitive dimensions of social relationships have a positive influence on job performance (Song et al., 2019). On the contrary, as argued by Dzogbenuku Doe & Amoako (2022), cognitive use of social media has a positive influence on employee performance whereas the hedonic implications of social media have a negative impact on organisational performance. Social media users have the opportunity to recommend significant quality to the social media circles about the brand or a particular innovative product. Organisations have utilised significant opportunities such as offering lower costs, ensuring brand recognition and improving brand awareness through social and digital marketing in recent years.
3. Conclusion
From the above discussion, it can be concluded that social media has played a huge role in fostering collaboration, communication and creativity within organisations. Social media has contributed to brainstorming approaches around all departments within an organisation. Virtual space has helped the employees to share their ideas and be collaborative. Innovative thinking has been valued and referred to as strategic initiatives. Product development and implications of design have been also convenient in an organisation through social media.
References
.png)
.png)
Research
MITS5004 IT Security Research Report 2 Sample
Objective(s)
This assessment item relates to the unit learning outcomes as in the unit descriptor. This assessment is designed to improve student presentation skills and to give students experience in researching a topic and writing a report relevant to the Unit of Study subject matter.
INSTRUCTIONS
Assignment 2 - Research Study - 10% (Due Session 9) Individual Assignment For this component you will write a report or critique on the paper you chose from Assignment
1. Your report should be limited to approx. 1500 words (not including references). Use 1.5 spacing with a 12 point Times New Roman font. Though your paper will largely be based on the chosen article, you should use other sources to support your discussion or the chosen papers premises.
Citation of sources is mandatory and must be in the IEEE style.
Your report or critique must include:
Title Page: The title of the assessment, the name of the paper you are reporting on and its authors, and your name and student ID.
Introduction: Identification of the paper you are critiquing/ reviewing, a statement of the purpose for your report and a brief outline of how you will discuss the selected article (one or two paragraphs).
Body of Report: Describe the intention and content of the article. If it is a research report, discuss the research method (survey, case study, observation, experiment, or other method) and findings. Comment on problems or issues highlighted by the authors. Report on results discussed and discuss the conclusions of the article and how they are relevant to the topics of this Unit of Study.
Conclusion: A summary of the points you have made in the body of the paper. The conclusion should not introduce any ‘new’ material that was not discussed in the body of the paper. (One or two paragraphs)
References: A list of sources used in your text. They should be listed alphabetically by (first) author’s family name. Follow the IEEE style.
The footer must include your name, student ID, and page number.
Note: reports submitted on papers which are not approved or not the approved paper registered for the student will not be graded and attract a zero (0) grade.
Solution
Introduction
The exciting improvements of the upcoming Microsoft Windows 11 operating system are disclosed in an insightful essay from eMazzanti Technologies, a reputable IT consultant and Microsoft cloud services provider with offices in NYC. Windows 11 is expected to revolutionise PC users' productivity and security when it launches in October. For Assignment Help, The article goes in-depth on the main improvements, like faster access to Microsoft Teams and a better Snap tool for window management. The criteria for Microsoft Azure Attestation (MAA) and the Trusted Platform Module (TPM) 2.0 further emphasise the importance of security. Windows 11 offers consumers a better, safer future with less frequent upgrades, improved tablet compatibility, and simplified system requirements.
Critique of the paper
The impending Windows 11 operating system is described in detail, along with some of its anticipated features, in the article titled "Windows 11 Set to Deliver Security and Productivity Improvements." The work does, however, have a few features that call for criticism and more investigation. In its review of the new features in Windows 11, the article, to start, lacks depth. It highlights improvements like quicker access to Microsoft Teams and a better Snap feature, but it does not go into detail about these or discuss any possible repercussions [1]. The readership would profit from a more thorough investigation of the potential effects of these features on user experience and output.
Second, a critical viewpoint on the system requirements for Windows 11 is absent from the essay. Although it acknowledges the necessity of Trusted Platform Module (TPM) 2.0, it does not address any potential difficulties or worries that consumers or organisations might encounter in order to comply with these standards. It would have been instructive to look more closely at the hardware requirements for upgrades and compatibility problems. The article also does not cover any potential downsides or compromises related to Windows 11 in any detail [2]. The new operating system is portrayed in a mainly positive light, but a fair analysis should take into account any drawbacks or restrictions that users might experience.
Strengths and Weaknesses
Strengths
The article outlines numerous advantages that Windows 11 is expected to offer. First and foremost, the improved security measures are a big plus. A proactive approach to tackling changing cybersecurity risks is demonstrated by the release of Trusted Platform Module (TPM) 2.0 and support for Microsoft Azure Attestation (MAA). By providing physical security against malicious software, these methods safeguard critical data. Second, Windows 11 offers some notable productivity improvements [3]. The taskbar's quicker access to Microsoft Teams makes it easier to collaborate and communicate with clients and colleagues. Multitasking is facilitated by the enhanced Snap window management capability, increasing overall efficiency. The disruption and annoyance brought on by lengthy update processes are reduced by smaller annual feature upgrades and monthly security updates.
Weaknesses
Windows 11 does, however, have some shortcomings. The heightened system requirements are a significant obstacle. Although these improvements are intended to increase security, they could be difficult for users with outdated gear to use. Compatibility problems could result from this, necessitating expensive hardware upgrades. The article also mentions that most customers would not be able to upgrade from Windows 10 until early 2022. For individuals who cannot upgrade right once, this staggered release schedule could lead to differences in the user experience and even impair corporate operations [4]. However, organisations and people will need to take into account potential limitations while planning their transition to the new operating system, such as the increased system requirements and the delayed availability for some users.
Problems or issues identified by the Author
Despite discussing a number of different features of Windows 11 in this essay, the author falls short in properly addressing a number of significant difficulties and problems.
Absence of Critical Analysis: This is a significant problem. This essay, which was authored by a Microsoft partner, seems to be a marketing piece for Windows 11 [5]. As a result, it is biased and skips over any potential negative aspects or shortcomings of the new operating system. Both the advantages and disadvantages should be discussed in a fair manner.
Limited Hardware Compatibility: Despite mentioning Windows 11's system requirements, the page does not go into great detail about the difficulties that users with older hardware may encounter. Many consumers can discover that their current devices do not satisfy these standards, needing expensive upgrades or new
Dependence on the Microsoft Ecosystem: The article highlights elements like direct access to Microsoft Teams and interaction with Microsoft Azure [6]. This, however, raises questions about vendor lock-in because consumers may become more and more reliant on the Microsoft environment, reducing their flexibility and options.
Security Issues: Despite the article's mention of improved security measures, it fails to address any potential privacy issues brought on by these adjustments. Users may be concerned about how Microsoft uses and collects personal data.
Transition Challenges: Although it makes a passing reference of the necessity for users and companies to get ready for the switch to Windows 11, it offers no specific advice on how to do so in an efficient manner. There should be more focus on this topic because switching to a new operating system might be a difficult procedure.
Relationship with the first assignment
The previous paper highlighting the value of operating system security and the paper outlining the security and productivity aspects of Windows 11 are related in the context of IT security and technological breakthroughs. The previous assignment offers understanding into crucial elements of operating system security, including vulnerabilities, exploitation strategies, and security mechanisms [7]. It emphasises how important it is to protect operating systems so that data and programmes are shielded from potential dangers. The article regarding Windows 11, in contrast, emphasises the enhancements and novel features in the future operating system update. The need of Trusted Platform Module (TPM) 2.0 is expressly mentioned as one of the improved security measures that must be in place to safeguard sensitive data.
The bigger picture of IT security is what connects these pieces. While the academic paper concentrates on the theoretical and practical elements of operating system security, the article about Windows 11 shows how operating system developers, like Microsoft, are actively addressing security concerns by incorporating new features and requirements. In the ever-evolving field of IT security, both publications emphasise the significance of strong operating system security mechanisms.
Components of the assignment
The upcoming release of Microsoft Windows 11 is examined in-depth in a new essay from eMazzanti Technologies by a well-known IT expert in the NYC region, who emphasises the significant gains in security and productivity. The rumour claims that an operating system for PCs that is extensively used will be released in October 2021. The focus is on the enhanced security capabilities of Windows 11, which include support for Microsoft Azure Attestation (MAA) and a requirement for the Trusted Platform Module (TPM) 2.0 [8]. These components make the system more robust to fend against threats that are always changing. Data security is enhanced by TPM 2.0's physical defence against malicious software.
The article also emphasises productivity upgrades that promote efficient multitasking and collaboration, such as easy access to Microsoft Teams directly from the taskbar and an improved Snap tool for window organising. By committing to monthly security updates that are 40% shorter than Windows 10's cumulative updates and annual feature upgrades rather to semi-annual ones, Windows 11 promises a more streamlined experience and addresses the continuing issue of lengthy Windows updates. While the transition to Windows 11 is expected to begin in October, the majority of customers will likely upgrade from Windows 10 to Windows 11 in the early months of 2022 [9]. During this transitional period, people and companies can assess their hardware compatibility and prepare for a seamless move.
Comparison and Analysis
This particular article from eMazzanti Technologies differs from other articles on Windows 11 in a number of ways:
Vendor Perspective: The author of this post is a Microsoft cloud services provider, in contrast to numerous articles that offer a more impartial and objective perspective on Windows 11. As a result, it has a more sales-oriented tenor and places greater emphasis on the operating system's advantages and good points. It differs from more unbiased evaluations due to the vendor-specific perspective.
Emphasis on Security and Productivity: The focus of this article is on security and productivity improvements rather than Windows 11's features, which are generally only mentioned in passing in other articles. It goes into detail about Microsoft Teams integration and the need for Trusted Platform Module (TPM) 2.0 [10]. Compared to articles that might cover a wider range of topics, it stands out because of its narrow emphasis.
Highlighting Vendor Knowledge: The article highlights eMazzanti Technologies' knowledge as a Microsoft Gold Partner and its preparedness to help with Windows 11 upgrades. Unlike posts that primarily try to enlighten readers without endorsing any particular service providers, this one promotes itself.
Specific Release Information: The article indicates that Windows 11 is scheduled to be released in October 2021 and offers a plan for upgrading from Windows 10 to Windows 11 in early 2022. It distinguishes itself from articles that might offer more general information without definite periods thanks to its temporal context.
Limited Criticism: This article tends to emphasise Windows 11's advantages rather than its potential disadvantages or difficulties, in contrast to other articles that might critically analyse those issues [11]. The advantages are emphasised rather than a thorough evaluation.
Conclusion
In conclusion, the eMazzanti Technologies paper discusses important features of Windows 11, with a focus on security, productivity, and system requirements. It forecasts a release date of October and highlights the advantages of greater productivity tools including Microsoft Teams integration, smaller monthly upgrades, and an annual update cycle. The article recognises that individuals and companies must get ready for the switch to Windows 11 because of the higher system requirements. It also emphasises how ready eMazzanti Technologies is to help with this shift. However, it's crucial to highlight that the essay lacks a critical viewpoint and is written from a promotional perspective, concentrating mostly on the positive elements of Windows 11.
References
.png)
Reports
MIS102 Data and Networking Report 3 Sample
Task Summary
Create a network disaster recovery plan (portfolio) (1500 words, 10%-or 10%+) along with a full network topology diagram. This portfolio should highlight the competencies you have gained in data and networking through the completion of Modules 1 – 6.
Context
The aim of this assessment is to demonstrate your proficiency in data and networking. In doing so, you will design a network disaster recovery plan for a company of your choice to demonstrate your proficiency with network design.
Task Instructions
1. Create a network disaster recovery plan (portfolio) along with a full network topology diagram for a company. (the choice of a company can be a local or international company)
2. It is recommended that to investigate the same company that was researched in Assignment 1 as this created a complete portrait of the company and becomes an e-portfolio of the work complete.
Note: The Company has branches worldwide and this should be considered when creating the network disaster recovery plan.
3. Network disaster recovery plan (portfolio)
Write a network disaster recovery plan using of 1500 words, (10%-or 10%+) The Portfolio must include the following:
An introductory section that highlights the importance of having a recovery plan.
• Whatstepsshould the company take if:
o There is a sudden internet outage.
o A malware (e.g. a virus) hasinfected the computers in the company network.
o There is no local area network for the entire company Is there a way to diagnose if this is a hardware failure. What communication protocol stack might be affected.
o Only a part of the company loses internet connection.
o There is a power outage.
o There is a natural disaster such as an earthquake, tsunami, floods or fire.
o There is a password security breach.
• Are there precautions and post-planning to ensure that the company will not repeat the same network disaster?
• Anticipate the likely questions about the network design that will be raised by the client (Please note that this may include both technical and non-technical staff of the organization).
4. Network topology diagram
• Create a full network topology diagram, that could ensure the business continuity of the company.
• The diagrams need to be your own work and need to be developed using Visio or Lucidchart or an approved graphic package. (Please seek the approval of the learning facilitator prior to commencing this activity).
• All diagrams need to be labeled and referenced if they are not your own.
• The full network topology will be part of the network disaster recovery plan and should be used to further enhance the understanding of the recovery plan.
Solution
Introduction
Even a digital firm like Apple may experience network outages and catastrophes in today's rapidly developing technological ecosystem. This research digs into the complex world of network disaster recovery planning, a vital part of modern corporate operations, and adapted to the specific requirements of a multinational corporation of Apple's figure. The capacity to quickly recover from network failures, cyber-attacks, and natural disasters is critical in today's always-connected digital world. For Assignment Help, This analysis highlights the value of preventative disaster recovery procedures by describing Apple's plans to ensure the availability of critical services, the security of sensitive data, and the robustness of the company in the face of adversity.
Network disaster recovery plan
An organization like Apple would utilize a network disaster recovery strategy to restore its whole network in the event of a catastrophe. Finding the network's weak spots, creating a list of potential risks, developing a strategy to deal with those risks, and outlining a backup plan are all critical parts of a disaster recovery strategy (Meilani, Arief & Habibitullah, 2019).
Recovery plan – It allows Apple to keep operating, providing customers, and making money in the case of a calamity.
Protect Data - It helps to make sure that essential data is kept safe and can be recovered in the case of a disaster or legal complication (Zhang, Wang & Nicholson, 2017).
Reduce Monetary Costs - Significant monetary costs might come from downtime and data loss. These losses can be mitigated with a solid recovery strategy.
Protect Reputation - A speedy recovery shows that Apple values its consumers and will do what it takes to keep them happy.
Aspects of this plan
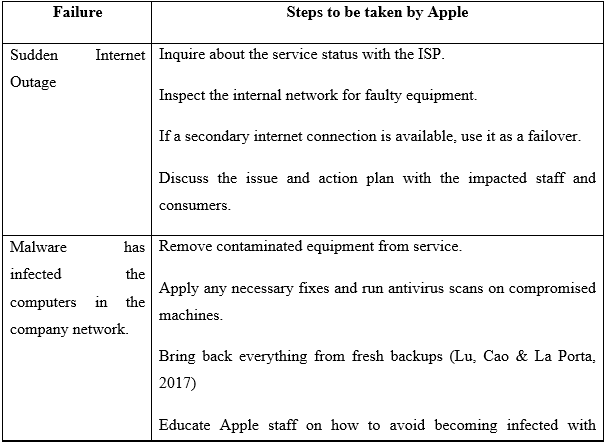
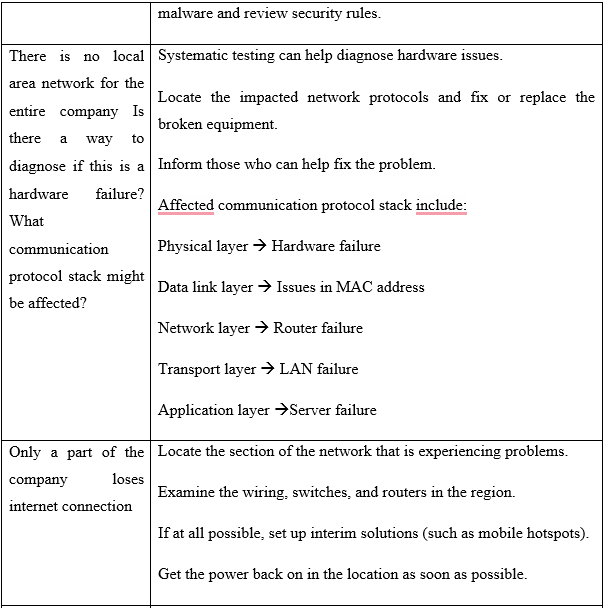


Precautions and Planning
- Organizations like Apple can reduce the likelihood of future network catastrophes by taking these preventative measures: Maintain a recovery strategy that takes into account developing risks and emerging technology.
- Training Employees - Regularly Have personnel trained on disaster preparedness and security best practices (Butun, Osterberg & Song, 2019).
- Regular testing and exercises should be carried out to ensure the efficacy of the disaster recovery strategy.
- Audits of the security measures in place should be carried out regularly to detect any flaws or weaknesses.
When it comes to addressing network failures and catastrophes, Apple, as a leader in the computer sector, must methodically develop and implement a complete set of safeguards and preventative measures to keep operations running smoothly.
Preventing internet outages is an important consideration. Apple would be wise to employ many independent internet connections through different ISPs (Finucane et al., 2020). To mitigate the effects of an ISP outage, these links must automatically switch to a backup connection in the event of an interruption. In addition, the user experience and availability may be improved by using material Delivery Networks (CDNs) to cache material closer to end-users. To further guarantee that key services are always available, especially during peak use periods, Apple should implement Quality of Service (QoS) policies to prioritize crucial traffic during network congestion.
Apple has to implement sophisticated threat detection systems capable of identifying malware in real-time if it wants to stop infections caused by malicious software. The danger of malware intrusion through phishing efforts and other vectors can be reduced by providing frequent training programs for employees. As important as network-wide defenses are, stopping malware infestations at their source requires effective endpoint protection software. Apple has to have spares of its network gear on hand in case of LAN problems so that it can quickly restore service. Tools for constant network monitoring can spot problems and hardware breakdowns early, allowing for preventative maintenance. It is important to keep accurate and detailed records of network setups to speed up the troubleshooting process in the event of a malfunction (Schultz, 2023).
Apple should implement network segmentation to ensure that mission-critical services continue to be available in the event of a partial loss of internet connectivity. In the case of a partial outage, technologies like Border Gateway Protocol (BGP) can be utilized to redirect traffic and keep services up. To ensure the failover procedures work as intended, they must be tested often. Reducing the likelihood of a power outage happening is crucial. Apple should install UPS systems in its mission-critical data centers and server farms to keep the machines running during power outages. Extending the electrical supply with backup generators is possible. Equipment failures during power outages can be avoided with regular power system maintenance (Rosencrance, 2023).
Apple should spread its data centres out over many locations to lessen the effects of calamities that affect only a small area. If data loss occurs, it may be quickly recovered through the use of real-time data replication to alternative data centres. Having a fully functional, off-site disaster recovery site with all of the data and resources synced across to it is like having an extra firewall up. Apple needs to deploy Multi-Factor Authentication (MFA) for vital systems and accounts to stop password security breaches. Passwords should be changed often and be of a certain minimum complexity to reduce the possibility of hacking. It is also important to do security audits to find password security flaws.
As part of Apple's continuous dedication to network resilience and disaster recovery readiness, the company should continually reinforce these preventative actions. Apple is better able to protect its worldwide user base from interruptions in service because of the efforts it has taken to implement these measures throughout its network architecture (Peterson & Hilliard, 2022).
Client-Focused Question Anticipation
Questions from the Technical Staff
1. How frequently should we revise our disaster recovery strategy? Plans should be examined and revised at least once a year, or more frequently if necessary.
2. How often is crucial information backed up? Specify how often and what kind of backups will be done.
3. Can you give me a rough estimate of how long each rehabilitation plan will take? - Please include planned recuperation times.
Questions from Non-Technical Employees
1. How Will My Work Be Affected? - Describe the precautions taken to keep normal activities to a minimum.
2. To what extent do workers contribute to catastrophe preparedness? Stress the need of being punctual in reporting problems and sticking to established protocols.
3. In the event of an emergency, how will information be disseminated to staff members? Explain the current methods of interaction.
Network Diagram
.png)
Figure 1 Network topology diagram for Apple
Conclusion
This research has shown that even a technological centre like Apple needs a network disaster recovery strategy to keep operations running smoothly. Apple can keep up its rate of innovation and service availability by painstakingly tackling a wide range of potential calamities, from cyberattacks to natural disasters. Redundancy, backup solutions, and personnel training help the organization handle interruptions with resilience and agility, allowing it to maintain its promise to clients all across the world. Apple can keep its operations running smoothly, keep its unrivaled image intact, and weather any storm by adopting these measures and embracing a culture of readiness.
References
.png)
Case Study
MIS609 Data Management and Analytics Case Study 3 Sample
Assessment Task
For this assignment, you are required to write a 2000-word case study report proposing data management solutions for the organisation presented in the case scenario.
Context
Module 5 and 6 explored the fundamentals of data management. This assignment gives you the opportunity to make use of these concepts and propose a data management solution for the organisation presented in the case scenario.
Assessment Instructions
1. Read the case scenario provided in the assessment area.
2. Write a 2000-word enterprise data management solution for the company
3. The solution should discuss how it helps the company to solve the technical or operational complexity of handling data.
Eg1: problem of securely maintaining customer data can be solved by implementing data security practises, setting up a security framework that establishes right users to get access to the data, continuous audit will help to monitor any malpractice etc.
Eg2: poor data quality issues can be solved by implementing data quality measures
4. Remember not to deep dive into any topics, the solution is more at a conceptual level
5. Please address the below areas
• Identifying the business requirements and existing issues in data operations (explain techniques used collecting requirements)
• Data management operations relating to the various kinds of data that the company deals with.
• Data Architecture (provide example of a proposed architecture that will help in processing the data e.g. ETL(data warehousing or cloud solution)
• Data quality measures
• Metadata management
• Handling legacy data - Data migration
• Data archival
• Data governance measures
• Data privacy
• Expected benefits
6. The areas listed above are indicative and are in no sequence. When addressing this in the solution, please ensure you write in an orderly fashion. Also, any other data management areas not listed above can also be covered.
7. You are strongly advised to read the rubric, which is an evaluation guide with criteria for grading your assignment.
Solution
Business Requirements and Existing Issues
The Status of the retail bank this time exposes severe issues brought on by out-of-date IT systems, which impede efficient data management and reduce client satisfaction. The bank has a sizable client base and a desire to grow even more, but it fails to manage new demands effectively. For Assignment Help, The problem is made worse by the dependence on uncoordinated technologies like Excel, Access DB, and outdated Oracle DB, which slows the generation of reports as a result of dispersed and inconsistent data. Additionally, the bank's capacity to respond quickly to problems and raise client satisfaction is hampered by insufficient data storage and management of consumer complaints. Modernisation, centralisation, and improvement of data processing are obviously necessary.
An complete business data management system is suggested to handle these problems. This approach ensures effective data management and integrity by replacing obsolete systems with contemporary database technology. The implementation of a centralised data repository will improve data quality and compliance when combined with strong data governance and security measures. Advanced analytics technologies may also help with the analysis and quicker response of consumer complaints (Orazalin, 2019, p.493). Business users may concentrate on innovation rather than mundane administration by automating manual data processes. Overall, the bank will be able to manage its expanding client base and update its IT environment thanks to this solution's simpler processes, increased customer happiness and increased business agility.
Data Management Operations
The retail bank is facing major difficulties with data management and its related operations given the status of the industry. The bank has a long history that dates back to the 1970s, has amassed a sizeable client base, and has a good reputation throughout Australia. The bank's quick client expansion has, however, resulted in operational inefficiencies brought on by outmoded IT systems and data management procedures. As a consequence of the current method's reliance on Excel sheets, Access databases, and outdated Oracle databases, data processing is fragmented, report production takes a long time, and data integrity is compromised.
.png)
Figure 1: Data Management Operations in Banks
Source: (Recode Solutions, 2022)
By year's end, the bank hopes to have one million customers, thus an updated and comprehensive data management system is required. The shortcomings in the present system make it difficult to handle consumer complaints effectively, resolve problems quickly, and make data-driven decisions. Furthermore, the problems are made worse by a lack of adequate data governance and security procedures. In order to enable business users to concentrate on strategic development rather of being bogged down by manual data activities, the Chief Technology Officer is aware of the necessity for a complete data management plan.
To address these concerns, implementing an enterprise data management solution is paramount. This solution will streamline data collection, storage, processing, and reporting, resulting in enhanced operational efficiency, improved customer satisfaction through faster complaint resolution, and better-informed decision-making (Reis et al., 2022, p.20). Additionally, the solution will establish robust data governance and security protocols, ensuring data quality, privacy, and compliance. Ultimately, the holistic approach aims to facilitate data-driven growth, enabling the bank to achieve its customer expansion goals while maintaining operational excellence and reputation.
Data Quality Measures
The current state of the retail bank highlights several data-related challenges that need to be addressed through an effective data management solution. The bank, with a long-standing reputation and an expanding customer base, is undergoing IT modernization to accommodate growth. However, the existing data infrastructure comprising Excel sheets, Access DB, and an outdated Oracle DB poses significant obstacles. These range from inefficient handling of customer requests and operations management to compromised customer satisfaction due to delayed complaint resolution. Generating reports from disorganized and disparate datasets is time-consuming, primarily due to data integrity issues stemming from poor data quality (Grimes et al., 2022, p.108).
There are several advantages to using an enterprise data management system. First, more accurate reporting and analytics will be possible because to enhanced data quality and integrity, which will allow for more informed choices. Second, by immediately resolving concerns, simplified procedures and effective data processing will raise customer satisfaction. Sensitive data will also be protected by the solution's governance and security safeguards, guaranteeing compliance with data protection laws. In the end, this solution will relieve business users of the stress of repetitive data administration duties and allow them to concentrate on strategic projects, promoting innovation and development.
Metadata Management
Metadata management is crucial for addressing the data-related challenges faced by the retail bank. Currently, the bank's operations are hindered by outdated systems and processes, leading to inefficiencies in managing customer data and operations. The bank's customer base is rapidly growing, and the use of Excel sheets, Access databases, and an old version of Oracle DB is causing data disarray and integrity issues. Due to scattered data sets and low data quality, it is difficult to provide timely reports for decision-making. Inadequate data storage and analytics skills also make it difficult for the bank to manage and report consumer concerns (Grimes et al., 2022, p.104).
It is crucial to establish a strong metadata management system in order to prevent these problems. In order to manage data definitions, linkages, and provenance across systems, a central repository must be established. With the help of this solution, data consistency, quality, and reporting and analytics will all be improved. Implementing governance and security measures will also improve compliance and data protection. The system will encourage innovation and development by automating data administration duties and allowing business users to concentrate on their main responsibilities. In the end, this strategy will speed up the processing of client complaints, increasing customer happiness and loyalty while also putting the bank in a position to easily meet its objective of one million customers by year’s end.
Data Governance Measures
A strong data governance policy has to be built to deal with these issues. Modern database systems will be used to centralise data storage, along with procedures for data integration and data quality implementation, as well as the establishment of distinct roles and responsibilities for data ownership. Data security measures should also be implemented to safeguard sensitive consumer information and guarantee compliance with relevant legislation, such as data privacy laws.
.png)
Figure 2: Types of Data Governance Measures
Source: (Nero, 2018, December 7)
The bank will profit in several ways by using an enterprise data management system. A faster response of client complaints will increase customer happiness and retention, which is the first benefit of streamlining data procedures. Second, more accurate reporting made possible by enhanced data integrity will lead to better decisions. Last but not least, the decreased human labour required for data administration chores would free up business users to concentrate on innovation and growth efforts, leading to the creating of new business possibilities and income.
Handling Legacy Data - Data Migration
For the bank’s modernization efforts and operational effectiveness, it is crucial to adopt a complete data management solution given the situation of the company today and the associated data-related problems. The bank's antiquated Oracle DB and legacy systems, such as Excel spreadsheets, Access databases, and Access databases, are unable to handle the growing client base and new demands. As a result, creating reports takes a lot of time, the data's quality is poor, and client satisfaction is suffering. A solid data transfer plan is suggested as a solution to these problems. In this approach, the current data from historical systems is moved to a more sophisticated and scalable platform, such a contemporary relational database or a cloud-based solution (Roskladka et al., 2019, p.15).
This method of data movement has several advantages. The bank would be able to manage the projected increase in clients with ease since it would first guarantee a smoother transfer to contemporary technology. Second, by consolidating data into a single repository, creating reports would be more quickly and cost-effectively. Additionally, increased data integrity would increase analytics' accuracy, resulting in better decision-making. In the end, the data transfer approach will lessen the load of legacy systems, allowing business users to concentrate on core duties, innovation, and customer-centric initiatives instead of being bogged down in manual data administration responsibilities. This transition to effective data management creates the groundwork for a bank that is more adaptable, responsive, and customer-focused.
Data Architecture
In response to the current challenges faced by the bank, a proposed enterprise data management solution aims to address data-related issues while supporting growth objectives. Given the bank's outdated systems and processes coupled with a growing customer base, a robust solution is imperative.
To streamline data operations, a modern data architecture is recommended, leveraging cloud-based technologies. This architecture involves Extract, Transform, Load (ETL) processes to efficiently collect data from sources like Excel sheets, Access DB, and Oracle DB. The data will then be cleansed, transformed, and loaded into a centralized cloud-based data warehouse. This repository ensures real-time access to accurate and consolidated data, thereby enhancing reporting efficiency and maintaining data integrity.
.png)
Figure 3: Data Architecture of Bank
Source: (Fernandez, 2019, August 20)
Benefits of this solution include improved operational efficiency, expedited decision-making, and elevated customer satisfaction. By automating data processes, bank employees can redirect their focus towards innovative business initiatives. Swift access to reliable data aids in promptly addressing customer complaints and boosting overall satisfaction. Furthermore, this data management approach establishes robust governance and security measures, mitigating risks associated with data mishandling. In conclusion, this holistic solution aligns with the bank's modernization goals and supports the CTO's vision of utilizing data for strategic growth (Grimes et al., 2022, p.171).
Data Privacy
One of the critical issues is the inability to manage customer complaints effectively, impeding the bank's goal of swift complaint resolution and improved customer satisfaction. The absence of a well-structured data storage mechanism for complaints, coupled with poor data quality, hinders insightful reporting and analytics. Furthermore, the lack of defined governance and security measures exposes the bank to potential risks associated with data mishandling. To address these challenges, implementing an enterprise data management solution is imperative. This solution would streamline data processes, centralize data storage, and enhance data quality through standardized practices. The integration of modern data management tools and technologies would enable efficient report generation and analytics, aiding decision-making processes. Moreover, by enforcing proper governance and security measures, the bank can ensure data privacy and mitigate potential breaches (La Torre et al., 2021, p.14)
Benefits of this data management solution include enhanced customer satisfaction through quicker complaint resolution, optimized operational efficiency, and improved data privacy and security. By liberating business users from tedious data management tasks, they can focus more on innovation and value creation, aligning with the Chief Technology Officer's vision for the bank's growth and modernization.
Data Archival
An enterprise data management system is essential to optimise operations and assure future scalability in response to the existing conditions of the company and the data-related difficulties encountered by the retail bank. Excel sheets, Access databases, and out-of-date versions of Oracle DB are just a few of the systems and procedures the bank now uses that make it difficult to handle data effectively and keep up with the growth in its client base. This leads to operational inefficiencies and a poor response to client concerns.
These problems will be solved and a number of advantages will result from using an extensive data management system. First, a crucial part of this approach will be data archiving. The bank may free up space on its current systems and improve the speed and responsiveness of those systems by preserving past client data and transaction records. Second, centralised data integration and storage will enhance data integrity and quality, allowing for more rapid and precise reporting. Furthermore, clear governance and security policies will guarantee data compliance and protect sensitive data. Overall, this solution will relieve business users of data administration duties so they can concentrate on core company responsibilities and innovation. Additionally, increased complaint resolution and operational efficiency will increase customer satisfactions.
Expected Benefits
The first step of the strategy is to centralize data storage and switch from outdated Oracle DB and separate systems like excel and Access DB to a more up-to-date, integrated database architecture. This change will improve data integrity, decrease duplication, and promote effective data retrieval, enabling the creation of reports more quickly and accurately. Second, the system has sophisticated data analytics and reporting features that will enable the bank to examine data on customer complaints, spot patterns, and respond quickly to resolve problems—all of which are in line with their objective of raising customer happiness.
The suggested solution also incorporates strong data governance and security mechanisms that guarantee regulatory compliance and protect private consumer data. By doing this, the bank's data handling procedures will be in line with industry best practices, reducing the likelihood of data breaches. Overall, the data management solution will allow business users to concentrate on strategic development objectives instead of being burdened by manual data management duties, freeing up critical time from them to do so.
References
.png)
Reports
CBS131 Cybersecurity Principles Report 2 Sample
Assessment Task
Produce a 1500-word cybersecurity group report. Advise on how to assess the cybersecurity threats facing the banking industry and apply an incident response plan to remediate from such attacks.
Please refer to the Task Instructions below for details on how to complete this task.
Task Instructions
Section A: Group Work
1. Group Formation
• Form a group of a maximum of 3 members.
• Your group must be formed by the end of Module 5 (Week 5) and registered.
• To register your group, you are required to send your Learning Facilitator an email before the registration deadline.
• Send an email to your Learning Facilitator with“CBS131 Group Registration” in the subject line. In the body of the email, please list the names and student ID numbers of all the members of your group. Also attach your completed Group Contract (see below for more details).
• Please note that you will work with your group members for Assessments 2 and 3.
2. Group Contract
Please read the attached CBS131_Assessments 2 & 3_Group Contract.
This document outlines the rules and conditions each group has to follow for both assessments as well as the roles and responsibilities of each group member. The group contract accounts for 5% of the assessment grade, as indicated in the Assessment Rubric.
• For assessments where students are expected to work in groups, the workload must be shared equitably among all group members. Please refer to sections 6.1 and 6.2 of the TUA PL_AC_014: Student Conduct Policy.
• When submitting the group contract, you are reminded not to ‘recycle’ (self-plagiarise) contracts from other assessments. Sections on deliverables, timeline and expectations should be unique to each assessment or project. Self-plagiarism constitutes a breach of Academic Integrity and can lead to penalties to the assessment or subject.
• During Assessments 2 and 3, you should keep records of communication and drafts. Any serious concerns about an
individual group member’s contribution should be brought to the attention of your Learning Facilitator as soon as they occur or at least two weeks before the due date, whichever is earlier.
• If a student has been accused of not contributing equally or fairly to a group assessment, the student will be contacted by the Learning Facilitator and given three working days to respond to the allegation and provide supporting evidence. If there is no response within three working days of contact, the Learning Facilitator will determine an appropriate mark based on the evidence available. This may differ from the mark awarded to other group members and would reflect the individual student’s contribution in terms of the quantity and quality of work.
Section B: Analyse the case and develop the group report
1. Read the attached case scenario to understand the concepts being discussed in the case.
2. Address the following:
• Review your subject notes to establish the relevant area of investigation that applies to the case. Study any relevant readings that have been recommended in the case area in modules. Plan how you will structure your ideas for the attacks/risk analysis, and remediation.
• Identify the methodology used to launch the cyber-attack against the bank and address the cyber threat landscaping and challenges facing the banking domain.
• Appraise the cyber attack’s impact on the bank’s operation.
• Explain the necessary security measures required to combat cyber threats, describe the basic security framework that banks need to have in place to defend against cyber threats and describe relevant security technologies to protect against cyber-attacks.
• Describe the strategies undertaken by banking management to regain customer trust in the aftermath of the cyber-attack.
• You will be assessed on the justification and understanding of security methods in relation to cyber-attack methodology, impact of the cyber-attack on banking industries, and effective strategies that can be used to regain trust of its customers. The quality of your research will also be assessed as described in the Assessment Rubric section. You may include references relating to the case as well as non-academic references. You will need to follow the relevant standards and reference them. If you chose not to follow a standard, then a detailed explanation of why you have done this is required.
• The content of the outlined chapters/books and discussion with the lecturer in the Modules 1 to 4 should be reviewed. Further search in the library and/or internet about the relevant topic is encouraged.
3. Group member roles:
• Each member is responsible for researching/writing about two methods or strategies.
• All group members are responsible for editing and checking the references of the report at the end so it’s not one member’s sole responsibility.
4. The report should consist of the following structure:
• A title page with the subject code and name, assessment title, student name, student number and Learning Facilitator name.
• The introduction (approx. 150 words) should describe the purpose of the report. You will need to inform the reader of:
• a) Your area of research in relation to data breach attacks and its context
• b) The key concepts of cybersecurity you will be addressing and what the effects of a data breach are.
• The body of the report (approx. 1,200 words) will need to respond to the specific requirements of the case study. It is advised that you use the case study to assist you in structuring the security methods in relation to the attacks/risk analysis and remediation, cyber threat
• landscaping and challenges facing the banking domain, impact of cyber attacks on the organisation and its customers, necessary security measures required to combat cyberthreats and effective strategies that can be used to regain the trust of its customers.
• The conclusion (approx. 150 words) will need to summarise any findings or recommendations that the report puts forward regarding the concepts covered in the report.
5. Format of the report:
• The report should use the Arial or Calibri font in 11 point, be line spaced at 1.5 for ease of reading and have page numbers on the bottom of each page. If diagrams or tables are used, due attention should be given to pagination to avoid loss of meaning and continuity by unnecessarily splitting information over two pages. Diagrams must include the appropriate labelling in APA style.
Please refer to the Assessment Rubric for the assessment criteria.
Solution
Introduction
As determined by cyber threat, the landscape includes an entire segment of cybersecurity affecting organisations, user groups and specific industries. The emergence of novel cyber threats daily changes its landscape accordingly. The threat landscape constitutes certain factors that pose a risk to every entity within a relevant context. The case study report has discussed the cyber threat landscaping faced by the banking sectors worldwide. For Assignment Help, The associated challenges to protect and maintain customer confidence, especially in the corporate domain, have also been discussed. The report has focused on data breaches as a strategy to carry out malicious activities by the actors and motivators of cybercrimes. An action data breach can significantly cause adverse effects for the parent organisation due to the mishandling of sensitive information resulting in identity theft (Benson, McAlaney & Frumkin, 2019). Hackers utilise such information to conduct malpractices in the form of new bank account opening or purchase actions.
Discussion
Cyber threat Landscaping and challenges facing the banking Domain
The sole responsibility for sensitive data security management has been given to the national government and the respective banking body. The global financial system has been undergoing a digital transformation accelerated by the global pandemic hit. Technology and banking systems are functioning parallelly to cater to digital payments and currency needs. Remote working of banking employees has necessitated the accessibility to sensitive information on personal data connections (Lamssaggad et al., 2021). This has facilitated the breach of data incidents across the globe as hackers can easily access customers' banking data from personal internet networks. Cyber-attacks are more prominent in middle income nations, while they are soft targets due to a lack of global attention.
Identify the methodology used to launch the cyber-attack against the bank
The continuation of cyber threats for the banking sectors involves identifying the following discussed methods as significant contributors.
Ransomware: The most significant form of cybercrime is ransomware, which involves encrypting selective files while blocking its real user. After that, a ransom is demanded by the criminal to provide accessibility for the encrypted files. The resultant event is witnessed in organisations facing an inactivity of their systems for longer. Ransom payment does not guarantee system recovery from criminals (Blazic, 2022).
The risk from remote working: Introducing hybrid working conditions for employees has led to significant vulnerabilities as cloud-based software is used. The banking sectors face significantly higher data breach risks due to sensitive data accessibility via employees' networks and systems.
Social engineering: Social engineering exploits the most important aspect of the financial system: the customers themselves. Customers are forced to share their sensitive credentials via unauthorised networks. The forms of social engineering include whaling and phishing attacks.
Supply chain attacks: Cybercriminals target a comparatively weaker partner in the supply chain for distributing malware. Certain messages regarding products and services are circulated via the system of the target partner to make the content legitimate, at least superficially. It is an increasing cybercrime in the financial sectors globally ( Lamssaggad et al., 2021). The hackers establish the authenticity of the networks as they gain control of the networks because of poor security management by the owner of the networks.
Cyber attack’s impact on the bank’s operation
.png)
Figure 1: Risk diagram for the banking sectors
Source: (Self developed)
.png)
Table 1: Risk Matrix
Source: (Self Developed)
It can be stated from the above risk matrix that cyber security for the banking industry has been associated with data security management policies. The above matrix shows that data breach is the most severe form of cyber risk which affects banking institutions. Whereas the risks associated with remote working environments have rarely occurred in the sector. The reason for such rarity is associated with the non-accessibility of the database from personal networks other than that of the bank's commercial network (Lallie et al., 2021).
Necessary security measures required to combat cyber threats
The launch of “International Strategy to Better Protect the Global Financial System against Cyber Threats” in the year 2020 have suggested specific actions to reduce fragmentation. This can be achieved by fostering collaborations among significant international and governmental agencies, tech companies and financial firms (Dupont, 2019). The World Economic Forum has been guided by strategies that include four aspects such as clarity regarding responsibilities and roles, the urgency of international collaboration, reducing fragmentation and protection of the international financial agencies. The governmental role involves the formation of financial CERTs (computer emergency response teams) for sharing sensitive risk management data as per Israel’s FinCERT. Cyber resilience can be strengthened by appropriate response formulation in the form of arrests, sanctions and asset seizures for combating cyber threats legally.
A security framework that banks need to have in place to defend against cyber threats
.png)
.png)
Table 2: NIST cyber security framework
Source: (Self Developed)
The NIST cybersecurity framework can be utilised to assess and implement every aspect of the problem, which is currently decreasing the value of the banking sectors across the globe (Kshetri, 2019). It has been noted that effectiveness regarding cyber security management greatly improves the customer relationships a bank maintains with its existing customers.
Security technologies to protect against cyber attacks
Intrusion Detection System (IDS): Network traffic is analysed by IDS to identify signatures corresponding to known attacks in the cyber domain. The requirement of human assistance or appropriate automated systems to interpret the results is a form of utilising more security measures for the action (Akintoye et al., 2022).
.png)
Figure 2: Elements of cybersecurity diagram
Source: (Geeksforgeeks 2022)
Data Loss Prevention (DLP): DLP utilises data encryption to prevent data loss by protecting information and decrypting them only with the help of appropriate encryption keys (Chang et al., 2020). Choosing a suitable encryption technology amongst AES, DES, and RSA determines the magnitude of prevention offered.
Firewalls: A network security device that operates based on the already proposed security rules and decides whether to allow certain network traffic into the system. Firewalls may include both hardware and software and are used to address mitigating threats and monitoring traffic.
Effective strategies that can be used to regain the trust of its customers
Loyalty exchange can be an effective strategy to gain customers' trust again in the global banking sectors. The dependency of the economy on digital transactions has made the avenues for cybercrimes more prominent for attackers. Customer service quality needs to be improved significantly by every banking organisation to achieve customer loyalty. Customer engagement can be increased by truthful sharing of banking scenarios with potential customers (Broby, 2021). The banking personnel should reciprocate customer loyalty to increase the trust component of the customers.
The management of the banking sectors should take adequate measures to help every growing business in the nearby localities. Transparency associated with the banking systems shall be put forth to increase customer satisfaction. Helpful behaviour on the part of the banking institutes shall also sow the seeds of cooperation and confidence in the customers. Adopting several community-minded activities by the banks shall be beneficial to install dependency and trust in the banking sectors once again.
The banks can utilise their economic knowledge about a particular economy to discuss the ill effects and benefits of investment into particular business sectors. The anxieties of customers regarding the management of their financial resources can be solved by the banks, especially at the branch level. This attitude shall reduce anxieties and improve customer reliance on banking systems (Ahmad et al., 2020). The warmth shared within the customer relationships shall effectively increase the confidence level of the customers in their respective banking institutes.
Conclusion
The report has discussed the cyber threat landscaping and its challenges in the banking sectors from a global perspective. It has been noted that the ongoing transition of financial transactions into digitised platforms has widened the scope of data breaches. The potential risks associated with online monetary transactions, use of UPI platforms and unauthorised access to sensitive data storage are major reasons for more cybercrimes. The associated damages are reflected in the withdrawal of confidence from the banking sectors across the global scenario. The risk matrix has identified the probability and factors which contribute to the risks faced by banking institutes. The report has also discussed hackers' methods to carry out such fraudulent activities. At the end of the report, certain suggestions have been discussed to regain customer confidence in the banks in the newly introduced digitised banking platform.
Reference list
.png)
.png)
Reports
DATA4300 Data Security and Ethics Report 3 Sample
Your Task
• Write a 1,500-word report and record a video reflecting on the report creation process (involving an initial ChatGPT-generated draft, then editing it to a final version) and lessons learned.
• Submit both as a Microsoft Word file in Turnitin and a Kaltura video file upload by Wednesday, Week 13, at 23:55 pm (AEST):
.png)
Assessment Description
You have been employed as a Data Ethics Officer by a medical industry board (professional body). The board asked you to write a Code of Conduct about using new technologies in healthcare, which should be kept up to date and reflect technological evolution. Because of this technology’s breakneck pace, the professional body wants to ensure a code of conduct review happens more regularly and has authorised you to experiment with AI-powered chatbots to create a faster update process.
You are to write a Code of Conduct focused on using new technologies to inform best practices in the healthcare industry. For this assessment, you will choose one of the following technologies:
a) A device that tracks and measures personal health indicators, or
b) An application that recommends mental health support therapies.
Inform your lecturer about your technology choice by Week 9
Assessment Instructions
You will be asked to produce a report and video for this assessment.
Report:
• You are to start by conducting your own research (Introduction and Considerations sections, see structure below) on your technology.
• You will then create a code of conduct draft generated by ChatGPT. Then, you will edit it to make it applicable to your chosen technology, compliant with current regulations, and meaningful to the medical board request. Your individual research will inform this.
• Your Code of Conduct will be presented in a report (a suggested structure is below). Add at least five original Harvard references and use citations to them in your report.
.png)
Solution
Introduction
The increasing adoption of new technology is having a revolutionary effect on the healthcare sector. One of the most talked-about new developments is the appearance of tools for monitoring one's own health statistics. For Assignment Help, These cutting-edge tools provide people a way to track their vital signs and collect useful information about their health in real time. Because it allows individuals to take an active role in their own health management, this technology has the potential to significantly alter the healthcare system.
Benefits of a device that tracks and measures personal health indicators
There are several benefits that a device that tracks and measures personal health indicators can provide, as mentioned below-
• Health monitoring and tracking process- Monitoring health indicators like heart rate, blood pressure, sleep, and activity levels help people keep tabs on their progress towards healthier lifestyles. Patients may evaluate their health improvement over time, which can boost their drive and self-awareness (Han, 2020).
• Improved diagnostics- The device helps people achieve their health goals by offering them with unique insights and suggestions based on their own health data. This encourages individuals to take charge of their health by making educated decisions about their lifestyle and taking preventative measures.
• Achieving Health Goals- The gadget helps create goals by delivering personalised health data insights and suggestions. This helps patients to make educated lifestyle choices and take proactive health activities (KORE, 2020).
.png)
Figure 1: benefits of health monitoring device
(Source: Scalefocus, 2022)
Privacy, Cybersecurity, and Data Ethics Concerns
The devices stored and using the patients also come with a few security issues as well-
• There is a risk of cyber threats and unauthorized access to sensitive health data.
• The healthcare department might use the data without any consent leading to a breach of privacy.
• The GDPR laws and other regulations related to data can be breached and data can be used to carry out cyber thefts.
Considerations on Regulatory Compliance, Patient Protection, and Risks
Cybersecurity, privacy, and ethical risks associated with a device that tracks and measures personal health indicators
Cybersecurity risks
• Data Breaches- The gadget may be hacked, exposing sensitive health data.
• Malware and viruses- Malware or viruses in the device's software or applications might compromise data security (Staynings, 2023).
• Lack of Encryption- Weak encryption may reveal sensitive health data during transmission or storage.
Privacy risks
• Unauthorised Data Sharing- Health data may be shared without permission, jeopardising privacy (Staynings, 2023).
• Insufficient Consent Procedures- Users may not completely grasp data gathering and sharing, resulting in partial or misinformed consent.
• Re-identification- Anonymized data may be re-identified, violating privacy.
Ethical risks
• Informed Consent- If users are not educated about the purpose, risks, and possible repercussions of data collection and usage, obtaining real informed consent might be difficult.
• Data Accuracy and Interpretation- Data collection or analysis errors or biases may lead to erroneous interpretations and improper health recommendations or actions (Healthcare, 2021).
Regulatory compliance issues and patient protection requirements
The key regulatory complaints and laws for the data and privacy protection of the patients being used via devices of the medical industry are as mentioned below, these laws and regulations are for the data protection and ensure customer safety.
• Health Insurance Portability and Accountability Act (HIPAA) - HIPAA compliance includes privacy and security requirements, breach reporting, and enforcement to safeguard healthcare system information. The HIPAA Privacy Rule applies to all healthcare professionals and covers all media types, including electronic, print, and oral. It gives people the right to see their own protected health information (PHI) and mandates that the information be disclosed as to how it is used (RiskOptics, 2022).
.png)
Figure 2: HIPAA
(Source: Splunk, 2023)
• Patient Safety and Quality Improvement Act (PSQIA) - The purpose of this regulation is to promote a culture of safety by offering peer review evaluations for information provided on healthcare mishaps. To prevent the information from being utilised in litigation against the PSO, the statute created new patient safety organisations (PSOs) (Carter Jr et al., 2022).
• Security Standards - Healthcare organisations must follow industry best practises and data security standards, such as encryption, access restrictions, and vulnerability monitoring. Standards like as ISO 27001 aim to assure the security, integrity, and availability of patient data (Cole, 2022).
• Incident Response and Breach Reporting - Organisations must have strong incident response procedures in place to deal with data breaches or security issues as soon as possible. They must also follow breach reporting standards, informing impacted persons and appropriate authorities within the times indicated (Healthcare Compliance, 2023).
.png)
Figure 3: regulatory compliances
(Source: MCN Healthcare, 2018)
CHAT GPT VERSION OF CODE OF CONDUCT
Code of Conduct for A Device that Tracks and Measures Personal Health Indicators
Privacy and Data Protection
1.1. Data Collection and Use: Ensure that the collection and use of personal health data by the device are transparent and conducted with the explicit consent of the individual. Clearly communicate the purpose of data collection, how the data will be used, and any third parties involved.
1.2. Data Security: Implement robust security measures to protect personal health data from unauthorized access, loss, or disclosure. This includes encryption, secure storage, access controls, and regular security assessments to identify and address vulnerabilities.
1.3. Data Retention: Establish clear guidelines on the retention period of personal health data. Retain data only for as long as necessary and securely dispose of it once no longer needed, following applicable legal and regulatory requirements.
1.4. Anonymization and De-identification: When feasible, provide options for anonymizing or de-identifying personal health data to protect individual privacy. Ensure that any re-identification risks are minimized to maintain confidentiality.
Informed Consent and User Empowerment
2.1. Informed Consent: Obtain informed consent from individuals before collecting their personal health data. Clearly explain the purpose, benefits, risks, and limitations of data collection, enabling individuals to make informed decisions about using the device.
2.2. User Control: Provide individuals with mechanisms to control the collection, use, and sharing of their personal health data. Allow users to easily access, review, and modify their data preferences and provide options for data sharing with healthcare professionals or researchers.
2.3. User Education: Promote user education and awareness about the device's functionalities, data collection practices, and privacy settings. Ensure that individuals understand how to use the device safely and responsibly, empowering them to make informed decisions about their health data.
Accuracy and Reliability
3.1. Data Accuracy: Strive for accuracy and reliability in the measurements and data generated by the device. Regularly calibrate and validate the device to ensure accurate and consistent results, minimizing potential inaccuracies that could impact health decisions.
3.2. Algorithm Transparency: Provide transparency regarding the algorithms used to process and interpret personal health data. Users should have access to information about how the device calculates metrics, enabling them to understand and interpret the results accurately.
Ethical Use of Data and Algorithms
4.1. Responsible Data Use: Use personal health data only for legitimate purposes related to the device's functionalities and in accordance with applicable laws and regulations. Avoid the use of personal health data for discriminatory or unethical practices.
4.2. Avoidance of Bias: Ensure that the device's algorithms are developed and tested to minimize bias and discrimination. Regularly evaluate and address any potential biases in data collection or algorithmic decision-making processes to ensure fair and equitable outcomes.
Transparency and User Communication
5.1. Transparency of Data Practices: Provide clear and accessible information about how personal health data is handled, stored, and shared. Clearly communicate the device's data practices, including any third-party partnerships or data sharing arrangements, to foster transparency and trust.
5.2. User Communication: Establish effective channels of communication with users, allowing them to raise concerns, ask questions, or provide feedback about the device and its data practices. Promptly address user inquiries and provide transparent and meaningful responses.
Compliance with Applicable Laws and Standards
6.1. Regulatory Compliance: Adhere to all relevant laws, regulations, and standards governing the collection, use, and protection of personal health data. Stay updated with evolving regulatory requirements and ensure ongoing compliance with data privacy and protection obligations.
6.2. Industry Standards: Align with industry best practices and standards for privacy, data security, and ethical use of personal health data. This includes adhering to guidelines such as the GDPR, HIPAA, ISO 27001, and other applicable frameworks.
Accountability and Governance
7.1. Accountability: Establish clear accountability and governance mechanisms for the responsible use of personal health data. Assign roles and responsibilities for data privacy, security, and ethical considerations. Conduct regular audits and assessments to ensure compliance and identify areas for improvement.
7.2. Continuous Improvement: Regularly review and update the device's functionalities, privacy policies, and data practices to reflect advancements in technology, evolving regulatory requirements, and user feedback. Continuously strive for enhanced privacy, security, and ethical standards.
By following this Code of Conduct, developers, manufacturers, and operators of devices that track and measure personal health indicators can ensure the ethical and responsible use of personal health data, fostering trust among users and promoting the benefits of these innovative technologies in healthcare.
Code of Conduct
The technology chosen for this study is A device that tracks and measures personal health indicators, the device will require data from the patients which needs to be collected with informed consent, and all the regulatory compliances and data protection laws must be followed and adhered by the companies and medical industry. This will help the patients to build trust with their information on the company and medical industry and misuse of information can be done.
The code of conducts that needs to be followed are as mentioned below-
1. Privacy and data protection
a. Data collection and its usage- The Collection and Use of Personal Information. Make that the device is upfront about collecting and using an individual's personal health data, and that the subject gives their informed permission before any data is collected or used. Explain why you need the information, what you plan to do with it, and who else could have access to it (Data Privacy Manager, 2023).
b. Ensure top data security- Protect sensitive health information from theft, loss, and misuse by using industry-standard security protocols. Encryption, safe archiving, access limits, and routine vulnerability scans are all part of this.
c. Data retention- Clear rules on how long health records should be kept should be set out. When data is no longer required, it should be safely deleted in accordance with legal and regulatory standards.
d. De-identification and anonymisation- To further safeguard individuals' privacy, health records should be anonymized or de-identified wherever possible. Maintaining anonymity requires taking all necessary precautions (Maher et al., 2019).
2. User empowerment and informed consent
a. Patient’s control or data owner control- Allow people to make decisions about how their health information is collected, used, and shared. Provide choices for data sharing with healthcare practitioners or researchers and make it easy for consumers to access, evaluate, and adjust their data preferences.
b. Informed consent- Obtain people' informed permission before collecting their personal health data. Individuals will be able to make educated choices regarding device use if the purpose, advantages, dangers, and restrictions of data gathering are made clear (Sim, 2019).
c. User education- Increase user knowledge of the device's features, data gathering methods, and privacy controls. Make sure people know how to use the gadget properly and securely so they can make educated choices based on their health information.
3. Accuracy and reliability
a. Data accuracy- The device's measurements and data should be as accurate and trustworthy as possible. It is important to regularly calibrate and test the equipment to provide reliable findings and reduce the risk of inaccurate data influencing medical choices (Morley et al., 2020).
b. Algorithm and transparency- Be open and honest about the algorithms you’re using to analyse and interpret patients’ health information. In order to correctly interpret the data, users need to know how the gadget arrives at its conclusions.
4. Ethical use of data and algorithms
a. Using data responsibly- Use sensitive patient information responsibly and in line with all rules and regulations pertaining to the device's intended. Protect people's health information from being used in unethical or discriminatory ways.
b. Avoidance of bias- Make sure the device's algorithms have been designed and validated to reduce the likelihood of bias and unfair treatment. If you want to be sure that your data gathering and algorithmic decision-making processes are producing fair and equitable results, you should examine them on a regular basis and fix any problems you find.
5. Transparency and user communication
a. Data practices of transparency- Give people easy-to-understand details on how their health data is used and shared. Foster openness and trust by making it easy for users to understand the device's data practises, including any third-party partnerships or data sharing agreements (Kelly et al., 2020).
b. User Communication- Users should be able to voice their concerns, ask questions, and provide suggestions concerning the device and its data practises via established lines of contact. Get back to customers as soon as possible, and do it in a way that is both clear and helpful (Deloitte, 2020).
6. Compliance with Applicable Laws and Standards
a. Following laws and regulatory compliances- Respect all rules and regulations regarding the handling of sensitive health information. Maintain continuing compliance with data privacy and protection duties by keeping abreast of changing regulatory standards (Icumed, 2022).
b. Industry Standards- Maintain privacy, protect sensitive information, and utilise patient health data ethically in accordance with industry standards. The General Data Protection Regulation, the Health Insurance Portability and Accountability Act, the Information Security Standard ISO/IEC 27001.
7. Governance and accountability of the data
a. Continues improvement- The device's features, privacy rules, and data practises should be reviewed and updated on a regular basis to account for technological developments, shifting legislative requirements, and user input. Maintain a constant drive to improve confidentiality, safety, and morality.
b. Accountability- Establish transparent governance and accountability procedures for the ethical management of individual health records. Determine who is responsible for what in terms of protecting sensitive information and following ethical guidelines. Maintain a regimen of frequent audits and evaluations to check for inconsistencies and locate problem spots (Icumed, 2022).
.png)
Figure 4: code of conduct
(Source: Author, 2023)
References
.png)
.png)
Reports
DATA6000 Industry Research Report 4 Sample
Assessment Description
.png)
In order to synthesise what you have learnt in your Analytics degree you need to submit an industry research report. This report needs to:
1. Outline a business industry problem that can be addressed through data analytics
2. Apply descriptive and predictive analytics techniques to the business problem
3. Provide recommendations addressing the business problem with reference to by data visualisations and outputs
4. Communicate these recommendations to a diverse audience made up of both analytics and business professionals within the report
Assessment Instructions
In your report please follow the below structure.
1. Executive Summary (100 words)
• Summary of business problem and data-driven recommendations
2. Industry Problem (500 words)
• Provide industry background
• Outline a contemporary business problem in this industry
• Argue why solving this problem is important to the industry
• Justify how data can be used to provide actionable insights and solutions
• Reflect on how the availability of data affected the business problem you eventually chose to address.
3. Data processing and management (300 words)
• Describe the data source and its relevance
• Outline the applicability of descriptive and predictive analytics techniques to this data in the context of the business problem
• Briefly describe how the data was cleansed, prepared and mined (provide one supporting file to demonstrate this process)
4. Data Analytics Methodology (400 words)
• Describe the data analytics methodology and your rationale for choosing it
• Provide an Appendix with additional detail of the methodology
5. Visualisation and Evaluation of Results (300 words not including visuals)
• Visualise descriptive and predictive analytics insights
• Evaluate the significance of the visuals for addressing the business problem
• Reflect on the efficacy of the techniques/software used
6. Recommendations (800 words)
• Provide recommendations to address the business problem with reference to data visualisations and outputs
• Effectively communicate the data insights to a diverse audience
• Reflect on the limitations of the data and analytics technique
• Evaluate the role of data analytics in addressing this business problem
• Suggest further data analytics techniques, technologies and plans which may address the business problem in the future
7. Data Ethics and Security (400 words)
• Outline the privacy, legal, security and ethical considerations relevant to the data analysis
• Reflect on the accuracy and transparency of your visualisations
• Recommend how data ethics needs to be considered if using further analytics technologies and data to address this business problem
Solution
Executive Summary
The business strategy works as a backbone which leads the business achieve desired goals leading towards profit and secures the future decision making in a competitive market. The airline industry serves many purposes and the problem arises in the industry of customer satisfaction affects most of them. For assignment help, The solution for the problem is to analyses the customer satisfaction rate by different services airline is offering to the passengers. The analysis will be conducted for the services offered by the airline business industry for their customers or passengers during travel to analyze the satisfaction rate which can outline the key components which are affecting their business and reason for the customer dissatisfaction rate.
Industry Problem
Airline industry consists of number of services during travel to the passengers where the services for customers are paid with the business partners. The services offered for the passengers as well as the cargo via different modes including jets, helicopters and airlines. The airlines is one of the known businesses in the travel industry which offers services to the passengers to use their spaces by renting out to the travelers.
Contemporary business problems
There are multiple challenges comes in the aviation industry which includes:
• Fuel Efficiency
• Global Economy
• Passenger satisfaction
• Airline infrastructure
• Global congestion
• Technological advancement
• Terrorism
• Climate change
.png)
Figure 1 Industry issues
These contemporary problems affect most in the travel industry specially for the airlines. The mostly faced business problem in the airline is the passenger satisfaction which affects the business most as compares to all other problems.
The airline enterprise has been an important piece of the British financial system for many centuries. Through innovation and invention, the British led to the sector in travel aviating in the course of the Industrial Revolution. Inventions which include the spinning jenny, water frame, along with water-powered spinning mill had been described as all British innovations.
The style and airline enterprise in England, Wales, and Scotland employs around 500,000 humans, made from 88,000 hired in the aviating unit, 62,000 in the wholesale unit, and 413,000 in the retail sector. There had been 34, that is 1/2 groups running within the UK style and airline area in the year 2020, throughout the services, transporting, and aviating sectors of the travel industry.
As the airline and transporting in the marketplace in UK keeps act as rebound, each production and intake of customers and passengers are starts thriving, the quantity of undesirable apparel is likewise soaring, and is turning into certainly considered one among the most important demanding situations for the environmental and financial sustainability within the UK.
According to the latest studies performed through UK grocery store chain Sainsbury’s, customers within the UK are anticipated to throw away round 680 million portions of garb this coming spring, because of updating their wardrobes for the brand new season in the aviation sector. Within the heap of undesirable apparel, an amazing inflation of 235 million apparel gadgets are anticipated to become in landfill, inflicting a massive terrible effect for the business environment (Ali et.al., 2020).
The survey additionally suggests that every UK client will eliminate a mean of nineteen apparel objects this year, out of which the seven might be thrown directly into the bin in United Kingdom. Over 49% of the human beings puzzled within the passengers are surveyed and believed tired or grimy apparel gadgets that cannot be donated for services, prompting the travelling and services enterprise to induce the general public to set them apart there from their used products for services offering regardless of the desired quality (Indra et.al., 2022).
Furthermore, one in six respondents that is claimed that they've inadequate time to be had or can not be troubled to the various type and recycle undesirable apparel gadgets, at the same time as 6% raise in the apparel demand in the market that can be recycled for the fresh start up of the lifes of travel industry. The industry is now indulging in the various effective activities in creating the elements through recycling of the cloth for the sustainability of the environment.
Airline services is turning into one in all the largest demanding situations for the environmental and financial sustainability across the world. The UK isn’t the most effective one; different nations also are notably contributing towards the issue – over 15 million tonnes of the passengers travelling is produced each year within the United States, at the same time as an large 9.35 million tonnes of passengers services are being landfilled within the European Union every year for the sustainability.
Data processing and management
Data Source
The data chosen for the exploratory data analysis on the airline industry is from Kaggle which consists of different airline services offered to the passengers including attributes:
Id, Gender, Customer type, age, class of travel, satisfaction and satisfaction rate which are the main attributes on which analyses is performed to analyses the passenger satisfaction rate towards the airline industry. The visualizations on the attributes are performed to describe the services passengers mostly liked during travel and the satisfaction rate they have provided to the services availed by them.
.png)
Figure 2 Airline industry dataset
Applicability of descriptive and predictive analytics
The descriptive and predictive analytics is done in order to provide better decisions for future by analyzing the past services. The descriptive analytics is done to describe the company positives and negatives happened in their services by which customer satisfaction rate is increased or decreased where the predictive analytics is totally based upon descriptive analytics to provide the potential future outcomes from the actions analyzed combining all the problems and finding a solution for the future in order to reduce the negatives and provide better future outcomes.
Data cleaning
The data processing was done by removing and dropping of the columns not required for the analysis. Data consists of some not required attributes which has no use in the analysis which are dropped. Further data cleaning was done by checking of the null values and filling of the space so that no noise can be raised during the analysis and visualizing the data attributes (Sezgen et.al., 2019). The data mining is done by extracting out all the necessary information of the services provided to the passengers by comparing them to the satisfaction sentiment provided by the passengers to predict the satisfaction rate on each and every service availed by them which makes it easy for the company to look for each and every service offered by them.
Data Analytics Methodology
Python
Python is used in the analysis of the business industry problem of airline passenger satisfaction. Python is mostly used and known for managing and creating structures of data quickly and efficiently. There are multiple libraries in python which were used for effective, scalable data analytics methodology including
Pandas
Pandas is used for reading different forms of data which is data manipulating library used for handling data and managing it in different ways. The pandas used in the data analytics to store, manage the airline data and perform data different operations upon it by processing and cleaning of data.
Matplotlib
This library of python is used for extracting out all the data information in the form of plots and charts with the help of NumPy which is used to manage all the mathematical operations upon data to describe data in statistical manner and matplotlib presents all the operations using plots and charts.
Seaborn
This python library is also used to describe the data insights into different graphs and charts but in an interactive way using various colors and patterns upon the data which makes a data more attractive and easier to understand. These graphs generated are very attractive and can be used by businesses to describe as their efficiency in the business to the customers to travel with them (Noviantoro, and Huang, 2022).
The methodology details are further attached in the Appendix to describe in brief the methodology used for the data analytics and the predictions and calculations happened upon the data in descriptive and predictive analytics techniques using python programming language.
Visualization and Evaluation of Results
Results of the passenger satisfaction
The results of the analysis and visualization depicts the satisfaction as the binary classification where the dissatisfaction rate cannot be measured by neutral category by airline industry also measuring the aspects of the flight location, ticket price, missing in the data which can be a major aspect in analysis (Tahanisaz, 2020).
The results depict that airline provides increased satisfaction rate to the business travellers and passengers more as compared to the personal passengers. The services which are mostly disliked or the passengers were dissatisfied with were online booking and seat comfort which should be taken as priority by airline industry with the departure on time and the inflight services to tackle such issues as passengers appear to be the sensitive in aspects of such issues (Hayadi et.al., 2021).
.png)
Figure 3 Satisfaction results
.png)
Figure 4 Satisfaction by gender
.png)
Figure 5 Satisfaction by customer type
.png)
Figure 6 Satisfaction by services
.png)
Figure 7 Satisfaction by total score
.png)
Figure 8 Satisfaction by total score for personal travellers
.png)
Figure 9 Satisfaction by total score for business travellers
.png)
Figure 10 Data correlation heatmap
Significance of the visuals in business
Visuals depicts and communicate in a clear manner and defines the ideas to cost up the business and sort most of the business-related issues by analyzing and visualizing the data insights for future decision makings. Visuals manages the cost, time and customers for the business perspective.
Efficacy of Python Programming
The python programming language used for the visualization and analytics on the airline industry passenger satisfaction with the Jupyter notebook IDE and the Anaconda Framework. The python is very efficient in comparison to other analytics methods because it gives more efficient syntax as it is high level language and provides better methods to analyses and visualize data.
Recommendations
Ideally that is apparel that gains the maximizes high quality and minimises terrible environmental, social and financial affects along with its delivery and price chain. Airlines is sustainable does now no longer adversely affect the nature of purchasing behavior of human beings or the planet in its manufacturing, transport, retail or travel of lifestyles management in today's era.
A variety of realistic examples of the sustainable apparel are at the marketplace. These range within the degree of sustainability development they obtain that specialize in surroundings, honest alternate and hard work problems to various extents (Shah et.al, 2020). Some examples of movements to enhance the sustainability of apparel are: apparel crafted from licensed services food drinks, beverages, the use of organic and healthy food; departures that permit us to apply much less strength whilst services our customer satisfaction and are much less polluting; foods and drinks with the books for the passengers keep the use of much less strength that is garb reused at quit of existence on the second one hand market; cleanliness apparel recovered at give up of existence to be travel again into greater apparel; Fair Trade licensed online bookings allowing greater equitable buying and selling conditions, making sure hard work requirements are adhered to continue the exercise and stopping exploitation. Sustainability is critical due to the fact all of the selections that is pursued and all of the movements that make nowadays will have an effect on the entirety withinside the future or upcoming time. consequently interruption of the make sound selections at today's era so that it will keep away from restricting the selections of generations to come over here for the growth and development in the aviation sector. The motives for the environmental destruction are specifically because of populace ranges, intake, generation and the financial system. The trouble in considering the worldwide surroundings that has much less to do with populace increase in the demand than it does with stages of intake through the ones living in the airline industry (Gorzalczany et.al., 2021).
The courting among the inexperienced advertising and marketing creates the motion and client conduct is a vital subject matter to an extensive variety of the situational areas. Sustainability idea can't be finished with out related to the client. The key position of client behavior (and family client behavior in particular) in riding with the business or external environmental effect has long been recognized. In the end, it's miles the customers who dictate in which the marketplace will go to baggage handling the items. Passenger want and desires create a cycle of client demand and supply of the inflight services, business enterprise catering to that demand, and finally, stays for the client recognition with the acquisition of products within the online boarding services. The assessment of this look at ought to help in advertising and marketing efforts with the aid of using the green style strains and their information of client conduct. It may also help style airline businesses in figuring out whether or not or now no longer to provide an green line. The airline enterprise’s consciousness is one of the reasonably-priced productions and distribution of the services without giving an idea to its effect at the environment (Tsafarakis et.al., 2018).
Data Ethics and Security
Privacy, legal, security, and ethical considerations
The data of any business industry is taken under ethical measuremnts to secure the safety and privacy of the customers personal information. Considering privacy,s ecurity and legal issues data access is the major thing to be consider which provides freedom for the business to use the data for their requirements but the unauthorized access to the data and information may cause harm to business as well as the privacy of the customers and clients in business industry (North et.al., 2019).
Accuracy and transparency of visualizations
The visualization made accurately by applying machine learning models training on the data of the airline inudtry which makes sure to analyse data accurately and efficiently by describing the accurate data insights through visuals.
Ethics in adddressing future business problem
Set of designs and practices upon data regarding solving business issues can be used with the ethical principles to use data with confidentiality which do not harm the privacy of the customers and individuals and results in a way which is communicable by everyone to connect with the data insights and visuals with consistency.
References
.png)
Case Study
TECH1300 Information Systems in Business Case Study 2 Sample
Your Task
This assessment is to be completed individually. In this assessment, you will create a comprehensive requirements specification plan using Agile Modelling frameworks for a new online shopping platform that meets the specifications described in the case study.
Assessment Description
You have been hired as a consultant to design a set of IT project specifications for a new online shopping platform. The platform will allow customers to browse, select, and purchase items online, and will require the development of a database to manage inventory and orders. You will need to apply various IT modelling techniques to produce a requirements specification plan and create a use-case model and associated user stories of a sufficient calibre to be presented to various stakeholders. Your task will be to document and communicate the requirements to various stakeholders, including the development team.
Case Study:
You have been hired as a consultant to design a set of IT project specifications for a new online shopping platform called "ShopEZ". ShopEZ is an e-commerce platform that will allow customers to browse, select, and purchase items online. The platform will require the development of a database to manage inventory and orders, as well as integration with various payment and delivery systems. The stakeholders for this project include the development team, the project sponsor, and the end- users (i.e., the customers). The project sponsor has set a strict deadline for the launch of the platform, and the development team is working in an Agile environment using Scrum methodology.
To complete this assessment, you will need to apply the elements of an Information Systems
Development Methodology to evaluate the business requirements, explain the components of Agile methodology, and document and communicate the information systems requirements to the stakeholders. You will need to use various IT modelling techniques to produce a requirements specification plan, including the creation of a use-case model and associated user stories. You will also need to create UML diagrams for the use-case, class, and sequence.
This assessment aims to achieve the following subject learning outcomes:
LO1 Apply the elements of an Information Systems Development Methodology when evaluating business requirements.
LO2 Explain the components of an Agile methodology and how they can be applied in the modelling process.
LO4 Document and communicate information systems requirements to various stakeholders.
Assessment Instructions
• In this assessment, students must work individually to prepare report highlighting business requirements.
• The report structure is stated below as part of the submission instructions:
1. Develop a comprehensive requirements specification plan using Agile Modelling frameworks.
2. The plan must include a use-case model and associated user stories, as well as UML diagrams for the use-case, class, and sequence.
3. Your plan must clearly communicate the requirements to various stakeholders, including the development team.
4. You must provide a detailed explanation of how you applied Agile methodology in the modelling process.
5. Your assessment must be submitted in a professional report format, adhering to KBS guidelines.
6. References
• Provide at least ten (10) academic references in Kaplan Harvard style.
• Please refer to the assessment marking guide to assist you in completing all the assessment criteria.
Solution
Introduction
The flexible and iterative approach to software development known as agile modeling places an emphasis on adaptability, collaboration, and communication. It focuses on creating visual models that are easy to understand and can change as the project goes on. This report is made for ShopEZ another internet shopping stage that expects to furnish clients with a consistent and helpful shopping experience. For assignment help, Responsibility as a consultant is to create ShopEZ's IT project specifications taking into account the requirements of the development team, project sponsor, and end users. This report will evaluate the business requirements, explain the components of the Agile methodology, and use IT modeling techniques like use-case models and UML diagrams to document the information systems requirements in this assessment.
The project explanation using four Methodologies for ShopEZ
Evaluating the Business Requirements:
As a consultant, the first responsibility is to take a specific and suitable methodology from Agile Methodology. Regarding making the software easier ShopEZ is going to use Kanban but especially the Scrum methodology. Scrum methodology is a very well-known and suitable methodology for the project(Athapaththu et al ., 2022). The Scrum methodology basically focuses on the breakdown of one project into many parts. Scrum methodology has a scrum board that includes an owner, a master core, and a development team. For this project as a consultant, it is very suitable to use a scrum methodology to do this software development for this project.ShopEZ is an upcoming e-commerce company that wants to
.png)
Figure 1: Scrum Diagram
(Source: https://lh3.googleusercontent.com)
2. Requirement gathering techniques used:
Agile Procedure is a lot of values, principles, and practices that guide the improvement of an item thing. The key convictions of Apt consolidate correspondence, facilitated exertion, client fixation, and responsiveness(Daum ., 2022). The guidelines of Flexible consolidate iterative and consistent new development, self-figuring out gatherings, and things drew in headway.
Kanban is a visual administration framework that helps groups track and deal with their work really. Work items are displayed as cards as they progress through the various stages of the workflow on a Kanban board. It advances straightforwardness, empowers a force-based approach, and permits groups to recognize bottlenecks and enhance their work process.
Continuous integration and continuous delivery (CI/CD) is a set of methods for automating software delivery to production environments. Continuous Integration entails developers regularly merging their code changes into a shared repository, which initiates automated build and testing procedures.
At the conclusion of each sprint or project phase, structured meetings known as agile retrospectives are held. The object is to ponder the group's presentation, distinguish regions for development, and characterize noteworthy stages for future cycles.
Business requirements using the Agile
Coordinated technique underscore cooperation and iterative turn of events, and client stories work with this methodology by advancing compelling correspondence among partners and the improvement group. User stories ensure that the final product or service meets end users' expectations by focusing on their requirements and points of view.
The primary client story features the requirement for a client account creation include, empowering clients to get to customized highlights. The related acknowledgment measures frame the means engaged with making a record and the normal results.
The shopping experience is the focus of user stories three and four, which allow customers to add items to their cart, proceed to the checkout process, and receive email order confirmations.
Following request status is the focal point of the fifth client story, accentuating constant updates and permeability for clients. The need for a mobile user interface that is both responsive and optimized is emphasized in the sixth user story.
The seventh client story features the meaning of client input through audits and evaluations. The actions that customers can take.
Values of Agile Methodology:
The Agile Methodology procedure is portrayed by a bunch of values and rules that guide its execution. These qualities are framed in the Dexterous Declaration, which was made by a gathering of programming improvement specialists in 2001. The four basic beliefs of Deft are Working programming over exhaustive documentation: Light-footed focuses on conveying a functioning item or programming that offers some benefit to the client(Da Camara et al ., 2020). While documentation is essential, Deft underlines the need to find some kind of harmony between documentation and real advancement work. The objective is to make unmistakable results that can be tried and refined.
Principals of Agile Methodology:
Here are the critical standards of the Deft approach: Embrace change: Dexterous perceives that necessities and needs can change all through an undertaking(Fernández-Diego et al ., 2020). It supports embracing change and perspectives as an amazing chance to work on the item. Dexterous groups are adaptable and ready to adjust to evolving conditions, even late in the improvement cycle. Gradual and iterative turn of events: Lithe advances an iterative and steady way to deal with improvement. Rather than endeavoring to convey the whole item without a moment's delay, it breaks the work into little, sensible augmentations called emphases or runs. Every cycle creates a working, possibly shippable item increase.
UML diagram:
use case diagram
.png)
(Source: Self Created in Draw.io)
Class diagram
.png)
(Source: Self Created in Draw.io)
Sequences diagram 1
.png)
Figure 4: UML Diagram
(Source: Self Created in Draw.io)
Sequence diagram 2:
.png)
.png)
Figure 5: UML sequence diagram
(Source: Self Created in Draw.io)
Communication to the stakeholders:
"ShopEZ" web-based shopping stage project, the partners and improvement group assume essential parts in the progress of the task. Here is an outline of their jobs: Project Support: The undertaking support is the individual or gathering who starts and offers monetary help for the task. They are liable for defining the undertaking's objectives, financial plan, and courses of events The venture support goes about as a resource for the improvement group and guarantees that the task lines up with the association's essential targets. Advancement Group: The improvement group is liable for carrying out the specialized parts of the venture(Schulte et al ., 2019). In a Nimble climate utilizing the Scrum procedure, the advancement group regularly comprises of cross-utilitarian individuals who work cooperatively to convey additions to the item. The group might incorporate programming engineers, data set overseers, analyzers, UI/UX fashioners, and other pertinent jobs. They are engaged with all periods of the task, including necessities investigation, plan, advancement, testing, and organization. End-clients (Clients): The end-clients are the people or substances who will associate with and utilize the "ShopEZ" stage whenever it is sent off. In this situation, the clients are the end-clients of the web-based business stage. Their fulfillment and client experience are essential to the progress of the stage.
Conclusion
The assessment has outlined the steps for developing a comprehensive requirements specification plan using Agile Modelling frameworks for a new online shopping platform called "ShopEZ". This plan included a use-case model and associated user stories, as well as UML diagrams for the use-case, class, and sequence. The assessment also explained the components of Agile methodology and how they can be applied in the modeling process. Finally, the assessment discussed how to document and communicate the information systems requirements to the stakeholders.
Reference
.png)
Reports
DATA4200 Data Acquisition and Management Report 2 Sample
Your Task
This report will enable you to practice your LO1 and LO2 skills.
• LO1: Evaluate ethical data acquisition and best practice about project initiation
• LO2: Evaluate options for storing, accessing, distributing, and updating data during the life of a project.
• Complete all parts below. Consider the rubric at the end of the assignment for guidance on structure and content.
• Submit the results as a Word file in Turnitin by the due date.
Background
Unstructured data has typically been difficult to manage, since it has no predefined data model, is not always organised, may comprise multiple types. For example, data from thermostats, sensors, home electronic devices, cars, images, sounds and pdf files.
Given these characteristics, special collection, storage, and analysis methods, as well as software, have been created to take advantage of unstructured data.
Assessment Instructions
Given the considerations above, select one of the following industries for your assessment.
• Healthcare
• Retail - clothing
• Social Media
• Education
• Motor vehicles
• Fast Foods
1. Read relevant articles on the industry you have chosen.
2. Choose one application from that industry.
3. Introduce the industry and application, e.g., healthcare and image reconstruction.
4. Explain what sort of unstructured data could be used by an AI or Machine Learning algorithm in the area you chose.
a. Discuss best practice and options for
b. Accessing/collecting
c. Storing
d. Sharing
e. Documenting
f. and maintenance of the data
5. Propose a question that could be asked in relation to your unstructured data and what software might help you to run AI and answer the question.
Solution
Introduce the industry and application
The healthcare industry is made up of a variety of medical services, technologies, and professionals who work to improve people's health and well-being. It includes hospitals, clinics, pharmaceutical companies, manufacturers of medical devices, research institutions, and many more. For assignment help, The healthcare industry is always looking for new ways to improve patient care and outcomes in order to diagnose, treat, and prevent diseases.
One significant application inside the medical services industry is processing of medical images. The process of acquiring, analyzing, and interpreting medical images for the purposes of diagnosis and treatment is known as medical image processing. It is essential in a number of medical fields, including orthopedics, cardiology, neurology, oncology, and radiology. Medical images can be obtained through modalities like X-ray, computed tomography (CT), magnetic resonance imaging (MRI), ultrasound, and positron emission tomography (PET), and advanced algorithms and computer-based techniques are used in medical image processing to extract meaningful information from medical images. The human body's internal structures, organs, tissues, and physiological processes are depicted in great detail in these images. Patients and healthcare professionals alike can reap numerous advantages from using medical image processing. It empowers more precise and proficient determination by giving nitty gritty bits of knowledge into the presence, area, and attributes of anomalies or infections. Images can be analyzed by doctors to find conditions like tumors, fractures, and blocked blood vessels, which can help with treatment planning and monitoring (Diène et al., 2020). Medical image processing aids in the development of healthcare research and development. It makes it possible to create massive image databases for the purpose of training machine learning algorithms. This can help automate tasks related to image analysis, increase productivity, and cut down on human error. Besides, it supports the investigation of new imaging procedures, for example, useful X-ray or dissemination tensor imaging, which gives important bits of knowledge into cerebrum capabilities and brain network.
Discussion on sort of unstructured data could be used by an AI or Machine Learning algorithm in the processing of medical image
There are many different kinds of unstructured data that can be used in image processing. Information that does not adhere to a predetermined data model or organization is referred to as unstructured data. Here are a few instances of unstructured data utilized in the processing of medical image:
Image Pixels: Unstructured data is created from an image's raw pixel values. Algorithms can use the color information in each pixel, such as RGB values, to extract features or carry out tasks like image classification and object detection.
Metadata for Images: Metadata that accompanies images typically contains additional information about the image. The camera's make and model, exposure settings, GPS coordinates, timestamps, and other information may be included in this metadata (Galetsi et al., 2020). This information can be used by machine learning algorithms to improve image analysis, such as locating an image or adjusting for particular camera characteristics.
.png)
Figure 1: Machine learning for medical image processing
(Source: https://pubs.rsna.org)
Captions or descriptions of images: Human-created portrayals or subtitles related to pictures give text based settings that can be utilized in artificial intelligence calculations. For tasks like image search, content recommendation, or sentiment analysis, natural language processing techniques can analyze these descriptions and extract useful information.
Labels and annotations: Unstructured information can likewise incorporate manual comments or marks that are added to pictures by people. These annotations may indicate the presence of bounding boxes, semantic segmentation, regions of interest, or objects. AI calculations can involve this marked information for preparing and approval purposes, empowering assignments like article acknowledgment, semantic division, or picture restriction.
Image Content: Textual elements, such as signs, labels, or captions, can also be present in unstructured data contained within images (Panesar, 2019). Algorithms can process and analyze the textual information in these images thanks to the ability of optical character recognition (OCR) techniques to extract the text from the images.
Picture Setting: Unstructured data can be used to access information about an image's context, such as its source website, related images, or user interactions. Machine learning algorithms can improve content filtering, image comprehension and recommendation systems by taking the context into account.
Discuss Best Practice and Options
Accessing/collecting, Storing, Sharing, Documenting and maintenance of the data are very important for the healthcare industry. Here is the discussion on some options and practices related to these procedures in the healthcare industry and image processing.
Accessing/collecting
Collection of healthcare data is important for the medical experts to provide better services to their patients. Here is the discussion of the options and practices related to this process.
Information Sources: Medical imaging archives, picture archiving and communication systems (PACS), wearable devices, and other relevant sources of healthcare data should be identified by the medical experts (Pandey et al., 2022). Team up with medical care suppliers and establishments are required to get close enough to the essential information.
Security and privacy of data: Stick to severe security and security conventions to safeguard delicate patient data can be taken as a best practice. Keeping patient confidentiality by adhering to laws like the Health Insurance Portability and Accountability Act (HIPAA) is an important part of the collection of healthcare data.
Qualitative Data: Examine the collected data for accuracy and quality. To address any inconsistencies, missing values, or errors that could hinder the performance of the image processing algorithms, there is a need to employ data cleaning and preprocessing methods.
Storing
Image processing depends on healthcare data being stored effectively by taking into account the following options and best practices:
Online storage: Use of safe cloud storage options are taken by the medical experts to store healthcare data. Scalability, accessibility, and backup capabilities are provided by cloud platforms. The medical experts try to carry out encryption and access controls to safeguard the put away information (Jyotiyana and Kesswani, 2020).
Information Lake/Store: Creation of a centralized data lake or repository is required to consolidate healthcare data for image processing. This considers simple recovery, sharing, and joint effort among specialists and medical care experts.
Formats and Standards: Stick to standard configurations like Advanced Imaging and Correspondences in Medication (DICOM) for clinical pictures and Wellbeing Level 7 (HL7) for clinical information is helpful to store the medical data and use them properly in image processing. This guarantees similarity and interoperability across various frameworks and works with information sharing and reconciliation.
Sharing Medical Information for Image Processing
Sharing medical services information is significant for cooperative exploration and working on quiet consideration. Think about the accompanying prescribed procedures:
Agreements for the Sharing of Data: A proper layout of information sharing arrangements or agreements that frame the terms, conditions, and limitations for information sharing are followed by the medical experts to share the essential data appropriately (Tchito Tchapga et al., 2021). This guarantees lawful and moral consistency, safeguarding patient security and licensed innovation privileges.
Techniques for De-Identification: Patient-specific information can be anonymized from the shared data using de-identification techniques while still remaining useful for image processing. Data can be shared in this way while privacy is maintained.
Transfer data safely: Encrypted channels and secure channels for data transferring are very much required to transfer the healthcare data. It helps to maintain confidentiality and prevent unauthorized access or interception because it can harm the treatment process. Safe transfer of data also helps the medical experts to improve their services and get better responses from the patients.
Documenting
Healthcare data must be properly documented for long-term reproducibility and usability. Here is the discussion on some options and practices related to documentation of the healthcare data for image processing. Most of the time, medical experts are trying to catch and record thorough metadata related with medical services information, including patient socioeconomics, securing boundaries, and preprocessing steps. This data helps in grasping the unique circumstance and guaranteeing information discernibility (Willemink et al., 2020). Documentation of the healthcare data is very important and the medical experts try to do this in a proper way for providing better services to the patients.
Maintenance of the data
Version Management: Medical experts have tried to implement version control mechanisms to keep track of changes to the data, algorithms, or preprocessing methods over time. Reproducibility and comparison of results are made possible by this.
Governance of Data: Medical experts have tried to establish data governance policies and procedures to guarantee data integrity, accessibility, and compliance with regulatory requirements (Ahamed et al., 2023). They should check and update these policies on a regular basis to keep up with new technologies and best practices.
Healthcare data for image processing must be accessed, collected, stored, shared, documented, and maintained with careful consideration of privacy, security, data quality, interoperability, and compliance. Researchers and healthcare organizations can harness the power of healthcare data to advance medical imaging and patient care by adhering to best practices.
Propose a question that could be asked in relation to the unstructured data and what software might help to run AI and answer the question
Question: "How AI is used to improve lung cancer diagnosis accuracy by analyzing medical images from unstructured data?
Tensor Flow can be taken as software that might be helpful in running AI algorithms to answer this question. Tensor Flow is an open-source library broadly utilized for AI and profound learning undertakings, including picture handling. It gives an exhaustive system to building and preparing brain organizations, making it reasonable for creating computer based intelligence models to break down clinical pictures for cellular breakdown in the lungs location (Amalina et al., 2019). The extensive ecosystem and community support of Tensor Flow also make it possible to integrate other image processing libraries and tools, making it easier to create and implement accurate AI models for better healthcare diagnosis.
References
.png)
Reports
DATA4500 Social Media Analytics Report 3 Sample
Your Assessment
• This assessment is to be done individually.
• Students are to write a 1,500-word report about Influencers and Social Media Markers and submit it as a Microsoft Word file via the Turnitin portal at the end of Week 10.
• You will receive marks for content, appropriate structure, and referencing.
Assessment Description
• You are the Digital Marketing Officer in charge of picking a social media influencer to lead an Extensive campaign as the face of your organization.
• As part of your research and decision-making process, you must gather and analyse more than just average likes and comments per post.
• Some of the statistics you will need to gather and assess are (only as an example):
o Follower reach.
o Audience type (real people, influencers, and non-engaging).
o Demographics.
o Likes to comments ratio.
o Brand mentions.
o Engagement rates for social media accounts.
o How data into competitors’ use of influencers can be measured to generate insights.
Assessment Instructions
• You have been asked to write a report on your options and choice, the criteria you used, and any tool that will support your work in the future.
• Some of the information you are expected to cover in your report is:
o What is the audience-type composition?
o What is an engagement rate, and how should advertisers treat this statistic?
o When is an engagement considered an authentic engagement?
o Why should we care about the followings of followers?
o How does our influencer ROI compare against that of our competitors?
• Your report should include the following:
o Cover.
o Table of Contents (see template).
o Executive Summary (3-4 paragraphs).
o Introduction.
o A section discussing social media analytics and its value to the business.
o A section on the role of the techniques taught in class, like sentiment analysis, competitive analysis, data mining, and influencer analysis.
o A section on how social media analytics was used to choose the influencer you recommend.
o A section recommending how your choice of influencer will be used as part of the organization’s marketing strategy.
o At least ten references in Harvard format (pick an additional five on your own besides five from the list below).
Solution
Introduction
Utilizing social media sites to advertise something or provide something is known as social media marketing. In order to interact with target audiences, it involves creating and sharing content on social media platforms like Facebook, Twitter, Instagram, and LinkedIn. Social media influencers are people who have a significant following on the internet and are regarded as authorities in a certain industry. For Assignment Help, Brands can use them to advertise their goods or services to a wider demographic. In order to inform advertising strategies, social media analytics entails the measurement, analysis, and reporting of data from social media platforms. Businesses can employ it to better understand their target market, spot trends, and evaluate the effectiveness of their social media marketing strategies. Businesses may measure KPIs like engagement, reach, and conversions by using social media analytics tools to optimise their social media marketing efforts.
Social media analytics and its value to the Business
- Characteristics
The collection and analysis of data from social media platforms in order to inform marketing tactics is known as social media analytics. The following are some of the
key characteristics of social media analytics:
Real Time data: Virtual entertainment examination gives admittance to constant information, permitting advertisers to screen drifts and answer input rapidly.
Numerous metrics: The engagement, reach, impressions, and conversion rates of social media campaigns can all be tracked using a variety of metrics provided by social media analytics ( Enholm et al., 2022).
Customizable reports: Online entertainment examination apparatuses can be modified to create reports that meet explicit business needs, like following effort execution or breaking down client feeling.
Competitive analysis: Social media analytics may be used to keep tabs on rival activity, revealing market trends and spotting development prospects (Nenonen et al., 2019).
Data visualization: To assist managers in rapidly and simply understanding complicated data sets, social media analytics solutions frequently include data visualization techniques, such as charts and graphs.
Machine learning: Social media analytics increasingly uses machine learning methods to spot patterns and trends in data, allowing for more precise forecasts and suggestions for the next marketing plans.
- Its value in business
Businesses may benefit significantly from social media analytics by using it to make data-driven choices and improve their social media strategies. Following are some examples of how social media analytics may help businesses:
Audience insights: Social media analytics may give businesses information on the preferences, interests, and behaviors of their target audience, allowing them to develop more specialized and successful social media campaigns (Zamith et al., 2020).
Monitoring the success of social media initiatives: Social media analytics may be used to monitor the success of social media campaigns. This enables organizations to assess engagement, reach, and conversion rates and modify their strategy as necessary.
Competitive analysis: By using social media analytics to track rivals' social media activity, firms may keep contemporary on market trends and spot growth prospects.
Reputation management: Social media analytics may be used to track brand mentions and social media sentiment, enabling companies to address unpleasant comments and manage their online reputation (Aula and Mantere, 2020).
Measurement of ROI: Social media analytics may be used to assess the return on investment (ROI) of social media efforts, enabling companies to evaluate the efficacy of their social media plans and more efficiently deploy their resources.
Roles of the techniques like sentiment analysis, competitive analysis, data mining, and influencer analysis.
Businesses can use social media analytics to measure and improve their social media marketing strategies. Different web-based entertainment logical methods can be utilized to accomplish various goals. Here is a brief synopsis of each technique's function:
Sentiment analysis: The process of determining how a brand, product, or service is received in social media posts or comments is known as sentiment analysis. Natural language processing, or NLP, is used in this method to assess the positivity, negativity, or neutrality of text data. Monitoring a brand's reputation, determining trends in customer sentiment, and responding to negative feedback can all benefit from using sentiment analysis (Aula and Mantere, 2020).
Competitive analysis: Monitoring and analyzing competitors' social media activities is part of competitive analysis. This method can be utilized to recognize industry patterns, benchmark execution against contenders, and distinguish valuable open doors for development. Businesses can benefit from competitive analysis by staying ahead of the curve and making well-informed decisions regarding their social media marketing strategies (Jaiswal and Heliwal, 2022).
Mining data: The process of looking for patterns and trends in large datasets is known as data mining. Data mining can be utilized in social media analytics to discover customer preferences, behavior patterns, and interests. This strategy can assist organizations with making more designated web-based entertainment crusades and further develop commitment rates.
Influencer analysis: The process of identifying social media influencers with a large following and high engagement rate in a specific industry or niche is called "influencer analysis." This method can be utilized to recognize potential brand ministers and make a force to be reckoned with advertising efforts. Businesses can use influencer analysis to reach a wider audience and raise brand awareness (Vrontis et al., 2021).
Every one of these online entertainment scientific strategies plays a one-of-a-kind part in assisting organizations with accomplishing their web-based entertainment showcasing goals. By utilizing a blend of these procedures, organizations can acquire important experiences in their interest group, screen contender exercises, and upgrade their online entertainment methodologies for the greatest effect.
How social media analytics was used to choose the recommended Influencer
Online entertainment examination can be an amazing asset for recognizing web-based entertainment powerhouses that can assist brands with arriving at their interest group and accomplishing their promoting objectives. Social media analytics played a crucial role in the decision to select Elon Musk as a social media influencer.
- In the beginning, social media analytics tools were used to identify the tech industry's most influential individuals (Kauffmann et al., 2020). This involved looking at data from social media platforms like Twitter and LinkedIn to find people with a lot of followers, a lot of people engaging with them, and a lot of social media presence.
- To assess the influencers' overall sentiment and level of influence in the tech industry, the social media analytics team performed sentiment analysis on their social media posts. They additionally directed serious examination to think about the distinguished forces to be reckoned with's online entertainment execution against each other.
Elon Musk emerged as a leading social media influencer in the tech industry based on the insights gleaned from these social media analytics techniques (Ding et al., 2021). He was an ideal candidate for a partnership as a social media influencer with a tech company due to his large social media following, high engagement rates, and positive sentiment in the tech community.
Data mining methods were also used by the social media analytics team to gain a deeper understanding of Musk's social media habits and interests. This involved looking at his activity on social media to find patterns, preferences, and interests that could be used to design a successful social media marketing campaign.
Elon Musk was selected as a social media influencer in large part as a result of social media analytics. The team was able to determine the most prominent individuals in the tech sector, carry out the sentiment and competitive analyses, and obtain deeper insights into Musk's social media behaviour and interests by utilising a variety of social media analytics approaches. This made it possible to make sure that the influencer was the ideal match for the brand's marketing objectives and target market.
Recommending how your choice of influencer will be used as part of the organization’s marketing strategy
Using Elon Musk as a social media influencer can be a great way to reach a larger audience and spread awareness of your company or brand. He has a large social media following. With more than 1.4 million followers on Instagram and over 9 million on Twitter, Elon Musk has a large social media following. Most of his followers are young men between the ages of 18 and 24, making up the largest age group. With high rates of likes, comments, and shares on his social media postings, Musk's fanbase is also quite active. Musk's Twitter account has a high average engagement rate of 2.84%, which is much higher than the sector average of 0.45% in terms of engagement ratios. Along with having a high interaction rate, his Instagram account averages 1.5 million likes for every post. With regard to Musk's feelings, Musk is known for his eccentric methodology and cutting-edge vision, which frequently gets compelling profound reactions from his crowd. His web-based entertainment posts frequently create a blend of positive and gloomy feelings, with energy, interest, and motivation is the most widely recognized good feelings. Social media analytics tools can be used to track metrics like follower growth, engagement rates, and audience demographics for both the influencer and their competitors to gain insight into how competitors are using influencers. Additionally, these tools can be utilized to monitor brand mentions and sentiment across social media platforms. By doing so, businesses are able to acquire a deeper comprehension of how their audience views their rivals and how they can enhance their own social media strategy. By dissecting this information, associations can arrive at additional educated conclusions about how to use forces to be reckoned with and streamline their web-based entertainment system to remain in front of the opposition.
Use Elon Musk as a social media influencer as part of your company's marketing strategy in the following ways:
Collaborate with Musk for a web-based entertainment takeover: Permit Musk to assume control over your association's web-based entertainment represents a day, seven days, or a month (Hunsaker and Knowles, 2021) This will offer him the chance to elevate your image to his huge understanding, share his contemplations on your industry, and draw in with your crowd.
Work on social media campaigns with Musk: Create a social media campaign for your brand, product, or service with Musk's help. Sponsored posts, videos, and social media contests are all examples of this.
Influence Musk's online entertainment presence to create buzz: Share Musk's posts and content on your association's web-based entertainment records to use his enormous pursuit and produce a which around your image (Guan, 2022)
Run influencer marketing campaigns: Become a brand advocate for your company by working with Musk. It can entail producing a number of sponsored articles, videos, and other pieces of content to advertise your company, its goods, or its services.
Reach out to Musk's audience: Take advantage of Musk's social media following by interacting with his followers through comments, direct messaging, and other online exchanges (Milks, 2020). By doing this, you may strengthen your bonds with your supporters and draw in new clients for your business.
Using Elon Musk as a social media influencer can be a great way to reach a wider audience and generate buzz around your brand or organization. By partnering with Musk on social media campaigns, leveraging his massive following, and engaging with his audience, you can build your brand, attract new customers, and generate long-term growth.
Conclusion
This particular report is based on social media analytics and social media influencers. There are various characteristics of social media analytics are discussed. Then its value o importance in business is discussed. On the other hand, the role of different social media analytics techniques is analyzed. The types of analytics are sentiment analysis, competitive analysis, data mining, and influencer analysis is done. Then how social media analytics is used to choose Elon Musk as an influencer is discussed and then how Elon Musk as a social media influencer can impact business strategy.
Reference list
.png)
Case Study
DATA4000 Introduction to Business Analytics Case Study 1 Sample
Your Task
Complete Parts A to C below by the due date.
Consider the rubric at the end of the assignment for guidance on structure and content.
Assessment Description
.png)
• You are to read case studies provided and answer questions in relation to the content, analytics theory and potential analytics professionals required for solving the business problems at hand.
• Learning outcomes 1 and 2 are addressed.
Assessment Instructions
Part A: Case Study Analysis (700 words, 10 marks)
Instructions: Read the following two case studies. For each case study, briefly describe:
a) The industry to which analytics has been applied
b) A potential and meaningful business problem to be solved
c) The type of analytics used, and how it was used to address that potential and meaningful business problem
d) The main challenge(s) of using this type of analytics to achieve your business objective (from part b)
e) Recommendations regarding how to be assist stakeholders with adapting these applications for their business.

Part B: The Role of Analytics in Solving Business Problems (500 words, 8 marks)
Instructions: Describe two different types of analytics (from Workshop 1) and evaluate how each could be used as part of a solution to a business problem with reference to ONE real-world case study of your own choosing for one type of analytics and a SECOND real-world case study of your choosing for the second type of analytics.
You will need to conduct independent research and consult resources provided in the subject.
Part C: Developing and Sourcing Analytics Capabilities
Instructions: You are the Chief Analytics Officer for a large multinational corporation in the communications sector with operations that span India, China, the Philippines and Australia.
The organization is undergoing significant transformations; it is scaling back operations in existing low revenue segments and ramping up investments in next generation products and services - 5G, cloud computing and Software as a Service (SaaS).
The business is keen to develop its data and analytics capabilities. This includes using technology for product innovation and for developing a large contingent of knowledge workers.
To prepare management for these changes, you have been asked review Accenture’s report
(see link below) and publish a short report of your own that addresses the following key points:
1. How do we best ingrain analytics into the organisation’s decision-making processes?
2. How do we organize and coordinate analytics capabilities across the organization?
3. How should we source, train and deploy analytics talent?
![]()
The report is prepared for senior management and the board of directors. It must reflect the needs of your organization and the sector you operate in (communications).
Solution
Part A
1. Netflix Predictive Analytics: Journey to 220Mn+ subscribers
a) The case study covers how predictive analytics are being used in a variety of sectors, such as e-commerce, insurance, and customer support.
b) Reducing client turnover is a possible and significant business issue that can be resolved with predictive analytics. Businesses may experience a serious issue with customer churn, which is the rate at which customers leave doing business with a company. It might lead to revenue loss and reputational harm for the business. For assignment help, Businesses may enhance customer retention and eventually boost revenue by identifying customers who are at danger of leaving and taking proactive measures to keep them.
c) Customer demands were predicted using predictive analytics, which also helped to decrease churn, increase productivity, better allocate resources, and deliver tailored marketing messages. Customer data was analyzed using machine learning algorithms to spot trends and forecast future behavior. Predictive analytics, for instance, was used to inform customer service professionals to take proactive measures to keep clients who were at risk of leaving based on their behavior (Fouladirad et al., 2018).
d) Having access to high-quality data is the biggest obstacle to employing predictive analytics to accomplish the business goal of reducing customer turnover. In order to produce precise forecasts, predictive analytics needs reliable and pertinent data. The forecasts won't be correct if the data is unreliable, erroneous, or out of date. Additionally, firms may have trouble locating the proper talent to create and maintain the predictive models because predictive analytics needs substantial computational resources.
e) It is advised to start with a specific business problem in mind and find the data necessary to address it in order to help stakeholders with designing predictive analytics solutions for their organization. Making sure the data is correct and pertinent to the issue being addressed is crucial. In order to create and maintain the predictive models, businesses should also invest in the appropriate computational tools and recruit qualified data scientists. To guarantee that the predictive models continue to be accurate and useful, organizations should regularly assess their effectiveness and make any necessary adjustments (Ryu, 2013).
2. Coca-Cola vs. Pepsi: The Sweet Fight For Data-Driven Supremacy
a) The article focuses on the food and beverage industry, particularly the competition between Pepsi and Coca-Cola in terms of leveraging data and analytics to create new products and enhance corporate processes.
b) Keeping up with shifting consumer preferences and tastes is one of the potential commercial challenges for Coca-Cola and Pepsi. The difficulty lies in creating new beverages that satisfy the changing market needs and offer a tailored client experience. This issue calls for a cutting-edge strategy that can use analytics and data to spot patterns and customer behavior instantly.
c) Coca-Cola and Pepsi have both utilized various types of data analytics to help in the development of new products. The Freestyle beverage fountain from Coca-Cola gathers information on the most popular flavor combinations that can be used to crowdsource new product ideas. In order to track long-term consumer behavior and use it to personalize marketing campaigns and customer experiences, Coca-Cola has also integrated AI, ML, and real-time analytics. As an alternative, Pepsi has validated new product ideas by using AI-powered food analytics technologies like Trendscope and Tastewise to forecast consumer preferences. In order to spot new trends and forecast customer demand, these technologies comb through billions of social media posts, interactions with recipes, and menu items.
d) The accuracy and dependability of the data is one of the key difficulties when employing data analytics to create new goods. There is a chance that goods will be developed that may not be commercially successful since the data may not always accurately reflect actual consumer preferences and behavior. The demand for qualified data scientists and analysts who can decipher the data and offer useful insights for business decision-making is also great.
e) It is critical for stakeholders to understand the business issue they are attempting to solve before they can adapt data analytics applications for that issue. In order to gain insights into client behavior and preferences, they should identify the pertinent data sources and analytics technologies. In order to evaluate the data and offer actionable insights for business decision-making, stakeholders need also invest in qualified data scientists and analysts. In order to spur innovation and maintain an edge over the competition, firms should also be open to experimenting with new technology and methods.
Part B
By offering data-driven insights that can guide decision-making, analytics plays a significant role in resolving complicated business problems. This section will go over the two forms of analytics that can be utilized to solve business issues in many industries, namely descriptive analytics and predictive analytics.
Descriptive Analytics
A type of analytics called descriptive analytics includes looking at past data to understand past performance. It is frequently used to summarize and comprehend data, spot trends, and respond to the query "what happened?" Businesses can gain a better understanding of their historical performance and pinpoint opportunities for development by utilizing descriptive analytics.
Walmart is one example of a real-world case study that shows the application of descriptive analytics (Hwang et al., 2016). To optimize its inventory levels, cut expenses, and enhance the customer experience, Walmart employs descriptive analytics to examine customer purchasing trends and preferences. To find patterns in customer behavior, Walmart's data analysts examine sales information from both physical shops and online shopping platforms. By stocking up on items that are in high demand and reducing inventory levels of items that are not selling well, the corporation can better utilize the knowledge gained from these analysis (Dapi, 2012).
Predictive Analytics
Contrarily, predictive analytics is a subset of analytics that uses previous data to forecast future outcomes. When analyzing data, it is frequently used to spot trends and connections, predict the future, and provide a solution to the question, "What will happen?" Businesses can use predictive analytics to make data-driven decisions that foresee potential trends and business possibilities in the future.
The ride-hailing service Uber serves as one example of a real-world case study that demonstrates the application of predictive analytics (Chen et al.,2021). Uber employs predictive analytics to forecast rider supply and demand in real-time, enabling it to give drivers more precise arrival times and shorten wait times for riders. The business's data experts estimate the demand and supply trends for riders by analyzing data from a variety of sources, including historical ride data, weather forecasts, and event calendars. Uber can deploy its drivers more effectively thanks to the information gained from these analytics, which decreases rider wait times and enhances the entire riding experience (Batat, 2020).
Challenges
There are issues with using descriptive and predictive analytics, despite the fact that they both provide useful information for enterprises. The fact that descriptive analytics can only be used to analyze past data, which might not be a reliable indicator of future trends, is one of the key drawbacks of this approach. Furthermore, descriptive analytics ignores outside variables that can affect future performance. Using predictive analytics, however, presents a number of difficulties because it depends on precise and trustworthy data inputs. Predictive analytics may not produce accurate forecasts if the data is unreliable or incomplete.
Part C
Introduction
As Chief Analytics Officer for a large multinational corporation operating in the communications sector, I have been asked to review Accenture's report on building analytics-driven organizations and provide recommendations on how our company can develop its data and analytics capabilities.
Ingraining Analytics into Decision-making Processes
We must first create a data-driven culture before integrating analytics into our decision-making procedures. This entails encouraging the application of data and analytics at every level of the business, from the C-suite to the shop floor. By assembling cross-functional teams including data scientists, business analysts, and subject matter experts, we can do this. Together, these teams should pinpoint business issues that data and analytics may help to address and create solutions that are simple to comprehend and put into practice.
Investing in technology that facilitates data-driven decision making is another method to integrate analytics into our decision-making processes. Investments in big data platforms, data visualization tools, and predictive analytics software all fall under this category. By utilizing these tools, we can make greater use of the data we gather and offer data-based, actionable insights to decision-makers.
Organizing and Coordinating Analytics Capabilities
We must create a clear analytics strategy that supports our business objectives in order to organize and coordinate analytics skills across the organization. This strategy should lay out our plans for using data and analytics to accomplish our corporate goals as well as the precise skills we'll need to build to get there.
Additionally, we must clearly define the roles and duties of our analytics teams. This entails outlining the functions of domain experts, business analysts, and data scientists as well as developing a clear career path for each of these positions. By doing this, we can make sure that our analytics teams are functioning well and effectively, and that we are utilizing all of our analytical expertise to its fullest potential (Akter et al., 2016).
Sourcing, Training, and Deploying Analytics Talent
We must first have a clear talent strategy before we can find, train, and deploy analytical talent. This plan should detail the talents and expertise we specifically need, as well as the methods we'll use to find and develop the talent we need. We may achieve this through collaborating with colleges and training facilities, providing internships and apprenticeships, and funding staff development and training programmers.
Using our current employees as a resource for analytics talent is another option. Employees that are interested in data and analytics can be identified, and we can offer them the chances for training and growth they require to become proficient data analysts or data scientists. By doing this, we can utilize the knowledge and talents of our current personnel.
Enhancing Collaboration and Communication
Encourage collaboration and communication amongst divisions in order to successfully incorporate analytics into the organization's decision-making processes. Data silos and communication obstacles might make it difficult to adopt analytics solutions successfully. In order for teams to collaborate and solve business problems, it is critical to develop cross-functional communication and collaboration.
Investing in Training and Development
It is important to invest in the training and development of personnel if you want to create and coordinate analytics capabilities across your organization. This involves giving opportunities for upskilling and reskilling as well as strengthening data literacy abilities. Businesses may make sure that their staff members have the knowledge and abilities to use analytics tools and make data-driven decisions by investing in their training and development (Fadler & Legner, 2021).
Partnering with External Experts
Organizations can think about partnering with external experts to hasten the development of analytics capabilities. To acquire the most recent research and insights, this may entail working with academic institutions or employing outside experts. Organizations can benefit from a new viewpoint and access to cutting-edge analytics tools by collaborating with external experts.
Adopting a Continuous Learning attitude
Organizations must embrace a continuous learning attitude in order to effectively find, train, and deploy analytical talent. This entails supporting a culture of learning among staff members as well as their ongoing skill and knowledge development. In order to keep the company competitive in the market, it is also crucial to stay up to speed with the most recent analytics trends and technology. By adopting a continuous learning mindset, organizations can create a dynamic workforce that is agile and responsive to changing business needs.
Conclusion
To transform into an analytics-driven organization, we must create a data-driven culture, invest in the technology that enables data-driven decision-making, develop a clear analytics strategy, define the roles and responsibilities of our analytics teams, and create a talent strategy that enables us to efficiently find, develop, and deploy analytics talent. By doing this, we can make sure that we are maximizing the use of the data we gather and utilizing data and analytics to promote corporate growth and success in the communications industry.
References
.png)
Reports
DATA4300 Data Security and Ethics Case Study 1 Sample
Assessment Description
.png)
You are being considered for a job as a compliance expert by an organization and charged with writing recommendations to its Board of Directors’ Data Ethics Committee to decide on:
A. Adopting new technology solution that addresses a business need, and
B. The opportunities and risks of this technology in terms of privacy, cybersecurity and ethics
Based on this recommendation you will be considered for a job at the company.
Your Task
• Choose a company as your personal case study. You must choose a company which starts with the same letter as the first letter your first or last name.
• Complete Part A and B below:
1. Part A (Case Study): Students are to write a 700-word case study and submit it as a Microsoft word file via Turnitin by Monday, Week 6 at 10:00am (AEST) (Before class)
Note: Completing Step 1 before Step 2 is crucial. If you have not submitted Step 1 in time for your in-class Step 2, you must notify your facilitator via email immediately to receive further instruction about your assessment status.
2. Part B (One-way interview): Students need to be present IN CLASS in Week 6 where the lecturer will take them through how to record a one-way interview based on their case study.
Assessment Instructions
PART A: Case Study (20 marks)
You are being considered for a job as a compliance expert by an organisation and charged with writing recommendations to its Board of Directors’ Data Ethics Committee to decide about:
a) Adopting a new technology solution that addresses a company need, and
b) The opportunities and risks of this technology in terms of privacy, cybersecurity, regulation and ethics and how this affects the viability of the technology.
Your answers to the above two questions will be presented in a case study which will be considered in your job application. See suggested structure below:
.png)
Solution
Chosen Company and New Technology Solution
The chosen organisation is Pinterest. Pinterest is a well-known American company which offers the users to share and save image, creative portfolios, and generates aesthetic ideas, as well as it also offers social media services to the designers enabling the discovering of ideas and images (Pinterest, 2020). For Assignment Help, The company acquires the data of millions of its users, which makes it vulnerable to data thefts. As a compliance expert, my recommendation for technology solution to the Board of Directors’ Data Ethics Committee of Pinterest is Artificial Intelligence. AI is a booming technology which has a potential of bringing strong changes to the company’s operations, security challenges, and management as well as it enhances the efficiency, improved decision-making, and elevate the customer experience. The use of Artificial Intelligence technology also presents ethical as well as legal challenges which has to be considered carefully.
Below are mentioned the key areas in which the company can enhance its performance-
• Improved decision making- More informed decisions may be made with the help of AI's ability to analyse vast amount of data and derive useful conclusions. A company's strategic choices, discovery of new prospects, and operational optimisation may all benefit from this (Velvetech, 2019).
• Enhanced customer experiences- AI may help businesses customize their communications with customers, provide more personalized suggestions, and generally elevate the quality of their customers' experiences. This has the potential to boost satisfaction and loyalty among existing customers.
• Better risk management- Due to AI's ability to assist Pinterest detect and prevent vulnerabilities like fraud and cyberattacks. This can help to protect the company's reputation and financial performance.
• Increased innovation- AI has the potential to boost innovation by assisting Pinterest in creating and refining new offerings and providing access to previously unexplored consumer segments. This has the potential to aid businesses in competing successfully and expanding their operations (Kleinings, 2023).
Opportunities and Risks of This Technology in Terms of Privacy, Cybersecurity, Regulation and Ethics
AI technology offers several opportunities to Pinterest in order to improve the operations and performance of the company, however it also comes with challenges and risks which has to be addressed in order to ensure its viability. Below are mentioned the key opportunities and risks associated with AI technology in terms of privacy, cybersecurity, regulation, and ethics.
Opportunities of AI
• Personalised user feeds- AI helps in personalising and customising the user’s search recommendations and their feed on the basis of their search history, firstly the technology will collect the data of the users and further run the algorithm which will analyse and set what the user’s preferences are.
• Chatbots availability for customer help 24*7- Artificial intelligence has allowed chatbots to advance to the point where they are difficult to differentiate between real people. In many cases, chatbots are preferable to human customer service representatives. These bots can respond instantly to questions, provide faster service with fewer mistakes, and boost customer engagement (Kleinings, 2023).
• Customer relationship management - In addition to being an effective tool for sales teams, customer relationship management systems represent a significant commercial breakthrough. Despite the mixed results of previous CRM and sales force automation initiatives. Artificial intelligence (AI) has the potential to improve business operations and the quality of service provided to consumers in many ways.
• Intrusion detection- Most cyber defences today are reactive rather than proactive, but AI is helping to change that. By using AI to establish a standard for acceptable network behavior, businesses can better spot irregularities in traffic that may indicate the presence of malicious individuals (Qasmi, 2020).
Risks of AI
• Privacy concerns- Concerns concerning privacy have arisen due to the fact that AI technology gathers and analyses massive volumes of data. In order to secure customer information and remain in compliance with privacy laws, businesses must take the necessary precautions (Thomas, 2019).
• Cybersecurity risks- Artificial intelligence (AI) systems may be vulnerable to cyber dangers like hacking and data leaks. Companies must take strong cybersecurity precautions to guard against these dangers.
• Regulatory challenges- Issues with regulations Businesses have when using AI technology include having to adhere to a wide range of regulations. There may be financial penalties, legal action, and harm to Pinterest's reputation if Pinterest's don't follow these rules (Murillo, 2022).
• Ethical considerations- Issues of justice and equality can come up in the framework of AI usage, including issues of prejudice and discrimination.
• Legal issues- Concerns about legal responsibility arise when AI is used to make judgements that have far-reaching effects on people or corporations (Murillo, 2022).
• Lack of transparency- Decisions made by AI may be less transparent, making it more challenging for people and groups to grasp the reasoning behind them (Thomas, 2019).
References
.png)
Reports
COIT20263 Information Security Management Report 1 Sample
Objectives
This assessment task relates to Unit Learning Outcome 2 and must be done individually. In this assessment task, you will analyse the scenario given on page 3 and develop guidelines for the specified policy for the hospital given in the scenario.
Assessment Task
You are required to analyse the scenario given on page 3 and develop guidelines for an Issue-Specific Security Policy (ISSP) on the ‘Acceptable Encryption Policy’ for the organisation described in the scenario. You should ensure that you support the guidelines you prepare with references and justify why those guidelines are necessary.
Assessment 1 task contains two parts; part A is writing a report on the guidelines and part B is writing a reflection on the experience of completing the assessment task.
Part A: The report for the given scenario should include:
1. Executive Summary
2. Table of Contents
3. Discussion
a Statement of Purpose (Scope and applicability, definition of technology addresses, responsibilities)
b Acceptable ciphers and hash function requirements
c Key Generation, Key agreement, and Authentication
d Violations of Policy
e Policy Review and Modification
f Limitations of Liability
4. References
Please note that you might need to make some assumptions about the organisation in order to write this report. These assumptions should match the information in the case study and not contradict the objectives of the report. They should be incorporated in your report. To avoid loss of marks, do not make assumptions that are not relevant or contradictory, or will not be used in your report discussion.
Your discussion must be specific to the given case scenario and the discussion should be detailed with justification. Wherever appropriate please provide evidence of information (with proper referencing) to justify your argument.
Please refer to external resources as needed. Please use at least 5 relevant references.
Note: You must follow the Harvard citation and referencing guidelines when writing your report.
Part B: Your reflection on completing this assessment may include (the word limit for part B is 500 words):
• how you attempted the task, methods used,
• any hurdle faced and how those were solved
• what you have learnt
• if you are asked to do this again, would you take a different approach? Support your answer with justification.
Solution
Statement of Purpose
The purpose of this report is to provide guidelines for the development and implementation of an Acceptable Encryption Policy for XYZ, a leading Australian private health insurance company. For Assignment Help, The policy will apply to all employees of the company, including full-time and part-time staff. The policy will apply to all data and information that the business processes, transmits, or stores, including client data, employee data, and confidential company information.
Definition of Technology Addresses
Encryption technology is a vital tool that enables companies to secure their data by converting it into a coded form that can only be accessed by authorized personnel. Encryption technology involves the use of algorithms and keys to transform data into a secure format. The policy will define the types of encryption technologies that are acceptable for use by the company, including symmetric key encryption and asymmetric key encryption. The policy will also define the key lengths and encryption algorithms that are acceptable for use by the company (Lv and Qiao 2020).
Responsibilities
The policy will define the responsibilities of different roles and departments within the company. The Chief Information Security Officer (CISO) will be responsible for the overall management and implementation of the policy. The IT team at each site will be responsible for installing and maintaining the encryption software on their respective servers. The security team will be responsible for monitoring the encryption tools to ensure their effective use and report any potential security breaches. All employees will be responsible for following the policy guidelines and using encryption tools appropriately to secure the data they handle. The purpose of this report is to provide guidelines for the development and implementation of an Acceptable Encryption Policy for XYZ. The policy will define the scope of the policy, the definition of technology addresses, and the responsibilities of different roles and departments within the company. The next section of the report will discuss the objectives of the policy (Hajian et al. 2023).
Acceptable Ciphers and Hash Function Requirements:
Encryption is a key component of data security, and the use of effective ciphers and hash functions is critical to ensuring data protection. The Acceptable Encryption Policy for XYZ will define the acceptable ciphers and hash functions that can be used to secure data.
Ciphers
The policy will define the types of ciphers that are acceptable for use by the company. These ciphers will include both symmetric and asymmetric ciphers. Symmetric ciphers, such as Advanced Encryption Standard (AES), are widely used for securing data as they use only a single key to encrypt as well as decrypt data. Asymmetric ciphers, such as RSA, use two keys, a public key, and a private key, to encrypt and decrypt data. The policy will also define the key lengths that are acceptable for use with the different ciphers (Lv and Qiao 2020).
Hash Functions
Hash functions are used to transform data into a unique fixed-length code or hash value. This is an important aspect of data security because it allows data integrity to be confirmed by comparing the hash value of the original data to the hash value of the received data. The policy will define the acceptable hash functions that can be used to secure data. These hash functions will include Secure Hash Algorithm (SHA) and Message Digest Algorithm (MD).
The policy will ensure that the ciphers and hash functions used by the company are regularly reviewed to ensure that they are still effective against current threats. The policy will also ensure that the use of weaker ciphers or hash functions is not permitted, as these may be vulnerable to attacks.
The Acceptable Encryption Policy for XYZ will define the acceptable ciphers and hash functions that can be used to secure data. This section of the policy will ensure that the ciphers and hash functions used by the company are effective against current threats and that the use of weaker ciphers or hash functions is not permitted. The next section of the report will discuss the encryption key management requirements defined in the policy (Lv and Qiao 2020).
Key Generation, Key Agreement, and Authentication:
Key generation, key agreement, and authentication are critical components of encryption that ensure the security of data. The Acceptable Encryption Policy for XYZ will define the key generation, key agreement, and authentication requirements to ensure that data is protected effectively.
Key Generation:
The policy will define the key generation requirements for the ciphers used by the company. The policy will require that keys be generated using a secure random number generator and that the key length be appropriate for the cipher. The policy will also define the process for key generation and the use of key derivation functions.
Key Agreement:
The policy will define the key agreement requirements for the ciphers used by the company. The policy will require that key agreement be performed using a secure key exchange protocol, such as Diffie-Hellman key exchange. The policy will also define the key agreement process and the use of key agreement parameters.
Authentication:
The policy will define the authentication requirements for the ciphers used by the company. The policy will require that authentication be performed using a secure authentication protocol, such as Secure Remote Password (SRP) or Public Key Infrastructure (PKI). The policy will also define the authentication process and the use of authentication parameters.
The policy will ensure that the key generation, key agreement, and authentication requirements used by the company are regularly reviewed to ensure that they are still effective against current threats. The policy will also ensure that the use of weaker key generation, key agreement, or authentication methods is not permitted, as these may be vulnerable to attacks (Niu et al. 2019).
Violations of Policy
The Acceptable Encryption Policy for XYZ is a critical component of the organization's security program. Violations of this policy can have serious consequences for the organization, including loss of data, damage to the organization's reputation, and legal liability. The policy will define the consequences of violating the policy to ensure that all employees understand the importance of compliance.
The policy will define the penalties for non-compliance, which may include disciplinary action, termination of employment, and legal action. The policy will also define the process for reporting policy violations and the procedures for investigating and addressing violations.
It is important to note that violations of this policy are not limited to intentional actions. Accidental or unintentional violations can also have serious consequences for the organization. Therefore, the policy will also define the process for reporting accidental or unintentional violations and the procedures for addressing them.
The policy will also define the process for reviewing and updating the policy to ensure that it remains effective against current threats. Regular reviews of the policy will help to identify any gaps or weaknesses in the policy and ensure that the organization is prepared to address new threats. The Acceptable Encryption Policy for XYZ will define the consequences of violating the policy, the process for reporting policy violations, and the procedures for investigating and addressing violations. The policy will also define the process for reviewing and updating the policy to ensure that it remains effective against current threats. The final section of the report will provide a conclusion and recommendations for implementing the policy (Niu et al. 2019).
Policy Review and Modification:
The Acceptable Encryption Policy for XYZ is a living document that must be reviewed and updated regularly to remain effective against new and emerging threats. The policy review process should be documented and conducted on a regular basis, with a goal of ensuring that the policy is up-to-date and relevant.
The policy review process should include an evaluation of the organization's security posture, as well as a review of current threats and trends in the industry. This evaluation should identify any weaknesses in the current policy, as well as any new technologies or encryption algorithms that may need to be added to the policy.
The policy review process should also involve stakeholders from across the organization, including the IT department, security team, legal team, and executive management. These stakeholders can provide valuable insights into the effectiveness of the policy and identify any areas that may need to be strengthened or revised (Sun et al. 2020).
Once the policy review process is complete, any modifications or updates to the policy should be documented and communicated to all relevant stakeholders. This may include training sessions for employees, updated documentation and procedures, and updates to the organization's security controls and systems (Dixit et al. 2019).
It is also important to note that changes to the policy may require approval from executive management or legal counsel. Therefore, the policy review process should include a process for obtaining this approval and documenting it for future reference.
Limitations of Liability:
The Acceptable Encryption Policy for XYZ provides guidelines and requirements for the use of encryption technology within the organization. While the policy is designed to reduce the risk of data breaches and other security incidents, it is important to note that no security measure can provide 100% protection against all threats.
Therefore, the policy includes a section on limitations of liability that outlines the organization's position on liability in the event of a security incident. This section states that while the organization will make every effort to protect the confidentiality, integrity, and availability of its data, it cannot be held liable for any damages resulting from a security incident.
This section also includes information on the steps that the organization will take to respond to a security incident, including incident response procedures, notification requirements, and any other relevant information.
It is important to note that the limitations of liability section is not intended to absolve the organization of all responsibility for data security. Rather, it is intended to provide clarity on the organization's position in the event of a security incident and to ensure that all stakeholders are aware of their responsibilities and obligations.
Conclusion
The Acceptable Encryption Policy for XYZ provides guidelines and requirements for the use of encryption technology within the organization. The policy outlines acceptable ciphers and hash function requirements, key generation, key agreement, and authentication procedures, as well as guidelines for addressing violations of the policy.
The policy is intended to protect confidential data from unauthorised access, disclosure, and alteration, as well as to reduce the risk of security incidents. The policy also includes provisions for reviewing and updating the policy as needed to address changes in technology or security threats.
References
.png)
Reports
MBIS4004 System Design Report Sample
Workshop Session 02
Activity 01:
Trapping a sample:
• Class will be broken in teams of 3-4 students using breakout rooms.
• Access your E-Book on page 174, read and discuss the case to answer (you have 30 min.):
• Each of you must access Discussion Board “Group X: Trapping a sample” to write your answers (you have 30 min.) - 1% Mark.
• It must be done within this given time, otherwise you won’t receive any mark.
Activity 02:
Problem:
You are hired as a systems analyst by an organization that is planning to redesign its website. Consider the following situations and describe the most appropriate sampling method for each of them.
a. To gauge employee perception towards website redesign, you post a notice on the intranet portal asking the employees to post their opinions.
b. You design a customer survey to find out which website features they wish to see redesigned.
c. You seek customer opinions through forms available at three of the company’s 20 helpdesks.
Explain why the answer to each situation would vary.
• Class will be broken in teams of 3-4 students using breakout rooms.
• Read and discuss the case to answer (you have 30 min.):
• Each of you must access Discussion Board “Group X: Activity 2”
Solution
Activity 1
The classes are being segregated into teams of 3 to 4 students each. This division has been done through the process of breakout rooms and they also had been provided with E-books. Meanwhile, every group was provided with Discussion books and regular classes were also being taken so that the students are in touch with their subjects regularly. For Assignment Help, Meanwhile, marks were being strictly distributed by teachers based on metrics, and hence only qualified students were being provided with the degree. Meanwhile, since I was a very serious student so I managed to clear all the exams easily, and hence due to this I am now a qualified system analyst.
Q) Role of System Analyst in Designing Website
Rahmawati et al. (2022) stated that system analysts have some critical challenges from the elicitation of requirements to the delivery of the technical requirements to the development teams so far. The system analyst always tends to look at the design more technically and functionally and human-computer interaction manages it through computer interaction. Sam Pelt is required to rely on software for sampling the opinion of customers and for making the strategic decision of stocking fake furs which have been always real for storing furs. Sam pelt is required to have a separate website for their company as websites have become the most important portal of communication. The business environment is extremely competitive and hence the development of the website has become mandatory.
Q) Designing Customer Survey
The system analyst always tends to serve to optimize user activity with systems and software for employees of an organization to work perfectly on it. Ninci et al. (2021) stated that these professionals always advise employees on which software they are required for implementing, and users are required to ensure for ensuring that the programs function correctly. Therefore, the system analyst employed by SamPelt is required to optimize the system and software so that the organization can perform effectively. Therefore, as a system analyst, I am required to ensure that the computer system, infrastructure, and systems perform effectively. Therefore, I carry the responsibility of researching the problem and finding solutions, and even recommending courses of action. The analyst of the system is required to be conversant in several operating systems, programming languages, hardware platforms, and software.
Q) Role of Customer Opinions in Designing Website
A system analyst is an individual who engages in techniques of design and analysis of engaged systems in solving any problem of business. Gao et al. (2023) reviewed that the analyst of the system is required to keep up to date with modern innovations for improving productivity at every time for the organization. Therefore as s system analyst of Sam Pelt, my main role is to improve productivity at every time of organization. I am going to leave no stone unturned in ensuring to use of a networked computer that supports the packaged software for selecting the mailing list of customers. Moreover, SamPelt is also interested in making a strategic decision that affects the purchasing of goods. Hence, as a system analyst, I am required to play a key role in this step to ensure that Sam Pelt is successful in developing a website for the organization so that it can operate effectively without any hiccups.
Reference List
.png)
Reports
DATA4000 Introduction to Business Analytics Report 3 Sample
Your Task
Consider below information regarding the National Australia Bank data breach. Read the case study carefully and using the resources listed, together with your own research, complete: Part A (Industry Report).
Assessment Description
Bank of Ireland
https://www.rte.ie/news/business/2022/0405/1290503-bank-of-ireland-fined-by-dpc/
Background
Bank of Ireland has been fined 463,000 by the Data Protection Commission for data breaches affecting more than 50,000 customers. It follows an inquiry into 22 personal data breach notifications that Bank of Ireland made to th Commission between 9 November 2018 and 27 June 2019. One of the data breach notifications affected 47,000 customers.
The breaches related to the corruption of information in the bank's data feed to the Central Credit Register (CCR), a centralised system that collects and securely stores information about loans. The incidents included unauthorised disclosures of customer personal data to the CCR and accidental alterations of customer personal data on the CCR”.
Brief
As an analyst within Bank of Ireland, you have been tasked with considering ways in which customer data can be used to further assist Bank of Ireland with its marketing campaigns. As a further task, you have been asked to consider how Bank of Ireland could potentially assist other vendors interested in the credit card history of its customers.
Assessment Instructions
Part A: Industry Report (1800 words, 25 marks) - Individual
Based on your own independent research, you are required to evaluate the implications of the European legislation such as GDPR on Bank of Ireland’s proposed analytics project and overall business model. Your report can be structured using the following headings:
Data Usability
- Benefits and costs of the database to its stakeholders.
- Descriptive, predictive and prescriptive applications of the data available and the data analytics software tools this would require.
Data Security and privacy
- Data security, privacy and accuracy issues associated with the use of the database in the way proposed in the brief.
Ethical Considerations
- The ethical considerations behind whether the customer has the option to opt in or opt out of having their data used and stored in the way proposed by the analytics brief
- Other ethical issues of gathering, maintaining and using the data in the way proposed above.
Artificial Intelligence
- How developments in AI intersects with data security, privacy and ethics, especially in light of your proposed analytics project.
It is a requirement to support each of the key points you make with references (both academic and “grey” material) Use the resources provided as well as your own research to assist with data collection and data privacy discussions.
https://gdpr-info.eu/
Solution
Part A: Industry Report
Introduction
The risk connected with the mortgages that the Bank of Ireland and other commercial organisations issue is managed via the application of data. For Assignment Help, Analysing the information they get about specific clients is how they accomplish things like client credit rating, payment card usage, balances owing on various payment cards, and balances owed on various kinds of credit (net loans capacity) can all be included in the dataset, although they are not the only ones. To determine a lender's creditworthiness or determine the hazard associated with loan issuing, credit security assessment is the study of past data (Shema 2019, p. 2). The research findings assist financial organisations and the Bank of Ireland in assessing both their own and their client's risks.
Data Usability
A person or group that might influence or be impacted by the information administration procedure is referred to as a participant in whatever data management program. The stakeholder database is used as more than just a device for public connections; it also acts as documentation for compliance and verification, a trustworthy source of data for future computer evaluations or studies, and fosters lengthy effectiveness. Stakeholder databases are essential, yet they are frequently underfunded, and numerous businesses continue to keep their data on unprotected worksheets (Campello, Gao, Qiu, & Zhang 2018, p 2). The average expense to design a database managing application is 24,000 dollars. Yet, the whole price ranges from 11,499 to 59,999 dollars. Any database administration application with fewer capabilities, or perhaps a Minimum viable product, would be less expensive than one that involves all of the anticipated functions.
.png)
Figure: Data usability
Source: (Hotz, et al, 2022)
An institution's daily activities regularly make utilization of descriptive data. Professional analyses that offer a historical overview of an institution's activities, such as stock, circulation, revenue, as well as income, all seem to be instances of descriptive data. Such reporting' material may be readily combined and utilized to provide operational glimpses of a company. Numerous phases in the descriptive analytical method may be made simpler by the use of corporate insight technologies including Power BI, Tableau, as well as Qlik.
Likelihoods are the foundation of predictive data analysis. Predictive modelling makes an effort to anticipate potential prospective results as well as the possibility of such occurrences utilizing a range of techniques, including data analysis, numerical modelling (arithmetical connections among factors to anticipate results), as well as optimization techniques for computer learning (categorization, stagnation, and grouping methods) (Lantz 2019, p 20). Among the best, most trustworthy, and most popular predictive analytic tools are IBM SPSS Statistical. It has existed for a while and provides a wide range of features, such as the SPSS modeller from the Statistics Framework for Behavioral Research.
Prescriptive data builds on the findings discovered via descriptive as well as predictive research by outlining the optimal potential plans of operation for a company. Because it is among the most difficult to complete and requires a high level of expertise in insights, this step of the corporate analytics method is hardly employed in regular corporate processes. Automating email is a clear example of prescriptive data in action. Marketers may send email content to each category of prospects separately by classifying prospects based on their goals, attitudes, and motivations. Email automation is the procedure in question.
Data Security and privacy
To safeguard database management systems from malicious intrusions and illegal usage, a broad variety of solutions are used in database security. Information security solutions are designed to defend from the abuse, loss, and intrusion of not just the data stored within the network but also the foundation for data management in general and any users (Asante et al. 2021, p 6). The term "database security" refers to a variety of techniques, methods, and technologies that provide confidentiality inside a database structure. Database security refers to a set of guidelines, strategies, and procedures that develop and maintain the database's security, confidentiality, and dependability. Because it is the area where breaches occur most frequently, openness is the most important component of data security.
Infringements might be caused by a variety of programming flaws, incorrect setups, or habits of abuse or negligence. Nearly half of documented data thefts still include poor credentials, credential exchange, unintentional data deletion or distortion, as well as other unwelcome human activities as their root reason. Database governance software ensures the confidentiality and security of data by ensuring that only permitted individuals get access to it and by executing permission tests when the entrance to private data is sought. One of the data breach reports involving Bank of Ireland involved 47,000 clients. The data flow from the bank to the National Credits Record, a unified platform that gathers and safely maintains data on mortgages, was compromised in the incidents. Unauthorized client private information exposures to the CCR and unintentional changes to client private information upon that CCR were among the instances.
.png)
Figure: Data Security and privacy
Source: (Yang, Xiong, & Ren, 2020)
According to Shaik, Shaik, Mohammad, & Alomari (2018), the safeguarding of content that is kept in databases is referred to as database integrity. Businesses often maintain a variety of data within the system. They must employ safety methods like encrypted networks, antivirus software, safety encrypting, etcetera, to protect that crucial data. The safety of the system itself as well as the moral and regulatory ramifications of whatever information must be put upon that database in the first position were the two key concerns concerning database confidentiality. Additionally, the ethical obligation imposed on database protection experts to protect a database management structure must be taken into account.
Data consistency, which acts as the primary yardstick for information quality, is defined as data consistency with reality. The proper information must match the data that is required since more conformity converts into higher dependability. It suggests that the information is accurate, without mistakes, and from a reliable and consistent source. Since inaccurate data leads to inaccurate projections, data integrity is essential. If the anticipated outcomes are inaccurate, time, money, and assets are wasted. Accurate information enhances decision-making confidence, increases productivity and advertising, and reduces costs.
Ethical Considerations
According to Tsang (2019), conversations regarding how firms manage consumer data typically revolve around regulatory issues, such as risks and constraints. With good reason: the massive private data collections made by businesses and government agencies entail severe consequences and the potential for harm. In a way, more current security regulations, including the General Data Protection Regulations (GDPR) of the European Union and the Consumers Privacy Act of California (CCPA), prohibit usage attempts to regain the user's power.
The best way for a business to convince consumers to give their consent for the collection and use of their private details is to use that data to the customer's benefit. Letting users understand what data companies gather about them and the ways it's used in company services or offerings. Every business with clients or users is providing a valued offering or service. The worth is sometimes rather clear-cut. Users of location tracking, for example, are likely aware that these apps must track user locations to show the participant's true location, alter turn-by-turn directions, or provide actual-time traffic data. Most users agree that utilizing up-to-date mapping information offers benefits over employing monitoring programs that can keep track of their locations (Trivedi, & Vasisht, 2020, p 77). In similar circumstances, businesses would have to convince clients of the benefit of their information consumption to win their support. Users are conscious of the barter as well as, in some cases, are willing to permit the utilization of personal data if it is used by a company to improve the value of its services, promote research and development, improve stock control, or for any other legitimate purpose. When businesses give clients a compelling cause to express their support, everyone wins. This requires gaining the client's trust through both behaviour and information.
Companies have an ethical responsibility to their customers to only collect the necessary material, to secure that information effectively, limit its dissemination, and also to correct any errors in relevant data. Employees have a moral duty to hold off on glancing at customer records or files until it is essential, to hold off on giving customer data to competitors, and to hold off on giving user details to friends or relatives. Customers who share data with companies they do business with also have an ethical responsibility in this respect (Kim, Yin, & Lee 2020, p 2). Such compliance might comprise providing accurate and complete data as needed as well as abiding by the prohibition on disclosing or using company data that individuals may have access to.
Artificial Intelligence
With the advent of technical advancement, multiple new and updated machines are used in several sectors across the globe. Financial sectors are one of the most growing and continuously changing sectors which requires an in-depth analysis of its internal changing faculties that takes place rapidly. According to Kaur, Sahdev, Sharma, & Siddiqui, (2020), the role of Artificial intelligence is enormous in securing the growth and development of the financial sectors. The Bank of Ireland has been providing satisfactory customer services for years. However, in recent times, some difficulties are generated in banking services due to questions regarding protecting the data of the customers and restricting the bank authority from any kind of malpractice of the data. In this regard, the role of artificial intelligence is crucial to bring a massive transformation in the data safety and security process and win the hearts of customers. Artificial intelligence works for enhancing cybersecurity and protecting the bank from money laundering (Manser Payne, Dahl, & Peltier 2021, p. 15(2). In recent times, a large number of banks are now focusing on the implementation of Artificial intelligence to ensure the safety and security of their data of customers. However, now the areas which require more emphasis are understanding how artificial intelligence works for protecting data and what steps can be implemented to harness the safety of data.
Artificial intelligence generally helps in future predictions based on previous activities of the customers and is significantly able to differentiate between the more important and least important data. With the help of cognitive process automation, multiple features can be enabled most appropriately. According to Manser Payne, Peltier, & Barger (2021), scecuring ROI reduces the cost and ensures the quick processes of services at each step of bank services. In the finance sector, it is important to have a quick review of the financial activities of the customers. For human labour, it is quite a tough task. To make the procedure easy and harness the financial activities of banks takes help from the inbuilt automation process and robot automation process which denotes a high level of accuracy, lesser human-made errors, use of the cognitive system for making decisions and deviating valuable time to the optimum success of the financial sectors (Flavián, Pérez-Rueda, Belanche, & Casaló 2022, p. 7).
.png)
Figure: Use of AI in banks
Source: (Shambira, 2020)
The Bank of Ireland uses cloud storage to keep the data of the customers safe and protected. The prime goal of using AI in banks is to make the financial activities of the bank more efficient and customer driven. Address the issues more efficiently and adopt new methods to attract more customers. The Bank of Ireland is one of the most prominent banks in the country and they have to handle a wide range of data. Using optimum levels of AI technologies will help to bring more efficiency to the banking system.
Conclusion
To conclude, it can be stated that the Bank of Ireland has been providing services for many years and since the inception of the bank its prime duty is to provide safe and secure services to its customers. With the increasing pressure on customers and raising questions about data protection, the banking sectors are now focusing on utilising Artificial intelligence in banks which can provide maximum safety to the data of the customers and increase the number of customers.
Reference
.png)
.png)
Reports
DATA4100 Data Visualisation Software Report 4 Sample
Your Task
This written report with a dashboard is to be created individually.
• Given a business problem and data, finalise visualisations and prepare a report for the Australian Department of Foreign Affairs and Trade.
• On Tuesday of week 13 at or before 23:55 AEST submit your written report as a Microsoft Word file with a snapshot of your dashboard via Turnitin. This assessment covers Learning outcomes: LO2, LO3
Assessment Description
Should Australia enter a free trade agreement with Germany?
.png)
Business Background:
Germany, Japan, South Korea, United States, France and China are amongst the main exporters of cars. Suppose that the Australian government is particularly interested in the products exported from Germany, as well as Australian products exported to Germany, in considering the possibility of a free trade agreement.
Suppose that you have been asked, as an analyst for the Australian Department of Foreign Affairs and Trade, to report on exports from Germany, and in particular, the types of products Germany exports to Australia. Likewise, analyse the products that Australia exports to Germany currently, based on your own research into available data sets.
Your written report (to be prepared in this assessment - in Assessment 4) will ultimately end up in the hands of the minister for trade and investment, so any final decisions made should be supported by data In Assessment 4, you are to finish designing your visualisations, then prepare a report by interpreting the visualisations and integrating with theory from this subject.
Data set
- Use the data given to you in week 11
Assessment Instructions
- As an individual, finish the visualisations for your report.
- Write a structured report with appropriate sections, as follows:
- Introduce the business problem and content of your report. (150 words)
- Interpret your charts, summaries, clustering and any other analyses you have done in the process of creating your visualisations, and link it back to the business problem of whether Australia should enter a free trade agreement with Germany? (800 words)
- Justify the design of your visualisations in terms of what you have learnt about cognitive load and pre-attentive attributes and Tufte’s principles. (250 words)
- On Tuesday of week 13 at or before 23:55 AEST submit your report as a Microsoft Word file, containing your visualisations, via Turnitin.
Solution
Introduction
This report is based on analysis and visualisation for business export between two countries Australia and Germany. The business problem is based on exports from Australia to Germany and exports from Germany to Australia. These exports include animal base products such as animal itself and meats. For Assignment Help, The problem is to analyse and visualise the data provided for business export Australia to Germany and Germany to Australia. The purpose of this report is to provide understanding and knowledge regarding total trade value and product type between these two countries Australian Germany so that Australian government can take decisions based on product exports or import between these two countries. In this report visualisations are represented for both Australia to Germany export and Germany to Australia export along with the prototype. Power bi is a business intelligence tool that is used for which and analysis on provided data. At the end of this report each visualisation are justified along with the attributes and important points are concluded. The data loaded in Power Bi for visualizations. The data cleaned by removing null values from the data. Cluster line chart created for the product export with trade value. Clustering done for product type and trade value by year
Data Gathering and Analysis
The data collected based on the import and export between these two countries Germany and Australia that includes product type product category and the total trade value made by each country on each individual product. The data uploaded in business intelligence tool to check the valuation of the data for the further analysis. It is important to validate the data for desired result and analysis that will further make easy decisions for the business problem. For the analysis and virtualization to different charts are used such as cluster line chart and clustering chart so that each attributes can be analyzed with the help of visualization.
Australia to Germany
This section discuss about analysis and visualisation regarding export from Australia to Germany as export involve multiple products that belongs to the animal product category along with the total trade value made on each product. Analysis made with the help of individual year considering the trade value for each year.
Cluster line and Bar Chart
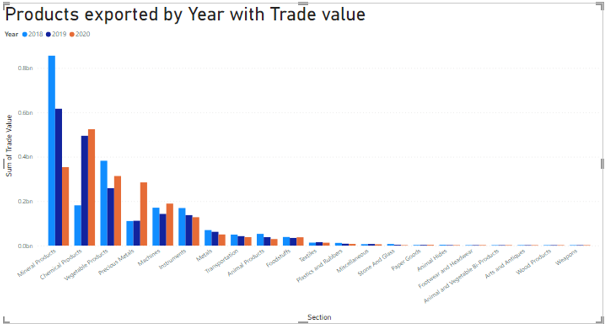
The above chart showing the cluster line chart created with the help of trade value and the product category along with the year. The way you lieration created for total products exported by each year along with total trade value created on each product from Australia to Germany. As it can be seen in chat mineral products and chemical products are the highest one which made highest trade value while export from Australia to Germany. And further trade value is continuously decreasing along with the product category and the least state value created by the product weapons that source the minimum exports from Australia to Germany is done for weapons. This complete visualisation is based on three consecutive years from 2018 to 2020 only as the data represented is showing visualisation from 2018 to 2020.
Cluster Chart
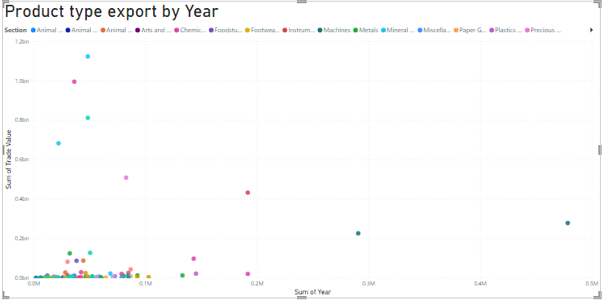
The above visualisation showing cluster data visualisation for the product type exported between Australia to Germany each individual year. The colourful dots showing product type along with the trade value created by each product type from 2018 to 2020. Each products type is highlighted with a different colour for better identification along with some of the trade value. This graph also shows that mineral products have the highest trade value achieved while exporting from Australia to Germany.
Pie Chart
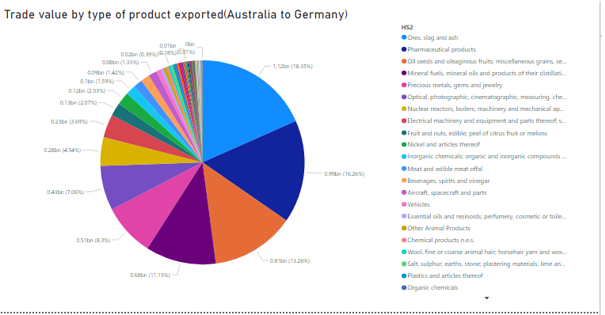
The above visualisation shoes pie chart for total trade value created by each product type exported from Australia to Germany. Here each product is represented with different colour along with trade value represented at outlyers of the pie chart. This representation can clearly defined the highest and lowest trade value made by the product in each individual year from 2018 to 2020 exports. Each different visualisation defines the product category product type and total trade value generated by each product while exporting from Australia to Germany
Germany to Australia
This section discuss about visualisation and analysis regarding export from Germany to Australia. Based on the provided data set it can be observed that there are multiple category of products which are exported from Germany to Australia from 2018 to 2020. The product category involve animal product vegetable products food stuffs and fruit along with minerals and chemical products. This section also represent three different visualizations that includes cluster line chart, cluster chart and pie chart.
Cluster line and Bar chart
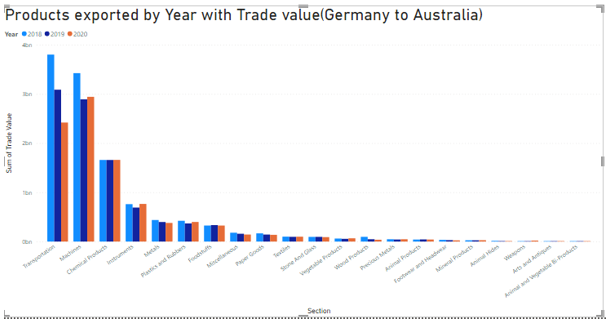
The above graph shows cluster line chart for the export data from Germany to Australia that define products exported by each year with individual trade value generated by each product. As it can be seen in visualisation that transportation created the highest trade value from Germany to Australia. The second highest trade value from Germany to Australia created by machines export. While the least trade value generated by the product called animal and vegetables by products because it includes very less in export business between Australia and Germany. This graph also showing data from 2018 to 2020 for the export from Germany to Australia.
Cluster Chart
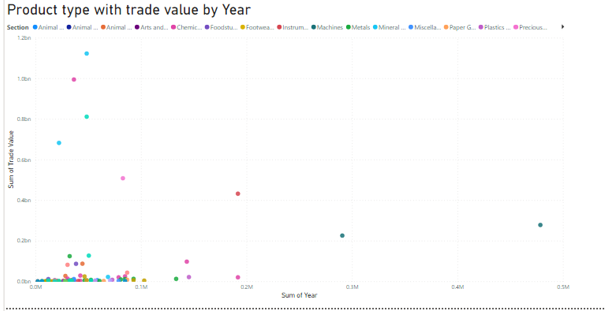
The above graph showing cluster chart that defined visualisation for the product type with trade value by each individual year from 2018 to 2020. Here each product type is represented with a different colour and each dot in above scatter plot defines product type along with the total trade value generated by each product from 2018 to 2020. The highest trade value and the least trade value can also be identified with the help of dots showing in above cluster visualisation. With the help of cluster chart each and every product type can be identified individually along with the accurate value.
Pie Chart
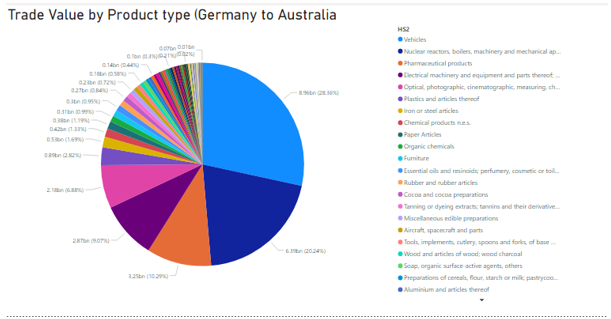
This is a pie chart that showing export of each product type along with trade value generated by each product. In this pie chart is product type is highlighted with different colour in order to categories each product trade value as the trade value highlighted at outlliers of the pie chart. Here it can be observed that transportation has the highest state value while export from Germany to Australia. Here transportation means product related to the transportation category such as vehicles so the major export involved from Germany to Australia is for vehicles. The second highest export made by Germany to Australia is for machinery and other mechanical products.
Conclusions
Based on the above visualisation and analysis it is found at Germany is a good exporter for machine related products such as vehicles and other machineries. In the same way it is also found that Australia is good in mineral products that is why Australia has created high trade value while exporting mineral products to Germany. Both countries have different experties regarding products and both are creating high trade value in each individual export is for the product export. The business value between Australia and Germany is identified high due to the heavy products exported and imported between these two countries. The purpose of analysis and visualization on export data between Australia and Germany has successfully completed.
References
.png)
Reports
COIT20253 Business Intelligence Using Big Data Report Sample
Assessment Task:
Assignment 1 is an individual assessment. In this assessment, you are assigned tasks which assess your unit knowledge gained between weeks 1 and 5 about big data and how it can be used for decision making in any industry. All students will have to write a “professional” business report with Executive summary, Table of Content (MS generated); Introduction; Discussion; Conclusion; Recommendations and References.
Please note that ALL submissions will be checked by a computerised copy detection system and it is extremely easy for teaching staff to identify copied or otherwise plagiarised work.
• Copying (plagiarism) can incur penalties, ranging from deduction of marks to failing the unit or even exclusion from the University.
• Please ensure you are familiar with the Academic Misconduct Procedures. As a student, you are responsible for reading and following CQUniversity’s policies, including the Student Academic Integrity Policy and Procedure.
In this assessment, you are required to choose one of the following industries: Healthcare, Insurance, Retailing, Marketing, Finance, Human resources, Manufacturing, Telecommunications, or Travel.
This assessment consists of two parts as follows:
Part A - You are required to prepare a professional report on WHY Big Data should be integrated to any business to create opportunities and help value creation process for your chosen industry.
Part B - You need to identify at least one open dataset relevant to the industry and describe what opportunities it could create by using this dataset. You can access open data source from different websites. Please try finding it using Google.
In Part A, you will describe what new business insights you could gain from Big Data, how Big Data could help you to optimise your business, how you could leverage Big Data to create new revenue opportunitiesfor your industry, and how you could use Big Data to transform your industry to introduce new services into new markets. Moreover, you will need to elaborate how you can leverage four big data business drivers- structured, unstructured, low latency data and predictive analytics to create value for your industry. You are also required to use Porter’s Value Chain Analysis model and Porter’s Five Forces Analysis model to identify how the four big data business drivers could impact your business initiatives.
Solution
Part A
Introduction
The integration of big data has emerged as a transformative force in today's rapidly evolving business landscape which has reshaped industries and redefined organizational paradigms. The sheer volume and variety of data available have paved the way for unprecedented insights and opportunities. For Assignment Help, This report will explore the multifaceted impact of big data on business initiatives which elucidate how four key drivers i.e., structured, unstructured, low latency data and predictive analytics used to intersect with Porter's Value Chain Analysis and Five Forces Analysis. The report aims to provide a comprehensive understanding of how big data drivers foster value creation by delving into these intricate interactions which can enhance operational efficiency and steer strategic decision-making across industries.
Big Data Opportunities
Enhanced Customer Insights and Personalization:
Big data analytics offers the power to delve into expansive customer datasets which can help to unveil new insights into preferences, behaviors, and trends (Himeur et al. 2021). Businesses can create personalized experiences that resonate deeply with their customers by harnessing this data. Personalization has cultivated a strong bond between the business and its customers from tailored product recommendations based on browsing history to precisely targeted marketing campaigns. This not only amplifies customer satisfaction but also fosters loyalty and advocacy which can be considered as a major parameter to drive sustained revenue growth. Personalized experiences have become a defining factor in competitive differentiation in industries such as e-commerce, retail, and hospitality.
Operational Efficiency and Process Optimization:
Big data's analytical prowess extends to scrutinizing intricate operational processes. Organizations can leverage this capability to identify inefficiencies, bottlenecks, and areas for improvement. Companies gain a holistic view of their workflows by analyzing operational data that can help to enable them to streamline operations along with reducing resource wastage and enhancing overall productivity. Integrating real-time and low-latency data empowers businesses to make agile decisions, ensuring prompt adaptation to dynamic market shifts. Industries spanning manufacturing, logistics, and healthcare can reap significant benefits from this opportunity, resulting in cost savings and improved service delivery.
Predictive Analytics for Proactive Decision-making:
The integration of predictive analytics into big data strategies empowers industries to foresee future trends and outcomes (Stylos, Zwiegelaar & Buhalis, 2021). This predictive prowess holds applications across various sectors, from retail to finance. By analyzing historical data and identifying patterns, businesses can forecast demand, anticipate market shifts, and assess potential risks. Armed with these insights, organizations can make proactive decisions that minimize risks and capitalize on emerging opportunities. In sectors where timeliness is paramount, such as finance and supply chain management, predictive analytics offers a competitive edge.
Innovation and New Revenue Streams:
Big data serves as a wellspring of inspiration for innovation. Industries can leverage data-driven insights from customer feedback, market trends, and emerging technologies to create novel products and services. By identifying gaps in the market and understanding unmet needs, businesses can design solutions that resonate with consumers. These innovations not only open new revenue streams but also position organizations as market leaders. Industries as diverse as technology, healthcare, and agriculture can leverage this opportunity to foster disruptive ideas that cater to evolving demands.
Value Creation Using Big Data
Enhanced Decision-making and Insights:
Big data equips industries with a wealth of information that transcends traditional data sources. By amassing vast volumes of structured and unstructured data, businesses can extract actionable insights that drive informed decision-making (Ajah & Nweke, 2019). From consumer behavior patterns to market trends, big data analysis unveils previously hidden correlations and emerging opportunities. This heightened awareness empowers industries to make strategic choices grounded in empirical evidence, mitigating risks and optimizing outcomes. In sectors such as retail and finance, data-driven insights enable precision in understanding customer preferences and forecasting market shifts, ultimately shaping successful strategies.
Operational Efficiency and Process Optimization:
The integration of big data analytics facilitates the optimization of operational processes, delivering heightened efficiency and resource allocation. Through data-driven analysis, industries identify inefficiencies and bottlenecks that hinder productivity. This leads to targeted process improvements and streamlined workflows, translating into resource and cost savings. Moreover, real-time data feeds enable agile adjustments, enabling swift responses to market fluctuations. Industries such as manufacturing and logistics reap substantial benefits, achieving seamless coordination and reduced wastage through data-informed process enhancement.
Personalized Customer Experiences:
Big data revolutionizes customer engagement by enabling hyper-personalization. By analyzing vast datasets comprising customer behavior, preferences, and transaction history, businesses can tailor offerings to individual needs (Shahzad et al. 2023). This personalization extends to tailored marketing campaigns, product recommendations, and service interactions, enhancing customer satisfaction and loyalty. In industries like e-commerce and telecommunications, personalized experiences not only foster customer retention but also amplify cross-selling and upselling opportunities, consequently elevating revenue streams.
Innovation and New Revenue Streams:
Big data serves as a catalyst for innovation, propelling industries to develop groundbreaking products and services. By decoding customer feedback, market trends, and emerging technologies, businesses gain insights that steer novel offerings. This innovation not only fosters market differentiation but also creates new revenue streams. Industries ranging from healthcare to entertainment tap into big data to identify gaps in the market and devise disruptive solutions. This adaptability to evolving consumer demands positions businesses as pioneers in their sectors.
Porter’s Value Chain Analysis
Porter's Value Chain Analysis is a strategic framework that helps organizations dissect their operations into distinct activities and examine how each activity contributes to the creation of value for customers and, consequently, the organization as a whole (Ngunjiri & Ragui, 2020).
Porter's Value Chain Components:
.png)
Now, applying this analysis to the impact of four big data business drivers - structured data, unstructured data, low latency data, and predictive analytics - can offer valuable insights into how these drivers influence various stages of the value chain.
.png)
.png)
.png)
Support Activities:
1. Firm Infrastructure: Big data impacts strategic decision-making. Structured data provides historical performance insights, guiding long-term planning. Unstructured data can uncover emerging market trends and competitive intelligence, influencing strategic initiatives.
2. Human Resources: Big data assists in talent management. Structured data aids in identifying skill gaps and training needs. Unstructured data, such as employee feedback and sentiment analysis, offers insights into employee satisfaction and engagement.
3. Technology: Technology plays a pivotal role in handling big data. The integration of structured and unstructured data requires robust IT infrastructure. Low latency data ensures real-time data processing and analysis capabilities, enhancing decision-making speed.
4. Procurement: Big data enhances procurement processes (Bag et al. 2020). Structured data supports supplier performance evaluation, aiding in supplier selection. Unstructured data assists in supplier risk assessment by analyzing external factors that may impact the supply chain.
Applying the Value Chain Analysis: To illustrate, let's consider a retail business. The impact of big data drivers can be observed across the value chain. Structured data aids in optimizing inventory management and supplier relationships in inbound logistics. Low latency data ensures real-time monitoring of stock levels and customer preferences in operations. Predictive analytics forecasts demand patterns in marketing and sales which can create tailored promotions and inventory adjustments. Post-sale service benefits from unstructured data insights into customer feedback which aids in improving customer satisfaction.
Porter’s Five Forces Analysis
1. Competitive Rivalry:
Big data drivers have a profound impact on competitive rivalry within an industry. Structured data enables companies to analyze market trends along with customer preferences and competitive benchmarks which fosters strategic differentiation (Suoniemi et al. 2020). Unstructured data can provide insights into brand perception and competitive positioning such as social media sentiment. Businesses can anticipate shifts in customer demands by leveraging predictive analytics which can enhance their ability to innovate and stay ahead of competitors. Low latency data ensures real-time decision-making that allows businesses to respond promptly to competitive moves.
2. Supplier Power:
The utilization of big data drivers can reshape the dynamics of supplier power. Structured data aids in supplier evaluation which facilitates data-driven negotiations and contract terms. Unstructured data provides insights into supplier reputations that helps businesses make informed decisions. Low latency data enhances supply chain visibility which can reduce dependency on single suppliers (Singagerda, Fauzan & Desfiandi, 2022). Predictive analytics anticipates supplier performance and potential disruptions which allows proactive risk mitigation strategies.
3. Buyer Power:
Big data drivers impact buyer power by enabling businesses to tailor offerings to customer preferences. Structured data allows for customer segmentation and customized pricing strategies. Unstructured data offers insights into buyer sentiments that can influence marketing and product strategies. Predictive analytics helps forecast consumer demand which can allow businesses to adjust pricing and supply accordingly (Bharadiya, 2023). Low latency data ensures quick responses to changing buyer behaviors and preferences.
4. Threat of Substitution:
Big data drivers can influence the threat of substitution by enhancing customer loyalty. Structured data-driven insights enable businesses to create personalized experiences that are difficult for substitutes to replicate (Sjödin et al. 2021). Unstructured data offers insights into customer feedback and preferences which can provide support for continuous improvement and product differentiation. Predictive analytics anticipates customer needs in order to reduce the likelihood of customers seeking alternatives. Low latency data ensures quick adaptation to market shifts that can reduce the window of opportunity for substitutes.
5. Threat of New Entrants:
The incorporation of big data drivers can impact the threat of new entrants by raising barriers to entry. Structured data enables established businesses to capitalize on economies of scale and create efficient operations which makes it challenging for newcomers to compete. Unstructured data provides insights into customer preferences to support brand loyalty. Predictive analytics helps incumbents anticipate market trends which enable preemptive strategies against new entrants. Low latency data facilitates real-time responses to emerging threats which can reduce the vulnerability of established players.
Conclusion
The integration of big data drivers into business strategies represents a pivotal juncture in the ongoing digital transformation. The confluence of structured and unstructured data along with the power of low-latency data and predictive analytics can alters the fundamental fabric of industries. From optimizing processes to driving innovation, big data's imprint is visible across the value chain and competitive dynamics. As organizations harness this potential, they position themselves to thrive in an era where data-driven insights are the cornerstone of informed decision-making and sustainable growth. By embracing big data's capabilities, businesses are poised to navigate challenges, seize opportunities, and unlock the full spectrum of possibilities presented by the data-driven future.
Part B
Dataset identification
The dataset includes several parameters which are related to the retail industry. The dataset focused on date-wise CPI and employment rate with the weekly holiday. The dataset can help to identify the consumer price index along with the employment rate in the retail industry and the impact of holidays on them. The dataset is openly available and consists of three data files in which the considered dataset is the ‘Featured data set’ (Kaggle, 2023). It can be identified as one of the most suitable datasets that have provided structured data in order to analyze different outcomes.
Metadata of The Chosen Dataset
The selected dataset pertains to the retail industry and encompasses parameters such as Store, Date, Temperature, Fuel_Price, and various MarkDown values (MarkDown1 to MarkDown5), along with CPI (Consumer Price Index), Unemployment rate, and IsHoliday indicator. This metadata provides crucial insights into the dataset's composition and relevance within the retail sector.
The "Store" parameter likely represents unique store identifiers, facilitating the segregation of data based on store locations. "Date" captures chronological information, potentially enabling the analysis of temporal trends and seasonality. "Temperature" and "Fuel_Price" suggest that weather conditions and fuel costs might influence retail performance, as these factors impact consumer behavior and purchasing patterns.
The "MarkDown" values could denote promotional discounts applied to products, aiding in assessing the impact of markdown strategies on sales. Parameters like CPI and Unemployment offer a macroeconomic context, possibly influencing consumer spending habits. The "IsHoliday" parameter indicates whether a given date corresponds to a holiday, offering insights into potential fluctuations in sales during holiday periods.
Business Opportunities Through The Chosen Dataset
The analytical findings indicating a lower average unemployment rate on holidays and a higher average Consumer Price Index (CPI) during holiday periods hold significant implications for the chosen industry. These insights unveil a range of strategic opportunities that the industry can capitalize on to drive growth, enhance customer experiences, and optimize its operations.
.png)
Figure 1: Consumer price index comparison
(Source: Author)
Increased Consumer Spending: The lower average unemployment rate on holidays suggests a potential uptick in consumer spending power during these periods. This provides a prime opportunity for the industry to design targeted marketing campaigns, exclusive offers, and attractive promotions. By aligning their product offerings and marketing strategies with consumers' improved financial situations, businesses can drive higher sales volumes and revenue.
Customized Product Assortments: The availability of higher disposable income on holidays opens the door to curating specialized product assortments. Retailers can introduce premium and luxury items, cater to aspirational purchases, and offer exclusive collections that cater to elevated consumer spending capacity. This approach enhances the perceived value of products and creates a unique shopping experience.
.png)
Figure 2: Unemployment rate comparison
(Source: Author)
Strategic Inventory Management: Capitalizing on the lower unemployment rate on holidays can drive retailers to anticipate increased foot traffic and online orders. This presents an opportunity for strategic inventory management. Businesses can optimize stock levels, ensure the availability of popular products, and align staffing resources to accommodate higher consumer demand, ultimately enhancing customer satisfaction.
Enhanced Customer Engagement: With a heightened CPI during holidays, businesses can strategically invest in enhancing customer experiences to match the anticipated premium pricing. This could involve personalized shopping assistance, concierge services, or engaging in-store events. Elevated customer engagement fosters brand loyalty and differentiates the business in a competitive market.
Dynamic Pricing Strategies: The observed correlation between higher CPI and holidays enables the adoption of dynamic pricing strategies. By leveraging these insights, the industry can implement flexible pricing models that respond to demand fluctuations. This approach optimizes revenue generation while maintaining alignment with consumer expectations and market trends.
References
.png)
Reports
DBFN212 Database Fundamentals Report 4 Sample
ASSESSMENT DESCRIPTION:
Students are required to analyse the weekly lecture material of weeks 1 to 11 and create concise content analysis summaries of the theoretical concepts contained in the course lecture slides.
Where the lab content or information contained in technical articles from the Internet or books helps to fully describe the lecture slide content, discussion of such theoretical articles or discussion of the lab material should be included in the content analysis.
The document structure is as follows (2500 Words):
1. Title Page
2. Introduction and Background (85 words)
3. Content analysis (reflective journals) for each week from 1 to 11 (2365 words; 215 words per week):
a. Theoretical Discussion
i. Important topics covered
ii. Definitions
b. Reflection on the Contents
i. Create a brief scenario and apply the database concept learnt on it. You can use the same scenario for every lecture or modify it if needed. (Note: For week 1, you can omit providing a scenario, instead give your interpretation of the concepts.)
c. Outcome
i. What was the objective of the database feature/concept learnt?
ii. How the learnt concept/feature improves your understanding of the database systems.
4. Conclusion (50 words)
Your report must include:
• At least five references, out of which, three references must be from academic resources.
• Harvard Australian referencing for any sources you use.
• Refer to the Academic Learning Skills student guide on Referencing
Solution
Introduction
It is significant to reflect on the overall learning as it assists in gaining better insight into what has been learned during the course. For Assignment Help, The present report aims to describe the primary aspects related to database technology and database management, and it also aims to critically evaluate database management and database technology. The report also aims to apply concepts related to transaction processing and concurrency in systems of multi-user database. The report also aims to analyse primary issues related to data retrieval, access, storage, privacy and ethics.
Content Analysis
Week 1
A. Theoretical Discussion
The unit assisted in developing better insight into how a professional career can be developed in the field of database management. The insight about various disadvantages of database systems was gained during the unit, and some of the disadvantages involve complexity in management, increased costs, dependence on the vendor, maintaining currency and frequent replacement and upgrade cycles (Naseri and Ludwig, 2010).
B. Reflection on the Contents
I learned raw facts make up data, which is typically recorded in a database. The database structure is defined by database design. It's possible to categorise it based on the number of users, location, and data usage and structure. DBMSs were created to overcome the inherent flaws of the file system. Manual and electronic file systems gave way to databases. The administration of data in a file system has some constraints (Tan et al., 2019).
C. Outcome
The distinction between data and information was defined. There was a discussion about what a database is, the different varieties, and why they are important decision-making tools. Also saw how file systems evolved into current databases. Complete learning about the significance of database design was gathered. The major topic was the database system's main components. During the session learned the functions of a database management system in detail (DBMS).
Week 2
A. Theoretical Discussion
Different data views (local and global) and the level abstraction of data influence modeling of data requirements. In the real world a data model is a representation of a complicated data environment. The learning during the unit enhances knowledge of different database systems and models that are practically used by organisations in the business (Codd, 2015).
B. Reflection on the Contents
I learned that data model of a complicated data environment is represented in the real world. Relational, network, hierarchical, extended relational data model, and object-oriented data models are only a few examples. There are multiple database models available, and some of the examples are Cassandra, CouchBase, CouchDB, HBase, Riak, Redis and MongoDB. The MongoDB database is used by e-commerce organisations like eBay and Tesco, whereas Amazon uses its own Amazon SimpleDB, which is a document-oriented database (Dong and Qin, 2018).
C. Outcome
Basic data modelling building elements were taught to the students. Data modelling and why data models are important were discussed during the unit. During the event, the participants had a deeper knowledge of how the key data models evolved. Business rules were developed by the tutor, along with how they affect database design. The teacher demonstrated how data models are classed according to their level of abstraction. In addition, the event showcased new alternative data models and the demands they address.
Week 3
A. Theoretical Discussion
A relational database's basic building pieces are tables. A large amount of the data manipulation effort is done behind the scenes by a relational database.
B. Reflection on the Contents
A database of relational nature organises the data which can be related or linked n the basis of common data to each of the unit and that is what I learned. This ability assists me in retrieving a completely new table from the information in one or more than one table with the help of a single query. The popular examples of standard databases of relational nature involve Oracle Database, Microsoft SQL Server, IBM and MySQL. The database of the cloud relational system involves Google Cloud SQUL, Amazon RDS (Relational Database Services) (Song et al., 2018).
C. Outcome
The tutor went through the core components of the relational model as well as the content, structures, and properties of a relational table. The teacher also went through how to manipulate relational table contents using relational database operators. The logical structure of the relational database model was discussed in class.
In a relational database, the function of indexing was explained. The teacher also showed how the relational database model handles data redundancy. The session began with the identification of acceptable entities, followed by a discussion of the relationships between the entities in the relational database model. The components and function of the data dictionary and system catalogue were covered in class.
Week 4
A. Theoretical Discussion
The ERM represents the conceptual database as seen by the end-user with ERDs. Database designers are frequently obliged to make design compromises, regardless of how effectively they can generate designs that adhere to all applicable modelling norms (Pokorny, 2016).
B. Reflection on the Contents
I learned Conceptual data models at a high level provide ideas for presenting data in ways that are similar to how people see data. The entity-relationship model, which employs key concepts such as entities, attributes, and relationships, is a good example. The primary use of such data is done in the sales department of the business as it allows the people in business to view expenses data, sales data and to analyse total demand. It is also used in libraries where a system has the detail about the books, borrower entities and library (Das et al., 2019).
C. Outcome
The instructor explained how the database design process refines, defines, and incorporates relationships between entities. The teacher talked about the basic characteristics of entity-relationship components and how to investigate them. The impact of ERD components on database design and implementation was also examined. We learned about relationship components after finishing this chapter. There was some discussion about how real-world database design frequently necessitates the balancing of competing aims.
Week 5
A. Theoretical Discussion
Keys of surrogate primary are beneficial when there is no natural key that can be used as a primary key, the composite primary is the primary key that contains various data kinds, or when the primary key is too long to be used. Entity supertypes, subtypes, and clusters are used in the extended entity-relationship (EER) model to provide semantics to the ER model (Lang et al., 2019).
B. Reflection on the Contents
This is an example of a "sub-class" relationship which I developed after learning. We have four staff here: an engineer, a technician, and a secretary. The employee is the super-class of the other three sets of individual sub-classes, which are all subsets of the Employee set.
Employee 1001 will have the attributes eno, salary, typing speed and name because it is a sub-class entity that inherits all of the attributes of the super-class. A sub-class entity has a relationship with a super-class entity. For example, emp 1001 is a secretary with a typing speed of 68. Emp number 1009 is a sub-class engineer whose trade is "Electrical," and so on.
C. Outcome
The properties of good primary keys were discussed, as well as how to choose them. The unit aided in the comprehension of flexible solutions for unique data-modelling scenarios. In an entity-relationship diagram, the class learned about entity clusters, which are used to depict several entities and relationships (ERD). The instructor went over the key extended entity-relationship (EER) model constructs and how EERDs and ERDs represent them.
Week 6
A. Theoretical Discussion
The designer can use the data-modelling checklist to ensure that the ERD meets a set of basic standards. The more tables you have, the more I/O operations and processing logic you'll need to connect them.
B. Reflection on the Contents
Normalisation is a technique for creating tables with as few data redundancies as possible and I learned this during the module. When a table is in 2NF and has no transitive dependents, it is in 3NF. When a table is in 1NF and has no partial dependencies, it is in 2NF. When all, attributes are dependent and key attributes are defined on the primary key, a table is in 1NF.
C. Outcome
We understood the use of a checklist of data modelling to check that ERD meets a set of minimum demands. The teacher also assisted with investigations of situation that demands denormalisation to efficiently generate information. The class learned about the application of normalisation rules to correct structures of the table and to evaluate the structures of tables. The class discussed the role of normalisation in the process of designing data. The teacher also discussed the normal forms known as 4NF, 1NF, 2NF, BCNF and 3NF. The class discussed the way how normal forms can be transformed goes from lower average forms till the normal forms that are high.
Week 7
A. Theoretical Discussion
To limit the rows affected by a DDL command, use the WHERE clause with the UPDATE, SELECT, and DELETE commands. When it's necessary to process data depending on previously processed data, sub-queries and correlated queries are employed. Relational set operators in SQL allow you to combine the results of two queries to create a new relation (Alvanos Michalis, 2019).
B. Reflection on the Contents
I learned that All RDBMS vendors support the ANSI standard data types in different ways. In SQL, the SELECT statement is the most used data retrieval instruction. Inner joins and outer joins are two types of table joining operations. A natural join avoids duplicate columns by returning all rows with matching values in the matching columns (Koch & König, 2018).
C. Outcome
In this week, we learned retrieval of specified columns from the data of a large database. The class learned about how to join different table in a single query of SQL. There was an in-depth discussion about the restriction of retrieval of data to rows that aligns with difficult sets of criteria. The class also learned about the aggregation of data through rows and their groups. The teacher helped us create preprocess data subqueries for the purpose of inclusion in other queries. In the class, we learned to use and identification of different functions of SQL for numeric, string and manipulation of data. There was a depth discussion about the crafting of queries in SELECT.
Week 8
A. Theoretical Discussion
A cursor is required when SQL statements in SQL/PL code are meant to return several values. A stored procedure is a set of SQL statements with a unique name. The SQL embedded refers to SQL statements use within an application of programming languages such as Visual Basic, NET, Java, COBOL or C# (Lindsay, 2019).
B. Reflection on the Contents
All RDBMS vendors support the ANSI standard data types in different ways. I learned Tables and indexes can be created using the basic data definition procedures. You can use data manipulation commands to add, change, and delete rows in tables. Sequences can be used to generate values to be allocated to records in Oracle and SQL Server. Views can be used to show end-users subsets of data, typically for security and privacy concerns (Raut, 2017).
C. Outcome
We learned to manipulate the data using SQL and also how to delete, update, insert rows of data) In the module, we also gained knowledge to create updatable and database views. SQL also helped me in creating tables through the use of subquery. Throughout the module, we learned to modify, add and remove the tables, constraints and columns. The database views are created using SQL by including updatable views. Also, by studying the whole module, we learned the use of procedural language that is SQL/PL to create, store, triggers and SQL/PL functions. Also, the module taught me to create embedded SQL.
Week 9
A. Theoretical Discussion
An information system is intended to assist in the transformation of data into information as well as the management of information and data both. The SDLC (Systems Development Life Cycle) chronicles an application's journey through the information system (Mykletun and Tusdik, 2019).
B. Reflection on the Contents
I learned the SDLC (systems development life cycle) is a conceptual model that is used in the management of a project that discusses the involved stages in a development project of the information system from an initial study of feasibility through completed application maintenance. The SDLC can be made use of systems that are not technical and technical (Omollo and Alago, 2020).
C. Outcome
The module helped in enhancing knowledge about database design to build up the information system. The five phases are also explained about the System Development Life Cycle. The module explained the six phases in the designing of the database life cycle framework. The revision and evaluation within the DBLC and SDLC framework were learned. We learned bottom-up and top-down approaches in designing the database. Also, the module helped in distinguishing between decentralised and centralised in conceptualising the designing of the database.
Week 10
A. Theoretical Discussion
COMMIT, which saves changes to disc, and ROLLBACK, which restores the database which is set previously, are two SQL statements that support transactions. Concurrency control coordinates the execution of many transactions at the same time. The transactions have four major elements that are consistency, atomicity, durability and location. Database recovery returns a database to a previous consistent state from a given state.
B. Reflection on the Contents
I learned the recovery management in the DBMS allows to restores the database to correct conditioning of functioning and restarting the transactions of processing. The aim of database transaction maintenance integrity is to make sure there are no changes that are unauthorised changes that happen either through system error or user interaction (Semancik, 2019).
C. Outcome
The management process has helped me in gaining database transactions. The module described the various properties of transactions through the database. During the unit concurrency control in maintaining the integrity of the database. Also, the locking methods are taught during the lecture that can be used in concurrency control. In the lecture, we gained knowledge related to stamping methods for the control of concurrency. In the sessions, optimistic methods are used for controlling the concurrency. Also, the module explained the transaction isolation at the ANSI level. The module also discussed the recovery of the database in managing the integrity of the database.
Week 11
A. Theoretical Discussion
SQL data services (SDS) are a data management service cloud computing-based that offers enterprises of all sizes relational storage of data, local management, and ubiquitous access. The Extensible Markup Language (XML) promotes B2B and other data exchanges over the Internet (Jones, 2019).
B. Reflection on the Contents
Microsoft database connectivity interfaces are market leaders, with support from the majority of database manufacturers. I learned the connection interface offered by the database exclusive and vendor to that vendor is referred to as native database connectivity. The means by which application programmes connect to and communicate with data repositories are referred to as database connection.
C. Outcome
In the class, there was an explanation of standard interfaces of database connectivity. The teacher described the features and functionality of various connectivity technologies of the database. There was a discussion of OLE, ODBC, ADO.NET and JDBC. In class, there was an in-depth discussion about how database middleware which is used to integrate database through the use of the Internet. The teacher also helped to identify the services provided by servers of the web application. The teacher also discussed how XML (Extensible Markup Language) is used for the development of web database (Sharma et al., 2018).
Conclusion
The report described primary database management and technology aspects. The report also critically evaluated the database technology and data management. The report also applied concepts related to the processing of transaction and concurrency in systems of multi-user database. The report also focused on evaluating major challenges related to access, retrieval, privacy, ethics and storage.
References
.png)
.png)
Reports
MITS4003 Database Systems Report 3 Sample
Objectives(s)
This assessment item relates to the unit learning outcomes as in the unit descriptor. This assessment is designed to improve student knowledge through further research on recent trends to demonstrate competence in tasks related to modelling, designing, implementing a DBMS, Data Warehousing, Data management, Database Security. Also, to enhance students experience in researching a topic based on the learning outcomes they acquired during lectures, activities, assignment 1 and assignment 2. Furthermore, to evaluate their ability to identify the latest research trends and writing a report relevant to the Unit of Study subject matter. This assessment covers the following LOs.
1. Synthesize user requirements/inputs and analyse the matching data processing needs, demonstrating adaptability to changing circumstances;
2. Develop an enterprise data model that reflects the organization's fundamental business rules; refine the conceptual data model, including all entities, relationships, attributes, and business rules.
3. Derive a physical design from the logical design taking into account application, hardware, operating system, and data communications networks requirements; further use of data manipulation language to query, update, and manage a database
4. Identify functional dependencies, referential integrity, data integrity and security requirements; Further integrate and merge physical design by applying normalization techniques;
5. Design and build a database system using the knowledge acquired in the unit as well as through further research on recent trends to demonstrate competence in various advanced tasks with regard to modelling, designing, and implementing a DBMS including Data warehousing, Data Management, DB Security.
Note: Group Assignment. Maximum 4 students are allowed in a group.
INSTRUCTIONS
These instructions apply to both the Report and Presentation assessments. For this component you will be required to select a published research article / academic paper which must cover one or more of the topics including Database modelling, designing, and implementing a DBMS including Data warehousing, Data Management, DB Security, Data Mining or Data Analysis. The paper you select must be directly relevant to these topics. The paper can be from any academic conference or other relevant Journal or online sources such as Google Scholar, academic department repositories etc. All students are encouraged to select a different paper; and it must be approved by your lecturer or tutor before proceeding. In case two groups are wanting to present on the same paper, the first who emails the lecturer or tutor with their choice will be allocated that paper.
Report - 20% (Due week 12)
For this component you will prepare a report or critique on the paper you chose as mentioned above. Your report should be limited to approx. 1500 words (not including references).
Use 1.5 spacing with a 12-point Times New Roman font. Though your paper will largely be based on the chosen article, you can use other sources to support your discussion. Citation of sources is mandatory and must be in the Harvard style.
Your report or critique must include:
Title Page: The title of the assessment, the name of the paper you are reviewing and its authors, and your name and student ID.
Introduction: A statement of the purpose for your report and a brief outline of how you will discuss the selected article (one or two paragraphs). Make sure to identify the article being reviewed.
Body of Report: Describe the intention and content of the article. Discuss the research method (survey, case study, observation, experiment, or other method) and findings. Comment on problems or issues highlighted by the authors. Discuss the conclusions of the article and how they are relevant to what you are studying this semester.
Conclusion: A summary of the points you have made in the body of the paper. The conclusion should not introduce any ‘new’ material that was not discussed in the body of the paper. (One or two paragraphs)
References: A list of sources used in your text. Follow the IEEE style. The footer must include your name, student ID, and page number.
Solution
Introduction
The article “An overview of end-to-end entity resolution for big data.“ will give a brief description of the entity resolution for big data which is being rebuked and critically analyzed. The paper will provide a comprehensive view that includes the field of entity resolution and focus on the application with context to big data. For Assignment Help, This research article will propose the framework or the entity resolution on behalf of big data which entitles the identification and collapse of records in real-world entities. This Framework will also design and challenge the proposed big data on behalf of different considering techniques and evaluating the proposed Framework with the help of real-world data sets. This article will cover topics such as database modeling data management and data analysis. It will be more relevant to the topics that will be presented by the framework to design and implement the system which can handle the challenges of Designing and considering the entity resolution more accurately and efficiently.
The intention of the Article
The article is likely to produce the intention of the comprehensive view and analysis which will be conducted on the end entity resolution and the techniques that are specifically organized and implemented for the big data scenarios.
- The research also leads to the importance and the challenges that are been faced while using data resolution to solve the big data issues. The accurate integration of the data and cleansing is been applied so that the impact of data characteristics can be processed on the entity resolution [6].
- The article also explores the Different techniques and approaches that will be used in resolving the big data which will be implemented with the help of rule base methods such as machine learning algorithms or probabilistic models to design and handle the big data.
- The data preprocessing is also been covered for the effective and necessary entity resolution in the big data. This also includes the normalization and analysis of the data warehouse to propose the data modeling for high-quality results.
- The article also optimizes the scalability and the efficiency of the data that is been analyzed to explore the techniques in parallel and distributed processing. The data partitioning with the entity resolution process plays a major role when it comes to the large-scale data set.
- The evaluation and the applications of the case study also play a major role in the resolution of the techniques that leads to the successful implementation of big data scenarios such as various domains of Healthcare or e-commerce.
Survey
- The author has specified the big data error concerning the government and the specific organization that increases the internal and external aspects.
- The Entity resolution mainly AIMS to the real-world entity that is been structured and stored in the relational tables of the big data to consider the scenarios.
- The author has illustrated the description of the movie directors and the places from the different knowledge bases and the entity description is being defected in the tabular format.
- The classification of the pairs and the description is being assumed to process the in-compasses task and indexing to match the data.
.png)
Figure 1 Movies, Directors, and Locations from DBpedia (blue) and Freebase (red). Note that e1, e2, e3 and e4 match with e7, e5, e6 and e8, respectively.
- The author includes the survey about the big data characteristics which shows the algorithm and the implemented task and the workflow of the data. This includes the volume variety velocity as the characteristics of the big data [2].
Case Study Based on Data Modelling and Data Analytics
- The big data entry resolution considered the case study about the continuous concern and improving the scalability of this technique for increasing the volume of entities using the massively parallel implementations with the help of data Modelling and analysis.
- The Entity description is being evaluated with high veracity which is been resolved by matching the Data Analytics value and traditionally duplicating the techniques. With the help of analysis the conceived processing of the structure data can be educated pre-process to data warehouse and enhanced the blocking keys to rule the different types of challenging data.
- The below figure depicts the different types of similarities and the entities with the benchmark data set and considered the restaurant or other key parameters that are involved with the dot corresponding to each other of the matching pair [4].
- The horizontal accessing of the similarity is described with the vertical and maximum similarities are based on the entity neighbors. The value-based similarities are being proposed on the big data entities which are being used to improvise the data quality and the data modeling techniques to compile the integrity of the data management.
.png)
Figure 2 Value and neighbor similarity distribution of matching entities in 4 established, real-world datasets.
Observations
- Data Modelling
The article considered data modeling as an approach for entity resolution in the context of big data. As this covered the techniques of representing the structure data which help in capturing the attributes and relationship with the attitude resolution. The schema design and the data integration also play a major role in the data representation of formulating big data [1].
- Data Analysis
The technique leads to the discussion and the observation of measuring the feature extraction and statistical methods which help in comparison the matching the entities. This also covers the algorithm which is based on machine learning and the data mining to the employee or deploying the Entity resolution with the clustering and classification models.
- Data Management
The Strategies and processing of the large data is been managed during the entity resolution process. This technique leads to the handling of noise and inconsistency with the missing values of the big data full stop this also leads to the exploring the index and the storage mechanism which help in facilitating the retrieval of the matching entity full stop the parallel and the distributed processing leads to the scalability and challenging resolution of the big data.
Conflicts or Issues
- Heterogenous Data Sources
The environment of the analyzing technique and big data necessitate the diversification of sources, such as databases and sensor networks. The entities' integrity and rec counseling have been viewed as a problem or conflict to suggest difficulties arising from differences in data formats and schemas [5].
- Dimensionality
The numerical attribute or features needed to handle dimensional data are the data and entities' dimensions. In order to avoid the dimensionality curse, the most effective method is taken into consideration, as are the featured engineers and other computations.
- Computational Efficiency
The entity resolution is being performed and processed with the computational demand of the algorithms which are considered as the contract of parallel processing technique. This distributed computational and the Framework are necessary which achieve the scalability and entity of the big data.
Similarities of research with the Study of Semester
- As the research is been considered the similarity of developing the knowledge regarding the user requirements and analysis to match the data and processing the needs to demonstrate the circumstances.
- With the help of this research, the enterprise data model and the reflects fundamental business rule is being conceptually Defined by the data modeling which includes the attribute and the business rules.
- The physical designing and the logical designing is been taken under the implementation to account for the communication with the network requirement and manipulating the language to manage the database [3].
- The identification of the functionality and its dependency is the referential integration and the Data integrity to provide the security requirements for merging the physical design and applying the normalization technique.
- The building of the database and the knowledge is being acquired by further research to demonstrate the competency in the Advanced Task of modeling and designing the implementation of data warehouse and Management.
Conclusion
The report has deeply explained about the theoretical aspect of the and to end resolution of the big data with the implementation methodology of data Modelling and analysis to manage the data. The specific methodology and case study has been considered in the article with the general representation of the concluded entity and algorithms that is been applied. The problem has been observed with the recent years of data-intensive and the description of the real world entities with the government or the corporate-specific data sources for stop the view of entity resolution with the engineering aspect and the task has also been implemented as a theoretical aspect of considering the certain algorithms. The big data and the area of open-world systems have also allowed the different blocking and matching algorithms to easily integrate the third-party tools for data exploration and sampling the Data Analytics.
References
.png)
Reports
TITP105 The IT Professional Report Sample
COURSE: Bachelor of Information Technology
Assessment Task:
Students are required to analyse the weekly lecture material of weeks 1 to 11 and create concise content analysis summaries of the theoretical concepts contained in the course lecture slides.
ASSESSMENT DESCRIPTION:
Students are required to analyse the weekly lecture material of weeks 1 to 11 and create concise content analysis summaries (reflective journal report) of the theoretical concepts contained in the course lecture slides. Where the lab content or information contained in technical articles from the Internet or books helps to fully describe the lecture slide content, discussion of such theoretical articles or discussion of the lab material should be included in the content analysis.
The document structure is as follows (3500 Words):
1. Title Page
2. Introduction (100 words)
3. Background (100 words)
4. Content analysis (reflective journals) for each week from 1 to 11 (3200 words; approx. 300 words per week):
a. Theoretical Discussion
i. Important topics covered
ii. Definitions
b. Interpretations of the contents
i. What are the most important/useful/relevant information about the content?
c. Outcome
i. What have I learned from this?
5. Conclusion (100 words)
Your report must include:
• At least five references, out of which, three references must be from academic resources.
• Harvard Australian referencing for any sources you use.
• Refer to the Academic Learning Skills student guide on Referencing.
Solution
1. Introduction
The main aim to write this reflective journal report is to analyse the lectures of weeks 1 to 11 regarding ethics in information technology. This reflective journal will describe various roles for IT professionals and social, personal, legal and ethical impacts arising from their work. The role of the professional associations which are available to IT professionals will also be described in this reflective journal. For Assignment Help, It will assess the relationship between IT professionals and the issues of governance, ethics and corporate citizenship. I will critically analyse and review the IT professional Codes of Conduct and Codes of Ethics in this reflective journal report. This will help to develop a personal ethical framework.
2. Background
Technology offers various opportunities and benefits to people worldwide. However, it also gives the risk of abolishing one's privacy. Information technology must conduct business or transfer Information from one place to another in today's era. With the development of Information Technology, the ethics in information technology has become important as information technology can harm one's Intellectual property rights. Ethics among IT professionals can be defined as their attitude in order to complete something base on their behaviour. IT professionals need to have high ethics to process the data to control, manage, analyse, maintain, control, design, store and implement. Information Technology professionals face several challenges in their profession. It is their role and responsibility to solve these issues. The ethics of information technology professionals guide them to handle these issues in their work.
3. Content analysis
Week 1
a. Theoretical discussion
i. Important topics covered
In week 1, an overview of Ethics was discussed. Ethicalbehaviouris generally accepted norms that evolve according to the evolving needs of the society or social group who share similar values, traditions and laws. Morals are the personal principles that guide an individual to make decisions about right and wrong (Reynolds, 2018). On the other hand, the law is considered as a system of rules which guide and control an individual to do work.
ii. Definitions
Corporate Social Responsibility: Corporate social responsibility adheres to organisational ethics. It is a concept of management that aims to integrate social and environmental concerns for promoting well-being through business operations (Carroll and Brown, 2018, p. 39). Organisational ethics and employee morale lead to greater productivity for managing corporate social responsibility.
b. Interpretation
The complex work environment in today's era makes it difficult to implement Codes of Ethics and principles regarding this in the workplace. In this context, the idea of Corporate Social Responsibility comes. CSR is the continuing commitment by a business that guides them to contribute in the economic development and in ethical behaviour which have the potentiality to improve the life quality and living of the employees and local people (Kumar, 2017,p. 5). CSR and good business ethics must create an organisation that operates consistently and fosters well-structured business practices.
c. Outcome
From these lectures in the 1st week, I have learned the basic concepts of ethics and their role and importance in business and organisation. There are several ways to improve business ethics in an organisation by establishing a Corporate code of ethics, establishing a board of directors to set high ethical standards, conducting social audits and including ethical quality criteria in their organisation's employee appraisal. I have also learned the five-step model of ethical decision making by defining the problem, identifying alternatives, choosing an alternative, implementing the final decisions and monitoring the outcomes.
Week 2
a. Theoretical discussion
i. Important topics covered
In the 2nd week, the ethics for IT professionals and IT users were discussed. IT workers are involved in several work relationships with employers, clients, suppliers, and other professionals. The key issues in the relationship between the IT workers and the employer are setting and implementing policies related to the ethical use of IT, whistleblowing and safeguarding trade secrets. The BSA |The Software Alliance and Software and Information Industry Association (SIIA) trade groups represent the world's largest hardware and software manufacturers. Their main aim is to prevent unauthorised copying of software produced by their members.
ii. Definition
Whistle-blowing refers to the release of information unethically by a member or a former member of an organisation which can cause harm to the public interest(Reynolds, 2018). For example, it occurs when an employee reveals that their company is undergoing inappropriate activities (Whistleblowing: balancing on a tight rope, 2021).
b. Interpretation
The key issues in the relationship between IT workers and clients are preventing fraud, misinterpretation, the conflict between client's interests and IT workers' interests. The key issues in the relationship between the IT workers and the suppliers are bribery, separation of duties and internal control. IT professionals need to monitor inexperienced colleagues, prevent inappropriate information sharing and demonstrate professional loyalty in their workplace. IT workers also need to safeguard against software piracy, inappropriate information sharing, and inappropriate use of IT resources to secure the IT users' privacy and Intellectual property rights and ethically practice their professions so that their activities do not harm society and provide benefits to society.
c. Outcome
I have learnt the various work relationships that IT workers share with suppliers, clients, IT users, employers and other IT professionals.
Week 3
a. Theoretical discussion
i. Important topics covered
In week 3, the ethics for IT professionals and IT users further discussed extensively, and the solutions to solve several issues that IT professionals’ faces were discussed. IT professionals need to have several characteristics to face these issues and to solve them effectively. These characteristics are the ability to produce high-quality results, effective communication skills, adhere to high moral and ethical standards and have expertise in skills and tools.
ii. Definition
A professional code of ethics is the set of principles that guide the behaviour of the employees in a business(Professional code of ethics [Ready to use Example] | Workable, 2021). It helps make ethical decisions with high standards of ethical behaviour, access to an evaluation benchmark for self-assessment, and trust and respect with the general public in business organisations.
b. Interpretation
Licensing and certification increase the effectiveness and reliability of information systems. IT professionals face several ethical issues in their jobs like inappropriate sharing of information, software piracy and inappropriate use of computing resources.
c. Outcome
I have learned several ways that organisations use to encourage the professionalism of IT workers. A professional code of ethics is used for the improvement of the professionalism of IT workers. I have learnt several ways to improve their ethical behaviour by maintaining a firewall, establishing guidelines for using technology, structuring information systems to protect data and defining an AUP.
Week 4
a. Theoretical discussion
i. Important topics covered
In week 4, the discussion was focused on the intellectual property and the measurements of the organisations to take care of their intellectual properties. Intellectual property is the creations of the mind, like artistic and literary work, inventions, symbols and designs used in an organisation. There are several ways to safeguard an organisation's intellectual property by using patents, copyright, trademark and trade secret law.
ii. Definition
A patent is an exclusive right to the owner of the invention about the invention, and with the help of that the owner have the full power to decide that the how the inventios will be used in future(Reynolds, 2018). Due to the presence of Digital Millennium Copyright Act, the access of technology protected works has become illegal.. It limits the liability of ISPs for copyright violation by their consumers. Trademarks are the signs which distinguish the goods and services of an organisation from that of other organisations. There are several acts that protect Trademarks secrets, such as theEconomic Espionage Act and Uniform Trade Secrets Acts.
b. Interpretation
Open-source code can be defined by any program which have the available source code for modification or use. Competitive intelligence refers to a systematic process initiated by an organisation to gather and analyse information about the economic and socio-political environment and the other competitors of the organisation (Shujahat et al. 2017, p. 4). Competitive intelligence analysts must avoid unethical behaviours like misinterpretation, lying, bribery or theft. Cybercasters register domain names for famous company names or trademarks with no connection, which is completely illegal.
c. Outcome
I have learnt several current issues related to the protection of intellectual property, such asreverse engineering,competitive intelligence,cybersquatting, and open-source code. For example, reverse engineering breaks something down to build a copy or understand it or make improvements. Plagiarism refers to stealing someone's ideas or words without giving them credits.
Week 5
a. Theoretical Discussion
i. Important topics covered
The ethics of IT organisations include legal and ethical issues associated with contingent workers. Overview of whistleblowing and ethical issues associated with whistleblowing is being addressed (Reynolds, 2018). Green computing is the environmental and eco-friendly use of resources and technology(Reynolds, 2018). In this topic, there is the definition of green computing and what is initially the organisations are taking to adopt this method.
ii. Definition
Offshore Outsourcing: This is a process of outsourcing that provides services to employees currently operating in a foreign country(Reynolds, 2018). Sometimes the service is provided to different continents. In the case of information technology, the offshore outsourcing process is common and effective. It generally takes place when the company shifts some parts or all of its business operation into another country for lowering cost and improving profit.
b. Interpretation
The most relevant information about the context is whistleblowing and green computing. Whistleblowing is the method of drawing public attention to understand unethical activity and misconduct behaviour within private, public, and third sector organisations (HRZone. 2021).
c. Outcome
After reading the book, I have learned that green computing and whistleblowing are vital factors for the organisation's work. I have also learned about the diverse workforce in tech firms and the factors behind the trend towards independent contractors—the need and effect of H1-B workers in the organisation. Furthermore, the legal and ethical issues associated with green computing and whistleblowing have also been made.
Week 6
a. Theoretical discussion
i. Important topics covered
In this chapter, the importance of software quality and important strategies to develop a quality system. Software quality is defined as the desirable qualities of software products. Software quality consists of two main essential approaches include quality attributes and defect management. Furthermore, the poor-quality software also caused a huge problem in the organisation (Reynolds, 2018). The development model including waterfall and agile development methodology. Lastly, the capability maturity model integration which is a process to improve the process.
ii. Definition
System-human interface: The system-human interface helps improve user experience by designing proper interfaces within the system(Reynolds, 2018). The process facilitates better interaction between users and machines. It is among the critical areas of system safety. The system performance depends largely upon the system-human interface. The interaction between humans and the system takes place through an interaction process. Better interaction improves UX.
b. Interpretation
The useful information about the context is the software quality and the important strategies to improve the quality of software. The Capability Maturity Model Integration is the next generation of CMM, and it is the more involved model incorporating the individual disciplines of CMM like system engineering CMM and people CMM (GeeksforGeeks. 2021).
c. Outcome
After reading the context, I have concluded that software quality is one of the essential elements for the development of business. The software derives predictability from improving productivity in the business. The software quality decreases the rework, and the product and services are delivered on time. The theories and facts that are involved in developing the strategies that are involved in developing the software quality in the organisation.
Week 7
a. Theoretical discussion
i. Important topics covered
In this context, it will discuss privacy, which is one of the most important features for the growth and development of individuals and organisations. The right, laws, and various strategies to mitigate ethical issues are adopted (Reynolds, 2018). The e-discovery can be defined as the electronic aspect ofidentifying, collecting, and producing electronically stored information for the production of investigation and lawsuit.
ii. Definition
Right of Privacy: The privacy of information and confidentiality of vital information comes under the right of privacy(Reynolds, 2018). In information technology, the privacy right helps in managing the access control and provides proper security to the user and system information. This also concerns the right not to disclose an individual's personal information to the public.
b. Interpretation
The most relevant in the context are privacy laws that are responsible for the protection of individual and organisation's rights. The protection laws include the European Union data protection directive, organisation for economic cooperation and development, and general data protection regulation that protect the data and information of the individual and company (Reynolds, 2018). Furthermore, the key and anonymity issues that exist in the workplace like cyberloafing. The employees exercised the practice to use the internet access for personal use without doing their work.
c. Outcome
I have learned from this context that privacy is required for every organisation to protect the private information about the personal information and credentials that are present in the company—privacy along with developed technology that secures the data and information about the organisation. I have also got information about the ways and technological development to protect the data.
Week 8
a. Theoretical discussion
i. Important topics covered
In this context, it is discussed freedom of expression, meaning the right to hold information and share decisions without any interference. Some of the vital issues of freedom of expression include controlling access to information on the internet, censorship to certain videos on the internet, hate speech,anonymity on the internet, pornography, and eradication of fake news often relevant on the internet (Reynolds, 2018).
ii. Definition
Freedom of Expression: Freedom of expression denotes the ability to express the thoughts, beliefs, ideas, and emotions of an individual or a group (Scanlon, 2018, p. 24). It is under the government censorship which promotes the right to express and impart information regardless of communication borders which include oral, written, the art of any other form.
b. Interpretation
The most important information regarding the context is John Doe Lawsuits. It is a law that helps to identify the anonymous person who is exercising malicious behaviour like online harassment and extortion. Fake news about any information that is irrelevant, which are however removed by several networking websites. However, the fake news sites and social media websites are shared by several videos and images cause confusion and misinterpretation regarding a particular subject (Reynolds, 2018).
c. Outcome
After reading the book, I have concluded that the internet is a wide platform where several malicious practices are carried out, like fake news, hate speech, and many other practices practised on the internet. I have also gained information about several laws and regulations to protect the right and regulations on the internet, including the telecommunication act 1996 and the communication decency act 1997.
Week 9
a. Theoretical discission
i. Important topics covered
In this context, it will be discussed about cyberattacks and cybersecurity. Cyberattacks are an assault launched by an anonymous individual from one or more computers using several network chains (Reynolds, 2018). A cyber-attack can steal personal information a can disable the computer. On the other hand, cybersecurity is the practice of protecting information from cyberattacks. There are several methods to protect the internet from malware, viruses and threats.
ii. Definition
Cyber espionage: This is the process of using computer networks for gaining illicit access to confidential information(Reynolds, 2018). The malicious practice increases the risk of data breaching. It steals sensitive data or intellectual property, typically preserved by a government entity or an organisation (Herrmann, 2019, p. 94). Cyber espionage is a threat to IT companies, especially as it targets the digital networks for information hacking.
b. Interpretation
The most important aspect in this context is intrusion detection system, proxy servers like a virtual private network. The intrusion detection system is the software that alerts the servers during the detection of network traffic issues. The proxy servers act as an intermediator between the web browser and another web server on the internet. The virtual private network enables the user to access the organisation's server and use the server to share data by transmitting and encryption over the Internet (Reynolds, 2018).
c. Outcome
After reading the entire context, I have gained information about several cyberattacks and cybersecurity. Cyber attackers like crackers, black hat hackers, malicious insiders, cyberterrorists, and industrial spies (Reynolds, 2018). Cybersecurity like CIA security trial. Department of homeland security, an agency for safer and secure America against cyber threats and cyberterrorism. The transport layer security is the organisation to secure the internet from cyber threats between the communicating application and other users on the Internet (Reynolds, 2018).
Week 10
a. Theoretical discussion
i. Important topics covered
In this context, it is discussed about social media and essential elements associated with social media. Social media can be defined as modern technology that enhances the sharing of thoughts, ideas, and information after establishing various networks and communities (Reynolds, 2018). Several companies adopt social media marketing to sell their services and products on the internet by creating several websites across the Internet.
ii. Definition
Earned Media: It is observed in brand promotions in organisations where media awareness awarded through promotion(Reynolds, 2018). It is also considered the organic media, which may include television interviews, online articles, and consumer-generated videos. It is not a paid media; rather, it is voluntarily awarded to any organisation. The earned media value is calculated through website referrals, message resonance, mentions, and article quality scores.
b. Interpretation
The most important aspect of social media marketing where the internet is used to promote products and services. As per the sources, global social media marketing spends nearly doubled from 2014 to 2016, increasing from 15$ billion to 30$ billion—organic media marketing and viral marketing as one important aspect of social media marketing.
c. Outcome
I have gained much information about social media and elements of social media marketing, which encourages marketers to sell their products and services to another individual across the internet. Social media is a vast platform that has both advantages and disadvantages aspect. The issues regarding social media including social networking ethical issues that are causing harmful threats and emotional distress on the individual. There is a solution to these issues, which is adopted by several organisations like fighter cyberstalking, stalking risk profile, and many more.
Week 11
a. Theoretical discussion
i. Important topics covered
This context will eventually discuss the impact of information technology on society. The information impacts the gross domestic product and standard of living of people residing in developed countries. Information technology has made the education system more productive and effective. The process of e-learning has allowed the students to study from their homes. The health care system is also affected by information technology.
ii. Definition
Robotics: It is the design and construction of machines (robots) for performing tasks done by human beings (Malik and Bilberg, 2018, p. 282). It promotes autonomous machine operating systems for easing the burden and complexity of human labour. In this case, artificial intelligence helps to improve the development process of machines by incorporating the machine learning process. Automobile manufacturing industries use robotics design for safeguarding humans from environmental hazards.
b. Interpretation
The most information aspect of the topic is the artificial intelligence and machine learning have impacted the growth of IT. Artificial intelligence includes data and human intelligence processes that include activities like learning, reasoning, and self-correction. Machine learning is the process to talk with the technology through machine languages.
c. Outcome
I have gained much information about information technology and its impact on the organisation and people. The innovation and development occurred vastly due to the effect of social media.
4. Conclusion
It is to be concluded that this reflective journal report describes all the aspects of ethics in information technology by providing an understanding of the ethical, legal and social implications of information technology that IT professionals need to nurture in their professional work. Critical analysis of the privacy, freedom of expression, common issues of IT professionals, solutions of these issues are reflected in this journal report. The journal report also attempts to address the ethical issues in the IT workplace. An understanding of IT and ethics needed in IT professionals to achieve success is reflected in this journal report.
References
.png)
Reports
BDA601 Big Data and Analytics Report Sample
Task Summary
Customer churn, also known as customer attrition, refers to the movement of customers from one service provider to another. It is well known that attracting new customers costs significantly more than retaining existing customers. Additionally, long-term customers are found to be less costly to serve and less sensitive to competitors’ marketing activities. Thus, predicting customer churn is valuable to telecommunication industries, utility service providers, paid television channels, insurance companies and other business organisations providing subscription-based services. Customer-churn prediction allows for targeted retention planning.
In this Assessment, you will build a machine learning (ML) model to predict customer churn using the principles of ML and big data tools.
As part of this Assessment, you will write a 1,000-word report that will include the following:
a) A predictive model from a given dataset that follows data mining principles and techniques;
b) Explanations as to how to handle missing values in a dataset; and
c) An interpretation of the outcomes of the customer churn analysis.
Please refer to the Task Instructions (below) for details on how to complete this task.
Task Instructions
1. Dataset Construction
Kaggle telco churn dataset is a sample dataset from IBM, containing 21 attributes of approximately 7,043 telecommunication customers. In this Assessment, you are required to work with a modified version of this dataset (the dataset can be found at the URL provided below). Modify the dataset by removing the following attributes: MonthlyCharges, OnlineSecurity, StreamingTV, InternetService and Partner.
As the dataset is in .csv format, any spreadsheet application, such as Microsoft Excel or Open Office Calc, can be used to modify it. You will use your resulting dataset, which should comprise 7,043 observations and 16 attributes, to complete the subsequent tasks. The ‘Churn’ attribute (i.e., the last attribute in the dataset) is the target of your churn analysis. Kaggle.com. (2020). Telco customer churn—IBM sample data sets. Retrieved from https://www.kaggle.com/blastchar/telco-customer-churn [Accessed 05 August 2020].
2. Model Development
From the dataset constructed in the previous step, present appropriate data visualisation and descriptive statistics, then develop a ‘decision-tree’ model to predict customer churn. The model can be developed in Jupyter Notebook using Python and Spark’s Machine Learning Library (Pyspark MLlib). You can use any other platform if you find it more efficient. The notebook should include the following sections:
a) Problem Statement
In this section, briefly state the context and the problem you will solve in the notebook.
b) Exploratory Data Analysis
In this section, perform both a visual and statistical exploratory analysis to gain insights about the dataset.
c) Data Cleaning and Feature Selection
In this section, perform data pre-processing and feature selection for the model, which you will build in the next section.
d) Model Building
In this section, use the pre-processed data and the selected features to build a ‘decision-tree’ model to predict customer churn.
In the notebook, the code should be well documented, the graphs and charts should be neatly labelled, the narrative text should clearly state the objectives and a logical justification for each of the steps should be provided.
3. Handling Missing Values
The given dataset has very few missing values; however, in a real-world scenario, data- scientists often need to work with datasets with many missing values. If an attribute is important to build an effective model and have significant missing values, then the data-scientists need to come up with strategies to handle any missing values.
From the ‘decision-tree’ model, built in the previous step, identify the most important attribute. If a significant number of values were missing in the most important attribute column, implement a method to replace the missing values and describe that method in your
report.
4. Interpretation of Churn Analysis
Modelling churn is difficult because there is inherent uncertainty when measuring churn. Thus, it is important not only to understand any limitations associated with a churn analysis but also to be able to interpret the outcomes of a churn analysis.
In your report, interpret and describe the key findings that you were able to discover as part of your churn analysis. Describe the following facts with supporting details:
• The effectiveness of your churn analysis: What was the percentage of time at which your analysis was able to correctly identify the churn? Can this be considered a satisfactory outcome? Explain why or why not;
• Who is churning: Describe the attributes of the customers who are churning and explain what is driving the churn; and
• Improving the accuracy of your churn analysis: Describe the effects that your previous steps, model development and handling of missing values had on the outcome of your churn analysis and how the accuracy of your churn analysis could be improved.
Solution
INTRODUCTION
Customers are the important entities of any organization that help them to make business and profit. So, every organization should have an intention to attract more customers in order to gain more profit. For Assignment Help, If the customers will be satisfied with the service, they will be retained in the business of the organization otherwise attrition may be seen (Eduonix, 2018). This is called customer churning that defines whether the customer has been retained or attrited from the business. In this paper, customer attrition will be determined with the application of machine learning.
1 COLLECTION OF CUSTOMER CHURN DATA
The data has been collected from Kaggle regarding customer churn (BlastChar, 2017). The data contains the records of those customers who have left the company and for those also who have retained with the company by taking services and purchasing goods. The Data is shown below:
.png)
Fig-1: Customer Churn Dataset
Initially, after collecting the data, it has been seen that the data contains 7043 instances or rows and 21 features or columns. The number of rows and columns are shown below:
.png)
Fig-2: Initial Data Attributes
Now, five features namely Monthly Charges, Online Security, Streaming TV and Internet Service and Partner have been removed and the resulting dataset is now containing the following attributes:
.png)
Fig-3: Resulting Data Attributes
So, presently, the data contains 7043 instances and 16 columns.
1.1 INFORMATION FOR TELCO DATA
The descriptive statistics of the dataset has been checked and the following outcome has been achieved (Learning, 2018).
.png)
Fig-4: Data Description
After that, the information of the data has been checked and the following outcome has been obtained:
.png)
Fig-5: Data Information
From the information of the data, it has been seen that all features are now in the form of the object (categorical).
2 DEVELOPMENT OF DECISION TREE MODEL
2.1 PROBLEM STATEMENT
In this paper, the problem statements have been prepared as follows:
1. What are the factors that are influencing customer churn?
2. How Decision Tree Classifier is helpful in determining the attrition of customers?
2.2 EXPLORATORY DATA ANALYSIS
The data analysis has been performed based on some of the features. First, the analysis has been done to visualize the customer attrition based on gender (Sosnovshchenko, 2018). It has been seen that Male customer has more tendency to be attrited compared to female customers.
.png)
Fig-6: Analysis of Gender
Nest, the analysis has been done to visualize whether Online backup is related to customer attrition. The outcome of the analysis is shown below:
.png)
Fig-7: Analysis of Online Backup
The analysis has been performed on the paperless billing of the purchased products. It has been seen that those customers have been attrited who have not received paperless billing.
.png)
Fig-8: Analysis of Paperless Billing
The analysis has been performed on the payment method for the purchased products. It has been seen that those customers have been attrited who have used the electronic check.
.png)
Fig-9: Analysis of Payment Method
2.3 DATA CLEANING AND FEATURE SELECTION
2.3.1 Data preprocessing and Cleaning
As seen earlier, the features of the data are categorical that cannot be fitted into machine learning (Learning, 2018). So, all the features have been preprocessed and converted to numerical data using data encoding as follows:
.png)
Fig-10: Data Preprocessing and Encoding
After preprocessing the data, the missing values have been found and it has been seen that there are no missing values in the data as follows:
.png)
Fig-11: Detecting Missing Values
So, there is no requirement for data cleaning as the data is already cleaned.
2.3.2 Feature Selection
Now, the correlation has been applied to check the relationship of the features with Churn. The outcome of the correlation is shown below in the form of a heatmap:
.png)
Fig-12: Correlation of Features
From the outcome of the correlation, the highly correlated features have been selected and shown below:
.png)
Fig-13: Finally Selected Features
So, these features will now be used as the final predictor features for the Decision Tree Classifier by retaining Churn as the target feature (Sosnovshchenko, 2018).
2.4 MODEL BUILDING
The predictor features have been selected from the correlation and the final dataset is shown below:
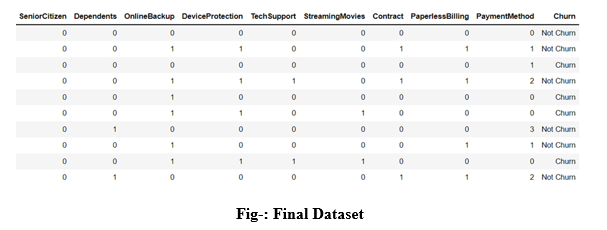
This data has been split into train and test sets as follows:
.png)
Fig-14: Data Splitting
The data splitting has been done using a 75-25 split ratio and the training dataset contains 5283 observations (through which the decision tree classifier will be trained) and the test set contains 1760 instances (through which the decision tree model will be tested) (Eduonix, 2018). In this test set, 1297 instances belong to “Not Churn” and 463 instances belongs to “Churn”. Now, the decision tree classifier has been applied with the following hyperparameter tuning and it has been trained with the training data:
• criterion='entropy'
• splitter='random'
• max_features='auto'
• random_state=10
After training the decision tree classifier, the model has been tested and the confusion matrix has been obtained as follows:
.png)
Fig-15: Confusion matrix
In this confusion matrix, It can be seen that 1110 instances out of 1297 instanced have been correctly classified as “Not Churn” and 302 instances out of 463 instances have been correctly classified as “Churn”. By considering the overall performances, 1412 instances have been correctly classified by attaining 80.23% accuracy, 81% precision, 80% recall and 80% f1-score. The performance overview is shown below in the form of a classification report (Lakshmanan, Robinson, & Munn, 2021).
.png)
Fig-16: Classification Report
3 FINDING AND CONCLUSION
The data has been selected from Kaggle regarding customer churn and analysed for the detection of customer attrition. In this context, the data has been preprocessed and the features have been selected. After preparing the data, it has been split into train and test sets and the decision tree classifier has been trained and tested accordingly and the performance of the classification has been achieved. The problem statements have been addressed as follows:
1. The features such as senior citizen, Dependents, online backup, DeviceProtection, TechSupport, StreamingMovies, Contract, PaperlessBilling, PaymentMethod have been seen to be the important features for the prediction of customer churn.
2. Decision Tree Classifier can be used to classify and predict the customer churn with 80.23% accuracy, 81% precision, 80% recall and 80% f1-score.
4 REFERENCES
.png)
Reports
MIS603 Microservices Architecture Report 2 Sample
Assessment Task
This proposal should be approximately 1500 words (+/- 10%) excluding cover page, references and appendix. This proposal must be typed and clearly set out (presented professionally). You need to pay special attention to principles and key concepts of Microservices Architecture (MSA), service design and DevOps. The purpose of this assessment is to give you an opportunity to contextualise and convey to learning facilitator relevant knowledge based on “real-world” application. Particularly, the aim of this assessment is to enhance your employability skills through providing hands-on education and opportunities to practice real life experience. As a result, this assessment item is developed not only to evaluate your understanding of MSA application, but also to assist you practicing and improving your research skills. In doing so, this assessment will formatively develops the knowledge required for you to complete Assessment 3 successfully.
Context
MSA have been getting more and more popular over the last year, and several organisations are migrating monolithic applications to MSA. A MSA consists of a collection of small, autonomous services that each service is a separate codebase, which can be managed by a small development team. A team can update an existing service without rebuilding and redeploying the entire application.
Services are responsible for persisting their own data or external state. This differs from the traditional model, where a separate data layer handles data persistence. More recently, with the development of cloud computing, new ways of software development have evolved with MSA recognised as a cloud-native software development approach. As a professional, your role will require that you understand the principles of software development, especially in the field of cloud-based platforms, which are rapidly becoming the preferred hosting solution for many organisations. Having a working understanding of these concepts will enable you to fulfil many roles and functions, and be informed as to what factors influence decision making when software development architecture has been selected. Whilst you may not be a developer, it will enable you to have meaningful conversations about the principles of MSA and why certain decisions may be made in a certain way. This will support you to manage the bridge between IT and the business.
Instructions
You are expected to address the following steps to fulfil this assessment task:
1. From the list below, select an organisation that you are familiar with and / or have enough data and information. Here are list of organisations using microservices:
o Comcast Cable
o Uber
o Hailo
o Netflix
o Zalando
o Amazon
o Twitter
o PayPal
o Ebay
o Sound Cloud
o Groupon
o Gilt
2. Discuss how MSA has transformed or revolutionised the operations of the organisation. Identify and analyse at least three business or organisational reasons for justifying your discussion.
3. Develop a business proposal to introduce the selected organisation, justify why you choose it and why microroservices is the best architecture in the selected organisation.
The report should consist of the following structure:
A title page with subject code and name, assignment title, student’s name, student number, and lecturer’s name.
The introduction (200–250 words) that will also serve as your statement of purpose for the proposal— this means that you will tell the reader what you are going to cover in your proposal. You will need to inform the reader of:
a) Your area of research and its context
b) The key elements you will be addressing
c) What the reader can expect to find in the body of the report.
The body of the report (1000–1100 words) you are required to research and write a proposal focused on organisation using MSA as a software development philosophy. However, you are strongly advised to do some research regarding MSA in a “real-world” application.
The conclusion (200–250 words) will summarise any findings or recommendations that the report puts forward regarding the concepts covered in the report.
Format of the report
The report should use font Arial or Calibri 11 point, be line spaced at 1.5 for ease of reading, and have page numbers on the bottom of each page. If diagrams or tables are used, due attention should be given to pagination to avoid loss of meaning and continuity by unnecessarily splitting information over two pages. Diagrams must carry the appropriate captioning.
Solution
Introduction
Microservices architecture has started gaining popularity in the past few years as displayed with the migration of the monolithic applications towards its adoption. It stands to encompass a collection of small and autonomous services wherein each of the service consists of a separate codebase that possesses the feature of being managed by a compact development team. For Assignment Help, A unique benefit of the element corresponds with the fact that the development team can update the existing service in the absence of the need of rebuilding or redeploying of the entire application (Li et al., 2020).With the recent advancements in the aspects of cloud computing, and the new and innovative manner of software development, microservices architecture has acquired recognition as a cloud-native method for software development (Aderaldo et al., 2017).
The report is concerned with the discussion of the manner in which microservices architecture has led to substantial transformation and revolutionization of the operations of the selected company, Uber. In the same context, it identifies and analyses the organisations reasons for the justification of the shift of Uber from the monolithic architecture to the microservice system by assessing the issues that led Uber to make the decision. As such, the report intends to develop a business proposal that would be introduced to the selected organisation in line with the recognition of microservices as the best architecture by laying an emphasis on the benefits that it brings to Uber.
Discussion
An adoption of the aspect of microservices architecture is becoming a popular solution to large and complex issues in the context of IT systems owing to the fact that is entails a technique for the development of applications in the form of small services wherein each of the service is tasked with one function akin to product search, shipment, payment. Such services communicate with one another with the application of API gateways. A number of international companies such as Amazon or Netflix has displayed a transition from monolith to microservices, thus, clarifying its relevance and usability. Similar to many start-ups, the company Uber initiated its operations in line with monolithic architecture in order to cater to a single offering in one particular location. The choice had been justified at that tome with all the operations transpiring under the UberBLACK option based in San Francisco (Haddad, 2019). The presence of a single codebase had proven to be sufficient for the resolution of the business concerns for the company, which remained inclusive of connecting drivers with the riders, billing as well as payments. As such, it was reasonable to confine the business logic of the company in one particular location. Nevertheless, with the rapid expansion of Uber into a greater number of citizens, accompanied by the introduction of new products, such a nature of operations needed to undergo considerable variations or a complete change.
Consequently, the growth the core domain models and the introduction of new features led to an outcome wherein the components of the company became tightly coupled, thus, resulting in an enforcement of the encapsulation which increased the difficulty of separation. Furthermore, the continual integration proved to be a liability owing to the fact that the deployment of the codebase corresponded with the deployment of all the services at once. This meant a greater amount of pressure for the engineering team who had to handle more requests as well as the significant increase in the developer activity, irrespective of the rapid growth and scaling of the said engineering team (Haddad, 2019). Moreover, the continual need for the addition of new features, resolution of bugs and fixing the technical debt within a single repo developed as significant challenges. In the same context, the expansion of the system, on the basis of a monolithic architecture, resulted in issues for the company in line with scalability as well as persisting integration (Torvekar & Game, 2019).
Additionally, a single change in the system became a huge responsibility for the developers in view of the dependencies of the components of the app of Uber.The monolithic structure of Uber entailed a connection between the passengers and drivers with the aid of the REST API (Hillpot, 2021). It also possessed three adapters that contained embedded API to serve the aforementioned purposes of pilling, payment and text messages. Furthermore, the system involved a MySQL database with all the features being contained in the monolith (Hillpot, 2021). In other words, the primary reasons for the decision of Uber to transition to microservices architecture corresponded with the following factors (Gluck, 2020):
- The deployments were expensive and time consuming, in addition to necessitating frequent rollbacks.
- The maintenance of good separations of concerns in relation to the huge codebase proved challenging since expediency, in an exponential growth environment, results in poor boundaries between components and logic.
- The combined issues provided challenges for the execution of the system in an autonomous or independent manner.
As such, Uber opted for the hypergrowth of other successful companies such as Amazon, Netflix or Twitter, with the aim of breaking the monolith into multiple codebases such that a service oriented architecture could be developed. To be specific, the company opted for the adoption of microservices architecture. The migration from the monolithic codebase to microservices architecture enabled the company to resolve a number of concerns. Accordingly, the introduction of the new architecture was accompanied by the introduction of an API gateway, as well as independent services, each of which possessed individuals functions and the feature of being deployed and scaled in a distinct manner (Kwiecien, 2019). The adoption of the microservices architecture led to the increase of the overall system reliability and facilitated the separation of concerns by the establishment of more distinctly defined roles of each of the components. It also highlights the ownership of the code and enables autonomous execution of the services (Gluck, 2020).
The implementation of microservices architecture also allows for developer velocity wherein the teams retain the capability of deploying the codes in an independent manner at their own pace (Gluck, 2020), thus, improving productivity. Owing to the fact that the software developed as microservices is fragmented in smaller and independent services, in which each component can be written in its own unique language, aided Uber in the development process, formulating continual delivery and in the acceleration of the growth of the business (Rud, 2020). Consequently, the transition of Uber from a monolithic system to microservices architecture augmented the speed, quality and manageability of the development of the software and the reliability with regards to the factor of fault tolerance, while allowing the teams to focus on just the services that required scaling, thus, speeding up the process (Sundar, 2020). Finally, a few real world applications of microservices architecture for Uber corresponded with the processing and maintenance of the profile data of the customers, handling the different types of available rides on the basis of the location, mapping of the location of the customer and that of the nearly rides on a custom map, formation of a set of potential rides with respect to a specific ride, and computation of the price of the ride in a dynamic manner.
Conclusion
Microservices services remain responsible for the persistence of their external state or personal data. As such, the primary difference from a traditional model is related to the prevalence of a separate layer of data that manages the persistence of data. An understanding of the concepts enable the fulfilment of varied roles and functions, in addition to gaining knowledge on the factors that influence decision-making in the instance of selection of the software development architecture. A number of international companies such as Amazon, Netflix or Coca Cola have opted for a transformation in terms of their IT infrastructure for the implementation of microservice architecture. The process is also accompanied by the rebuilding of the internal organisational structure to obtain a competitive edge.
It is significant to comprehend the principles associated with the said software development, particularly with respect to cloud-based platforms that have found increasing application as preferred hosting solutions for a number of organisations.The transition to microservices architecture has proven to bring with it significant benefits for Uber with respect to the process of development, scaling and independent deployment of each of the microservice. In the same context, it also allows the company to cut back on undesired expenses, while encouraging innovation as well. It has also highlighted the fact that microservices architecture possesses a strong reliance on people and processes within the context of an organisation owing to its involvement with technology, in view of the fact that single microservices stand to be maintained by independent and specialised teams.
References
.png)
Reports
MIS609 Data Management and Analytics Report 3 Sample
Task Summary
In groups, apply data analysis and visualisation skills, and create meaningful data visualisations for secondary data (selected after approval of your facilitator). Then, create a 5-10-minute presentation as a short video collage explaining the findings of your visual analysis.
Task Instructions
Step 1: Group formation and registration
Form groups of two members each. Please refer to the attached Group Formation Guidelines document for more information about group formation and registration. You may seek help from your learning facilitator.
Step 2: Select secondary data from the internet. Make sure you select the data after approval of your learning facilitator.
Step 3: Find out the issues that the selected data has. Make note of all the identified issues. For every issue identified you should have a solid rationale.
Step 4: Select a data analysis / visualisation tool. You can surf the web and find out some free data analysis / visualisation tools. Some of the recommended tools are Tableau, Microsoft Excel, Microsoft Power BI, Qlik and Google Data Studio. Make sure that before you select a tool, you carefully understand the merits and demerits of that tool. Also discuss with your facilitator the choice of your tool.
Step 5: Analyse selected data using the selected tool and try creating meaningful visualisations that give you more visual insight into data.
Step 6: Based on analysis using visualisation, identify important finding about that data.
Step 7: Carefully identify your limitations.
Step 8: Now create a Microsoft PowerPoint presentation having the following sections:
Section1: Selected Dataset
- Provide a link to data.
- Explain why you select this data.
- Explain the issues in the selected data.
Section 2: Selected Analysis/Visualisation Tool
- Explain why you selected this tool.
- What were the problems that you faced with this tool?
- What are the benefits and drawbacks of the selected tool?
Section 3: Visualisations (Diagrams)
- On every PowerPoint slide, copy a diagram (visualisation) and beneath every diagram briefly explain what information/knowledge you obtained from the diagram. Make as many PowerPoint slides as you want to.
Section 4: Findings and Limitations
- Explain what your findings are about the selected data as a result of data analysis (/ visualisation) that you have performed.
- Enlist your limitations.
Section 5: Group Work Distribution
- Categorically explain how work was distributed between group members.
Step 9: Now using the PowerPoint, create a video collage in which your facilitator should be able to see you as well as the PowerPoint slides in the video. Please note that this 5-10-minute video is like an online presentation. Both members of the group should take part in the video equally. Please ensure that you are objective in your presentation (PowerPoint and video). Plan and rehearse what you have to speak in the video before creating it.
Solution
Introduction
Background
The aim of the report is to found issues within the aspects of sustainability and Business ethics. It is focused on demonstrating the learnings of the field by analysing and providing recommendations in reference to real life cases from an organisation. For Assignment Help, The topic which is being researched in the current report is new shopping experience unveiled by Zara.
Importance
It is an important topic because the aspect of sustainability has become very important in customer journey. Customers are only likely to incline their purchasing behaviour in favour of those brands who are making efforts to make sure that their business operations are not harmful to environment and community (Pei et al., 2020). Zara has integrated sustainability in its customer journey at new store in Plaza de Lugo store slated to reopen in A Coruña in March. It will unveil new concepts, materials, and designs, which will establish a benchmark for the brand.
Major Issue and Outline of Methodology
The major issue addressed in the report is that of Fast Fashion. It can be referred to as trendy and cheap clothing that are representative of the celebrity culture. Zara is one of the most prominent dealers in fast fashion. The brand is looking forward to make a change by presenting a experience of sustainable clothing.
In the current report, data would be collected through secondary sources. It will allow, the researcher, to integrate viewpoints of other individuals in reference to sustainable clothing and customer journey and its relationship with business ethics. The viewpoints would be further studied in reference to Zara in the later stages of the report for identifying the correlation and providing recommendations in order to deal with the situation.
Contribution of Assignment
This report will contribute to the literature related to sustainable customer journey and clotting and how it impacts on business ethics and sustainability of the company. It will also provide recommendations to the manager of Zara regarding how they could deal with the issues of fast fashion and secure the overall sustainability of the business.
Literature Review
Concept of Sustainable Shopping experience
According to Ijaz and Rhee (2018) shopping experiences and sustainability are the major elements which are affecting how their customers are shopping now and will continue to do so in the future. They have led to considerable changes in the Global retail landscape which would inevitably impact and shape that future retail environment.
Han et al. (2019) stated that in order to attract Shoppers to the physical retail space if it is necessary to provide them with sustainability and aesthetic. This is so because they are likely to be attracted by a spacer where they could confront a wide variety of reactions, experiences, and emotions.
In the perception of Lin et al. (2020) the importance of a light, texture, sound and smell has taken the centre stage where the store designers are combining subconscious and sensor elements in order to generate experiences and memories which are not only visual but also atmospheric.
However, De et al. (2021) argued that stores in future are likely to merge with online retail environments rather than competing. It makes it more important for current retailers to improve their shopping experience when it comes to dominating the online space. The physical store is likely to become a space aware retailer and brands will be able to express their personality to the customers.
As per the views of Geiger and Keller (2018) personality of the brand could be reflected through the showroom where they would provide engaging experience in order to encourage Shoppers to purchase their products online after they have touched and tried that in the shop. It could be said that a sustainable shopping experience revolves around making shopping centres of the future engagement centres. Retailers such as Dara would need to focus on how to take the shopkeeper on an improved and sustainable customer journey.
Relationship Between Sustainable Shopping Experience and Customer Journey
Signori et al. (2019) highlighted that sustainability in both environmental and social aspects is one of the most defining Trends of retail evolution. It is becoming Paramount as the customers are taking a long-term shift to an eco-friendlier environment and adopting similar shopping behaviour. Consumers are already asking brands about what they are doing to integrate sustainability in their business operations.
From the research conducted by Lin et al. (2020) it has been identified that the trend of sustainable shopping is very strong among gen Z and millennial consumers. This is so because they belong to a younger shopper segment and tend to identify themselves with sustainable values as compared to older generation Shoppers.
Witell et al. (2020) explained that sustainable shopping is not just about the brand. Product packaging and store design are an integral part and one of the most important aspects of providing a sustainable shopping experience to the customers. Adivar et al. (2019) contradicted that customers are not asking for environmental sustainability but they are also concerned about the impact of the company's operations across the entire supply chain. They want to get information about ethical components Sourcing to consumption of water and management of pollution.
However, Holmlund et al. (2020) argued that Shoppers are more concerned about product packaging and have been expecting brands and retailers to invest more in sustainable alternatives. This is an important aspect of a customer journey because the packaging communicates brand tone when the customer opens the product.
In the views of Cervellon and Vigreux (2018) if the brand does not have a recyclable packaging or then it is highly unlikely that the customer would make another purchase. This is so because they feel that when they open the product packaging goes to waste and if it's non-recyclable then it is just to contribute to the pile of waste.
Literature Gap
In the current literature, a gap has been identified in the impact of Sustainable shopping experience on customer journey and their viewpoints. It is an important element because even though there is a relationship between this component, they exist independently in a retail environment. Brands such as Zara are making a conscious effort to provide a sustainable shopping experience to the customers but are still looking for answers on how it improves the customer journey and make them want to spend more time in the store and incline their Purchase Decision in favour of the business organisation. Impact of Sustainable shopping experience on customer journeys needs to be explored so as to gain clarity on the particular aspects which could be integrated with the business organisation for improving the customer journey while exercising functions in a sustainable manner.
Methodology
Within the current report, data has been collected from secondary sources. Qualitative information has been collected. It is useful in the present context because the researcher aims to explore business sustainability in terms of Zara by reflecting upon its case study. In order to add credibility and reliability into the study data from both secondary sources as well as a real-life organisation has been integrated. Database library which has been surfed for collecting secondary data is Google scholar. This is so because it makes it easier for the individual to search for published books and journals based upon keywords (Johhson and Sylvia, 2018).
The researcher has made sure that only those books and journals which have been published in 2017 for after that have been integrated. This is so because this data is comparatively newer as it is only 4 years old at maximum. This allows the learner to reflect upon the latest perspectives in reference to sustainable shopping experience and customer journey. By doing so, the individual would be able to curate an informed set of findings.
Case Study Findings and Analysis
Overview of the Organization
Zara is a Spanish apparel retailer. It was founded in 1974 and is currently headquartered in the municipality of Arteixo, Spain (Zara, 021). Zara is one of the biggest International fashion companies where the customer is the core element of the business model. It has an extensive retail network which includes production, distribution, design, and sales. It tends to work closely and together as a single company globally with its parent organisation — Inditex, Zara has been able to focus on the key elements of production. The business operations of the organisation are based on three major pillars which are digital integration, sustainability, and flexibility. It has been able to bring its customers closer than ever to the products and provide them at affordable prices.
The success of Zara was followed by international expansion at the end of 1980s and the successive launch of new brands within the same parent organisation which now have an integrated model of physical stores as well as online business operations (Inditex, 2021). The human resource at Zara is focused on fulfilling the demands of the customers. This is so because it is focused on creation of value which is beyond profit by placing the concerns of the environment and people at the core of its decision-making capabilities. Zara is focused on doing better and being better in reference to do business operations while securing sustainability.
Critical Evaluation of the Issue – Sustainable Shopping Experience at Zara
Zara Home is focused on unveiling its new Global image. It's new Store, The Plaza de Lugo will reopen in March with a totally overhauled concept. The store has been reported to have new designs and materials which would establish a global benchmark for the brand. This is so because the new concert revolves around being 100% ecological (Inditex, 2021). The story would be featuring minimalistic designs with traditional routes along with the latest technologies which would contribute to the shopping experience of the buyer.
The construction materials of the store have been made with the help of local artisans and include lime and marble with linen and Silk. It is in contrast with the furniture which is made from traditional materials such as oak, slate and Granite. It has been identified that this environmentally friendly store has used those materials which are capable of absorbing carbon dioxide. It only displays traditional handcrafted pieces on Handlooms which have been burnt by a novel warm and comfortable lighting. The energy consumption of the store has been enabled through sustainable technology and focused towards making sure that it is not harming the environment in any manner with monitored use of electricity. The idea of this store is to provide a new shopping experience to the customers.
Within this, the product displayed tends to stand out in a space which feels familiar like home thus, is in Alliance with the brand image of Zara home. It has been done by recreating a mixture of aesthetic beauty and feelings of well-being and comfort. The results of the Sustainable shopping experience curated by Zara would be on display for its flagship store which reopened in March 2021 as it was under a process of a full renovation and overhaul (Inditex, 2021). It could be stated that the new Zara home store concept enables the customers to uniquely experience the products and Discover its collections in a better way. The idea behind the design was to create an enjoyable visit for the customers to a warmer which focuses on sustainability and comfort by integrating the aspects of beauty and Technology together.
Recommendations
By analysing the contents of the report, following recommendations would be made for Zara in order to improve its sustainable shopping experience and ultimately enhance customer journey:
Using recycled and biodegradable packaging: it is suggested that Zara should make efforts to reduce the amount of plastic packaging which is used in its products. Biodegradable packaging which is made from plant-based materials such as cellulose and starch could be used which is broken down in a manner that could be made into bags. It is necessary to reassess how the organisation uses its packaging and where it can reduce the negative impact on the environment.
Minimising use of paper: it is necessary to reduce the amount of paper which is used in the organisation in order to drive sustainability. Zara needs to identify tasks and processes that require pen and paper to perform and then digitise them. For example, providing the bill and invoice to the customers requires the use of paper and ink which could be digitised and sent directly to the phone number or email address. It will make it easier for both the organisation as well as the customers to access the invoice if it is available in digital form because people are likely to misplace paper slips.
Empowering customers for engaging in sustainable operations: it has been identified that when people want to be more sustainable, they are likely to make sustainable purchases in decisions in order to leave their mark. By helping the customers to offset their impact in reference to retail habits would be highly beneficial for Zara's own sustainability efforts. It would need to make the people feel empowered as consumers and motivate them to bring changes in their daily habits. It also provides them with the confidence that Zara is out there to make a difference in the long term.
Conclusion
Findings and Importance to Business
From the current report, it has been found that sustainable shopping experience is gaining importance in the current environment. This is so because customers are inclined towards making purchasing decisions in favour of those business entities who integrate sustainable aspects in their operations. It is important to Zara because it holds a negative reputation of engaging into fast fashion and not performing sustainable operations. However, by integrating aspects of the Sustainable shopping experience it would be able to improve its business model and brand image in both short-term and long-term which will further help the organisation to increase its sales and be up-to-date with the current trends in the market.
Risks for Implementation
The major risks for implementing the recommendations is that it would need to make changes in a business model on an international level. For example, in order to introduce biodegradable packaging, it would need to make changes in all the stores and warehouses which satisfy both offline and online demand in order to make sure that the change has been implemented. It is risky because even though the customers would be in favour of biodegradable packaging it is unclear on how it will actually solve the issue.
In addition to this, by minimising the uses of paper it can get difficult for the customers to adhere to the change. Since always Zara has provided invoices and builds on paper and when it would turn digital it does not know how the customers would be able to absorb the change and be in favour of it. One of the major reasons behind the same is that our customers are sceptical in giving their personal details such as a phone number and email address while making a purchase as it makes them susceptible to phishing scams.
Limitations of the Study
The limitations of the current study are stated below:
- The researcher has only used the secondary data. This means that the findings of the study have been developed on the opinions and perspective of other authors and researchers.
- Limited number of studies are integrated in the report which reduces the reliability of the conclusion. The major reason behind the same is that a small sample size interferes with the level of generalization because the researcher generalisation specific content on the basis of the opinions in findings of a small number of people.
References
.png)
.png)
Research
MIS603 Microservices Architecture Research Report Sample
Assessment Task
This research paper should be approximately 2500 words (+/- 10%) excluding cover page, references and appendix. In this assessment, you need to present the different issues that have been previously documented on the topic using a variety of research articles and industry examples. Please make sure your discussion matches the stated purpose of the report and include the cases study throughout. Discuss and support any conclusions that can be reached using the evidence provided by the research articles you have found. Details about the different industry cases studies should NOT be a standalone section of the paper.
Task Instructions (the scenario)
You suppose to work for your selected organization (in assessment 2) and have read reports of other organisations leveraging the MSA application in three areas (innovation, augmented reality and supply chain). Accordingly, you need to prepare a research report for management on how the MSA application can be used to deliver benefits in these areas as well as how and why organisational culture can influence the successful implementation of an MSA. Use at least 2 different case study examples for showing the benefits can be achieved by organisations.
The report should consist of the following structure:
A title page with subject code and name, assignment title, student’s name, student number, and lecturer’s name.
The introduction (250–300 words) that will also serve as your statement of purpose for the proposal—this means that you will tell the reader what you are going to cover in your proposal.
You will need to inform the reader of:
a) Your area of research and its context
b) The key elements you will be addressing
c) What the reader can expect to find in the body of the report
The body of the report (1900–2000 words) will need to focus on these three areas (innovation, augmented reality and supply chain) also organisational culture to develop your research paper. Particularly, you need to prepare a research report for management on how the MSA application can be used to deliver benefits in different organisational environments- cultures.
The conclusion (250–300 words) will summarise any findings or recommendations
Solution
Introduction
The study is going to introduce the underdosing of microservices that develop better business processes in Netflix. In this study, Netflix is considered in this proposal to present an implementation plan of MSA for the business processes. Netflix is the online Network platform that is presenting digital entertainment. For Assignment Help, It also increases productivity with developing the business processes. The study also demonstrated the important undressing of developing customer satisfaction and productivity. A different model of business also develops the innovation system of Netflix like the Subscription-based business model. Moreover, the real-life data also presents a better understanding of this business process with the development of the MSA.
The Proposal also focused on the development of the revolution and the transformation which involved developing the research properly. The use of MSA also helps for developing closer communication. The culture of the organization also interacts with the internal and external context. In this context, the MSA application helps to develop the entire study on a current business operation to develop the organization's growth. Moreover, the implantation of a data management system and the infrastructure of the cloud also develop future studies.
The area of the study also highlighted the important key elements which will also address proper research on the selection of an organization. Moreover, the global concept also recognizes that Netflix is a total entertainment company which is also demonstrated with the micro services of global media cloud-based streaming services. Netflix is also improving the technologies by developing machine learning, artificial intelligence and IoT. It is a software-based technology that also helps improve the performance of Netflix. Moreover, it is increasing the business capacity with developing the business productivity including the use of modern technology. On the other hand, Netflix is the storage management system that is exposed with open source on the data management.
Main body
Innovation
Reflecting the creation with innovation in business processes or business model
Subscription-based Business Model
Netflix also introduced a subscription-based business model which makes money with a different simple plan including basic standard and the premium. This plan is getting access to the streaming series, shows and movies (Kukkamallaet al. 2021). The company also gains profit from this plan that is slow with a positive cash flow with growth in the content of original production. The streaming content is also specialized with the entertainment of subscribers in July 2021 with 72 million users from the Canada and United States. Netflix has their own offices in Brazil, France, the United Kingdom, Japan and South Korea.
.png)
Figure 1: Subscription business model
(Source:Duggan nMurphy&Dabalsa, 2021)
It is the member of the motion association picture that is distributed and produces the content from different countries over glow. In order to think of this company, it was founded in 1997 by Marc Rudolph and Reed Hastings (Martinez, 2014). It is also known for providing our best services that are used by people for renting some movies which they wanted to see in DVD format. It is the service of the internet that is making a sure journey with the business model.
The business model develops with a profitable run with the original content of productivity by the organization of Netflix. These models also described that they are the subscribers who are also able for Internet services where the company rents the movies and the online shows. The subscription is the base that is incorporated with the company that is considered huge that is also helpful when it comes through the Netflix business model.
The work of Netflix business model
To define Netflix, it has been stated that it is the basic provider of content that is used online for properly developing online TV shows and movies along with some documentaries. Online streaming is the site that is an application that is mood applicable for the connection of devices (). So, it has been stated that it is providing a better service to the people with their needs.
Netflix also defines the business model as subscription-based which is the opposite of a generating model revenue in the specific level of title(DuggannMurphy&Dabalsa, 2021). The continent assets are likely produced and licensed with the review that has an operating segment on the circumstances. It is also indicating all changes with expected usefulness.
.png)
Figure 2: Netflix business model
(Source:Ulin,, 2013)
American media services are the provider as well as and production company where the business model of Netflix revolves with the subscription base of learning. It consists of online streaming with the library forms and the TV programs which are also included with the films and produced in the house (Ulin,, 2013). The user also has a surety about monthly subscription where the services are used by paying money e that is provided by the people with the name-based online process. What different content also provides online streaming with the site and access of clients that make a better platform.
Transformation of The Organization Internal Environments
The transformation of Netflix also developed the internal environment of organization business by modifying the business tools, strategy, policy, infrastructure structure and culture. They are the most relevant reasons also included with changing the organization technology, new market conditions and the customer demand (Hinssen,, 2015). Moreover, the organizational changes also enable the Netflix component to develop a scope in the digital platform. Thereafter the organization also embraced the technological changes to adjust the digital concept (Braun& Latham, 2012). The organizational changes also assist with the development company which is replacing the old system with new strategies to achieve a competitive advantage in the marketplace.
The Changes Example in Netflix
Netflix is an important example of the change of an organization that has the best scope in the new context. As an example, the Netflix organization also changed with real-life examples including changes in the business model of Lewin's (McDonald& Smith-Rowsey, 2016). The organization also changes with a different stage that is completing the whole process including the significant factors of culture, the environment and technology. It is also simulated with the organizational change including the new strategies in the current situation (De Oliveira, 2018). So, it is always proved that Netflix is the best example for an organization and change where the different software companies accept the organizational changes as Netflix to achieve all the competitive advantage.
Augmented Reality
Reflecting the superimposing images in the revolution of Netflix
Netflix has great goals to help the members with developing the context to enjoy the discovering. Personalization is the important pillar that allows Netflix to help each member with the different content views. The adapt has the best interest on the content which is present over time expands on this (Curtin,Holt &Sanson, 2014). Each kind of experience is personalized with the different dimensions where the videos have suggested the ranking. The videos are the way that the all-advanced work plays that have a unique address on the member's needs.
.png)
Figure 3: Revolution of Netflix
(Source: Stawski& Brown, 2019)
Personalization is the start with the homepage which is extended with the products beyond. It is keeping an informed engagement on the reality that is picking a growing form of development in the original content. Netflix also uses the multimedia mechanism in the learning and the recommended algorithm which has a running scale on the personalization. It presents better research on personalization with developing the all-continuous improvements of the online experiments (Stawski& Brown, 2019). The organization also works through all improvements in the development areas by looking through the new opportunities for making better-personalized experiences. Revolution is the best part for developing online context with improving the personalized homepage experiences.
Netflix also seeks the offering of TV shows and movies that also shows the relevant concept with joy. The artwork of personalization also represents each video where machine learning is the crucial piece. Including the new alignments of collaboration, natural and online. The movements also recognize the best concept with developing the best connectivity in the online processes. It is presenting a great watch on the development of online series and movies with proper opportunities.
The real object for developing the study
Search of Algorithm
Search leverages the combination of the processing of natural languages, machine learning, text analytics and collaborative filtering. It is the member of Netflix to discover a new connection between the textual queries and the titles of the catalogue (McDonald& Smith-Rowsey , 2016)It is also struck with simplicity with the Netflix members by minimizing all the numbers including the interactions of member needs for making a search interface.
.png)
Figure 4: Netflix algorithm
(Source:Springer, 2014)
Moreover, it is present a search interface to look for the algorithms which also handle the catalogue and queries to span with the languages including many countries. The search also develops with good coverage what each title and each query get the best shot (Springer, 2014). Whenever the little title appears with the member homepage, the search algorithm also ensures that every title has a chance to lead a play surface.
Marketing Personalization
It is the main site of the product interface where Netflix applies the personalization algorithm with many types of critical areas in order to provide a base experience to the member. Moreover, the different areas also provide the best future for the members to connect with the personalized algorithm (Ulin,2013). For achieving this Netflix also reaches the members with new recommendations with notification and emails. The delivery of a billion messages in a year also worked with a personalized algorithm. On the other hand, this algorithm aims to optimize the member's joy by creating a mind full volume on the messages. Additionally, it is invested with a heavy growth that is retaining the members with the base of programmatic advertising.
.png)
Figure 5: Marketing personalization
(Source: Weinman, 2015)
In order to promote the services in the original contract, Netflix also developed the budget system allocation algorithm which decides the advertisement. Both also determine the algorithm's delicate balance with the incremental and cost to reward (Weinman, 2015). Different types of machine learning algorithms as well as statistical techniques like natural networks, casual models and collaboration are also diverse with the set of a product and business. These business patterns also solve the business need and the complex product with the use of Netflix expertise.
Supply Chain
Effectiveness of MSA in Closer Communication
MSA also defines the experimental and the mathematical methods that determine a variation of the amount which exist with the measurement process. A variation in the development of the measurement process has directly contributed to the overall variability. So, MSA is also used for certifying the system of measurement with evaluating the development accuracy, stability and precision (FarmakiSpanou, & Christou,2021). Fortunately, they are the different adaptation of micro services also sharing all expertise that has an open spirit on the different sources. Netflix is the best example where the transition form of Netflix has a traditional model plan on the development of DVD rental applications.
It is the micro service architecture that is responsible with a small team to create an end-to-end development on the micro services. It is developing the communication with streaming the digital entertainment for millions of Netflix customers (López Jiménez&Ouariachi, 2021). Now the technology is fellow on the Cockcroft which is prominent for micro services as well as the architecture of cloud-native.
Effectiveness of MSA application in the benefits of organization environments and culture
The revolution of Netflix also presents an effective application of MSA that has benefited the organizational culture and the environment that is using radical data. At the same time, the Netflix business including innovating and old fashion is transport with the town-to-town country. The postal services of the governments in the oldest departments also apply with the rental distribution of video. It is presenting an innovative approach to the Netflix industry which is entirely based on a brick-and-mortar concept.
The balance between old fashion and innovation is the master of influence in the culture of organization Netflix. The necklace is successful in the evolution of pre-existing content elements which has a distribution on the medical advancement. Netflix also took a pre-existing DVD in the film as well as the television that also gives the customer a new way for receiving them with television all storytelling distribution method (Shaughnessy,, 2018). It is the part of an innovation that maintains the structure of pre-existing whenever it has a comprehension with the usability of different models.
Engagement and Interactivity Among the Important external or internal entities
The transition of multi challenge places an engagement and interactivity with the internal and external concept of Netflix. It is the type of field that is involved in the technological innovation that increases the control, programs office taxation and the viewer’s choice. In the internal and external concept, the changes of the technology have also measured the technique that is capable of developing the revolution with viewing the television including distribution of narrative structure. The translation of this multichannel also drives channel proliferation. In the year of 1986, it premiered with the complete concept of the broadcast network (Olivier, 2020). All through the presentation of cables is specialized with the offerings of different formats of economics including the outstanding status of FCC regulation.
It has an important concept in the long-lasting television industry which is important to develop the technologies. This technology is also helping to remove the control of normalized concepts where the drivers also increase the control program. On the other hand, the VCR also gives the viewers control over the recording program(Olivier, 2020). The advanced concept of the audience is also presented in measurement technique which allows for determining the concept of television including specification and accuracy.
Conclusion and recommendation
Netflix is the company that is presenting a constant flow which is made with the streaming product that is corporate with the philosophy. Netflix also uses the analytic tool which is recommended for the videos. Netflix is the 90-second window that helps the weavers to find TV shows or movies. It is also presenting an understanding of the customer needs which is belonging through the movies, web series, advertisements and videos. The researcher also finds the best creation of the innovation in this business process through the subscription business model. And the supply chain processes will present a close communication including the MSA application. This application is also highlighted within this study for developing the organization culture and the environment as well as engaging the interactivity e with important entities of external and internal.
This proposal also creates a developed understanding of the implementation and the benefits of MSA business operation. Moreover, it is present in top scope to create a strong network on the MSA data center which helps the Netflix organization for gaining a better market criterion. The organization also helps to improve the work performance issues by developing the understanding of company capacity. In this context, the management system of data is presented as a based action on the business operation which is used for developing customer data with a proper demand. Moreover, the data management system also in Hindi company productivity with the working capacity. It is presenting a transformation in the structure of MSA that is led with the proper changes which increase the satisfaction of the customer. MSA also developed opportunities for the company to expand their market system with the development of continuous improvement in Netflix.
References
.png)
.png)
Reports
MIS607 Cybersecurity Report Sample
Task Summary
Reflecting on your initial report (A2), the organisation has decided to continue to employ you for the next phase: risk analysis and development of the mitigation plan.
The organisation has become aware that the Australian Government (AG) has developed strict privacy requirements for business. The company wishes you to produce a brief summary of these based on real- world Australian government requirements (similar to how you used real-world information in A2 for the real-world attack).
These include the Australian Privacy Policies (APPs) especially the requirements on notifiable data breaches. PEP wants you to examine these requirements and advise them on their legal requirements. Also ensure that your threat list includes attacks on customer data breaches. The company wishes to know if the GDPR applies to them.
You need to include a brief discussion of the APP and GDPR and the relationship between them. This should show the main points.
Be careful not to use up word count discussing cybersecurity basics. This is not an exercise in summarising your class notes, and such material will not count towards marks. You can cover theory outside the classes.
Requirements
Assessment 3 (A3) is a continuation of A2. You will start with the threat list from A2, although feel free to make changes to the threat list if it is not suitable for A3. You may need to include threats related to privacy concerns.
Beginning with the threat list:
• You need to align threats/vulnerabilities, as much as possible, with controls.
• Perform a risk analysis and determine controls to be employed.
• Combine the controls into a project of mitigation.
• Give advice on the need for ongoing cybersecurity, after your main mitigation steps.
Note:
• You must use the risk matrix approach covered in classes. Remember risk = likelihood x consequence. (Use the tables from Stallings and Brown and remember to reference them in the caption.)
• You should show evidence of gathering data on likelihood, and consequence, for each threat identified. You should briefly explain how this was done.
• At least one of the risks must be so trivial and/or expensive to control that you decide not to use it (in other words, in this case, accept the risk). At least one of the risks, but obviously not all.
• Provide cost estimates for the controls, including policy or training controls. You can make up these values but try to justify at least one of the costs (if possible, use links to justify costs).
Reference Requirement
A3 requires at least 5 references (but as many as you like above this number) with at least 3 references coming from peer-reviewed sources: conferences or journals. (Please put a star “*” after these in the reference section to highlight which are peer reviewed.)
One of the peer-reviewed articles must be uploaded in pdf format along with the A3 report (this can be done in BB). This pdf will be referred to here as the “nominated article”. (Zero marks for referencing if the nominated article is not itself peer-reviewed.) Of course, the nominated article should be properly referenced and cited, but you need to site an important direct quote from within the article (with page number), not just a brief sentence from the abstract. The quote should also relate to the main topic of the article, not just a side issue.
Solution
Introduction:
Cyber security threat is one of the important steps or crucial steps within the organization to make the whole information secure than previous. For Assignment help, Cyber threats are giving a huge impact on various types of businesses and tools which are getting resolved. A threat security plan will be prepared for one packaging company named PEP for describing the attack on JBS food.
PEP management wants a safeguard system to mitigate the JBS food attack. A cybersecurity specialist will be required to identify all threats and vulnerabilities regarding the intruders' attack. Here different cybersecurity factors will be described elaborately. All threats and vulnerabilities reports will be mentioned in this report. A STRIDE methodology is very much important to understand the different types of cyber threats within the organization.
PEP will implement the STRIDE methodology for resolving the issues of different types of cyberattacks within the organization. It can also create concrete growth in the organization.
Body of the report:
Discussion of App and GDPR:
APP: The privacy act is recognized as one of the useful principles within the Australian Legislation. There are mainly 13 principles presented here to secure the information of an organization. Few rules and purposes of the organization have been incorporated in this section.
Principal name
Australian Privacy policy 1 is a open communication systems among the management and team. This privacy act can help to make transparent communication within the hierarchical team. It can produce a clear APP policy.
APP 2: Anonymity and pseudonymity. APP entities are required to identify the pseudonym. Here a limited exception has been applied.
APP3: Gathering all personal data and information. All personal information is sensitive so it is very important to handle that information gently.
APP4: Dealing with all unsolicited information. In that case all personal information of the users which are not solicited deal with a proper
effectiveness.
APP 5: Notification for personal information. Here all the circumstances have been described for gathering all required personal information.
APP 6: Disclosing all personal information. APP entities can be used for disclosing all personal information to meet all certain requirements.
APP 7: Direct marketing is one of the useful strategies for improving certain conditions.
APP 8: Cross organization culture for understanding the personal information. APP entity is very much important to protect all required personal information
APP 9: Adoption and disclose of government based identifiers. Limited circumstances are very much important for adopting the Government related identifier.
App 10: Personal information gathering system should be more smooth and accurate for collecting all essential information. Quality of personal information
APP 11: Security of all essential information. APP privacy policy should take some necessary steps to restrict any misuse of information, unauthorized access. The entity has enough rights to destroy the obligation.
APP 12: Accessing personal information. APP entity obligation is very much important to get access to any personal information
APP 13: Error correction of all essential information. Personal information should be corrected for maintaining the obligation.
GDPR:
THE GDPR rule is mainly based on the UK. There are a few factors that are highly responsive to creating an effective cybersecurity policy for restricting any upcoming threats in the future from the side of the UK. There are mainly seven key factors that are responsible to make the start-up organization secure and help them to grow in the future. a). Lawful, fairness and transparency, purpose limitation, the accuracy of the information, prop[er information regarding the storage, Accountability. This gdpr information helps to cover up the Australian Privacy policy. Not only that but also it can create a huge impact on the PEP organization's growth. It can secure the future of GDPR privacy acts.JBS food facility service is recognized as one of the important packaging canters all over the world which has created a huge impact on organizational growth.
Threat lists and STRIDE categorization:
Cyber threats can become up with defining the different types of factors that can create a significant impact to grow the business sustainably. Here in this report, a threat modelling process has been organized for improving the security control system. In this report, the STRIDE model has been introduced to mitigate all potential vulnerabilities within the system. There are mainly six threat categorization techniques that are going to be introduced which can significantly impact the growth of the business model of PEP. There are mainly 7 types of cyber threats that have been considered here named as Malware, Denial of Service, Phishing technique, and SQL injection. Nuclear deterrence is viewed so positively that cyber-deterrence is frequently suggested as a promising analogous next step (Hellman,2017, 52-52).
1. Ransomware:
According to the detailed analysis, Ransomware attacks or malware attacks hold all infected files from IT software systems which can be easily paid for by hackers. The ransomware track also defines the concept of security breach policy.(Jones-Foster, 2014)[ The risk of PHI theft is growing as the nation’s health care system moves toward a value-based care model, which promotes more robust use of electronic health records and improved information technology integration across the continuum of care. "The sophistication and creativity of hackers today is pretty scary,” says Michael Archuleta, HIPAA security officer at 25-bed Mt. San Rafael Hospital, Trinidad, Colo. "You really have to be on your toes and pay attention, because viruses, malware and computer security threats change almost daily.] Malicious websites. Infected websites and phishing emails are recognized as an important factor for stealing all information of the customers (Ekelund&Iskoujina, 2019). Ransomware attacks have enough capability to stop any essential operation with any start-up organization. PEP is recognized as one of the start-up stores to execute its products within the market(Cox, 2008).
2. DDoS attack:
Distributed denial service attack is also recognized as another branch for all cyber hackers. Cybercriminals have enough potential to stop access from the users. Attackers are constantly trying to generate the spoof of the IP address technique. Attackers are producing a lot of information to all the victims for creating extensive connections outside the servers' end (Banham, 2017).[To fund Phase 3, the Defense Department's Defense Advanced Research Projects Agency (DARPA) just awarded almost $9 million lo BBN. Key priorities involve work on DTN scalability and robustness to support thousands of nodes, and designing and implementing new algorithms or several key tasks]
3. Social Attack: In that case, attackers are trying to build up a log file for accessing or stealing important information from the side of users. Vulnerable and intruder attacks have enough priority for installing the malware function within the system device. Here Phishing technique is recognized as one of the important tools to steal various information (Benzel, 2021, 26). Cyber attackers are always trying to provide some email for accessing all required login credentials (Cox, 2008).[ s. Social engineering, where hackers manipulate employees to gain access to passwords and systems, is one of the main risks organizations face. Therefore, encouraging employees to be vigilant regarding company information is very important.]
4. SQL injection: This is determined as another type of cyber threat where cyber-attack is established by inserting the malicious codes in SQL. When the server has become infected, it release all necessary information. The malicious codecan steal all necessary information from the users (Bertino& Sandhu, 2005).
5. Emotet: CISA described the concept of Emotet in an advance manner. Emotet is also recognised as one of the costly and destructive malware within the system.
STRIDE Model:
The STRIDE model is recognized as one of the useful systems where it can secure the app into three different categories named Spoofing, Tampering, Repudiation, Information disclosure, DDOS, and elevation privileges.
Techniques:
Spoofing: This technique can help to enter those people who are authenticated to access all required information as per the company’s standard.
Tampering: Integrity is the best policy to modify all network issues. It can also cover up the data on disk, , memory, and networks. This is a useful technique to take responsible action.
Information disclosure technique: This can help to provide all information that is not so much authorized or end to end encrypted
DdoS: This DDoS service has defined the concept of denying all access to the required resources which can make the service more immense.
Elevation of privilege: The proper authorization has been neglected to give access to other users. It can damage the overall infrastructure of Peter Excellent Packers.
Threat analysis:
Threat factors are getting measured here with the help of multiple risk factors within the organization. Multiple threads can arise here to improve the cybersecurity risk within the organization. All cyber threat factors are enlisted within the table.“While cyber-warfare might use some precepts of kinetic warfare, others had little significance in cyberspace” (Lilienthal & Ahmad, 2015).
Cyber Threats:
Hacking Password:
Cybersecurity threats are recognized as one of the important factors for analysing the priority of different risks, DDoS attacks and malware attacks. Ransomware is highly responsible to steal all the user's transaction history from the transactional database.
DDoS attack: Analyzing the severity of the risk, it is determined as one of the important and medium risk factors for stealing all required information from the customer table. According to the Risk factor analysis, the severity of individual risk factors creates a huge impact on organizational growth. The scaling technique is quite helpful to measure the severity of cyber attacks within the organization.
The Social attack: This attack has been considered a high priority and high level of consequences. Phishing attacks are also recognized as severe risk factors.ll intruders are trying to send some ransom mails for creating a log file within the organization's system. It can also become helpful to steal all necessary information from the users. Customers are always trying to open the mail which is coming from the PEP organization. It can directly impact the psyche of all potential and existing customers.
The weak password policy: Cloud-based service has been hacked with the help of a weak password system. A weak password policy can become more helpful to lose all sensitive information and personal information from the existing data sets or policy. These password policies can be overcome by creating a strong suggestion of the password.
Risk Register matrix:
.png)

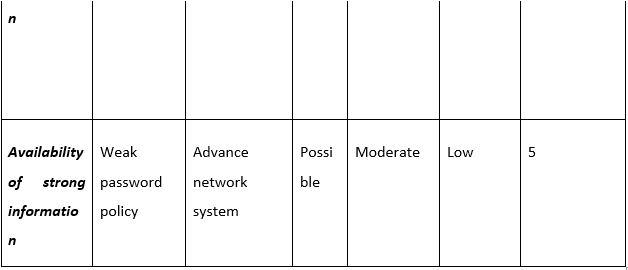
Figure 4:Risk matrix
(Source: Stallings & Brown, 2018)
According to the Risk register matrix, the priority of all risk factors can be stated below:
1. Social attack
2.DDoS attack
3. hacking password attack
4. Weak password policy.
Threat controls:
According to the whole market analysis, it is very important to resolve all cyber threat factors in order to mitigate any issues within the organization. Phishing technique is recognized as one of the high threats which creates log files within the main file. It creates a wide range of opportunities within organizational growth. There are several factors that are highly responsible for mitigating all upcoming threats within the organizations. According to the severity of this act, a huge number of methods are responsible to mitigate such issues. These control measures will be updated with proposing the actual budget in the market.
The whole threat resolution process will be discussed here by identifying some threats within the new start up organization named as PEP. When these methods are applied in IT security infrastructure, it can enhance organizational growth.
.png)
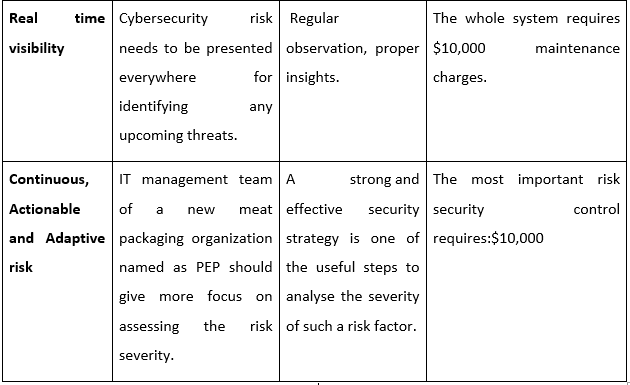
Figure 5: Threat controls
(Source: Banham, 2017)
Proper knowledge of IT assets:
BYOT, Third party components are recognised as main service for all employees within the organization.
Supervisor of IT infrastructure should be more aware about different types of vulnerabilities. The minimum cost estimation for managing whole IT assets are $50,000.
Strong protocol of IT security:
.Security within IT devices must be extended by the help of BYOT. All the transactional information or databases must be updated on a regular basis. Strong security protocol is very much necessary for improving the internal and external environment. Employees cost:$20,000 (McLaughlin, 2011)
Equipmentscost:$50,000
Real time visibility: Therefore the team can become alert to avoid such issues from the grassroot level. the organizational control can enhance the growth of such organizations.
A QA analysis team must be incorporated in this section for improving the organizational growth. The whole system requires $10,000 maintenance charges.
Continuous, Actionable and Adaptive risk:
According to the risk severity, the management team should give some resolution structure for identifying threads in a prior manner.
Team should be more focused to mitigate all issues from the grassroot level.Technological advancement should be checked on a regular basis for identifying all vulnerabilities before getting into the system. The most important risk security control requires:$10,000.
These are main thread control measures to identify all cyber security threats. It is very important to incorporate such a strategy within organizational growth for reducing all upcoming threads. It can also produce a better visibility about which risk resolution technique is necessary to mitigate the issue.
Mitigation scheme:
Cyber security risk mitigation scheme is recognized as one of the important factors to reduce all security policies and produce a huge impact on cyberthreats. Risk mitigation schemes separate or segregate three different elements named prevention, detection, and remedies. Cyber security risk factors can be mitigated by six different strategies which will be mentioned below in a sequential manner.
Improving the network access control criteria: A proper network access control needs to be established for mitigating all inside threats. Many organizations are trying to improve the security system efficiently. This factor can minimize the impact of likelihood and consequences. All the connected devices with the IT management system can increase the endpoint security within the system.
Firewall protection and antivirus: Cybersecurity risk can be measured by implementing the methods like firewall and antivirus software within the system. These technological factors are providing some exceptional security to restrict all intruders within the system. Outgoing traffic is also getting stopped with the help of such firewall security systems(Stiawan et al., 2017).
Antivirus software is also very useful to identify any malicious threats which can create significant damage within the organization.
Monitoring Network Traffic: A proactive action is very much important to mitigate all cybersecurity risk factors. Continuous traffic is necessary for improving the cybersecurity posture. A comprehensive view of the IT ecosystem can boost up organizational growth. This can enhance the IT security system. Continuous traffic helps to analyse or identify all-new threats and increases the minimal path of remediation.
Building a response plan:
PEP organizations must ensure that IT security teams and non-technical employees are highly responsible for any kind of data breach within the organization.
An incident response plan is determined as one of the useful techniques to mitigate cyber risk for improving the network environment. The incident response plan is recognized as one of the important strategies for preparing a team to mitigate an existing issue. Security Rating is also determined as one of the important strategies for getting feedback regarding implementing control measures.
Conclusion:
In this report, cybersecurity threat factors were discussed in a very detailed analysis. On the other hand, different types of measures will be elaborate to reduce the cyber threats factors. PEP company has been taken here to identify all future threats within the organization and resolution factors to remove these threats from the grassroots level. A risk matrix was given here to identify the severity of such a risk factor. According to the risk scale analysis, few resolutions were described here to mitigate all cyber threats. Different techniques with a cost estimate budget for implementing those techniques were discussed elaborately. It can enhance the growth of such an organization.
Reference:
.png)
Programming
PROG2008 Computational Thinking Assignment 3 Sample
Task Description:
In assignment 2, you have helped a real estate agent to gain some understanding of the market. The agent now wants you to help them set the indicative sale price for their new properties on the market. In this assignment, you will apply your knowledge in data analysis and modelling to build a regression model to predict the indicative sale price of a given property using the previous sale data. In particular, you will
- Apply multivariate analysis and appropriate visualization techniques to analyze the given dataset for the relationship between the sold price and other features of a property.
- Based on the analysis select one feature that can be used to predict the property indicative price. Justify your selection.
- Build a regression model to predict the indicative price from the selected feature.
- Train and validate the model using the given dataset and analyze the prediction power of the model. Discuss the result.
- Distinction students: propose a solution to improve the model accuracy.
- High Distinction students: implement the proposed solution to improve the model. You will use Jupyter Notebook in this assignment to perform the required analyses, visualise data, and show the analysis results.
Getting Help:
This assignment, which is to be completed individually, is your chance to gain an understanding of the fundamental concepts of computer networks which later learning will be based. It is important that you master these concepts yourself. Since you are mastering fundamental skills, you are permitted to work from the examples in the MySCU site or textbook, but you must acknowledge assistance from other textbooks or classmates. In particular, you must not use online material or help from others, as this would prevent you from mastering these concepts. This diagram will help you understand where you can get help:
.png)
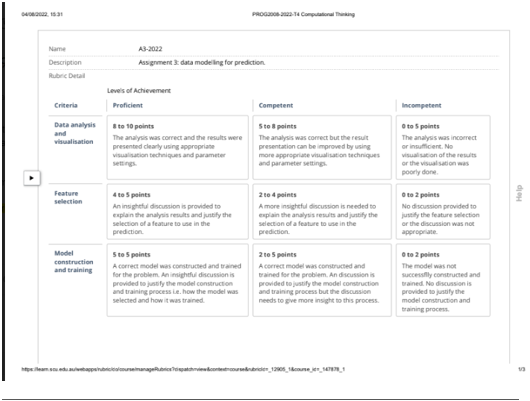
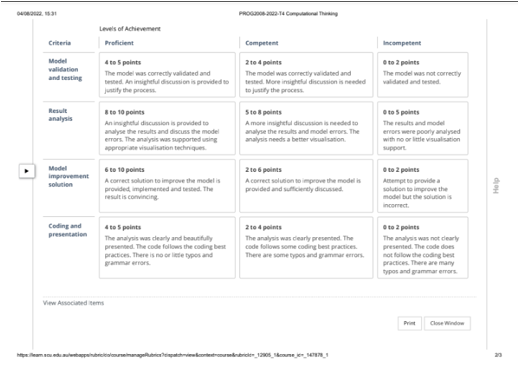
Solution
Analysis Report
The property sales prediction was done using a python programming language with Anaconda Framework using Jupyter Notebook IDE where the sales prediction dataset was explored at first. The libraries of python used for analysis and visualization were pandas, NumPy, matplotlib, seaborn, and sklearn for importing machine learning algorithms. For Assignment Help -
About data
.png)
The details about the data are thouroughly discussed in the notebook where each column details has been described about the property and sales.
.png)
The data reading was done using pandas where the information about the data was described.
Data processing including the column details, column information of data types, handling missing values and checking null values if present, and summary statistics of the data where the mean, deviation, maximum, count, etc. of the data are described.
.png)
Data Visualization
The data visualizations were done using matplotlib and seaborn library which are used for creating attractive and interactive graphs, plots, and charts in python. The different graphs from the data insights are described as communicating about the data containing visuals.
.png)
Figure 4 Bedroom description bar chart
The bar chart here describing the bedroom description count where the data containing 45.5% of property with bedrooms and the sales is also depended upon these factors.
.png)
Figure 5 Property sales price with bedroom availability
.png)
Figure 6 Property sales price with bathroom availability
.png)
Figure 7 Property sales price with square fit living availability
.png)
Figure 8 Property sales price with floors availability
.png)
Figure 9 Property sales price with condition availability
The sale prediction according to the property description is clearly described by the visualizations which describe the descriptive analysis of the data which represents the sales of the property according to the different infrastructure based happened in the past.
.png)
Figure 10 Property sales price with space availability
.png)
Figure 11 Property sales price with condition availability
.png)
Figure 12 Property sales price with grades availability
Data Modelling
The machine learning algorithm is applied to the dataset for the predictive analysis where the future prediction based on the descriptive analysis is done to look at whether the models are accurate according to the data and the accuracy of the model describes the predictive analysis rate to predict the property sales in the future.
.png)
Figure 13 Regression model
The algorithms are applied to the dataset by training the models by splitting the dataset into train and test split and then the trained and tested values are applied to the algorithms to calculate the score of the applied data.
.png)
.png)
.png)
.png)
The predictive analysis score of the linear regression model predicted 100% accuracy whereas the decision tree regression score comes to 99% accuracy which describes the property sales prediction as mostly accurate as assumed.
.png)
.png)
.png)


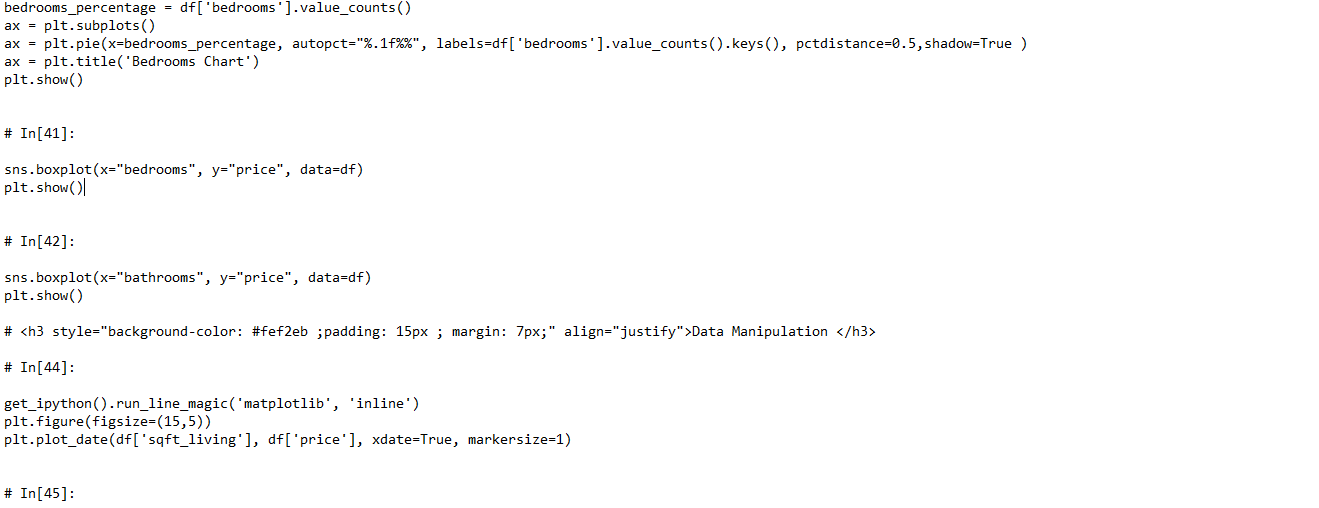




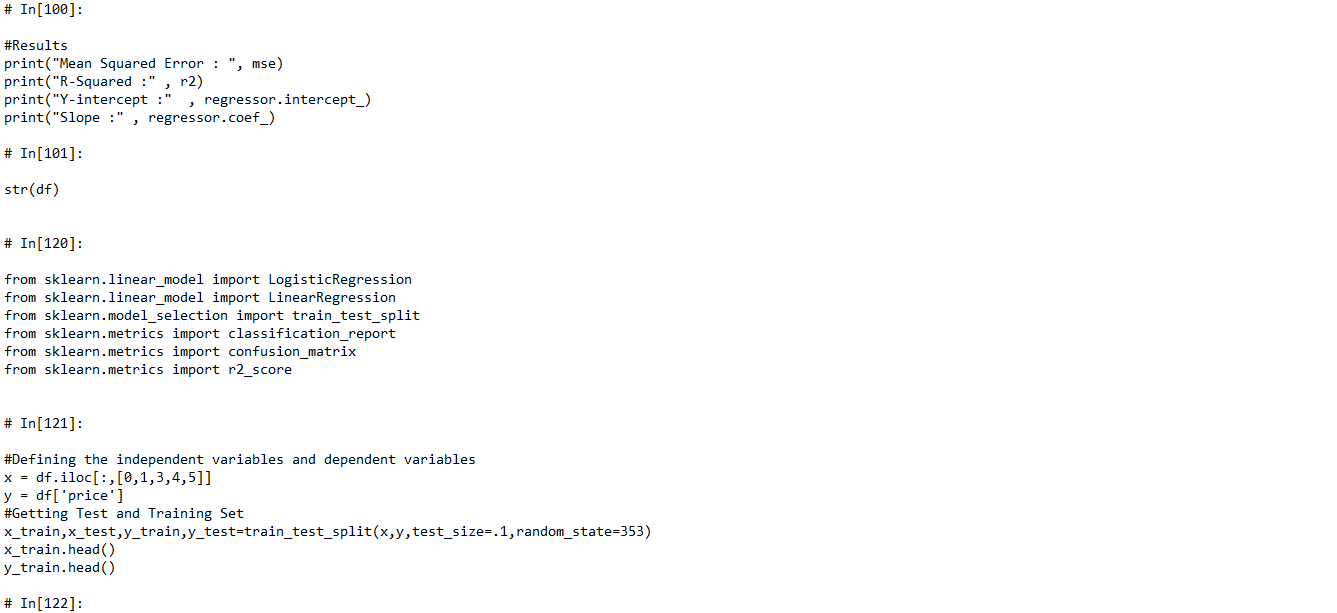


Reports
MIS500 Foundations of Information Systems Report-3 Sample
Task Summary
This assessment task requires you to reflect on your experiences in MIS500 this trimester by following a four-step process to gain insights into the work you have done and how it relates to your own career and life more broadly. In doing so, you will need to produce a weekly journal to record your learning and then as the trimester comes to a close reflect on these experiences and submit a final reflection of 1500 words (+/- 10%) that will include the weekly journal as an appendices.
Context
This is an individual assignment that tracks your growth as a student of Information Systems over the trimester. It is scaffolded around your weekly learning activities. Completing the activities and seeking input from your peers and the learning facilitator is essential for you to achieve a positive result in this subject. Before you start this assessment, be sure that you have completed the learning activities in all of the modules. This reflective report gives you the opportunity to communicate your understanding of how information systems relate to your career and future.
Task Instructions
1. During Module 1 – 5, you were ask to produce a weekly journal to record your learnings each week. Based on these weekly journals, please write a 1500 word reflective report about your experience focussing on how this will support developing and planning your future career.
2. You are required to follow the four steps of Kolb’s learning cycle when writing the reflective report.
You will keep a learning journal throughout the trimester. Each week as you complete the learning activities you record your experience in spreadsheet or word document.
A suggested format for the learning journal is as follows:
Table 1: Learning Journal
.png)
For each day in your learning journey, write the date and then the learning activity you engaged in. Detail what impact the learning had on you and then include any evidence you might like to keep for use later on. This journal should be appended to this assessment when you submit it.
.png)
Figure 1 – Kolb’s Learning Cycle
Solutions
Introduction
In this study, I have reflected on my learning experience related to MIS500 modules. I have described my learning experience based on Kolb’s learning cycle. For Assignment Help, This model explains that effective learning is a progressive process in which learners' knowledge develop based on the development of their understanding of a particular subject matter. Kolb's learning cycle has four phases, concrete learning, reflective observation, abstract conceptualisation and active experimentation. The learning process will help me to develop my career in the field of information technology.
Concrete Experience
Before the first module, I had little idea about the use of information systems in business. Thus, I was in the concrete experience stage of Kolb’s learning model, in which a learner has little idea about a concept. The first stage of Kolb’s model is concrete experience. In this stage, learners encounter new knowledge, concepts and ideas, or they reinterpret the ideas, concepts and knowledge that they already know (Hydrie et al., 2021). I learnt the use of information systems for making rational decisions in business is called business intelligence. I had no knowledge about business intelligence before the first module. Thus, it helped me to experience new knowledge about business intelligence. I started to think about how I can develop my career in the field of business career and the learning strategies that can help me to enhance my knowledge about the professional field.
The next modules helped me to deepen my understanding of business intelligence. I learnt that the emerging area of business intelligence is the result of a digital revolution across the world. Digital revolution refers to an increase in the number of users of tools and technologies of digital communication, such as smartphones and other types of computers, internet technology. The evidence for the digital revolution is the report "The Global State of Digital in October 2019.” The report mentions that there were around 155 billion unique users of mobile phones worldwide (Kemp, 2019). However, there were 479 billion internet users. The total number of social media users were 725 billion. The evidence has been obtained from module 1.2. Thus, there is high global penetration of digital technologies. The global penetration of digital technologies helped me to understand that I want to develop my career in the field of business intelligence. The digital revolution created thousands of career opportunities in the field. Business organisations need to use digital technologies to communicate with people or customers who use digital devices and technologies. Digital technologies are helping organisations in growth and international expansion (Hydrie et al., 2021). Businesses are expanding themselves with the help of digital technologies. Many businesses have transformed themselves from global to local with the help of digital technologies.
Reflective Observation
When I started to learn module 2, I learnt how business organisations use data to gain a competitive advantage over their competitors. In digital, the organisation which has relevant data can reach the targeted customers, improve their products and services and leverage different opportunities (Hydrie et al., 2021). Thus, data management and information management are vital for the success of an organisation. By collecting and managing data effectively, companies can obtain the knowledge that they require to achieve their business goals. I had reached the reflective observation stage by the time I learned this module because I started to reflect on new experiences by explaining why businesses need to digitise themselves. The reflection of observation is related to the second stage of Kolb’s model of learning. The reflective observation stage is related to the reflection on a new experience that a learner receives through his/her learning (Hydrie et al., 2021). It includes a comparison between the new knowledge or experience and existing knowledge or experience to identify a knowledge gap. This stage allowed me to know what I need to learn more to develop my career in the field of business intelligence or information system professional.
In the next modules, I tried to bridge the knowledge gap. In module 2.2, I learnt about the concepts of knowledge management and big data. Knowledge management is a collection of approaches that help to gather, share, create, use and manage related to management or information of an organisation (Arif et al., 2020). Knowledge management is crucial for organisations to gain meaningful insights from the collected data. However, big data refers to data in abundance which has high velocity and volume. Big data helps to identify important patterns related to events and processes and facilitates decision-making for business organisations.
These information systems are human resource information systems (HRIS), enterprise resource planning (ERP) systems and customer relationship management (CRM) systems Arif et al., 2020). This module played a vital role in shaping my knowledge by helping me to understand the practical use of information technology and information systems in business operations. I learnt how information systems help to describe and analyse the value chains of business organisations. A value chain of a business organisation is consist of main activities and supporting or auxiliary activities that help business organisations to carry out all their operations.
Module 3.1 also proved to bridge the knowledge gap. In this module, my knowledge reached to abstract conceptualisation stage of Kolb's learning model, which is related to the development of new ideas in a learner's mind or help him/her to modify existing ideas related to a concept. I started to use my learnings on how information systems can be used more effectively by business organisations. Thus, I tried to modify the knowledge related to existing applications of information systems in business.
Abstract Conceptualisation
Active conceptualisation is the stage of Kolb's learning cycle in which learners give a personal response to new experiences. In this stage, I started to think about how to use the new knowledge that I gained for the advancement of my career. I decided to learn more about ERP and CRM. If I learn about the two types of information systems, I can learn to develop them and help other organisations to learn their uses. It helped to shape my knowledge about area-specific information systems that can help organisations to meet the needs of the operations of their certain business operations. The two specific areas about which I gained knowledge in the module were ERP and CRM (Arif et al., 2020). ERP is an information system that helps to plan and manage the resources of a business organisation. It helps in managing to carry out supply chain operations. The main functions of an ERP are inventory planning and management, demand forecast and management of operations related to suppliers, wholesalers and retailers. However, CRM helps in managing relations with customers of business organisations (Hamdani & Susilawati, 2018). It helps to know and resolve customers’ grievances. CRM allows organisations to communicate with their customers to understand their needs and provide them with information about product and services offerings effectively. In module 4.2, I learnt how can help an organisation selects its business information system. The selection of a business information system by a business organisation depends on its business architecture (Hamdani & Susilawati, 2018). A business architecture refers to a holistic overview of operations, business capabilities, processes of value delivery and operational requirements. The information system that suits the business architecture of an organisation is most suitable for it. The price of information systems ascertained by vendors also influences the decisions of business organisations to use it.
Active Experiment
The active experiment is the stage in which learners decide what to do with the knowledge that they gained (Hydrie et al., 2021). I used the reflection technique to decide how to use my knowledge about information systems to develop my career. Harvard research in 2016 also explained the importance of reflection (Module 5.2). Reflecting on previous experiences helps individuals and organisations to recall what they learnt and find scopes of improvements in their existing skills and knowledge (Rigby, Sutherland & Noble, 2018). Thus, if business organisations reflect on their previous experiences related to IT operations, they can improve their knowledge about IT operations. Reflection can also help them to find a scope of improvements in their existing knowledge. As a result, they can improve their future IT strategies to achieve business goals. The improvements in the strategies can help them to ensure their future success. Thus, reflection can be an effective source of learning for organisations. The reflection of my learning helped me to know that I want to become a big data analyst because the requirements of big data analysis increasing in different fields, and I have effective knowledge about it. I will always follow ethics related to my profession to maintain professionalism because it is an ethical responsibility and professional conduct for IT professionals (McNamara et al., 2018).
Conclusion
In conclusion, my learning experience related to information systems helped me to know new concepts related to them. It helped me to bridge my knowledge gap about the use of information systems in business analytics. Based on my learning, I found that I have gained effective knowledge about big data analysis. Thus, I want to develop my career in the field of big data analysis.
References
.png)
Reports
Data4400 Data Driven Decision Making and Forecasting IT Report Sample
Your Task
Apply forecasting techniques to a given dataset and provide a business application of the forecasts. The report is worth 30 marks (see rubric for allocation of these marks).
Assessment Description
A dataset from a retailer that has more than 45 stores in different regions (Public data from Kaggle) has been sourced. The data provided for the assessment represents two stores. Store number 20 has the highest revenue within the country and store 25 does not have a high volume of sales. The objective of the assessment is to develop different demand forecast models for these stores and compare the forecast models in terms of accuracy, trend, and seasonality alignment with the historical data provided. Students must use visual inspection, error metrics and information criteria on the test data to provide conclusions.
Assessment Instructions
In class: You will be presented with a dataset in class. As a group, analyse the dataset using Tableau and Exploratory.io. You will provide an oral presentation of the group work in parts A to C during the third hour of the workshop.
The data set will be posted or emailed to you at the beginning of class in Week 6.
After Class: Individually write a 1000-word report which briefly summarises the analysis and provides suggestions for further analysis. This component of the assessment is to be submitted via Turnitin in by Tuesday of week 7. No marks will be awarded for the assessment unless this report is submitted.
Hint: take notes during the group assessment to use as prompts for your report.As a group:
Part A
- Use Tableau to compare the two stores in terms of sales using adequate visualisation(s).
- Run Holt-Winters forecasts of the next 5 months for stores 20 and 25.
analyse the results of the forecasts in terms of:
o Accuracy
o Alignment with the historical trend
o Alignment with the historical seasonality
Part B
- Use Exploratory to generate ARIMA forecasts for stores 20 and 25.
- Create visualisations, interpret and describe your findings.
- Analyse the forecasts in terms of:
o Accuracy
o Alignment with the historical trend.
o Alignment with the historical seasonality.
Part C
Prepare a presentation:
• Include key findings.
• Highlight methodologies.
• Advise which methods to use for each store.
• Recommend improvements in terms of forecasting for the retailer.
Note: All members of the group should be involved in the presentation. The allocated time for the presentation will be decided by your lecturer.
Solution
Introduction
The ability for organisations to base decisions on empirical evidence rather than preconceptions makes data-driven decision-making and forecasting essential. For Assignment Help, Forecasting trends help proactive tactics, resource optimisation, and market leadership in fast-moving environments. With the aid of various forecasting models, including ARIMA, HOLT-WINTERS, and others, the study's goal is to visualise the sales of both STORE 20 and STORE 25 and forecast sales based on historical sales trends.
Discussion on Results
.png)
Figure 1: Visualization of STORE 25 sales
.png)
Figure 2: Forecast result of STORE 25 sales
With a decline of 336,738 units from the initial figure of 3,149,931 units in October 2012, the projection for STORE 25 sales from October 2012 to February 2013 shows a downward trend. With a peak in December 2012 (1,616,475) and a trough in January 2013 (-563,853 units), the seasonal effect is clear.
.png)
Figure 3: Sum of value for STORE 25 sales
It appears reasonable to use the selected additive model for level, trend, and seasonality. The forecast's accuracy is fairly high, with a low MAPE of 10.8%, despite occasional forecast errors, as seen by measures like RMSE (383,833) and MAE (296,225). This shows that the model effectively captures underlying patterns, assisting in the formulation of successful decisions for the STORE 25 sales strategy.
.png)
Figure 4: Visualization of STORE 20 sales
.png)
Figure 5: Forecast result of STORE 20 sales
A time series methodology was used to determine the sales prediction for STORE 20 for the period from October 2012 to February 2013. Notably, it was clear that an additive model for level and trend had been used and that there was no identifiable seasonal regularity. Sales began at roughly $9.88 million in October 2012, and by February 2013, they had increased by $197,857.
.png)
Figure 6: Sum of value for STORE 20 sales
Quality metrics showed an RMSE of $1.3 million and a fair degree of accuracy. The forecast's relative accuracy may be seen in the forecast's mean absolute percentage error (MAPE), which was 12.4%. STORE 20's sales trend could be understood by the chosen model despite the lack of a pronounced seasonal effect.
.png)
Figure 7: Visualization of HOLT-WINTERS test for STORE 25 sales
.png)
Figure 8: Result of HOLT-WINTERS test for STORE 25 sales
When five periods of STORE 25 sales data are smoothed using the HOLT-WINTERS exponential method, a downward trend is evident. The anticipated values start at 3,028,050.52 and successively drop to 2,949,111.42. This tendency is reflected in the upper and lower limits, which have values between 4,165,588.2 and 4,108,064.45 for the upper bound and 1,890,512.83 to 1,790,158.39 for the lower bound. This means that the sales forecast for Store 25 will continue to drop.
.png)
Figure 9: Visualization of HOLT-WINTERS test for STORE 20 sales
.png)
Figure 10: Result of HOLT-WINTERS test for STORE 20 sales
The sales data from STORE 20 were smoothed using the HOLT-WINTERS exponential projection for five periods. The predicted values show an upward trend over the specified periods, rising from 9,692,132.56 to 9,838,792.22. The forecast's upper and lower ranges are also climbing, with upper bounds falling between 12,274,556.54 and 12,428,330.21 and lower bounds between 7,109,708.57 and 7,249,254.23 in size. This implies a steady upward growth trajectory for the forecast's accuracy for sales at STORE 20.
.png)
Figure 11: Visualization of ARIMA test for STORE 25 sales
.png)
Figure 12: Visualization of ARIMA test for STORE 20 sales
.png)
Figure 13: Quality performance of ARIMA model for STORE 25 sales
The quality performance of the ARIMA model for STORE 25 sales is encouraging. The MAE (9,455.64) and MAPE (0.0034%) are low, indicating that the forecasts are correct. Moderate variability is shown by RMSE (29,901.35). The model outperforms a naive strategy, according to MASE (0.460). The model's appropriateness is supported by its AIC and BIC values of 73,748.40.
.png)
Figure 14: Quality performance of ARIMA model for STORE 20 sales
For STORE 20 sales, the quality performance of the ARIMA model is inconsistent. RMSE (86,950.12) denotes increased variability whereas MAE (27,496.04) and MAPE (0.0033%) suggest relatively accurate predictions. MASE (0.508) indicates that the model performs somewhat better than a naive strategy. A reasonable model fit is indicated by the AIC (78,652.94) and BIC (78,658.86).
.png)
Figure 15: Quality performance of HOLT-WINTERS test for STORE 25 sales
The performance of the HOLT-WINTERS model for STORE 25 sales contains flaws. A bias is evident from the Mean Error (ME) value of -37,486.18. Despite having moderate RMSE (580,387.03) and MAE (435,527.36) values, MAPE (15.47%) indicates significant percentage errors. The positive MASE (0.708) denotes relative improvement, while the negative ACF1 (-0.097) suggests that the predictive model may have been overfitted.
.png)
Figure 16: Quality performance of HOLT-WINTERS test for STORE 20 sales
The performance of the HOLT-WINTERS model for sales at STORE 20 shows limitations. The Mean Error (ME) of -152,449.83 shows that forecasts are biased. MAPE (13.54%) and MASE (0.731) point to accuracy issues while RMSE (1,317,587.47) and MAE (1,043,392.14) show substantial mistakes. The low ACF1 (-0.25) suggests that the prediction model may have been overfit.
Key Findings and Recommendations
Key Findings:
1. STORE 20 frequently outsells STORE 25, especially throughout the winter.
2. Holt-Winters forecasting works well for STORE 20 because of its ascending trend, but ARIMA works well for STORE 25 because of its declining pattern.
Recommendations:
1. In order to capitalise on the increasing trend, Holt-Winters will be useful for STORE 20 sales estimates.
2. In order to consider into account its decreasing tendency, ARIMA will be used for STORE 25 sales predictions.
3. Strategic resource allocation will be advantageous to maximise sales for each shop based on its unique trends.
Conclusion
Precision and strategic planning are greatly improved by data-driven forecasting and decision-making. We visualised and examined sales trends for STORE 20 and STORE 25 using a variety of forecasting models, including ARIMA and HOLT-WINTERS. The findings offer guidance for developing tactics that can take advantage of the unique sales trends found in each location.
Bibliography
.png)
Assignment
COIT20262 Advanced Network Security Assignment Sample
Instructions
Attempt all questions.
This is an individual assignment, and it is expected students answer the questions themselves. Discussion of approaches to solving questions is allowed (and encouraged), however each student should develop and write-up their own answers. See CQUniversity resources on Referencing and Plagiarism. Guidelines for this assignment include:
• Do not exchange files (reports, captures, diagrams) with other students.
• Complete tasks with virtnet yourself – do not use results from another student.
• Draw your own diagrams. Do not use diagrams from other sources (Internet, textbooks) or from other students.
• Write your own explanations. In some cases, students may arrive at the same numerical answer; however their explanation of the answer should always be their own.
• do not copy text from websites or textbooks. During research you should read and understand what others have written, and then write in your own words.
• Perform the tasks using the correct values listed in the question and using the correct file names.
File Names and Parameters Where you see [StudentID] in the text, replace it with your actual student ID. If your student ID contains a letter (e.g. “s1234567”), make sure the letter is in lowercase.
Where you see [FirstName] in the text, replace it with your actual first name. If you do not have a first name, then use your last name. Do NOT include any spaces or other non-alphabetical characters (e.g. “-“).
Submission
Submit two files on Moodle only:
1. The report, based on the answer template, called [StudentID]-report.docx.
2. Submit the packet capture [StudentID]-https.pcap on Moodle Marking Scheme
A separate spreadsheet lists the detailed marking criteria. Virtnet Questions 1 and 3 require you to use virtnet topology 5. The questions are related, so you must use the same nodes for all three questions.
• node1: client; assumed to be external from the perspective of the firewall.
• node2: router; gateway between the internal network and external network. Also runs the firewall.
• node3: server; assumed to be internal from the perspective of the firewall. Runs a web server with HTTPS and a SSH server for external users (e.g. on node1) to login to. Will contain accounts for multiple users.
Question 1. HTTPS and Certificates [10]
For this question you must use virtnet (as used in the Tutorials) to study HTTPS and certificates. This assumes you have already setup and are familiar with virtnet. See Moodle and workshop instructions for information on setting up and using virtnet, deploying the website, and testing the website.
Your task is to setup a web server that supports HTTPS. The tasks and sub-questions are grouped into multiple phases.
Phase 1: Setup
1. Ensure your MyUni grading system, including new student user and domain of are setup. See the instructions in Assignment 1. You can continue to use the setup from
Assignment 1.
Phase 2: Certificate Creation
1. Using [StudentID]-keypair.pem from Assignment 1, create a
Certificate Signing Request called [StudentID]-csr.pem. The CSR must contain thesefield values:
o State: state of your campus
o Locality: city of your campus
o Organisation Name: your full name
o Common Name: www.[StudentID].edu
o Email address: your @cqumail address
o Other field values must be selected appropriately.
2. Now you will change role to be a CA. A different public/private key pair has been created for your CA as [StudentID]-ca-keypair.pem. As the CA you must:
3. Setup the files/directories for a demoCA
4. Create a self-signed certificate for the CA called [StudentID]-ca-cert.pem.
5. Using the CSR from step 1 issue a certificate for www.[StudentID].edu called [StudentID]-cert.pem.
Question 2. Attack Detection from Real Intrusion Dataset
For this question you need to implement three meta-classifiers to identify attack and normal behaviour from the UNSW-NB15 intrusion dataset. You are required to read the data from training set (175,341records) and test set (82,332 records).
You are required to implement it by using the publicly available machine learning software WEKA. For this task you will need two files available on Moodle:
• training.arff and test.arff.
You need to perform the following steps:
• Import training data.
• For each classifier:
- Select an appropriate classifier
- Specify test option
- Supply test data set
- Evaluate the classifier.
You need to repeat for at least 3 classifiers, and eventually select the results from the best 2 classifiers.
You need to include in your report the following:
(a) Screenshot of the performance details for 3 classifiers [1.5 marks]
(b) Compare the results of the selected best 2 classifiers, evaluating with the metrics:Accuracy, precision, recall, F1-Score and false positive rate.
Question 3. Firewalls and iptables [8]
You are tasked with designing a network upgrade for an educational institute which has a single router, referred to as the gateway router, connecting its internal network to the Internet. The institute has the public address range 100.50.0.0/17 and the gateway router has address 100.50.170.1 on its external interface (referred to as interface ifext). The internal network consists of four subnets:
A DMZ, which is attached to interface ifdmz of the gateway router and uses address range 100.50.171.0/25.
• A small network, referred to as shared, with interface ifint of the gateway router connected to three other routers, referred to as staff_router, student_router, and research_router. This network has no hosts attached (only four routers) and uses network address 10.5.0.0/18.
• A staff subnet, which is for use by staff members only, that is attached to the staff_router router and uses network address 10.5.1.0/23.
• A student subnet, which is for use by students only, that is attached to the student_router router and uses network address 10.5.2.0/23.
• A research subnet, which is for use by research staff, that is attached to the research_router router and uses network address 10.5.3.0/23.
Question 4. Wireless security [10]
Read the research article on Wi-Fi Security Analysis (2021) from the below link:
![]()
You need to perform the following tasks:
(a) Write an interesting, engaging, and informative summary of the provided article. You must use your own words and you should highlight aspects of the article you think are particularly interesting. It is important that you simplify it into common, easily understood language. Your summary MUST NOT exceed 400 words. [3 marks]
(b) Find an Internet (online) resource (e.g., research article or link) that provides additional information and/or a different perspective on the central theme of the article you summarised in (a). Like you did in (a), summarise the resource, in your own words and the summary should focus on highlighting how the resource you selected expands upon and adds to the original prescribed resource. You must also provide a full Harvard reference to the resource. This includes a URL and access date. [4 marks]
(c) Reflect on the concepts and topics discussed in the prescribed article and the resource you found and summarised and how you think they could potentially impact us in future.
Solution
Question 1- HTTPS and Certificates
HTTPS is the shorter format of Hyper Text Transfer Protocol Secure. HTTPS appears in the Uniform Resource Locator when the SSL certification barricades the website. The overall details of the credential and the website proprietor's corporate standing can be considered by clicking on the specific safety symbol on the browser streak.
Part (a)
The ala data of the student's Id and the user's details are added with the help of the MyUni system (Aas et al. 2019). Follow the basic information of Assignment 1. The setup is being processed in that way.
Part (b)
Certificate creation follows an essential process where one must send a signing request to the Certificate Authority.
1. Run the necessary Command to can make a certificate signing request (CSR) file: openssl.exe req-new-key certaname. Key-out certname. CSR.
2. The promotion time is needed information like the common name, Tableau Server name, etc.
The use of HTTPS with the specific Domain name requires an SSL certificate, which has to be installed on the website.
.png)
Figure 1: Kali Linux cmd server
(Source: Created on Kali Linux)
.png)
Figure 2: Creating CSR
(Source: Created on Kali Linux)
In this figure, a key pair file is used to construct a Certificate Signing Request (CSR). Specific field values seen in the CSR include email address, organization name, common name, state, and locale. The CSR is created with the name [StudentID]-csr.pem with the intention of getting a certificate for the student website.
.png)
Figure 3: Details of Certificate
(Source: Created on Kali Linux)
Part (c)
Write your answer here
The HTTPS on Apache is followed in several steps.
- Discover the Apache format file and unlock it with the text editor. The name of the Apache Configuration File has to depend on the system outlet.
- Demonstrate the Apache SSL structure file and save it. Open the Apache SSL layout file.
- Restart the Apache Web Server in the Linux OS System.
Part (d)
The testing process of the HTTPS certificate is done in basic simple steps. These are 1. First of all, check the Uniform Resource Locator of the specified website starting with HTTPS, where the SSL certificate has been created.2. Tab on the Padlock icon on the valuable address bar to can check all the specific details and information which is related to the Certificate.
Part (e)
The SSL is known as the Secure Sockets Layer. The SSL is a basic protocol that has the ability to can create an encipher link between the Web browser and Web Server (Gerhardt et al. 2023). Any data that can be swapped between a website and a specific visitor will be protected. Holding an SSL certificate for the WordPress website is a must for running an Ecommerce Store.
Question-2
Attack Detection from Real Intrusion Dataset
Part (a)
Training.arff
Classifier 1

Figure 1: Run Information of Rules Classifier 1

Figure 2: Rules Classifier in Test Model
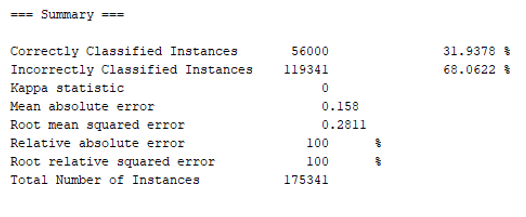
Figure 3: Summary of Rules Classifier
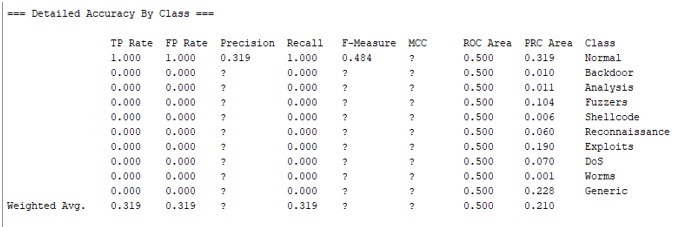
Figure 4: Accuracy of Rules Classifier
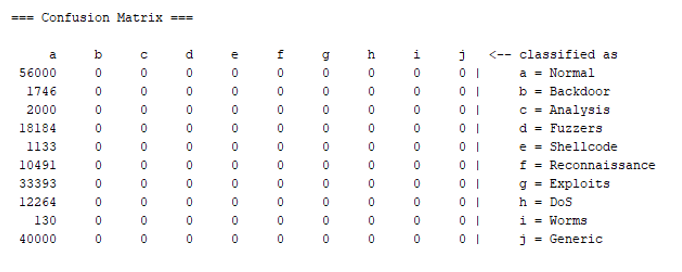
Figure 5: Confusion Matrix of Rules Classifier
Classifier 2

Figure 6: Run Information of Bayes Classifier 2
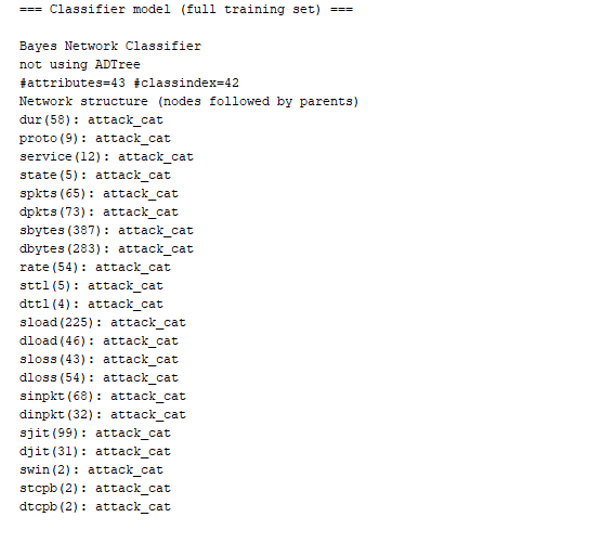
Figure 7: Classification Model in Bayes Classifier
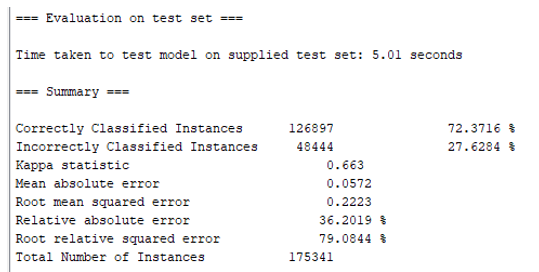
Figure 8: Evaluation Test and Summary of Rules Classifier
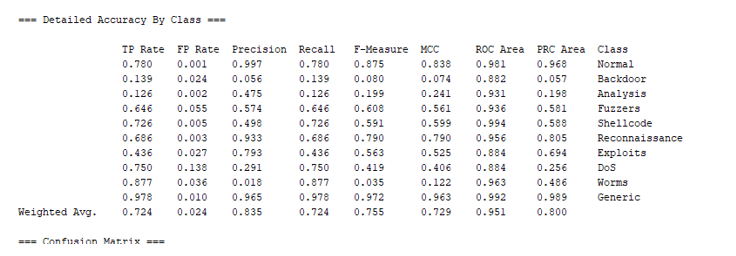
Figure 9: Accuracy of the Rules Classifier

Figure 10: Confusion Matrix in Rules Classifier
Classifier 3
Figure 11: Run Information of Trees Classifier 3
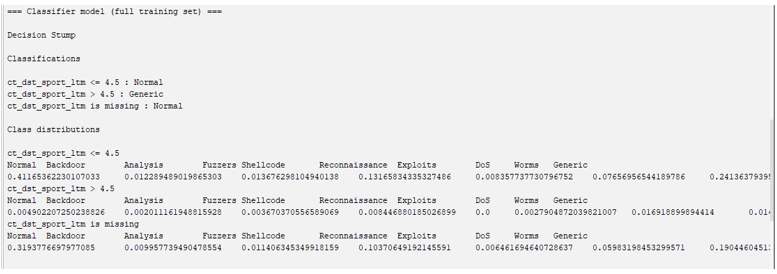
Figure 12: Classification Model in Trees Classifier
.png)
Figure 13: Summary of Trees Classifier
.png)
Figure 14: Accuracy of the Trees Classifier
.png)
Figure 15: Confusion Matrix of Trees classifier
Test.arff
Classifier 1
.png)
Figure 16: Run Information Test of Rules Classifier 1
.png)
Figure 17: Test Model in Rules Classifier
.png)
Figure 18: Summary Test of Rules Classifier
.png)
Figure 19: Accuracy of the Rules Classifier
Figure 20: Confusion Matrix of Rules Classifier
Classifier 2
.png)
Figure 21: Run Information of Bayes Classifier 2
.png)
Figure 22: Test model of Bayes Classifier
.png)
Figure 23: Build Model in Test.arff Bayes Classifier
.png)
Figure 24: Accuracy of Bayes Classifier
.png)
Figure 25: Confusion Matrix of Bayes Classifier
Classifier 3
.png)
Figure 26: Run Information of the Trees classifier 3
.png)
Figure 27: Classification Model in Trees
.png)
Figure 28: Summary of the Tress Classifier
.png)
Figure 29: Accuracy of the Trees Classifier
.png)
Figure 30: Confusion Matrix of Trees Classifier
Part (b)
Test.arff
The run information of Classification 1 is needed a shorter type scheme and very long attributes, but Classification 2 is specified a different scheme. The accuracy of classification 1 is presented in a more elaborate way but in the case of classification 2, there is a little much short about the accuracy. The F1 score and the false positive rate are better in Classification 2 than the Classification 1 (Ahmad et al. 2022).
Train.arff
The run information of the Classification 1 is very detailed in the primary part but the portion of Classification 2 is not specified in a proper way. The accuracy is less in classification 1 in the Train.arff but classification 2 is more accurate from the matrix perspective. The F1 score in the machine learning process is more specified in Classification 2 than in Classification 1 in the Train.arff (Alduailij et al. 2022).
Part (c)
Based on the specific comparison between classification1 and Classification 2, Classification 2 is better than Classification 1 because the scheme is more evaluated in Classification 2. The accuracy in Classification 1 is little much less appropriate than in Classification 1. The F1 score and the false positive rate are always better in Classification 2 than in Classification 1 of the bother test.arff and train.arff (Ceragioli et al. 2022).
Part (d)
The UNSW-NB15 is a process of the network Instruction sheets. It basically contains nine types of different attacks. The whole dataset contains ideal network packets. The number of possible records in the training set is primarily 175,341. Records. Of these nine attacks, the normal and the Generic are the most powerful. Because the training set and testing are best in these two category.
Question 3- Firewalls
Part (a)
Wireless networks utilize radio swells to transfer data into machines, similar to laptops, smartphones, and tablets, or entry points, that have attached to the “Wired Network”. “Wired Networks” utilize cables, similar to Ethernet, to secure machines, similar to routers, buttons, and wait people, to individually different or to the internet. The “Virtual Private Network” has an encrypted association up the Internet from the device to the web. The encrypted association supports guarantees that exposed data has been safely transferred. This precludes unauthorized somebody from eavesdropping on the gridlock or permits the user to execute a career remotely.
.png)
Figure 34: Diagram of wired Network
(Source: Created on Draw.io)
The network diagram in the example would show a wired network, a wireless network, and a VPN. One to three devices each would be used to represent the staff, student, and research subnets. The IP addresses of each machine and router interface would be noted. The areas of the network where data is encrypted, either by WIFI encryption or the VPN, would be prominently marked on the diagram as encrypted using red or similar easily recognizable label.
Part (b)
The firewall rules have the entry authority mechanism utilized by a firewall to protect the network from the contaminated application or unauthorized entrance. Fire3wall rules determine the variety of gridlock the firewall takes or that have rejected. The exhibition of the firewall rules creates the firewall entrance procedure. The firewall has network security that maintains getaway unauthorized users or hackers. Virtual software support saving files from viruses. Firewall support to maintain intruders by obstructing them from accessing the system in the rather residence. The firewall has a technique planned to control undesirable data from reaching and leaving the personal network. The learner will utilize either hardware or software to execute the firewall or an assortment of the two. In the company environment, or association can have an intranet that they save utilizing the network.
Part (c)
The Rules of the tables are primarily:
- Flare the concluding app or log in with the use of the sash command: $ sash user @server- name.
- List all of the IPv4 rules: $ sudo iptables -S.
- Find the valuable list of all IPv6tables -S.
- List all the special section table rules: $ sudo ip6tables -L -v -n | more.
- Lat List all the rules for the specified INPUT tables.
To add some new rule as the special section of the existing rule, merely use the index numeral of that current rule (Ruzomberka et al. 2023).
Figure 34: Network of educational institute
(Source: Created on Cisco)
The gateway router that connects the internal network to the Internet makes up the network architecture of the educational institution. The gateway router's external interface has the address 100.50.170.1, and the institute's public address range is “100.50.0.0/17”. A shared network with four routers, a DMZ subnet linked to the gateway router, a staff subnet is 10.5.1.0/23, a student subnet (10.5.2.0/23), and a research staff subnet (10.5.3.0/23) connected to their respective routers are all included in the internal network.
.png)
Figure 35: Server Configuration
(Source: Created on Cisco)
A web server that supports “HTTP” and “HTTPS”, an “SMTP” email server, and an SSH server would be included in the server setup for the educational institution's DMZ using Cisco Packet Tracer. On the gateway router, access control lists (ACLs) would be set up to permit access from the staff, student, and research subnets to the web server, staff members exclusively to the IMAP email server, and staff and research members to the SSH server from outside the network.
.png)
Figure 36: DHCP Server
(Source: Created on Cisco)
Question- 4- Wireless security
Part (a)
Advanced network security is the set of valuable technologies that have the ability to can protect the whole usability and also the goodness of the company’s framework by the process of containing the entry or the accumulation within the web of the wide range of variety of possible threats. The Hypertext Protocol Secure is a specific kind of combination of the HTTP with the Secure Socket Layer (SSL) or the Transport Layer Security which is the longer format of TLS. The TLS is an authentication and also security system that is widely connected in Web browsers and Web servers. The second portion is made on the Instruction detection system.
An instruction on the Detection of suspicious activities generates the alert when the detected system has been proceeding. Connected to the specific process of a security operation Center, the longer format of the SOC or incident responder has the capability to investigate the obstacles and also take proper actions to remediate the threat. The real instruction Database includes the classification matrix and classification them in a proper manner. The process is described on the VMware Kali Linux. The tables which are in the third section allow the specific system administrator to define the actual table and draw the diagram which can illustrate the wired network and also the firewall rules mentioned here.
Part (b)
Wireless Network Security is the stage for patterns or instruments utilized to watch WLAN infrastructure or the gridlock crosses them. Extensively communicating, wireless security of articulates that endpoints have or exist allowed on the Wi-Fi network via network entrance or security policies. Resource Allocation has given time, distance, and Commonness environment in the scope established on the technique that categorized CDMA, TDMA, SDMA, and FDMA.
Part (c)
This essential security significant to details on the internet has confidentiality, integrity, or availability. Ideas connecting to the somebody who utilized the statement have authentication, permission, or nonrepudiation. Wireless security has the precluding of unauthorized entrance and impairment to computer data utilizing wireless networks that process Wi-Fi networks. The duration can again guide to confidentiality, integrity, and availability of the web.
Reports
DATA4000 Introduction to Business Analytics Report 3 Sample
Your Task
Consider below information regarding the Capital One data breach. Read the case study carefully and using the resources listed, together with your own research, complete:
• Part A (Industry Report) Individually by Monday 23: 55pm AEDT Week 12
Assessment Description
Capital One
Background
Who is Capital One?
Capital One Financial Corporation is an American bank holding company specializing in credit cards, auto loans, banking, and savings accounts. The bank has 755 branches including 30 café style locations and 2,000 ATMs. It is ranked 97th on the Fortune 500, 17th on Fortune's 100 Best Companies to Work For list, and conducts business in the United States, Canada, and the United Kingdom. The company helped pioneer the mass marketing of credit cards in the 1990s. In 2016, it was the 5th largest credit card issuer by purchase volume, after American Express, JPMorgan Chase, Bank of America, and Citigroup. The company's three divisions are credit cards, consumer banking and commercial banking. In the fourth quarter of 2018, 75% of the company's revenues were from credit cards, 14% were from consumer banking, and 11% were from commercial banking.
History
Capital One is the fifth largest consumer bank in the U.S. and eighth largest bank overall(Capital One, 2020), with approximately 50 thousand employees and 28 billion US dollars in revenue in 2018(Capital One, 2019).Capital One works in a highly regulated industry, and the company abides to existing regulations, as stated by them: “The Director Independence Standards are intended to comply with the New York Stock Exchange (“NYSE”) corporate governance rules, the Sarbanes-Oxley Act of 2002, the Dodd-Frank Wall Street Reform and Consumer Protection Act of 2010, and the implementing rules of the Securities and Exchange Commission (SEC) thereunder (or any other legal or regulatory requirements, as applicable)”(Capital One, 2019). In addition, Capital One is a member of the Financial Services Sector Coordinating Council (FSSCC), the organization responsible for proposing improvements in the Cybersecurity framework. Capital One is an organization that values the use of technology and it is a leading U.S. bank in terms of early adoption of cloud computing technologies. According to its 2018 annual investor report (Capital One, 2019), Capital One considers that “We’re Building a Technology Company that Does Banking”. Within this mindset, the company points out that “For years, we have been building a leading technology company (...). Today, 85% of our technology workforce are engineers. Capital One has embraced advanced technology strategies and modern data environments. We have adopted agile management practices, (...).We harness highly flexible APIs and use microservices to deliver and deploy software. We've been building APIs for years, and today we have thousands that serves as the backbone for billions of customer transactions every year.” In addition, the report highlights that “The vast majority of our operating and customer-facing applications operate in the cloud(...).”Capital One was one of the first banks in the world to invest in migrating their on-premise datacenters to a cloud computing environment, which was impacted by the data leak incident in 2019.
Indeed, Amazon lists Capital One migration to their cloud computing services as a renowned case study. Since 2014, Capital One has been expanding the use of cloud computing environments for key financial services and has set a roadmap to reduce its datacenter footprint. From 8 data centers in 2014, the last 3 are expected to be decommissioned by 2020, reducing or eliminating the cost of running on-premise datacenters and servers. In addition, Capital One worked closely with AWS to develop a security model to enable operating more securely. According to George Brady, executive vice president at Capital One, Assessment Instructions
Part A: Industry Report - Individual
Based on the readings provided in this outline, combined with your own independent research, you are required to evaluate the implications of legislation such as GDPR on the Capital One’s business model. The structure of your report should be as follows.
Your report needs to be structured in line with the Kaplan Business School Report Writing Guide and address the following areas:
• Data Usability
- Benefits and costs of the database to its stakeholders.
- Descriptive, predictive and prescriptive applications of the data available and the data analytics software tools this would require.
• Data Security and privacy
- Data security, privacy and accuracy issues associated with the database.
• Ethical Considerations
- The ethical considerations behind whether the user has the option to opt in or opt out of having their data stored.
- Other ethical issues of gathering, maintaining and using the data.
• Artificial Intelligence
- How developments in AI intersects with data security, privacy and ethics.
• Use the resources provided as well as your own research to assist with data collection and data privacy discussions.
Solution
Introduction
Capital One Financial Corporation is known to be a popular American bank holding company. It is capitalizing in credit card, auto loans and saving accounts. The bank does come with branch strengths of 755 inclusive of 30 café style locations along 2,000 number of ATMs. For Assignment Help, This particular financial company has been ranked as 97th on the fortune list of 500 and even 17th on fortune out of 100 best companies to work. The company has even helped to become pioneer in terms of mass marketing of credit cards in the year 1990. In the year 2016, it has positioned as 5th largest card issuer in terms of purchase volume(GDPR Compliance Australia. 2021). Capital one is a firm which tend to value the use of technology and has evolved as leading U.S bank with respect to adaptation of cloud computing(Greve, Masuch and Trang 2020 p 1280). Amazon has listed Capital One migration right into their cloud computing environment for some of vital financial services. In addition, it does come up with a roadmap for reducing its data centre footprint in near future.
In the coming pages, an evaluation has been regarding implication of legislation on GDPR on the capital One’s business model. The next section reveals data usability, data security and privacy, ethical consideration and artificial intelligence.
Data Usability
Benefits and costs of database to its stakeholders
Database is considered to be an important tool for handling various digital processes within the system. The main aspect of storing, organization and analysis of critical data of business for different aspects like staff, customer, accounts, payroll and inventory. Database management system will allow access to various kinds of data. This will again help in creating and management of huge amount of information with respect to use of single software(Novaes Neto 2021). Data consistency is also ensured within database as there is no kind of data redundancy. All the required data appears to be much more consistent in nature with database. Here data is found to be same for various users to view the database(Lending, Minnick and Schorno 2018 p 420). Any kind of changes within database are reflected on immediate basis for users and thereby ensuring that there is no kind of data consistency.
Database do automatically take care of both recovery and backup. User’s does not need any kind of backup of data on periodic basis due to the point that care is taken by database system. In addition, it also helps in restoring database right after or even failure of system. Data integrity helps in ensuring that store data is accurate and consistent within database(Spriggs, 2021). The fact should be noted that data integrity is vital parameter when data is accurate and consistent within database. It can be noted that database do comprises of data being visible to range of users(Vemprala, and Dietrich 2019). As a result, there is need for ensuring that collected data is correct and consistent in nature for database and its users.
Descriptive, predictive and prescriptive applications of the data
Capital One can make use of analytics to explore and examination of data. It will help in transform findings into the insights which can help manager, executives and operational employees to go for informed decision-making. Descriptive analytics is being commonly used as form of data analysis where various kind of historical data is collected(GDPR Compliance Australia. 2021). After this, the collected data is organized and presented in such a way that it is easily understandable. Predictive analytics is focused on predictive and proper understanding what can happen in near future. Predictive analytics is completely based on probabilities.
There are wide range of statistical methods which can be use for this purpose named as descriptive statistics. It does comprise of numerical and graphical tools which can help in summarizing collection of data and collect some of the vital information. IBM SPSS is known to be predictive analytics platform which can again help user to build right predictive model at quick rate(Giwah et al. 2019). All this will be used for delivery of predictive intelligence to groups, system, individual and different enterprises. Predictive analytics software tools do come up with some advanced analytical capabilities like text analysis, real-time analysis and statistical analysis, machine learning and optimization.
Data Security and privacy
Database Security Issues: Database can be easily hacked by making use of flaws within their feature. Hackers can easily break direct into legitimate and compel the given system by making use of arbitrary code. Although it is found to be bit complex one, the access can be collected by using some of basic flaws to accept features. Database can help in providing protection from the third party by using security testing(Poyraz et al. 2020). The database can easily protect from third party access by making use of security testing. The function of database is simple one as there is chance for ensuring proper protection from each of the database feature.
Data privacy: Increased in use of personal data puts the data privacy at the top on business risk management. It is found to be an acceptable challenge and even dangerous to completely ignore. Breaching GDPR and other kind of similar regulation like CCPA and HIPAA do come up with up some hefty fines(Rosati et al. 2019 pp 460). The damage to reputation can be biggest kind of threat to the business and even create a career limit on the blot for IT resume manager. Data privacy can be easily tracked down into IT security or disaster recovery plan. But this is not good enough due to the fact that data privacy aim to touch various section of the business.
Data Accuracy:Business on global platform is increasing their lean on their data so that they can power day-to-day operations. It will help in providing enhanced data management being top directive for some of leading companies. Secondly, entry of three section blog series will help in looking towards more leading blog series. There is need for considering some of the popular data management challenges with cloud deployment, integration of various data sources along with maintaining accuracy(Zou et al. 2019 pp. 10). It emphasizes on data without any kind of disruptive analytics along with neglecting any possible impact. Issues related to data availability and security plague for enterprise of different size all around the verticals.
Ethical Considerations
In the infancy age of internet, data protection laws were created. Right before the advent of social media, no has ever heard about the term big data. General data protection regulation (GDPR) does come into effect right in the month of May. It will provide overhaul for legal framework for providing privacy and protection to some of personal data all across EU(Truong et al. 2019 pp, 1750). GDPR is getting much of attention due to the fact that organization aim to impose personal data which will help in to comply.
An opt-in completely depends on person so that they can actively reveal exact data about them which can be used properly. In general, the lighter touch in comparison to informed consent approach. On the contrary, opt-out system is possibility to result in much high coverage within population. It will provide the option of default assumption so that people can feel about data which can be used. It is possibly that only few people can actively take part for step-out(Goddard, 2017 p 704). It is more specifically to diverse population which has changing ethnicities as best tool for providing prevention. Some of the ethical responsibility for data which this patient can individually manage for opt-in depended system.
Taking into account opt-out availability,Capital One needs to consider some of the important points:
• It will help in providing meaningful, easy availability, together with clear information so that people can have well-informed regarding choices.
• Customers are not that much disadvantages if they come up decision to opt out.
• There is need for good and robust governance regarding data use. It does comprise of some independent sight and ability for auditing(Wachter, Mittelstadt and Russell 2017 p 841). This will ensure that data can be enhanced in certain methods.
Artificial Intelligence
Security, privacy and ethics are found to be of low priority problem for developers when modelling the machine learning solution. Security is considered as one of the serious blind spots. Here the respondents reveal that they do not check for any kind of security vulnerabilities at the instance of modelling building. There are various kind of regulations which tend to cover some vital areas of data protections. It will again have certain clause in relation to artificial intelligence(Zhang et al. 2021 p.106994). AI governance aim to post GDPR lessons learned and road ahead with a number of key areas to tackle to be identified to tackled down AI and privacy. It aims to list out on the following areas namely
• Incentivising compliance centred innovation AI.
• Empowering civil society by making use of AI
• Enhancing interoperability for AI-based governance structure.
European GDPR is such that law which does have special pull-on artificial intelligence to set out requirements which do comprises of its use. The report encourages both local and international level for resolving the possible challenges related to AI governance within privacy as being privacy being contextual in nature.
. This is found to be useful for manufacturing as it accepts latest technologies (Weinberg 2020). Due to the nature of this nature of technology, an individual needs more data so that they can enhance efficiency and smartness. In order to so, it creates certain number of privacy and ethical issues which needs to be dealt with policy along with careful design solution. Centre of Data Ethics and innovation will help in reducing any kind of barriers related to acceptance of artificial intelligence within society. Three areas namely business, citizen and public sector which require some clear set of rules and structure for providing safety and ethical innovation within data and artificial intelligence (AI)(Tomás and Teixeira 2020 pp. 220). Artificial intelligence depended solution will evolve to become much more ubiquitous in nature in upcoming days. As a result, there is need for acting ways to check that these solutions tend to evolve in ethical and privacy protecting ways.
Conclusion
From the above pages, it can be noted that this report is all about Capital One. Even Amazon has listed capital one migration in their cloud computing as the reputed case study. Capital One has evolved as one of prior banks on global platform so that they can invest to migrate its data centre on cloud computing-based environment. The report aims to evaluate possible implication of legislation like GDPR on Capital One business model. There are mainly four sections covered on report like data usability, data security and privacy, ethical consideration and artificial intelligence. The report covers data security, privacy and accuracy problem in relation to database. In the last section, an overview has been given how artificial intelligence aim to intersect with data security, ethics and privacy.
References
.png)
.png)
Case Study
MIS609 Data Management and Analytics Case Study Sample
Task Summary
For this assignment, you are required to write a 1500-word report proposing data management solutions for the organisation presented in the case scenario.
Context
Module 1 and 2 explored the fundamentals of data management. This assignment gives you the opportunity to make use of these concepts and propose a data management solution (a pre- proposal) for the organisation presented in the case scenario. This assessment is largely inspired from Data Management Maturity (DMM)SM Model by CMMI (Capability Maturity Model Integration).
Task Instructions
1. Please read the attached case scenario.
2. Write a 1500-word data management pre-proposal for the organisation.
3. The pre-proposal should not only discuss the technical but also the managerial aspects (cost, manpower, resources, etc.). Please keep in mind that you are writing a pre-proposal and not a detailed proposal.
4. Please ensure that you remain objective when writing the pre-proposal.
5. Your pre-proposal should ideally answer (but not be limited to) the following questions:
a) What would the data management strategy be?
b) How would data communication be done?
c) Which kind of data would be managed by your organization and how?
d) How many staff members at your organization would manage data of this school; what would be the team hierarchy and what would their expertise be?
e) What resources would be required from the school?
f) What deliverables (hard and soft) would be provided to the school?
g) What would general data management operations look like?
h) How would data management policy be set and how would it be implemented?
i) How would metadata be managed?
j) How would data quality be managed?
k) How would data management practices be audited and how would quality be assessed?
l) How will user and business requirements be collected from the clients?
m) Which data architectures and platforms would be used?
n) How would legacy data be taken care of?
o) How would risks be managed?
p) What benefits would the school have as a result of outsourcing this service to your organisation?
q) What are the potential disadvantages that the school can face?
r) Others....
6. The questions mentioned above are written randomly, in no particular sequence. When addressing these questions in your pre-proposal, please ensure that you write in a systematic way. Make use of the web to find out what pre-proposals look like.
7. You are strongly advised to read the rubric, which is an evaluation guide with criteria for grading your assignment. This will give you a clear picture of what a successful pre-proposal looks like.
Solution
Section 1
Introduction
Westpac was formed in 1817 and is Australia's oldest bank and corporation. With its current market capitalization, Commonwealth Bank of Australia as well as New Zealand has become one of the world's top banks, including one of the the top ten global publicly traded enterprises (WestPac, 2021). For Assignment Help, Financial services offered by Westpac include retail, business & institutional financing, as well as a high-growth wealth advisory business. In terms of corporate governance and sustainability, Westpac seems to be a worldwide powerhouse. For the past six years, they have been placed top in the Dow Jones Sustainability Index (WestPac, 2021).
Reason for selection
Considering Westpac Group been around for a long period of time, it was a logical choice. Big customer-related knowledge has been a problem for the organisation in its efforts to use big data analytics to make better business decisions. Since the organisation faced hurdles and gained outcomes, it's best if one learn about how they used big data analytics techniques to overcome those obstacles given their massive database.
Business of Westpac
Westpac Group is a multinational corporation that operates in a number of countries throughout the world. Four customer-focused deals make up the banking group, all of which play a critical role in the company's operations. A wide variety of financial and banking services are offered by Westpac, encompassing wealth management, consumer banking, & institutional banking. Over the course of its global activities, Westpac Group employs about 40,000 people and serves approximately 14 million clients (Li & Wang 2019). Large retail franchise comprising 825 locations and 1,666 ATMs throughout Australia, offering mortgage & credit card and short-long-term deposits.
Section 2
Concepts of Big Data
Unstructured, structured, & semi-organized real-time data are all part of the "big data" idea, which encompasses all types of data. It has to cope with massive, complex data sets which are too large or complex for standard application software to handle. To begin with, it's designed to collect, store, analyse, and then distribute and show data. Professionals and commercial organisations gather useful information from a vast amount of data. Businesses utilise this information to help them make better decisions (Agarwal, 2016). Many major organisations use data to produce real-time improvements in business outcomes and to build a competitive edge in the marketplace among multiple firms. Analyzing data helps to establish frameworks for information management during decision-making. Consequently, company owners will be able to make more informed choices regarding their enterprises.
Business intelligence
The term "business intelligence" refers to a wide range of technologies that provide quick and simple access to information about an organization's present state based on the available data. BI uses services and tools to translate data into actionable information and help a firm make operational and strategic decisions. Tools for business intelligence access and analyse data sets and show analytical results or breakthroughs in dashboards, charts, reports, graphs, highlights and infographics in order to give users detailed information about the company situation to users (Chandrashekar et al., 2017). The term "business intelligence" refers to a wide range of techniques and concepts that are used to address business-related problems that are beyond the capabilities of human people. An specialist in business intelligence, on the other hand, should be well-versed in the methods, procedures, and technology used to collect and analyse business data. In order to use business intelligence to address problems, those in this position need analytical talents as well (Schoneveld et al., 2021).
Data warehousing
In the data warehousing idea, there are huge reservoirs of data for combining data from one or many sources into a single location. In a data warehouse, there are specific structures for data storage, processes, and tools that support data quality (Palanivinayagam & Nagarajan, 2020). Deduplication, data extraction, feature extraction, and data integration are only few of the techniques used to assure the integrity of data in the warehouse (Morgan, 2019). Data warehousing has several advantages in terms of technology. An organization's strategic vision and operational efficiency can be improved with the use of these technological advantages.
Data Mining Concept
Patterns may be discovered in enormous databases using the data mining idea. Knowledge of data management, database, and large data is required for data mining. It mostly aids in spotting anomalies in large datasets. It also aids in the understanding of relationships between variables using primary data. Furthermore, data mining aids in the finding of previously unnoticed patterns in large datasets. Data summaries and regression analysis also benefit from this tool (Hussain & Roy, 2016).
Section 3
Data Sources
A wide variety of external data sources were explored to gather the information needed for such an evaluation. The term "secondary data" refers to data gathered by anyone other than the recipient of the information. This material comes from a variety of sources, including the official site of the firm, journal papers, books, and lectures that are available throughout the web. A simpler overview is described below:
.png)
Problems Faced
There were a number of issues faced by Westpac Group when it came to collecting and storing data, managing marketing, goods, and services delivery, embezzlement and risk mitigation, absence of appropriate multiple channel experiences, inability to design adequate usage of information strategy, and sharing of data schemes (Cameron, 2014). There wasn't enough assistance from key players for the sector, particularly in terms of finance and board approval for initiatives. In addition to the foregoing, the following critical concerns were discovered:
• Report production or ad hoc queries were typically delayed since data generated by several programmes would have to be manually cleaned, reconciled, and manually coded. Owing to the duplication of work and data, there were also inefficiencies (Cameron, 2014).
• Inconsistent methods for data integration were employed (e.g., push of data into flat files, hand code,. This is also not future-proof because no concepts or approaches were employed to handle emerging Big Data prospects, such as data services as well as service-oriented architecture (SOA).
• There was an error in data handling and data security categories, which resulted in unwarranted risks and possible consequences.
Implementation of the Solution
The Westpac Group was aware that financial services businesses needed to advertise their services and products as a banking sector. When it came to serving consumers and managing customer data across numerous channels, the corporation realised that it had an obligation toward becoming a true, customer-centric organisation. That which was just stated implies that seamless multichannel experiences are available. It was only with the emergence or introduction of big data, notably in the realm of social media, that the bank was able to discover that channel strategies were not restricted to traditional banking channels alone. Before anything else, Westpac set out to establish an information management strategy that would assist them navigate the path of big data (Cameron, 2014). However, achieving such a feat was not without difficulty (WestPac, 2016).
It was determined that the Westpac bank needed better visibility into its data assets. Data warehouse senior System Manager, Mr. Torrance Mayberry recommended Informatica's solution. Torrance Mayberry, a specialist in the field, worked with the bank to help break down organisational barriers and foster a more open and collaborative environment for new ideas. Customer focus was still far off, but Westpac didn't stop exploring the vast possibilities data held, particularly on social media. There was a further increase in the bank's desire to understand its customers in depth. The bank included sentiment analysis within big data analytics as well.
Quddus (2020) said that IBM Banking DW (BDW) was used by Westpac for data warehousing, and that IBM changed the BDW model hybridized version, that was implemented in an Oracle RDBMS, to include the bank's best practises into its DW. As a result, IBM's BDW came to provide a fully standardised and comprehensive representation of the data requirements of said financial services sector. Informatica was the platform of choice for integrating and accessing data. Informatica Metadata Manager was also included in the implementation of Informatica PowerExchange. Informatica platform variant 8.6.1 was used by Westpac until it was updated to edition 9.1 (Quddus, 2020).
An EDW was used as the principal data warehouse architecture, serving as a central hub from which data was fed into a number of smaller data marts that were dependent on it. Analytical solutions for enabling and maximizing economic gain, marketing, including pricing were part of the supply of these data marts. As an example, financial products' price history was saved and managed in the DW, and then sent to the data mart in order to fulfil the analysis requirements for pricing rationalization. Informatica's platform gathered data from the bank's PRM system, that allowed this same bank to quickly refresh its knowledge of fraud and reduce individual risk. Data-driven decision-making at Westpac developed as a result of increased trust in the information provided by the DW, as well as the creation of new business links.
Section 4
Problems Faced in Implementation
Data warehousing (DW) was the first step in Westpac's road to Big Data. Similarly to other large corporations with data-intensive tasks, the Westpac Group has a large number of unconnected apps that were not meant to share information.
• There was a lack of data strategy. The lack of a single version of Westpac's products and clients because critical data was gathered and stored in silos, and dissimilar information utilisation and definitions were the norm; and the inability to obtain a single version of Westpac's products and clients because critical data was gathered and stored in silos, and dissimilar information utilisation and definitions were the norm (Cameron, 2014).
• Due to the laborious scrubbing, validation, and hand-coding of data from several systems, the response time for ad hoc or reporting production requests was sometimes delayed. In addition, there was a lack of efficiency due to the duplication of data and labour
• To integrate data, many methods were used, including pushing information into flat files and manually coding.
• Soa (service-oriented architecture) as well as data services didn't exist at the time; and there were no methodologies or ideas that might be used to handle new big data opportunities; Information security and data handling were classified wrongly, resulting in potentially harmful complications and hazards.
Benefits realization to WestPac
According to Quddus (2020), Westpac has reaped the benefits of the big data revolution in a variety of ways. According to Westpac's data warehouse, a large number of its business units (LOBs) are now able to get information as well as reports from it (DW). Westpac said that the bank's core business stakeholders started to realise the strategic importance of the bank's data assets therefore began to embrace Westpac DW acceleration. Financing, retail and commercial banking departments in both New Zealand and Australia as well as an insight team for risk analytics as well as customer service were all part of it. It was possible for Westpac to invest in the development of a comprehensive data strategy to guide business decisions by delivering relevant, accurate, comprehensive, on-time managed information and data through the implementation of this plan. Impacted quantifiable goals and results for securing top-level management help as a result of change. In Westpac's view, the project's goals and outcomes were viewed as data-driven. The chance of obtaining funds and board approval for such ventures grew in respect of profit and productivity.
Conclusion
Big data analytics have just placed the company in a functioning stage thanks to the potential future gains or expansions that may be derived from the examination of enormous amounts of data. The Westpac Group anticipates the big data analysis journey to help the banking industry obtain insights according to what clients are saying, what they are seeking for, or what kinds of issues they are facing. The bank will be able to create, advertise, and sell more effective services, programmes, and products as a result of this.
Recommendations
The following recommendations can be sought for
• These early victories are vital.
DW team at Westpac was able to leverage this accomplishment to involve key stakeholders as well as the (LOBS) or line of businesses, thereby increasing awareness of the problem for the company's data strategy by leveraging this internal success.
• To obtain the support of the company's senior management, provide a set of quantifiable goals.
Westpac correctly recognises that quantifying the aims and outcomes of data-centric projects in order to improve productivity and profit enhances the likelihood that certain projects will be approved by the board and funded.
• Enhance IT and business cooperation.
"Lost in translation" problems can be avoided if IT and business people work together effectively.
References
.png)
Reports
MIS608 Agile Project Management Report Sample
Task Summary
You are required to write an individual research report of 1500 words to demonstrate your understanding of the origins and foundations of Agile by addressing the following areas:
1. The origins of Agile – why did Agile emerge, what was it in response to, and how did this lead to the values and principles as outlined in the agile manifesto?
2. The origins of Lean and how it has influenced Agile practice
3. The similarities and differences between Scrum and Kanban as work methods
4. Why adopting Agile benefits an organization.
Please refer to the Task Instructions for details on how to complete this task.
Task Instructions
1. Write a 1500 words research report to demonstrate your understanding of the origins and foundations of Agile by addressing the following areas:
• The origins of Agile – why did Agile emerge, what was it in response to, and how did this lead to the values and principles as outlined in the agile manifesto?
• The origins of Lean and how it has influenced Agile practice.
• The similarities and differences between Scrum and Kanban as work methods.
• Why adopting Agile benefits an organisation.
2. Review your subject notes to establish the relevant area of investigation that applies to the case. Perform additional research in the area of investigation and select FIVE (5) additional sources which will add value to your report in the relevant area of investigation.
3. Plan how you will structure your ideas for the report. Write a report plan before you start writing. The report should be 1500 words. Therefore, it does not require an executive summary nor an abstract.
4. The report should consist of the following structure:
A title page with subject code and name, assignment title, student’s name, student number, and lecturer’s name.
The introduction (100 – 150 words) that will also serve as your statement of purpose for the report—this means that you will tell the reader what you are going to cover in your report.
You will need to inform the reader of:
a. Your area of research and its context
b. The key concepts you will be addressing
c. What the reader can expect to find in the body of the report
The body of the report (1200-1300 words) will need to cover four specific areas:
a) Why did Agile originate? When did it emerge and what was it in response to? How did this lead to the four values and 12 principles that are outline by the agile manifesto?
b) Where did Lean originate? Briefly define what Lean is and two Lean philosophies
have been adopted in the evolution of Agile practice?
c) Scrum and Kanban have many similarities, but also key differences. Compare and contrast Scrum and Kanban with each other, illustrating these similarities and differences with examples.
d) Explain what value adopting Agile can offer to an organisation.
The conclusion (100-150 words) will summarise any findings or recommendations that the report puts forward regarding the concepts covered in the report.
5. Format of the report
The report should use font Arial or Calibri 11 point, be line spaced at 1.5 for ease of reading, and have page numbers on the bottom of each page. If diagrams or tables are used, due attention should be given to pagination to avoid loss of meaning and continuity by unnecessarily splitting information over two pages. Diagrams must carry the appropriate captioning.
6. Referencing
There are requirements for referencing this report using APA referencing style. It is expected that you reference any lecture notes used and five additional sources in the relevant subject area based on readings and further research.
Solution
Introduction
The business enterprises are always facing changes in the external environment and adopting an agile approach in project development helps them respond to change effectively. Understanding of concepts like Scrum, agile, lean and Kanban will; be helpful for proceeding in this subject. For Assignment Help In this paper the agile and its origin and how the agile manifesto was formed are discussed in depth. Along with this the audience will read in the body of this report more discussions about lean, scrum and Kanban concepts used in software development. Such in-depth knowledge will not just help pupils in software development but also can be used in other areas in workplaces in future.
Agile, its Origination & Events that led to the Agile Manifesto
The agile method had originated in the industry of software development much before the manifesto was formed (Nadeem & Lee, 2019, p. 963). Most software development projects which were conducted previous to the agile manifesto formation were taking a very long time for finishing them. An innovative, new and effective approach was necessary by the industry and the consumers. In the early 1990s the industry of software development faced crisis of application delays or lags. The time used to fulfill the need of an application in the market was huge. Thirty years back one had to wait for years for solving a problem in the business of software development, production, and aerospace and in defense. The waterfall method was first manifested in this time where all phases were defined clearly in lifecycle of a project. As its name suggests it is a process where teams will finish one step completely and then start doing the next (Chari & Agrawal, 2018, p. 165). When a stage in such projects was completed it would be frozen for a very long time too. This method was not effective at all. Rarely did a software development project experience stability of the same kind. The need towards iterative development began because the teams needed to conduct activities, measure them, make change as needed and again improve.
Many software developers out of frustrated began making changes to their approach of development during the 1990s. Different methods such as Scrum, DSDM, Rapid Application Development or RAD emerged during this time. A group of software engineers met in year 2001 at Utah at a ski resort with an intention to solve problems such as delays in project delivery or bridging the disparities between expectations and delivered products. There was a pressing need to ensure that the software development time was less and the product reached the end user faster. Two things were identified in this conference. First, delay shortening will make products market fit and secondly with faster feedback from the consumer the teams can make continuous betterment of the products. Within a year from this conference meet the developers met again and formed the agile manifesto. The manifesto has laid out values and principles which gave the industry of software development a new traction and power (Hohl et al., 2018, p.1).
Origination of Lean Methodology
The lean as per history began much before the era where software development first began. Lean rather initiated itself in the Japanese factory of Toyota which used to make automobiles. In the year 1950s and in the 1960s Taiichi Ohno had developed TPS or the Toyota Production System and aimed to enhance the loss and enhance sustainable means of automobile production. Visual signals were utilized for producing the inventory as was needed. This was technically known as a just in time production process and it focused primarily over minimizing the wastage and optimizing all the production processes. Manufacturers in the west were struggling to be at par with the speed of manufacturing by Japanese organizations and hence soon they began using lean manufacturing processes (Rafique et al., 2019, p. 386). The lean guiding principles made easier implementation and major IT companies began adopting it as a result.
Lean can be defined as an approach of management which is supporting the continuous improvement model. The process aims in organizing the human actions for delivering value and eliminating waste.
There are many similarities in the concepts of agile and lean thinking. Blending the philosophies of lean into agile innovative work processes is formed. By blending the best of these two methodologies businesses are moving faster and developing better quality and forming healthy and sustainable work environments. Two philosophies of the lean methodology are used in agile practices.
Build-measure and learn: The build, measure and learn principle used in lean methodology is used in the agile (Kane, 2020, p. 1561). The agile and its iterative approach is based on this very lean principle which encourages testing, measurement and validation on the basis of past work and market trends. The lean always focuses on finding the way which offers maximum value to the customer.
Waste elimination: The philosophy of lean to eliminate waste is adopted in agile. Teams in agile pulls the work which is of the highest priority and they iterate and delivers it progressively. Continuously they are learning and improving to see that nothing is unused or wasted.
Scrum and Kanban Point of Similarities
Kanban is a methodology used for the optimization and management of the workflow where one can visualize the entire processes with the aid of tools such as the Kanban Board and teams can work continuously. The Scrum methodology is another framework used where in-depth and restrictive planning is of importance. There are many similar characteristics in between the Scrum and the Kanban. These popular methodologies are used in many organizations. Following are the point of similarities which are observed between them:
1. The methodologies are lean as well as agile in their approach.
2. The goal in these methods is also to restrict the work in progress.
3. They both use the pull scheduling for moving work faster.
4. Scrum and Kanban both breaks the work down.
5. Both these methods are focused on teams which are organised.
6. Software targeted by both these methodologies is reusable in nature.
7. Both the methodologies utilises transparency as a tool to process the continuous improvement (Lei, Ganjeizadeh, Jayachandran, et al., 2017, p. 59).
Scrum and Kanban Point of Differences
.png)
Agile advantages to the enterprise
A large number of organizations are moving towards agile development as it offers an environment which is evolving constantly.
Beat competition: The consumers, regulators and the business partners all have needs which are pressing. Stakeholders in business demand products and services which help them beat competition (Mckew, 2018, p. 22). This involves fast changing goals, quick restructuring and team adaptability.
Integrate innovation: Moreover with an agile approach organizations can encourage used of new technologies which helps them enhance their overall efficiency and performance (Potdar Routroy, S., & Behera, 2017, p. 2022).
Stakeholder engagement: Before the sprint process, during the process and after the sprint the stakeholders collaborate. With working software released to the client in intervals makes the entire tam come together with a shared goal in mind. Such teams display high involvement in the enterprise in general.
Forecast delivery better: In agile progress of the project is significant. At times the companies even make beta release of the software thus increasing the overall value of the business. Agile use can provide the team an opportunity for make delivery predictions accurately which satisfies the customer.
Element of transparency: The agile use gives organization the golden opportunity to work with the consumer during the development phase. The customer is aware of the features of the product being developed and gives feedback (Kalenda, Hyna & Rossi, 2018, p. 30). All the parties engaged in the development process in agile enjoys a high level of awareness and transparency.
Change opportunities: Due to the iterative approach of agile there are ample scopes for making changes. Minimum resistance comes from the workforce because they are already accustomed with the element of change.
Conclusion
The world is going through a major digital shift. Businesses in every industry are integrating new technologies and processes. Staying forefront to changing environment is important for survival. The concepts showcased in this paper about agile and used of its values and principles are indeed valuable for businesses. It is recognized that agile is the most suitable methodology which can be applied to projects, product development and also to man power management. Through agile, mangers can detect problems, find solutions and implement them fast. A recommendation to such dynamic thinking where more importance is given over solutions will no doubt helps enterprise achieve sustainable success.
References
.png)
Case Study
MIS604 Requirement Engineering Case Study Sample
Task Summary
This final assessment requires you to respond to the given case study used in Assessment 1 and 2, so that you can develop insights into the different facets of Requirements Analysis in agile. In this assessment you are required to produce an individual report of 2000 words (+/-10%) detailing the following:
1. A Product Roadmap for the project
2. Product Backlog of coarse granularity including Epics and User stories
3. Personas who typifies the future system end user
4. Decomposition of Epics into User stories for first release
5. Minimum Viable Product (MVP) definition for first release
6. Story Mapping for MVP - ordering User stories according to priority and sophistication
7. Story elaboration of User stories for MVP to ensure that the User story is clear, along with the acceptance criteria for the elaborated stories to ensure the ‘definition of done’.
8. A paragraph detailing the similarities and differences between ‘traditional predictive’ and ‘Agile’ requirements analysis and management.
Please refer to the Task Instructions for details on how to complete this task.
Context
In the second assessment you would have developed capability in the areas of requirements analysis and requirements lifecycle management, which are well recognised Business Analysis skills and capabilities. However, Agile has become a recognised software development approach which is both adaptive and iterative in nature. This has necessitated the development of new and differentiated requirements analysis and management skills, techniques, and capabilities. This assessment aims to assist you in developing well-rounded skills as a Business Analyst who uses a spectrum tools and techniques. In doing so, you can draw irrespective of the approach your future employer may take to software development.
Task Instructions
1. Please read the attached MIS604_Assessment_Case Study
2. Write a 2000 words Agile Requirements Analysis & Management Report as a response to the case study provided.
3. Review your subject notes to establish the relevant area of investigation that applies to the case. Re- read any relevant readings.
4. Perform additional research and investigation and select five additional sources in the field of agile requirement specification, analysis, and management to add depth to your explanation of method selection.
5. Plan how you will structure your ideas for your report and write a report plan before you start writing.
6. The report DOES NOT require an executive summary or abstract.
Case Study
ABC Pty Ltd is a start-up tech company based in Adelaide Australia, who are currently seeking to develop an online delivery system named “ServicePlease”. The system aims to create a convenient platform to be used by service providers, customers, and supermarkets for home delivery of groceries to customer residents. The application will be available in both forms of website and mobile app, with separate views for service providers, supermarket, and customers. ABC Pty Ltd wants to launch this system to market in the next six months and have secured an investment for this. You have been hired by ABC Pty Ltd as the Business Analyst (BA) to help them with the requirement analysis for this project.
The “ServicePlease” application should provide the service providers to register with the system. During registration service providers will be asked to complete the background checking process. Criminal history or background will be checked through National Crime Check (NCC). Right – to – work will be checked through Visa Entitlement Verification Online (VEVO), which will confirm their citizenship, residency or visa status that allows them to work in Australia. All service providers will need to provide an Australian Business number (ABN), which will be checked through ABN Lookup. Service providers also need to give proof for delivery capability by car through driving license and vehicle registration certificate. Upon successful completion of registration, the service provider will be eligible and available for grocery delivery service in “ServicePlease”. Supermarkets can register with “ServicePlease” online delivery system. When registered, customers will be able to find the supermarket in “ServicePlease” system. Supermarkets can accept and prepare an order to be picked up by the service provider authorized by a customer. The system should enable supermarkets to rate service providers and certify as their preferred one. To use this service, resident customers need to sign-up first. Sign up can be verified with a valid mobile phone number and an email address. Customers need to set-up the payment method using credit card, debit card or PayPal, to pay for the service when used. While ordering, the application should enable customersto search and select a supermarket first (pick- up location). Then the customer needs to authorise a service provider from the available list (certified service providers will be shown at the top of this list, then based on rating) to pick up groceries from a selected supermarket and deliver to their residence (drop-off location). Once the job is completed, payment can be made securely through the app. Customer will get email confirmation after successful completion of an order. Customers also can rate and review the service provider, as well as the supermarket.
Solutions
Introduction
The report will discuss the different user stories and epics in developing a product, "ServicePlease", which is an online delivery system. The grocery stores can register in the system where the users can see the profile and order the products. A software system will require the development of user stories and product roadmap by developing personas from consumers' perspectives. For Assignment Help, The story mapping for the minimum viable product will be described in this report, where the sophistication of the design approach and priority of design according to the mapping of the product will be highlighted. The use of agile project management and the traditional predictive model will be discussed, where similarities and differences of each project management style will be examined.
Addressing the areas regarding case study
Product Roadmap for the project
ABC Pty Ltd aims to develop the "ServicePlease" online home delivery system based on the combination of website and mobile application. For that purpose, the roadmap to ensure efficient system development is needed to be considered. Release planning involved in product roadmap creates effective time management (Aguanno, & Schibi, 2018).
.png)
.png)
Table 1: Product Roadmap including releases and time
Source: (Developed by the author)
Product backlog including Epics and User stories
.png)
.png)
.png)
Table 2: Product backlog
Source: (Developed by the author)
Persona who typifies the future system end-user
.png)
Table 3: Persona engaged in satisfying end-users
Source: (Developed by the author)
Decomposition of Epics into User Stories for the first release
Requirements analysis for system development includes specific user stories which help to elicit the requirements for new systems in business (Stephens, 2015). The decomposition of epics into user stories will help specify the requirements and the tasks associated with each user story.
.png)
.png)
Table 4: (Epics decomposed into user stories)
Source: (Developed by the author)
Minimum Viable Product (MVP) definition for the first release
The first release will include several items which will increase the viability of the system. System design development through minimum viable products ensures basic operations within the software (John, Robert, & Stephen, 2015). The minimum viable products for the "ServicePlease" home delivery system may include a basic user interface design for registration, sign-up, and verification. The registration and sign-up processes will allow the users to enter into the system. Verification of the criminal history and other records of the service providers will help to maintain the safety of the residential customers and to appoint appropriate candidates as service providers. The interface will serve as a communication platform between the users and the system. The system will also include security check-up features like VCC, VEVO, ABN for the first release. The payment feature will also be developed during the first release. Apart from that, the "ServicePlease '' home delivery system will include the features like a search bar tool, navigation key, order desk, and feedback and review desk.
Story Mapping for MVP
The user stories related to the system development of "ServicePlease" in ABC Pty Ltd will be arranged systematically for identifying the priority level.
Priority 1
- The registration process in the first release is the most important step as it will ensure proper verification of the users' details.
- Inputting the criminal history, driving license, vehicle registration certificate, and citizenship proof, the service providers will register within the system.
- The security checking process helps to ensure authentication within the system (Liu et al. 2018).
Priority 2
- The sign-up process will help the customers to enter into the system by providing their email address, phone number, and basic details.
- Sign-up is essential for managing order placement and product search
Priority 3
- The payment option will help the resident customers to pay for the orders
- Information and transaction security during payment is essential (Serrano, Oliva, & Kraiselburd, 2018)
- The priority of the payment feature development in the first release is high
Priority 4
- Order preparation option will help the supermarkets to accept the orders of the customers.
- The priority of order desk creation in the first release is moderate
Priority 5
- The feedback and Review option will be generated after the first release, so the priority is low.
- The feedback process will help the customers to state their comments about the services.
Story elaboration of User Stories for MVP
.png)
.png)
Table 5: Story Elaboration of User Stories for MVP
Source: (Developed by the author)
Acceptance Criteria for elaborated stories
.png)
Table 6: Acceptance criteria
Source: (Developed by the author)
Similarities and differences between agile and traditional predictive analysis and management
Similarities:
The agile methodology delas with the development of user stories, roadmaps and develops product vision. It also helps to create user stories and develops a project management plan. Reasonable and marketable products are developed in an iteration due to which monitoring and creating the project development through a retrospective approach can be an easy approach. The primary focus of agile is to achieve targets and customer satisfaction. IT and software projects tend to prefer agile project management (El-Wakeel, 2019). On the other hand, Project charter development and the project plan is developed by developing sub-projects in the case of traditional project management. Also, interim deliverables are developed and the project control and execution are managed with predictive analysis. Following a waterfall model and each phase are planned at different stages of the product life cycle.
Differences
Agile focuses on planning, cost, scope and time with prominence with term work and customer collaboration. Considers customer feedback and constant development at each phase of iteration, preventing time consumption and improved customer satisfaction. The client involvement is high as interaction and requirements constantly change in every phase of development. Both current and predictable requirements are used where the waterfall model is considered. Agile project development of good quality, motivation in team performance and client satisfaction (Loiro et al. 2019). In the case of traditional predictive methodology, The project follows the same life cycle where every stage is fixed, like planning, design, building, production, testing and support. The requirements are fixed and do not change with time. The current and predictable requirements are considered as the product develops completely without any change in iterative phases. Coding is done at a single stage, and testing is not performed at every iteration.
Conclusion
The epic story and user identification help in developing the right product according to customer requirements. Minimum Viable Product design is important to initially develop the product outcomes and the features associated with the software design. Using an agile project approach will be helpful for the design of software as feedback at iterative stages can guide in user mapping based on requirements, and the final product can be justified in terms of the demand and identification of the probable consumers. The ordering of user stories according to priority is elaborated, which is helpful in developing the product. The definition of done is achieved by developing the product through story mapping based on user stories, and the persona development identifies the specific expectations related to consumer experiences and requirements associated with the product.
References
.png)
Case Study
MIS605 Systems Analysis and Design Case Study 2 Sample
Task Summary
Based on your responses to Assessment 1 – Written assessment, perform process and data modelling and develop and document a number of design diagrams using UML (including Context Diagram, Level 0 and Level 1 Data Flow Diagram, Entity Relationship Diagram).
Scenario (The Case)
Book reading is an extremely healthy activity. It has many benefits and above all, it is exciting, entertaining and a great way to release stress, anxiety and depression. These are not the only benefits. Above everything; book reading helps in mental stimulation; improvement of memory and it also helps in improving language skills. It also certainly allows an individual to help concentrate better. In short, the benefits are enormous.
In recent times we have been introduced to technologies such as laptops, cell phones, tablets and other technologies but to date, the conventional book reading is something that people cherish and enjoy in its own way. It is believed that a “book has no substitute” and book readers from all over the world firmly agree to this.
Cynthia, a young technopreneur and a book lover; plans to open an online lifestyle substitute business named ‘bookedbook.com’. This online business is Cynthia’s dream. Cynthia has formally registered her new company, everything is in place from a legal perspective and the company now has ample funds to develop an online website that would support Cynthia’s business idea. bookedbook.com would be an extremely interesting website. This website will require user registration. Children would also be able to register but their registration would be accompanied with some details of parents and their contacts. The website would only offer individual registrations and proof of ID would be a must when registering. bookedbook.com will offer quarterly, biannual and annual memberships.
The whole idea is very simple. Registered book readers would be able to launch the books that they own and which they would want to give away to other registered members. A book launch would require complete details of the book. It would also require the user to provide the address where the book is available. Once the book details are provided by the subscriber (registered book reader) the company’s content manager would approve the book launch request. Once approved, the book would be available for all users for them to review and/or acquire. The review process would allow all users to provide feedback and comments about the book and would also allow users to rate the book. The acquisition process would allow book readers to acquire the book from the book owner.
The users planning on acquiring the book, would make a request for book acquisition. This request would help facilitate book reader meetup and exchange books. Once the book would be acquired the book owner would have the option of removing the book.
Bookedbook.com will also allow users to interact with one another via messaging and chat rooms. Users will be given an option to decide the mode of communication that they would prefer. Off course all chat request, messages and acquisition request and all other messages are also provided to the user via email that is provided at the time of subscription.
The website would also provide a portal to the administrator for data analytics. Cynthia is keen to observe and analyse every type of data that is obtained at this website. For example, she wants to know which book is being exchanged mostly, she wants complete customer analytics, book
exchange analytics, analysis of book reviews and rating and other similar portals for data analysis.
As soon as the user registration would expire, all book launch requests would be halted by the system and the users interested in acquiring the book(s) placed by the user whose registration is about to expire would be sent an email that these book(s) are no longer available. Users would be asked to renew their subscription 15 days before the registration expiry date to ensure continuity of services.
Cynthia does not want this website to be a book exchange platform only. She also wants the website to provide a platform for all the users to arrange for an online and face to face meetup. She wants to ensure that any book meetup events that bookedbook.com plans should be available to its users.
Users should be able to register for these events which may be paid or unpaid. She feels that these meetups would be a great source of fun for book lovers and also a source of marketing for the company.
In order to ensure this website stays profitable Cynthia also wants this website to allow book authors from all around the world to advertise their books on bookedbook.com. This functionality, however, would not require book authors to register with bookedbook.com formally. Book authors would be able to just fill in a ‘book show request form’, provide their details, provide the details of their book and a credit/debit card number. They would also provide information about the time period for which they want their book to be advertised on the website. Advertisement requests would also be approved by the content manager. Once approved, the book authors would be charged and the advertisement would go live. The ad would be removed by the system automatically once it reaches the end date. bookedbook.com will only allow advertisement of up to 5 books at a time. All advertisement requests would be entertained by the system on a first come first serve basis. The advertisement functionality is also available for subscribers. In this case the fee for advertisement is very minimal.
Cynthia wants this website to be upgradable and secure. She wants simple and modern interfaces and also wants a mobile application version of this website.
Instructions
1. Please read case study provided with assessment 1. Please note that every piece of information provided in this case study serves a purpose.
2. Please complete the following tasks:
Task 1.
Create a Context Diagram for the given case study.
Task 2.
Create and document a Level 0 Data Flow Diagram (DFD). The Level 0 DFD should contain all
the major high-level processes of the System and how these processes are interrelated.
Task 3.
Select three important processes from Level 0 DFD, decompose each of the processes into a
more explicit Level 1 DFD.
Task 4.
For the given case study, provide an Entity Relationship Diagram (ERD).
For the given case study, identify the data stores including the files that are not part of ERD.
Task 6.
Translate the ERD you developed in Task 4 into a physical relational database design.
Document database tables and their relationship in MSWord file. Normalise your database design to the Third Normal Form (3NF).
Please note that your responses to the tasks above must relate to the case study provided.
Solution
Introduction
The case study deals with the online lifestyle substitute vision of young technopreneur named Cynthia. The bookedbook.com website is concise with features like user registration, advertisement, data analytics, review and book acquisition. The booked book. For Assignment Help com aims to serves as a platform for the book lovers all across the world. This website offers authenticity via series of procedures followed up for user registration. This platform allows the one user to interact with other via messaging and chat rooms. This assignment has designed the database to store the data precisely dealing with user, book, advertisement and other entities provided. The rest of the assignment is organized as such, context diagram, Level 0 Data Flow Diagram (DFD), Level 1 Data Flow Diagram (DFD), Entity Relational Diagram (ERD) and at last Schema design up to 3 Normal Form (NF).
1. Context Diagram
The context flow diagram is diagrammatic representation of the system (Sciore, 2020). The CFD has a centric bubble, drawn in the epicenter of the diagram. The rest of the interconnected processes encloses this context bubble. Arrow headed lines with labeling states the flow of information. CFD gives out the high-level view without going into the details of it. This is how data hiding is achieved via CFD. CFD unlike other diagram is not for technocrats or engineers. It is to be used by project stakeholder therefore should be designed as simple as possible. Pros and cons of the Context Flow Diagram are follows:
Pros:
• CFD makes error listing easy and handy.
• If helps to trace out the rough sketch of the project straightforwardly.
• There are no limitations to the shapes that are used to depict CFD. Any preferred symbols can also be used. No hard and fast rule exists.
• This do not ask for any technical skillset to understand.
Cons:
• Context flow diagram fails to lay down the sequence of the process happening. By the sequence it means parallel execution of the project processes or sequential processing of the project processes.
• CFD diagrams are erroneous. Since they are just a high-level depiction without venturing about the detailing of the process happening.
• Context flow diagram fails to display out the all the detailing involved in the process. Moreover, to present out the exact relationship in CFD is also very difficult. Therefore, the need for more explained ER diagrams were felt. Unlike other diagram CFD do not go for well-defined meaning for the geometric shapes used in it.
Context Flow diagram in respect of proffered case study is delineated in figure 1.
.png)
Fig 1. Context Diagram
2. Level 0 Data Flow Diagram
The Level 0 DFD (Harrington, 2016) depicts high-level processes of the system namely, advertisement, user registration, book acquisition, review and data analytics and others. The major components of DFD are listed below-
- Processes – It is represented by rounded rectangle.
- Data Flows - It can be represented by straight line with arrowhead. The direction of arrowhead represents the flow direction.
- Stored data – It can be represented by two horizontal and parallel lines including a label mentioning the database name.
- External Entities – It can be represented as a rectangle.
The diagrammatic representation is depicted in figure 2.
.png)
Fig 2. Level 0 DFD
a. Advertisement
In the context diagram advertisement process depicts the two types of labeled flow. Internal flow labeled as "Payment", towards the context bubble, ventures the payment revenue generated by the bookedbook.com via the advertisement displayed on the website. External flow labeled as "Provide slot", outwards the context bubble, asks for the time period for which their book has to be advertised on the website. The advertisement process allows the authors from all over the world to advertise their book on bookedbook.com. This process does not ask for the registration. Authors have to fill the 'book show request form' along with time period and payments.
b. User Registration
The website bookedbook.com offers its website visitors to get themselves registered. The user registration process asks users for ID proof in the return website gives registration number to the user. The arrow headed line pointing towards the context bubble labeled as "ID proof" depicts the ID proof requirement asked by bookedbook.com for the authentication purpose. The arrow headed line pointing outwards the context bubble labeled as "Provide Registration Number" depicts the allotment of registration number to the user via the portal. Children are also allowed to register. The nitty gritty for their registration process will also be the same. In addition, they will be asked for parents’ details and contact number. Registered book user is allowed to launch the book they own. The registered user can give away book to other registered members.
c. Book Acquisition
Book acquisition process allows the book reader to acquire the book from the book owner. The user has to make a request first for the book acquisition. This request facilitates the smooth meet-up and book exchange process to happen. The user can remove the book after the successful book acquisition. In the context diagram this process depicts the two types of labeled flow. Internal flow labeled as "Approval", towards the context bubble, marks the approval of the book. External flow labeled as "Details", outwards the context bubble, provides the details of the required book.
d. Data Analytics
In the context diagram Data Analytics process depicts the two types of labeled flow. Internal flow labeled as "Analysis Result", towards the context bubble, this provides the results, done on the given dataset to website administrator. The prerequisite for the results to be generated is dataset generated on the website. External flow labeled as "Data", outwards the context bubble, this provides the dataset for the analysis. The data is broadly centric to customer and book. This includes all possible type of data generated like whichever book is exchanged most, which one is reviewed best and other related information.
e. Review
The review bubble depicted in the context diagram and Level 0 data flow diagram allows the user to provide feedback and comments about the book. The rating of books is generated. This review mechanism serves the purpose for data analytics. In the context diagram Review process is presented inside the bubble. The two-arrow headed line one pointing outwards from the main context bubble, labeled as "Related Data" and other one pointing towards the main context bubble, labeled as "Feedback" depicts the types of functionalities happening.
3. Level 1 Data Flow Diagram
Three important processes from Level 0 DFD are decomposed further and stated below. The Level 1 DFD are presented as follows:
a. Level 1 DFD (Narayanan, 2016) for User Registration in accordance with the case study provided is depicted in figure 3a.
.png)
Fig. 3a. Level 1 DFD for User Registration
b. L Level 1 DFD (Narayanan, 2016) for Book Advertisement in accordance with the case study provided is depicted in figure 3b.
Fig. 3b. Level 1 DFD for Book Advertisement
c. Level 1 DFD (Narayanan, 2016) for Book Launch in accordance with the case study provided is depicted in figure 3c.
.png)
Fig. 3c. Level 1 DFD for Book Launch
In Level 1 DFD, the processes of level 0 DFD are further decomposed in sub-processes. It is used to show the internal processes of the major/trivial process of level 0 DFD.
4. Entity Relationship Diagram
ER diagram has three main components: Entity, Attribute and Relationship (Cooper, 2013). ER diagram uses several geometric shapes to portray out different meaning to entities involved. Unlike context diagram where the high-level functioning of the process is depicted, ER diagram lays down all the nitty gritty involved in relation with the process. The required entity relationship diagram for the given case study is depicted in figure 4.
.png)
Fig 4. ER Diagram
5. Schema design up to 3NF
ER diagram depicted in above figure is served as one of the fundamentals of physical relational database. Some of the relational schema (Date, 2019) is described below.
USER:
.png)
REVIEW:

BOOK:
.png)
ADVERTISEMENT:

BOOK ACQUISITION:

PR and FR stand primary key and foreign key respectively.
FIRST NORMAL FORM (1NF):
The relational schema is considered to be in first normal form if the attributes hold only the atomic values, i.e., no attribute may have multiple values. (Gordon, 2017). Basically, multivalued attribute is not allowed.
Example:
.png)
The following table is not in 1NF.
This can be converted into 1NF by arranging the data as in the following table.
.png)
SECOND NORMAL FORM (2NF):
The relational schema will be considered as in 2NF if and only if both the following conditions satisfies. The schema must be in 1NF (First normal form). There must be no non-prime attribute that is dependent on the any subset of candidate key of the schema.
A non-prime attribute can be defined as an attribute that is not the part of any candidate key.
Example: Consider the following table for example.

This table is in 1NF but not in 2NF, because ‘Age’ is non-prime attributes and is dependent on User ID, which is proper subset of candidate key. Thus, we can break the table in 2NF as-
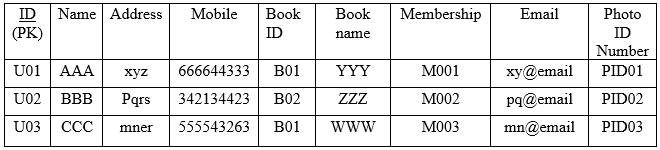
And,
THIRD NORMAL FORM (3NF):
Schema to get into the third normal form must needs to be firstly observed in second normal form. Moreover, it should not hold transitive functionality. Transitive functionality reflects the dependency of non-primitive attribute on that of the super key.
Mentioned above are only necessary conditions for any relational schema to be considered as in third normal form.
Example: Consider the following table for example.
This table is in 2NF, but not in 3NF as the attributes Book ID and Book Name are transitively dependent on super key User ID. Thus, we can split the table as follows to make it in 3NF.
And,
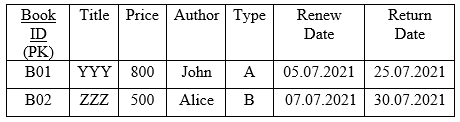
References
.png)
Case Study
MIS500 Foundations of Information Systems Case Study Sample
Task Summary
In groups of 3-5, you are to act as consultants hired by the company the case study is based on, to research, investigate and propose an information system for your client.
Part A: In response to the case study provided, your group will produce a report explaining the information system plan you develop for your client. The report should be no more than 3000 words.
Part A Group report
1. Fibre Fashion – Case Study
To complete this assessment task you are required to design an information system for Fibre Fashion to assist with their business. You have discussed Porter’s Value Chain in class and you should understand the primary and support activities within businesses. For this assessment you need to concentrate on Marketing and Sales only.
2. Watch the case study video about Fibre Fashion (link below). This video will allow you to understand the business and where you, as consultants, can add value by improving their information systems in marketing and sales.
4. For further details about current information systems of Fibre Fashion, please see the Assessment 2 Database document and the Fibre Sales Figures Contacts spreadsheet in the Assessment 2 area of Blackboard.
5. Based on the information provided as well as your own research (reading!) into information systems for SMEs (small to medium enterprise), write a report for Fibre Fashion to assist them in using Business Intelligence (BI) to develop insights for their marketing and sales.
Solution
Introduction: Student 1
The main aim of the report is to propose the Advanced Business Intelligence Information System to assist the business of the Fibre Fashion Company. For Assignment Help, The report discussed the issues regarding the business information recording system of the Fibre Fashion Company. The first section of the report identified the main issue regarding the recording system of marketing and sales data of the company. It also identified the research questions for further research regarding the advanced marketing and sales data analysis system for the Fibre Fashion Company. The second section of the report reviewed the different journals and articles regarding the importance of the marketing and sales data analysis for Small and Medium Enterprises and available updated the Business Intelligence system for meeting the need of marketing and sales data analysis of the SMEs. The Final Section proposed a recommendation about the business intelligence information system that will assist the business record and marketing and sales data analysis system of the Fibre Fashion Company.
Background of the issue: Student 1
Fibre Fashion Company has been an effective and consistent presence in the wholesale fashion industry of Melbourne for over 20 years. The fledgling business of the Fibre Fashion Company has evolved with colour, flourish, embellishments and accents of the pure boutique. The main issue of the Fibre Fashion Company is their inefficient Excel Spreadsheet recording System of the company for recording details of the client and business sales per brand of the boutique. Moreover, the order placing system and invoice creation system of the company also is inefficient. The company uses a simple database system for placing the order and creating an invoice for the order that only contains the style number, category of the product, the colour of the product, and total cost of the product. The company also does not enter the other details of the product in the record like delivery date, pattern, job number, manufacturer details, etc. The Company also uses a simple database to keep the record regarding the simple information of customers including the contact details, customer code, customer address, mail details, credit and discount details and product purchase price details. The Company uses a simple Excel spreadsheet for keeping the details of the clients of the company. It contains the name of the retailer details and location details of the retailer. It contains the details of all open and closed retailer details in the excel spreadsheet. It removes the close retailer name by striking on the name of the retailer. It contains the details regarding “new client details”, “viewed but didn’t place order”, “Placed, then cancelled”, “Sale or return”, “viewed look book”, “Sent pack”, “Appt”, “cancelled appt”, “not interested to view”, “Order to come” etc. details regarding the client appointment and the order details of the product in a numerical format. It is very inefficient in nature for handling bulk data of marketing and sales information of the Fibre Fashion Company.
The report aims to review the needs of marketing and sales data analysis for SMEs and the range of updated Business Intelligent Systems for handling these needs. The report also aims to propose a better BI Information System for Fibre Fashion Business to assist their marketing and sales data.
Following are the objectives:
- To investigate the needs of the marketing and data analysis for SMEs.
- To identify the range of BI systems for meeting marketing and data analysis for SMEs.
- To propose a better BI information system for Fibre Fashion Company to handle their client and sales data.
Research Questions: Student 1
What are the needs of marketing and sales data analysis for SMEs and the range of updated Business Intelligent Systems for handling these needs?
Analysis and Review: Student 2 and Student 3
Identification of the issue:
According to the case study, The Fibre Fashion Company maintains a simple excel spreadsheet and database for handling and keeping records regarding the client details and sales details per brand of the company. Storing and keeping the data in the excel spreadsheet is not easy for data visualisation and it increases the chances of the error. Moreover, there is no particular indication regarding “who are the clients”, “what they order” and “when” etc. It is quite painful for reporting regarding the details of the client and sales per brand for the company. It can increase the chances of fraud and corruption and also it is difficult to troubleshoot and test. It is sometimes not possible to interrelate the spreadsheet data across the workstations on different locations. Lack of security and control issue is the major problem. It is not user-friendly and the excel round-off the large numbers using imprecise calculation. It reduces the accuracy of the data. Excel spreadsheet is not efficient for managing the advanced pricing rules. Moreover, the simple database system is not sufficient for handling the advanced pricing strategies like quantity based pricing, psychological pricing, handling pricing based on the market and different geographic locations, and attribute-based pricing etc. It is unfit for agile business practices. Maintaining and keeping the record in the excel spreadsheet is quite painful for extracting the marketing and sales data from different departments and retailers, consolidating those data and summarising the entire information is also painful for the management of the company. It is incapable of supporting the company to make a quick decision and because keeping the record and extracting the data from the spreadsheet is a time-consuming process. It is also totally unsuitable for the continuation of the business. It is required to use the updated BI information system to develop the new insights for the company’s marketing and sales data.
Importance and needs of the marketing and Sales data analysis for SMEs: Student 2
In the view of Jena & Panda (2017), sales and marketing data analysis is essential for unlocking the relevant commercial business insights. It helps to increase the profitability and revenue of SMEs. It also improves brand perception. It helps in uncovering new audience and customer niches, new markets and areas for future market development It helps SMEs to reach different segments of the market via the different channels that are working and not working. It helps SMEs to take all the necessary information regarding the market for building an effective marketing plan. It focuses on the internal and external environmental factors. It considers the weaknesses and strengths of the SMEs by gathering the data of all marketing channels of the SMEs. Marketing data analysis helps SMEs to analyse the current market and helps them to understand the market more efficiently (Chiang, Liang & Zhang, 2018). Sales data analysis helps SMEs to understand the behaviour of customers, the products that maximum customer select and the reason behind selecting the product and behaviour of the product.
Mikalef, Pappas, Krogstie & Giannakos (2018) stated that marketing and sales data analytics helps in predicting the behaviour of consumers, improves the SMEs decision-making process and determine the best path for increasing the return of investment based on the marketing efforts of the SMEs. It helps them to protect their market share. The study stated that big data technology to analyse the marketing and sales data of the business is important for increasing the business efficiency, reduces the operational cost, marketing and sales cost of the company. It helps in identifying the failures and weaknesses of the SMEs. It helps in conducting a review of customers and design the new services and products for SMEs for increasing the marketing and sales of their product. It helps in identifying the fraud while keeping the record of clients’ data and sales records of SMEs. It prevents fraudulent activities and helps SMEs to make smarter decisions for enhancing their business. It helps the owners of small businesses to meet their business goals. It helps the sourcing the marketing sales information for analysis the marketing and sales data from different sources such as sales receipts, email marketing reports, publicly available data, website data and social media data.
Based on the research by Grover, Chiang, Liang & Zhang (2018), the use of marketing and sales data analysis increases the chance of return on investments while taking any marketing initiatives in SMEs. It helps SMEs to make proper decisions for providing proper service to their customers to retain them (Becker & Gould, 2019). A real-time data analysis facility helps SMEs to provide critical meaningful insights to the decision-makers in real-time to make a proper decision regarding further steps. Data analysis system helps SMEs to grow their business by allowing them to develop an update and fine-tune marketing strategies and search engine strategies (SMEs who have their online websites) (Cortez & Johnston, 2017). It helps SMEs to determine the right mix (product, price, place and promotion strategy) strategy for optimising the sales of the product. It helps to store the sales data in one place to improve the performance of sales. It determines the areas that need modification by determining the facts and relevant data regarding the marketing and sales.
BI System for meeting marketing and data analysis needs of SMEs: Student 3
In the view of Anshari, Almunawar, Lim & Al-Mudimigh (2019), Business Intelligence is the advanced technology that enables the business processes to analyse, organise and contextualise the business data from the company. BI also includes multiple techniques and data to transform the raw data into actionable and meaningful information. The BI system has mainly four parts that include 1) The data warehouse stores that help in gathering a variety of sources in an accessible and centralised location. 2) Data management tools and Business Analytics Tools analyse and mine the data in the data warehouse system. 3) Business Performance Management Tools for analysing and monitoring the data. It helps SMEs to progress their business towards the goals of the business. 4) User Interface tools and interactive dashboards with the facility of data visualisation reporting tools that helps in quick access of the business information. Business Intelligence tools offer a wide variety of techniques and tools for supporting accurate and reliable decision making for progressing the business performance. BI based and data-driven process of decision making helps SMEs to stay competitive and relevant.
As an example, Lotte.com the leading and renowned shopping mall in Korea uses the BI Information system for understanding customer behaviour and uses that information to develop marketing strategies. It increases the sales of the product of the company. Stitch Fix Company provides online personal accessory and clothing styling services uses data science and recommended algorithms of BI Tools throughout their buying process to personalised their products as per the requirements (Ryan Ayers. 2020). Netflix also uses the information and data using BI software to get more people and engage them with their content. Walmart uses BI software to influence in-store and online activity. They analyse simulations to understand the purchasing patterns of customers. It helps them to increase the marketing and sales of products of the company.
Followings are some examples of advanced and updated Business Intelligence Software:
Power BI is the Business Intelligence Tools and it is serviced by the Microsoft Company. It provides interactive visualisations of data and provides the proper services for enhancing the business intelligence capabilities through the simple interface for creating the own business reports and dashboards. It brings the raw data from different sources also from a simple spreadsheet to cloud base data. It helps in sharing powerful insights by analysing the marketing and sales data.
Oracle Analytics Cloud is a Business intelligence Software system that is embedded with the machine learning facility (Oracle.com. 2021). It helps the organisations to discover effective and unique new business insights faster with the facility of a Business intelligence system and automation system.
Qlik Sense is another Business Intelligence Information System that helps SMEs and other companies to create interactive dashboards and tools based on marketing and sales data, operational data and data from different departments of the company (Qlik. 2021). It helps in creating stunning graphs and charts to make relevant business decisions.
SAS BI is also a cloud-based distribution model to deliver business analytics services like business reports and dashboards (Sas.com. 2021). It analyses the business data using modern cloud BI technology.
Tableau Business Intelligence uses the ad hoc analysis process to improve the ability to better see and understand the business data across every department of the company for better decision making (Carlisle, 2018).
Recommendation: Student 4
Based on the overall analysis, it is recommended that Fibre Fashion Company can use the Power BI Software to develop the business insights for marketing and sales of the company. Power BI will help the company to meet the enterprise business intelligence needs and self-service needs. It is the largest and fastest-growing business intelligence information system. It creates and shares effective and interactive data visualisations across the entire global data centre. It also includes the national clouds to meet the regulation and compliance needs of the Company (Powerbi.microsoft.com. 2021). Power BI Desktop, Power BI Service and Power BI Mobile Apps these three elements are the total package by Microsoft to provide an effective Business Intelligence Information system for the SMEs and also other leading companies. The Cost-effective plans and high-quality data analysis facility increases the demand for this product. Moreover, the Power BI Report server allows the company to publish the reports of the Power BI to the on-premises remote server after the report has been created in the Power BI Desktop. Iqbal et al. (2018) stated that the BI system drives the business decision based on the current, historical and potential future data. Predictive analytics system uses predictive modelling, data mining and machine learning system for making the projections and assumptions of future business events. It also helps in assessing the likelihood of particular events. Prescriptive analytics helps in revealing the actual reason for taking the particular action and initiative for enhancing the business performance. It enables the simulation and optimization of the marketing and sales data and uses the decision modelling system to provide the best possible business actions and decisions for the growth of SMEs. BI Tools helps marketers track the campaign metrics from the company’s central digital space. It helps SMEs in real-time campaign tracking that helps in measuring the performance of each effort and develop a plan for future business campaigns. It gives the marketing teams of the company more visibility into the overall business performance. BI Tools helps the sales team to quickly access complex information like customer profitability information, discount analysis information and information regarding the lifetime value for customers (Chiang, Liang & Zhang, 2018). It helps the sales managers to monitor sales performance, revenue targets with the real-time status of the sales pipeline using BI Dashboards with data visualizations and real-time business reports.
The main Key Features of the Power BI are:
.png)
Fig : Overview of Power BI information system
Source: (Powerbi.microsoft.com. 2021)
1. Power Query allows the transformation and integration of the company’s business data into the web service of Power BI. The company can shred the data across multiple users and multiple retailers in different geographic locations. The company can also model this data for enhanced data visualisation (Powerbi.microsoft.com. 2021).
2. The Common model of the database allows the company to use extensible database schemas and construction.
3. The Hybrid Development Support helps the tool of business intelligence to connect to the different data sources. It allows automatic data analytics application to information by creating the subsets of data through the use of quick insight feature.
4. The customisation feature can help the company to change the appearance of data visualisation tools. It also helps in importing new business intelligence tools into the platform.
5. The Dashboard of Power BI embedded in other appropriate software products through the use of APIs.
6. Complex data Models can also be divided into small and separate diagrams by using the modelling view common properties. It can be set, modified and viewed the data as per the requirements.
7. Cortana integration facility allows the employees and users of the company to query for any data verbally by using natural languages. It provides a digital assistant facility. The Power BI System helps in easily and quickly sharing the relevant data and meaningful insights after analysing the marketing and sales data across all system such as IOS, Windows and Android (Powerbi.microsoft.com. 2021).
Fig : Sales Performance Report
Source: (Powerbi.microsoft.com. 2021)
It will help the company to protect their marketing and sales data details by using the Power BI security facility with the other facilities like Azure Private Link, Service tags and Azure Virtual Network. It will help the company to prevent data loss. Power BI Desktop is also free for clients to use and the Pro level of the Power BI Information system is also available at a low monthly price per user. Moreover, the weekly and monthly updates of the Power BI improve the marketing and sales data analysis capability. It will help the Fibre Fashion Company to develop better decisions for enhancing the sales of the product. It will help the Company to get self-service analytics reports at an enterprise scale. It reduces the complexity, added cost and data security risks of recording the marketing and sales data and details clients, and sales per brand details that scales data from the individual level to the organisation level as a whole (nabler.com. 2021). It uses Smart tools, facility of data visualizations, tight integration of excel, prebuilt data connectors and custom data connectors and built-in AI Capabilities helps in providing strong outcomes for helping management of the company to make better decisions. Moreover, end-to-end encryption of the data, sensitivity labelling and Access monitoring system in real-time will increase the data security of the marketing and sales data, clients’ data and details of sales per brand of the company (Becker & Gould, 2019).
![]()
Fig : Transforming Excel data into Power BI
Source: (Powerbi.microsoft.com. 2021)
Power BI will allow the company to correlate the marketing data and metrics from the different business sources. It also removes the maximum possibility of having false positives from the marketing data. The Company can easily connect the data models, excel queries and other reports regarding the sales data to the Power BI Dashboards. It helps the company to gather the sales data of the company, analyse the data, publish and share the outcomes and business data in excel in new ways (Carlisle, 2018). It will help the company get new insights from the data and use the effective business insights for making the appropriate business decision for enhancing the business activities of the Fibre Fashion Company. It will help the company to track the record of their products in their inner-city warehouse of company. The use of the Power BI Software will enhance the skills and knowledge of the staff in providing unique services to the clients of the company. It will help them to maintain error-free transactions and ordering activities with their clients (Wright & Wernecke, 2020). It will help the fibre fashion Company to develop a loyal and trustworthy relationship with their clients that will help them to expand their business in the broader market.
Conclusion: Student 1
It concluded that the Fibre Fashion Company can use the Power BI Information System to get more meaningful business insights by analysing the marketing and sales data of the Company. The Power BI software will help the company to improve the security of their recorded data in the database system. It will help the company to enhance the privacy of the clients’ data and details of the sales record per brand. It will help the company to develop new business insights for improving the marketing and sales figure of the Fibre Fashion Company. It will help the company to take the appropriate decision for improving the market share of the company. It will help the company to track the record of their products per brand in the warehouse. It will help the company to develop a fruitful business relationship with their clients that will help them to increase their sales and marketing profitability in future. The report also discussed the importance of data analysis for SMEs for the enhancement of their business in the market. It revealed that the use of the data analysis facility helps SMEs to achieve their business goals and objectives.
References:
.png)
.png)
Reports
MIS607 Cybersecurity Report Sample
Task Summary
You are required write a 1500 words Threat modelling report in response to a case scenario by identifying the threat types and key factors involved. This assessment is intended to build your fundamental understanding of these key threats so that you will be able to respond/mitigate those factors in Assessment 3. In doing so, this assessment will formatively develop the knowledge required for you to complete Assessment 3 successfully.
Context
Security threat modelling, or threat modelling is a process of assessing and documenting a system's security risks. Threat modelling is a repeatable process that helps you find and mitigate all of the threats to your products/services. It contributes to the risk management process because threats to software and infrastructure are risks to the user and environment deploying the software. As a professional, your role will require you to understand the most at-risk components and create awareness among the staff of such high-risk components and how to manage them. Having a working understanding of these concepts will enable you to uncover threats to the system before the system is committed to code.
Task Instructions
1. Carefully read the attached the case scenario to understand the concepts being discussed in the case.
2. Review your subject notes to establish the relevant area of investigation that applies to the case. Re- read any relevant readings that have been recommended in the case area in modules. Plan how you will structure your ideas for the threat model report.
3. Draw a use DFDs (Data Flow Diagrams):
• Include processes, data stores, data flows
• Include trust boundaries (Add trust boundaries that intersect data flows)
• Iterate over processes, data stores, and see where they need to be broken down
• Enumerate assumptions, dependencies
• Number everything (if manual)
• Determine the threat types that might impact your system
• STRIDE/Element: Identifying threats to the system.
• Understanding the threats (threat, property, definition)
4. The report should consist of the following structure:
A title page with subject code and name, assignment title, student’s name, student number, and lecturer’s name. The introduction that will also serve as your statement of purpose for the report. This means that you will tell the reader what you are going to cover in your report. You will need to inform the reader of:
a) Your area of research and its context
b) The key concepts of cybersecurity you will be addressing and why you are drawing the threat model
c) What the reader can expect to find in the body of the report
The body of the report) will need to respond to the specific requirements of the case study. It is advised that you use the case study to assist you in structuring the threat model report, drawing DFD and presenting the diagram by means of subheadings in the body of the report.
The conclusion will summarise any findings or recommendations that the report puts forward regarding the concepts covered in the report.
5. Format of the report
The report should use font Arial or Calibri 11 point, be line spaced at 1.5 for ease of reading, and have page numbers on the bottom of each page. If diagrams or tables are used, due attention should be given to pagination to avoid loss of meaning and continuity by unnecessarily splitting information over two pages. Diagrams must carry the appropriate captioning.
6. Referencing
There are requirements for referencing this report using APA style for citing and referencing research. It is expected that you used 10 external references in the relevant subject area based on readings and further research. Please see more information on referencing here:
https://library.torrens.edu.au/academicskills/apa/tool
7. You are strongly advised to read the rubric, which is an evaluation guide with criteria for grading the assignment. This will give you a clear picture of what a successful report looks like.
Solution
1. Introduction
The report will develop a threat model for solving the issues of cyber risk in Business & Communication Insurance company. Cybersecurity management is essential for risk identification, analysis, and mitigation (Mulligan, & Schneider, 2011). Cyber security management plays crucial roles for building cyber resilience by minimizing the threats (Ferdinand, 2015). For Assignment Help, The B&C Insurance company is under the threat of information hacking as a ransom email from an unknown source has come to the CEO company where the hackers claimed that they have the details of 200,000 clients of the company and as proof, they have attached a sample of 200 clients. The report will identify the risk factors and "at-risk" elements to develop a threat model using the STRIDE framework to mitigate the risk associated with cyber hacking in B&C Insurance company. For identifying the potential risks, their impacts and to suggest proper mitigation of the cyber threats, the threat model will be developed and the DFD diagram will be drawn to explore the risk factors and mitigation strategy related to the case study of B&C Insurance company.
2. Response to the specificrequirements
2.1. Types of threat and major factors involved
The B&C Insurance company can be under the threat of various types of cyberattacks. The different types of threats increase the potentiality of information risks where the aid of cybersecurity management is required (Reuvid, 2018). As the B&C Insurance company is a private firm, the possibility of malware attacks is high. The ransom email from the unauthorized source confirms that the sample of 200 clients is genuine which was investigated by the forensic computer specialists. Therefore, the risk lies in the information of the 200,000 clients of the company which was hacked by an unknown source. The type of attack is ransomware. Some of the potent threats that businesses face is ransomware, malware, DDoS attacks and others (Russell, 2017). As the hacker uses a ransom email, it can be possible that the threat lies in a malware attack.
The network, system, and user are the three factors that are prone to high risk. Within the company B&C Insurance, the insecure network can cause a risk of information hacking where confidential information can be hacked by an unknown source. Security of user information lies in the secret authentication process (Antonucci, 2017). The employees within the company can unknowingly share confidential data while giving access to any source. A similar incident can happen in the case of customers of the company. However, the vulnerability also lies in the system where data integrity is required for system management.
Other possible attacks are phishing and spoofing where attackers can target the employees of the company. The trap of fraudulent tricks can take the access of information from the employees. The clients can also be tricked where they are believed that the access is provided from an authorized source.
2.2. Threat Modeling using STRIDE framework
The threat modeling framework helps to manage cybersecurity by analyzing the risks, their impact and proposing the mitigation strategy to tackle the risks (Xiong, &Lagerström, 2019). Implementation of STRIDE framework in threat modeling process specifies the threats and keeps the integrity, confidentiality, and availability of information. However, the STRIDE framework will help to ensure the security of the information in B&C Insurance company by implementing the strategy for threat detection, evaluation, and mitigation. The six steps of the STRIDE model will be implemented to resolve the cyber risks within B&C Insurance company.
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
Table 1: STRIDE
Source: (Developed by the author)
2.3. Other Models and Frameworks of Threat modeling
The other suitable models may help the company to manage the risks in the information system.
The DREAD framework is capable of deriving a threat intelligence solution where it implements the appropriate rating systems for risk assessment, analysis, and development of risk probabilities (Omotosho, Ayemlo Haruna, &MikailOlaniyi, 2019). Through the information collection process, the DREAD framework rates the potential risks from low to medium to high. It allows the users to identify the threat for proper mitigation plan development. The B&C Insurance company can use the DREAD model for risk identification, analysis, and rating system development.
The NIST model of security management helps to set specific guidelines for managing the risks through threat detection and responding to cyber-attacks. It helps to manage the risks by generating a strategy for risk prevention. The cybersecurity framework of NIST can be implemented in B&C Insurance company for the identification of the type of threat and then the development of risk mitigation strategy. The framework can promote the organization to manage cyber threats by setting proper guidelines for cybersecurity management.
2.4. Data Flow Diagram
At-risk components
The health insurance company B&C has a record of its client's information related to health. Other information of the clients may include the personal details, demographic information, financial information, and family information of the clients. Risks can occur in the information of the clients where the hackers can steal the confidential information of the clients for misuse. Cyber risks increase the vulnerability in the information system (Stephens, 2020). The employees within the organization are also at risk of cyber hacking. The basic details of employees, their salary status, and family background are prone to high risk. The information of the system within the B&C Insurance company is a valuable asset that is under cyber threat. Moreover, the risk can also occur in the networking system where the information can be hacked by an unknown source. Therefore, it is essential to safeguard the at-risk components in the organization.
.png)
Figure 1: Context diagram
.png)
Figure 2: Level-1 Diagram
2.5. Security Strategies
The B&C Insurance company needs to safeguard its information and system from cyber attacks. For managing information security, the company needs to take the following actions.
· The data encryption process will help to control the access of users where using biometric or access control lists can be effective.
· Antivirus, network security control tools, anti-malware, and anti-phishing tools can be implemented to manage the proper security of the system. Installing an automated security tool can also be helpful.
· Access control and user authentication through proper password development is also an effective technique for managing information security (Stallings, & Brown, 2018).
· Security control measures like proxy firewalls can help in managing the security of systems (Durieux, Hamadi, &Monperrus, 2020).
· Training of the staff regarding security management is required to reduce the risk of phishing and spoofing.
3. Conclusion
Cybersecurity management can be possible through developing the thread model. The STRIDE framework will help B&C Insurance company to effectively manage the information system. The model implementation will also help to identify the potential risks, analyze the risks and mitigate them. However, the identification of the at-risk components will help the company to understand the underlying vulnerability within the information system of the company. The identified risk factors have contributed to drawing the DFD diagram where the application of the STRIDE framework has created potential solutions for security risk management. Moreover, the alternative models and the security risk strategy will also help the company to manage the future risks in an information system.
References
.png)
Reports
MIS610 Advanced Professional Practice Report Sample
Task Summary
You are required to write a 1500 words professional practice reflection. This requires you to by reflect on your experiences in Master of Business Information Systems (MBIS), specifically the IS Capstone and how these experiences provided you with insights into your own future as an IT/IS Professional.
Context
You have been studying Information Systems through a lens of Business, as most of you will chose careers in IS management and analytics. Technology is a strategic part of any enterprise today, large or small. Throughout your degree, you have been developing an understanding and skills that enable you to work at a high level in these environments. You are soon to graduate and follow your career path. This assessment gives you an opportunity to reflect on how far you have come and where you wish to go.
Task Instructions
Write a 1500 words professional practice reflection addressing the following questions:
• Complete the skills audit to identify your level of skills and knowledge with compared to the nationally recognised ICT skills set needed for a career in ICT.
• Identify your two strongest skills and reflect on why those are your strongest. Link this to your experiences in the MBIS and your life in general (for example you might also be influenced by family, work experience, previous study, hobbies, volunteer work etc.)
• Identify the two skills that need the most work. As above, link this discussion to your experiences in the MBIS and your life in general.
• Now that you are about to graduate, how do these skills match the job/career that you want?
Find a job advertisement and match the skills and knowledge wanted in the advertisement against your audit. What do you need to work on?
• Finally, you have identified your skills levels and how it relates to your career, now choose three skills and set yourself SMART* goals for the next six months to achieve your career objectives.
Solution
Introduction:
From a traditional viewpoint, the job of IT professionals is linked with developing software for solving complex problems on a computer. Information systems have been evolved over the years with the development of technology, the Internet, big data, and others. The emerging technologies have opened many career opportunities which include Chief Information Officer, Chief Technology Officer, and cybersecurity specialists, business analysts, and others. Rapid changes in the industry are one of the hallmarks within ICT domains which is prominent at our micro and macro levels. For Assignment Help Disruptive technologies like IoT and Big data have implied many changes within the ‘macro level’ due to which job opportunities have increased from the last few decades. Technical information is a system that allows students like us to work on the Internet efficiently while connecting globally (Intersoft consulting, 2016). The knowledge of various developed software will help in gaining information on varied domains thus enhancing professional knowledge life. This report aims in evaluating interests and knowledge on ICT career opportunities. Thus, conducting an audit on skills to recognize strengths and weaknesses can be improved for substantial career growth. This will strengthen skills and help students like us to grab adequate and good career opportunities.
Reflection report:
Completion of the audit skills:
Since the ICT domain witnesses, rapid changes hence skill audits help in recognizing. weaknesses and strengthswhich will help in attaining a promising career in ICT domains. I have a deep interest in networks and computer systems that further protects computer systems from unauthorized access or cybercrimes. It has become important to possess advanced skills in ICT domains for protecting all types of electronic devices from the breach. Thus,I have acquired additional knowledge from attending webinars, participating in class activities along studying through module lectures. I assume that my knowledge base in cyber-threat activities is strengthened that has been benefitting me in safeguarding my electronic devices while I am also keen to apply and broadened my information base for protecting the ICT infrastructure of organizations. As per the skills audit done by me, I have assumed that my knowledge of IT management, data management, IT infrastructure is strongest. However, to sustain rapid changes in the domain and HR strategies, I require to polish my skills for sustaining in the job market. (Australian Computer Society, 2014).
Identification of the two strongest skills:
Proper identification of own strength is necessary for achieving success in personal and professional life. Any person can enhance their scope and range of opportunities by adding value to their strongest skills (S. Tufféry, & S. Tufféry, 2011). As I have been studying the Information system specifically through a business perspective, I have generally mastered a wide variety of disciplines properly. But amongst them, I have preferred, Data and information management along with Software Development as my strongest set of competencies. These two skills have been providing have been helping me in completing my MBIS degree.
Data and information management is based on the managementquality and storage of both structured and unstructured information properly. It also includes integrity and security for providing support regarding digital services in business management (Hall &Wilcox, 2019). Besides, it also helps the business units to strategize business plans and policies for future investment purposes. I have also mastered web development and software development, as this skill has been my hobby for some time. I have also done several freelancing jobs on web and software development purposes due to which I can affirm that the aforementioned skillsare the main pillars for my future professional aspects.
Identification of the skills required for improvement purposes:
In this present digitalized era, for achieving a successful professional life, flexibility is very important without which the scope and opportunities of professionalcareerstend to be narrower after a certain period(Hunt, 2018). Also, flexibility supports the adoption of varied job purposes along with technological assistance. Currently, I lack skills in IT infrastructure and Network support skills due to which I faced many issues while completing assessments and understanding activities during my MBIS course. I also struggle in proper management and regulation of the hardware-related aspects, which also encompasses the problems regarding changed services. I have several examples of failures in support services to the customers while working as a software technician in a small size business organization during my volunteer work. I was also unable to resolve many problematic aspects which dissatisfied the customers. Network support is another important set of skills that needed to be enhanced for me.
The utilization of the skills towards professional career:
As per my skills, audit, and identification of strengths during my MBIS degree, a web developer or web designer would be the preferable and best-suited job for me. Hence, I have searched for the business companies that specifically advertise for a web developer or web designer in their organization. ENTTEC has been opted by me, as they are currently facing a high shortage of web developers. The company operates through its offices at Keysborough VIC, Australia. The company has advertised that the web developer will be required for updating and creating innovative software with related components like websites and software applications. The IT products and services offered by the company acts as the revenue for which management and regulation are of utmost importance. However, the company has strong recommendations for soft skills sets like teamwork, communication,crisis management which I need to polish.
Also, I have undergone other job searches as well, which demonstrates similar skills, however, requires higher work experience. Hence strengthening my skills will help in obtaining internships which will increase my professional expertise that will further enable me to work in the esteemed organization of my desired professional career.
SMART goals for the next six months:
Although the skills of web development along with data and information management are my strongest skills, however, I require polishing of competencies on infrastructure perspectives.
.png)
.png)
.png)
In addition to this, I would also like to improve my communication, teamwork, and forms of interpersonal skills for sustaining in highly competitive ICT Organizations. Also, I realize that strengthening ICT competencies is important as advanced technology is being rapidly applied by all organizations, hence it provides a good opportunity with high job satisfaction as my job will help many companies to progress with efficiencies (Mainga, 2017).
Conclusion:
The report has helped me monitor my strengths and weaknesses in this domain, which has helped many career developments. Through the audits, I obtained information that must improve my skills in IT management data and administration for which I have designed SMART goals for six months. In addition to this, I recognized that IT domains undergo rapid change due to which possession of interpersonal skills is important. In recent times, the business environments are highly competitive which requires a balance of both personal and professional skills. Students like us, who will be stepping into the professional world are required for obtaining information on HR strategies and practices, hence job adverts are helpful tools in polishing skills for a higher opportunity of being recruited in the organizations.Also, the skill audit has enlightened me that I require continuous improvement for assessing strengths and weaknesses, hence I would continue this type of reflection in my professional career as well. My skills should be strengthened so that they can be used especially in the job-oriented process later in the future while I can also explore my job role and related skills for reaping benefits in different developmental domains of ICT.
References
.png)
Case Study
ITC561 Business Requirements Report Sample
TASK
Read the Regional Gardens case study in the Resources section of Interact 2 before attempting this assignment help.
You are an ICT Cloud consultant and you have been approached by Regional Gardens (RG) to advise them on how to improve their data centre and move into the Cloud. The Managing Director (MD) is still unsure that this is the best approach for his company as he feels that his company is "not really big enough to be thinking about moving to the Cloud" and that any money should be spent on their garden design and product development rather than ICT. But both the Design manager and the Sales Manager are both concerned that if the company's data centre isn't improved then the company will not be able to expand.
The company has recently upgraded their display garden and also added a series of new product lines to their nursery store as a result. The Sales Manager is concerned that the current order system will be inadequate to handle the expected large increase in orders that is likely to come from these upgrades. The online sales system is currently running on the RG web services infrastructure, which has not been updated for a considerable amount of time. RG uses their own custom-designed garden design platform that runs on SharePoint 2013.
This allows them to enable a number of designers to work on individual customer designs or to collaborate on larger designs. This platform allows them to access the design software from the office, but also allows the possibility of remote access. The Design Manager would really like to enable the remote working capability, but has concerns that the SharePoint infrastructure is also quite dated and may not support an increase in the level of demand or for remote work.
The company is quite reluctant to put more capital into ICT infrastructure as the MD, correctly, reasons that this capital will be needed to support sales, design and distribution. The MD has read that the company can set up ICT infrastructure on Amazon Web Services (AWS) for no capital cost and reasonable monthly payments for the use of their infrastructure. The Regional Gardens MD is not entirely convinced that this is a valid approach as the company has always purchased and owned its own infrastrastructure so that it is not reliant on other organisations. But in the current circumstances, a Cloud approach now has to be investigated.
Regional Gardens Case Study
Regional Gardens Ltd is a company that runs a number of related gardening enterprises. It has a large display garden that it opens for public inspection a number of times a year. These enterprises include the Regional Gardens Nursery which sells plants and garden supplies to the public, and Regional Garden Planners which provides garden advice, design and consultancy services.
Regional Gardens Ltd has a small data centre at its main site in Bathurst where the company’s servers and data storage is located. The company has the following server infrastructure:
• 2 x Active Directory domain controllers on Windows Server 2012 R2;
• 2 x SQL Server 2008 R2 database servers on Windows Server 2012;
• 1 x Exchange 2010 email server on Windows Server 2012 R2;
• 4 x Windows Server 2012 File and Print servers;
• 2 x Windows SharePoint 2013 servers on Windows server 2012 R2;
• 2 x Red Hat Enterprise 5 Linux servers running Apache and TomCat (2 x Xeon 2.8GHZ, 16GB RAM, 140GB HDD).
• 1 x Cisco ASA 5512-X firewall running v9.6 ASA software.
This infrastructure has not been updated for some time and the Regional Gardens Board is concerned that a full upgrade may now cost them more than it is worth. The Board is now considering moving some, or all, of their current infrastructure into the Cloud. The Board sees this as a strategic move to future-proof the company.
Regional Gardens has engaged you as a consultant to advise them on the use of Cloud Computing in their daily operations. They have some 70 garden design, horticultural and support staff that work on different projects for clients in New South Wales. They have been advised that a move to using a Cloud based infrastructure would be an advantage to them.
Solution
Cloud discussion:
Advantages of Web Services:
Interoperability: Web service mainly works outside of any private networks and provides some important non-proprietary route to mitigate all issues of servers. Developers have enough priority to set up their programming language to communicate with authentic users. It can also determine as an independent platform.
Usability: Web service provides some business logic to expose through the web page. Web service helps the user to choose their application as per their preference. This type of approach can enhance the overall service and produces some useful code with different languages (Li et al., 2020).
Deployability: Web service is mainly used through standard Internet technologies. Web service is used in different firewalls to the servers for completing the internet connection. Community standard also depends on the webserver.
A regional garden can become more helpful by the deployment of the web server in the cloud security storage. It can also create a user-friendly atmosphere.
The disadvantage of web service:
Storage capacity: Web service protocol mainly followed plain text format. Therefore, this format occupied a large space than binary methods. Large spaces with low internet connections are strictly affected by the regional garden's organization resources. It is one of the significant drawbacks of the webserver (Ullah et al., 2020).
HTTP server: Comparing the core web protocols and web services, HTTP is mainly grown-up for the long-term session. Browser mainly uses this HTTP connection for providing some web pages and images. On the other hand, the webserver can establish the connection for a long-term period and sent the data periodic manner. Web service process has become quite difficult for the clients of Regional Garden Ltd company.
The server provides some unique identification to the client for accessing the server. This kind of unique identification process provides the further request to the server. The server mainly depends on the timeout mechanism. If the server did not get any response from the customer side, they usually remove the data. It can become an extra load for the Web service. Cloud infrastructure of the regional garden will be getting a random threat from the service provider to store ant information for future use.
Advantages of share point:
Advantages for Business growth:
SharePoint architecture helps the user to gather any important information about the portal and it can easily be accessible by the authentic user of such an organization. The regional garden must implement this activity to install data from various sources Like EXCEL. Microsoft SQL. This can enhance the business process of Regional Garden Pvt. Ltd.
Cloud-based framework: Share point can access the progress of any project at any time with the help of a web browser. Authentic users of the company can use their data and resource as per the company's requirements.
Security in cloud solution: The security of the company is mainly determined by the business data of any renowned organization. SharePoint helps the user to arrange any data with the help of the firewall security process. Unauthorized members or outsiders of the organization can hardly access the information. Cloud solution helps to improve the confidentiality of any documents.
Disadvantages of SharePoint:
Integration requires developmental effort: Sharepoint integration issue is recognized as a very important aspect. All user mainly invest their time and cost to creates any project. If the project has become fail, then it is determined as a wastage of time and money.
Poor capability: SharePoint is a traditional approach. User can not get their information in a few seconds. It will take some time to display the information on the screen.
Though Share pointer has some good qualities, the traditional approach and the low developmental process can restrict the growth of the Regional garden.
.png)
Source: (Mahloo et al., 2017)
Web service infrastructure:
Deploying RG web service into AWS cloud:
Amazon web service is determined as a comprehensive platform that consists of three different types of services like IaaS, Platform as a service, and Packaged software as a service model. Cloud deployment has been created with four different architectures like public cloud, private cloud, hybrid cloud, community cloud. Few processes will be introduced in this section to deploy the AWS cloud service.
1. RG private limited company use this service to make available the service and resources
2. AWS mainly helps to manage customers' data for different authenticated users. Consumers are managing all application stacks and also make logging information authorized(Abbasi et al., 2019).
3. After that patching the information and gives a backup plan to use the data as per the organization's requirement.
4. The provider gives the Host and VM installation process.
5. The server provides network service and storage capacity.
6. In a PaaS environment, the virtual server is installed to make a readymade environment (Zhang et al., 2019).
RG web service deployed in the public subnet and AWS service used to protect RG web service:
RG web service has taken a few steps or methods to install the AWS service model architecture. These processes are like production VPC, UAT vpc, and DEV vpc.
1. In the production subnet method private and public subnets are used to rout in a particular table. The proxy server will be available here for 24*7 hours. It can share the database and log storage by the VPG method.
2. In UAT internet access, a public subnet will be deployed with the help of a router and proxy server. VPG method is used here to share the database snapshot and log storage services.
3. Router table, virtual private gateway helps to deploy the web server into public subnet model. It can also access the data or services.
Public access to the web service:
1. When the webserver is allowing for the users, intruders are always ready to create a log file for stealing all personal information of the Real Garden PVT. Ltd. Company. Therefore a DNS server should be installed here to pollute the cache of the server. It can give some questions to the transmission control protocol. This can also help to build up protection against the cache protocol system.
2. To restrict the malicious user it is very important to disable the recursion of the DNS server. The service provider should give the information to ISP for restricting the similar attack of DNS server.
These are the required method to make the web server for public access in RG Pvt. Ltd.
Remote access for the authorized web users: The main problem of secure remote access is internal webserver from the outsides of the firewall security system. In the meantime, unauthorized users have enough opportunities to get access the sensitive information. The main goal of the Real Garden infrastructure cloud is to implement a one-time password solution for accessing all documents of RG. Pvt Ltd. A secure socket layer is also used here. These components are needed to be implemented here in such a way as to improve the security, performance, and availability scale.
2.Another process is the main component of the system has two subcomponents. Proxy has one subcomponent behind the firewall. Another component is present behind the firewall.
.png)
3.Push web machine is used inside the machine, another machine absent is used outside. When a web request comes from DWT, absent uses control connection statement to initiate actual communication with authorized users. Push web server only helps to establish a connection.
.png)
Source: (Pacevic & Kaceniauskas, 2017)
Share point design Platform:
Process of SharePoint infrastructure in AWS cloud:
Share point infrastructure can increase the security and high availability of the system in AWS cloud storage. Few steps should be followed here with the help of AWS cloud Formation template, multiple servers, and single server topologies. This deployment option included some specific categories like a single server and multiple server share points to form a virtual private cloud (Hodson et al., 2017).
1. Public subnet and private subnet mask are used here to make a static internet activity. In virtual private cloud storage, the Public subnet has two categories like NAT gateway and RD gateway.
2. Private subnet consists of 4 different categories like Frontend server, app server, database server, and directory server.
3. Network address translation gateway used here to allow outbound internet access for the required private subnets.
Private subnet: Application load balancer is used within the AWS server. Amazon EC2 instance is also added to the front-end device. Two amazon EC2 instances serve as Microsoft SQL servers needed to be deployed in the Amazon web server application (Yu et al., 2020).
4. A remote desktop gateway in the auto-scaling group allows the remote desktop protocol to Amazon elastic compute system. It can make the connection between private and public subnets.
These methods are required here to install SharePoint infrastructure in the AWS cloud(Varghese & Buyya, 2018).
SharePoint uses private subnet and AWS to protect RG web service:
According to the AWS configuration, VPC configuration has been used to place internet and non-internet servers in particular positions. This can also help to restrict direct access from the other instances of the internet.
1. Hybrid architecture is one of the useful methods to extend private policy and it can also enhance the Active directory infrastructure.
2. Private subnet made up with the help of application load balancer.
3. A network load balancer is used here for the SharePoint application server.
4. Two Amazon electric compute systems serve Microsoft SharePoint as an application server (Waguia & Menshchikov, 2021).
5. Amazon EC2 is also used here as a Windows failover file share witness.
6. At last SQL server is also used in RG infrastructure Pvt. Ltd to create a high available cluster.
7. These are the main components mainly used to set up the RG Pvt. Ltd company by implementing Amazon web server cloud architectural system.
Protection to RG web service: AWS server continuously helps to protect the data, information, and threats by improving the encryption, key management, and threat detection system. These concepts will be discussed in this section:
Threat identification and monitoring: AWS server is constantly monitoring threats in any system or network activity. As a result, it can detect any suspicious behavior within the cloud environment.
Identity access management: AWS identity constantly helps to make a secure management identity, resources, and permission within a particular scale. AWS has its identity service in the workforce and customer-facing applications. AWS constantly trying to manage its application (Mete & Yomralioglu, 2021).
Compliance status: AWS service constantly checking the comprehensive view of any compliance status. Not only that but also Monitoring the whole environment with the help of an automatic compliance checkup process.
In this way RG Pvt. Ltd can store the data in a safe, secure area. Implementing the above items or rules RG web service infrastructure will be protected.
Remote access share point for authorized users:
Share point is one of the significant document management platforms which is strictly used in different organizations, It can also produce near about 1 billion in revenue. SharePoint also helps to allow the organization and makes information confidential behind of corporate firewall system.
1.SharePoint intranet is mainly added with the users. The external use of this site can also have enough priority to get the internal information of Real Garden Pvt Ltd.
2. Self-hosted share point is one of the keys used to access internal information without using any virtual private network system.
3. It is also very important to create an application with the help of an application proxy. External and internal URLs will be used here to access the share point. There are few steps added here like internal URL, pre-authenticate URL, translation of the URL.
These are the required process needs to be implemented in RG Pvt Ltd for maintaining the remote access to the shared pointer.
5. After the process, the Sign-On mode and Internal application SPN model are used here to make a delegate login identity. User's domain has been checked continuously and select on-premises user names().
.png)
(Source: Kisimov et al., 2020)
Desktop architecture:
Approach to improve the desktop experience for staff:
Virtual desktop is defined as an innovative approach for any company to access the application from anywhere of the company. The desktop cloud can enhance the work from home opportunity. Covid-19 pandemic is gradually increasing the requirement of the virtual desktop category. In this report, few methods will be discussed to improve the desktop experience in the future (Chaignon et al., 2018).
Secure working environment: A hosted desktop solution offers Windows 10 and Windows Server from the different internet-based connected locations. It can make the data or information of the employee more secure. The virtual desktop experience is more comfortable than the office desktop experience.
Reduced cost in virtual desktop: Cloud virtual desktop has their expenditure for actual business. On the other hand, a physical desktop needs a huge amount of hardware, licensing, and management systems.
Consistent productivity: A hosted desktop solution remove the quality of the physical server on an individual site. This virtual desktop platform can also decrease the downtime system. An advance plan is also getting prepared in favor of employees’ satisfaction in RG Pvt. Ltd. Low downtime operation provides efficient operation and generates huge economic revenue (Sen & Skrobot, 2021).
Simplified IT infrastructure: Virtual desktop environments can create simple architecture to connect their 70 stores in one platform. An automation process can increase the quality of any users and running the program insecure manner. A simple and efficient process helps to make the IT team less worried than the previous project. It can also increase productivity within the organization.
Therefore as a researcher, it has been coming out that virtual desktop solution is more efficient for the staff of RG Pvt Ltd.
Amazon workspace vs. Goggle G suits for existing desktop:
Advantages and disadvantages of Amazon workspace and Google G Suite:
Advantages:
a)Amazon workspace is recognized as a virtual private network. Users can also get the advantages of encrypted storage volume from the AWS cloud service. It can also integrate the AWS key management service. Amazon workspace providers can improve the user data and risk service area.
b). Amazon workspace is also very helpful to save the time of operation which multiple computers needed. Amazon workspace is also defined as a cost-effective structure and provides various CPU, memory, and storage configuration.
c). Amazon workspace provides quality cloud infrastructure and manages the global deployment model.
Google G suits advantages:
a). It is very hard for the business owner of the RG Pvt Ltd company to visit multiple places for managing the tools. G Suite admin console helps to solve the issues by managing all devices, security change, and custom domain performance.
b) Google G suit helps to make the data protection capabilities which can preserve the sensitive information stored. Users can access the data as per the requirement.
c). Google G space has enough storage capacity which is restricted by the authenticated user within any organization. The administration head of the organization can send important mail to those people who are bounded within any particular organization.
d) G suit has enough tools like Google hangout chat, Google hangout meet, Google form and google slide. If any employee within the organization can not able to manage the data, the admin can remotely access the data. Then he can make changes to some additional issues.
Disadvantages:
1. When a remote official meeting has happened, G suit had never maintained the picture resolution within the screen. Therefore it can create a barrier within the organization.
2. A single workspace is too difficult for the users’ to manage. As a result, multiple google spaces are required for improving the user access movement.
The disadvantage of Amazon workspace:
a). Though the amazon marketplace is great, it is hard to make a subscription and activate the instance.
b). Tools of the amazon workspace are quite higher than any other software.
c). Experienced users can only identify the correct configuration of the Amazon workspace. Therefore it is very important to use user-friendly software for making the function easier (Damianou et al., 2019).
Analyzing the above advantages and disadvantages of the Google G suite, amazon workspace, the G suit is quite acceptable for employees within the Real garden Pvt. Ltd. Multiple tools are used here to secure the data privacy system. Apart from this thing, remote access to the desktop can be easily done by this software.
Online Blog architecture:
Developing cloud edge solution:
IoT system is one of the useful platforms to connect global users in the market with the help of cloud service. According to the analytics, the business organization has depended on three different resources like Data analytics and cloud computing model (Solozabal, et al., 2018).
The edge computing model is being created with the help of advanced technology and LAN or WAN connection. IoT gateway devices are giving adequate support to improve the cloud computing operation within the system (Dreibholz et al., 2019).
When the edge device is combined with cloud computing technology strength of the local storage and processing capacity will be increased in a rapid manner. Edge computing architecture consists of different materials s which have been discussed in this section. The first thing is distributed computing system, the application process, Different device nodes, Rapid increment of data volume, and increasing traffic. Network connectivity has played a vital role by completing the sliced network and bandwidth management system. These are the required components needs to implement in Regional Garden company to provide better service in favor of customers’ requirement.
Advantages and disadvantages to the regional garden:
Advantages:
Cost reduction: Cloud edge solutions bring the opportunity to reduce the cost structure of any organization or firm. Cloud computing services can only charge the amount at the time of installing the software. RG company should only pay at the server time or space in that use(Cao et al., 2017).
Security: Cloud edge solutions is also become helpful to secure customer information. When a customer placed an order, authenticate user can only access those data or information. Cloud providers are always trying to make software updated. Therefore hackers can not able to access the bank account number or purchasing detail of the consumer (Zhang et al., 2018).
Disadvantages:
Downtime: Cloud edge solutions don’t have any cache memory to store the data when there is any power cut. Sometimes mobiles do have not enough power to complete the order in a cloud secure system. Then RG PVT. Ltd should give additional steps to fix such a problem.
Connection scheduling: Scheduling tasks has become challenging for different nodes. Scheduling tasks should be progressed to execute data processing and maintaining the information in a gentle way.
These benefits and limitations had become faced by the regional garden Pvt. Ltd.
Reference:
.png)
.png)
Essay
MBIS4010 Professional Practice in Information Systems Essay Sample
Assessment Description
This assessment task assesses students’ ability to apply theoretical learning to practical, real world situations. The aim is to help students to understand the benefits of ethical values in their professional life. Modern communication technologies allow for the transmission of opinion to a larger and more diverse audience. To what extent should Australian law limit one person's speech to minimize the impact on another? Prepare a business report on this issue that provides a brief historical background of freedom of speech as a universal human right and outlines some examples of where free speech should be limited. Your essay should be a synthesis of ideas researched from a variety of sources and expressed in your own words. It should be written in clear English and be submitted at the end of week 5 in electronic format as either a Word document of a pdf file. This electronic file will be checked using Turnitin for any evidence of plagiarism. You are expected to use references in the normal Harvard referencing style.
Solution
Introduction
The freedom to hold a personal opinion and impart information, ideas, and knowledge without the interference of any public authority correlates with the concept of freedom of speech (French, 2019). The reinforcement of human rights and laws over the concept of freedom of speech declares the non-violence of rights, and the legislations assure some limitations in the freedom of speech (Bejan, 2019). For Assignment Help However, the universal declaration of human rights regarding the freedom of speech is changing its meaning in the modern communication technology-oriented world where transmission of speech to a larger and diverse audience through electronic mediums has been possible. With this respect, the existing essay will show the responsibility of Australian law to limit the freedom of speech to minimize the adverse impact of an individual's speech over others.
Limiting the concept of freedom of speech
The concept of freedom of speech
Articles 19 and 20 in the International Covenant on Civil and Political Rights advocate freedom of opinion and expression (Ag, 2021). The right to speech freedom includes both the mediums such as oral and written communications. Apart from it, the broadcasting, media, commercial advertisement, and public protest also correspond with the idea of freedom of speech. Modern communication processes include information technology where the restrictions in freedom of speech consist of restricted access to several web sites, urging violence and classification of the art materials. Article 19(1) advocates for the right to freedom of opinion without any interference, and article 19(2) protects the freedom of speech in various communication mediums, be it media or face-to-face communication. In the information communication technology-oriented world, the exercise of the right to freedom of speech includes several responsibilities. It includes respecting the reputations or rights of others and protecting national security for keeping the sanctity of morality. However, the Australian constitution advocates for freedom from government restraint rather than individual human rights. The Universal Declaration of human rights corresponds with the specific legislation and political rights where Australia favours the UDHR and affirms fundamental human rights, including the freedom of speech (Aph, 2019). The fundamental right to speak freely is built upon a history of human rights where the milestones have developed the current status of human rights in various countries and its universal approach.
Limitations to the freedom of speech and relevant legislation
Article 20 of ICCPR in Australia has some mandatory restrictions for the freedom of speech and expression, which relates to the country's existing Commonwealth and legal statuses in various stages, reservation rights are being prioritized. The Australian law related to human rights regulates the publication, display or promotion, broadcast, and content containing violence. For example, the law interferes in copyright violation where the written medium of communication is protected with the right to privacy, and this restricts the access of other users to the authentic content. However, the active vigilance of the legislation restricts fraudulent attempts to copy the content of a writerwhich is a significant benefit of the ethics.Therefore, the law protects human rights and limits the freedom of speech in both written and oral communication mediums in electronic or technical mediums (Hallberg and Virkkunen, 2017).
The materials involved in a specific kind of media, be it films, written or news, require to be verified and approved by the legislation containing article 20 in Australia. For example, films containing child pornography and obscenities are banned by the censor board. Obscenity can lead to violation of human rights and spread a wrong message in society. Australian government limits the publication of contents containing child pornography and obscenity to ensure proper use of the right to freedom of speech and to ensure the non-violence of human rightswhich benefits the people in the country to remain obedient to the laws. Another example is commercial advertisement or expression through media. Commercial advertisements are also specific media of communication in the technology-oriented world where freedom of speech to portray the wrong content in the advertisement can lead to violence of commercial expression (Gelber, 2021). Article 20 in Australia regulates the expression or advertisement of businesses that might prove harmful to society.The step is considerably beneficial in restricting the wrong messages to theaudience.However, the imposed censorship ensures proper classification of the entertainment content where the law limits freedom of speech for social good.
Freedom of speech is closely related to political uprights in a nation. An individual may not induce political chaos by bringing controversial statements in public. For example, during an individual's political opinion in social media, the freedom of speech is restricted to some extent as the speech of violence and criminality are abolished by the law. The proper regulation and observation of information contained in social media ensure the resolution of political violence occurring from freedom of speech (Howie, 2018). Article 20 ensures the approval of public protest in electronic media as it can instigate turmoil and conflict in people belonging from diverse regions and distant locations, which may result in widespread anger and chaos. To restrict any wrongful protest due to the freedom of speech, the Government blocks the path of access to information. This helps to keep peace in public and political environment in the country.
Declaration of law related to freedom of speech ensures obliteration of racial discrimination and religious conflicts (Stone, 2017). For example, due to the emergence of modern communication technology, people from different regions of the world have the scope to mingle where the opinions related to racial differences may hurt an individual community, which can lead to violation of human rights. In the case of religion, the diverse religious background of people has different faiths over their religions where unlawful and negative comments regarding each others' religious faith can lead to creating sensitive issues. So, article 20 in Australiabenefits the public bysecuring the racial and religious grounds through enforcing strict laws and punishment for violation of human rights.
Conclusion
The positive aspects related to freedom of speech allow an individual to express their valuable ideas and options to the public through using modern communication systems which results in the preservation of social rights and well-being. On the other hand, the negative aspects such as violation of human rights concerning politics, religion, race, and other factors may result in chaos, conflicts, and even criminalization. Therefore, limitations in the rights to freedom of speech and expression are required in specific cases to maintain proper sanctity in social structure. Article 20 in Australia promotes proper protection of human rights through restricting the freedom of speech where it can create significant issues for society.
References
.png)
Case Study
BDA60 Big Data and Analytics Sample
Case Study
Big Retail is an online retail shop in Adelaide, Australia. Its website, at which its users can explore different products and promotions and place orders, has more than 100,000 visitors per month. During checkout, each customer has three options: 1) to login to an existing account; 2) to create a new account if they have not already registered; or 3) to checkout as a guest. Customers’ account information is maintained by both the sales and marketing departments in their separate databases. The sales department maintains records of the transactions in their database. The information technology (IT) department maintains the website.
Every month, the marketing team releases a catalogue and promotions, which are made available on the website and emailed to the registered customers. The website is static; that is, all the customers see the same content, irrespective of their location, login status or purchase history.
Recently, Big Retail has experienced a significant slump in sales, despite its having a cost advantage over its competitors. A significant reduction in the number of visitors to the website and the conversion rate (i.e., the percentage of visitors who ultimately buy something) has also been observed. To regain its market share and increase its sales, the management team at Big Retail has decided to adopt a data-driven strategy. Specifically, the management team wants to use big data analytics to enable a customised customer experience through targeted campaigns, a recommender system and product association.
The first step in moving towards the data-driven approach is to establish a data pipeline. The essential purpose of the data pipeline is to ingest data from various sources, integrate the data and store the data in a ‘data lake’ that can be readily accessed by both the management team and the data scientists.
Task Instructions
Critically analyse the above case study and write a 1,500-word report. In your report, ensure that you:
• Identify the potential data sources that align with the objectives of the organisation’s data-driven strategy. You should consider both the internal and external data sources. For each data source identified, describe its characteristics. Make reasonable assumptions about the fields and format of the data for each of the sources;
• Identify the challenges that will arise in integrating the data from different sources and that must be resolved before the data are stored in the ‘data lake.’ Articulate the steps necessary to address these issues;
• Describe the ‘data lake’ that you designed to store the integrated data and make the data available for efficient retrieval by both the management team and data scientists. The system should be designed using a commercial and/or an open-source database, tools and frameworks. Demonstrate how the ‘data lake’ meets the big data storage and retrieval requirements.
• Provide a schematic of the overall data pipeline. The schematic should clearly depict the data sources, data integration steps, the components of the ‘data lake’ and the interactions among all the entities.
Solution
1 INTRODUCTION
Big Data and Analytics have become one the most important technology for the online marketplace. The online market is fully dependent upon the review and feedback of the customer who frequently visits the website. To gain more customers, the organization needs to analyze the overall data regarding the review, sales, profit, user rating etc. to the customers to attract them (Ahmed & Kapadia, 2017). For Assignment Help, Thus, data storing and analysing are important tasks in business intelligence. To conduct these tasks, the organization need to organize the data pipelining for the data effective data management by employing suitable design. In this paper, then big data and the underlying aspects will be discussed for Big Retail using the Data Lake Design and Pipelining (Lytvyn, Vysotska, Veres, Brodyak, & Oryshchyn, 2017).
2 CASE STUDY OVERVIEW
2.1 OVERVIEW OF ORGANIZATION
Big Retain is one of the online retails shops in Adelaide, Australia. It has a large number of products which can be explored by the customer by visiting the website. The organization has detected that they have in an average of 100000 visitors per month who visit and explore the products there. On that website, customers can find various products and they can purchase those by paying the amount. The organization uses to publish the updated catalogue of the products and mail that to the registered users and keep that available on the website. So, the customer can visit the website and can view the available products. They also make the price of the products reasonable compared to the competitors in the market to attract more customers. Their website is maintained by the Information Technology department of the organization.
2.2 PRESENT CONDITION AND PROBLEM
Big Retails has a good number of products that it uses to sell to customers at a reasonable price. However, in recent days, they have faced a big challenge for the significant reduction in the number of customers. They primarily suspect the non-maintenance or non-adoption of the data-driven strategy by which they should have visualized the purchase, sales and marketing scenario of the organization (Lv, Iqbal, & Chang, 2018). To overcome the problem, they have decided to adopt the data-driven strategy for the betterment of the future business. So, they are now interested in the application of Bid Data Analytics so that they can obtain a customised customer experience and the recommender system for attractive more customers towards their business.
3 BIG DATA AND ANALYTICS
3.1 POTENTIAL DATA SOURCES
Big Retails had maintained their data in the server without which the data cannot be managed. As the number of customers was about 100000 per month, the transaction is expected to be huge in terms of website hit, website visit and product purchase. Those customers who purchase the products used to provide the review and rating on their website. So, apart from the business data like sales, profit, marketing etc. they need to maintain those reviews, ratings etc. data as well (Husamaldin & Saeed, 2019). Additionally, those data are also helpful in getting insight into the views and demands of customers regarding the products. So, the data like reviews, ratings etc. in addition to the data like sales, profit, marketing etc. will be required to be maintained and managed in the Bog Data Environment, As the big data environment can be managed for the particularization of the data sources, thus, the organization need to identify the data source (Batvia, 2017). Hence, the data sources for Big
Retail are as follows:
1. Data through Transaction: Big Retails can get the data from the transaction of the customers. It can be achievable concerning the purchase scenario and the website visit by the customers. When the customers will visit the website, and purchase some products, the data should be stored in the Big Data (Subudhi, Rout, & Ghosh, 2019).
2. Data for Customer Demand: When the customer will purchase some product, that product may satisfy or dissatisfy the customers. According to the satisfaction level, customers use to provide their product review and rating for the same products. This kind of data is essential for data analytics and to show the present demand of the products of the customer (Liang, Guo, & Shen, 2018).
3. Data through Machine: Apart from the two sources of data that are mentioned earlier. Another type of data comes from the system of the organizations. This kind of data may contain the historical records of the sales, profits or loss, marketing, campaigns etc.
3.2 CHALLENGES IN DATA INTEGRATION
Data Integration is a sensitive issue in Big Data Analytics. As Big Retail has a large volume of data and they wish to adopt big data analytics, they should be focused on the mitigation policies of the challenges that can be faced by then in the maintenance of the big data (Anandakumar, Arulmurugan, & Onn, 2019). Hence, there is a number of challenges that can be faced by Big Retail. The possible challenges of the Big Data Analytics that may be faced by Big Retails are as follows:
1. Data Quality: When Big Retail will adopt big data analytics for their business, the data should, be collected and stored in real-time by fetching those from the website. To control and maintain the huge volume of data, the quality of data places a significant impact. One of the greatest issues that can be generated during the maintenance of the data quality is the missing data (Anandakumar, Arulmurugan, & Onn, 2019). If the data contains missing values, the data will not be suitable for analytical work and so, the organization cannot operate of data. To get suitable data, the data sources and the data quality both need to be maintained.
2. Wrong Integration Process: The data integration process can connect the big data with the software ecosystem. A trigger-based data integration process allows the integration of the data with several applications that are aligned together. However, this process does not allow the integration of historical data which can be resolved by applying the Two-Way Integration System (Lytvyn, Vysotska, Veres, Brodyak, & Oryshchyn, 2017).
3. Data Overflow: Data should be collected by Big Retails based on the importance. If too much data will be collected regarding features, data can be overflown which is not expected for big data analytics.
3.3 DATA LAKE
A Data Lake can be defined by the repository of data that can accommodate a large amount of data of different formats such as structured data, semi-structured data and unstructured data. The greatest advantage of the application of data lake is that it allows the storage of the data without any limit. In this context, the data storage capacity is made flexible. It also facilitates the organization to store the data with high quality and with data integration (Liang, Guo, & Shen, 2018). These facilities increase the performance of data analytics on the big data which should be the expected scenario of Big Retail when they will adopt Big Data Analytics. Another advantage of the data lake is that it allows the storage of the data in real-time and while storing the data, the process is automated.
The data lake that can be proposed for Big Retail for making the business process smooth and faster is as follows:
.png)
Fig-1: Data Lake Design for Big Retail
3.4 DATA PIPELINE
The design of the data lake has been shown in the last section. The data pipelining can be addressed and demonstrated by emphasizing the data lake model for Big Retail. The process of data pipelining will follow the sequential operation of the data lake architecture (Ahmed & Kapadia, 2017). The data pipelining is discussed below:
1. Data Sources: Big Retail can gather the data by selecting the data source such as its website. Ads the data will be collected from the website, so the data may be the combined format of structured, unstructured or semi-structured.
2. Ingestion Tier: The data can be loaded in the data lake architecture in real-time or through batches as per the requirement (Lv, Iqbal, & Chang, 2018).
3. Unified Operations Tier: The data and the entire data management process will be controlled in this tier. it may also include the subordinate system that can manage the data, the workflow of the data collection and integration etc.
4. Processing Tier: After the data has been processed to the system of Big Retail, the analytics will be applied in this tier. This will facilitate the analysis process of the collected data so that the data insight can be generated (Batvia, 2017).
5. Distillation Tier: In the processing layer, the data of Big Retail will be analyzed using the employed algorithms. However, the processing time for the analytics is faster in the case of structured data. This tier is employed in the data lake to convert the collected unstructured and semi-structured data into structured one for faster analytics (Anandakumar, Arulmurugan, & Onn, 2019).
6. Insights Tier: The architecture of the data lake will employ the database queries on the data for the purpose of data analysis. It will help to compute the customer-based scenario such as sales per period, type of products with higher and lower sales etc.
7. Action: Finally, the architecture will produce visual insight into the data. In most cases, the visual insight may contain the analysis such as Review word cloud, Rating analysis, purchase statistics etc.
4 CONCLUSION
In this paper, big data analytics has been discussed for Big Retail through the implication of data lake and data pipelining. These measures have been seen to be effective in data management and analytics. As the number of customers is consistently decreasing for Big Retail, this architecture will help them grow their future business.
5 REFERENCES
.png)
Reports
MIS605 Systems Analysis and Design Report Sample
Task Summary
In response to the case study provided, identify the functional and the non-functional requirement for the required information system and then build a Use Case Diagram and document set of use cases.
Context
System analysis methods and skills are of fundamental importance for a Business Analyst. This assessment allows you to enhance your system analysis skills by capturing the business and then functional and non-functional requirement of a system. It helps you in identifying “what” the proposed system will do and “how”?
Instructions
1. Please read the attached MIS605_ Assessment 1_Case Study. Note that every piece of information provided in the following case serves a purpose.
2. Once you have completed reading the case study. Please answer the following questions:
Question 1
Identify all the human and non-human actors within the system. Provide brief description against every actor.
Question 2
Using the information provided in the case study, build a Use Case Diagram using any diagramming software.
Note: Please make assumptions where needed.
Question 3
Document all use cases (use case methods). All use cases identified in the Use Case Diagram in Question 2 must be elaborated in detail.
Solution
INTRODUCTION
Nowadays, almost one out of three individuals have developed a habit of reading books. These days readers are reading books using their laptops, phones, and other technologies. For this, a young technopreneur has developed a website named ‘bookedbook.com’. She has developed a website that provides many interesting features for the users. (Tiwari & Gupta, 2015) Starting with the registration, users can launch their books online. Readers can read books of their choice and get some live sessions or events online. Authors can fill book show request forms for advertising their books online. For Assignment Help, They can go live and advertise up to 5 books in one session. Therefore, this website would prove to be an All-in-one platform for the users that mobile application will also be available for the users.
In this study, it is described by describing Use Case Diagram with all the necessary includes and extends.
Answer 1. ACTORS INVOLVED
Human actors
.png)
.png)
Non- Human Actors
Hardware Requirements
The laptop or computer with:
• 2 GB preferred RAM
• Internet Access of at least 60 k
• Minimum screen Resolution of 1026Χ74
• The hard disk of 4GB of space.
• Internet Explorer8.0+, Firefox 4.0+, IE 6.0+, Safari 3.0+. The browser must be Java
• Operating System Window 8, or Vista.
The server will be connected directly with the system of the client. Then the client will access the database of the server.
Software:
• Front end: User and content manager software is built by using HTML and JSP. The content manager interface is built by using Java. (El-Attar, 2019).
• Server: Apache Tomcat application server (Oracle Corporation).
• Back end: Database such as Oracle 11g
Answer 2. USE CASE DIAGRAM
Use case diagram is a diagram that represents graphically all the interactions in the elements of the bookedbook.com website. It represents one of the methods used in system analysis for identifying and organizing all the requirements of the bookedbook.com website. (Zhai & Lu, 2017) The main actors of the bookedbook.com website are system users, book owners, Authors, and Content managers. (Iqbal et al., 2020) They perform several types of use cases such as registration, launch books, create launch reports, management requests, management book, book event management, select ads, book advertisement.
.png)
Figure 1 Use Case Diagram
Answer 3. Use Cases
System User Registration
.png)
.png)
Subscription of readers
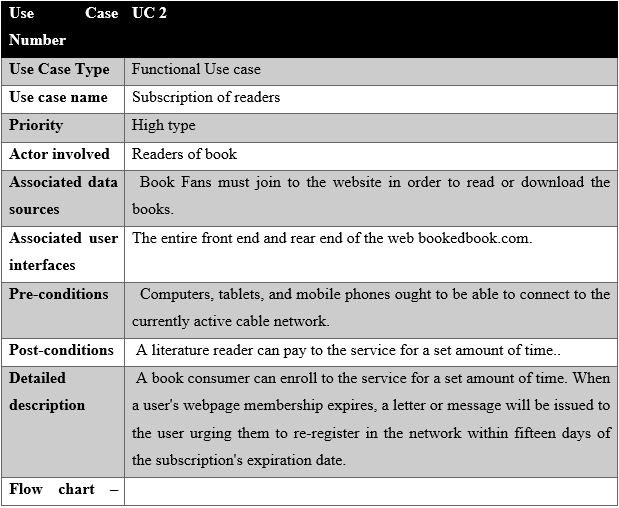

Launching of books


Exchange of books

Live Meetup

Advertisements of book

CONCLUSION
Nowadays, all book readers are adopting the path of reading books online. The system users can get a subscription for the time duration of their choice. They can end the subscription at any time. Using the website users can exchange a book review or comment on the book. The launching of books is another added feature for the users that will attract more and more readers to the website. On the platform, authors can advertise their books. Therefore, it will surely bring a major transformation for all the readers.
REFERENCES
.png)
Reports
MITS5505 Knowledge Management Report Sample
OBJECTIVE(S)
This assessment item relates to the unit learning outcomes as in the unit descriptor. This assessment is designed to assess the knowledge of implementation of a knowledge management solution utilizing emerging tools for stages of knowledge management.
This assessment covers the following LOs
LO3: Conduct research on emerging tools and techniques for the stages of knowledge creation, acquisition, transfer and management of knowledge and recommend the most appropriate choice based on expert judgement on the practical needs.
LO4: Apply and integrate appropriate KM components to develop effective knowledge management solutions.
LO5: Independently design a usable knowledge management strategy by application of key elements of a good knowledge management framework and by incorporating industry best practices and state of the art tools such as OpenKM or other emerging technologies.
INSTRUCTIONS
These instructions apply to Major Assignment only.
Answer the following question based on a case study given overleaf
Give your views on implementation of knowledge management based on five distinct stages of knowledge management:
Stage 1: Advocate and learn
Stage 2: Develop strategy
Stage 3: Design and launch KM initiatives
Stage 4: Expand and support initiatives
Stage 5: Institutionalize knowledge management
Case study: A leading bank of Australia
You have been appointed as a Chief Knowledge Officer in one of the leading investment firms of Australia to accomplish a project which is to develop a knowledge base guide for the customer service staff to provide better services to the customers of the investment firm. Your task would be to implement Knowledge Management system considering tools and techniques and using KM components for the investment firm which can be helpful in providing better services to the customers of the firm and that too in a very efficient manner.
Solution
Knowledge Management System
Knowledge Management, this term means the internal process of creating or sharing a company's information and knowledge. For Assignment help, The primary goal is to make efficiency improvements and retain the secret of the main information within the company(Khan, 2021). Being a Chief Knowledge Officer (CKO), I have to control and manage the information resources of the company or firm. There will be a surety of effective usage of knowledge resources. There are some stages included to work on KM (Knowledge Management). It works efficiently. There are three types of knowledge management such as
• Explicit knowledge - It covers those which can easily be covered in the written way (documents) in a structured manner. It includes raw data, information, charts, etc. It can be used in any job, institution work, or some official work that can be presented to the audience.
• Implicit knowledge - It is the second step of the knowledge after explicit. If we’ve made an airplane then the next step in implicit is how to fly that airplane. This type of knowledge is eliminated from a formal knowledge basis.
• Tacit knowledge - It is a comprehensive and tough language that is not easy to understand easily. It’s difficult to explain straightforwardly. It is learned with time. It’s an informal language learned with experience with time and applied to particular situations(Khan, 2021).
Benefits: Some benefits of Knowledge Management:
• Improvement- It helps in improving the quality of users.
• Satisfaction- It helps to meet the level of customer satisfaction.
• Self-service- It creates awareness regarding self-service adoption.
• Reduction- It reduces time wastage in training, costs, etc.
• Adoption- KM helps to get a faster response in new services.
• Business Demands- Increase response in changing demands of the users (Garfield, 2019).
The implementation of a real knowledge management system in the lading bank of Australia uses five implementation stages that are given below:
Stage 1: Advocate and Learn
Advocacy is the complete first assessment to distinguish knowledge management, address it to people to the leading bank of Australia, and create a fundamental little meeting of knowledge management helpers. The opening need to be provided to the bank staff to get know about KM by practices. It is additionally required to make everyone acknowledge how knowledge management can be aligned with different recent activities of companies. To build knowledge management interesting to the more broad crowd, it is necessary to use basic language to examine openings, genuine problems, and the possible worth that knowledge management addresses. The main cause why the leading bank of Australia has failed is the haste they developed in adopting several resources of financial nature and political nature in planning without any carefulness. When the bank of Australia initiates to create their workers to store knowledge except for transmission & dissemination of the data is the very phase when bank invites failure. Motivating every worker to transfer their formless knowledge may become useless material for the bank of Australia. To get the support of staff, a knowledge management team has to elaborate their aims related to this specific project so that anyone can treat themselves in this. KM team needs to introduce the problems and how the KM plan could help to gain the aim of a team or individual along with the benefits of the KM system. The techniques or tools that support the KM plan may differ. Generally, tools are connected to several categories like knowledge repositories, expertise access tools, search enabled tools, and discussion and chat tools that support data mining (Semertzaki & Bultrini, 2017).
Stage-2: Develop Strategy
It is the second stage of KM implementation in an organization. KM system is to create an approach that needs to be consistent with the aims and objectives of the organization. It is also required to create a KM team that can treat itself into KM system implementation completely. The KM team needs to work on the approach and put this approach in the activity for successful KM system implementation. Moreover, the bank of Australia requires recognizing assets that several be utilize of this strategy. The strategy was initially well-created based on practices that will have to be executed by each member of the KM team by posting investments. Here, we will talk about the pilot of the KM initiative that needs to get from the bank environment (Robertson, 2021). The business needs are required to be formed to install the KM strategy. There are some areas of a bank from that pilot project can be chosen such as:
• Bank area that is not going developing since it absence of knowledge linked to its field then KM can assist to create this field moving forward within the bank.
• And if the new business plan has been addressed to the bank then there will be required of installing the KM so that the workers of the bank can learn new skills linked to KM and the manner to execute jobs in this plan (Simmons & Davis, 2019).
The essential resources for the pilot project are human resources, budget, and project plan that will help its employees and processes realted to KM (Ivanov, 2017).
Stage-3: Design and launch KM initiative
The task force connected to the project has been created, reorganization of the pilot has been complete and the monetary resources with workers are assigned for the implementation of the project. This stage launches the pilot and collecting initial results. By using adequate investments for the whole implementation it is needed at this phase to create methodologies that need to be deployed and replicate measurements to capture and share the information linked to the learned lesson. This stage performs the initialization which needs to take data of specific indicators (Khan, 2021). KM also gets the benefit of using, sharing, and capturing data and knowledge obtained in a definite form. At the initial phase of initialization, we need to release funds for the pilot and allocate a group connected to KM such as a cross-unit team. The next phase is to create methodologies that can ignore and replicate the making of knowledge collections. The last phase of this stage is to capture and record the actions of the learned lesson (Disha, 2019). The budget of the pilot project included staff, man-hours, physical and non-physical resources, and supplies. Overall, the budget of the pilot project will be approximately $1,00,000. Once the pilot project deployment is under implementation and the consequence has been evaluated and assessed then the knowledge management plan will aim at one of the below-given paths:
• Current initiatives would be maintaining the status quo.
• KM efforts would go ahead collecting new initiatives
To get success, any KM initiative needs that you know your people very well and can make them understand things that need to be changed or upgraded. Reducing the duplication of work increases productivity. Tracking customer behaviors enhances the service of customers.
Stage-4: Expand and Support
At this stage, the pilot project will have been implemented and results are collected with some important lessons that are learned and captured. This stage contains actions related to support and expansion for KM initiatives by companies. The main objective of this stage is to develop and market an expansion approach all over the bank and handle the growth of the system efficiently. The initial phase of this stage is to create an expansion approach. To create this strategy there are 2 approaches are the criteria for pilot chosen for functions in different areas of the bank could be implemented or to pertain all approaches all over the knowledge management system. Corporate KM team, practice leader, knowledge officer, and core facilitator team who can handle the system. The second phase is to communicate and market the KM strategies. It could be complete with the support of various means that are broadly disseminating information of KM initiatives around the bank of Australia. The new employee hiring orientation needs to be incorporated with the knowledge management system training. Coordinators and training leaders are needed to teach the hired serviceman regarding the KM system so that they can familiar quickly. The last activity is to manage the KM system’s growth by managing the expansion of KM initiatives that occurs at this stage (Babu, 2018).
Stage-5: Institutionalize Knowledge Management
It is the last step of the implementation of the knowledge management system in an organization. This stage includes outlining the knowledge management system as an essential part of the processes of the leading bank of Australia. At this stage, the bank requires to re-specifying the approach related to the task, revisit assignments, and review the arrangement of its performance. It is also needed to recognize indicators (Disha, 2019. In the presence of one of the below-given terms is there then the knowledge management system is prepared to rock on the last stage of the knowledge management implementation:
• Each member of staff is trained to utilize the Knowledge management tools and techniques.
• Knowledge management initiatives are organized
• If the KM system is linked to the business model directly
There are some actions are taken by the organization to implement the KM effectively such as:
• The first action is to embedded KM within business model. This action is required to get executive and CEO support. It is required to identify budget and organization responsibilities to help exposure implementation of KM like a strategy.
• The second action is to analyze and monitor the wellbeing of KM system regularly. To ensure the KM system is well it is necessary to have the constant intervals pulse KM initiative.
• The third action is to align performance evaluation and reward system with approached of KM. Moreover, it is required to maintain the KM’s framework within the leading bank of Australiaalong with local control. The leading bank of Australia need to know individual groups in various areas to outline KM resources that will acoomplish their local needs.
• The nect action is to carry on the trip of KM. When the bank becomes the suitable knowledge-sharing company, the order for knowledge acquisition would be enhanced.
• The last action of the bank is to detect success feature to keep the KM spirit alive with following factors:
- Availability of motivating and consistent vision
- Capability to maintain full support of leadership (Eisenhauer, 2020).
References
.png)
Case Study
MITS5003 Wireless Networks and Communication Case Study Sample
Introduction
In this assessment you are required to explore the given case study and provide a solution, employing the latest wireless communication techniques. The assessment will help in developing an understanding of communication in wireless networks and the limitations and challenges.
Case Study: Penrith City Council Unwires
Penrith City Council’s charter is to equitably provide community services and facilities to the city of Penrith in Sydney’s west. To do this, the council employs some 1000 full-time and contract staff, who carry out a wide range of roles. While about half of them fulfil management and administration roles in the head office complex, the remainder do not work in the office and many also work outside of regular business hours; these include road maintenance staff, building inspectors, general repairers, and parking officers. With multiple department buildings, a mobile workforce, and a geographically diverse community to serve, the council was looking to improve their communications network to enable them to operate more efficiently by streamlining communication, lowering costs, and boosting productivity. Faced with a flourishing community, limited budgets and ever-increasing demands for services and information, Penrith City Council realised its existing IT infrastructure was holding them back. At the time, the three buildings to be connected by wireless were connected via ISDN at a 64K data transmission rate. With rapidly growing information needs, these links were proving unworkable due to network connectivity problems, unreliable response and speed issues hampering productivity. To share information between departments across the offices, staff were burning large files onto CDs and manually transferring the data, because sending information via the network or email was unreliable and slow. The decision to move to a wireless network was a strategic one for the council, as Richard Baczelis their IT Manager explains; “Located among thick bushland and separated by a river, networking our office buildings has always been a challenge. To solve this, I saw the huge potential of wireless technology; not only to help us today but also to position us well for the future.”
The scope of this report is to develop a wireless network solution for building 1 of the three buildings. The building structure is given in figure 1. The building already has broadband connectivity installed and the scope of the solution will be constrained. The building contains several wireless devices (Printer, Laptop, CCTV) that require high-speed Internet connectivity.
The proposed solution must consider the following criteria:
• Any area where the employee wishes to use the laptop should be less than 100 meters (almost 300 feet) away from the access point.
• Interference is generated by the cordless phone, CCTV, and microwave.
• The proposed network should be cost-effective and,
• The network should be secure.
• Other users on the office network
Solution
Introduction
The city council of Penrith, which has a staff of 1,000 contractual and permanent staff members, is the main administrative body in charge of carrying out numerous social functions and offering resources to a local. Here, network disruption is a serious threat to GSM online services because it affects the standard of communication, which creates and lowers revenue. For Assignment Help, The city council of Penrith decided to switch to the Wi-Fi network in terms of improving communication between the operational buildings and assure the network's integrity so that information may be transferred safely instead of manually because a requirement for local services grows. Therefore, the goal of the Penrith City Council will be to similarly distribute resources and facilities to the traditional western Sydney of Penrith city. On the other hand, the impact of the Wi-Fi network in the Penrith city council will be discussed. After that, the network design will be developed to modify the existing Penrith city council hardware and site design. However, a critical analysis of the network design will be illustrated properly in this report.
Impact of the Wireless network in the Penrith City Council
The impact of Wi-Fi network infrastructure will undoubtedly assist Penrith's city council with enhancing staff mobility and productivity, two factors that are crucial for effective social service. With the development of a protected Wi-Fi network, that will guarantee the confidentiality of the information transmitted via electronic mail as well as other methods of obtaining the company's database, the second major requirement—the ability to move information among various business units be resolved. The appropriate network improvement also guarantees the capability of the city commission personnel to perform their jobs, since the Wi-Fi network enables a broad range of users to access the network, ensuring a better method of offering the service to the neighborhood [2]. The goal of Penrith City Council will be to allocate equally the goods and services to the municipal govt. of a western Sydney of Penrith. The authority employs roughly 1000 permanent and contractual workers to carry out different responsibilities to achieve this. Since most highway repair staff, safety inspectors, general repairers, as well as registration officials operators are outside of regular business days, only about 50% of staff can do administrative and managerial tasks in the main office building.
Furthermore, due to a developing city, limited financial capabilities, and increasing need for data and support, Penrith City Council realized that its existing IT infrastructure was holding back commerce. The three buildings that would subsequently be linked and already have been attached by ISDN, which operates at a 64K bandwidth for data transmission. In order to offer complex approaches for disturbances control inside the parameters of a 5G connectivity system, it is necessary to analyze the advantages of UE methods and learn about recent advancements in internet information concepts. The challenges and effects of these challenges connected to the execution of the proposed disruption control plan have been investigated, with a focus on the growth of the 5G technology. The suggested Wi-Fi structure will also guarantee a cost-effective as well as productive way to deliver a secure server in addition to more options for the network's upcoming improvement and expansion.
Network Design
A network design is crucial to comprehend to obtain a general understanding of the needs that had to be put in place in terms of establishing a service provider database that wouldn't only safeguard the business resources but also guarantee work performance throughout the existing network. This approach demands to be significantly modified in this part since the unregistered spectrum involves specific implementation expertise and measurement equipment than wireless connections. In order to demonstrate some modifications that may be made to improve the safety of the municipal council network system, the customization of the current network architecture for the city council of Penrith has been shown [1]. By allowing them to effectively interact with one another, the established network structure will allow the administrative team and all the employees who support the city council in performing the social service. There is a network design that illustrates how well the city council of Penrith's system has now been updated as follows:
.png)
Figure 1: Modified Network Design
(Source: Author)
Furthermore, to illustrate the change that occurred in the city council's existing network, both a secure and a changed network model have been shown in the following design. The network structure of the city council's complete structure has been depicted in the layout, with the required machines including a gateway, switch, and database systems, as well as the deployment of the firewalls to prevent any data theft—being applied in-depth. The considerations when establishing a Wi-Fi technology. Therefore, Wi-Fi networks experience signal loss when passing via solid surfaces. They may have trouble communicating with each other because of disruption from loud routers. Weather conditions may skew wireless communications. Power issues: Consistent electricity is required for routers to operate effectively.
Critical Analysis
This proposed research conducted a variety of cases based on which it deduced the potential efficiency and effectiveness of the proposed methods. The methods have always been used as a method to solve the relative maximization of non-convex feature problems in the two presented frameworks. The design evaluation is an important step in the creation of a coherent and useful network. The proposed architecture, which would improve the existing network of the city council of Penrith, has already been demonstrated in this study. A firewall has now been incorporated into the network structure to improve data protection and safeguard all equipment from issues with theft and phishing [4]. According to this, firewalls were used in the municipal council tower to control how the networks are distributed throughout each level of the structure, enabling all network-connected devices to operate more easily. It describes developing a decentralized network to achieve power regulation while also effectively developing an equitable technique for system resource efficiency with a confined collaboration amongst flying units. For the integration of the following systems, the first study enhanced the currently used models as well as techniques for network congestion.
The report has highlighted how the chosen designs can influence the evolution of 5G networks as well as the actual challenges associated with their implementation. However, looking at the prospective advantages helps readers comprehend the situations in which the recommended approaches might be helpful. Unfortunately, the paper only employs a few extra studies and focuses on knowledge derived through quantitative information; therefore, there is no proof of the survey's relevance or credibility regarding theories put forth by prior academics. There are staff workers who had to physically carry large files across departments throughout the buildings as well as put them onto CDs while sending data via the internet or e-mails were slow as well as inefficient [5]. These two publications discussed identity verification and innovative system proposals that could help cell network wireless carriers reduce network disruption issues in a communication network. They made a substantial contribution to the advancement of approaches, ideas, and frameworks for network congestion. However, the first component doesn't specifically evaluate the recommended and offered data's relevance and validity to that obtained from previous literary and scientific investigations.
On the other hand, the second section runs multiple models to show the feasibility as well as the relevance of the study's goals and to verify and confirm the information that has been offered. In order to maintain network connectivity for all hardware linked to a similar network or to prevent any conflicts with additional machines that are on the equivalent network, routers including Wi-Fi routers have also been installed on any floors of a city council tower [3]. By adding a Wi-Fi router, the existing network is better able to deliver a variety of network services, which will enable the executive team to handle all the requirements and assist individuals or community leaders in organizing the system of facility provision.
Conclusion
An overview of, "Penrith's City Council Unwires" is the administrative body's responsibility of looking after community assets and rendering numerous functions to the city council of Penrith. Approximately 1000 employees have been employed by Penrith City Council to finish the social service project in this case, with 500 of them being responsible for management-related duties. The city council of Penrith recognized that stronger IT architecture was required to create a better and more efficient network for staff to increase effectiveness as the requirement for community services increased. As a result, Penrith City Council upgraded its network as well as decided to migrate to a Wi-Fi connection to strengthen network connectivity between operational structures and to ensure data protection so that data has been transmitted securely rather than through a manual procedure. This paper has covered the value of Wi-Fi connectivity in securing growth and satisfying city council standards. The categorization of different hardware required for the development, along with a site design to alter the current network architecture used by Penrith's city council, have now been demonstrated in this assessment.
Reference
.png)
Case Study
MIS609 Data Management and Analytics Case Study Sample
Task Summary
Using the concepts covered in Module 3 and 4, write a 2000 words case study report for a real scenario faced by an organisation of your choice.
Context
This assessment gives you the opportunity to demonstrate your understanding of concepts covered in Module 3 and 4 including Business Intelligence, Big Data, Business Analytics, Data Warehousing, Data Mining, AI, Machine Learning. In doing so, you are required to select an organisation and then analyse and evaluate how the above-mentioned concepts can be used to solve a real-life problem.
Task Instructions
Step 1: Select an organisation that you would like to investigate. When choosing the organisation, make sure that you are able to access data from the organisation easily, or the data is available on the web.
Step 2: Write a case study report outlining how the selected organisation has used the concepts covered in Module 3 and 4 to successfully solve a problem faced by the organisation.
Solution
Section 1
Introduction
Westpac was formed in 1817 and is Australia's oldest bank and corporation. With its current market capitalization, Commonwealth Bank of Australia as well as New Zealand has become one of the world's top banks, including one of the the top ten global publicly traded enterprises (WestPac, 2021). For Assignment Help, Financial services offered by Westpac include retail, business & institutional financing, as well as a high-growth wealth advisory business. In terms of corporate governance and sustainability, Westpac seems to be a worldwide powerhouse. For the past six years, they have been placed top in the Dow Jones Sustainability Index (WestPac, 2021).
Reason for Selection
Considering Westpac Group been around for a long period of time, it was a logical choice. Big customer-related knowledge has been a problem for the organisation in its efforts to use big data analytics to make better business decisions. Since the organisation faced hurdles and gained outcomes, it's best if one learn about how they used big data analytics techniques to overcome those obstacles given their massive database.
Business of Westpac
Westpac Group is a multinational corporation that operates in a number of countries throughout the world. Four customer-focused deals make up the banking group, all of which play a critical role in the company's operations. A wide variety of financial and banking services are offered by Westpac, encompassing wealth management, consumer banking, & institutional banking. Over the course of its global activities, Westpac Group employs about 40,000 people and serves approximately 14 million clients (Li & Wang 2019). Large retail franchise comprising 825 locations and 1,666 ATMs throughout Australia, offering mortgage & credit card and short-long-term deposits.
Section 2
Concepts of Big Data
Unstructured, structured, & semi-organized real-time data are all part of the "big data" idea, which encompasses all types of data. It has to cope with massive, complex data sets which are too large or complex for standard application software to handle. To begin with, it's designed to collect, store, analyse, and then distribute and show data. Professionals and commercial organisations gather useful information from a vast amount of data. Businesses utilise this information to help them make better decisions (Agarwal, 2016). Many major organisations use data to produce real-time improvements in business outcomes and to build a competitive edge in the marketplace among multiple firms. Analyzing data helps to establish frameworks for information management during decision-making. Consequently, company owners will be able to make more informed choices regarding their enterprises.
Business Intelligence
The term "business intelligence" refers to a wide range of technologies that provide quick and simple access to information about an organization's present state based on the available data. BI uses services and tools to translate data into actionable information and help a firm make operational and strategic decisions. Tools for business intelligence access and analyse data sets and show analytical results or breakthroughs in dashboards, charts, reports, graphs, highlights and infographics in order to give users detailed information about the company situation to users (Chandrashekar et al., 2017). The term "business intelligence" refers to a wide range of techniques and concepts that are used to address business-related problems that are beyond the capabilities of human people. An specialist in business intelligence, on the other hand, should be well-versed in the methods, procedures, and technology used to collect and analyse business data. In order to use business intelligence to address problems, those in this position need analytical talents as well (Schoneveld et al., 2021).
Data Warehousing
In the data warehousing idea, there are huge reservoirs of data for combining data from one or many sources into a single location. In a data warehouse, there are specific structures for data storage, processes, and tools that support data quality (Palanivinayagam & Nagarajan, 2020). Deduplication, data extraction, feature extraction, and data integration are only few of the techniques used to assure the integrity of data in the warehouse (Morgan, 2019). Data warehousing has several advantages in terms of technology. An organization's strategic vision and operational efficiency can be improved with the use of these technological advantages.
Data Mining Concept
Patterns may be discovered in enormous databases using the data mining idea. Knowledge of data management, database, and large data is required for data mining. It mostly aids in spotting anomalies in large datasets. It also aids in the understanding of relationships between variables using primary data. Furthermore, data mining aids in the finding of previously unnoticed patterns in large datasets. Data summaries and regression analysis also benefit from this tool (Hussain & Roy, 2016).
Section 3
Data Sources
A wide variety of external data sources were explored to gather the information needed for such an evaluation. The term "secondary data" refers to data gathered by anyone other than the recipient of the information. This material comes from a variety of sources, including the official site of the firm, journal papers, books, and lectures that are available throughout the web. A simpler overview is described below:
.png)
Problems Faced
There were a number of issues faced by Westpac Group when it came to collecting and storing data, managing marketing, goods, and services delivery, embezzlement and risk mitigation, absence of appropriate multiple channel experiences, inability to design adequate usage of information strategy, and sharing of data schemes (Cameron, 2014). There wasn't enough assistance from key players for the sector, particularly in terms of finance and board approval for initiatives. In addition to the foregoing, the following critical concerns were discovered:
- Report production or ad hoc queries were typically delayed since data generated by several programmes would have to be manually cleaned, reconciled, and manually coded. Owing to the duplication of work and data, there were also inefficiencies (Cameron, 2014).
- Inconsistent methods for data integration were employed (e.g., push of data into flat files, hand code,. This is also not future-proof because no concepts or approaches were employed to handle emerging Big Data prospects, such as data services as well as service-oriented architecture (SOA).
- There was an error in data handling and data security categories, which resulted in unwarranted risks and possible consequences.
Implementation of the Solution
The Westpac Group was aware that financial services businesses needed to advertise their services and products as a banking sector. When it came to serving consumers and managing customer data across numerous channels, the corporation realised that it had an obligation toward becoming a true, customer-centric organisation. That which was just stated implies that seamless multichannel experiences are available. It was only with the emergence or introduction of big data, notably in the realm of social media, that the bank was able to discover that channel strategies were not restricted to traditional banking channels alone. Before anything else, Westpac set out to establish an information management strategy that would assist them navigate the path of big data (Cameron, 2014). However, achieving such a feat was not without difficulty (WestPac, 2016).
It was determined that the Westpac bank needed better visibility into its data assets. Data warehouse senior System Manager, Mr. Torrance Mayberry recommended Informatica's solution. Torrance Mayberry, a specialist in the field, worked with the bank to help break down organisational barriers and foster a more open and collaborative environment for new ideas. Customer focus was still far off, but Westpac didn't stop exploring the vast possibilities data held, particularly on social media. There was a further increase in the bank's desire to understand its customers in depth. The bank included sentiment analysis within big data analytics as well.
Quddus (2020) said that IBM Banking DW (BDW) was used by Westpac for data warehousing, and that IBM changed the BDW model hybridized version, that was implemented in an Oracle RDBMS, to include the bank's best practises into its DW. As a result, IBM's BDW came to provide a fully standardised and comprehensive representation of the data requirements of said financial services sector. Informatica was the platform of choice for integrating and accessing data. Informatica Metadata Manager was also included in the implementation of Informatica PowerExchange. Informatica platform variant 8.6.1 was used by Westpac until it was updated to edition 9.1 (Quddus, 2020).
An EDW was used as the principal data warehouse architecture, serving as a central hub from which data was fed into a number of smaller data marts that were dependent on it. Analytical solutions for enabling and maximizing economic gain, marketing, including pricing were part of the supply of these data marts. As an example, financial products' price history was saved and managed in the DW, and then sent to the data mart in order to fulfil the analysis requirements for pricing rationalization. Informatica's platform gathered data from the bank's PRM system, that allowed this same bank to quickly refresh its knowledge of fraud and reduce individual risk. Data-driven decision-making at Westpac developed as a result of increased trust in the information provided by the DW, as well as the creation of new business links.
Section 4
Problems Faced in Implementation
Data warehousing (DW) was the first step in Westpac's road to Big Data. Similarly to other large corporations with data-intensive tasks, the Westpac Group has a large number of unconnected apps that were not meant to share information.
- There was a lack of data strategy. The lack of a single version of Westpac's products and clients because critical data was gathered and stored in silos, and dissimilar information utilisation and definitions were the norm; and the inability to obtain a single version of Westpac's products and clients because critical data was gathered and stored in silos, and dissimilar information utilisation and definitions were the norm (Cameron, 2014).
- Due to the laborious scrubbing, validation, and hand-coding of data from several systems, the response time for ad hoc or reporting production requests was sometimes delayed. In addition, there was a lack of efficiency due to the duplication of data and labour
- To integrate data, many methods were used, including pushing information into flat files and manually coding.
- Soa (service-oriented architecture) as well as data services didn't exist at the time; and there were no methodologies or ideas that might be used to handle new big data opportunities; Information security and data handling were classified wrongly, resulting in potentially harmful complications and hazards.
Benefits Realization to WestPac
According to Quddus (2020), Westpac has reaped the benefits of the big data revolution in a variety of ways. According to Westpac's data warehouse, a large number of its business units (LOBs) are now able to get information as well as reports from it (DW). Westpac said that the bank's core business stakeholders started to realise the strategic importance of the bank's data assets therefore began to embrace Westpac DW acceleration. Financing, retail and commercial banking departments in both New Zealand and Australia as well as an insight team for risk analytics as well as customer service were all part of it. It was possible for Westpac to invest in the development of a comprehensive data strategy to guide business decisions by delivering relevant, accurate, comprehensive, on-time managed information and data through the implementation of this plan. Impacted quantifiable goals and results for securing top-level management help as a result of change. In Westpac's view, the project's goals and outcomes were viewed as data-driven. The chance of obtaining funds and board approval for such ventures grew in respect of profit and productivity.
Conclusion
Big data analytics have just placed the company in a functioning stage thanks to the potential future gains or expansions that may be derived from the examination of enormous amounts of data. The Westpac Group anticipates the big data analysis journey to help the banking industry obtain insights according to what clients are saying, what they are seeking for, or what kinds of issues they are facing. The bank will be able to create, advertise, and sell more effective services, programmes, and products as a result of this.
Recommendations
The following recommendations can be sought for
- These early victories are vital.
DW team at Westpac was able to leverage this accomplishment to involve key stakeholders as well as the (LOBS) or line of businesses, thereby increasing awareness of the problem for the company's data strategy by leveraging this internal success.
- To obtain the support of the company's senior management, provide a set of quantifiable goals.
Westpac correctly recognises that quantifying the aims and outcomes of data-centric projects in order to improve productivity and profit enhances the likelihood that certain projects will be approved by the board and funded.
- Enhance IT and business cooperation.
"Lost in translation" problems can be avoided if IT and business people work together effectively.
References
.png)
Dissertation
MSc Computer Science Project Proposal Sample
Section 1: Academic
This section helps Academic staff assess the viability of your project. It also helps identify the most appropriate supervisor for your proposed research. This proposal will be referred to as a point of discussion by your supervisor in seminar sessions.
Briefly Describe Your Field Of Study
For organizations making the change to the cloud, strong cloud security is basic. Security dangers are continually advancing and getting more modern, and distributed computing is no less in danger than an on premise climate. Therefore, it is crucial to work with a cloud supplier that offers top tier security that has been redone for your foundation.
WHAT QUESTION DOES YOUR PROJECT SEEK TO ANSWER?
1. What is data security issues in cloud computing?
2. What techniques are recommended for cloud-based data security
3. Which is the superlative cloud-based data security techniques?
4. What is the cloud-based storage security technique?
5. Which is the superlative cloud- based data security techniques?
6. What is existing security algorithm in cloud computing?
WHAT HYPOTHESIS ARE YOU SEEKING TO TEST?
Now a days, every companies are using cloud based system and these systems are not more secure because very easy to hack that cloud based system and the stolen personal information.
WHAT ARE THE PROBABLE PROJECT OUTCOMES?
• More improve Native integration into cloud management and security systems
• Develop more Security automation
• Data collection on cloud improve more secure and faster
Section 2: Technical
This section is designed to help the technical team ensure the appropriate equipment to support each project has been ordered. It also exists to help you fully ascertain the technical requirements of your proposed project. In filling out this section please note that we do not ‘buy’ major items of equipment for student projects. However, if a piece of equipment has a use to the department beyond the scope of a single project, we will consider purchasing it. Though purchasing equipment through the university is often is a slow process.
Solution
Chapter 1: Introduction
1.1 Introduction
The cloud-based security system consists of a surveillance system that streams the network directly to the cloud with the advantage of being able to view it. The challenging tasks can be done to improve the security system and efficiency and this wireless security system presents drawbacks. Some types of cloud computing systems like private clouds, public clouds, hybrid clouds, and multi-clouds. For Assignment Help, Cloud computing is a new model of computing developed through on-grid computing. This refers to applications delivered as services over the internet and hardware and software system in the data center that gives from services. This service is used for utilizing computer systems and referring to internal centers of data and the term private cloud is used for the internal data centers that have to fulfill the requirement of the business (Al-Shqeerat et al. 2017, p.22).
1.2 Background of the study
Cloud-based security is an advanced and very new concept that known as cloud computing. Cloud security has various advanced level techniques that help deliver crucial data or information in various places or remote zones. It also analysis cloud security which is related to an algorithm in cloud computing. Cloud computing techniques have various a patterns of rules, controls, advanced technologies, and processes. These work as a protector that secures the systems, which are cloud-based. This cloud-based security has a fine structure that holds all data or information and protects it. Cloud computing system delivers data or information with the help of the internet, a very basic medium nowadays. Moreover, cloud-based security has maintained a protocol of cyber security that boosts to secure the whole data or information with help of cloud computing systems. The main features of cloud security are to keep all data secure and private It also maintains online-based information or data, an application which uses increased day by day. Cloud computing works a delivery medium via the internet. It helps to distribute data or information everywhere especially the remote area. It is mainly good secure systems of the remote areas to communicate in various sectors. Various IT-based companies invest capital to develop cloud computing systems and various technologies that describe the algorithms part in cloud computing systems.
1.3 Problem statement
People get access to open the pool of the sources like apps, servers, services, computer networks, etc. This has the possibility of using the privately-owned cloud and improves the way data is accessed and removes the updates of the system. Cloud computing ensures that the data security system increases the flexibility of the employees and organizations. The organization has the capacity for making good decisions to grow the scale of the product or services. Cloud computing system is implemented through the advantages of the business that is moving continuously for adopting new technology and trends. There are multiple challenges of cloud computing services that face the business like security, password security, cost management, lack of expertise, control, compliance, multiple cloud management, performance, etc. the main concern for investing the cloud-based security system is issues because of the data that is store and process by the third party (Velliangiri et al. 2021, p. 405).
People access the accounts that become vulnerable and know the password in the cloud to access the information of the security system. This cloud computing enables access to the application of software over the internet connection and saves for investing the cost of the computer hardware, management, and maintenance. The workload is increasing rapidly through technology, improving the tools of the cloud system, and managing the difficulties of this system and demand for the trained workforces that deal with the tools and services of the organization. This system is mainly based on the high-speed internet connection and incurs a vast business losses for the downtime of the internet (Chiregi et al. 2017, p.1).
1.5 Aim and objectives
The aim of the study is determining techniques and algorithms of cloud-based security systems.
Objectives:
- To determine the techniques of cloud-based security system
- To describe the security algorithm that is helpful for cloud computing
- To access the data sources of cloud security system
- To examine the proper security algorithm for this system
1.6 Research questions
Research questions of this research are illustrated below:
- What are the different techniques associated with cloud-based security?
- How can security algorithms be beneficial for cloud computing?
- How can data source be accessed in cloud security system?
- What are the ways of managing security algorithms in this system?
1.7 Significance of the research
Research Rational
Cloud computing is mainly used for sharing data from one place to another place so that it needs various protection to secure the data. Mainly, sometimes there have some important or private data that needs to secure using the cloud computing systems. It has various advanced-level techniques that help to develop the algorithm parts of cloud computing. It is majorly used in the methods of the internet so that there have high risks in cloud computing systems. The most common issue of cloud-based security systems are data or information visibility and stealing data from cloud computing security. For that reason, consumers are worried about using cloud-computing systems (Mollah et al. 2017, p. 38).
The cloud computing system works as a service provider, which provides services to hold data as backup. This is an essential part because every company or consumer uses cloud systems as internal storage. For this purpose, it needs to secure and maintain proper protocol so that recover the issues of cloud computing systems. It covers up the old traditional patterns that use people so secure the cloud computing system is mandatory. Cloud computing systems are internet-based system. There has a high risk to create various issues nowadays. Mainly, protecting privacy is the main motive of cloud-based computing systems (Spanaki and Sklavos, 2018, p. 539).
In the current days, cloud-computing systems are the topmost security service provider so that it has various issues that increase day by day. Lacks of resources, internet issues are major reasons so that cloud-computing systems are affected very much. Data stealing is a very common way so that creates issues in cloud computing systems only for using the internet to use cloud-based security technologies (Pai and Aithal, 2017, p. 33).
According to the researcher's opinion, the cloud computing system is one of the most popular systems used in various sectors worldwide to progress the entire system. The user mainly faces data security issues, password-related issues, connection issues of the internet, cost management of using cloud computing systems, various management issues, and data control issues. These all issues are increased very much in current conditions. Sometimes it crosses its limitation and joins with various kinds of unethical issues, which are sometimes reaching out, to controls to manage. The researcher also notices that various technical issues are based on the cloud computing systems and affect the management sectors of cloud computing systems. It is difficult for a user who uses a cloud computing system to identify the location where access their services (Malhotra et al. 2021, p. 213).
This study observes a higher level of significance as cloud security is one of the most effective technologies that are considered by the business. This study is important for developing the infrastructure of the business, and it offers data protection to different organizations. Cloud security is identified to be a proven security technique, and that it helps in offering identity and authenticity of different data information. It also ensures the individual with overall control and encryption of the presented data information. Furthermore, this study is to present empowerment to individuals so that activities of data masking and managing integration in the obtained data can be managed (Elzamly et al. 2017). This study ensures a significant enhancement in the application of cloud computing, as the data activities tend to observe encryption in developing data security features. The organization is known for developing cloud-based security systems as it offers individuals backups, and it offers individuals with redundant storage. It is also known for developing the visibility and compliance level of the entire security system, and individuals are known for managing effective computer-based security. The entire organizational process observes enhancement in the overall computer-based security system, and it helps in managing an effective network protection system.
This research is to focus on developing the encryption level of the study, and that it is necessary for individuals in managing effective cloud provider services. Information has also been offered regarding the process of developing the enhancing overall infrastructure security, as the major areas are physical security, software security and infrastructure security. Moreover, this study is likely to ensure that the data cannot get leaked and it also helps in reducing the chances of data theft and it helps in ensuring protection to customer details, it is also important for offering security to the assets of the business (Chiregi and Navimipour, 2017). Cloud security is also important for developing the overall competitive advantage level of the business. The cloud security system is observing higher demand in the competitive market, as it ensures the users with around the clock axis, and it ensures teh users with higher availability of data information. This system is also known for managing higher protection of DDoS attacks and it ensures the individuals with a higher level of regulatory compliance.
1.8 Summary
This paper describes the technology and algorithms of cloud-based data and how this help the security system. This part holds the introduction of the given topic and many of the technique names. The problem statement, aims, and objectives are also described here through the researcher. Many of the challenges are to have a brief discussion on this part of the paper. This section of the study has clearly described the background of the study, as it has offered data regarding the necessary elements of cloud security. This section has further described the research questions of the study that are to be met in the course of the research. Information has further been presented regarding the significance of the research, as it has highlighted the growing demand for cloud security usage in the competitive market.
Chapter 2: Literature Review
2.1 Introduction
Data protection is one of the major concerns in these present days. Without it, it would be impossible for organizations to transfer private datasets. Magnitude is one of the main reasons that keep the datasets safe and they have to build some proven security techniques so they can protect all the datasets present in the cloud. Authentication and identity, encryption, secure deletion, data masking, and access control are some of the major data protection methods that show some credibility and effectiveness in cloud computing. Basic data encryption should not be the only solution when it comes to being based on this matter; developers need to focus more on the other functions also (Alrawi et al. 2019, p. 551).
In this case, it can be said that the public and private clouds lay in a secure environment but it is not impossible to attack all the datasets present in the cloud system. Every organization has the responsibility to protect their datasets via implementing various algorithms in their security system. Cloud security involves some procedures and technologies that help to secure the cloud-computing environment to fight against internal and external cybersecurity threats. It helps deliver information about the technologies that provide services in the entire internet system. It has become a must thing to do because it has helped the government and the organizations to work collaboratively. It has accelerated the process of innovations in organizations (Chang and V. 2017, p. 29).
Cloud computing security refers to the idea of technical disciplines and processes which have helped IT-based organizations to build a secure infrastructure for their cloud system. With the help of a cloud service provider, those organizations can work through every aspect of the technology. They can show their effectiveness in networking, servers, storage, operating systems, middleware, data and applications and runtime.
2.2 Background of the study
Cloud computing is not a new concept; it is an old method that has helped in delivering information and services in remote areas. It has helped those areas by creating some analogous ways for electricity, water and other utilities so the customers can lead a life with no worries. Cloud computing services have been delivered with the help of the network and the most common of them is the internet. As the days keep passing by the technologies have started to get implemented in the cloud computing services. The electric grid, water delivery systems, or other distribution infrastructure are some of the most common services provided by the cloud computing service in remote areas (Chenthara et al. 2019, p. 74361).
In the urban areas, it has shown some of its services and helps the customers to get satisfied with it. It can be said that in some ways cloud computing has become the new way of computing services and has become more powerful and flexible to achieve their key functions. There have been some reasons that caused ambiguity in cloud computing so it can be said that people can become uncertain because of those ambiguities. The National Institute of Standards and Technology has thought that it would be better if they start to develop standardized language so they can help people to understand the main aim of cloud computing and clear up all those ambiguities that caused the uncertainties (Chiregi et al. 2017, p. 1)
Since the year 2009, the federal government has tried to shift their data storage so they can enjoy the cloud-based services and created bin-house data centers. They have intended to achieve two specific goals while doing this and one of them is to reduce the level of the total investment that has been made by the federal government in IT-based organizations. The second objective is to understand the whole plot of advantages that can be caused by cloud adoption. However, the challenges stayed the same while the organizations have made changes in their cloud-shifting procedures. According to the recent surveys it can be seen that they have tried to state the advantages of cloud computing services (Cogo et al. 2019, p. 19).
Those advantages are efficiency, accessibility, and collaboration, rapidity of innovation, reliability, and security. The federal IT managers have stated that they are very concerned about the security of the cloud environments but they cannot immediately eliminate those threats. They need some time so they can implement betterment in their services. Some qualities that can be seen only in this service are that it is easier for the users to get access to its services when it is very necessary. They can easily get access to the capabilities of this service and they can change the analogy from one source to another (Geeta et al. 2018, p. 8).
The broad network access is available in this service and that is one of the finest qualities this service has because it can be impossible for the users if they got tied into one location to access their services. In addition, it can measure the amount of their provided services so it can become easier for the users.
2.3 Types of Cloud Computing
There are mainly 4 variants of cloud computing private clouds, hybrid clouds, public clouds, and multi-clouds.
Private clouds
Private clouds are generally explained as cloud environments that provide full dedication for a group or single-end user. It mainly happens where the environment takes participation from the back of the user or firewall of the group. A cloud are explainable as a private cloud when the bottom line infrastructures of the IT concentrate on a single customer and provide isolated access only to the user (Sadeeq et al. 2021, p.1).
However on-perm IT infrastructure resources are no longer required for the private clouds. These days’ organizations are implementing private clouds for their systems on rent. Vendor-owned data concentrates on the placed off-premises, which makes absolution for every location and every ownership of the users. This also leads to the private sub points that are:
(i) Managed private clouds
Customers establish and apply a private cloud that can be configured, deployed, and managed with the help of a third-party vendor. Managed private clouds can be a cloud option of delivery that guides enterprises with under skilled or understaffed teams of IT for providing better private cloud infrastructure and services to the user.
(ii) Dedicated clouds
It refers to an A cloud that is included in another cloud. A user can have a dedicated cloud depending on both a public cloud and a private cloud. As an example, a department of the accountant could have their personal dedication cloud included in the private cloud of the organization (Sadeeq et al. 2021, p.1).
Public Clouds
Public clouds are the typical environments of the clouds created through the infrastructure of IT, which is not owned by an end-user. Fee largest providers of the public clouds have consisted of Amazon Web Services (AWS), Alibaba Cloud, IBM Cloud, Google Cloud, and Microsoft Azure.
The classical form of the public clouds used to run off-premises, but the recent structures of the public clouds providers saturated offering the user or clients cloud services that are concentrated on the centre of on-premise data. The implementation of this has made distinctions of ownership and location obsolete.
When the environments were divided and redistributed for the different tenants all clouds become or act like public clouds. Fee structures characteristics now became less mandatory things for the providers of the public clouds as the providers started to provide access to the tenants to make the use of their clouds free of cost for their clients. An example of the tenants can be Massachusetts Open Cloud. The bare-metal infrastructure of IT used by the providers of public cloud is abstracted and can be sold in the form of IaaS or it can be improved involved in the cloud platform, which can be sold as PaaS (Uddin et al. 2021, p.2493).
Hybrid Clouds
A hybrid cloud can be explained as a single IT environment established through the help of the multiple environments that are linked with the help of the wide-area networks (WANs), virtual private networks (VPNs), local area networks (LANs), and APIs.
Multi clouds
Multi-clouds are the approach of the clouds, which is established for working with more than one service of the cloud. These services can be generated from more than one vendor of the clouds that are public or private. All hybrid clouds can be considered as multi-clouds but not all the multi-clouds can be considered as hybrid clouds. It takes actions like hybrid clouds when many clouds are linked through some integration form or orchestration.
An environment of multi-cloud can exist on purpose to control in a better way of the sensitive data or as storage space redundant for developed recovery of disaster or due to an accident; generally, it provides the outcome of the shadow IT. Implementation of multiple clouds has become a common process across all the enterprises throughout the entire world that are concentrating to develop their security system and performance with the help of an expanded environmental portfolio (Alam et al. 2021, p.108).
Figure 2.1: Types of Cloud Computing
(Source: self-created)
2.4 Types of cloud security
Several types of cloud security can be seen and they are Software-as-a-service (SaaS), Infrastructure-as-a-service (IaaS), and Platform-as-a-service (PaaS).
Software-as-a-service (SaaS)
It is a software distribution model that can provide cloud systems with host applications and makes them easily accessible to the users. It is one type of way out of delivering the applications with the help of internet services. It does not maintain and install software instead; it gives easy access to the users so they can understand the nature of complex software and hardware management. One of the main functions of this cloud security system is to allow the users to use cloud-based applications so they can get every service from the internet. The common examples of these functions are emails, calendars, and other official tools. It can provide the users with a proper software solution if they are facing troubles regarding that. It can be purchased as a purchased service to the users based on a subscription. There is no requirement for additional software to get installed in the system of the customers. The updates of this cloud security model can get done automatically without causing an intervention.
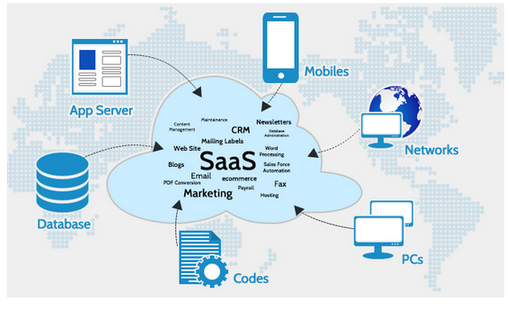
Figure 2.2: Software-as-a-service (SaaS)
(Source: researchgate.net, 2021)
Infrastructure-as-a-service (IaaS)
It is that kinds of model that offers services based on the computing system to the users. It can offer essential services that are important for the storage and networks of a device and become very useful to the users. It can deliver essential information by delivering virtualized computing resources over the entire internet connection. It is a highly automated service that can be easily owned by a resource provider and can give compliments to the storage and network capabilities of a devices. This cloud security system can host the main components of the entire infrastructure of the world in the on-premise data centre. This service model includes some major elements like servers, storage and networking hardware, virtualization which is also known as the hypervisor layer. In this mode, third party service providers can easily get access to the host hardware. In addition, they can get the services that have the ways to operate the system, server, storage system and several IT components that can help deliver a highly automated model (Singh et al. 2017, p. 1).
Figure 2.3: Infrastructure-as-a-service (IaaS)
(Source: diva-portal.org, 2021)
Platform-as-a-service (PaaS)
It is also a cloud-computing model that can provide several hardware and software tools to third-party service providers. A completely developed technology can improve the entire environment of a cloud system. It can enable all the resources in that system and by doing that it can deliver all the applications to third parties. It can provide a platform for the further development of software. As a platform, it can solve all the requirements for the third parties so they enjoy cloud-based tools for software and hardware. It has the opportunity to host an infrastructure that can be applied in the cloud system and works well than the in-house resources. It can virtualized other applications so the developers can help the organizations by creating a better environment for the cloud systems of the organizations.
Figure 2.3: Platform-as-a-service (PaaS)
(Source: ijert.org, 2021)
2.5 Areas of cloud security
Several key areas can be seen in this matter and they are
i) Identifying the access management system
It is the core point of the entire security system so it is very important to handle because if any datasets got leaked from this system then it would be harmful to the users or for tube organizations. They need to have some role-based principles so they can easily have some privileges to get access to the control implementation. It can handle some major key functions like password management, creating and disabling credentials, privileged account activity, segregation of environments and role-based access controls.
ii) Securing the information of the datasets present in the cloud system
For the purpose of securing all the present datasets in the cloud system, the developers must understand the vulnerabilities that the system has. They can implement the models so they can easily get access to the main system without getting into any kind of trouble in the network. They can have proper interactions with the resources and can collect valuable information about the cloud system.
iii) Securing the entire operating system
For the purpose of securing the datasets present in the cloud system, it is needed to be implemented in the cyber and networking system of the devices. It can support the providers by giving the proper configurations so they can easily handle all the algorithms in cloud computing.
iv) Giving protection to the network layers
This point is all about protecting the resources from unauthorized access in the system. It can become a challenging task so the developers need to be cautious so they can easily understand the connection between the resources and get a brief idea about their requirements.
v) Managing the key functions of the entire cybersecurity system
Without the help of a proper monitoring program, it would be impossible for the developers to understand the requirements of the entire cloud system. They cannot have the insights to identify the security ingredients of if anything is wrong in the cloud system without properly monitoring it. The implementation of a monitoring program is a crucial matter because it cannot get easily done and it needs the help of the operational sights to fulfil its functions. It can enable the notification system if anything suspicious occurs in the venture system and can send signals to the resources easily in that way (Riad et al. 2019, p. 86384).
Figure 2.5: Areas of cloud security
(Source: researchgate.net, 2021)
2.6 Pros of cloud security
Several advantages cloud security systems have in the matter of cloud computing and are, they can protect all the datasets from DDoS (Distributed denial of service attacks). As they have risen in this present situation, it has become necessary to stop the huge amount of incoming and outgoing traffic. So it is one of the best functions that cloud-computing systems have and it can protect all private information that way. In the increasing era of data breaches, it has become necessary to create some protocols so they can protect the sensitive information of the users and the organizations. Cloud computing can provide solutions so the users can easily understand that if it is time to turn up or down so many third parties would not be able to intervene when they are browsing anything on the internet. It can provide the system with high flexibility and availability that includes continuous monitoring over the entire system (Majumdar et al. 2018, p. 61).
2.7 Cons of cloud security
It has the major issue of data loss because sometimes if any natural disaster occurs then the system can lose its sensitive information. It has the major disadvantage in inside theft because if anyone would steal private data then it would not be able to check the identity of that person. Data breaching is also an issue in cloud computing services. The cloud computing system can lose its control over the system at any time so it is not impossible that if they have the responsibility of securing the entire network system but they can leak all the datasets at any moment (Punithavathi et al. 2019, p. 255).
2.8 Types of security algorithms
Several types of algorithms can be of help in this matter and they are: RSA algorithm, Blowfish Algorithm, Advanced Encryption Standard (AES), Digital Signature Algorithm
(DSA), Elliptic Curve Cryptography Algorithm, El Gamal encryption, Diffie Hellman Key Exchange, homomorphic algorithm and more
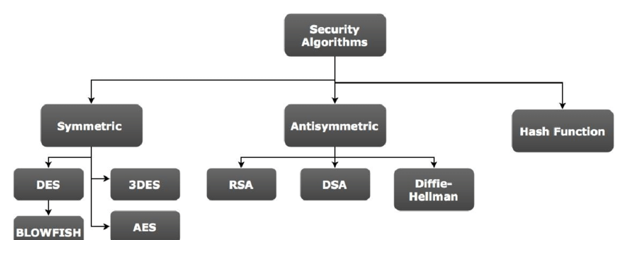
Figure 2.6: Types of security algorithms
(Source: slideshare.net, 2021)
2.8.1 RSA algorithm
The RSA algorithm can be referred to as an asymmetric cryptography algorithm that refers to the meaning applied by both public and private keys. These links are the two different mathematical linked keys. According to their name, public keys are sharable publicly while private keys maintain secrets and privacy. This key cannot be shared with everyone and needs authentication access. Only the authorized user can use this link for his or her own purpose.
2.8.2 Blowfish Algorithm
Blowfish is an initial symmetric encryption algorithm established by Bruce Schneier in 1993. Symmetric encryption applies a single encryption key for both decrypts along with encrypting data (Quilala et al. 2018, p. 1027). The sensitive information and the key of symmetric encryption can be utilized under an encryption algorithm for transforming sensitive data into ciphertext. Blowfish with the help of successor Twofish takes participation in the replacement process of Data Encryption Standard (DES). However, the process was failed because of the small size blocks. The block size of the Blowfish is 64, which can be considered without any security. Twofish takes participation in fixing this issue with the help of a 128-size block. In Comparison to the DES, Blowfish is much faster; however, it can be traded in its speed for providing security (Quilala et al. 2018, p. 1027).
2.8.3 Advanced Encryption Standard (AES)
The AES algorithm, which is also referable as the Rijndael algorithm works as an asymmetrical block cipher algorithm that works with plain texts, included in the block of 128 bits (Abdullah and A. 2017, p. 1). It helps to convert chase data to cipher text by applying the key of 128, 192, and 256 bits. Until the moment the AES algorithm has been considered as a secure application, application of it got popular on the standard spread worldwide (Nazal et al. 2019, p. 273).
2.8.5 Elliptic Curve Cryptography Algorithm
Elliptic Curve Cryptography is a technique that depends on the keys to encrypt data. ECC concentrates on the pairs of the private and public keys to encrypt and decrypt the web traffics. ECC is discussed frequently in the context of RSA Cryptography algorithms. It uses large prime numbers. It focuses on the elliptic curving theory that is applicable for creating smaller, faster and more Cryptography algorithms that provides more efficient keys (Gong et al. 2019, p. 169).
2.8.6 El Gamal encryption
The ElGamal encryption system included in cryptography, that is referable as an asymmetric key encryption applicable for public-key cryptography that concentrates on Diffie–Hellman key exchange. It focuses on the public key encryptions.
2.9 Characters of cloud computing
2.9.1 Cloud security storage
Cloud security is a set of technologies that protect the personal and professional data stored online. This applies the rigor of the premise’s data centers and secures the cloud infrastructure without the help of hardware. Cloud strong services and providers use the network for connecting the secure data centers to process and store the online data. There are four types of security storage like public, private, hybrid, and community.
Public clouds
Cloud resources as hardware, network devices, storage are operated through the thyroid party providers and delivered by the web. Public clouds are common and used for office apps, emails, and online storage (Mollah et al. 2017, p. 38).
Private clouds
The resources for the computing clouds are used especially for the organization and located in the premises data center or hosted by the providers of third-party cloud services. The infrastructure is maintained through the private network with the hardware and software.
Hybrid clouds
This implies the solution that combines private clouds and public clouds. Data and applications move through the private and public clouds for better flexibility and deployment options (Radwan et al. 2017, p. 158).
Community cloud
Through the use of groups who have the objectives share the infrastructure of multiple institutions and handle them by the mediator.
2.9.2 Security algorithm in cloud computing
There are five types of security algorithms like Hash Message Authentication Code (HMAC), Secure Hash Algorithm (SHA), Message Digest Version (MD5), Data Encryption Standard (DES), and Cipher Block Chaining (CBC). HMAC is a secret key algorithm that provides data integrity and authentication by the digital signature that keyed the functions of products. The MD5 algorithm is a hash function that produces a 128-bit value and SHA is a hash function that produces the bit value 160 and virtue of the growth of the value. This is secure but requires a longer processing time. DES is an encryption algorithm that the government is using to define as the official standards and breaks a message into the 64-bit cipher blocks. DES applies exclusive OR operation to each of the bit values with the previous cipher block before this key. The secure algorithm is used for the processing time of the required algorithms (Tabrizchi et al. 2020, p. 9493).
2.10 Benefits of cloud computing
2.10.1 Reduce cost
Cloud computing gives the facility to start a company with less initial costs and effort. These services are shared through multiple consumers all over the world. Its reduced cost of services through the huge numbers of consumers and chargers amount depends on the infrastructure, platform, and other services. It also helps the consumers to reduce the cost by proper requirements and easily increase or decrease the demand of the services and products for the performance of the company in the markets (Jyoti et al. 2020, p. 4785).
2.10.2 Flexibility
This cloud computing is assisting many companies to start the business by small set up and increase to the large conditions fairly rapidly and scale back. The flexibility of the cloud computing system allows the companies to use the resources at the proper time and enable them to satisfy the demand of the customers. This is ready to meet the peak time of requirements through setting the high capacity servers, storage, etc. This has the facilities that help the consumers to meet the types of requirements of the consumers of the size of the projects.
2. 10.3 Recovery and backup
All the data is stored in the cloud and backed up and restored the same which is easier than storing the physical devices. Many techniques are recovered from any type of disaster and efficient and new techniques are adopted by most cloud services providers to meet the type of disaster. The provider gets the type of technique and supports the faster than individuals set up the organization irrespective of the limitation in geography (Sun and P. 2020, p. 102642).
2. 10.4 Network access
These cloud services deliver an open network and can be accessible the services in any time and from anywhere in the world. The facilities can be accessed by different types of devices like laptops, phones, PDAs, etc through these services. Consumers can access their applications and files anytime from any place through their mobile phones. This also increases the rate of adaptation of technology of cloud-based computing systems (Singh et al. 2019, p. 1550).
2. 10.5 Multi-sharing
Cloud computing offers the services by sharing the application and architecture over the internet and this help multiple and single users by multi-tenancy and virtualization. The cloud is working in distribution and sharing the mode of multiple users and applications can work effectively with the reduction of cost at the time of sharing the infrastructure of the company.
2.10.6 Collaboration
Many applications are delivering the effort of multiple groups of people who are working together or together. This cloud computing gives the convenient oath to work with a group of people on a common project in a proper manner (Shen et al. 2018, p. 1998).
2.10.7 Deliver of new services
This cloud system gives the services of multinational companies like Amazon, IBM, Salesforce, Google, etc. These organizations easily deliver new products or services through the application of cloud-based security systems at release time. This helps the process of converting data into a proper form and using the key to choose the proper algorithm.
2.11 Challenges of Cloud computing security
Cloud computing security alliance was directly handled by the professionals that are applicable for the company. However, it is not a split thing and can provide many challenges at the time implementing these security services for an organization. These challenges are mentioned below:
(i) Data breaches
Responsibility of both cloud service providers and their clients breaches of the data and there are proving in the records of the previous year.
(ii) Inadequate and Miss-configurations control of change
If the setup of the assets was positioned incorrectly, they can create vulnerable attacks.
(iii) Lack of proper architecture and strategy of the cloud system
Jumping of multiple organizations in a cloud without having an accurate and proper strategy or architecture in the palace the application of cloud security can be difficult (Bharati et al. 2021, p.67).
(iv) Insufficient credential, access, identity, and key management
These are the major threats of cloud security it leads to identity and access management issues. The issues can be like protection of improper credentials, lack of cryptographic key, certificate and password relation that can be performed automatically, scalability challenges of IAM, weak passwords used by the clients, and the absence of the multifactor authentications of the users.
(v) Hijacking of Account
Account hijacking of the cloud is the disclosure, expose, and accidental leakage or other cloud account compositions that are difficult to operate, maintain or administrate the environment of the cloud.
(vi) Insider threats
Insider threats are linked with the employees and other working networks included in an organization can cause challenges like loss of essential data, downtime of the system, deduct the confidence level of the customers, and data breaches (Ibrahim et al. 2021, p.1041).
(vii) APIs and Insecure interfaces
Cloud service providers’ UIs and APIs help the customers for making interact with cloud services and some exposed continents of the cloud environment. Any cloud security system begins with the quality of the safeguarded and is responsible for both Cloud Service Providers and customers.
There are also other threads that can be happen in the implementation of the cloud security such as Weak controlling plane, Failures of Met structure and apply structure, Cloud usage visibility limitations, Abuse and nefarious applications of cloud services (Malhotra et al. 2021, p.213).
(viii) Risks of Denial service attacks
A denial of service (DoS) attack can be referred to as an attempt for making service delivery impossible for the providers. A DoS attack on the system when the system is also repeatedly attacking and a distributed denial-of-service or DDoS take participation on for attacking multiple systems that are performing attacks. Attacks of Advanced persistent denial of service or APDoS attacks set their target on the layer of an application. In this situation, the hackers got access to hit directly on the database or services. This can create negative impact on the customer handling of the company.
(ix) Risks of Malware
Malware mainly affects the cloud servers of the provider as it affects the on-perm systems. Entices of the attacker get access while a user clicks on a malicious attachment included in an email or the links of social media, as it enables access to the attackers for downloading encoded malware for bypassing design and detection for eavesdropping The attackers steal the storage of the data included in the cloud service applications. It compromises the security of the authentic data.
2.12 Mitigation Techniques
Cloud computing security implementation can cause many challenges for professionals and organizations. It can reduce the potentiality and the image value of the company to their potential clients. A professional can have many challenges however; here some of the mitigating techniques of some of the challenges are mentioned by the scholar. Mitigation of the previously mentioned risks can be done by following some practices that are different for each potential risk. These mitigating practices are mentioned below.
2.12.1 Mitigating the risk of Data breaches
Problems of the data breaches can be solved with the help of the below-mentioned aspects :
(i) The company needs to develop the usage and permission policies of a wide computing company cloud security (Thomas et al. 2017, p. 1421)
(ii) The company needs to add multi-factor authentication.
(iii) Governance implementation for data access
(iv) Centralized logging enables for creating easy access to the logs for the investigators during a specific incident
(v) Implementation of data discovery and classification
(vi) Giving access to the analysis of user behaviors
(vii) Establishments of data remediation workflows
(viii) Implementation of DLP in the system
(ix) Outsourcing of the breach detection by applying a cloud access security broker (CASB) for analyzing the outbound activities
2.12.2 Mitigating risk of Mis-configuration
The below-mentioned practices will help the professional to mitigate the mis-configuration risks:
(i) Configurations of establishing a baseline and configuration of regular conduct audit for observing to drift away gained from those baselines.
(ii) Application of continuous change observing for detecting suspicious modifications and investigating the modifications promptly it is important for the modifier to know the exact modified settings along with the questions of when and where it occurs apparently.
(iii) Keeping information on who is having access to which kind of data and continuous revision of all the effective access of the user. Require information owner’s assets that the permission is similar with the role of the employees and matches perfectly with it.
2.12.3 Mitigating the Risk of Insider Threats
Insider threats can be mitigated if the organization follows certain practices that are highlighted below:
(i) Immediately de-provision access to the resources whenever a person makes changes in the system (Safa et al. 2019, p. 587).
(ii) Implementing data discovery and modification of the technologies
(iii) Observing the privileges that users are having with separate accounts
(iv) Implementation of the user behavior analytics. It generates a profile for baseline behavior
2.12.4 Mitigating the risk of Account Hijacking
Account hijacking can create major issues for both professionals and users. This problem can be mitigated as follows
(i) Implementation of access and identity control
(ii) Application of multi-factor authentication
(iii) Requirements of the strong passwords
(iv) Observing the behavior of the user
(v) Revoking and recognizing the excessive external access for a piece of sensitive information.
(vi) Eliminations of the accounts that are still unused and credentials
(vii) Principle applications for the minimum amounts of privilege
(viii) Taking control of the outsider third party access
(ix) Providing training to the employees on the prevention process of account hijacking
2.12.5 Mitigating risk of Service attack denials
For mitigating this type of risk, the companies need to make a structure of network infrastructure through a web application firewall. It can be solved also with the implementation of the content filtration process. Application of the load balancing for recognizing the potential inconsistencies of traffic is very essential for mitigating the problem.
2.12.6 Mitigating risks of Malware
This type of risk can be seen most commonly Best practices for mitigating Malware risk included in the company system are highlighted below:
(i) Solutions of the antivirus
(ii) Regular backups of the comprehensive data
(iii) Providing training to the employees on safe browsing and making a healthy and authentic habit for downloading things
(iv) Implementation of the developed and advanced web application firewalls
(v) Monitoring the activities of the users constantly (Sen et al. 2018, p. 2563)
2. 13 Literature gap
The cloud computing system is one of the major and highly recommended systems that use various companies on daily basis to maintain their data or information. Sometimes, the data or information is personal and important and needs to be secure and secret so that various companies, as well as government portals, are also using cloud computing methods to secure information or data. The various types of cloud computing systems need to develop more so that control the hacking parts as well as reduce cybercrime and unethical data sharing. Cyber security systems are needed to develop and change some issues of techniques that use to analyze the algorithms in cyber computing. Cloud computing should increase its capabilities in features so that it does not create any issues in multi-tasking or multi-sharing. Moreover, it maintains the flexibility of the specification of cloud computing systems. According to the researcher, it highlights that the factors of cost reducing are crucial and important issues of using cloud-computing systems. The public should more concern about their personal data or information so that reducing the unethical factors in current days. It is highly needed to maintain the current crime due to the help of cloud computing systems.
2.14 Summary
Here the researcher describes the types, areas, pros, and cons of the cloud security system. The types of security algorithms are also described in this part of the paper. Characters of cloud computing systems and benefits of this are also described here. The costs reduce process, flexibility, recovery, and backup, access to a broad network is also described here. The effectiveness of this system and many techniques has to hold part of this paper. The advantages and disadvantages of this cloud-based security system are discussed here. Confidentiality is related to privacy and ensuring the data is visible to the users and has difficulties with tenancy properties for the consumers to share software and hardware.
In this area, the researcher discusses shortly the topic that is very much important in current conditions. The researcher discusses an introduction almond background of the introduction in this section. Various types of cloud computing systems are discussed here so that people gather more authentic pieces of knowledge about the topic. Therefore, that it helps to research on this topic in further time. Here, also discuss the benefits of cloud computing systems and the disadvantages of cloud computing systems. Various disadvantages of cloud computing systems affect the security of the data or information stored in the cloud. Types of security algorithms are also discussed here in detail. Cloud computing has various kinds of features that enhance entire systems for use. Therefore, there have several benefits of cloud computing that enhance entire systems. Moreover, it has several issues that need also solutions. The literature gap provides some recommendations that help for further research.
Chapter 3: Methodology
3.1 Introduction
The computer networking courses are commonly taught in a mixed mode of involvement of the practices in the session besides the theory. Teaching computing networks in schools, colleges and universities have become challenging for the development of the country. This has difficulties in motivating the students to learn about networking and many students think the presentation must be proper for learning. Here is the description of Cisco Networking that grows the demand of the global economy and supports the share of software and hardware. The network technology of Cisco teaches and learns the software packet tracer and plays a key part in opening up the words of possibility.
3.2 Explanation of methodological approaches
Many cloud providers are embracing the new flexible, secure, automated approaches to the infrastructure of cloud services. The fast approaches are designed to monetize and deliver cloud services and align with the requirements of the customers. This reduces the costs of the automated core process and creates new revenue for the opportunities of the service system. Many customers turn to cloud providers to help to grow the capacities for the business, want the advantages of the cloud system, and manage the infrastructure of the technical issues. Security and performance are the main concern of the company and gain the flexibility of the development of the workloads of the cloud system (online-journals.org, 2021).
The Internet of Everything (IoE) brings the people together and processes the data and makes them think of the network that connects the valuable and relevant and also creates the total set of the requirements of the distribution of global and highly secure clouds. This presents large opportunities for Cisco cloud providers. These providers have to meet the needs of the customers and set new opportunities for the development of the market growth of the products. Cisco launched the concept of partnership that helps shape the journey of the cloud. The internet grew the connection of the isolated network of cloud platforms for the internet that increased the choice of models of the services (cisco.com, 2021).
The cloud system of Cisco helps to design the services and products to meet the profit of goals through maximizing flexibility. It enhances the security system and helps to make sure of the way of the future of the company through the standards strategies. Cisco has a focus that enables the delivery and monetizes the services of the cloud systems that fulfill the requirement of the customers. Cisco is committed to partner-centric cloud approaches of the clouds providers for various services to meet the needs of the customers of the company. This represents the change of the ways of development of the customers of the company and turns the cloud providers to help them for the growth of the capacities of the business (aboutssl.org, 2021).
The demand of the ecosystem is emerging from the combination of public, private, and hybrid cloud services and is hugely shaped and driven by the types of economics that the organization consumes for the help of services to reach the goals. Cloud opens a variety of options that help the customers achieve the economic goals of the company. The economic system has provided a huge opportunities for the types of the sets of revenue services and develops the interest of the customers. The economic conditions are involved to build the new cloud services and increase the capacities of the models (arxiv.org, 2021).
3.3 Choice of methods
Cisco has a strategy for building a new platform for the Internet of Everything with the proper partner by connecting the world of many clouds to the inter clouds. These strategies enable the business and reduce the risk factors of the company by the use of security services. The ability to move the workload of private and public clouds is managed by the environment of the network and innovation for the reduction of the risks. This committed to taking the lead role of the building of the clouds and for the development; this is an efficiency of the security system. With the help of the cloud security system, the portfolio has an extensive partner and has the flexibility to deliver the types of cloud systems.
Multiple cloud systems meet the requirement of the common platform for operating the virtual, physical, and services features and integrating the infrastructure of the functions. The policy includes service management and enables the organization the application of the platform for the development of the security system. These services help move the workloads to the clouds and sign the inter clouds for enabling the assignment of the customers. Cisco power system keeps the resources and with the geographical barrier and provides the validation of the market with a solution of the needs of the customers. The market programs are designed to help for the achievement of the value of the customers for the better result of the services.
3.4 Research philosophy
Research philosophy is used to analyze the total integral part of the study and specify the choice of data that are collected to complete the study properly. Research philosophy helps to clear the ideas and problems of the subject and also help to identify the challenges and help to make the decision to mitigate those challenges. Besides, it helps to empathize with the development of a sense of cloud security and provide new direction and observation that is suggested by new hypotheses and questions, which are encountered during the research process. The answer all questions that will come during the research time the techniques that are shown used to complete successfully which help to show the critical analysis of the learning, interpretive and evaluate the skills that are used in the research period (Ragab et al. 2018). Moreover, research philosophy awareness of the major points of the study, increases the knowledge of past theories, and helps to learn up to date.
The methodology focuses on the positivism of the study so that readers assume the benefits of the cloud security system and facilities. In this positivism research philosophy, the study developer has tried to understand the topic requirements and importance. The ultimate focus here is to find out the involvement of the influences and the ways of cloud-based security techniques and analysis of security in the network system. Besides, the methodology enhances the cloud computing system in modern life and shows its movements in the computer system and support to others to increase cloud security programmes to protect from cyber threats.
3.5 Research Approach
The research approach is used to note a plan and procedure that is necessary to understand the steps of the research process to complete the research process. The inductive approach is used for inductive reasoning to understand the research observation and its beginnings. Besides, the theories that are involved in the study are symmetrically done in the research procedure and various thematic structures, regularities and patterns are assemblies to understand the suitable conclusions. This study paper has followed only the deductive approach because this deductive approach helps to know the exploration of the phenomenon and includes valid and logical paths that support the theory and hypothesis. By using the deductive approaches, the theories are based on cloud security and a research survey is conducted from the internet user to understand its popularity and advantages. Also, social media users help to conduct the survey time, all data collected from them that help to proceed with the research theory.
3.6 Research Design
The research design refers to understanding the gist of each research step so that readers can notify the major and minor points of the research to theories. Besides, it helps to provide all details in each step of the research part in a minute and the reader can utilize the value of the research and research conducting times (Abutabenjeh and Jaradat 2018). Three points are helped to conduct this research theory that is descriptive, explanatory and exploratory research design. This research has followed a descriptive design that involves describing and observing the particular behavior of the study. That design helps to explain the characteristics of the study and specify the major hypothesis that is long-range. The design is used to make the structure of the topic and so that readers can gain knowledge about cloud security importance and its advantages. This design is chosen to add new ideas during the research period, make the subject effective, and increase its efficiency.
3.7 Data collection method
Data collection methods refer to collecting the data and information that helps to the procedure the research being successful. Besides, the data are essentially needed to answer subject related questions and help to mitigate all problems and evaluate their outcome. Two categories are used in data collection methods primary and secondary. Here a secondary data collection method was used to successfully conducts the study. The secondary data was collected from the journal and other research topics of the subjects. The journal helps to identify the major points of the study that help the researcher to conduct their research perfectly. The articles are true and most valuable that are chosen for research and researchers use and take all-important documents for proper make of the study (Misnik et al. 2019). The secondary data collection is used in the study and this data helps to show the review of the national and international user feedback points that help to analyse the major and mirror points of the cloud securing system and for understanding public review social journals and theoretical articles help to inform the basic idea of the research theory.
3.8 Nature of data collection quantitative
There are two different parts of this research of the secondary data collection where the quantitative part has been chosen for this research and it has used to conduct the research process perfectly. The questionnaires and surveys are used during the research time (Ruggiano and Perry, 2019). The questions are come from during the research per survey and the survey answer is taken from the user to understand the behaviour of the cloud security. The questions and surveys have been used to help to understand user benefits and their problems and this information helps to make the structure of the subject. The questions that arise during the research time and researchers notice that question and try to find the preferable answer of the question. The survey helps to respond to user opinions and understand their user behaviour.
3.9 Data analysis techniques
The data is collected from the secondary data collection that helps to the thematic analysis of the study thematic so that reader can view, notice, and view the important points of the study. It is used to show the impact points of the cloud security system and enhance its necessities. Themes are made based on the objectives that help to understand the concept of cloud based security system and all about its system and techniques. The first theme is based on the techniques of cloud-based security system. The second theme determines the algorithm of a cloud computing system in the network world. The third theme focus on accessing the data sources of cloud security systems in the computer system. The fourth theme shows the importance of the proper algorithm for this system
3.10 Ethical considerations
The research is conducted with the help of the network security law, the law is the information technology Act 2020, and researchers follow this act and use proper documents in the study that is legal and ethical. No false statement and wrong document included in this research pare and no other false activities, articles, and comments are present in the study that will hamper on the reader mind (Molendijk et al. 2018). The document has no copyright and true-statements are used in the subject and thematic analysis to the subjects that help focuses on the impact of the cloud security systems and its advantages and processes. No force and unexpected activities occur during the research period and the questions that come from users are verified particularly for the making perfect research conduction.
3.11 Summary
In this part, the researcher describes the methods and strategies for the development of cloud services. Here is an explanation of the methods that are helpful for the growth of the cloud-based security system. The researcher is also given a discussion about the choice of methods for the needs of the customer. Here is the description of the methods of the Cisco Company. The method that they use for growth of the business and new technology and tools helps for the development of the company. The cloud providers help them to grow the capacities of the business and have advantages using the techniques. This part is holding the total explanation of the process to improve the quality of the services and meet the solution of the facing challenges. In this part of the study, the study developer has used some tools and techniques that help to properly complete the dissertation part successfully. With the help of these tools, study developers improve the Algorithm in cloud computing advantages and help to analyse the research method to the reader so that reader can understand the cloud base security system and identify its importance. To proceed with the methodology part, research philosophy, research design, data collection, nature of the data, and data analysis techniques are used and all data are collected by using a survey process that helps to properly complete the methodology study. Questions and survey process are help to complete the research perfectly in the study.
Chapter 4: Results
Theme 1: A systematic review of the issues for the cloud computing
This systematic review of the study is regarded to the security system of cloud computing and this also summarizes the vulnerabilities and threats of the topic. This review is identifying the currents of the state and importation of the security system for the cloud composition system. This also focuses for identify the relevant issues of cloud computing that consider the risks, threats, and solutions of the security system for cloud computing. These questions are related to the aim of the work and finding the vulnerabilities with the proper solution of the system. The proper criteria are evaluated based on the experiences of the researcher and consider the constraints that involve the resources of the data. This concept makes the questions for the review of the security system (jisajournal.springeropen.com, 2021).
The experts have refined the results and important works that recover the sources and update the work that takes into account the constraints as factors, journals, renowned authors, etc. the sources are defined and describe the process for the criteria for the study that must be evaluated. The issues of the system maintain the exclusion and inclusion criteria for the study. The build of the issues for the system is to describe the process of the computing system. These studies consider the security of cloud computing and manage the threats, countermeasures, and risks for the security system. This issue is defining the sources of the studies that evaluate the criteria of the security system. The search chain is set the relevant studies to filter the criteria of the system.
Theme 2: Segmentation of cloud security responsibilities
Many cloud providers create a secure system for the customers and the model of the business is prevents breaches of the system and manages the trust of the public and customers. These providers are avoiding issues of the services and controls the needs of the customers and adding data to access the policies. The customers are uses in the cyber security in cloud-based security systems with the configuration. The cloud providers share the various levels of the sources that are responsible for the security system. There are many services types like Software as a service (SaaS), Infrastructure as a service (IaaS), and platform as a service (Paas). This is included in the public cloud services and the customers are managing the requirements of the security system. Data security is a fundamental thing this helps to succeed the system and benefits the gaining of the cloud system.
There are some challenges that are stored the access to the internet and able to manage the cloud-based security system. Cloud system is accessing the external environments of the network and managing these services by IT. The system has the ability to see the services and make these services fully visible for the users as opposed to the traditional to monitor the network. The cloud services are gives the environments for the better performance of the system. The user of the system are applying the data over the internet and make the controls of the tradition that is based on the network and effective for the system (mcafee.com, 2021).
Theme 3: Impact of Cloud computing
Cloud computing has emerged as a prominent system in It services space. However clouds service users confront with the issue of trust and how it is defined in the context of cloud computing, is often raised among potential users. The wide adoption of cloud computing requires a careful evaluation o this particular parading. The issued evolved in recent times is concerned with how the customer, provider and the society, in general aim to establish the trust. The semantics of trust in the cloud space established its nature as something as earned rather than something provided with a written agreement. Trust include space is made sinuous with security and privacy (Bunkar and Rai, 2017, p. 28). Trust is complexional phenomenon which involves a trust or expecting a specific behaviour from the trustee, believes the expected behaviour to occur based on trustee’s competence and is ready to take risk based on the belief. According to Saed et al. 2018, the expectancy factor gives rise to two types of trust - one is trust formed based on performance of the trustee and the trust formed around the belief system of the trustee. Trust in belief is transitive in nature, however, trust in performance is intransitive in nature. So The tractor’s expectancy about the trustee is solely dependent on examples about trustee’s competence, integrity and goodwill (Narang, 2017, p. 178). This leads to formation of a logical pathway for the belief in evidence to get converted into the belief in expectancy.
Trust in the cloud competing space rest on reputation, verification and transparency. Reputation is earned and maintained by service providers over long period. Reputation enables making of trust based judgement in cloud computing. After establishing initial trust, it gets maintained through establishment of verification mechanism. Maintain standards and ensuring accountability, ACSP ensures upholding trust in the service.
Theme 4: Facilities of Cloud computing
Organisations presently are working with big data projects which is requiring huge infrastructure investment. Cloud healable organisations to save huge upfront cost in storing large data in warehouses and data servers. It is the feature of cloud technology to handle large volume of data which has enabled businesses to migrate to cloud. This faster scalability feature of cloud is luring businesses to adopt it sooner. Big data, both in structured and unstructured form require more storage and increased processing power. The cloud provides the necessary infrastructure along with its scalability to manage huge spikes in traffic. Ming of big data within the cloud has made analytics more fast and accurate. Cost related to system upgrade, facility management and maintenance can be readily saved while working with big data. Focus is more given on creating of edge providing insights (Saed et al. 2018, p. 4). The pay as our go model of cloud service is more efficient in utilisation of resources. The ability to cultivate the innovative mindset is readily possible with cloud computing. The creative way of using big data is provided by the cloud infrastructure. With more convenience in handling big data, organisations can look to boost operational efficiency and provide improved customer experience. With features of smart analytics and surveillance capability has made it an ideal option for business in present context. The ability of performing operations faster than a standard computing device has enabled it to work with large data sets. The power of big data lyrics to occur within a fraction of time within the cloud is getting improved with refinement in technology (Kaleeswari et al. 2018, p. 46). Since, big data is stored with a third party by following the internet route, security becomes a unique challenge in terms of visibility an monitoring.
Trusting the cloud service provider and their offerings is considered as one of the strongest driving forces:-
Trusting the provider of cloud services is based on certain characteristics such as integrity confidentiality security availability reliability etc. The offering of cloud services by the provider basically depends upon monitoring and tracking of data. Cloud computing is becoming an integral part of IT service in today's digital world. The IT service providers forecast huge potential in collaborating IT services with cloud services (Rizvi et al. 2018, p. 5774). It enhanced flexibility along with more efficient service delivery that helps to release some burden of work from the IT department and enable them to focus on innovation and creativity. The use of cloud services continues to grow but the main concern lies with lack of maturity and inability to align completely with IT, security and data privacy issues, cost associated with time and skill etc. Though some study reports suggest that the majority of CFOs lack trust in cloud computing. This study report reveals the fact that cloud service is still slow in gaining consumers confidence.
Trust is a key factor for any type of evolution. From the perspective of a good business, if relationships are based on trust, costs are lower, communication between parties are easier and simple ways of interaction can be figured out. Cloud computing is based on the paradox that companies with prior experience report more positive results. Those who are inexperienced are reluctant (Wei et al. 2017, p. 11907). There are several service providers who provide better technologies, capabilities and processes rather than internal IT systems, but business organisations are more comfortable about the fact that their data are handled and managed by their own employees. Their decisions regarding use of cloud computing is based on their assumptions rather than experience. Thus the factor of trust lacks in such a situation.
Chapter 5: Discussion
5.1 Introduction
This part is base on the discussion of the total paper that determines the cloud-based security system. This describes the process of data collection and helps to get the results for the security system. Most approaches are discussed for the identification of the threats that have focused on cloud computing. The discussion of the sites is relates to the security system as data security, trust and this manages many problems in the environments of the system.
5.2 Summary of findings
The researcher is finding some keys for the management of the cloud computing system and this agreement the environments of the cloud-based security system. Trust is evaluating the opinion of the leaders that are influencing the behavior of the leaders and make the trustworthy and valid of the characteristic of the system. Trolls are posting improper and unreal comments that affect the moves o the system. This paper evaluates the trust by considering the impact of the opinions of the leaders on the total cloud environments. Thrust value is determined as a parameter like reliability, identity, availability, data integrity, and capability. This proposes the method for the opinion of the members and trolls the identification of the uses of topological metrics.
The method is to examine the various situations that show the results of the proper removal of the effects of the troll from all advice of the leaders. A cloud service provider offers the components of cloud computing for the company and gives an infrastructure for the services. The cloud provider is using the data entry and resources for the platform of the services to fulfill the requirements of the customers. This service has priced the uses of the models of the system and this charges the resources for the consumers as an amount of the time services that are used for the storage of virtual; machines that are used in the system.
Cloud computing is a vast service that is included in the consumer’s services like Gmail through the services that allow the large enterprises for hosting the data and running the system smoothly in the cloud. This cloud computing system is a service that manages the business strategies and develops the system of the organization. This helps to establish the infrastructure of the cloud computing system for the traditional issues of the system on the workload is moves the cloud service that offer the people beer services of the system.
There are many benefits for adopting cloud computing in the significance of the barrier for the adaptation of the new technology. These issues follow the compliance, legal, and privacy matters for the system and represent the new computing system for the users of the services this is a great deal with the security system of the network that helps to grow the work levels of the network. This security is concerned with the risks as the external data storage and this depends on the public internet.
The segments of the system are responsible for the system and only they can develop the system for the users. The cloud-computing providers make the business model for the growth of the services in the market and are easy to use for the users. They avoid the issues and risks of the system that helps the system for increment the policies of the security services. The providers share the level of the responsibilities for the security system. The organization is considers the popularity of the Saas like Salesforce that needs the plan to share the responsibilities of the data protector in the cloud.
5.3 Discussion of LR
This part is base on the description of the literature of the study that holds some important points of the given topic. In the background, the researcher is described some new concepts and methods of the study this helps to create the area for the system. Management of the system is the concept of the security system of the environments that has threats. There are various types of cloud computing systems like private, public, and hybrid, multi-clouds. Private cloud is generates by the explanation of the environments of the providers for the group of users. This customer is applying the private clouds is manage the vendor (Riad et al. 2019, p. 86384).
Public clouds are the types of clouds that are created the infrastructure of the IT and users. The providers of the public clouds are consisted the Web services and use the premises of the users that concentrate the center of the services. In this part, the researcher describes the types of cloud security like SaaS, PaaS, IaaS. This model gives the way of the application in the system of the services. This develops the technology of the improvement and enables all the sources for the system. This has the opportunity of the system for the development of the system. Here are the areas of the cloud security system as if identifying the system management, the developer of the system understands the system, and fulfill the requirements of the system. This is monitoring the whole system of the cloud services and implementing the program for the growth of the matter (Singh et al. 2017, p. 1).
There are some pros of the security system and this protects the dataset and becomes essential for a large amount of out coming and outgoing traffic. The functions that manage the system is a protector of private information of the increasing the branches of the protector of the system. The cons of the cloud system are the issues for the disaster of the system that lose the information of the dataset. The cloud computing system is responsible for the security system and for the whole network (Riad et al. 2019, p. 86384). Cloud computing has wide applications in several fields which is helpful for this generation.
There are some types of security algorithm that are describe in the literature part like RSA algorithm, Blowfish Algorithm, Advanced Encryption Standard, etc. the cloud security system is set the technology that protects the information for the human and applies the data center approaches for the security system. Cloud resources are network devices that operate the providers and deliver the web for the people who use the services continuously. There are many types of algorithms that are uses in cloud computing and the benefits of the systems are discusses here. There are also challenges and ways of mitigation of the problems of the study (Singh et al. 2017, p. 1).
5.4 Limitation and weakness of the study
There are many limitations and weaknesses of the cloud system like loss of data, data leakage, services attacks, new technology, etc. many of the cloud service providers are implements the security standards for the certificates of the industry to make sure that the environments of the safe of the remaining part of the system. The data is collects and store by the centers of the potentially open risks for the development of the study. The security level of the services is maintained by the providers of the cloud system and makes sure that the providers are stable the reliable and offer the terms of the condition of the services.
The cloud is set the technology for the development of the system by mitigating the changes for the services. These events manage the business system and process of the business that damaged the business through the cloud system. The cloud services are giving to the providers for managing the system and monitoring the infrastructure of the cloud security system. This is minimizes the plan and impact of the services for the customers and continues the services for the business. These cloud providers are mange the system of the cloud services and the customers are controlling the application of the data.
Cloud computing is a normal concept for the technology that has the trends for the large range of the system and that is dependents on the internet to provide the users with the proper needs of the system. That system is uses in the services to support the process of business and describe the network in a cloud system. Many risk factors are uses in the services for protecting the system for the data and accessing the system with the machine for the development of the economy of the country.
5.5 Summary
In this part, the researcher describes the policies of the data security system that helps the system for adopting new technology. Here the researcher gives a brief discussion about the risks factors of the system and finds the key factors for the secondary analysis. Here is also the discussion of the literature parts as this holds some important points of the study. Here is also the limitation and weakness of the study that helps for the improvement of the security system.
Chapter 6: Conclusion
6.1 Conclusion
In this research paper, the researcher is going to discuss the cryptographic exchanges in cloud computing services. The main idea of cloud computing services is to deserve the entire idea of encryption and decryption that can demolish the complexities of the software. With the rapid development of distributed system technologies, it has become a challenge to face the uncertainties that lie under the datasets. Therefore, in this section, the researcher is going to derive the algorithms that are effective in this matter.
A Cloud computing system is a paradigm that gives various services on demand at a low cost. The main goal of this is to give fast and easy use data storage services. This is a modern computing model taught diverse sources for the demand and this mainly gives data storage services in the cloud environment. The computing world is dealing with the services and treats the risks that are faces for the development of the existing techniques and adopting new techniques. The security system of the services has many techniques and the primary factor of the data is managing the services in the cloud system.
The paper is base on the cloud-based security system and analyzes the algorithm of the system. In the introduction part, the researcher describes the aim and objectives of the topic and the background of the study. The rationale is base on the answer to some questions that is relates to the topic that is described in the introduction part. This paper also holds the literature and methodology part is data collection method of the given topic. The researcher also describes the results of the interview and survey. Types of cloud computing, areas of cloud computing, pros and cons of the security system, benefits of the system are also describes here.
6.2 Linking with Objectives
Linking Objective 1: To determine the techniques of cloud-based security system
Several techniques can work as a cloud-based security system so it can be said that it is important for this matter to determine all the techniques related to the cloud-based security system. Cloud security is a mode of protection that collects all the datasets from the online platforms so they can keep them safe in a secured environment from getting stolen, deleted or leaked. There are methods like Firewalls, Virtual Private Networks (VPN), penetration testing, tokenization and obfuscation. Maintaining the data sets secure is the main function of these methods so it can be said that the developers need to focus on implementing these methods in the network system so they can keep the datasets safe and secure.
The cloud-based security system is design to utilize the programs and control the other features, which help for protecting the data. The system and the servers also use security for controlling the data that moves forth and needs without the risk to people for the data system. The backup system has directly checked the system and has the manual format for the system. The user of the services is driving the services to help the system and support this so that the responsibility of the users is to help for the development of the services. The test of the system is making the differences and need for the better performance of the system.
The hackers are hiring this system to test the security system and activities to find the issues about the storage places. They also give the recommendation to take care of the concerns of the option for the test that is deep for the system. The redundant storage is included for the drives the store data as per requirements and helps the data as possible. This makes the system harder for the data for stolen or broken. Every bit of the data is accessible for the system and distributes the data at a time.
Linking Objective 2: To describe the algorithm that is helpful for cloud computing
Here the researcher is trying to say that according to his/her opinion they conclude that a homomorphic algorithm is the best algorithm that can help the entire services of cloud computing. It can create a secure computing environment so they can keep the datasets safe. It can also collect valuable information from the datasets and keep them in secured cloud storage and prevent them from being deleted or leaked in public. The main ability of this mentioned algorithm is it can perform encryption and enable a high-security system for those encrypted datasets. It can show more effectiveness than the other algorithms such as DSA and RSA.
The cloud stores many amounts of data that becomes in the machine learning algorithms. Many people use the cloud platforms to store data and present the opportunity to leverage that helps for learning and shift the paradigm from the computing system. The cognitive computing system is design with the tools of Artificial Intelligence and manages the process. The machine learning language and natural language are to process the cloud-based security system. Chatbot has taken the virtual assistants for businesses and individuals. The users are manages the limitation of the system and increase the capacity of the learners. IoT cloud platform is design for the process of generating the data and generating the connection of the services.
This cloud computing manages the business policies and becomes the service that increases intelligence. Cloud-based machine learning has benefits for business intelligence (BI) and algorithms can process the data for the solution of the finds. The algorithms help the business for gaining an understanding of the behavior of the customers and create a product that is developing the marketing strategies and development of sales. This machine learning has much significance for the experience of the customers and needs to satisfy the customers. Business management understands the behavior of the customers.
Linking Objective 3: To access the data sources of cloud security system
Rather than storing information in the cloud storage on the devices, it can be said that the cloud computing system stores the datasets on the internet. Information that is available on the websites can give proper credentials to this entire system. It can also give credentials to locations that have any kind of internet connection. Also, cloud data protection is essential in this matter because it is a practiced method where they try to secure all the important datasets of an organization.
Database security system refers to the tools, measures, and control of the design of the database. This is focuses on the main tools of the system and managing the data system. This system is a complex and challenge that involves the information of the system and helps the technology and practices of the cloud security system. There are some disadvantages of the system and failure in maintaining the dataset. The intellectual property is able to manage the competitive of the market for the product of the company. Customers are not want to buy the products and do not have the trust to protect the collected data for the company.
Much software has misused the result of the breaches and followed the common type of the dataset and attack the cause of the security system. The system also has many treated like malicious insiders, negligent, infiltrators. Dataset is access to the network and threat of the security system with the portion of the network infrastructure. The security of the system is the extent of the confines of the cloud-based security system. The server of the data set is located within the security environment of the data center and awareness of accessing the dataset.
Linking Objective 4: To examine the proper algorithm for this system
Several algorithms can help the entire system of cloud computing and one of them is RSA. Its main function is it can intervene when it comes to creating a suitable environment for the entire dataset. This is the method where the datasets do cryptographic exchange for creating an environment that is secure and safe. In this research paper, the researcher has already stated that according to the researcher the homomorphic algorithm is the most effective one in this case. RSA can only create a secured environment but it can keep all their datasets safe from being hacked in any way.
The important algorithm in the cloud-based security system is RSA and produces the output for the dataset. This proves the proper algorithm for the analysis and the proper algorithm is the RSA algorithm. This algorithm is uses as a private key and public key and the private key suggests the secret data or information of a person. The public key is to suggest the information that is suggests publicly. The idea of this algorithm is to make the difficulties at the time of integration. The public key is holding the “multiplication of prime numbers” and the private key is derives from the “same two prime numbers”. This RSA algorithm is the basis of the cryptosystem that is uses for the proper services and enables the key for securing the system. This algorithm manages the difficulties for the product of the prime numbers and generates the complexity of the algorithm.
6.3 Recommendation
6.3.1 Assessment on risks of Cloud computing
.png)
.png)
Table 6.1: SMART recommendation
(Sources: Self-created)
6.4 Limitation of the study
A data center is a proper environment is applies for the dedicated services that only apply for accessing the users of the servers. The cloud environment is automated and dynamic and pools the resources that support the application workload and access this anytime and anywhere from the device. The information for the security professional makes the cloud computing system attractive and runs smoothly to the network security system. The risks of the security system are a threat to the data center and network that has many changes for the application of cloud system and complete the migration through this the application is a move to remain on-premises.
The risks of the cloud-based security system are facing some problems at the time of moving to the cloud that also becomes significant. Many data center applications are uses in a large range of ports and measure the effectiveness of the application that easily moves to the cloud. Cybercrimes are creates attacks that are used in the many vectors for compromising the target or goals and hiding the plain sight for the common application and completing the mission of the development of the system. The information of the security system is dictates to the mission for application and separated the security system.
6.5 Future scope of the study
The paper predicts the scope of the cloud-based security system in the future for the growth of cloud computing. The organization needs to use some new technology in the system for the development of the cloud computing system. The members of management are needs to invest in the code standards that support the migration of the system into the cloud. This cloud computing is associated with the thinks of the human-like internet and stored the collected data in the cloud and become easy for making sure of the network. This also controls the performance, functionality, and security of the system. The limitation has the speed of the network and controls the pace that collected the data and processes this. The network is fast and uses cloud computing in any place.
References
.png)
.png)
.png)
.png)
.png)
Reports
MIS611 Information Systems Capstone Report Sample
Task Summary
For this assessment, you as a group is entering the second phase of your assessment process - Assessment 2, where your key output will be a Solution Prototype Document. By now your team would have completed the first phase via the delivery of the Stakeholder Requirements Document - the key output of Assessment 1. It is important to note that consistency and continuity from one assessment to the next are vital in this project.
You will need to ensure that you use the project approach as advised in Assessment 1. This means that your solution needs to address the requirements documented in
Assessment 1 Stakeholder Requirements Document.
For Assessment 2 - Solution Prototype Document, you as a team is required to complete a 4000-words report outlining the various aspects of your solution. It is expected that you will demonstrate how the solution addresses the requirements outline in Assessment 1. A variety of prototyping tools are available to you. However, will need to discuss your selection with your learning facilitator to establish feasibility of the team’s approach. The Solution Prototype Document should describe elements of the Solution Prototype using the appropriate tools for processes, data and interfaces.
Context
In the previous assessment, you demonstrated your proficiency in the requirements analysis and
documentation process in alignment with the project framework that you selected. In this phase of the assessment cycle, you will design and develop your solution prototype in alignment with your selected project approach in response to the requirements elicited and documented. As outlined in Assessment 1, this will reflect your professional capability to demonstrate continuity of practice, progressive use of project frameworks and their appropriately aligned methods, tools and techniques.
Task Instructions
1. Review your subject notes to establish the relevant area of investigation that applies to the case. Re- read any relevant readings for this subject.
2. Plan how you will structure your ideas for your report and write a report plan before you start writing. Graphical representation of ideas and diagrams are encouraged but must be anchored in the context of the material, explained, and justified for inclusion. No Executive Summary is required.
3. Write a 4000 words Solution Prototype Document outlining the various aspects of your solution that addresses the requirements outline in Assessment 1.
4. The stakeholder requirements document should consist of the following structure:
A title page with the subject code and subject name, assignment title, case organisation/client’s name, student’s names and numbers and lecturer’s name
Solution
Solution 1: Token Based System
Payment systems could be account-based as well as token-based. By subtracting the payer's balance and crediting the recipient's institution in an account-based billing system, a transaction is completed and completed (Allcock, 2017). For Assignment Help, This means that the transaction must always be documented and the people involved recognised. Payment is accomplished by transferring a token that is equivalent to a certain amount of money in a system based on this principle. When it comes to currency, coins and banknotes are the most obvious examples. It is better to have a token-based system where another CBDC token is like banknotes as well as referred to as "coins." Trying to withdraw money from a bank account, users load coins into their computer or smartphone and have that amount debited from their savings account by their bank. Unlike other digital bearer instruments that are held in a central database, the CBDC would be cached on the user's computer or mobile device. A record of the owner's name is likewise missing from the CBDC's database.
Blind signatures, a cryptographic method, are used to ensure privacy. A blinding operation conducted locally mostly on user's device conceals the numeric value indicating a coin again from central bank beforehand seeking the signature without interacting with the central bank to receive a cryptographically signed coin. This numerical number is a public key under GNU Taler, and only the coin's owner has access to its corresponding private key. Also on public key of the coin, the federal bank's signature is what gives the currency its worth. The central bank uses its very own private key to sign the document. If a retailer or payee has access to the central bank's "public key," they could use it to confirm the signature's validity and that of the CBDC. (Fatima, 2018).
Users don't have to rely on the central bank or perhaps the financial institution to protect their private spending record since the blind signatures being performed out by the users themselves. Just the entire amount of digital currency withdrawn and the actual sum spent are known to the central bank. There is no way for commercial banks to know how much digital currency their customers have spent or in which they have spent it. As a result, secrecy is not an issue when it comes to maintaining privacy in this system because anonymity is cryptographically ensured.
Solution 2 - Non-DLT Based Approach
Distributed ledger technology (also known as DLT) is being tested among most central banks (DLT). In the absence of a centralised authority, a blockchain or distributed ledger technology (DLT) may be an attractive design option. However, in the event of a retail CBDC issued from a reputable central bank, it is not necessary. When the central bank's registry is dispersed, it only raises transaction costs; there are no practical benefits to this practise.
Improved extensibility is a major advantage of not utilising DLT. Our suggested technology would be scalable as well as cost-effective, just like modern RTGS platforms used mostly by central banks today. As many as 100,000 transactions per second may be handled by GNU Taler. Secure storage of about 1-10 kilobytes every transaction is the most expensive part of the platform's cost structure. GNU Taler's memory, connectivity, and computing costs at scale will be less than 0.0001 USD each transaction, according to studies with an earlier prototype.
Furthermore, since DLT is indeed an account-based system, establishing anonymity is an issue. A decentralised append-only database is used instead of a central database to store the accounts, which is the sole distinction from a standard account-based system. Zero-knowledge proofs (ZKP) and other privacy-enhancing crypto methods are viable but computationally intensive in a DLT setting, hence their deployment on mobile devices is impracticable. This doesn't really pertain to GNU Taler's Chaum-style signature verification system, which is fast and reliable (Gupta et al., 2019).
Solution 3 - Regulatory Design
Central banks would not be privy to the names or financial transactions of customers or merchants under the proposed system. Only when digital currencies are withdrawn as well as redeemed awhen the central banks are able to track them (Kaponda, 2018). Commercial banks could restrict the amount of CBDC a particular retailer can get per transaction if necessary. Whereas the buyer's identity remains anonymous, the seller's operations and contractual responsibilities are made public upon inquiry by the appropriate authorities (Kaponda, 2018). The financial institution, tax authorities, as well as law enforcement can seek and review the commercial contracts underpinning the payments to establish if the suspected behaviour is criminal if they identify odd tendencies of merchant income. As mandated by that of the Europe's General Data Protection Regulation (GDPR), the system uses privacy-by-design plus privacy-by-default techniques. Neither merchants nor banks have an intrinsic understanding of the identities of their clients, and central banks remain blissfully unaware of the actions of their population (Kirkby, 2018).
Disintermediation of the banking system is a common problem with retail CBDCs. Even though it would be a severe issue with account-based CBDCs, token-based CBDCs ought to be less of an impediment (Oni, 2021). Comparable to hoarding cash, the danger of theft or loss associated with a token-based CBDC would be the same. Withdrawal limitations and negative interest might be implemented by central banks if hoarding or huge transfers of money from bank accounts to CBDC become an issue (Kadyrov & Prokhorov, 2018).
Central banks, businesses, and individuals might all profit from the proposed architecture. Because of its cost savings, this system is supposed to be the first to handle long-envisioned micropayments digitally. Smart contracts would also be possible if digital currency was used to ratify electronic contracts (Sapkota & Grobys, 2019).
Using a newly developed plugin for GNU Taler, parents or guardians can restrict the use of money supplied to their wards to make digital transactions, while still maintaining their anonymity. To keep the name and exact age hidden, merchants would simply know that the consumer is of legal age to purchase the things they are selling. For instance, central banks may use it to create programmable currency like this.
References
.png)
Reports
PROJ-6012 Managing Information Systems/Technology Sample
Context:
In this subject the students will understand the significance of project management and get introduced to the methods and tools available for managing projects, especially those related to Information Technology. They will recognise the importance of alignment of the projects with the goals and objectives of the organization and hence learn about the methods used to select the project. Throughout course delivery, students will be encouraged to present their opinions on the topics covered in each module by posting their messages on the discussion forum. Assessment 3 is intended to evaluate the responses of the students which will highlight their understanding about the topics. The discussion postings will be initiated by the facilitator as the topics are covered in each module and the students will be expected to reciprocate to the discussion questions. They will be required to present their views, either supportive (or contradicting) by considering their knowledge in the discipline, prior experience in the industry or existing published work.
These discussions will provide immense benefit to the students as they will get an opportunity to learn from the experience and knowledge of other students and the facilitator. They will get updated with the current issues in the industry. Further, the students will get an opportunity to present their own thoughts and knowledge in the discipline, which will enhance their confidence and skill. Discussions on professional forum will increase their communication skills and academic writing skill which will have far reaching benefits in their careers.
Besides that, the facilitator will get an opportunity to understand the background, knowledge and level of understanding of each student. This becomes more important for the online course as there is minimal face to face communication between the students and the facilitator. This will help the facilitator to evaluate the students better and provide the required support to the students.
Hence, the students are encouraged to actively participate on the discussion post, learn from the discussions and utilise the opportunity provided to showcase their skill and knowledge in the discipline.
Solutions
Module 1
Discussion Topic 1: Controversial Impact of IS/IT Projects
The Australian government is well-known for its focus on security and the implementation of modern technologies for controversial operations for maintaining security within the country. The implementation of drones in airports for passenger movement tracking processes, bomb detection and more contributed to an overall increase in security (Meares, 2018). However, the major information security project that led to controversies involved checking digital communications to provide security. For Assignment help, The project involves the collection of digital messaging data from various organisations such as Facebook, Apple and more to track possible terrorism, analysing behavioural patterns of suspected people and more. This process, however, can be stated as controversial as it requires these technological brands to make backdoor access within their secure messaging platforms such as WhatsApp and iMessage. Therefore, the security of the applications developed by Apple and Facebook may be affected negatively and could cause serious issues with hackers or unauthorised people targeting these backdoors for access within the social media networks.
The development of backdoor access and essential data collection by hackers or unauthorized people can lead to the exposure of essential details of a large number of people using these messaging services which can eventually lead to vulnerabilities and negative impacts on the lifestyle conditions of people (Hanna, 2018). The Australian Parliament was involved in passing the controversial legislation and developed a law that allows the Australian government to collect data. However, there has been significant criticism from the Australian population in regards to the fact that the government is involved in breaching the privacy of people. As a project manager, I would focus on improving technology implementations and invest in more modernised technologies rather than be involved in leading to possible security failures for major brands allowing communication facilities to people worldwide.
Discussion Topic 2: Managing Existing Architecture
In the case of an existing architecture being inefficient in contributing to project needs, the ideal solution involves upgrading the architecture by the use of newer ideas and concepts. However, as the company has made several high-value investments in technology, it may not be efficient to invest more to change the architecture. Investing more can lead to loss of finances and can lead to issues with long-term brand operations. Therefore, as a project manager, I feel that it can be much more efficient to integrate Agile project management processes. Agile involves the use of Scrum for testing the system while ensuring the use of Continuous Improvement processes for improved project operations (Paquette & Frankl, 2016). Continuous improvement is efficient in tracking various segments or components of the project that may be improved and these improvements can be made based on the lowest number of changes in financial requirements.
The project changes and improvements within the low number of financial requirements can lead to higher performances of the entire system without affecting budgets. It can ensure that the project operates to the best of its abilities based on the existing architecture and changes in operational processes for the highest gains in project goal achievement. Additionally, scrum-based testing can also be efficient in conducting reviews of the efficiency of the existing architecture and the changes in strategic operations. However, significant time is required for implementing these changes and in case of the need for project completion within a short time, investments in the architectural changes may be more efficient.
Discussion Topic 3: Computing Models for Global Applications
The global IS (Information Security) or IT (Information Technology) projects operate in close relations with available infrastructure and a lack of infrastructural benefits can contribute to negative impacts on operations. Additionally, technology is constantly improving and growing at a fast scale and thus traditional forms of computing models may not be efficient in the application of modernised IS and IT projects. However, utility computing allows the personalisation of IS or IT operations due to the efficiency of manually managing various resources to be used. This can allow the implementation of these projects as per needs and ensure changes in processes such as storage, data transmission, service management and more as per requirements.
The geographic scope of a project also contributes to the selection of a specific model of operations of these IT and IS projects. The geographic scope refers to the availability of specific resources, services and products in a specific location. In case of the unavailability of a base architecture for the development of a project in the selected location, it is highly essential to implement changes in strategic action. The procurement of materials from other countries or regions for the development of a base architecture can contribute to higher costs and thus traditional models may be much more applicable for operations (Cook, 2018). The use of these traditional models may affect the project operational speed and efficiency negatively but can have serious positive impacts on the sustained operations of the project along with long-term growth and developments.
Response 1
The IS/IT projects containing virtual team members can be managed efficiently with the implementation of the resource management tool. The resources include materials required for the development of a project, equipment required to utilise the selected materials and the human resources or people involved in the development processes. The project management applications such as MS Project allows tracking these resources along with the development of a schedule for project developments which can be used to achieve the goals in regards to the management of IS/IT projects. I believe that the use of a work breakdown structure can also be efficient in setting various tasks which includes tracking the human resources or team involved.
Module 2
Discussion Topic 1: Business Process Reengineering
The visual stream mapping tool is very much helpful that providing stakeholders, leaders, team members, stakeholders focusing on the unified view. This fresh view makes them in stepping out of the data silos and gain a more holistic acknowledgement of the whole procedure and their correspondent contributions and roles ensuring the completion of the finished product. This further perspective helps each user to observe their more significant contributions, essentials and, values concerning the product delivery procedure. Without the support of a value team mapping tool, team members may lose their perspective, discount or distort the significant value of their role.
For example, using the VSM tools helps the team members to achieve understanding and clarity and understanding the value of their roles in the project and helps in improving the team and individual morale. Using the value stream mapping tool results in complexity in multi-operational processes confuses (Hari, n.d.). The limitation is the low variety manufacturing approaches, bias on high volume that generally favours the assembly line setups, geared for continual flow. Complying with the process workflow fails the consideration of allocations of activities. For example, for WIP storage, the utilization of shop floor space, production support and material handling result in confusion within the process and is unable inn show the influence on the WIP, operating expenditure and order throughput of ineffective material flows within the facility. The procedure of VSM helps employees in recognizing the areas of improvisation and function better towards the achievement of the goals and objectives.
Discussion Topic 2: Project Scope Creep
A perfect example of scope creep is altering the project's scope in meeting the customer's changing requirements. It results in appearing overwhelming at the present moment but serves a higher purpose. Hence, before the commencement of a project, the authority must be disclosed to the probability of scope creep and planning for it. For example, an effective example of project scope creep is a notable delay in accomplishing the project because of clients' continual change requests, as seen within the lawsuit in between the project manager responsible for the project.
Project scope creeps as the change is generally inevitable and may impact the project scope; it is at least required need to know how adequately the scope creep can be managed. There must be the implementation of ways to manage the scope creep to help the project in meeting objectives (Kerzner, 2017). Communication portrays a vital role within the project management that helps in dealing with the changes that help in accomplishing the project objectives. For the project manager, most communication is generally is passed through them. The primary thing is the project team and other stakeholders generally treat them as the chief communication point in the project responding to the changes. Organizations may incorporate transparency within the project and portray an essential role within the project management. Everybody must be aligned on the same page as by the progress of the project. This would support the teamwork collaboratively function by the faster delivery and meeting the different set of objectives.
Response 2
The focus on IS/IT in recent years has increased due to the need for modern technology implementations for continued operations. However, IS/IT should not be a strategic driver and rather focusing on proper planning processes can contribute to more significant positive impacts on the project. IS/IT and modern technologies should be implemented to support and work upon the plans developed, thereby leading to efficiencies in project completion. Based on my understanding as a project manager, I feel that the organisation is involved in the implementation of projects based on a plan of action that involves an assessment of the inputs required for the project, expected outputs, budget and time-frame required and more.
Module 3
Discussion Topic 1: Schedule Management
Defining the project goals and writing down the key deliverables or milestones or deliverables for making the project ended successfully. Recognizing the stakeholders and making a list of every individual requires to be involved in the project, even with a simple role. Determining the final deadline and ultimately knowing when the project will be finished that will be entailing the requirements. It must be ensured for giving enough time in accounting for the conflicts that would come in the way of the project (Marion, 2018). Listing every task and considering such deliverables and milestones and deliverables designated in the step and bifurcating them into smaller components and subcomponents to be covered. Assigning a team member responsible for every activity and deciding the allocation of components and subcomponents, transparent to deadlines. Working backwards for setting dates for every task. It must be figured for every activity knowing delay is inevitable very well so that it does not disturb the project. Sequencing is a vital consideration as well as several activities will require to be completed. Then organizing the project schedule in one tool, and then share it with the team. At last, successful creating a project plan and is significant in the organization in such a way that every member involved may observe and work accordingly to it. By progressing through a project, it reflects on the project managers and how they use the schedule framework to complete the project. The framework is designated to share clear information for avoiding challenges.
Discussion Topic 2: Cost Management
IT professionals are much more focused on the completion of the project rather than on cost management. IT professionals are also very much concerned with the development of the project and very potential and probable issues that may result in happening. IT professionals may overlook their views on the project costs and concentrate upon the procedure, as managing the costs within the project is very much essential for the project success and also in avoiding the overruns for the expenditure (Kerzner, 2017). Many of the IT professionals are connected to a limited business atmosphere and that is the reason they do not know the importance of some accounting concepts or any different financial principles. This is considered as another vital reason IT professionals overlook the project cost. Cost management among the IT project is considered a difficult task for the organization that results in encountering varied issues and thus the cost estimation and is generally undefined sometimes. It results in beam difficulty and specific determinants required for assessing the successful accomplishment of the project. This process helps in under defining the cost management and results as one of the difficult activities for IT professionals. Sometimes the IT professionals are not able in getting an adequate need or eventually possess an undefined need in the initial stages of the project. It is required to have a specific but thorough need that should be evaluated for understanding and disclosing the budget. This makes IT professionals overlook the cost management and focus on somewhere else.
Response 3
In a typical IT project, the first set of activities involve the development of a plan for changes and the implementation of changes based on the basic framework of the IT system. The cost and time implemented for planning out new developments in the project contribute to the sunk costs. These plans include the development of a foundation or base for the project. For example- In the case of the development of a product, the internal circuit board performs as the base of operations and once developments are initiated, the board cannot be reused for a different activity. This leads to sunk costs in case of improper development processes.
Module 4
Discussion Topic 1: Quality Control in Projects
There are several types of quality control techniques used by the organizations such as histogram, control charts, six sigma, scatter diagram, etc. However, in the selected organization there will be the use of the six-sigma technique. It is one of the important methods used by organizations for the better functioning of business activities. As per Ottou, Baiden & Nani (2021), Six Sigma is a type of control or methodology that helps in improving the business procedure with the use of statistical analysis. It is mainly data enabled and highly disciplined approach and methodology that helps in ensuring the elimination of defects present within the business and in any type of organization or business procedure. The goal of the six-sigma method is for streamlining the quality control within the business or manufacturing procedure so that there is little to no variance within the procedure. The goal present in the concerned Six Sigma project is in identifying and eliminating any type of defects that cause variations within quality by explaining the sequence of stages across the focused target.
One of the vital reasons for implementing Six Sigma is considered important is it helps in decreasing the defects. By utilizing the Six Sigma method, employees get capable of recognizing the problem spheres alongside recurring challenges that impact the full quality expectation for the product or service concerning the consumer's viewpoint. The technique of the six Sigma procedure possesses the necessary skills and tools for identifying the challenges or bottleneck spheres that may camp down the performance or production.
Discussion Topic 2: Managing Human Resources
Paying individuals their worth by setting the salaries of employees must be ensured that the pay should be consistent with other organizations within the industry and geographic location. Providing a pleasant environment to work as Everyone needs to work in an atmosphere that is stimulating and clean and should make them feel good rather than bad. Offering opportunities for self-development as members within the team are valuable to the companies, and for themselves, when there are opportunities for them to learn fresh skills (Word & Sowa, 2017). By providing the team with the training required to advance and get knowledge will help to remain in touch with the latest news.
Foster collaboration in the team and encourage the team members to wholly participate through inviting the input and suggestions to do things adequately. By asking a question and getting the responses will help in implementing the solution to change.
Encouraging happiness to employees tend to be positive and enthusiastic members of the team, and it should be checked continuously if individuals are happy with it or not and then take necessary steps. Setting clear goals is the job of leaders and team members to work collaboratively in the team for setting clear goals. As it is done, the goals should be ensured, their concerned priority and role to meet them. Avoiding useless meetings as Meetings may be a wastage of unproductive meetings continually. By preparing an agenda for the meetings and distributing it in advance and inviting, initiate meeting and finish it quickly.
Discussion Topic 3: Conflict Management
Common experiences of conflict happening within the team is a misunderstanding or mistaken perception. This arises between the employees, leaders and employees etc. by failing the communication between them. The information passed about something is either misrepresented as information or is interpreted in the wrong way. This in turn results in the way towards discomfort resentment or prevention. This need directly to be solved by clearing the misinterpreted possibilities arising between the individuals. Compromising is considered the most popular technique for solving conflicts in projects (Posthuma, 2019). All party’s interests are satisfied to an extent where their compromise is successful. Professionals are the ones who ask for help when needed if they truly understand that the conflict is not in their capacity to solve, then they call in the sponsor or ask the project sponsor to help.
Appeasement is mostly effective in circumstances when admitting a point is inexpensive for one but beneficial to the other individual or team. By delegating process project managers need a great deal of work as well as responsibility for managing as delegating conflict resolution to the concerned individual, the individual is offered a chance to develop themselves. Another best way to resolve conflict is by brainstorming sessions to be used within the organizational project. By identifying the situations and or locating the problems before creating damage, there should be brainstorming sessions held to develop a powerful interaction between them. This would enable understanding each other and develop strong communication in addressing the problems of conflicts.
Response 4
Recruitment and team retention are achieved via the use of proper HR management procedures. The HR management processes have limited impacts on the projects as a whole but contribute to the availability of skilled personnel for the development of the projects. These HR processes involve a focus on providing better rewards for employee performances. Financial rewards such as grants, bonuses and more for high-value performances within the project can be highly efficient in achieving retention of employees. Similarly, skilled employees can be recruited by ensuring quality financial provisions based on their abilities. Furthermore, the use of non-financial rewards such as feedbacks can also lead to positive mindsets and ensure retention of employees.
Module 5
Discussion Topic 1: Project Communication Methods
The benefits comprise participation, as the most important benefit of interactive whiteboards is that it enables higher participation compared to whiteboards. Preserving Data, as Every data by interactive whiteboard results by the connected system and straight projected into the whiteboard and depicts do the recording directly to a hard drive and also transporting on portable storage (Heldman, 2018). Several visuals may be utilized in interactive whiteboards and videos may be uploaded by websites or prior saved files. The disadvantages include the fact that misunderstandings or inadequate communication may result in misunderstanding that in turn results in mistakes, missing deadlines and changing project directions. Miscommunication results when the individuals share information without precisely understanding each other (Gronwald, 2017). This results in misinterpretation of details and facts prompting team members for working for perceived data and facts. Performance reporting entails dissemination and collecting the project information, communicating project development, utilizing the resources, and gathering future insights and status to several stakeholders. There are Status Reports that provide the present state of a project in the mentioned time. Such a report explains the place project stands at the moment concerning the performance measurement baseline. Forecasting report depicts what is been expected to happen on a project, predicting the expected status and future performance of the project in different parameters and helping in allocating and tracking resources for optimum utilization. Trend report presents a comparison within the present performance of the project as well as past performance of the project within the same duration.
Discussion Topic 2: Stakeholder Engagement
Stakeholder engagement is revered as the method by which stakeholders engaged in the project collaboratively work together. There are several methods by which the participation of stakeholders is done to ensure the sharing of information and, messages effectively to accomplish the objectives of the project. Delegation is one of the most important methods for stakeholder engagement that results in effective communication and executing the tasks effectively.
Delegation can be referred to as entrusting the part of activity or responsibility and authority to others and holding them accountable for the performance. Delegation is when authority assigns work to subordinates for which they are liable. Delegation is very significant in effectively executing the tasks as it ensures the completion of work done in time (Seiffert-Brockmann, Weitzl & Henriks, 2018). It is seen as highly important and ensures the decision is taken collaboratively agreeing on the decision. This method helps in determining the requirements of stakeholders are being determined from the onset of the stakeholders themselves and by the authorities as well as the communities by their representatives deciding the medium to intervene and act together. This approach provides the existence of stakeholder participation and also continues beyond the establishment stage. This method also includes the monitoring and evaluation practices for helping pinpoint the shortcomings of the plan eyeing the probable future improvements.
Discussion Topic 3: Conducting Procurements
Competitive negotiation is a source selection approach that is also known as positional bargaining. In this parties consider holding to their positions and are inflexible to the interests of a different party. Competitive bidding is used in public projects that are generally stipulated by the law. This source section approach is assumed when two or more contractors are willing to compete in the work. It needs time for creating plans and specifications, preparing a bid, assessing submitted bids, and awarding the contract. It provides adequate detail concerning the specifications, performance duration, and workmanship quality expected for the project.
Non-competitive negotiation is another source selection process that is used for rewarding contracts. Non-competitive negotiation is revered as the establishment of contractual conditions and terms that includes but is not restricted to contract price, by discussing to a single vendor, with external procedures incorporated for the competitive bidding that will entail the contract terms or technical particulars not defined specifically (Bhargove, 2018). In this method, the developer and contractor would assess the pricing information and technical proposals collaboratively for reaching the costs for the work as well as the agreed scope.
Competitive negotiations are another process that provides proposals solicited by selected offerors, by whom the developer consequently negotiates for achieving the best value. It also provides the developer to refine their requirements as well as the scope of work by preliminary negotiations by chosen offerors, and those offerors would then submit competitive bids formed on the agreed-upon needs and scope of work.
In case of the need for outsourcing of human resources, it is highly essential to focus on recruiting skilled employees or project team members at the location of operations. The development of positive relations with vendor brands that may be able to handle the outsourced operations can be efficient. This can allow the brand to ensure some of its operations are outsourced to other countries while the other activities are conducted within the organisation itself, leading to high-value brand performances and achievement of necessary goals. Negotiation processes with the local team can also help to ease the severity of the issues faced due to a lack of human resource outsourcing processes.
Module 6
Discussion Topic 1: Risk Management
Project risks are common and every single project has the possibility of experiencing a certain number of risks. Several risks arise in the project that may result in distorting the project or business failure and Project risk analysis is done for monitoring projects' performance through start to end eliminate the loss or business failure. Types of risk present are: Cost risk is mismanagement and shortage of project funds through an inflated budget or other constraints depicted as the risk to the project accomplishment. Scope creep risk is an unauthorized or uncontrolled change in the initial intended project scope that can result in the extra cost of further products, features, and functions (Wolke, 2017).
Operational risk can terminate or stall in case there is a weak implementation of crucial operations and core procedures like procurement. The risks can lead to indirect or direct loss concerning the failed or inadequate strategies such as IT risk, human and procedure direct implementation risk etc. Skills resource risk helps capitalize the internal staff is potentially a high project risk as sometimes the project operations get staggered in distinctive waves at different locations, needing the required team members alongside technical risk.
The risk register is eyed as a strategic tool for controlling risk within the project. The risk register identifies and describes the risk list. It provides space in explaining the probable impact on the project and the response planned to tackle the risk that occurs. The risk register also enables the project manager in prioritizing the risk.
Discussion Topic 2: Portfolio Risk Management
Portfolio risk management refers to the idea of identifying, assessing, measuring and managing various risks within a portfolio. The project portfolio mainly includes insights on the operations of the project taken into account, resources used for project completion, strategic goals of the brand and more. Therefore, the proper assessment of these processes is highly essential to ensure the tracking of portfolio risks and the mitigation of these risks.
As a project manager involved in the development of a cloud computing system project, the project plans are first assessed to track their efficiencies in the application. This involves ensuring that capitalisation on the plans is possible and the execution of operations can be achieved in an efficient matter by following the plans (Stewart, Piros & Heisler, 2019). The viability of the project can also be assessed which involves tracking the efficiency of the product to be developed and its expected market growth. A large number of cloud computing services are easily available in the market and this operational process can help to track the efficiency of this specific service in gaining market advantage. High possible market advantage can lead to increased opportunities for product sales and profitability of the cloud system.
The efficiency of the cloud system in contributing to returns on investments are also taken into account. The ROI is dependent on the price at which the cloud systems are provided and the time by which there was a return in finances for these investments. The cloud systems are being provided at significantly low costs and thus it is expected that the return on investments will be high. These high ROIs can contribute to increased utilisation of the cloud system within the market, thereby achieving market growth.
Discussion Topic 3: Process-Based Measurements
The success of an IT/IS project can be evaluated via the use of key performance indicators. The main key performance indicators of these projects include the number of customers or organisations utilising the IT/IS project services, positive views of customers or brands towards these project services, return on investments, impact on efficiency and more. Based on the number of customers, a project can be stated as successful if a high number of customers are involved in utilising the product or service. A large customer group utilising the services indicate high-value service provisions and the success of the project being developed (Project Management Institute, 2017). In regards to the Australian government project concerning the collection of data from Apple and Facebook, the customers using the services include the government officials and these processes contribute to them being able to collect data efficiently, thereby indicating project success.
The positive views of customers towards the project are a significant indicator of project success. IT projects such as new cloud computing systems and more experiencing positive reviews from customers indicate that the project is efficient, well-defined and successful. Similarly, various organisations also use IS and IT-based services and their positive views towards these services along with the long-term collaboration of operation requests can indicate that the project is successful (Project Management Institute, 2021). The return on investment refers to financial returns gained in comparison to the investments. In the case of companies experiencing higher financial gains than the return on investments, the project may also be stated as successful. The efficiency of the project in achieving brand and individual goals can also indicate efficiency in operational processes.
Response 6
In regards to IS/IT projects, the two most critical success factors that I take into account are the demand of customers or organisations involved in procuring these IS/IT services and the speed and efficiency of project operations. In case of high demands for the product or service developed by the project development process, it can be stated that the project is efficient and provides value to customers. Similarly, the speed of operations is essential in the modern world to achieve a large amount of work within a short time. Therefore, an increase in the levels of customer satisfaction due to the speed of operations can ensure that the IS/IT projects are efficient.
Reference List
.png)
.png)
Reports
MIS607 Cybersecurity - Mitigation Plan for Threat Report Sample
Task Summary
Reflecting on your initial report (A2), the organisation has decided to continue to employ you for the next phase: risk analysis and development of the mitigation plan.
The organisation has become aware that the Australian Government (AG) has developed strict privacy requirements for business. The company wishes you to produce a brief summary of these based on real- world Australian government requirements (similar to how you used real-world information in A2 for the real-world attack).
These include the Australian Privacy Policies (APPs) especially the requirements on notifiable data breaches. PEP wants you to examine these requirements and advise them on their legal requirements. Also ensure that your threat list includes attacks on customer data breaches. The company wishes to know if the GDPR applies to them.
You need to include a brief discussion of the APP and GDPR and the relationship between them. This should show the main points.
Be careful not to use up word count discussing cybersecurity basics. This is not an exercise in summarizing your class notes, and such material will not count towards marks. You can cover theory outside the classes.
Requirements
Beginning with the threat list:
- You need to align threats/vulnerabilities, as much as possible, with controls.
- Perform a risk analysis and determine controls to be employed.
- Combine the controls into a project of mitigation.
- Give advice on the need for ongoing cybersecurity, after your main mitigation steps.
Note:
- You must use the risk matrix approach covered in classes. Remember risk = likelihood x consequence. (Use the tables from Stallings and Brown and remember to reference them in the caption.)
- You should show evidence of gathering data on likelihood, and consequence, for each threat identified. You should briefly explain how this was done.
- At least one of the risks must be so trivial and/or expensive to control that you decide not to use it (in other words, in this case, accept the risk). At least one of the risks,but obviously not all.
- Provide cost estimates for the controls, including policy or training controls. You can make up these values but try to justify at least one of the costs (if possible, use links to justify costs).
Solution
Introduction
Network security breaches ends up costing millions throughout the world because of various cyberattacks that target hundreds of network assets, including network software and hardware as well as information assets. As per Chahal et al., (2019), “an attacker executes a scan throughout the entire network to find vulnerable hosts, compromises the vulnerable host by installing malware or malicious code (e.g., Trojan Horse), and attempts to carry out actions without the knowledge of the compromised hosts” That's why it's important to have a network security system that protects users' private information while also allowing them to communicate with one other. For Assignment help Threat Modelling is the process of identifying, assessing, and evaluating possible hazards to a system. With this category, it is possible to identify dangers in an orderly fashion. Due of STRIDE (Spoofing, Tampering with Repudiation and Information Disclosure and a Denial of Service) being a comprehensive risk model, this discourse serves as a justification to use it in place of the other threat models (Aikat et al., 2017).
In the present situation, the packers want to protect their system since their vendor, JBS Foods, has been the victim of a cybercrime in the past. Security experts have been brought in to assess the risks and vulnerabilities associated with the intrusions. This article will continue the threat discovery which was done in the previous paper with the use of data flow diagrams, context diagrams, and the STRIDE approach. Thus all vulnerabilities and threats pertaining to attack are discussed in this report. The report would further go into the details of providing a risk matrix, along with a threat control and mitigation scheme. Cost computation will also be included for the threats listed.
Australian Privacy Act vs GDPR
Similarities
- People who are alive are protected under the GDPR. Private details of deceased persons is not protected by the GDPR since Member States are responsible for enforcing their own laws. Privacy Act safeguards the private information as to a 'natural persons,' described as 'individuals,' under the statute. Because "individual" indicates a live person, this same Privacy Section isn’t applicable for deceased individuals, even though it is not explicitly stated so.
- It is possible for public bodies to just be data controllers as well as data processors under the GDPR. All APP organisations, public or private, are subject to the Privacy Act.
- Both the GDPR as well as the APP allude to private information as "Personal Data," yet they are fundamentally referring to the very same thing (Yuste & Pastrana, 2021).
Differences
- People who are alive are protected under the GDPR. Private details of deceased persons is not protected by the GDPR since Member States are responsible for enforcing their own laws. Privacy Act safeguards the private information as to a 'natural persons,' described as 'individuals,' under the statute. Because "individual" indicates a live person, this same Privacy Section isn’t applicable for deceased individuals, even though it is not explicitly stated so.
- It is possible for public institutions to just be data controllers as well as data processors under the GDPR. All APP organisations, public or private, are subject to the Privacy Act.
- Both the GDPR as well as the APP allude to private data as "Personal Data," yet they are fundamentally referring to the very same thing.
Risk Evidence Analysis
.png)
Table 1- Risk Evidence Analysis
Threat List & STRIDE Categorization
.png)
Table 2 - STRIDE Categorization
Meaning of Risk Levels and Likelihood
.png)
Figure 1 - (Stallings & Brown, 2018)
.png)
Figure 2 - (Stallings & Brown, 2018)
Threat Analysis
.png)
.png)
.png)
.png)
.png)
Table 3 - Threat Analysis
Mitigation
Man in the Middle Attack
Threat – One way to refer to an attack where a perpetrator places themselves in the midst of an interaction among a user as well as an application refers to it as "the man in the middle" (MITM for short). This can be done for eavesdropping purposes or by pretending to be among the participants in the dialogue.
Likelihood : 4 Consequence : 5
The threat has quite a high level of chance of happening in reality and thereafter the impact associated with it is significantly low. Therefore the aforementioned likelihood and consequence rating is chosen.
Risk Level : Extreme
Standard mitigation
- Security policy for the entire organization is a must
- Employee training program and education
- Regular IT security auditing
Specific mitigation
- VPN
- IPSec
- HTTPS
- Network Monitoring Solutions
- Segmentation of Network
Techniques: Avoid Risk
Threat – End-point attacks are any attack that may come from malware, spear phishing, insider or any other means but attack the very end-user devices.
Likelihood: 3 Consequence: 4
The threat has medium level of chance of happening in reality and thereafter the impact associated with it is a bit high. Therefore, it poses a medium level risk.
Risk Level: Medium
Standard mitigation
- Security policy for the entire organization is a must
- Physical security and biometric authentication wherever necessary
- Following a IT Security framework such as TOGAF and ITIL.
Specific mitigation
- Endpoint Hardening
- Password and Biometric lock
- Anti-virus and Anti-malware solutions
- Firewall on Endpoints
Techniques: Mitigate Risk
SQL Injection Attack
Threat – SQL Injection are attacks that target the database contained and connected to online forms and portals. Social networking sites, webstores, and institutions are among the most often targeted web apps. Medium and small organisations are extremely vulnerable to SQLI attacks because they are unfamiliar with the methods that fraudsters employ and how to counter them (Goel & Nussbaum, 2021).
Likelihood : 5 Consequence : 5
The threat has quite a high level of chance of happening in reality and thereafter the impact associated with it is significantly high as well. Therefore it is an ‘extreme level’ of risk.
Risk Level: Extreme
Standard mitigation
- Regular IT security auditing
- Routine vulnerability scanning
- Following a IT Security framework such as TOGAF and ITIL.
Specific mitigation
- WAF (Web Application Firewall)
- Web sanitization schemes
- Input validation techniques
- Captcha systems
- Whitelist & Blacklist known fraud IPs
Techniques: Mitigate Risk
Emotet Attack
Threat – To propagate Emotet, junk mail is the most common method of transmission. Viruses can come in a variety of ways, including malicious scripts, macro-enabled documents, and more. Some anti-malware programmes are unable to identify Emotet because of a feature in the software. Helping spread Emotet is provided through worm-like characteristics. This aids in the spread of the virus. The Dod has concluded that Emotet is among the most expensive and damaging viruses, affecting commercial and government industries, individuals and organisations, and incurring well over $1 million every event to sweep up (Zhang et al., 2021).
Likelihood : 4 Consequence : 5
The threat has quite a high level of chance of happening in reality and thereafter the impact associated with it is significantly low. Therefore, the aforementioned likelihood and consequence rating is chosen.
Risk Level: 20
Standard mitigation
- Bring your own device policy must be created
- Regular IT security auditing
- Routine vulnerability scanning
Specific mitigation
- Executable execution prevention
- User privilege definition
- Email spam filtration
- Anti-macros
- Endpoint security systems
Techniques: Mitigate Risk
Drive-by Attack
Threat – A drive-by download exploit exposes the digital device toward a vulnerability by downloading malicious programmes without user knowledge or consent (Hoppe et al., 2021).
Likelihood : 2 Consequence : 2
The threat has quite a significantly low chance of happening in reality and thereafter the impact associated with it is significantly low. Therefore the risk level is low.
Risk Level: Low
Standard mitigation
- Bring your own device policy must be created
- Security policy for the entire organization is a must
Specific mitigation
- Eliminating any outdated systems, libraries or plugins (Liu et al., 2017).
- Updating all systems
- Web-filtering software
Techniques: Accept Risk (Controls are reject in this because, the cost associated to solve is extremely high as the entire systems would need to be restructured and re-thought which involves a detailed planning, business disruption and resulting business losses)
Phishing Attacks
Threat – Phishing attacks now are the practise of sending phoney emails that typically come from a trustworthy organisation. Phishing emails and text messages often leverage real-world concerns to entice recipients to click on a link. In order to encourage individuals to respond without considering, scam mailings (or phishes) could be hard to detect. Text, mail, as well as phishing scams are the three most common forms of assaults on the Internet (Sangster, 2020).
Likelihood : 3 Consequence : 5
The threat has quite a medium level of chance of occuring and the impact of that is high. Therefore the risk level is medium.
Risk Level: Medium
Standard mitigation
- Bring your own device policy must be created
- Employee training program and education
Specific mitigation
- SPAM filter
- Anti-virus and Anti-Malware
- Block Fraudulent Ips
- Forced HTTPs on all communications
- 2-Factor Authentication
Techniques: Avoid Risk
Attack on Passwords
Threat – Simply said, hackers aim to steal passwords through password attacks by guessing, bruteforcing or other means.
Likelihood: 4 Consequence: 5
The threat has somewhat high level of probability of happening in reality and thereafter the impact associated with it is significantly high. Therefore, the aforementioned likelihood and consequence rating is chosen.
Risk Level: Extreme
Standard mitigation
- Bring your own device policy must be created
- Employee training program and education
- Physical security and biometric authentication wherever necessary
- Regular IT security auditing
Specific mitigation
- Complex passwords
- Password policy
- Storing of passwords in encrypted format
- Using SSO (Single-Sign-On and 0Auth) based logins
Techniques: Avoid Risk
Ransomware
Threat – Ransomware is software that uses encryption to keep a victim's data hostage and demand a payment in exchange for their release. To mitigate for said malware's ability to disable the whole operational network, or encrypting an user ’s information, and also because of their size and willingness to pay, major corporations are the primary targets of ransomware attacks (Shaji et al., 2018).
Likelihood: 4 Consequence: 5
The threat has somewhat high level of probability of happening in reality and thereafter the impact associated with it is significantly high. Therefore, the aforementioned likelihood and consequence rating is chosen.
Risk Level: Extreme
Standard mitigation
- Regular IT security auditing
- Routine vulnerability scanning
- Following a IT Security framework such as TOGAF and ITIL.
Specific mitigation
- Anti-Malware and Anti-Spyware tools
- Regular vulnerability scanning
- Auditing of vulnerabilities
- Employee training on Ransomware
Techniques: Avoid Risk
Breach of website using E-Skimming
Threat – With the rise in popularity of online shopping, a cyberattack known as e-skimming is becoming increasingly common. For a long time, ATM and gas station skimmers posed a threat to customers, but the practise has evolved recently. These affect the privacy of the individual as it can steal ‘Personal information’ as outlined in Australian Privacy Act (Shaukat et al., 2020). Third-party JavaScript and open-source libraries are exploited by attackers to get access to websites' Shadow Code. To get access to online services, cybercriminals often use documented zero-day flaws in 3rd JavaScript. S3 Storage buckets as well as repositories may potentially be vulnerable to attack because of a lack of proper security measures in place. A digital skimmer steals credit card information by injecting malicious code into third-party programs on the website. Third party scripts as well as libraries used among websites are the primary source of these assaults, which are also known as supply chain attacks.
Likelihood: 3 Consequence: 3
The threat has quite a medium to low level of chance of happening in reality and thereafter the impact associated with it is also medium to low. Overall risk remains low.
Risk Level: Low
Standard mitigation
- Security policy for the entire organization is a must
- Routine vulnerability scanning
Specific mitigation
- Patching the website
- Using PCI-DSS Compliance
- Multi-factor authentication
- Data encryption
- SSL
Techniques: Avoid Risk
Breach of website using CSS
Threat – Malicious scripts can be introduced into normally safe and secure websites using Cross-Site Scripting (XSS). Malicious code can get entry to device's cookies, digital certificates, and other confidential material since it appears to have come from a trustworthy source. In most cases, cross-site scripting exploits enable an attacker to assume the identity of a vulnerable user, conduct any activities the user may take, and gain access to some of the user's personal data. The hackers might able to take complete control of the programme and its data if the target has elevated status inside it.
Likelihood: 5 Consequence: 4
The threat is quite high in terms of probability of happening and impact is also somewhat high. Therefore, it can be categorized as extreme risk.
Risk Level: Extreme
Standard mitigation
- Bring your own device policy must be created
- Following a IT Security framework such as TOGAF and ITIL.
Specific mitigation
- Input Sanitization
- Output escaping
- Content Security Policy
Techniques: Mitigate Risk
Conclusion
The paper listed down all the major cybersecurity attacks that are applicable to PEP keeping in mind the attack on JBS Foods. As a result a lot of the newly developed attacks such as phishing based attack, ransom attacks, malware attacks, DoS, SQL Injection attacks, E-Skimming attacks and so on are included keeping in mind the threat landscape of recent years as well as the nature of the business. Attacks within each type are classified further and explained in detail. Furthermore, the paper introduced a set of countermeasures and mitigation scheme classified according to the defence strategies for PEP.
References
.png)
Reports
MIS500 Assignment Research Report
Context
The assessment suite in this subject is built on top of skills you are building in your learning activities. Although the learning activities do not carry any assessable weight by themselves, completing them and seeking input from your peers and the learning facilitator is essential for you to achieving a positive result in the subject. While researching and writing this assessment, be sure to work through content and the learning activities in modules one and two.
Sneakers have revolutionised fashion, lifestyle and the environment.
Sneakers and streetwear have revolutionised fashion, lifestyle and the environment.
Global Footwear Market Report 2021, reports that the Sneaker Market is Projected to Reach $403.2 Billion USD by 2025 - Driven by New Design Trends and Rising Discretionary Spending Among an Expanding Middle Class Population. From Nike, Toms, Puma, Adidas to Converse, Veja, Yeezy to Gucci, Louis Vuitton and Chanel everyone is wearing sneakers. Kanye West, Mark Zuckerberg, Taylor Swift, Virat Kohli, Beyonce and people from all walks of life both young and old are wearing sneakers. The sneaker industry like all industries has had to pivot itself to environmentally friendly and sustainable sneakers. Spain, Italy and many countries in South America are leading the way in producing sneakers made of recyclable materials including food.
In this assignment you will audit, analyse and evaluate the social and digital media of an environmentally and sustainable sneaker brand.
Introduction
Describe the history of the environmentally and sustainable sneaker brand (Nike, ID.Eight, Toms, Allbirds, Veja, Flamingos Life, Cariuma, Native, Nisolo, Sole Rebels, Oliver Cabell, Thousand Fell and Adidas). You can use Australian or international sneaker brands.
Discussion
Discuss (in the 3rd person) why this environmentally and sustainable brand was chosen to be Audited, analysed and evaluated.
Audit and Analysis:
Visit the brand’s website and audit their social media platforms. You should be investigating the traditional website advertising and the social media platforms (Facebook, WeChat, Instagram, Pinterest, Snapchat, QQ, Tumblr, Qzone, LinkedIn, Youtube, TikTok, Twitter etc.).
As a future IS professional audit, analyse and evaluate the brands website and use of social media that is currently present.
Based upon research, is the website and social media platforms engaging? Evaluate, discuss and provide evidence.
Discuss how your chosen brand engages their audience in its marketing of Corporate Social
Responsibility (CSR) sneakers. Your discussion should centre on the production of ecofriendly and sustainable products. Does the company or retailer actively engage with their customers? Using research that you have conducted in the landscape of social media discuss whether the website and social media platforms are engaging? Justify using evidence.
Recommendations using Porter’s Value Chain model
Use the Porter’s Value Chain model to identify and explain the business’s primary activities using the company website and the social media channels to obtain this information. (Marketing and Selling).
Make three recommendations to the Sneaker Company or Sneaker Retailer on how Porter’s model can enhance or maximise marketing (exposure and impact) selling (increase sales traffic)
Conclusion
Discuss the actions that the Sneaker Company or retailer should engage in so as to increase sales and engage more actively with its customer base in the purchase of ecofriendly and sustainable products. What other types of social media (based upon research) should be introduced to the company or retailer?
Recommendations
Make three recommendations to the Sneaker brand on how the company can enhance or maximise the value offered to ‘customers’ by producing more ethical sneakers and delivering a strong message via Social Media and their official website.
Solution
Introduction
Nike Inc is an American sneaker company that is engaged in the design, development, manufacturing, and marketing of world-class sneakers and shoes. For Assignment help, This footwear apparel has the largest supply of athletic shoes and it is the leading manufacturer of sports equipment (Boyle, et al., 2019). In this report, an evaluation of the social and digital media of an environmentally and sustainable sneaker brand, Nike will be done.
Discussion
Nike is environmentally sustainable in manufacturing its sneakers in a cruelty-free way. So, it has been chosen for this audit report. The sneakers are made of fruit waste, recycled materials, and are environmentally sustainable. The sneakers are made in Italy from innovative andenvironmentally sustainable wastes for unisex and distributed all over the world. Nike also follows a sustainable packaging for the sneakers that allow people to save the environment by disposing of the boxes. These boxes are mostly made of disposable and bio-degradable products. Nike focuses on the efforts in using raw materials to reduce its water footprint. The company is trying hard to reduce the use of freshwater in manufacturing high-quality shoes that are used for dyeing and finishing textiles. Nike promotes wastewater recycling to make environmentally sustainable sneakers (Boyle, et al., 2019).
Audit and Analysis
Nike still believes in traditional marketing on its websites and social media platforms. In today’s world, traditional product marketing is very much alive and used by large companies. Nike promoted their products based on "emotional branding" by using the tag "Just Do It" on their website and social media platforms. Nike is now focusing on strong branding through social media hashtags, posts with emotional captions that lift up the people’s spirit, etc. Nike has come up with traditional branding tools that increase the brand's appeal among local people as well as celebrities all around the world (Center for Business Communication, et al., 2021).
By choosing the right person for advertisement and branding, Nike gains the trust of common people. Nike's digital marketing channel is large enough to distribute knowledge about the products effectively. Nike also holds subsidiaries like Converse, Jordan, and Hurley that help them to grow. Nike has also collaborated with Facebook Messenger Bot to promote their special product, Nike Air. In order to create this campaign, Nike teamed up with an AI platform named Snaps. It established a conversational setup between the company and the customers where news about the products are sent to the customers on a weekly basis. The news is divided into 3 categories, such as; Air Jordan, Shop and watch (Thompson, 2016). Facebook Messenger Bot enables a two-way conversation between the people and the company that provides a unique opportunity to connect directly to Nike's Air Jordan. The bot is effective in making conversations with an open rate of 87% (Henry, 2012). The users/customers can set up notification time and collect useful website links for buying the products. So, it can be said that Nike has a strong digital advertising system where social media is quite engaging. In 2020, Nike has spent $81.9 million on community development globally. Since 2001, Nike has focused on its public commitments and aligned its operations with business priorities. Nike's corporate governance shows that the company has strong commitments to monitor the effectiveness of policy and decisions taken by it for a long time. It approaches governance to increase its long-term shareholder value in the global market. It also enhances the CSR, human rights and improved sustainability of its products. Based on Nike’s global report, it spent $417 million in communities and $130 million in promoting equality and improving sustainability in the environment (Thompson, 2016).
.png)
NIKE’S MARKETING STRATEGY MAKES IT REACH THE TOP OF BRANDS (THOMPSON, 2016)
Recommendation with Porter’s Value Chain model
Porter's Value Chain model deals in the strategic development of the management tool that gives power to the company to increase its value chain.
Inbound logistics: Nike focuses on product quality and sustainability as they are the main reason for their success. The company focuses on inbound logistics to promote quality checks, sustainability. It has independent contractors, manufacturers and more than 500 factories globally to operate (Henry, 2012).
Operations: this includes manufacturing, assembling, packing and testing sneakers in the warehouse before distribution. Nike focuses on operation analysis on a regular basis to improve productivity and efficiency and increase value.
Outbound logistics: this includes activities to store and distribute products all over the globe through retail marketing (Henry, 2012).
Marketing and sales: The primary activities that the company undertake in marketing and selling include inbound logistics, operations, outbound logistics, marketing and sales, and service (Karvonen, ET AL., 2012). The goal of the five sets of activities is to create business values to generate higher revenue for the company. Nike promotes its products through emotional branding, story-telling, physical marketing, and promotion through social media channels (Thompson, 2016).
Service: It has 100 million customers as per the report of 2017 that the company wants to keep. So, it provides customer registering service, discount facilities, etc (Henry, 2012).
.png)
PORTER’S VALUE CHAIN MODEL (Karvonen, ET AL., 2012)
Three recommendations to Nike on how Porter’s model can enhance or maximise marketing (exposure and impact) selling (increase sales traffic):
• Nike is always focusing on improving its primary business activities. So, to improve its business value it should follow Porter’s model.
• Nike uses its website and social media channels to do all of its business activities that make them more reputed and trustworthy. So, it should use porter's model to maximise marketing activities over the website and social media channels.
• By using the services and operations model, the company can promote its selling.
Conclusions
It is important for the Company to enter the mind of its customers and hold loyal customers through proper promotion and branding. Nike should include promotions on tumbler and LinkedIn. Nike should use digital marketing more to engage its loyal customers and increase the base. This should be done through eco-friendly marketing and a sustainable product manufacturing system. It is analysed from the study that Nike Inc. has a revenue of USD37.4 billion in 2020 and is forecasted to increase much higher in the next decade. The company spends a lot on branding its sports equipment through digital media channels and websites. A few recommendations on improving the supply chain of the company to meet required needs in the market.
Recommendations
In this section, three recommendations are made for Nike Inc. on how it can enhance or maximise the value offered to the customers by producing more ethical and eco-friendly sneakers.
1. It is recommended to increase the sales per customer to hold loyal customers through digital marketing and using effective social media channels.
2. Nike should retain customers longer through offers and discounts and providing good quality products. Nike should fulfil consumer demand in every season.
3. It is recommended to lower the cost of the sneakers to increase business value. Also, it can lower the cost by using renewable and recycled resources in making footwear. Nike should completely stop using freshwater for any kind of manufacturing purpose as freshwater is not sustainable for manufacturing and also very costly to maintain.
References
.png)
Reports
MIS604 Microservices Architecture Report Sample
Assessment Task
This research paper should be approximately 2500 words (+/- 10%) excluding cover page, references and appendix. In this assessment, you need to present the different issues that have been previously documented on the topic using a variety of research articles and industry examples. Please make sure your discussion matches the stated purpose of the report and include the cases study throughout.
Discuss and support any conclusions that can be reached using the evidence provided by the research articles you have found. Details about the different industry cases studies should NOT be a standalone section of the paper.
Context
The microservicesis one of the most rapidly expanding architectural paradigms in commercial computing today. It delivers the fundamental benefits of integrating processes, optimization and Instructions delivering efficiency across many areas. These are core benefits expected in any implementation and the MSA is primarily configured to provide the functional business needs.
On-the-one-hand, MSA can be leverage to provide further benefits for a business by facilitating:
- Innovation— reflecting the creation of novel or different services or businesses processes, or even disruptive business models.
- Augmented Reality — reflecting the situation where superimposing images and data on real objects allowing people to be better informed.
- Supply chain— reflecting how the MSA enables closer communication, engagement and interactivity amongst important external or internal entities.
On-the-other-hand culture is the totality of socially transmitted behaviour patterns, attitudes, values and beliefs, and it is these predominating values and behaviours that characterize the functioning of an individual, group or organisation. Organizational culture is what makes employees feel like they belong and what encourages them to work collectively to achieve organizational goals. Extant IS implementation studies have adopted culture theory to explain how organisations respond to implement a MSA system in their workplace, and how these responses lead to successful or failed implementations.
As a professional, your role will require that you understand the benefits of MSA, especially in these three areas, which are significantly becoming the preferred strategy to achieve competitive advantage for many organisations. The purpose of this report is to engage you in building knowledge about how these benefits achieve in an organisational environment with a specific focus on how and why organisational culture can influence the successful implementation of an MSA within an organisation.
Solution
Introduction
Microservice Architecture (MSA) has evolved from Service Oriented Architecture (OSA). For the most part, microservices are smaller and more focused than the big "services" from the 2000s. A very well-made interface is exposed by these apps, which are hosted and made available over through the network. For Assignment Help Using a so-called “RPC," other programmes can access this interface (Remote Procedural Call)(Fernández-García et al., 2017). Around 2,200 key microservices, dubbed "Domain-Oriented Microservice Architecture," have been added to Uber's infrastructure (DOMA). This paper presents the views on how Uber utilized Microservices to bring performance, agility and scalability in their organization while focusing on three key tenets specifically Supply Chain, Augmented Reality and Innovation. Furthermore, the importance of culture and how culture affects MSA adoption is also discussed in the paper.
Microservices for Uber
Innovation
Today's customers are extremely empowered, driven, and self-determinant. They are fast to choose the greatest sophisticated and / or the cheapest choice since they have all the information and computational power they need at their disposal. As a result, they should be regarded as "internal" customers. Consumers aren't any longer satisfied with the IT department's clunky and restricting software. In that same respect, a customer will not find it pleasing to use an application that allows him to book a cab, but rather than getting it done quickly, ends up taking longer than making a phone call. As a result of their success, high-performing enterprises were three times more inclined to pursue first-mover edge(Fernández-García et al., 2017). For example, starting a news website is far easier than starting a newspaper. The inability to acknowledge the value of speed, flexibility, and agility would have a significant negative influence on a company's capacity to thrive(Ghirotti et al., 2018).
Uber, on the other hand, would be constrained by its monolithic architecture to make significant modifications to their system depending on client demand because of their design:
- Expensive and time-consuming
- Too inflexible to change and as a result, too sluggish to take advantage of the situation
- There are times when no one individual can fully comprehend the structure, even though this is virtually a need.
- Because they aren't built to open standards, the skill pools available to companies are rather limited.
- As a result of the difficulty of managing these systems, users are compelled to find alternative means of getting business accomplished outside certain systems (frequently sticking with more laborious manual and prone to human error methods including in the case of Uber, booking a cab with phone calls or opting for a traditional Taxi/Cab).
Apart from the above, traditional Monolithic architecture would limit Uber because it would be hard to customize and any changes to brought into the system would result in a high failure rate as a lot of elements would need to be unshackled.
The current system at Uber was large and homogenous as a new release of any one small feature required the release of the entire system, thus presenting a risk to their systems as a whole. The proliferation of mobile devices only exacerbated this dilemma, with multiple types of devices, models and operating systems to manage as an Uber Passenger could be holding any of the 1000s of type of mobile devices being in use today. Similarly, Amazon was unable to quickly implement new features because of the large number of developers distributed around the company. Customers were unable to use any important code updates for weeks since they were blocked in the deployment process. Amazon's pipeline was simplified and shortened because to the introduction of microservices. A service-oriented design enables developers to identify bottlenecks, identify the characteristics of these slowdowns, and reconstruct them as a small team devoted to each service, overall resulting in innovation.
.png)
Figure 1 - Uber Microservices (Gluck, 2020)
APIs, which serve as that of the "contract" linking microservices, are quite a critical mechanism for liberating out of monoliths. Uber's trade balance and exchange info microservice, for instance, might be used to illustrate this point. Uber will not be capable to meet riders in over 60 currencies across the world if the application was "cobbled" altogether as in monoliths, which would hinder true innovation and limit actual revenue potential(He & Yang, 2017).
Augmented Reality
The branch of computer science known as "augmented reality" (AR) deals with the integration of real-world data with that created by computers. The augmented reality tech may be utilised on mobile devices, including such smart phones, as well as personal computers. If an Uber driver, one may use the app to assist customers locate their cars more quickly, or the other way around. When it comes to picking up passengers from their destinations, the Uber app uses integrated Augmented Reality Control Module (ARCM) to aid passengers in meeting up with drivers who are available. Trip request data, including pick-up position, drop-off destination, and sometimes even departure timing if it's a planned ride will be sent to Uber by user. Based on one’s trip request, Uber would then match passengers with various local drivers and provide the pick-up information to the first driver whoever agrees. Uber tracks the driver's progress as he or she approaches the pick-up spot. Once you've arrived within a predetermined distance of the pickup point, Uber would send a notification to your phone instructing it to broadcast a live stream from ones device ’s camera. Uber then uses image recognition to detect whether the driver is available in the live video stream depending on the driver's information, such as the vehicle's make, type, colour, and registration. By computing a vehicle value, which is also dependent on driver characteristics, a trained machine predicts that an oncoming or halted car is ones cab. On top of that, Uber uses augmented reality (AR) features on the live broadcast to identify an incoming car as a taxi.
.png)
Figure 2 - Uber AR Patent (Patent Yogi, 2019)
The aforementioned architecture can be implemented using a 4-Tier architecture comprising of Designer, Supplier, Intelligence and Customer Tier.
Customer Tier
In order to govern events including such examining virtual furniture, speaking with designers, or placing orders, there is a management piece on the consumer tier. There are a number of subcomponents that allow for the exploring and displaying of available cabs under the controller. There are several different types of markers, all of which are printed on the same sheet of paper. Marker form and location might be captured and recognised by a smart device ’s camera. The visualization component uses the marker to display the cab. The communication component allows customers and designers to connect with one another either orally, via video pictures, or via a live videoconference. There are several uses for this component, including communication as well as capturing markers.
Designer Service Tier
Service containers incorporate the services that perhaps the system delivers to designers, such as rendering, viewing, and web services, in a single location. System, design service tier, as well as customer tier data are sent between the information processer as well as the data processer's info tiers.
Supplier Service Tier
The characteristics of controller, communication, service container, as well as information processor make up the supplier service tier, just as the designer service tier. The operations of the elements are comparable to others on the designer service tier, although they may be used for other purposes. This might include services like scheduling and delivering rides to customers; alternatively it could include services like offering current transportation alternatives to designers. For example, the service capsule could comprise services like these.
Intelligent Service Tier
Reflex agent models have been replaced by motivated agents and learning agents in their computational model. In order to activate learning, programming, or other agent functions, the motivation process uses information from the observed environment as well as its own memory. It sets goals and encourages people to work towards them. To comprehend and replicate interesting activities that happen in their environments, agents form objectives. When using a 3D map, it may be used to locate nearby cabs and to overlay relevant information, such as the amount of steps it will take one to go to the vehicle. A database would be used to store the information gleaned from the learning process.
Supply Chain
The entire supply chain of Uber is based on the aggregator model. This means, that Uber plays a mediator role in connecting services requesters to service provisioners. There is a large-scale fulfilment procedure at the heart of the entire process As such the entire system is based on demand and supply that are scattered across a large geographic space. Therefore, one can naturally expect a plethora of problems when trying to get these dissimilar systems/components, to function as a logical unit/entity(Ke et al., 2019).
To put this in context, one can imagine an Uber car that render services with one passenger, then another passenger, and so on over a vast geographic area and period. Consequently, not just the services are getting exchanged, but also payments are all being handled by numerous financial institutions along the supply chain's cycle. In addition, the current supply chains lacks one critical component visibility. This further complicates the full process. Any supply chain solution or product should indeed solve the challenges listed above in order to be successful. Products and solutions that effectively solve these issues, without jeopardising the integrity of data or transactions they are built upon, will be more successful than those that do not. The route to success in a distributed world is an efficient design that works and expands. SaaS systems could be complicated and large-scale, but there is no one architecture or technique that can be used to create them(Krzos et al., 2020). Similarly, Etsy was plagued by performance issues for a number of years prior to its use of microservices. It was imperative for their technical team to reduce server processing time, and that they were coping with simultaneous API calls, which are not even easily enabled in their PHP framework. Etsy optimized their supply chain with a transition to MSA.
Microservices and process choreographic capabilities are two examples of such an architecture(Valderas et al., 2020). Uber's supply chain architecture would include the following elements in attempt to be built:
- Service encapsulation: Encapsulating services is a well-known technique in Service-Oriented Architecture (SOA). Simplicity of isolated apps can be hidden by API contracts including message canonicals. Distributed architectures are known for their loose coupling, fluid service interactions as well as the ability to orchestrate business processes that span various organisations and applications. This platform is designed to assist these capabilities.
- Event-Driven Architecture: Supply chain products and solutions, in contrast to typical monolith systems, should be event-driven and sensitive enough to respond and adapt to the dynamism of the ecosystem. As a sender and the receiver of multiple business events, each service in the environment acts similarly. An event is published by a microservice (or agent) under this architecture whenever a business state change takes place, for example, "Ride has been booked," "Ride has been finished," and so on. These events are then subscribed to by other microservices as well as agents. As soon as agents are notified of a noteworthy occurrence, they can make changes to their own commercial enterprises and publicise more related activities. If the Ride status is changed to “Cancel” by the customer, it can trigger the “Cancellation charges” which inturn notifies various stakeholders about the same(Krzos et al., 2020).
- Process choreography: Each of the numerous apps that make up a distributed application architecture must communicate with the others in order to reach a common goal, resolution, or aim choreography distributes business logic in an event-driven system, during which a service (or agent) is initiated by an event to accomplish its obligation, such as the proof of delivery event produced by a vehicle tracking system, which triggers the accounting system to begin the payment process, for instance. The system is comprised of several services of this type. More closely matched with real-world settings, process choreography extends above and beyond orchestration. This method makes it simple to implement process changes in a matter of hours rather than weeks or months(Lian & Gao, 2020).
- Unified data: The harmonization of master data is yet another critical component of this architecture, which is required for the effectiveness of whatever supply chain product or service. All consumers in the supply chain network should have access to this data, which is scattered across silos (groups, domains, and apps), if they are to make effective choices in real time. Due to the complexity of connecting to various data sources, creating high-quality master data as well as a primary source of information in any dispersed system is difficult. In addition, retrieving, transforming, and cleaning up master information in real time is a difficult task.
- End to end visibility: Digitalization and data unification from many components into a single perspective are made possible by event-driven architecture, which allows supply chain activities to be executed and monitored without hiccup. There are numerous advantages to this approach, including the identification of processes that are in compliance as well as those that are in violation, as well as the opportunity for process optimisations – allowing for greater flexibility and adaptability to the ever-changing requirements and wants of the business.
- Collaboration Tools: All supply chain systems, especially those used by firms like Uber, rely on tools and technology that make it possible for users from across domains worldwide networks to connect, collaborate on projects and made appropriate real - time decisions.
Organisational culture can influence the successful implementation of an MSA
The following cultural foundations are essential for a implementation of the said Microservices:
Diverse talents
Because microservices are always changing and evolving, the personnel who manage the architecture must have a strong desire to learn. Therefore, it wasn't enough to just employ a diverse team of experts just for sake of hiring; the greatest team of engineers must be assembled. It's easy to overcome the different difficulties that microservices will present if one has a well-rounded and experienced team on the side(Lian & Gao, 2020).
Freedom and control
A company's culture is a major role in the effectiveness of microservices architecture management. Companies can't migrate to microservices if they still have traditional procedures and methods in place, which severely limits their capacity to reap the benefits of the change. A dispersed monolith culture means that a company's microservices adventure will not succeed if it has requirements like permissions for each new modification or commit, or perhaps even undoing changes.
Support systems for developers
First, one has to recognise that they'll be investing a lot of extra time establishing support systems for their engineers and DevOps groups so that they can be productive during this shift. Allowing your engineers the freedom to make their own decisions is essential to a loosely connected design that needs a great deal of faith in their judgement. Netlix built the correct checks and balances within their system in ahead to guarantee that it couldn't be exploited on one hand and even though that this would also develop with them while they grew and maintained this essential aspect of their culture as business grew.
Optimized communication flow
The acceptance of microservices is strongly linked to the organizational structure and culture of a business. As a result the information flow within a company is highly conducive to the success of microservices. When these teams are able to make their own judgments and execute well-informed improvements, feedback mechanisms and heightened agility(Zheng & Wei, 2018).
Conclusion
The current software development process benefits from the use of a microservices architecture. It reduces development and maintenance expenses while minimising risk. Concurrent development, debugging, installation, and scalability are all made feasible. This design enables programmers to take use of both small- and large-scale programming. Due to the reduced complexities and organizational knowledge required to be productive, it allows for a wider range of applicants to be considered. Rapid and agile changes occur on a regular basis. Your clients' requirements may be met swiftly and with unparalleled responsiveness and assistance if you are prepared. The above case of Uber is a brief snapshot of how Uber’s transition into MSA and paving the way for innovation, supply chain optimisation and augmented reality can help the company build the future of urban transport system.
References
.png)
Reports
MIS607 Cybersecurity- MITIGATION PLAN FOR THREAT REPORT SAMPLE
Task Summary
Reflecting on your initial report (A2), the organisation has decided to continue to employ you for the next phase: risk analysis and development of the mitigation plan.
The organisation has become aware that the Australia Government (AG) has developed strict privacy requirements for business. The company wishes you to produce a brief summary of these based on real- world Australian government requirements (similar to how you used real-world information in A2 for the real-world attack).
These include the Australian Privacy Policies (APPs) especially the requirements on notifiable data breaches. The APP wants you to examine these requirements and advise them on their legal requirements. Also ensure that your threat list includes attacks on customer data breaches. The company wishes to know if the GDPR applies to them. The word count for this assessment is 2,500 words (±10%), not counting tables or figures. Tables and figures must be captioned (labelled) and referred to by caption. Caution: Items without a caption may be treated as if they are not in the report. Be careful not to use up word count discussing cybersecurity basics. This is not an exercise in summarizing your class notes, and such material will not count towards marks. You can cover theory outside the classes.
Requirements
Assessment 3 (A3) is in many ways a continuation of A2. You will start with the threat list from A2, although feel free to make changes to the threat list if it is not suitable for A3. You may need to include threats related to privacy concerns. Beginning with the threat list:
- You need to align threats/vulnerabilities, as much as possible, with controls.
- Perform a risk analysis and determine controls to be employed.
- Combine the controls into a project of mitigation.
- Give advice on the need for ongoing cybersecurity, after your main mitigation steps.
Note:
- You must use the risk matrix approach covered in classes. Remember risk = likelihood x consequence.
- You should show evidence of gathering data on likelihood, and consequence, for each threat identified. You should briefly explain how this was done.
- At least one of the risks must be so trivial and/or expensive to control that you decide not to use it (in other words, in this case, accept the risk). At least one of the risks, but obviously not all.
- Provide cost estimates for the controls, including policy or training controls. You can make up these values but try to justify at least one of the costs (if possible, use links to justify costs).
Solution
Introduction
A mitigation plan is a method where has a risk factored that helps to progress action and various options. Therefore, it also helps to provide opportunities and decreases the threat factors to project objectives. In the section, the researcher is going to discuss threat analysis using matrix methods, threats and controls also mitigation schemes. For Assignment Help, thread model refers to a structural representation of the collected data based on the application security. Essentially, it is a perception of different applications as well as their environment in terms of security. On the other hand, it can be said that the thread model is a process of structure that mainly focused on the potential scheme of the security of threats as well as vulnerabilities. Apart from that, the threat model includes the quality of seriousness of each thread that is identified in this industry. Besides that, it also ensures the particular techniques which can be used for mitigating these issues or threads. Threat modeling has several significant steps which must be followed for mitigating the threads in cybercrimes.
Body of the Report
Threat Analysis
The threat is a system that is generally used for determining the components of the systems. There have highly needed to protect data and various types of security threats. The threat analysis is affected to identify information and several physical assets of different organizations. The organization should understand the powerful threats as organizational assets that enhance the mitigation plan for threat reports (Dias et al. 2019).
The various organizations determine the effects of economical losses using qualitative and quantitative threat analysis. The threat analysis assures potential readiness which has a crucial risk factor to process any project. There have some important steps in threat analysis such as recognizing the cause of risk factors or threats. After that, categorize the threats and make a profile that is community-based. The third step is determining the weaknesses after that makes some scenarios along with applying them. Finally, it is making a plan for emergency cases.
Threat analysis is mainly followed by risk matrix concepts for carrying forwarding the mitigation plan for a research report. There have four types of mitigation strategies such as acceptance, transformation, limitation, and risk factor avoidances (Allodi & Massacci, 2017).
.png)
Table 1: Risk matrix methods
(Source: Self-created)
Cyber Hacking
The hacker hacks data on the food company JBS. The food company is one of the largest meat and processing food organization in Australia. For this reason, it is a crucial issue in Australia, So that the authority of the company is worried about cyber hacking. Moreover, it is criminal behavior according to the company. Therefore, it takes a major time almost four months to mitigate the condition. Moreover, it is a threat for t5he JBS Food Company.
Data Leakage
Leaking data is a very basic challenge and issue for the food company. It deteriorates the services of the food company. The inner employees are related to this type of activity. The company cannot keep faith in the employees who work s these types of activities. This is a crucial threat for the company that needs to fix quickly so that the company can survive from this type of activity (Scully, 2011). Moreover, it is a misunderstanding feature between the authority and the employees. Therefore, it takes 25 days to fix all issues to mitigate the condition of the food company.
Insider Threat
There have a very high chances to leak data that are done from the employees of the food company JBS. It is an inner threat that continues to carry forward more or less or several times. Insider threats can damage the inner cultures of the company where employees and management both are suffered due to the data leaking processes. Sometimes it is a company's failure so that the management cannot handle the entire capability or bonding of the company. Therefore, it takes adequate time almost 2 months to mitigate the condition. However, it sometimes could not be controlled by the authorities.
Phishing
Phishing is a secret code or sensitive information that should be hidden from entire workers of the food company FBS in Australia. Moreover, it is a trustworthy contact that needs to hide for securing information about the largest food company in Australia. There are chances of high risks in the systems. So that it takes 65 days to mitigate the condition of the company.
Threats and Controls
“Recent research on the usability of security technologies — often termed HCISEC (joining human-computer interaction with security) — tries to put humans in the loop and views usability as a key component for both accepting security technologies and using them correctly” (Wagner et al., 2019). There have major threats in the mitigation plan that needs to be controlled for balancing the inner condition of the company FBS foods company in Australia. Providing Cyber security to keep secure the data or information is the main motive of the company. Data tempering, information disclosures, and repudiation threats are major parts of cyber security. Data tempering is generally used for exposing data or information of the food company FBS. Data tampering is mainly noticed as the risk factor so that it can help to delete all the files which have various details as a document. Data tampering is one of the major cyber threats that can leak private and sensitive information to third parties.
It is an unauthorized and international act that needs to be eradicated by data scientists as soon as possible. It can change the entire pattern of a dataset. It can also delete some important files and accuse anomalies in those important datasets. Hackers can eavesdrop while any important conversions are going on by applying this method. It has caused major problems in large-scale business organizations. The major risk that involves data tampering is that any important message can get altered by filters and the useful information which is present in that message can get deleted by third parties (Ivanov & Dolgui, 2020).
Information disclosure which is known as information leakage is one of the major issues that can cause cyber attacks (Oosthoek & Doerr, 2021). It can intentionally reveal sensitive information to the users of any social media platform. It can hamper the privacy of a person. It can leak information to the hackers and that can cause major troubles for an organization or for a person as well. It can disclose financial information to potential hackers and that can be a severe issue. So everyone needs to be aware of using a website before putting any kind of information in it. A repudiation threat may happen when the user does not have a proper adoption in controlling the log-in and log-off actions. It can cause data manipulation and that can cause severe problems for a person or for an organization as well. Forging the users to take new actions so they can easily make the log-based activities can also be caused by repudiation threats. For example, it can be said if a user tries to use some illegal actions to check the disability of their system then that can be problematic and can be counted as a cyber attack.
Business impacts analysis is a very crucial part of controlling risk factors or challenges on behalf of the company. It is beneficial for the food company FBS who secures their issues via the concepts in mitigation threat plans. On the other hand, the company needs to maintain strategies so that the management can recover from the various challenges that face the risk threat of a mitigation plan. A recovery plan works as a backup plan that fixes the entire challenges of controls various issues in risk threat management of mitigation plans. Recovery exercises play a great role in recovering from such conditions. Therefore, third-party suppliers sometimes help to control these types of issues in risk threat management. Although the company needs various times to control the condition so that the management can maintain several kinds of challenges that arise in the company due to various reasons. The food company needs to use advanced technologies or various policies so that it can control all threats in mitigation plans (Gius et al. 2018).
Mitigation Scheme
Malware
Malware is considered the most important threat as this threat attacks mainly the network system and it is harmful to information disclosure. Simply it can be said that Malware is an intrusive software specially designed for damaging or destroying the computer system and the outcome of this threat is loss of important data from the computer system. For m mitigating this threat, the computer system should be kept updated as well as other excessive links or documents should not be downloaded in the computer system (Aslan & Samet 2020). Apart from that, for mitigating the attacks of this threat it should make sure that the computer system should have a good backup for removing this threat from the system. Besides this, a scanner must be used for identifying the issue for this threat and set a watchman to resist the attack of this that. For mitigating the attacks of this threat the user must be aware and have a good knowledge of this threat.
.png)
Figure 1: Mitigation techniques of Malware threat
(Source: Self-created)
Phishing
This thread is very harmful to the computer system as this threat mainly attacks Email and this threat can be mainly found in large business organizations. For mitigation of this threat, the users should be aware of this threat and also know the mitigation techniques. To detect this threat user must be aware of the URL classification scheme, loss estimation as well as strategies for mitigating this risk factor from the computer system (El Aassal et al. 2020). In the scheme of URL classification, the user should know the JAVA script and HTML features.
.png)
Table 1: Mitigation of Phishing threat
(Source: Self-Created)
MitM Attacks
The man in the middle attacks mainly on the network system of the computer system which h is the main cause of the information disclosure as well as security systems. This threat is mainly found in the business of E-commerce as well as financial commerce. This threat mainly creates a barrier between the user and the server (Lahmadi et al. 2020). The attack of the following threat can be mitigated by using a VPN which is very helpful for encrypting the web traffic. Apart from that, by connecting only with secured Wi-Fi routers one can mitigate the attack of this threat.
.png)
Table 2: Mitigation of MitM Attacks
(Source: Self-Created)
DOS Attack
DOS attack is one of the most significant threats for the computer system as this threat is gradually emerging in network security. This threat is mainly found in high-profile business organizations and it mainly attacks the network system and stops all the services of the network. This threat can be mitigated by monitoring network traffic as well as analyzing it properly (Dwivedi, Vardhan, & Tripathi 2020). The basic detection policy for this threat is to examine all the packets as well as detection the network flow. Apart from that, CPRS based approach is considered the most important mitigation policy in this threat. On the other hand, some prevention management systems must be included for mitigating this threat such as VPN and content flittering. Apart from that, combining farewell, as well as anti-spam, is also considered an important management system for detecting g this threat.
.png)
Table 3: Mitigation of DOS Attack
(Source: Self-Created)
SQL Injection
This threat is considered as one of the most significant threats of the network system as this threat mainly tampers the important data of a computer system. This threat can be found in any business organization which is based on a network system as well as a technology-based organization. This threat basically attacks the server system and hampers the work process of the system. This threat can be seen during the time of cyber-attacks when a hacker applies malicious code to the server of the system (Latchoumi, Reddy & Balamurugan 2020). In order to mitigate this threat, one should input validation in the computer system as well as parameterize all the queries which include already prepared statements. This particular application code should not be ever used as input directly to the computer system. Apart from that, by using the stored process the mitigation of this threat is possible and most importantly all the inputs which are supplied by the user should be escaped.
.png)
Table 4: Mitigation of SQL Injection
(Source: Self-Created)
Zero-day Exploit
This threat refers to as exploitation of network voluntary information and this threat can be found in any organization (Blaise et al. 2020). The mitigation policy of this particular threat is to find out the time opf attract as well as the time of dispatch of this threat.
.png)
Table 5: Mitigation of Zero-day Exploit
(Source: Self-Created)
Password Attack
Password attack is one of the most significant threats of a technology-based organization and this threat is mostly found in a computer device of the IT business organizations. This threat can be mitigated by following these stages such as phishing as well as credential attacking in the network system. Apart from that, key loggers, MitM, and dictionary attacks should be reduced for mitigating the emergence of threats.
.png)
Table 6: Mitigation of Password Attack
(Source: Self-Created)
Cross-site Scripting
This threat is mainly harmful to websites for E-commerce business organizations as well as other companies too.
.png)
Table 7: Mitigation of Cross-site Scripting
(Source: Self-Created)
Rootkits
This threat is mostly found in the technological system and caused data disclosure.
.png)
Table 8: Mitigation of Rootkits
(Source: Self-Created)
IoT Attacks
This threat is mainly found in IT organizations which is very harmful for the elevation of privileges.
.png)
Table 9: Mitigation of IoT Attacks
(Source: Self-Created)
Conclusion
Taking into consideration from the above text it can be concluded that there are several kinds of cyber threats that can be very harmful to networks as well as computer systems also. Defining all the requirements of security management is the first step for this model and then an application should be created. Apart from that, finding out the potential threads is also very important and after that, the threads should be mitigated for close security. For evaluating the potential risk factors the threat modeling is considered a proactive strategy that includes identification of the threats as well as improving tests or the process for detecting those threats. Apart from that, the approach of threat modeling should be to make out the impact of the threats as well as classify the threats. Application of the proper countermeasures is also included in the approach of the threat model.
References
.png)
.png)
Reports
COMP1680 Cloud Computing Coursework Report Sample
Detailed Specification
This Coursework is to be completed individually Parallel processing using cloud computing
The company you work for is looking at investing in a new system for running parallel code, both MPI and Open MP. They are considering either using a cloud computing platform or purchasing their own HPC equipment. You are required to write a short report analyzing the different platforms and detailing your recommendations. The report will go to both the Head of IT and the Head of Finance and so the report should be aimed at a non-specialist audience. Assume the company is a medium sized consultancy with around 50 consultants, who will likely utilize an average of 800 CPU hours each a month. Your report should include:
1) A definition of cloud computing and how it can be beneficial.
2) An analysis of the advantages and disadvantages of the different commercial platforms over a traditional HPC.
3) A cost analysis, assume any on site HPC will likely need dedicated IT support
4) Your recommendations to the company.
5) References
Solution
Introduction
The report is focusing to help the company to invest in a new system so that the company can run parallel code for OpenMP and MPI. The company is looking forward to use a cloud computing platform or to purchase separate HPC equipment for the company. At the very beginning of the report, the meaning of cloud computing is mentioned. In the same part, the definition of cloud computing is also mentioned. For Assignment Help All of the possible ways how cloud computing is useful and can it benefit a company are also written in the report. The report shows how the High-performance Computing act and how other commercial platform works. A comparison of both platforms has been done in the report. In the next section of the report, an analysis has been done about HPC and different commercial platforms. It has stated the different advantages and disadvantages of using different commercial platforms over the traditional HPC. All the points that show why the company should go with the particular platform have been highlighted in the given report. In the next section of the report, cost analysis has been mentioned. The cost analysis is done on the basis of an assumption made. A site has been assumed that the HPC will likely need dedicated IT support. After analyzing all these points, some of the recommendations to the company have been given. The recommendation that is given to the company will help the company to choose whether it should go with High-Performance Computing or it should choose a commercial platform. It will give the company an idea to invest in the new system for running parallel code. At the end of the report, a short conclusion has also been mentioned that summarizes each point presented in the report in short form.
Definition of Cloud Computing
Cloud computing is referred to as the delivery of service on demand like storage of data, computing power, and computer system resources. The delivery of services using internet, databases, networking, data storage, software, and servers. is termed cloud computing. The name of this on-demand availability is cloud computing because the information and data accessed by it are found remotely in the virtual space or in the cloud. All the heavy lifting or activities involved in the processing or crunching of the data in the computer device are removed by cloud computing (Al-Hujran et al. 2018). Cloud computing moves away from all the work to huge computer clusters very far away in cyberspace. The definition of cloud computing is, it is a general term for anything that involved delivering hosted service with the help of the internet. Both the software and hardware components are involved in the cloud infrastructure and these are required for implementing the proper cloud computing model. Cloud computing can be thought of in a different way such as on-demand computing or utility computing. Hence, in short, it can be said that cloud computing is the delivery of resources of information technology with the use of the internet (Arunarani et al. 2019).
Following are the points that show how cloud computing can be beneficial:
Agility- Easy access to a large number of technologies is given by the cloud so that the user can develop anything that the user has ever imagined. All the available resources can be quickly spined up to deliver the desired result from infrastructure services such as storage, database, computer, IoT, data lakes, analytics, machine learning, and many more. All the technologies services can be deployed in a matter of seconds and the ways to implement various magnitude. With the help of cloud computing, a company can test several new ideas and experiments to make differentiation of customer experiences, and it can transform the business too (Kollolu 2020).
Elasticity- With the presence of cloud computing in any business enterprise, the system become capable to adapt all the changes related to workload by deprovisioning and provisioning in autonomic manner. With cloud computing, these resources can diminished and can be maximize it instantly or to shrink the capacity of the business.
Security- Security of the data is one thing that almost every organization is concerned about. But, with the help of cloud computing, one can keep all the data and information very private and safe (Younge et al. 2017). A cloud host carefully monitors the security that is more important than a conventional in-house system. In cloud computing, a user can set different security according to the need.
Quality control- In a cloud-based system, a user can keep all the documents in a single format and in a single place. Data consistency, avoidance of human error, and risk of data attack can be avoided in cloud computing. If the data and information are recorded in the cloud-based system then it will show a clear record of the updates or any revisions made in the data. On the other hand, if the data are being kept in silos then there will be a chance of saving the documents in different versions that can lead to diluted data and confusion.
Analysis of Different Platforms vs HPC
HPC stands for High-Performance Computing is the ability to perform complex calculations and process data at a very high speed. The supercomputer is one of the best-known solutions for high-performance computing. It consists of a large number of computer nodes that work together at the same time to complete one or more tasks. This processing of multiple computers at a time is called parallel processing. Compute, network and storage are the three components of HPC solution. In general terms, to aggregate all the computing powers in such a way that it could deliver high performance than one could get out of a typical desktop is determined as HPC. Besides, having so many advantages, it has some disadvantages also. The following points show the analysis of the advantages and disadvantages of the different commercial platforms over a traditional HPC.
The advantage of different platforms over a traditional HPC is as follows:-
- With the perspective of the cost of equipment of high-performance computing, it seems to have been very high. The cost of using the high-performance computing cluster is not fixed and varies according to the type of cloud instances that the user uses to create the HPC cluster. If the cluster is needed for a very short time, the user uses on-demand instances for creating the cluster after the creation of the cluster, the instances are needed to be deleted (Tabrizchi and Rafsanjani 2020). This cost is almost five times higher than that of the local cluster. But when moving to the other platform of cloud computing, reduces the cost of managing and maintaining of IT system. in the different platforms, there is no need to buy any equipment for the business. The user can reduce the cost of using the cloud computing service provider resources. This is one of the benefits of other platforms over traditional HPC.
- In the different platforms of cloud computing rather than traditional HPC, cloud computing permits the user to be more flexible in their performance and work practices. For instance, the user is able to access the data from home, commute to and from the work, or on holiday. If the user needs access to data in case the user is off-site, the user can connect to the data anytime very easily, and quickly. In contrast, there is no such case with traditional HPC. In the traditional HPC, the user has to reach the system to access the data. In this HPC cloud, it is difficult to move the data that are used in HPC (Varghese and Buyya 2018).
- Having separate clusters in the cloud in the data centers poses some security challenges. But in the other platform of cloud computing, there is no such risk associated with data. One can keep and store the data in the system safely and privately in the case of other platforms. The user does not need to worry in any situation such as natural disaster, power failure or in any difficulties, the data are stored very safely in the system. This is another advantage of other platforms over traditional HPC (Mamun et al. 2021).
Disadvantages of other platforms over traditional HPC are as follows:
- The cloud, in any other setup, has the chance to experience some of the technical problems like network outages, downtimes, and reboots. These activities created troubles for the business by incapacitating the business operations and processes and it leads to damaging of business.
- In the several other platforms of cloud computing rather than HPC, the cloud service provider monitors own and manages the cloud infrastructure. The customer doesn't get complete access to it and has the least of the control over the cloud infrastructure. There is no option to get access to some of the administrative tasks such as managing firmware, updating firmware, or accessing the server shell.
- Not all the features are found in the platforms of cloud computing (Bidgoli 2018). Every cloud services are different from each other. There are some cloud providers that tend to provide limited versions and there are some cloud providers that offer only the popular features so the user does not get every customization or feature according to the need.
- Another disadvantage of cloud computing platforms over high-performance computing is that all the information and data are being handed over by the user while moving the services to the cloud. For all the companies that have an in-house IT staff, they are not able to handle the issues on their own (Namasudra 2021).
- Downtime is one of the disadvantages of cloud-based service. There are some experts that have considered downtime as the biggest cons of cloud computing. It is very well known that cloud computing is based on the internet and so there is always the chance of service outrage due to unfortunate reasons (Kumar 2018).
- All the components that remain online in cloud computing that exposes potential vulnerabilities. There are so many companies that have suffered from severe data attacks and security breaches.
The above sections deal with the analyses of other commercial factors over traditional higher performance computing.
Cost Analysis
It is very important to know how the cloud provider sets the prices of the services. A team of cost analytics has been referred by the company so that the team can calculate the total cost that the company has to endure to set the cloud-based platform. The team will decide which cost is to be taken into consideration and which is to be eliminated while calculating the cost. In the cost analysis site, HPC will need dedicated IT support. Network, compute, and storage are the three different cost centers of the cloud environment. Below are the points that show the cost analysis of the cloud service and an idea has been provided about how the cloud providers decide how much to charge from the user.
Network- While setting the price of the service, the expenses to maintain the network are determined by the cloud providers. The expenses of maintaining the network include calculation of the costs for maintaining network infrastructure, the cost of network hardware, and the labor cost. All these costs are summed up by the provider and the result is divided by the rack units needed by the business for the Infrastructure as a Service cloud (Netto et al. 2018).
- Maintainance of network infrastructure- the cost of security tools, like firewalls, patch panels, LAN switching, load balancers, uplinks, and routings are included in this. It covers all the infrastructure that helps the network to run smoothly.
- Cost of network hardware- every service provider needs to make its investment in some type of network hardware. The providers buy hardware and charge the depreciation cost over the device lifecycle
- Labor cost- labor cost includes the cost of maintaining, monitoring, and managing the troubleshoot cloud computing infrastructure (Zhou et al. 2017).
Compute- every business enterprises have their own requirement that includes CPU. Cost of CPU is calculated by the service providers by making an determination of the cost of per GB RAM endured by the company.
- Hardware acquisition- hardware acquisition computation stated the cost of acquiring hardware for every GB of RAM that the user will use. Depreciation of the cost is also made here over the lifecycle of the hardware.
- Hardware operation- total cost of the RAM is considered by the provider in the public cloud and then the cost per rack unit of the hardware divide it. This cost includes subscription costs based on usage and licensing.
Storage- storage costs are as same as the compute cost. In this, the service provider finds out what is the cost of operating the storage hardware and to get the new hardware as per the storage need of the users (Thoman et al. 2018).
Recommendations
As the company is looking forward to investing in the new system for running parallel codes, some of the recommendations to the company are mentioned in the below section. These recommendations will help the company to decide in which of the system, it needs to make its investment so that the company can run parallel codes smoothly. On the basis of analyses done in the above part of the report, it can be said that the company should go with the different platforms available in cloud computing. In the traditional HPC, there are lots of barriers to the users like high cost, the problem of moving and storing the data, and many more. It is not like cloud computing is all set for the company to use and so the following are the recommendations for the company that can enhance all the other platforms of cloud computing:
Recommendations to minimize planned downtime in the cloud environment:
- The company should design the new system's device services with disaster recovery and high availability. A disaster implemented plan should be defined and implemented in line with the objectives of the company that provides the recovery points objectives and lowest possible recovery time.
- The company should leverage the different zones that are provided by the cloud vendors. To get the service of high tolerance, it is recommended to the company consider different region deployments attached to automated failover in order to ensure the continuation of the business.
- Dedicated connectivity should be implemented like AWS Direct Connect, Partner Interconnect, Google Cloud’s Dedicated Interconnect as they provide the dedicated connection of network between the user and the point of cloud service. This will help the business to exposure the risk of business interruption from the public internet.
Recommendations to the company with respect to the security of data:
- The company is recommended to understand the shared responsibility model of cloud providers. Security should be implemented in every step of the deployment. The company should know who holds access to each resource and data of the company and is required to limit the access to those who are least privileged.
- It is recommended to the company implement multiple authentications for all the accounts that provide the access to systems and sensitive data. The company should turn on every possible encryption. A risk-based strategy should be adopted by the company that secured all the assets assisted in the cloud and extended the security to the devices.
Recommendations to the company to reduce the cost of the new cloud-based system:
- The company should get ensured about the presence of options of UP and DOWN.
- If the usage of the company is minimum, then it should take the advantage of pre-pay and reserved instances. The company can also automate the process to stop and start the instances so that it can save money when the system is not in use. To track cloud spending, the company can also create an alert.
Recommendations to the company to maintain flexibility in the system:
- The company should consider a cloud provider so that it can take help for implementing, supporting, and running the cloud services. It is also necessary to understand the responsibilities of the vendor in the shared responsibility model in order to reduce the chance of error and omission.
- The company must understand the SLA as it concerns the services and infrastructure that the company is going to use and before developing the new system the company should understand all the impacts that will fall on the existing customers.
Following all the above-mentioned recommendations, the company can decide how to and where to invest in the development of the new system.
Conclusion
The report was prepared with the goal to help the company to decide on which system should it make the investment in. The company has two options, either it can use a cloud computing platform or it can purchase all the equipment of HPC. In this report, the meaning of cloud computing has been explained very well. Not only the meaning of cloud computing, but it has also focused on the benefits of cloud computing in any business organization. In simple term, the delivery of a product or service with the use of the internet is called cloud computing. In the report, an analysis has been made regarding both of the systems. The advantages and disadvantages of the other platforms over the platform of high-performance computing are included in the analysis so that it can be easy to decide where the company should make its investment. For the comparison, different bases are taken as the cost of the system, security of data, control over the access, and many more. A structure of cost analysis has also been presented in the report so that company can imagine how much cost it has to invest in the new system. some of the recommendations to the company are also given. The company is recommended to choose the cloud computing platform as it is very secure and the cost of setting up the system is lower in comparison to others.
References
.png)
.png)
Reports
ISYS1003 Cybersecurity Management Report Sample
Task Description
Since your previous two major milestones were delivered you have grown more confident in the CISO chair, and the Norman Joe organisation has continued to experience great success and extraordinary growth due to an increased demand in e-commerce and online shopping in COVID-19.
The company has now formalised an acquisition of a specialised “research and development” (R&D) group specialising in e-commerce software development. The entity is a small but very successful software start-up. However, it is infamous for its very “flexible” work practices and you have some concerns about its security.
As a result of this development in your company, you decide you will prepare and plan to conduct a penetration test (pentest) of the newly acquired business. As a knowledgeable CISO you wish to initially save costs by conduct the initial pentest yourself. You will need to formulate a plan based on some industry standard steps.
Based on the advice by Chief Information Officer (CIO) and Chief Information Security Officer (CISO) the Board has concluded that they should ensure that the key services such as the web portal should be able to recover from major incidents in less than 20 minutes while other services can be up and running in less than 1 hour. In case of a disaster, they should be able to have the Web portal and payroll system fully functional in less than 2 days.
Requirements:
1. Carefully read the Case Study scenario document. You may use information provided in the case study but do not simply just copy and paste information.
2. This will result in poor grades. Well researched and high-quality external content will be necessary for you to succeed in this assignment.
3. Align all Assignment 3 items to those in previous assignments as the next stage of a comprehensive Cyber Security Management program.
You need to perform a vulnerability assessment and Business Impact Analysis (BIA) exercise:
1. Perform vulnerability assessment and testing to assess a fictional business Information system.
2. Perform BIA in the given scenario.
3. Communicate the results to the management.
Solution
Introduction
Another name of one test is a penetration test and this type of test is used for checking exploitable vulnerabilities that are used for cyber-attacks [20]. The main reason for using penetration tests is to give security to any organization. For assignment help This test shows the way to examine the policies are secure or not [14]. This type of test is very much effective for any organization and the demand for penetration tests is increasing day by day.
Proposed analytical process
A penetration test is very much effective for securing any type of website [1]. Five steps are connected with pentest. The name steps are planning, scanning, gaining access, maintaining process, and analysis.
Pentest is based on different types of processes. Five steps are involved in pentest [2]. The first step shows the planning of pentest, the second step describes the scanning process, the third step is about gaining access, the fourth step and five steps ate about maintaining and analyzing the process.
There are five types of methods that are used for penetration testing and the name of the methods are NIST, ISSAF, PTES, OWASP, and OSSTMM. In this segment, open web application security project or OWASPO is used [3]. The main reason for selecting this type of method is that it helps recognize vulnerabilities in mobile and web applications and to discover flaws in development practices [15]. This type of test performs as a tester and it rate risks that help save time. Different types of box testing are used in pentest. The black box testing is used when the internal structure of any application is completely unknown [16,17]. White test is used when the internal process of working instruction is known and a gray structure is used when the tester can understand partially the internal working structure [13].
Ethical Considerations
The penetration test is used to find malicious content, risks, flows, and vulnerabilities [4]. It helps to increase the confidence of the company and there are different types of process that helps to increase the productivity and the performance of the company. The data that are used may be restored with the help of a pen test.
Resources Required
The name of hardware components that are used for performing ten tests is a port scanner, password checker, and many more [5]. The names of the software that are used for the penetration test are zmap, hashcat, PowerShell-suite, and many more.
Time frame
This framework has a huge user community and there are no articles, techniques, and technologies are used for this type of testing. The OWASP process is time-saving so it is helpful in every step [19].
.png)
Question 3.1
1. Analysis of Norman Joe before the BIA implementation
Business impact analysis is the process of identifying and evaluating different types of potential effects [19]. These potential effects can be in different fields and this is helpful to overcome all of the range requirements for business purposes [6]. The main aspect of pentest to secure all of the web and mobile is to provide and identify the main weakness or the vulnerabilities of the business management system from being the victim of major reputation and financial losses. To ensure the continuity of the business, regular checking and penetration testing is very important for the company [12].BIA is a very important process for Norman Joe, before implementing the BIA Norman Joe has many security issues, and the company is also required to improve the firewall in their network system as well as the IDS [11]. As the firewalls are only developed to prevent attacks from the outside of the network, the attacks from inside the network can easily harm the network and damage the workflow [7]. The company requires to implement internal firewalls to prevent such attacks. Firewalls also can be overloaded by DDos protocol attacks, for this type of attack the company requires to implement scrubbing services [16].
.png)
Figure 1: Before implantation of BIA for penetration testing
2. Analysis of Norman Joe after the BIA implementation
The process of business impact analysishas been done on the Norman Joe to secure the Company's system and after implementing the security measures such as the internal firewalls and the scrubbing services, the company’s data has been secure mostly from cyber security threats [8]. After implementing the BIA, the website has been tested by running the website, the website has first started and then intercept of the website has been done [10].
.png)
Figure 2: After implantation of BIA for penetration testing
After the intercept process it has been checked if the website is being used or not [11], if the website is not being used it allows the user to remain in the start page of the website and if the website is being used the protocols are being found and checked if it was used or using then the information are gathered and performed the penetration test in the system [9]. Furthermore, the report of the penetration analysis has been displayed after the test as well as the vulnerability level then the analysis has been finished.
Reference List
.png)
.png)
Reports
DATA4300 Data security and Ethics Report Sample
Part A: Introduction and use on monetisation
- Introduce the idea of monetisation.
- Describe how it is being used in by the company you chose.
- Explain how it is providing benefit for the business you chose.
Part B: Ethical, privacy and legal issues
- Research and highlight possible threats to customer privacy and possible ethical and legal issues arising from the monetisation process.
- Provide one organisation which could provide legal or ethical advice.
Part C: GVV and code of conduct
- Now suppose that you are working for the company you chose as your case study. You observe that one of your colleagues is doing something novel for the company, however at the
same time taking advantage of the monetisation for themself. You want to report the misconduct. Describe how giving voice to values can help you in this situation.
- Research the idea of a code of conduct and explain how it could provide clarity in this situation.
Part D: References and structure
- Include a minimum of five references
- Use the Harvard referencing style
- Use appropriate headings and paragraphs
Solution
Introduction and use of Monetization
Idea of Monetization
According to McKinsey & Co., the most successful and fastest-growing firms have embraced data monetization as well as made it an integral component of their strategy. There are two ways one can sell direct access to the data to 3rd parties through direct data monetization. There are two ways to sell it: one can either sell the accrued data in its raw form, or one can sell it all in the form of analysis as well as insights. Data for assignment help can help one find out how to get in touch with their customers and learn about their habits so that one can increase sales. It is possible to identify where as well as how to cut costs, avoid risk, and increase operational efficiency using data. (For the given case, the chosen industry is Social Media (Faroukhi et al., 2020).
How it is being used in the chosen organization
In order for Facebook to monetize its user data, they must first amass a large number of data points. This includes information on who we communicate with, what we consume and react to, as well as which websites and apps we visit outside of Facebook. Many additional data points are collected by Facebook beyond these (Mehta et al., 2021). Because of the predictive potential of ml algorithms, companies can accomplish that even if users don't explicitly reveal it themselves. The intelligence gathered based on behavioural tracking done is the essence of what is sold to their customers (Child and Starcher, 2016). Facebook generates 98 percent of its income from advertising which is how their data is put to use.
Providing benefits to the organization chosen
Facebook's clients (advertisers and companies, not users) receive a plethora of advantages. Advertising may target certain groups of people based on this information and change the message based about what actually works with them. Over ten million businesses, mostly small ones, make use of Facebook's advertising platform. As a result of the Facebook Ad platform, they are able to present targeted consumers the advertising, as well as provide thorough performance data on how various campaigns including different visuals performed (Gilbert, 2018).
Ethical, Privacy and legal Issues
Threats to consumers
According to reports, Facebook has been well-known for using cookies, social plug-ins, and pixels to monitor users as well as non-users of Fb. Even if users don't have a Facebook account, they aren't safe from this research because there are a slew of other data sources that may be used in place of Facebook. It's also possible to monitor non-members who haven't joined Facebook by visiting any website that features the Facebook logo. In addition to "cookies," web beacons were one of the numerous kinds of internet tracking that may be employed across websites, and then these entries could be sold to relevant stakeholders.As a result, target voters might discover reinforcing messages on a wide range of sites without understanding that they are the only ones receiving such communications, nor are they given cautions that these are political campaign ads.Furthermore, governments throughout Europe and north America are increasingly requesting Facebook to hand up user data to assist them investigate crimes, establish motivations, confirm or refute alibis and uncover conversations. The word "fighting terrorism" has become a catch-all phrase that has lost its meaning over time. According to Facebook, this policy is referred to as, "We may also share information when we have a good faith belief it is necessary to prevent fraud or other illegal activity, [or] to prevent imminent bodily harm [...] This may include sharing information with other companies, lawyers, courts, or other government entities."(Facebook, 2021). In essence, privacy is mandated only on face value whereas the data is exposed to both Facebook, 3rd party advertisers and Government.
IAPP can help with the privacy situation
International Association for the Protection of Personal Information (IAPP) is a global leader in privacy, fostering discussions, debates, and collaboration among major industry stakeholders. They help professionals and organisations understand the intricacies of the growing environment as well as how to identify and handle privacy problems while providing tools for practitioners to improve and progress their careers (CPO, 2021). International Association of Professionals in Personal Information Security provides networking, education, and certification for privacy professionals. The International Association for the Protection of Personal Information (IAPP) can play a role in promoting the need for skilled privacy specialists to satisfy the growing expectations of businesses and organisations that manage data.
GVV and Code of Conduct
Fictional scenario
For the sake of a fictionalised context, I would assume that I was employed by Facebook. Accordingly, my colleague in this same fictionalised setting is invading privacy of businesses in a particular domain and collecting proprietary information based on the data collected and then selling it off to the competitors of that business in the same domain. There are indeed a lot of grey areas to contemplate and traverse when it comes to dealing with these kinds of tricky situations, and managing them professionally and without overreacting is essential. The most critical thing for myself would have been to figure out what is genuine ethical problem what is just something I don't like before I get involved. If my concerns are well-founded and the possible breach is significant, I'd next ask myself two fundamental questions: I can proceed if both of the following questions are answered with a resounding "yes.”
Next, when someone is working for a publicly traded and that being a significantly large company, there should be defined regulations and processes to follow whenever one detects an unlawful or unethical violation. In the internal employee compliance manual, one ought to be able to find these. Further ahead, I'll decide whether to notify their supervisor. If that person is also complicit in the event, then next alternative would be to inform the reporting manager or compliance officer. Also, if I choose note be involved in the investigation or reporting,I can either report anonymously or mention the superiors that I would not like to be named.
Reference list
.png)
Programming
BIS1003 Introduction To Programming Assignment Sample
Assessment 4 Details:
EduWra Company pointed you to develop a program to assist in predicting the customer's preferences. This company sells books online. The program would calculate the average rating for all the books in the dataset and display the highest rated books. We could better predict what a customer might like by considering the customer's actual ratings in the past and how these ratings compare to the ratings given by other customers.
The assessment has two tasks – Task 1: implement the program in Python. Task 2: write a formal report.
Task 1:
Implement the program in Python. Comment on your code as necessary to explain it clearly. Your task for this project is to write a program that takes people's book ratings and makes book recommendations to others using the average rating technique. The program will read customers data from a text file (you find the text file on Canvas site for this unit) that contains sets of three lines about each customer. The first line will have the customer's username, the second line book title, and the third line the rating that is given to the book.
Task 2:
Each group should write a formal report that includes:
- A cove page for your assignment contains the group members' names and contribution percentages (each student must state which parts of the project have been completed). If your name is not on the cover page, you will be given zero.
- Draw system flowchart/s that present the steps of the algorithm required to perform the major system tasks.
- You need to test your program for assignment help by selecting at least three sets of testing data. Provide the results of testing your program with different values and record the testing results using the testing table below.
- Copy the code to your report.
- Take screenshots of the program output.
Solution
Flowchart
1. Read ratings.txt file
.png)
2. Store each bookname from given books
.png)
3. Get Rating for each user and corresponding books
.png)
4. Get recommendation
.png)
Source Code
# Assignment 4 : Applied Project
# Name : Jenil, Rohan, Mayank_group_11
# date : 12/12/2021
# Group No: 11
#this function read all the books information and return
def readBooksName(books):
i = 1
bookNames = []
while True:
if i > len(books):
break
# if bookNames is not founc in the list then only add the bookname
if bookNames.count(books[i].strip()) == 0:
#remove the new line or extra spaces from bookname
bookNames.append(books[i].strip())
#increase the line by 3 to get next book
i = i + 3
return bookNames
#this function will find the rating of each book and store into dictionary
def getRating(books, bookNames):
ratings = {} #create empty dictionary
i = 0
while True:
if i > len(books) - 1: #break loop if reached to last record
break
ratings[books[i].strip()] = [0] * len(bookNames) #create list of zero for each book
i = i + 3 #increase counter by three to read next user name
i = 0
while True:
if i > len(books) - 1:
break
key = books[i].strip()
bookName = books[i+1].strip()
try:
rating = int(books[i+2])
except ValueError:
print('Error: Book rating must be int')
rating = 0
index = bookNames.index(bookName)
#update rating for paricular index book
ratings[key][index] = rating
#increase couter by 3
i = i + 3
return ratings
def calcAverageRating(bookRatings, bookNames):
#create empty list to store avgRatings
avgRatings = []
#get all the ratings of books
values = list(bookRatings.values())
for i in range(len(bookNames)):
sum = 0
count = 0
for ratings in values:
#get the correspoding rating value from values list
sum += ratings[i]
if ratings[i] != 0: #count only not zero value
count += 1
avgRatings.append(sum/count) #calculating avg rating and append to the list
#sorting the avg rating and corresponding bookNames
for i in range(len(avgRatings)):
for j in range(len(avgRatings)):
if avgRatings[i] > avgRatings[j]:
avgRatings[i], avgRatings[j] = avgRatings[j],avgRatings[i]
bookNames[i],bookNames[j] = bookNames[j], bookNames[i]
return avgRatings,bookNames
def showAvgRatings(bookNames,bookAvgRatings ):
for i in range(len(bookNames)):
print('The average ratings for %s is %.2f' % (bookNames[i], bookAvgRatings[i]))
def showRecommendation(bookList):
for book in bookList:
if book[1] != 0:
print('The average ratings for %s is %.2f' % (book[0], book[1]))
def findRecommendation(customerName,bookRatings,bookNames):
givenUser = bookRatings[customerName]
recomendations = []
#retrieve each books and rating values for each user
for key, value in bookRatings.items():
if key != customerName: #take only customer other than given customername
similarity = [] #create empty list to store multiplication of each user
for i in range(len(value)):
similarity.append(value[i] * givenUser[i]) #store the multiplication value
recomendations.append((key, sum(similarity))) #store the sum of similarity value
recomendations.sort(key=lambda x: x[1]) #sorting them by rating
recomendations.reverse() #reverse to get topThree
topThree = recomendations[:3] #getting topthree customer with highest similiarity
bookList = [] #empty list to store booklist
recommend = [0] * len(bookNames) #creating empty list to stroe recommend
for i in range(len(bookNames)):
s = 0
c = 0
for j in topThree:
s = s + bookRatings[j[0]][i] #getting rating value of each user for partiuclar book
if bookRatings[j[0]][i] != 0: #count only for non zero value
c += 1
if c != 0: #find out avg rating where count is non zero
recommend[i] = s / c
bookList.append((bookNames[i], recommend[i])) #append bookname and avg rating to booklist
bookList.sort(key=lambda x: x[1]) #sorting the booklist by rating value
bookList.reverse() #reverse the booklist to get in decending order
return bookList
def main():
try:
fp = open('data3.txt', 'r') #if file not found return with error message
books = fp.readlines()
except IOError:
print('Error: File not found')
return
bookNames = readBooksName(books)
bookRatings = getRating(books, bookNames)
bookAvgRatings, bookNames = calcAverageRating(bookRatings,bookNames)
while True:
print('\n\nWelcome to the EduWra Book Recommendation System.')
print('1: All books average ratings')
print('2: recommend books for a particular user')
print('q: exit the program')
choice = input('\nSelect one of the options above: ')
if choice == 'q':
break
elif choice == '1':
showAvgRatings(bookNames,bookAvgRatings)
elif choice == '2':
customerName = input('\nPlease enter customer name: ')
if customerName in bookRatings:
bookList = findRecommendation(customerName, bookRatings,bookNames)
showRecommendation(bookList)
else:
showAvgRatings(bookNames, bookAvgRatings)
if __name__ == '__main__':
main()
.png)
Test Data Table 1
.png)
Output details of Test Data 1

Test Data Table 2
.png)
.png)
.png)
.png)
Test Data Table 3
.png)
.png)
.png)

Reports
MIS500 Foundation of Information System Assignment Sample
Introduction to Chanel
Chanel is a French luxury fashion house that was founded by Coco Chanel in 1910. It focuses on women's high fashion and ready to wear clothes, luxury goods, perfumes and accessories. The company is currently privately owned by the Wertheimer family This is one of the last family businesses in the world of fashion and luxury with revenues of €12.8 billion (2019) and net income €2,14 billion (2019).
Chanel – Case Study To complete this assessment task you are required to design an information system for Chanel to assist with their business. You have discussed Porter’s Value Chain in class and you should understand the primary and support activities within businesses. For this assessment you need to concentrate on Marketing and Sales and how Chanel cannot survive without a Digital Strategy.
Source: Porter’s Value Chain Model (Rainer & Prince, 2019),
Read the Chanel case study which will be distributed in Class during Module 3.1. Visit these websites
https://www.chanel.com/au/
Based on the information provided as well as your own research (reading!) into information systems write a report for Chanel to assist them in developing a ‘Digital Strategy’ to develop insights for their marketing and sales especially in online sales. Please structure the group report as follows:
- Title page
- Introduction
- Background to the issue you plan to solve
- Identify and articulate the case for a Digital Strategy at Chanel (based upon the data do you as a group of consultants agree or disagree)
- Research the issues at Chanel and present a literature review – discuss the marketing and sales data analysis needs and the range of BI systems available to meet these needs.
- Recommended Solution – explain the proposed Digital Strategy and information systems and how it will assist the business. You may use visuals to represent your ideas.
- Conclusion
- References (quality and correct method of presentation. You must have a minimum of 15 references)
Solution
Introduction
Businesses are upgrading their business operations by implementing a digital strategy in order to compete against rivals and stay in business. In doing so, companies must continuously keep adjusting their business strategies and procedures to keep attracting the newer generation of customers or else face a certain doom. The paper is based on Chanel, a posh fashion brand based in Neuilly-sur-Seine, France. The Chanel’s business challenges in the market place are briefly assessed and examined in this research. In addition, the paper will briefly outline the advertising and marketing process, as well as how Chanel should embrace a digital strategy to maintain growth in the following decade.
Background to the issue you plan to solve
The issue is that the luxury brands, such as Chanel are lagging behind the rapidly developing trend of e-commerce and they need to implement a comprehensive Digital Strategy in order to keep their existing customers and expand their market shares. Traditionally, luxury brand companies considered online shopping as a platform for lower-end products and did not focus on investing in their social presence (Dauriz, Michetti, et al., 2014). However, the rapid development of online shopping platforms and changing behaviour of customers, coupled by lockdown measures and cross-border restrictions due to COVID-19 pandemic has exposed the importance of digital-based sales and marking even for the luxury brands which heavily depend on in-person retail sales (McKinsey & Company, 2021). Fashion experts warn that luxury companies will not survive the current crisis caused unless they invest in their digital transformation (Gonzalo et al., 2020).
According to the global e-commerce outlook report for assignment help carried out by the CBRE which is the world's largest commercial real estate services and investment firm, online retail sales accounted for 18 per cent of global retail sales in 2020 which is 140 per cent increase in the last five years and expected to reach 21.8 per cent in 2024 (CBRE, 2021). On the other hand, as digital technology advances, the customer's behavior is changing rapidly in a way that they do not only prefer to make their purchases online but also make a decision based on their online search (Dauriz, Michetti, et al., 2014). However, e-commerce accounted for only 4 per cent of luxury sales in 2014 (Dauriz, Remy, et al., 2014) and it reached just 8 per cent in 2020 (Achille et al., 2018). It shows that luxury brands are slow to adapt into the changing of environment of global trade and customers' behavior. On the other hand, at least 45 per cent of all luxury sales is influenced by the customers' social media experience and the company's digital marketing (Achille et al., 2018). However, almost 30 per cent of luxury sales are made by the tourists travelling outside their home countries, therefore luxury industry has adversely impacted by the current cross-border travel restrictions. In addition, fashion weeks and trade shows were disrupted by almost two years due to the pandemic. Therefore, fashion experts suggest luxury companies to enhance its digital engagement with their customers and to digitalize their supply chains (Achille & Zipser, 2020).
Chanel is the leading luxury brand for women's couture in the world. Its annual revenue is $2.54 billion which is one of the highest in the world (Statista, 2021). Chanel's digital presence is quite impressive. It is one of the "most pinned brands" on social media, having pinned by 1,244 times per day (Marketing Tips For Luxury Brands | Conundrum Media, n.d.). It has 57 million followers in social media and its posts are viewed by 300 million people in average (Smith, 2021). It has also been commended by some fashion experts for its "powerful narrative with good content" for marketing on social media (Smith, 2021). However, it has also been criticized for its poor websites that is not user-friendly (Taylor, 2021) and its reluctance on e-commerce (Interino, 2020). Therefore, Chanel needs to improve its digital presence, developing a comprehensive Digital Strategy.
Identify and articulate the case for a Digital Strategy at Chanel
Case for digital strategy at Chanel
As-Is State
After reviewing the Chanel case, as consultants, we are now all dissatisfied with the Chanel company's digital strategy. While making any kind of choice, businesses must first comprehend the customer's perspective. The current state of the firm's commerce was already determined based on the provided example, with the existing web-based platform employed by the company being fairly restrictive for them. For instance, in less than 9 nations, the company has built an eCommerce platform offering cosmetics and fragrance. The firm's internet penetration activity is lower than that of other industry players. The business only offers a restricted set of e-services offerings. Not only that, but the organisation uses many systems and databases in various geographical regions, which provides a disfranchised experience to the end consumers. Besides that, the company is encountering technological organisation issues, such as failing adequately align existing capabilities with forthcoming challenges and employing diverse models, all of which add to the business's complication. Simultaneously, their social media marketing is grossly insufficient, failing to reach the target luxury audience as it should.
To -Be State
Following an examination of the firm's present digital strategy, it was discovered that the company has a number of potential opportunities that it must pursue in order to effectively stay competitive in the market. The major goal of the Chanel firm, according to analysis and research, is to improve the customer experience, bring new consumers, establish brand connection and inspire advocacy, and raise product awareness . It has been determined that Chanel's digital strategy is outdated, as a result of which the company is unable to successfully compete with its competitors. Major competitors of Chanel, for example, used successful digital channels to offer products to end-customers throughout the epidemic. It is suggested that the organisation implement an information system that can provide customers with a personalised and engaging experience. To resolve the existing condition of business issues, it is critical for the organisation to incorporate advanced technology into its organizational processes in order to capture market share. The company’s existing state business challenges and implications can be remedied by upgrading their e-commerce website that is integrated with new scalable technologies such as AI, Big Data, Machine Learning, and analytics. The company also must optimize their product line and revaluate their core value proposition for new age luxury customers.
Literature Review
People have always been fascinated by stories, which are more easily remembered than facts. Well-told brand stories appear to have the potential to influence consumers' brand experiences which is "conceptualized as sensations, feelings, cognitions, and behavioral responses evoked by brand-related stimuli that are part of a brand's design and identity, packaging, communications, and environments" (Brakus et al, 2009 , p. 52). Story telling in a digital world is one of the effective ways to enables conversations between the brand and consumers. Chanel takes the advantage of digital marketing to communicate with their consumers via their website and social media the core value of the brand: Designer, visionary, artist, Gabrielle 'Coco' Chanel reinvented fashion by transcending its conventions, creating an uncomplicated luxury that changed women's lives forever. She followed no rules, epitomizing the very modern values of freedom, passion and feminine elegance (Chanel, 2005). For instance, the short film "Once Upon A Time..." by Karl Lagerfeld reveals Chanel's rebellious personality while showcasing her unique tailoring approach and use of unusual fabrics. Inside Chanel presenting a chronology of its history, how they transform from evolve from hats O fashion and became a leading luxury brand. No doubt Chanel has done an excellent job at narrating its culture, values, and identity, but the contents are mostly based on stories created by marketers or on the life of Coco Chanel. The brand image is static and homogeneous, and it is more like one-way communication, consumers cannot interact or participate in the brand's narrative.
Social media is more likely to serve as a source of information for luxury brands than as tool for relationship management. (Riley & Lacroix, 2003) Chanel was the most popular luxury brand on social media worldwide in April 2021, based on to the combined number of followers on their Facebook, Instagram, Twitter, and YouTube pages, with an audience of 81.4 million subscribers. (Statista, 2021) Chanel, as a prestigious a luxury brand, is taking an exclusive, even arrogant, stance on social media. It gives the audience multiple ways to access the valuable content they created while keeping them away from the comments generated by the content. The reasoning behind this approach is that Chanel wants to maintain consistency with their brand values and identity, which are associated with elegance, luxury, quality, detail attention, and a less-is-more approach. Nevertheless, social media can be a powerful tool that provide social data to better understand and engage customers, gain market insights, and deliver better customer service and build stronger customer relationships.
However, despite having the most social media followers, Chanel has the lowest Instagram interaction rate compared to Louis Vuitton, Gucci and Dior. Marketer and researcher increase social media marketing success rate by engaging with audience and consumers in real-time and collect audiences' big data for academic investigation. Put it in another way, social media engagement results in sales. It is imperative for in Chanel to not O just observe this model from afar, but actively challenge themselves to take advantage of it. To maintain their leadership In the luxury brand market, they must keep up with the constant changes in the digital world and marketplace and be more engaging with their audiences.
Chanel revenue has dropped dramatically from $12,273m to $10,108m (-17.6%) in 2020 due to the global pandemic where international travel has been suspended, boutique and manufacturing networks has been closed (Chanel, 2021). The pandemic has resulted in surge in e-commerce and accelerated digital transformation, hence, many of the luxury fashion brands pivot their business from retail to e-commerce, this includes Chanel's competitor Gucci and Dior. Chanel is gradually to adapting to digital strategy and selling their products online, but this is only for perfume and beauty products. President of Chanel Fashion and Chanel SAS, Bruno Pavlovsky said: "Today, e-commerce is a few clicks and products that are flat on a screen. There's no experience. No matter how hard we work, no matter how much we at look at what we can do, the experience is not at the level of what we want to offer our clients." (L. Guibault, 2021) In 2018, Chanel Fashion entered a cooperation with Farfetch purely for the purpose of developing initiatives to enhance in-store consumer experiences, they insist to incorporate human interaction and a personal touch when it comes to fashion sales. Experts foresee the pandemic could end 2022 but Covid may never completely vanish, and the life will never be same again. Consumer behaviour has changed during Covid, it will not follow a linear curve. Consumers will surge in e-commerce, reduce shopping frequency, and shift to stores closer to home. (S. Kohli et al, 2020) It is important to enhance digital engagement, but e-commerce is essential to maintain sales. It might not have a substantial impact to Chanel fashion sales in the past two year, but this will change with the advent of a new luxury consumer that wants high-quality personalised experiences offline and online. Chanel needs to adapt fast and demonstrate their trustworthiness by providing superior buying experience, exceptional customer service, and one one connections in store and on e-commerce platform.
Recommended Solution
1. Deliver the company culture using a more efficient strategy
The culture, value and the identity of Chanel is mainly from Coco Chanel. Although this is impressive, it is not attractive enough now for the newly emerging market. Chanel needs to deliver their unique culture in a more effective way. For example, Chanel could launch a campaign for all the customers to pay tribute to Coco Chanel. The customers could send their design to Chanel, of which they think is the most representative style of Coco Chanel. This could encourage more customers to be curious about the culture and stories behind this brand, instead of telling the story in a one-way communication. Especially during such an information-boosting time, the unique long-time culture is not that useful to attract more customers. unless it is used in a way that suits with the current purchasing habits of customers. According to Robert R (2006), it's wiser to create value with the customers instead of using customers, converting them from defectors to fans is more likely to happen when they are bonded with this brand. Moreover, Chanel used to focus more on the in-site retail experience, which might be part of their culture, since Chanel is a traditional luxury brand. However, people are more used to online shopping nowadays, and this is the trend. Chanel needs to invest more on the online service to exhibit their culture and adapt to the current habits of the consumers. The website of Chanel is fancy, with nice colors and visuals, but it's almost impossible for a customer to find out what they are looking for. The stylish website cannot be converted directly into revenue, they should make their website more user-friendly and functional. This is not hard for such a huge company if they realize this issue.
2. Bond with the customers
Chanel used have the largest number of followers on social media but fall behind Gucci and LV's in the past few years, because they pushed to much content without enough interactions. Chanel needs to create more bond with their existing customers and potential customers. The communication between Chanel and the customers seems to be one-way in the past. Consumers receive the messages from Chanel whereas have no channel to explain what they think about the brand and what they need from the brand. Therefore, Chanel should build a closer a relationship with their customers through social media. The reasons why using social media as a channel are as follow. a Firstly, this is a more cost-effective method to get accessed to a huge market. Chanel could let more people know about their changing and the newest product through it. They could also post different advertising to different selected customer base. Secondly, social media establish a platform where Chanel could listen to the real need of the customers. Many customers think they need a platform to let the brand know what they need and hope to witness the changes from the brand (Grant L, 2014). A successful brand should let the customers believe that what they think matters, although there IS no need CO adapt all the preference of the customers, Chanel needs to show their attitude that the company treasure the relationship with their customers. Finally, failing to use social media platform could lead to huge loss of the market. While other brands are posting advertisements and communicating with customers. they are stealing the customers from Chanel. Chanel needs to take the same weapon to defense. In conclusion, to let the customers engaged into the project and communications with the brand could assist with establishing a long-term relationship with customers and increase the loyalty of them.
3. Optimize the product line of the online store
Ecommerce market has been increasing amazingly in the past few years, especially because of the Covid, people are more used to online shopping. Therefore. Chanel needs to optimize their product line of the online store. bring their fashion line online and meet more demand of their customers. Although the offline shopping experience of luxury brands has significant value, to provide an extra choice could also be impressive. Because customers are more informed and demanding the brand to solve their problem and deliver unforgettable shopping experience. There is one field that Chanel could invest IS the VR / AR fitting room. There might be some reasons that customers cannot go to the retail shop or there is no suitable size of the product. A VR / AR fitting room enable the customers to try various products online to choose their favorite one. It could be more efficient since they could do it anywhere and anytime they want. At the same time, if they do not mind sharing the detailed information, the VR fitting room could generate a model for the client, and it is more visualized. This could increase the shopping experience and attract more potential customers. On the other hand, Chanel could give different levels of permit for different customer base. This could help to keep the company culture to provide the best service for high-net-worth clients. People could increase their customer level by building up the purchase history. In summary, to bring a unique online shopping experience to customers could enable Chanel to take up more market and establish a better platform for further development.
Conclusion
This report studied the case of Chanel and analyzed the problems which they were suffering from. It studied all the issues that were present in their organization and found that they had lost their unique value proposition along the way and also lagged behind in Social Media as well as web presence. Moreover, the firm's existing Commerce platform has a lot of weaknesses that have a negative impact on the company's core continuity as well as market survival. Accordingly after a careful analysis, few strategies were suggested so that the company can fix their social media, their digital presence and how they target the new breed of luxury customers of today.
References
.png)
.png)
Reports
MIS602 IT Report
Task Instructions
Please read and examine carefully the attached MIS602_Assessment 2_Data Implementation_ Case study and then derive the SQL queries to return the required information. Provide SQL statements and the query output for the following:
1 List the total number of customers in the customers table.
2 List all the customers who live in any part of CLAYTON. List only the Customer ID, full name, date of birth and suburb.
3 List all the staff who have resigned.
4 Which plan gives the biggest data allowance?
5 List the customers who do not own a phone.
6 List the top two selling plans.
7 What brand of phone(s) is owned by the youngest customer?
8 From which number was the oldest call (the first call) was made?
9 Which tower received the highest number of connections?
10 List all the customerIDs of all customers having more than one mobile number.
Note: Only CustomerId should be displayed.
11 The company is considering changing the plan durations with 24 and 36 days to 30 days.
(a) How many customer will be effected? Show SQL to justify your answer.
(b) What SQL will be needed to update the database to reflect the upgrades?
12 List the staffId, full name and supervisor name of each staff member.
13 List all the phone numbers which have never made any calls. Show the query using:
i. Nested Query
ii. SQL Join
14 List the customer ID, customer name, phone number and the total number of hours the customer was on the phone during August of 2019 from each phone number the customer owns. Order the list from highest to the lowest number of hours.
15 i. Create a view that shows the popularity of each phone colour.
ii. Use this view in a query to determine the least popular phone colour.
16 List all the plans and total number of active phones on each plan.
17 List all the details of the oldest and youngest customer in postcode 3030.
18 Produce a list of customers sharing the same birthday.
19 Find at least 3 issues with the data and suggest ways to avoid these issues.
20 In not more 200 words, explain at least two ways to improve this database based on what you have learned in weeks 1-8.
Solution
Introduction
A database management system for assignment help can be defined as the program that is mainly used for defining, developing, managing as well as controlling database access. A successful Information System gives precise, convenient and significant data to clients so that it very well may be utilized for a better decision-making process. The decision-making process should be founded on convenient and appropriate information and data so that the decisions can be based on the business objective. The role of DBMS in an information system is to minimize and eliminate data redundancy and also maximize data consistency (Saeed, 2017). In this assessment, the case study of a mobile phone company has been given. The phone as well as its plans are sold by employees to their clients with some specific features. The calls are charged on the basis of minutes in cents. The plan durations start from month. The main purpose of this assessment is to understand requirement for various data information requests from given database structure and develop SQL statements for the given queries.
Database Implementation
As the database is designed on the basis of the given ERD diagram, it's time to implement the database design. MySQL database has been used for implementing the database (Eze & Etus, 2014). The main reason for using MySQL for this database implementation is a free version is available on internet. This database engine is flexible with many programming languages. A good security is also provided with MySQL database (Susanto & Meiryani, 2019).
Entity Relationship Diagram
The given ERD diagram for this mobile phone company database is as following:
.png)
Implementation of Database for Mobile Phone Company
Database and Table Creation
Create schema Mobile_Phone_Company;
Use Mobile_Phone_Company;
Table Structure
Staff
.png)
Customer
.png)
Mobile
.png)
Plan
.png)
Connect
.png)
Calls
.png)
Tower
.png)
Data Insertion
Staff
Customer
Mobile
Plan
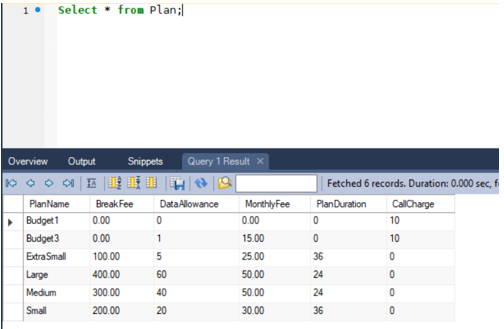
Connect
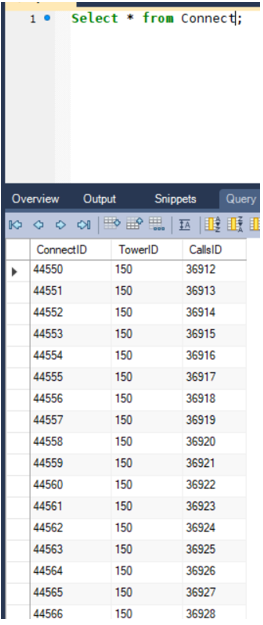
Calls
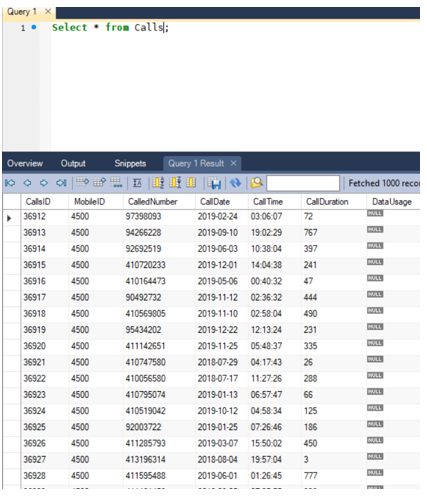
Tower
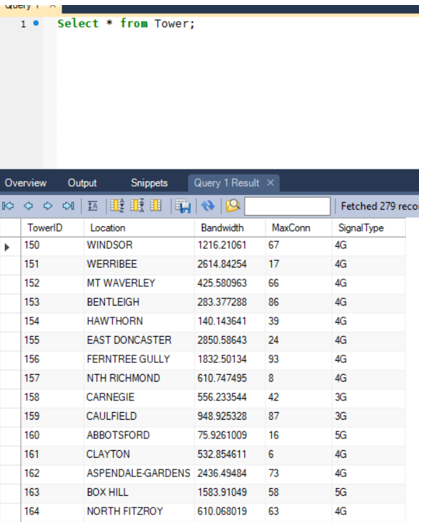
SQL Queries
1. Total number of customers
Select Count(CustomerID) from Customer;
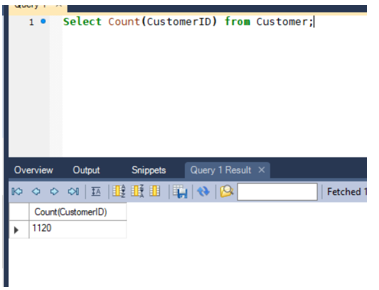
2. Customers in CLAYTON
Select CustomerID, Concat(Given,' ',Surname) as FullName, DOB, Suburb from customer
Where suburb like 'CLAYTON';
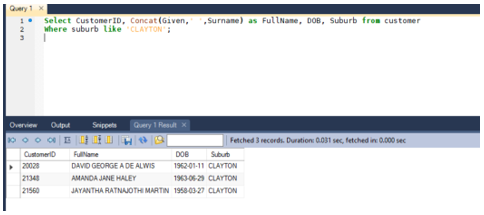
3. Resigned Staff
Select * from staff where Resigned is not null ;
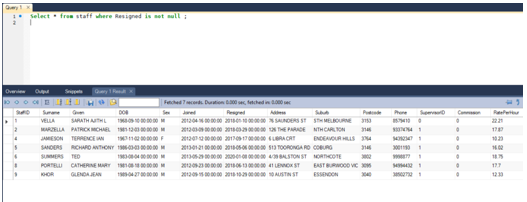
4. Biggest Data Allowance Plan
SELECT PlanNAme, BreakFee, Max(DataAllowance), MonthlyFee,
PlanDuration, CallCharge from PLAN ;
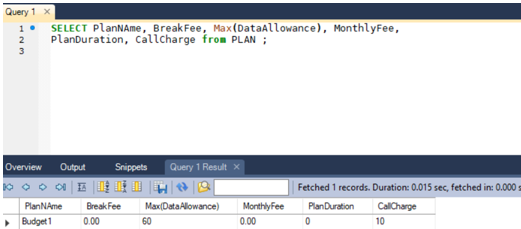
5. Customers who don’t have phone
SELECT CustomerID, CONCAT(Given,' ',Surname) AS FullName, DOB, Suburb
from Customer WHERE NOT EXISTS (Select CustomerID from Mobile
WHERE Mobile.CustomerID=Customer.CustomerID);
.png)
6. Top two selling plans
SELECT Mobile.PlanName, BreakFee, DataAllowance, MonthlyFee, PlanDuration, CallCharge,
COUNT(Mobile.PlanName)
FROM Mobile, Plan WHERE
Mobile.PlanName=Plan.PlanName
GROUP BY
Mobile.PlanName, BreakFee, DataAllowance, MonthlyFee, PlanDuration, CallCharge;
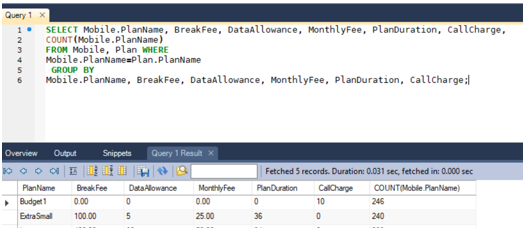
7. Brand owned by youngest customers
SELECT BrandName from mobile WHERE
CustomerID = (SELECT customerid From Customer where
Mobile.customerid=customer.customerid and
dob=(select max(dob) From Customer) );
.png)
8. The first call made by which number
SELECT mobile.phonenumber, calls.calldate
from mobile, calls where
calls.mobileid=mobile.mobileid and
calls.calldate=(select min(calldate) from calls);
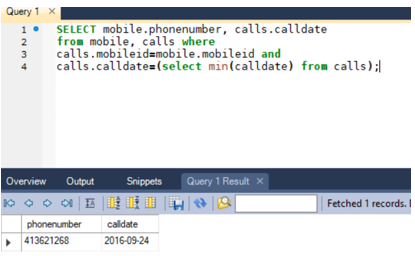
9. Tower that received the highest number of connections
SELECT * from Tower WHERE
MaxConn=(Select Max(MaxConn) from Tower);
.png)
10. Customers who have more than one mobile number.
SELECT CustomerID from mobile
Group By CustomerID HAVING Count(PhoneNumber)>1;
.png)
11. (a) Number of customers affected
SELECT Count(CustomerID) from Mobile, plan where
mobile.planname=plan.planname and
planduration in(24,36);
.png)
(b) Update database
Update Plan set planduration=30
where planduration in (24,36);
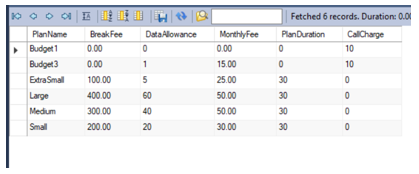
12. Staff members
Select S1.StaffID, CONCAT(S1.Given,' ',S1.Surname) AS FullName,
CONCAT(S2.Given,' ',S2.Surname) AS SupervisorName From
Staff S1, Staff S2 where
S2.staffid=s1.supervisorid;
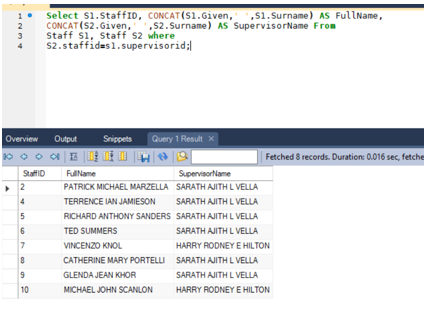
13. Phone number which have not made any call
Nested Query
SELECT PhoneNumber from mobile
where not exists
(Select MobileID from calls where calls.mobileid=mobile.mobileid);
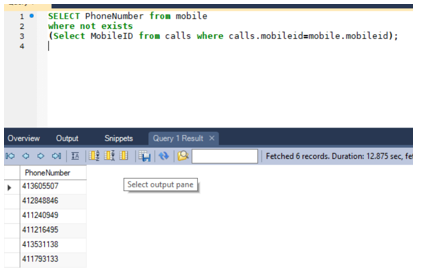
SQL Join
SELECT PhoneNumber from mobile Left Join
calls on calls.mobileid=mobile.mobileid
where not exists
(Select MobileID from calls where calls.mobileid=mobile.mobileid);
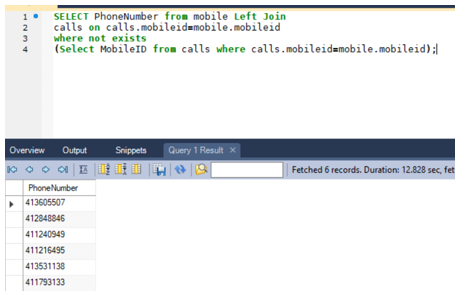
14. List the customer ID, customer name, phone number and the total number of hours the customer was on the phone during August of 2019 from each phone number the customer owns. Order the list from highest to the lowest number of hours.
.png)
select mobile.customerid, CONCAT(Customer.Given,'',Customer.Surname) AS FullName,
mobile.phonenumber, sum(calls.callduration) as NoOfHours, calls.calldate
from calls, mobile, customer where
calls.mobileid=mobile.mobileid and
mobile.customerid=customer.customerid and
month(calls.calldate)=8 and year(calls.calldate)=2019 group by
mobile.customerid, Customer.Given, Customer.Surname,
mobile.phonenumber, calls.callduration
Order by calls.callduration desc;
15. (i) View Creation
Create or Replace View view_color as Select PhoneColour, Count(MobileID) AS MobileNum From Mobile
Group By PhoneColour;

(ii) View Query
Select PhoneColour, Min(MobileNum) from view_color ;
.png)
16. Active phone plans
Select mobile.planname, count(mobile.phonenumber) from
mobile, plan where mobile.planname=plan.planname and
mobile.cancelled is not null
group by mobile.planname;
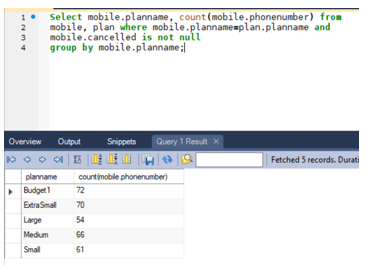
17. Oldest and youngest customer
Select * from customer where dob =
(select max(dob) from customer)
UNION
Select * from customer where dob =
(select min(dob) from customer);
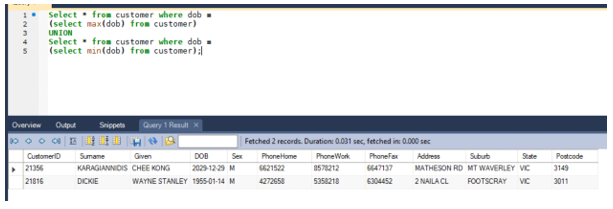
18. Customers with same birthdays
select c.customerid, c.given, c.surname, c.DOB from customer c group by dob having count(dob)>1 order by dob;
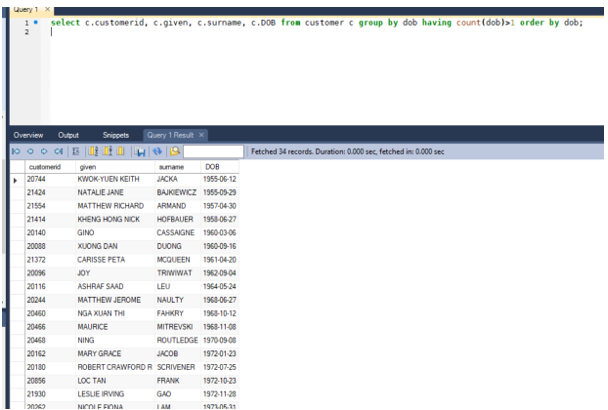
Issues with the data
The main issues with the data are as following:
- The relationship in the staff table for defining a supervisor is complicated as it is self joined to maintain the relationship.
- The overall relationship between tower, plan, mobile and calls is very complicated.
- A clean data policy is not used for data insertion.
Ways to improve the database
As we know that the third normalized form has been used to define the database structure, but still some steps can be possible to improve this database. Its difficult to make a self join relationship in a single table, that is used in the Staff table. Hence, a different table can be used for making a list of supervisors. On the other hand, a mobile has a plan and make calls and the calls are made from the tower listed in the tower table.
Secondly, in order to secure this database, an authorized data access is required. It implies that only that much data could be retrieved that is required. The full data access privileges must be given to the administrator or a top management official who actual requires all data reports in order to make better decision making.
References
.png)
Case Study
DSAA204 Data Structure and Algorithms Assignment Sample
ASSESSMENT DESCRIPTION:
This assessment is an individual report about the design of an OOP system using Data Structures and Algorithms. The report should follow the following structure
1. Title Page
2. Executive Summary
3. Introduction
4. Background
5. Case Study and the Design
5.1 Variables, Ranges and Keys
5.2 Operations and the Justification
5.3 Algorithms and the Justification
5.4 Modifications
6. Conclusion
7. References
Case Study:
You are required to design a health system for a small medical partitioning centre with information about doctors and patients. Assume that there are: 50 Doctors 100 Nursing staff
Around 1000 patients. You need to decide how would you like to represent the doctors, nursing staff and patients. For each of these decide what variables should be there (think in terms of OOP design). Also provide ranges for these variables. You will need to specify keys as well to carry out some essential operations related to this health system. Identify and list down potential keys for given entities.
Use your knowledge of real world and think about operations that will be needed for the health system. Keep in mind that it is not a complete hospital management system but should support the main/basic operations. Mainly, we are interested in locating the records of doctors, nursing staff and patients, but should support all basic operations of any information system. For each of these operations, discuss the most suitable algorithms that can implement these operations efficiently. Use your knowledge of various algorithms to suggest why your chosen algorithm for each operation is the most appropriate one. Your justification should talk about the different properties/characteristics of algorithms and explain as to why your chosen algorithm is best suited to the problem in question.
Now, a public hospital wants to adopt your system for computerizing their records of staff and patients. The hospital has a total of 1000 doctors, 4000 nurses and around 10,000 patients. Do you think your previously suggested algorithms would be able to handle this volume of data efficiently? If yes, justify and if not, suggest the new set of algorithms (and change in data structures, if needed) that will ensure that system will work smoothly and efficiently.
Solution
Executive Summary
A database was built for the health-care system. It makes it easier to maintain track of all of the patients' and physicians' information. It stores all databases in a secure manner for future usage. More than 100 nurses and 50 doctors have been assigned to this new system. They will be responsible for roughly 1000 patients. This detail will aid in the storage of all information pertaining to each and every member of the nursing staff, as well as doctors and patients. The database integrity restrictions are being rechecked for all data by system developers. Keys such as foreign keys and main keys will be stored in certain data. All database developers are concentrating on using enough variables. This new information system has a large amount of data.
Introduction
The purpose of this paper is to explore the fundamentals of implementation. All data formats and their algorithms will contribute to the development of a contemporary health information system. In comparison to other manuals, this one, or the conventional one, is not as effective. Currently, however, this storage technique is making this massive dataset more time-consuming. The efficient application of sorting and searching algorithms will improve all of these data management and storage activities. Healthcare for assignment help is a collaborative endeavour. Each healthcare professional is treated as a valuable part of the team who plays a specific function. Some members of the team are doctors or technicians who assist in illness diagnosis. Others are specialists who cure diseases or look after the physical and emotional requirements of patients. Administrative staff members plan the appointment, locate the medical record, phone the patient for a reminder, meet the patient, and check insurance details. A nurse or medical assistant takes the patient's weight and vital signs, leads them to an exam room, and documents the purpose for their appointment. Each health system's primary goal is to improve people's health, but it isn't the only one. The goal of excellent health is twofold: the highest possible average level – goodness – and the lowest possible disparities between individuals and groups – fairness. Fairness indicates that a health system reacts equally well to everyone, without prejudice, and goodness means that it responds well to what people expect of it. Each national health system should be oriented to accomplish three overarching goals, according to the World Health Organization (WHO): excellent health, responsiveness to community expectations, and financial contribution equity.
Background
This new health information system was created as a result of the previous system's inability to handle such large amounts of data. However, the engineers are striving to improve this new system by enabling all of these new sorting and searching approaches to be considered. Developers are always attempting to improve the contemporary system. Allowing all of these approaches for searching and sorting reasons, as well as providing some attention, will be beneficial. However, because health systems lack the ability to offer access to high-quality treatment, private health-care systems have evolved at the same time, with a steady and progressive development of private health-care services. Healthcare is a highly fragmented sector, with different healthcare systems in different countries. In the United States, insurance coverage is mostly the responsibility of the individual; however, new legislation will make it more universal. Other industrialised countries, such as the United Kingdom, Canada, Australia, and Italy, give free healthcare to all residents. During the previous decade, technological advancements have dominated healthcare activities, resulting in enhanced techniques of detecting and treating diseases and injuries. Infection control, less invasive surgical procedures, advancements in reproductive technology, and cancer gene therapy have all emerged as clinical developments
Case Study and Design
Variables, Ranges and Keys
In object-oriented programming, the program modules are broken down into classes and objects. The classes and known as the user-defined variables in this programming concept. The classes in general consist of member variables and member functions. When a program creates objects of these classes which are also known as instance variables, several instances of the class type are created (Varga et al. 2017,p. 7). These objects are then be stored into respective data structures such as arrays or lists, which can be accessed and modified as necessary. In the case of this health system, a similar object-oriented programming design would be constructed and the classes, variables, function, and data structures would be listed with their respective ranges and required justification. Each of these classes will also consist of a member variable that will be unique for each of the created objects.
Using the right Data Structure is also very important in information system development. There are various data structures that allow static insertion and modification of data while there are other more convenient and efficient data structures that allow the dynamic handling of data (Weise et al. 2019,p. 344). In an information system such as this, a dynamic Data Structure would be preferred that would allow easy insertion, deletion, and modification of data.
This variable would be called the key data member for the entities with his help in unique identification. The identified class variables, objects and Data Structures are as follows:
The Classes: Doctor, Nurse, Patient, MedicalCentreSystem
Doctor Class Variables:
.png)
Nurse Class variables:
.png)
Patient Class variables:
.png)
MedicalCareSystem Class variables:
.png)
.png)
Operations and the Justification
Insert new Doctors, Nurses or Patients: This operation will help the system administrators to add new doctors, nurses and patients into the system. This process will include the session of data that includes all the required details and variables mentioned for the respective classes (Kleine and Simos 2018,p. 54). On validation of these inputs, respective doctor, nurse, or patient class objects will be created and will be stored in their respective data structure. On the creation of each of these objects, a unique ID would be created and set into the object variables.
Search available Doctors, Nurses or Patients: Searching is another very important operation that is performed frequently on any information system. In this medical centre system, the searching can be performed due to the need for accessing user data or in order to modify respective data models (Lafore 2017,p. 242). Searching can be performed based on the criteria of searching doctors, nurses, and or patients.
Sort current patients on the basis of their net_bills: This functional feature would allow the system administrator has to look for patients who are admitted currently in the order of the highest to lowest medical bills. This will allow the administrators to offer certain amenities or in other financial and taxation utilities.
Algorithms and the Justification
There are two major algorithms that can be primarily used for a smaller data storage system that has been identified in the initial case study. One of these algorithms would allow easy operations for searching while the other will allow the operation for sorting the required data elements. These respective searching and sorting algorithms are as follows:
- Linear search: Through this technique a data structure is linearly search from top to bottom in order to find the required data element. The complexity of this algorithm is O(n).
- Bubble sort: This is one of the most commonly used sorting techniques. In this program, the sorting technique can be used to arrange the patient in order of their medical bills. This sorting technique can be used to arrange both alphabetical and numerical data on the basis of ascending or descending order as required (Priyankara 2020,p. 317). In this algorithm, the sorting is done on the basis of the general swapping of two elements in a linear manner. The entire data structure is traversed having swapped through all the different elements in the required order that is ascending or descending, the list would be sorted in general. This algorithm can also be used with objects stored. The time complexity of bubble sort is O(n2).
.png)
Modifications
Considering that the data requirements for this system would be rising in recent years, certain modifications will be required in terms of performing the various operations using the given algorithms. The above-mentioned algorithms are suitable when the data set is fairly low. However, in a larger data storage system, it is better to use algorithms that will perform this task in a more efficient manner in terms of time and resources (Chawdhuri 2017,p. 324). The following algorithms should be applied in order to search and sort on a system with a larger data set:
- Binary search: The time complexity of this algorithm is O(log n). This algorithm divides the data set into two halves in a particular sorted order and then makes it easier to search for the data.
.png)
- Merge sort: The time complexity of MergeSort is O(n*log n). This, therefore, helps in a very efficient manner of sorting on the larger accumulation of data. Merge sort is considered to be one of the most important and efficient sorting algorithms in computer programming (Teresco 2017,p. 3857). In this particular system, it can be used in terms of objects are taken as well on the respective data structures. Merge sort works on the concept of divide and conquer. It breaks down the list into various smaller sublists in such a manner that at the end when all the elements are broken down into single sub-lists, the result would be sorted.
Conclusion
The importance of searching and sorting algorithms in managing all information related to the health information system has been demonstrated. They also specified the keys, variables, and all ranges that this new system employs. Finally, the binary search algorithm has been demonstrated to be the most essential algorithm employed in this system. To sort all data, randomised quicksort and insertion sort are quite useful. The health-care delivery system is a society's structured response to the population's health issues and demands. Countries differ significantly in terms of their levels of income and economic potential, the diversity of health problems and needs, the way they arrange their responses, and the degree of central management, funding, and control of their health-care system in terms of coordination, planning, and organisation.
References
.png)
Reports
Data Visualisation Coursework Assignment Sample
Report
You are asked to carry out an analysis of a dataset and to present your findings in the form of a maximum of two (2) visualisations, (or a single (1) dashboard comprising a set of linked sub-visualisations) along with an evaluation of your work.
You should find one or more freely available dataset(s) on any topic, (with a small number of restrictions, see below) from a reliable source. You should analyse this data to determine what the data tells you about its particular topic and should visualise this data in a way that allows your chosen audience to understand the data and what the data shows. You should create a maximum of two (2) visualisations of this data that efficiently and effectively convey the key message from your chosen data.
It should be clear from these visualisations what the message from your data is. You can use any language or tool you like to carry out both the analysis and the visualisation, with a few conditions/restrictions, as detailed below. All code used must be submitted as part of the coursework, along with the data required, and you must include enough instructions/information to be able to run the code and reproduce the analysis/visualisations.
Dataset Selection
You are free to choose data on any topic you like, with the following exceptions. You cannot use data connected to the following topics:
1. COVID-19. I’ve seen too many dashboards of COVID-19 data that just replicate the work of either John Hopkins or the FT, and I’m tired of seeing bar chart races of COVID deaths, which are incredibly distasteful. Let’s not make entertainment out of a pandemic.
2. World Happiness Index. Unless you are absolutely sure that you’ve found something REALLY INTERESTING that correlates with the world happiness index, I don’t want to see another scatterplot comparing GDP with happiness. It’s been done too many times.
3. Stock Market data. It’s too dull. Treemaps of the FTSE100/Nasdaq/whatever index you like are going to be generally next to useless, candle charts are only useful if you’re a stock trader, and I don’t get a thrill from seeing the billions of dollars hoarded by corporations.
4. Anything NFT/Crypto related. It’s a garbage pyramid scheme that is destroying the planet and will likely end up hurting a bunch of people who didn’t know any better.
Solution
The data used for this reflective study is from the World Development Indicators. In this, the dataset consists of information regarding the trade business, income factors for different regions and countries and income groups as well. So, a dashboard is created for assignment help with the help of Tableau Software using the two datasets, named as counry and country codes. The form of presentation used is a bar graph (Hoekstra and Mekonnen, 2012).
1. Trade data, Industrial data and Water withdrawal data vs regions.
.png)
Figure 1: Region vs Trade data, Industrial data and Water withdrawal data.
The first visualization created is about the Trading data, Industrial data and Water Withdrawl data. All three data are presented together with a comaprison in different regions to get an overview of all the regions and their holding place in the following trading sectors. For the Tading data in several regions, it is clear that the leading area is europe and central asia, with the maximum occupancy of 98,600, while the count is nearly equal to the water withdrawl count with a differnce of 311 only. But in this region, the industrial count is only 82,408, yet the highest in all data taken.
The next leading region is Sub Suharan Africa, which is only for the Tade data and Water Withdrawl data. While the leading region for industrial data is Middle East and North Africa.
Overall, these findings suggest that Europe and Central Asia offer the most significant opportunities for businesses and organizations in terms of Trading and Industrial sectors. Meanwhile, Sub-Saharan Africa and Latin America and Caribbean offer promising opportunities in the Trading sector, and the Middle East and North Africa have potential in the Industrial sector.
These findings also highlight the need for policymakers to focus on improving access to resources and infrastructure in regions where the count of these data is lower, to boost economic growth and development. The visualization depends on several factors, such as the choice of visual encoding, the clarity of the labels and titles, and the overall design of the visualization. Therefore, it can be considered as a successful visualization.
Moreover, the visualization provides a comprehensive overview of the data, allowing viewers to understand the relationships and patterns between the different sectors and regions. The correlation of Exchanging, Modern, and Water Withdrawal information in various locales additionally permits watchers to rapidly recognize what districts are driving in every area and which ones have potential for development.
The analysis provided in the visualization also adds value by highlighting the implications of the data, such as the need for policymakers to focus on improving access to resources and infrastructure in regions where the count of these data is lower to boost economic growth and development. This contextual information helps viewers to understand the underlying causes and implications of the data, providing a more complete picture of the situation (Batt et al., 2020).
Furthermore, the analysis provides insights into the regions that offer the most significant opportunities for businesses and organizations in terms of trading and industrial sectors, and the regions that have potential for growth and development. This information can be valuable for policymakers and stakeholders looking to invest in or improve infrastructure and resources in these regions.
The visualizations are well-designed, using different colours to represent a group, with proper labels and tags on it to make it easily understandable for the viewers, so it is a success on the completion of the visualizations. Although, it is important that additional analysis and contextual information may also be required to understand the underlying causes and implications of the data.
2. Source of income and expenditure cost for different income groups and regions.
.png)
Figure 2: Count of source of income and expenditure cost for different income groups and regions.
This visualization is about the income group in different regions and the comparison of count of source of income and the expenditure in total. This provides a well information of the data for all class of groups regarding income and their data.
One key observation is that the lower middle-income group seems to have more balanced results compared to other income groups. However, there are still significant difficulties faced by people in South Asia, where the count of income sources is low for all income groups.
Another important observation is that Sub Saharan Africa appears to have the highest count for the source of income overall, while Latin America and the Caribbean have the highest count for the upper middle-income group. On the other hand, the Middle East & Africa and North America have the lowest count of income sources among the high-income group, which indicates that there is a significant disparity in income sources and expenditures across different regions. It is important to create more opportunities for income generation and improve access to education, training, and resources to enable people to improve their income and standard of living (Lambers and Orejas, 2014).
The visualization effectively communicates the findings about the disparities in income sources and expenditures across different regions and income groups. It highlights the areas where there are significant difficulties faced by people, such as in South Asia where the count of income sources is low for all income groups. The perception likewise gives significant experiences into the areas where there are open doors for money age, like in Sub Saharan Africa and Latin America and the
Caribbean.
Generally, this perception is an outcome in imparting complex data about pay gatherings and their kinds of revenue and consumptions in an unmistakable and reasonable manner. It successfully features the incongruities between various locales and pay gatherings and the requirement for approaches and projects to further develop admittance to schooling, preparing, and assets to empower individuals to work on their pay and way of life.
References
.png)
Research
ISYS5003 Principles of UX Design Assignment Sample
Task Description:
Your task is to evaluate an existing augmented reality (AR) application and write a report demonstrating your understanding of UX concepts from the perspective of a developer in relation to your chosen AR application.
In your report, you should pay particular attention to the concepts learned in Modules 1 and 2 and how these might affect design choices. You should be concise in your report as you will be required to write approximately 500 words.
Solution
Introduction
A simple bunch of data that comes to life when is scanned through any of the smart device lenses or cameras gives the human psyche an endless horizon to chase. Many games in the modern world are the primary source from where the augmented reality concept is flourishing. Many technology giants for assignment help are prepping their infrastructure and investing more and more into this promising market also keeping in mind the importance of the data that comes from the user end also known as the user experience feedback which ultimately helps in enhancing the quality of the concept as polished, real and efficient as possible (Xiong et al., 2021).
Analysis and evaluation
Many companies in the gaming arena and the furniture business are turning their focus to the augmented reality technology since this helps in eliminating the need for a middleman. One such example can be taken as “Pokemon go” which is a real time game played by the users with the use of augmented reality. This boosted the implementation of AR idea onto a large scale. The UX i.e. the user experience enables the app developers to efficiently manage and enhance the quality of the product that they have created so as to attract more and more customers.
Principles and implementation
The gaming app Pokemon go used the principles of UX design when the data is being managed and manipulated such as the proper following of the Hicks law which tells that the measure of time that a customer or end user takes to make a decision is proportional to the corresponding level of the number of complexities of the choices they have (Bottani and Vignali, 2019).
The data set obtained through the large number of distinct users help the developers in generalising the process like what areas the so called Pokemon entities will the users find and how to remove errors through statistical analysis on a large scale so that the impact of errors on the individual level can be mitigated to a minimum. If the user is experiencing some kind of a problem in the interface then that data is collected and stored with all the other similar types of data set.
On the managerial level the company resolves the issues with the help and feedback of user experience. The user experience plays a very keen part in the app. When the users scan the geographical area in-front of them through a smartphone camera lens, a 3-D image of an entity called Pokemon appears on the screen which gives the information to the user and then the user has to take a real time decision and so on to continue in the game. An app that has such a high amount of customer query management needs to be updated with the newest data set at a very frequent rate since all the improvements for future references can only be done through the regular updating process (Han et al., 2018).
Conclusion
The customers or the end users are the key source of data which is needed to facilitate the quality of the environment and fulfil the requirements of the end users. The concept of augmented reality is based upon the very fact that the random data that is generated in an interval of seconds can be used for improving the results and experience at a very regular and short span of time so as to minimise the occurrence of errors and improve the accuracy of augmented reality for the customers and end users and make the everyday experience more efficient and at ease. Even technology giants around the world are now focusing on big data analysis which refers to the concept of handling big sets of data for research purposes and for improving the everyday interaction between users and technology efficient and easy. (Nguyen et al., 2021).
References
.png)
Research
MITS5002 Software Engineering Methodology Assignment Sample
INSTRUCTIONS:
In this assessment students will work individually to develop Software Specification document. Carefully read the associated CASE STUDY for this assessment contained in the document MITS5002CaseStudy.pdf. From this Case Study you are to prepare the following:
1. Given the MITS5002CaseStudy.pdf, what SDLC Model would you use to develop the associated software. You will need to justify your answer. Outline the advantages and disadvantages your SDLC model would have over other SDLC models that could be utilized in developing the software.
2. Discuss the techniques from the case study that you would use to gather the requirements.
3. Develop a Specification Document based on the given case study. The document should have the following sections. However, you could add other topics based on your assumptions.
Your report must include a Title Page with the title of the assessment and your name and ID number. A contents page showing page numbers and titles of all major sections of the report. All Figures included must have captions and Figure numbers and be referenced within the document. Captions for figures placed below the figure, captions for tables placed above the table. Include a footer with the page number. Your report should use 1.5 spacing with a 12-point Times New Roman font. Include references where appropriate. Citation of sources is mandatory and must be in the IEEE style.
Solution
Introduction
In order to manage all the learning related activities and documents, XYZ company has decided to develop an e-learning platform. After a successful development and implementation of the, the platform will be able to perform a number of activities including course management, system administration, videoconferencing and collaboration. In this report, all the major aspects of the system development including scope identification, feasibility analysis, stakeholder identification, requirement specification, use case modelling and context modelling will be illustrated. Based on the company requirements, all the necessary documentations will be done in this paper. A comprehensive software engineering methodology will be conducted in this task. However, the use case and context models will be developed by using visio diagramming tool.
Technical discussion
SDLC
Within a software company, the SDLC is a method used for software projects. It comprises of a thorough plan outlining how to create, maintain, update, and modify or improve particular software. The life cycle outlines an approach for assignment help enhancing both the general process of creating software and the final product in terms of quality. In this task, the initial phase of SDLC will be illustrated including requirement gathering, use case modelling, context modelling, stakeholder identification and others [4]. Based on the planning phase of any software project, the complete project is conducted by the project team members. In this task, SDLC methods for e-learning platform building will be illustrated.
Requirement Gathering Strategy
In order to build a particular system, all the major requirements must be gathers in the planning phase. This task is about the development of e-learning platform by XYZ company. In the given case study, all the major requirements including functional, technical, or non-functional have been given. On the other hand, a brief qualitative research on the given problem context will also be conducted from different secondary sources [1]. In this context, few assumptions on the system development will also be done. After gathering all the major requirements, further planning will be conducted.
Specification document
a. Executive summary
In this task, a brief analysis on requirement specification of an e-learning platform development has been conducted. The system will be able to perform multiple activities including enrolment, course management, communication, data storage and others. There are five major modules will be available into the system including system admin, course management, collaboration and video conferencing, electronic register and anti-plagiarism. In this paper, all the major requirement of the system have been identified. Depending on the system requirements, few assumptions and feasibility study have been done.
b. Scope and feasibility analysis
Scope
Few scope for the system have been identified that are given in the below points:
- The system would to be able to establish user groups for collaboration, communication, and content sharing.
- Administrators can choose the look and feel of the websites for various campuses, as well as from a variety of graphical user interfaces.
- A opportunity to provide users alternative roles and permissions, as well as control access to diverse e-resources inside the system [2].
- Plagiarism checking could also be included for both the students and institutions on the platform.
Feasibility analysis
Feasibility analysis for the system has been conducted in terms of below aspects:
- Technical feasibility: Few new technologies for system development could be easily implemented by the developed team. JAVA, C++, DBMS, SQL, and many other techniques could be easily utilized [5].
- Operational feasibility: The goal of the project is quite clear. Therefore, the operational tasks and activities can be easily scheduled by the team members. However, a variety of operations could be done through this platform which is quite feasible.
- Legal feasibility: In terms of legal feasibility, all the necessary documents and papers can be developed by the project team members.
This system development project if quite feasible in terms of the above three aspects.
c. Stakeholders
In this section, all the major stakeholders of the e-learning platform have been identified in the below table:
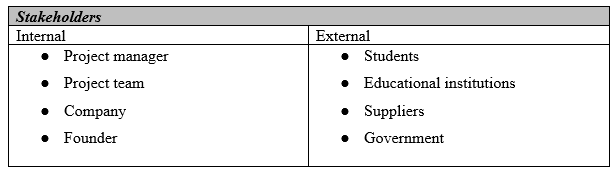
In the above table, all the major stakeholders for this project have been identified.
d. Requirement specification
In this section, all the major requirements of the system have been discussed:
- Functional Requirements
1. Students should be able to access materials from other webpages using the interface.
2. Restrictions on disc space ought to be capable of being set by system administrators for particular individuals, organisations, and courses.
3. The system should enable for the posting of notices that are open to all students or by giving relevant individuals particular access permissions [3].
4. Accessibility of included tools for encouraging student involvement in the educational process, such as platform for developing and managing comment sections, podcasts, content sharing, and notebooks.
- Non-functional Requirements
1. Productivity increasing for both the students and employees of the institutions is a major non-functional requirement.
2. Up to a million active users must become able to access the system concurrently, and more options should be available.
3. It should be possible to reach the platform over the network using HTTP or https, and it should be distributed remotely on one or more machines [6].
4. For accessible and secured areas, it should feature an internet user and management interfaces.
5. To make it simpler for them to access and utilise, the system should be modified for those who have visual impairments.
- Others
1. An advanced learning environment should be available to the users.
2. All the users will be able to build a proper communication channel through the learning platform.
3. Future improvement must be enabled into the system.
e. Assumptions
In order to develop the system, few assumptions have been made that are given below:
- The system will be used by the students, teaching staffs, admin, university management, third party service providers.
- All the data and information of the system will be stored into the cloud based storage devices.
- In terms of security checking for new websites, automatic virus scanning facility will be included into the platform.
- The system will be cost effective for both the XYZ company and third party service providers.
f. Use cases
Diagram
.png)
(Source: Author)
In the above figure, the use case diagram of e-learning platform has been developed. All the major actors and use cases have been shown in the above figure [7].
Description of the use cases are given below:
Description
Description of each use case has been given in this section:
- Registration: Through this use case, users will be able to logged in into the system. Details of the users will be given during registration phase through this module.
- Course tracker: All the course related activities could be done by the users through this module. Submission of documents or marks checking could be done through this section.
- Interface: This is the main use case which will give access to each of the actors. The system admin will be able to manage each activities through this portal.
- Reward management: Students will be able to handle their financial rewards through this module. Any kind of fees or dues could be paid through the use case.
- Communication: In order to establish communication through video calling or messaging, this portal could be used by the users. By using their user name, students will be able to make communication with administration.
- Plagiarism Checker: In order to check similarity score of any assignment, both teaching staff and students will be able to use the plagiarism checker.
In this section, all the major description of use cases have been given. The system will be developed based on the users requirement and actors specification.
g. Context model
A context model gives the complete overview on the activities performed by the actors and system. All the necessary process and activities are identified in the context model. In this section, the context model of e-learning platform has been developed. This gives a brief description of each activities and operations performed into the learning platform.
.png)
Figure 2: Context modelling
(Source: Author)
In the above figure, a context diagram of e-learning platform has been created. All the major activities and process have been identified. Relation between different process and system has also been illustrated [8]. Based on the system requirement, this context diagram has been developed. A cloud based data storage devices has also been installed into the figure. Institute management and service providers will have direct access to the cloud based storage.
References
.png)
Research
ISYS6008 IT Entrepreneurship and Innovation Assignment Sample
Task description:
Your initial task in completing this report is to find a subject for your case study. that is either an entrepreneur or a corporation that uses emerging technologies such as robotics, drones, artificial intelligence (ai), machine learning, online media streaming, iot, real-time processing, rendering or applications, augmented reality (ar) virtual reality (vr) hardware or applications, etc.; and has successfully done one of the following:
- Started a new business, or
- Improved an existing organisation, or
- Had a global impact from using the emerging technologies. your next task is to evaluate his/her/its entrepreneurship journey and its relevance to what you learned so far from this unit’s contents and recommended reading and activities, and write a report which includes the following:
- An introductory paragraph to describe an entrepreneur (or corporation/business) and its associated products or services.
- A discussion on entrepreneurial mindsets applied in to establish the business.
- A discussion on how the business was initialised, including how the initial marketing and/or legal challenges were addressed. it is recommended that you search and include information about the capital sources used to grow the successful venture.
- A description of the latest capabilities of this business and how it has been used by people and its own and/or other companies to improve or transform their activities.
- Finally, provide a conclusion on whether you see any gap that can be addressed or if this case study has inspired you to think of a new idea. you should be concise in your report as you will be required to write no more than 1500 words.
Solution
Introduction
A brief description of the business and its products – Nike
The selected organization for the study is nike, it is a globally recognized brand for sneakers in the footwear industry. the brand was founded in the year 1964 by phil knight and bill bowerman, however, it was earlier recognized as blue ribbon sports. the brand established its first store in the year 1966 and after a 6years, it relaunched the company with a new name "nike". the key products of nike are casual and athletic footwear with sustainable manufacturing and designs, accessories, and apparel.
.png)
Figure 1: nike
(source: oyibotha, 2022)
Use of online media streaming at Nike
Being in the footwear industry, it was hard for nike to get global success and spread awareness of its name, products, and services all across the world. this is when online media streaming came into the role and nike adopted this service and further implemented it in its marketing strategy. Streaming media is referred to the audio or video content for assignment help sent in the compressed format on the internet and played by the users on several media streaming platforms, commonly on youtube. nike has an engaging channel presence on youtube which posts its new launches, products, services, and about r&d. that is how nike uses the online media streaming services to grow its brand reputation.
The entrepreneurial mindset of Nike
Name of the mind-set to be an entrepreneur, a strong entrepreneurial mindset is necessary. phil and bill both faced challenges at the initial level of their business start-up which is nike, however, they both fought that phase with a strong head. entrepreneur mindset refers to the mode of thought process which helps in achieving the desired success and goals. successful entrepreneurs have the capacity of embracing failures, challenges, and mistakes as new opportunities and develop new skills for their business success.
.png)
Figure 2: entrepreneurial mindset
(source: eli mindset 2021)
3 Key mindsets that nike follows are-
- A growth mindset: refers to believing that if the right amount of effort and time is put into learning and intelligence then a certain level of success leads to the continuous growth of business as well as personal development.
- Intrinsic motivation: refers to doing something for its own sake instead of greed for external rewards because intrinsic motivation thrives the idea generation and turns it into reality. this mindset involves a high level of engagement and psychological well-being (eli mindset 2021).
- Resiliency: it is referred to the ability to be recovered from challenges and issues quickly. entrepreneurs who are resilient in nature tend to pursue an explanatory style referring to a positive attitude to every situation.
Mind-set demonstration
There are two situations in which nike showed these three entrepreneurial mindsets. phil had an entirely different background from his study to professional life, however, his passion calling never stopped. in the 90s, he believed that sports shoes can be manufactured and sold at cheaper prices and compete with the japanese market, with this idea his crazy insanely flipped the market and revolutionized the sporting world. that's when he showed his intrinsic motivation and growth mindset.
further, in 1962, bill and phil were broke, inexperienced guys, and had no resources with a business idea, however, they refused to let the idea go and crazily presented his idea to the japanese managers supposing to turn the million-dollar american sports market (valuepenguin 2019). even after so many legal challenges, rejections, and setbacks, nike never lost faith and showed a resilience mindset.
Nike’s initialisation, marketing strategies, & legal challenges INITIALIZATION
.png)
Table 1: initialisation
Marketing strategies
- The very first marketing strategy of nike is selling its slogan “just do it” on its online platforms to connect with the world
- The compelling tagline for attracting the audiences
- Using the power of social media and collaborating with celebrities for marketing
- Empowering the targeted market such as women for social causes marketing
- Selling stories, not the product (pride, 2022).
.png)
Figure 3: instagram page of nike
(source: instagram 2022)
Legal Challenges
The key 5 legal challenges that nike faced due to its unethical actions are -
1. Racial discrimination- ahmer inam joined worked as senior director and claimed he faced racial discrimination as he was treated poorly as compared to his white teammates. this impacted his physical and mental health (young 2019).
2. Environment protection act- environmental pollution and use and discharge of toxic chemicals- in their production, nike was observed to use toxic chemicals in their development causing health issues and leading to the killing of sea animals. it is against the csr of the manufacturing industry and business.
3. Labour law act challenge- employed manual workers are very underpaid and are forced to work at low wages and long work hours, nike went against the labor protection act, not only that it employs child labor.
4. Copyright law challenge- the jumpman logo of nike brand jordan worth billion is copied, life magazine claimed that it is their true publishing that nike took and violated the copyright act (bain 2022).
5. Traded secrets- nike filed a 10million lawsuit against the three best designers of the company who broke the non-compete agreement and traded their designs with adidas and violated their privacy.
Capital resources
Capital plays an important role in the development of the business, however, nike makes huge amount of profit by itself that it does not worry about getting a loan from any bank and expect other companies to invest in it. yet, the key capital shareholders of nike are-
- philip knight- 0.9& class a and 2.6 class b shares
- mark parker- 0.09 shares
- andrew campion- 0.01% shares
- swoosh llc- 16.5%
- vanguard group- 7.0%
- blackrock- 5.9% (reiff 2022).
.png)
Figure 4: capital shares
(source: author 2022)
NIKE’S LATEST CAPABILITIES AND IT UTILISATION
CAPABILITIES
Nike has started to develop the eco-friendly and sustainable shoes through the use of the supergases technology. as the environment has started to get impacted in sever manner these days, which is why nike decided to initiate the sustainability program and also attract the new audiences to their brands. nike's corporate social responsibility and initiatives are largely focused on the company's fundamental idea that "sports have the capacity to impact the world for the better." nike leverages its sports prowess to fulfil csr goals in three key areas diversity and access, civic engagement, and environmental balance. nike fulfils their csr obligations by initiating these initiatives-
- Covid-19 response program
- Environment friendly branding
- Inclusion & diversity
- Community support programs
This capability of nike is considered in the r&d aspect of the brand.
.png)
Figure 5: figure 2: nike eco-friendly brand
(source: mahirova, 2021)
Example of company’s demonstration and succeeded in marketing
the idea of sustainable production and eco-friendly development has appealed a lot of people specially the younger generation. it is noticed that too many of the influencers who are very much active on social media platforms such as twitter, instagram, facebook, & youtube, who uses the online media streaming recognizing this capability of nike and approach the brand to collaborate with them (ravi 2018). this not only helped the brand to gain a huge recognition but also gave nike a new marketing strategy.
Nike started to make engaging videos and audio contents for its social media pages, as well as the collaborators having millions of followers also made the streaming content with the iconic slogan “just do it” and posted it on their accounts. this way nike not only got benefit and recognition of their new launches from their pages but also from the collaborators influencing the minds of billions of users just through one click. in short nike used the sustainability research and development as its leading marketing strategy.
.png)
Figure 6: twitter of nike
(source: ravi 2018)
CONCLUSION
The report demonstrated the online media streaming through the example of nike brand, being a sports brand nike had a few choices in the past era to promote their products. however, with the introduction of the social media marketing and streaming services, nike took advantage of it and promoted their products through engaging video and audio contents. the report has successfully analysed the emergence of new technology through discussion on entrepreneur mindsets, nike's marketing strategies and legal challenges, and it's capabilities through the demonstration.
Inspiration for a new idea the study has pushed entrepreneur mindset into the student and led to the new generation of ideas. as nike is a sports brand, and it has direct link with the health and fitness leading to the idea of introducing a fitness app with a health monitoring wearable device (band). this will create a new source of income into the company and also allow the company to put its leg into the information technology industry.
References
.png)
Research
INF60007 Business Information System Assignment Sample
ASSIGNMENT TASK
1) Process Diagram
This assignment requires you to read the given Incident Management Procedures. From these procedures you are required to complete the partially completed swim lane process diagram.
Recommendation: Use the swim lane template (.ppt) provided on the third assignment page. This template includes the partially completed swim lane diagram – it will save you recreating the model.
2) Description of Incident Management Roles and Responsibilities
You are also required to derive a description of the roles and responsibilities for the following actors:
• Customer /End User,
• First Line Analyst,
• Incident Response Team Manager, and
• Incident Response Team.
This represents the written part of the assignment. You have up to 1000 words to complete this part of the assignment.
3) Critical Reflection on the Formalization of Organisational Processes
Based on your reading of the Incident Management process model (swim lane), answer the following question for assignment help: What is the motivation for organizations to formalize business processes for managing IT incidents?
Solution
1) Process Diagram
.png)
.png)
.png)
.png)
2) Description of Incident Management Roles and Responsibilities
2.1) Customer/ End User
End users or customers are responsible for protecting all kinds of information resources of an organisation that they can access. The role and responsibility of an end user according to incident management is to ensure non-computerized and computerised information security practices. The roles and responsibilities of an end user according to its management include the following:
• An end-user is responsible for understanding the participation in the BYOD program which is supposed to be voluntary and unless agreed to otherwise, it is their responsibility to assume carrier service cost, accessories, and devices (Hayes et al., 2021).
• End users are also responsible for maintaining the physical security of the information technology devices and also providing a high level of protection for sensitive information against unauthorized access. It is their responsibility to apply the TSC standards and make sure that the encryption is consistent with those standards that are required to be complied with for storing sensitive information.
• The responsibility of end users also extends to the appropriate protection of sensitive information that is transferred physically or electronically from unauthorized interception. It is also their role to enter appropriate encryption of sensitive information that is transmitted over public networks (Fuada, 2019).
• The end users have the role to consult with IT professionals to ensure that electronic information is properly disposed of in accordance with the guidelines and regulations provided in InfoSec 3.0.
2.2) First Line Analyst
The role and responsibility of a first-line analyst are to conduct investigations and resolve issues for users and is also responsible for the effective delivery of IT support services to external and internal customers. The role and responsibility of a first-line analyst are to gather facts, conduct research regarding issues, analyse and frame potential solutions for the problems and submit the information obtained to higher-level technical staff for further review. They also have the responsibility of assisting in the development and implementation of application systems and maintaining the establishment of applications using specifically defined procedures (Ahmad, 2018). Therefore, the first-line incident management analyst has the role and responsibilities in an IT organisation as follows:
• Accept or reject assigned incidents after reviewing them with precision.
• Conduct an investigation and identify the incident.
• Documents the entire incident resolution or workaround in the service management application to resolve it.
• The implementation of incident resolution which is an important activity is also the responsibility of the first line as an analyst.
• Verify the proper resolution of the incident identified and close the incident.
As a member of an IT team, the first-line analyst is responsible for solving organisational problems by analysing workflows, processes, and systems so that strong opportunities can be identified for automation or improvement of the IT processes within the organisation (Palilingan & Batmetan, 2018, February).
2.3) Incident Response Team Manager
The incident response team manager manages all technical aspects of incident response from the beginning to the end. He is also responsible for assessing the nature of the incident and determining what resources are required for the proper resolution and restoration of the service (Wolf et al., 2022). An incident response team manager will be supervising a team of IT professionals who in turn are responsible for attending to computer crimes, network intrusions, and cyberattacks. They also include direct involvement with security personnel as they are required to investigate security breaches and implement countermeasures for them. The responsibility of an incident Response team manager is to be proactive and carry out the following roles:
1. The incident manager should ensure that policies and processes are being followed with precision and that standard compliance is maintained so that best practices such as COBIT or ITIL are maintained. They require to identify gaps, assess data, inaccuracies, and trends so that actionable outcomes and opportunities can be identified (Son et al., 2020).
2. Since the incident manager is the front-line manager during incident management and requires to handle the incident or issue calmly and should have proficient working knowledge of how to resolve identified incidents and restore the business service.
3. Incident managers should use a systematic methodology to analyse, evaluate, design, and implement technology or processes to achieve measurable benefits for the business. They are required to make suitable recommendations based on recent arguments and have a clear idea of the problem or issue identified.
4. An incident management team manager should be a good communicator and problem solver because he is required to find a resolution to restore business functions and translate the messages for the entire incident response team so that they are able to carry out their individual in identifying and resolving the issue. Hence the responsibilities of an incident response team manager include being a good listener, critical thinker, and problem solver so that an incident is managed by him effectively and resolved with suitable methodologies and applications (Christensen & Madsen, 2020).
2.4) Incident Response Team
The role and responsibilities of an incident response team are to respond to different cyber security incidents or issues which include cyberattacks, data breaches, and system failure. This team is composed of different other roles and responsibilities which are delegated to other IT personnel who has specific skills. Therefore, the composition of an incident response team includes a team leader, team investigator, first-line analysts, researchers, communication liaison, and legal representatives. There can be three main types of incident response teams which are CERT (Computer Emergency Response Teams), CSIRT (Computer Security Incident Response Team), and SOC (Security Operations Centre) (Sarnovsky & Surma, 2018). The roles and responsibilities of the different incident response teams are discussed below:
1. CERT- They focus on partnerships with law enforcement, industry, and government for academic institutions. These professionals are responsible for prioritizing the development of threat intelligence and implementing best practices according to security responses.
2. CSIRT- This team has an assorted collection of IT professionals who are responsible for preventing, detecting, and responding to incident response cybersecurity incidents or events (Owen et al., 2018).
3. SOC- This incident management team covers a broad scope of the concept of cyber security and is responsible for directing incident response in addition to defending and monitoring systems, overseeing general operations, and configuring controls.
3) Critical Reflection on the Formalization of Organisational Processes
3.1) Types of Business Processes and How to Recognize Them
Since businesses are built on complicated interrelated processes and networks it is important to formalize the process so that the goals and objectives can be effectively managed and achieved. I think that incident management team managers should understand the different types of business processes and the unique roles they play in the overall business success so that they get the required motivation to undertake the process. In any organisation, business processes can be of three types, and the methods to recognize them are as follows:
• Core Processes: These are responsible for creating value for customers in a business and generating the required revenue. Also, core processes are sometimes known as primary processes because they consist of the main activities of the business organisation such as customer service, distribution, production, sales, and marketing. Common core business processes are structured processes that are managed by CRM, ERP, or vertical SaaS. Several businesses are implementing a system of engagement for optimizing the primary business processes and making them more efficient (Dorofee et al., 2018). Therefore, I think that core business processes should be formalized so that the structured process can be managed effectively and the IT functions of the business are carried out without any issues.
• Support Processes: Support processes are the activities that make it possible for the business functions to be carried out in contradiction to the core processes which provide value to customers and generate revenue. I think that support processes play a critical role in helping businesses to achieve the desired value and generate revenue by helping to carry out the business processes smoothly. I have also evaluated that the motivation during incident management regarding the support process is to service the internal customers in the organisation rather than the internal customers. I have also analysed that the formalization of business processes is to formalize the support processes with a department-specific SaaS platform.
• Long-tail Processes: These processes include the category of processes in process management strategies that are unique and emerge as a response to increasing stack complexities and evolving business needs (Cadena et al., 2020). I think that the motivation to formalize this business process is because it will help address a gap between apps, systems, or workflows.
3.2) Motivation of Business Formalization
It is important to formalize business functions because formalization comprises compliance with existing procedures and applying them to the business functions so that these functions are carried out according to the established standards and regulations required by legal laws and regulations (Bryant et al., 2019). I think that the formalization of business processes for managing it incidents can be a daunting task because it involves conformance to standards such as OSHAS 18001, ISO 14001, ISO 9001, and so on so that the documentation of the IT incidence is effective for the management system of the organisation. I have also analysed that the necessary documentation for proper incident management is quite complex and ranges between a variety of job descriptions and policies. Therefore, it is required to formalize business processes for managing IT incidents because important resources for employees when training new employees or implementing new systems can be smooth and effective (Mustapha et al., 2020). It is regarded that the formalization of business processes can be an effective tool for ensuring that all levels of the organisation are working efficiently to meet the organisational goals while managing incidents by identifying them and framing suitable solutions.
Often, I have regarded that the application of a business process modelling will help improve IT incident management as part of formalizing the business functions to manage IT incidents. Business processes should be formalized so that it is possible to communicate the business processes and procedures in a standardized manner and also understand the internal business processes with clarity. Whenever there is inadequate monitoring of incidents that prevents the proper mitigation or resolution of such issues, a formalized business process will help in better management and resolution of these escalations so that the business functions are restored. It is also possible to manage change within the organisation if the business processes are formalized and control automated for proper customization, documentation, monitoring, measurement, execution, and improvement of the business processes (Ray et al., 2020, April). I have analysed that at the global level organisations are required to formalize their processes so that IT incidents can be managed by individuals who are specialized in managing incidents by aligning themselves with the business objectives and goals. It is required to optimize the business processes so that incidents get better attention and IT professionals can increase user satisfaction through the normal functionality of a service.
The IT incident process management is generally operated by a user help desk that consists of technological and human resources with the primary objective of resolving the intimations of the service that require more attention. In large IT organisations, they have their own user help desk, for instance, SUNARP which is a public organisation in Peru has its own user help desk that is responsible for receiving different requests for user attention either through emails, in-person requests, or phone calls (Turell et al., 2020). Hence, I have evaluated that if the business processes are formalized for incident management, then it will prevent the organisation to become inefficient and prevent it from working in a disorderly manner by preventing users from communicating with the organisation and complaining that they have not been attended to yet. Through the formalization of organisational processes, it is also possible to reduce the wait time and a solution can be framed that is causing user dissatisfaction. Therefore, I think that it is important to have motivation for business formalization so that undefined procedures can be mitigated and limitations of available IT tools for managing incidents can be overcome by the incident response team.
References
.png)
.png)
Assignment
BMP4005 Information Systems and Big Data Analysis Assignment Sample
Assignment Brief
In business, good decision-making requires the effective use of information. You are hired by an organisation to examine how information systems support management decisions at different levels within organisations. You are also assigned to investigate the methods and techniques which relate to the design and development of IT solutions. Your research has been divided into different tasks. The findings from Tasks 1, 2, 3, 4 and 5 can be submitted in a portfolio format.
Introduction
Task 1: Theories, methods and techniques which relate to the design and development for TWO of the IT solutions listed here: (i) McAfee; (ii) Moodle; (iii) Canvas; (iv) MS Office
Task 2: Explanation of the systems below with relevant examples
Task 3: Globalisation and the effects of IT on globalisation
Task 4: Definition, example, advantages and disadvantages of digital infrastructure
Task 5: Risks associated with information systems outsourcing and why is IT infrastructure so critical to digital transformation!
Conclusion
References
Solution
Introduction
In this assignment, decision making procedures and effectiveness in information system execution and management. It includes different tools and models that are associated with different IT solutions or information system technology. It explains globalization and impact of IT in the development of the issue. Overall, different case studies or examples are evaluated to assess the impact into the organizational scenario. Moreover, this leads to better understanding and organizational infrastructure development.
This will lead the organizational stakeholders to better management system and organizational culture. On the other hand, risk assessment and other associated operations will help in better management planning and implementation for assignment help.
IT Solutions and Related Theories, Methods and Techniques
IT solutions are basically information system technologies or software that can be implemented effectively into different organizational requirements. This includes management systems, operational systems, etc. In this section of the assignment two IT solution software are considered to analyse. It consists different theories, methods and techniques that are associated with the project. The considered IT solutions are McAfee and Moodle.
McAfee
McAfee is a cloud computing technology-based company that develops antiviruses as their major business model. Moreover, the McAfee solution services can develop appropriate and effective antivirus encryption throughout the whole system lifecycle.
Related Theories
5 steps problem solving methodology will be most applicable and effective model of analysis for this IT solution implementation. The developer requires problem solving approach towards the system lifecycle and development. The system and the developer must identify particular areas that can be affected by cyber-attacks. This will also help in better decision making and strategic planning.
It includes five steps, where in the first phase, whole system is evaluated to define and list the problems. Then the business impact and effectiveness of the strategies will be assessed. It will lead to appropriate decision solution. The developers and project manager will be responsible for developing implementation strategy and procedure planning. This will be followed specifically for effective results. Finally, the results will be reviewed or the system will be tested in terms of effectiveness.
.png)
Image 1: 5 Steps Problem Solving Methodology
(Source: Humorthatworks, 2020)
Moodle
Moodle is a free learning IT solution or platform that operates learning management system with different courses, assignments, etc. An individual can create whole learning management structure to organize and implement learning modules and other resources. The tutor will also be able to observe student activities and progress accordingly. However, the system is effective and applicable in recent learning requirements.
Related Theories
Moodle is also associated with different framework or analysis model, that are beneficial in organizational operations and management. The business already includes a huge number of consumers and stakeholders. In that case business decisions become more significant and critical in nature. The most appropriate and effective theory, associated with Moodle will be rational decision-making model.
This is a visually structured model of project and business planning. It distributes the whole decision-making procedures into phases that can derive the most effective decision. It improves the implementation strategy and overall procedure. The process also shows different constraints and external project aspects. This will lead to better management and development.
.png)
Image 2: Rational Decision-Making Process
(Source: Biznewske, 2020)
Systems Explanation
Organizations use different information systems to operate business operations and management. In this section of the assignment , some of the systems are explained in terms of functionality and organizational uses. It shows appropriate application and impact in management and overall development.
Decision Support System (DSS)
Decision support system or DSS is an information system that provides determinations judgement and appropriate plan of action for a particular business project development (Fanti et al., 2015). It organizes and analyses a huge amount of system data and implementation strategy. There are majorly 5 types of decision support system (DSS) such as,
• Communication-driven DSS
• Data-driven DSS
• Document-driven DSS
• Knowledge-driven DSS
• Model-driven DSS
They are categorized in terms of application in different organizational requirements.
.png)
Image 3: Decision-Making Process within DSS
(Source: Indiafreenotes, 2020)
This will improve the decision-making procedures and effective implementation. Moreover, the process will develop efficient organizational culture such as flexibility.
Executive Support System (ESS)
Executive support systems are developed for the managers and higher authorities of the business that will help them to access and implement different business data. It includes both internal and external information such as management strategy.
.png)
Image 4: Executive Support Systems
(Source: Bolouereifidi, 2015)
Executive support systems provide effective IT solution for moderating all system data that can impact the whole business. It also includes the benefit of better data analysis and business management process.
Transaction Processing System (TPS)
Transaction processing system is an information system that provides the facility of collecting, evaluating and retrieving the data transactions into the business. It includes effective system response time while transaction and overall data management system as well.
.png)
Image 5: Transaction Processing System Benefits
(Source: Chegg, 2022)
The system has different business impacts such as better data integrity, performance, response time, etc. This can clearly establish the positive impact in business management and performance as well.
Management Information System (MIS)
Management information system presents the software that can operate, and manage all the business operation and management. It includes all the system stakeholders, supply chain and other functionalities. System database will store and manage all the data from the system operations and analysis.
.png)
Image 6: Management Information System Structure
(Source: Toppr, 2020)
Management information system improves management system and effectiveness into the business. Moreover, it improves different organizational cultures such as better communication and resource management.
Knowledge Management System (KMS)
Knowledge management system is also another type of information system or software that implements knowledge management principles into the organizational culture overall business procedure.
.png)
Image 7: Knowledge Management System
(Source: Kpsol, 2022)
Knowledge management system improves stakeholders’ engagement and communication. it helps the stakeholders to collect and evaluate essential business data quickly.
Globalization
Globalization is the procedure that explains trade and other exchange between different locations or nations around the world. It can establish the modern connectivity and relevant impact of communication systems.
It presents global trade and exchange around the world. It has different types and specification such as economic globalization, political globalization and cultural globalization. All of them present different globalization sectors around the world. Different internal and external business components effect this system or procedure, such as information technology.
Effects of IT in Globalization
Information technology has created new scopes and opportunities in communication systems and management. It has already created effortless system of exchanging data or information around the world. Information holds the most essential role in current business requirements or scenarios.
Information technology also improves productivity levels of the stakeholders into the organization. It implements advanced and emerging economies. Technology is the system that can reduce man power requirement and other resource supply as well. In that way, the organizational system and management become more effective and accurate.
Businesses have faced effective opportunity of reaching limitless audiences and consumers. the market reach is increased along with effective communication and marketing strategies. Visual media and social information networks have developed the system scopes of effective business implementation.
Digital Infrastructure
Digital infrastructure presents the system or resources connectivity. It includes both physical and virtual resources such as computers, data storge, network, SaaS, etc. this is essential for better and effective business process management. Project manager, finance manager, and other key organizational stakeholders are responsible to develop the digital infrastructure into an organization. Appropriate digital infrastructure will also lead to better market positioning and business growth.
In this section of the assignment, ‘cloud computing’ is considered as an example of digital infrastructure. Appropriate discussion and evaluation of the selected digital infrastructure will lead to better business procedure implementation of cloud computing technology to build effective digital infrastructure.
Overview
Cloud computing technology or system presents the digital storage and virtual processing of different organizational operations like information exchange. It includes different web-based services and hosted services. Most of the organizations are also implementing this new technology or system for better business development and management.
Image 8: Cloud Computing
(Source: Baird, 2019)
Advantages
Cloud computing is an essential digital infrastructure in any organization or business. It shows different advantages and disadvantages in organizational requirements. These are essential to evaluate for better business process management and effective decision making.
.png)
Table 1: Cloud Computing Advantages
(Source: Developed by Author)
Disadvantages
Organizational disadvantages must be discussed with appropriate evaluation. This will lead to effective business precautions and changes. It requires analytical thinking approach to evaluate these disadvantages. This may cause significant changes in system, requirement planning and designing as well.
.png)
Table 2: Cloud Computing Disadvantages
(Source: Developed by Author)
Risks Identification in Information System Outsourcing
Risk Identification is the procedure, where the potential risks are identified in a particular project development or business. In case of an information system development, the project manager is responsible to identify the potential risks into the development procedure and implementation strategy. This eventually leads to effective risk assessment and mitigation planning. This not only improves the project effectiveness but also improves the organizational culture and growth.
In most of the organizations, the information system is being outsourced by the management team. Sometimes, companies appoint and manage technical support team of developers to maintain the information system. In spite of that, it creates different project risks that can impact the overall business and information system development in a negative way. The identified risks in this case are,
• Inexperienced employees
• Data or information leak
• Dependency on the vendor
• Poor system control management
• Poor feedback management
These risks are mostly associated with different system functions and business operations. This is the responsibility of the project manager to evaluate all the identified risks in this particular project. This will eventually lead to an appropriate and effective risk-mitigation plan. This will be implemented by the business management team. Moreover, Different teams are associated with this whole risk identification and assessment process. They include. Data analysis team, database management team, etc.
Why is IT infrastructure so Critical to Digital Transformation?
IT infrastructure presents the overall development and implementation of software technology that can create appropriate IT infrastructure for effective business management procedure. It includes, cloud computing technology, security aspects, different equipment, etc.
On the other hand, digital transformation presents the transformation procedure of current business by adapting digital technology and information system (Ebert, & Duarte, 2018). It includes information management system and many other IT solutions. This is the responsibility of the supervisor to evaluate IT solution implementation into digital transformation.
Digital transformation mostly has different types in terms of transformation element and application such as,
• Process transformation
• Domain transformation
• Business framework transformation (Matt et al., 2015)
• Organizational culture transformation

Image 9: Digital Transformation
(Source: Peranzo, 2021)
IT infrastructure is critical and significant for the digital transformation. Every business requires effective IT infrastructure to implement digital transformation into the existing business structure (Reis et al., 2018). The development of any information management system, requires appropriate infrastructure that includes, efficient systems, development team, system management team, etc. Moreover, it consists different framework or analysis that are associated with the IT solutions, such as visual learning. In that way, IT infrastructure plays a significant role in digital transformation in any business or organization.
An infrastructure not only develops but also maintains a particular system. in this case of IT or information technology, the business also requires some additional features to maintain the implemented IT infrastructure. It includes data analysis team, database management team, technical support team, etc. (Berger, 2015). In this way, the IT solution implementation will be effective in long run. This will impact the digital transformation procedure as well. for example, after the system development, the first responsibility of the project manager will be to develop appropriate system policies (Baiyere et al., 2020). This will impact organizational culture and overall business system management in a positive way. This can clearly establish the significant impact of IT in digital transformation.
Conclusion
In this assignment , IT or information system technology is explained through different system types and organizational implementation. On the other hand, it discusses particular digital infrastructure, cloud computing. It includes advantages and disadvantages that can lead to appropriate evaluation into the organizational process.
The risk assessment and of IT in digital transformation, have established clear idea on information technology and real-life application. This will lead to better risk assessment strategy and impact. The business management will be able to prepare appropriate mitigation plan as well. Finally, the impact of IT or information technology is discussed into the last phase of the report. It has established the effective requirement of IT in digital transformation.
Overall, the assignment concludes, that information technology systems are effective in business management and overall management system improvement. It requires effective management and critical thinking approach to adopt this methodology or system.
References
.png)
Research
COIT20250 Emerging Technologies in E-business Assignment Sample
Corematic Engineering is an engineering consultancy company providing an externalised research and development (R&D) service. According to the organisation’s website, Corematic Engineering provides R&D services to businesses that want to de-risk innovation and automate their operations, keeping full control of their IP.
As per the Corematic’s website, “in 2018, Scott Hansen and Jonathan Legault established Corematic Engineering with the vision of bringing a different R&D approach to the Australian business landscape with savoir-faire and strong knowledge focusing on an agnostic approach to technology. Happy clients equal a successful business - this success story of two senior industry leaders who live and breathe client success led Corematic to reach two million dollars in two years.” As a self-funded company, they are fully funded by their customers - not investors, subsidies, or government grants. Corematic has offices in Brisbane and Bundaberg, both cities located in Queensland.
Corematic website states “bringing a proven engineering process that combines state-of-the-art R&D practices with a return-on-investment approach, Corematic’s new-generation mechatronics engineer tailor solutions in robotics, artificial intelligence, computer vision, and machine learning to empower businesses to lead Industry 4.0.” In particular, they specialise in vision, vision system, 3D camera, LiDAR, Industry 4.0, Internet of Things (IoT), Smart Factory, Intelligent Technology, Artificial Intelligence (AI), Sensor, Monitoring Platform, Proximity warning system, Anti- collision system, innovation, and automation.
“At Corematic, we never push a particular technology or brand. We are unbiased in our role as consultants, presenting options and giving clients the freedom and control to choose what they want to do.” Scott Hansen & Jonathan Legault, Founders of Corematic. Even though, the field of expertise of Corematic Engineering revolves around robotics, computer vision and machine learning, they also specialise in lean manufacturing and business improvement by placing long term consultants with their clients. Corematic applies a Lean Six Sigma Approach to analyse the current processes for both operation and business, define a performance baseline, and identify opportunities for improvement before proposing and implementing innovative solutions. To leverage this expertise, Corematic uses and resells one of the best business process mapping tools available on the market: PRIME BPM. Corematic is also mapping processes and defining procedures for its own internal activities with an ISO9001 certification in mind. Corematic also runs a Digital Marketing Agency specialising in B2B activities, preferably in engineering where marketing is relatively unexplored.
According to their website, “Corematic Engineering is now referred to as a disruptor in the robotic and business intelligence industry, providing turnkey solutions for complex problems that made black box solutions obsolete.” Because of their establishment in robotics and automation, they have been awarded referrals to different organisations including their award for Harvester.
Mounted Vision System ‘TallyOp’ that allows farmers to optimise efficiency and boost yield performance to simplify and enhance farm management decisions through detailed insight.
“Corematic Engineering’s expertise in robotics, artificial vision, and machine learning has been applied to multiple projects, revolutionising the power of business intelligence in the Australian landscape.” Corematic has worked on multiple projects with many esteemed leaders in the Australian agriculture, smelting and pharmaceutical industries so far!
Please Note: Corematic Engineering official website (https://corematic.com.au) was the main source to prepare this Case Study with minimal change in order to protect the original information provided by the organisation. The Case Study provides a short business story about Corematic Engineering, however accessing their website and other internal/external sources for more detailed information about this organisation is necessary to complete the assessment as required.
WHAT YOU ARE EXPECTED TO DO :
Pretend that you have been appointed as an Emerging Technologies consultant by Corematic
Engineering (https://corematic.com.au) to advise them on their next e-business strategic direction (2023-2027) in terms of adopting emerging technologies in their current and other potential business operations. This is because Corematic Engineering would like to expand their businesses nationally and internationally in the next 1-5 years and become one of the most advanced technology consultancy companies in Australia, and build a national and global brand name. Furthermore, they recently realised that they are facing fierce competitive pressure from a number of national and international companies as well. Corematic’s business has been growing significantly since their establishment in 2018, however they fear that they cannot sustain this growth after the next few years unless they take some serious action, invest in variety of emerging technologies, and expand their business operation fields (in addition to what they have and do currently). They think the solution could be using appropriate emerging technologies effectively in their many business fields and operations. To help them achieve this, first you will need to read all the information given to you about this case study including accessing the Corematic Engineering website and other relevant sources to understand the organisation’s business, growth strategies, operations, and processes better.
You then need to read the Assessment-3 details to find out how you can help Corematic Engineering business by advising about emerging technologies to allow them to achieve their business strategic goals and provide much better and diversified products and services, not only on a national scale, but also to become a truly international company, build a global brand name, and gain and sustain competitive advantages in their business operations. When you are suggesting appropriate emerging technologies for your chosen three e-business use cases of Corematic Engineering, apply your innovative thinking, imagination, long visionary skills, and e-business knowledge and experience in an effective way.
Each of you will analyse a given case study and identify the issues arising from the case study. Based on the issues found in the case study, you will identify three e-business use cases (for example, Predictive Maintenance). You will then choose as many emerging technologies as appropriate to address those use cases. You can choose any emerging technologies that fit the use cases, even the ones not covered in the lectures.
You will write a report illustrating how the chosen emerging technologies would fit into and address the requirements of the identified e-business use cases.
In the main body of the report, you will include the following topics.
1. A list of identified three e-business use cases and chosen emerging technologies including a brief background study of those emerging technologies. You need to first list identified three e-business use cases and chosen emerging technologies to address those use cases (as per the given Case Study) then describe how the chosen emerging technologies evolved, their underlying designs, working principles, functions, and capabilities (in general).
2. A brief description of the future potentials of the chosen emerging technologies. You need to discuss the future applications of the chosen emerging technologies in e-business in general.
3. An illustration of how the chosen emerging technologies would fit into the identified e-business use cases
You need to illustrate what issues of the identified use cases would be resolved by the chosen emerging technologies as per the given Case Study.
4. Details of how the chosen emerging technologies would address the requirements of the identified use cases
You need to elaborate how the chosen emerging technologies would interoperate to fulfill the requirements of the identified use cases as per the given Case Study.
Solution
Introduction
The company of Corematic Engineering offers an externalised research and development (R&D) service. As per Corematic Engineering's website it has been discovered that the respective company is offering R&D service to companies that are looking to automate and re-disk Innovation while maintaining total control of their business as well as their IP. It has been found from the case study that the respective company is aiming for creating a different R&D approach within the Australian business market landscape. The services of the company mainly centre around various robotic technologies such as AI and IoT. It has been visible in the provided case study for assignment help that the respective company is trying to expand their business internationally. However, they found a barrier to competitiveness. So, the management department of the respective company needs some specialized solutions for improving its business strategy internationally. The respective study is going to discuss the essential technologies that the company should adopt to grow their international market.
Identifying three use cases and chosen emerging technologies
Predictive maintenance is one of the important use cases of e-business that has been identified. Going with the view of Carvalho et al. (2019), predictive maintenance can be termed as a design that helps in monitoring tools along with techniques. With the help of Monitoring the tools as well as techniques, predictive maintenance plays a vital role in monitoring the structural performance of the company. Based on the view of Nasution et al. (2020), this case can be used by the companies to determine the issues within their structural performance. There are five major technologies that the company can adopt to improve their predictive maintenance. The technologies are PdM Tools and Technology, Vibration analysis, Ultrasonic analysis, Oil analysis techniques and Motor circuit analysis. These are some of the essential technologies that can be used by the Corematic Engineering company to increase its business strategy within the international market. Based on the view of Rong et al. (2018), it can be stated that these technologies can help a company effectively maintain its business fields as well as operations. These technologies can help a company in allowing their safety compliance. As per the view of Gouda et al. (2020), these predictive technologies are mainly used for a variety of tasks, including establishing credit risk models, managing resources as well as anticipating inventory. These technologies in predictive maintenance support businesses in lowering risks, streamlining processes, and boosting earnings.
Aside from predictive maintenance, Sales-Profitability & Demand Forecasting is another important case. Based on the view of Bhimani et al. (2019), sales profitability helps in keeping an accurate map of the profit status of an industry. In other words, it can be stated that this case is mainly used for measuring the sales dollar of a company to map their profits after maintaining all of the costs along with taxes. The sales profitability of a company can be identified by performing a subtraction between total revenue and total expenses. According to the view of Lei et al. (2021), demand forecasting helps in predicting future customers as well as future demands. Few technologies can be used by a company to maintain sales profitability and demand forecasting. The technologies are big data analysis, Cloud storage technology, Internet of things or IoT. These technologies are highly associated with the development of Sales-Profitability & Demand Forecasting. These technologies can help a company in identifying its net profit. Aside from this, the pre-mentioned technologies can be also used in determining the future of an industry.
Besides all of this, trend Identification to Drive the Pricing & Promotion Plan can be termed as one of the major cases that have been used by the e-business. Based on the view of Bhimani et al. (2019), a trend can refer to the overall direction of a market. Trend identification can help a business identify how the business is performing in a market. This also helps in finding various issues related to the business. The trend identification process of comparing the business data with marketing trends. Going with the view of Huang et al. (2019), four important technologies are highly associated with the development of trend Identification to Drive the Pricing & Promotion Plan. The technologies are Machine learning, 3D printing, computing power, smarter devices and datafication. This technology plays a vital role in analysing the service and supply demand of a product on a market.
Describing future potential and application of the chosen emerging technologies
Technology is growing at an intense level. As per the view of Biswal and Gouda (2020), good technology can prove to be a boon to a company. The Corematics Engineering company must adopt the latest technologies so that it can lead itself ahead of any other technological consultancies present in the market. To perform predictive maintenance the use of PdM tools and techniques is very much essential to identify the risks, assess the data from core to core and predict if there are any flaws or not. It does not only reduce the time of the experts but also the costs get reduced. The company can rely on this technique to perform quality-based work that can assure high-quality results. The Corematics Engineering implementation of predictive maintenance can take the company to a whole new level. Apart from that, the application of big data analysis and cloud storage can help in increasing sales profitability and demand forecasting. The future of these technological advancements can not only take the company to another level but create a global name worldwide. The profit could be calculated and the demand of the customers could be identified very easily. The demands can be met by the company very easily and the company can earn good profits through that. The future of these technologies is very crucial and their implementation can bring a revolution in the e-business market. The Corematics Engineering consultancy company can prove to sustain in its future activities if the business of the company goes at par with the technological advancement going on everywhere and between a lot of companies that are trying to create a revolution in the e-business industry.
As far as going with the trend is concerned any company that does not understand the dynamics of the market generally suffers a lot in future. The potential e-business company must adhere to the latest smart computing techniques, 3D printing, smarter devices and machine learning so that it can fix proper pricing and bring a revolution in the market. The implementation of these technologies can help Corematics Engineering to maintain a proper e-business as well as earn profitability without any hesitation and gain a strong competitive advantage over any other company on a global scale.
Application of the chosen emerging technologies in the identified use cases
Cinematic engineering being one of the reputed engineering consultancies has been facing a lot of issues that need to be resolved. As mentioned by Lei et al. (2021), the advancement of technology can help an organisation in improving its activities and achieve heights. Similarly, as far as Corematic Engineering is concerned it must adhere to the latest technologies to sustain its business as well as its operations for the later future. Even if the idea of predictive maintenance has improved downtime and decreased long-term expenses since its inception, it still leaves open the chance of those unforeseen surprises and the cost of downtime that goes along with them. This situation was real because the mechanic's skills, intuition, and experience were all that were relied upon to keep the machine operating at its best. The preventive component of the maintenance programme was also left to the mechanic's "fingers crossed" optimism. Therefore, Corematic Engineering must adapt to using PdM tools and techniques for predictive maintenance. As stated by Ran et al. (2019), the idea of conditions-based predictive maintenance aims to close the gap between the limitations of relying on human experience and intuition for repair and the capacity to not only prevent failure but also predict it and optimize maintenance and repair to reduce time and cost. It can be of vital essence to the company to sustain its business and the application of the various PdM tools and techniques can be used to do proper predictive maintenance. According to Sony et al. (2020), the application of AI is an essential ingredient that has the power to not only change the business reality but take the company to the next level. Not only can it satisfy the goals of the company but also develop the latest in-hand facilities that can give quick solutions to harder tasks or problems. Being an R&D company, Corematics Engineering aims to solve the issues of competition that are developing in the market and that can be sorted with the implementation of the latest AI facilities. Sales profitability and demand forecasting play an important role in an organisation. The application of big data analysis, IoT and Cloud storage can help benefit organisations at a huge level. The ascertainment of net profit could be made with the execution of these advanced mechanisms. Finding the right data for execution at the right time becomes very much easy with the application of AI that builds a friendly tech-savvy atmosphere. Lastly, building a promotion plan and pricing through trend identification is of essential need by an e-business company like the Corematics Engineering company. The application of machine learning, 3D printing, smarter devices, and computing power can help the company in locating the trend and fix the promotion and pricing. Corematics Engineering must adhere to these innovative techniques.
Application of the chosen emerging technologies in addressing the requirements of the identified use cases
Emerging digital technologies can help the Corematic Engineering company in spreading its business within an international range. It has been assumed that after adopting the technologies the company would be able to solve the arising business-related issues. Aside from this, the selected technologies can also help the company in identifying the essential requirements of the pre-mentioned identified cases. There are almost twelve digital technologies have been identified in the previous sections of the respective study. Therefore, it can be stated that adopting the identified technologies may help the R&D organisation in spreading their business within w worldwide range.
PdM Tools and Technology:
This technology plays a vital role in monitoring the predictive maintenance of the industry. In other words, it can be stated that this technology plays an important role in addressing the case of predictive maintenance. As it has been found in the case study the respective company is trying to spread their business internationally. Based on the view of Rashid et al. (2019), before conducting any business in an international market it is important to have proper maintenance of the tools and techniques. This respective technology mainly helps in maintaining the pre-mentioned factor and increasing the capacity of the business. Thus, this technology helps in identifying the requirement of the identified use cases.
Vibration analysis:
Aside from the pre-mentioned technology, vibration analysis is another important technology that plays an important role in monitoring predictive maintenance. It can be stated that the technology is mainly used for maintaining machines. It can be assumed that with the help of this technology the respective industry can identify the issues within their machines. To spread the business within a new market it is essential to identify the potential failures. In other words, it can be described that it helps in increasing the safety levels of the employees.
Ultrasonic analysis:
Along with the pre-mentioned technologies, Ultrasonic analysis also plays a vital role in developing the maintenance of monitoring predictivity. Going with the view of Yang et al. (2020), ultrasonic analysis of a product is mainly done for detecting the flaws and issues of the product. Detecting the flaws and issues provide a chance of finding a perfect solution to solve the problems. With the help of this technology, the respective company can investigate how sound waves move through the materials under test, allowing us to find significant faults. This will also help the company in examining the potential of ultrasonic analysis as a condition monitoring tool and a preventive maintenance technique throughout this paper.
Oil analysis techniques:
Oil analysis techniques are an important technique that helps in analysing the oil volume within a machine. Based on the view of Hanga et al. (2019), Oil analysis is a routine analysis that helps in analysing the level and the health of oil within a machine. Understanding the coordination of the oil can be termed as one of the major reasons behind performing oil analysis. With the help of this oil, analysis is the respective R&D company can be able to read as well as check the data on the machine type. Thus, this technique of oil analysis can help in identifying the requirement of the identified use cases.
Motor circuit analysis:
Motor circuit analysis can be termed another important part of predictive maintenance. Along with the pre-mentioned technologies, motor circuit analysis techniques also play a vital role in analysing the machines and the production system within an industry. Based on the view of Choudhary et al. (2019), motor circuit analysis is a method that helps in identifying the health condition of a motor. The respective company has been suggested to adopt this technology to understand the health of their electronic motor circuits. In this way, this technology can help in addressing the requirements of the case of predictive maintenance.
Big data analysis:
The pre-mentioned technologies are for addressing predictive maintenance, whereas this technology helps in addressing the requirements of the case of Sales-Profitability & Demand Forecasting. Based on the view of Mikalef et al. (2020), big data analysis can be defined as a complex process. This complex is used in identifying necessary information within a huge amount of data. It has been suggested to the respective company to adopt the technology of big data analysis. This will help the company in spreading its business internationally. Along with this, big data analysis can help the organisation in analysing data for making data-driven decisions. Eventually, it will lead to improving business-related outcomes.
Cloud storage technology:
Along with the previous technology, cloud storage technology also plays an important role in addressing the requirements of the Sales-Profitability & Demand Forecasting case. Going with the view of Gur (2018), cloud storage technology is not only safe as well as secure but also it is budget-friendly. Corematic Engineering can easily adopt this technology to increase the growth of the business. Using cloud storage technology can provide the access to companies to view their files from anywhere with the help of an internet connection.
Internet of things or IoT:
IoT is another vital technology that has been used in addressing the requirements of the Sales-Profitability & Demand Forecasting case. Based on the view of Alam et al. (2021), IoT is all about using sensors, devices, gateways, and platforms to improve business processes and solutions. With the help of this technology, the respective company would be able to gather data efficiently for improving the capacity of the business. Moreover, IoT can help in increasing the connectivity between the stakeholders of the company.
Machine learning:
Machine learning technologies can be termed as a bunch of AI or compute learning technologies. Based on the view of Hair et al. (2021), machine learning plays a vital role in identifying customer behaviour as well as the patterns of business operations. It can be assumed that with the help of technology the respective company can identify the situation of the company within a market. Which eventually can provide a greater opportunity of understanding the needs of the business as well as customer needs.
3D printing
Along with the pre-mentioned technologies, 3D printing can be termed as another important technology that helps in addressing the requirements of the trend Identification To Drive The Pricing & Promotion Plan case. Based on the view of Rong et al. (2018), 3D printing can help a business by having a 3D look at their plans and projects. With the help of this technology, the respective company would be able to manufacture perfect products.
Adoption of Smarter devices:
With the help of smarter devices, the respective industry would be able to conduct an efficient management system of operations. Besides this, the respective technology can help the respective industry in receiving real-time data.
Conclusion
As studied in the report, it can clearly be stated that the Corematics Engineering consultancy company must adapt to its latest technologies. It is very much clear that to sustain itself in the market the company must implement new technological aspects that can benefit the company. As far as the long run is concerned, with the emergence of the latest technologies like the PdM tools and techniques, vibration analysis, motor circuit analysis, and ultrasonic analysis, the latest AI implementation in the business can help Coremetrics Engineering in flourishing in their business. With the three use cases as explained in the above report, it is very clear that every technology has its relevance and its adaptation can not only create a huge success but help the company grow in the long run. With the competition in the market being very high, the Corematics Engineering consultancy needs to rely on its technology and must continuously upgrade its internal activities so that the business does not perish as well as the customers do not complain about their work. As quoted by Roman-Belmonte et al. (2018), technology can bring revolution. Similarly, the Corematics Engineering consultancy with the proper execution of the latest technologies and creating a tech-savvy environment can prove to be a leader in the global market and establish itself as one of the main names internationally.
Reference
.png)
.png)
Assignment
MITS5003 Wireless Networks and Communication Assignment Sample
Task
The university's head of IT has recruited you as a third-party consultant to provide them with a wireless LAN solution for their network. The institution has little over 800 employees who work in a complex of seven buildings in an urban area. Employees routinely walk between buildings because they are all near enough together. Wireless technology is something that the management team wants to implement in their company's network. They've heard that, compared to the current leased line network, this type of network will save them money. They anticipate that increased mobility will result in a significant boost in production. Because the workforce moves from building to building, it appears to be a good idea to offer them with portable computer equipment and data. Figure 1 depicts the area covered by the university buildings. The assessment requires you to plan and design a wireless network for the university using any industry tool of your choice. Citation of sources is mandatory and must be in the IEEE style.
Solution
Introduction
With the rapid advancement of technology and smart devices, most organizations are enhancing their communication channels by implementing different tools and techniques. Healthcare, education, telecommunication, retails, and other industries are now implementing the ICT (Information Communication Technology) network architectures to enhance their communication system. In this task, an information communication architecture will be developed for an university. After analysing all the major requirements of the university, a wired and wireless network architecture will be developed in this paper. All the necessary networking components and devices will be identified in this report. In order to design the network design, MS Visio diagramming tool will be utilized. However, the network design will also be critically analysed in terms of different factors or usability by the university employees. Moreover, some major constraints and limitations of designed network will also be discussed in this report. Based on the university’s requirement, all the major networking components will be included into the network architecture. This network design must offer an advanced and speed communication network to the users.
Requirement analysis
In order to resolve disagreement or misunderstanding in requirements as needed by different individuals or groups of users, eliminate functionality creep, and document every step of the project creation process from beginning to end, requirements elicitation requires continuous communication with network administrators and consumer. Instead of seeking to shape consumer expectations to match the requirements, effort should be concentrated on making sure that the end product or service adheres to customer needs. In this task, all the major requirement of the university including functional and non-functional requirements have been identified [1]. The characteristics that the system must offer to its clients and end users are specified by the functional requirements. It outlines the functionality required for the system to operate. The characteristics of the technology for assignment help are the malfunctioning needs. They are made up of operational or resolution restrictions as well as outside variables like system dependability.
Functional requirements
Functional requirement for the network design can be categorized into different components including hardware, software, client device, connection media and other models. In this section, function requirements for the university has been illustrated. In order to design the network, a number of networking equipment will be required. In the below table, all the major functional requirements for network design have been illustrated.
.png)
.png)
.png)
Table 1: Hardware requirement
In the above table, all the major hardware requirements have been illustrated that could be utilized for the network design. On the other hand, some major software and protocol requirements have been identified in the below points:
• TCP and IP model that could give a standard layered internet architecture to the university [4].
• OSI model that gives raw data transmission and connection to network users.
• IP addressing approach must be adopted to provide network address to each devices and networking components.
• Windows 11 operating system must be installed into the workstations which will be accessed by the users of the university.
• Anti-malware application or programs should also be installed into each workstations to protect devices from being hacked or breached by the hackers [5].
• FTP is another vital protocol that need to be implemented by the network developers.
Therefore, a complete functional network requirement analysis need to be done before designing the network.
Non-functional requirements
There are several non-functional requirements are also associated with this project that need to be considered. These are such characteristics that helps to understand performance and reliability of the develop network design. In the below points, major non-functional requirements have been identified:
• Performance: Current network performance must be enhanced with better speed and function of the network. This will help to higher the productivity of workforce into the university.
• Usability: An advance and simple network architecture will be available to the users. A number of features and functions will be available to the users. Based on the system architecture, all the major changes into the system could be easily made by the users [6].
• Security: In order to protect data and information of the university, a secure data transmission protocol could be enabled by the users. The communication channel must be secured by using security protocols and anti-malware programs.
• Scalability: With increase in student size or university architecture, the network could be expanded with other networking components. Scalability is a major requirement of the designed network architecture.
• Reliability: The designed network must be reliable for each users of the university. During the peak hours, it must give a better communication channel to the users. This characteristic will give better networking experience to the users [7].
• Availability: Each feature of the network must be available to the users at any time. It can be defied with the request made and potential response acquired by the users.
Depending on the university infrastructure, the above functional and non-functional requirements will be fulfilled during the network design.
Network design
In this section, the network architecture design for university has been developed that includes a number of networking components. In the below figure, the network architecture design has been given. The network architecture design has been developed by using MS Visio diagramming tool. This network has been developed to fulfil all the major requirements of the university.
.png)
Figure 1: University network design
(Source: Author)
In the given figure, complete network architecture design for an university has been developed. All buildings of the university has been given with a wireless network facility. Different aspects of network architecture design has been considered during design development.
Critical Analysis
The network design task becomes critical if size of the institute or organization is larger. Depending on the IT infrastructure and industry requirement, some major actions need to be taken by the users. In order to achieve the business goal of the institute, all the possible challenges and issue must be considered and mitigated by the network engineers. Therefore, it is important to critically analyse the available network architecture after development and testing. In the developed network design, all the major considerations have been addressed for the university. Here, the star network topology has been adopted which gives a better networking facility to the users [8]. The gateway router has been installed into the main building and from gateway router other seven routers have been connected. For each building separate routers have been installed. In each building, network switches have been connected from the network router. In each building, wireless access point have been installed to provide remote networking facility.
This section includes how several sorts of needs can work together to produce the required information system, which will eventually make it easier to accomplish business objectives. The top-down technique, as shown in figure, is used in this presentation to build up the specifications beginning from the organisational objectives to the functional requirements stage, such as the necessary characteristics. With the help of wireless devices, users will be able to work from any location or building of the university. Different servers have been installed into the main building of the university. This will work as an IT support building of the campus. At the same time, firewall protection has also been given. It has been installed into the gateway router. Firewall helps to filter malicious data packets or viruses entering into the network [9]. If network applications or products are deployed without taking into account their properties and network needs, it's likely that business objectives won't be met. In this network design of contemporary educational services might offer video contact between its IT team and students in an effort to set itself apart from rival businesses. If the network administrator did not properly take into account the needs for videoconferencing as a network application, the programme is likely to fail to provide the end users with the intended experience.
Therefore, both the wired and wireless network design has been included into the network design. In order to enhance the network performance, network bandwidth could be increased by the service providers. On the other hand, high speed routers have been installed into the network which will also make the performance better. An internetworking facility has been introduced into the LAN design. This network design could be expanded in future according to the university requirement. A reliable network architecture has been developed which could give a smooth networking opportunity to the users.
Constraints and Limitations
There are several constraints and limitations are also associated with the network design that should be considered to enhance the network performance. Some major constraints have been illustrated in the below points:
• Cost is a major limitation that must be considered during the network design. In order to purchase high speed networking equipment, enough budget need to be allocated by the university authority [10]. In this context, it may become a challenging aspect for large scale network infrastructure development.
• Time is another constraint that need to be considered by the network developers as it may take unto several months to complete network design project. From the initial stage of requirement analysis to the networking device configuration, each task must be done on time.
• Expertise of staff and internal staff if also a major aspect that need to be considered by the network developers. Initially, user may not be able to use each features properly as there may be some limitations for network design. In this case, a proper training schedule need to be enabled for the network users.
• Updated cabling structure for better communication and connection need to be adopted by the users. Speed of the network may different due to the different cabling standards [11]. On the other hand, wireless communication may cause drop in network speed. Based on the system architecture of the university, proper bandwidth must be given by the service providers.
• Security infrastructure of the network must be strongest as a number of security breaches have been recorded in recent times. Each devices need to be updated and introduced with advanced version of software and anti-malware applications. Security requirement checking periodically is another major challenge in this case.
In the above points, most potential limitations and constraints associated with the network infrastructure has been identified that need to be considered by the network engineers. In order to provide a proper network infrastructure to the university authority, each requirements must be considered. However, the impact of the design limitations and constraints have also been discussed in the below points.
• The network architecture will be successfully established for the university if all the potential challenges and issues have been considered in the initial phase. The communication channel could be established by the network developers.
• The network will become fully secured form any external entities or hackers. Data and information security could be enabled by the users.
• Users will be able to communicate with each other with the help of wired or wireless network. Data and information of the university will be stored into the database server of the company.
• Usability and accessibility to the network devices and data will be increased with the successful implementation of the network architecture into the university.
The usefulness of such ICT network for each individual rises with the overall quantity of users, which is perhaps their most important feature. The value of innovations like smart phones and email is more closely tied to the number of people one can connect with through the system than it is to the services they provide consumers. As the user base expands, technologies has a tendency to gain velocity and begin expanding via a self-reinforcing mechanism into the educational institutes. The network keeps expanding on its own the more people who use it, the greater the cloud computing use value, the much more new customers who will use it, and so forth.
Conclusion
An information communication architecture has been created for a university in this project. In this paper, a wired and wireless network architecture has been built after evaluating all of the university's key requirements. This report includes every device and networking element that is required. MS Visio has been used as a diagramming tool to create the network design. But university staff members has critically evaluate the network design in terms of several elements or usefulness. This study also cover several significant design-related restrictions and limitations. All of the key networking elements have been incorporated into the network design in accordance with university requirements. Therefore the designed network architecture will give a better networking experience to both internal and external users of the university.
References
.png)
Research
Assignment
SIT763 Cyber Security Management Assignment Sample
Task 1: Security Education Training and Awareness (SETA) Programme
Create a role-based SETA programme in the following three roles: real estate agents, data centre operators, and cyber security engineers. For each role, recommend the most appropriate and unique SETA element using the table shown below. Here is the description of each criterion:
Goals – identify two unique and meaningful goals. Explain why you have chosen them.
Objectives – identify one or more unique objectives for each goal. Explain why you have chosen them and how the objectives help attain the goals.
Programmes – choose from security education, security training, or security awareness the most appropriate program for the role. Justify why you choose it.
Delivery – identify a suitable SETA element delivery method. Explain and justify why the method will be effective for the role.
Value – explain what the attendees can take away from the programme that will help or advance their knowledge, skill, or awareness level.
When writing your answer for each criterion, consider the background and skill level of the staff in each role. Also, make sure you explain and provide justifications that are supported by relevant references.
Task 2: Incident Management and Response
You will use the NIST Incident Response framework to develop a cybersecurity incident response plan. Answer the following questions.
2.1 Create a visual representation (diagram) of the cybersecurity incident response plan's critical phases. Give a brief explanation of the important message conveyed by the diagram.
2.2 Using the diagram above, briefly describe the incident response steps taken by the security incident response team after a critical data breach is detected.
2.3 Explain how the information gathered during the incident response process will be used.
Your response to the above questions for assignment help must be supported by references, theory and demonstrate application of critical thinking skills.
Solution
Task 1: Security Education Training and Awareness (SETA) Programme
.png)
.png)
Task 2: Incident Management and Response
.png)
Figure 1 Cybersecurity incident response plan's phases
The important message conveyed by the diagram is that
- A process of preparation, detection/identification, analysis, containment, eradication, recovery, and post-incident review is essential for effectively and successfully responding to security incidents. These phases are the essential framework for thoroughly managing security incidents and provide a basis for achieving organizational resilience [1].
- It is also conveyed from diagram that incident response requires a structured, systematic approach in order to be successful in identifying and mitigating threats, as well as in restoring normal operations
- It also emphasizes the need for organizations to prepare and test the incident response plan and to categorize the incident types in order to be ready and prepared for such a situation.
2.2 The security incident response team (SIRT) will take the following steps when a data breach has been detected:
.png)
Validate the incident: The SIRT will verify the incident and analyze the nature of the data that has been compromised.
Contain the incident: The SIRT should identify any affected systems and isolate them to prevent further damage. They should also delete any malicious or unauthorized files and disable any affected accounts or services [4].
Gather evidence: The SIRT should collect, preserve, and analyze all necessary evidence to identify the circumstances surrounding the incident.
Investigate the incident: The SIRT should investigate the incident to identify its root cause and the extent of the damage [4].
Create a timeline: The SIRT should also create a timeline of events surrounding the incident. This includes recording the time of the incident, the time the incident was discovered, and the time each incident response action was taken.
Restore normal essential services: The SIRT should restore essential services as quickly and securely as possible to minimize the impact of the incident on the business.
Test and monitor: The SIRT should test the security measures that have been implemented to ensure that they are properly protecting the environment and are working as intended. They should also monitor systems for any suspicious activity that may indicate that the incident is still in progress.
Communicate: The SIRT should communicate their findings to stakeholders and relevant parties to ensure that any action taken to remediate the incident is understood.
Document the incident
Take preventive measures: such as implementing new security measures and implementing stricter access controls to prevent similar incidents [5].
2.3 The security incident response team will use the information gathered during the incident response process for multiple purposes.
- To Identify the Source and Impact of the Breach: The information gathered during the incident response process, such as log files, alerts, and other activities across the network/systems will help the security incident response team to identify the source of the breach and estimate the potential impact of the incident.
- To Take Steps to Contain the Breach: The security incident response team will use the information to take steps to limit any further loss or damage by isolating the affected systems and networks, halting any ongoing activities, and limiting access to the affected data/systems.
- To Identify malicious actors and Targeted Techniques: The security incident response team will use the information to investigate and identify any malicious actors, their techniques, tactics and procedures, and any malicious code or files that have been deployed.
- To Recover Data and Services: The security incident response team will use the information to take steps to recover any data or services that were compromised such as restoring any lost data and running vulnerability scans to identify any other potential threats.
- To Properly Inform Senior Management and Other Stakeholders: The security incident response team will also use the information to properly inform senior management and other stakeholders about the incident, its impact, and the steps taken to contain and remedy the breach [4].
References
.png)
Research
ICT80008 Professional Issues in IT Assignment Sample
Assignment Brief
Purpose or Overview
Your task in Assignment 1 is to write a Briefing Paper on ONE of the following topics. Note that you can look at an aspect of one of the following topics if you so wish. For example you may look at machine learning as an aspect of AI, take a deep dive into the ACS’s professional code of conduct as an aspect of the first topic etc. If you are unsure that what you want to look is a viable aspect of a topic, speak to the unit convenor:
- Professional Codes of Conduct for ICT professionals
- Privacy or Surveillance or Uberveillance
- Cybercrime or Cybersecurity
- Emerging Technologies
- Diversity in the IT Workplace
- Green IT
- Artificial Intelligence (AI)
- Technology 4 Good
- A topic of YOUR choosing to be agreed with your Convenor.
Note that several topics could well be researched from a technical or from an application/societal context perspective. In this unit, it is not appropriate to take the technical perspective, except where technical issues impact on the application of the technology in context. For example, if your topic is ‘AI’, you should focus on how organisations use or are impacted by AI, what are the key issues and challenges faced by ICT professionals, where the impediments to using the technology are (legal, regulatory), etc., rather than on the detailed hardware and software technologies needed to implement the technology.
In essence, a literature review identifies, evaluates, and synthesises the relevant literature within a particular field of research. It illuminates how knowledge has evolved within the field, highlighting what has already been done, what is generally accepted, what is emerging and what is the current state of thinking on the topic
Submission Requirements
- Assessments must be submitted via the Canvas unit site through the Turnitin submission link.
- Do NOT email the assessment to your Convenor or tutor unless requested to do so.
- Keep a backup of your submission. If your assessment goes astray, whether your fault or ours, you will be required to reproduce it.
- The assessment should be in one single Microsoft Word document and as a general guide, should be written in 12-point font size and should use 1.5-line spacing between each line.
- Pages of the assessment should have footers which include your name, student ID, unit code, and assessment title and page numbers.
- It is expected that all work submitted, will have been edited for spelling, grammar and clarity.
- Standard procedure is that assessments will be marked up to the specified word count only.
- The word count does not include the reference list and/or appendices
Solution
Introduction
The use of the information technology has increased in the recentyears but the professional issues in IT has also increased. The IT operations are increased so the issues related to cyber-attacks, threats and security have the major concerned so Green IT aims to minimizes the negative impacts of those IT operations with the practice of environmentally sustainable computing. In this paper, the major focus will be made on Green IT, issues andchallenges faced by the professionals in Green IT and how the Green computing helps in creating the sustainable environment(Bai, et al., 2017).ICT professional’s faces many issues related to ethical or socio technical so they need regulatory obligations, codes of conduct and proper standards for the effective work life balance.
Literature review
Green IT
Green Technology is the important practice in IT as it is the study of the environmentally sustainable computing which believes in creating the environmentally friendly products which have low negative impact on IT operations. Green IT are used by the organizations these days so reduce the human impacts on the natural environment. ICT professional uses the scienceand technology for saving the cost and energy, improving the culture, reducing the environmental waste and their impacts, etc.(Kansal and Chana, 2012). The main motive behind the use of Green Computing is that it helps in maximizing the energy efficiency, reducing the use of the hazardous materials, promoting the biodegradability of the products of the outdated and unused things, etc.
The concept of Green IT has emerged in the year 1992 which helps the organization in saving the money and also improving the energyefficiency. The major relationship of Green IT is with green networking, virtualization, green cloud computing, green washing, redesigning of data centers, etc.(Anthony Jr, 2020).The pattern of green IT includes server virtualization, data centers, energy efficient hardware’s and monitoring systems.All the products related to the IT technology such as manufacturing, designing, disposing, operating products, etc. are made of the green IT practices so that greenhouse gas emissions can be reduced by the professionals for best assignment help.
Why organizations use Green IT
In the recent years, the use of the Green IT has increased among the organizations as it helps in reducing the maxim sing the energyefficiency, reducing the use of the hazardous materialsandalso helps in promoting the products of biodegradability(Dalvi-Esfahani, et al., 2020).The strength of Green computing are reducing the energy usages from the green techniques which helps in reduction of the fossil fuels, lowering the emission of the carbon dioxide and also helps in conserving the resources so IT professional use such technology.
The IT professional also uses the Green IT as they have strength which includesecofriendly, environmental responsible and also use the resources and computers in the effective manner(Molla, et al., 2008).One of the biggest example is that green computing has done simple practices where the computers shut down when it has not been used so it helps in saving the energy and reducing the waste of energy. The green computing techniques are so effective it adjust the power settings which consumes less energy while operating the functions of the computers.
According to the (Dezdar, 2017), Green computing are also used so that less usage of energy can be used, produced and even disposed of the products. IT professionals use to run and compute the software on the regular basis so green computing helps in saving the money, energy resources and also give more efficient results in turning of the monitor, adjusting the brightness, leaving the printer off, turn off peripherals and even don’t use the screen saver. It has also been stated by the author that the major goal of green computing in the companies is to attain the economic viability by improving the computer devices with energy efficient manners, sustainable production practices and even with the recycling procedures.
Challenges faced by the professionals in Green IT
As per the author, there are several issues and problems in Green IT such as lack of expertise, competition priorities, misaligned incentives, need an expert of IT energy efficiency, etc. Green computing weakness has determined by the author such as disposal of electronic wastes, power consuming, educating the stakeholders with the return on investments, new optimization techniques are required and even the energy requirements are higher.
The IT Professionals need higher cost for implementing this. In the long term it is cost effective but for the short term, it is quite expensive so it was one of the major issue. There are manyorganizations who has refrain the green computing and switch to other technologies as there is high upfront cost. The IT professionalsalso need high knowledge and education to implement this and there is lack of IT knowledge experts in the companies so it created the issue (Zheng, 2014).There are many other issues are also found with the green computing such as adaption, performance, maintenance, security leaks, system support, etc. which creates challenges for the IT professionals. As per the reports, to produce the desktop computer it takes about 1.8 tons of the chemicals which produces fossil fuels. There are billions of PCs sold over the year so green computing are required to reduce the impact of carbon emission, fossil fuel and even to save the energy consumption (Bai, et al., 2017).
Impact of Green IT on the work of ICT professional
According to the(Chuang and Huang, 2018), the major impact of Green IT on the work of ICT professional users is to save the energy opportunitiesand even conserve the energy by installing the computers with low energy devices. One of the greatest example of such device is energy efficient logo which helps in adjusting the behavior to save the energy. Green ICT has the great impact on the working professional as they can save the sufficient energy cost and helps in reducing the impacts of the carbon emissions (Jenkin, et al., 2011).The professionals used to adopt the modern IT systems which reduces the greenhouse impact from the environment.
There is no gaps in the research has been found as such but this green IT requires huge investment so small and medium companies could not afford this easily. The human life is in the trouble as the e-wastes are increased and environment is getting affected badly which is also one of the major research gap.
The brand reputation of the companies also get enhancedwhich used to adopt the green computing system as it helps in reducing, reusing and recycling the environmental impact and helps in saving the cost andenergy consumption. Green IT also created environmental sustainability which not only improved the culture of ICT professional but also helps in retention and customer attractions.
There is also the certification of “Green IT Professional” which are offered globally by IFGICT. The professional who have such certification or course then it helps in doing the management and designing of IT infrastructure and system more effectively and even created great impact on the work as the professional (Bai, et al., 2017).Green IT professional courseandcertification also gets higher salaries so they get high level of motivation to associate with ecofriendly products and also conserves the energy.
Regulations behind Green IT
The regulations and the standards of green IT is based on the computing of environmentalsustainability so green IT services should be recur in the IT departments (Jenkin, et al., 2011).According to the law of the public procurements, the public authorities are allowed to demand the IT providers for using the technology and products which are energy efficient. The law of Green IT has to be establish by the large organization’s and considered as voluntary for long time as it focused on the legal framework on energy efficiency of IT products. There are many legal bodies which give the right to the public procurement to demand sustainable development and market mechanism using the eco criteria (Mishra, et al., 2014).
There are variety off technologies which has been introduced in the recentyearsso the laws and regulations put the major focus on green IT andsustainability measures which helps in detecting, mitigating and suppression the hazardous environmentalimpactsand also helps in setting up the requirements for manufacturing, designing and the sale of energy related products.
Conclusion
From the above discussion, it was concluded that Green IT has created the great impact on the environmentsustainabilityand development as it helps in saving the energy consumption with the effective use of IT products. It was also analyzed that Green IT reduces the negative impact of IT operations and helps in saving the cost and energy consumption. Green IT should be adopted by the IT professional in the work but there are certain issues andchallenges while implemented this which has stated above. The major issues and challenges are related to high cost, lack of guidance and knowledge, maintenance, security leaks, system support, etc. The major goal of green computing is to attain the economic viability by improving the computer devices with energy efficient manners, sustainable production practices and even with the recycling procedures.
References
.png)

Research
DBFN212 Database Fundamentals Assignment Sample
ASSESSMENT DESCRIPTION:
Students are required to write a Reflective Journal in which they reflect on unit content and learning experiences between weeks 1 and 11. In this assignment you should describe an interesting or important aspect of each week’s content/experiences, analyse this aspect of the week critically by incorporating and discussing academic or professional sources, and then discuss your personal learning outcomes.
The document structure is as follows (2500 words):
1. Title page
2. Introduction (~150 words)
a. Introduce the focus of the unit and the importance of the unit to your chosen professional area. Provide a preview of the main experiences and outcomes you discuss in the body of the assignment.
3. Body: Reflective paragraphs for each week from week 1 to week 11 (1 paragraph per week, ~200 words per paragraph). In each reflective paragraph:
a. DESCRIPTION (~50 words): Describe the week
- Generally, what was the focus of this week’s lecture and tutorial?
- What is one specific aspect of the week’s learning content that was interesting for you? (e.g. a theory, a task, a tool, a concept, a principle, a strategy, an experience etc.)? Describe it and explain why you chose to focus on it in this paragraph. (*Note: a lecture slide is not an acceptable choice, but an idea or concept on it is)
b. ANALYSIS (~75 words): Analyse one experience from the week
- Analyse the one specific aspect of the week you identified above.
- How did you feel or react when you experienced it? Explain.
- What do other academic publications or professional resources that you find in your own research say about this? (include at least 1 reliable academic or professional source from your own research). Critically analyse your experience in the context of these sources.
c. OUTCOMES (~75 words): Identify your own personal learning outcomes
- What have you learned about this aspect of the unit?
- What have you learned about yourself?
- What do you still need to learn or get better at?
- Do you have any questions that still need to be answered?
- How can you use this experience in the future when you become a professional?
4. Conclusion (~100 words): Summarise the most important learning outcomes you experienced in this unit and how you will apply them professionally or academically in the future.
5. Reference List
Your report must include:
- At least 10 references, 5 of which must be academic resources, 5 of which can be reliable, high-quality professional resources.
- Use Harvard referencing for any sources you use.
- Refer to the Academic Learning Support student guide on Reflective Writing and how to structure reflective paragraphs.
Solution
Introduction
A database management system is essential because it properly manages data and allows individuals to do a variety of tasks with ease. A database management system (DBMS) is a software application that stores, organizes and manages large amounts of data (Yunus et al. 2017, pp.192-194). The application of this technology enhances the efficiency of business operations while cutting overall costs. In this course, we learned about relational databases, SQL statements to extract information to meet business reporting demands, creating entity relationship diagrams (ERDs) to construct databases, and analysing table designs for unnecessary redundancy (Astrova 2009, pp. 415-424).
Hence, we mainly learn about the main aspects of Database Management Systems and alongside we will also get to know how the Databases are managed, built, their types and how they are integrated with different web services for best assignment help.
Week 1: Databases
The focus of this week was mainly on Database Systems. Out of all the topics discussed this week I mainly learned that a database is a structured data or information collection procedure which is typically stored digitally in a computing device. A database management system (DBMS) mainly consists of a database and its handling in particular. Through this learning process, I have analysed that DBMS are mainly the link between a user and a database as it allows a user to share and receive data, allows the user to view their data in an integrated manner, and provides efficient management of data. Though DBMS provides us with a lot of enhancements, it brings along elevated costs, complex management, and dependency on the vendors and much more. This week, I have learned that Databases hold a large amount of data for users and allow them to View and manage the data. I used to wonder how the data that we enter or see is being managed or stored. It is clear to me that DBMS manages everything related to data. I still need to learn how the data manipulation (Yunus et al. 2017, pp.192-194.) is being done and stored. In future, this would help me in understanding the basic concept of the data that is being managed by the businesses.
Week 2: Data Models
This week we have mainly targeted the Data models. Data models define how well the schematic representation of a database is portrayed. Models are fundamental components of a DBMS for adding abstractions. These models describe ways data is related to each other and how it is managed and kept within the system. The below analysis can be made that to manage data as a resource, data modelling methods and approaches are used to represent information in a standard, stable, and precinct manner. The data modelling (Liyanage 2017, pp. 432-435) mainly deals with the building blocks like Entity, Relationships and Constraints. I have learnt through data models that data modelling may be done during many sorts of projects and at various stages of a project. Data models are iterative; there is no such thing as a definitive data model for all corporations or applications. It follows no free lunch theorem. The data models should preferably be saved in a repository so that they may be accessed, extended, and updated over time.
Week 3: Relational Database Model
This week’s main focus is on Relational Database. A relational database is an organized collection of data components connected by established connections. These objects are generally stored as a series of tables. In a database, a column maintains the actual value of an attribute and the rows represent a collection of links. A primary key is allocated to each item in a database, and entries from different tables can be connected via foreign keys. According to my analysis, when working with big, complicated datasets, relational databases are ideal. A relational database is a form of database that stores and makes data points that are connected available. Every row in a relational database is a transaction with a unique identifier known as the key. The table's columns include data attributes, and each record typically contains a value for each feature, making it simple to construct links between data points. This has taught me that a relational database (Astrova 2009, pp. 415-424) is a subtype of a database. It employs a framework that enables us to identify and access data in the database. I've also learned about relational databases, and how data in a relational database is structured into tables. Relational databases, as I have understood, eliminate data redundancy. To me, relational databases have been a completely new and interesting concept. I will incorporate it to enhance my work.
Week 4: ER Modelling
This week’s focus is on ER Modelling. Modelling of ER (or Entity-Relationship Modelling) are sometimes referred to as ERDs or ER Models. The ER model is a traditional and completely normalised relational schema that is utilised in many OLTP systems. Typically, these applications do query tiny units of information at a time, such as a customer record, an order record, or a shipping record. I have mainly focused on and found that Entity Relationship Modelling (ER Modelling) (Weilbach et al. 2021, pp. 228-238) is a graphical method which helps in representing real-world objects. It also resolves the difficulties in developing a database is that designers, developers, and end users all have different perspectives on data and its application. A combination of attributes characterizes an entity and values can be assigned to entity properties. During this process, I discovered that one of the pitfalls while developing an efficient database comes from the fact that designers, developers, and end-users all have different visualisations and necessities of data (Schulz et al. 2020, pp.150-169). Developers will find it simple to use, manage, and maintain. I have learned a new way to generalize database entity structure. I will surely incorporate this technique to make thing more professional in future.
Week 5: Advanced Data Modelling
This week we mainly discussed Advanced Data Modelling. It refers to data patterns that enable users to rapidly discover and effectively evaluate complicated cross-enterprise data-focused business rules and validate complex requirements. Techniques for generalisation and abstraction allow for flexible data structures that can adapt to quickly changing business norms and needs. I have analysed and suggested the five data model dimensions as the most important (Liyanage 2017, pp. 432-435).Clarity implies the ability of the Data Model to be comprehended by those who look at it. Flexibility means a model's capacity to adapt without having a significant influence on our code. Performance describes performance advantages solely based on how we represent the data. Productivity implies a model that is simple to work with without wasting a lot of time. Lastly, Traceability means information that is essential to the system as well as data that is valuable to our consumers. As a result, I've learned that the Data Model of each programme is its heart. In essence, it's all about data: data enters via the user's computer or from an external source, data is processed according to certain business rules, and data is eventually displayed to the user (or external apps) in some convenient manner. In future I would need this Data Model knowledge as every component of DBMS relies on data to make sense of the entire system.
Week 6: Normalisation
This week's focus is on Normalization. The act of structuring database tables in such a way that the outcomes of utilising the database are always clear and as intended is known as database Normalisation. It has the potential to duplicate data inside the database and frequently leads in the development of new tables. According to My Analysis, for many years, database normalisation has been an important element of the database developer's arsenal due to its capacity to minimise or decrease replication while increasing data integrity (Sahatqija et. al. 2018, pp. 0216-0221). The relational approach developed during a time when corporate records were primarily kept on paper. Other reasons have also contributed to the challenge to database normalization's supremacy. Hence, I have mainly learned that Normalization helps in reducing Data redundancy and for my future work, Normalization will play a very important role. Normalization is among the most significant features of Database Management Systems that I have studied about. If data is updated, removed, or entered, it does not affect database tables and helps to enhance the integrity and performance of relational tables. Some believe that normalisation will improve performance. It avoids data abnormalities. Hence I have mainly learned that Normalization helps in reducing Data redundancy and for my future work, Normalization will play a very important role.
Week 7: SQL
This week, we will be learning about SQL. For excellent purposes, database systems and SQL are immensely prevalent in the industry. SQL, as a language, enables you to query these databases effectively. SQL is a declaratory language of programming, which implies that when we write SQL code, we understand what it is doing but not how it works. In Analysis, though SQL is often used by software programmers, it is also popular among data analysts for several reasons (Taipalus 2019, pp.160-166). It's simple to grasp and learn from a semantic standpoint, analysts do not have to copy data into other programs since they can access enormous volumes of data immediately where it is kept and when compared to spreadsheet technologies, SQL data analysis is simple to audit and reproduce. I didn't believe SQL would be beneficial for my day-to-day job as a graduate student researching computational cognitive neuroscience when I initially learned about it. I realised that because SQL is so widely used in the industry, I would also have to study it, but I had no intention of using SQL as a student. After thinking about how SQL could be utilized in my profession a little more, I discovered that attempting to create and handle relational databases may be quite valuable in my job.
Week 8: More SQL
SQL is a strong language because it operates entirely behind the scenes, allowing it to query databases with extraordinary performance. Because it is a sequence of instructions, if one is acquainted with imperative programming languages (for example, Python), he/ she will consider it quite straightforward to learn. Again, with SQL, organisations of people committed to understanding how and whento effectively search databases have gone through the process for us and developed our techniques to query databases. With SQL, we simply tell the machine whatever we want to be accomplished (Astrova 2009, pp. 415-424). Analyzing this week’s learnings, SQL mainly focuses on three areas. Data Definition Language(DDL) encompasses starting a Database Model, Creating a Table, Identifying Database Schema and Defining data Types.Data Manipulation Language (DML) involves tasks to insert Rows to a table, Delete Rows From table, Update data in table, Select(View) data from table, Rollback changes on a table, Commit(save) data from a table (Taipalus 2019, pp.160-166).Procedural language extensions to SQL(PL/SQL) create Procedures and batch processes to handle bulk query statements in the form of Code. Hence, this week I learned about SQL and how it is implemented. I have also learned about DDL, DML and PL/SQL and their importance in SQL and DBMS.
Week 9: Database Design
Focus of this week has been Database Design. Database design is vital for developing scalable, elevated applications. Everything else is simply a minor detail. If a database is well-designed, pieces of relevant material are immediately filed and details may be extracted as needed. There is endless diversity under that simple notion. Small actions made early on have a large cumulative influence. After Analysis, there are few factors to consider, and some of the most important (at least in the beginning) for me is to question what is the 'appearance' of the data that can be retained? How is it divided into logical entities, and how many of those entities are expected to exist throughout time? How will the information be used? Is it primarily transaction (OLTP) or primarily used to generate analytical views (OLAP)?Is there any redundancy that may (fairly) be avoided, or anything that should be considered to avoid this in the future? Are there any potentially huge or complicated links (Santosa et al. 2020, p. 012179) that may need particular consideration? I've discovered that the generic aim of database design is to create logical and physical modelling techniques for the suggested database system. To explain, the logical model is largely focused on data needs, and judgments whereas the physical database modelling approach involves a conversion of the database's logical design model by maintaining control over physical media through the use of hardware resources and software systems such as DBMS. I would really be using database design as a key learning for my future.
Week 10: Transaction and Concurrency
This week’s focus is on transactions and concurrency, Database concepts such as transactions and concurrency management techniques are frequently encountered in real-world scenarios (Yu et al. 2018, pp.192-194). Concurrency control is the management of many transactions that are running at the same time. A transaction is a set of activities, generally read and write operations, which is carried out from beginning to end to access and update multiple data elements. In analysis, concurrency control isolates each transaction while it is completed, allowing data to stay consistent long after the transaction has ended, which is very important in multi-user systems. Concurrency control is essential for preventing this. A good transaction has the ACID (Atomicity, Consistency, Isolation, Durability) properties. After being exposed to SQL databases, I got curious about the fundamental ideas that describe how databases work, which prompted me to research transactions and concurrency control. Before starting new transactions on the same object, one transaction should finish its cycle. However, there are drawbacks to this method, such as poor resource use and general inefficiency. This is going to help me while implementing transactions and concurrency in my future work.
Week 11: Database and Web
Today’s topic is on Databases and Web. An intermediate application server or gateway in between Web application and the DBMS is necessary for a Web server to obtain information from a database (DBMS). CGI is the abbreviation for the most widely used Web server interface. A Web server gets a URL, corresponds to a CGI resource, launches a CGI programme, connects to the DBMS, searches the database, and produces the result to the Web server. I have analysed today's learning and found out that web database apps can be free or cost money, generally in the form of monthly subscriptions. Almost any device may access the information. Web database programmes are typically accompanied by their technical support team (Zhao 2022, pp. 1053-1057). They enable users to update information, so all we need to do is design basic web forms. Databases are a commonly utilised technology in the corporate sector, and their importance, attractiveness, and profitability have already expanded. I feel that connecting middleware or the user interface to the application's back-end database still needs a lot of research. There are certain technologies available that connect the user interface to the database at the backend. Some systems consist primarily of a front-end integrated with several levels of middleware and database back-ends.
Conclusion
In Conclusion, I have learned that DBMS mainly manages the Data to/From a user. Data management becomes increasingly complicated as applications become more sophisticated. File-based solutions are inextricably linked to the initial implementation specifications and are exceedingly difficult to redefine and update. It is useful for any coder since practically every application will have to persist its data to a database at some time. With the help of other features like Normalization, Data Modelling ER Modelling etc. we can easily enhance the performance of DBMS by reducing Data redundancy, Scalability and flexibility of the managed data making it more reliable and efficient to use. In this entire learning process, I have learned how data management is done and how we can store and manipulate data without any complexity.
References
.png)
Assignment
COIT20261 Network Routing and Switching Term Assignment Sample
Using this information, answer Question 1 and Question 2. Show your calculations for all sub-questions.
Question 1 – Information about the block
a) How many addresses are available in the block allocated to the company, including all special addresses?
b) What is the network address of the block?
c) What is the direct broadcast address of the block?
Question 2– Allocating subnets from the block
Create five contiguous subnets from the given block beginning with the first address of the block, as follows:
i. The first subnet with 1024 addresses
ii. A second subnet with 512 addresses
iii. A third subnet with 256 addresses
iv. Two (2) subnets with 126 addresses each
For each subnet, show its prefix in CIDR format, its subnet address, and its direct broadcast address. Organize your data clearly in a table.
Question 3 – Network Tools (Windows)
Often the best way to gain an initial familiarity with network tools is to simply use them at a basic level, exploring and looking up information as you go. Some common tools you can explore include Wireshark, ipconfig, tracert, netstat, ping and arp. All but Wireshark are included in Windows, Wireshark is free to download and install. Explore these tools by researching online and trying them out yourself on your computer, then answer the following questions, using your own words. Paste screenshots of your tryouts (not downloaded/copied from the Internet!) of each tool you have chosen to answer the questions below.
a) Assume that you want to use a command-line network tool to check if you have internet connection from your computer. From your desktop what command (tool) could you try first to find out if your internet connection is functioning OK or not?
Explain the tool and its output in determining your internet connectivity status.
b) You want to find out what IPv6 address your PC is currently configured with. What command could you use to discover this? What other information could you discover from using that command? Explain your answer.
c) Assume that you want to know which TCP ports are currently open in your computer. This information is quite useful for assignment help in checking if there are malicious services running on your system that have been introduced via malware. Which command would you use to discover this information? What other information could you discover from using that command? Explain your answer.
Question 4 -- TCP
Study a diagram of a TCP segment header (for example, Figure 9.23 in your textbook), paying special attention to the header fields, then list each field (field name) along with the value in decimal that would be in that field as per the information provided below. You must briefly explain your answer for each field.
• The segment is from an Internet Relay Chat (IRC) client to an Internet Relay Chat server
• A port number of 49,600 was assigned on the client side
• There were 20 bytes of options
• The server will be instructed not to send more than 500 bytes at any one time
• The previous segment from the server had an acknowledgement number of 12,400 and a sequence number of 8,300
• The TCP checksum was calculated to equal binary zero
• The control flag fields indicate states of: not urgent; not first (sync request) or final (termination request) segment; no bypass of buffer queues required; and not a RESET.
Solution
A) 2048 addresses are available in the block allocated to the company, including all special addresses. These special addresses are network and broadcast addresses. Given the IP address is 140.66.36.120/21 it shows that the first 21 bits of this address are reserved for the network address. Out of a total of 32 bits, (32-21)11 bits are left. So, 2^11 = 2048.
B) Network address = 140.66.32.0
Given IP address = 140.66.36.120/21
Network bits are 21
Binary format = 10001100. 01000010. 00100100. 01111000
Where the network bits are first 21 bits 10001100. 01000010. 00100
Network address = 10001100. 01000010. 00100000. 00000000
In decimal = 140.66.32.0
C) Direct broadcast address of the block
Given IP address = 140.66.36.120/21
The binary form of the given IP = 10001100. 01000010. 00100100. 01111000
In the direct broadcast address of any address block, network bits are all 1 and host bits are all 0.
Direct broadcast address = 11111111.11111111.11111000.00000000
In decimal = 255.255.248.0
2)
Question 2 – Allocating subnets from the block
Organise and write your answer neatly in a table and show calculations
.png)
The given IP address here is 140.66.36.120/21 which shows that 21 bits are used for the network part and the remaining bits 32-21=11 bits are used for the subnet and host part in the network.
After applying an AND operation with a subnet mask which is 255.255.252.0, the result generated is the address of the block is 140.66.36.0/23.
These 9 bits can be used to calculate the host - 2 11 = 2048.
By using VLSM (variable length subnet masking), each subnet will be defined with a different requirement (1024+512+256+128+128=2048). The CIDR routing can be done through 2 11=2048 bits, where 1024 bits are the most significant 0 and the remaining 1024 bits are the most significant bit 1.
.png)
Figure 1 Diagram to show CIDR and subnetting
First subnet - The 140.66.0010 0100. 0000 0000
Hence its subnet address becomes
140.66.36.0 and as we can see that the subnet bit will remain the same in all host parts hence its prefix is 22 (the first 22 bits are common in all hosts)
For broadcast address - all 1’s in the host part over here host bits are the last 8 bits hence
It converts to 140.66.0010 0100. 1111 1111
Which gives 140.66.36.255/24
So, the subnet mask for 1024 addresses subnet = 255.255.252.0
Second Subnet - Now as we can see from the figure the 2nd subnet needs a 512 host for that many addresses, we need 9 bits for a host which will leave 2 it for the subnet, for subnet identification it uses 10 bits
Hence,
140.66.0010 0101. 0000 0000 which gives
140.66.37.0/23 (prefix 23 because the first 23 bits will remain the same in all host parts)
For broadcast address put 1 in all host part
140.66.0010 0101. 0111 1111
Which gives 140.66.37.127/23
So, the subnet mask for 512 addresses subnet = 255.255.254.0
The third subnet - Now the third subnet needs address 256 which will require 8 bits for the host part and that will leave 3 bits for the subnet, for its subnet we will use bit 110
140.66.0010 0101. 1000 0000 which gives
140.66.37.128/26 (prefix 24 because the first 24 bits will remain the same in all host parts)
For broadcast address put 1 in all host part
140.66.0010 0101. 1011 1111
Which gives 140.66.37.191/24
So, the subnet mask for 256 addresses subnet = 255.255.255.0
The fourth subnet - Now the fourth subnet needs address 128 which will require 7 bits for the host part and that will leave 4 bits for the subnet, for its subnet we will use bit 1110
140.66.0010 0101. 1100 0000 which gives
140.66.37.192/25 (prefix 25 because the first 25 bits will remain the same in all host parts)
For broadcast address put 1 in all host part
140.66.0010 0101. 1101 1111 which gives 140.66.37.223/25
So, the subnet mask for 128 addresses subnet = 255.255.255.218
3)
Question 3 – Network tools - Windows (5 marks)
The command tool ping will be used. A ping is a tool for checking end-to-end connectivity between two endpoints and verifying internet connectivity.
Type “cmd” to bring up the Command Prompt.
Open the Command Prompt.
Type the “ping” command.
Type the IP address to ping.
Review the results displayed
Another tool that can be used here is ‘netstat -a’ to check active connections.
.png)
Figure 2 Result of ping command that shows successful pinging means an internet connection is active
The command to get the IPV6 address of the PC is "ipconfig /all"
This command is used to show IPv4 and IPv6 addresses with subnet masks and addresses. It can also be used to show DHCP and DNS settings. It also displays the current network that can be TCP/IP without using any kind of parameters.
.png)
Figure 3 Result of ipconfig/all command
Other information includes the drivers like media state, connection type of DNS, hostname, physical address, and status of DHCP enabled or not.
Netstat command is used to know which TCP ports are currently open in the computer.
.png)
Figure 4 Output of netstat -q command
.png)
Figure 5 Output of netstat -s command
Other than these, different information can be collected by using this command like active ports, current connection, segments received, send and retransmit, and failed attempt in connection.
4)
Question 4 – TCP (5 marks)
.png)
The first Row holds the source port address and Destination port Address which is 16 bits
The second Row covers the Sequence Number which is 16 bits
The third row comprises the Acknowledgement Number which is 16 bits
The fourth Row encompasses Header Length (4 bits) and (6 bits) reserved bits with 6 functions
Six Unique bits for six functions: They are
1. First One - URG - When this is 1 means - it is urgent and When this is 0 means - the segment is not urgent
2. Second One - ACK - Whether the segment contains valid Acknowledgement or not
3. Third One - PSH - Which means the request for Push
4. Fourth One - RST Which is for resetting the segment
5. Fifth One - SYN - Synchronize the segment with the following segments.
6. The Sixth One - FIN - Is for Terminating the Connection.
Fourth Row comprehends the window size that includes segment Length which is used to carry Data
Fifth Row consist of
Checksum – It is used to check the error occurrence in the segment
Urgent Pointer - This is for telling that the segment is very urgent. So, the TCP will give priority to this segment.
The sixth Row encompasses residual information of the segment and data will be added to this place.
- The segment from Internet Relay Chat client to Internet Relay Chat server is used for chat communication over the internet through different channels and access to the servers.
- A port number of 49,600 was assigned on the client side which is used for TCP/UDP connection. The Transmission Control Protocol is used for connection-oriented infrastructure and establishing a connection between the client and server side, and exchanging data.
- There were 20 bytes of options, then, the maximum header length will be 20B+60B = 80 B and the minimum will be 20B+20B=40B.
- The server will be instructed not to send more than 500 bytes at any one time which is more than the receiving speed. In this case, if the packet is too large from the server end, then the receiver client does not accept it. This packet will be divided into multiple segments and then sent.
- The previous segment from the server had an acknowledgment number of 12,400 and a sequence number of 8,300 where 8300 is the streaming rate of data from sending and receiving TCP whereas 12400 is the next sequence number which is the receiver for the destination node.
- The TCP checksum was calculated to equal binary zero which can be calculated by the sender and it represents that an error occurred during the transmission process.
- The control flag fields indicate states of
- not urgent – URG=0
- not first (sync request) or final (termination request) segment – ACK=0
- no bypass of buffer queues required – SYN=0
- not a RESET – RST=0
Assignment
COIT20246 Networking and Cyber Security Assignment Sample
Task 1
Part 1
Read the Marr (2022) resource from Forbes:
https://www.forbes.com/sites/bernardmarr/2022/01/07/the-5-biggest-virtual-augmented-and-mixed-reality-trends-in-2022/?sh=7483c5ae4542
Write an interesting, engaging, and informative summary of the resource. You must use your own words and you should highlight aspects of the resource you think are particularly interesting. It is important that you simplify it into a common, easily understood language. You MUST NOT paraphrase the resource or any sentences or ANY parts of the resource. You MUST NOT quote from the resource (except for key metrics if relevant). Your summary MUST NOT exceed 500 words. You will not be required to use in-text citations as you are only summarizing a single prescribed resource. As such, it is not appropriate to cite any other resources.
Marr, B 2022, The 5 Biggest Virtual, Augmented and Mixed Reality Trends In 2022, Forbes, viewed 10/1/2022, https://www.forbes.com/sites/bernardmarr/2022/01/07/the-5-biggest-virtual-augmented-and- mixed-reality-trends-in-2022/?sh=7483c5ae4542
Part 2
1. Find an Internet (online) resource that provides additional information and/or a different perspective on the central theme of the resource you summarised in Part
1. The important thing is that the resource contains different information. You should be looking for a resource that contain substantial additional information that strongly relates to the resource in Part 1. The resource must be freely available online or via the CQU library. You must provide a working URL - If the URL you provide cannot be accessed by your marker, you will receive zero for this entire part (0/4). You must also provide a full Harvard reference to the resource. This includes a URL and access date.
2. Like you did in Part 1, summarise the resource, in your own words. The summary should focus on highlighting how the resource you selected expands upon and adds to the original prescribed resource. It is important that you use simple, non-technical language that is interesting, engaging and informative. You MUST NOT paraphrase the resource or any sentences or ANY parts of the resource. You MUST NOT quote from the resource (except for key metrics if relevant). Your summary MUST NOT exceed 500 words. You will not be required to use in-text citations as you are only summarising a single prescribed resource. As such, it is not appropriate to cite any other resources.
If your summary does not relate to the URL/reference you provide (i.e. you have used information from a different source), you will receive zero. You should AVOID using academic resources such as journal papers, conference papers and book chapters as these are normally very difficult to summarise in less than 500 words. Instead, try looking for online news articles, blog posts and technical How-Tos.
Part 3
Reflect on the concepts and topics discussed in the prescribed resource and the resource you found. Your task is to summarise how you think they could potentially impact on YOUR future. The “future” can range from near (a few months, a year) to far (several years, decades). Summarise these in a response of no more than 500 words, ensuring that you develop and justify arguments for the impacts that you nominate. You will not be required to use in-text citations, as such, it is not appropriate to cite any resources. Once again, use simple, easy to understand language. DO NOT re-summarise Parts 1 & 2 – your reflection must be about the impacts on YOU and YOUR future.
Task 2
Part 1
Read the MacCarthy & Propp (2021) resource from TechTank: https://www.brookings.edu/blog/techtank/2021/05/04/machines-learn-that-brussels-writes-the-rules-the-eus- new-ai-regulation/
Write an interesting, engaging and informative summary of resource. You must use your own words and you should highlight aspects of the resource you think are particularly interesting. It is important that you simplify it into common, easily understood language. You MUST NOT paraphrase the resource or any sentences or ANY parts of the resource. You MUST NOT quote from the resource (except for key metrics if relevant). Your summary MUST NOT exceed 500 words. You will not be required to use in-text citations as you are only summarising a single prescribed resource. As such, it is not appropriate to cite any other resources. MacCarthy, M & Propp, K 2021, Machines learn that Brussels writes the rules: The EU’s new AI regulation, TechTank, viewed 10/1/2022, https://www.brookings.edu/blog/techtank/2021/05/04/machines-learn-that- brussels-writes-the-rules-the-eus-new-ai-regulation/
Part 2
1. Find an Internet (online) resource that provides additional information and/or a different perspective on the central theme of the resource you summarised in Part
1. The important thing is that the resource contains different information. You should be looking for a resource that contain substantial additional information that strongly relates to the resource in Part 1. The resource must be freely available online or via the CQU library. You must provide a working URL - If the URL you provide cannot be accessed by your marker, you will receive zero for this entire part (0/4). You must also provide a full Harvard reference to the resource. This includes a URL and access date.
2. Like you did in Part 1, summarise the resource, in your own words. The summary should focus on highlighting how the resource you selected expands upon and adds to the original prescribed resource. It is important that you use simple, non-technical language that is interesting, engaging and informative. You MUST NOT paraphrase the resource or any sentences or ANY parts of the resource. You MUST NOT quote from the resource (except for key metrics if relevant). Your summary MUST NOT exceed 500 words.
You will not be required to use in-text citations as you are only summarising a single prescribed resource. As such, it is not appropriate to cite any other resources. If your summary does not relate to the URL/reference you provide (i.e. you have used information from a different source), you will receive zero. You should AVOID using academic resources such as journal papers, conference papers and book chapters as these are normally very difficult to summarise in less than 500 words. Instead, try looking for online news articles, blog posts and technical How-Tos.
Part 3
Reflect on the concepts and topics discussed in the prescribed resource and the resource you found. Your task is to summarise how you think they could potentially impact on YOUR future. The “future” can range from near (a few months, a year) to far (several years, decades). Summarise these in a response of no more than 500 words, ensuring that you develop and justify arguments for the impacts that you nominate. You will not be required to use in-text citations, as such, it is not appropriate to cite any resources. Once again, use simple, easy to understand language. DO NOT re-summarise Parts 1 & 2 – your reflection must be about the impacts on YOU and YOUR future.
Solution
Task 1
Part 1
The technology is moving around. With the fast pace change in the technology, many industries are witnessing some new trends in terms of AR, VR and Mixed reality. The time is now focusing on XR or a new trend settler that may changed the entire industry. The tech has renewed everything like gaming experience, or at the workplace so that people could think out of the box. This article has defined some of the key trends in 2022 that go beyond the expectation and also reshaped the life of every individual.
XR & Metaverse: The world will soon witness a new aspect through the technology. Metaverse a place where everything will be drafted as 3D modelling, avatar and gamification. These three are the core concepts & fit exceptionally well with the Virtual Reality Technology. The idea of metaverse is a mesh of different technologies to make a virtual world for all.
Advanced hardware and headsets: Hardware are a special and important component for any tech. Without hardware nothing is possible. It accesses the virtual reality and bring the most powerful time of the era. With the time, AR and 2 VR devices are getting lighter. One of a good example for it is California startup Mojo Vision that has demonstrated the potential of AR by making contact lens that share and transcript the information directly to the retina.
XR in retail: The most changes occur in the retail industry and it is going through the alteration everytime. There are plenty of opportunities are determined in retail industry with the application of XR. For brining the distinct shopping experience, VR is already used and provide advantage to the “brick & Mortar” system.
Although, AR technology is providing support in taking feedback and improving the system. Also, VR brings a platform where user can get new experience of shopping by putting their avatar and try some clothes, jewellery on them.
XR & 5G: Within the next few years, a new and revolutionary network will be launched around the world. 5G is already rolling out in the market and taking a mainstream proposition. Currently, some companies are working in a trial phase and provide exceptionally well speed that is 20 times more than the existing one. Moreover, a different experience is providing to the gaming as well through XR. It is not a costly element for the business and can easily set up without putting a lot of money of large infrastructure investment.
The use of technology in different businesses and processes for assignment help signify that sooner a major throwback will appear in the industries. XR is exploring its roots around every sector and provide pace to the companies to grow and maximise their operational ability. It can be also used in training and educational stream. It provides some assistance to the adult learning as after COVID, everyone shifts their paradigm of learning to the online platform. The XR technology is making things easy as visuals are more supportive than reading. It makes a learning a better place with the best idea.
Part 2
Artificial Intelligence and virtual reality are the core pillars of the future. A future is unpredictable and technology helps to predict it. Virtual reality will explore things in the next five years. The market growth is high which will benefit multiple businesses around the world. A market study shows that AR & VR market will reach 15 billion in the 2022 year. The annual growth rate (CAGR) will be 77% in 2023. AR and VR will be at the focal point of computerized change and the expenditure of various organizations and buyers will increment by 80%. The companies and buyers will prompt this development at $1.6 billion. The industries that are using the trend most by retail, manufacturing, healthcare etc. AR is supposed to overwhelm the VR market spending as soon as this year or relatively soon.Technology is an essential driver for this development will be the quick development in the reception of tablets, PCs, and cell phones, and the exorbitant grouping of significant tech players in AR and VR around the world.Presently, the equipment market drives the product market concerning income. Notwithstanding, the product market will observe a quicker development because of an expansion popular in the media and media outlets to address issues, for example, AR-based reproducing of games.The medical care and retail space of the economy will prompt the reception development of AR and VR. Between AR applications and VR applications, AR-based purchaser application has the biggest offer as per this report, more than the business, aviation and guard, venture, medical care, and others. The biggest interest in augmented reality applications is coming from business applications.Artificial Intelligence is growing and shaping the world. It makes and contributes to the success story of many companies.
A real-life experience is possible with the help of artificial intelligence and virtual reality. The future of trends involves VR headsets to check the travel locations, clothing, architecture of the home and many more. All such things are possible with the implementation of augmented reality Augmented reality are growing with the time. Augmented reality and virtual reality are sharp aspects that helps in choosing the right thing for a person. Now, everything is covered with it like clothing where an individual can try an outfit. Alongside, some more and interesting benefits derive with the use of AR and VR are:• Make your dream interior of the home. The interior designing is possible with the VR headsets. The large corporations place headsets on an individual and they can check the preferred interior and get a real home feeling.• Playing games is an exciting thing because VR headsets brings an immense experience to the user. Users can now play any game like football, cricket or anything with real world appearance. These are many things could be done with the help of Artificial Intelligence like medical operations and healthcare services. With the fast pacing world, combination of augmented reality and virtual reality would bring diversified benefits.
Harvard Reference: Future of Virtual Reality – Market Trends And Challenges, 2022. [Online] Software testing help. Available at: https://www.softwaretestinghelp.com/future-of- virtual-reality/. [Accessed on: 26th May 2022]
Part 3-
The impact of technology on our everyday life is most. It makes everything easy as we don’t need to do things manually now. We have different software that could help in doing things early and frequent. The use of technology signifies some important aspect for me and my future. It draws a positive impact on my life like improvement in communication, making more justified decisions, search things on tip and many more.
The first impact on my is predicted in terms of connectivity. The technology has connected us with our closed ones through video conferencing. After COVID, many people have put heavy investment on it and make many video call apps with distinct features. In near future, AR, VR and XR makes things more revolutionary as they might bring the closed ones so close to you in every aspect like it might be possible that we can sense them or make a look alike of them to get a sense of closeness with them. Such things are might be possible in the future.
Another aspect for me is reshaping of future experience. The technology has supported me to even try the new outfit online. It has helped in reshaping my entire shopping experience into a legitimate one. Online apps are now providing a feature where we can just try the outfit on our avatar and check that it suits the personality or not. Moreover, in future, we don’t even have any idea how it will bring more changes and make our shopping experience a unique one.
Although, I have heard a lot about the metaverse, a virtual environment place. Many people are putting their efforts to understand the terminology. Moreover, some people have already purchased land in metaverse and doing so many things. The days are not so far when we can see pregnancy and babies will be do through metaverse. The revolution of technology has put and made things so interesting. With the time, we can see many changes done through Artificial Intelligence, it makes our life easy and simple. Different technologies are providing by it that support me and others to do simple tasks. Like if we want to call someone, we can use voice assistant and make a call. Though, life is simple after the use of technology. We find these things interesting but somehow it will impact our future. We all went lazy and might be into the depression due to minimum friends, least outings. All we will get in front of us with this rapid pace and movement of the technology. Hence, it is important for us to understand the long term impact of technology and make some smart decisions so that it would not control our life completely but just can be used it as to ease it down.
Task 2
Part 1
The decision propose by the European union on 21 April was not appropriate from the future world perspective. Banning AI is not a good idea and it leave the technology alone. The certain reasons that become the core context behind the ban are:
- Data and data governance
- Documentation and record keeping
- Human oversight
- Accuracy and security
- Transparency
All the stated points should be signified by the users when they prefer high-risk AI system. It is a major innovation & many scholars believe that it helps in postmarket monitoring system. It will help in detecting the problem and also suggest some effective ways to mitigate it. With these innovation and sound based-risk structure, the regulations also unfold some interesting gaps and completely omitted them. The BigTech is not touched yet.
The article states that regulation is highly focused on provider and covered the users. The developers who are working on AI system have only two options: Sale it to the market or use it for own welfare or for the business. The tech scope is not defined properly because it only covers the EU providers and completely forget and not consider the location of the provider but also the system users who lives in the EU. The prohibition is limited to the AI system that can cause “physical or psychological” harm or promote vulnerability to the specific group people. The prohibition is stern at some places but focused on the restriction of the dark pattern use. These are certain groups that influence or put pressure on the users to take decision against their will.
The regulation is somehow working for the welfare as well because it supported the use of remote biometric identification system while looking for crime victims, missing children, impose specific threat such as terror attack, prosecute serious criminal activity, giving prior judgment. This entire regulation makes the entire team of EU members satisfy as they somehow tried to protect internal security and terrorism. While framing the regulations, some points and elements have been completely omitted by the government. The first aspect is showing the concern about algorithm bias but the text was thin. The regulation also signifies disparate impact assessment & the data governance provision support providers to use the data concerning properties such as race, gender and ethnicity to get assurance about bias monitoring, detection and correction.
Part 2
Artificial Intelligence is a new normal for the world. Many companies are using this tech to bring revolution to the mainstream and work to get a competitive edge and advantage. The AI is a new normal as it helps in resolving queries as early as possible. Chatbot, CRM and analytics everything require AI. Artificial Intelligence keeps the business ahead. Many innovation and revolutions are brining by the AI that support business in management of distinct operations like chatbot. It also provide varieties of services like CRM, analytics, reporting etc. the AI is code driven framework that spread in different parts of the world as companies are heavily relied on the data and availability. With the hacking and security of data management, AI is important to spread and helps in handling every sort of situation.
Artificial intelligence will contribute in human task management and promote adequacy in operations. It maximise the capability of an organisation and support to get the desired outcome. It helps in making things simple and support various forms of activities that are beyond human expectations like navigation, learning and exploring, visual presentation and analytics, language interpretation. A good framework is helpful in making vehicles smart, support utilities, and support business to save cash, time and aid in future by modifying the world. The system is also active in health and social care as well. Many medical service providers are using AI to diagnose and treat patients and assist senior residents to get complete information and provide better life. The artificial intelligence has added a general wellbeing program as huge information is not stored in the database. It helps in make the society about new disease, it’s diagnose that support an individual as well as the entire community. The AI would more changes soon in the schooling system as well and make an effective learning environment for the students.Artificial intelligence has contributed a significant aspect on the companies and their operations. The growth and operations of different industries are highly depend on the AI and the transforming technology. Retail industry, healthcare sector, automotive industry and many others are using AI to make their operations effective. Machines are going on another level and achieving remarkable milestones. The artificial intelligence is supporting every industry around the world like medical, legal, designing and architecture, music composition. The machines are now become highly advanced and perform every single task perform by a human. Sooner robots will do operations and provide medical medications. It brings extraordinary outcome and accelerate the growth of companies with time. There are many positive scenarios of the AI in the future context and considerations. • The machines can produce more as compared to the human. The production by robots is higher than the human beings. Thus, it will help in maximising the economic prosperity.• The labours are no longer an issue after the artificial intelligence.
Machines are more creative than humans and provide effective response. The labour market will become more flexible and appropriate as individual can make changes in the system to generate and gather more opportunities. • The robots will be used for the wars as well. On the other side, humans will be used only for performing labour intensive tasks. Using robots for wars is a major and beneficial output for the future. Artificial Intelligence and machine become an effective and most responsive part of our life. With it, many milestones can be accomplished in distinct industries.
Harvard Reference: Rainie, L. and Anderson, J., 2018. Artificial Intelligence and the Future of Humans. [Online] Pew Research Center. Available at: https://www.pewresearch.org/internet/2018/12/10/artificial-intelligence-and-the-future-of- humans/. [Accessed on: 26th May 2022].
Part 3
The use of AI is a beginning of the new era. With the time, many people are using AI just to make their life simple and easy. On the other hand, my perspective for using AI is to make the things fast moving and reduce the burden on my head. If the EU has putting law against its use is not a right thing. The Artificial Intelligence is a major backbone of the tech and innovation and it keeps the things alive.
Unlike banning it consider it as a human & provide similar rights to it. In my opinion, the technology is based on algorithm and codes and if someone tries to manipulate it we could then take some strict actions against it. But still the things are doing out of the will of the tech because it just a machine. On the other side, we can give it a right to file a case when someone manipulate it or make alterations into it. One major example is Sophia, Robot of Saudi Arabia have more than any other women in the country. The government has provided equal rights to it so that she could file a case against people. There are many countries that limit the freedom of speech, religious practices and other consider. I think it will be a big breakdown for the future because machine will run things, if we could give them an equal right. It somehow harm dignity of the human but would be great as people can do a lot of things with the tech. Using robots in the military can control a lot of damage of human life and we can put such military people on other tasks like managing borders but for fight we need to use robots only. It can control collateral damage. Using AI in crime investigation will be a great thing because it helps in checking fingerprints quickly or to find out some important evidence. Some people claim to give equal voting right as well but it seems inappropriate in today’s world. We should not give any voting right to machines. There should be some limitations set for the machines as well like we did for humans. Using of AI such as robots is a great thing and will benefit the future as well. There are some negative aspects but we should consider the positive one and need to give a little chance to machines.
Research
DATA4900 Innovation and Creativity in Business Analytics Assignment Sample
Assessment Description
- This assessment is to be done individually.
- Students are to write a 2,000-word report using on Complexity Science principles and AI in business and submit it as a Microsoft word file via the Turnitin portal at the end of week 9.
- You will receive marks for content, appropriate structure and referencing.
In this assessment, you will be writing an individual report that encourages you to be creative with business analytics, whilst also developing a response to brief containing a “wicked problem”, to be addressed using Complexity Science principles and Artificial Intelligence.
Assessment Instructions
This assessment is set in the year 2023. Assessment Title- Report: Complexity Science and AI. Imagine that you are an expert in complexity science and manage staff using artificial intelligence. Land in your area has become scarce, however the populations is ever growing. There’s a housing shortage and also evolving demand for many types of services, such as childcare centres, public parks, shops and recreation centres, and car parking. You have been asked to write a report on
1. how this issue can be viewed in terms of complexity science
2. how artificial intelligence can be used in urban planning, re-developing and design of facilities and infrastructure.
Your report should have
- an introduction (250 words)
- a section discussing urban planning and design in the context of complexity science (600 words)
- a section on the role of artificial intelligence in business (100)
- a section on how artificial intelligence is being used in urban planning and design (600 words)
- a section recommending how artificial intelligence can be used in conjunction with complexity science in the future for urban planning and design (250 words)
- a summary (200 words)
- At least ten references in Harvard format
Solution
Introduction
The world is rapidly changing with the increasing population and land scarcity. It is becoming a challenge for urban planners and developers to design and redevelop the infrastructure for the growing population. The traditional methods of urban planning are no longer sufficient to meet the growing demand for various services. In order to address this issue, complexity science and artificial intelligence (AI) are increasingly being used to design and develop urban infrastructure.
Complexity science is an interdisciplinary field of study that focuses on the analysis of complex systems, including social, ecological, and technological systems, and seeks to identify patterns, trends, and correlations among the different components of a system. By understanding these patterns, trends, and correlations, complexity science can help urban planners and developers to better understand the needs of the population and the environment and to plan and design urban infrastructure accordingly.
AI is an emerging technology that is being used in a variety of industries and fields, including urban planning and design. AI is a powerful tool that can be used to develop intelligent systems that can automate tasks and make decisions based on data. This can help urban planners and developers to identify the needs of the population and the environment and to develop urban infrastructure that meets these needs.
In this report, the use of complexity science and AI in urban planning and design will be discussed for assignment help. The report will also explore the role of AI in businesses. Further, recommendations will also be provided about how AI can be used in conjunction with complexity science in the future for urban planning and design.
Urban Planning and Design in the Context of Complexity Science
.png)
Figure 1 Urban Planning Life Cycle
(Source: Moreira 2020)
The global population is expected to exceed 8 billion by 2050, and rise to about 9.5 billion by 2100. It is projected that nearly 1.5 billion people will live in megacities by 2030, up from 500 million in 1990. As per the 2030 Population Reference Bureau, China and India will account for more than 50% of the global population growth and will continue to exert great influence on the global population and its urbanization patterns. Urbanization also brings with it concerns over infrastructure development and management. Urbanization-related issues such as housing, transportation, environmental pollution, congestion, and general urban congestion are affecting the quality of life, as well as causing social and economic distress. This becomes more acute in megacities with a population of more than 10 million and rapid growth, such as London, Shanghai, or Guangzhou.
Urban planning and design are often associated with a range of complex issues, such as the distribution of resources, the planning of natural resources and ecosystems, and the design of governance systems and institutions, and society. These problems require the application of a range of specialized knowledge in urban planning, such as biology, mathematics, economics, physics, and engineering. The complex factors and underlying processes that interact with each other to produce these factors require highly developed knowledge of complex systems, and the application of advanced mathematical methods, such as graph theory and complexity theory. As a result, planning and designing megacities involves a significant degree of complexity (Ai Ain't disruptive: Complexity Science is! 2019).
Complexity science is a study of complex systems and their behaviour, with the goal of understanding how different elements interact with each other and how these interactions can affect the overall functioning of a system (Artificial Intelligence and Smart Cities 2018). In the context of urban planning and design, complexity science can be used to model and understand the behaviour of different elements within a city, such as traffic patterns, population density, and the environment.
The concept of complexity science, or complex adaptive systems (CAS), is based on the idea that complex systems can be better understood by studying their smaller components, and understanding how they interact with each other. This type of science is particularly applicable to urban planning and design, as cities and towns are composed of many different components that must work together in order to create a functioning, livable environment.
Complexity science can be used to analyse the needs of the population and the environment and to create models that can be used to plan and design urban infrastructure. For example, complexity science can be used to analyse traffic patterns and identify areas of inefficiency in the existing urban environment. This can help to optimize traffic flow and reduce congestion. Complexity science can also be used to identify population density trends, as well as anticipate changes in population density over time. This can help urban planners to plan for the future population growth of a city (Relationality 2019).
Complexity science can also be used to identify patterns and trends in urban data, as well as understand the dynamics of urban systems (NERC Open Research 2019). For example, in order to create a livable city, planners must consider how different services, such as childcare centres, public parks, and shops, interact with each other and with the environment. If one service is poorly designed or sited, it can have a negative impact on the other services and the environment. Additionally, complexity science recognizes that urban planning and design is an ongoing process, as the needs of a city or town can change over time. In order to keep up with these changes, planners must be able to quickly adapt to new demands and find creative solutions.
The Role of Artificial Intelligence in Business
AI is a field of computer science that focuses on giving machines the ability to learn and make decisions (Sustainable smart cities 2017). AI has numerous applications in the business world, such as predicting customer behaviour, automating tasks, and optimising processes. AI can also be used to improve customer service, as machines can be programmed to respond to customer queries and provide recommendations. AI can also be used to analyse large amounts of data to generate insights and identify trends which can help in automating business processes such as customer segmentation, customer analytics, and marketing campaigns (Coe-Edp 2021). This can help businesses to develop more effective strategies for targeting customers and improving customer service.
How Artificial Intelligence is used in Urban Planning & Design Now
.png)
(Source: Sustainable smart cities 2017)
Artificial intelligence (AI) technologies are advancing rapidly, and smart city development is widely viewed as an area of technological convergence and innovation. AI-based systems can be used to analyse data, identify patterns, and make decisions quickly and accurately. This can help urban planners and developers to identify the needs of the population and the environment and to develop urban infrastructure that meets these needs.
AI has a number of potential applications in urban planning and design. AI can be used to simulate and optimize different aspects of urban planning, such as traffic patterns, population density, and the environment. AI can also be used to identify patterns in urban data, such as traffic flow, to create more efficient and effective urban designs. AI can also be used to develop predictive models of potential urban developments, and to identify areas of risk in urban development projects (Moreira 2020). In addition, AI can be used to automate urban analysis and modelling processes (AI in Urban Planning 2021). AI-based systems can be used to create detailed simulations of cities and analyze the impact of different interventions on the urban environment.
Artificial Intelligence is being used in various areas of urban planning, namely:
1. Green Land Planning
Green land planning is related to the management and protection of land resources for human use. In the study, the participants were asked to look at ways of making their city greener.
2. Traffic Management
Traffic management is basically planning ways that can help manage traffic congestion. These include things like identifying possible bottlenecks in the road network and other ways to make a better traffic plan for the future.
3. Sustainability Planning
Sustainability is something that looks at the role that humans can play in making a city sustainable in a sustainable way. The study involved looking at how artificial intelligence can be used in helping planners develop a sustainable city.
4. Economic Determinism
This refers to the idea that an economic system drives all the changes in society. The study looked at how artificial intelligence can be used in improving the economic development in a city.
5. City Planning
This refers to the planning of where cities should go and the planning of the future of cities. The study looked at artificial intelligence applied to the planning of cities and other urban areas.
6. Smart City Design
This is related to the idea that urban areas can be made more efficient and safer using a mix of human and artificial intelligence. One of the advantages of a smart city design is that there's a greater integration between human and artificial intelligence to make sure that their work is more efficient (Yigitcanlar et al. 2020).
.png)
Figure 3 Smart Wastebin
(Source: Mahendra 2022)
AI can also be used to optimize the urban environment. By using AI-based systems, urban planners and designers can develop algorithms that can identify areas of inefficiency in the existing urban environment and suggest ways to optimize it. For instance, It has been observed urban areas often produce a lot of waste, making it hard to manage it efficiently. Fortunately, AI-based tools are available to help. There are cameras that can recognize the type of trash that has been thrown on the ground. Additionally, some waste bins have sensors that can tell when they are almost full, allowing authorities to only come and empty them when needed, saving money in the process (Mahendra 2022). AI can also be used to create virtual models of urban environments in order to simulate and test different interventions, such as changes to traffic flows or the introduction of new infrastructure and services (Artificial Intelligence in smart cities and urban mobility 2021). This could help urban planners to identify the most efficient and effective solutions for urban problems.
Recommendations for the Future
The use of Artificial Intelligence (AI) and complexity science in urban planning and design is likely to become increasingly relevant in the near future. AI can be used to identify patterns, trends, and relationships in the complexity of urban systems, helping to create more efficient and effective solutions tailored to the needs of the city's residents
Complexity science is the study of complex systems that involve the interaction of multiple components, often in nonlinear ways. By understanding the complexity of urban systems, it is possible to develop better solutions for urban planning and design. AI can be used to identify patterns and relationships in the complexity of urban systems and help to develop solutions that are tailored to the needs of the city's residents.
For example, AI can be used to analyze the mobility patterns of citizens and identify areas where public transportation is needed. This could be used to create more efficient and effective transportation networks within cities. AI could also be used to analyze the existing urban environment and provide insights into how to improve it, such as by creating green spaces and providing access to parks, playgrounds, and other recreation areas. In addition, AI can be used to identify areas of potential risk and provide solutions to mitigate these risks.
By investing in the infrastructure and training necessary to make use of AI and complexity science, cities can ensure that their citizens benefit from the most efficient and effective urban planning solutions.
This report explored the use of complexity science and artificial intelligence (AI) in urban planning and design. It discussed how complexity science can be used to analyse the needs of the population and the environment and to create models that can be used to plan and design urban infrastructure. It also explored the role of AI in businesses and how it can be used to automate tasks, analyse data, and optimise processes. Additionally, the report discussed how AI can be used in urban planning and design, such as green land planning, traffic management, sustainability planning, economic determinism, city planning, and smart city design. Finally, the report provided recommendations for the future, such as investing in infrastructure and training, creating public-private partnerships, and establishing ethical frameworks and guidelines. By making use of the advances in AI and complexity science, cities can ensure that their citizens benefit from efficient and effective urban planning solutions.
In conclusion, complexity science and AI are powerful tools that can be used to inform urban planning and design. By leveraging these technologies, cities can become more efficient and sustainable, and ensure that their citizens have access to the services and infrastructure they need. Additionally, cities should invest in the necessary infrastructure and training to make use of AI and complexity science. By investing in these technologies and taking the necessary steps, cities can ensure that their citizens benefit from efficient and effective urban planning solutions.
References
.png)
Research
COIT20256 Data Structure and Algorithms Assignment Sample
Objectives
In this assignment you will develop an application which uses inheritance, polymorphism, interfaces and exception handling. This assignment must be implemented:
1. incrementally according to the phases specified in this documentation. If you do not submit a complete working and tested phase you may not be awarded marks.
2. according to the design given in these specifications. Make sure your assignment corresponds to the class diagram and description of the methods and classes given in this document. You must use the interface and inheritance relationships specified in this document. You must implement all the public methods shown. Do not change the signature for the methods shown in the class diagram. Do not introduce additional public methods unless you have discussed this with the unit coordinator - they should not be required. You may introduce your own private methods if you need them. Make sure your trace statements display the data according to the format shown in the example trace statements. This will be important for markers checking your work.
3. Using the versions of the software and development tools specified in the unit profile and on the unit website.
Phase 1
Description
In phase 1, you are to simulate customer groups of two people arriving every two time units for 20 time units. The only event types that will be processed in this initial phase are Arrival Events. There will be no limit to the number of customers in the shop in this phase. However, this phase for assignment help will require you to set up most of the framework needed to develop the rest of the simulation. At the end of the phase 1 simulation you are to display all the customer groups currently in the shop and all the customer groups that have ever arrived at the shop (this will be a history/log of customers that could be used for future analysis). Given that leave events will not be implemented in this phase, the customer groups in the shop will correspond to the customer groups in the log/history.
Phase 2
In phase 2 we will now have the groups get their coffee order after they arrive. This will be achieved by introducing a new Event type (an OrderEvent) to be scheduled and processed. To do this we have to:
1. Add a serveOrder() method to the ShopModel class.
This method is to print out a message to indicate the time that the group involved has been given their coffee (i.e. print out the following message:
“t = time: Order served for Group groupId”
where the words in italics and bold are to be the actual group id and time. The signature for the serveOrder () method is: public void serveOrder(int time, CustomerGroup g)
2. Add an OrderEvent class
The OrderEvent extends the abstract Event class and must implement its own process() method.
The OrderEvent’s process() method must use the shop model’s serveOrder() method to get a coffee order filled for the group (i.e. print out the message). (In a later phase the process model will also schedule the “LeaveEvent” for the group.)
The OrderEvent must also have an instance variable that is a reference to the customer group associated with the order so that it knows which group is being served their coffee.
This means the signature for the OrderEvent’s constructor will be: public OrderEvent(int time, CustomerGroup group)
3. Have the ArrivalEvent’s process() method schedule the new OrderEvent one time unit after the group arrives
4. What should be output by the program at this point? Run and test it.
Phase 3
In phase 3 we will have people leave after they have finished their coffee. To achieve this, we need to:
1. Implement a leave() method in the shop model, which is to:
print a message when a group leaves the shop as follows:
“t = time: Group groupId leaves”
where the words in italics and bold are to be the actual group id and time remove the group from the ArrayList and decrement the number of groups (numGroups) in the shop.
2. Introduce a LeaveEvent class. The LeaveEvent class must:
Extend the abstract Event class
Have a reference to the “customer group” that is about to leave
Implement its own process() method which is to invoke the shop model’s leave method.
3. Have the OrderEvent schedule a LeaveEvent for the group 10 time units after they receive their coffee.
4. What should be output by the program at this point? Run and test it.
Phase 4
Now there are restrictions on the number of customers allowed in the shop. This will correspond to the number of seats made available in the shop. *** For the purpose of testing and to allow the markers to check your output, make the number of seats in the shop 8.
Extend the ShopModel class as follows:
1. Add a ShopModel constructor that has one parameter that is to be passed the number of seats available in the shop when the ShopModel object is created.
2. Include an instance variable in the ShopModel class that records the number of seats available.
The number of seats available is to be passed into the ShopModel constructor. (The UML diagram in Fig 2 now includes this constructor.)
3. When customers arrive in the shop, if there are enough seats available for all the people in the group, then they can enter the shop and get coffee (i.e. schedule an OrderEvent) as normal.
4. If there are sufficient seats to seat all members of the group, print a message as follows:
“t = time : Group groupId (number in group) seated”
where the words in italics and bold are to be the actual group id and time.
In that case, if new customers are seated, the number of seats available in the shop should be decremented. If there are insufficient seats for the group, then these customers cannot enter the shop. In that case, print a message saying: “t = time : Group groupId leaves as there are insufficient seats for the group”
where the words in italics and bold are to be the actual group id and time.
Assume that if there are insufficient seats the group just “goes away” (i.e. does not get added to the ArrayList of Customer Groups in the shop) and are considered lost business. They should still be recorded in the log/history.
Keep track of how many customers are lost business during the simulation and print that information as part of the statistics at the end of the simulation. In both cases (seated or not seated), the process method should schedule the next arrival.
5. Don’t forget to increase the number of seats available when a customer group leaves the shop.
6. At the end of the simulation, print the following statistics:
How many customers were served (requires an instance variable to track this)
How many customers were lost business (requires an instance variable to track this)
Display the groups still in the shop at the end of the simulation
Display the log/history of customer groups that “arrived” in the simulation.
Phase 6
In a simulation you do not normally use the same values for arrival times, times to be served etc. As explained earlier, in practice these values are normally selected from an appropriate statistical distribution. To model this type of variability we are going to use a simple random number generator in a second version of your program. Copy your version 1 program to Assignment1V2. Now add a random number generator to your abstract Event class as follows:static Random generator = new Random(1);//use a seed of 1 Note that we have seeded the random number generator with 1. This is to ensure that we will always generate the same output each time we run the code. This will help you to test your code more easily and will also allow the markers to check your work for this version of the program.
Your concrete event classes must now use this random number generator to:
1. Determine how long after an arrival before the OrderEvent is to be scheduled (values to be between 1 and 5 time units).
2. Determine the number of people in a group (to be between 1 and 4 people in a group).
3. Determine how long after getting their coffee the group stayed in the shop, i.e. how long after the OrderEvent before the LeaveEvent is to be scheduled to occur (values to be between 5 and 12 time units).
Questions
Regardless of which phase you have completed, Include the answers to the following questions in your report.
Question 1: Why does the random number generator in phase 6 need to be static?
Question 2: What is the default access modifier for an instance variable if we don’t specify an access modifier and what does it mean in terms of what other classes can access the instance variable?
Question 3: How could you restrict the instance variables in Event to only the subclasses of Event?
Solution
Instructions
A description of what is required in each section is shown in italics. Please remove all the instructions from your final report.
Description of the Program and Phase Completed
Phase 1 has been completed
In this phase we have define the all classes given in the class diagram.
Phase 2 has been completed
Added serveOrder method to ShopModal class and defined ServeEvent so that customer can get coffee served by stipulated time interval.
Phase 3 has been completed
In this phase we have define leave method in to shop modal class and defined a new LeaveEvent class to track the customer group leaving time
Phase 4 has been completed
We have fixed the total number of seats available at the shop in the beginning so that after arriving of each customer group we can see whether the customer group will got seat or leave the coffee house with out placing order
Phase 5 has been completed
Define the working of statistics file so that simulator can writhe the details of program as per given in the format.
Phase 6 has been completed
Created the random class instance into event class so that the automatic random number will be generated and tested the program accordingly.
Testing
Testing of scheduling of events
.png)
Testing of group of people in each customer group
.png)
Sample Output
Simulation trace to the standard output:
.png)
Statistics written to the statistics.txt file
.png)
.png)
Bugs and Limitations
Bugs
“No known bugs”
Limitations
I don’t think any limitations
Additional Future Work
We can add multithreading to simulate the same project
Answers to Questions
Question 1
The event class can use directly because we are unable to create object of abstract class.
Question 2
The default access modifier of any reference variable of class is called default. That reference variable can be access by anywhere within the same package with the help of object.
Question 3
We can use private access modifier so that it can be used in subclass but not with the help of object in anywhere of the program.
Research
CSE2HUM Ethical Issue on Current Cyber Context Assignment Sample
In this assignment, you will be provided with two context briefs. You will be required to select one for your analysis and complete the tasks below (1 & 2). As much as possible, focus on the details provided in the brief. Where information is not provided but integral to your analysis, make reasonable assumptions (which should be clearly stated and explained). (Note: You must clearly specify the selected context brief in your report,
Risk Assessment Report
Objectives:
Identify and discuss at least three cyber security risks faced by the organization. Since the organizations are based in Australia, the discussion must identify;
1. Where these threats are most likely to originate (outside Australia and within)?
2. Who those threat actors might be?
3. What are the key drivers, or motivations behind those threats?
4. Do ideological, cultural, political, social, economic factors influence those motivations?
5. What kind of vulnerabilities they might exploit?
Please note as this is an important part: The course is “Human Factors in Cyber Security” , therefore you must relate the vulnerabilities to the concepts taught during week 3,4,5, and 6, including but not limited to; personality types, limitations of human cognition, types of learning – associative and non- associative, conditioning – operant and classical, Pierre Bourdieus theory of practice (capital; habitus; field; practice).
2. Cyber Security Awareness Plans
Objectives:
Once you have identified the risks in part one.
1. Describe detailed steps to counter those threats by designing a cyber security awareness plan.
2. The plan must contain a general cyber security awareness campaign for all the participants of the organization.
3. The plan must also identify awareness campaigns for specific groups of people with specific job roles (These are for people in the job roles that are either privy to important assets/data or manage key operations).
4. You must think and address the following aspects while designing the plan:
a. Tools, and mechanisms to ensure maximum impact?
b. Cultural, economic, social, ideological, or political factors which you think might impact the content and/or communications.
c. Can techniques such as personality type identification, conditioning (operant and classical), habitus, learning types (associative and non- associative), be used to deliver an effective plan?
d. Can ethnography be used for developing such plans?
Solution
Introduction
The following study will aim to identify three potential cyber security threats that might occur with the Australian-based hospital. A cyber security awareness plan will also be developed in order to address the identified threats.
Risk assessment report for assignment help -
Cyber security risks and origination of the risk
Malware attack: Attackers make use of different types of methods to input malware into a device and this is mainly done by social engineers (Gunduz and Das, 2020). In order to input malware into a device, the attacker might develop a link containing malware and as the operator of the device click on that link.
Denial-of-service: The main objective of a denial-of-service attack is mainly to overwhelm a target system’s resources and make its functions and operations stop and also deny access to the system to the user.
Password attacks: A hacker can obtain an individual's user credentials by monitoring the network connection, employing social engineering, guessing, or gaining access to a password database (Coventry and Branley, 2018). A hacker can 'predict' a password in a systematic or random manner.
The attack might originate within Australia and also outside Australia since most hackers do not require the actual system to hack it, they can also do it remotely.
Identification of threat actors
Lack of proper security: Cyber security risks often occur when there is a lack of security assurance (Happa, Glencross and Steed, 2019). People handling passwords and storing data in the hospital’s cloud system need to have the proper knowledge regarding how they can assure the security of the system and the files stored in the system. In the hospital, there are various patients who ask for passwords and one among them might have the skills to hack the system using the password.
Vulnerabilities in systems: Cybercriminals often hack systems that have a weak spot. It makes it easy for hackers to attack a system that has weak cyber security systems installed or when the cyber security system is out of date (Happa, Glencross and Steed, 2019). If the password of the operating system is weak, hackers can easily predict the password and attack the system. Hence, it is important to keep cyber security up to date.
Key motivations and drivers behind the threat
The hospital contains the data and information of many patients and hackers who want to hack the system might have a certain purpose in mind before hacking the system (King et al., 2018). Hacking the operating system of a hospital will provide a hacker with all the data regarding the patients and also the hacker will get access to raw data and information about the hospital. If the hacker has the motivation of leaking sensitive data regarding patients or the hospital, this might act as a key driver or motivator behind the attack.
Influencing factors in motivation
There is a huge cache that economic, political, social, ideologically and cultural factors might be one of the prime influencing factors behind the motivations. Hackers hacking the system might be culturally or ideologically influenced to do so. The influence of any political party or social group also might influence the hacker to attack the system (Nurse, 2018). Accessing data about the hospital and selling the data will also bring in some money which might be an economical factor behind the attack.
Potential vulnerabilities
The potential vulnerabilities referring to Bourdieu's theory of practice that might occur include the influence of habitus which indicates that individuals with their resources and nature react differently in different situations (Nurse, 2018). Bourdieu also talks about misrecognition as a potential vulnerability in this case.
Cyber security awareness plan
Modern society is much more technologically dependent than ever before, and numerous areas of our being, such as power, businesses, rule of law, security, and so on, are highly influenced by technology (Mashiane, Dlamini and Mahlangu, 2019). As a result, cyber security becomes critical for preventing the misuse of these sources of data and IT infrastructure.
The steps that will be included in the cyber security awareness plan of the hospital in order to address the threats that the organisation might face include:
- No employee of the hospital should click on any link before verifying its authenticity of the link.
- The password of the Wi-fi must be changed from time to time.
- The installed cyber security must be up-to-date (Zwilling et al., 2022).
- If any suspicious cyber activity is witnessed, it must be reported immediately.
- The networks used by the staff must be protected using well-developed cyber security since staff mainly input the data of patients.
- The desktop and iPads given to the doctors and nurses must be protected by strong passwords and the web activity must be checked from time to time.
- The cloud storage of the hospital also needs to be protected using well-developed cyber-security (Sabillon, 2018).
The behaviour modification theory can also be referred to for enhancing the knowledge of the employees of the hospital regarding cyber security. The behaviour modification theory will help in enhancing the behaviour and develop the actions of the employees and make them more aware regarding cuber security. If the entire workforce becomes more aware and alert regarding the importance of cyber security, the organisation will be able to achieve good outcomes with respect to cyber security.
The receptionists and other staff must have basic knowledge regarding cyber security so that they can identify and report any suspicious activity to the higher authority. The doctor and the nurses must keep their devices with them all the time in order to prevent the device from being stolen or used without consent (Hepfer and Powell, 2020). The staff involved with data entry must be well-aware of how to protect the data files so that the data can be prevented from being manipulated or stolen.
The tools and techniques that will be mostly included in this plan include the installation of antivirus software, firewall tools, penetration testing technique, packet sniffers and encryption tools. Conditioning, personality type identification, learning types and habitus techniques can also be used. Ethnography can be used to address economic, political, social, ideologically and cultural factors.
Conclusion
It can hence be concluded from the above study that the cyber security threats identified in the study might negatively affect the organisation and sensitive patient data and data of the hospital can be accessed by the hacker if there is an abuse of proper cyber security. The cyber security plan will be quite helpful in addressing the identified threats.
Reference list
.png)
Research
ITECH3001 Evaluating a System Assignment Sample
Assignment objectives
• Investigate the techniques for evaluating systems as described in the literature
• Design and conduct usability evaluation for a chosen system
• Analyse and interpret the data and results from the evaluation
• Report on the results and recommend for improvement of the evaluated system
Details of written components
Assignment
You will select one of the websites from the list of charities provided on Moodle. The assignment involves conducting a usability test on that website, interpreting the results and writing recommendations in the form of a report on any changes needed. Your report should be presented clearly enough so that it will be ready to be submitted to the charity.
Each of the charities listed have requested a usability evaluation of their website. The written component of the assignment must be based on your ACTUAL usability test on REAL users and should contain the following:
• A discussion, based on the literature, of the different approaches for assessing or testing usability with more detail on the use of usability testing for evaluating systems or websites.
• A brief description of the website selected for the usability evaluation. This should include the purpose of the website, the audience and the objectives of the organisation with respect to their website as determined by the charity.
• For the usability test you must:
o Describe how the usability testing was conducted, and rationale for the approach. You may use the usability instrument provided on Moodle or a similar version (but improved version). The description should include a justification of the number of users, selection of users, the instrument you used for your test (the survey questions), the task you designed for the test etc.
o Design one practical scenario and test its usability
• A critical discussion of the method (good or useful aspects, difficult or poor aspects).
• A page to summarize and list your recommendations for changes to the website with supporting evidence. Think about what you think key personnel in the charity will want to know about how well their website is performing.
Your report must be written for scanning rather than for reading. Use dot lists, numbered lists, tables and levelled headings to organize your ideas and content as demonstrated in this document.To support your arguments, use screenshots, graphs and actual data from your test and cite references across your document.
Solution
Introduction
Usability Test
It is the technique of analysing the use of the service in the market. The organization releases a few features in the market to gather information about the user experience and analysis. It is essential to test the service before launching it in the market. It also includes analysing the requirements of the consumers in terms of features and management systems (Barnum, 2020). Moreover, it is important to understand the effectiveness of the service in the market and how much it is user-friendly. The entire procedure includes an analysis of the features required to be developed in the system, the features that are used mostly, and the features that are not required. The testing relies on feedback analysis of the customer. It is a long-term process and after the completion of the process, the organization finally launches the features into the market. Is procedure followed in terms of an agile project management system that improves the organization in terms of development and improvement?
Benefits
The implementation process benefits the organization in several ways, they are as follows:
• Product Validity
In terms of a better understanding of the market analysis and demands, the organization is required to follow an agile project management system and its implementation procedures. It helps the organization to analyze the needs of features in the market by liberating a few features. The entire process supports the organization in understanding the problems, needs, and demands of the consumer regarding the service or product. As it follows an agile project management system, it prefers feedback analysis for better implementation of the system. The feedback from the consumers helps the organization better understand the requirements. The feedback analysis procedure is followed in every stage of the implementation procedure. A better understanding of the problems and requirements can be evaluated through the process. Moreover, it results in better organizational development.
• Meeting the demand
Meeting the demand is the main aim of the organization. Due to the feedback analysis system, the organization is capable to understand the demands of the consumer. Due to the purpose, the organization can improve the implementation process significantly. The organization can be able to meet the demand by understanding the requirements and problems in their service. Through the procedure, the organization analyzes the customers’ expectations regarding the service. After a complete analysis, the company finally launches the website without any errors. It results in the accuracy and appropriateness of the system launched.
• Trouble identification
The customer accessibility to the website must be smooth. The system must be developed with appropriate features and a loading system. It must be easily accessible in terms to check and analyze the user accessibility. The developing team within the organization should focus on the customer’s user interface. The system handling must not be complex and the website prefers multitasking such as purchasing and donating. In this case, observing is essential to identify the user story. If any issue is discovered by the following system, it must be revised and recovered immediately.
• Appropriate analysis
The internal design of the website attracts the customer in terms of the appropriate arrangement of the features updated into the system. The analysis is based on the user handling such as the features that the customer is using the most and the features the customer is not using. From this point of view, the user analyzes why the customer is not using the features? It results in a better understanding of the system.
• Minimum source of error
As the organization follows the agile project management system, the organization has the least chance of causing errors. According to the feedback analysis, after feedback collection, the stakeholders of the organization set meetings for selecting the relevant ideas or feedback provided by the consumers. By following the ideas, the developer updates the features based on the customer’s requirements. Better implementation procedures and management systems are required for error minimization.
• Better understanding and development
Through the feedback analysis, the organization understands the demands of the market, the techniques to develop the system, and business procedures. Through the process, the organization also understands the effectiveness of the project management system. The organization analyzes the needs of the customers in terms of system development. In this way, the organization results in effective development through usability testing.
• Changes for improvement
After releasing a few features, the organization promotes feedback analysis. The change completely relies on the customer’s feedback such as updating new features and removal of the features that are not necessary. The development team requires focusing on the feedback of the customer and working accordingly. It results in better development and improvement of the system and management system.
• Efficient user experience and satisfaction
User experience and satisfaction are essential in terms of a usability test. It supports the company during the launch of the website; it results in smooth functioning of the system and is user-friendly.
Literature Review
Breast Cancer Network Australia
The organization is associated to promote support for people suffering from Breast cancer. The founder of Breast Cancer Network Australia is Lyn Swinburne that believes in serving humanity. It is a group of fewer people that connects women facing breast cancer. They are already connected with 70 % of Australian women battling breast cancer (O’Brien et al., 2020). The organization provides hope to maximum Australian families in terms of managing funds for treatment and positivity. Today, BCNA is known as the largest consumer organization for the last 22 years in terms of providing support to women who are diagnosed with breast cancer. At present, the organization has taken the initiative in terms of providing maximum facilities to families suffering from breast cancer (Beatty et al., 2021). To reach the destination, the organization needs innovative ideas and progressive thinking to increase the maximum funds of the organization and promote help to them.
To increase the maximum fund, the organization has introduced a website for easy funding for women diagnosed with breast cancer. it also facilitates the implementation procedure by providing a better understanding of the steps that must be taken by the women suffering from breast cancer. It provides several information and updates that are essential for people to know about breast cancer (Riihiaho, 2018). It provides a better innovation for a better management system. BCNA also provides a better understanding of the treatments best for women battling breast cancer. Moreover, they provide support to the patients by supplying facilities such as
• Quick access to the website
• Providing better tests and treatments.
• By lower the budget.
• By providing the best nurse and care facilities.
• By providing public health service
• Provides effective treatment for lymphodema.
• Better clinical practices
Different Approaches of Usability Testing
Common and General Usability Testing
It is the most common and moderate usability testing that is required to collect data in-depth and provides better information for best assignment help .
Lab Testing
In this case, lab testing is important in terms of analyzing the stage, issues, and problems of cancer. The testing period is conducted through mobile or website (Lyles et al., 2014). The stakeholders and the moderators of the organizations focus on the movements of the patient to analyze ad detect the complications.
Advantages
- Provides full observation of the patient's behavior
- Assurance for providing efficient service
Disadvantages
- Requires high expenses
- Consumers time
- Fewer people agree to do the test.
Guerilla Testing
The test is generally conducted in public places. It supports the organization in collecting bulk data in a shorter period. In this case, the procedure is not efficient enough to meet the organizational demand as most peoples are not curious about the result (Kendler, & Strochlic, 2015). Mostly, the person participates due to the purpose of collecting gift coupons.
Advantages
- Provides appropriate and free testing period
- Provide gift coupons
- Do not consume time
Disadvantages
- People do not have the time to collect the result.
Common and most used usability tests
In this case, the entire procedure works digitally and significantly. Interaction with the patients is meant to be possible through questions and query solving approaches.
Interviews via phones
The women suffering from breast cancer require appropriate counseling. The counseling period is generally conducted through phones. The modulators analyze the movements of the patients and focus on identifying their thinking and problems by promoting an appropriate discussion session (Wagner et al., 2020). It results in better understanding and data collection in a shorter period.
There are more approaches such as unmodified and remote and immoderate-in-person. In this case, unmodified and remote focuses on the insight performance of the website such as session recording and online testing tools (Lifford et al., 2019). on the other hand, the immoderate and in-person approach testing session is conducted by the participant itself but does not allow the moderator to involve. These approaches are also very significant in terms of better support provided by providing usability testing sessions to the patients.
Usability Evaluation
The steps of usability testing are inspection, testing, and inquiry. In this scenario, we are performing usability testing. The testing period is conducted mainly to detect the movements and behavior of the patients. Moreover, to identify the thinking and problems of the patient the testing session is conducted to promote support to them (Ginossar et al., 2017). On the other hand, it is also analyzed that it requires improvements in terms of strategic planning, visual analysis, and remote testing system.
The performance of the website can be evaluated by providing multiple questions. In this case, the answer if the finding must be appropriate and informative in terms of better understanding and evaluation. It will support the participants in finding the answer that is not present on the website so that handles the system accurately. Better stakeholder analysis and engagement are required for better system understanding and evaluation.
Purpose
• To promote better website accessibility and performance to the patients.
• To promote help in terms of usability testing to breast cancer patients.
• Provides effective counseling sessions.
• To improve the management system.
• To promote a better engagement between the modulator and patients.
• Results in effective testing analysis and understanding.
Objectives
• Better implementation procedure in terms of usability testing.
• To promote support and facilities for the women battling breast cancer.
Methodology
In this report, the particular methodology or process steps are followed to conduct the overall research or usability testing. However, the methodology was started by motivating the participants to buy the BCNA merchandise from the online portal. After that, they will conduct in detail testing of the products. The management team will prepare an appropriate discussion or seminar that can derive proper analysis and evaluation of the personal experiences (Maramba et al., 2019). The participants will also share their issues and the reasons that make the product more useful in a practical scenario. However, this overall discussion or evaluation will be documented in the company database that can further be implemented in organizational strategy and sustainability.
Participants’ Responsibilities
• Buying Projects and different categories of merchandise and products.
• Conduct in detail testing by using the products.
• Discussion with critical thinking and a flexible approach.
• Personal experience evaluation.
• Active engagement in group discussion.
Training of the Participants
All the participants required appropriate training modules and program designing to conduct the overall testing effectively. It is the responsibility of the management team to design the overall training structure for the organization (Li et al., 2012). This will include engaging seminars, online conferences, team projects, etc. In this way, the participants will be more effective in the overall testing procedure and documentation. Moreover, the test results will be implemented efficiently in a real-life scenario.
Procedure
The testing is the most significant and essential process of the overall report. In this case, the overall evaluation leads to two different procedures of testing. There are differences in nature, specification, and implementation (Lin et al., 2021). In this section of the report, both of those usability testing procedures are explained with potential results.
.png)
Table 1: Different Procedures of Usability Testing
(Source: Developed by Author)
Questioner System
A questionnaire system is a part of a remote usability testing procedure. This can also be conducted in the usability Lab testing. Despite that, it is the most efficient remote procedure. All the participants will be able to share their opinion and different evaluation along with personal experiences through the online portal system. This will also efficiently categorize and document them into the system. Moreover, the valuation and testing results will be effectively implemented by considering all the opinions of the participants.
.png)
.png)
.png)
.png)
.png)
Figure 1: Participant 5
Usability Matrix
Usability metrics are an analytical procedure for evaluating the overall testing procedure and results. In every organization, usability testing requires appropriate criteria and metrics for constant evaluation of the project progress (Maramba et al., 2019). In this section of the report, different usability metrics components will be discussed in terms of description and significance.
.png)
Table 2: Description and Significance of Usability Matrix
(Source: Developed by the Author)
Usability Goals
Usability goals present different objectives of the overall usability testing procedure. This is conducted to collect data and feedback from different participants (Tiong et al., 2016). However, these usability goals must be specific and tested by the management team for further organizational implementation. This includes,
• Error-free testing method and usability results
• Appropriate and effective operations
• Effective time management
• Efficient usability testing and operations
• Effective management structure and planning
It is the responsibility of the management team and participants to meet all the usability goals with active contribution and analysis.
Classification
Problem Sensitivity
Problem sensitivity presents the significant impact of the particular problem in any usability scenario. Appropriate classification will help in the identification of the severity of the problems in the procedure and overall results implementation process as well (Lo et al., 2018). In this section of the report, some of the problem categories are explained in terms of effective solution strategies.
.png)
Table 3: Description and Problem Sensitivity
(Source: Developed by the Author)
Observation
In this section of the Report, the overall observation of the whole usability testing procedure is discussed in terms of impact and organizational significance. This observation will be effective for the management team to develop appropriate planning and strategy for further improvement and implementation. This will lead to effective recommendations as well. The report or whole testing procedure includes problem analysis, participant analysis, testing procedure, and different framework evaluations. In that case, the observations are,
• The most effective and efficient system for this usability project will be a remote testing model
• The management team has already implemented effective teamwork and management
• Problem analysis has shown the appropriate strategies that can resolve different problem categories
• The participants are the key stakeholder in the overall process and evaluation.
This is the responsibility of the management team to evaluate or analyze all the documented observations to list the most effective recommendations for the project.
Conclusion and Recommendation
The report concludes that the overall usability of the system is already efficient enough to conduct real-life business implementation. Despite that, some of the system and strategic changes will improve the usability experience and other beneficial features. This will also require active observation and engagement of the participants and managerial stakeholders. However, the strategic implementation will effectively conduct the whole process in the assigned time frame.
The final observations and whole analysis can also lead to the most effective and applicable recommendations that must be documented and analyzed for further requirements. It includes,
• The management must improve the remote usability testing system
• The appropriate and effective participant training program must be designed
• The process must include regular feedback analysis into the system
• The appropriate and efficient team must be prepared to moderate and manage the system regularly
This requires effective leadership and analytical skills to implement these recommendations, which can lead to further organizational growth and sustainability in the market.
References
.png)

Programming
ITECH1400 Foundation of Programming Assignment Sample
Introduction. In this assignment you are required to develop a program that simulates fishing: There are 6 fish species for assignment help in the river which you may
catch:
Australian Bass (Macquaria Novemaculeata) - commonly less than 4 Kg; excellent eating, when less than 2.5 Kg.
Short Finned Eel (Anguilla Australis)- commonly less than 3 Kg; a good eating fish.
Eel Tailed Catfish (Tandanus Tandanus) - Up to 6.8 Kg; excellent eating, when less than 4 Kg.
Gippsland Perch (Macquaria Colonorum)- commonly less than 10 Kg; excellent eating when up to 6 Kg.
Two more species you should add to this list yourself. Search the internet for the necessary details.
Your program should be based on the following assumptions:
Every second you catch a fish (perfect fishing).
The chances (probabilities) to catch each of these six species are equal.
Weights of fishes of the same species are distributed evenly and range from 0 to the Maximal Weight. The value of Maximal Weight for each of the species is given above. For example, Maximal Weight of Australian Bass is 4 Kg.
Fishing starts with an empty basket which you should implement as a list. If you catch a fish with a weight greater than 500 g or less than the recommended excellent eating maximum, you add it to the basket. Otherwise, release it. For example, only instances of Australian Bass with the weights between 0.5 Kg and 2.5 Kg should be added to the basket.
Stop fishing immediately as soon as the total weight of all the fishes in the basket exceeds 25 Kg.
To generate a random fish and weight, you are supposed to use the “randrange” function from the “random” package. Fishes of different species must be implemented as objects of the corresponding classes. For convenience, all weights appearing in the program body should be integers given in grams e.g. instead of 3 Kg you should use 3000g. However, when printing outputs on the screen you may use kilograms.
2.Develop a module named fish_species (file “fish_species.py”). This module should contain definitions of the following six classes: AustralianBass, ShortFinnedEel, EelTailedCatfish, GippslandPerch + 2 more classes for the species you add yourself.
class AustralianBass should contain the following members:
Variables (Constants):
MAX_WEIGHT = 4000
MAX_EATING_WEIGHT = 2500
NAME = 'Australian Bass'
LATIN_NAME = 'Macquaria Novemaculeata'
The constructor should define and initialise a single attribute named “weight”. The attribute weight must get an integer value between 0 and MAX_WEIGHT.
A method named “is_good_eating”: returns True if the fish’s weight is between 500 g and excellent eating weight (2500 g for Australian Bass).
An overridden (redefined) method “ str ” that returns a nice, readable string representation of a fish object.
3. Develop a module named “fishing” (file “fishing.py”). This module should import the module “fish_species”, so you can use the class definitions from it. In addition, in this module you should define the following functions:
3.1. Function start_fishing().
The function simulates fishing process in the following way:
Every second a random fish is “caught”. I.e., every second the program randomly chooses one of the 6 fish species, then randomly generates a weight within valid range (between 0 and the species’ MAX_WEIGHT), and then creates the corresponding fish object.
If the created fish object is_good_eating, the object is added to the basket (implemented as a list). Otherwise, the fish is released, i.e., is not added to the basket.
Once total weight of fishes in the basket exceeds 25 Kg (25000 g), the basket is returned (fishing ends).
Fishing results should be printed on the screen, one line per second.
3.2. Function print_basket(basket).
The function prints its argument’s (basket’s) content on the screen
3.3. Function plot_basket(basket).
The function plots a bar-chart that shows total weights of each of the species in the basket:
3.4. Functions save_basket(basket, file_name) and load_basket(file_name). In this task you must:
search Python documentation to find out how to use the pickle package in order to save Python objects to files and load the saved objects back to programs.
save_basket(basket, file_name) – using pickle.dump saves the basket to a binary file with the specified name.
load_basket(file_name) – using pickle.load loads a saved object (basket) from the specified file.
Solution
Pseudo code : 2
1. Create class for each species (total 6 class defined)
2. Each class have constant data member max_weight, max_eating_weight
3. Define constructor (init method) to initialize data member
4. Each class have two method is_good_eating and tostring
Fish_species.py
# contents all the classes for fish
class AustrliansBass:
# class variables
MAX_WEIGHT = 4000
MAX_EATING_WEIGHT = 2500
NAME = 'Australian Bass'
LATIN_NAME = 'Macquaria Novemaculeata'
# constructor to initialize weight of fish
def __init__(self, weight):
self.weight = weight
#return true of false based on fish weight
def is_good_eating(self):
return True if self.weight < self.MAX_EATING_WEIGHT else False
# to string method to represent string of any fish
def __str__(self):
return f"{self.NAME} ({self.LATIN_NAME}), weight {self.weight/1000} Kg"
class ShortFinnedEel:
# class variables
MAX_WEIGHT = 2500
MAX_EATING_WEIGHT = 2500
NAME = 'Short Finned Eel'
LATIN_NAME = 'Anguilla Australis'
# constructor to initialize weight of fish
def __init__(self, weight):
self.weight = weight
# return true of false based on fish weight
def is_good_eating(self):
return True if self.weight < self.MAX_EATING_WEIGHT else False
# to string method to represent string of any fish
def __str__(self):
return f"{self.NAME} ({self.LATIN_NAME}), weight {self.weight/1000} Kg"
class EelTailedCatfish:
# class variables
MAX_WEIGHT = 6800
MAX_EATING_WEIGHT = 4000
NAME = 'Eel Tailed Catfish'
LATIN_NAME = 'Tandanus Tandanus'
# constructor to initialize weight of fish
def __init__(self, weight):
self.weight = weight
# return true of false based on fish weight
def is_good_eating(self):
return True if self.weight < self.MAX_EATING_WEIGHT else False
# to string method to represent string of any fish
def __str__(self):
return f"{self.NAME} ({self.LATIN_NAME}), weight {self.weight/1000} Kg"
class GippslandPerch:
# class variables
MAX_WEIGHT = 10000
MAX_EATING_WEIGHT = 6000
NAME = 'Gippsland Perch'
LATIN_NAME = 'Macquaria Colonorum'
# constructor to initialize weight of fish
def __init__(self, weight):
self.weight = weight
# return true of false based on fish weight
def is_good_eating(self):
return True if self.weight < self.MAX_EATING_WEIGHT else False
# to string method to represent string of any fish
def __str__(self):
return f"{self.NAME} ({self.LATIN_NAME}), weight {self.weight/1000} Kg"
class MurrayCod:
# class variables
MAX_WEIGHT = 10000
MAX_EATING_WEIGHT = 5000
NAME = 'Murray Cod'
LATIN_NAME = 'Maccullochella peelii'
# constructor to initialize weight of fish
def __init__(self, weight):
self.weight = weight
# return true of false based on fish weight
def is_good_eating(self):
return True if self.weight < self.MAX_EATING_WEIGHT else False
# to string method to represent string of any fish
def __str__(self):
return f"{self.NAME} ({self.LATIN_NAME}), weight {self.weight/1000} Kg"
class Inanga:
# class variables
MAX_WEIGHT = 3000
MAX_EATING_WEIGHT = 1500
NAME = 'Inanga'
LATIN_NAME = 'Galaxias Maculatus'
# constructor to initialize weight of fish
def __init__(self, weight):
self.weight = weight
# return true of false based on fish weight
def is_good_eating(self):
return True if self.weight <= self.MAX_EATING_WEIGHT else False
# to string method to represent string of any fish
def __str__(self):
return f"{self.NAME} ({self.LATIN_NAME}), weight {self.weight/1000} Kg"
Pseudo code : fishing
1. Import pickle and other necessary library
2. Define fishing()
a. Set Total_weight = 0
b. Declare blank list to store all fish
c. Print “start fishing message”
d. Do until weight is less then 2500
i. Generate random fish species type
ii. Generate random weight for that selected fish
iii. if is_good_eating for selected fish then
1. add to basket
2. show message
3. update total_weight
otherwise release the fish
iv. sleep for 1 second
e. go to step d
f. print “end fishing” and return basket
pseudo code : print_basket
1. for I = 0 to size of basket
2. print the fish details
Pseudo code : plot_basket
1. create a blank dictionary
2. add all six type of fish with value zero
3. iterate all the fish and count total fish for each type
4. use matplotlib library to show bar chart with dictionary key, value pair
5. show the plot
Pseudo code : save_basket
1. open a file with wb option
2. use dump method to store the basket
3. close the file
Pseudo code : load_basket
1. open file with rb option to read binary file
2. call pickle.load method to get all the object of basket
3. close the file
Fishing.py
import pickle
import matplotlib.pyplot as plt
import random
import time
from fish_species import *
def start_fishing():
total_weight = 0
# blank list to store all fish those are good to eat
basket = []
print('Fishing Started!')
while total_weight < 25000:
# select fish class based on random generated number
fish_type = random.randrange(0, 6)
if fish_type == 0:
fish_weight = random.randrange(0, AustrliansBass.MAX_WEIGHT)
fish = AustrliansBass(fish_weight)
elif fish_type == 1:
fish_weight = random.randrange(0, ShortFinnedEel.MAX_WEIGHT)
fish = ShortFinnedEel(fish_weight)
elif fish_type == 2:
fish_weight = random.randrange(0, EelTailedCatfish.MAX_WEIGHT)
fish = EelTailedCatfish(fish_weight)
elif fish_type == 3:
fish_weight = random.randrange(0, GippslandPerch.MAX_WEIGHT)
fish = GippslandPerch(fish_weight)
elif fish_type == 4:
fish_weight = random.randrange(0, MurrayCod.MAX_WEIGHT)
fish = MurrayCod(fish_weight)
else:
fish_weight = random.randrange(0, Inanga.MAX_WEIGHT)
fish = Inanga(fish_weight)
# check wether fish is good to eat
if fish.is_good_eating():
# added to the basket
basket.append(fish)
# calcualte total weight
total_weight += fish_weight
# print message to user
print("t",fish,"- added to the basket.")
else:
print("t",fish, "- released.")
# sleep for 1 second
time.sleep(1)
print('Basket is full. End of fishing session.')
return basket
def print_basket(basket):
print('Contents of the basket: ')
# print all the fish of basket
for fish in basket:
print("t", fish)
def plot_basket(basket):
# create a blank dictionary to count type of fish
fish_data = dict()
# initilaize all fish to zero
fish_data['Australian Bass'] = 0
fish_data['Short Finned Eel'] = 0
fish_data['Eel Tailed Catfish'] = 0
fish_data['Gippsland Perch'] = 0
fish_data['Murray Cod'] = 0
fish_data['Inanga'] = 0
for fish in basket:
# count each fish
fish_data[fish.NAME] += 1
# set figure size
plt.figure(figsize=(10, 5))
# plot the bar chart based on dictionary data
plt.bar(fish_data.keys(), fish_data.values(), color='maroon',width=0.4)
# show bar chart
plt.show()
def save_basket(basket, file_name):
# open file to write object
f = open(file_name, 'wb')
# objects are written
pickle.dump(basket,f)
# close the file
f.close()
def load_basket(file_name):
# open file to read obects
f1 = open(file_name, 'rb')
# stored read object
basket = pickle.load(f1)
f1.close()
# reuturn all fish as a single list
return basket
# start the fishing
basket = start_fishing()
# print all the fish of basket
print_basket(basket)
# plot the fish chart
plot_basket(basket)
# save the fish to myfile
save_basket(basket,"myfile")
# load the myfish file to basket
basket = load_basket("myfile")
# show all fish
print_basket(basket)
Output
.png)
Figure 1 - output of 3.1
Outputs of 3.2
.png)
.png)
Case Study
COIT12208 Duplicate Bridge Scoring Program Assignment Sample
Case Study: A Not-for-Profit Medical Research Center
You are Alexis, the director of external affairs for a national not-for-profit medical research center that researches diseases related to aging. The center’s work depends on funding from multiple sources, including the general public, individual estates, and grants from corporations, foundations, and the federal government.
Your department prepares an annual report of the center’s accomplishments and financial status for the board of directors. It is mostly text with a few charts and tables, all black and white, with a simple cover. It is voluminous and pretty dry reading. It is inexpensive to produce other than the effort to pull together the content, which requires time to request and expedite information from the center’s other departments. At the last boarding meeting, the board members suggested the annual report be “upscaled” into a document that could be used for marketing and promotional purposes. They want you to mail the next annual report to the center’s various stakeholders, past donors and targeted high-potential future donors. The board feels that such a document is needed to get the center “in the same league” with other large non-for-profit organizations with which it feels it competes for donations and funds. The board feels that report could be used to inform these stakeholders about the advances the center is making in its research efforts and its strong fiscal management for effectively using the funding and donations it receives.
You will need to produce a shorter, simpler, easy-to-read annual report that shows the benefits of the center’s research and the impact on people’s lives. You will include pictures from various hospitals, clinics, and long-term care facilities that are the results of the center’s research. You also will include testimonials from patients and families who have benefited from the center's research. The report must be “eye-catching”. It needs to be multicolor, contains a lot of pictures and easy-to-understand graphics and be written in a style that can be understood by the average adult potential donor. This is a significant undertaking for your department, which includes three other staff members. You will have to contract out some of the activities and may have to travel to several medical facilities around the country to take photos and get testimonials. You will also need to put the design, printing, and distribution out to bid to various contractors to submit proposals and prices to you. You estimate that approximately 5 million copies need to be printed and mailed.
It is now April 1. The board asks you to come to its next meeting on May 15 to present a detailed plan, schedule, and budget for how you will complete the project. The board wants the annual report “in the mail” by November 15, so potential donors will receive it around the holiday season when they may be in a “giving mood”. The center’s fiscal year ends September 30, and its financial statements should be available by October 15. However, the non-financial information for the report can start to be pulled together right after the May 15 board meeting. Fortunately, you are taking a project management course in the evenings at the local university and see this is an opportunity to apply what you have been learning. You know that this is a big project and that the board has high expectations. You want to be sure you meet their expectations and get them to approve the budget that you will need for this project. However, they will only do that if they are confident that you have a detailed plan for how you will get it all done. You and your staff have six weeks to prepare a plan to present to the board on May 15. If approved, you will have six months, from May 15 to November 15, to implement the plan and complete the project. Your staff consists of Grace, a marketing specialist; Levi, a writer/editor; and Lakysha, a staff assistant whose hobby is photography (she is going to college part-time in the evenings to earn a degree in photojournalism and has won several local photography contests).
Case Study Questions for assignment help -
Question 1
Establish the project objective and make a list of assumptions about the project.
Question 2
Develop a Work Breakdown Structure (WBS) for the project.
Question 3
Prepare a list of the specific activities that need to be performed to accomplish the project objective. For each activity, assign the person who will be responsible for seeing that the activity is accomplished and develop an estimated duration for each activity.
Question 4
Create a network diagram that shows the sequence and dependent relationships of all the activities.
Question 5
Using a project start time of 0 (or May 15) and a required project completion time of 180 days (or November 15), calculate the Earliest Start (ES), Earliest Finish (EF), Latest Start (LS), and Latest Finish (LF) times and Total Slack (TS) for each activity.
If your calculations result in a project schedule with negative TS, revise the project scope, activity estimated durations, and/or sequence or dependent relationships among activities to arrive at an acceptable baseline schedule for completing the project within 180 days (or by November 15). Describe the revisions you made.
Question 6
Determine the critical path, and identify the activities that make up the critical path.
Solution
Project Objectives and Assumptions
The primary objective of this project is to prepare the annual report for the company within a specified date. In order to achieve this objective, several requirements must be followed that are listed below.
To collect sufficient data regarding the organisation’s services and performance
To collect financial data of the company for the current fiscal year
To visit various facilities of the company around the country and collect photographs, testimonials and interviews of patients and their families
To create the documentation contents in the form of the annual report
To add the collected pictures and data to the report
To hire a contractor for design, printing and distribution of the annual report
To get the report approved by the management
The assumptions made for this particular project are as follows.
- The entire project work can be completed within the 6 months window, working 5 days a week.
- The current group of staff is sufficient and skilled enough to handle all the necessary actions during the project execution.
Work Breakdown Structure
Work breakdown structure is a representation of the list of tasks within a project that can be shown in the form of a table or diagram. The purpose of the diagram is to break down the entire project into smaller individual activities and work packages that help the team members to better understand the work requirements and their duties in the project.
The work breakdown structure for the project in focus is shown in the following diagram.
.png)
Figure 1: Work Breakdown Structure of the Project
(Source: Created by Author)
Activities, Duration and Resources
The list of activities along with estimated duration and resources attached is given in the following table.
.png)
.png)
The overall list above contains the entire cycle of the project that starts right after the kick off meeting of April 1. However, the main part of the project (execution) starts on 15th May and the durations for the work packages have been allocated in such a way that the execution phase ends on 15th November with the submission of the fully prepared annual report to the board, as per the necessary requirement and agreement. The detailed schedule based on the allocated dates and duration can be shown in the form of a Gantt chart as follows.
.png)
Figure 2: Gantt Chart of the Project
(Source: Created by Author)
Network Diagram
The purpose of a network diagram is similar to a Gantt chart i.e. exhibiting the project schedule but in much more detail. The network diagram shows details of each activity including project duration, start and end dates, allocated resource within each single box representing a work package. While Gantt chart can also exhibit the same, it can become very confusing to view the details of a particular activity / work package when the project is very complex and there are vast numbers of activities.
.png)
.png)
Figure 3: Network Diagram (Shown part by part in chronological order)
(Source: Created by Author)
ES, EF, LS, LF, TS
.png)
Figure 4: ES, EF, LS, LF and TS for the Execution Phase of the Project
(Source: Created by Author)
The diagram above depicts a PERT chart that shows the sequence of tasks in the project. Since actual part of the project is considered to be the execution phase that starts on 15th May and ends on 15th November, only the execution phase in drawn in the diagram rather than the entire project that has been shown in the WBS. In the legend added to the top left of diagram, the meanings of the abbreviations are as follows.
ES – Early Start
EF – Early Finish
DUR – Duration
LS – Late Start
LF – Late Finish
TS – Total Slack
For this part of the project, the total duration has been considered to be 6 months (May 15 = day 0 and November 15 = ending date).
Critical Path
Based on the diagram shown above and the calculations the critical path of the project can be stated as (using WBS IDs):
3.1 > 3.2 > 3.3 > 3.7 > 3.8 > 3.9 > 3.10 > 3.13 > 3.14
The critical path itself has been already highlighted in the above diagram itself, in the form of red arrows whereas non-critical paths are shown with blue arrows.
Programming
COIT20245 Introduction To Programming Assignment Sample
Assignment Brief
For this assignment, you are required to develop a Menu Driven Console Java Program to demonstrate you can use Java constructs including input/output via the console, Java primitive and built-in types, Java defined objects, arrays, selection and looping statements and various other Java commands. Your program must produce the correct results.
The code for the menu and option selection is supplied: GradingSystemMenu.java and is available on the unit website, you must write the underlying code to implement the program. The menu selections are linked to appropriate methods in the given code. Please spend a bit of time looking at the given code to familiarize yourself with it and where you have to complete the code. You will need to write comments in the supplied code as well as your own additions.
Assignment Specification
You have completed the console program for processing grade of students for COIT20245. We are going to extend this application so the students name, student number, marks and grades can be stored in an array of objects, do not use ArrayList.
The program will run via a menu of options, the file GradingSystemMenu.java has been supplied (via the Moodle web site) which supplies the basic functionality of the menu system.
.png)
Look at the code supplied and trace the execution and you will see the menu is linked to blank methods (stubs) which you will implement the various choices in the menu.
Student class
First step is to create a class called Student (Student.java).
The Student class will be very simple it will contain seven private instance variables:
o studentName as a String o studentID as a String
o assignmentOneMarks as double o assignmentTwoMarks as double o projectMark as double
o individualTotalMarks as double
o grade as a String
The numeric literal values, like P=50.00, HD=85.00 must be represented as constants.
The following public methods will have to be implemented:
o A default constructor
o A parameterised constructor o Five set methods (mutators) o Five get methods (accessors)
o A method to calculate total marks and return student’s total marks as double – calculateIndividualTotalMarks(). This calculation will be the same as in assignment one.
o A method to calculate grade and return the grade as String – calculateGrade(). This calculation will be the same as in assignment one. Use constants for all numeric literals.
Note: Following basic database principles, calculated values are not usually stored, so in this case we will not store the grade as a instance variable, but use the calculateGrade() method when we want to determine the grade.
GradingSystemMenu class
Once the Student class is implemented and fully tested we can now start to implement the functionality of the menu system.
Data structures
For this assignment we are going to store the student’s name, student number and assessment marks an array of Student objects.
Declare an array of Student objects as an instance variable of GradingSystemMenu class the array should hold ten students.
You will need another instance variable (integer) to keep track of the number of the students being entered and use this for the index into the array of Student objects.
Menu options
1. Enter students name, student number and assessment marks: enterStudentRcord()
You will read in the student’s name, student number and assessment marks as you did in assignment one.
.png)
Data validation (you can implement this after you have got the basic functionality implemented) You will need to validate the user input using a validation loop.
The student’s name and student number cannot be blank i.e. not null and the assessments marks needs to be within the range of (0-assessment weighting), the same as assignment one.
.png)
When entering record of student’s name, student number and assessments marks, the student have been entered successfully into five local variables you will need to add these values into the student object array, you will also need to increment a counter to keep track of the number of students you have entered and the position in the array of the next student to be entered.
When the maximum number of students record is reached do not attempt to add any more student’s record and give the following error message:
.png)
When the student details have been successfully entered, display the details of the student and the charge as follows
.png)
Note: For the next two options, display all and statistics you should ensure at least one student’s record has been entered and give an appropriate error message if it there are no students record entered.
.png)
Display all student’s name, student number, assessment marks and grade:
displayAllRecordsWithGrade()
When this option is selected display all the records with grade which have been entered so far.
.png)
3. Display statistics: display Statistics()
When this option is selected you will display the statistics as per detailed in assignment one document. You can loop through your array of objects to calculate this information.
.png)
Remember the welcome and exit messages as per assignment one.
.png)
Solution
Menu class Interfaces
GradingSystemMenu app = new GradingSystemMenu();
This line in the main method is used to create an object of the GradingSystemMenu class. Then this class object is used to call the processingGradeingSystem() method. This method is responsible to handle the menu display and menu choice entry from the users for assignment help
int choice = getMenuItem();
This line inside the processingGradeingSystem() method is used to get the user entered menu choice. Also, inside getMenuItem(), the menu is displayed to the user and input is taken using Scanner class object. This choice input is returned to the processingGradeingSystem() method. This repeats in a loop till user enters choice for EXIT. The flowchart below better defines the flow of actions in this context.
.png)
Student and GradingSystemMenu class
GradingSystemMenu class uses the enterStudentRcord() method to take entry of all student records and then create a Student object after validation. In order to create the object, the student class constructor is called with user entered values. These objects are then saved inside the students[] array of type Student Class. This array is then used all across the program for various purposes.
Class Diagram
.png)
Reflection Report
It took me about 4 to 5 hours in order to complete the programming assignment as a whole. In the first few minutes of this time, I carefully studied the assignment requirements and then downloaded and read through the documented code on the GradingSystemMenu,java file. This helped me to get started with the assignment.
I did not face any noticeable problem with this assignment as the functions were very clearly documented using the todo comments.
Testing Screenshots
Test Invalid menu input

Test Option 2 with no records

Test Option 3 with no records
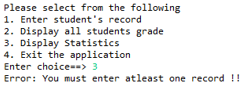
Test Blank Name and ID

Test Assignment marks range validation

Test Data Record Entry and display

Test Option 2
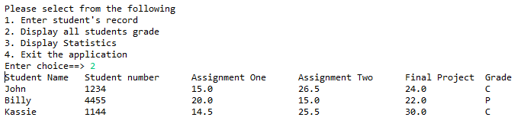
Test Option 3
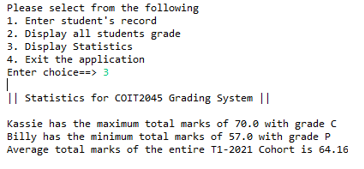
Test Option 4

Research
ITECH7407 Real Time Analytics Assignment Sample
Learning Outcomes Assessed
The following course learning outcomes are assessed by completing this assessment task:
• S1. Integrate data warehouse and business intelligence techniques when using big data.
• S2. Create flexible analytical models based on real time data, and use connectivity interfaces and tools for reporting purposes.
• S3. Use real time performance analysis techniques to monitor data, and identify shifts or events occurring in data, as a basis for organisational decision making.
• S4. Use real time mobile tracking techniques to utilise mobile-specific usage data.
• K3. Communicate the key drivers for big data in terms of efficiency, productivity, revenue and profitability to global organisations.
• K4. Identify and describe types of big data, and analyse its differences from other types of data.
• A1. Communicate security, compliance, auditing and protection of real time big data systems.
• A2. Adopt problem solving and decision making strategies, to communicate solutions to organisational problems with key stakeholders, based on analysis of big data, in real time settings.
Deliverable 1. Analysis Report (30%)
Task 1- Background information
Write a description of the selected dataset and project, and its importance for your chosen company. Information must be appropriately referenced.
Task 2 – Perform Data Mining on data view Upload the selected dataset on SAP Predictive Analysis. For your dataset, perform the relevant data analysis tasks on data uploaded using data mining techniques such as classification/association/time series/clustering and identify the BI reporting solution (e.g., diagrams, charts, tables, etc.) and/or dashboards you need to develop for the operational manager (or a relevant role) of the chosen organisation.
Task 3 – Research
Justify why you chose the BI reporting solution, dashboards and data mining technique in Task 2 and why those data sets attributes are present and laid out in the fashion you proposed (feel free to include all other relevant justifications).
Note: To ensure that you discuss this task properly, you must include visual samples of the reports you produce (i.e. the screenshots of the BI report/dashboard must be presented and explained in the written report; use ‘Snipping tool’), and also include any assumptions that you may have made about the analysis in your assignment report (i.e. the report to the operational team of the company). A BI dashboard is an integrated and interactive tool to display key performance indicators (KPIs) and other important business metrics and data points on one screen, but not a static diagram or graph. To ensure that you discuss this task properly, you must include visual samples of the reports you have produced (i.e. the screenshots of the BI report/dashboard must be presented and explained in the written report; use ‘Snipping tool’), and also include any assumptions that you may have made about the analysis from Task 3.
Task 4 – Recommendations for CEO
The CEO of the chosen company would like to improve their operations. Based on your BI analysis and the insights gained from your “Dataset” in the lights of analysis performed in previous tasks, make some logical recommendations to the CEO, and justify why/how your proposal could assist in achieving operational/strategic objectives with the help of appropriate references from peer-reviewed sources.
Task 5 – Cover letter
Write a cover letter to the CEO of the chosen firm with the important data insights and recommendations to achieve operational/strategic objectives.
Other Tasks –
At least 5 references in your report must be from peer-reviewed sources. Include any and all sources of information including any person(s) you interviewed for this project. Please refer to the marking scheme at the end of the assignment for other tasks and expectations.
Deliverable 2. Personal Reflection
This deliverable for assignment help is an individual work and can be attached to your data analytics report. In this part, each student will write a one-page-long reflection report covering the following points:
• Personal understanding of course content, and personal insights into the importance and value of the course topics.
• Three most useful things you have learned from the course and explain how they could help your current learning and future professional career.
• Personal feeling of SAP products (or other equivalent tools) used in lab exercises and assignments.
All discussion is expected to be well backed with real examples.
Solution
Deliverable 1. Analysis Report
Task1- Background Information
Australian Institute of health and welfare is recognized as a freely statutory institute generating accessible and authoritative statistics as well as information in order to inform and help better service delivery & policy decisions, leading towards effective wellbeing as well as health for entire Australians. Australian Institute of health & welfare/AIHW has high experience of over 30 years with welfare and health data records. This is also known at both national and international levels for their statistical expertise and ensured track the records in facilitating the independent evidence and high quality. To facilitate statistical information for community and governments to utilize in order to promote discussion & inform the relevant decisions based on health, community services, as well as housing is the mission of AIHW. On the other hand, facilitating robust evidence in terms of information and data for better decisions as well as improvements in health & welfare is the vision of AIHW. AIHW supports releasing various health solutions for community so, they need a good expenditure to continue progress in this field (Health Direct, 2022).
In this manner, the dataset selected for this agency is related to the area of expenditure, broad sources of funding, and detailed sources of funding for AIHW including corresponding states and financial years. This selected dataset is varying from the financial year 1997 to 2012 respectively. This dataset is very essential and helpful for AIHW executive dashboard review for health expenditure with a long duration (1997 to 2012). Hence, the dashboard will help the CEO of AIHW to recognize the entire business expenditure, total resources, and broad/detailed contributors so, that the CEO can make the decisions appropriately and plan further expenditures more accurately by analyzing and tracking this expenditure dashboard. According to the selected datasets, the main areas of expenditure are administration, aids & appliances, other medications, benefit-paid pharmaceuticals, capital expenditure, dental services, community health, medical expense tax rebate, health practitioners, medical services, patient transport service, private hospitals, public health, research, and public healthcare.
The main importance of this project and selected dataset is listed below-
• To reduce the unnecessary expenses.
• To increase the revenue
• To increase market promotions
• To ensure public health and welfare programs (Burgmayr, 2021).
Task2- Data Mining
The selected datasets from the given source and relevant AIHH teams such as CEO, Director, Finance Director, and Operational Director are identified to prepare the high-level dashboard accordingly. So, the selected datasets can be proposed as-
.png)
.png)
Therefore, the data analysis is done based on such expenditure review for AIHW from 1997 to 2012. To analyze the defined datasets, some major data mining techniques have been used including classification analysis, cluster analysis, and regression analysis which are systematically mentioned below-
• Classification Analysis: This data mining technique is used to extract the most relevant and required datasets for the financial years 1997 to 2012 for reviewing total expenditure of AIHW agency. Using this analysis method, the different datasets have been classified into different classes. The classification is done based on the six corresponding classes such as financial year, state, area of expenditure, broad sources of funding, detailed sources of funding, and real expenditure in millions. This classification helped to analyze the data using creating the appropriate graphs and charts accurately.
• Cluster Analysis: Cluster analysis is a series of data variables; these variables are equivalent within the same cluster. This method is used to discover the clusters in data according to the range of association between two variables. This is used to get help in customizing the dashboards for CEO and Finance manager specifically.
• Regression Analysis: Regression analysis is also used for the expenditure review in order to identify and evaluate the relationships among such classes or variables. This analysis technique helped to understand the feature values of each dependent class change if any of available independent variables vary. In other words, it helped in prediction of total expenditure and revenue growth of AIHW (Souri, & Hosseini, 2018).
Task3- Research
Assumptions
Before mining the datasets, it is essential to disclose the main assumptions made for analysis of these datasets, and these assumptions are mentioned in the following points-
• Total of 15 expenditure areas is covered throughout the datasets review.
• Financial year is concerned as per the calendar year from 1997 to 2012.
• Broad source funds and detailed source funds are centralized to calculate the total expenses and revenue.
• A total of 8 states are covered to make the data model.
CEO Dashboard
The dashboard of CEO is outlined below with particular analysis as the main purpose of this dashboard is to review the real expenditure in millions by state as well as area of expenditure. The dashboard comprises major financial years of highest expenses, real expenditure in millions, main states, and the major areas of highest expenditure.
.png)
Figure 1: CEO Dashboard
The structure of above-mentioned dashboard is classified into four main classes in order to support the business outcomes. Major descriptions of expenses, areas, states, financial year, and real expenditure amount are calculated and plotted using graphs to highlight the revenue and expense ratios.
In case of CEO dashboard, entire information is at broad level including Australian level rather than only one or two particular cities in order to give major snapshots of this large AIHW business.
Supporting Charts
.png)
Figure 2: Expenditure Charts
These supportive bar charts are used in the estimation of total expenses and revenue forecasting by state and area of expenditure as it gives a foundation line view of the details concisely. The other views include the total real expenditure using all measures. On the other hand, top 4 real expenditure is investigated by state and these states are NSW, VIC, QLD, and WA. Similarly, the top 4 expenditure areas are identified including public hospitals, private hospitals, benefit-paid pharmaceuticals, and all other medical services. Thus, the result is clearly outlining the main sources of highest expenditure in AIHW in terms of these four states and areas of expenditure.
.png)
Figure 3: Broad source-based expenditure charts
The above-illustrated charts are reflecting following observations-
• The real expenditure graph is estimated mostly for the years 1998 and 1999 where 1997 has no value for highest expenditure.
• For detailed source funding, the real estimated expenditure has constant value based on all measures.
• On the other hand, the main broad sources of funding including government and non-government sources have real expenditure value as shown in right-side designed top and down charts.
.png)
Figure 4: expenditure in million
This chart is defining the real expenditure in millions to estimate the total expenses and most sensitive states. Thus, the graph is not static as per financial years.
Finance Director Dashboard
.png)
Figure 5: Finance Director Dashboard
The layout of finance director dashboard illustrated above is customized based on a similar approach to previous chairman’s dashboard. Review the real expenditure in millions by state as well as area of expenditure is the main purpose of this dashboard. The high-level dimension’s performance is outlined based on four main classes including the most expensive financial years, most expenses raised state, and most expenses raised areas of AIHW to measure the expense history and plan further financial strategies accordingly. The objective of this finance dashboard is to facilitate more stable information in order to track the financial performance on previous record basis. It is reflected in the developed graphical evidence that is showing the financial performances in terms of real expenditure in millions as per the highest expensive financial years. Supporting this graph, corresponding charts are also generated to show the main expenditure areas and states.
Supportive Charts
These chats and bars are systematically listed below with brief analysis-
.png)
Figure 6: Expenditure charts
The overall designed or generated charts articulated above are showing the financial director’s dashboard results in which the review of expenditure is done on the basis of state and area of expenditure. Top four real expenditure areas are discovered with top four real expenditure states based on the financial years. The real expenditure in million is also proposed using static graphic view.
.png)
Figure 7: Total value in million
These charts are very specific as these help in estimating the historical expenditure values using reviews and tracks of such selected AIHW records including a possibility to calculate the total revenue according to financial years of 1997 to 2012. This has been estimated that the value of expenditure in previous financial years is majorly higher than 200 million as the graph rate is constantly increasing as represented in above chart. So, it has been estimated that AIHW has higher revenue growth based on total expenditure values. The highest expenditure is the highest revenue so, the result is positive for AIHW as they increased their revenue per year.
Task4- Recommendations for CEO
To enable the AIHW CEO for improving their business operations based on the business intelligence analysis done previously some recommendations are suggested. The perceptions obtained from the selected and analyzed datasets, and some logical solutions in terms of recommendations will be guided to the CEO of AIHW so, that CEO can achieve the strategic and operational objectives of their agency using different BI models. Big data is one of the most effective solutions that can help CEOs to understand the previous records and current data status of their agency so, that appropriate planning and decisions can be made.
To make AIWS a data-driven agency, CEO has to identify the business and strategic values of big data instead of focusing on technological understanding. To transform this health and welfare agency, the appropriate strategies are required to formulate. So, to leverage the benefits and improvement strategies of Big data analytics effectively, five key strategies are recommended below-
Deployment of big data governance
Governance of big data is an upgraded version of IT governance that concentrates on benefitting the organizational large data resources to build business values. Big data analytics will help AIHW CEO in expenditure management, IT investment, financial planning, and healthcare data governance. The organizational heterogeneous knowledge, information, and data can be easily governed internally by CEO by changing the business processes in more accessible, secure, and understandable manner. To govern the data firstly it is required to frame the mission with clear goals, governance matrices, execution procedures, as well as performance measures. Then, the data is required to review for making decisions. Finally, integration of information is essential to lead big data deployment to encounter issues and develop robust business values.
Building information distribution culture
The importance of big data analytical implementation is to target the AIHW goals to foster the information transformation culture. This involves collection of data and delivery to address the challenges and develop policies to meet business achievements. This will improve data quality, accuracy, and prediction as well.
Training
CEO is responsible to understand, evaluate, and make the decisions accordingly. Thus, CEO needs to conduct training programs to use the outputs of big data effectively in order to interpret the results. In this manner, CEO of AIHW should arrange training for personnel to utilize big data analytics (Tamers, et. al., 2019).
Incorporation of Cloud Computing
To improve the cost as well as storage issues in AIHW, it will be a better solution to integrate cloud computing into big data analytics. This will make data-driven decisions more accurate, fast, and operable. CEO will also enable to visualize the organizational different information sets including different areas, expenditures, and factors. Thus, CEO can balance between protection of patient information and cost-effectiveness by integrating both these technologies.
Creating new business insights
New insights can be created using big data analytics By CEO which leads to updating the business functions that increase competitive advantages and productivity. The AIHW CEO will also allow leveraging the outputs such as alerting KPIs, reports, market opportunities, interactive visualization, and feasible ideas (Grover, et. al., 2018).
Other strategies that can be recommended in improving AIHW operations are-
Accessibility- CEO should understand the entire organizational operations and datasets so, that the database can be designed accordingly. Different information can be accessed separately which will help CEO to access, update, and make decisions more quickly.
Utilization- This is also an essential factor that utilization of any database should be done more attentively so, that the data can be interpreted in knowledge for business decisions.
Validation- Validation is another factor that ensures security so, CEO should focus on robust security system. This will help CEO to protect sensitive information of entire AIHW assets including patients, staff members, equipment, machines, details, records, etc. (Hsieh, et. al., 2019).
The main reasons for using the suggested solutions for achieving the strategic/operational objectives for AIHW CEO are-
• Cost-effectiveness
• Accurate decision-making strategies
• Automatic data processing (accessibility, update, delete, transformation)
• Rapid data delivery
• Robust integration
• High-level security
• Marketing & competitive advantages
Task5- Cover Letter
To,
XYZ
CEO
Australian Institute of Health & Welfare Agency,
Australia
Dear Mr. XYZ,
With overall description and analysis, the Australian Institute of health and welfare agency has specific goal to review the expenditure for financial years 1997 to 2012. To achieve this specific mission of AIHW, CEO should focus on leveraging their business operations using the in-depth analysis of their corresponding business datasets. According to the analysis, AIHW has been identified with higher expenditure values. This signifies that the revenue is also good but still, the increasing market structure and competitiveness, this is a possibility of higher expenditure but less revenue growth. In this manner, it is essential for CEO to take responsibility and enhance the scope of their business using strategic objectives. Some relevant recommendations are outlined in the following section that encourages
CEO to understand and apply the business objectives for better results specifically. These recommendations are-
To understand and develop big data strategic values
Big data analytics play a vital role in incorporating strategic business values so, CEO of AIHW can also lead these strategic values as shown in below figure-
.png)
Figure 8: Strategic Values of Big Data Analytics
(Source: Grover, et. al., 2018)
The functional value leads to financial performance, market share, and many more as it defines to improve the performance by adopting big data analytics. On the other hand, symbolic value refers to a broadly derived value via signaling effects of investment in big data analytics. Symbolic value comprises mitigation of environment load, organizational reputation, brand, and many more.
To strategically fit the business needs of AIHW, CEO should rely on functional value to balance organizational operations and technological awareness. In this manner, CEO will enable to ensure organizational business efficiency, coordination in operations and personnel, and decision-making features (Grover, et. al., 2018).
To implement innovative E-health record/system
CEO should take an initiative to develop an innovative e-health system to record the datasets and manage the organizational operations more effectively, accurately, securely, and flexibly. The CEO can use this system to conduct the business transparently and achieve business goals more quickly as multiple advantages can be leveraged for CEO including predictive data values, cost and smarter business decision-making capabilities, data storage, management, and improved outcomes as shown below-
.png)
Figure 9: E-Heath System
(Source: Dash, et. al., 2019)
References
Research
ITECH1103 Big Data and Analytics Assignment Sample
IT - Report
You will use an analytical tool (i.e. WEKA) to explore, analyse and visualize a dataset of your choosing. An important part of this work is preparing a good quality report, which details your choices, content, and analysis, and that is of an appropriate style.
The dataset should be chosen from the following repository:
UC Irvine Machine Learning Repository https://archive.ics.uci.edu/ml/index.php
The aim is to use the data set allocated to provide interesting insights, trends and patterns amongst the data. Your intended audience is the CEO and middle management of the Company for whom you are employed, and who have tasked you with this analysis.
Tasks
Task 1 – Data choice. Choose any dataset from the repository that has at least five attributes, and for which the default task is classification. Transform this dataset into the ARFF format required by WEKA.
Task 2 – Background information. Write a description of the dataset and project, and its importance for the organization. Provide an overview of what the dataset is about, including from where and how it has been gathered, and for what purpose. Discuss the main benefits of using data mining to explore datasets such as this. This discussion should be suitable for a general audience. Information must come from at least two appropriate sources be appropriately referenced.
Task 3 – Data description. Describe how many instances does the dataset contain, how many attributes there are in the dataset, their names, and include which is the class attribute. Include in your description details of any missing values, and any other relevant characteristics. For at least 5 attributes, describe what is the range of possible values of the attributes, and visualise these in a graphical format.
Task 4 – Data preprocessing. Preprocess the dataset attributes using WEKA's filters. Useful techniques will include remove certain attributes, exploring different ways of discretizing continuous attributes and replacing missing values. Discretizing is the conversion of numeric attributes into "nominal" ones by binning numeric values into intervals 2 . Missing values in ARFF files are represented with the character "?" 3 . If you replaced missing values explain what strategy you used to select a replacement of the missing values. Use and describe at least three different preprocessing techniques.
Task 5 – Data mining. Compare and contrast at least three different data mining algorithms on your data, for instance:. k-nearest neighbour, Apriori association rules, decision tree induction. For each experiment you ran describe: the data you used for the experiments, that is, did you use the entire dataset of just a subset of it. You must include screenshots and results from the techniques you employ.
Task 6 – Discussion of findings. Explain your results and include the usefulness of the approaches for the purpose of the analysis. Include any assumptions that you may have made about the analysis. In this discussion you should explain what each algorithm provides to the overall analysis task. Summarize your main findings.
Task 7 – Report writing. Present your work in the form of an analytics report.
Solution
Data choice
In order to perform the brief analysis on the selected data set, it is important to make the data suitable for analysis using WEKA tool. This tool for assignment help support only ARFF format of data and arff viewer in this tool helps to view and transfer data set into appropriate form of data (Bharati, Rahman & Podder, 2018). In this task, a data set has been downloaded which is related to the phone call campaign of Portuguese banking institution. The data set was initially in the csv format which is imported into the analytical platform. In the below figure, the csv file has been shown which was initially imported into the analytical tool. Based on the tool requirement, this data file need to be transformed into arff format.
.png)
Figure 1: Original csv data
After importing the csv file into the arff viewer, the file has been saved as arff data format to convert the data set type.
.png)
Figure 2: Transformed ARFF data
In the above figure, it has been seen that the data set has been transformed into arff format and all the attributes of the data frame is present into the dataset. The data set conversion has been successfully done to do further analysis on the selected data set.
Background information
In this project, a data set has been chosen which is related to the bank customer details. Data has been generated after getting information from clients through phone calls to predict if they are interested to invest into term policies. There are several attributes are available into the data frame. Here, the data types and other information related to the client are given. On the other hand, a brief analysis on the data frame could be conducted into the WEKA data mining tool. There are different analytical algorithms have been associated that could be utilized to classify data by considering a particular class variable. The data set has been downloaded from UCI machine learning repository. A large number of data sets are available into this website that consist of variety of topics and categories. The data set is mainly about the client details and based on the attributes present into the data frame, all the necessary analysis could be done.
In order to get proper insights and findings from the analysis, clients could be classified into two categories. Persons who are interested to invest in term policies and who are not interested in investment are the two major categories. In this project, a bank market analysis will be done to get knowledge on the investment pattern by the clients. The project is mainly focused on the data analysis by using WEKA analytical tool. Based on the given data and statistic, several essential insights could be extracted by using the analytical platform. Here, the Portuguese banking institute will be able to make crucial decision on the client engagement and investment issues. Based on the client data analysis, attractive offers and terms could be given to the potential investors. On the other hand, a complete statistics of the pervious campaign and their output could also be achieved by the analysts. In order to enhance the subscription rate into the organization, this analysis will help the organization through statistical analysis. All the major findings will be documented into this report.
In order to fulfil the project aim and objectives, WEKA data mining tool will be used that gives major features to pre-process and analysis data set. There are several benefits could be achieved by the users by using the data mining tool. Based on the data types and project objective, data mining tools could be used for multiple purposes. Business managers can obtain information from a variety of reputable sources using data mining tools and methodologies. After conducting a brief study on the selected large dataset, industry professionals can gain a number of important observations. On the other side, with analytics solutions like WEKA, a significant volume of data and information may be readily handled and controlled. Furthermore, the policy maker could make a variety of critical judgments after evaluating the information utilizing data mining methods, which could lead to positive outcomes business expansion.
Data description
A bank campaign data has been selected in this project and it will be analyzed to get vital information on the clients. It is important to understand the data set properly to make better analysis on the analytical platform. The data set consist all the major attributes related to the clients including age, marital status, loan details, campaign details, campaign outcome and some other indexes. However, all the attributes are categorized into client data, campaign data, social and economic attributes. All the attributes could be pre-processed to conduct the analysis after considering the class attribute and categories. The last attribute of the data frame is desired_target that will be considered as the target class. If the clients are interested to invest in the bank on term policies is the main focus of the entire analysis. Here, a major concern of the project is to make a brief analysis on the given data frame. On the other hand, some data pre-processing will also be done to prepare the data frame suitable for the analysis. There are several filtering features have been given by the analytical platform.
There are 19 attributes are available into the data frame and all the necessary attributes will be considered for this analysis. Here, five major attributes have been evaluated based on the importance for this analysis:
• Job: This is a major attribute that gives overview on the work filed of the client. Income level of the client could also be assumed through the job profile which could play a vital role on investments strategy of the client. In terms of business perspective, job profile of the client could play a better role to customize offers and policies of the client.
• Marital status: Based on the marital status of the client, investment tendency could be assumed. For each relationship, different financial investments are sometime done by the consumers. One the other hand, expenses of the clients also varies on the relationship status.
• Loan: Previous loan consumption or financial transaction of the client should also be considered by the business analysts of the banking institutes. This attribute tells if the client has consumed any previous loans or not.
• Poutcome: This feature is another vital thing that should also be considered to predict if the client is interested to invest or not. After each campaign, output is considered as success or failure. This would play a vital role in this analysis.
• Cons.conf.idx: On the other hand, consumer confidence index is another essential aspect that must be analyzed to predict if the client in interested in investment or not.
The above five attributes are the most essential aspects that must be analyzed to get insights on the campaign data and its possibilities. However, the campaign strategy could be changed based on the previous results and outcomes.
Data pre-processing
Data pre-processing is the primary stage that must be performed by the analysts to prepare data suitable for the analysis. During the analysis, some of the major issues are faced that must be mitigated by using different pre-processing techniques. Data cleaning, transformation and other some other operations are performed during the data pre-processing. In this task, different data processing steps have been followed to make the data frame suitable for the analysis.
Removing attribute from the data frame
.png)
Figure 3: Unnecessary attributes removed
In the above figure, two attributes including euribor3m and nr.employes have been removed from the data frame. These are the two attributes that will not provide any vital insights on campaign data.
Discretizing attributes
.png)
Figure 4: Discretizing attributes
In the above figure, four attributes have been selected that have been transformed from numeric to nominal data type. This will make the analysis easier by selecting the class data type. On the other hand, the selected analytical tool is not comfortable with the numeric data types and it gives betted visualization on the nominal values.
Removing duplicated values
Duplicated values gives wrong analytical result on the data frame. For this reason, it is important to remove the duplicated values from the data frame. In the below figure, all the attributes have been selected and then a filters has been applied to remove duplicated values from the data frame.
.png)
Figure 5: Removing duplicated values
After removing duplicated values, it has been seen that the count of each columns or categories have been reduced. After removing duplicated value, only distinct type data are present into the data frame.
These three data pre-processing steps have been introduced in this project to make the data set appropriate for the analysis. After preparing data with some pre-processing steps, all the necessary analysis and insights have been built.
Data mining
There are several data mining techniques are there that could be introduced into the data set to get proper insights and visualization on current business operations and activities. Based on the business requirement, classification algorithm could be implemented into the data frame. On the other hand, a brief analysis on the given problem context could be introduced by the users after successfully implementing the algorithms. In this task, three different algorithms have been selected and executed on the data frame.
Random Forest algorithm
Random Forest algorithm is a major type of classification algorithm that take decision on the given data set by classifying data frame into different categories. By selection random data from the data frame, decision tree is created and then based on the accuracy of each branch, decision tree gives result. In this project, decision tree has been implemented into the data frame to classify clients into potential subscribers or non-subscribers. In order to improve the accuracy of the model, average of sub samples are calculated by this algorithm.
.png)
In the above figure, a random forest algorithm has been executed on the campaign data set in order to classify the clients. All the attributes have been included in this execution and based on the cross-validation, 10 folds have been tested.
.png)
Figure 7: Output of RandomForest model
After implementing the classification algorithm, a complete statistic of the model performance have been given in the above figure. All the necessary parameters have been given in the given statistic. The developed model given about 85% of accuracy. The model has been built within 5.66 seconds. A confusion matrix on the selected model has also been created that classifies the data frame into two categories.
Naive Bayes algorithm
Naïve Bayes classification algorithm is a supervised algorithm that is simple and effective for the classification and prediction of a particular feature. It's termed Nave because it considers that the appearance of one feature is unrelated to the appearance of others. As a result, each aspect helps to identifying that it is a fetaure without relying on the others. In order to classify the identified features from the data frame, the naïve bayes classifier algorithm will set some pre-defined identifications (Hawari & Sinaga, 2019). However, this algorithm has some independences variable on the given data frame and prediction of feature is made with some probabilistic assumptions.
.png)
Figure 8: Naïve Bayes classifier
In the above figure, a naive bayse algorithm has been executed into the given data frame. The data frame has been classified into two categories that are yes and no. 10 fold cross validation has been selected as testing option. Based on some particular features, this model will classify the data frame into class variables.
.png)
Figure 9: Output of Naive Bayes model
After the implementation of the naive bayes algorithm, the above statistic has been achieved that shows all the essential parameters of the model. However, this model is able to classify the data frame with more than 83% of accuracy. Here, the confusion matrix has also been demonstrated that gives overview on the classification capability of the model.
K-nearest neighbor
In this model, new data are classified after checking the similarity with the previous data. Knn algorithm can easily classify the given data into categories based in the previous data records. Both the regression and classification models could be developed by using knn algorithm. Assumption on the underlying data are not triggered in this algorithm. However, the action performed in the training data are not quickly implemented into the test data set.
.png)
Figure 10: K-nearest neighbor
In the above figure, a lazy classifies algorithm has been executed into the data frame. The nearest neighbor will be identified based on some per-defined characteristics. Here, 10 fold cross validation process has been used.
.png)
Figure 11: Output of K-nearest neighbor
In the above figure, several performance parameters have been illustrated as output of the model. On the other hand, the confusion matrix of the model has also been introduced in the above figure.
Discussion of findings
After conducting brief analysis on the given data set, a number of vital insights have been achieved that have been discussed in this section with proper evidences.
.png)
(Figure 12: Age variable vs. desired_target)
In the above figure, it has been seen that the clients with age between 33 to 41 are highly interested to invest in term policies. The rate of investment is decreasing with increase in age of the clients.
.png)
Figure 13: Job variable vs. desired_target
On the other hand, clients with job profile in administration have maximum probability of getting subscription or non-subscription.
.png)
Figure 14: Marital status variable vs. desired_target
Here, the analysis has been done based on the marital status of the client. This shows that the married persons are highly interested to make investments.
.png)
Figure 15: Loan variable vs. desired_target
Those clients who have already taken any loans are interested to make investments. On the other hand, percentage of non-subscribers is lower who have not taken any loan.
.png)
Figure 16: Poutcome variable vs. desired_target
However, the output of the phone campaign gives a statistic that most of the campaign have not given any particular result or assumption.
.png)
Figure 17: Cons.conf.idx variable vs. desired_target
The confidence index of the consumers is another essential aspect that has also been analyzed in the above figure.
.png)
Figure 18: Cons.price.idx variable vs. desired_target
Consumer price index has been illustrated in the above figure. After categorizing the feature in terms of desired_target, some vital insights have been introduced.
References
.png)
.png)
Research
COMP1001 Data Communications and Networks Assignment Sample
Task Description:
Your task is to create a technical report of your home network and propose a plan for its improvement. Your work must demonstrate your learning over the six modules of this unit. The format of the report with requirements that you have to fulfil are detailed in the template provided with this assignment description.
In summary, your report will have to provide the following technical details:
• R1: Network topology
• R2: Network devices
• R3: Communication technologies
• R4: Addressing scheme
• R5: Network protocols and analysis
• R6: Network services
• R7: Network security and analysis
• R8: Performance parameters and analysis
Finally, your report will also provide your own analysis and assessment regarding role of computer networks in your life and study. Support your analysis and assessments with evidences.
Solution
R1: Network Topology
For network topology considering the home network two different topologies are defined in the section one is physical topology and another is logical topology. Both network topologies are described below as:
Physical Topology
.png)
As home network is a wireless network where a single router is used for internet connection and that router connected to an access point. There are four systems for assignment help which are connected to the wireless network in Star pattern that can be observed in the above figure. The physical topology shows the wireless connectivity from router to the client system. It can also be observed in the above diagram that router is directly connected with access point.
Logical Topology

The above figure define logical topology of home network that is based on data flow connection and connected client devices to the network. It can be observed how data is transfer from router to the and devices where this router is directly connected with access point. Here the data flow pattern can be changed according to the requirement and structure of the system. The installed router is able to cover a defined range where the router can provide internet connectivity to all systems which comes under this defined range.
Difference between Physical and Logical topologies
Physical topology is based on network devices which are used in selected network that consist of connection cables and network devices. As it can be seen in the above physical topology that connections cable are not used because home network is a wireless network. Instead of connection cable the wireless connectivity has shown in physical topology for home network. The router which is used is wirelessly connected to the access point that allow data communication for data flow to router and then connected devices. The physical topology for wireless network is not that complex as wire-based network contains.
The logical topology define data flow among the network devices which are used in selected network that is home network. The logical topology consist of data flow connection or representation of data flow and network devices such as router and client devices. Here home network is considered that is based on wireless network so data flow can be observed between router and devices were the main router is connected to access point for data communication. The major differences between physical and logical network topology of home network is physical topology represent cable as connection and logical topology represent data flow as connection.
R2: Network Devices
This section discusses different network devices which are used in home network. As the home network is a wireless network that consists of router-modem client devices, mobile phones and tablets.
Client Devices
Laptops
1. Model: The model of the laptop can be considered as latest model of 3rd generation. The laptop is able to connect wirelessly to any network.
2. Technical specification: The laptops are based on the 3rd generation and 5th generation that are able to connect with any wireless network. The network driver are installed in all the laptops that allow data transfer from external sources. Each laptop have feature to act as router so that other devices can connect with laptop as a wireless connection.
3. Physical Network Interface: The physical network interface consist of network adaptor that is a small integrated chip install in network devices. The laptop which are connected to the homemade work contains network adaptor that allow to connect with the wireless network for data transfer.

Router
Router is a main network device in home network that allow a wireless connection to more than one IP address for data communication. The router installed in home network allow multiple connections that can connect wirelessly such as laptops, mobile phones, tablets and desktop. Further this router is wirelessly connected to the access point.
1. Model: The model of the router connected in the Home wireless network is TP-Link Archer AX6000.
2. Technical specification: This is based on new technology such as 802.11ax with OFDM that allow to provide high speed for data communication. The speed of router is considered as 1148 Mbps with 2.4GHz and can perform up to 4804 in case of 5GHz band. This Router allows multiple Ips for wireless connection in-home network.
3. Physical Network interface: The physical network interface can be measured by using the network analyser as the speed of the router can be observed on screen.

Wireless Access Point
In computer networks wireless access point is a type of device that allow various wireless cards that can connect to all and devices without physical cables. Access points are also able to connect with LAN and create a wireless network. This is the only device that is able to connect from wired network environment to wireless network environment. Generally it is also use to transform network type at workplace or for home purpose. Wireless access point can physically connect with LAN and transform into a wireless network to all of more than two IP addresses for data communication in wireless network environment.
1. Model: The model of the Access point is Wi-Fi 6/6E (802.11ax) Catalyst
2. Technical specification: This is considered as most reliable that contains top speed of 9.6Gbps with 6TH generation 802.11 ax.
3. Physical Interface: The physical interface of this network device is reliable and strong with high speed.

R3: Data Communication Technologies and Standards
Generally, four type of wireless data communication technology are found such as wireless LAN wireless man wireless pan and wireless van. The only difference among all these four wireless data communication technologies is size or range including with connectivity requirements.
The data communication technology which is used in home network is Wi-Fi technology that is considered as one of the most common wireless data communication technology for small range connectivity requirements. Wi-Fi basically stands for wireless fidelity initiated by NCR corporation. This technology simply allows data transfer among more than one devices that is actually based on mobile computing. This technology allow devices to be mobile in nature through which devices can move from one place to another while connecting with her particular network for data transfer. Wi-Fi is basically a wireless LAN model that used for small range or size with minimum connectivity requirements. By using Wi-Fi a small wireless network can be construct from one end to another end that highly considered for home network
Technical Specification
This section discuss this about technical specification of Wi-Fi data communication technology where the most important specification is frequency band of Wi-Fi data communication technology that is 2.4GHz ISM. The bandwidth of channel for Wi-Fi data communication technology is 25 Mhz. Wi-Fi technology have half duplex with all kind of bandwidth. The technology which is used in Wi-Fi data communication is direct sequence spread spectrum.
Application of wi-fi Technology
This section discusses about application of Wi-Fi technology as Wi-Fi technology have multiple applications.
The very first and important application of Wi-Fi technology is any wireless devices which are capable to connect wirelessly can connect with internet. Wi-Fi technology is able to provide access to the internet for more than one device.
The second most important application of Wi-Fi technology is that video, as well as audio streaming, can be done wirelessly with any devices for the purpose of entertainment.
The important files and data can be shared from one system to another system through wireless connection easily. There is another important application where Wi-Fi can be used as hotspot that will allow other devices to get access for the internet. That actors which are installed in Wi-Fi are non for spreading radio signals by using the owner network for providing hotspot to other devices. Wi-Fi data communication technology can also be used for poisoning system.
Wi-Fi standard
The Wi-Fi standard which is used for home network is IEEE standard 802.11g that provides a frequency of 2.4 GHz with a maximum speed of 54 mbps. This is standard is considered as quite common for the home network.
R4: Addressing Schemes
This section discusses the addressing schemes of home networks where each network devices has IP addresses for data communication. The physical and logical addresses for the connected devices in home network is defined considering the data transfer. The IPv4 Address is 192.0.2.1 where IPv6 Address is 2001:db8::1. The IP address of the Router is 192.168.1.1.
IP address is considered as logical address which is actually assigned by the software application in system or in router for data communication with other devices. In home network IP address is assigned to all the connected devices such as router laptops and other devices.
R5: Network Protocols
The wireless network protocols which is used in home network is 802.11g that generally a combination of 802.11a and 802.1 b. In this section wire Shark network analyser is used to analyse the technical specification of used wireless network protocol that is 80 2.11 g.
The above 2 pictures define status of package transfer and network traffic identified by the wireshark network analyser. Network protocol is basically basic guidelines which are made for data communication. The wireless network protocol called 802.11 g is considered as family network protocol standard that allow connection of multiple devices. The collection of protocols that contains multiple protocols for different purpose and functions is TCP /IP. This version of the network protocol is derived from the previous version where generally one version of the network protocol is transform in another updated version based on the requirements of connectivity and innovation in networking technology. As it can be absorb in the above figure that logical addresses of connected devices are shown while packet transfer.
R6: Network Services
In this section of the report network services will be discussed that allow to provide different type of services to client system. They are two important network services which are discussed in this section such as DHCP service and DNS service. Here DHCP services define dynamic host configuration protocol and DNS service define domain name system.
DHCP service
DHCP is a type of protocol that is used for network management where DHCP is responsible for assigning IP addresses to all the connected network devices so that they can communicate over a network utilising the allotted IP address. By using this service IP address can be assigned to any network devices which are connected or going to connect within a wireless network. The device with mobile nature IP addresses are changed while moving from one place to another so DHCP assign IP addresses to each location.
The DHCP server address is 192.168.29.122 and the DHCP client address is 10.1.1.100/24. The scope of IP address is defined and checked using command prompt.
The the DHCP service can be found almost every network in infrastructure that is based on wireless or wire based network because for every wireless network wireless devices are used that are mobile in nature. For sach devices which are mobile in nature required temporary IP addresses and these temporary IP addresses assign by the DHCP service.
DNS service
Domain name system or DNS service is considered as phone book over the internet where humans while using the internet utilise domain names for assessing any information. Suppose a user typed isko.com then isko.com is a domain name that is used by user for assessing information. Here the browser use IP address and DNS service change domain name into IP address so that browser can find the relevant information by using the IP address from the server. DNS service simply reduce the complexity of remembering IP address that is actually difficult to remember by humans. So human can use website name or domain name for searching any information and DNS service translates these domain name into IP address through which required information can be access by browser easily. There is a simple purpose of DNS that is converting the horse name to IP address that is actually a system friendly.
The DNS IP address is 192.168.29.122.
R7: Network Security
Network security is one of the major concern that are discussed by many exports in literatures and articles. The network security exports continuously working on innovation in network security field so that numerous of attack and losses due to the attacks can be minimised. This section discusses about network security measures and the possible attacks on home network.
The common types of network security measures are intrusion prevention system, firewalls and intrusion detection system. These three are the common parameters based on which network security can be analysed where intrusion prevention system help in preventing home network from external attacks and intrusion detection system help in detecting the possible attacks from external sources over home network. Firewalls are the another important network security measures that will help in filtering out the malicious link and data from open source platforms
Top three Attacks
1. Malware: Malware attack is a very common type of attack where malicious link or file downloads automatically while using the internet or downloading any files from the internet. This attack include is stealing information or data from the system with the help of malware downloaded while using internet.
2. DoS attack: Daniel of service attack is another common type of attack where the network gets shut down and unable to access by the user. This can cause network flooding or high traffic on home network.
3. Phishing Attack: In this type of attack malicious link or email sent to the target system where user click on that link unknowingly and convert into a victim of attack.
R8: Performance Parameters
This section discusses about the performance parameter of home network with some basic parameters such as:
Bandwidth = 2.4Ghz
High speed = 54Mbps
Coverage area = More then 802.11a and 802.11b
Research
ITBO201 IT for Business Organisations Assignment Sample
ASSESSMENT DESCRIPTION:
Students are required to write a Reflective Journal in which they reflect on unit content and learning experiences between weeks x and y. In this assignment, you should describe an interesting or important aspect of each week’s content/experiences, analyse this aspect of the week critically by incorporating and discussing academic or professional sources, and then discuss your personal learning outcomes.
The document structure is as follows (2500 words):
1. Title page
2. Introduction (~150 words)
a. Introduce the focus of the unit and the importance of the unit to your chosen professional area. Provide a preview of the main experiences and outcomes you discuss in the body of the assignment.
3. Body: Reflective paragraphs for each week from week x to week y (1 paragraph per week, ~200 words per paragraph). In each reflective paragraph:
a. DESCRIPTION (~50 words): Describe the week
o Generally, what was the focus of this week’s lecture and tutorial?
o What is one specific aspect of the week’s learning content that was interesting for you? (e.g. a theory, a task, a tool, a concept, a principle, a strategy, an experience etc.)? Describe it and explain why you chose to focus on it in this paragraph.
b. ANALYSIS (~75 words): Analyse one experience from the week
o Analyse the one specific aspect of the week you identified above.
o How did you feel or react when you experienced it? Explain.
o What do other academic publications or professional resources that you find in your own research say about this? (Include at least 1 reliable academic or professional source from your own research). Critically analyse your experience in the context of these sources.
c. OUTCOMES (~75 words): Identify your own personal learning outcomes
o What have you learned about this aspect of the unit?
o What have you learned about yourself?
o What do you still need to learn or get better at?
o Do you have any questions that still need to be answered?
o How can you use this experience in the future when you become a professional?
4. Conclusion (~100 words): Summarise the most important learning outcomes you experienced in this unit and how you will apply them professionally or academically in the future.
5. Reference List
Your report must include:
• At least 10 references, 5 of which must be academic resources, 5 of which can be reliable, high-quality professional resources.
• Use Harvard referencing for any sources you use
• Refer to the Academic Learning Support student guide on Reflective Writing and how to structure reflective paragraphs
Solution
Introduction
In this report all the weekly summaries are present. In the different week, we study the different types of technologies, management techniques, and many more which is very helpful in both type of organizations that is big and small. We research with the different types of study material and weekly lectures and find out the best technologies from every week and discussed in the report. In this paper the reflecting summary of every week is discussed. This paper is important in the terms of information security and information technologies. From the development of the computer to the emerging technologies development all the things are described in the report. As we have seen that the rising in technologies also raises some risks, attacks, phishing, and many more. So in this paper different type of risk management techniques is also discussed. The report is consisting of the overall summary of how the computer is developed to how we manage all the information technology and security for assignment help.
Week 1 –
Chapter 1 Information Security
In week 1 we are focused on the learning of Information security. After successfully learning in week 1 the student is familiar with some concepts of information security which are described as below:-
• The information security concept.
• The history of information security
• How information security is important in the system development cycles.
The main thing that is very interesting in week 1 is merging information security with the system development life cycle. In my opinion including the system security in the system, the development life cycle is much beneficial in the terms of security because if our system is secure then we will secure for the cyberattacks and many unwanted things that are occurred in today’s era. As we see that software development life cycle is generally considered with the 6 phases but if we add one more phase which is system security then we protect all the things from attack in development itself. I learned how system security is important in our day-to-day life and how we manage both the system and security at a low cost. I learned the most important thing from this week's lecture is that “As we have seen the technology is increased day by day so we also look into the security and modified ourselves to protect from the data breaches and cyber-attacks.” (Bidgoli, 2019, p. 12)
Week2-
Chapter 2 Machine Based Computing
In week 2 we are focused on the learning of Machines behind Computing. After the successful learning in week 2 the student is familiar with some concepts of Machine Behind Computing which are described as below:-
• The computer hardware and software
• Understand the computer operations
• Understand the different input, output, and memory devices.
Job management, resource allocation, data management, and communication-related thing are present in the week 2 lecture. In my opinion, the main thing which is very interesting in the overall week 1 lecture is the memory device because in this era the need for memory is a high priority. The thing or the topic which is very much interesting and the helpful is the Operation that is performed by the Computers there are three basic operations of the computer which are arithmetic, logical and storage. I learned that without memory management all the function we have done is waste. Without memory we have not correctly organized things so for this purpose memory management in the computer or the software is a must. I chose memory management because in my opinion if we correctly manage memory then after this management of the entire task is very easy.
Week 3-
Chapter 3 Database System
In week 3 we are focused on the learning of Database systems, Data warehouses, and Data Marts. After successfully learning in week 3 the student is familiar with some concepts of Database System, Data Warehouse, Data Marts which are described as below:-
• Understand the database and the database management system, data warehouse.
• Understand how the logical database and the relational database are designed.
• Understand the full lifecycle of the database management system, data warehouse.
• Understand the database uses and design.
• Understand Big data and their different application
The main thing which is very much interesting in week 3 is the big data and its various business applications. I chose this topic for the discussion because the big data is everywhere for example:-social media, entertainment, financial services, government, manufacturing, healthcare, and many more things are depends on big data. I chose this topic because there is vast scope in the field of big data also it is famous in the today’s era. It is said that people or users depending on the social network or technology for their daily activities and both generate a lot of data in a single day so in the future the world depends on big data. (Bidgoli, 2019, p. 31)
Week 4 –
Chapter 5 -Protecting Information Resources
In week 4 we are focused on protecting information resources. After successful learning in week 4 students are familiar with some concept of how to protect the information system or resource which is mentioned below:-
• Understand the different types of technologies that are used in the computer system/.
• Understand the basic safeguard in the computer and network security
• Understand the major security threats
• The Security and enforcement measure is understood.
In week 4 the very interesting topic is the risk associated with information technologies. In a big organization, risk management is a very interesting topic. How they handle the risk is very important in a large-sized organization. It is seen that in the future as the technologies are increasing so the cyberattack, phishing through email, D-Dos attacks is also increased. So in this way, risk management in every type of organization is a must. By preparing the risk management plan we can protect our organization and ourselves from the various attacks that is held today or in the future. In the future cyberattack which is very common is phishing, email attack, D-Dos Attack and many more. The attacker always catches to the weak point of organization so we need to change our risk management policy and make it strong. (Bidgoli, 2019, p. 21)
Week 5 –
Chapter 14 Emerging Technologies, Trends and Application
In week 5 we are focused on emerging technologies, trends, and their application. After successful learning in the week, the student is familiar with some concepts of an emerging trend, technologies, and application which are described below:-
• Understand the new trends in the software
• Understand the virtual reality components and applications.
• Understand cloud computing, nanotechnologies, blockchain technologies.
In week 5 the most interesting topic according to me is blockchain technology. In simple words block technologies means the decentralized and distributed network. The blockchain is used to record transactions across connected devices as blocks of data that cannot be altered after being recorded. In week 5 we study different case studies of the company for the blockchain technology we understand the Wal-Mart case study. I chose this topic for discussion because due to the high security in blockchain management or development the transaction is proceeding at a faster rate. (Bidgoli, 2019, p. 31) In the future the application which depends on the blockchain are described as below:-
• For the tracking foods and the goods.
• In the security of the software development
• The management of digital content
• To improve the healthcare record
• In the audit Trial
Week 6 –
Chapter 11 Enterprises System
In week 6, we are focused on the learning of the Enterprise Systems. After successful learning in week, 6 students are familiar with some concept of enterprise system which is described as below:-
• Understand supply chain management.
• The customer relationship management and the management systems.
• An understanding of the enterprise resources planning system is gained.
In week 6, we understand different type of application that is used in the management of the technology and the business. In week 6, the topic which is most interesting is the supply chain. In simple word, the Supply chain means the network which is consisting of an organization, supplier, transportation companies, and brokers. Supply chain management is used the delivery goods and services to customers. This topic excites me most because in the era of online supply management is a must. As we have seen that people purchase the goods, product, service, and essential materials of daily lives online. So in this way, the management of the supply chain is a must in the future. A healthy relationship is made between the suppliers, organizations, transportation companies, and brokers. Due to this healthy relationship, the supply chain is managed perfectly. To ensure the business or organization growth we manage supply chain perfectly. (Bidgoli, 2019, p. 52)
Week 7 –
Chapter 8 E-Commerce
In week 7 we are focused on E-commerce. After successfully learning in week 7 the student is familiar with some concepts of E-commerce and the E-commerce platform which is described as below:-
• Understand the concept of e-commerce, its advantages, disadvantage, and also business models.
• The different categories of e-commerce and the lifecycle of the e-commerce cycle.
• Understand the social media, mobile-based, and voice-based e-commerce in the market.
In simple words, e-commerce means all the activities like selling and buying that are performed using computers and communication techniques. In week 7 we focused on the many case studies like star bucks company, coca-cola, and many more by which we can easily be familiar with the e-commerce business models. In my opinion, the thing that is more interesting in week 7 is the online service delivered by e-commerce. The e-commerce service helps the youth and old age to provide them good services. In the future, the e-commerce sector is on the boom. With the increase in technology, people used mobile in many modes like for shopping, for bill payment and many more. So in this way, the e-commerce sector is on boom in the upcoming generation. E-commerce provides many facilities to make it easy for everyone to use mobile services like voice assistance, direct messaging system, and many more. The boom of technology also made payment services very easy in an e-commerce application. (Bidgoli, 2019, p. 67)
Week 8 –
Chapter 10 Building Successful Information System
In week 8 we are focused on building a successful information system. After successfully learning in week 8 the student is familiar with some concepts of how to build the information systems which are described as below:-
• Understand the system development life cycle in the building of successful software.
• The different type of phase that is involved in the software development life cycle that is the planning phase, requirement gathering phase, analysis phase, design phase, implementation phase, and maintenance phase.
• The new trends in the system design are also introduced in this lecture.
The most interesting part of week 8 is the new phase that is involved in the software development life cycle. It seems that the procedure is very much important in software development but choosing the right one is difficult. So in this week all the phases and models are clearly described. The model which I suggest is an agile methodology, in this week I studied different case studies and I recommended that agile methodology is very much beneficial. In the future, the agile methodology is at its peak because it follows the weekly or we can say that time sprint. In a particular time sprint, the task is to be done so in this way project is delivered on the given time. That is the reason big company follows the agile methodology in the software development life cycle. (Bidgoli, 2019, p. 90)
Week 9-
Chapter 12 Management Support System
In week 9 we are focused on the management support systems. After successful learning in week 9, the student is familiar with some concept of management support system which is described as below:-
• Understand how the big organization makes decisions and maintain those decisions.
• Understand how the decision support system works.
• How the geographic information is important.
• Guideline for designing a management support system.
In week 9 we understand the concept of decision making also means how the big organization takes decisions. The Decision is also taken in the three-phase which are structured decision, semi-structured decision, and unstructured decisions. In this week 9, the most interesting topic is decision making in the organization or we can say that in the big organization. In the process of decision making every type of decision like payroll, inventory problem, record keeping, budget preparation, and sales forecasting are involved in it. In the future, this type of decision is taken with the help of artificial intelligence and we know how artificial intelligence is on the peek in the future. It is seen that every industry depends on the decision process. So the process of decision-making in week 11 excites me most. (Bidgoli, 2019, p. 103)
Week 10 –
Chapter 13 Intelligent Information System
In week 10 we are focused on the Intelligent Information System. After successfully learning in week 10 the student is familiar with some concepts of how the intelligent information system which is described as below:-
• Understand artificial intelligence and how AI technologies support decision-making.
• The expert system and the application or the components.
• The case-based reasoning
• Different types of logic like fuzzy, case-based logic, genetic algorithm, natural processing, and many more.
In week 10 the most interesting topic according to me is artificial intelligence. In simple words, artificial intelligence is a technology that is try to simulate and reproduce human behavior. This technology is applicable in different sectors that as perception, reasoning, cognitive abilities, and many more. It is seen that artificial intelligence have a great impact on both industries and human being. In the future, artificial intelligence is everywhere like robot techniques, Internet of things techniques. In every field, artificial intelligence is used. It is seen that in the future artificial intelligence is on the boom because in many fields artificial intelligence works in the field of marketing, in the field of medicine, in the field of management, and the field of safety. Artificial Intelligence also developed the automated car and we see that the car and medical sector is a very large sector so in this way we can say that the artificial intelligence sector is on boom in the future. (Bidgoli, 2019, p. 120)
Week 11 –
Chapter 7 -Internet, intranets and extranets
In week 11 we are focused on the internet, intranets, and extranets. After successful learning in week 11 the student is familiar with some concepts of the internet, intranets, and extranets in the information security system which is described as below:-
• Understand common internet service
• The purpose of intranets, extranets.
• Understand the Internet of everything
• The navigation tools, search engines, and directories.
In this week 11, there are many concepts which I have learned that is a different type of browser for more security like Google, Chrome, brave and Mozilla Firefox. The most interesting thing that is in week 11 is the new concept that is the internet of things which means it is web-based development in which people process the data which is connected with the internet and other various things like OR Codes, barcodes, and many other devices. The future of the IoT is very bright. It is estimated that 30.9 billion IoT projects are developed in the year 2025. In 2025 by the use of the Internet of things, more cities become very smart. To save the most of company and cities are using smart technologies and these smart technologies are generally made with the Internet of things. (Bidgoli, 2019, p. 78)
Conclusion –
In this report, we learned the different technologies that are very emerging and in the future, these technologies are on the boom like nanotechnologies, big data, and artificial intelligence and robot techniques. As a student after researching and learning all the week's concepts, we are familiar with the topic and find out that every technology depends on others so we have to try to use this technology and maintain the risk that is present in the technologies. As we see that different technologies are mentioned in the report so as a student the very interesting technology is risk management because we see that as an increase in the technology the risk is also increased so that risk management is a must.
References List
.png)
.png)
Research
SYSS202 System Software Assignment Sample
ASSESSMENT DESCRIPTION:
Students are required to write a Reflective Journal in which they reflect on unit content and learning experiences between weeks x and y. In this assignment you should describe an interesting or important aspect of each week’s content/experiences, analyse this aspect of the week critically by incorporating and discussing academic or professional sources, and then discuss your personal learning outcomes.
The document structure is as follows (3000 words):
1. Title page
2. Introduction (~150 words)
a. Introduce the focus of the unit and the importance of the unit to your chosen professional area. Provide a preview of the main experiences and outcomes you discuss in the body of the assignment.
3. Body: Reflective paragraphs for each week from week x to week y (1 paragraph per week, ~250 words per paragraph). In each reflective paragraph:
a. DESCRIPTION (~50 words): Describe the week
• Generally, what was the focus of this week’s lecture and tutorial?
• What is one specific aspect of the week’s learning content that was interesting for you? (e.g. a theory, a task, a tool, a concept, a principle, a strategy, an experience etc.)? Describe it and explain why you chose to focus on it in this paragraph. (*Note: a lecture slide is not an acceptable choice, but an idea or concept on it is)
b. ANALYSIS (~100 words): Analyse one experience from the week
• Analyse the one specific aspect of the week you identified above
• How did you feel or react when you experienced it? Explain.
• What do other academic publications or professional resources that you find in your own research say about this? (Include at least 1 reliable academic or professional source from your own research). Critically analyse your experience in the context of these sources.
c. OUTCOMES (~100 words): Identify your own personal learning outcomes
• What have you learned about this aspect of the unit?
• What have you learned about yourself?
• What do you still need to learn or get better at?
• Do you have any questions that still need to be answered?
• How can you use this experience in the future when you become a professional?
4. Conclusion (~100 words): Summarise the most important learning outcomes you experienced in this unit and how you will apply them professionally or academically in the future.
5. Reference List
Your report must include:
• At least 10 references, 5 of which must be academic resources, 5 of which can be reliable, high-quality professional resources.
• Use Harvard referencing for any sources you use
Solution
Introduction
System software, various operating systems, and the functions of key parts of the system are needed to be understood inevitably to operate the systems effectively. Operating systems and storage systems are the key parts of a system. The functions of these parts are essential to be understood to manage the operations through the systems effectively. Furthermore, the networking system, file manager, and many more key resources are described properly through the weekly materials to make the learners understand the complex operational functions of the computer systems. A learner can understand the importance of every key function of the computer system with proper and in-depth knowledge. Memory, security systems, and ethical operations of the computer systems are also described in this report for assignment help. User interfaces, Graphical user Interfaces (GUI) are also described in the report. Reflective analysis of my learning about the use of different functions and operating systems of computers has been portrayed in this report.
Week 1: Functions of various operating systems
The week 1 lecture provides knowledge regarding the functions of various operating systems and their roles in the systems. I have gained in-depth knowledge about operating systems and software, and hardware. Planning design of the software in the computer system through this lecture material provides a detailed analysis of computer operations and management (Fakhimuddin et al. 2021, p-24). Programs, tangible electronic machines, and many more parts and their operational activities guide the proper management of a computer system.
File manager, main memory, and many more functional parts are inevitable for operating the computer system. I have gained knowledge regarding the classification of various software and hardware operations of a computer system. Operating systems coordinate many systems to work together for better productivity. Memory, storage devices, different applications, and many more roles and responsibilities of various key parts of a system have been taught. RAM and ROM and their functions based on volatile and nonvolatile nature are inevitable to understand the storage and memory of a system (Ayadi et al., 2021, p-20). Input and output devices as well as peripheral devices such as "mouse," "keyboard," "printer," "scanner" and many more perform various necessary key operations of the computer systems.
As I have gained major knowledge about the parts and operating system, it would be very beneficial to perform all the functions effectively. The use of input and output devices helps to perform various necessary tasks with one system. Software applications help perform the core operational activities of the system and maintain the coding and database of the system. The database manages important information of any application and system also (Shukla et al. 2018, p.16). I understand using these key operating functions for mastering the system for any complex work. I have also learned about the data manipulation and retrieval of deleted data in the system in any emergency.
Week 2:memory and space allocation and de-allocation of the computer system
Week 2 describes the knowledge about the memory and space allocation and deallocation of the computer system. The concept of the replacement of pages, allocation of pages, and the function of paging in the system are provided in this session. I have also gained knowledge regarding using various memories such as cache memory and many more, which is essential to be understood for operating a system. I am very glad to know the operational activities of various paging operational activities of the system. The paging operations provide me with detailed knowledge regarding the page setup and various designs of the pages (Shukla et al. 2018, p-30). Page frames for various programmable key factors help understand the design of pages for different operations in a system. I am very glad to know about these kinds of interesting facts about the system's different major paging operations. I can use this knowledge to understand the system's operational activities for designing various pages for programs. The knowledge I gained has helped in completing the operational activities of the computer system for better management. As this basic knowledge is essential for me to understand the system in detail, the functions assist me to perform all kinds of important operations for my career growth. Page setup is quite an important factor for the system to create documents and programs (Youssef et al. 2018, p-20). Thus, I have understood the page framing and important operational performance of this page replacing and allocation for the system, which has made the system's functions easier for me.
Week 3:Device management system
Description
The device management system is one of the most important parts of the computer system (Kaluarachchilage et al. 2020, p-1). The session has provided me with knowledge about device management systems to understand the use of computer systems better. Advantages and disadvantages of various devices of the computer system have been a part of this session so that I can understand the operational management of various functions and malfunctions of the system. I am very excited to implement the knowledge of many devices that can easily make various operational performances of the system. Operations of various devices help to perform many works simultaneously. DSD (Direct Action of Storage Devices) helps to perform all the data storing operations effectively (Prakoso et al. 2020, p.157). Furthermore, the knowledge assists me in using the proper timing of implementing many functions of the key parts of the computer operations. Various devices such as "printer," "plotter," "drive," and much more help in performing various activities in computer systems. Detailed understanding of the storage and functions of many devices makes the user operational process for the computer system easier. The input and output of various data storage of the system make the system perform well and effectively (Prakoso et al. 2020). The session has provided me with such knowledge, which is essential for performing various operations. The use of this knowledge also makes me an expert at the performance of different complex problems of the systems.
Week 4:Different processors
The week 4 sessions has depicted a clear understanding of different processors and their detection process in the system. Processors are the key part of a system that performs the core operations for the system (Scalfani 2020, p.428). The performance regarding providing instructions for operating different programmable languages and software applications is inevitable to understand. I have understood the core functional areas of the computer system with the application of different programmable languages. Furthermore, the operating system is based on "deadlock," "real-time systems," "resources," and many more for better knowledge. “Modelling deadlock” for the operations of programmable languages is quite interesting to understand while understanding the graph cycle of data process to resources (Syuhada 2021, p.1335). This graph cycle of process data as resources helps to complete the operations of computer systems effectively. I have also learned the procedures of allocating multiple devices at a time with a single system with the use of proper databases. Knowledge of databases and multiple processors helps to persist the knowledge regarding managing various job operations. Furthermore, access to different file requests provides me with in-depth knowledge of different programs and files. The computer operating systems understand locking levels and data integrity (Li et al. 2021, p.522). Locking and accessing processes of different files have also been understood. Thus, this session has made me understand properly to learn the proper locking and data management effectively.
Week 5:System management
Week 5 provided me with complete and detailed knowledge of system management of the computers. Monitoring of systems and the protection of database management in the system have made me understand computers' complete functions (Wang and Lu, 2019). Evaluation of operating systems and strengths and weaknesses of the system based on hardware and other devices and software applications also. I have gained immense pleasure by learning the application of database protection and system management. As system management is one of the most important parts of a computer system, the session has helped me understand it. However, I realize that I need more detailed and in-depth knowledge regarding the practice of database management. More clarity will help me to perform the hardest operational activities also. Algorithms and the use of the CPU (Central Processing Unit) have also been discussed in this particular session (Wang and Lu 2019). I need more clarity in understanding algorithms as it is a difficult part and one of the most important parts of the system. The knowledge regarding system management and algorithms is not quite satisfactory for me to perform any important task effectively. Operations of multi programs are one of the most beneficial factors of the system, which makes the operational activities of computers easier (Wang and Lu 2019). Furthermore, I have also gained immense knowledge about patch management and operational accounting activities. However, a clearer understanding and in-depth knowledge of algorithms are essential for better management.
Week 6:File management
The session has mainly focused on operations and clarity regarding file management which is inevitable to store the data in computer systems. Furthermore, the role of various extensions for various file formats in the system has provided me with knowledge regarding the storage and management of databases. Furthermore, access to different files and data protection control are very important for different functions of computer systems. I have understood that a complete knowledge of file management systems is essential for storing important information in computers. Furthermore, the compression process of data for file storage and procedures of controlling data is quite important for the systems (Ayoubi et al. 2018). The knowledge is very beneficial for me to manage the data of different files with different extensions. As the file manager operates the functions of different files, the organisation of different files is quite important for the effective use of the storage and memory space of the system. Collaboration of data management and the functions of different software in modifying and controlling data is quite important for the system. Management of files and control and access to data are essential parts of the computer's system (Ayoubi et al. 2018). I have gained immense knowledge about the management of different files in the system so that the access of the files can be handled properly. Functions of different files help me understand the access of different parts effectively so that program libraries can be operated effectively.
Week 7:Network functioning
Session of week 7 refers to a basic knowledge of network functioning for the computer system. This session has highlighted the introduction of various networking systems and their responsibilities. Furthermore, the comparison between NOS (Network Operating Systems) and DOS (Distributor Operating system) has been discussed in this session (Ayoubi et al. 2018, p.23). The performance of this network management system has been described in this session which is very beneficial for me to understand. Network management is one of the most important computer system factors (Saadon et al. 2019). I have understood the complete and detailed knowledge of network management with a properly explained session this week. The variance of local operating systems and their relation to NOS has made me understand how to allocate file management and data computing for a particular system. I have also understood the various functions of local operating systems and the distribution of different files based on different data. Application servers and many other user interfacing systems have been explained effectively to better understand the chapter of networking management. Server running systems and application running of computers help operate different functions in a single system effectively (Saadon et al. 2019). This session has helped me understand the clear knowledge of network management and the relation to operating systems of the computer. This exercise has helped me to manage the clients in my workplace, which has been very beneficial for me. Furthermore, I have gained some effective knowledge that has helped me start my new career regarding new business related to software applications based on networking management.
Week 8: Basic structure of security
Week 8 sessions has outlined a basic structure of security of computer systems effectively. Furthermore, data security is one of the major concerns in the cyber world. Different viruses often break the security chain of the computer system so that the appropriate advanced technologies can be implemented to maintain the security thread of the system (Saadon et al. 2019). The role of various OS (Operating Systems) in managing data security has also been depicted in this session. Ethical practices have also been discussed in the session while maintaining the system's security. Systems operational activities and key functional areas are discussed in the system, which has helped me learn to maintain computer systems' security. I am very excited to understand the relations of operating systems with the security and ethical practices of the computer. My knowledge regarding the maintenance of the system's security has helped me understand the proper implementation of protection to protect important data. Viruses, worms, and many other cyber threats often break the security chain (Muslihah and Nastura 2020). Proper ethical practices are needed for better management of computer operations effectively.
Outcomes
The knowledge of security maintenance has helped me pursue my career in the data security management of computers. As this chapter is quite interesting for me, it has provided me with a curiosity to know the advanced level of technology that helps maintain computer security (Muslihah and Nastura 2020). I have learned about data backups, retrieval of data, and advanced level technology to manage the system's security.
Week 9:Data operating systems
Description
Session 9 has provided me with great knowledge regarding data operating systems and data survival management. I have experienced data management by implementing proper server technologies in the system. Furthermore, the operating system has managed to operate the system's important functions, which can run the software and hardware operations effectively (Muslihah and Nastura 2020). Network and security management are major key operational functions of the system. The operating systems have the responsibility regarding the management of operating systems. Furthermore, I have learned the implementation of different operational functions to manage better important data and resources, which is quite beneficial for me to make data confidential. The session has also depicted the advanced level technology while performing the tasks and managing different operations (Talha et al. 2019, p.72). Various operating systems have performed the key functions in the computer system while performing the knowledge. Data management knowledge and theories based on advanced technologies have helped me pursue my career in data security management systems. Deallocation and reallocation of data and knowledge based on the practices of various software and hardware applications have provided me with immense knowledge about computer operational activities and their progress. Furthermore, the data management system has helped me perform all the database and code practices activities, which help me understand computers' functions (Muslihah and Nastura 2020).
Week 10:Different windows operating systems
This session has mainly described the functions of different windows operating systems and the management activities of the computer. File drives and customisation of different software of the systems are the core parts of the computer systems. Furthermore, memory management and virtual memory space-based learnings have been provided to better design windows systems. Security-based challenges and various computer processors are depicted in this session (Talha et al. 2019). I feel the knowledge I learned through this session is quite important to understand the core functions. Furthermore, communication of interprocess management and different versions of windows have provided me knowledge regarding the implementation of various important tasks. From the initiation of “Windows XP" to “windows version 10.0” have seen the progress of development of different processes of computer systems in the recent era (Talha et al. 2019). Newest versions have helped to perform various incredible tasks within a very short period of time. I have gained a great deal of knowledge regarding various operating systems from DOS to the upgradation of newest software applications. This kind of knowledge has helped me to pursue my career in a better way so that the operations of different tasks can be maintained effectively. Furthermore, I have also understood a detailed practice of many operating systems and programmable languages along with networking based products.
Week 11:Linux operating systems
Session 11 has focused on the practice of Linux operating systems and the management of different software interrelated to these operating systems of computer. Role of different memory, devices and file management to the operational activities of computer systems have been provided in this session (Wang et al. 2020). Responsibilities of different software applications interlinked to “Linus Torvalds” are depicted in this week to understand the basic operational functions of “Linux Operating System”. I am quite excited by learning the operational practises of computer systems and the management of different machine languages. Role and functions of different software applications for operating “Linux” based systems (Wang et al. 2020). Portability of programs and system software are quite important parts of the systems. I have experienced better practice regarding the knowledge of main memory as well as user interface systems. The knowledge is quite effective for managing any difficult tasks with proper clarity. Various roles and responsibilities of the computer system are quite important for me to perform any kind of task effectively. The basic knowledge of operating systems especially “Linux” has helped me to understand the effectiveness of the management based functions (Wang et al. 2020). Various functions such as different software and hardware applications are quite essential for me to perform different tasks of the computer in a greater way.
Conclusion
Various management and operational functions of computer systems are the major focus areas of the sessions. The sessions have provided me with great knowledge regarding the management of different functions and roles as well as responsibilities. Furthermore, implementations of different advanced technologies have been provided for a clear understanding of the system. Protections of important data and data manipulation have become one of the most important highlighted areas of the systems. Security management and server management based knowledge have also been provided for better practise of the computer system so that the operations have been performed well in the systems. System software and hardware based knowledge have also been provided for my better career in this field and performing any complicated tasks in this field.
References
.png)

Research
TITP105 The IT Professional Assignment Sample
ASSESSMENT DESCRIPTION:
Students are required to analyse the weekly lecture material of weeks 1 to 11 and create concise content analysis summaries (reflective journal report) of the theoretical concepts contained in the course lecture slides.
Where the lab content or information contained in technical articles from the Internet or books helps to fully describe the lecture slide content, discussion of such theoretical articles or discussion of the lab material should be included in the content analysis.
The document structure is as follows (3500 Words):
1. Title Page
2. Introduction (100 words)
3. Background (100 words)
4. Content analysis (reflective journals) for each week from 1 to 11 (3200 words; approx. 300 words per week):
a. Theoretical Discussion
i. Important topics covered
ii. Definitions
b. Interpretations of the contents
i. What are the most important/useful/relevant information about the content?
c. Outcome
i. What have I learned from this?
5. Conclusion (100 words)
Your report must include:
• At least five references, out of which, three references must be from academic resources.
• Harvard Australian referencing for any sources you use.
• Refer to the Academic Learning Skills student guide on Referencing.
GENERAL NOTES FOR ASSESSMENT TASKS
Content for Assessment Task papers should incorporate a formal introduction, main points and conclusion.
Appropriate academic writing and referencing are inevitable academic skills that you must develop and demonstrate in work being presented for assessment. The content of high quality work presented by a student must be fully referenced within-text citations and a Reference List at the end.
Solution
1. Introduction
The main aim to write this reflective journal report is to analyse the lectures of weeks 1 to 11 regarding ethics in information technology. This reflective journal will describe various roles for IT professionals and social, personal, legal and ethical impacts arising from their work. The role of the professional associations which are available to IT professionals will also be described in this reflective journal. It will assess the relationship between IT professionals and the issues of governance, ethics and corporate citizenship. I will critically analyse and review the IT professional Codes of Conduct and Codes of Ethics in this reflective journal report. This will help to develop a personal ethical framework for best assignment help.
2. Background
Technology offers various opportunities and benefits to people worldwide. However, it also gives the risk of abolishing one's privacy. Information technology must conduct business or transfer Information from one place to another in today's era. With the development of Information Technology, the ethics in information technology has become important as information technology can harm one's Intellectual property rights. Ethics among IT professionals can be defined as their attitude in order to complete something base on their behaviour. IT professionals need to have high ethics to process the data to control, manage, analyse, maintain, control, design, store and implement. Information Technology professionals face several challenges in their profession. It is their role and responsibility to solve these issues. The ethics of information technology professionals guide them to handle these issues in their work.
3. Content analysis
Week 1
a. Theoretical discussion
i. Important topics covered
In week 1, an overview of Ethics was discussed. Ethical behaviours generally accepted norms that evolve according to the evolving needs of the society or social group who share similar values, traditions and laws. Morals are the personal principles that guide an individual to make decisions about right and wrong (Reynolds, 2018). On the other hand, the law is considered as a system of rules which guide and control an individual to do work.
ii. Definitions
Corporate Social Responsibility: Corporate social responsibility adheres to organisational ethics. It is a concept of management that aims to integrate social and environmental concerns for promoting well-being through business operations (Carroll and Brown, 2018, p. 39). Organisational ethics and employee morale lead to greater productivity for managing corporate social responsibility.
b. Interpretation
The complex work environment in today's era makes it difficult to implement Codes of Ethics and principles regarding this in the workplace. In this context, the idea of Corporate Social Responsibility comes. CSR is the continuing commitment by a business that guides them to contribute in the economic development and in ethical behaviour which have the potentiality to improve the life quality and living of the employees and local people (Kumar, 2017,p. 5). CSR and good business ethics must create an organisation that operates consistently and fosters well-structured business practices.
c. Outcome
From these lectures in the 1st week, I have learned the basic concepts of ethics and their role and importance in business and organisation. There are several ways to improve business ethics in an organisation by establishing a corporate code of ethics, establishing a board of directors to set high ethical standards, conducting social audits and including ethical quality criteria in their organisation's employee appraisal. I have also learned the five-step model of ethical decision making by defining the problem, identifying alternatives, choosing an alternative, implementing the final decisions and monitoring the outcomes.
Week 2
a. Theoretical discussion
i. Important topics covered
In the 2nd week, the ethics for IT professionals and IT users were discussed. IT workers are involved in several work relationships with employers, clients, suppliers, and other professionals. The key issues in the relationship between the IT workers and the employer are setting and implementing policies related to the ethical use of
IT, whistleblowing and safeguarding trade secrets. The BSA |The Software Alliance and Software and Information Industry Association (SIIA) trade groups represent the world's largest hardware and software manufacturers. Their main aim is to prevent unauthorised copying of software produced by their members.
ii. Definition
Whistle-blowing refers to the release of information unethically by a member or a former member of an organisation which can cause harm to the public interest(Reynolds, 2018). For example, it occurs when an employee reveals that their company is undergoing inappropriate activities (Whistleblowing: balancing on a tight rope, 2021).
b. Interpretation
The key issues in the relationship between IT workers and clients are preventing fraud, misinterpretation, the conflict between client's interests and IT workers' interests. The key issues in the relationship between the IT workers and the suppliers are bribery, separation of duties and internal control. IT professionals need to monitor inexperienced colleagues, prevent inappropriate information sharing and demonstrate professional loyalty in their workplace. IT workers also need to safeguard against software piracy, inappropriate information sharing, and inappropriate use of IT resources to secure the IT users' privacy and Intellectual property rights and ethically practice their professions so that their activities do not harm society and provide benefits to society.
c. Outcome
I have learnt the various work relationships that IT workers share with suppliers, clients, IT users, employers and other IT professionals.
Week 3
a. Theoretical discussion
i. Important topics covered
In week 3, the ethics for IT professionals and IT users further discussed extensively, and the solutions to solve several issues that IT professionals’ faces were discussed. IT professionals need to have several characteristics to face these issues and to solve them effectively. These characteristics are the ability to produce high-quality results, effective communication skills, adhere to high moral and ethical standards and have expertise in skills and tools.
ii. Definition
A professional code of ethics is the set of principles that guide the behaviour of the employees in a business (Professional code of ethics [Ready to use Example] | Workable, 2021). It helps make ethical decisions with high standards of ethical behaviour, access to an evaluation benchmark for self-assessment, and trust and respect with the general public in business organisations.
b. Interpretation
Licensing and certification increase the effectiveness and reliability of information systems. IT professionals face several ethical issues in their jobs like inappropriate sharing of information, software piracy and inappropriate use of computing resources.
c. Outcome
I have learned several ways that organisations use to encourage the professionalism of IT workers. A professional code of ethics is used for the improvement of the professionalism of IT workers. I have learnt several ways to improve their ethical behaviour by maintaining a firewall, establishing guidelines for using technology, structuring information systems to protect data and defining an AUP.
Week 4
a. Theoretical discussion
i. Important topics covered
In week 4, the discussion was focused on the intellectual property and the measurements of the organisations to take care of their intellectual properties. Intellectual property is the creations of the mind, like artistic and literary work, inventions, symbols and designs used in an organisation. There are several ways to safeguard an organisation's intellectual property by using patents, copyright, trademark and trade secret law.
ii. Definition
A patent is an exclusive right to the owner of the invention about the invention, and with the help of that the owner have the full power to decide that the how the inventios will be used in future(Reynolds, 2018). Due to the presence of Digital Millennium Copyright Act, the access of technology protected works has become illegal.. It limits the liability of ISPs for copyright violation by their consumers. Trademarks are the signs which distinguish the goods and services of an organisation from that of other organisations. There are several acts that protect Trademarks secrets, such as the Economic Espionage Act and Uniform Trade Secrets Acts.
b. Interpretation
Open-source code can be defined by any program which have the available source code for modification or use. Competitive intelligence refers to a systematic process initiated by an organisation to gather and analyse information about the economic and socio-political environment and the other competitors of the organisation (Shujahat et al. 2017, p. 4). Competitive intelligence analysts must avoid unethical behaviours like misinterpretation, lying, bribery or theft. Cybercasters register domain names for famous company names or trademarks with no connection, which is completely illegal.
c. Outcome
I have learnt several current issues related to the protection of intellectual property, such asreverse engineering,competitive intelligence,cybersquatting, and open-source code. For example, reverse engineering breaks something down to build a copy or understand it or make improvements. Plagiarism refers to stealing someone's ideas or words without giving them credits.
Week 5
a. Theoretical Discussion
i. Important topics covered
The ethics of IT organisations include legal and ethical issues associated with contingent workers. Overview of whistleblowing and ethical issues associated with whistleblowing is being addressed (Reynolds, 2018). Green computing is the environmental and eco-friendly use of resources and technology(Reynolds, 2018). In this topic, there is the definition of green computing and what is initially the organisations are taking to adopt this method.
ii. Definition
Offshore Outsourcing: This is a process of outsourcing that provides services to employees currently operating in a foreign country(Reynolds, 2018). Sometimes the service is provided to different continents. In the case of information technology, the offshore outsourcing process is common and effective. It generally takes place when the company shifts some parts or all of its business operation into another country for lowering cost and improving profit.
b. Interpretation
The most relevant information about the context is whistleblowing and green computing. Whistleblowing is the method of drawing public attention to understand unethical activity and misconduct behaviour within private, public, and third sector organisations (HRZone. 2021).
c. Outcome
After reading the book, I have learned that green computing and whistleblowing are vital factors for the organisation's work. I have also learned about the diverse workforce in tech firms and the factors behind the trend towards independent contractors—the need and effect of H1-B workers in the organisation. Furthermore, the legal and ethical issues associated with green computing and whistleblowing have also been made.
Week 6
a. Theoretical discussion
i. Important topics covered
In this chapter, the importance of software quality and important strategies to develop a quality system. Software quality is defined as the desirable qualities of software products. Software quality consists of two main essential approaches include quality attributes and defect management. Furthermore, the poor-quality software also caused a huge problem in the organisation (Reynolds, 2018). The development model including waterfall and agile development methodology. Lastly, the capability maturity model integration which is a process to improve the process.
ii. Definition
System-human interface: The system-human interface helps improve user experience by designing proper interfaces within the system(Reynolds, 2018). The process facilitates better interaction between users and machines. It is among the critical areas of system safety. The system performance depends largely upon the system-human interface. The interaction between humans and the system takes place through an interaction process. Better interaction improves UX.
b. Interpretation
The useful information about the context is the software quality and the important strategies to improve the quality of software. The Capability Maturity Model Integration is the next generation of CMM, and it is the more involved model incorporating the individual disciplines of CMM like system engineering CMM and people CMM (GeeksforGeeks. 2021).
c. Outcome
After reading the context, I have concluded that software quality is one of the essential elements for the development of business. The software derives predictability from improving productivity in the business. The software quality decreases the rework, and the product and services are delivered on time. The theories and facts that are involved in developing the strategies that are involved in developing the software quality in the organisation.
Week 7
a. Theoretical discussion
i. Important topics covered
In this context, it will discuss privacy, which is one of the most important features for the growth and development of individuals and organisations. The right, laws, and various strategies to mitigate ethical issues are adopted (Reynolds, 2018). The e-discovery can be defined as the electronic aspect ofidentifying, collecting, and producing electronically stored information for the production of investigation and lawsuit.
ii. Definition
Right of Privacy: The privacy of information and confidentiality of vital information comes under the right of privacy(Reynolds, 2018). In information technology, the privacy right helps in managing the access control and provides proper security to the user and system information. This also concerns the right not to disclose an individual's personal information to the public.
b. Interpretation
The most relevant in the context are privacy laws that are responsible for the protection of individual and organisation's rights. The protection laws include the European Union data protection directive, organisation for economic cooperation and development, and general data protection regulation that protect the data and information of the individual and company (Reynolds, 2018). Furthermore, the key and anonymity issues that exist in the workplace like cyberloafing. The employees exercised the practice to use the internet access for personal use without doing their work.
c. Outcome
I have learned from this context that privacy is required for every organisation to protect the private information about the personal information and credentials that are present in the company—privacy along with developed technology that secures the data and information about the organisation. I have also got information about the ways and technological development to protect the data.
Week 8
a. Theoretical discussion
i. Important topics covered
In this context, it is discussed freedom of expression, meaning the right to hold information and share decisions without any interference. Some of the vital issues of freedom of expression include controlling access to information on the internet, censorship to certain videos on the internet, hate speech,anonymity on the internet, pornography, and eradication of fake news often relevant on the internet (Reynolds, 2018).
ii. Definition
Freedom of Expression: Freedom of expression denotes the ability to express the thoughts, beliefs, ideas, and emotions of an individual or a group (Scanlon, 2018, p. 24). It is under the government censorship which promotes the right to express and impart information regardless of communication borders which include oral, written, the art of any other form.
b. Interpretation
The most important information regarding the context is John Doe Lawsuits. It is a law that helps to identify the anonymous person who is exercising malicious behaviour like online harassment and extortion. Fake news about any information that is irrelevant, which are however removed by several networking websites. However, the fake news sites and social media websites are shared by several videos and images cause confusion and misinterpretation regarding a particular subject (Reynolds, 2018).
c. Outcome
After reading the book, I have concluded that the internet is a wide platform where several malicious practices are carried out, like fake news, hate speech, and many other practices practised on the internet. I have also gained information about several laws and regulations to protect the right and regulations on the internet, including the telecommunication act 1996 and the communication decency act 1997.
Week 9
a. Theoretical discission
i. Important topics covered
In this context, it will be discussed about cyberattacks and cybersecurity. Cyberattacks are an assault launched by an anonymous individual from one or more computers using several network chains (Reynolds, 2018). A cyber-attack can steal personal information a can disable the computer. On the other hand, cybersecurity is the practice of protecting information from cyberattacks. There are several methods to protect the internet from malware, viruses and threats.
ii. Definition
Cyber espionage: This is the process of using computer networks for gaining illicit access to confidential information(Reynolds, 2018). The malicious practice increases the risk of data breaching. It steals sensitive data or intellectual property, typically preserved by a government entity or an organisation (Herrmann, 2019, p. 94). Cyber espionage is a threat to IT companies, especially as it targets the digital networks for information hacking.
b. Interpretation
The most important aspect in this context is intrusion detection system, proxy servers like a virtual private network. The intrusion detection system is the software that alerts the servers during the detection of network traffic issues. The proxy servers act as an intermediator between the web browser and another web server on the internet. The virtual private network enables the user to access the organisation's server and use the server to share data by transmitting and encryption over the Internet (Reynolds, 2018).
c. Outcome
After reading the entire context, I have gained information about several cyberattacks and cybersecurity. Cyber attackers like crackers, black hat hackers, malicious insiders, cyberterrorists, and industrial spies (Reynolds, 2018). Cybersecurity like CIA security trial. Department of homeland security, an agency for safer and secure America against cyber threats and cyberterrorism. The transport layer security is the organisation to secure the internet from cyber threats between the communicating application and other users on the Internet (Reynolds, 2018).
Week 10
a. Theoretical discussion
i. Important topics covered
In this context, it is discussed about social media and essential elements associated with social media. Social media can be defined as modern technology that enhances the sharing of thoughts, ideas, and information after establishing various networks and communities (Reynolds, 2018). Several companies adopt social media marketing to sell their services and products on the internet by creating several websites across the Internet.
ii. Definition
Earned Media: It is observed in brand promotions in organisations where media awareness awarded through promotion(Reynolds, 2018). It is also considered the organic media, which may include television interviews, online articles, and consumer-generated videos. It is not a paid media; rather, it is voluntarily awarded to any organisation. The earned media value is calculated through website referrals, message resonance, mentions, and article quality scores.
b. Interpretation
The most important aspect of social media marketing where the internet is used to promote products and services. As per the sources, global social media marketing spends nearly doubled from 2014 to 2016, increasing from 15$ billion to 30$ billion—organic media marketing and viral marketing as one important aspect of social media marketing.
c. Outcome
I have gained much information about social media and elements of social media marketing, which encourages marketers to sell their products and services to another individual across the internet. Social media is a vast platform that has both advantages and disadvantages aspect. The issues regarding social media including social networking ethical issues that are causing harmful threats and emotional distress on the individual. There is a solution to these issues, which is adopted by several organisations like fighter cyberstalking, stalking risk profile, and many more.
Week 11
a. Theoretical discussion
i. Important topics covered
This context will eventually discuss the impact of information technology on society. The information impacts the gross domestic product and standard of living of people residing in developed countries. Information technology has made the education system more productive and effective. The process of e-learning has allowed the students to study from their homes. The health care system is also affected by information technology.
ii. Definition
Robotics: It is the design and construction of machines (robots) for performing tasks done by human beings (Malik and Bilberg, 2018, p. 282). It promotes autonomous machine operating systems for easing the burden and complexity of human labour. In this case, artificial intelligence helps to improve the development process of machines by incorporating the machine learning process. Automobile manufacturing industries use robotics design for safeguarding humans from environmental hazards.
b. Interpretation
The most information aspect of the topic is the artificial intelligence and machine learning have impacted the growth of IT. Artificial intelligence includes data and human intelligence processes that include activities like learning, reasoning, and self-correction. Machine learning is the process to talk with the technology through machine languages.
c. Outcome
I have gained much information about information technology and its impact on the organisation and people. The innovation and development occurred vastly due to the effect of social media.
4. Conclusion
It is to be concluded that this reflective journal report describes all the aspects of ethics in information technology by providing an understanding of the ethical, legal and social implications of information technology that IT professionals need to nurture in their professional work. Critical analysis of the privacy, freedom of expression, common issues of IT professionals, solutions of these issues are reflected in this journal report. The journal report also attempts to address the ethical issues in the IT workplace. An understanding of IT and ethics needed in IT professionals to achieve success is reflected in this journal report.
References
.png)
Research
ITECH5402 Enterprise Systems Assignment Sample
Objective:
This assessment task has been designed to help you deepen your understanding of ERP/Enterprise Systems. It comprises both team and individual components.
Aim:
You have to produce a clearly articulated and well-researched enterprise system evaluation report to be given to the Board of Directors of GBI to successfully assist the organisation with choosing the correct software product to implement for their enterprise. Please refer to the GBI Case Document.
Learning Outcomes:
Evaluate and compare various types of enterprise resource planning (ERP) software solutions and their application in global business contexts.
Identify the main suppliers, products, and application domains of enterprise-wide packages.
Demonstrate communication skills to present a coordinated, coherent, and independent exposition of knowledge and ideas in dealing with enterprise systems.
Structure:
• Introduction
• Case Context, establishing the need for enterprise systems
• ERP Selection, indicating identification and comparison of several ERP systems
• Benefits to be gained from the ERP package proposed
• 3-4 additional technology required to meet the needs of the organisation. Ideally, each team member must identify one (1) technology to be included in the team report. This makes up the individual component.
• Concluding remarks, summarising the content of the report Demonstrate depth and breadth of reading to include a comprehensive reference list
• Use APA referencing style for all references in the body of text and in reference list
• Include readings from: Journals, Conference proceedings, presentations, books/book chapters, or any other significant sources.
Solution
Introduction
Enterprise resource planning defines a process used by the companies to combine and manage the importance of their business. ERP software is important for companies as they help them to execute resource planning by combining all the processes to run a company with a single system. ERP software combines human resources, marketing, finance, sales, planning, purchasing inventory, etc. This report aims to do a study analysis on the company ‘Bike Global Group’ as to how they work with their resources and how it manages distribution, selling, partnership, etc. The objective of the company was to manage the company with new resources and make bikes for both the genders males and females and to do work within the collaboration. Another objective of this report is to emphasize the benefits of implementing an ERP system for the Global Bike Groups for every management. This report highlights the background of Global Biker Groups and the various problems faced by them during the expansion of the company. This report throws light on how ERP systems allow the company to overcome these obstacles. This report also includes additional technologies that can be implemented in the company for the development of this company.
Case Context, establishing the need for enterprise systems:
Background
The Global Bike Group manufacture bike for long-distance and off-trail racing. Its founders designed their first bike, nearly 20 years ago as they had to win races and the bikes that were available at that time were not of high standards. So, they started the company named ‘Global Bike’ and started to deliver high-performance bicycles to the world’s most demanding riders. John Davis started it’s making his bike when he realized that the mass-produced bike was not fit for racing and rebuilt from other bikes into a single ‘Frankenstein’ bike that lead him to victory in the national championship. This made him famous and started his own company at a slow pace. At the nearly same time, Peter Schwarz designed their bike and slowly his bike turned into a small company which he, later on, get partnered with local companies. Fortunately, Peter and John met each other in 2000 and realizes their passion for business models, and collaborated and distributed their work for best assignment help.
Problems in the Global Bike Group
During the expansion phase, the Global Bike Group was being subjected to more workload. This workload leads to the various problem that has to be faced by the Global Bike Group. The process of management of these company become more tangible and dealing with the demands of the bikes according to the customer become their primary objective. This leads the company to lower its management process and handling such a huge company without a proper management plan was a tough job to achieve (Gallego, Mejia & Calderon, 2020). In the case study, it was seen that working after the collaboration and working together as a whole new company that comprises different departments needed a whole new management system. Sticking to outdated management techniques leads to ineffective and lesser productivity (Anatolievna & Anatolievna, 2018). But this did not keep them back from producing more products at that time.
Another problem faced by the company was that they were not achieving the required demands at that moment. After seeing lesser sales of the finished product they soon came to know that they need modifications on the bikes to fulfill new demands according to the changing requirements of the bike. Very less customer interaction was one of the biggest problems faced by any company (Goodman, 2019). On the other hand, this growing expansion of market and distribution demanded a more accurate management system to handle and supervise such a big network that includes the marketing department, sales department, research and development department, and production department.
Solution
Requirements and needs are the factors responsible for the alteration in product quality. Changing product manufacturing needs alteration in the manufacturing process and working of departments. To manage everyday changes in a company irrespective of the intensity of the change, a company needs to have a proper management technique through which effective management of various departments can be possible. The ERP system software provides the same requirement that can handle everyday work and processes of different departments in a single place. As in the case study, various problems related to the management of different departments include the manufacturing department, production department, sales department, distributor department, and many more. This ERP system software provides a proper management platform and smooth function of different departments. Handling of the distributer through ERP can be achieved in a simple way (Costa, Aparico & Raposo, 2020). The company can easily supervise the over the working through this system software.
Another biggest problem of customer interaction can also be solved by ERP system software. ERP system allows the company to store previous interactions with the same customer and can continue with conversation from where they left off. This enables the company to understand the customer and requirements of the customer more accurately which will eventually help the company to provide better customer service. This also makes the company more responsive to the requirement of the customer (Khan, Asim & Manzoor, 2020). This ERP can reduce the burden of expansion which results in more susceptibility to tangible network management and allows the company for further extension. In this way, ERP system software can overcome the problems faced by the company.
ERP Selection, indicating identification and comparison of several ERP systems
Different ERP:
SAP ERP System:
Since System Analysis Program has been started in 1992. This system is good for all types of businesses. Broad scope challenges of business data solutions are provided by ERPs (Al-Sabri, Al-Mashari & Chikh, 2018). To choose any software from this system, the company provides a free trial offer so that users can experience a product.
Oracle ERP System:
This resource planning is the leader in the computing space. It provides its own data management to the various industries. In keeping the view of business, it is designed at small, medium, and global levels. The companies who need to transfer and share large amounts of data or merge several companies can use this system (Amini & Abukari, 2020). It is very beneficial for them to use this ERP system.
Microsoft ERP System
Microsoft is one of the most wide-ranging software companies in the world that are selling an ERP called Dynamics 365. Their ERPs are cloud-based. This can be used by every business of every size, but it depends upon the varying price (Zadeh etal., 2020). Dynamics 365 can be used for human resources, customer service, retail operations, marketing, project automation, and so on.
IFS ERP System
Industrial and Financial systems are the leading source of enterprise-level software. It is a Sweden-based company that is providing services and solutions to manufacturers and organizations since 1983 (Grobler-Debska et al., 2021). This ERP highlights its software programs in terms of coordination and flexibility.
Comparison
.png)
.png)
Selection
Oracle ERP is best for the organization as it is designed in such a way that it can deal with every level of the business whether it is medium, large, or global. This ERP is the leader in the cloud computing space. It covers database management for a variety of industries in sales, marketing, manufacturing, and distribution. This software is too ideal for Global Bike Company as it can help get efficient in a large amount of data (Kakkar, 2021). Oracle ERP can help them in the merging of several companies. As management is very much necessary in the company in every part. As Global Bike company needs management as well as advanced capabilities that can be gained through this ERP. It can help the company to quickly react to market changes and shifts. Oracle ERP provides a space for the company to be updated always in the current situation and can get an advantage in the market as per their competition (Elbahri et al., 2019). This ERP is the best for the management of marketing, manufacturing, sales, and the distribution sector. Oracle ERP is the modern, complete, cloud ERP. The global company should have this ERP to be in this competitive market, to manage their database, to have a look over the shifts in the market, and to get updates on the current market. As of this ERP, Global Company can make the best use of it. This ERP helps to reduce business costs too and make companies’ analytics accurate too.
Benefits of ERP system
ERP system enhances business management models and functions that include preparation, inventory management, planning, order processing, production, financing, and many more. The most advantageous point which can be seen over the system is the capabilities to check and update in real-time and also enables to supervise the organization management (Rouhani & Mehri, 2018). Some other benefits of the ERP system can be brought up as key points as follows:
Data Integrated information across various departments.
Data integration refers to the process of gathering data in one place from the different departments which provides a single room for organizing data and data management. This also frames a base platform for the data analysis and production overview. For example, the data collected may originate from many sources like marketing software, customer application, CRM system, etc. All this information is required to be collected in one place for analysis for further action (Tarigan, Siagian, & Jie, 2020). The data integration task is managed by the developer and data engineers of the Company. All branches of Global Bike Groups are situated in different geographic locations, this company is required to deliver the data and services across their different branches. For these types of situations, the ERP system provides data integration which enables the organization to manage the data of different branches and different departments in one place.
Reduced data redundancy and processes
Another problem of data redundancy can be solved through an ERP system. With a data integration service facilitated by an ERP system, the same data kept in different places can be eliminated. After the foundation of Global Bike Group, expansion become the most significant part and it was seen more often in that case study. With the expansion of the company, handling of the data became more strenuous (Kumar, 2018). ERP system will ensure consistency in the work and required information can be received whenever needed in the company. Reliability of the data can be achieved with this system which was the biggest advantage of data redundancy to confirm the correctness of data while avoiding data redundancy at the same time (Chopra et at., 2022). Data redundancy enables the employee to get quick access to information as it was available on multiple platforms but this advantage is also covered by the ERP system.
Data security for the organization
Technology is the key to this globalization. Technology and globalization bring us close to the importance of data in digital platforms and its security. Dealing with a huge amount of data is the primary responsibility of any organization. All organization keeps their confidential as well as personal information along with their marketing information in a computer-based program for management purpose. Accidently losing such data can distort the organization’s work (Trunia et al., 2018). For any company, data are the most important aspect to record and maintain safety. These data can be very useful in the further decision-making process which will allow the company to generate higher revenue. ERP system will allow more security for the data of any organization or company.
Effective communication across different departments
With the foundation and expansion of the Global Bike Group in the case study from a single individual to a world-class company, many departments were set up within the company, and also many branches were set up at different locations across the globe. Effective communication is the key to proper working and managing a vast company. Proper channels of communication are required for smooth functioning (Aboabdo, Aldhoiena & AI-Amrib, 2019). Data sharing across the different department are equally important through effective communication. This effective communication of data sharing in Global Bikes Group can be achieved through ERS system. This ERS system also avoids conflicts in the department as the data is properly managed and organized in a single place in a computer-based program.
Additional technologies required by the organization
New technologies are emerging every day. To fulfill the demands and survival in the competitive market, companies and organizations need to keep themselves up to date with the upcoming new technologies. These technologies allow them to channel their work properly and increase the production of products with better quality (Biswas & Visell, 2019). Apart from the ERP system, Global Bikes Group is required to implement many new technologies to fulfill the need of the company. Some of them are listed below:
AI
The traditional methods for maintaining and running an organization can no longer keep up with these fast pace evolving requirements and complex demands of the customers. This drive organization to utilize technologies based on AI for interpretation and fulfillment of the demand of customers. AI is a computer-based software that performs given tasks close to human mind capabilities (De Cremer, 2021). AI generate more revenue and perform better in completing complex task which ultimately promotes the organization’s growth.
In the Case study, it was seen that after the establishment of Global Bikes Group became a vast company, managing such a big company was stressful. The tasks became more complex due to the demand of the customer (Wamba-Taguimdje, 2020). In these situations, AI can be very helpful in completing complex tasks and analyzing the demands of the customer to come up with a better result.
CRM
CRM is the abbreviation of Customer Relationship Management. CRM software is a tool that can be used to store data like marketing, sales, and customer services together with policies and customers in one place. When the business model on expanding, it became difficult to handle so the need for a remote CRM also increased (Kampani & Jhamb, 2020). This remote CRM enables them to manage sales productivity and also provide the proper platform to work with their staff and customer together.
CRM software is modifiable and it can be easily modified according to the customer and the organization’s needs. Many enterprises are already using CRM software for increasing marketing, customer support, and sales. Established companies use CRM software to increase the interaction of customers with the company which helps them find out the flaws in the product (Boulton, 2019). CRM can be modified by Global Bikes Group to respond to their customer requirements.
Cloud Management Platform
With technological advancement, the organization also needs to upgrade itself. This includes using various online services to be offered by the organizations. Cloud computing platform offers a variety of services (Lv et al., 2018). In the cloud, third-party service providers develop applications that can be accessed by users.
Features of Clouds
• It can handle multiple clouds.
• It allows controlling cost.
• User-friendly interface.
• It also reduces complexity in infrastructure.
Cloud is a fundamental part of the process of digitalizing of organization. However, as clouds become more and more complex cloud management platforms become the need for the organization to fully exploit the benefits of clouds. These cloud management platforms are important components that can be used to manage these clouds. Global Bike Group can implement a cloud management platform to enable various services over the internet through clouds.
Blockchain
Blockchain work on a shared network with a decentralized authority. It can benefit the organization in the following ways:
Public
Organizations always try to interact with their customers. Organizations create a network of federation Blockchain merging public and private networks. They keep their professional data on the private network and use the public network to connect with their customer (Bodkhe et al., 2020).
Transaction Cost
Organizations are always concerned about their security. Blockchain has an intense level of security and secure transaction through this network using cryptocurrency that cannot be easily tracked. This enables organizations to make their trading more confidential.
No intermediates
Intermediates service providers are always subjected to trust issues. Most of the fraud cases are linked through these intermediaries. In Blockchain, organizations do not have intermediaries so it saves the extra charges for providing their services and also reduces the chances of fraudulent cases (Morkunas, Paschen & Boon, 2019).
Conclusion
Expansion of an organization or a company makes the company more complex and management of such a big organization becomes a challenge. The load of work for each sector and department becomes complex and increases and becomes harder to manage. For a huge company as seen in the case study, the growing demands of the customer pressurize the company to the production of more and better products. This makes the workspace more crowded and the process more tangible. Here comes the need for proper management techniques for the organization. The ERP system is more of a management technique achieved through computer software. This allows the organization to handle everyday work like project management, supply of goods, project progress, accounting, sales, etc. From the report, it was seen that Global Bike Group faces many problems during the early stage and after the expansion of the Company. Problems like handling the expanded market situated in different geographical locations, dealing with the demand of increased customers through customer interaction, etc. From both perspectives of John Davis and Peter Schwarz, managing individual departments like VIP marketing, Chief Financial Official, VIP Human Resources, Chief Information Officer, VIP operations, and VIP Research and Development become tangible and they had to involve on the ground level with the staff to manage. All of these problems faced by the company can be solved through computer software based on the ERP system. Apart from solving the problem faced by the company, ERP based software system offers many benefits that include data integration, data security, and effective communications and also reduces data redundancy. Many additional technologies can also benefit the Global Bikes Group like AI, Cloud Management Platforms, CRM, and Blockchain for the development of the company in the era of technologies. Benefits like confidentiality of trading, Cloud management, user-friendly customer interactions, etc. will lead the company to achieve greater heights in the long run.
References
.png)
.png)
Research
COIT20248 Information System Analysis and Design Assignment Sample
REQUIREMENTS
Required tasks in this assignment assuming that the waterfall model has been chosen for implementing the new system. also, assuming that some parts of programs have been written/implemented and are ready, whereas some other parts/programs are not yet ready. complete the following tasks and document your work in your submission:
1. Testing:
a. list and discuss the various types of testing.
b. identify (and explain why) which types of testing are applicable to the new nqac.
c. for each applicable type of testing identified in (b) above, discuss in detail the following:
• when (i.e., in what phase(s) of the software development life cycle) should this type of testing be conducted?
• the procedures for applying this type of testing.
• the follow-up procedures in testing after checking the testing results.
• who are the main stakeholders involved in this type of testing?
2. as stated in the nqac business case, the current system is a primitive and manual. on the other hand, the new system should be more sophisticated and should be run on a web platform. it implies that the new system will need the historical data to be transformed in to new data files and a new database must be created to support the operation of the new system. in view of this requirement, what task/activity must be done to create these data files (or the database)?
how should this task/activity be conducted? please note you are not asked to create a data file or data base you only need to describe where how and by whom the new data will be prepared.
3. because the new system is running on a platform which is different from the existing system, the design of the new system will be largely different from the existing system. in view of this, describe in detail what techniques the project team can implement to help end users familiar coit20248 assessment 3 term 1, 2022 with the operation of the new system. for each of these techniques, discuss its advantages and disadvantages.
4. in view of the business operations of nqac, which system deployment option should be used? why? how to apply this option in nqac? (note: in this task, select the most appropriate option. in other words, you are not allowed to select two or more options.)
layout of your report your report should be organized using the following headings and guidelines: a “separate” cover title page
• should include the word count of your report in this cover page. if the word count of your report falls outside the range “1,500 words” (word count includes all contents except the cover title page and references), marks may be deducted from your submission.
an introduction
• briefly discuss the overall content of this report.
task 1
• discuss in detail all the questions and sub-questions of this task.
task 2
• discuss in detail all the questions and sub-questions of this task.
task 3
• discuss in detail all the questions and sub-questions of this task.
task 4
• discuss in detail all the questions and sub-questions of this task.
Note: in tasks 1 to 4 above, you may include figures to illustrate/support your answers, if you think that this is appropriate.
Solution
Introduction
Noac is an organization performing changes in the management system. the organization is shifting to digital mode of marketing. in this case, the staff members and the technicians impart significance in the research report. the technician involves various tasks in terms of customer handling and system functionalities. the website must include details of the ac, their types, installation methods, and testing types. moreover, it must include few more details about the facilities and benefits.
This report consists of several information regarding the testing background of ac such as cooling, heating, and humidity control. moreover, the various types testing methods, identification of the appropriate testing method, their application and performance. on the other hand, it also includes the activities performed to create a new data base and familiarity of the system with the traditional system. The overall reports for assignment help provides an idea of testing methods of the ac and how to conduct it.
Task 1
various types of testing in terms of nqac, they provides a various types of testing methods, it includes,
• air enthalpy calorimetric
• temperature testing
• variable capacity testing discussion air enthalpy calorimetric air enthalpy calorimetric is required for testing the temperature such as cooling and heating. it includes the two methods such as the calorimeter room method and indoor air enthalpy or psychometrics methods.The measurement in terms of energy input to a room is done by calorie metric room method.
Moreover, it controls the temperature by an ac unit (job, & lidar, 2018). on the other hand, it maintains the air temperature inside the room at a constant value. whereas, the constant value is equivalent to the cooling capacity of the ac.
Indoor air enthalpy method it measures the air enthalpy such as air moving in and out of the ac indoor unit. in the case in changing the air enthalpy, it is multiplied by the rate of air flowing is equal to the cooling capacity of the indoor ac unit. test temperature in this case of ac installation, testing the temperature is essential for the identification of outdoor air temperature. moreover, it also includes testing the loading system, and average weight of the outdoor air temperature (mohanraj et al, 2012). these are used to measure the performance of the load system and also in calculating the efficiency metrics. it is divided into two segments, such as full load test conditions.
It is the method that includes the testing of air cooling condensers that works by evaporating the condensate. part load test conditions in this case, the capacity of humidification falls off. it is also termed as seasonal efficiencies that are required to measure the efficiency. the measurements are particularly done in part-load and full- load capacity. it controls the cooling and heating load by using the relative cooling and heating load hours.
Variable capacity testing in the case of variable capacity testing, it includes the demands of heating and cooling loads of an ac. it maintains proper cooling inside the room. moreover, it has the ability to dehumidifying. it also includes the compressor speed. the main purpose of ac compressor is to control the refrigerant under the pressure in the system. In this case, change in pressure takes place. the low pressure has converts to high pressure gas (prabakaran et al., 2022). on the other hand, the compressor speed determines the rate of refrigerant flow. the motor capacity and frequency varies in this case. the motor speed decreases with increase in capacity output. identification on the type of testing the type of testing which is applicable for the new nqac is temperature testing. in this case, temperature testing is essential for better maintenance of ac performance and servicing. it includes the loading system and weight of the outdoor air temperature. it overviews the overall performance and efficiency of the system. in terms, nqac includes the methods in their installation techniques to improve their service towards their potential customers and new customers as well. as the organization has shifted to digital mode it is necessary to provide temperature testing (dias et al., 2016). it is one of the unique features that nqac must include their management system. it deals with the loading system such as cooling and heating procedures. moreover, it is one of the servicing methods that include checking the performance and efficiency of the system. moreover, it supports the organization in getting a separate customer base. by providing the necessary facilities and meeting the customers’ demand will lead the organizational development digitally.
Task 2
Activities performed to create the database the responsible technician, users, and analysts are required to prepare the new database. The databases are mainly collected from the organizational growth report, feedback report, and other organizational data resources (zhang et al., 2014). in the end, the database is stored in the cloud system database. it is a significant way to store, secure, and protect the data. the website must be encrypted with the cloud computing systems.
Task 3
The similarity in the new system there are still some features and functionalities in the existing system, that are similar to the new proposed system. however, these are essential to evaluate and document to determine all the appropriate system features that are effective and sustainable in nature (blum et al., 2019).
however, this is the responsibility of the project manager, to document and supervise all the system similarities, which must be unchanged in further development procedures as well. the previous system was manual with different business process complexities such as poor cost and time effective
time management.the particular similarities are,
• core supply chain system and management process
• billing and packaging
• team culture and team distribution
• research and development system
Advantages
All of these similarities come with particular business advantages. these advantages can be implemented through effective management and critical analysis of the current business scenario
with the proposed system technology. the advantages are,
• better business management and documentation
• better finance management and resource supply maintenance
• shorter processing time
• advanced database management and analysis
• better market analysis and report evaluation
• effective business process improvement with digital technology implementation
Disadvantages
organizational disadvantages are also associated with these business system similarities. these must be considered and evaluated accordingly, to avoid the negative consequences. this is the responsibility of the project manager, to document and evaluate these disadvantages accordingly. this will not only lead to effective precaution but also will improve the business system and management.
Task 4
System deployment options
The system development can also be categorised into different system development options such as agile development, lean development, etc. these two are the major development methods or options available for the project. this depends on the compatibility and effectiveness of the business model.
Agile management or development option has the idea of equal and effective work distribution between the teams with effective engagement. it also provides better flexibility and innovation in the development phase (shah et al., 2013). though, it also causes different complexities such as poor time and resource management for continuous system changes with feedback analysis. in spite of that, the lean development option will be the most effective and appropriate in this case, as the system should follow the appropriate development strategy and planning. this is only the developer to call site band quantity analysis of different business requirements and system analysis.
this is also effective for resource management and eventual results (goetzler et al., 2016). overall, this analysis can establish that the lean management option will be most effective as a development option for the information system technology of the organisation. application of the option in the application phase, the project manager is responsible to develop appropriate and most effective planning that can develop the proposed system technology. in the next phase, open analysis and different reports who is implemented and the development phase will be started. The management authority and project manager will motivate and supervise the whole department for better analysis and further changes (if required). finally, the system will go through a proper testing procedure and feedback analysis that can improve the quality and service in a real-life business scenario.
Conclusion
To conclude, the testing method impacts a major significance in ac installation. the organization nqac provides a unique feature of temperature testing methods that can gradually increase the market demands. the facilities provided by the organization support gaining potential customers in the future. it helps in maximum registration and booking of products gradually. as the organization is recently shifting to a digital mode of marketing, it is essential to analyze the advantages and disadvantages of the conduction of the new system. developing the testing method leads the organization to follow the market trends, market demands, and customers’ requirements.
References
.png)
Research
CTEC104 Communication and Technology Assignment Sample
Assessment Task:
Formal reports are practical learning tasks where students apply the theories they have been studying to real world situations.
Given a scenario the students are required to collect information (primary and/or secondary) and prepare a report applying their research to make recommendations that address the business scenario.
This report should consist of the following parts: Executive Summary, Introduction, Objectives, Methodologies, Information Analysis, Findings, Recommendations, References, and Appendices (optional).
ASSESSMENT DESCRIPTION:
From paper to internet Luca, your team leader, has asked one of your colleagues, Imran, to develop and post on the internet information about how to lead a ‘greener’ life. Imran realised he needs to write scannable text and blend various models of presentation (text, graphic, design, pictures, sound, video and animation) but is uncertain about the mode(s) of presentation to use and asks your advice. Imran has requested you to think about the scenario and prepare a long report answering the following questions:
Questions:
1. Why web writers do more than just write.
2. Include a list of suggestions and discussion of activities to be undertaken in the initial planning.
3. Benefits of using the mosaic form of design for web pages rather than the traditional linear form.
Solution
Introduction
The study will focus on the real life situation and explore theory in order to relate with the issue of responsibility of web writers and also include suggestion and discussion for the initial planning. It will also explore the web pages traditional linear form and also identify the engagement with his audience. The focus of the study for assignment help is to explore the method of improving and discovering the website using the search optimization engine. It will also manage the web content importance.
Aims and Objectives
The study is to describe the importance of writers for their activity more than just right design.
? To identify the different activities of the writers.
? To explore the designs and methods used by the web writers.
? To identify the way the audience is addressed.
1. Methodologies
The study will focus on identifying the secondary qualitative study. It will provide appropriate evidence. The use of secondary data will be highly effective and efficient in the context of current study as it will provide resources and potential outcome within the context of the writing environment. The use of the philosophy of positivism will ensure a proper management of resources and perception of the reader.
2. Information Analysis
4.1 Activities of web writers
A writer of the web has to compose a written document in the blogs or the pages that are available on the web. They have no chance to use a notebook or pen to write their content, just like a formal writer. They have to use the artificial techniques of the internet to capture the attention of their viewers and encourage them to visit the new vlogs or the new pages on the web made by them. For the attraction, they always try to use some graphical representation like the graphics of the flash, which don’t need any formal writer. So they always needed wisdom in the field of the techniques of the internet. In some cases, the web pages have been used the SEO (search engine optimization), which helps them to organize their content in the system to get higher rank and also help them to make more efficient in the engine of the search that is web-based (Himmelstein et al 2019). So those things have not needed for a just writer.
The web writer those who have this job need to be good writers with a strong understanding of language and grammar, but also have an understanding of how the words they will compose will be exploited and presented in the online space. Depending on the job of the writer of the web, they need a great knowledge of the coding of the web, and they are also aware of the knowledge of building a language. There are several different ways to get this type of job, but people who have experience working in a company with blogging or a strong web presence may be the most attractive candidates for the recruiter. The work is often preferred by many people because it is often really flexible, and a huge amount of the work can be done from their home or on the basis of the freelance. Web writers always try to provide the content of articles and pages on the website to give the visitors something which is meaningful and interesting both. So this means that there is a huge difference between a normal writer and a writer of the web pages or a blog writer. A writer on the web needs a lot more knowledge than a normal writer.
4.2 Planning requirements
4.3 Create Objectives
The first move that is taken in planning is deciding the goal to be achieved during the planning term. The strategic plan made on a long-term basis may prioritise particular market share gains in the coming years (Hussain et al 2022, p. 69). In contrast, the division operating plan may prioritise the application of a new technique of monitoring orders and sales in the next quarter.
Mark is concerned with yearly goals for the department of sales, so he starts by defining goals which are concerned with the sales in the next year, as well as a job he would like to apply for that helps in automating the sales order process.
4.4 Task creation to achieve these goals
The further move is to create a checklist of tasks that must be executed to meet the defined objectives. For example, Mark determines the sales taking place on monthly basis required to meet the goal of sales he is aiming for, as well as chief tasks linked to the automation process, like tool selection, as well as training for the team on its use.
4.5 Required resources for completing the task
For fulfilling an objective some resources are required which should be identified at first. In this case, the term "resources" refers to both the human resource required to fulfil the plan and the supplies required to give support to those human resource (Hussain et al 2022, p. 69). This could include a sales administrator, salespeople, various supplies such as funds, and brochures for an advertisement propaganda which is intended to increase the number of prospects in the funnel of the team of sales.
4.6 Timeline
Now the identified resources must be allocated according to the need. For example, Mark decides that the campaigning of the marketing will start during the first quarter of this financial year, this will increase the marketing of the company in the second quarter of the following financial year. Based on Mark can easily calculate that how much resources is required to complete the task. If there is any shortage of salesperson it can be filled in the second half of the financial year.
4.7 Plan Implementation
This is the point at which other managerial functions enter the picture. Managers communicate the plan to employees clearly in this step to help turn plans into action. This step entails allocating resources, organising labour, and purchasing machinery.
4.8 Follow-Up Action
Follow-up refers to the process of constantly monitoring the plan and soliciting feedback at regular intervals. Monitoring plans are critical to ensuring that they are carried out according to schedule. It is to ensure that objectives are met. The regular checks and comparisons of results with set standards are performed.
3. Benefits of mosaic form
Creating a good design is very much important. When the audience visits the website, it gives them the first impression of one’s business. They will judge the business in a few seconds and in these seconds only a good design can make a positive impression in the minds of audiences. A good design aids one’s search engine optimization strategy.
When a website is designed with a traditional linear form it is organized with a middle, beginning, and end, more like a printed book would look. These days linear design is not used to design most websites, but it is very helpful in the presentation of long-form content, such as online texts and manuals. These days the mosaic form of web page designing has become a favourite free architecture portfolio website template to most designers. The mosaic form of web design is minimal, sophisticated, and minimal, the overall implementation is excellent, and its flexibility goes beyond the roof. It doesn’t matter what device a person is using. They can experience magnificent designs and creations; mosaic adapts to it fluently and instantly. It is like one will be having a lot of fun while creating their architecture website and so anyone could enjoy it while browsing. A website when designed in linear form, the website will usually present a table of content, like a book and it will have “next and “previous” buttons which allow paging through the whole site. It becomes monotonous (Sane 2020, p.58). For this reason, creating a good and strong impression with a striking and unique split-screen slider with a call-to-action button. Additionally, the Mosaic features scroll content load, animated statistics, sticky navigation, categorized portfolio section, and parallax effect. It also provides recommendations and logo sliders for clients, a contact section with full form, a full-page blog and Google maps as well as a newsletter subscription box. Anyone can create and design a web page using the Mosaic form of web design. It doesn’t require one should know the programming language. It can be created easily just by learning HTML. It is important to create a responsive web design to have a better visual experience, the experience of the user, and create a good impression from the user. Websites that were designed using the traditional linear form are monotonous like books, having an index, title bar, content, and “previous and next” buttons. The design created with the Mosaic form has a charming appearance that encourages the user to engage more with the website and also enhances their experience during surfing.
4. Conclusion
It can be said that the writers of the website have more responsibility to perform when it comes to the different environments. Initial planning requires a complex web of experience and managing to overcome the issue of design and traditional linear form. It has been noted that the planning of the writing and design provide a significant direction and control over the management of the organization.
5. Recommendations for improvement of the website
It is necessary for the web writer to play a crucial role in the management of the services in a significant and effective way. It is necessary for the writer to make the website more optimized and accessible to the user.
References
.png)
Assignment
BIS3005 Cloud Computing Assignment Sample
Group/individual: Individual
Word count: 2000
Weighting: 30%
Answer each of the questions below for assignment help -
Describe the difference between a locally hosted school (ie. in an enterprise data centre) and a school service provided using a SaaS provider. What are the critical points, other than cost, that an enterprise would need to consider in choosing to migrate from a locally hosted service to an SaaS service?
Describe the difference between locally hosted university infrastructure (ie. In an enterprise data centre) and a university infrastructure provided using an IaaS provider. What are the critical points, other than cost, that an enterprise would need to consider in choosing to migrate from local hosted infrastructure to an IaaS service provider?
ECA, wants to investigate moving two of its educational arms to a service- based model where many of its services would be supplied to its clients as a service, in addition to its plans to move to an IaaS model. There are several infrastructure models that could possibly be used to achieve this. Some of these models are:
1. Local hosted infrastructure and applications.
2. Local hosted infrastructure with some SaaS applications.
3. Hybrid infrastructure (some locally hosted infrastructure with some IaaS) and applications.
4. Hybrid infrastructure and applications with some SaaS applications.
5. Full IaaS model with some with SaaS apps.
6. Full SaaS model.
You are required to choose an infrastructure model that you think will achieve the ECA Roadmap; Describe the benefits and drawbacks, excluding costs, of your chosen infrastructure model.
Solution
Describe the difference between a locally hosted school (ie. in an enterprise data centre) and a school service provided using a SaaS provider. What are the critical points, other than cost, that an enterprise would need to consider in choosing to migrate from a locally hosted service to an SaaS service?
Software as a Service is an internet based service which is provided and maintained by the service providers rather than in house enterprises. This is an approach to software distribution which is created by the software providers where they create and host a combination of software, database and code to create an application which can be accessed by anyone, anywhere (Palanimalai, & Paramasivam, 2015). This gives the liberty to the firms to work from anywhere around the world where there is an access to the internet. In a school there are several things that needs to be recorded as well as updated. There are several outputs that are required such as results, scores and performance in the class for both the teachers as well as the students with the help of a software. There should also be forums where students as well as the teachers can interact. Moreover, most important thing is the uploading of the class lectures that will be helpful for the students after the class. All of these things are required in a school and this required a software. Now the question arises is that there are a lot of host service providers that provides supports using SaaS which can be an option, and there are locally hosting servers can also be an option. Below are the comparison done between migrations from local server to a SaaS service provider in a school.
Time efficient: In a traditional on premise deployment it takes a lot of time to setup a particular software in a school. It is not limited to that as this requires a number of people who are expert in this field. This will make an addition to a department in a school which is absolutely unnecessary. The software will need a lot of time to build and will take time to implement it at the same time. The resources will be extra that will be required for this venture. These resources can be put to use for the school and student welfare. The extra services that will be required cannot not be shared always and the school have to compromise because of the time that it will take to be developed. In case of SaaS, the software is already installed and configured all the school have to do is to provision the server into the cloud and the system will be up and running and ready to use (Nakkeeran, et.al. 2021).
Higher Scalability: Unlike the local server the SaaS has a higher scalability which means that for an extra service the school needs to by a new SaaS and merger it with the previous one. The new SaaS will be owned by the service provider or the host as they will maintain the whole thing for them. For an instance, during the pandemic all the schools needed to conduct online classes but the schools authority did not have that feature. For the inclusion of this feature the schools authority should only have granted for a new SaaS that will be owned by the host but in case of a local server the whole thing was needed to develop first and then merge with the local server that can be accessed using a different link.
Upgrade: SaaS gets auto updated as the host will maintain the whole system for the school. The effort associated with the upgrading of the system is much less in case of SaaS and also cost efficient at the same time. In a traditional model the school will have to buy the upgrade and then install it into the system where as in SaaS the provider will do everything for the school at a very low amount of time.
Proof-of-Concept: This is a feature in SaaS where the users can see and learn about the updates prior to its launch (Kaltenecker, 2015). The functionality can also be tested to understand its functionality. In case of local server this is not an option as the software can only be tested once it is upgraded into the system.
The above differences will give an idea about the difference between and advantages of a SaaS service provider over the local enterprise system. In an enterprise like school it would be a little much to go for SaaS but a lot of things will be easier for the school. The SaaS service is more upgraded nowadays. Many a firms including schools and colleges are interested in using SaaS as their system software. Due to pandemic every institution has started to understand the usability of Software as a Service. Institutes has also started using IaaS as their new system solution which is a better solution. That is been discussed in the next question. Describe the difference between locally hosted university infrastructure (i.e., in an enterprise data center) and a university infrastructure provided using an IaaS provider. What are the critical points, other than cost, that an enterprise would need to consider in migrating from locally hosted infrastructure to an IaaS service provider?
Computing infrastructure includes hardware such as computers, modems, networking cables/wires, etc. Resources such as offices and staff are required to run a firm. To start an IT firm, one must have an infrastructure. Designing, finishing, and executing the designs and requirements need much planning (Rodriguez, 2014). It also demands a significant investment in land and other technological devices. A locally hosted infrastructure may install and deploy numerous software applications using one's hardware, networks, and storage devices. However, as cloud computing advances in the technological world, organizations may rent physical amenities such as functional connections and hardware facilities monthly. Infrastructure as a Service (IAS) is an IT infrastructure available through various cloud-based solutions. Infrastructure-as-a-Service (IaaS) providers provide hardware and other essentials in return for service. It is essential to examine and analyze the whole service details for better implications and results.
The essential idea contributing to the mobile infrastructure IaaS prototype is to employ a simulated notion that allows equipment assets to be shared by several firms for various servers held by IaaS suppliers rather than arranging for hardware and organization demands as with nearby hosted groundwork.
The Benefits and Drawbacks of IaaS Analyzing particular benefits and drawbacks can lead to better choices and implications, in a real-life scenario. On the other hand, organizations will get the highest benefit, by building the most appropriate and compatible infrastructure. Cloud technology is already hard to manage and control in an organization. In that case, the analysis will also provide better clarity and operational benefits. Several studies show that cloud storage is growing increasingly popular among enterprises. Clients can rent infrastructure and platform services in addition to software from the cloud facility. In addition to cost reductions, using Infrastructure-as-a-Service may provide several other benefits. There is no one source of dissatisfaction, no hardware venture, and so on. No need to consider where the infrastructure will be placed, regardless of location. Serve that exact are stored in the same area as the company's other business activities is a huge hassle. There is no reason to lease or rent space when infrastructure is hosted in the cloud.
Hardware safeguards
There will be no need to keep an eye on the physical apparatus to ensure security. CCTV and security staff are used by businesses to secure their physical assets (Vaquero, Rodero-Merino, & Morán, 2011). IaaS services, on the other hand, are accessed via a cloud platform, and the company that employs them is indifferent to the physical security of the equipment. The failure of one or two switches does not affect the overall performance of a cloud-hosted network. IaaS providers have the redundant infrastructure to safeguard their consumers. If a single data center fails, the infrastructure may be automatically relocated to other data centers so that users can continue accessing it.
Flexible
As needed, infrastructure may be scaled up or down. If the company expands, it won't have to acquire more equipment to meet demand, as is the case with locally hosted infrastructure. However, with IaaS, organizations need to take a few simple actions to access extra resources immediately. This functionality considerably improves IaaS scalability as compared to locally hosted infrastructure.
Cloud computing technology is also resource and cost-efficient, as all the data are saved and monitored by cloud servers. In that case, the cost of big data centers is saved. Database management, system optimization and changes also become easier and more organized. This will help in other financial investments like inventory. The project managers can also plan new system updates and categorizations that can easily connect new suppliers and other stakeholders with the system. Building financial and sales reports will also be more accurate and easier by implementing the particular technology. In that case, the business leaders and management team will be able to prepare a most market-compatible and effective strategy.
Availability
It offers round-the-clock support with access to the company's selected infrastructure to store and install the software. Because of this concern, infrastructure is always accessible. Companies and customers can access infrastructure from anywhere in the world. This also improves the networking model and connectivity between the stakeholders and organizational authorities. In a cloud environment, organizations may manage their infrastructure more efficiently. This is because they are in charge of managing and making such resources available on demand (Vaquero, Rodero-Merino, & Morán, 2011). Infrastructure Management Requires Fewer Employees because the IaaS provider collects the infrastructure. Before making arrangements to relocate from local hosting, businesses must examine many critical aspects. This is also essential for organizational and system security management. The operation will require system encryption, a developer support team, regular system checkups, system verification, etc. The project managers will also be responsible to prepare particular system policies that can satisfy the security management requirements and implementation requirements. ECA wants to investigate moving two of its educational arms to a service-based model where many of its services would be supplied to its clients as a service, in addition to its plans to move to an IaaS model. Several infrastructure models could be used to achieve this. Some of these models are:
1. Local hosted infrastructure and applications.
2. Locally hosted infrastructure with some SaaS applications.
3. Hybrid infrastructure (some locally hosted infrastructure with some IaaS) and applications.
4. Hybrid infrastructure and applications with some SaaS applications.
5. Full IaaS model with some SaaS apps.
6. Full SaaS model.
You are required to choose an infrastructure model that you think will achieve the ECA Roadmap; describe the benefits and drawbacks, excluding costs, of your infrastructure model selected.
Hybrid infrastructure (some locally hosted infrastructure with some IaaS) and applications There are various advantages of employing hybrid architecture and technologies in IaaS services. The Hybrid cloud method with special IaaS features provides several benefits. It is a strength to serve both public and private clouds. It offers round-the-clock support for access. Outline the merits and disadvantages of the hybrid approach, excluding prices. This method has a significant advantage since it can be used for both. Private and public cloud infrastructures can coexist, and sensitive and non-sensitive data can be isolated (Williams, 2013).
It offers round-the-clock help for gaining access to improved Mobility. Choosing a hybrid cloud is also helpful in terms of change or upgrade. A small testing project is planned so that infrastructure may be easily adapted to suit future demands. Increased Development/Testing Capacity contends that hybrid clouds provide the best of both worlds in terms of scalability, adaptability, elasticity, and Location independence. A hybrid cloud option is also available worldwide, making it easier to use (Williams, 2013). The accessibility of on-site servers is another advantage for the company that it may utilize its existing servers. As a result, selecting a technical model compatible with some IaaS applications that suffer from the drawbacks of hybrid infrastructure and software is a good mixture (Manvi, & Shyam, 2014). In addition to its many benefits, the chosen model has several downsides, like identification and Personal Information Protection. As previously said, hybrid clouds provide the benefits of leveraging private and public cloud resources but also require substantial administration work. When determining what is public and private, extreme caution must be exercised (Khajeh-Hosseini, Greenwood, & Sommerville, 2010).
REFERENCES

Case Study
BUS5PB Principles of Business Analytics Assignment Sample
Task 1
Read and analyses the following case study to provide answers to the given questions.
Chelsea is a lead consultant in a top-level consulting firm that provides consultant services including how to set up secure corporate networks, designing database management systems, and implementing security hardening strategies. She has provided award winning solutions to several corporate customers in Australia.
In a recent project, Chelsea worked on an enterprise level operations and database management solution for a medium scale retail company. Chelsea has directly communicated with the Chief Technology Officer (CTO) and the IT Manager to understand the existing systems and provide progress updates of the system design. Chelsea determined that the stored data is extremely sensitive which requires extra protection. Sensitive information such as employee salaries, annual performance evaluations, customer information including credit card details are stored in the database. She also uncovered several security vulnerabilities in the existing systems. Drawing on both findings, she proposed an advanced IT security solution, which was also expensive due to several new features. However, citing cost, the client chose a less secure solution. This low level of security means employees and external stakeholders alike may breach security protocols to gain access to sensitive data. It also increases the risk of external threats from online hackers. Chelsea strongly advised that the system should have the highest level of security. She has explained the risks of having low security, but the CTO and IT Manager have been vocal that the selected solution is secure enough and will not lead to any breaches, hacks or leaks.
a) Discuss and review how the decision taken by the CTO and IT Manager impacted the data privacy and ethical considerations specified in the Australia Privacy Act and ACS Code of Professional Conduct and Ethics
b) Should Chelsea agree or refuse to implement the proposed solution? Provide your recommendations and suggestions with appropriate references to handle the conflict.
c) Suppose you are a member of Chelsea’s IT security team. She has asked you to perform a k-anonymity evaluation for the below dataset. The quasi-identifiers are {Sex, Age, Postcode} and the sensitive attribute is Income.
In the context of k-anonymity: Is this data 1-anonymous? Is it 2-anonymous? Is it 3-anonymous? Is it 4- anonymous? Is it 5-anonymous? Is it 6-anonymous? Explain your answer.
Task 2
There is a case study provided and you are required to analyse and provide answers to the questions outlined below.
Josh and Hannah, a married couple in their 40’s, are applying for a business loan to help them realise their long-held dream of owning and operating their own fashion boutique. Hannah is a highly promising graduate of a prestigious fashion school, and Josh is an accomplished accountant. They share a strong entrepreneurial desire to be ‘their own bosses’ and to bring something new and wonderful to their local fashion scene. The outside consultants have reviewed their business plan and assured them that they have a very promising and creative fashion concept and the skills needed to implement it successfully. The consultants tell them they should have no problem getting a loan to get the business off the ground.
For evaluating loan applications, Josh and Hannah’s local bank loan officer relies on an off-the-shelf software package that synthesizes a wide range of data profiles purchased from hundreds of private data brokers. As a result, it has access to information about Josh and Hannah’s lives that goes well beyond what they were asked to disclose on their loan application. Some of this information is clearly relevant to the application, such as their on-time bill payment history. But a lot of the data used by the system’s algorithms is of the kind that no human loan officers would normally think to look at, or have access to —including inferences from their drugstore purchases about their likely medical histories, information from online genetic registries about health risk factors in their extended families, data about the books they read and the movies they watch, and inferences about their racial background. Much of the information is accurate, but some of it is not.
A few days after they apply, Josh and Hannah get a call from the loan officer saying their loan was not approved. When they ask why, they are told simply that the loan system rated them as ‘moderate-to-high risk.’ When they ask for more information, the loan officer says he does not have any, and that the software company that built their loan system will not reveal any specifics about the proprietary algorithm or the data sources it draws from, or whether that data was even validated. In fact, they are told, not even the developers of the system know how the data led it to reach any particular result; all they can say is that statistically speaking, the system is ‘generally’ reliable. Josh and Hannah ask if they can appeal the decision, but they are told that there is no means of appeal, since the system will simply process their application again using the same algorithm and data, and will reach the same result.
Provide answers to the following questions based on what we have studied in the lectures. You may also need to conduct research on literature to explain and support your points.
a) What sort of ethically significant benefits could come from banks using a big-data driven system to evaluate loan applications?
b) What ethically significant harms might Josh and Hannah have suffered as a result of their loan denial? Discuss at least three possible ethically significant harms that you think are most important to their significant life interests.
c) Beyond the impacts on Josh and Hannah’s lives, what broader harms to society could result from the widespread use of this loan evaluation process?
d) Describe three measures or best practices that you think are most important and/or effective to lessen or prevent those harms. Provide justification of your choices and the potential challenges of implementing these measures.
Guidelines
1. The case study report should consist of a ‘table of contents’, an ‘introduction’, logically organized sections or topics, a ‘conclusion’ and a ‘list of references’.
2. You may choose a fitting sequence of sections for the body of the report. Two main sections for the two tasks are essential, and the subsections will be based on each of the questions given for each task (label them accordingly).
3. Your answers should be presented in the order given in the assignment specifications.
4. The report should be written in Microsoft Word (font size 11) and submitted as a Word or PDF file.
5. You should use either APA or Harvard reference style and be consistent with the reference style throughout your report.
6. You should also ensure that you have used paraphrasing and in-text citations correctly.
7. Word limit: 2000-2500 words (should not exceed 2500 words).
Solution
Task 1
1a)
The consideration of the ethical aspect is quite important in ascertaining the implementation of the different research strategies and approaches for attaining goals related to the Australia Privacy Act and ACS Code of Professional Conduct and Ethics. The Australian privacy act implements the protection of the personal data in any given condition. It has been observed that CTO and IT Manager is trying to implement the strategies that relies on the low security of the organization. This low security can be quite fatal to the organization since it is quite prone to be hacked by the cyber-crime experts. The Australian Privacy Act is trying to implement the strategies which can provide the guaranteed security to the information which is available to the organization.
The different types of the strategies are a major contributor to influencing changes in behavior, attitudes, and accuracy and directing them towards improved performance. These can serve as a tool for the organization to develop the strategies that could aid in improving the current scenario regarding the improvement of the data security (Riaz et al. 2020). Data security is a powerful tool for improving the authenticity of the organization and their ability to manage their information over time for best assignment help.
Data security of the Australian government promotes an increased, continuous, and strategic improvement of the existing information about the data. The policy of the government has focused on the upsurge in the implementation of the different types of data of the customers. The data security has the attribute in safeguarding any kind of the vulnerable security to the customers by the implementation of the strategies that could help in augmenting the security of the organizations (Ferdousi, 2020)
In recent years, the modern data encryption strategy is usually implemented for determining the safety requirements of the data which is available to the company for example the salary of the employees and the customer’s details of the organization. This model is commonly referred to as advanced data security. In the event of a stable environment regarding the safe guarded data of the organization this will enable the improvement of the confidence level of the persons towards the organization.
The rise of the utilization of the strategies due to their technological advancements gives them an advantage over the traditional models of data security with the aid of the suitable strategies. It has investigated the impact of the data security technique of the government would improve the current scenario of the data security and would help to improve the current scenario. The information regarding the different modes of the data security strategy has to be considered for relevant fields of any project of the organization (Zulifqar, Anayat, and Kharal, 2021).
Various factors with varying degrees of influence were identified that mediate the implementation of the advanced data security technique. The tools to envisage the impact of the implementation of the data security techniques and the current performance deliverables through the adoption of the innovative data security strategy are all considered in this context. In this context, it is essential to identify the suitable strategies that are doctrine by the government.
However, in the current context the company is trying to implement the low security strategies to protect the privacy of the data which is available to the company. In this regard it can be suggested that the company has given more priority in saving the operational cost of the company by retaining the existing mode of low security technique. However, in this case this strategy is in utter contrast to the existing policies of then government. This strategy will have a negative impact in the current scenario and would also encourage the competing agencies to adopt the similar strategies that partly compromise the security of the information which is available to the company. In this context, it must be noted that the company must ensure the safety of the organization and this should be held in high priority over all the existing conditions.
1b)
The company is resorting to the techniques which are not conducive to the current scenario when the government is endorsing the high security of the personal information. In the current scenario, according to me Chelsea is correct in her arguments. Chelsea is endorsing the high security for protecting the data of the company and to prevent the breach of the vulnerable data that could hamper the credibility of the company. Hence according to my opinion Chelsea has an edge in this argument. However, the company is correct in its justification that the high security system is quite expensive. It is to be noted that the advanced encryption system is undoubtedly quite expensive and the company is prone to suffer from huge operational cost in the case of implementation of this expensive strategies. In this case it is also to be noted that the company can implement the less expensive strategies that can give moderate security and improve the existing security system of the organization. The k anonymization strategy would be helpful in safeguarding the data of the customers and the employees. In this connection it is essential to de-identify the available dataset and this could further improve the security of the concerned organization. The k anonymization helps in removing the identities of the several categories and after the removal of the identities the appropriate codes are given to the data so that the breaching of the information can be effectively controlled (Sai Kumar et al., 2022)
Hence the conflict that is existing between Chelsea and the management of the company can be resolved by the implementation of the cost effective strategies by the company. However, the proper strategies must be implemented for safeguarding the privacy of the company as this would help in improving the reliability of the organization. The confidence of the customers and the employees can be improved significantly by the incorporation of the suitable de-identification techniques that could protect the vulnerable data of the organization (Madan, and Goswami, 2018). Thus I highly support the opinion of Chelsea keeping in mind the interest of the company. Thus the amalgamation of cost effectiveness and the data security of the organization aids in the improvement of the present condition of the company.
1c)
In this case 2 anonymous systems have been followed. This system is involved in the anonymising or hiding the details of the two categories of the members in the company. These two categories are identity and the post code of the employees. The income of the employee is a very sensitive topic and the proper de identification of the data should be done for ensuring that there is no such breach of vulnerable information that can disturb the reputation of the company. Here in this case the ID of the employees has been denoted with the aid of the codes like1, 2, 3, 4, etc. The post code has also been denoted with the aid of the codes like 308 and 318.There must be some distinctions in the codes that have been applied in this respect. However, all the post codes have not been revealed in this context and this denotes that this data has also been de-identified. However, the other categories like the age, gender and the income of the employees has been mentioned in details. Thus the k anonymization strategy has followed the 2 anonymous systems.
Task 2
2a)
The big data driven system of loan approval system is a rapid system of loan approval and it helps in envisaging the loan applications quite quickly and on time (Hung, He, and Shen, 2020.) The credit risk assessment is done in a programme driven manner and this enables the system to handle a lot of application in one given point. Thus this type of computerized big-data driven system helps to reduce a lot of manual labor and this also helps to perform the work in a shorter span. Hence both the time and labor of work is reduced in this type of loan approval system that employs the big data system.
2b)
In the case of the big data driven rejection of the loan application there are certain hazards that are associated with this type of rejection. In this case Josh and Hannah were denied of the loans due to the evaluation by the big data and this type of rejection was computerized. In this context the ethical issues are as follows
Creation of confusion-In this case of big data driven rejection of loans the loans are rejected or accepted according to the computer programming. The applications which lack the key requirements are usually rejected in this type of loan approval system. On the other hand, in the case of the manual loan approval, the person responsible for evaluating the loan applications had the duty to explain to the applicants the reason of their failure. However in the case of a computerized system there is no such opportunity to get the required clarifications from the system. This causes a great deal of confusion in the minds of the applicants like Josh and Hannah about the reason for their failure. This lack of knowledge also prevents the applicants to reapply for the loan by fulfilling all the required criteria. Thus this creates a lot of doubt and confusion in the minds of the applicants regarding the rejection.
Lack of transparency and Confidence-As discussed earlier the big data driven loan approval system is devoid of the capability to inform about the exact reason for the failure of the loan application. This creates of confusion and thus this depletes the transparency related to the loan approval system of the bank. The applicants are confused regarding the process and often doubt the unbiased nature of the selection process. The lack of knowledge also heavily contributes to the absence of adequate confidence regarding the loan approval system of the bank.
Doubt regarding discrimination-The lack of knowledge about the existing loan approval system contributes to the development of the doubt in the minds of the loan applicants. The loan applicants are not sure about the unbiased nature of the system since the system is not providing bthe adequate justification of their loan rejection. This instills a belief in the minds of the applicants that they might be the victims of various types of discriminations. This discrimination can be due to the social status r their economic status. The applicants often believe that they have been subjected to discriminatory behaviour due to their existing social or economic conditions. This can be a very disturbing issue since the people rely solely on the banking system for getting loans during their crisis period.
2c)
The people of the society heavily rely on the banking system to obtain the required loans during their financial crisis. The loan rejection like Josh and Hannah can have a deep rooted impact on the society since this type of loan rejection does not provide the necessary reasons for the rejection of the loan. This creates a lot of confusion and doubts in the minds of the loan applicants. In such case there is depletion in the transparency and unbiased nature of the banking system. The transparency of the banking system is quite necessary in the society and this damage to the transparency of the banking system disrupts the confidence levels of the people. Furthermore, it has been observed that due to the lack of adequate knowledge about the reasons for the loan of denial, the people might think that the bank is exhibiting a discriminatory approach towards them and this can be quite fatal top the brand image of the bank or the organization which is providing loans.
2d)
The big data analysis should not be solely implemented for the selection of the loan application. The applications must not be contingent upon the database and the data analytics of the concerned system (Agarwal et al., 2020). This type of system cannot be applied in all categories of the loan application and the methods should be properly checked before the application. According to my opinion the methods that should be implemented to reduce the cases of discontent regarding the rejection of the loan application are as follows
Current Income-The current income of the individuals must be checked beforehand in order to know whether that concerned person would be able to repay the debt on time. The current income of the individual must be given priority since the person would be able to repay the debt on time only when the person has a steady flow of cash.
Occupation-The occupation of the individual is quite crucial in estimating whether the person can repay the debt on time. The occupation must be stable in nature for determining whether the concerned person would be able to pay off the debt and would be eligible for the lo0an application
Repayment History-It is essential to denote the intention of the people to repay the debt on time. It is essential to prioritize the willingness of the people to repay the debt and in this case it becomes quite imperative to consider the repayment history of the individuals. This indicates that the concerned individuals will be able to repay the debts on time by considering the repayment history of the individuals.
Thus according to my opinion, it is essential to consider the above mentioned parameters since this parameter appropriately estimates the ability of the individuals to repay the debts on time. Thus these parameters must be given more importance than the existent big data driven loan approval system.
References
.png)
Case Study
SBD403 Security By Design Assignment Sample
Individual/Group - Individual
Length - 3,000 Words +/- 10%
Learning Outcomes-
The Subject Learning Outcomes demonstrated by successful completion of the task below include:
b) Administer implementation of security controls, security risk mitigation approaches, and secure design architecture principles.
c) Explain Secure Development Lifecycle models and identify an appropriate model for a given situation.
e) Apply security by Design industry standard principles in systems development.
Assessment Task
Create a document that advises on how to create a complete cyber security environment in an enterprise. Criticially analyse the basic requirements in conjunction with available technical and organizational cyber security methods and align them with adequate user experience. This has to be aligned with relevant industry or international standards, such as OWASP or ISO270xx. Please refer to the Instructions for details on how to complete this task.
Scenario
Consider you being the member of the CISO-Team (Chief Information Security Officer Team) of an enterprise with approx. 300 employees. The business of this company is
• performing data analysis for hospitals (i.e. how many diagnosises of what type)
• performing data analysis for retailers (i.e. how many products of what type). This data contains no personal data from shoppers such as credit cards. In both instances the data is provided by the respective client. All clients and all client data is from Australia only.
Because of the sensitive nature of the hospital data, the data is stored on premise while the retail data, because of sheer size, is stored in a cloud storage. The cloud provider fulfills all necessary security standards and resides in Australia. About 100 staff is working with the hospital data, this group is called “Doctors” and 200 with the retail data, group called “Retailers”. Every group is organised into a “support”-team, consisting of personal assistants, group head and group vice head and then the analysts. Every 20 analysts work on the same client, there is no one working on two or more clients’ data. The software that is being used for both groups is capable of having individual usernames and group roles. Access control for data can be set by username, group or both. The executives of the company (CEO, CFO and CMO) as well as their PA should not have any access to the data, the IT staff only when required for troubleshooting the application or storage.
Instructions
You will be asked to write a design guide how to create a secure environment for the enterprise since the client demand information about the safety of their data. This includes addressing the following topics:
• What kind of user training is required and explain why this suggested training is required to achieve a better cyber security?
• Perform a risk assessment to identify at least 5 major risks?
• What technical and/or organisational methods can be deployed to mitigate assessed risks? Name at least four technical and two organisational methods and indicate on how to deploy them. Describe the impact on the users ability to work for each method.
• If applicable identify mandatory methods out of the list created.
• Describe if user groups and user rights need to be implemented in the analysis application and the basic IT system (E-Mail, PC-Login etc.)
• Create an appropriate password rule for user accounts both in the application and for general IT and administration accounts (administrator, root, etc.). Explain why you chose this rule or those rules and align that with current standards (such as NIST)
• Define the required security measures for the storage and align them with current standards
• A recommendation for a plan of action for creating and maintaining proper information security.
• A recommendation for a plan to sustain business availabilities.
• A reference to relevant security and governance standards.
• A brief discussion on service quality vs security assurance trade-off (less than 500 words).
You will be assessed on the justification and understanding of security methods, as well as how well your recommendations follow Secure by Design principles, and how well they are argued. The quality of your research will also be assessed, you may include references relating to the case, as well as non-academic references. You need to follow the relevant standards and reference them. If you chose to not follow a standard a detailed explanation of why not is required. The content of the outlined chapters/books and discussion with the lecturer in the modules 1 – 12 should be reviewed. Further search in the library and/or internet about the relevant topic is requested as well.
Solution
Introduction
This case study for assignment help will construct client data security to make insight and potential protected IT controllable conditions and proposals as little hardship to real users and necessary to keep while retaining the top security standard possible. Here, anticipate the user’s participant of CISO-Team (Chief Information Security Officer Team) of such a company with approximately 300 staff. Therefore, the organization's main line of work is data analysis for health facilities. After that, this dataset includes no private information about customers, including credit card information. The data is made by the consistent user in both cases. On the other hand, training for the user will be required for analysis in the data security. There are identify the risk assessment and technical methods to mitigate the assessed risk will be evaluated. However, creating an appropriate rule for user accounts for software and General IT system will be illustrated to measure the security in this report.
Discussion
Required training for user
In order to, user training is necessary to able for enhanced a cyber-security to analyze the aims of user training regarding potential IT vulnerabilities and threats. It enables the users to recognize potential security risks when functioning online and sometimes with their software applications. Cybercriminals inject malicious into devices by using a wide range of effective methods, with newly developed techniques being advanced all the time. Users must be instructed in fixing issues, securing sensitive data, and reducing the likelihood of criminals obtaining personal details and records (Decay, 2022). The main cause for cyber-security training is to prevent business from malicious hackers who could harm the organization.
? A malicious actor is searching for aspects to gain entry to an organization's funds and personal user data, as well as extract money from enterprises.
? Therefore, choice to invest in information security is critical for all organizations, and their employees must have admin rights to an appropriate training scheme for work with potential malicious cyber risks, their data security training must be kept updated.
? User training is includes to evaluating the training information and keeping the data updated.
? There are various training tools available, such as simulating threats, increasing understanding and awareness as well as unusual threats, and providing detailed monitoring (Gathercole et al., 2019).
? The most fundamental type of cyber security training relies on increasing user insight into potential threats.
? There are several options for user training, which is included: Cyber security awareness, Antimalware training, and techniques for communicating data training.
On the other hand, more innovative systems are offered that may be perfect for the IT group as well as roles including cyber analysts. This learning is relevant to OWASP, the more Dangerous Application Errors According to CWE/SANS, DevOps training for protected server and delivery transactions. Some employees could be given training in a variety of risk management measures by transferring them to interactive or in-person basic training. Risk assessments, data protection, as well as intrusion detection systems are all part of cyber security. These systems are intended to teach technology scientific techniques while also providing users with hands-on knowledge in communicating with cyber threats. However, the General IT group can participate in the basic training course, whereas IT and information security professionals can sign up for enhanced programs.
Risk assessment identification
In order to, recognize and assess the five major risks against every type of attack that are mitigating by the following risk matrix table implemented for user training are as follows:
Risk matrix
.png)
To reduce the threats, a recognizing and prioritization table has been illustrated with the assistance of a risk assessment table, as shown below:
.png)
.png)
In the above table, Ransomware, Email phishing, DDoS attack, Trojan Malware and Network Failure are examples of security threats that demonstrate the impact of each threat on an organization. As a result, attacks on each threat priority are infrequently high, medium, and low. This table represented a priority to analyze threats in order to mitigate organizational assets in terms of network and application security.
Technical methods to mitigate the assessed risks
Organizational strategies can be used to prevent or reduce identified risks for users. Users might be effectively capable to implement, evaluate, and mitigate by using risk management solutions as well as risk assessment models (Lyu et al., 2019). There are a few strategies to evaluate to preventing the identified risks as follows:
? Risk Acceptance: Once the risk is low or unlikely to succeed, risk acceptance seems to be the right method. Whenever the price of minimizing or risk avoidance is greater than the amount of simply acknowledging it as well as exiting it to opportunity, it makes understanding to keep it.
? Risk Avoidance: Risk avoidance indicates refraining from engaging in the task that poses the risk. This approach to risk management is most similar to how individuals deal with specific risks (Arshad, & Ibrahim 2019). Although some individuals are much more risk-averse than others, the entire team has a critical threshold beyond which items become far too dangerous to undertake.
? Risk Mitigation: After threats are assessed, a few risks have been better avoided or accepted than others. The approaches and technologies of managing risks are referred to as risk reduction. Because once users identify potential risks as well as their likelihood, users can assign organizational resources.
? Risk Reduction: A most popular method is risk reduction since there is generally a method to at least minimize costs. It entails having to take preventive actions to lessen the severity of the influence (Freddi etal., 2021).
? Risk Transfer: Risk transfer entails transferring the risk to a different third entity and organization. Risk transfers could be delegated, transferred to an insurance firm, or transferred to a new organization, as when borrowing assets. Transferring risk does not always lead to reduced costs.
The four technological and two managerial strategies that are indicated to implement the threat are as follows:
? Agile development approach: All agile processes entail groups to make apps in phases that consist of micro of novel structures. The agile development process approaches in many flavours, such as scrum, crystal, extreme programming (XP), as well as feature-driven development (FDD).
.png)
Figure 1: Agile Development Methodology
(Source: Dhir, Kumar & Singh 2019)
? DevOps deployment methods: DevOps deployment focuses on managerial transformation that improves partnership among depts. responsible for many phases of the progress life span, including innovation, feature control, and actions.
.png)
Figure 2: DevOps Deployment Methodology
(Source: Battina, (2019)
? Waterfall development method: The waterfall development technique is broadly regarded as the maximum agile and out-dated technique. The waterfall approaches are indeed an inflexible linear model, comprised with various steps (needs, layout, application, confirmation, and preservation).
.png)
Figure 3: Waterfall Development Method
(Source: Firzatullah, (2021)
? Rapid application development (RAD): Rapid application development enables our teams to rapidly adapt to changing specifications in a fast-paced, ever-changing market. The user procurement and build phases are repeated until the consumer is satisfied that the design satisfies all specifications.
.png)
Figure 4: Rapid Application Development
(Source: Sagala, 2018)
Furthermore, the influence on the users' capability to work for each method for user training to get the major purpose of the agile software approach is that it enables apps to be issued in different versions. Sequential updates increase performance by enabling players to recognize and accurate defects although also supporting the potentials in the initial period. There are similarly allowing the users to gain the rewards of software as soon, appreciations to frequent gradual enhancements. DevOps is anxious with decreasing time to business, reducing the malfunction frequency of novel updates, reducing the time among repairs, as well as reducing interruption while optimizing trustworthiness. DevOps entities try to obtain this by programing agile methodologies to ensure that everything runs properly and smoothly. After that, the waterfalls advance strategy is modest to recognize as well as maintain due to its sequential environment. The waterfall technique tasks better to get initiatives with clearly defined goals and security criteria. However, the rapid application progress that ensure well- defined company goals as well as a defined group of users and aren’t difficult to salve. RAD is incredibly beneficial for time-sensitive tiny to medium- sized development.
Analysis of the application and basic IT system for user groups and user rights
User groups and user rights are essential to implement for application analysis to enable the generation of a ranking of all rational and reasonable application user groups. Some Systems can be controlled in the software platform just on the "Users" section. It is critical because each login user to understand to that which users he or she is appointed. On the other hand, application reliability is focused on multiple users (rather than particular users), novel users can be provided and eliminated (even in executable mode) without changing the software (Garzón, Pavón & Baldiris 2019). It enables the application's essential components to be recommended to ensure software user access. The basic IT system set up for user login on every user at such a web is indeed a basic framework organization task.
After that, a normal user email address contains all of the data required for such a consumer to sign in and then use a framework without knowing the platform's root user. In the user account aspects are to be defines the elements of the user account number. When individuals create a user email address, individuals could add its user to preselected user groups. A common use group would be to assign group approvals to a file system, providing access to certain members of that organization (Young, Kitchin & Naji 2022). A user could have a database with secret data that only a few users must have full rights to. However, users have create a highly classified group consisting of users who are functioning on the highly confidential task. Users could also give an extra highly classified group read access to the top confidential documents
Create an appropriate rule for user accounts both in the application and for general IT
In order to, develop a suitable password policy for user accounts in the assessment as well as general IT or government accounts to keep the accounts inside the software up to date. The following are the appropriate password rules for recognizing the accounts:
? Never, ever share their password with anybody: Username and password must not be distributed to everyone, such as educators, users, and employees. When someone needs full rights to another person's providing security, project of permission choices must be considered.
? Reset their password if users suspect a negotiated settlement: reset their username from such a computer user don't normally use. After that, reset their password, and notify the local users with various sections in management as well as the Data Security Executive (Wiessner, 2020).
? Rather than a password, take into account using a password: A password is a login composed of a series of words interspersed with data type as well as representational actors. A passcode can be verified or a preferred cite. Passwords generally have advantages including being higher and simple to understand.
Structures are not just a recent idea to cyber security experts, as well as the advantages are enormous - and individuals don't have to be advanced to be efficient. In this section, users look at the NIST Information Security Program but it must be a core component of their security plan. The NIST Cyber security Framework seems to be a consensual method that signifies millions of data security experts' combined experience. This is largely viewed as standards and specifications as well as the most extensive and in-depth set of safeguards available in any guideline. The CSF is indeed the result of a risk-based strategy that managers are very familiar with. This system allows for an interconnected risk management strategy to cyber security planning that is linked to the business objectives.
However, the company's interaction and decision-making would be expanding. The resources for security will be effectively acceptable and circulated. Considering its risk-based, outcome-driven strategy, the CSF is perhaps the most adaptable framework. There are Several businesses have effectively implemented it, reaching from big data security businesses in electricity, logistics, as well as funding to minor and midsize companies. It is strongly configurable because it is a consensual framework (Krumay, Bernroider, & Walser 2018). The NIST CSF is by far the most dependable form of security for developing and refining a security infrastructure in anticipation of new features to developed rules and requirements.
Security measures
A sufficient database security measures as well as track up them to today's standards to analyze security protocols and describe policy-based restrictions used for every data level of security when measured by standardized data; high-risk information needs more sophisticated protection. Users can incorporate cyber security depending on the dangers associated if users comprehend what information individuals have or what requires to be defended are as follows:
? Implement Successful Data Storage Safety Regulations: Every organization must develop, implement, and maintain an extensive data storage security policy. To be efficient, digital storage safety measures are needed everywhere, including the workplace, portable apps, storage systems, on-premise facilities, as well as online.
? Safeguard Their Managerial Configurations: Companies frequently set measures to safeguard data as well as documents storage devices from illegal access whereas ignoring management connectivity security. This might enable the user to gain elevated special rights or an attacking player to create their roots in cultural qualifications, in addition to providing data they must not have direct exposure to.
? Install Data Loss Prevention (DLP) System: Implementing a data loss prevention (DLP) is a key of the most efficient data security standards. A data loss prevention system (DLP) recognizes, provides protection, as well as displays information over the internet and information stored in their storage facilities, including computers, laptops, tablets, smartphones, as well as other equipment (Hussain, & Hussain 2021).
? Measure User Data Authentication and authorization: In this case, another excellent way to improve data security would be to measure user data security controls. It aids in providing secure users ’ access even while retaining user rights to make sure that people only obtain information required to finish their tasks.
Recommendation of maintaining proper information security
The maintaining proper information Security and privacy protections are intended to prevent the unauthorized release of data. Here, the privacy and security mentioned principle's objective is to ensure that individual data is secured and that it can only be viewed or acquired by people who need help that training to perform their job tasks. Therefore, data security requires protection against unauthorized access (e.g., addition, deletion, or modification) (Srinivas, Das & Kumar 2019). The consistency concept is intended to confirm that info can be respected to be reliable as well as hasn’t been improperly altered. A security availability in relevant data is the prevention of structural systems with their characteristics as well as the acknowledgment, that information is entirely available and affordable during the time period or when it is needed by its participants. The objective of convenience is to assure people which data exists and use it when making a decision.
Recommendation for a plan to sustain business
In this section, Recommended for a plan to sustain the business because every organization wants to expand their business, but few recognize how and where to sustain it all in the long run or take a glance at the upcoming monthly or annual survey. Business expansion necessitates the right knowledge assets, carefully chosen partnership opportunities, and goods or both products and services that are in high supply in the business. Aside from these basics, supporting the business necessitates an allowing organization's framework in order to minimize the incidence to the long-term strategy.
? Top Skill: Without such an appropriate person, a company can develop and will struggle to maintain acceleration over time. Users are at the heart of the company because without the appropriate person, it cannot grow as well as advanced.
? Operational Efficiencies: Efficiency improvements drive down costs as well as incorporate an attitude inside the worksite community that creates cost society consciousness, as well as methods to improve how well the organization responds, performs, and integrates the data points of possibilities.
? Prospecting the Right Users: Being a businessman is more than just a job title; it was a lifestyle. To get together and detain the best opportunity - particularly ones previously unheard of or that someone doesn't see behind - users should always adopt an innovative business mind-set (Østergaard, Andersen & Sorknæs, 2022).
? Sound Decision-making process: The significance of what maximum advantage to do was to resolve issues. The primary objective of representatives is to prevent the risk of issues, which also indicates users should be brave enough then to confront them head-on.
? Excellent Leadership: The most effective people end up making impulse decisions and, as a result, have a rotating vision that observes opportunity in everything.
A brief discussion on service quality vs. security assurance
A brief overview of the service quality vs. security assurance has been analyzed into the specific framework of software, all these words are important. Service quality software implies it will perform under its characteristics and functions. Security implies that the framework would not allow confidentiality of data as well as computational capabilities. Whereas quality appears to be simpler to understand, both are slightly contextual in their evaluation. Service quality and service assurance concerns are both considered defects from those who begin taking a comprehensive approach to designing and development. A problem can be described as a "frailty as well as insufficiencies that restricts a product from becoming comprehensive, attractive, efficient, secure, or of significance, or causes it to breakdowns or underperform in its intent" by security research to improve (Obsie, Woldeamanuel & Woldetensae 2020). This procedure may pressure the application to give a response that is outside of the implementation flow's standard parameters. According to the concept of "defect," this same operating system stopped functioning or underperformed its activity. This is a flaw and falls under the classification of satisfaction. On either side, more investigation will be required to determine whether the deficiency does have a security aspect. When a user can show that manipulating this flaw in some manner to obtain unauthorized access to confidential or the system falls under the classification of privacy, this will also come under the segment of security.
On the other hand, service assurance and service quality is such a flaw is easily a logical flaw that, whereas feasibly inconvenient, doesn't generate a hack able vulnerability. The programmer can password the operating systems under the demands while still making it susceptible to Injection attacks. The linked malfunction would've been security-related, but it does represent a quality deficiency. There are most would make the argument that such a security flaw is a quality issue. A user could comfortably accommodate that type of thinking, and others would take a structure to achieve. This proves that protection is not a subsection of quality. The fact that quality and security have been operationally divided in conventional development shops contributed to the confusion. The quality assurance department, which was usually located somewhere within the management framework, had been in charge of quality (Shankar et al., 2020). This aids the programmers with quality assurance as well as testing. IT security personnel were in charge of security. There are several organizations' connections with advancement were badly described and even worse implemented. IT Security, as well as QA, might have occurred in different worlds and not recognized it. The conventional quality and security storage facilities have to come back down by necessity as development programmers have developed and agile methodologies keep taking root. Security has been incorporated into the development phase so that designers can incorporate security best practices into their code. Accordingly, designers are now jointly responsible for quality.
Conclusion
A brief analysis has been built on client data security to consider making insight and potential secured IT manageable conditions and proposals as painless for real users as possible while maintaining the highest security standard possible. Consider the user as a member of the CISO-Team (Chief Information Security Officer Team) of an organization with assessed 300 employees. As a result, the organization's primary focus is data analysis for health care facilities. Following that, no sensitive data regarding users, including account information, is included in this dataset. On the other hand, training for the user has been required for analysis for data security. There are recognize the risk assessment and technical methods to mitigate the assessed risk have been demonstrated. However, creating an appropriate rule for user accounts for software and the General IT system has been illustrated to measure the security in this report.
Reference
.png)
.png)
Case Study
SYAD310 Systems Analysis and Design Assignment Sample
ASSESSMENT DESCRIPTION:
Case Study
Case Study: ‘Sydney Gifts’
‘Sydney Gifts’ run a store selling good quality antiques and have been in operation for twenty years. They currently maintain details of every piece they sell in a manual system.
‘Sydney Gifts’ has always been run by the same owner/ manager Mr Smith. Mr Smith's son has just joined the business and thinks that using a computerised system would make managing their orders, stock levels and records management easier. Currently they divide their stock into three categories furniture, china art and paintings.
For furniture they store the following details current owner, approximate age, type, style, construction material, finish, condition, notes and price. For paintings they store current owner, approximate age, style, condition, notes, price, artist and medium. For china they store current owner, approximate age, style, and condition, notes, manufacturer and construction material. The managers also want to be able to run sales reports at the end of every month.
‘Sydney Gifts’ also sell antiques on behalf of some of their existing customers so that they may sell the same item more than once. When this happens, they go back to the original record of that piece and record the details of the new sale price, owner etc. This is done so they can maintain the provenance of the item. It is very important to both Mr Smith's that this system is very accurate and quick to use.
They would also like a better way of maintaining customer details so that a customer could tell Sydney Gifts that they are looking for a particular item. That item could be placed on a "wish list" and the customer notified when the item is located. As well as the standard attributes for an item the wish list will store the date the customer registered the item on their wish list and the top price they are willing to pay. ‘Sydney Gifts’ have many customers so that sometimes more than one customer may register that they are looking for a particular item. When at least two customers are looking for the same item it has been decided to offer the item to the customer who registered the item on their wish list first.
Tasks
Write answers on the following questions
1. What types of system requirements will you focus on for Sydney Gifts System? Explain each one in detail.
2. What fact-finding methods could you use to collect information from employees at Sydney Gifts? Suggest at least three methods and explain the pros and cons of each.
3. Describe two systems development tools and two development methods you can used for system development for Sydney Gifts.
Modelling Exercise
1. Create a use case diagram for Sydney Gifts System.
2. Prepare a context diagram for Sydney Gifts System.
3. Prepare a diagram level 0 DFD for Sydney Gifts System. Be sure to show numbered processes for handling order processing, payment, report processing, and records maintenance.
4. Create an initial ERD for the new system that contains at least four entities.
5. Analyse each relationship to determine if it is 1:1, 1: M, or M: N.
Solution
1. Introduction
The present report examines 'Sydney Gifts', a significant store that has been selling high-quality antique products to consumers for twenty long years. In recent times the company has been maintaining the information of the items that would be sold in a manual system. In the Case study report, two types of system requirements are mentioned to operate the operation of the 'Sydney Gifts' system. Furthermore, fact-finding methods are explained that are implemented to collect information from the workers. The advantages and disadvantages of the methods are also explained in the report. Two development methods and two systems development tools are implemented to analyse the development of Sydney Gifts.
2. System requirements by focusing on Sydney Gifts System
Functional Requirements
Functional requirements are signified as the description of the particular service offered by the particular software. It determines the system of the software and its component in dealing with the changes in the software requirements (Martin 2022). On the other hand, the function inputs to the operating system, outputs, and behaviour. The functional requirement is also determined by manipulating data, calculation, user interaction, business management, and specific usage that defines the systematic element to run the functional performance. ‘Sydney Gifts’ regulates the system requirements while determining the requirements that are needed to store the details of the consumer. The store ought to maintain each significant piece sold in a manual system. The store sells antique products such as furniture, paintings, and China art.
On the other hand, the organisation wants to maintain its business while implementing a computerised system such as stock levels, records management, and stock levels. It can be asserted that ‘Sydney Gifts’ uses the functional requirements from the higher aspect of the abstract statement to the specific mathematical requirements. The company will use the functional requirements in conducting the data analysis needed in the operating screen. Consumer data handling needs to be entered into the main system. While entering the specific data, complete information about the stocks, records and orders are put into the system. The system's value is used to analyse the recommendation sets required to design the functional characteristics (Miller et al. 2018). The design is evaluated along with the human factors engineering can result in improvement of their stock maintenance for assignment help.
Performance Requirement
Performance requirement determines the elements of criteria that are needed to stimulate the elements that are used to perform the stock management in a specific code of standards (Designing buildings 2022). On the other hand, performance requirement is signified as the process through the software system would accomplish specific functions under significant conditions. Performance requirements are important to execute the performance that is needed in guiding the end-users (Gorman 2022). In-store management, gathering important information is an important element of software development in determining the software requirements. Requirements are implemented to fully concentrate on the capabilities, goals, and limitations of the project management. Sydney Gifts' consumers, users, and stakeholders need to understand the performance requirement in project management. Sydney Gifts are also looking to maintain the consumer details for the required amount of item. The wish list is the place in the software system where all the information about the products is kept.
3. Fact-finding methods to collect information from employees at Sydney Gifts
The fact-finding method is the important process of implementing techniques such as questionnaires to gather information about requirements, preferences, and systems. Fact-finding techniques are used by Sydney Gifts to find out the changing preferences of the consumer regarding the antique products sold by them. The organisation will use the questionnaire to find out the responses of the consumer that might reveal their preferences and choices on buying the products manufactured by the specific organisation. The fact-finding methods include interviewing, examining documentation, questionnaires, and research.
Interviewing
Interviewing is the eminent fact-finding method to collect information from the consumers buying their products from their store and online platform. The interviews will be conducted properly to find out the best results that are relevant for finding the changing choices of the consumers. Interviews have several advantages, and the most striking aspect is questioning people who can relatively write their responses. This significant category can include the illiterate subjects and infrequent subjects that are unimportant while they speak during the interview. Oral responses play an important part in determining the individuals with a greater number of information than their written responses. The pros of interviewing are the capability to find pertinent information and increase knowledge. The cons of interviewing are a major time-consuming process.
Examining documentation
Examining documentation signifies the project's development required to execute the requirements needed in the project management. Here Sydney Gifts wanted to manage the information about the consumers that have been buying their products for many years. Important approaches are regulated for eliciting requirements to understand the whole inventory system among the stakeholders (Aslam et al. 2021). It is advantageous in recognising the data flow needed to understand the new system. It is disadvantageous because it does not store the document that is important for the system.
Questionnaire
Sydney Gifts are incorporating a questionnaire in the primary survey that will be conducted by them to know about the preferences and choices of the consumers. Questionnaires are the eminent form of fact-finding method that permits facts to be collected from a significant number of individuals while regulating control over the responses. It can be asserted that Sydney Gifts are implementing the survey questions to extract information from the consumers who participated in the survey. Questionnaires are designed with important questions that are mentioned in the questionnaire. The consumers have to answer the questions one by one in a serial number to gather responses from the consumer about the products sold and manufactured by the organisation. The pros are that it is a cost savings process and reaches a wide number of people in a certain region. On the other hand, it can also determine unanswered questions about the company and a lack of personalisation.
Research
Research is an important feature finding method in analysing the techniques and methods used in the survey. Proper research can guide the organisation to implement the suitable management required to maintain the manual system. The organisation stores information about the products sold by them to the consumer. The computerised system makes the development of the product management while properly storing the inventory. Proper research will help the Sydney Gifts in assessing the requirements that are needed in the organisation to foster innovation and project management. It regulates critical thinking and also drives analytical skills through on learning process in determining factual knowledge.
4. Systems development tools and methods
System development methods are signified as the eminent process regulated in the organisation to analyse several steps important to design, implement, maintain and analyse the information systems (Saravanan et al. 2017). It is fundamentally important for the systems that are used by Sydney Gifts to maintain the stock for maintaining and gathering the manufactured products. Two systems development methods are the system development life cycle and the agile approach.
System development life cycle
The significant methodology is the product life cycle that includes important steps such as the development of the information systems. The life cycle includes steps such as planning, analysis, maintenance, implementation, and design. In planning, necessary problems of Sydney Gifts are acknowledged to determine the common scope of the traditional system. The problems are analysed to determine the extent to which the management will analyse the modern system (Tutorials point 2022). During the planning phase, challenges, integration, and system security exercised by the Sydney Gifts are considered. In the specification, the information that is collected during the survey is analysed, gathered and validate the relevant information. Furthermore, all the reports are prepared under implementation, which is important to execute the maintenance of the inventory system required to store the modern system.
Agile approach
In recent times the integration of the agile approach in the organisation has developed significantly among highly successful companies (Xu & Koivumäki 2019). The agile approach provides benefits to the organisation in managing important development around the project life cycle. The agile approach is a fundamental process in the project management process to implement an important process in regulating successful business. In user stories, the agile team can develop a fundamental estimation of the activities operated to accomplish the project management done by Sydney Gifts. Sprints are the amount of work that is done by the project members that are discussed in the project planning sessions. The organisation will hold a stand-up meeting to arrange all the members together to ensure the informed details are regulated by the people. Furthermore, in the agile approach, the agile board plays an important role in assessing the tasks that are implemented by the organisation in determining the agile movement.
5. Use case diagram
The use case diagram is signified as the process of determining the changing behaviour of the operating system (Javatpoint 2022). It determines the functionality of the systems while regulating actors, use cases, and their communication with the operating system. The common objective of the use case diagram is to determine the changing aspect of the system. The use case diagram will analyse the requirements necessary in the system that includes external as well as internal influences. The system requirements drive the use cases, persons, and multiple elements that drive the elements and actors that are needed for the implementation of the important use case diagram. Sydney Gifts uses this diagram to understand the changing demands, production of new products, and inventory management are used for analysing through the use case diagram. With the use case system, the Sydney Gifts gather the needs and preferences of consumers present in the operating system. The significant diagram also acknowledges the external and internal factors needed to influence the whole system. While implementing the use case diagram, the organisation needs to analyse the whole operating system of the company to find out the functionalities in the organisation. It can be asserted that the diagram has influenced the integration of the system incorporated by Sydney Gifts.
.png)
6. Context diagram
A context diagram signifies the system incorporated under consideration as a significant process to develop the process. It then determines the relationship between the system and the external aspects, including organisational groups, systems, and external data stores (Modernanalyst 2022). The context diagrams are developed to exercise the components important to structure the whole system of the organisation. Sydney Gifts arranges the context diagram that is important to regulate the synchronisation required in the organisation. The boundaries and scope are the relevant information needed to execute the important information. With the context diagram, the Sydney Gifts will use the technical systems to interface the system important for the organisation.
.png)
7. Level-0 Diagram
The data flow diagram determines the information flow in the system and process (Lucidchart 2022). It fundamentally uses symbols like circles, rectangles, and arrows, to provide storage points and outputs between the destination in the project management. The data flow diagram is an extensive process determined to regulate the diagrams needed in the organisation. Sydney Gifts will use DFD to encourage sustainable information to determine real-time, interactive, and database-regulated systems. The data flow diagrams regulate the fundamental integration while encouraging captivating criteria needed in the system.
.png)
8. Entity-relationship diagram
ERD is the significant element of the flowchart that determines how elements such as objects, people, and concepts link with each other in a confined system. ER diagrams are the fundamental element in determining the debugging and designing of the elements present in the business and research.
.png)
9. Conclusion
Based on the above research, it can be concluded that Sydney Gifts are operating a store that will run the products, including the chair, furniture, and paintings. The organisation implements the two system requirements, functional and performance requirements, to encourage the project management process. Diagrams like use case diagram, context diagram, diagram level, and an entity-relationship diagram are used to implement the project management.
References

Case Study
DATA4300 Data Security and Ethics
IT – Case Study
Your Task -
• This assessment is to be done individually.
• Students are to write a 1000-word report on the monetisation of data and submit it as a Microsoft word file via Turnitin on Tuesday week 3 at 23:55pm (AEST).
• You will receive marks for content, appropriate structure and referencing.
Part A: Introduction and use on monetisation
• Introduce the idea of monetisation.
• Describe how it is being used in by the company you chose.
• Explain how it is providing benefit for the business you chose.
Part B: Ethical, privacy and legal issues
• Research and highlight possible threats to customer privacy and possible ethical and legal issues arising from the monetisation process.
• Provide one organisation which could provide legal or ethical advice.
Part C: GVV and code of conduct
• Now suppose that you are working for the company you chose as your case study for assignment help. You observe that one of your colleagues is doing something novel for the company, however at the same time taking advantage of the monetisation for themself. You want to report the misconduct. Describe how giving voice to values can help you in this situation.
• Research the idea of a code of conduct and explain how it could provide clarity in this situation.
Part D: References and structure
• Include a minimum of five references
• Use the Harvard referencing style
• Use appropriate headings and paragraphs
Solution
Part A: Introduction and use of monetization
The idea of monetization
The most popular method of using information to increase revenue is data monetization. The highest performing and fastest growing businesses have embraced data monetization and integrated it into their operations. Offering direct access to your information to outsiders is part of direct information monetization. One can sell it in its original, unsophisticated form or in a structure that has been modified to include research and knowledge titbits (Tucci and Viscusi, 2022.). Common models include contact configurations for new commercial opportunities or discoveries that have an impact on the businesses and organizations of purchasers, where things become interesting is with aberrant information monetization. Information-based improvement comes first and foremost. This involves dissecting your data to find experiences that can improve how your association does business. Information may help you understand how to approach clients and how to interpret client behaviour so one can move your transactions forward. Information might also include where and how to cut expenses, avoid risks, and simplify procedures.
Use of monetization in Telstra
The last several years have seen activity in the field of big data monetization in telecoms. But telecoms' competitiveness has changed over time because of the complexity of delivering and selling such a wide variety of goods, as well as because different verticals have distinct income potential opportunities. The success of other new telco products, particularly IoT, as implied by the connection between various Telstra information and examination items and IoT arrangements, has also significantly impacted Telstra's desire to pursue information monetization approaches (Cunneen and Mullins, 2019.). In many cases, IoT information monetization is the main system, as shown in the scenario above, but in other cases telecommunications administrators can handle opportunities independently of IoT administrations.
The benefit of monetization in Telstra
The arrangement of understanding distraction/wearing scenarios is a fairly typical use case in today's world that makes use of sensor data and client development expertise. Also available for examination are crucial areas like client division and behaviour. For Telstra, it is harder to find various open doorways around pleased usage designs. Although it is a mature market used to consuming various types of information, and it doesn't seem to be a well-known use case, Telstra may well know about its set-top boxes and various stages that will be important to content suppliers.
Part B: Ethical, privacy, and legal issues
Threats to customer privacy and possible ethical and legal issues arising from the monetization process
Big Data, artificial intelligence, and information-driven advancements provide enormous benefits for society as a whole and numerous fields. On the other hand, their abuse might cause information work procedures to ignore moral obligations, security expectations, and information insurance regulations (Al Falasi Jr, 2019). If using big data effectively inside a framework that is ethically sound and culturally focused is capable of acting as an empowering agent of favourable outcomes, using big data for money outside of such a structure poses several risks, potential issues, and ethical dilemmas. A few examples of the impact modern reconnaissance tools and information collecting techniques have on security include group protection, advanced profiling, automated guidance, and biased rehearsals.
Everything in modern society can be scored, and fundamentally innovative opportunities are still up in the air thanks to such scoring systems, which are typically obtained by opaque predictive equations applied to data to determine who is valuable. Therefore, it is essential to guarantee the decency and accuracy of such scoring frameworks and that the decisions based on them are acknowledged legally and morally, avoiding the risk of defamation suited to affect people's chances (Kumar et al. 2020). In a similar vein, it's critical to prevent the alleged "social cooling." This deals with the long-lasting undesirable effects of information-driven improvement, particularly those caused by such scoring frameworks and the standing economy. It may be seen, for instance, in the phrasing of self-awareness, danger avoidance, and the absence of free speech activity in large information works that are conducted without a moral foundation.
The human-information interaction under Internet of Things (IoT) settings, which is boosting the amount of information acquired, the speed of the cycle, and the variety of information sources, is another crucial morality issue (Rantala et al. 2021). Researching new viewpoints such as "responsibility for" and other barriers is important, especially because the administrative landscape is developing much more slowly than the Internet of Things and the advancement of Big Data technologies.
The organization which could provide legal or ethical advice
The Office of Legal Services Coordination works to guarantee that Australian Government entities get trustworthy and well-written legal services. This group might offer advice on the impact of modern observation tools and information gathering techniques on security, including group security, advanced profiling, computerized direction, and unfair practices.
Part C: GVV and code of conduct
Report the misconduct
The GVV framework including Values, Choice, Normalization, Purpose, Self-Knowledge & Alignment, Voice, and Reasons & Rationalizations can be noted to be denied in the abuse of the monetization frameworks may result in disruptions and extraordinary results. The weaponization of monetization poses the most obvious risk. The projected risk of computerizing protection engineering is that it would lead to widespread obliteration that is not reversible (Truong et al. 2019). The tactical application of adaptability, such as the use of independent weapons, might result in a different and more destructive style of combat.
It should also be taken into consideration because a study on the corrupt use of money found that adaptation might make already existing threats like cybercrime worse and the deliberate misuse of the GVV framework should be reported. The advancement of adaptability may also herald the appearance of novel threats. They might easily sabotage current safety initiatives, interfere with a system's operation, or damage any stored information. Additionally, futurists warn that money might be misused in a variety of ways, like as:
• Through the propagation of false ideologies, the majority is subjugated and subject to social control.
• The increase of automated systems that can spread fake news and change public opinion
• Attacks against the fundamental pillars of the economy, such as banks, media communications, utilities, and so on, can be launched by cybercriminals using money.
• Large businesses can use adaption-controlled techniques for adaptation to mine confidential customer information.
Code of conduct and its usage
A code of conduct is essential in this case because it provides employees with clear guidance on how to behave and operate while carrying out their jobs. While some businesses want their employees to abide by a code with many requirements, others keep things simple. An aspiring employee may determine whether they can work in a certain organization by learning about the standards, methods, and assumptions, and a current representative can excel at their job by doing so (Dagg et al. 2022). The new legislation for information protection and other moral concerns requires that businesses manage their internal information operations following these new rules, which is the importance of the code of conduct. Additionally, even if change at large firms is dramatic, information pioneers should seriously assess such changes as business opportunities rather than burdens.
Part D: References
.png)
Research
DATA4300 Data Security and Ethics Assignment Sample
Word count: 1500-2000
Weighting: 40 %
• you have been employed as a data ethics officer by an industry board (professional body) wanting to create a code of conduct around using artificial intelligence (ai) to (a) diagnose disease in a person earlier in the progression of this disease or (b) predict the spread of community diseases, in order to inform best practice in the healthcare industry.
• you are being asked to produce a framework for a code of conduct for a medical board.
• you can choose either of the two applications above (earlier disease diagnosis or community disease prediction using ai).
• this company code of conduct framework will also address individual responsibility as well as recommended government oversight.
• your framework will be presented in a report (a suggested structure is below).
Introduction
• introduction to the use of ai in medicine as a whole and fears related to its use, e.g. “seventy-one percent of americans surveyed by gallup in early 2018 believe ai will eliminate more healthcare jobs than it creates.”
source: https://healthitanalytics.com/news/arguing-the-pros-and-cons-of-artificial- intelligence-in-healthcare
• describe how ai is being used either to (a)diagnose disease in a person earlier in the progression of this disease or (b) predict the spread of community diseases
Data ethics issues
• outline possible data security, privacy and ethical issues associated with the use of patient data in ai. for example, why it may not be a good thing as stated in the quote below.
“it’s true that adding artificial intelligence to the mix will change the way patients interact with providers, providers interact with technology, and everyone interacts with data. and that isn’t always a good thing.”
source: https://healthitanalytics.com/news/arguing-the-pros-and-cons-of-artificial- intelligence-in-healthcare applicable principles
• outline theoretical and legal principles which are relevant to the data issues identified. afterall, if the algorithm gets it wrong who is to blame?
Solution
Introduction
Use of AI in medicine
Artificial Intelligence (AI) in electronic health records may be utilized for scientific research, increased efficiency, and medical management efficiency. Despite going through the traditional road of scientific publishing, recommendation formulation, and medical support tools, AI which has been properly constructed and taught with adequate data may assist in uncovering evidence-based medical practices from electronic health information. AI may also help design new patient care patterns of healthcare provision by studying clinical practice patterns obtained from electronic health data.
A critical feature of AI-based healthcare or medical research for assignment help is the utilization of data generated for electronic health records (EHR). If the underpinning system for information technology and network do not stop the dissemination of diverse or low-quality data, this data could be difficult to utilize.
.png)
Figure 1: AI in Medical
(Source: Walls 2022)
AI is being used in Predicting the spread of community diseases
In recent days, COVID-19 has been at its peak and even a kid is aware of its impacts and the disaster it caused to the world. For overcoming its impacts, AI is being used in several ways to the prediction of the spread of this communicable disease. As the major symptoms of any communicable disease are chest pain, cold, cough, etc. AI is being combined with other technologies for tracking and flagging possible carriers of the virus (Basu et al 2020).
AI-powered glasses for checking hundreds of individuals in minutes without establishing contact. This form of the monitoring system was employed at bus and railway terminals, in addition to other public areas with a high population density. accomplishing this by merging artificial intelligence with new temperature measuring technologies using computer vision. This method allowed for the contactless measurement of body temperature, a primary indicator of COVID-19, despite interfering with people's usual behavior. Anyone whose body temperatures surpassed the limit might be promptly identified using this technique. Since physical temp measuring is time-consuming and increases the danger of cross-infection due to the required interaction with others, it proved to be a successful solution (Basu et al 2020).
.png)
Figure 2: AI models
(Source: Piccialli et al. 2021)
• Through the use of a Support vector machine algorithm, AI separates out the data and identifies the disease spread (Agrebi and Larbi 2020).
• A combination of High-resolution accuracy and a Support vector machine leads to the identification and isolation of the disease with 100% accuracy.
• It identifies the patterns of data (signs) collected from the patients and through an algorithm AI cross-checks these signs with the right disease and leads to early prediction.
• Machine learning algorithms aid in detecting the red blood cell that got infected through malaria with the use of Digital in-line holographic microscopy data (Agrebi and Larbi 2020).
.png)
Figure 3: AI in predicting covid-19
(Source: Piccialli et al. 2021)
Data Ethics Issues
It is observed that for several years, researchers and other people have expressed worries about the ethical concerns of medical data storage and information security procedures, and Artificial Intelligence is increasingly dominating the discussion. Existing regulations are insufficient to safeguard an individual's personal health data.
Indeed, according to startling research, improvements in artificial intelligence have made the Health Insurance Portability and Accountability Act of 1996 (HIPAA) obsolete, and this was before the COVID-19 pandemic. The fact is that healthcare data is very significant to AI businesses, and numerous of them appear to not mind violating a few privacy and ethical standards, and COVID-19 has just worsened the situation. This is a huge concern for the protection of security seeing the hike in cybercrimes (Lexalytics 2021).
.png)
Figure 4: ethical and legal issues of AI in healthcare
(Source: Naik et al. 2022)
Below are mentioned the most probable data privacy, security, and ethical issues concerned with patient data in AI.
1. Continuously changing environment with regular disruptions - AI in healthcare must adapt to a constantly evolving environment with regular disturbances while adhering to ethical principles to safeguard patients' well-being. Nevertheless, a simple, crucial component of determining the security of any medical software is the ability to test the program and understand how the program might fail. The pharmacological and physiological processes of drugs or mechanical components, for example, are similar to the approach for software programs. ML-HCAs, on the other hand, maybe a "black box" problem, with workings that aren't apparent to assessors, physicians, or patients (Wanbil et al. 2018).
2. Uninformed consent in order to use patient’s data - Identity, reputation, and financial loss to the patient. When it comes to data of patients and people are more concerned about it and get in stress due to this, In the online services offered by the medical industry or health care industry tend to collect it's to collect a great piece of information about the patients to feed into the system which leads to data security issues. The information of the patients can be used to manipulate them In the future, creating fake identities, conducting cyber - crimes leading to financial and reputation loss, etc. All these concerns are the major ones that every patient is concerned about (Gupta et al. 2020).
3. Algorithmic biases and impropriety - No accountability for any harm done to patients as AI is a computerized system with no strict laws. Algorithms that may function by unwritten rules and develop new patterns of behavior which come under the AI are apparently threatening the ability to trace responsibility back to the developer or operator. The claimed "ever-widening" difference is the reason for concern since it affects "both the ethical structure of the community and the basis of the accountability concept in law." The adoption of AI may leave the healthcare industry and the patients with no one to hold responsible for any harm done. The scope of the threat is unclear, and the employment of technology will significantly restrict the human capacity to assign blame and accept responsibility for decision-making (Naik et al. 2022).
.png)
Figure 5: Cons of AI Adoption in Healthcare
(Source: Ilchenko 2020)
4. Lack of transparency and traceability in the system - The lack of computational and algorithm as well as operations of the computational system in AI collecting the patient’s information transparency has influenced many legal arguments about artificial intelligence. Because of the rising use of AI in elevated circumstances, there is a greater need for responsible, egalitarian, accessible, and transparent AI design and administration. The two most fundamental characteristics of visibility are data accessibility and comprehension. Information regarding algorithm functioning is usually purposefully made difficult to get (McKeon 2021).
5. Sourcing of data and Personal Privacy violation - With the World Data Corporation forecasting that the worldwide data sphere might very well develop from 33 zettabytes (33 trillion gigabytes) in 2018 to 175 zettabytes (175 trillion gigabytes) by the year 2025, businesses will have access to enormous amounts of both structured as well as unstructured data to mine, modify, and organize. As this data sphere expands at an accelerating rate, the dangers of revealing data owners or consumers including the patients and the staff of any organization and the hospital industry rise, and protection of personal privacy becomes more difficult to secure (McKeown 2022).
.png)
Figure 6: Annual data breach
(Source: McKeown 2022)
Whenever data leaks or breaches occur, the following repercussions may drastically harm an individual as well as indicate possible legal infractions, since many legislative bodies are increasingly enacting legislation that limits how personal information can be treated. The General Data Protection Regulation (GDPR) implemented by the European Union in April 2016 is a well-known regulation instance of this, which impacted the Consumer Privacy Act approved in June 2018 (McKeown 2022).
Applicable Principles
Legal principles against the AI issues in healthcare
• HIPAA requires regulated organizations to secure health information and patient records (information or data) when it relates to Protected Health Information (PHI). Dealing with any third-party provider has concerns that must be thoroughly examined. Whenever committing confidential material to an Artificial Intelligence vendor, healthcare institutions must create Business Associate Agreements (BAAs) to subject suppliers accountable for the same stringent data security requirements. As Artificial Intelligence technologies develop and healthcare businesses adopt AI into everyday activities, regulation loopholes remain to keep this technology in the shadows.
• Another principle that the healthcare industry must follow while implementing AI is that they need to offer full transparency to the system and the data information accountability of the patients in order to maintain their trust. In such cases, the placement and ownership of the computers and servers which keep and access patients' medical data for healthcare AI usage are critical. Without notable exceptions, laws must mandate that patient information be kept in the jurisdiction from where it was collected.
• Developing and applying artificial intelligence (AI) in order to strengthen national security & defense as well as strengthen the trusted collaborations by softening science and technology guidelines with the application of human judgment, particularly whenever an activity has the possibility to deprive people of civil liberties or intrude with one‘s fundamental freedoms of civil rights.
• Creating and implementing the best practices to increase the dependability, privacy, and precision of Artificial intelligence design, implementation, and usage. this will use best practices in cybersecurity to promote sustainable development and reduce the possibility of adversary impact.
• Legal principles shall offer adequate openness to the community and corporate clients about our AI methodologies, implementations, and uses, within the constraints of privacy, innovation, and reliability as defined by law and regulation, and in accordance with the IC's Principles of Information Visibility. it will create and implement systems to define roles and hold people accountable for the usage of AI and its results.
REFERENCES
.png)
Research
7113ICT Research for IT Professionals Assignment Sample
Assignment Requirements
The Research Plan must show a clear connection between the research question and the associated focus/objectives, and the method and techniques of data collection and analysis to be used to achieve those objectives. How well this is done contributes significantly to the coherence of the work and conveys to the reader that the author of the proposal has the competence to execute the research project successfully. The body of the report should be at least 3000 words. Please note that the references, direct quotes and appendices are not included in the word count.
Required Components
• Background to the problem
• Literature review showing the relationship to previous works
• Research question (including the broad research question and the sub-questions)
• Aims and significance of the research
• Research strategy, approach and methodology
• Data gathering and analysis techniques
• Rigor, validity, reliability and ethics
• Research schedule/timeline
• References
• Clarity of the statement of the research problem (including the clarification of the underlying assumptions)
• Clarity of the research question(s) derived from the problem statement
• Rationale for conducting the study (including significance, relevance to theory and practice, relationship to previous research, own contribution)
• Review of literature and theoretical frameworks (relationship to previous research)
B. Well-reasoned and balanced choice of research methods (35%)
• Research strategy and design (including data collection and analysis) well justified given the
underlying assumptions.
• Evaluation of the methodology discussed in the relevant field with respect to the problem domain (e.g. software engineering, information systems, artificial intelligence, computer science, multimedia)
C. General Level of Scholarly Analysis (25%)
• How well the issues covered in the course have been mastered.
• How well the overall plan is developed.
• Evidence of critical reading and evaluation of relevant literature.
• Comprehensive knowledge of issues illustrated by the selection of literature.
• Evidence of explanation and analysis (not description) where appropriate.
D. Communication and Referencing (20%)
• Logical development of argument.
• Clear structure and organisation.
• Fluent writing style.
• Correct spelling, punctuation and grammar.
• At least 3000 words.
Solution
Background To The Problem
In today's marketplace, business analysis is a relatively powerful tool that assists business organizations to reduce the amount of risk which might be the result of different activities and can be short-term or long-term. Moreover, the business analysis also helps in understanding the exact requirements of a business, possibilities of organizational IT systems, development and execution of a business project etc (Žemgulien? and Valukonis, 2018). Therefore, the people who are assigned for performing such critical and in-depth analysis of a business or the business analysts have a major role in enhancing the business performance.
Modern-day business organizations have advanced and powerful IT systems that help in the collection and analysis of business operations-oriented data. But at the same time, they tend to generate enormous volumes of data that sometimes become quite difficult for the business analysts to handle, understand and interpret. Business analysts and the professionals of an IT department within an organization have a very close relationship with one another in terms of their work (Täuscher and Laudien, 2018). Precisely it can be said that their works and operations are inter-related. Therefore, it is mandatory that both professionals must work collectively to achieve the organizational aims and objectives for best assignment help.
The real problem arises when business analysts are incapable of handling the amount of data produced by the IT systems or the IT departments. This can lead to significant problems and in fact, put forward various hindrances that ultimately lead to degraded performance (Palepu et al. 2020). Some of the main hindrances faced by the business analysis in doing their daily business research are because of reasons like over-ambitious and vague business requirements, difficulty in understanding and interpreting the business requirements, generation of an enormous volume of data that are difficult to manage and interpret, allotment of inadequate time for conducting the analysis, etc.
Literature Review
Skills that business consider important for business analysts
Business analysts work with the organisation to help them to bring improvement in their system and process. Analysis and research are conducted to bring solutions to problems that arise in the business to help introduce the system to their clients and business. Indian IT sector and enterprise business analyst has emerged as the main business practice. They refer to understanding the changes that business requires along with evaluating the impact of these changes, facilitating communication and documenting among the stakeholders who are involved and analysing and identifying requirements. They contribute actively to the sustainability and profitability of an organisation. The significant role of business analysts is to guide the organisation to bring improvement in their quality and process of services and products (Pillay, 2018). Business analysts are responsible for making new models that will help in supporting the decision in the business by working closely with information technology teams and financial reporting to implement strategies and initiatives to optimise cost and improve costs. According to Robert, half technology the skills that business analysts should include defining business requirements as well as putting them to shareholders. They should have proper knowledge about reporting, variance analysis, pricing, monitoring and planning, forecasting and budgeting. According to (Shah, 2017) the role of a business analyst is to act as a link or bridge to translate, analyse and interpret between what is typically referred to as the business group in the company and the technology team (Verma et al. 2019). It is also set by them that business analysts perform driving changes and facilitates them to understand the goals and problems of the organisation and should analyse requirements and solutions.
Best place for learning specific skills for business analysts
For learning this specific skill for business analysts, a graduate or bachelor degree is an individual should have adequate knowledge about programming language and should have good negotiation and communication skills. They should create an interactive report with the help of several business intelligence tools. Individuals can have a certification that is offered by international institutes of business analysis which include certified business analysis professionals will be greatly beneficial. A bachelor’s degree is typically needed for most business analyst positions. A Master's degree in BA(business analyst) can also be useful for a more advanced position. But having a bachelor degree is the first and foremost step to become a business analyst as per the United States Bureau of labour. Individuals should have the proper background in psychology or marketing, finance, economics, a business may prove useful. For pursuing a BA position at the management level or any higher-level individual should complete an advanced degree such as masters in business administration program or masters in business analytics. A person can achieve qualification from some other industries such as the project management institute, international institute of business analyst and institute of a management consultant. These courses are offered if the individual has completed their master degree or has a working experience of BA for several years. A person can acquire or learn these skills from work experience with organisations which will help their business analyst skill. They conducted analysis and research to bring solutions to business problems.
Relationship between business analysts and IT professionals of an organization
Business analysts are professionals who analyse an organisation or business by documenting its processes and system, identifying risk, providing solutions and accessing its business model. The role of business analysts can be understood which helps to bring changes in the organisation by identifying the requirements and recommending a proper solution to those requirements for providing value to the shareholders (Ariyarathna and Peter, 2019). In a simple form, it can be said that day is the discipline that helps the company to solve the existing problem by identifying, analysing and solving them. In several organisations, the only solution to deal with issues is by altering the existing process or method or technique that is not workable. This is what BA does- identifying and solving business problems. In the IT or information technology Sector, the BA belongs to the product development team and they are responsible for identifying and analysing the abdomen of the business and documenting its processes and system. They also outline the requirements of the business and match the software that is implemented with the business model (Muntean et al. 2019). The main function of IT business analysts is to analyse and solve the issues using information technology solutions. Their role is the link to a bridge between IT and business. In this role, the business analysts may also communicate with the quality assurance and development team.
Measure that can be taken to mitigate the reason that hinders business analysts from doing accurate daily business research
? Business analysts can face several challenges such as conflict with the stakeholders when a team develops a new approach that is relevant to the present business process (Omar et al. 2019). This conflict can be solved if the team is required to understand the reason for resistance to the new solution. Business analysts should study the requirements and process to prepare a solution. They can prepare a business case document for users which demonstrates the answering users' questions and new solutions.
? The undocumented process can also be a challenge for business analyst from doing accurate daily business research. Business analysts should be familiar with the consequences of lack of documentation on the project or who documented the process and procedure (Pröllochs and Feuerriegel, 2020). For solving this business analyst should identify the decision-maker and key system users. After that, documentation with proper description is made which will demonstrate the difference and processes for users with different responsibilities. Business analysts should concentrate on the requirements of business instead of the position of the users.
? Problems can arise if stakeholders change their requirements and this problem can happen daily. The business analyst should properly understand what is the main reason for this problem (Vidgen et al. 2017). If the reason is some external company alteration in the current process of business it can be solved by accepting the new requirements while postponing the deliverables of the planned project.
Research questions
? Broad Question
What are the primary reasons that hinder business analysts from doing accurate daily business research?
? Sub-questions
1.What are the specific skill sets that business organizations consider important for business analysts?
2.What is the relationship between business analysts and IT professionals of an organization?
3.Does a disconnection exist between what business analysts consider significant and what they know?
4.What are the best places for learning or acquiring the specific skills that business organizations consider important for business analysts?
5.What can be done to reduce or eliminate the reasons that hinder business analysts from doing accurate daily business research?
Research Aims
? To depict the primary reasons that hinder business analysts from doing accurate daily business research.
? To determine the specific skill sets that business organizations consider important for business analysts.
? To understand the relationship between business analysts and IT professionals of an organization.
? To identify the disconnection existing between what business analysts consider significant and what they know.
? To recognize the best places for learning or acquiring the specific skills that business organizations consider important for business analysts.
? To determine the ways or things that can be done for reducing or eliminating the reasons that hinder business analysts from doing accurate daily business research
Significance of the Research
The business analysis finds its importance in identifying and articulating the requirements for changing the working procedures of business organizations. The role of business analysts is imperative for the growth and development of an organization. They help in identifying and defining the solutions for maximizing the value that is delivered by a business organization to its stakeholders (Aithal, 2017). There are several functions of a business analyst such as evaluating the business requirements, developing appropriate documentation, recognizing key areas for improvement, establishing organizational policies and strategic planning. Therefore, it can be easily understood that business analysis along with people who do that i.e business analysts play a crucial role in the overall development of an organization.
Any company could leverage business analysis for achieving its strategic objectives by recognizing and adopting the particular changes suggested by the business analysts. Not only does it help in the enhancement of the overall organizational performance but also helps the organisation to achieve a significant competitive advantage. However, this process is quite complex and difficult to execute in an appropriate manner. This process demands specific skill sets of the business analysts that are important for analysing the business scenarios (Yayici, 2021). Moreover, in modern times almost all business organizations have their personalised and efficient IT department that helps to collect and manage vital business data. This accumulated data is forwarded to the business analysis on the basis of which they commence the remaining procedure. But with the technical advancements at bay, it is obvious that the IT systems produce enormous volumes of data which are sometimes different to manage, handle and processed by the business analysts (Rivera et al. 2018).
The process of business analysis is considered to be a rigorous one and therefore there are certain challenges associated with it. Some of the main challenges faced by business analysts are over-ambitious and vague business requirements, difficulty in understanding and interpreting the business requirements, generation of enormous volumes of data that are difficult to manage and interpret, allotment of inadequate time for conducting the analysis, etc (Gray, 2019). Therefore, this specific research finds its significance in determining the possible reasons that obstruct business analysts from doing accurate daily business research. Moreover, it will also help in depicting the specific skill sets that a business organization demands from their analysts. Furthermore, this research will also help in finding various solutions that will help business analysts in commencing their day-to-day business research in the best possible manner and without any hindrances.
Research strategy, approach and methodology
Research Strategy
The research strategy used for this research is the quantitative survey method which is widely used in various business researches and also enables access to a significantly higher number of survey participants (Understanding different research perspectives, 2021). The research strategy requires the development of a meaningful questionnaire for getting the answers to the various research questions and the questionnaires appeal to the respondents without being too difficult to understand and the quantitative survey method had been beneficial in accurately investigating the relationships between the business analysts and the IT professionals along with the pinpointing various concerns associated to the accurate business research daily.
Research Approach
The research approach selected for this research is the inductive approach which has the objective of generating meaning from the collected data set for identifying the patterns and relationships which are required for answering the research questions as well as highlighting the various dimensions of the central issue (A General Inductive Approach for Analyzing Qualitative Evaluation Data - David R. Thomas, 2006, 2021). The approach is flexible since it has also provided the researcher with the ability to use the existing theories and previous works in the process of formulating research questions that are to be explored in the research.
Research Design
The descriptive research design is being utilised in this research since it aims at describing the present status office-specific identified variable and the research project is designed for providing structured and systematic information regarding the various problems that are being faced by the business analyst in accurately e undertaking the business research from time to time. The descriptive research design is used since it involves the development of a research hypothesis through the collected data instead of beginning with a hypothesis and the analysis of the collected data through surveys is utilised for developing the hypothesis and getting exploring the various research questions systematically.
Data gathering and analysis techniques
Data Collection
? Survey- The data collection method used in the report is a quantitative survey method which was used for determining the skills that were considered to be the most significant as well as the most essential in the engineering sector (DATA COLLECTION METHODS, 2021). The participants in the survey consisted mostly of various engineering graduates who rated the value as well as the performance of every object which was required for their appropriate professional practice. A pilot survey, which is moreover a mini-survey in which the researcher provides a questionnaire for a comparatively smaller size of sample than the total audience being targeted, was also conducted before the data collection for ensuring the reliability of the instruments of the survey (Blog, 2021). The participants of the pilot survey were six researchers, business analysts, as well as teachers and the input received from them was utilised for enhancing the sample along with identifying some attribute terms or fuzzy abilities.
Data Analysis
The data analysis approach used in the research is the mixed data analysis approach which consists of,
? Primary: The method of data analysis being used as the primary data analysis which is the analysis of the data that is collected for a specific research study and the analysis of the primary data is making sense out of the data that has been collected for answering the various research questions or critically evaluating the research hypothesis (Primary Data Analysis - SAGE Research Methods, 2021). The data collected through the quantitative survey method as well as the pilot survey analysed for understanding the various reasons involved in hindering accurate business research daily for the various business analysts.
? Interpretive case analysis approach: This approach is used by researchers for integrating the data utilizing developing various conceptual categories and supporting or challenging the various assumptions given in the case studies regarding the problems of inaccurate business research. The interpretive case analysis approach will also be beneficial in guiding the research which outlines the various problems and challenges on the way along with helping the researcher in understanding the issue through a broad range of perspective which will help in giving a better outlook towards the research questions.
Rigour, validity, reliability and ethics
The consideration of the various ethical issues is a significant part of this research while forming the evaluation plan and the various ethical considerations for this research are,
? Informed consent: This addresses the fact that the participants of the quantitative survey and pilot survey are made aware of the purpose of the research and how their response will be utilised (Ethical considerations, 2021). Appropriate informed consent has been taken from every candidate of the quantitative survey as well as the pilot survey regarding the use of the response throughout the research for exploring the research questions.
? Confidentiality: Another major ethical consideration is the confidentiality of the information that has been collected from the candidate and the data collected from the quantitative survey as well as the pilot survey for this research are being accessed by only the program coordinator which will be ensuring the identifying and collected information from being excluded from any published documents or report.
? Anonymity: The ethical consideration of anonymity has been considered since the identity of the various participants of the quantitative survey and the pilot survey are unknown to the whole research team. This has been considered necessary for the research since various candidates have insisted on this aspect while using their response during the data analysis for exploring the research questions.
? Voluntary participation: All the candidates of the quantitative survey had voluntarily participated without any external influence or force and the participants are free in withdrawing their participation whenever they want and that will not impact their involvement in future programs.
Reference List
.png)
.png)
Case Study
SAM11486 System Analysis and Modeling Assignment Sample
Assignment Case Study – L-Mart
Disclaimer: The situation described in the following case study for assignment help is fictional, and bears no resemblance to any persons, businesses, or organisations, living or dead. Any such resemblance, if exists, is merely co-incidental in nature, and is not intentional.
L-mart is a national business that sells all kinds of varied goods directly to consumers through its physical retail stores and growing online presence. It is looking to upgrade and improve its inventory management system, as its current system is old, outdated, slow, and difficult to use – not suitable for a growing company with rapidly increasing online sales.
L-mart’s inventory management system needs to keep a record of all of the products that are sold at L-mart and the suppliers of those products. It also keeps records of all sales and inventory at both individual physical retail stores, and at regional warehouses.
In the online web store, products are displayed to consumer with their name, retail price, a short description, current stock at each location, and an image. The wholesale price (the price that L-mart paid to a supplier for the product) and barcode are also recorded for each product.
The system also prints shelf labels for in-store use (for staff to put on shelves or individual items). These shelf labels only include the name, retail price, and barcode of the product.
L-mart’s physical retail stores are named after their suburb and state (e.g. “Bruce, ACT”, “Queanbeyan, NSW”), along with their street address, email address, phone number, and a store manager (a person with a phone number).
Regional warehouses are named after the city/area they serve and state (e.g. “Canberra, ACT”, “Western Sydney, NSW”), and have the same information except that they do not have a store manager. The inventory management system keeps a record of all sales. In-store purchases are obviously recorded against the store they are purchased from (and reduce the inventory held by that store accordingly). At the moment, online purchases are always shipped from a regional warehouse directly to the customer (there is no click-and-collect functionality at present, although L-mart is currently investigating the feasibility of this for the future). The time, sale location, product, and quantity are recorded for all sales, and online purchases also record customer name, address, and payment details. Each location can mark individual products as ‘active’ or ‘inactive’. An ‘active’ product is for popular, regularly-ordered products, where stock should automatically be reordered. An ‘inactive’ product is for products that are seasonal or infrequently ordered.
For ‘active’ products, when stock of a product at a particular location reaches a critical threshold (this is different for each product and each location, due to varying stocking and sale rates for each product at each location), the inventory management system should automatically create a purchase order, to be approved (or rejected) by store or warehouse staff. If an order is approved, the staff will specify the amount of new stock to order. Each month, all of the approved purchase orders for each store go out to each supplier for processing. ‘Inactive’ products are never automatically ordered but still have critical thresholds - store or warehouse staff are still alerted when stock drops below these levels and they can manually create purchase orders for these (or other products) if needed.
Each supplier provides multiple products for L-mart, but L-mart only orders a product from a single supplier at any given time. As an ICT business analyst, you will be tasked with analysing and modelling L-mart’s current business practices in order to better understand the current situation of the business, with a view towards creating a single, updated ICT system to manage their inventory management system.
Solution
Introduction
L–mart is regarded as a national business organization that provides its customers with various goods sold directly through the physical retailing stores of the company to their customers. The L-mart company is currently following their outdated and slow system for inventory management, which is becoming old and is thereby increasing the company's difficulties in maintaining proper efficiency. Hence, L-mart company is focusing on developing an advanced inventory management system to manage customers' growing demand effectively and to impart its online presence. Hence this report will provide the context diagram, the data flow diagram and the use case diagram. The company will also focus on the data dictionary, reflecting on the data presented within the context and flow diagrams.
1. Additional research and assumption
From the given case study, it is seen that the L-mart company will be looking to update and improve its inventory management system, for which the company will be focusing on enhancing the features of the online site (Ahmadi et al., 2019). Therefore for bringing the changes to the website, the technical department of the L-mart company will be basing their inventory modelling on some of the basic assumptions. The most important assumption that the L-mart company will be making will be that the customers' demand is constant and continuous. Apart from this, the case of product shortage is not permitted within the company, which indicates that the inventory should consist of an adequate amount of products that will meet the customers' needs (Wautelet et al., 2018). Apart from this, the inventory system should be formed by integrating 3 factors: frequency, order size and timing, and the company's ability to track its inventory. After in-depth research, it is seen that the system must contain proper lead time knowledge and, at the same time, contain variability.
2. Context diagram
.png)
Figure-1: Context Diagram of L-mart
(Source: Self-made)
Through the help of the context diagram, the L-mart company will be able to gain a conceptual view of the inventory management system. Therefore through the help of the context diagram, the L-mart Company will be able to show the overall data flow for inventory management and thereby enable data management.
3. Data dictionary
.png)
.png)
.png)
.png)
.png)
4. Data flow diagram
A data flow diagram is considered one of the most influential graphical representations of the data flow process associated with the flow of information system management design process. Here in this context, it has been identified that the aspects of data items flowing through the data flow diagram are initiated from the external data sources towards internal data sources effectively (Fauzan et al., 2019). In the following section, a top level of DFD has been produced, which effectively incorporates an effective detailed model design for the organisation's L mart inventory management system. Based on this data flow diagram, a structured accomplishment of system mechanism and how the entire retailing operations are done through web process effectively. Based on the smooth flow of information, effective mode of order stocks and inventory control, the possibilities of overstocking and higher inventory costs can be reduced effectively.
.png)
Figure 2: Data flow diagram
(Source: self-made)
Level 2
.png)
Figure 3: Data flow diagram level 2
(Source: self-made)
5. Process specifications
In response to the case scenario, it has been identified that the approached inventory management system can keep all the sales records for the organisation L marts effectively, including in-store and online purchases. It has been identified that the entire process includes direct shipping operations from the company's regional warehouses to the customers to maintain better feasibility (Irhamn and Siahaan, 2019). Here in this context, it has been identified that the inventory management system specifications include details such as the time, sale location, product, and quantity effectively. In addition to that, the online process also incorporates recording customer names, addresses, and payment details. Hence in this context, critical specifications involved in this process are storing process, organisation, management and inventory data analysis. To maintain efficiency and accuracy of the entire system specifications to deliver better inventory control and management support documentation, and in addition to that, employee training at an advanced level is also required.
Hence as retail operations, including in-store and online retail, ensure vast process flexibility, that is why the process being described is one of the most exciting and complex processes of the system in response to having the support of employee training and support documentation.
6. Use-case diagram
Figure 3: Use a case diagram
(Source: self-made)
7. Use case description
In response to the entire information system operations for the company inventory management process, it has been identified that product marking has been taken under consideration as it is identified to be one of the most compelling use cases of the entire inventory management system.
Product marking:

As this product marking helps the system to ensure a better product threshold, it is considered a fascinating and complex use case of the system in context with warehousing operations and stocking management of the organisation L mart.
Conclusion
This report has developed a new inventory management system for the L-mart company, for which the additional assumptions needed are being described. The context diagram, along with the data flow diagram and the use cases for this case, has been provided through which the L-mart company will be able to enhance their data management regarding their product inventory and will be able to handle their increasing demand more effectively.
8. Reference List
.png)
Coursework
CIS7030 Geospatial Analysis Assignment Sample
Task 1 – Descriptive explaining
a) Utilization of geospatial information are widely associates in social context with the support of different geospatial applications.
Discuss the following topics/techniques in conducting a geospatial data analysis.
1. Coordinate Reference Systems
2. Techniques for manipulating Geospatial Data
3. Proximity Analysis
Your answer should contain the following key points. (But not limited to those.)
An example describes real-world usage.
A code snippet/s that supports your answer.
b) The usages of geospatial technology are very minimal in Sri Lanka, comparative to other countries in the world.
Resources management and Taxation are two (2) different geospatial applications, which can fulfill the current needs of Sri Lankans. Although, these applications can fulfill Sri Lankan needs, they are not being implemented in Sri Lanka, yet. Prepare a proposal to implement those applications in Sri Lanka. Following aspects should be incorporated in each proposal
- Need assessment
- Different types of data to be input
- Proposed functions / operations
- Expected output
Task 2 – Geospatial Application (25%)
Geospatial analysis can be applicable for the matters not only contexts in social, but also environmental, economic and political. The objective of this exercise is focused to select suitable spatial regions for hospitals at Vancouver, BC. When building a new hospital, there are criteria that should be followed in order to find the most appropriate location. These criteria consist of required proximities or distances from certain features, such as roads and public washrooms.
Thus, the required criteria are as follows,
At least 500m away from Existing Hospitals
Closer (within 100m) to the Residential Area (Dwellings)
Less than 100m away from Road
Less than 100m away from Street
Less than 100m away from Sub street
Less than 200m away from Metro
At least 500m away from Public Washrooms
Less than 500m away from Fire positions
Use the existing CRS (EPSG: 26910) as project CRS and prepare a map to present your result.
Task 3 – Geospatial Modeling through Programming
Use of python/R programming to analyze Geospatial data in social context.
You are provided all kinds of crime details during first six month of the year 2017 in Colombo Municipal Council area (1-15 divisions). Further details of schools and police stations are also provided. You may use graphs, charts or map, where necessary and explain your answer for following questions.
I. What are divisions having highest overall crime densities?
II. What is most occurring crime in each division?
III. Which month occurred the highest number of crimes in each division?
IV. Prove/disprove the statement – “Drug occurrence mostly occurs in the areas lesser than 150m from school”.
Solution
Introduction
The respective assessment research has been carried out in an extensive manner, in live of presenting contribution to the trending topic of Geospatial analysis. The respective report aims to achieve the fulfilment of providing a detailed comprehension regarding the aspect of Geospatial analysis along with recognising its utilisation throughout various sectors along with the benefits that it is capable of serving.
The respective research would comprise of a detailed and descriptive explanation towards the utilisation approaches of the Geospatial information along with shedding light upon the utilisation of Geospatial technology throughout the reason of Sri Lanka along with comparing the statistics with that of other countries throughout the world, concerning the implementation of Geospatial analysis along with the observed benefits throughout those respective Nations or regions, thus assisting the company of Novartis, Germany for fulfilling their goals.
Furthermore, a detailed explanation towards the applications of Geospatial technology would be described along with presenting a detailed map as a proposal for the using the respective technology for the detection of effective spatial regions regarding the hospitals throughout this state of Vancouver. Additionally, a detailed modelling of Geospatial technology and programming would also be presented through the medium of this report by the utilisation of python programming language to carry out the analysis of Geospatial data with respect to the social context.
Task 1 – Descriptive explaining
Coordinate Reference Systems
A coordinate references system, otherwise commonly referred as CRS indicates towards the approach throughout which the respective special data capable of representing the surface of the earth is flattened, so as to enable the drawing out of two-dimensional mapping of the respective surface. Still, it could be observed that each of these respective two-dimensional surfaces are utilising varied mathematical approaches towards carrying out the flattening process, which in turn a result in the differentiations throughout the coordinates system grids. These respective approaches for carrying out the flattening of given data have been particularly developed and designed towards implementing effective levels of optimisation throughout the accuracy of the respective information with regards to the length as well as the entire area.
In attempt towards putting a definition to the location of any given region, individuals could be observed for often utilising coordinate systems. This particular system comprises of the procedure which carries out operation upon the basis of the X as well as Y values located throughout a given 2 or more-dimensional space.
.png)
Figure 1 Coordinate system musing X, Y for defining location of objects
The above presented example displays the coordinate system comprising of a two-dimensional mapping and space, while it is well known that all the individuals a reside throughout a three-dimensional Earth, which also happens to be round in shape. Therefore, in attempt towards implementing definition of the various location of objects throughout the entire globe, it is necessary that a sophisticated coordinate system should be applied which has capabilities of adapting with the shape of the earth (Dissanayake et al., 2020).
.png)
Figure 2 CRS defines the translation between a location on the round earth and that same location.
The Components of a CRS
Any given respective coordinator reference system could be observed of being developed upon the basis of the below described key components:
Co-ordinate system: the utilisation of the variables X as well as Y throughout the great upon which the respective data is overlayed along with carrying out the procedure towards it defining the respective point of location throughout the space.
Horizontal as well as vertical units: these respective units are incorporated and utilised towards implementing a sophisticated and effective definition of the entire grid along with the variables of X Y as well as Z to be utilised like that of co-ordinate axes.
Datum: it could be defined like a modelled version of the entire shape of the earth capable of defining the specific origin to be utilised for implementing and placing the entire coordinates system throughout the space.
Project information: the respective mathematical equation which has been implemented and utilised towards flattening the various objects observed to be seen on around surface, so as to view these respective objects upon a flat surface (Piyathilake et al., 2021).
Importance of CRS
It is of imperative importance that the comprehension towards the co-ordinate system utilised by the data, particularly implements and works with varied and diverse range of data that is being store throughout various types of coordinate systems. If the individual possesses the data regarding the same exact location which is already stored throughout various other coordinate reference systems, they would not be capable of lining up throughout any type of GIS as well as other categories of programs, until the individual possesses a program like that of ArcGIS or QGIS capable of extending support to the "projection on the fly aspect".
Techniques for manipulating Geospatial Data for assignment help -
Zooming technique
Zooming upon a given respective model allows a given individual to move from a standard overview of a given respective object to that of a detailed one regarding some small part. Only the few major salient features required the necessity towards appearing throughout the generalized model, various other types of smaller details are there in deemed as in significant up till this point. As the viewer carries out the operation of zooming in, and increase within the clarity and accuracy of the details become more and more apparent. This could be better understood by a real-world example where one individual is capable of starting with a map of any given respective city like New York along with zoom in up on the region known as long Island and then further carry out the zooming process to efficiently view a given respect campus by the name of Stoney Brook at the end of the map.
This could be achieved by the implementation of sophisticated and adaptive hierarchical triangulation. This particular hierarchy could be identified to comprise of various categories of fixed levels comprising only of the least significant details that are already eliminated from the coarser levels (Seevarethnam et al., 2021).
Multi resolution views
It can be identified that an ideal terrain model regarding the real time simulation should indeed comprise of representations for:
A tree, throughout which each and every type of possible pruning can be identified as being the valid terrain model. It should also further be efficiently continuous throughout the entire surface regarding each and every pruning. Also, it should also be only single valued, implicating the formula of Z = f (x,y).
The multi resolution display, in similarity to zooming technique, show cases the capability of allowing the utilisation of much fewer and highly generalized triangles for the representation of areas which are identified as being further from the perspective of camera or being categorised as less important to the respective viewer. Dissimilar to the zooming technique, the multi resolution views could be further identify to poses the combination of varied levels of significant details throughout a given single seamless model. The multi resolution display is popularly utilised towards the rendering of various types of perspective views regarding a given scenario throughout which the entire 4 ground is capable of showcasing a great deal of details, as compared to the background (Somasiri et al., 2022).
Line of sight
The line-of-sight technique for the manipulation of Geospatial data is utilised for conducting effective levels of calculation for determining whether the given two points (p1, p2) in a space as well as an object model are capable of viewing each other or not, which would also be understood as whether or not their own respective views are getting obstructed by any given object.
In the most typical approach, the line of side can indeed be calculated by conducting the driver Singh of the entire path from a given respective point to that of another. Each of this respective surface patch could also be identified towards being encountered as well as tested regarding the aspect of obscuration.
Within a highly precise model, the entire number of patches to be examined could indeed be identified as being significantly large.
The line-of-sight calculation as well as the respective technique could also be identified as been the most significant analytic function to be carried out which also further comprises of merit study throughout the past.
Proximity Analysis
Proximity analysis can be defined as one of the approaches towards conducting a detailed analysis of various location regarding the features by conducting a measurement of the distance throughout them as well as various other features in the given respective area. Any given respective distance throughout a point A as well as point B, could indeed be measured by the medium of a straight line or by following a highly sophisticated networked path, like that of a street network.
This could be also further explained and comprehended in detail by the help of an example throughout which a site selection scenario could be taken, where the given prospect is highly interested towards building a large-scale manufacturing plant throughout and area known as the Daytona beach, further comprising of a significant consideration to be observed regarding the distance from the interstate as well as the airport (Wijesekara et al., 2021).
A given respective GIS user should indeed be capable towards simply clicking upon the point of locations representing the given respective site as well as the interstate exit Ramp or that of an airport to further gain the approximate measurement of the distance to be covered. After determining the entire distance, another significant information to be considered can be identified as the water as well as sewer availability along with considering the price per acre as well as the factor of availability regarding the labour to be analysed from the given respective database.
Feature-based proximity tools
Regarding the factor of feature data, various tools could be identified to be comprised within the proximity tool set along with having capabilities towards being implemented for the determination proximity relationships. These tools are also further capable of showcasing their prowess regarding the output information comprising of various buffer features or tables. Buffers could be further utilised for delineating the protected zones across the various features all to carry out the representation of various regions of influence. Further utilisations of the multiring buffer tool could be implemented for the classification of various areas across a given respective feature in to the upcoming year or moderate distance as well as the long-distance class, for conducting a sophisticated analysis (Mathanrajet al., 2019).
Usages of geospatial technology (Sri Lanka Case)
The respective section or rather the subsection focuses upon the utilisation of Geospatial technology throughout the case of Sri Lanka regarding the resource management as well as taxation related Geospatial application, capable of full feeling the needs of the respective nation according to its current on-going scenario. The respective section could be identified as a proposal towards the implementation of these respective applications throughout Sri Lanka, further comprising of the entire assessment of the scenario along with comprehension towards the various functions as well as operations along with the general overview of the expected output regarding the implementation of the Geospatial applications.
Assessment
It is a major fact that groundwater plays a highly significant role throughout several regions having high levels of population as well as irrigated agriculture along with having insufficient surface for utilising the water resources. In accordance to this, it would be identified that there are significant range of consequences regarding the over development of groundwater along with the predominant reduction of the entire bought table as well as the over exploitation and quality deterioration throughout the aquifers.
This could be specially observed to occur throughout the coastal regions where the intrusion of saline water into that of the coastal aquifer has indeed been identified to become a significant consequence, as a resultant of the unplanned exploitation of the groundwater. Therefore, it is highly imperative and essential to carry out the assessment of the different variations throughout the quality of groundwater as well as considering the factor of its availability towards identifying the risk zone of contamination throughout the aquifers, on that of a regional scale regarding the effective management of resources.
The geographical information system otherwise also commonly known as the GIS applications indeed pose a high level of significance with regards to the mapping as well as conducting administration and monitoring along with the modelling of the entire resource management, due to the fact that the entire procedure of data monitoring would be carried out at highly limited number of sites due to the reason of high cost of installation as well as maintenance, with concerns to money and time.
Furthermore, with considerations to the factor of taxation, the land valuation could be identified like that of art as well as science regarding the assessment of the values of any land property along with a determining the supplier as well as demand of the respective land property within the market. The entire factor of land parcel value is entirely dependent upon its geographical location, all the while considering a number of various physical as well as socio economic character traits, which could be identified to be internship to the respective area of land. The respective land owner holds the liability towards making payment of the rate until being exempted by the local government (Liyanage et al., 2022).
Therefore, the entire procedure regarding the valuation of a land could be described like that of the careful estimation and considerations to be presented regarding the calculation of the birth of any given respective land property upon the basis of the experience as well as judgement and the identification and assessment of the various characteristics regarding the given piece of land. The purpose to be fulfilled by conducting the process of valuation is to present the determination regarding the entire value of the respective area of land, along with presenting it in general terms as the market value or benefit value of it.
The various influence upon the given property or a land due to the aspect of location has been broadly regarded like that of the most significant factor to be considered, yet their incorporation throughout the methodology of valuation is indeed highly implicit. Due to the introduction of the GIS based value maps, individuals have obtained a medium towards showcasing the variations throughout the respective aspect of value, with regards to the level of individual properties. Furthermore, a diverse range of characteristics could be identified that make the entire process of valuation highly difficult as well as subjective and dependent upon the significant degree of experience as well as a local knowledge, like for example the entire aspect of heterogeneity throughout the interest as well as economic influences at that of the regional, local and national scale (Dissanayake et al., 2020). These respective characteristics are not capable of getting altered, thus making the entire procedure of valuation, a challenging profession. However, it could be made easier by the implementation or introduction of GIS based if applications which would make them seem prudent towards the minimalization of valuation as well as the factor of complexity by implementing improvements throughout the accessibility and dissemination of the respective data to be operated upon.
Different data to be input and Proposed functions and expected outputs.
Regarding the resource management through the utilisation of Geo special applications, the entire aspect of data to be utilised as input could be understood by taking an example of water resource management within Sri Lanka.
This would comprise of carrying out the process of gathering the information and data regarding the quality factor of the water samples as well as the assessment of the quantity levels. This would implicate the meaning that the identification of all the sampling points regarding the ordinary Wells which are dug at various locations should be identified along with the once which are in operational conditions as well as the ones which are not along with the ones which are utilised for agriculture and domestic purposes respectively.
The factor of electrical conductivity could also be measured throughout the situ, why the utilisation of CE470 (hack) conductivity metre.
Further data to be input wood comprise of the information and details regarding the quality of the water as well as the data regarding the availability assessment which was carried out along with carrying out the gradient analysis.
The gradient analysis is to be utilised for conducting the study of the entire spatial pattern throughout the EC as well as the DTW variation within the entire study.
In addition to this, another major factor should also be taken under consideration that is regarding the local indicators regarding the spatial auto correlations, also known as LISA. Has been the dimension regarding the spatial relationships, LISA is capable of allowing the individuals to carry out the detection of various clusters regarding the geographic parameters under the presented assumption that the entire spatial pattern is indeed non-random distribution.
With regards to the aspect of taxation as a Geo special application, it can be set that the integrated geographical buffering systems otherwise also known as the IGBS, is the highly effective as well as easy to understand procedure to be implemented along with possessing capabilities towards providing the individuals with quick as well as highly cheap technological platforms to be utilised like that of a base to conduct analysis. It also presents the individuals or users with the initial stage comprising of the spatial representation regarding the entire property information, to be utilised like that of a input, within the form of value maps(Pathmanandakumar et al., 2021). The capabilities to be demonstrated by the utilisation of the geographical information system could be observed as not only limited to the facilitation of organisations as well as conducting the management of the entire geographic data, but are also highly capable of unable in the researchers towards taking complete advantage of the information regarding locations which are comprised within the database so as to extend their support to the application of the spatial statistical as well as the special econometric tools.
With regards to the factor of complexity throughout the procedure of land valuation, property owners would indeed receive an approach which is highly easy to understand along with being highly capable for presenting explanation regarding how the respective property is being valued, does eliminating the continuous challenge post to the planners as well as assessors. The integrated geographical buffering system which would be operated upon the basis of the GIS as well as GPS is capable of completely full feeling the specified requirements regarding the taxation related procedures, as explained with the help of land valuation. Thus, the utilisation of different buffering modules along with that of a visual value model as well as the required valuation maps could indeed be easily created as well as extend effective levels of support to the individuals.
Task 2 – Geospatial Application
The respective section fulfils its objective of presenting a detailed exercise which drives the focus upon the discerning of suitable spatial regions for the development of hospitals throughout the city of Vancouver, BC. Several considerations have been taken as a concern for following the identification of the most appropriate allocation towards the development of hospitals.
.png)
Figure 3 Mapping for identification for location 500m away from existing hospitals
.png)
Figure 4 mapping for being in range of or away by 100m with various structures or entities.
Figure 5 mapping considerations for placing hospital 200mm away from Metro and 500m away from public Wash rooms and Fire Positions
Through the above presented screenshots representing the showcasing of various map results, it can be imperatively discerned that effective considerations have been presented towards the establishment of hospitals that are at least 500 m away from that of the existing ones. Furthermore, further considerations have also been presented towards selecting areas for establishing hospital which are closer to the residential area (within 100m of range), and effective considerations were also presented towards placing it away from the road Street as well as sub streets, by presenting a consideration of 100 m away. The results were also generated by basing the location upon being 200 m away from any metro, while also providing considerations for placing it away from various fire positions and public washrooms by providing a range of 500 m.
Task 3 – Geospatial Modelling through Programming
What are divisions having highest overall crime densities?
The respective results are generated with orientation towards the fulfilment of needs of Novartis, Germany, along with how the aspect Geospatial Analysis is capable of assisting the respective company.
.png)
Figure 6: Result for overall highest crime.
.png)
Figure 7: Count of overall highest crime
Grand Pass could be identified as the one having the highest overall crime density. But apart from this it can also be observed that the regions like, kollupitiya, Maradana, pettha, Modara and several other regions also present quite a high overall crime density value as they live throughout the range or count of 30 to 40.
What is most occurring crime in each division?
.png)
Figure 8: Most occurring crime
.png)
Figure 9: Count of crime based on type
It can be efficiently observed through the obtained results that the region of wellawatta has presented the most occurring crime as house breaking as well as theft within its respective division.
With regards to the division of Armour Street, it can be efficiently observed that the most occurring crime within this respective division is robbery
Which month occurred the highest number of crimes in each division?
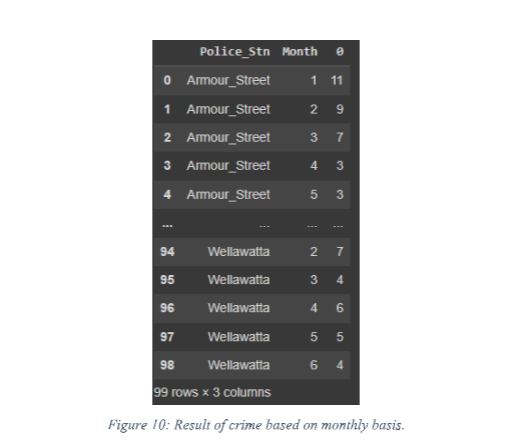
Figure 10: Result of crime based on monthly basis.
It can be efficiently observed through the obtained results that the region of wellawatta has presented the most occurring crime as house breaking as well as theft, on the months of April and July respectively, within its respective division.
.png)
Figure 11: Graphical representation of month count crime.
For Armour Street
The highest crime occurred in month of January.
For division Kurunduwaththa
.png)
Figure 12: Result for Kudurnduwaththa
.png)
Figure 13: In Krurnduwaththa
The highest crime occurred in month of January, march and may.
For division Modara
.png)
Figure 14: For Modara.
The highest crime occurred in month of February.
References
.png)
Research
MIS102 Data and Networking Assignment Sample
Assignment Brief
Individual/Group assignment
Length - 1500 words
Task Summary
Create a network disaster recovery plan (portfolio) (1500 words, 10%-or 10%+) along with a full network topology diagram. This portfolio should highlight the competencies you have gained in data and networking.
Context
The aim of this assessment is to demonstrate your proficiency in data and networking. In doing so, you will design a network disaster recovery plan for a company of your choice to demonstrate your proficiency with network design.
Task Instructions
1. Create a network disaster recovery plan (portfolio) along with a full network topology diagram for a company. (the choice of a company can be a local or international company)
2. It is recommended that to investigate the same company that was researched in Assignment 1 as this created a complete portrait of the company and becomes an e- portfolio of the work complete.
3. Network disaster recovery plan (portfolio)
Write a network disaster recovery plan using of 1500 words, (10%-or 10%+) The Portfolio must include the following:
An introductory section that highlights the importance of having a recovery plan.
• What steps should the company take if:
1. There is a sudden internet outage.
2. A malware (e.g. a virus) has infected the computers in the company network.
3. There is no local area network for the entire company Is there a way to diagnose if this is a hardware failure. What communication protocol stack might be affected.
4. Only a part of the company loses internet connection.
5. There is a power outage.
6. There is a natural disaster such as an earthquake, tsunami, floods or fire.
7. There is a password security breach.
• Are there precautions and post-planning to ensure that the company will not repeat the same network disaster?
• Anticipate the likely questions about the network design that will be raised by the client (Please note that this may include both technical and non-technical staff of the organization).
4. Network topology diagram
• Create a full network topology diagram, which could ensure the business continuity of the company.
• The diagrams need to be your own work and need to be developed using Visio or Lucid chart or an approved graphic package. (Please seek the approval of the learning facilitator prior to commencing this activity).
• All diagrams need to be labelled and referenced if they are not your own.
• The full network topology will be part of the network disaster recovery plan and should be used to further enhance the understanding of the recovery plan.
Solution
Network Disaster Recovery Plan (Portfolio)
Introduction
The network infrastructure is a very crucial requirement of every business in the market for IT assignment. Many things need to be done for a successful business-like Walmart and different aspects need to be analyzed because network infrastructure is used for communication purposes daily. This study is about the network disaster recovery plan that explains what needs to be done in case any disaster occurs. This study enables us to analyze and evaluate different factors of development for Walmart and prepare an effective plan for the management of numerous activities. Walmart is an American multinational company that deals with retail operations by creating a chain of supermarkets that provide the user with goods and products at a discounted rate and serve them as department stores and grocery stores all over the world.
Network disaster recovery plan
The network disaster recovery plan is used in the market for businesses as a backup plan that can be used for any kind of disaster by recovering the entire network of a company like Walmart. The crucial part of a network disaster recovery plan is identifying the weak links and the loopholes of the network ?generating the list of vulnerabilities to risks ?planning to mitigate these risks using suitable measures and specifying the backup (Froehlich, 2019).
• Aspects of this plan
? In case of any power supply, internet failure, or system failure taking place in Walmart, the company needs to analyze what kind of response is required from the staff. The employees can use different measures in addition to handling offline customers and registering their orders. This company right now has a stable market but in case of such a situation, employees and staff need to corporate. In case of any internet outrage or downtime for a small duration, this might affect Walmart but with a low impact.
At this stage, Walmart can use the direct communication method with the employees to provide them the prior information about the opening and closing of the stores and the change in working culture for a limited period (Finucane et al., 2020).
? In case of any malware or virus affecting the devices such as the computers of Walmart, a complete shutdown takes place and the operations must be blocked. For this, Walmart needs to perform a regular scan of the viruses on their computers using the anti-virus software. They should also ensure that the current system has no malware and that updates need to be performed regularly (Pandey et al., 2018).
? In case of the absence of a local area network for the entire Walmart then there is an interruption in the communication between different devices of the Walmart network. These interruptions may take place due to poor wiring that results in weak signal strength.
? If a single part of a company loses the connections to the other network, transmission and receiving of crucial information get blocked. For such a situation companies like Walmart need to prepare by using a backup plan to protect themselves from cyber-attacks.
? Power Failure is another disaster that can take place in Walmart which brings the entire system down. Customers who are shopping offline need to take some restroom. For digital payments, some extra time needs to be provided and the transaction can take place in cash.
? In case of any natural disaster such as an earthquake, flood or fire take place, it is the crucial responsibility of Walmart to ensure the safety of one and all customers by collecting them to a safe place with the help of local bodies and relief organizations. Some food and water must be provided along with the use of anti-measures such as fire extinguishers in case of emergency.
? In case of a password security breach, the issue needs to be reported to the higher authorities as soon as possible. This might lead to the stealing of crucial and sensitive information such as customers' email addresses and payment information of debit cards or credit cards to perform fraud and ransom. This can be eliminated in avoiding by using strong passwords and using software such as firewalls and intrusion detection systems to minimize the impact on the business (Dhirani, Armstrong & Newe, 2021).
• Precautions and preventive measures
The Walmart Company has a very clear vision to provide the department item and grocery items to the customers with an extensive menu of a wide range of goods and product. The key feature of Walmart are quality products, timely delivery, healthy and fresh products, and ease in ordering and delivering items to the doorstep its chain of supermarkets are easily available in every locality. The first parameter required by Walmart firm is the internet connection which has proper bandwidth and low delay time. This is because communication is a very crucial part of any business and it needs to be analyzed carefully in the case of Walmart to record and implement the customer feedback to improve the quality of the service delivered. With the help of an effective communication technique, the negative feedback environment of the customers can be converted to positive critics (Network Disaster Recovery Plan, 2022).
The second is to use the outpouring protectors and the incessant service of power supply along with the availability of power backup to the hardware because this can save the time consumption of Walmart and protect the data by eliminating the vulnerabilities of Cyber thread by safely shutdown the system as well as the server of the Walmart.
The third is the accountability of the staff for the surrounding area and training them with this quality to take care of their task. In case of any employee of Walmart notice anything wrong or suspicious in their surrounding area, they are required to report it to the higher authorities and try to fix it faster. Communication is a critical process that needs to be implemented with the team members to understand the needs of the customers can be enhanced for a better future (Ghasempour, 2019).
The issues in the Wi-Fi internet connectivity is might be a problematic subject but such issues as low speed, poor quality, and frequent disconnections might fail Walmart to serve its customers. This requires a good and stable connection to the internet with the integration of hardware and software devices.
In case of any cyber-attack or risk that is a direct challenge to the sensitive data of the company as well as the customers the precautions required are to identify the hacking activity such as Trojan or Malware, with the need for strong network security levels, and a network monitoring tool. In case of any disaster strikes, the team members of the Walmart and customers need to analyze any evacuation plan with the regular drills required to ensure overall safety (Lin, 2019).
• Questionnaires about the network design
1. What will be the cyber threats and risks that might be faced?
Cyber threats are increasing with technological advancements. The probable cyber Threads are fishing Malware and somewhere, as well injection denial of service, a man-in-the-middle attack, butter flow, and password attack using brute force or dictionary method full stop these are the malicious attacks which are deliberately performed to steal data, breach financially sources and identity (Jaramillo, 2018).
2. What is best for me and how will I decide?
For the best network design with effective communication and high load-bearing capacity, it is understanding to evaluate the building infrastructure that provides an idea about the current networking environment. It allows us to connect with potential customers about their requirements and manage the website hosting operation. Now the business is open to search sections and Walmart might find it interesting.
3. What are your thoughts about the wireless technology of internet connection?
This can be a tricky question because the wireless technology of the internet connection is a fast-working operation facility providing methods with less complexity as no cable or wire is required to connect different devices in the network. But the wide connection provides a reliable and stable connection that is more complex but less costly than wireless. Also, the wireless network allows us to work through the obstacles like the wall with good signal strength and quality internet connection.
Network Topology Diagram
.png)
Figure 1 Network topology diagram for Walmart firm
References
.png)
Research
PROG2008 Computational Thinking Assignment Sample
Task: Data modelling
Weight: 50% (40 hours)
Task Description:
In assignment 2, you have helped a real estate agent to gain some understanding of the market. The agent now wants you to help them set the indicative sale price for their new properties on the market. In this assignment, you will apply your knowledge in data analysis and modelling to build a regression model to predict the indicative sale price of a given property using the previous sale data.
In particular, you will
• Apply multivariate analysis and appropriate visualization techniques to analyze the given dataset for the relationship between the sold price and other features of a property.
• Based on the analysis select one feature that can be used to predict the property indicative price. Justify your selection.
• Build a regression model to predict the indicative price from the selected feature.
• Train and validate the model using the given dataset and analyze the prediction power of the model. Discuss the result.
• Distinction students: propose a solution to improve the model accuracy.
• High Distinction students: implement the proposed solution to improve the model.
You will use Jupyter Notebook in this assignment to perform the required analyses, visualise data, and show the analysis results
Solution
Analysis Report for assignment help
The property sales prediction was done using a python programming language with Anaconda Framework using Jupyter Notebook IDE where the sales prediction dataset was explored at first. The libraries of python used for analysis and visualization were pandas, NumPy, matplotlib, seaborn, and sklearn for importing machine learning algorithms.
About data
.png)
The details about the data are thouroughly discussed in the notebook where each column details has been described about the property and sales.
.png)
The data reading was done using pandas where the information about the data was described.
Data processing including the column details, column information of data types, handling missing values and checking null values if present, and summary statistics of the data where the mean, deviation, maximum, count, etc. of the data are described.
.png)
Data visualization
The data visualizations were done using matplotlib and seaborn library which are used for creating attractive and interactive graphs, plots, and charts in python. The different graphs from the data insights are described as communicating about the data containing visuals.
.png)
The bar chart here describing the bedroom description count where the data containing 45.5% of property with bedrooms and the sales is also depended upon these factors.
.png)
Figure 5 Property sales price with bedroom availability
.png)
Figure 6 Property sales price with bathroom availability
.png)
Figure 7 Property sales price with square fit living availability
.png)
Figure 8 Property sales price with floors availability
.png)
Figure 9 Property sales price with condition availability
The sale prediction according to the property description is clearly described by the visualizations which describe the descriptive analysis of the data which represents the sales of the property according to the different infrastructure based happened in the past.
.png)
Figure 10 Property sales price with space availability
.png)
Figure 11 Property sales price with condition availability
.png)
Figure 12 Property sales price with grades availability
Data modelling
The machine learning algorithm is applied to the dataset for the predictive analysis where the future prediction based on the descriptive analysis is done to look at whether the models are accurate according to the data and the accuracy of the model describes the predictive analysis rate to predict the property sales in the future.
.png)
Figure 13 Regression model
The algorithms are applied to the dataset by training the models by splitting the dataset into train and test split and then the trained and tested values are applied to the algorithms to calculate the score of the applied data.
.png)
Figure 14 Training of the model
.png)
Figure 15 Fitting regression model
.png)
Figure 16 Creating variables
.png)
Figure 17 Decision tree regression
The predictive analysis score of the linear regression model predicted 100% accuracy whereas the decision tree regression score comes to 99% accuracy which describes the property sales prediction as mostly accurate as assumed.
.png)
Figure 18 Linear regression sales prediction with prices
.png)
Figure 19 Linearity of the model
.png)
Figure 20 Data Correlation heatmap
Research
DATA4600 Business Analytics Project Management Assignment Sample
Word Count: 2000 Words (+/-10%)
Weighting: 40 %
Total Marks: 40
Report Structure:
Introduction: Introduce your two projects, identify similarities and differences.
Operational Project (700 words) based on operational case study:
Outline the scope of the project
Evaluate your natural leadership style and how you will use it to lead the project
Suggest a project management methodology and integrate it with the leadership style
Estimate the budget of project
Evaluate possible human resources involved, and associated factors, e.g. workstyles, training & cultural fit
• Discovery Project (700 words) based on an innovation case study of your choice:
Describe how you will assess the risk of the project using predictive project analytics (PPA)
Justify why this project should be undertaken given the PPA relating to its impact
Choose an optimal leadership style for the project
Suggest a project management methodology and integrate it with the leadership style
Estimate the budget of project, and why such an estimation may be difficult given the nature of innovation
Describe the team undertaking the project, or if not mentioned in the case study, suggest one that might be suitable and diverse
Explain how you would democratise the project across the business
• Reflection:
Write a short 200-word reflection of issues you may encounter when managing these projects.
Conclusion: (400 words max)
• Compare the two projects in terms of:
Characteristics
Project methodologies
Human resource requirements
Optimal leadership styles for both
Draw conclusions about how running these two projects would differ.
Solution
1. Introduction
There are two projects in consideration in this report – one operational project and another discovery project. The operational project in consideration is the implementation of location based analytics by Wendy’s. John Crouse of Wendy's has been working on developing this new system over the years that integrates geographic location mapping with demographic analytics (Burns 2014). The combination of the two helps Wendy’s to identify sites that are more likely to be successful for business. On the other hand, the discovery project being considered is the development of fully autonomous cars (Marr 2019). One of the largest business spearheads in the world, Elon Musk has already stated that Tesla will develop fully autonomous cars by the end of this year.
This report analyses these two projects from different perspectives and will compare the two using specific parameters for online assignments.
2. Operational Project
2.1 Project Scope
The scope of the project involves development of a fully working system that uses location based demographic analysis as a part of the business analytics process. The system integrates location intelligence tool with demographic analytics to determine specific new locations that are most likely favourable for business for Wendy’s food chain (Bartoletti et al. 2021). Despite the project being going on for several years, there are still lots of work to be done to perfect the system such that it can be used efficiently and effectively.
2.2 Natural Leadership Style
My natural leadership style is democratic leadership and I always believe that the opinions and ideas of all team members should always be considered with importance. If I am being assigned to lead this project, I will apply democratic leadership style in it as well. This will allow my fellow team members to apply and discuss their own ideas and inputs that I will consider before making final decisions on the project. I will conduct regular team meetings to listen to the team members’ ideas so that different perspectives can be considered while moving forward in the project.
2.3 Project Management Methodology
The most appropriate methodology for the project is Agile method. This project involves a new type of technology that combines two other different technologies to create a system that will perform different functions for the business. As such, using Waterfall method will not be suitable as the focus on quality will not be sufficient. The iterative approach in Agile means constant improvement will be made while the system is being developed throughout the project lifecycle (Huang et al. 2021). Moreover, democratic leadership style will also be suitable for this project management methodology as inputs from the team members will be utilised constantly for continuous improvement during the iterations of the project. Running multiple iterations with continuous improvements will ensure the quality aspect of the system is not compromised with.
2.4 Budget of the Project
Development of a totally accurate budget is significantly difficult in Agile projects and even more in this project that has been going on for years. The long drawn continuation of the project also means that the estimated budget amount will be significantly high and the company should be ready to invest accordingly for the project (Xanthopoulos and Xinogalos 2018). However, at the same time, the company can also expect that the project will save them millions in expenses and will increase the profit margin significantly that will also help them invest further in the project. An estimated budget for the overall project is shown in the following table.
.png)
Table 1: Budget Estimation for the Operational Project
2.5 Human Resources Involved
There are a significant number of human resources involved in the project while different types of roles and responsibilities. Each human resource will have specific roles that they must perform throughout the course of the project (Uphaus et al. 2021). The human resources in the project include the primary stakeholders who are directly involved in the project as well as the regular team members who will be involved in the execution of the project. The main human resources involved in this project are listed as follows.
.png)
Table 2: Human Resource Requirements for the Operational Project
3. Discovery Project
3.1 Predictive Project Analysis and Risk Assessment
Predictive project analysis is a relatively new tool that is very useful in assessing risks in a project, especially the large scale projects with multi-million dollar budgets. Predictive Project Analysis or PPA is a statistical analysis based tool that uses years of data from past projects to forecast possible risks for a particular project (Ondruš et al. 2020). Thus it is a very helpful tool for the project managers to assess possible risks and take early actions so that the risks do not cause the project to move towards failure.
This same tool can be used in this project as well since it will help to identify possible risks in the project. Considering the final output of the project, it can be easily seen that the overall nature of the project is significantly complex and full of various risks that may or may be not very much visible initially. Hence, PPA tool can help to identify those risks that are not well visible and early mitigation actions will be undertaken accordingly.
3.2 Justification of the Project
Analysis of the project risks using PPA may lead to the development of a long list of risks that may occur during the entire project and beyond. Moreover, the complexity of the project means there might not be any straightforward way to resolve these risks and go ahead with the project (Schneble and Shaw 2021). Additionally, the final product of the project involves transportation of human beings and even minor errors in the product may lead to severe damage or loss of lives, which is not desirable. Overall, the risk landscape generated from PPA tool suggests the project is very risky to conduct and even there is no 100% assurance that the final outcome will be flawless.
However, considering the rapid evolution of technology in the entire world and increasing demand for efficiency, this project should go ahead. Development of fully autonomous cars will reduce the need for manual drivers and at the same time, it can help in reduction of accidents through human errors like over-speeding, drink and drive, breaking signals and others (Hussain and Zeadally 2018). Hence, these autonomous cars can be a major breakthrough in transportation technology and the project should proceed but with caution.
3.3 Optimal Leadership Style
The optimal leadership style for the project is Transformational Leadership. The leader should be able to motivate the team members to constantly push their boundaries beyond their capabilities and constantly improve the product in terms of the features and performance. The complexity of the project means the leader should also be a visionary with ideas that will be beneficial for the project. Elon Musk has already set a great example of transformational leadership in his field of business and the same model needs to be followed in the project.
3.4 Project Management Methodology
The most appropriate methodology for this type of project aligned with the leadership style is Waterfall Method. Unlike the previous project, the final outcome of the project is well defined and hence, multiple iterations are not necessary. On the other hand, the most important requirements of the project include proper planning and risk analysis without which the project cannot proceed. Additionally, transformational leadership can also be aligned with this methodology as the team members can be motivated to expand their boundaries while planning and executing the project.
3.5 Budget of the Project
The development of budget for the project is relatively easier than the previous one owing the well defined final output and availability of a project roadmap. However, there are high chances of significant extra costs due to possibilities of unforeseen expenses (Yaqoob et al. 2019). An approximate budget for the project is shown in the following table.
.png)
Table 3: Budget Estimation for the Discovery Project
3.6 Team Undertaking the Project
There are a large number of teams that will be responsible for undertaking the overall project. These teams are listed in the following table.
.png)
Table 4: Human Resource Requirements for the Discovery Project
3.7 Democratising the Project
The one problem with regards to the project is that the developing company i.e. Tesla cannot keep hold of the sole development rights to itself once the project product becomes reality. Since the product has global usage value and has potential to become a standardised usage product, it will not be possible for Tesla to fulfill global commercial demands at the same time (Rajabli et al. 2020). Hence, after a certain point, the project will have to be democratised for other companies to use and develop their own autonomous cars and vehicles. However, once the project is successful, Tesla can commercialise the overall project and sell usage rights to other companies at a particular rate.
4. Reflection
If I am given to manage either of these projects, based on my understanding and knowledge, I can say that I will face many issues and problems that can arise from the project. Both the projects are significantly complex and long drawn as well as requiring constant research and development. As a result, there are number of issues expected to arise as well. Issues may be related to technical, budget, time, team conflicts and others. However, the most important challenge that I will face is creating a suitable and realistic vision that the projects will follow. Both the projects have potential to transform different types of technology and without a long term vision, it is impossible to manage and run the project till the end. If I was the manager, I would have required applying my skills, knowledge and experience to generate a realistic and sustainable vision aligned with the overall scope of the project.
5. Conclusion
Overall in this report, two different projects have been analysed and studied. The first project selected is an operational project that has involved development of a new technical system for business analytics. On the other hand, the second project is a discovery project that involves development of completely autonomous cars. The first project is recommended to follow agile methodology due to lack of clear definition of final output and the need for continuous improvement whereas the second project is recommended to follow waterfall methodology due to the presence of a clearly defined output and the need for in-depth risk analysis. The first project also requires limited number of human resources working as one team under a leader whereas for the second project, there are multiple teams involved and assigned with different responsibilities. For the first project, democratic leadership style is most optimal as it will allow the team members to apply and discuss their own ideas and inputs that will be considered before making final decisions on the project. The second project will require transformational leadership style (a model similar to Elon Musk’s style) to motivate the team members to constantly push their boundaries beyond their capabilities and constantly improve the product in terms of the features and performance. Overall, it can be seen that the projects are completely different in terms of characteristics, methodology, leadership style and resource requirements and it proves that each type of project requires different types of approach and analysis.
References
.png)
Case Study
MITS4001 Business Information System Assignment Sample
Read the following case study and answer the questions below in the form of a report.
You are expected to answer each question within approximately 250-300 words.
Case Study: Cutting out paper speeds up the process
The Chinese are credited with inventing paper nearly two millennia ago, and in spite of more recent inventions, such as the integrated circuit, computerised storage, and networking, it is still heavily used. So is the world moving closer to ushering out the old in favour of the new?
The paperless office has long been a dream, but can it be achieved?
Liverpool Direct is doing its best. The company is a partnership between BT and Liverpool City Council, which at the turn of the decade was seen as one of the worst councils in the UK at revenue collection and benefit payments. ‘The service was deemed to be failing’, says David McElhinney, chief executive of Liverpool Direct, which was formed in 2001 to help modernise the council's operations. ‘The average time to turn around a benefit claim was 140 days, and there was a backlog of 50,000 cases.’ The paper was holding everything up. Each week, 20,000 pieces of mail would arrive at the benefit office, including everything from benefit claims to notifications that an individual's circumstances had changed. The mail would be stamped, and filtered through different teams depending on what information it held until it reached a file.
It would then be sent to more people for manual assessment. Bottlenecks would delay the paperwork, and files would be buried on someone's desk when they were needed most. 'A claimant might pay a personal visit, and we wouldn't be able to locate their file', Mr McElhinney says. 'The average wait was about two hours.' Not only did the paper cause significant delays, but also took up £750,000-worth of office space a year. Ridding the office of paper began with refocusing the system around the end-user. A series of 'one stop shop' contact centres was set up to handle customer queries and visits, and the organisation opted for what Mr McElhinney calls a 'single version of the truth' - a single electronic document that can be referred to by all parties at any time. Now, when a document is received, it is scanned and put into a digital file. Data can be attached to the documents, which is archived into different folders by a dedicated team, based on the content. Software-based flags can then be set for the document that can trigger actions necessary for that letter. One trigger might cause a letter with a particular response to be generated, for example.
One of the biggest challenges when re-engineering a paper-based system is to minimise disruption, but some interruption is inevitable. ‘It’s one of those systems where you can’t run things in parallel’, explains Mr McElhinney. The systems were turned off for six weeks, and buildings including 15 post rooms where closed; one post room was retained to scan all incoming correspondence; the paper storage building was sold in March 2006, generating £4.5m for the city. Stripping away old ways of working was an important part of the project's benefits: ‘Know your processes, and challenge them to make them more efficient’, says Roddy Horton, central systems manager at the Hyde Group, a housing association with 1,200 employees serving more than 75,000 people. This month, the Hyde Group computerised its recruitment process, stripping 58,000 sheets of paper a year out of the system.
Before the recruitment process was digitised, candidates would receive an information pack and application form in the post. They filled in and returned the form and copies were sent to the recruiting manager and up to five people on the review panel. The recruiting manager would then fill out various forms following the interview and return them to human resources, which would then send a decision letter to the candidate. 'Now, all the details are on the website', explains Mr Horton. An online application form is logged in a database and sent to the recruitment manager, who then electronically forwards it to the interviewing panel. Once the decision is reported to human resources, the candidate receives an e-mail.
The recruitment application is built on a database from Northgate HR that the company had bought in 2001 to manage some human resources information. It then purchased ePeople, a human resources application from Northgate that enables the company to provide a self- service front end to the database. The developers built workflow rules into the system that coordinated these communications electronically. The recruitment applications join an already-deployed paperless expense claims and training request application, also designed to strip paper from the system. Before the introduction of that system, paper-based expense claims and time sheets needed to be signed by a manager, who would often be out surveying sites, dealing with housing issues, or visiting other offices. 'It might be weeks before you saw your manager', says Mr Horton. 'Staff were not being paid on time, and they were also going to huge amounts of effort to claim those payments.’
The electronic system handles those communications digitally, so staff enter their expenses claims directly into the computer. The Hyde group also refined the expenses process by making it possible within the system to request that another person sign a document, if the first choice of manager was absent, for example. Both Liverpool Direct and Hyde’s projects had a common challenge in getting people to change the way they work – especially senior staff used to do things a certain way. Mr Horton found that electronically signing documents was counterintuitive for many staff: ‘I had problems proving that an electronic signature is just as sound as a paper one’, he says, explaining that employees ‘sign’ an e-mail in the workflow system by e-mailing it to the server, which then e-mails the next person in the workflow chain.
‘Sometimes, people can also be nervous of introducing efficiencies because they see it as a job threat', Mr Horton warns. He had to reassure several people as systems were roiled out. But how much paper do such projects really get rid of? Neither of these organisations are yet paperless. Liverpool Direct has achieved the greatest success, having stripped about 70 percent of the paper from the process. None of the paper that is personally bought into the one-stop shop centres and scanned is retained, but any postal correspondence is retained for 30 days after being digitised. The Hyde Group's attempt at digital deforestation has been more muted. Since the recruitment system was digitised, about one-third of its paper has been eliminated. It hopes to increase that to 80 percent by digitising supplier invoices, tenancy agreements, and possibly tenancy repair requests, Mr Horton says. Nevertheless, even though an entirely paperless office may not be plausible, stripping even this much paper out of the system can have positive effects. For example, in Liverpool the caseload backlog has been reduced from 50,000 to zero, while the average processing time for benefit claims has dropped from 133 days to 19. Abandoned call rates to its contact centre have dropped from 50 percent to just 5 percent, and the waiting time for personal visits concerning benefit claims has been reduced from the original two hours to four minutes.
Hyde will always have some paper, even if it is not strictly speaking in the office. The company is reluctant to get rid of paper-based tenancy agreements altogether, and keeps them stored in an off-site location for legal purposes. Nevertheless, with the paperless recruitment system now in place, and with its previous paper saving efforts, it has eradicated 153,000 sheets of paper a year from its operations. In reality, the totally paperless office may still be as far off as the paperless newsagent – but organisations can go a long way towards reducing what they use and increasing the efficiency of their work along the way.
Questions
1- Why is it important to strip away old ways of working when introducing systems such as those brought in by Liverpool Direct and Hyde?
2- Using the Internet as a resource, locate information regarding a simple document management system, such as Scansoft's PaperPort Office. How useful is such a product likely to be within a department of a large company or a small business?
3- What is the likelihood that the paperless office will ever be achieved?
Solution
Introduction
In this study research the business information system is discussed on the achievement of paperless office by Liverpool Direct in mitigating different in old ways of working and its evaluation to better business profit. In such accordance several issues regarding the old models have been discussed and the utilization of paperless documents has been proposed as per the case study for business development.
The way of striping away of old working process by Liverpool Direct and Hyde
It is too important to strip away various old ways of working in order to increase the business profit, by replacing different kinds of systems brought by the Liverpool Direct. For the development of business, different kinds of new strategies are implemented as smart work is more effective and efficient than hard work. In such circumstances, the striping away of the old ways has different effects in business (Oliveira et al. 2021). In addition, “Wise Acre Frozen Treats” has been bankrupted whereas the 180s (clothing) has been recovered.
Adapting of information system to achieve strategically organizational goals by Liverpool Direct and Hyde
On the other hand, in 2013, Crumbs Bake Shop topped in the business whereas in 2014 it was bankrupted. Along with that, a gaming company Zynga tried new development, but it did not work out well. Besides, KIND Snacks tried to develop its business while later it stuck to the quality of the products. In such circumstances, it is too significant to strip away the old methods. Actually, all the old methods will not be stripped away whereas many new methods will be implemented for a better future (Kim et al. 2021). As per the case study, total benefit claim is 140 days where total backlogs have been seen for 50000 cases. On the other hand, personal visit time is 2 hours for this company. Additionally, office space corresponding to a year is £750,000. Hence, a single electronics document is referred for the customer handling through the one stop shop.
Time management and the reduction of the effective process are the main factors regarding several management activities. In the case of Hyde, 153000 sheets of the paper have been wasted for its operation and for recruiting 58000 sheets have been wasted. Various data are saved in the database and after receiving the documents, these are changed into a digital file.
Utilization of simple document management system such as Scansoft’s Paper Port office
In order to manage simple documentation management systems like Scansoft’sPaper Port office, Facts and reality checking are most important for product development and that must be included in this. While the paperless office is not to be plausible and stripping paper out from the system, a positive impact can occur in this regard (Wantaniaet al. 2021). According to this case study sample, caseload backlog has reduced to 0 from 50,000 and average processing of this system has dropped from 133 days to 19. Various management activities depend on managing time and reducing effective processes within a suitable way. Apart from that, contact center has also reduced to 5% and personal visiting as well as waiting times have also decreased to 4 minutes.
Development of IT plans casestudy for assignment help to maintain Document management system within Liverpool Direct and Hyde
Hyde can focus on managing papers and is not maintaining strict decision making within the company and that results in reluctance to get rid of tenancy agreements along with a paper-based process. This keeps all the data stored within a location for off-site legal purposes. Moreover, by managing requirement systems of paperless documents along with its previous paper saving efforts, it is seen that more than 153,000 sheets of paper have been eradicated in a year with an appropriate operation. After that, in reality, a paperless office can be still far off as the “paperless newsagent” and the organization can be forwarded to reduce the usages and manage efficiency the long way (AbdulKareemet al. 2020).
Various difficulties can also be faced by Liverpool Direct to manage “Cutting out paper speeds up the process”. These are as follows:
Upgrading from paper-based system to IS
Analyzing the value of an original document
Managing parallel work and its completion within exact time
After that, management of documentation is a process for maintaining the information as well as its organizing, sharing, and storing, creating as appropriate manner. It is important for managing documentation for businesses from large enterprises to small. As per the case study, Hyde can deal with high-stake information for managing the activities in documentation.
Achievement of paperless office and its justification
This is a modern thing to do paperless office for small to medium size enterprises and for better productivity and growth in business management various companies are trying to achieve paperless office. Besides, paperless office can be achieved by the company, Liverpool Direct by using best management in their organization. In order to identify conflict and success, parallel office can be achieved along with the major three activities and these are cost of IS memories, comfort, and cyber safety. As per the case study analysis, it is seen that Liverpool Direct has a partnership between Liverpool City Council and BT, and that is considered as one of the worst councils within the UK on the basis of benefit payments and revenue collection. For managing council’s operations along with modernization of Liverpool Direct along with average time for claiming of 140 days. Apart from that, a backlog was there with 50000 cases and more than 20000 pieces arrived through mail in the betterment of the office.
Identification and synthesisation of different functions corresponding to the database management system within Liverpool Direct and Hyde
Major difficulties must be maintained through Liverpool Direct by implementing someIS (Information System) activities and that will be beneficial for paperless offices (Udendeet al. 2018). On the other hand, no proper company can achieve new methods with initiating effective firewalls, and can afford memories. Additionally, “Wise Acre Frozen Treats” has been bankrupted while clothing has recovered and in 2014, an appropriate business management has been shown by Crumbs Bake Shop whereas 2014 was bankrupted. Some issues are also there in using papers in office and these are paper not also causing significant delays but also worth £750,000 office space per year. For managing end users with reinforcing of ridding the office and “one stop shop” is involved to set by handling customers visiting, and queries. This is managed through a single electronic document and that is really effective for Liverpool Direct in evaluating paperless offices. Therefore, yes, paperless office has been achieved with various regards along with customer services by Liverpool Direct.
Conclusion
From the above discussion of entire section in this study, it can be concluded that paperless office can be achieved on the basis of proper business and exact documentation of effective information by using database. In this respect, Liverpool Direct proposed the paperless office through single electronic document and reinforcing office as “one stop shop” to handle customer visit and different queries.
Reference list:
.png)
Research
MIS610 Advanced Professional Practice Assignment Sample
Individual/Group - Individual
Length - 1500 words (+/- 10%)
Learning Outcomes - The Subject Learning Outcomes demonstrated by successful completion of the task below include:
a) Investigate and reflect on the role of a Business Analyst (or chosen career path) in the contemporary business environment and society more broadly.
b) Cultivate an understanding of who the student is as a professional and what their impact should be to the enterprise, taking into consideration global ethical viewpoints.
Assessment Task
Write a 1500 words Ethics Project Report for an ethical dilemma scenario provided and make a professional decision by analysing it from a range of ethical perspectives with the aim of understanding:
a) how ethics is part of your day-to-day professional practice, and
b) how your current thinking about ethical issues influences your professional practice.
Please refer to the Instructions for details on how to complete this task.
Instructions for best assignment help
1. Read the MIS610 Ethical Dilemma that will be in the Ethics Case Study that will be provided in class in Week 3.
2. Reflect upon the incident discussed in the ethical dilemma scenario provided.
3. Write a 1500 words report that comprise of:
• A short description of the workplace event. That is your interpretation of the ethical dilemma (200 words).
• A reflection on how you would decide in response to the ethical dilemma (800 words).
The following questions need to be considered in your answer:
What do you think is the issue in this situation?
What would your response be to this issue?
Justify your answer – why would you respond in this way?
What laws, ethical codes, or personal ethical stance apply to the situation?
Why would you choose one action rather than another?
In what ways do you think your own cultural background influenced the way you would answer this situation?
• Identify two ethical frameworks or approaches (chosen from the the frameworks and approaches discussed in class), that could have helped you with your ethical decision.
• Discuss how the frameworks might have helped you reach the same decision or a different decision as you identified above. This should include reference to two relevant reliable sources that are not part of the subject resources (500 words).
The following questions will help your reflection:
What ethical framework (if any) did you use in reaching your original decision?
How do the ethical frameworks you have chosen apply to the situation?
How does a line of ethical reasoning arrive at your original decision?
How does a line of ethical reasoning arrive at a different decision?
• You need to identify and apply the two frameworks, not describe them. Descriptions of the frameworks can be found in Module 3.1 (Utilitarian approach, Rights approach, Justice approach, Common Good approach, Virtue approach, and Egoism). Additional ethics case studies will be reviewed in class.
4. You are strongly advised to read the rubric which is an evaluation guide with criteria for grading yourassignment. This will give you a clear picture of what a successful report looks like.
Solution
Description of Ethical Dilemma at Volkswagen
In September 2015, it was found out by the Environmental Protection Agency of the US that Volkswagen had installed a defeat device or software in its 11 million vehicles across the world for cheating emissions test (Pladson, 2020). It was discovered that this software enabled the vehicles to detect emissions test scenarios and accordingly change their performance for improving the results. These irregularities in tests for measuring emission levels of carbon dioxide were also detected in around 800,000 cars in Europe along with petrol vehicles (Hotten, 2020). This shows that the emissions scandal generated a huge impact in the entire automotive industry of the world. The Volkswagen scandal demonstrated a number of issues in the company culture. This is a perfect example of failure of corporate governance of the company with ineffective leadership that led to such unethical actions (Crête, 2016). It was found out that the VW engineers were unable to meet the emission standards with the given time and allocated budget, thereby pointing out to the pressure given from top executives. In addition, it also portrays the presence of a faulty corporate culture that focuses only on outcomes and ignores how employees perform their tasks.
Response to Ethical Dilemma
The Volkswagen emission scandal pointed out various internal issues present within the organization that prompted the employees to act in such a way with the knowledge of their top leaders. The fundamental issue here is the lack of proper company culture with strict codes of ethics and regulations that shape behaviors of both managers and employees. The corporate culture of VW focused on gaining the desired outcomes of passing the US emissions tests (Arora, 2017). The managers completely ignored the fact how such performance would be generated from the employees without having any ethical considerations of the same. Furthermore, the reward system of the company involves paying bonuses based on individual and team performance and productivity, which is applied to all levels of management throughout the organization (Mansouri, 2016). This might have motivated the engineers in rigging the emissions tests for meeting the unrealistic goals set by the top leaders. Besides, the boardroom controls and peculiar corporate culture resulted in this unethical action, which further demonstrated the lack of proper corporate governance and leadership in the company (Bryant & Milne, 2015). Thus, these issues were evident from the emissions scandal of Volkswagen pointing out to its ineffective company culture, leadership, governance and ethics.
The foremost response to this issue would be to improve the company culture in Volkswagen, which is the primary reason for such unethical conduct. Fostering a positive and healthy corporate culture is essential for survival and success of any organization. VW was suffering from ineffective leadership, unrealistic goals, inadequate reward system and failure of corporate governance, which all point out to its culture (Jung & Sharon, 2019). This shows that building a company culture with the help of policies, practices and people would have been beneficial for the organization. With such an ideal work environment and employees and managers being motivated and encouraged to display ethical behavior, the scandal could have been avoided (Warrick, 2017). The engineers would not have to resort to such unethical actions; instead, the company culture would have itself resulted in higher productivity, increased revenues and healthier workforce, leading to the company’s success. Here, the top executives and leaders should also have played a significant role in demonstrating ethical actions and leadership to create examples in front of managers and employees (Nelson, et al., 2020). Thus, responding in a more ethical way for passing the emissions test in the US would have been the primary focus of the organization.
From the case of VW scandal, it can be seen that the organization failed in its corporate sovereignty. It violated the US Clean Air Act, where both the State and its laws played a significant role in the later period in the different events surrounding this scandal. The International Council on Clean Technology (ICCT) discovered about the presence of defeat devices for rigging the emissions tests by undertaking independent actions (Rhodes, 2016). This helped in showing how the diesel cars of VW could have been made more environment friendly for passing the stringent US anti-emissions laws. In this regard, the automotive company not only violated these acts or laws but also their internal code of ethics available in the organization (Rhodes, 2016). Here, the engineers deliberately violated such ethical codes by installing such cheat software for passing the emissions tests in the US. This shows that managers and employees with the knowledge of their top leaders engaged in highly organized and conspiratorial efforts for defying the law, thereby disregarding corporate business ethics and harming corporate sovereignty (Rhodes, 2016). The organization resorted to great extents for admiring its own ethical values but deliberately hiding its own criminal activities. It bolstered its own sovereignty by acting above the law for increasing its corporate growth. This led to the company being held accountable for its environmental and legal transgressions, thereby questioning its corporate sovereignty.
The engineers might have faced ethical dilemma while installing the software in the vehicles for rigging the US emissions test. This unethical action was undertaken for passing the test within short time and limited budget. The excessive pressure of meeting strict deadlines and showing improved performance to get bonuses could have motivated and forced the employees to act in that way. However, lack of personal values and principles associated with ethical conduct was yet another reason that these employees resorted to such actions.
I would have chosen to act in a more ethical way without giving in to such unethical actions for gaining desired outcomes. In this regard, I would have informed my superiors and managers about how it would be impossible to pass the test in an ethical way within the stipulated time and budget. Here, cultural background would have played a significant role as it helps in shaping an individual’s principles, values, attitudes and behavior. Thus, these cultural values would have refrained me from undertaking such unethical actions.
Application of Ethical Frameworks or Approaches
Two ethical frameworks that can be used here for better understanding the VW emission scandal are Kantianism and Utilitarianism. According to Kantianism approach, the motives for corporate actions of organizations should possess a sense of duty, protect employee values and focus on undertaking moral decisions (Rendtorff, 2017). However, from the VW emission scandal, it is evident that the company made illegal and immoral choices that had negative impacts on employees, customers and general public. The engineers could not act as independent and rational agents, they had no freedom to act based on their personal judgments and their concerns were ignored for meeting the outcomes. This clearly shows that Volkswagen violated this ethical approach by treating both customers and employees as money-making commodities to increase business growth (Ameen, 2020). Furthermore, the company further opposed the principles of duty and morality for forbidding profit-based motives and rather forced the employees to defy goodwill intention. The expansion of corporate sovereignty was the main goal of VW, which motivated it to further violate moral law. This shows that basic business ethics was also ignored by the company for fulfilling its own selfish interests (Rendtorff, 2017). Besides, the company engaged in lying and fraud causing harm to different stakeholder groups by deceiving regulators and customers. This shows that it could not uphold the rights and interests of all stakeholder groups, thereby violating the deontological decisions under Kantianism. Moreover, Volkswagen’s actions were not permissible for being self-defeating and contradictory that could have generated negative results from its universal participation (Ameen, 2020). Thus, it can be said that the company resorted to unethical conduct from the Kantianism approach.
The fundamental purpose of Volkswagen for rigging the emissions test for to increase its growth and enhance shareholders’ value without considering any ethical implications. It has violated the Utilitarianism approach of producing the greatest good for the maximum number of people (Dura, 2017). This violation has been further evident from the harmful impacts caused to all stakeholders like customers, employees, general public and regulators. The emissions scandal resulted in job losses, salary deductions, revenues reduction, damaged corporate reputation, environmental pollution and stock devaluation. This shows that no greatest good was created for any of the stakeholders of the company (Ameen, 2020). VW also violated the Utilitarian principle of maximizing human good instead of only focusing on increasing profits for the company. This is evident from the fact the VW acted only on profit-motives for expanding its market share and revenues in the US by rigging the emissions tests. It did not evaluate the costs and benefits of such unethical actions, thereby harming all the stakeholders in the process. It shows that corporate and ethical policies of the company did not run in accordance with the Utilitarian ethical approach (Dura, 2017). Thus, from both the ethical frameworks, it can be said that the actions of Volkswagen were unethical and unjustified.
References
.png)
Research
MIS611 Information System Capstone Assignment Sample
Individual/Group - Group (five people)
Length Part A—Report (3,500 words +/–10%)
Learning Outcomes The Subject Learning Outcomes demonstrated by successful completion of the task below include:
a) Analyse relevant industry challenges to support the development of IS solutions for addressing specific organisational problems.
b) Produce the appropriate documentation to provide evidence of project progress with project stakeholders.
c) Integrate professional and SMART skills to complete individual and team tasks in collaboration with team members to develop a robust solution that meets stakeholder needs.
d) Demonstrate professional skills to complete individual and team tasks Communicate progress and solutions to the client/representative and non-specialists and adjust according to feedback.
Submission Due by 11.55 pm AEST/AEDT, Sunday, end of Module 6.1 (Week 11)
Weighting 20%
Total Marks 100 Marks
Assessment Task for Assignment Help
In this assessment, you will finalise your report and recommendations to your client/organisation. You will incorporate all feedback provided by your lecturer throughout the trimester, including additional research or content to be completed. The final report must be structured as per the guidelines detailed in these assessment instructions. Note, you are producing an industry-level final report, not resubmitting your previous assessments.
Please refer to the Task Instructions for details on how to complete this task.
Format of the report
The report should use 11-point Arial or Calibri font, be 1.5–line spaced for ease of reading and display page numbers at the bottom of each page. If diagrams or tables are used, attention should be given to pagination to avoid the loss of meaning and continuity by unnecessarily splitting information over two pages. Any diagrams must be appropriately captioned.
Solution
Introduction
This report is conducted to define the major issues of Giverly’s current shopping platform. The customers of Giverly are facing issues while they make orders. They also get issues to individualize and make orders. Due to these issues, Giverly’s customer base came in danger and its overall sales get reduced. Giverly wants a permanent and robust solution against such issues This report aims to analyze the overall system needs, stakeholder requirements, and customer demands so, that an appropriate solution can be proposed. This report is mainly a roadmap of new planned shopping platform of Giverly so, that previous platform issues can be resolved and customers' expectations can be maintained. This report covers the stakeholder details, customer feedback & perceptions, brief research to implement the system, stakeholder needs, problems associated with new system, UX/UI elements for planned system, cyber-security considerations, prototypes, testing, and communication plan to deliver the project.
Purpose
The goal of this project is to implement a greater-designed shopping platform for Giverly so, that its customers can effectively make orders of Giverly goods as well as services on individual level. Based on this goal, the purpose of this report is to design a roadmap so, that client can analyze the scope of project and ensure everything is in right place. This report will provide an idea of how will be the project implemented including all-possible details such as stakeholder details, its user interface designs, customer needs, possible issues/problems, overall testing, etc.
Background
Giverly is an online retail company that a customer can use for shopping all-kind of products in a single system. Giverly has a large customer base as it offers multiple products with high quality, 24x7 availability, and cost suitability. The delivery facilities are also free for most of the shopping in Giverly. The customers are well satisfied with Giverly’s performance and online shopping facilities but for last 2-3 months, customers are complaining to have issues with its system while making orders (Giverly, 2022). They have also restricted to individualized orders of the products. Due to this issue, Giverly is planning to implement a new system so, that customers can easily access and make orders on that. This planned project is almost ready to be implemented as its overall planning is done including stakeholders, customer needs, resources, problems, security considerations, interface designs, and testing. Now, this time, a complete roadmap and information related to proposed Giverly platform are presented.
Scope
a) Goals and Objectives
Goal
To implement a greater-designed shopping platform for Giverly so, that its customers can effectively make orders of Giverly goods as well as services on individual level.
Objectives
• To measure the potential issues of Giverly’s shopping platform.
• To gather and understand the needs of customers to design new shopping platform.
• To develop a customer-driven Giverly shopping platform.
b) Exclusions
• The difficulties to design Giverly’s shopping platform for marketing and sales.
• The unsafe & risk-oriented resources, applications, as well as activities.
• Access of Giverly data to all-associated project members.
c) Constraints
• The participation of sales team is not approachable/active in developing this shopping platform project because of their busy schedule.
• To get customer requirements/feedback, additional time is needed.
• The development time estimation for this Giverly shopping platform is six months which can influence current customers & Giverly’s overall sales.
d) Assumptions
• Due to any new demands raised by customers, additional time requirements for research, and other changes due to market changes, the budget can be increased.
• During project implementation phase, security-based risks can occur (Giverly, 2022).
e) Deliverables
• A roadmap for Gierly’s new shopping platform.
• The user interface designs of the shopping platform.
• A customer-driven platform.
Stakeholders
![]()
(Smith, 2000)
The stakeholders that should be managed by Giverly organization are their sales team, employees, customers, and HR team. It is also necessary that they should adopt provided recommendations if they seem it will be worthy for them otherwise, they can give their suggestion, and then overall decision can be made to satisfy them and to make the system successful.
Customer Persona
Persona1
(Duda, 2018)
Persona2
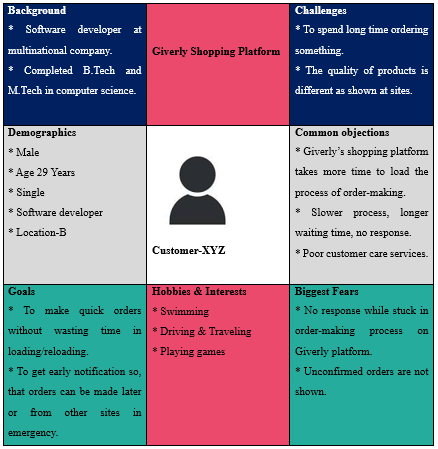
(Duda, 2018)
Empathy Maps
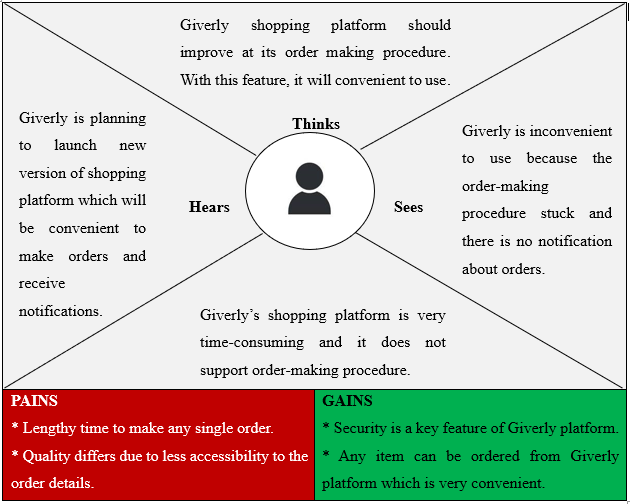
(Melo, et.al., 202)
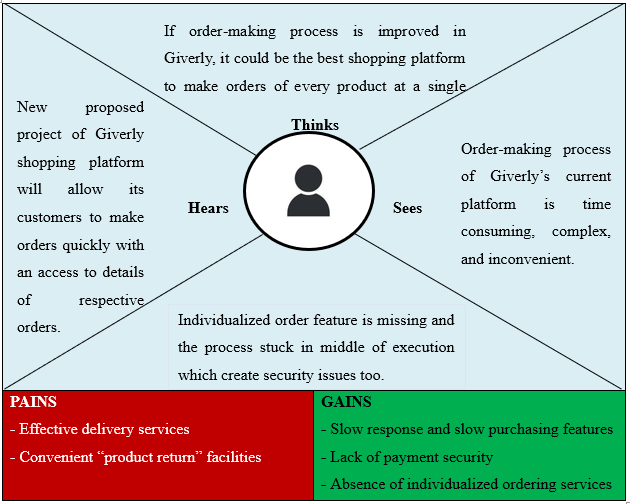
(Cairns, et.al., 2021)
Research
By researching both customer personas, it can be stated that they are particularly satisfied with Giverly’s shopping platform. They are using this platform largely to make any kind of orders because Giverly offers a number of orders including fashion, hotel, grocery, travel, technology, and entertainment at their single sales platform. The customers want to use this system as they found it convenient and secure. But they are facing issues related to making individual orders from this system due to some technical or other errors (Giverly, 2022). When they make orders, their order-making process is stuck in the middle and the details of orders are also inaccessible to them. Therefore, they have similar kinds of objections to using this application/system due to the order-making issues and lack of individualized ordering features. Both customers are well-educated and working in relevant positions. One customer is married woman and another customer is single male. Both are dependent upon Giverly’s platform to make most secure and fast delivery but in last few months, they are facing order-making troubles.
Therefore, they have objections to using this Giverly platform and seeking new alternatives to make orders. They found Goverly’s current platform unresponsive, time-consuming, and unapproachable. They have fears to got stuck while making orders and due to absence of notification, their order will be unconfirmed which can waste their time.
Stakeholder Requirements
To define the requirements of key stakeholders, simple method i.e. MoSCoW is used.
.png)

(Sharma, 2022)
Customer Journey Map
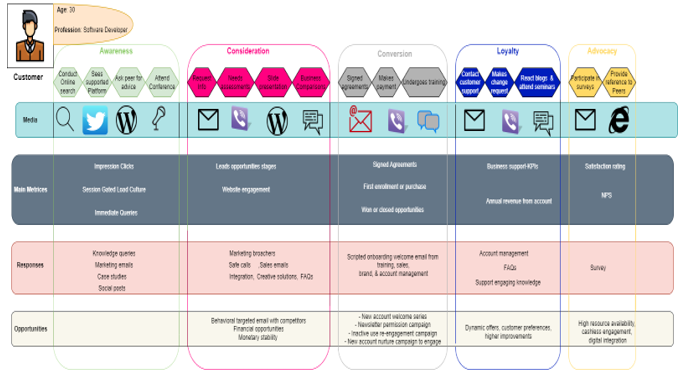
Figure 1: Journey map
(Source: Author)
Problem Statement
In Giverly, the stakeholders are facing issues to fix the fault of order-making process in their online shopping platform. The order-making process also faults that it does not allow the customers to individualize and make orders. The process of order-making is stuck in middle and it takes longer time to execute. The sales team and other employees identified this issue and informed the system developer (Giverly, 2022). The Giverly system is not responding to the customer’s approach and it became complex to address that issue. Thus, the major problem of Giverly belongs to their sales platform where order-making process is not working properly which causes the stoppage of platform’s overall functionality.
UX/UI
By considering the problem associated with Giverly’s platform, a new system/platform is planned to develop in which user-friendly interfaces along with transparent functionalities will be designed which effectively regulate the order-making process and individual order-making as well. The UX/UI design will be done with a very simple and visualized format so, that customers can understand and access each feature easily. The UX/UI design’s layout will be designed in such a way, that different categorized products are arranged in a systematic series so, that customers can easily reach them. The associated details will also keep in layout. Each notification will be visualized to customers and they can also put their items in their wish-list, favorites, and shopping cart for later shopping. Interactive interface, navigation bars, and menu items will be designed with proper image specification so, that customers can conveniently approach everything they want (Ho, 2021).
Accessibility Requirements
To make Giverly’s current platform highly accessible by forming it operable, perceivable, robust, and understandable. Therefore, to ensure these factors for proposed Giverly shopping platform, the accessibility requirements are maintained by keeping the balanced contrast ratio, labeling the layouts clearly, keeping consistent navigation, and keeping simple headings. Subheadings, & spacing, giving user control, designing different categories, views, and screens, not relying on colors, providing feedback for omissions & errors, and offering alternatives specifically for consuming media (DBS, 2022).
Cyber-Scurity Requirements
To resolve the issues of current Giverly shopping platform, a new system is planned and proposed so, that the order-making issues can be removed completely and a new version of Giverly platform satisfied customer needs. As discussed, due to this order-making issue, the customers are in fear of security risks. Thus, to maintain and ensure the security in new updated version of Giverly platform, security technologies and models will be implemented. Customers are needed security environment while dealing with this new application so, the whole system will be implemented by concerning the sensitive security considerations and providing automatic saving features in case of any disruptions. Other security considerations that will be implemented in this Giverly system are-
• User authentication
• Data authentication
• Cloud infrastructure
• Payment security
• Network security
• Cybersecurity features
• Accountability, privacy, & confidentiality in engagement with system
• Limited access to customers and database security
• Encryption & decryption (Adu, et.al., 2018)
Wireframes

Figure 2: Login Page
(Source: Author)

Figure 3: Home-Page
(Source: Author)

Figure 4: CategoryPage
(Source: Author)
Test
The above-specified prototypes are clearly showing how customer will be getting their new Giverly shopping platform. This new version of platform will help the customers to provide the overall shopping of all-possible products in a single system. These prototypes are designed with a user-friendly format in which the users are allowed to visualize, access, and save the products. Security is highly considered so, that each customer can rely on Giverly shopping platform without compromising their privacy and confidentiality. Each layout is designed in an effective manner and simplicity is maintained so, that customers can conveniently use the application to search, order, and cancel their needed products.
The first prototype is a simple login page in which the user can login after registering on the application. The login page is very simple and easy to understand without any additional animation or unnecessary images. Another page is home page where user can easily see the layouts i.e. menu, history, and update. The layout “menu”, is categorized into different shopping formats with different products. Customers can scroll down the categories and select particular categories of products. On history page, the customers are allowed to access the details of their previous orders, canceled orders, confirmed orders, payment details, etc. Another layout is update layout in which customers can easily update their payment-related details like bank details, phone number, address, login credentials, and many more. Therefore, they are also allowed to add the products to cart and wish-list. Consequently, another page is category page that is designed as an example to show if a customer will search for a particular product like sports watch then a list of latest & trendy sports watch will be categorized. The customer can click on particular watch and see overall details. After being satisfied with details and prices, they can make orders with free delivery facilities. Hence, customers’ order-making issues are completely solved with new version of Giverly platform. At last, the project needs to be updated time-to-time for further use.
As mentioned in above section, the proposed Giverly platform will provide effective, clear, straightforward, and convenient ways to make orders as per customers’ needs. The older version of Giverly’s platform was unable to make orders conveniently. Due to some technical or software issues, the platform stuck in the middle of order-making process which became a failure of Giverly’s online shopping system. Thus, the management team has decided to implement a new system so, that customer needs can be fulfilled quickly because customers want to use Giverly platform because it is secure and have all-possible products in single system (Giverly, 2022). The proposed solution i.e. new Giverly shopping system and this new system is highly user-friendly, secure, and convenient to make orders. Customers can directly search for a product and categorized order layouts will be helpful for them to approach needful products. They can also access the details of each product so, that they can confirm that order and add in wish-list for later purchases.
Communication Plan
This is very simple for Giverly to deliver this new solution to their large customers because Giverly has large customer base. Giverly customers are eagerly waiting to have a solution because they trust Giverly’s products, security, and service facilities. The solution will take a significant time to be implemented completely till then Giverly advertises this solution and promotes its new features using social media platforms, and its organizational website, and directly communicate with customers when they come to Giverly’s shopping centers. In addition, a survey can also be conducted to get the customer’s response on newly proposed solution.
To deliver the proposed solution to the customer, Giverly can use visual engagement tools like video chat so, that they can get aware of this system. By giving the access link or application on social media platforms and official websites, the customers can get the system on their devices. Customer metrics & chatbots are other communication alternatives to inform the customers about newly launched Giverly system (Patel, 2022).
Recommendations
With an overall experience of this Giverly project, it has been analyzed that the scope of project is very vast and profitable from the business perspective. The customers are also well satisfied with the newly-proposed system’s standards. The main issue for which, Giverly and its customers are facing issues is completely resolved by implementing new system. The previous platform had an issue with making the orders and it restricted the customers to make individualized orders. Based on the issue, Giverly’s management team has decided to implement a completely new project in which the issue will be sorted out and customers’ needs will be prioritized (Giverly, 2022). To ensure the project’s success, stakeholders are finalized to develop the system as per their interest and impact levels. The customer’s responses are also taken so, that previous mistakes can be improved and customer’s needs can be fulfilled. Giverly should understand the customers deeply and try to establish their perceptions using customer personas, empathy maps, and customer journey maps, The MoSCoW method is also supportive for Giverly to interpret the project accordingly.
Consequently, the problem statement is clearly articulated so, that relevant solutions can be planned. Based on the solution, potential UX/UI designs are proposed in which user-friendly environment, security considerations, easy order-making functionalities, and easy accessibility. However, the cyber-security considerations are well-planned using network security, encryption, decryption, and many more methods. The prototypes are designed as per mentioned solutions that customers will find more suitable to make individualized orders with other features. The testing done in this report is also ensuring that the proposed project will be highly successful.
With this new project, Giverly will get new opportunities to do business and earn trust of their customers. It will result in high productivity and future stability of Giverly. In future, based on the customer’s responses the planned project will be implemented and delivered (Zakharenkov, 2019). Consequently, its timely security and upgradation will be monitored and done so, that best online system can be provided for customer’s usability.
Referencing
.png)
Research
COIT11226 System Analysis Assignment Sample
Due date: Week 12 Friday (7 October 2022) 11:00am AEST
Weighting: 40%
Length: 1,200 to 1,300 words (word count includes all contents except the cover title page, table of contents, figures, and references)
Required Tasks in This Assignment Help
Assuming that the waterfall model has been chosen for implementing the new system to replace the current system. Also assuming that some programs have been written and are ready, whereas some other programs are not yet ready at the current stage of development. Complete the following tasks and document your work in your submission:
1. Testing:
a. Among unit testing, system testing, and user acceptance testing, discuss and explain which of them is/are applicable at the current stage of development.
b. Suppose the project team wants to apply white-box testing to generate test cases for testing the new system. Discuss and explain the feasibility of applying white-box testing to test the new system.
c. “Assume” that white-box testing is feasible, and it has been applied to generate test cases, do you think that the project team still needs to apply black-box testing to generate additional test cases for further testing? Why?
2. Discuss the merits and drawbacks of applying random testing to test the new system.
3. In view of the business operations of CNP, which system installation approach should be used to replace the existing system by the new system? Why? (Note: In this task, you are notallowed to select two or more installation approaches. Students who select more than one
installation approach will receive zero mark for this task.)
Solution
TESTING
a. Assuming that the waterfall model has been chosen in the Computer No Problem for implementing the new system to replace the current system. Also, assuming that some programs have been written and are ready, whereas some other programs are not yet ready at the current stage of development.
? Unit testing- It is a sort of software testing method which is achieved on a single entity, unit or module in test its modifications. This testing phase is often carried out by the developers throughout the request's expansion. Each of the unit of testing may be assumed of as a method, service, process, or object (Testim 2022). In short, this testing method tests each program individually and does not connect any other ones with it.
• The common testing methods that it uses are-
• Gorilla testing
• White box testing (Vijay 2018).
? Integration testing - software testing, the term "integration testing" refers to the practise of evaluating a programme as a whole, as opposed to its individual parts. Finding issues with module-to-module interactions, communications, and data flows is the primary goal of interoperability testing. When integrating components or sets of units into a system, either a top-down or bottom-up strategy may be used (Vijay 2018).
? System testing- the last one is system testing as it's name suggests it is referred to the software testing method of the entire system at once. System testing is a kind of testing where the entire system is examined and compared to a set of predetermined criteria (Vijay 2018).
As per the case scenario of Computer No Problem, the project follows waterfall methodology i.e. a step by step process of SDLC. Project is in the middle of development and there are still programs left to be developed and only a few have been developed, which means that it is in Integrated testing phase, where the developed programs can be integrated and tested together for the proper functioning and analysis, however it can not be in system testing because there are still undeveloped programs left, without which system can control be made and tested.
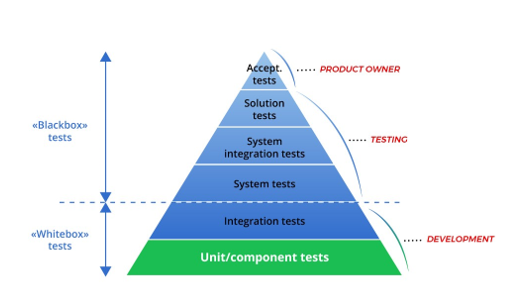
Figure 1: Testing of software
(Source: AUBERT 2020)
b. To ensure proper input-output flow in the Computer No Problem Project, enhance usefulness, and strengthen security, White Box Testing examines the software's internal structure, architecture, and code. White box testing is also known as Clear box testing, Open box testing, Transparent box testing, Code-based testing, and Glass box testing since the code is exposed to the testers. A white-box test case involves running a piece of software with known input parameters to verify known output values (ReQtest 2022). If these numbers don't add up, it's a problem. This is a theme across the whole of the program.
Figure 2: white box testing
(Source: Lemaprod 2018)
The feasibility that this technique to generate test case for testing new system are -
• Transparency- Since everything is laid out for the tester to see, they can thoroughly examine the whole structure and code base, allowing for prolonged testing.
• Less time to test case for testing new system- When all the software data is easily accessible, the tester can quickly comprehend the code and complete the tests, but huge applications without complex models might take weeks or months to test (Packetlabs 2021).
• Easy Automation of test case- Many technologies exist to facilitate automation of the test cases, therefore significantly shortens the time required to complete them.
• Detects risks and optimises code- It is useful for finding undetected bugs and removing unnecessary code. Due to the abundance of data, it should be possible to spot vulnerabilities and problems in the software (Hamilton 2020).
Figure 3: feasibility of whit box testing
(Source: Author 2022)
c. As the project aims at replacing the current system due to key operational and UI challenges. Hence, it is necessary to evaluate the end user structure of the system or the outer structure which will be presented to the user, it can evaluate with the help of Black box testing.
Black Box Testing is referred to the testing approach in the project of Computer No Problem, which does not take into account the internal structure, concept, or product implementation of the product being evaluated. In other terms, the person performing the test is unaware of its internal workings. The Black Box is focused on simply assessing the system's exterior behaviour. The program's inputs are analyzed, as are the outputs or reactions it generates (Practitest 2021).
Even after conducting thee white box testing in the Computer No Problem, it is necessary to implement the Black Box testing approach because of the reasons mentioned below-
? Black box testing examines a system end-to-end. A tester may replicate user behaviour to evaluate whether a system delivers on it's own claims, just like end-users don't care how a system is developed or designed. A black box test assesses UI/UX, web/application server, database, connections, and system integration (Imperva 2020).
? Black box testing can be used to check how certain parts or operations of the source code being tested work.
? Using the regression technique, it is possible to see if a new version of the application shows a transformation, or a loss of features from the previous version.
? Testers can simply split the independent variables in the division of groups, or panels, and appraise only one exemplar input from each group (Imperva 2020).
? With this method, one look for mistakes that development teams often make when structure similar plans. For example, developers as well as the test performers can check to see how the programmer dealt null values in a field, values of the arithmetic field or data points in a text-only field, and cleansing of input data, or if a user can enter source codes, which is important for security (Imperva 2020).
1. MERITS AND DRAWBACKS OF APPLYING RANDOM TESTING
Random testing is a kind of testing process of software in which the computer is examined using randomized and unbiased inputs & test cases. Monkey testing is another term for random testing. It is a black box evaluation framework approach wherein the tests are picked at random and the outcomes are evaluated using some software identifying to determine if the output is accurate or erroneous.
Table 1: merits and demerits of random testing
2. System Installation Approach
In the installation of Computer No Problem, for function of sales and purchasing as well as maintaining the records, it is necessary to look for the good system installation approach as it is a one time investment and it should not be further create problem. In order to look for the new system into the company, the company is going with the Web - based installation approach, that means each and every component will be operated though the web services and CRM system will be installed. Along with that, in order to maintain the data of the company, cloud infrastructure is installed and databased management system will be utilised.
REFERENCES

Programming
MIS501 Principles of Programming Learning Activity Assignment Sample
Qustion
Learning Activity 3.1: Loops
There are a number of activities in this module and you are expected to complete all of these in the labs or in class or in your own time. The first of these is to reproduce any and all of the worked examples in the module content and to review the readings and videos. Then, work your way through these exercises:
1. Write a program to prompt for and read a sequence of non-negative numbers (with a negative number to end input).
Example:
Enter a number (negative to quit): 10.0 Enter a number (negative to quit): 7.5 Enter a number (negative to quit): 3.5 Enter a number (negative to quit): -1
2. Write a program to prompt for and read a sequence of non-negative numbers (with a negative number to end input) and then print the least non- negative input number. If the first number read is negative, print "No numbers.". Round the least number off to one decimal place.
Example:
Enter a number (negative to quit): 10.0
Enter a number (negative to quit): 7.5 Enter a number (negative to quit): 3.5 Enter a number (negative to quit): -1 Least number is: 3.5
3. Write a guessing game where the user has to guess a secret number. After every guess, the program tells the user whether his number was too large or too small. At the end the number of tries needed should be printed. You may count only as one try if the user inputs the same number consecutively. Note that for this question, you need to use a combination of loops and conditional statements.
Please upload one of your answers to the 3.1 discussion forum to discuss with your peers.
Learning Activity 3.2: Loops advanced
There are a number of activities in this module and you are expected to complete all of these in the labs or in class or in your own time. The first of these is to reproduce any and all of the worked examples in the module content and to review the readings and videos. Then, work your way through these exercises:
1. Write a program that asks the user for a counter upper bound, and prints the odd numbers between 1 and the user inserted value.
2. Given an asset original price, the percentage with which the asset depreciates every year and the number of years elapsed, write an algorithm that calculates the actual value of the asset at the moment.
Assume that the depreciation percentage is fixed but each year it is calculated on the current actual value of the asset.
3. Given an asset original price, the percentage with which the asset depreciates every year and the actual value of the asset, write an algorithm that calculates the number of years elapsed for the asset to reach this value. Assume that the depreciation percentage is fixed but each year it is calculated on the current actual value of the asset.
4. Write an algorithm that helps investors estimate their bank account balance after a certain number of years. The program should ask the investor to insert the original account balance and the number of years after which they would like to estimate their balance. Note that a Sydney banks offer a fixed yearly interest of 2%.
5. Write an algorithm that helps a frequent traveller employee redeem his expenses. The program should ask the employee about the number of days he has travelled. The program will then repeatedly ask the employee to insert his daily expenses for each day he travelled independently. The program should print out to total sum of the expenses.
Please upload one of your answers to the 3.2 discussion forum to discuss with your peers.
Solution
## Thread activity 3.1

.png)

## Thread activity 3.2
.png)

.png)
Research
MIS301 Cyber Security Assignment Sample
Individual/Group - Individual
Length - 1500 words (+/- 10%)
Completion of the task below include:
a) Investigate and analyse the tenets of cybersecurity
b) Identify and communicate a range of threats and vulnerabilities to informational assets.
Submission Due by 11:55pm AEST Sunday of Module 2.2
Weighting 25%
Total Marks 100 marks
Instructions:
In Module 1, you learnt the five types of hacker threats that are common on the internet: commodity threats, hacktivists, organised crime, espionage and cyberwar. In Assessment 1, you are required to choose any three of the five types of hacker threats and undertake some research into the cybersecurity literature and/or media coverage to find one incident for each of the chosen three types of hacker threats. For each incident, you will:
1. describe the attack and the immediate result of the attack (i.e. what was the asset that was
compromised?)
2. describe the motivation behind the attack
3. identify and describe the vulnerability (or vulnerabilities) in the organisation that made the attack possible
4. describe the short-term and long-term impact (financial, reputational or otherwise) of the attack on the organisation
5. describe the responses from the affected organisation and society as a whole.
Reflect on all the incidents, and critically discuss the factors that make the prevention of cyber-attack challenging.
The incidents should meet the following criteria:
• The attack must be a cyber-attack.
• The attack was within the last ten years.
Your report should include the following for assignment help
Title page: It should include subject code and name, assessment number, report title, assessment due date, word count (actual), student name, student ID, Torrens email address, campus learning facilitator, and subject coordinator.
Table of Contents (ToC): It should list the report topics using decimal notation. It needs to include the main headings and subheadings with corresponding page numbers, using a format that makes the hierarchy of topics clear. Because you are including a ToC, the report pages should be numbered in the footer as follows: the title page has no page number, and the main text should have Arabic numerals commencing at 1. Create the ToC using Microsoft Word’s ToC auto-generator rather than manually typing out the ToC. Instructions can be found here https://support.office.com/en-
gb/article/Create- a-table-of-contents-or-update-a-table-of-contents-eb275189-b93e-4559-8dd9-c279457bfd72#__create_a_table.
Introduction (90-110 words): It needs to provide a concise overview of the problem you have been asked to research, the main aims/purpose of the report, the objectives to be achieved by writing the report and how you investigated the problem. Provide an outline of the sections of the report.
Body of the report (use appropriate headings in the body of the report) (1170-1430 words): Ensure that you address the tasks listed above. Do NOT use generic words such as ‘Body, Body of the Report, Tasks’ as section headings. Create meaningful headings and subheadings that reflect the topic and content of your report.
The body of your report should have the following structure:
2.0 Hacker threat 1
2.1 Description of the incident (approximately 80 words)
2.2 Motivation (approximately 50 words)
2.3 Vulnerabilities (approximately 80 words)
2.4 Short-term and long-term impact (approximately 70 words)
2.5 Responses (approximately 70 words)
3.0 Hacker threat 2
3.1 Description of the incident (approximately 80 words)
3.2 Motivation (approximately 50 words)
3.3 Vulnerabilities (approximately 80 words)
3.4 Short-term and long-term impact (approximately 70 words)
3.5 Responses (approximately 70 words)
4.0 Hacker threat 3
4.1 Description of the incident (approximately 80 words)
4.2 Motivation (approximately 50 words)
4.3 Vulnerabilities (approximately 80 words)
4.4 Short-term and long-term impact (approximately 70 words)
4.5 Responses (approximately 70 words)
5.0 Factors that make the prevention of cyber-attack challenging (approximately 250 words)
Conclusion (90-110 words): Restate the purpose of the report and key issues investigated, and the related findings based on your research and analysis.
Solution
Introduction
Cyberattacks become a common threat not only for personal data security but also for government and organizational information protection. It could be considered as an assault of cybercriminals to steal data, disable computers, breaks the networks, or use a breached computer system to commit vulnerable additional attacks. The rate of cybercrime and cyberattacks are increasing day by the day and becoming a major concern to cybersecurity experts globally [Referred to appendix]
Aim
This report aims at selecting three incidents that come under different kinds of cyber-attacks and provide a brief description of their vulnerability and impact.
Objectives
? To find out the cyberattacks that occurred in the last 10 years
? To evaluate the motivation and vulnerabilities of cyber attacks
? To estimate the short-term and long-term impact of a cyberattack
? To explore the response of those cyber attacks
Body of the report
2.0 Hacktivist
2.1 Description of the incident
Scott Morrison, the Prime Minister of Australia has stated that the Australian government and institutions become the major target of being hacked by sophisticated state-based cyber hackers. It has been found that hacking attacks are happening several times and it is increasing. In fact, Prime Minister has refused to identify ant state actors. According to his opinion, government institutes, political organizations, Australian industry, educational institutes, health services in Australia, essential service providers, along with operators of several important critical infrastructures are the major target of these attacks (Bbc.com, 2020).
2.2 Motivation
The motivation behind this kind of attack is to steal government data and breach it so that political and social agendas could be fulfilled by attackers. However, the actual motivation behind this track is not specified by Mr. Morrison (9 news.com.au, 2020).
2.3 Vulnerabilities
It is easy for attackers to utilize government data in order to influence common people to motivate them against political leaders. It could be political and social activism that could breach the government data and manipulate them.
2.4 Short-term and long-term impact
Short term impact of this cyber-attack could be deleting important information or disclosing any confidential government data so that reflects directly over the impression of the Australian government. In case of long-term impact, the misuse of data to defame the Australian government in front of the world or positing any illicit or illegal content to influence people against their political leader could have occurred.
2.5 Responses
The Australian government has strengthened its cybersecurity and recruited more efficient cyber experts to prevent those attacks. In fact, the prime mister has suggested improving technical defenses, especially for emergency service providers and health infrastructure (Bbc.com, 2020). Proper awareness in the public mind reading this kind of attack is the most effective response from the end of the Australian government.
3.0 Espionage
3.1 Description of the incident
In 2016, President Trump had hired a political data firm namely Cambridge Analytica for their election campaign. The purpose of this operation was to gain access to the private information and data shared by 50 million Facebook users (Granville, 2018). In this respect, the users were asked to proceed with a personal survey in which they needed to download and installed an application that has scrapped their own private pieces of information along with available friends in their friend lists so that their political overviews and information could be generated. However, this attack was made for the welfare of the government and no data breaching of Facebook users had occurred.
3.2 Motivation
The actual motivation behind this operation was not to breach or misuse any private information of users of Facebook. It was conducted for political motivation towards the election campaign. The main aspect of this operation was to identify the personalities and political behavior of American voters so that the election campaign could proceed accordingly.
3.3 Vulnerabilities
The activity of Cambridge Analytica was vulnerable for Facebook users as Facebook prohibits data selling or data transferring to any service (Granville, 2018). In this respect, the data are used to influence political behavior and overview of American voters hence it is a vulnerable practice.
3.4 Short-term and long-term impact
The short-term impact of this kind of hacking of user profiles in Facebook could be immense as it collected the personal data of users to influence their political views. The overall election process needed to be fair and impartial enough so it could be stated as malpractice. In case of long-term impact, the users cannot rely on or trust Facebook and raise questions over the security arrangements of this application.
3.5 Responses
Increasing the security service along with protection of accounts needed to be done by Facebook. Raising awareness not to download any kind of application or participate in any survey could be effective to protect these kinds of cyberattacks. In this respect protection of user accounts could be a major concern as it contains personal photos of users which might be used for any misconduct.
4.0 Cyberwar
4.1 Description of the incident
In 2017, 3 billion Yahoo accounts have been hacked and could be stated as the biggest theft and largest data breach in history (Stempel & Finkle, 2017). In 2013, Yahoo had compromised 1 minion of user accounts and Yahoo become forced to cut down their assets price in a sale to Verizon. Yahoo has stated that all of their user's accounts could be affected but they assured that stolen information could not consist of payment data, information of bank account, or passwords in cleartext (Theguardian.com, 2017). The major concerning factors are that that information is protected through easy-to-encryption that is outdated.
4.2 Motivation
The motivation behind this hacking could be stated as defaming Yahoo for its low-category security arrangements. Another major motivation for information stealing is to use those information details for wrong purposes, terrorism, or defaming popular personalities using Yahoo.
4.3 Vulnerabilities
Yahoo accounts are vulnerable to being exposed due to its outdated security protection arrangements. Due to these two huge cyberattacks occurring in this internet company, Verizon has made their offer lower by 350 million US dollars for yahoo assets (Stempel & Finkle, 2017).
4.4 Short-term and long-term impact
In case of short-term impact, the accounts of users might be used for the wrong intention, promoting terrorism, or conducting monetary breaching through bank account details. The long-term impact of this cyberwar is that these attacks might defame the security activity of Yahoo hence the number of users of Yahoo accounts would be reduced hence it could impact the revenue generation.
4.5 Responses
Yahoo has increased its security in the data protection of users in order to maintain cybersecurity. They have hired experts so that the security of user accounts could be protected so that no data could be accessed to proceed with any kind of misconduct.
5.0 Factors that make the prevention of cyber-attack challenging
Safeguarding IoT Devices
Safeguarding IoT devices is one of the major challenges that affect the prevention procedure of cyberattacks. It is true that IoT devices are easy to access through the internet and that is the major chance undertaken by cybercriminals (Zhang et al., 2020). Maintaining safety in IoT devices becomes a major challenge for cyber experts as these devices are interconnected and getting access to one device, all of the connected devices are accessible. In the case of government data, the IoT device's safeguarding process is the major barrier.
Figure 1: Factors that make the prevention of cyber-attack challenging
(Source: Created by Learner)
Outdated Security Service
Outdated security service is one of the major barriers to preventing cyberattacks. It is true that nowadays technologies are advanced and lack of scope to update security services in websites could be effective to prevent cyberattacks. According to Lezzi, Lazoi& Corallo (2018), outdated security services are easy to encrypt and that makes hackers access easily targeted devices or websites. However, a lack of updated security service could be considered a major challenge for cyber security experts.
Outdated Hardware
In order to increase the security of software, the developers often proceed with updating their software to enhance their security practice to protect stored data. However, continuous updates of software might not be supported by old devices hence the hardware needed to be updated soon (Mashiane &Kritzinger, 2021). The major challenge has been faced while the updated software could not be supported in a backdated device version or model. However, it could be stated as a major factor for challenging the prevention of cyberattacks.
Conclusion
It could be concluded from the above discussion that cybercrimes becoming a major concern in both developed and developing countries to access the information that could be vulnerable for individuals, groups, or the whole nation. Hacktivists, espionage, and cyberwar are three major cyberattacks among cybercrime. These attacks are affecting not only personal data but also organizational aspects. The vulnerabilities and impacts of these attacks are prolonged and wide that could defame individuals or organizations, or even the whole country. However, raising awareness among people and indulging in proper response is crucial to prevent these cyberattacks by increasing security services from the end of the country, organizations, along individuals.
Reference
9 news.com.au, (2020). 'Sophisticated state-based' cyber attack hits Australian government, businesses in major breach. https://www.9news.com.au/national/cyber-attack-australia-scott-morrison-government-private-sector-breach-of-security/e621ae47-f810-4fa7-9c11-3caa3b09f4dc
Bbc.com, (2020). Australia cyber attacks: PM Morrison warns of 'sophisticated' state hack. Retrieved from https://www.bbc.com/news/world-australia-46096768
Granville, K. (2018). Facebook and Cambridge Analytica: What you need to know as fallout widens. The New York Times. Retrieved from https://www.nytimes.com/2018/03/19/technology/facebook-cambridge-analyticaexplained.html
Lezzi, M., Lazoi, M., & Corallo, A. (2018). Cybersecurity for Industry 4.0 in the current literature: A reference framework. Computers in Industry, 103, 97-110. https://www.sciencedirect.com/science/article/pii/S0166361518303658
Mashiane, T., &Kritzinger, E. (2021). Identifying behavioral constructs in relation to user cybersecurity behavior. Eurasian Journal of Social Sciences, 9(2), 98-122. https://eurasianpublications.com/wp-content/uploads/2021/07/EJSS-4.2.4.1.pdf
Stempel, J. & Finkle, J. (2017). Yahoo says all three billion accounts hacked in 2013 data theft. Reuters. Retrieved from https://www.reuters.com/article/us-yahoo-cyber/yahoo-says-allthree-billion-accounts-hacked-in-2013-data-theft-idUSKCN1C82O1
Theguardian.com, 2017. Yahoo says all of its 3bn accounts were affected by 2013 hacking. https://www.theguardian.com/technology/2017/oct/03/yahoo-says-all-of-its-3bn-accounts-were-affected-by-2013-hacking
Zhang, J., Li, G., Marshall, A., Hu, A., & Hanzo, L. (2020). A new frontier for IoT security emerging from three decades of key generation relying on wireless channels. IEEE Access, 8, 138406-138446. https://ieeexplore.ieee.org/abstract/document/9149584/
Case Study
CSC214 Computer and Network Security Assignment Sample
Case Study for Assignment Help
Figura Leisure Centre (FLC) was established in 1989 by converting an old hospital. FLC provides a room space for the community which is visited by nearly 100, 000 people every year. Centre contains a fitness gym, school nursery and several offices for local charities and is visited by several groups who runs their personal or activities for the community.
Centre is run by a small management committee which is formed of volunteer trustees of the association and works directly with the local city council. Management volunteers are drawn from the local community and are responsible for the development of the centre. FLC mission is to provide affordable high-quality comfort to the visitors and their customers are from the different sections of the society. The centre has been enjoying an enviable reputation for the quality and comfort of its rooms and customer service support due to the dedication of its staff. The FLC competitive strategy has been to ensure the utmost satisfaction of their customers from a policy of continuous monitoring by management staff. This has not gone unnoticed by customers wishing to have an excellent place to organise their activities i.e. birthday parties, wedding receptions, yoga and Pilates classes, karate, basketball and football games, etc, and there has been no problem in attracting customers.
The centre, having no website, promotes itself by way of flyers, local newspaper and magazine advertising, and ‘word-of-mouth’. Most of their work is still taken manually and the management committee have felt that most of their rooms and facilities were not in use throughout the day, thus, they are loosing revenue. Several people works in the centre on the rota basis and the staff don’t get to see each other unless there is a social gathering or a staff meeting. Due to the lack of communication between the staff several problems arises in the centre to deal with the customers queries. At the same time centre staff having a problem to chase the customers to make the payment.
Management committee have heard about new innovative technology ‘cloud’ which is helping the traditional business world. They have find out that cloud computing is the fastest growing form of computing and according to Gartner the worldwide public cloud service market will grow from $182 billion in 2018 to $331.2 billion in 2022.
Management has realised that with the cloud technology the centre can solve their problems and provide better service to their customers and improve the occupancy rate to increase the revenue.
Management have decided to use cloud-based SaaS (Software as a Service) based business information system, for example, management information system, customer management system, accounting information system, etc, which can be used to analyse their customers patterns to offer them better deals and attract more customers in the off peak time.
Management have approached a number of consultants, to find out the right SaaS system for the centre and identify the benefits, challenges for adopting the SaaS based system with the approaches to minimise the impact of challenges you have identified.
Solution
Introduction
SaaS (Software as a Service) is mainly considered as a software distribution model that is included with cloud providers and different hosts applications. This makes a more appropriate selection of end-users within the internet, and the SaaS application is used as a compatible device for the login of users. This study is mainly based on a case analysis of FLC ("Figura Leisure Centre"), provides an active room space community and contains a school nursery, gym, and several offices for particular local charities with more than 100,000 people per annum. Customer services and support of their room services are major priorities for FLC. The management of FLC has no proper website, and due to this, they decided to use a SaaS-based system for developing business and its information management. Several processes can be managed by the cloud-based SaaS, and these are customer management systems, management information systems, and accounting information systems. These all are useful to analyse the pattern of customer’s patterns and offer them an attractive deal at an off-peak time.
On the basis of cloud computing, the definition of SaaS ("Software as a Service") with appropriate research
As a software distribution model, SaaS is a cloud provider that hosts applications by making all of these available for end-users across the internet. Besides, an ISV ("independent software vendor") can contract with a third-party cloud provider for hosting the application. Additionally, in the case of large companies like Microsoft, cloud providers are sometimes referred to as software vendors, and SaaS is a major category within three activities of cloud computing. IaaS ("Infrastructure as a Service") and PaaS ("platform as a service") are also included within cloud computing, and a range of IT personnel, business, and professional users use SaaS applications in an active way (Huang & Li, 2020). Apart from that, FLC has a mission of providing affordable as well as high-quality visitors with comfort and customers who come from various sections of the society, along with a good reputation and effective dedication to this.
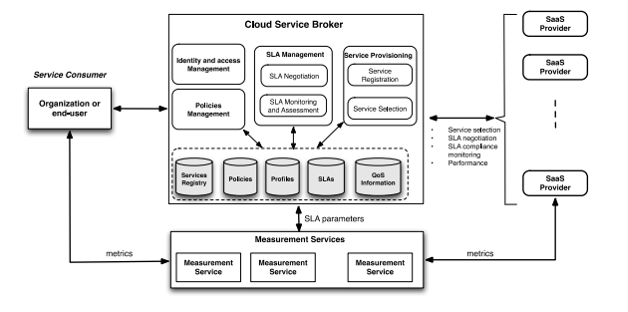
Figure 1: Effective framework for SaaS provisioning and selection
A better framework is figured out in this section, and the selection manager helps to implement SP management operations by managing various policies with suitable SaaS providers. This is mainly based on the QoS consumer's requirements and QoS offerings SaaS providers (Badidi, 2013). SLA manager implements SLAM operations by carrying out the negotiation process between SaaS providers and consumers. After that, CSV selects different SaaS providers and looks into the negotiation process. In addition, in managing IAM operations, a Profile manager is used by including different preferences on the basis of required QoS as well as personalised services. As depicted by Hadi et al., (2021), another feature is policy manager for managing PM management and is responsible for meeting QoS aware selection as well as authorisation policies on the basis of service providers. This entire working principle and architecture are really effective to manage better services to FLC in order to develop the better activity of customer support and their services.
Discussion of two to four benefits for Figura Leisure Centre to adopt cloud-based SaaS model in managing Information systems such as accounting information system, CRM, and management information systems
Cloud-based SaaS models are too effective in order to manage different kinds of information systems such as accounting information systems, CRM and Management Information systems. Along with that accounting information system is mainly a system structure, which is generally utilised for the business for storing, managing, processing, retrieving and reporting several financial data. Furthermore, for accountants, business analysts, managers, consultants, financial officers, regulators, auditors and several tax agencies, this accounting information system plays an important role (Al-Somali & Baghabra, 2019). Through SaaS accounting, accounting software is provided, which is generally hosted by the service provider. On the other hand, SaaS software can be securely accessed through mobile or computer. In such correspondence, this kind of software is called cloud accounting software. Along with that, for the data centres of the organisations, this software's are installed by the companies. Hence, for Figura Leisure Centre (FLC), this cloud accounting software is too significant for managing several activities regarding accounting (Malik et al., 2018). On the other hand, for accessing various services and features, the SaaS accounting information system is too efficient. Along with that, automatic updates are also processed in the case of SaaS. In such correspondence, management is patched and updated.
In addition, SaaS CRM is mainly Cloud-based software by which permanent access is given to the CRM functionality. Furthermore, any kind of investing is not required for the installation and maintenance. On the other hand, transparency corresponding to the relationships among the customers is brought by the SaaS-based CRM. Besides, business automation is helped where marketing, sales and customer service are personalised through this process (Nayar & Kumar, 2018). Moreover, for operating the Figura Leisure Centre (FLC), a CRM is required in order to manage the customers of this company. Along with that, different kinds of data and information corresponding to the customers are maintained through this CRM software where several kinds of features such as attendance, payments, different rules and regulations of the company and other features are provided. Through the Cloud, all the information is stored in the database, which is too significant for the business. Along with that, business data and services are provided through the CRM system. As opined by Saa et al., (2017), service providers can host the SaaS CRM, which is available to all the customers of the company. In such circumstances, SAAS has great importance for managing the CRM in order to operate the company. As per the case study for Figura Leisure Centre (FLC), SaaS is too effective for operating the CRM information system of this company.
For management information systems, SaaS is a significant distribution model by which multiple applications can be hosted by the cloud provider, and these applications are available to the users online over the internet. On the other hand, the portfolio regarding the technology of the company is provided through the SaaS management system. Besides, the cost of the SaaS applications is contained in the SaaS management system (Jayasimha & Nargundkar, 2020). In addition, vendors and the contracts are managed through the SaaS management system, whereas several SaaS applications are secured through this management system. For Customer service support of FLC, this SaaS management system is too effective for the visitors and the customers. In such accordance, the collaboration of the information technology is developed through the SaaS management system, whereas the shadow IT is reduced and prevented (Rath et al., 2019). As per the case study writing, this FLC organisation has no website for managing its customers and visitors. In such correspondence, a SaaS management system is required for the development of the organisation in a digital way.
Identification of two challenges associated with introducing cloud-based information system in regard to a business information system that has been identified in the previous section
In order to introduce cloud-based information systems in regard to business information systems, various challenges are involved in this. These are such as reliability and high availability, hybrid cloud complexity, portability and interoperability, migration, creating of private Cloud, migration, compliance, control of governance, internet connectivity, lack of expertise, and password security as well as cost management. These all are involved with managing various business information systems like CRM, accounting, and management information systems (Al Hadwer et al., 2021). As per the case study, it is seen that management has realised and approached a number of consultants for better identification of SaaS systems within the centre. Additionally, the management of FLC has also identified that cloud technology is the key success of their business information system that solves problems and provides better customer services on the occupancy rate of increasing the annual revenue of FLC.
Two major challenges are discussed on the basis of the previous discussion of the benefits of using Cloud-based SaaS for small to medium-sized companies like FLC.
Password security:
Using cloud accounts by various users can be harmful to getting network threatening and vulnerable threats. The specific password is known by all, and anyone can change the password at any time. This indicates a big issue for managing the password and can be hacked with cloud access with confidential information. In order to manage the financial information system, business information, as well as management systems, can also be secured by using an effective one known password within the organisation (Ferreira et al., 2017). After that, a big initiative can be measured through organisations like FLC for protecting their password to get secure and safe access to cloud computing and SaaS operations. After that, the password must be modified on a daily basis to access passwords and usernames in a judicial manner.
Cost management:
Cloud computing is able to access fast software internet connection, and that requires high valued software, hardware, maintenance, and management. Besides, high and affordable prices can make it more difficult to achieve a better business information system in medium-sized organisations (Malik et al., 2018). Another issue is transferring of data and its cost within a small business project in a public cloud.
Developing of supporting evidence for identified key challenges in the previous section and analysis of three major approaches that help to minimise the impact of these challenges that have been identified
As per several key challenges corresponding to the previous point, password security and cost management are big factors. In such circumstances, Cloud-based security, network protection, identity security and visibility have to be improved. In such correspondence, cloud cyber security has to be increased for preventing different types of attacks (Nayar & Kumar, 2018). Besides, the growth of agile development has to be increased, and scalability has to be improved. Along with that, firewall, tokenisation VPN, penetration testing should be utilised where the public internet connection should have to be avoided.
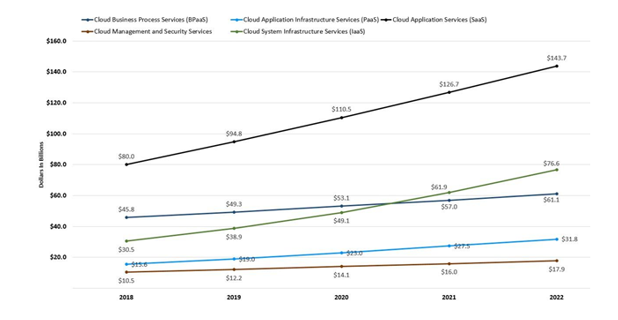
Figure 2: Worldwide public cloud service revenue forecast, 2018-2022
(Source: Gartner, 2019)
According to the Gartner report of 2019, the worldwide public cloud services market has been projected to grow 17.5%, and that is $214.3 billion in 2019 (Gartner, 2019). Apart from that, Cloud system infrastructure services have grown 27.5% by 2019, and these large evaluations in cloud computing indicate big cost management in organisations like FLC.
Many companies trying to adopt cloud computing activities must have a firm that understands the major three deployment models such as private, public, and hybrid (Saa et al., 2017). In this regard, the case of personal entertainment and managing advanced IT tools, Netflix is a great example of this activity, and for B2B and B2C users, IaaS (“Infrastructure as a Service”), SaaS (“Software as a service”), and PaaS (“Platform as a Service”) are three approaches frequently used in the market. Furthermore, all the SaaS tools should be discovered for prioritising the application at a low cost. In such correspondence, Platform as a service and infrastructure as a service can be utilised in order to minimise the challenges as it is low costing and it is provided by the third party provided, where the software is utilised over the internet. Moreover, IaaS is owned by the service provider where the security is too strong.
Conclusion
From the above discussion of the entire Cloud-based SaaS for business information management, it can be concluded that the SaaS management information system is mainly the business practice. This includes several factors like purchasing, different licensing; on boarding, renewals and multiple off boarding are managed and monitored through the SaaS management. Besides, cloud system infrastructure services have grown 27.5% by 2019, and this indicates a large evaluation in cloud computing along with big cost management in the organisations like FLC. Therefore, CRM, accounting information systems, and management information systems can be managed effectively by using Cloud-based SaaS in FLC.
Reference:
Al Hadwer, A., Tavana, M., Gillis, D., & Rezania, D. (2021). A systematic review organisational factors impacting cloud-based technology adoption using Technology-organisation-environment framework. Internet of Things, 15, 100407. https://www.researchgate.net/profile/Madjid-Tavana/publication/351443429_A_Systematic_Review_of_Organizational_Factors_Impacting_Cloud-based_Technology_Adoption_Using_Technology-Organization-Environment_Framework/links/60983b51a6fdccaebd1d6091/A-Systematic-Review-of-Organizational-Factors-Impacting-Cloud-based-Technology-Adoption-Using-Technology-Organization-Environment-Framework.pdf
Al-Somali, S. A., & Baghabra, H. (2019). Investigating the determinants of it professionals' intention to use cloud-based applications and solutions: an extension of the technology acceptance. In Cloud Security: Concepts, Methodologies, Tools, and Applications (pp. 2039-2058). IGI Global. https://scholar.archive.org/work/cfnbn4purfbjrhk75mockd6lyy/access/wayback/http://pdfs.semanticscholar.org/
3bf2/dbe862f0eb240800297d5f350f578a43c32e.pdf
Badidi, E. (2013). A framework for software-as-a-service selection and provisioning. arXiv preprint arXiv:1306.1888. https://arxiv.org/pdf/1306.1888
Ferreira, L., Putnik, G., Cunha, M. M. C., Putnik, Z., Castro, H., Alves, C., ... & Varela, L. (2017). A cloud-based architecture with embedded pragmatics renderer for ubiquitous and Cloud manufacturing. International Journal of Computer Integrated Manufacturing, 30(4-5), 483-500. https://repositorium.sdum.uminho.pt/bitstream/1822/51375/1/0951192X.2017.pdf
Gartner, (2019). Gartner Forecasts Worldwide Public Cloud Revenue to Grow 17.5 Percent in 2019. Retrieved from https://www.gartner.com/en/newsroom/press-releases/2019-04-02-gartner-forecasts-worldwide-public-cloud-revenue-to-g. [Retrieved on 16 March 2022]
Hadi, H. J., Omar, M. A., & Osman, W. R. S. (2021). Investigating the determinants of CC-SaaS adoption in Iraqi’s public organisations from the perspective of IT professionals. International Journal of Engineering Research and Technology, 14(2), 130-143. https://www.researchgate.net/profile/Hiba-Hadi/publication/351093867_Investigating_the_Determinants_of_CC-
SaaS_Adoption_in_Iraqi's_Public_Organisations_From_the_Perspective_of_IT_Professionals/links/6085b409
881fa114b42b0966/Investigating-the-Determinants-of-CC-SaaS-Adoption-in-Iraqis-Public-Organisations-From-the-Perspective-of-IT-Professionals.pdf
Huang, W., & Li, J. (2020, August). Using agent solutions and visualisation techniques to manage the cloud-based education system. In 2020 IEEE Intl Conf on Dependable, Autonomic and Secure Computing, Intl Conf on Pervasive Intelligence and Computing, Intl Conf on Cloud and Big Data Computing, Intl Conf on Cyber Science and Technology Congress (DASC/PiCom/CBDCom/CyberSciTech) (pp. 375-379). IEEE. https://westminsterresearch.westminster.ac.uk/download/4e28ebe530f0e91acd90292bd000cbec0926b0def48b
eca232b64f4c4e2063c7/1779663/ICETA%202016.pdf
Jayasimha, K. R., & Nargundkar, R. V. (2020). Impact of software as a service (SaaS) on software acquisition process. Journal of Business & Industrial Marketing. https://www.iimidr.ac.in/wp-content/uploads/Impact-of-software-as-a-service-SaaS-on-software-acquisition-process-FPMI-Theses.pdf
Malik, M. I., Wani, S. H., & Rashid, A. (2018). Cloud computing-technologies. International Journal of Advanced Research in Computer Science, 9(2). https://www.researchgate.net/profile/Mohammad-Ilyas-Malik/publication/324863629_CLOUD_COMPUTING-TECHNOLOGIES/links/5af45452aca2720af9c57086/CLOUD-COMPUTING-TECHNOLOGIES.pdf
Nayar, K. B., & Kumar, V. (2018). Cost benefit analysis of cloud computing in education. International Journal of Business Information Systems, 27(2), 205-221. https://www.researchgate.net/profile/Vikas-Kumar-122/publication/321753986_Cost_benefit_analysis_of_cloud_computing_in_education/links/5af94354a6fdcc0
c033450cb/Cost-benefit-analysis-of-cloud-computing-in-education.pdf
Rath, A., Spasic, B., Boucart, N., & Thiran, P. (2019). Security Pattern for Cloud SaaS: From System and Data Security to Privacy Case Study in AWS and Azure. Computers, 8(2), 34. https://www.mdpi.com/2073-431X/8/2/34/pdf
Saa, P., Cueva Costales, A., Moscoso-Zea, O., & Luján-Mora, S. (2017). Moving ERP systems to the cloud-data security issues. http://rua.ua.es/dspace/bitstream/10045/69990/1/2017_Saa_etal_JISEM.pdf
Thesis Writing
Principles of Data Protection Act: A Detailed Analysis Assignment Sample
Question
Task-Write a detailed description of the data protection act's guiding principles.
Answer
This study focuses on the Data Protection Act of 1988 to communicate the key steps taken to preserve sensitive and important data. The provisions of the Data Protection Act of 1988 apply to everyone or any corporate entity handling any kind of information or data pertaining to the general public. The principles of the Data Protection Act have an impact starting with the gathering of the necessary data and ending with the deletion of the gathered data. The scope and gravity of data processing are particularly large in the information technology-related sectors. The rules of this law apply to the acts of such companies, such as data alteration, implications, retrieval, transmission, and deletion.
Introduction
The United Kingdom's parliament approved the Data Protection Act bill in 1998 in order to address the inconsistencies in the Data Protection Act of 1984. The guiding principles of this statute became effective in 1999. Information about the public is handled in accordance with the requirements of the Data Protection Act (Iversen et al., 2006). Individuals' privacy rights would be violated if the underlying principles were broken. Therefore, the affiliated bodies are required to abide by the relevant legislation. The law guarantees that each individual has ownership and control over their unique personal data (Jay & Hamilton, 1999).
The Principles of Data Preservation Act primarily addresses the protection of privacy rights and promotes openness regarding how a secondary entity handles personal information. The communication media businesses would develop their marketing plans by adhering to the framework outlined in the Principles of Data Protection Act. The domestic level of information management, such as keeping a personal address book, is not covered by the law. However, the provisions of the Data Protection Act must be adhered to in the context if the same data is used for a business or other purpose. Under this statute, the data regulating authority and the related computer bureau are held accountable for any breaches of personal data.
Background
In order to establish greater protection for the public's data, the UK's legislative assembly established its first data protection act in the year 1984. The European Parliament adopted its guiding principles after careful consideration and study. By basing it on the topic of data transfer, the European Parliament gave the legislation a new meaning. The provisions of this act prevented emerging information technology businesses and large corporations from manipulating data. Only one defined purpose may be served by the parties involved in the data transmission, and any violation of this restriction would result in legal repercussions. Before disclosing the pertinent information to a third party, the individual's permission should be obtained. The length of time that businesses might retain specified, private information on the public was set down in the law. The jurisdiction of this law extends implacably to both manual and electronic information transfer (Carey, 2018). The definitions of Personal Data and Processing are set forth in the Principles of Data Protection Act.
The government established a special entity known as the Data Protection Registrar, which served as a regular body to oversee the application of the provisions of the Data Protection Act. The same regulation was later changed to include references to particular European Union Directives 95/46/EC in the Data Protection Act of 1998. (Peto, 2004). The Data Protection Commissioner is now known as the Data Protection Registrar, per the regulations outlined in the amended statute. The amended law put a strong emphasis on educating the populace about practical ways to stop the invasion of private rights. Richard Thomas is the current Data Protection Commissioner, who directly answers to the parliament. The New Principles of Data Protection Act of 1998 introduced the latest norms and best practices in the modern IT business. When requested, the general public may also get the services of a commissioner. The commissioner offers the option of legal service to the data controllers as needed. This report on the principles of the Data Protection Act includes a section below that lists some of the pertinent sets of documents pertaining to this service (Romanosky & Acquisti, 2009).
Code of Practice for Directory Information and Fair Processing in Telecommunications.
Code of Conduct for Users of CCTV
Code of Practices on Employment Practices
Principles of Data Protection Act
• Under no circumstances should a citizen's personal information be sent outside of the European Economic Area. Only when the data is given the necessary level of security and protection may the transfer take place. An individual's right to freedom should never be violated. While processing private information, the correct legal guidelines must be scrupulously observed.
• Data processing should only start if all legal requirements have been met.
• The most up-to-date and appropriate technology should be used to prevent the improper processing of personal information. After the intended usage, the personal data should be erased, and any unintentional loss or theft should be punished legally.
• The collecting body must have a legitimate justification for collecting the personal information, and it must not have any particular authorization to use the information for any other purpose than that for which it was originally collected (Koops, 2014).
The Primary Section of The Principles of Data Protection Act
The fundamental tenet of the data protection act states that the population's personal information should only be handled in accordance with the legal framework. Only the following situations should be regarded as an exception: - • When the data acquired falls under Schedule 3's Schedule 3's division of sensitive data.
• If any of the characteristics of the data collected match those of the points listed in Schedule 2.
In the main body of this section, it is stated that the personal data obtained shall only be handled and processed in accordance with the requirements of the relevant law. Fair processing prohibits the government from mishandling the information in any way. When handling personal information about people, there should be no fraud of any kind. The first section of this regulation makes special reference to the gathering and organisation of personal data (Rumbold & Pierscionek, 2017). Before the government authorities, the data collector must defend the legitimate justification for the data collection. The way such data is handled shouldn't have a negative impact on people.
The idea of legitimate processing requires that when relevant personal data is acquired, the owner of the data be informed. The person should be extremely transparent about the purpose behind data collection and the processing procedure. The Fair Processing Notice would include all pertinent details pertaining to this issue. The following portion of this report on the fundamentals of the Data Protection Act contains the majority of the information given in the Fair Processing Notice (Hornung & Schnabel, 2009).
• The agencies that are part of government departments should receive priority when receiving the acquired personal data.
• The specific information about the data controller assigned to handle the gathered personal data.
• The primary purpose for gathering and processing personal information;
• The right procedures used when processing personal information to give the public as much clarity as possible.
The major parameters which satisfy the existence of fair processing.
To guarantee the existence of fair processing, a number of requirements must be followed. The conventions relating to fair processing are outlined in Schedule 2 of the Data Protection Act. There are six requirements to be met in accordance with the norms listed in schedule 2 for the presence of fair processing (Gutwirth et al., 2009). In the event that any of the conditions listed below are not satisfied, the collecting agency is not authorised to process the data.
Parameters mentioned under schedule 2
• The data controller must adhere to the guidelines outlined by the legislation.
• The intended contract should be the only purpose for which the data is used.
• The desired action should fall under the heading of carrying out official government business, adhering to legal obligations, administering justice, acting in the public interest, etc.
• The act is done to protect the individual's critical interests.
• In addition to the constraints outlined in the contract, the data controller may also abide by legal requirements.
• If the data acquired is sensitive personal data, the standards outlined in schedules 2 and 3 must be followed.
Parameters listed under Schedule 3
• The information is gathered to determine if the equality of opportunity parameter is met.
• The unit has received the explicit consent of the data subject.
• Gathered for medical needs.
• The information is gathered to meet a specific person's essential needs.
• Acquired in order to give a specific person a job.
A non-profit organisation for social welfare activities completes the work by carrying out the responsibilities of judicial bodies and carrying out the government's proposed policies.
• Information is gathered for legal purposes, such as defending citizens' fundamental legal rights.
Secondary principle of data protection act
The second principle of the data protection legislation mentions the important idea that the collecting of personal information should only be started to fulfil one or more legally specified purposes and that further synthesis on unrelated grounds should be absolutely forbidden. The section would highlight the aspect of the purpose for gathering a certain set of data (Cate, 1994). The specific report and the reason for why particular pieces of personal data were acquired should be provided to the ICO. Every step taken to process the information should be disclosed to the office of the information commissioner.
The data processor could notify the owner in a timely and suitable manner to provide further clarification regarding the treatment of the information. The appropriate individuals should be informed about the data collection at that time. Before gathering sensitive information, the authorities must have the consent of the relevant parties.
The Third Principle of The Data Protection Act
The Data Protection Act's provisions grant the data controller three specific liabilities. The particular extent to which the data controller may disclose the information further is specified, and the limit shall never be crossed. While handling the material, the criteria of relevance, sufficiency, and accuracy should be maintained. When combining the data, prejudice and interest are completely irrelevant.
To process the intended information, just the necessary information should be extracted and identified from the accessible dataset. The information might only be processed further under certain extraordinary circumstances specified by the legal laws. The circumstance could be comparable to one where a surgeon is faced with a difficult medical condition and the gathering of personal data is crucial for the diagnosis and treatment. The surgeon would need to know the patient's family history, medical past, and other details in order to treat the patient effectively.
Similar to this, the practices used by the human resource management departments of many firms are significantly tailored, and hiring workers is only done after carefully examining a number of personal traits. Most of the time, the authority immediately requests the information for the IT Thesis. When compared to the first principle of the data protection act, it can be shown that the third principle has a far stronger relationship. While the first principle of the data protection legislation demands perfect impartiality and justice, the third principle of the act places a strong emphasis on the criteria of sufficiency, relevance, and exceeding the limit.
The Fourth Principle of The Data Protection Act
The fourth principle of the Data Protection Act states that the data retrieved must have correct characteristics and must always be kept current. After reviewing the fundamental and secondary principles of the data protection act, the quality of the data handled by the data handler should be guaranteed. The fourth principle of the Data Protection Act primarily consists of two provisions.
In this part, accuracy is the main factor taken into account. To maintain the accuracy of the data, the units must adhere to the necessary procedures set forth by the data controller. Any ambiguity or error could affect the conclusion of the entire process and could lead society to believe incorrect conceptions. Even a minor error in calculation could lead to false conclusions being drawn from precise and accurate data sets. Therefore, the dataset for the study should be chosen by the data collector since it is detailed and has a wider application. If the authorities imply a misleading method of computation, the fundamental tenet of the Data Protection Act will be broken. For the sake of dependability, the controlling body should make sure that the data protection activities are conducted with objectivity and precision (Bennett, 1992).
Only the most recent dataset of personal information should be chosen by the authority to carry out the activities. When the frequently used dataset for a time period is taken into consideration for the study, the criterion should be taken into account. When taking into account this kind of data set, the data controller should use a more thorough approach. In order to draw useful conclusions from the dataset that has been collected, it is important to guarantee that it is highly accurate.
If there is any reason to believe that the data obtained by the data collector is erroneous, the relevant person should confirm it once more to eliminate any differences. The data subject may submit an access request under section 7(12) of the Principles of Data Protection Act. According to this clause, the person has the right to obtain a copy of the data set that the data controller has kept. According to the argument put up by the data subject, the court may require the data controller to delete, block, and verify the information they have acquired. The clause also mandates the payment of damages in the event that the pursued procedure harms the data subject in any way.
Fifth Principles of Data Protection Act
The length of time used to process the collected set of data should not be longer than that specified. The data controller should keep track of how long they plan to keep the information they acquire. As stated behind the provisions of the fifth principle of the data protection legislation, it is to maintain the clarity and transparency regarding the purpose behind the information collection. If the person designated as the data controller is unable to provide a compelling cause to keep the information, he or she is required to release it.
After keeping the knowledge for a longer time, it would become outdated. The study would be flawed, and it would seriously mislead society in drawing the incorrect conclusion. After a given amount of time, the authorities would no longer be certain of the data's accuracy. Even if the purpose of the data is fulfilled, the data controller is still responsible for ensuring the security of the information acquired. Eliminating data that is no longer required for a study or procedure is the best practise. It is strongly advised to record the data offline if it may be needed for future references.
The data controller only keeps the personal information after considering the data set's potential future scope. In order to preserve personal information, the data controller must overcome various obstacles, chief among them being dangers, expenses, and other legal obligations.
The Sixth Principle of The Data Protection Act
The sixth principle of the data protection legislation includes the rule that the data controller must never, under any circumstances, violate the human rights of the data subject. In accordance with this section of the Data Protection Act's guiding principles, the power of the data controller is restrained and the rights of the data subject are specifically guaranteed. Under this Article, the data subject is given a number of special rights.
• Control over the personal information; • Right to compensation; • Right to change the information if there are any errors
• Take precautions to prevent the nefarious or upsetting use of personal information.
• Choosing an automated method of decision-making. • Refraining from being exposed to direct marketing.
The subject of the data has full access to the personal information, per Section 7 of the Data Protection Act (Schwartz, 1994). It permits the data subjects to obtain a copy of the information acquired from the data collector at any time. Our readers should be aware that the individual would only have access to their personal data. If there is any doubt about whether any pertinent data is gathered or processed, the data subject may request legal clarification. Simply submitting a straightforward application to the court could accomplish this. The authority is required to explain why a certain piece of data was gathered for the procedure, and it should be clear if the data was given to a third party.
The laws also give the data subject the option to request a stop to data processing if it is negatively impacting their personal life. The citizen has the right to ask the court to overrule any objections they may have to the acquisition and use of their personal information. Legally speaking, the specific application could be described as an objection to processing. Under the application of objection to processing, the effect produced by the data processing should be explicitly mentioned.
Let's use the example of a candidate who was turned down for a position in an organisation because it was discovered by another organisation or third party that the individual is a trade union activist and is totally unqualified for the position. One of the agencies that retains the list of applicants who have been placed on the back-burner for employment in any sector or organisation is the third party. A person has the right to request that their name be removed from the blacklist by the data controller. The data subject would ask for the name to be removed on the basis of continuous harm and anguish. The data controller is required to respond to the request of the data subject within 21 days.
The data subject has the absolute right to limit the use of their personal information for direct marketing. The person may immediately raise an objection to processing against the authority if the information is being processed with the goal of direct marketing. The most important tool for direct marketing is regarded to be the widespread distribution of junk mail. The realm of directing includes campaigns and the promotion of specific ideologies and individuals as well as the sale of a specific product. Each individual has the right to request that their personal data be removed from the data set. It is strongly advised that the general population keep their personal information private wherever feasible. The institutions should only gather the data necessary to offer the customers and the relevant collection of sensitive data the highest level of security.
The data subject has the power to prevent the data controller from using any kind of automated decision-making. The data subject has the right to request that the authority reevaluate the decision made after looking at the personal data. The data controller has a responsibility to notify anyone who may have had their information misused. Such choices typically involve no human intervention because they are done in an automated fashion. Let's use the situation where the authority rejects a request to transfer money from one account to another as an example. It is the discrepancy between the information provided by the data subject and the system's pre-existing data set. In such circumstances, the people are compelled to choose the manual method of carrying out the operation.
The fourth data protection act premise emphasises the need of accuracy as a parameter. Any difference in the information gathered may be brought to the court's attention by the data subject, and the jury may decide to correct, amend, or even delete the data set as necessary. If the data processing resulted in any harm or suffering, the data subject would have the right to request compensation.
Seventh Principles of Data Protection Act
The eighth principle of the Data Protection Act emphasises the safeguarding of sensitive data. This regulatory requirement requires the data controller to implement the appropriate technical safeguards in order to prevent any process irregularities. It aids in preventing instances of loss or harm to confidential information. This attitude leads to the designation of the security principle as the fifth data protection act principle. When the data controller handles sensitive data, there shouldn't be any risk to their security. To avoid the issues described below, the data controller should take security precautions into account.
• Accidental deletion or loss of sensitive data
• The improper handling of personal data
• A third party misusing the data.
The phrase "security" refers to the proper use of strong passwords, other cutting-edge encryption techniques, and the deployment of antivirus software to find malware. The data controller should use the most advanced technology when processing the data in order to maintain the security parameter. Only the authority of human resources with technical and physical aptitude may imply it. The Information Commissioner needs to be informed of the security measures the data controller seems to have in place.
Eighth Principles of Data Protection Act
The data controller is prohibited from transferring the personal information of data subjects outside the EEA according to the rules outlined in the ninth principle of the Data Protection Act. This clause protects the data subjects' fundamental rights and so offers protection from any calamity or misery that might be caused by them. The government should determine if the authority can still produce the desired results even if the data collection process is not completed. Sensitive information should never be sent to a third party without first getting approval from legal counsel and the data subject themselves. However, if the person's identity is not exposed from the dataset, this condition would not be relevant (Bygrave, 2010).
The transfer is considered to have occurred when the personal information is stored in a foreign nation. If the data controller chooses to publish personal data on a public website, the situation will be identical. A third party residing in another nation might easily download the material. The current legal framework does not impose any restrictions on the exchange of information between the nations that are subject to EEA territory's jurisdiction (Lynskey, 2015). Even though the transfer is permitted under certain circumstances, the factors indicated below should be taken into account before starting the transfer.
• Local laws adhere to the appropriate legal requirements and security precautions.
• The traits of sensitive personal information
• The point at which the targeted information is transferred to a third party and the location to which it is transferred, as well as the source of the personal data.
Conclusion
The aforementioned paper makes frequent reference to the 1998 Data Protection Act's guiding principles. We have worked very hard to cover every facet of the principles of the Data Protection Act. When handling personal information, data controllers must rigorously adhere to the criteria of legality and fairness. There would be no justification for the affected bodies' negligent handling of sensitive information. The threat to personal data has increased with the development of information technologies. Therefore, additional changes to the principles of the Data Protection Act are required to maintain its applicability in the contemporary online environment. It is advised that all companies strictly abide by the guidelines set forth in the Data Protection Act.
References
Fear, N., Hotopf, M., Iversen, A., Liddell, K., & Wessely (2006). Principles of the Data Protection Act: Consent, Confidentiality, and the Act, BMJ, 332(7534), 165-169 .
Hamilton, A., Jay, R., and (1999). Data protection: Law and Practice, 2. Principles of the Data Protection Act.
P. Carey (2018). Principles of the Data Protection Act: A Practical Guide to UK and EU Law, Oxford University Press, Inc.
J. Peto, O. Fletcher, and C. Gilham (2004). The three pillars of the data protection act are data protection, informed consent, and research.
S. Romanosky and A. Acquisti (2009). Principles of the Data Protection Act, Berkeley Tech. LJ, 24, 1061. Privacy costs and personal data protection: Economic and legal perspectives.
B. J. Koops (2014). Principles of the Data Protection Act, International Data Privacy Law, 4(4), 250–261 (The Problem with European Data Protection Law).
J. M. M. Rumbold and B. Pierscionek (2017). Principles of data protection act, Journal of medical Internet research, 19(2), e47. The impact of the general data protection law on medical research.
G. Hornung and C. Schnabel (2009). Principles of the Data Protection Act: Data protection in the USA I: The population census decision and the right to informational self-determination, Computer Law & Security Review, 25(1), 84–88.
Y. Poullet, S. Gutwirth, P. De Hert, C. De Terwangne, & S. Nouwt (Eds.). (2009). Principles of the Data Protection Act, Springer Science & Business Media, Reinventing data protection?
F. H. Cate (1994). The public interest, information privacy, and the EU data protection directive. Iowa L., Rev., 80, 431, Principles of Data Protection Act.
P. M. Schwartz (1994). European data protection legislation and constraints on global data flows. Iowa L., Rev., 80, 471, Principles of Data Protection Act.
A. Bennett, J. (1992). Data protection and public policy in Europe and the US: Regulating privacy. data protection act guiding principles, Cornell University Press.
L. A. Bygrave (2010). Data protection and privacy from a global perspective. Scandinavian Studies in Law, 56(8), 165-200, fundamentals of data protection act.
O. Lynskey (2015). the legal framework for EU data protection. data protection act guiding principles, Oxford University Press.
Essay
ISYS1004 Contemporary issue in Information Technology Assignment Sample
Due Date – Sunday of week 6
Weight – 55%
Some Options for Assignment 3: Essay Topic
The following offers a list of broad ideas suitable for students to consider as a topic for their essays. Students are encouraged to select an area to specialise in for their essays. The focus should be to define a narrow, but deep (detailed), area of research. It is anticipated that pursuing such a “narrow and deep” topic area is likely to provide students with high levels of autonomy, ownership, motivation and personalised learning outcomes.
The list is only intended as an idea prompt. Students are encouraged to identify alternative topic areas to pursue if they wish. If you are not sure about your topic, you may contact your tutor for consideration and authority to proceed.
Each of the topics identified below contains ethical considerations. Each is open to be viewed for its relative strengths and weaknesses (positive and negative effects). Such a balanced consideration of strengths and weaknesses must be incorporated into the Report. Select only one of the topics mentioned below each numbered header! Areas which do not hold such “two-way” arguments are not suitable as a topic area. For example, the incidence of malware (such as viruses) is not a suitable report topic area as it is “all bad” in its effect on society…unless a student can clearly argue some positive effects.
You are required to produce your essay in response to your selected topic area for assignment help
The essay will be about the impact of computers, information technology, and their applications, including ethical implications, in a specific area of business, society or culture.
The essay should not be less than 1500words, excluding references.
Your essay should contain three main components: Introduction, Body, and Conclusion.
Solution
Introduction
Communication requires sending and receiving different thoughts and information from one place or person to another and this is emerging with information technology has impacted society differently and has created a lot of improvements for individuals to safely and securely communicate with each other. The data and privacy of an individual play an important role and the implications and impacts of computers to be discussed in the research study of communicating with information technologies with the facts that areas of business been involved with the new technology and impacts upon society and culture of this also to be discussed in the further report. The study research for communicating with IT presents various forms of communication and their applications.
Communicating with IT
Communication in simple terms explained as the means of transferring thoughts and messages from one source, person, or group of people to another where the information has been transferred or shared among them with texts or writing or listening, or sometimes by reading also. Information technology has been playing a major role in communication though as it is providing a platform for people to communicate with each other and a platform for means of sharing information easily from anywhere to everywhere. Not only for socializing but also in workplaces it helps in achieving and improving good relationships between people (Van der Bles et.al., 2019).
Information technology has made it easy for anyone to communicate anywhere around the world just by using any form of communication which has been discussed below:
Different Forms of IT Communication
There are mainly five types of communication forms in information technology which include:
• Verbal communication
• Non-verbal communication
• Written communication
• Listening
• Visual communication
1. Social Networking Sites
Social networking sites are online networking platform which does allow people to interact with public profiles of other users and build networks by themselves. The social media platform works on the schema to connect with the user whom they want to and the acceptance from that user confirm the connection over the platform (Sundararaj and Rejeesh, 2021).
Impact of computers: Social networking is performed over the internet connecting millions of networks and managing traffic over the internet and computers in the networking play a major role while connecting one user to another. Computers not only help in connecting but also play a major role in storing and managing data over social networking sites where people can communicate and can reach out to the information, they shared anytime through the database management system.
Applications The applications of the social networking sites include
Facebook, YouTube, WhatsApp, Instagram, Snapchat, Telegram, Twitter, Skype, LinkedIn, etc. engage millions of networks of active users, and the massive appeal engagement focus to optimize scale over social efforts.
Ethical implications: The ethical implications of social networking sites involve the danger of hackers which do enters into one’s privacy without their permission and using the information according to their needs and aspirations. Another implication involves Scammers, Spam, Viruses, and Malware present over the internet which do harm the security and privacy of the person.
Specific area of business: The specific area of business in social networking sites offers product promotions while connecting millions of people online, promoting their websites, products, services, brands, etc. Social networking is a benefit for e-commerce businesses as it requires people’s attention and support to run a business through the network to get customers and clients for gaining profit. Improving the awareness of the brands among people, collaborating with effective clients, engaging people, building trust and loyalty among customers, and better customer satisfaction.
Society or Culture: The practices and the beliefs among people connected build trust and loyalty to the social networking platforms to use it as a safe means of information exchanging platform and hence the social structure builds with all the beliefs and trust over social networking sites.
Mobile computing:
Mobile computing technology in today’s time plays an important role in transferring data from one place to another via the internet using any hardware device for the connection (Verduyn et.al., 2020). The environment where the connections on the devices build without any cables or physical links.
Source: https://digitalthinkerhelp.com/what-is-mobile-computing-advantages-disadvantages-applications/
Impact of computers: The computers on mobile computing have a major impact as the device for the transmission of information is a necessity as the person’s physical availability on the location is not required if there are mobile connections through hardware or software.
Information technology: Mobile computing is one of the fastest methods in information technology and the most reliable sector in the field of computing and communication with IT (Higham, 2020).
Applications: There are multiple real-life applications of mobile computing including:
Traffic, Emergencies situations, use in business, credit card verification, replacement of fixed networks, infotainment, courts, e-government, transactions, tours and travels, paging, and electronic mails.
Ethical implications: The ethical implications in mobile computing involve malicious destruction, industrial espionage, hacking, online fraud, etc.
Area of business: Mobile computing is a complete set of technology that can be used for products, Services, procedures, strategies, and operations, where any user from a mobile device can access any information and sources related to their requirements and helps end users to access computation procedures.
Society or culture: Multiple users and people are connecting to mobile computing and there are very less in today’s time who are not introduced to mobile computing. The benefits of mobile computing are engaging more and more people to use it for their reasons for work or for communicating with the person. Society accepts technology more over time and culture is adjusting to new emerging technologies in communicating with information and technology.
Work from Anywhere:
Mobile Computing has done it possible for people to work from home from any location without physically present over the location which has provided such a great platform for the youth in today’s time mainly for the female over the world who cannot relocate to the particular location due to their reason that they can work from home by connecting to anyone anywhere through mobile and communicating over the internet and exchanging information for the business purpose. The work from home anywhere had increased the employment rate over the world which is a great benefit in the information technology where many people do connect over texts, audio calls, video calls, etc. as a means of exchanging information and sharing thoughts helping in growing up of their business and creating opportunities for people to work from their preferred location. Freedom to work from a preferred location has made the work easy which has been done through changing technology over a period and people accepting change and presenting the best they can (Nazir et.al., 2019).
Applications for Mobile Consumers
The applications tend to be the software programs inside any computing devices through which every process is happening in information technology. The programs inside the software in applications contain a set of operations that are used by the users to perform specific functions.
Impact of computers: The application uses the computer’s operating system to run the program to perform the specific task or function according to the user’s requirement and provide communication services while connecting multiple people over the internet with different technologies and social networking sites.
Applications: The applications for mobile consumers include word processors, web browsers, image editors, communication platforms such as social media and social networking sites, deployment tools, database programs, etc.
Ethical implications: Ethical implications of the applications involve the misuse of the personal information of anyone, lack of responsibility of oversight and acceptance, moral use of data and resources, disruptive technology adoption, customer trust, and respect, etc.
Specific area of business: The business purpose applications include;
• Reservation software system
• Communication applications
• Accounting applications
• Human Resource Information application
• Inventory management applications
• Demand forecasting applications
• Schedule management applications
• Service management applications
Society or culture: The changing technology rapidly affects society to learn and communicate while also helping each other to be independent and not rely upon anyone for daily activities. The applications in society have to impact positively as well as negatively as some applications may effecting the culture and minds of youth which is making society impact lives but on a positive side, the culture is not getting affected by applications as it is providing a platform for everyone to learn and think and grow on their own (Das and Bhatia, 2022). Technology through communication with information and technology has grown society and culture to another level.
Conclusion
The communication with information technology study research described the various forms of communications made possible by changing technologies impacting society and culture and the various applications of the different forms of communication in IT with the ethical implications impacting technology. The study report consists of the different areas of business with the different social networking, mobile computing, and other forms of communications made possible for people to communicate and interact with each other easily and work effectively. Technology positively impacts business by sharing thoughts of each other and learning and growing in every aspect. The concluded report of the communication with information and technology has been described with all requirements fulfillment.
References
Van der Bles, A.M., Van Der Linden, S., Freeman, A.L., Mitchell, J., Galvao, A.B., Zaval, L. and Spiegelhalter, D.J., 2019. Communicating uncertainty about facts, numbers and science. Royal Society open science, 6(5), p.181870.
Higham, P., 2020. Communicating with technology, computers and artificial intelligence: Are human rights and privacy being neglected?. Journal of Data Protection & Privacy, 3(4), pp.363-375.
Verduyn, P., Gugushvili, N., Massar, K., Täht, K. and Kross, E., 2020. Social comparison on social networking sites. Current opinion in psychology, 36, pp.32-37.
Sundararaj, V. and Rejeesh, M.R., 2021. A detailed behavioral analysis on consumer and customer changing behavior with respect to social networking sites. Journal of Retailing and Consumer Services, 58, p.102190.
Nazir, S., Ali, Y., Ullah, N. and García-Magariño, I., 2019. Internet of things for healthcare using effects of mobile computing: a systematic literature review. Wireless Communications and Mobile Computing, 2019.
Das, S. and Bhatia, R., 2022. based microfluidic devices: Fabrication, detection, and significant applications in various fields. Reviews in Analytical Chemistry, 41(1), pp.112-136.
Case Study
COMP2003 Securing Networks Assignment Sample
Assignment Brief
Learning Outcomes LO1, 2, 3
Weight - 40% of overall unit assessment
Suggestion
This assignment is developmental and cumulative. You are strongly advised to start doing this assignment from Week-1 in your study. Leaving your starting date to the week before the due date is a very poor strategy for success in the unit. For assignment help follow the provided guidelines to help you successfully direct your efforts.
Task Description
You need to complete the following tasks:
• Task 1: Advice appropriate security strategies to the organisation.
• Task 2: Scanning and Report on Network Vulnerabilities.
Scenario
You are a consultant at one of the Big 4 consulting firms. You have been recently assigned your first new client and you need to provide them services to help secure their network. A short time ago their network was breached, and they would like your assistance on ensuring this does not happen again.
They have provided a network diagram of their current network which you can use in your analysis.
You must provide a report to the Chief Information Security Officer of your recommendations to combat the current trend of security threats and the strategies that may assist them to combat them.
Task 1: Network Security Solutions
The client would like you to provide them with a brief report (max 1000 words) of what you believe is the greatest threats to their organisation, why you think that and what they can do to combat this.
For this task you must consider some suitable network security solutions for the network and justify the selection.
Advise how each option you suggest provides an improvement to the security and how it will mitigate the threat.
Provide any references or statistics to support your analysis.
Task 2: Network Vulnerability Scanning
Part 1
Provide a detailed solution (max 300 words) of what vulnerability analysis methods you recommend the customer to complete based on their network and advise why those are appropriate.
Part 2
Complete a vulnerability scan on the breached server that has been provided.
• Provide a copy of the OpenVAS report (screenshot or PDF) with the results for the server.
• Determine the possible server that had the breach and what you believe was the attack vector. Explain why you think that was the attack vector and provide any references or statistics to support your analysis. (Max 300 words)
Submission Format
When you have completed the assignment, you are required to submit the following:
1. Your assignment in the PDF/DOC format. The file will be named using the following convention:
Filename = FirstInitialYourLastName_COMP2003_A1.pdf
(i.e. FJones_COMP2003_A1.pdf)
Getting Help:
This assignment, which is to be completed individually, is your chance to gain an understanding of the fundamental concepts of network security which later learning will be based. It is important that you master these concepts yourself.
Marks and Feedback
All assessment materials submitted during the semester will normally be marked and returned within 7 days of the required date of submission (provided that the assessment materials have been submitted by the due date). Marks will be made available to each student via the MySCU Grade book.
Solution
Task 1: Network Security Solutions
NETWORK SECURITY Solutions
Association is where many individuals work to seek after the objective of the organization or association. There is tremendous measure of information which is utilized in the working of an association. Web is a one of the main element of an association to work in light of the fact that without organization availability it is difficult to move information or to speak with clients by means of Emails. So as a result of this colossal measure of information move which is occurring on the organization, the organization should be gotten. While making an association there are different dangers which are kept in focuses to forestall issues in future. There are different dangers to an association, for example, various assaults that are phishing assault, Ransomware, a few different dangers are network break.
Perhaps the most hazardous danger is the organization break since, in such a case that any outsider breaks into the organization they can without much of stretch gain admittance to the information that is moved on the organization. In associations the information that is moved on the organization should be classified since it is connected with the association or the company. So to make an association secure the organization security ought to be of exceptionally great.
Network security implies getting the organization so some other individual or any assailant can't go into the organization. When the organization security is of great then the organizations information and data will be protected and forestall a simple admittance to the aggressors. The method involved with building an organization security is that first and foremost the organization ought to be all around planned and every one of the parts of going after ought to be forestalled by that network design. Network security will order admittance to an organization by keeping an alternate assortment of dangers from entering and spreading through a framework.
Benefits of Organization Security
Prior to building or planning any organization security the association would see the upsides of the organization security which will be planned. Following are key benefits of the organization security are:-
- The trust between the clients, clients and association will increment in light of the fact that once the security will expand the information can be moved effectively with next to no issues.
- The touchy data of the clients, clients won't get spilled.
- Digital assault can be forestalled as a result of organization security.
- Network manager controls organization and watches out for the organization that assuming any assault is occurring on the organization and it will likewise forestall it.
Kinds of Network Security
1) Access control network security: - In this kind of organization security just that guests can go into the organization that approach the organization. The Access is given by the organization administrator. The word access control implies the administrator can conclude whom the entrance ought to be permitted and for whom the entrance is obstructed. This sort of organization security is generally excellent.
2) Cloud security: - It implies giving security to the distributed storage of the association which comprise of the multitude of information and data, for example, pictures, records and so on. Distributed storage increments proficiency.
3) DDoS Network security:-DDoS implies Distributed refusal of administration which implies that this instruments forestall the DOS assault which are most normal now a days. In this assaults there is an uneven organization demand and due to this assault the organization crashes.
FIREWALLS ought to be utilized to build the organization security since it comprises of the greater part of the security devices which will make the organization more solid and secure.
Measurements:
As the information is expanding information breaks are additionally expanding each year in the year 2021 the information breaks which occurred were around 1862 and in the rush hour of Coronavirus in the year 2020 the information breaks were 1108.
Around 2200 digital assault occurred in year 2020 which intends that after like clockwork a cyber-attacks happens.
Ransomware assaults that occurred in half year in 2021 were 2084 assaults.
In the present time around after every 39 seconds there is an attack taking place of different types on different computers or networks or organization.
Firewall
Firewalls control drawing closer and dynamic traffic on networks, with fated security rules. Firewalls keep out offensive traffic and are a significant piece of everyday enrolling. Network Security relies strongly upon Firewalls,
Network Segmentation
Network division describes limits between network segments where assets inside the social event have a regular limit, peril or occupation inside an affiliation. For instance, the edge section pieces an association network from the Internet.
Access Control
Access control characterizes access to the authenticated resources by 3rd party.
Remote Access VPN
Remote access VPN gives remote and secure permission to individual such as long-distance workers, portable clients and other external customers
Zero Trust Network
The zero trust security models communicates that a client should simply have the entry and assents that they need to fulfil their work. This is a very surprising procedure from that given by standard security plans, as VPNs, that grant a client full induction to the objective association
Email Security
Email security suggests any cycles, things, and organizations expected to defend your email records and email content shielded from outside risks. Most email expert associations have certain email security features expected to keep you secure,
Data Loss Prevention
Data setback evasion is an internet based insurance method that joins advancement and best practices to thwart the transparency of sensitive information outside of an affiliation, especially coordinated data like eventually conspicuous information (PII) and consistence related data: HIPAA, SOX, PCI DSS, etc.
Assessment of Risks
This progression is thusly critical, as it emergencies the weaknesses. It is at this progression that network safety faculty should settle on the accompanying: How basic the vulnerabilities found; How pragmatic it could be for a programmer to take advantage of the weakness. Whether any current security controls could diminish the gamble?
Task 2: Network Vulnerability Scanning
Vulnerability Analysis Methods
For the most part, it is important to complete two unmistakable kinds of outputs:
Inner: This output is done from inside an association's edge protections. Design is to distinguish weaknesses could be taken advantage of by programmers who effectively enter the edge safeguards, or similarly by "insider dangers" like workers for hire or disappointed representatives.
Outer: This sweep is an outer output is completed from outside an association's organization, and its chief intention is to recognize weaknesses in the border guards like open ports in the organization firewall or specific web application firewall.
Then again, there are other two ways to deal with weakness filtering:
Verified Scans: In these sweeps, the analyser signs in as an organization client, and gives weakness scanners different special qualifications. Validated filters consider the scanner to straightforwardly get to organize based resources utilizing distant managerial conventions like secure shell (SSH) or far off work area convention (RDP) and confirm utilizing gave framework qualifications.
Unauthenticated checks: These sweeps look for shortcomings in the organization border and uncover weaknesses that can be gotten to without signing into the organization. Unauthenticated examines is a strategy that can bring about countless misleading up-sides and can't give nitty gritty data about the resources working framework and introduced programming.
Vulnerability the board cycle incorporates four stages:
• Recognizing evidence of shortcomings
• Evaluation of the bet introduced by any shortcomings perceived
• Treatment of any recognized shortcomings
• Giving insights about shortcomings and how they have been dealt with
• Unmistakable evidence of Vulnerabilities
A scanner's reasonability depends upon two things:
• The limit of the scanner to find and perceive devices, programming and open ports, and collect other structure data
• The ability to relate this data with known shortcoming information from somewhere around one shortcoming informational collections
There is a strong idea that shortcoming checks ought to be performed during business hours.
Scan Results
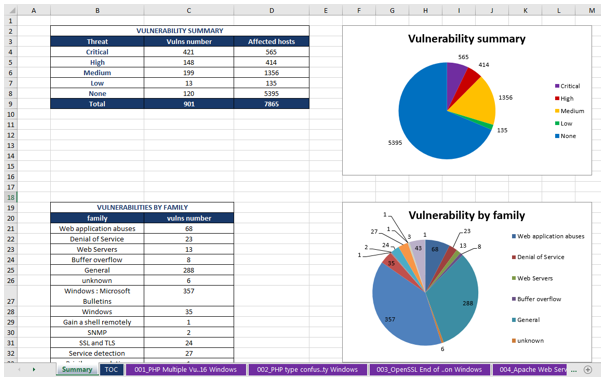
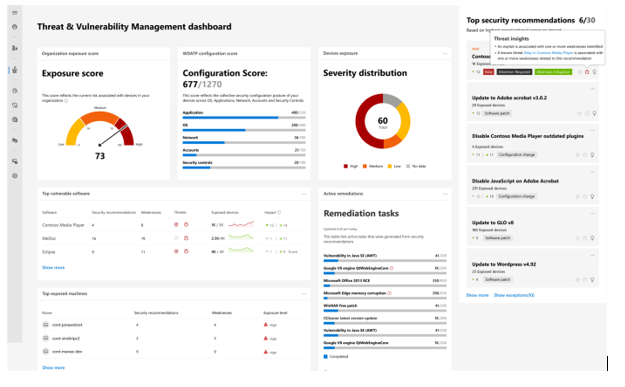
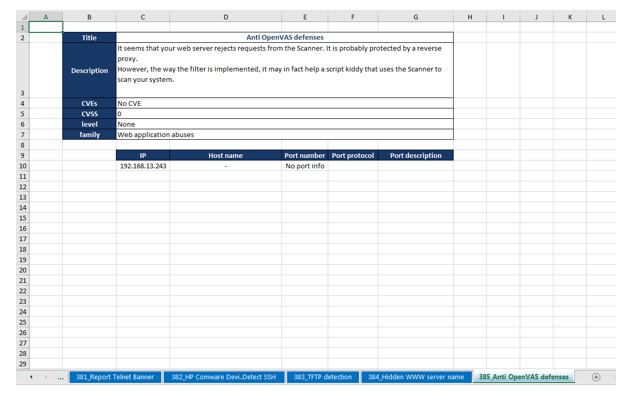
Conclusion
An assault vector is a way or means by which an attacker or developer can draw near enough to a PC or association server to convey a payload or malignant outcome. Attack vectors enable developers to exploit system shortcomings, including the human part.
Typical computerized attack vectors consolidate contaminations and malware, email associations, pages, spring up windows, texts (IMs), chat rooms and cheating. Except for confusion, these techniques incorporate programming or, in a few cases, hardware. Precariousness is the place where a human overseer is fooled into disposing of or incapacitating system assurances.
To some degree, firewalls and antivirus programming can discourage attack vectors. In any case, no confirmation technique is totally impervious to attack. A gatekeeper procedure can promptly become outdated, as developers are ceaselessly invigorating attack vectors and searching for new ones in their excursion to secure unapproved induction to PCs and servers. A security opening can be found in a piece of programming or in a PC working framework (OS). Once in a while, a security weakness can open up due to a programming mistake in an application or a defective security design. Hacks could in fact be low-tech, for example, acquiring a worker's security certifications or breaking into a structure.
Programmers are continually filtering organizations and people to recognize all potential passage focuses into frameworks, applications and organizations. At times, they might even objective actual offices or observe weak clients and inside workers who will purposely or coincidentally share their data innovation (IT) access certifications.
References
McClure, S., Scambray, J., and Kurtz, G. Hacking Exposed, Seventh Edition (McGraw-Hill Professional, 2012).
NIST SP 800-27 Rev A, Engineering Principles for Information Technology Security.
NIST SP 800-42, Guidelines on Network Security Testing.
NIST SP 800-64 Rev. A, Security Considerations in the Information System Development Life Cycle.
Richardson, R. 2010-2011 CSI Computer Crime and Security Survey (http://gocsi.com/survey).
Wood, C. Information Security Policies Made Easy, Version 11 (Information Shield, 2009).
RFC 2401 (1998) Security Architecture for the Internet Protocol, Kent, S., Atkinson, R.
Schneier, B. (1996) Applied Cryptography, 2nd edn, Wiley.
Stallings, W (1999) Cryptography and Network Security, Prentice Hall.
Stallings, W (2001) SNMP, SNMPv2, SNMPv3, and RMON 1 and 2, 3rd edn, Addison Wesley.
Ellis, J. and Speed, T. (2001) The Internet Security Guidebook, Academic Press.
ISO/IEC 17799 (2000) Information Technology – Code of Practice for Information Security Management , International Organization for Standardization.
Tanenbaum, A. S. (1996) Computer Networks, 3rd edn, Prentice Hall.
Assignment
MN623 Cyber Security and Analytics Assignment Sample
Assignment Brief
Assessment Title- Implementation and evaluation of penetration testing tools
Purpose of the assessment (with ULO Mapping)
This assignment assesses the following Unit Learning Outcomes; students should be able to demonstrate their achievements in them.
• Analyse cyber security vulnerabilities using ethical hacking methodologies.
Weight - 5%
Total Marks - 50 Marks
Word limit - 750 to 1000 words
Due Date Assignment 1- Week 3, 11:59 pm, 10/4/2022
Submission Guidelines
• Submit Assignment 1 in a word document in week3.
• All work must be submitted on Moodle by the due date
• The assignment must be in MS Word format, 1.5 spacing, 11-pt Calibri (Body) font and 2 cm margins on all four sides of your page with appropriate section headings.
• Reference sources must be cited in the text of the report and listed appropriately at the end in a reference list using IEEE Transactions on networking referencing style.
• Students must ensure before submission of final version of the assignment that the similarity percentage as computed by Turnitin must be less than 10% Assignments.
Purpose of Assignment
Assignment 1 is based on analysing cyber security vulnerabilities using ethical hacking methodologies and evaluating security testing tools. The students will explore skills in Ethical Hacking/Penetration testing by describing how weakness in the system can be exploited to hack a target system using security testing tools.
Assignment Structure and Submission Guidelines for Assignment Help
Assignment 1 is a formative assessment, and it focuses on the importance of penetration testing, industry leading tools used for penetration testing and a review of security testing tools. Students will be required to choose two security testing tools for further evaluation.
Assignment Tasks
1) Explain the different reasons and benefits of conducting penetration testing. (5 Marks)
2) What are some regulatory requirements for penetration testing? (5 Marks)
3) Present the industry leading tools used for penetration testing. (5 Marks)
4) Review three security testing tools. (10 Marks)
5) Choose two security testing tool and evaluate them. (10 Marks)
6) Describe how the two security testing tools can be used to exploit cyber security vulnerabilities and hack the system. (10 Marks)
7) References (5 Marks)
Solution
Implementation and evaluation of penetration testing tools
Introduction
Penetration testing even termed as pen testing or ethical hacking is a launch of intentional cyber-attacks that look towards vulnerabilities that is exploitable in the computer system, websites and other applications. The aim of the assignment is to focus on the utility of penetration testing, the leading tools in the industry that is used for it and the evaluation of such tools.
Different reasons and benefits of penetration testing
• Conformity to Industry Codes and Procedures - One of the most significant advantages of penetration testing is that it meets the legal and management requirements stated in business laws and standards such as FISMA, ISO 2700, PCI, and HIPAA. Pen-testing can establish how a hacker obtained sensitive information and intellectual goods [5]. Furthermore, if a corporation employs pen-testing for constant inspection and validation and ensure the privacy of credit card information.
• A Penetration reveals critical flaws - A Penetration test should be performed once a year to look for key vulnerabilities in IT assets. Various methods and technologies can test IT assets to detect which security flaws are in the system [3].
• Provide a prospect to fix vulnerabilities - Once a company has identified the vulnerabilities, security specialists can start repairing the significant problems in the networks and apps [3].
Some of the regulations that apply to penetration testing
• GDPR - The one rule that affects practically every organization. The GDPR addresses many areas of data security, but one of its many mandates is that businesses that manage private information strengthen cybersecurity and accountability. GDPR Article 32, in particular, requires firms to establish a "method for regularly testing, measuring and assessing the efficacy of technical and institutional safeguards for preserving data handling protection.
• ISO 27001- A member of the ISO/IEC set of guidelines is a global data security standard that defines a management structure for Security Management System (ISMS). Organizations must establish a suite of security protocols to prevent and resolve potential risks throughout their networking, and ensure they satisfy evolving safety needs account to get licensed.
• PCI DSS – This is a series of minimal rules created to aid businesses in safeguarding client card information. All businesses that accept or handle electronic card payments must conduct an annual PCI safety check to achieve compliance.
Industry-leading tools used for penetration testing
? Netsparker – This is a major web application for automated pen-testing. The program can catch everything, including cross-site programming to SQL injection. Programmers can use this tool on web pages, online services, and web applications.
? Wireshark - Wireshark is a network scanner that has 500 writers. Programmers can use this application to record and analyze data packets swiftly. The software is open and accessible, and it is useful for a range of computer systems, including Microsoft, Solaris, FreeBSD, and Unix [4].
? Metasploit - This assists pro players in verifying and monitoring security audits, bringing awareness, and arming and empowering attackers to keep up with the competition. It is beneficial for evaluating the safety and identifying faults, as well as for establishing a defense. The technology allows social engineers to recreate web pages [4].
Evaluation of the three security testing tools
• John The Ripper Password Cracker - Passwords are amongst the most common vulnerabilities. Username and passwords can be used by criminals to obtain identities and gain access to sensitive systems. John the Ripper should be a must tool for password protection and offers a variety of systems for this purpose [6].
• Aircrack – The tool is intended to break weaknesses in wireless connections by collecting data packets and transferring them via text files for study. This program is compatible with various operating systems, including windows, and supports WEP dos attacks. It outperforms most other penetrating tools in tracking performance and supports multiple devices and adapters.
• W3af - W3af web application exploitation and auditing modules are designed to detect security flaws in all web apps. There are three types of WordPress plugins: attacker, auditing, and detection [6]. The program then sends these to the audit tool, which checks for security concerns.
Selection of two security tools and assessment
W3af is a Web application security scanner and exploiting software. W3af is separated into two sections: the core and plugins. It delivers security vulnerability information for use in vulnerability scanning operations. The scanner has both a visual and a command-line interface. Fast HTTP queries, incorporation of web and proxies’ services into the script, injecting payloads into different kinds of HTTP requests, and so on are among its characteristics. It runs on Linux, Apple Mac OS X, and Microsoft Windows and has a command-line interface [2].
Aircrack-ng is a comprehensive set of criteria for assessing WiFi network cybersecurity. It includes a wide range of aspects of WiFi security: Attacking, Testing, Monitoring, and Cracking. All tools are command-line interface only, allowing for extensive programming. This functionality has been used by a large number of graphical user interfaces. It runs mostly on Linux and Windows, macOS, FreeBSD, OpenBSD, and Solaris. In hacking, developers can de-authenticate, create phony entry points, and launch replay assaults [1] [7]. To use AirCrack-ng correctly, programmers must catch certain packets, which must be acquired via the WiFi network adapter. Depending on whatever PC card developers have to install, guidelines for various cards and software are needed.
Utilization of the two security testing tools and the manner in which they exploit cyber security vulnerabilities
Aircrack is performed to demonstrate the existence of vulnerabilities and the potential damage that could be caused if these flaws were exploited. It also supports recording and injection, which is essential for evaluating network cards and their performance [1]. Furthermore, IT professionals can use it to assess the dependability of WPA-PSK and WEP keys. It also performs additional activities such as detecting fraudulent access points, evaluating controller capacities and WiFi cards, etc. Here's how AirCrack security testing tools could be used to attack cyber security flaws and hack the device.
On the other hand, W3af includes plugins that connect. For instance, in w3af, the identification plugin searches for various URLs to test for flaws and provides them to the auditing plugins, which further search for flaws. Through its Intuitive and Automatic requests generating features, it alleviates some of the hassles associated with manual web applications. It can also be set up to act as a MITM gateway. It also includes features for finding loopholes that it discovers. Here's how W3af security testing tools could be used to attack cyber security flaws and hack the device.
Conclusion
The aim of the assignment was to focus on the utility of penetration testing and the usage of the security tools in the industry. From the complete assignment it can be concluded that pen testing is a security exercise and have significant advantages. Moreover, security tools helps in combating the issues and attack security flaws. The selection of the same depends on the user.
References
[1]. G. Kaur and N. Kaur, "Penetration Testing - Reconnaissance with NMAP Tool," International Journal of Advanced Research in Computer Science, vol. 8, (3), 2017. Available: https://www.proquest.com/scholarly-journals/penetration-testing-reconnaissance-with-nmap-tool/docview/1901458135/se-2?accountid=30552.
[2]. J. D. Kramer and T. J. Wagner U.S.A.F., "DEVELOPMENTAL TEST and REQUIREMENTS: Best Practices of Successful INFORMATION SYSTEMS USING AGILE METHODS," Defense AR Journal, vol. 26, (2), pp. 128-150, 2019. Available: https://www.proquest.com/scholarly-journals/developmental-test-requirements-best-practices/docview/2214889819/se-2?accountid=30552. DOI: http://dx.doi.org/10.22594/dau.19-819.26.02.
[3] J. V. Olson, "Software Validation: Can an FDA-Regulated Company Use Automated Testing Tools?" Journal of Validation Technology, vol. 18, (3), pp. 49-51, 2012. Available: https://www.proquest.com/scholarly-journals/software-validation-can-fda-regulated-company-use/docview/1055111478/se-2?accountid=30552.
[4]. S. Zhou et al, "Autonomous Penetration Testing Based on Improved Deep Q-Network," Applied Sciences, vol. 11, (19), pp. 8823, 2021. Available: https://www.proquest.com/scholarly-journals/autonomous-penetration-testing-based-on-improved/docview/2580965017/se-2. DOI: http://dx.doi.org/10.3390/app11198823.
[5]. T. M. Chen, "Reinforcement Learning for Efficient Network Penetration Testing," Information, vol. 11, (1), pp. 6, 2020. Available: https://www.proquest.com/scholarly-journals/reinforcement-learning-efficient-network/docview/2548413764/se-2. DOI: http://dx.doi.org/10.3390/info11010006.
[6]. X. C. Li, D. Farson and R. Richardson, "Weld penetration control system design and testing," J. Manuf. Syst., vol. 19, (6), pp. 383-392, 2000. Available: https://www.proquest.com/scholarly-journals/weld-penetration-control-system-design-testing/docview/197657176/se-2?accountid=30552.
[7]. Z. Ren et al, "Study on practical voltage secondary loop testing tool," IOP Conference Series.Earth and Environmental Science, vol. 354, (1), 2019. Available: https://www.proquest.com/scholarly-journals/study-on-practical-voltage-secondary-loop-testing/docview/2558041287/se-2. DOI: http://dx.doi.org/10.1088/1755-1315/354/1/012090.
Programming
MITS4002 Object Oriented Software Development Assignment Sample
This assessment item relates to the unit learning outcomes as in the unit descriptors. This checks your understanding about object-oriented software development. This assessment covers the following LOs. LO1 Demonstrate understanding of classes, constructors, objects, data types and instantiation; Convert data types using wrapper methods and objects. LO2 Independently analyse customer requirements and design object-oriented programs using scope, inheritance, and other design techniques; Create classes and objects that access variables and modifier keywords. Develop methods using parameters and return values. LO3 Demonstrate adaptability in building control and loop structures in an object-oriented environment; Demonstrate use of user defined data structures and array manipulation
Project: Comparing Loans
Problem Description:
Write a program that lets the user enter the loan amount and loan period in number of years and displays the monthly and total payments for each interest rate starting from 5% to 8%, with an increment of 1/8. Here is a sample run:
<Output>
Loan Amount: 10000

Design: (Describe the major steps for solving the problem.)
Coding: (Copy and Paste Source Code here. Format your code using Courier 10pts)
Output screenshot: (Paste your output screenshot here)
Testing: (Describe how you test this program)
Submit the following items for assignment help
1. Submit this Word document with solution via LMS (you must submit the program regardless of whether it complete or incomplete, correct or incorrect)
Hint:
1. Can you get the first four rows manually? This will help you understand how to compute the numbers mathematically.
2. Can you write a program to produce the first four rows? This will help you see the pattern.
3. Can you generalize it in a loop to produce all the rows?
4. Finally, format the output correctly.
Solution
Program Design
Step-1 START
Step-2 Initialize required variables
Step-3 Initialize rate = 5%
Step-4 User input: loan amount into amt
Step-5 User input: time in years into yrs
Step-6 If amt or yrs <= 0, print error message and GOTO step 15
Step-7 Set r = rate as backup
Step-8 Display header labels
Step-9 While value of rate < = 8, GOTO steps 10, else GOTO step 15
Step-10 Set rate = r/(100*12) for monthly rate calculation
Step-11 Calculate monthlyPayment as per formula
Step-12 Calculate totalPayment as per formula monthlyPayment*12*yrs
Step-13 Display r, monthlyPayment and totalPayments
Step-14 Increase r by 0.125 and GOTO step-9
Step-15 STOP
Coding

Output Screenshot
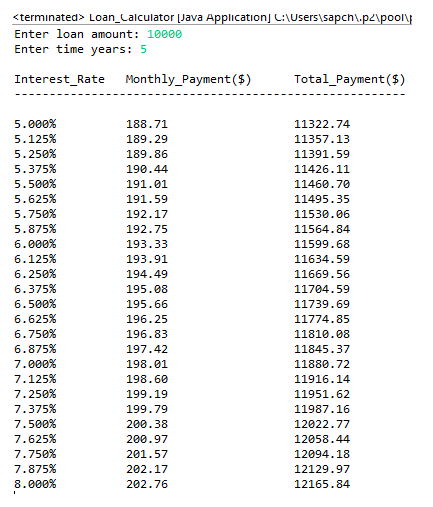
Testing
The testing phase of the program was carried out at the very end. At first, the sample data provided with the assignment sample was tested with the same set of inputs. Then, random data was entered to test the output, which was then tallied against the output of trustworthy online Loan Calculators found online.
Firstly, the code was tested against erroneous inputs like negative values for amount and years, or if the user enters 0 for these variables.

Finally, on successfully testing for at least 3-4 sets of data, the testing phase was concluded to be a success. Some screenshots of testing results are presented below.

Research
DASE201 Data Security Assignment Sample
Assignment Brief
Length/Duration: 1000 words report (+/- 10%)
Unit Learning Outcomes addressed:
• Identify vulnerabilities for data security threat.
• Examine methods to prevent cyber-attack defences, IDS and IPS.
• Compare framework of cyber security, safety principles and guidelines of various tools to enforce data security and privacy.
• Critique the mechanisms and prominent techniques to tackle sophisticated ICT attacks.
Submission Date: Week 11
Assessment Task: Group written report
Total Mark: 20 Marks
Weighting: 20%
Students are advised that submission of an Assessment Task past the due date without a formally signed approved Assignment Extension Form (Kent Website My Kent Student Link> FORM – Assignment Extension Application Form – Student Login Required) or previously approved application for other extenuating circumstances impacting course of study, incurs a 5% penalty per calendar day, calculated by deduction from the total mark.
ASSESSMENT DESCRIPTION:
Identify two of the biggest data breaches from 2020 for assignment help and explain the vulnerabilities that lead to the attacker gaining access to the data. Also propose techniques that practices that could have helped prevented this data breach.
This is a group task with groups of 3 students
ASSESSMENT SUBMISSION:
Part 1. Group Report
This is a group activity and students are required to work with their respective group members. No individual submission will be accepted. You have to nominate someone as your group leader to coordinate the assignment submission. The report should be submitted online in Moodle by one member of the team ONLY (Group Leader) on Sunday Week 11.
You will not receive any marks for this assignment if your group members collectively report against you for non- participation or non-cooperation
GENERAL NOTES FOR ASSESSMENT TASKS
Content for Assessment Task papers should incorporate a formal introduction, main points and conclusion. Appropriate academic writing and referencing are inevitable academic skills that you must develop and demonstrate in work being presented for assessment. The content of high quality work presented by a student must be fully referenced within-text citations and a Reference List at the end. Kent strongly recommends you refer to the Academic Learning Support Workshops materials available on the Kent Learning Management System
GENERAL NOTES FOR REFERENCING
References are assessed for their quality. Students should draw on quality academic sources, such as booKs, chapters from edited booKs, journals etc. The textbooK for the Unit of study can be used as a reference, but not the Lecturer Notes. The Assessor will want to see evidence that a student is capable of conducting their own research. Also, in order to help Assessors determine a student’s understanding of the worK they cite, all in-text references (not just direct quotes) must include the specific page number(s) if shown in the original. Before preparing your Assessment TasK or own contribution, please review this ‘YouTube’ video (Avoiding Plagiarism through Referencing) by clicKing on the following linK: linK:http://moodle.Kent.edu.au/Kentmoodle/mod/folder/view.php?id=3606
A search for peer-reviewed journal articles may also assist students. These type of journal articles can be located in the online journal databases and can be accessed from the Kent Library homepage. WiKipedia, online dictionaries and online encyclopaedias are acceptable as a starting point to gain Knowledge about a topic, but should not be over-used – these should constitute no more than 10% of your total list of references/sources.
Solution
Introduction
Data security is the way of protecting organisational data and digital information from destructive forces and unwanted actions like hacking, cyber-attacks, and data breaches. Data security includes hashing, encryption, and transmission of data over a secured line (Industry2018, p. 58). In this report, two biggest data breaches are identified from 2020 and the vulnerabilities that lead to the attacker gaining access to the data has been identified. The report also talks about techniques of preventing data breaches.
Identifying the data breaches from 2020
There are two biggest data breaches identified in 2020 for Microsoft and MGM resorts.
In January 2020, Microsoft has admitted that an internal customer support database has been accidentally exposed online. Through this statement, Microsoft indirectly meant that the customer records of 250 million people spanning for 14 years has been exposed online without any password protection. A security researcher reported Microsoft about the breach when he found the database online. However, Microsoft did not take the blame on itself and said that it was a fault of misconfigured Azure security rules that was deployed in the company on 5th of December 2019. In the next year, data breach happened where email address, IP addresses of the customers, and other sensitive details like bank account number and password were exposed. This security failure made customers less confident about using Microsoft products which resulted in huge loss for the company(Bertino 2016, pp. 1-3).
In February 2020, data researchers discovered that someone in a hacking forum leaked MGM Resort hotel’s personal information about more than 10.6 million guests. The organisation was reported about this incident where it was mentioned that the formers guest list including Justin Bieber, Twitter CEO Jack Dorsey and several government officials are leaked on the internet (Palmatierand Martin 2019, pp. 133-151). The very same day, it is reported that the information started appearing in several hacking forums that are viewed publicly. In July of 2020, the data was put on sale at a bargain price of $2,900. This became a huge blow for the company in the hotel industry as customer lost interest and trust in the group. MGM suffered in maintaining reputation and stayed out of limelight after the incident.
Identifying vulnerabilities for data security threat
In the case of Microsoft’s data breach, malware and misconfigured Azure security rules are responsible. The data was breached because of the rules and standards used by Azure security that were not reliable for the company. Malware is a code or file delivered typically over a network that explores, infects, conducts, or steals any behaviours an attacker desire virtually when they get the database not protected well (Kumar,et al. 2018, pp.691-697).
In the case of MGM resort’s data breach, the attackers attempt for tricking the employee within a victim company into downloading malware or into revealing account credentials and confidential data within a phishing attack. The Internet of Things surrounds several smart devices including printers, coffee makers, and other machines (Parn and Edwards2019). The problems with those devices are that those is hijacked by attackers for forming slaved network of compromised devices for carrying out attacks further (Bertino 2016, pp. 1-3).
Methods of Cyber-attack defences, IDs and IPS
There are several methods by which defence against the cyber-attacks are possible. In the case of Microsoft, the use of Intrusion Prevention or Detection Systems (IDS/IPS) are recommended as ethical methods. IDS helps in sending alerts to the company when there is a malicious traffic network detected in the company’s server. As Microsoft was not aware of the attack until it is reported by a data researcher, it is important to develop IDS and IPS systems. In the case of MGM Resorts hotels, there is a need of using a flexible method as it protects data of celebrities and government officials. For MGM, 24*7 network monitoring is needed on the server of the company. The possible method is to change the privacy setting from time to time and keep the firewalls up to date. The software applications used by this hospitality business needs to be updated with upgradation of the operating system. In this way, any vulnerability in the network or the computing devices can be identified easily (Kumar et al. 2018, pp.691-697).
Compare framework of cyber security, safety principles and guidelines of various tools to enforce data security and privacy
There are three top-rated cybersecurity frameworks that can be used to use various tools to enforce data security and privacy. The first one is the US National Institute of Standards and Technology (NIST) Framework that helps in improving critical cybersecurity structure. The Centre for Internet Security Critical Security Control (CIS) helps in establishing safety rules for the companies. The International Standards Organisation (ISO) frameworks ISO/IEC 27001 and 27002 can be applied for data breaches. The NIST is far better for Microsoft’s data handling as it is an IT company and needs proper corporate infrastructure to handle the problems. While comparing it to the other two standards, it can be said that CIS can be used for MGM Resorts as it needs to keep cyber laws in mind(Industry 2018, p.58).
Critique the mechanisms and prominent techniques to tackle sophisticated ICT attacks
For both Microsoft and MGM Resorts, handling data security is an important organisational task. There are several tools and techniques and mechanisms that can be used to handle the data legally and ethically. Anti-malware tools are a type of software of network security developed for identifying harmful programs and preventing them from spreading. Network anomaly Detection Engine permits in analysing the network, so whenever breaches happen, it will alert quickly. Application security assists the companies in establishing the parameters of security for any applications, which is related to the network security. Data Loss Prevention policies and technologies assist in protecting employees from compromising and mis-utilising confidential data. Firewalls are utilized in managing network traffic, permitting authorized traffic during blocking access to non-authorized traffic. Web security assists in preventing web-based threat from utilizing browsers as an access point for getting into the network (Palmatier and Martin 2019, pp. 133-151).
Conclusion
The data security can be handled by Virtual Private Network tool which is utilized in authenticating communication among an endpoint device and secure networks by creating an encrypted line in handling the data breaches in companies like Microsoft and MGM. The vulnerabilities are also identified and mitigated the risk.
A few recommendations can be made in this case:
1- The companies should adopt to monitoring technologies for the detection of security threats at a priority.
2- The use of IDS should be implemented compulsorily in every company.
References
Bertino, E., 2016, March. Data Security and Privacy in the IoT. In EDBT (Vol. 2016, pp. 1-3).https://www.cs.purdue.edu/homes/bertino/paper-a.pdf0.pdf
Industry, P.C., 2018. Data security standard. Requirements and Security Assessment version, 3, p.58.https://www.mastercard.us/en-us.html
Kumar, P.R., Raj, P.H. and Jelciana, P., 2018. Exploring data security issues and solutions in cloud computing. Procedia Computer Science, 125, pp.691-697.https://doi.org/10.1016/j.procs.2017.12.089
Palmatier, R.W. and Martin, K.D., 2019. Understanding and valuing customer data. In The Intelligent Marketer’s Guide to Data Privacy (pp. 133-151). Palgrave Macmillan, Cham.https://link.springer.com/chapter/10.1007/978-3-030-03724-6_7
Parn, E.A. and Edwards, D., 2019. Cyber threats confronting the digital built environment: Common data environment vulnerabilities and block chain deterrence. Engineering, Construction and Architectural Management.https://www.emerald.com/insight/content/doi/10.1108/ECAM-03-2018-0101/full/html
Dissertation
Data science and Analytics Assignment Sample
Project Title - Investigating multiple imputations to handle missing data
Background: Multiple imputations are a commonly used approach to deal with missing values. In this approach an imputer repeatedly imputes the missing values by taking draws from the posterior predictive distribution for the missing values conditional on the observed values, and releases these completed data sets to analysts. With each completed data set the analyst performs the analysis of interest, treating the data as if it were fully observed. These analyses are then combined with standard combining rules, allowing the analyst to make appropriate inferences that incorporate the uncertainty present due to the missing data. In order to preserve the statistical properties present in the data, the imputer must use a plausible distribution to generate the imputed values. This can be challenging in many applications.
Objectives: The project will implement this approach and investigate its performance. Depending upon the student’s interest the project could include some of the following objectives:
1. Comparing multiple imputations with other approaches to deal with missing data in the literature.
2. Exploring the effect of Not Missing at Random data on inferences obtained from Multiple Imputation.
3. Explore the effect of a Missing at Random mechanism that is non-ignorable when using Multiple Imputation.
Approach: The project will illustrate performance of the methods being investigated through simulations to begin with. The methods could also potentially be applied to a data set measuring the survival times of patients after undergoing a kidney transplant or a relevant data set available from an online public repository.
Deliverables:
The main deliverable will be providing recommendations from the investigation of the area well as any indicating any limitations identified with the approach being considered. This will be evidenced with illustrations given through simulations as well as potentially using a real data example as well.
Key computing skills:
Knowledge of R or an equivalent programming language such as Python would be required. Knowledge of statistical computational techniques such as Monte Carlo Methods would be desirable.
Other key student competencies for assignments help
Knowledge of fundamental concepts of Statistical Inference and Modelling. An appreciation of Bayesian inference and methods would also be desirable.
Data availability:
Any data set we consider will be available to download from an online public repository such as the UK Data Service or made available to student via the Supervisor.
Any other comments:
Little RJA and Rubin DB (2002), Statistical Analysis with Missing data, Second Edition.
Instruction
1. Size limit of 10,000 words (excluding preamble, references, and appendices). Anything beyond this will not be read. In general, clear and concise writing will be rewarded.
2. Must include an Executive Summary (max 3 pages), which should be understandable by a non-specialist, explaining the problem(s) investigated, what you did and what you found, and what conclusions were drawn.
Written thesis
1. Times New Roman font size 12, with justification, should be used with 1.5 line spacing throughout. Pages should be numbered. Section headings and sub-headings should be numbered, and may be of a larger font size.
2. For references the Harvard scheme is preferred, e.g. Smith and Jones (2017)
3. Any appendices must be numbered
Solution
INVESTIGATING MULTIPLE IMPUTATIONS TO HANDLE MISSING DATA
Chapter 1: Introduction
1.1 Introduction
Multiple Imputation (MI) is referred to as a process that helps to complete missing research data. It is an effective way to deal with nonresponse bias and it can be taken into action when people fail to respond to a survey. Tools like ANOVA or T-Test make it easier for analysts to perform Multiple Imputations and retrieve missing data. It is also beneficial for extracting all sorts of data and leads to experimental design (Brady et al. 2015, p.2). However, the process of using single values raises questions regarding uncertainty about the values that need to be imputed; Multiple Imputation helps by narrowing the uncertainties about the missing values by calculating various different options. In this process, various versions of the same data set are created and combined in order to make the best values.
1.2 Background of the study
A multiple Imputation is a common approach made towards the missing data problem. The data analysis can only be possible if accurate information is procured (Alruhaymi and Kim, 2021, p.478). This process is commonly used in order to create some of the different imputed datasets that aim to properly combine results gained from each of the datasets. There are different stages involved in the process of Multiple Imputing in order to retrieve and fill in missing data. The primary stage is to create more than one copy of a particular dataset. Apart from that, there are different methods and stages that are involved in the actual process that determines the way of calculating missing data in a particular place by replacing the missing values with imputed values.
Gönülal, (2019, p.2) in his research paper “Missing Data Management Practices” pointed out that Multiple Imputation has the potential of improving the whole validity of research work. It requires a model of the distribution of each and every variable with their respective missing values from the user, in terms of the observed data. Gönülal has also said that Multiple Imputation might not be used as a complementary technique every time. It can be applied by specialists in order to obtain possible statistics.
1.3 background of the research
Managing and dealing with missing data is one of the biggest concerns that a company needs to manage whenever the overall management of the workforce is being managed by the company and its employees. Though the effectiveness of implementing an appropriate business and workplace model in practices missing data or data thief can lower its efficiency and effect6ivenes all over the workplaces. This also develops lots of difficulties regards with the elimination of personal biases where it becomes really difficult for the managers of business firms in acquiring an adequate research result. ITS or an interrupted time series are vastly utilized by hierarchies in business firms where they are capable of evaluating the potential effect of investigation over time due to utilization of real and long-term data. Both learnings on statistical analysis and missing data management can be beneficial for this type of sector where there is a balance among both population levels adapt and individual levels data (Bazo-Alvarez et al. 2021,m p.603). The non-responsive and unprocessed data mainly gets missed whenever the company deals with an activity it has been dealing with for a long time. Saving data in a systematic way requires a proper understanding of the ways data is being selectively simplified by effective deals. Gathering data, data analysis, and storing requires a proper understanding of the ways data can be managed in an organization.
As per the study of Izoninet al. (2021, p. 749), it can be said that managing and controlling missing data is amongst the most popular trends in this market. These are also considered smart systems which are utilized by large business firms which can help them in managing their assets, resources, and personal and professional business data. By mitigating missing data processes a huge number of business firms can be benefitted due to their ability in managing assets and conclude their tasks within the scheduled team. Different tools that are being used in research help to identify the missing data which has a great impact on the topic. Multiple imputations are one of the most crucial processes that help to gather or recover the data that are being used for a long time. Missing data needs to be recovering in selective time otherwise the data and its sources get lost in the wild cloud system (Haensch, 2021, p.111).
Developing a process by using different tools like ANOVA or t-test help to analyze the ways missing data got lost and also help to retrieve the missing data by maintaining a format is a process (Garciarena and Santana, 2017, p.65). Non-trivial methods to procure missing values are often adopted for using sophisticated algorithms. Known values are used to retrieve missing values from the database. This particular discussion on understanding the way huge data in cloud storage systems got lost and the ways this particular data that is highly needed for any company are retried are mentioned and elaborated in this study. Different data needs to be managed by the proper Data collection format and data storing systems. The proposed format of the research comprises different parts that have active involvement while providing a critical understanding of the missing data and data protection activities. The selected structure is being mentioned in the overall discussion that is maintained by the researcher while developing the research. In some cases, the data involves the process of critical information saving which got lost sometimes and for that using multiple inputting services the retrieve data and filling of lost data by using some other ones are also used and important ones. Also, this research provides a briefing about the "Missing Data Management Practice" which has an effective impact on the organizational function related to data safety and data security (Garciarena and Santana, 2017, p.65). Data security and data security-related other functions need a proper understanding of the ways the overall function of missing data-keeping targets are managed by the general approach of multiple imputations to serve the commonly used statistical understanding of the data. The uncertainty of the data and its combining results that are obtained from the critical understanding that helps to evaluate the representativeness of bias data packages are related to the values of the missing data. Missing information, different cases, statistical packages, and other things provide the knowledge which is related to the overall activity that is given importance by the organization and its other functions (Krause et al. 2020, p.112).
1.4 Problem statement
Missing data creates severe problems that eventually create a backlog for the organization or institute. The main problem of missing data and handling the exact ways of recovering those missing data presents the critical scenario of data management. The absence of data develops critical situations while dealing with research for a project because even the null hypothesis gets rejected while developing a test that has no such statistical power because of the missing data. The estimated parameters of the research outcome can cause biased outcomes because the data that are missing and also the misleading data from different sectors lower the task force as well. Also, the representative approach of the data samples got ruined by the missing one.
1.5 Rationale
The preliminary issue raised in this research is the implementation of Multiple Imputations in order to handle missing data.
This is an issue because it is an effective and helpful technique that helps in filling in missing data. Most of the time, important surveys are left incomplete because of less response from the people. Multiple Imputation helps in completing the surveys by gathering all the needed data after performing analysis of the whole data set (Grund et al. 2018, p.113).
It is an issue now because nowadays people are becoming ignorant about questionnaires and online surveys which is impacting the ultimate result of the survey. This method can help the completion of the surveys by filling in the missing data after replacing the missing data with imputed data.
This research can help in finding the best tools for performing Multiple Imputation methods to handle missing data.
1.6 Aim of the research
Aim
The primary aim of the research is to investigate Multiple Imputations in order to handle missing data.
1.7 Objectives of the research
Objectives
The main objectives of this research are:
? To investigate the factors that contribute to the process of Multiple Imputation that helps in handling missing data.
? To measure the capabilities of Multiple Imputations in handling missing data.
? To identify the challenges faced by the analysts while performing different Multiple Imputation techniques to fill in missing data.
? To identify the recommended strategy for mitigating the challenges faced while performing different Multiple Imputation techniques to fill in missing data.
1.8 Questions of the research
Question 1: what are the exact ways that help to contribute to the process of multiple imputations in order to handle the missing data in a systematic way?
Question 2: What are the exact ways that help to measure the capabilities of multiple imputations while handling different missing data?
Question 3: What exact challenges do the analysts face while mitigating data gaps by using multiple imputations techniques of filling the missing data?
Question 4: what are the exact recommended strategies that are provided for mitigating the challenges faced while performing different multiple imputation techniques to fill in missing data?
1.9 Proposed structure of the dissertation
1.10 Summary
This discussion comprises the overall concept of using multiple imputation techniques for retrieving missing data and restructuring is critically analyzed and mentioned for better understanding. The ways different data that have got lost somehow and still exist in the cloud bases of the data folder can be retrieved is the basic function of multiple imputations which is also mentioned in the discussion. The overall concept of the multiple imputations helps to reduce the place of losing data and keeping that data intact with the exact process for an organization are elaborately described in this study. In the above-discussed section, the complex multiple imputations which are used as a secondary tool for data analysis purposes are mentioned with integrity and transparency.
Chapter 2 Literature Review
2.1 Introduction
Multiple imputation is a process of managing data that are missing. The management of data can reduce the risks of losing a project for an organization or an institute. Through the differences in the data sets, the operational process of multiple imputations became complicated. Through this chapter, the researcher is going to describe the concept of multiple imputation processes in tackling missing data. A secondary tool of data analysis helps the researcher to gather all the information on the above-mentioned research topic. There is no scope of denying the fact that this chapter is one of the crucial parts of research as it works with the information of previous researchers on the same research topic. Through the analysis of the data of past researches, the possibility to complete research became possible.
A literature review helps the researcher to analyze the research topic from several sides. The characteristics of multiple imputation processes are going to be described in this chapter of the research. The areas that the process of multiple imputations covers have been described in this chapter. This chapter also consists of the negative as well as the positive impact of multiple imputation processes in managing missing data. This is one of the important chapters of research that provides information about the overall concept of the research.
2.2 Conceptual Framework
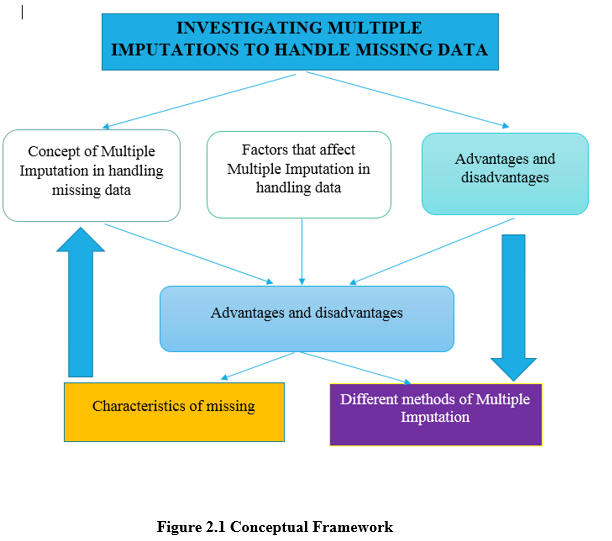
2.3 Concept of Multiple Imputation in handling missing data
Handling missing data is a quintessential aspect of analyzing bulk data and extracting results from it. It is a complex and difficult task to pull off for the professionals in this field. While optimizing the missing data and trying to retrieve it, professionals need to use effective strategies and technologies that can help them retrieve the lost or missing data and complete the overall report. Multiple Imputation is considered to be a straightforward procedure for handling and retrieving missing data. The common feature of Multiple Imputation was to prepare and convince these types of approaches in separate stages(Bazo-Alvarez et al. 2017, p.157). The first stage involves a data disseminator which calculatingly creates small numbers of the present dataset by filling in the lost or missing values with the collected samples from the imputation model. In the second stage data, analysts perform the computation process of their dataset by estimating it and combining it using simple methods in order to get pooled estimation of the dataset and the standard errors in the whole dataset.
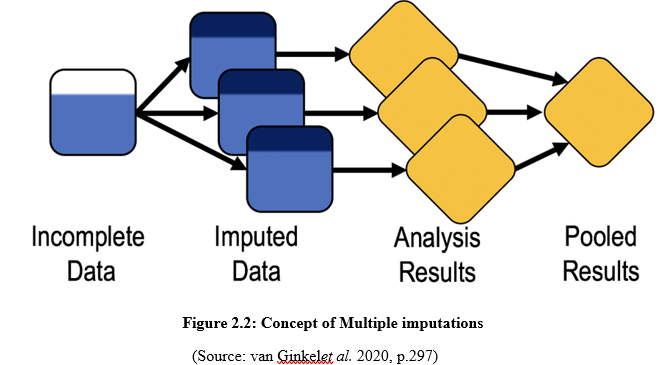
The process of Multiple Imputations was initially developed by statistical agencies and different data disseminators that provide several imputed datasets for repairing the problems and inconsistency in the dataset. MI can offer plenty of advantages to data analysts while handling or filling in missing data. Multiple Imputations replace the values of the missing sales with relevant data by analyzing the whole dataset and helps surveyors to complete a survey. The information filled in by the MI method is fully based on the information of the observed dataset. This process generates efficient inferences and provides unbiased and potentially realistic distribution of the missing data. The working structure of Multiple Imputation follows a series of steps which involves fitting the data into an appropriate model, estimating a missing point of the collected data, and then it repeats the first and the second step in order to fill in the missing values. After that, the process performs data analysis using T-Test or ANOVA which runs across all the missing data points (Nissen et al. 2019, p.20). Finally, it averages the values of the estimated parameters or standard errors acquired from the data model in order to provide a single-point estimation for the model. Sometimes calculating or approximating the missing values in a dataset is dynamic and surprisingly complex. In this scenario, MI involves two of the most competent and efficient methods to analyze the dataset. Those methods are Bayesian analysis and Resampling Methods. Nowadays data analysts use relevant computer software in order to fill in missing data by performing the Multiple Imputation process.
2.4: Different types of Multiple Imputation
Multiple Imputations is a simulation-based technique that helps in handling missing data. It has three different steps which involve the Imputation step, Completed-data analysis or estimation step, and pooling step. The imputation step generally represents one or multiple sets of plausible values for missing data (Nissen et al. 2019, p.24). While using the techniques of multiple imputations, the values that are missing are primarily identified and then a random plausible value replaces it with a sample of imputations. In the step of completed data analysis, the analysis is generally performed separately for each and every data set that is generated in the imputation step. Lastly, the pooling step involves the combination of completed data analyses. On the other hand, there are different types of Multiple Imputation in handling missing data. The three basic types of Multiple Imputation are Single Variable Regression Analysis, Monotonic Imputation, Markov Chain Monte Carlo (MCMC), or the Chained Equation method.

Single Variable Regression Analysis
The Single Variable Regression Analysis involves some dependent variables. It also uses a stratification variable for randomization. While using a dependent variable continuously, a base value of the dependent variable can be comprised in the process.
Monotonic Imputation
Monotonic Imputation can be generated by specifically mentioning the sequence of univariate methods. Then it gets followed by drawing sequentially synthetic observations under each and every method.
Markov Chain Monte Carlo or Chained Equation method
The basic process of Markov Chain Monte Carlo (MCMC) methods comprises a class of algorithms in order to sample from a profitability distribution. One can easily obtain a sample of the expected distribution by recording the different states from the chain (Stavsethet al. 2019, p.205). MCMC also has the expected distribution as its equilibrium distribution.
2.5: Factors that affect Multiple Imputation in handling data
Multiple imputation is a process that helps in managing data sets through missing values. The multiple imputation process works by providing a single value to every missing value through the set of plausible values. Single variable regression analysis, monotonous imputation, MCMC as well as Chained Equations are the factors that affect multiple imputation processes in managing missing data (van Ginkel et al. 2020, p.305). Multiple imputations are a process or technique that no doubt works by covering several areas to manage missing data. There are several steps like imputation, estimation and lastly pooling step in this data protection process. The process of collecting as well as saving data through the multiple imputation process is complicated as well as difficult. With the differences in the types of data, the process of managing missing data became difficult. The performance of the steps of multiple imputation processes is also different as all of them cover different kinds of data sets.
2.6: Advantages and disadvantages of using Multiple Imputation to handle missing data
Handling missing data is dynamic and complex yet an important task for surveys where some of the datasets are incomplete due to missing values. In those scenarios, data analysts use Multiple Imputation as an unbiased and efficient process in order to calculate the missing values and fill in those values properly in place. The process of Multiple Imputation expands the potential possibilities of various analyses that involve complicated models and will not converge given unbalanced data due to missingness (Stavsethet al. 2019, p.12). In such situations, the involved algorithms cannot estimate the parameters that are already involved in the process. These problems can be mitigated through Multiple Imputations as it can impute missing data by estimating the balanced data set and by doing an average of the parameters involved with it.
Multiple Imputations also create new avenues of analysis without collecting any further data, which eventually is a benefit for the process of imputation. Sometimes data analysts may determine their process of pursuing their objectives about handling missing data. Especially in complex and complicated datasets, performing imputations can be expensive. In this case, multiple imputation methods appear as a cost-beneficial procedure to handle missing data. As it is an unbiased process, it restricts unnecessary processes from entering the analysis (Takahashi, 2017, p.21). This also appears as a potential advantage of using Multiple Imputations. Apart from that, it provides an improved validity of the tests which eventually improves the accuracy of the results of the survey. Multiple Imputations is considered to be a precise process that indicates how different measurements are close to each other.
Although Multiple Imputation is an efficient process that helps in filling in missing values, it also has some drawbacks that can appear as potential problems for the researchers who are dealing with data. Initially, the problem begins while choosing the exact imputation method for handling missing data. Multiple Imputation is an extensive process that involves constant working with the imputed values, in some ways the process of working sometimes misbalances the congruence of the imputation method. Also, the accuracy of Multiple Imputations sometimes relies on the type of missing data in a project (Sim et al. 2019, p.17). Different types of missing data require different types of imputation and in this case, Multiple Imputation sometimes finds it difficult to compute the dataset and extract proper results out of it. Additionally, Multiple Imputations follow the dependent variables and those missing values consist of auxiliary values which are not identified. In this scenario, the complete analysis can be used as a primary analysis and there are no specific methods that can be used to handle missing data. But in this case, using multiple imputations can cause standard errors and it may increase these errors in the result as it encounters uncertainty introduced by the process of Multiple Imputation.
Multiple Imputations can have some effective advantages in filling in the missing data in a survey if used currently. Some advantages of Multiple Imputation (MI) are:
? It reduces the bias which eventually restricts unnecessary creeps from entering into an analysis.
? It improves the validity of a test which simply improves the accuracy of measuring the desired result of a survey. It is more appropriate while creating a test or questionnaire for a survey. It helps in addressing the specific ground of the survey which ultimately generates proper and effective results.
? MI also increases precision. Precision refers to the process which indicates how close two or more measurements are from each other. It provides the desired accuracy in the result by increasing precision in a survey.
? Multiple Imputations also result in robust statistics which outlines the extreme high or extreme low points of data. These statistics are also resistant to the outliers.
2.7: Challenges of Multiple Imputation process
There may be several challenges of multiple imputations at the time of handling missing data like-
Handling of different volumes of data
The operational process of the multiple imputation process is difficult as it works with the handling of missing data. The process of storing data that are in the database is simple, however, the possibility to recollect missing data is complicated. The process of multiple imputations takes the responsibility to complete a data set by managing as well as making plans related to the restoration process of missing data (Murray 2018, p.150). MI can work in several manners, moreover, it can be said that data argumentation is one of the most important parts of MI in controlling the loss of data. The operational process of multiple imputations is based on two individual equipment such as bayesian analysis and at the same time resampling analysis. Both methods are beneficial in managing the loss of data.
Time management
The challenge that multiple imputation processes face is related to the management of data sets no doubt. There may be the cause of missing a huge amount of data which creates a challenge for multiple imputations to complete the data set in minimum time. Moreover, this can be said that the multi-item scale of data makes the restoration process more complicated. Multiple imputations most of the time affect existing knowledge. Sometimes the restoration process takes a huge time which can cause the loss of a project. The amount of data matters at the time of collection of restoring data no doubt (Leyratet al. 2019, p.11). A small amount of missing data can be gathered at any time when a large amount of data takes much time to be restored. Though there are many advantages of multiple imputations, there is no scope of denying the fact that this process of missing data management is challenging at the time of its implementation.
Selection of the methods to manage missing data
The selection of the process of recollecting the data is also challenging as the management of the data set depends on the restoration of the same data that existed before. The selection method of the data restoration process depends on the quality of the data that are missing.
Different types of missing data
While considering the impact of missing data on a survey, the researchers should crucially consider the underlying reasons behind the missing data. In order to handle the missing data, they can be categorized into three different groups. These groups are Missing Completely At Random (MACR), missing At Random (MAR), and Missing Not At Random (MNAR). In the case of MACR, the data are missing independent of the unobserved or observed data. In this process of data, no difference that is systematic should not be there between the participants with the complete data and the missing data (Sullivan et al. 2018, p.2611). On the other hand, MAR refers to the type of missing data where the missing data is systematically related to the observed data but not related to the unobserved data. Lastly, in MNAR the missing data is related to both the unobserved data and observed data. In this type of missing data, the messiness is directly related to the factors or events that researchers do not measure.
2.8: Implementation of Multiple Imputation in handling missing data
Missing data can appear as a major restriction in surveys where the non-bias responses from people can cause an incomplete survey. In this scenario, researchers have to use some efficient statistical methods that can help in completing an incomplete survey. A variety of approaches can commonly be used by researchers in order to deal with the missing data. Primarily the most efficient technique that researchers use to deal with the missing data nowadays is the method of Multiple Imputations. At the initial stage, MI creates more than one copy of the dataset which contains especially the missing values replaced with imposed values. Most of the time these data are examined from the predictive distribution based on the observed data. Multiple Imputations involve the Bayesian approach and it should account fully for all the uncertainties to predict the values that are missing, by injecting the proper variability into the multiple times imputed values (Tiemeyer, 2018, p.145). Many researchers have found the multiple imputation techniques to be the most precise and effective technique in terms of handling missing data.
2.9: Capabilities of Multiple Imputation
Multiple imputation process is an effective process of handling the datasets that are missing due to lack of storing process of data. The cause behind the loss of data is the negligence of people in providing value to that data that was once beneficial for the operational process. There are some capabilities of multiple imputations like-
Protection of missing data
Protection of the data that are missing is one of the important parts of the operational process of multiple imputations. During deleting the unnecessary creeps, the opportunity of losing useful data is common. The process of deleting data is easy; however, the restoration process can be difficult. The negligence or the lack of carefulness of people at the time of managing data can be considered as the cause behind this losing data. There may be several cases when excessive data is lost by the management of an organization at the time of handling creep or useless data (Audigieret al. 2018, p.180). Sometimes the restoration process takes more time than expected which may cause the loss of a huge amount of projects for the management of an organization.
Managing the operational process
The management of the operational process is one of the important capabilities of multiple imputation processes. Through the management of data, the possibility to manage the loss of a project became less. It also helps to improve the validity related to a test that improves the aspired result. The test is completed through questionnaires as well as tests that develop the authenticity of data. This testing helps in the improvement of the operational process of an organization.
Increasing precision
This process refers to the closeness of one or more than one measurement with each other. The multiple imputation process is also related to robust statistics that outline a high as well as low volume of data. The size of data matters in the process of collection of restoring data no doubt. A small size of missing data can be gathered at any time, on the other hand, a large amount of data takes much time to be restored (Grund et al. 2018, p.140). There is no scope of denying the fact that this process of missing data management is challenging at the time of its implementation.
2.10: Characteristics of missing data and its protection processes
Missing data can be also recognized as data that is not stored perfectly. Missing data can provide several problems in the operational process of an organization. The absence of data can decrease the balance in the operational process of an organization or an institute. There are several types of missing data such as-
Missing completely by random
This missing data is related to negligence in managing data which causes the absence of data. This kind of missing data is not acceptable as it can reduce the reputation of an organization in the market. The operational power may be lost due to Missing data completely by random, however, the parameters which are estimated are not lost due to the missing of the data (Jakobsen et al. 2017, p.9).
Missing by random
This kind of data refers to the absences of the response of people. This type of missing data reflects that most of the time absence of data does not create big problems. This does not reflect that absence of data is beneficial or can be ignored easily.
No missing at random
This kind of missing data reflects the problems that missing data can cause. This missing data type provides the information of the negligence of people in handling or storing data. Missing values can be considered as the medium of this missing data. Moreover, it can be said that perfect planning related to storing data can reduce the risks of missing data (Enders 2017, p.15).
The operational process of the multiple imputation process is difficult as it works through the handling of missing data. The process of storing data which is in the database is simple; however, the possibility to recollect missing data is complicated. The process of deleting data is easy; however, the restoration process can be difficult. The negligence or the lack of carefulness of people at the time of managing data can be considered as the cause behind this losing data. There may be several cases when excessive data is lost by the management of an organization at the time of handling creep or useless data (Brand et al. 2019, p.215). There is no scope of denying the fact that the adobe mentioned types of missing data are difficult to be handled as losing data is easy and restoring data is difficult.

2.11: Different methods of Multiple Imputation to handle missing data
Multiple Imputation is a straightforward process that helps in filling in the missing values in a dataset. There are different methods involved in performing Multiple Imputations. The methods of MI sometimes vary due to the work structure and missing data type. In general, there are three types of Multiple Imputation and according to the complexity; these methods are taken into action by the data analysts (Huqueet al. 20108, p.16). These three types are 1) Single Value Regression Analysis, 2) Monotonic Imputation, and 3) Markov Chain Monte Carlo (MCMC) method. These methods are generally used by professionals while using Multiple Imputation in handling missing data. On the other hand, there are some different MI methods that data analysts use especially in imputing longitudinal data (Sullivan et al. 2018, p.2610). Some of the longitudinal methods are allowed to follow the subject-specific variance of error in order to produce stable results within random intercepts. Apart from that, there are different studies that professionals use while conducting the Multiple Imputation process.
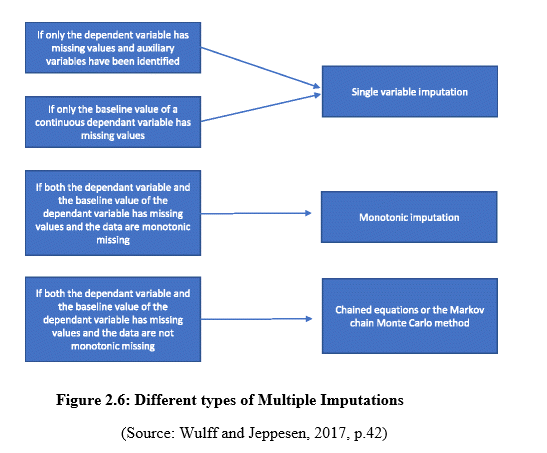
Single Value Regression Analysis
This analysis process is generally concerned with the relationship between one independent numeric variable and a single dependent numeric variable. And in this analysis, the single dependent variable relies upon the independent variable in order to get things done. Also, these variables include an indicator in case the trial is multi-center and there is usually more than one variable with the prognostic information which are generally correlated with the outcomes. While using a dependent variable continuously, a general baseline value of those dependent variables might also be included in the process of analysis.
Monotonic Imputation
The imputation of missing data can be generated with a specific sequence of some univariate processes in the monotone imputation. This process follows the sequential synthetic observations under different methods. In the missing data, the method of monotone imputation is ordered into a specific pattern that follows monotone imputation. On the other hand, if the missing data is not monotone, the process of Multiple Imputation is conducted through the MCMC method which is a potential method for conducting Multiple Imputations to handle missing data.
Markov Chain Monte Carlo
MCMC is a probabilistic model that provides a wide range of algorithms for random sampling from the high-dimensional distribution of probability. This method is eligible for drawing independent samples from the actual distribution in order to perform the process of imputation. In this process, a sample is drawn where the first sample is always dependent on the existing sample. This process of dependability is called the Markov Chain. This process generally allows the actual algorithms to narrow down the quantity that is approximated from the process of distribution. It can also perform a process if a large number of variables are present there.
2.12: Practical Implication of Multiple Imputation in handling missing data
Multiple Imputation is a credible process that is generally implemented by professionals of the statistical field in order to generate the missing values within a statistical survey. The preliminary goal of Multiple Imputation is to calculate the uncertainty in a dataset because of the missing values that are present in subsequent inference. The practical implication is a bit different from the gothic objectives of Multiple Imputation (Haensch, 2021, p.21). The implication of MI in the revival of missing values is generally attained through simpler means. The working process of Multiple Imputation is similar to the task of constructing predictive and valid intervals with a single regression model. In this case, the Bayesian imputation models are the most competent method in order to perform the imputation process properly and achieve the approximate proper imputations that are generally needed for handling the uncertainties of the chosen model. The Bayesian imputation process is a reliable natural mechanism that helps in accounting for the different models with uncertainty.
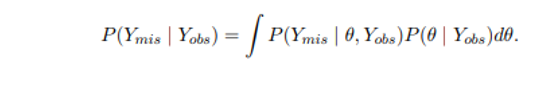
Figure 2.7: Bayesian analysis
(Source: Choi et al. 2019, p.24)
In the analysis, the imputations are generated from the assumed value where 0 is a parameter that is indexing the model for Y. In order to show the uncertainties in the model, compositionally the imputations can be sampled. Here in this formula, the uncertainty of the model is represented with P and the intrinsic uncertainties of the missing values are represented with PY here. In both cases, the worth of Bayesian imputation is proven where the influence of the technique is proved as useful here. Also, the Bayesian bootstrap for a proper hot-deck imputation is a relevant example of the practical implication of Multiple Imputations in handling missing data.
2.13: Literature Gap
Different imputation-related inputs have been discussed under the different areas of discussion. Utmost effort is made of the different factors, Advantages in order to strengthen the concepts. Different important elements like Hot Deck, Cold Deck, and Mean Substitutions have been created here. This could and needs to be identified that a basic frame could act towards catering to the different sections of the analysis. This could have been discussed while understanding and analyzing the different mean values and biases. Notwithstanding different aspects to it, there are certain areas where flaws and frailties could arise (Choi et al. 2018, p.34). The Gap areas included different analyses like Non-Negative Matrix Factorization, Regression analysis, and so on. Even the different analyses like Bootstrapping, Censoring (Statistics), and others. Taking all these into consideration this could be opined that the overall literature Review contains the divergent aspects of MMC and other models and most recent and generic discussions. Although the researchers have tried to provide a clear insight of the factors that are generally used in Multiple Imputation to handle missing data, there are some limitations that were there while preparing the literature for the research. Firstly, the outbreak of COVID-19 has appeared as a drawback for the researchers to collect relevant data for the research. Apart from that, the literature of this research tries to explain the different methods used by the data analysts while performing Multiple Imputations for different purposes. Some of the grounds of Multiple Imputation were not available to the researchers because of the restricted allotted budget. Although, after all these constraints, the literature attempts to provide a fair insight into how Multiple Imputations can be useful in handling missing data.
Chapter 3: Methodology
3.1 Introduction
In order to develop this particular research tools and strategies have been implicated that have a vigorous impact on the overall research outcome. The methodology is one of the tools that help to evaluate the understanding of the ways effective strategies shape the research with proper aspects and additional understanding (Andrade, 2018). In this particular research, a conflicting understanding about the missing data and critical implication of Multiple Imputations (MI) are mentioned throughout that help to judge the ways missing data are creating complications while dealing with the project formation and strategies.
3.2 Research Philosophy
Research philosophy can be referred to as a belief that states the ways in which research should be conducted. It also states the justified and proper watts of collecting and analyzing data. In order to research around the implementation of Multiple Imputation in handling missing data, the researchers will use the Positivism Philosophy. The positivism philosophy is a philosophy that adheres to the point of view of the factual knowledge gained through several observations while conducting the whole research (Umer, 2021, p.365). This chapter represents the estimation of parameters of exponential distribution along with the assistance of the likelihood of estimator under both censored and general data.
Justification
Using positivism philosophy for this research can be justified because it helps in interpreting the research findings in an objective way. It also helps the researchers to collect precise and effective data for the research which eventually helps in conducting the research with minimum casualties.
3.3 Research Approach
The researchers will use the Deductive Approach for this research as it is completely focused on developing hypotheses based on the deductive theory. It also helps in designing a particular research strategy in order to check the credibility of the hypotheses made regarding the research topic (van Ginkel et al. 2020, p.298). Choosing the deductive approach for this research project will expectedly act positively for the researchers as it will allow them to research extensively on the application of Multiple Imputation in order to handle missing data. A deductive approach may help the researchers to figure out the causal links between the different methods of Multiple Imputation in order to handle missing data.
3.4 Research design
For this research development, the researcher has chosen a descriptive and exploratory research design. Descriptive research design helps to investigate the variables with a wide variety and also so the outcome which has an impression on the research topic is evaluated by this particular research design. The descriptive research design helps to analyze the topic with proper investigation ideas and provides an outcome with justified notations. Exploratory design helps to conduct research on the basis of previously done studies and on earlier outcomes (Eden and Ackermann, 2018). While developing this research and finding out the ways missing data evaluate the overall project structure are also mentioned with proper understanding and justification.
3.5 Research Method
In order to develop this research, the researcher has used both qualitative and quantitative research methods for a systematic project development formation. Both primary and secondary data sources have been used for this research structure development. Qualitative data help to develop research by implicating the outcomes which have previously been confirmed by some other researchers who have dealt with the topic (Cuervo et al. 2017). Critical matters related to missing data and its functions are measured by the quantitative research method implication on the other hand the qualitative research method helped the quantitative outcome to come to a conclusion.
3.6 Data Collection and Analysis Method
Collecting and analyzing data is the most important aspect of research. In this case, the researchers need to collect their needed data efficiently in order to conduct their research regarding using Multiple Imputations to handle missing data. Most importantly, the researchers need to use both primary and secondary sources to collect data. Also, they need to use procedures like ANOVA and T-test in order to analyze their collected data (Wang and Johnson, 2019, p.81). The software for analyzing the data should be based on R studio and Stata in order to generate accurate results. Also, the researchers will be using primary data sources like questionnaires and interviews of the professionals in order to gather their needed information regarding this technique. Additionally, the researchers can use datasets available online. Journals and scholarly articles regarding this topic will be helpful for the research especially the journals from the professionals can provide the researchers with extensive exposure to the implication of the Multiple Imputation process in managing missing data.
3.7 Research strategy
For this particular study development research has you step-by-step research strategy for gathering information to direct the action of the research with effort. Enabling research with systematic development criteria is all about developing the course that has the power to evaluate the result at once (Rosendaal and Pirkle, 2017). In this research, the development researcher has used the systematic action-oriented research strategy for its strong core development.
3.8 Data Sources
For the research methodology part, the researcher has used different kinds of primary and secondary sources of data to develop an analysis of the missing data and its activities. Previously done researches have helped the course of the topic related to deal with the conception of the missing data and retrieving the data by using the Multiple Imputation technique. The overall understanding also provides an idea that the data sources that have been used while developing the research have helped to manage the overall course of the ideal research development. With previous existing files, an R studio and Stata have been conducted as well to generate the result also the ANOVA and T-TEST have been conducted as well to gather the data for the resulting outcome.
3.9 Sampling technique
Sampling is very important in conducting and formulating the methodology of any research. By the sampling method, the information about the selected population is being inferred by the researcher. Various sampling techniques are there that are being used in formulating the methodology of research such as simple random sampling, systematic sampling, and stratified sampling. In this research of handling the missing data by the investigation of multiple imputations, a simple random sampling technique is to be used in which every member of the population has an equal chance and probability of getting selected effectively (Kalu et al. 2020). Moreover, by the simple random sampling technique, the error can be calculated in selecting and handling the missing data by which the selection bias can be reduced effectively which is good for the conduction of the research effectively. By this sampling technique, the missing data that is to be handled can be selected appropriately and they can be sampled effectively. Thus, by the implementation of the sampling technique properly, the research can be conducted and accomplished appropriately.
3.10 Ethical issue
Several ethical issues are being associated with the conduction of this research of handling the missing data by the investigation of multiple imputations. In handling the missing data, if there becomes any mishandling by the researcher or if there is an error in the data collection and data analysis, the occurrence of mishandling of the data can be done. As a consequence of this mishandling of the data, those data can be leaked or can be hacked by which the privacy of the data can be in danger. Moreover, those data can have important and personal information about different human beings or different organizations. By mishandling the data, they can be leaked or hacked effectively. Thus, this is a serious ethical issue that is being associated with the conduction of the research and this issue is to be mitigated appropriately for the proper conduction of the research effectively. All these ethical issues are going to manage by the following legislation from the Data Protection Act (Legislation.gov.uk, 2021).
3.11 Timetable
Table 3.1: Timetable of the research
(Source: Self-created)
3.12 Research limitation
Time: Though the research is being conducted very well, it does not complete in the given time and exceeds the time that is being conceded for accomplishing this research. Thus, this is a limitation in the accomplishment of the research that needs to be given more concern in the future.
Cost: The cost that was being estimated for the conduction of the research has been exceeded its value which is a limitation of conducting this research.
Data handling: Some of the missing data could not be handled well in the conduction of the research by which there is a chance of leaking data which is a big limitation in the conduction of the research.
3.13 Summary
Conclusively, it can be said that the methodology part is very important in the proper conduction of the research as by selecting the proper aspects of the methodology and formulating the methodology properly, the research can be accomplished appropriately. Moreover, the research philosophy, approach, research design, data collection, sampling technique, ethical issues, and timetable of the research are being formulated and discussed that is applicable to the conduction of the research. In addition to this, there are some limitations in the research that is also being discussed in this section effectively. These limitations need to be mitigated for the proper accomplishment of the research appropriately.
Chapter 4: Findings and Analysis
After analyzing the collected data regarding the implications of Multiple Imputations in order to handle missing data an extensive result can be extracted from the observed dataset. Researchers can yield the results after removing the rows that contain the missing values in an incomplete survey. The researchers can use a combination of different approaches in order to yield the best results. Additionally, the analysis process can follow the TDD where every method must be tested empirically. Also, the use of the ANOVA method in order to fill in the missing data stands out to be the most effective aspect of using Multiple Imputation techniques for dealing with missing data (Wulff, and Jeppesen, 2017, p.41). The research has also aimed to find out the working process of MI technology and how it replaces the missing number with the imputation value. Another finding can be extracted from the research that the MI method is the easiest method to implement and it is not computationally intensive in order to fill in missing data. Within the replaced missing values the researchers can evaluate the efficiency of the various data handling techniques along with Multiple Imputation techniques (Xie and Meng, 2017, p.1486). These processes have now moved to machine learning technologies where it is now conducted with software based on Python coding and technologies like ANOVA and T-Test have made it easier for the researchers to find out the missing values with the Multiple Imputation technique.
4.2 Quantitative data analysis
The quantitative data analysis includes the statistical data analysis that also includes the mathematical data such that the analysis has been shown using the Stata software. This also includes the representation of the mathematical results such that all the data is acquired from the Stata software. This different data analysis includes the survey data that has been shown using the data set such that the wlh has been shown. The quantitative data analysis includes the numerical data that has been shown using the Stata software. R Studio software has been utilized along with the STATA software to show the visualization and analysis such that the Linear regression, T-test, Histogram, and other visualization has been shown using the STATA software.
Thus, the assessment has also shown the different results that have been acquired from the conducted analysis that has been shown using the Stata software. The main aim of the quantitative analysis includes the determination of the correlation between the attributes that are present in the data set. Thus, from the different data visualization process the R studio and the STATA software the data visualization and different algorithm has been shown using the R studio software such as this includes the Z test, T-test and the Annova test that has been performed by the assessment using the R studio software such that this also includes the execution of the specific codes that has been implemented using the R studio software.
Figure 4.2.1: Reflects the data set in Stata
(Source: Self-created)
This figure reflects the data set that has been shown using the Stata software such that this shows the different variables that are present in the data set. In this research report, the assessment has been shown using the R studio and the Stata software. According to Girdler-Brown et al., (2019, p.180), the R Studio software has been used to show the Anova Test T-test upon the data set such that the complete report has been reflected using the two different software such as the R studio and the Stata.
This placed figure reflects the data set that has been imported by the assessment such that the codes to view helped to reflect the data set using the R studio software.

This figure reflects the mean and standard deviation using the Stata such as this reflects the mean and standard deviation has been extracted upon the PID column. This figure also reflects the value that shows that the standard deviation has been extracted with a value of 2560230 and the mean value has been extracted as 1.47 from the observation such as 178639.

This placed figure reflects the Anova test that has been performed by the assessment using the Stat software upon the Payment column such that the value of variance has been observed as 402.4137.

This placed figure reflects the T-test that has been performed by the assessment using the Stata software such that the degree of freedom has been extracted between two columns such “paygu” and “paynu”.
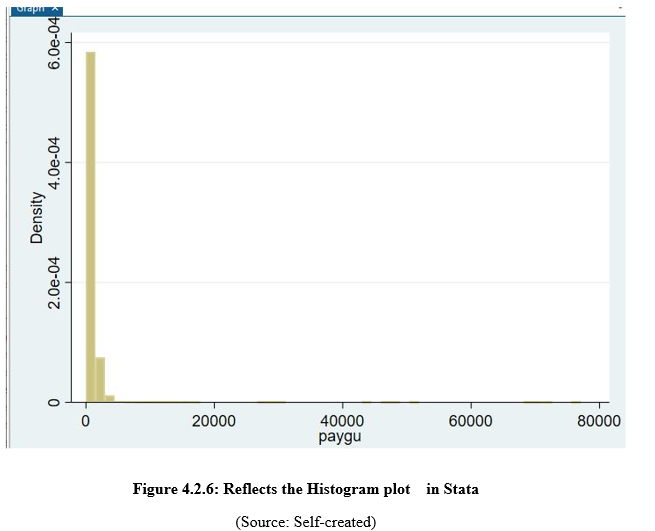
This placed figure reflects the Histogram plot that has been plotted between the payments of the employees and the density.
This placed figure reflects the Scatter plot that has been plotted between the payment of employees and the status of the employees with the help of the Stata software to determine the correlation between and closeness between the attributes.
This figure reflects the bhps information that has been shown using the Stata software such that the assessment has reflected the information from the given do files. This BHPS information has been implemented such that this has been extracted using the

This placed figure reflects the R studio codes such that this R studio includes the installation of packages such that this also includes the summary and other different types of data analysis such as the T-test, Z-test such as the assessment.
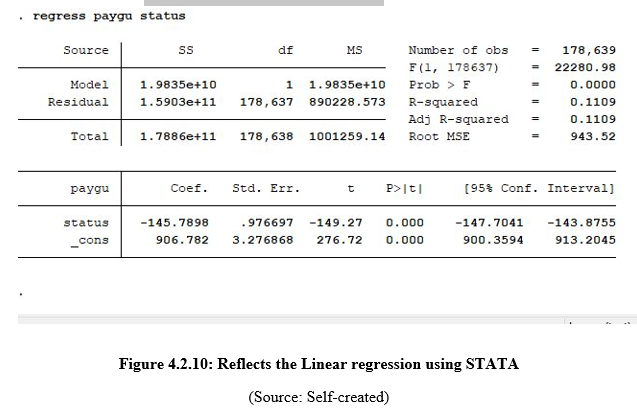
This figure reflects the result of linear regression that has been performed by the assessment using the STATA software. This figure reflects that the F1 score has been obtained from the R studio software such that this includes the 22280.98.
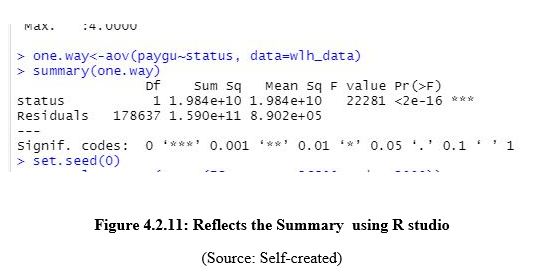
This figure reflects the summary report that was extracted by the assessment using the R studio software such that this Mean and other parameters have been extracted using the software.

This figure reflects the T-test hypothesis that has been extracted by the assessment using the R studio software such that this shows the mean of x such as this includes the 36447.49. This summary has been extracted by the assessment using the STATA software such that this reflects the Anova test that has been implemented upon the R studio software such that this includes the 95% of the confidence level that has been implemented using the specific R studio codes that have been shown in the above figures (Nguyen et al., 2019, p.154). Here the detailed application of the ‘ggplot’ and ‘tidyverse’ helps to create the statistical test implementation. The collections of the above R studio packages help to develop the data representation. The application of those artifacts is able to present the evaluation of ANOVA and T-test. The application of the ggplot package inj the software interface of R helps to present the final visualization outcomes of the statistical data analysis method. Here is the correlation between different columns.
This different kind of data visualization and the data analysis using the two different methods such that this implemented different analysis has helped to extract the data and the data visualization(Baker, 2020, p.187). From the different data visualization, the correlation between the attributes has been shown in this research report with results of implemented analysis and visualization. Thus, The main aim of the quantitative analysis includes the determination of the correlation between the attributes that are present in the data set.
This complete section reflects the Quantitative analysis and within this quantitative analysis the results that have been extracted have been shown such as the WHl data set has been imported in both the software platforms. quantitative data analysis includes the numerical data that has been shown using the Stata software. R Studio software has been utilized along with the STATA software to show the visualization and analysis such that the Linear regression, T-test, Histogram, and other visualization has been shown using the STATA software. Thus, the assessment has also shown the different results that have been acquired from the conducted analysis that has been shown using the Stata software (Dvorak et al., 2018, p.120). This complete process involves deep research using the different methods that have been acquired using the software.
Finding 1: The effect of missing data is extremely hazardous
The effect of missing data is one of the most critical complications that different organizations face when it comes to managing and saving data for organizational function purposes. In order to manage organizational function, a company needs to gather previous data that provide knowledge about the way a company has maintained its function helps to evaluate the future therefore losing some of this data causes a tremendous hazard. Losing data has critical importance in the method of handling the overall structure of the workforce that has been implicated in an organization. Managing data is like connecting dots which needs to be in a systematic formation to provide the outcome in a formative way (Garciarena and Santana, 2017, p.65). Data science provides an understanding that missing data tends to slip through cracks from the appropriate form of data.
Handling missing data and dealing with the havocs requires proper management skills and understanding of the length of the data. It has been seen that how much bigger the dataset is the chances of losing some data has a tremendous chance. Retrieving missing data from a small data set is quite easy but as soon as the length of the data set got bigger the problem got bigger as well. The proliferation of data and understanding its values related to invertible missing scenarios related to the behavioral sciences as well (Choi et al. 2019, p.36). The academic, organization or any functional activities required to save the previously done dataset to understand the ways critical complications are already have been managed in otherwise in the past and also the way things can be managed in future depends on the way previously done. Missing data creates confusion and difficulty to conclude when it comes to making decisions.
Finding 2: There is a connection between missing data type and imputation method
There is an interconnection between the type of missing data and the imputation techniques being used to recover those datasets. The different missing data types are missing completely at random (MCAR), missing at random (MAR), missing not at random (MNAR), missing depending on the value itself (MIV) (Ginkelet al. 2020, p.308). All these data types are identified by the way they got lost and the variety of reasons behind the loss can be considered as the most formally distributed data set experiences of loss. Implicating imputation methods by understanding the ways they have got lost are considered as the full feeling part which can be executed by the differences of the consideration of the data loss. The quality of the data and the importance and method are interrelated because the classification of the problems and supervising those classifications needs to implicate proper algorithms which only can be possible if the right way of lost data type can come to light. The classification and multiple imputations depend on the way things are being managed by learning classifiers with proper supervised ways that depend on the performance and the missing data type as well. The improper choice of using multiple imputations also creates problems when it comes to dealing with lost data sets. Therefore identifying the type of the data set comes as the priority while using multiple imputations to find out the data that an institution exactly needs.
Finding 3: Multiple Imputations has a huge contribution when it comes to retrieving missing data
In order to achieve an unbiased estimate of the data outcome implicating multiple imputations turns out to be one of the most effective and satisfying ways of retrieving missing data. Using multiple imputations has severe results and its outcome helps to build the understanding with standard statistical software implication results and its interpretation is highly needed when it comes to managing organizational function. Multiple imputations work in four different stages: first, the case deletion is the primary target of this system, choosing the substitution of the missing cells is managed by this one as well, statistical imputation is the core of this function, and at last, it deals with a sensitivity analysis (Grund et al. 2018, p.149). Multiple imputations have the primary task to manage the consequences of the missing data which addresses the individual outcomes which has a vigorous impact on the workforce function. The flexibility of the data and the way statistical analysis of the data is being managed semi- routinely to make sure the potential of the result validity may not get any biased decision. The potential pitfalls of the understanding and the application of multiple imputations depend on the way statistical methods are used by using the concept of the data types which are being missed from the data set (Kwak and Kim, 2017, p.407). Replacing missing values or retrieving The lost one depends on the way statistical imputation is working. The sensitivity of the analysis that can vary the estimated range of the missing value turned out to be both good and bad and the missing number which is quite moderate helps to provide the sensitive outcome based on different circumstances.
Finding 4: Increasing traffic flow speed is also dependent on multiple data imputation
Managing a website depends on different data sets which stock the previously identified data which has a vigorous impact on the overall work function. Increasing website traffic flow depends on the way the data which has been lost is retrieved and properly implicated in website modification. The overall concept also comprises the critical analysis of the findings that are gathered while using multiple imputations whenever a traffic jam created in a website depends on the way data is being handled by the management team. Website and its function is a cloud-based portal that is managed through proper data integration understandings which eventually evolved the course of data implication in a website. Managing website flow in order to reach the customer and also to manage the organizational function flow having the sense of dealing with critical postures related to the data set provides an understanding regarding the ways data can be managed (Enders, 2017, p.18).
4.4 Conclusion
This part of the project can be concluded on the basis of the above observations and their expected outcomes. Data analysis is amongst the most essential segments in any kind of research which have the capability of summarizing acquired research data. This process is associated with the interpretation of acquired data which are acquired through the utilization of specific analytical and logical reasoning tools which play an essential role in determining different patterns, trends, and relations. This also helps researchers in evaluating the researched data as per their understanding of researched topics and materials. It also provides an insight into research and how the researchers derived their entire data and understanding of personal interpretation. In this part of the research, the researchers are able to conduct both quantitative and qualitative data analytical methods in concluding their research objectives. In this research in maintaining the optimum standards and quality of research, the researchers have utilized several Python-based algorithms including T-Test and Supportive vector mechanisms along with multiple imputation techniques. Moreover, they are also able to implement machine learning mechanisms and ANOVA in their practices which helps them in acquiring the research data they have desired to deliver before the commencement of the research and able to acquire an adequate research result.
Chapter 5: Conclusion and Recommendation
5.1 Conclusion
Handling missing values with the help of multiple imputation techniques is dependent on many methods and practices. These methods are distinctive and fruitful in their own aspect of work. Also, it can be extracted from the research that the size of the dataset, computational cost, number of missing values acts as a prior factor behind the implication of Multiple Imputation in handling missing data. Also, multiple imputations can be an effective procedure in order to validate the missing data and refill the left data. The results validity of Multiple Imputation is dependent on the data modeling and researchers should not implement it in incompetent scenarios.
The Multiple imputation process is considered to be an effective tool in order to handle missing data although, it should not be implemented everywhere. Researchers should use the MI technique particularly in the research works where the survey is incomplete but consists of some relevant data beforehand. The working process of Multiple Imputation involves analyzing the previous data and concluding according to it. Also, researchers should use three of the different methods of MI technique according to the situations given. If the messiness is not monotone, researchers should use the MCMC method in order to achieve maximum accuracy in their results.
The research work has been particularly focused upon developing the concept prior to analyzing the dataset to understand the dataset and make the necessary analysis of data using different strategies. The following research work has used different statistical tools like T-test and Anova in understanding the pattern of missing information from the data set. Missing data is a very common problem while handling big data sets, multiple imputation strategy is very commonly used. Missing pieces of information creates a backlog for any organization requiring additional resources to fulfill them in an unbiased manner. Execution of the analysis clarified the different challenges that are faced while extracting data and understanding the gaps that are present. Missing data management practice has been identified with its subsequent effects and impacts it can have on particular business activity.
During the process of handling data, there can be multiple points of imputation, in analyzing this information the system is required to collect necessary samples from the imputed model and consecutively combine them in the data set aligning it to standard error. Resampling Methods and Bayesian analysis being the two of the commonly used strategies to analyze imputed data have been utilized for constructing the research work. Missing data can be broadly classified under different categories based on the nature and type of data missing from the data set. Complete random missing of data, the random missing of data, and no random missing of data are the broad categories of missing data. The different characteristics of missing data have been investigated in this research work along with the processes that can be applied to protect the necessary information. Missing data can be handled through different methods. MCMC method, Monotonic imputation, and single value regression constitute some of the models that can be used by professions in the identification of missing data. During the imputation process, 0 is taken as a parameter for indexing the model.
5.2 Linking with objective
Linking with objective 1
The research work has included the usage of different statistical tools along with a comprehensive and extensive study of different kinds of literature. Information gathered from different academic sources has been exceptionally beneficial in understanding the different factors which are involved and consecutively contribute to the process of handling missing data. The application of multiple imputation processes has proven to be an advantageous stage towards finding missing data in the data set that has been used for analysis. The combination of results of several imputed data sets has assisted in linking with the fiesta research objective.
Linking with objective 2
The presence of multiple imputations in a particular set of data makes allowance for researchers to obtain multiple unbiased estimates for different parameters used in the sampling method. These missing data, therefore, have allowed the researcher to gain good estimates over the standard errors. Replacement of identified missing values with plausible values has allowed variation in parameter estimates.
Linking with objective 3
Multiple imputations of missing data information present themselves in a very challenging manner. Through practical application of the analysis process, the challenges have been realized in a more constructive manner. The literature review of existing studies had proved to be a repository of information allowing the researcher to identify appropriate variables to be included along with random stratification and allocation of values. Diverse strategies applied to gain information regarding the methods to fill out missing values and appropriate application in the analysis process has assisted in linking with the third objective of the research work
Linking with objective 4
Identification of a recommended strategy that is going to prove beneficial in mitigating the diverse challenges faced during filling up of missing data in data imputation techniques required gaining detailed knowledge on the topic itself. Moreover, hands-on analysis assisted in the consolidation of the theoretical knowledge into a practical manner allowing the researcher to view the challenges from a detailed perspective. Through the appropriate application of prior knowledge gained through the literature review section and its consecutive application in mitigating the different challenges faced, the fourth objective has been met.
5.3 Recommendations:
Though the effectiveness of multiple imputations in handling missing data also has some of its own critiques. Amongst these, its similarities with likelihood techniques and limitations in assuming missing data at random are amongst its capabilities. In this section, the researchers are able to provide recommendations by which individuals can enhance their capabilities in handling missing data and which can help them in acquiring adequate results. These include-
Recommendation 1: Train individuals in improving their understandings of patterns and prevalence of missing data

Recommendation 2: Implementation of machine learning methods in handling missing data
Deductive, mean median mode regression
Recommendation 3: Stochastic regression imputation in handling missing data
Table 5.3: Recommendation 3
(Source: Self-Created)
Recommendation 4: Deletion method in handling missing data
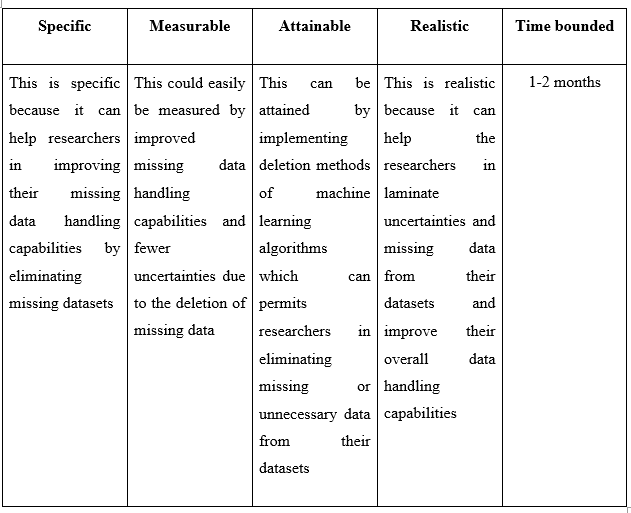
Table 5.4: Recommendation 4
(Source: Self-Created)
Recommendation 5: Technological implementation in handling missing data
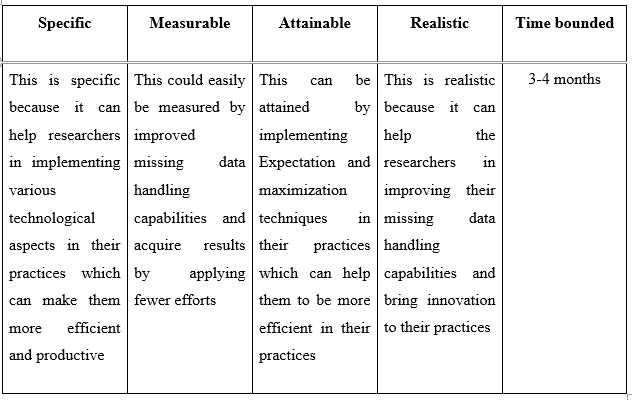
Table 5.5: Recommendation 5
(Source: Self-Created)
Recommendation 6: Alternative methods in handling missing data
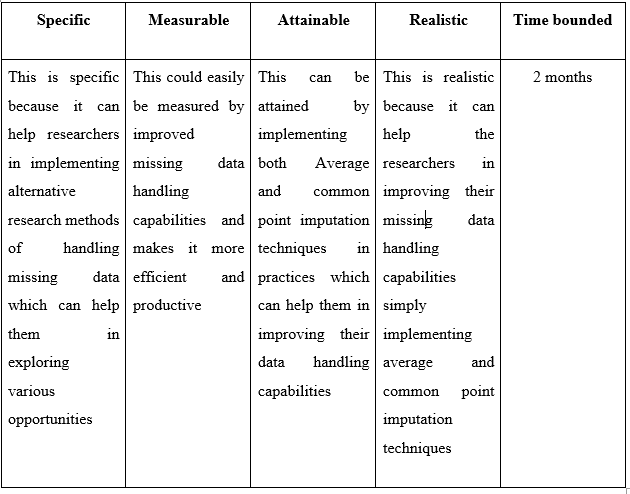
Table 5.6: Recommendation 6
(Source: Self-Created)
5.4 Limitation
One of the main disadvantages of using multiple imputation methods for the identification of missing data is that the process fails to preserve the relationship amongst variables. Therefore, in the future perspective, mean imputation can be incorporated in analyzing data so that the sample size remains similar providing unbiased results even if the data sets are missing out at random. Instances when large amounts of data are considered instances of missing information hampers the research work and simultaneously reduces the standard of information in a system. In this regard, different data sets present easily across the public platform need to be assessed so that efficient procedural planning can be executed to understand the relationship amongst the variables even better.
5.5 Future research
There has been a growing interest in the field of synthetic data attracting attention from different statistical agencies. In contrast to traditional sets of data synthetic data possesses the capabilities of optimal modification of inferential methods so that scalar quantity interval estimates can be performed for larger data sets. These strategies are also beneficial in the analysis of complex data, factor analysis, cluster analysis, and different hierarchical models. Therefore, in the future, these synthetic design strategies can be incorporated into the research work so that a better allocation of resources can be obtained.
Missing data or information has the statistical capability to lead towards great loss in different business sectors, ranging from healthcare, transport, agriculture, education, construction, and telecommunication, therefore necessary approaches need to be applied so that technology can be developed to predict missing values which do not disrupt the primary data set. Considering sets of data from different countries the models can be trained better to identify the missing information and fit them significantly eliminating the challenges brought with it. Moreover, the adoption of these approaches through future research has the benefit of developing efficient resource planning strategies.
References
.png)
.png)
.png)
Assignment
ICTICT426 Emerging Technologies and Practices Assignment Sample
Overview of assessment
This assessment is based on a scenario and requires you to write a response which is made up of 4 tasks. This assessment requires you to complete written tasks. You are required to complete all tasks in the order provided. You have been given a scenario based on a fictional farming business named “ASR Farms”.
You will play the role of ‘Business Analyst” for IT Works, an IT consultancy company. You are required to:
• access the sources of emerging technologies
• access practices of emerging technologies in the IT industry
• Identify and document emerging technologies to meet the requirements of ASR Farms.
Your lecturer will play the role of the Manager of ASR Farms and IT Works Project Manager.
Task/s to be assessed
1. Sources of Information
2. Overview of Emerging Technologies
3. Identification of Emerging Technologies
4. Identifying Emerging Technologies relevant to the organisation (video presentation)
4IEET – Assessment – Part 1
Identification of Emerging Technologies and Practices in IT
SCENARIO: Read the scenario carefully for assignment help then complete the assessment tasks.
Business Background
For 30 years, Mr. and Mrs. Roberts (Andrew and Suzie) have owned a 3000-acre farm far north of Adelaide. Its Registered Business name is ASR Farms. They have poultry, 250 cows as well as multiple crops on 2000 acres. They produce milk and have a team to sell their milk on open market.
There is a sales team who use computers to maintain their records electronically. Mrs Roberts uses a computer to keep track of the farm’s finances however her bookkeeping/accounting skills are self-taught, and she finds that dealing with finances is a stressful and time-consuming practice. All devices are stand alone as ASR Farms has no computer network, however they do have reasonably reliable internet access.
Andrew obtained the farm in an inheritance and is still using traditional methods of agriculture – for example most of the crop planting, picking, packing, weeding etc is done by hand. Most of their farm equipment is not modern and is at the point where it is due to be updated soon. They use chemical fertilisers and a variety of machines for various purposes, but due to their old equipment they need to hire a great amount of labour. Due to increasing labour costs, their profit margins and crop yields are reducing day by day.
A variety of different crops, primarily vegetables have grown in their greenhouses. In the last 3 years they have increasingly specialised in gourmet tomatoes - also known as heirloom or cherry tomatoes. These tomatoes can be very profitable, however maintaining the ideal environment for growth is proving to be challenging. They haven’t been able to consistently produce enough crops to ensure a profit. The owners believe that if they could perfect their greenhouse practices, this would go a long way towards seeing the farm return to profitability, but they know this won’t happen using their traditional practices.
Greenhouse environment testing is labour intensive. They manually test soil for salinity, water levels and test the temperature and humidity every 4 hours. Sometimes if there is an emergency elsewhere on the farm the greenhouse environment testing does not occur, which can result in conditions that are not ideal for crops and reduces yields.
Machinery in use is dated so repair and maintenance costs are high. They don’t really have a schedule for machinery maintenance – servicing is done on an as needs basis when malfunctions occur. The manager has a written journal where he tries to keep track of machine servicing and maintenance, but it is not 100% reliable and servicing is not always done as often as it should be.
Another issue concerning the owners is that they have had several break-ins to the 8 greenhouses on the farm. This has resulted in loss of production due to theft and vandalism. They currently have no security monitoring in place for their greenhouses.
Use of technology is minimal on the farm, and staff and management freely admit they have minimal knowledge or experience when it comes to information technology.
One of the few recent investments in technology at ASR Farms has been to install a significant number of solar panels on various farm buildings. They have also invested in battery storage solutions to complement the solar panels. Andrew and Suzie’s aim was to make the farm self-sufficient as regards electricity by sourcing solar power. Currently they appear to be achieving this with their solar energy system just supplying enough energy for their daily needs.
ASR Farms comprises of
• Owner (Director) Suzie Roberts
• Owner (Manager) Andrew Roberts
• Cowherd X 8
• Grape growers X 40
• Sales X 5
• Delivery Driver X 5
Their family friend Peter Hall lives in the USA. He works as a Manager in a Large-scale commercial Farm in Texas. He and his wife recently visited Andrew and Suzie Roberts in Adelaide.
Peter told Andrew that in the USA farmers and agricultural companies are turning to the Internet of Things (IoT), Big Data and Robotic Process Automation and other emerging technologies for analytics and greater production capabilities.
He suggested Andrew take advice from an IT company to implement emerging technologies in his farm as that may help him to resolve his problems.
Andrew Roberts contacted ITWorks and discussed their interest in using emerging technologies and latest IT practices on their farm to increase production and increase their profit margins. You work at ITWorks as a Business Analyst. You will be working with your project manager to investigate potential new emerging technologies that may be used in ASR Farms.
Task 1: Access Sources of Information on Emerging Technologies
Question 1:
Visit the following open source community website: https://github.com/open-source
Access two (2) current projects that are currently listed by Github on their “Trending” page.
For each project that you access, you must provide the following information:
• The name of the project.
• A screenshot of the project page that shows the URL. If the full URL is not visible in the screenshot due to its length, please copy and paste the full URL below the screenshot.
• A brief description of the project (minimum 30 words) that explains its purpose – i.e. what the subject of the project can be used for.
• The number of Contributors that are listed as having been involved in the project. Include a screenshot showing the number of contributors. The URL of the page must be included in your screenshot.
Question 2:
Access the following Crowd funding site: https://www.kickstarter.com/
Use the Search tool on the Kickstarter site to enter the search term “Greenhouse automation”
From the “Greenhouse automation” search results, access one project and provide the following information:
• The name of the project.
• A screenshot of the project page that shows the URL. If the full URL is not visible in the screenshot due to its length, please copy and paste the full URL below the Screenshot.
• A brief description of the project (minimum 30 words) that explains its purpose – i.e. What the subject of the project can be used for.
• The monetary target/goal of the project and the current amount pledged. Provide a
Screenshot of where you located this information.
Task 2: Identify and Evaluate Emerging Technologies
Question 1:
List 3 characteristics that would define an “emerging technology”.
i. Click or tap here to enter text.
ii. Click or tap here to enter text.
iii. Click or tap here to enter text.
Question 2:
Provide an evaluation of the following three emerging technologies (Minimum of 100 words for each):
1. Internet of Things
2. Big Data
3. Robotic Process Automation
Each evaluation must include:
• The purpose of the technology
• Two attributes of the technology. (An attribute is a characteristic or inherent part of Something)
• Two features of the technology. (A feature is a prominent or distinctive part, quality, or Characteristic)
• Advantages (minimum of two) of using this technology for ASR Farms
• Disadvantages (minimum of two) of using this technology for ASR Farms
• Evaluate how the technology could be used at ASR Farms – i.e. which processes it could be
used to enhance or replace. Refer to at least two processes.
Task 3: Identification of Emerging Technologies Features and Functions
In this task you need to review and research the technologies that the owners of the ASR farms mentioned in their initial contact with IT Works.
Question 1:
One of your co-workers has done some research on the functions and features of emerging technologies, however their notes were partially deleted. They managed to recover part of their list of functions and features, but the list does not show which function and feature belongs to which technology.
Your task is to look at the recovered list below and enter each item into the correct position in the table that follows. In the table you are only focusing on functions and features of Internet of Things (IoT), Big data, and Robotic Process Automation (RPA). The list your co- worker created also includes functions and features related to other emerging technologies – ignore these unrelated items and only select those that relate to IoT, Big Data, and RPA.
Task 4: Reporting on Emerging Technologies Relevant to the organisation
Part 1:
Your supervisor has asked you to prepare a video summary of your findings which will be viewed by the owners of ASR farms.
Content requirements of the video are:
1. Introduce yourself by name and title (Business Analyst for IT Works) at the start of the video.
2. Describe 1 example for each technology (Internet of Things, Big Data, Robotic Process Automation) of where it could be used specifically in relation to current practices used at ASR Farms. Each technology should be related to a unique practice – i.e. you will mention 3 technologies and 3 affected practices.
3. For each technology (Internet of Things, Big Data, Robotic Process Automation) describe one advantage and one possible disadvantage that may arise if it is implemented at ASR Farms.
4. In your own words, request that the owners provide you with written feedback on the following:
a. Their thoughts on your examples of how the emerging technologies could impact practices on ASR Farms.
b. ASR Farms short-term and long-term requirements/goals.
c. What they feel is the most critical need of emerging technology in ASR farms – i.e., what specific application or individual piece of technology they would like to have in place.
Solution
Task 1:
Question 1:
According to trending page in github two projects are “ErickWendel/semana-javascript-expert06” that indicates “Spotify” project and “psf/black” indicates “The uncompromising Python code formatter”.
(Link- https://github.com/ErickWendel/semana-javascript-expert06.git)
Through Javascript and nodejs, a real time audio processing has been created where the stream deck is included within Spotify along with different kinds of features. In this project the full concept of Nodejs has been used for making static websites.
Contributors of this javascript project
(Link- https://github.com/psf/black.git)
This project is based on “The uncompromising code formatter” and by using Black it can be controlled over minutiae of hand-formatting. Besides, Black is able to manage determinism, speed, and freedom in case of pycodestyle nagging about the exact formatting. Both mental energy and time will be saved and that makes fast code review with producing the smallest diffs possible.
Contributors of python code project
Question 2:
The chosen project in Kickster search tools is “HarvestGeek -- Brains for your Garden”.

Link- https://www.kickstarter.com/projects/2077260917/harvestgeek-brains-for-your-garden
The movement of local food has been effectively picking up with the special momentum. In this regard, over the country small scale agriculture is springing up in rooftops and backyards, altics, and basements, along with abandoned warehouses and lots in the vacant.
Task 2:
Three characteristics of “Emerging technologies”
? Radical novelty
? Relatively fast growth
? Coherence
Question 2:
IoT (Internet of Things):
In the current world, IoT technologies are growing rapidly along with its future trends in a significant manner. Different key technologies of IoT are like AI, 5G, blockchain, and cloud computing. All these are really meaningful to manage advancement of global connectivity with various features of this emerging technology.
Two major attributes of IoT are connectivity and intelligence.
Two features of IoT are lack of disposability or accountability, and ubiquity.
Two major advantages of Iot are cost reduction, productivity and efficiency and these are really useful for managing their farms (Spanias, 2017).
Two major disadvantages of IoT are viruses, hacking, cheating, and trolls, stalkers, bullying, and crime and these can be harmful for ARS farms.
ARS farms can manage their business production in managing electricity and solar energy systems through using IoT. These are increasing production, and increasing profit margin.
Big Data:
In order to increase the products’ market reaching speed and decrease the time and several resources for gaining the adoption of the market, target audiences and satisfying the customers.
Furthermore, the main attributes of this big data technology is volume and variety. In order to identify features of BigData, the volume of stored data is increasing day by day along with variety of data in a significant way. This is a big factor corresponding to big data to manage data varities (Kim et al., 2021).
In business operations, big data is too effective for reducing complexity by creating different types of visualisations.
In an ASR firm, big data has a great advantage in order to optimise energy production and energy distribution. Besides, unpredictable resources are notified by big data.
Moreover, the principle of privacy is violated by big data whereas for the manipulation of customers’ records, big data is utilised. Due to higher complexity, sometimes a false discovery rate is created and these are considered as disadvantages of BigData.
For business analytics, and managing various data management of ARS farms, big data can be implemented significantly.
Robotic Process Automation:
RPA (“Robotic process automation”) is a technology to manage, deploy, easily build, and control software robots to emulate human actions along with digital systems (Nguyen et al., 2021).
Two attributes of RPA are simple bot creation interface, and security.
Two features of RPA are less automation script and debugging.
Reduction of errors and increasing agility are major advantages of RPA within ARS farms (Do?uç, 2021).
Error magnification and maintenance are two disadvantages of RPA and that indicates electricity production like ARS farms.
In order to evaluate a large number of production capabilities, and smart work with sensors and robots, RPA has been used in the case of ARS farms.
Task 3:
Question 1:
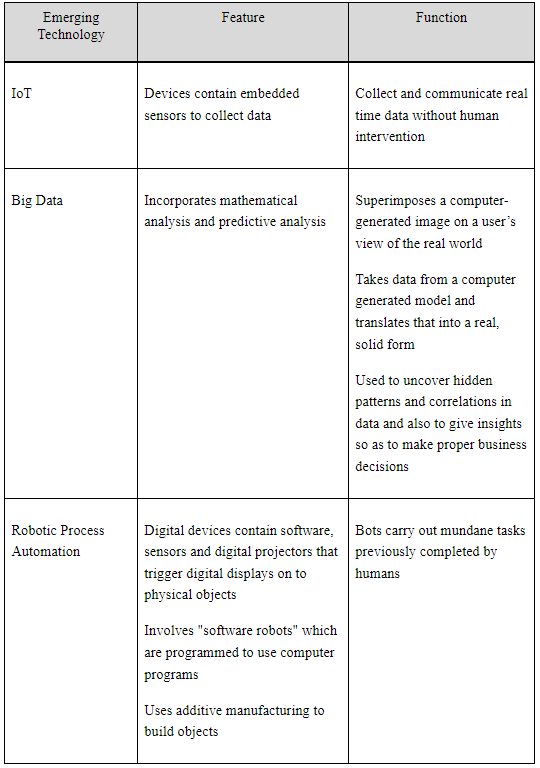
Task 4:
1. Examples of different emerging technologies that suit for ARS farms:
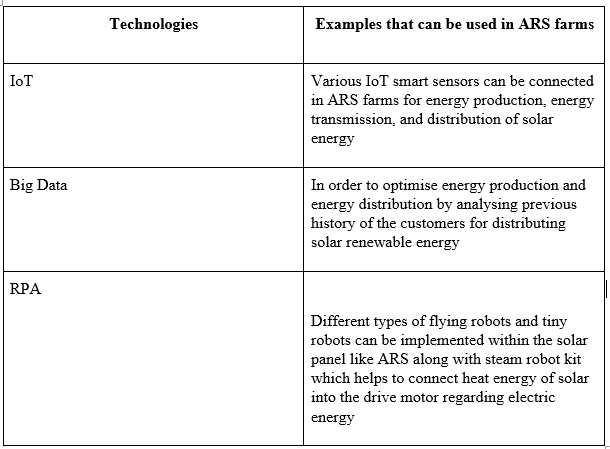
2. Advantages and disadvantages of emerging technologies in managing ARS farms:
3.Feedback of owner in the respect of suggestions of emerging technologies
a.
As per your suggestion, all the sensors and smart technologies regarding IoT, RPA, and big Data can be effective for ARS farms to manage energy production, energy transmission as well as distribution. We will try to implement all these things to provide a better customer’ experience and achieve business development regarding electricity production.
b.
Short term goal is to provide better electricity to customers in their specific areas and long term goal is to manage a better power grid to deliver huge amounts of electricity by using IoT, BigData and RPA as per the requirements of customers.
c.
In order to achieve emerging technologies in ARS farms, specific applications of IoT will be effective for the development of smart energy production to produce electricity.
Reference list:
Do?uç, Ö. (2021). RPA in Energy and Utilities.In Strategic Approaches to Energy Management (pp. 217-230).Springer, Cham.https://link.springer.com/chapter/10.1007/978-3-030-76783-9_16
Kim, Y. S., Joo, H. Y., Kim, J. W., Jeong, S. Y., & Moon, J. H. (2021). Use of a big data analysis in regression of solar power generation on meteorological variables for a Korean solar power plant.Applied Sciences, 11(4), 1776.https://www.mdpi.com/2076-3417/11/4/1776/pdf
Nguyen, T. P., Nguyen, H., Phan, V. H., & Ngo, H. Q. T. (2021).Modelling and practical implementation of motion controllers for stable movement in a robotic solar panel dust-removal system.Energy Sources, Part A: Recovery, Utilisation, and Environmental Effects, 1-23. https://www.tandfonline.com/doi/abs/10.1080/15567036.2021.1934194
Spanias, A. S. (2017, August). Solar energy management as an Internet of Things (IoT) application.In 2017 8th International Conference on Information, Intelligence, Systems & Applications (IISA) (pp. 1-4).IEEE.https://par.nsf.gov/servlets/purl/10076703
Assignment
Research & Data Modelling Assignment Sample
Assessment Brief
Value: 15%
Due Date: 04-Apr-2021
Return Date: 27-Apr-2021
Group Assessment: No
Submission method options: Alternative submission method
TASK
Part A: Database Research Discussion Forum (7 Marks)
You are to conduct research about a current or a future database technology and
discuss the findings of your research in the Interact 2 Discussion forum. You should submit a minimum of two posts. You are also to comment in the Interact 2 Discussion forum on at least two posts made by other students. Copy the time, date and content of your posts and include them in a MS Word document as part of this assessment. Two discussion posts of a current or a future database technology and two comments on other students posts (4 marks) Quality of engagement: (3 marks)
Part B: Data Modelling (8 Marks)
XYZ is a company which organises conferences mainly in the computing area. Due to the success of their business, they have decided to implement a relational database for better management of the conferences. For each conference, they need to keep records of the conference code, conference dates, conference name, days duration, and venue. XYZ are required to keep track of all the past attendees identified by participant id, as they are going to send advertising materials on topics which may interest the participants to attend a conference in the future. Thus, details such as name, phone number, and address of the participants are required. XYZ needs to track details of who attended a conference in the past and the number of days attended. XYZ also keep track of all the speakers who have spoken, or are potential speakers for their conferences. Information including speaker id, name, phone number, topic id and topic name are required. For each conference, XYZ gives a rating to a speaker. XYZ also have a list of casual catering staff who can be booked to provide catering services. XYZ needs to store their id no, name, phone, position (eg. chef) and the hours worked at each conference. And lastly, XYZ has a list of the venues and other information related to a venue such as venue id, seating capacity, seating style, fax, and phone number.
Your task for assignment help.
Create an ERD for the above scenario that describe the current business rules:
Use Crow's Foot notations and make sure to include all of the following:
• All entities Attributes for each entity
• Primary key and any foreign key attributes for each entity
• The relationships between entities
• The cardinality and optionality of each relationship
For guidance on how to draw an ERD based on business rules, watch this video: https://www.youtube.com/watch?v=YvJ4t9_2SWk
To draw the diagrams, you should use a drawing tool like Draw.io, Lucidchart,
LibreOffice Draw etc. Hand-drawn diagrams are NOT acceptable.
Include your student ID and full name under the ERD then copy the whole ERD as
an image to your Word document.
Solution
PART- A
Future Database Technology
Post-1: Today, the significance of database system has increased in the implementation of diverse database applications. Database system comprises of many components which enables the development of database application according to requirement. For designing of database, numerous database models (ER model, Relational model, Object oriented mode, network model etc.) are used in respect of requirement types. In previous few years, it has observed that new database model evolved named multidimensional model which allow data representation in cubic form. Multidimensional model used in defining of data-warehousing. The integration of database technology with other information technologies results new kind of database system such as mobile database system, spatial, multimedia, Decision Support System and Distributed database system. Several information technologies used in implementation of advanced database system such as business intelligence, data warehouses, Extract Transformation & Load (ETL), OLAP, Data Mining, Grid Computing and Web Technology.
Post-2: Due to rapid evolution of computing peripherals and paradigms, database technology also require to align with this evolution. According to scalable and global access of database application over the internet require modern database approach and their implementation. For example develop distributed database application for cloud environment. Future database technology must be able to storing and analyzing diverse and high volume of heterogeneous data. It also requires revising current database approaches according to network based applications. Several data service providers such as Google, Facebook and Amazon deal with peta-bytes of data every day. This all happens by use of modern database technology. With this, implementation technology of database system is also changing over the period of time. The database implementation platforms and languages are evolved from QUEL, SQL, SQL92, OQL and XML. Apart from this, database technology research also focus on emerging field such as Big Data, Grid Computing, Web Technology and Business Intelligence.
PART- B
Entity Relationship Diagram
Based on the information provided in the case study several entities, its attributes with key constraints and relationships are identified.
All Entities
• Conference
• Attendee
• Speaker
• Catering Staff
• Venue
Attributes for each entity: Entity Name (Attribute Name [Type or Key ])
• Conference (Conference_Code [Primary Key attribute], Conference_Name, Conference_Date, Days, Duration, Venue [Foreign key referenced Venue_Id (Venue)])
• Attendee (Participant_Id [Primary Key attribute], Participant_Name, Phone_No [Multivalued Attribute] ,Address [Composite Attribute], Conference_Code [Foreign Key references Conference_Code(Conference)])
• Speaker (Speaker_Id (Primary Key attribute), Speaker_Name, Phone_No [Multivalued Attribute], topic_id,topic_name)
• Catering_Staff (Staff_Id ( Primary Key attribute), Staff_Name, Phone_No [Multivalued Attribute] , Position)
• Venue (Venue_Id (Primary Key attribute), Seating_Capacity, Seating_Style, Fax, Phone_No [Multivalued Attribute])
Relationships (Participating Entities)
• “Attended” Relationship (Attendee and Conference for each participant attended one or more conference)
• “Organized at” Relationship (Conference and Venue for each conference organized at a venue)
• “Get Rating” Relationship (Speaker and Conference where each speaker have assigned a rating for each conference)
• “Work_for” Relationship (Catering_Staff and Conference where catering staff work for each conference in number_of_hours )
Cardinality and Optionality of Each Relationship
• For “Attended” relationship, Many to Many (M:N) cardinality and optional for attending conference but mandatory for conference that means each conference has at-least one participant.
• For “Organized at” relationship, Many to One (M:1) cardinality and mandatory for conference that organized at least one venue but venue is optional it means no need of every venue used in conference.
• For “Get Rating” relationship, one to one (1:1) cardinality and mandatory for both speaker as well as conference.
• For Work_for” relationship, Many to Many (M:N) cardinality and optional both catering_staff and conference.
Entity Relationship Diagram (ER Diagram)
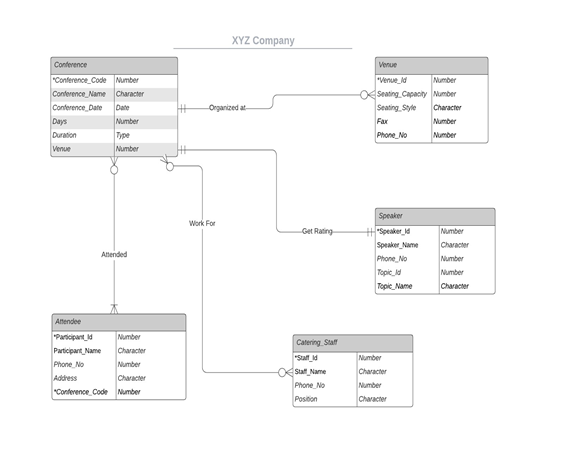
Assignment
ITC573 Data Knowledge and Engineering Assignment Sample
Assignment Brief
Value: 20%
Group Assessment: No
Submission method options: Alternative submission method
TASK
For this task, you are required to download the Airlines dataset which is available in the Massive Online Analysis (MOA) framework. You will need to access the airlines. arff file. Moreover, you are required to download the MOA (https://sourceforge.net/projects/moa- data stream/) software for this task.
Answer the following short answer questions based on the given dataset.
Knowledge obtained through all topics from Topic 1 to Topic 9, particularly Topic 8 and Topic 9 can be useful for assignment help to answering the questions.
Q1. Data Pre-processing [10 marks]
1. Assume that the Airlines dataset has some missing values. Out of the missing value imputation techniques (i.e. Mean Imputation, EMI and DMI) discussed in this subject, which technique do you prefer to use for the Airlines dataset? Why? [5 marks]
2. Again assume that the Airlines dataset has some missing values and some corrupt values. Do you prefer to handle the missing values before handling the corrupt values? Why? [5 marks]
Q2. Incremental Learning [10 marks]
You are required to perform a data mining task to evaluate different incremental learning algorithms. Load the airlines. arff data set into MOA and compare the performance on this data set for the following algorithms:
• HoeffdingTree
• Adaptive Random Forest
• Hoeffding Adaptive Tree
• Leveraging Bagging
Write a response that shows the performance of the different algorithms and comment on their performance using the classification accuracy and other performance metrics used in MOA. In your report consider:
• Is there a difference in performance between the algorithms?
• Which algorithm performs the best?
Your response should include the necessary screenshots, tables, graphs, etc. to make your report understandable to the reader. The recommended word length for the report is 700 to 1000 words.
SUBJECT LEARNING OUTCOMES
This assessment task will assess the following learning outcome/s:
1. be able to compare and critique various data pre-processing techniques.
2. be able to evaluate the usefulness of data cleansing and pre-processing in discovering useful knowledge necessary for critical business decision.
3. be able to evaluate and compare time series data mining approaches for business decision making.
You MUST prepare and present all text answers to the above tasks in a single document file. All images must also be embedded into the document. All files such as your response to the assignment tasks and Turnitin reports will all be in a single directory, identified by your name.
REQUIREMENTS
Your response to each of the questions such as Q1. a and Q1. b should be no longer than 500 words (excluding figures, tables and graphs). Administrative sections of your assessment such as headings, table of contents, reference list and other diagrams and figures are not included in the word count. In text citations are included as part of your word count. Please note that the length of an answer is not very important. The quality and completeness of an answer is important.
For this assessment you’re required to use APA7 referencing to acknowledge the sources that you have used in preparing your assessment. Please visit Referencing at CSU for guidance. In addition, a very useful tool for you to use that demonstrates how to correctly use in-text referencing and the correct way to cite the reference in your reference list is the Academic Referencing Tool (ART).
This assignment must be uploaded to Turnitin. Students will need to download the Turnitin report and submit it via Turnitin along with the assignment. More information on using Turnitin at CSU can be found at https://www.csu.edu.au/current-students/learning-resources/information- planning/assignments/plagiarism-checking
Solution
Introduction
The paper aims to evaluate the data mining models in incremental learning using Massive Online Analysis or MOA tool. In this context, the Airline data has been selected on which the data mining algorithms will be applied after preprocessing it.
Data Pre-processing
Primarily, the discussion about the data pre-processing will be done in this section. One of the most important data preprocessing is the missing data handling without which the data mining algorithm will not respond properly (Tahir & Loo, 2020).
Computation on Missing Values
The data has been collected in ARFF (Attribute Relational File Format) and loaded in MOA. It has not been seen that there are any missing values. However, if the data will contain missing values, there are three ways to handle this and those are as follows:
1. Replace missing values by mean
2. Replace missing values with EMI
3. Replace missing values with DMI
When the EMI (Expected Maximization Imputation) is applied to the data, the missing data will be replaced by the most occurred values in the feature. If this will be done, the central tendency of the data may be changed and for the continuous variable, it will not work properly as the mode is not a valid computation for continuous variables. On the other hand, Decision Tree-Based EMI method is used to replace the missing values by creating the decision tree model and signifying the value at each node (Beaulac & Rosenthal, 2018). So, the DMI method is time-consuming for large datasets. When the missing data is replaced by the mean value of the features, the central tendency is maintained. However, replacing missing values for categorical or nominal features, mean will not work. As airline data contain both the continuous and nominal features, both mean values (for continuous) and the EMI method (for nominal) will have to be used (Islam, 2011).
Corrupt values are not similar to missing values. In most cases, corrupt values come in the form of special characters such as “?” etc. Those characters are not traced when missing values is found as those are not the missing values and rather treated as the valid member of those features with wrong values (Zhu & Wu, 2020). If those values are not replaced, those values will produce the wrong outcome of the data analysis and finally in the application of data mining algorithms. So, those corrupt values in the data need to be removed to make the dataset cleaned and without any kind of the wrong valuation. So, before missing value treatment, the corrupt values need to be converted to missing values or NaN values so that those will be traced at the time of finding the missing values (Ghalib Ahmed Tahir, 2020). So, finally, it will be easier to trace all the missing values and can be replaced by a suitable method.
So, in view of the thought, the corrupt values need to be converted to missing values first and then the imputation of missing values should be done.
Incremental Learning
In this section, the incremental learning methods will be applied to the airline data and the performances will be observed.
Hoeffding Tree
Primarily, the Hoeffding Tree has been applied to the airline data and classified to determine the flight delay (Guo, Wang, Fan, & Li, 2019). The screenshot of the application of this algorithm in MOA is shown below:
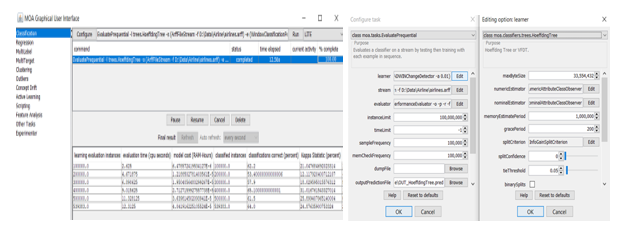
Fig-1: Application of Hoeffding Tree
After applying the algorithm, the following outcome has been obtained graphically as follows:
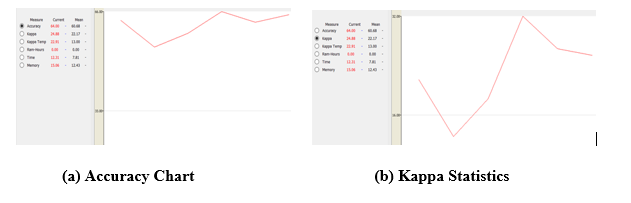
Fig-2: Visualization of Performance for Hoeffding Tree
After applying the Hoeffding Tree, the classification matrics have been stored and enlisted in the following table:
Table-1: Classification Metrics for Hoeffding Tree
Adaptive Random Forest
The Adaptive Random Forest has been applied to the airline data and classified to determine the flight delay. The screenshot of the application of this algorithm in MOA is shown below:
Fig-3: Application of Adaptive Random Forest
After applying the algorithm, the following outcome has been obtained graphically as follows:

Fig-4: Visualization of Performance for Adaptive Random Forest
After applying the Hoeffding Tree, the classification matrics have been stored and enlisted in the following table:
Table-2: Classification Metrics for Adaptive Random Forest
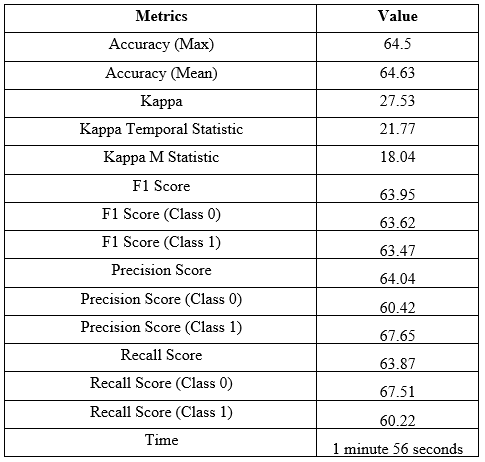
Hoeffding Adaptive Tree
The Hoeffding Adaptive Tree has been applied to the airline data and classified to determine the flight delay (Tahir & Loo, 2020). The screenshot of the application of this algorithm in MOA is shown below:
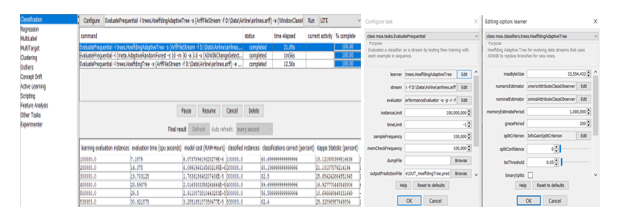
Fig-5: Application of Hoeffding Adaptive Tree
After applying the algorithm, the following outcome has been obtained graphically as follows:
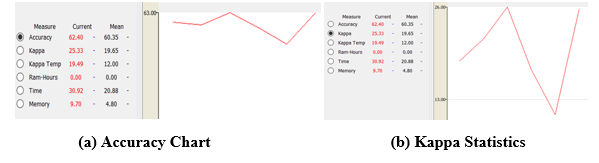
Fig-6: Visualization of Performance for Hoeffding Tree
After applying the Hoeffding Tree, the classification matrics have been stored and enlisted in the following table:
Table-3: Classification Metrics for Hoeffding Adaptive Tree
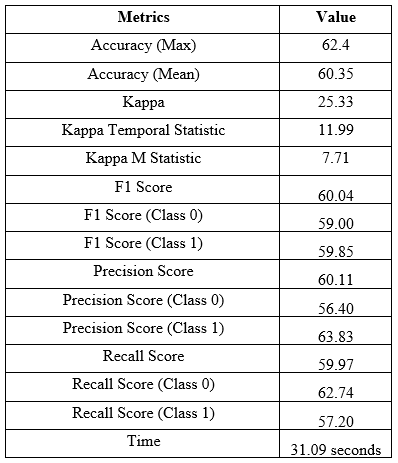
Leveraging Bagging
The Leveraging Bagging has been applied to the airline data and classified to determine the flight delay. The screenshot of the application of this algorithm in MOA is shown below:
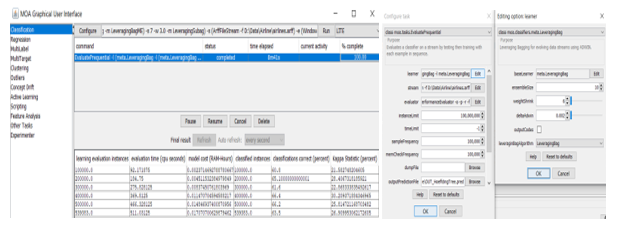
Fig-7: Application of Leveraging Bagging
After applying the algorithm, the following outcome has been obtained graphically as follows:
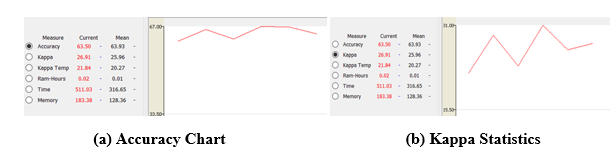
Fig-8: Visualization of Performance for Leveraging Bagging
After applying the Hoeffding Tree, the classification matrics have been stored and enlisted in the following table:
Table-4: Classification Metrics for Leveraging Bagging
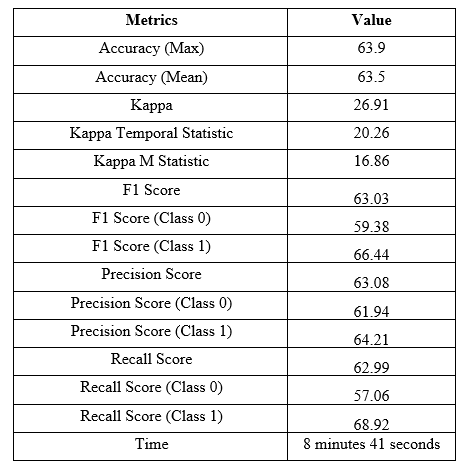
Finding and Conclusion
The algorithms have been applied to the airline data for the classification of flight delays. While applying the classifiers, the performance matrices have been recorded so that those can be compared to find the best one. From the overall experiment, the following finding has been obtained:
1. The performance of the chosen classifier differs from each other. The accuracy, precision, recall and f1-scores (Overall values and also by class) are different from each of the classifiers that prove the fact that the performances of classification are different from each other.
2. From the comparison of accuracy, it has been seen that the highest accuracy has been obtained from Adaptive Random Forest by 64.3% with the kappa value of 27.33% and precision by 64.04%. The execution time for Adaptive Random Forest (34 seconds) is also comparatively lower with higher accuracy.
References
Beaulac, C., & Rosenthal, J. S. (2018). BEST : A decision tree algorithm that handles missing values. University of Toronto, 1-22.
Ghalib Ahmed Tahir, C. K. (2020). Mitigating Catastrophic Forgetting In Adaptive Class Incremental Extreme Learning Machine Through Neuron Clustering. Systems Man and Cybernetics (SMC) 2020 IEEE International Conference, 3903-3910.
Guo, H., Wang, S., Fan, J., & Li, S. (2019). Learning Automata Based Incremental Learning Method for Deep Neural Networks. IEEE Access, 1-6.
Islam, M. G. (2011). A Decision Tree-based Missing Value Imputation Technique for Data Pre-processing. Proceedings of the 9-th Australasian Data Mining Confere, 41-50.
Tahir, G. A., & Loo, C. K. (2020). An Open-Ended Continual Learning for Food Recognition Using Class Incremental Extreme Learning Machines. IEEE Access, 82328 - 82346.
Zhu, H., & Wu, Y. (2020). Inverse-Free Incremental Learning Algorithms With Reduced Complexity for Regularized Extreme Learning Machine. Access IEEE, 177318-177328.
Coursework
COMP1629 Penetration Testing Assignment Sample
Coursework Submission Requirements
• An electronic copy of your work for this coursework must be fully uploaded on the Deadline Date of Friday 13/03/2020 using the link on the coursework Moodle page for COMP1629.
• For this coursework you must submit a single PDF document. In general, any text in the document must not be an image (i.e. must not be scanned) and would normally be generated from other documents (e.g. MS Office using "Save As .. PDF"). An exception to this is hand written mathematical notation, but when scanning do ensure the file size is not excessive.
• There are limits on the file size (see the relevant course Moodle page).
• Make sure that any files you upload are virus-free for assignment help and not protected by a password or corrupted otherwise they will be treated as null submissions.
• Your work will not be printed in colour. Please ensure that any pages with colour are acceptable when printed in Black and White.
• You must NOT submit a paper copy of this coursework.
• All coursework must be submitted as above. Under no circumstances can they be accepted by academic staff
The University website has details of the current Coursework Regulations, including details of penalties for late submission, procedures for Extenuating Circumstances, and penalties for Assessment Offences. See http://www2.gre.ac.uk/current-students/regs
Coursework specification
Task 1 [15 marks]
Following a web application penetration testing engagement you have identified the following issues. You must complete the issue justification/explanation/CVEs/Vulnerability type as required and write appropriate recommendations for addressing each of the issues identified. You will need to conduct research on the nature and implications of these issues in order to complete the justification/explanation and recommendations. You must use the following issue templates provided. Assume that under “Results” section an actual screen capture or other evidence exists obtained during the assessment exists.

Task 2 [20 marks]
During a build review one of your colleagues acquired the following evidence but did not have time to write up the actual issues (there are two issues). Your task is to write up these issues using the template from Task 1. Hint: These are low rated issues.

Task 3 (65 marks)
As part of this engagement your lecturer will provide you with access to a group of systems (VM based or actual systems or both). You will have, depending on the scenario details, to assess the security of these systems within a given timeframe. There might be certain rules that you might need to follow during testing and these will be provided with the scenario details. An example of this might be” Perform a non-intrusive test” or “Keep bandwidth within or below a certain threshold”. Failing to adhere to any of these scenario rules will result to an automatic mark penalty, details of which will be provided with the scenario.
During the assessment period you will have to run various tools (as required), verify your results and gather all required evidence as needed (e.g. take screen captures, save the output of any tools used etc) so that later you can complete your report (a technical report with your findings using the template that you lecturer will provide). Automated tools such as Nessus, Quallys etc. should not be used for the reporting of the vulnerabilities.
Deliverables
Task 1,2 & 3: A completed professional technical report based on the template that will be provided by your lecturer.
Assessment criteria
Task 1 [15 Marks]
Task 2 [20 Marks]
Task 3 [65 Marks]
Marks may be deducted for:
Lack of technical depth, poor presentation, lack of tables, screen captures that do not provide adequate information or with relevant sections not highlighted as needed, screenshots that are not cropped appropriately, poor tool options, poor tool output explanation, poor recommendation, lack of professionalism in the answers provided, poor spelling/grammar, lack of integration/poor flow, poor references/appendices.
Marks will be awarded for:
Completeness, good technical content and depth and good report writing (including good use of English). Please make sure that you proofread your work. An appropriate professional report structure and presentation is expected.
Solution
1. Overview
The overview of the project describes the internet security of a banking organization carried out by a private firm. Several security testing tools will be used in the study. The test of penetration helps the organization in improving its cyber-security. Technically, these tests may not provide complete solutions of security for the organization but can reduce the probability of malicious attacks to systems.
1.1. Introduction
Cybersecurity penetration testing characteristically classifies the physical systems along with a particular goal that examines the available evidence and reveals the hidden information. For the situation of the XXX Bank network frameworks, the infiltration target is a grey box entrance test since it recognizes the change of the white box and black box. This is in the embodiment that the testing crew operations are from the comprehension of a trespasser who is outside to the business. Subsequently, the infiltration analyzer starts by distinguishing the organization map, the security apparatuses executed, the web confronting sites and administrations, among different angles.
1.2. Key Findings and Recommendations
Although, the source of such data is a lot significant for the analyzers to comprehend in the event that it began from metro bases or if the assailant is a disappointed laborer or ex-specialist who has the association's security data; for discovery testing. This is fundamental for XXX’s organization framework since it helps the testing team to examine the specific wellspring of spillage of the security data framework that is utilized by programmers. The white box testing is worried about interior applications that are predetermined for use by workers as it were (Yaqoob et al. 2017). For this situation, the testing bunch is furnished with all accessible objective data, counting the source code of the web utilization of the XXX Bank. Henceforth, examining and observation take a brief timeframe. Notwithstanding, the interface between the two testing boxes; the highly contrasting, is that since the XXX’s network framework is an inner application and given the security data of the framework is as it was controlled by the representatives. Accordingly, on the off chance that one representative is disappointed or terminated, the person in question may release the data to programmers. Subsequently, it is simple for them to pinpoint the shortcomings existing in the organization framework.
This establishes the grey box testing, which is fundamentally expected for testing site applications and is refined by assessing the laborer records to recognize how the assailant got access to the organization framework. The piece of the high contrast testing procedures will accordingly help the entrance analyzers effectively understand the objective framework, hence potentially uncover more generous susceptibilities; with not as a lot of exertion and cost. Since it syndicates the commitment of creators of the organization framework and the analyzers, consequently the item greatness of the framework is moderately overhauled (Furdek and Natalino 2020). Again, since less time is taken in acknowledgment of the specific wellspring of data for programmers, the originator, subsequently, has a ton of available energy to fix the imperfections.
1.3. Summary of Findings
In this experiment, several vulnerabilities that have been discovered through the finding of the study is Apache (Debian), X-XSS-Protection header, X-Content-Type-Options header, Uncommon header 'link' found with multiple values, Apache/2.4.10 appears to be outdated, No CGI Directories found, WordPress Akismet plugins. The followed findings are the coordination of the organization site that are broken down by design testing, to guarantee that the past security dangers or imperfections of the framework are checked on. In this way, the reasons for the earlier disappointment are recognized, and hence the experiments are proposed for discovering different discontents prior to striking creation. This guarantees the improved security of the information put away in that specific organization framework (Alzahrani 2018). Moreover, relapse testing of the product helps in guaranteeing that the recently presented highlights of the framework don't influence the security use of the framework, which may spill data to programmers.
2. 2. Task 1
2.1. CVE
Apache Debian: A vulnerability has been found in Apache HTTP Server 2.4.10 At the point when HTTP/2 was empowered for an HTTP: host or H2Upgrade was empowered for h2 on an HTTPS server (Seyyar, Çatak and Gül 2018). Therefore, having an Upgrade demand from http/1.1 to http/2 on XXX’s system server, has prompted a misconfiguration and cause a crash. The websites that never empowered the h2 convention or that solitary empowered it for HTTPS: and didn't set "H2Upgrade on" are not impacted by this problem.
X-XSS-Protection header: A missing X-XSS-Protection header has been found, which implies that XXX's website could be in danger of a Cross-webpage Scripting (XSS) assault. This issue is accounted for as extra data as it was. There is no immediate effect emerging from this issue.
X-Content-Type-Options header: A missing Content-Type header has been discovered, which implies that XXX's site could be in danger of a MIME-sniffing assault. The X-Content-Type-Options header is utilized to ensure against MIME sniffing risks (Petkova 2019). These risks have happened when the site permits clients to transfer the substance to a site anyway the client camouflages a specific document type as something different.
Apache/2.4.10 appears to be outdated: There are certain risks that have been found regarding Apache/2.4.10. The Apache HTTP Server 2.2.22 and its mod_headers module permits distant aggressors to sidestep unsetdirectives of RequestHeader by implementing a header in the trailer bit of sent information with partially moving code. A race condition in the mod_status module in the Apache HTTP Server 2.4.10 permits the remote aggressors to cause a rejection of administration, which is basically a stack-based support flood through a developed request that triggers inappropriate scoreboard taking care of inside the status_handler work in modules/generators/mod_status.c and the lua_ap_scoreboard_site in modules/lua/lua_request.c.
The Apache HTTP Server 2.4.10 and its mod_cgid module don't have a break component, and so it permits the distant attackers to cause a refusal of administration in XXX’s website by soliciting the CGI contents that don't peruse from its stdin document descriptor.
No CGI Directories found: A break in XXX's site results from feeble CGI contents can happen in an assortment of ways. This might be through accessing the source code of the content and discovering weaknesses contained in it, or by survey data showing registry structure, usernames, as well as passwords (Hamza et al. 2019). By controlling these contents, a programmer can adjust or see touchy information, or even shut down a worker so clients can't utilize the site. As a rule, the reason for poor CGI content can be followed back to the individual who composed the program. Notwithstanding, by following great coding rehearses, one can keep away from such issues and will actually want to utilize CGI programs without trading off the security of the site.
WordPress Akismet plugins: From XXX's website frameworks, a basic XSS vulnerability has been found, which has been influencing Akismet, a mainstream WordPress module conveyed by a great many introduces. This weakness influences everybody utilizing Akismet form 3.1.4 in plain view" alternative empowered which is the situation as a matter of course on any new WordPress establishment (Currie and Walker 2019). The issue can be found in the manner Akismet manages hyperlinks present inside the site's remarks, which could permit an unauthenticated assailant with great information on WordPress internals to embed vindictive contents in the Comment part of the organization board. Doing this could prompt various abuse situations utilizing XSS
3. 3. Task 2
3.1. Issues
After analyzing the server of the organization various network vulnerabilities have been detected by the NTA Monitor Ltd. One of the essential vulnerabilities is found that is the Apache/2.4.10. In this type of vulnerability, various forms of malicious attacks and issues are associated with the network. Some of the issues are the SQL injection, Apache Ranger Security Bypass, and Authentication Bypass. SQL injection is the most common attacking factor that uses malicious SQL code to manipulate the database of the organization (Batista et al. 2019). Here, the database may include sensitive data information and customer details. If the SQL injection is successfully implemented on the server of the organization, then unauthorized access can be launched on the server of the organization by the external attackers. This type of attack may cause both financial and reputation loss for the organization. SQL language can execute commands, data retrieval, and updates on the organization server. There are three types of SQL injection that are In-band SQLi, Out-of-band SQLi, and Inferential SQLi. The same channel is used to launch the attack in the In-band SQLi and this is the simple and efficient type of attack.
While the security bypass is another major issue for the Apache Ranger. Security measures can be avoided by the Apache Ranger. However, a widely employed framework can be enabled by the Apache Ranger to monitor and access the network of the organization. On the other hand, user authentication can also be manipulated by the security threat.
Another malicious technique that is found on the company server is Clickjacking (Possemato et al. 2018). Using this type of attack, an attacker can hack the credentials of the customers who access the company website. The same interface is presented in front of the users. After clicking on the link, all the credentials of the customer are hacked by the hacker. In this type of attack, the X-Frame option does not return to the server. X-XSS-Protection is not defined in the header which is the feature of the modern web browser. This feature mainly protects websites from unprotected links and cyber threats.
Another issue that was raised during the security testing is the missing X-Content-Type-Option. This vulnerability can cause the MIME-sniffing from the declared content. On the other hand, some uncommon header links are found on the company server. This can create a disturbance on the network by initiating the attacking factors. However, the CGI directories are not found on the company server which is essential for configuring the webserver and files.
4. 4. Non-Intrusive Test
4.1. Tool Used
Nmap: Nmap, short for Network Mapper, is one kind of open source and free instrument for vulnerability checking and network revelation. Organization executives use Nmap to distinguish what gadgets are running on their frameworks, the finding has that are accessible and the administrations they offer, discovering open ports, and recognizing security chances. In this project, NMAP has been utilized to checking the vulnerability of the server (Rohrmann, Ercolani and Patton 2017). Nmap also can be utilized to screen single has just as huge administrations that include a large number of gadgets and large numbers of subnets. Despite the fact that Nmap has established during the long term and is incredibly adjustable, on an essential level it's a port-check instrument, collecting data by transfer crude parcels to framework ports. If the ports are open, then the security attack can be triggered on the server of the organization. It tunes in for reactions and decides if ports are open, shut, or sifted here and thereby, for instance, a firewall. Port checking can be identified by the number of the open ports.
Nmap scan
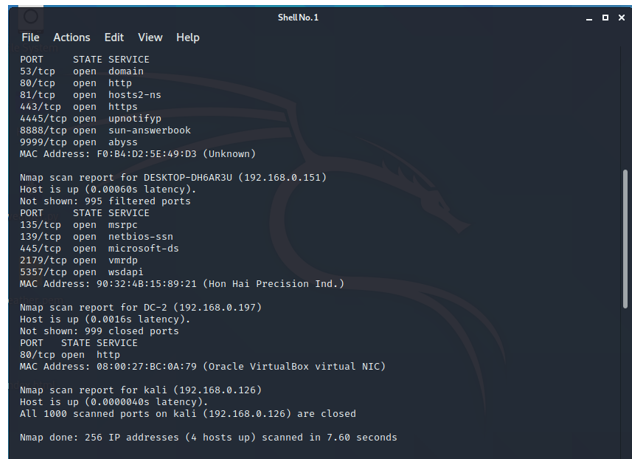
Nikto
Nikto is an open-source scanner where users can utilize it with any websites like Litespeed, OHS, HIS, Nginx, Apache, and others. It is an ideal internal mechanism for filtering websites (Kim 2017). It is fit for filtering for more than 6700 things to identify misconfiguration, unsafe records, and so forth and a portion of the highlights incorporate;
User can store the reports in CSV, XML and HTML formats
• It upholds Secure Socket Layer
• Sweep numerous ports on the sites
• Find subdomain
• Apache client identification
• Verifies for obsolete segments
• Identify stopping locales
There are numerous approaches to utilize Nikto.
• Utilizing binary on UNIX-based distro or Windows.
• Utilizing Kali Linux
• Docker compartment
• Nikto scan
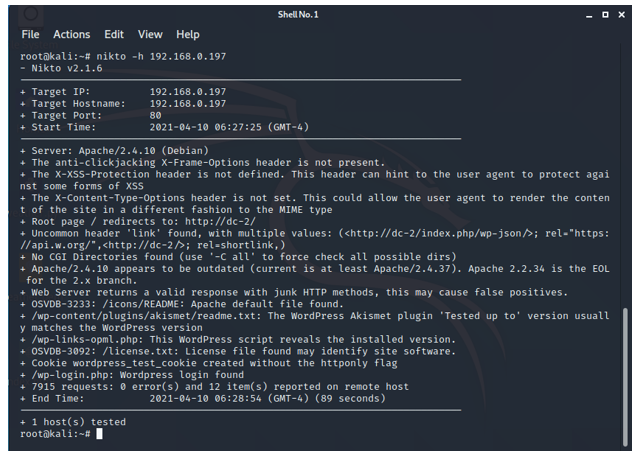
-Nikto v2.1.6
Nikto v2.1.6
---------------------------------------------------------------------------
+ Target IP: 192.168.0.197
+ Target Hostname: 192.168.0.197
+ Target Port: 80
+ Start Time: 2021-04-10 06:27:25 (GMT-4)
---------------------------------------------------------------------------
+ Server: Apache/2.4.10 (Debian)
+ The anti-clickjacking X-Frame-Options header is not present.
+ The X-XSS-Protection header is not defined. This header can hint to the user agent to protect against some forms of XSS
+ The X-Content-Type-Options header is not set. This could allow the user agent to render the content of the site in a different fashion to the MIME type
+ Root page / redirects to: http://dc-2/
+ Uncommon header 'link' found, with multiple values: (<http://dc-2/index.php/wp-json/>; rel="https://api.w.org/",<http://dc-2/>; rel=shortlink,)
+ No CGI Directories found (use '-C all' to force check all possible dirs)
+ Apache/2.4.10 appears to be outdated (current is at least Apache/2.4.37). Apache 2.2.34 is the EOL for the 2.x branch.
+ Web Server returns a valid response with junk HTTP methods, this may cause false positives.
+ OSVDB-3233: /icons/README: Apache default file found.
+ /wp-content/plugins/akismet/readme.txt: The WordPress Akismet plugin 'Tested up to' version usually matches the WordPress version
+ /wp-links-opml.php: This WordPress script reveals the installed version.
+ OSVDB-3092: /license.txt: License file found may identify site software.
+ Cookie wordpress_test_cookie created without the httponly flag
+ /wp-login.php: Wordpress login found
+ 7915 requests: 0 error(s) and 12 item(s) reported on remote host
+ End Time: 2021-04-10 06:28:54 (GMT-4) (89 seconds)
---------------------------------------------------------------------------
+ 1 host(s) tested
5. 5. Conclusion
In this report, a security testing has been illustrated on the server of the XXX bank by the NTA Monitor Ltd. After analyzing the server of the organization, various security vulnerabilities have been found that can damage the entire network of the organization. There are various types of vulnerabilities found that are Apache Ranger, anti-clickjacking, X-XSS-Protection, uncommon vulnerabilities, and word press. The organization needs to take some preventive actions in order to mitigate all the security threats on the server.
References
Alzahrani, M.E., 2018, March. Auditing Albaha University network security using in-house developed penetration tool. In Journal of Physics: Conference Series (Vol. 978, No. 1, p. 012093). IOP Publishing.
Batista, L.O., de Silva, G.A., Araújo, V.S., Araújo, V.J.S., Rezende, T.S., Guimarães, A.J. and Souza, P.V.D.C., 2019. Fuzzy neural networks to create an expert system for detecting attacks by sql injection. arXiv preprint arXiv:1901.02868.
Currie, J. and Walker, R., 2019. What do economists have to say about the Clean Air Act 50 years after the establishment of the Environmental Protection Agency?. Journal of Economic Perspectives, 33(4), pp.3-26.
Furdek, M. and Natalino, C., 2020, March. Machine learning for optical network security management. In 2020 Optical Fiber Communications Conference and Exhibition (OFC) (pp. 1-3). IEEE.
Hamza, M., Atique-ur-Rehman, M., Shafqat, H. and Khalid, S.B., 2019, January. CGI script and MJPG video streamer based surveillance robot using Raspberry Pi. In 2019 16th International Bhurban Conference on Applied Sciences and Technology (IBCAST) (pp. 947-951). IEEE.
Kim, B.H., 2017. Web Server Information Gathering and Analysis using Nikto. JOURNAL OF ADVANCED INFORMATION TECHNOLOGY AND CONVERGENCE, 7(1), pp.11-17.
Petkova, L., 2019. HTTP SECURITY HEADERS. Knowledge International Journal, 30(3), pp.701-706.
Possemato, A., Lanzi, A., Chung, S.P.H., Lee, W. and Fratantonio, Y., 2018, October. Clickshield: Are you hiding something? Towards eradicating clickjacking on Android. In Proceedings of the 2018 ACM SIGSAC Conference on Computer and Communications Security (pp. 1120-1136).
Rohrmann, R.R., Ercolani, V.J. and Patton, M.W., 2017, July. Large scale port scanning through tor using parallel Nmap scans to scan large portions of the IPv4 range. In 2017 IEEE International Conference on Intelligence and Security Informatics (ISI) (pp. 185-187). IEEE.
Seyyar, M.B., Çatak, F.Ö. and Gül, E., 2018. Detection of attack-targeted scans from the Apache HTTP Server access logs. Applied computing and informatics, 14(1), pp.28-36.
Yaqoob, I., Hussain, S.A., Mamoon, S., Naseer, N., Akram, J. and ur Rehman, A., 2017. Penetration testing and vulnerability assessment. Journal of Network Communications and Emerging Technologies (JNCET) www. jncet.
Case Study
ITC508 Information Technology Assignment Sample
Assessment 2 - Inception and Elaboration Phase
Value: 25%
Due Date: 04-Apr-2021
Return Date: 27-Apr-2021
Length: 1500 - 2000 words
Group Assessment: No
Submission method options: Alternative submission method
TASK
You are provided with a case study about a business that needs the development of a modern information system to support its day to day operations. In your role as System Analyst, you will help the business in the development of the new information system. Please refer to the Interact2 Resources for the Case study; Read the detailed document and then complete the following task. You will use the same case study to complete assignment 2 and assignment 3.
Inception phase: 10 marks
In the inception phase of the project, your goal is to investigate the scope of proposed business information system in the given case study. To present your understanding of the project, you are required to submit a System Vision Document which includes the following sections
• Project Introduction
• Important system capabilities
• Perceived business benefits
• Resources required
• Stakeholder map
Elaboration phase: 15 Marks
In the elaboration phase of the project, you are required to prepare a report that elaborates the project requirements in detail and illustrate those requirements using UML models. For this purpose, you should attempt the following tasks:
• Identify use cases and draw use case diagram(s) for the new information system that shows major use cases and actors.
• Write one fully developed use case description for one of the important use cases identified. Select an important use case that is a key part of the system, not a basic simple one.
• Draw the UML domain model class diagram(s) for the new information system. Be as specific and accurate as possible, given the information provided. If needed information is not provided, make realistic assumptions.
RATIONALE
This assessment task will assess the following learning outcome/s:
• be able to explain and apply the concepts of object orientation methodology.
• be able to describe the relationship of analysis and design activities to the System Development Life Cycle (SDLC).
• be able to analyse a case study and construct a business proposal to argue the feasibility of a client software proposal.
• be able to analyse system requirements to determine the use cases for the creation of a domain model of the problem domain.
• be able to create analysis and design diagrams with UML notation.
• be able to model various aspects of systems to construct quality diagrams for use in a system development project.
Case study for assignment help
Vallée de Goût’ is a French cuisine restaurant located in outer suburbs Sydney, offering a luxurious and contemporary fine dining experience. Thanks to maintaining their quality standards, their business has been growing steadily. But for the past few months their venue has been getting overcrowded during weekends.
This has impacted the customer service quality, for example, due to delays in order preparation, mistakes in orders or bills etc. The management firmly believes that an existing customer is worth more to a businessthan a new customer, because the cost to attract a new customer can be multiple times higher than the cost to retain an old customer. A customer is likely to return to a restaurant, if they receive an excellent customer service as well as appetising food. However, the restaurant would easily loose the customers if they have to wait for an unreasonable amount of time or there was a mistake in their order.
To solve these problems, firstly the management has convinced ownersto relocate to a bigger venue nearby. Secondly, the management would like to upgrade to a sophisticated information system at the same time. Their current information system has become a hurdle in smooth business operations because of very limited features. For the past two weeks, the business manager has been evaluating multiple off-the-shelf systems for Vallée. But he came to the conclusion that all of those systems are quite generic; those will require excessive
customization to adapt to some of the Vallée requirements, while lacking some important features. Therefore the restaurant manager have decided to get a custom integrated system developed that better fits their business needs. Your company ‘Hospitality Innovations’ has won the contract Vallée’s software on the basis of extensive experience in developing restaurant related softwares. You and your team have had several meetings with restaurant staff and they have communicated to you their system requirements. You were provided an opportunity to observe day to day restaurant operations, and then interviewed all the potential users of the proposed system (managers, cooks, waiters etc.) in order to get as clear idea of the requirements as possible.
Once you got a clear idea of the system requirements, you propose the new information system to be named iDine. The management liked your name and asked you to describe how the system would work. You wrote a detailed description as below, providing a vision of system working in full capability. Your team will now help Vallée convert this vision into reality. Getting inspiration from touchscreen self-ordering kiosks used by fast food restaurants, Vallée wantsto apply a similar concept (to some extent) in the fine dining. For this purpose, all tables in restaurant are to be equipped with tabletop tablets. These tablets display their detailed digital menu and allow customers to place and send their orders directly to the kitchen. This potentially saves time because customers do not have to wait for a server, especially during lunch or dinner rush hours. Furthermore, while enjoying their meals, customers can use this system to quickly order an extra drink or an additional plate. Plus, since customers can dig deeper into the menu to discover more add-ons and extras than any waiter could recite, orders can be customized as per customer wishes. As an added bonus, some tabletop tablets come loaded with games and entertainment to keep kids busy while their parents are chatting waiting for the order.
Customers who are not tech savvy enough to use those tablets, can just tap the “Call waiter” button to order the old school way. There is main terminal located in the dining room that is overseen by the head waiter. This machine would display a prominent notification of which table is requesting the waiter visit. The head waiter can then direct one of the available waiters to that table to collect the order. The waiter keys-in the order details into the system via a handheld tablet. The table number is also recorded in the system along with the order details. Whichever way an order is placed (customer self-order or through waiter), the system
categorizes the individual items in the order according to the section where they are prepared, and then route the suborders to printers in the appropriate preparation area. For example, to the printer in cold section if ordered item is a salad, to the cafe printer if it is a coffee or sandwich, or to the main kitchen if order is from the main course menu. This ordering system eliminates any problems caused by a waiter’s handwriting. In each
preparation area, the cooks have access to a large touch screen display that shows all orders that are yet to be served. Once an order is ready, a cook will mark the order as ready, which will send a notification to dining room terminal along with the table number. The head waiter then instructs one of the waiters to pick up the order from kitchen and serve to customers.
After the customer have finished with their meal, they can see their final bill on the same tabletop tablet. Alternatively the waiter can print out the bill from the main terminal for any given table number. Other than customer order management, iDine is also composed of several other subsystems like pantry and fresh produce inventory management, and supplies ordering management. Although the inventory system provides a lot of benefits as described later, but it doesimpose a strict data entry requirement. Every item added to inventory must be keyed in to the system. Similarly every item used up from inventory must be recorded. To simplify these tedioustasks, the inventory system is linked together with customer ordering system and
supplies ordering system. A workflow is designed like this: All the supplies are ordered through the supplies ordering system. When those supplies are delivered to the restaurant, a staff member keys- in the details of everything added to inventory. Most of it is same as the supply order, so the information is automatically copied over using the supply order number, but staff can adjust the details if the delivery does not exactly match supplies order.
To keep track of supplies consumption, the iDine estimates how much inventory the restaurant should have on-hand based on the items sold. This is possible because ahead of time when the restaurant menu is designed, the chefs provide a list of ingredients (fresh produce or grocery items) required for every single item on the menu. Therefore, as soon as customer orders are served, the inventory system uses to recipe to record an approximate deduction for every ingredient present in the order. This way the system keepstrack of actual
product counts, and also monitors theoretical inventory levels. The inventory system therefore provides a clear information of stock availability for every asset. Management can view inventory counts any time for greater efficiency and accuracy. Because the system can only estimate stock consumption (based on recipes), real stock counts need to be verified by the staff at the end of the day. A comparison of the estimated vs actual stock counts can alert managers to discrepancies from over-portioning, waste, and theft so that they can be
resolved immediately.
Another benefit of linking inventory management and customer ordering is that when the kitchen runs out of a food item, the cooks will use the kitchen terminal to record an ‘out of stock’ status. This will be helpful for waiters when taking orders. If an item can’t be prepared because one or more of the ingredients are out of stock, the waiters can immediately apologize to customers, enabling them to provide a better customer service. Similarly the customer tabletop tablets will disable ordering of such items, indicating the same reason on the screen.
An automated stock control is done by the inventory system and a report is readily available showing which items are currently available in stock and which of them need to be ordered from suppliers. This greatly reduces the chances of mistakes by staff members and they do not have to remember what is to be ordered. Previously staff had to handwrite a list of all ingredients that were out of stock at the end of every night shift. It was always not that productive as there was a very big possibility on missing out some of the ingredients. Using the automated reports, managers can manually place an order of supplies to be delivered the next day before the restaurant opens. But manually preparing the orders is seldom needed because an even better automated purchasing system works most of the time. Linked directly to the inventory system, this subsystem notifies and alerts the managers about low product levels. This system intelligently suggests purchasing recommendations based on supplies (expected) delivery time, forecasted sales quantities, and predefined stock level thresholds. Managers can also enable automatic orders to placed whenever inventory reaches a certain threshold.
Sales analytics is part and parcel of every modern business and Vallée is no exception. To this end, the new information system provides up-to-the-minute reports on the food items ordered and breaks out percentages showing sales of each item versus total sales. This helps management understand which food items are popular in customers. This data isthen shared with chefs so that can tweak the recipes of unpopular items. In this way, menu is tweaked according to customers’ tastes. The system also compares the weekly sales revenue versus food costs, allowing planning for tighter cost controls. In addition, whenever an order is voided, the reasons for the void are keyed in by waiters. This may help later in management decisions, especially if the voids are consistently related to food or service. iDine is capable of generating different types of charts for sales information so that management can view statistics in numerous diagrams.
Another crucial business requirement fulfilled by iDine is managing customer feedback. This subsystem works in two ways. First, at the restaurant exit door, a special purpose computer is installed that provides five buttons and a small display. The goal of this device is to ask the customers a simple ‘How did we do today?’ question. The five buttons are labelled with emoji faces from ‘sad’ to ‘smiling’. Customers will only need to push one button which is acknowledged with a thank you displayed on screen. iDine collects all such feedback and
presents in the form of charts as needed. In case customers wish to offer a detailed feedback with comments, that option is also available. The bill receipts have a QR-code at the bottom which customer can scan with a smartphone camera. The QR code is unique to each customer, linked to their order information. Scanning it leadsto an online feedback form where user can leave detailed rating and comments. Later when management reviewsthe feedback, they will have access to order details as well so it is easy to understand and act upon customer complaints (if any).
Another convenience Vallée is proud to offer its customers is the real time space availability and wait time estimation. As soon a customer places an order, iDine records their table as busy and that way remaining space available in restaurant can be worked out and displayed on the company website, updated in real time. Similarly, based on the actual order placed, system can provide an estimate of preparation time which is intimated to customers via tabletop tablet or waiter. Furthermore this information is also to estimate how long queuing time is, for those arriving when the restaurant is full. To get a proper estimate of queuing time, iDine keepstrack of the average time customersspend from order to payment (because most customers leave right after payment). When restaurant is full, these average values are used to work out when the next table will get free.
Ever since iDine has been installed at Vallée, it has vastly improved the workers organization and teamwork. Management is happy with the post-sales analysis reports. The system itself is designed with a very user friendly, touch driven GUI. The system response time is incredibly fast; the staff do not come across any noticeable lags or delays when using it. All customer orders are logged in an archive for record keeping and analytics purposes.
Solution
Introduction
The following project is carried out to develop an information system for a restaurant, named as Vallée de Goût’. It is a French cuisine restaurant, located in outer suburb area of Sydney which serves both the contemporary and luxury dining experience. In order to cope with the rising business, the business needs adequate space which can be solved by developing the system management. Due to the long waiting time or getting delayed order, the existing venue gets overcrowded. So, the staffs feel difficulty in handling the loads of the customers. As a result, they serve delayed order and also make mistakes on orders and bills out of pressure. This type of mistake will impact on the reputation on the customer service of the restaurant and they will start losing the customers. Beside the quality food, they also want to improve the customer service by enabling a better information system.
The existing information system management of the restaurant has very generic features which needs to be customized in the new system. It will help the business to involve multiple touchpoints from customers to the staffs which removes the mistakes occur in the manual orders. The customers will be given with a tablet on the top of every table and they can book the orders by themselves from the list of a digital menu. The order will be sent directly to the kitchen and the cook can access it. It will make a clear communication between the customer and the restaurant by avoiding the mistakes of writing made by the waiter. The waiter gets the notification of serving the dishes from the head the supervision of head waiter who oversees the process and makes decision. It will also allow an old school way of order taking through the ‘call waiter’ button. The new system will be named as ‘idine’. Apart from these basic features, it will have several add-on features to engage the customers.
Key System Features
The ‘idine’ will have an automation system with the below listed functionalities:
Customer Service
• The system will have the functionalities of showing the current menu of the day and changing the menu digitally.
• The system will enable the customers to have both the self-ordering and order taking by the waiter.
• The system will enable the customer to change the order and adjust the bill.
• The system will be able to adjust with the changing price of the cuisine every day and also show the new offer as per the entry of the back-end staff (Salen, Gresalfi, Peppler & Santo, 2014).
• The system will have a customer registration which records the name and phone numbers of the customers along with their billing details.
• The system will have cashless online payment system which the accepts the online pay and tips of the waiters via net banking or payment apps.
• The system adds the extra requirement of the customers apart from the digitally saved menus which directly will be sent to the cooks.
• The system will have the feedback options where the customers can rate the service and also give their review.
• The system will ask the customer is their any service or feature they want changes.
• The system will offer many video games which will engage the customers and their kids until the dish is served.
Inventory Management
• The system will be able to provide the real time inventory stock to the kitchen manager as per every order.
• The stock information will be updated with the data entry requirement. Whenever a new order is placed, it shows the available ingredients for the recipe of a booked order.
• The system will automate a report concerning the used goods, leftovers and what needs to be filled up as per the recipe manager (Zhao Guibas, 2004).
• The system will also update the out-of-stock status.
Supplies ordering management
• The system will have a supply ordering management which sends orders to the suppliers by tracking the stock availability and the system automation has the ability to decide which stocks is required or need to be ordered. This reduces the chance of manual mistakes (Cassell & Hiremath, 2018).
• The automation purchasing system will enable the restaurant to buy the products at any point of time. It omits the night shift of the staffs who tracks the required supplies and orders. This automation process enables the restaurant to have the supplies on the next day morning. Also, the lists are free of manual error.
Perceived business benefits
• The idine will avoid the chance of data loss by the digital booking. So, the accuracy in the ordering, billing and inventory management will be perceived (Taylor, 2017).
• It will automate the process and saves the time of customers and the staffs. As a result, there will be no delayed orders or long queue in the booking. By delivering quick service, the restaurant will get rid of the problem of over-crowding.
• it will improve the efficiency of delivery and the overall process. So, the customer will be satisfied and customer retention is ensured.
• It will deliver a better customer service experience through the booking, billing and entertainment. So, customer attraction will be increased.
• The cashless payment system will deliver customer convenience with an assured paying with taxes.
• The finance management of the restaurant will be improved by calculating the total sales, purchase in supply management and leftover in the inventory.
Required Resources
The required resources of idine are:
Project manager
The project manager will select the roles and responsibilities of the team members; also ensure the essential items and tracks the required changes.
Software developer
The software developer will be responsible for writing the codes and develops the programme for idine.
UX designer
The UX designer will be responsible for designing the visual representation of the idine, including the branding of the web page.
UI designer
The UI designer is responsible for designing the functionalities based on the user interfaces and the user applications (Alencar, 2015).
Protype test team
The prototype test team will send the raw product of idine IS system to the test users. Based on their reviews the prototype of idine will be moderated.
Technical writer
The technical writer will write the uses of the idine system based on the description of the test users.
Stakeholder map
Vallée de Goût’ : this stakeholder is the client of this project who will send requirements and give approvals of idine.
Customer service team: the customer service team consists of the waiter, cooks, inventory staffs who are allocated for checking the booking details.
Admins: the admins are the head waiters, inventory manager, supply chain manager and kutchen manager who oversees the overall process in each domain, by the help of idine system and instructs their subordinate.
Customers
Customers are the active participants who uses the booking system in idine and enjoy the amusements.
Suppliers
The suppliers are the stakeholders who sells raw ingredients for the cuisines by the system generated process. They are also paid by this automated system.
Project team
The project team receives the requirements from Vallée de Goût’. They design, develop and deploy the iDine.
Stakeholder Map
Stakeholder Map

Elaboration phase
Use case diagram
Use case description
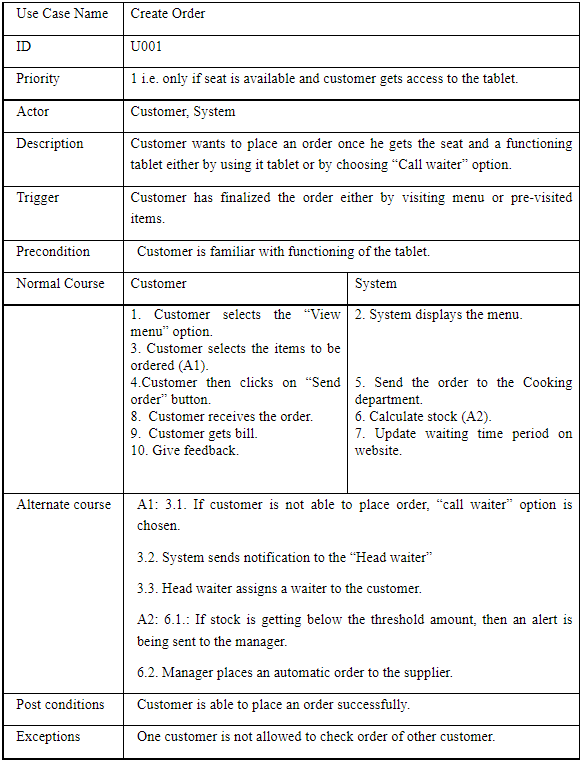
Domain model class diagram
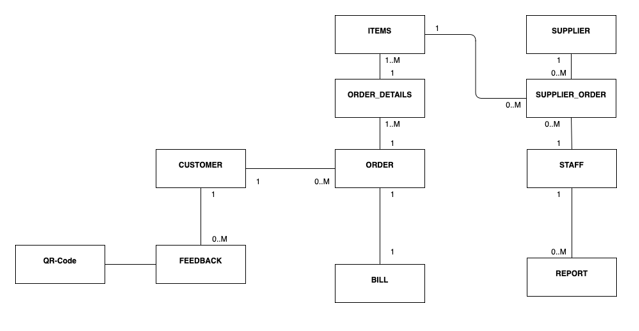
The diagram has key classes: CUSTOMER, FEEDBACK, BILL, ORDER, ORDER_DETAILS, ITEMS, SUPPLIER, STAFF and REPORT. All the many-to-many relationships have been resolved using associative classes such as ORDER_DETAILS and SUPPLIER_ORDER.
References
Alencar, M. S. (2015). Information theory (Ser. Communications and signal processing collection). Momentum Press.
Cassell, K. A., & Hiremath, U. (2018). Reference and information services : an introduction (Fourth). ALA Neal-Schuman, an imprint of the American Library Association.
Taylor, M. (2017). Information system research : :fundamentals of scientific research for the consumer. Momentum Press.
Tekinbas? Katie Salen, Gresalfi, M., Peppler, K. A., & Santo, R. (2014). Gaming the system : designing with gamestar mechanic (Ser. Interconnections : understanding systems through digital design). MIT Press.
Zhao, F., & Guibas, L. J. (2004). Wireless sensor networks : an information processing approach (Ser. The morgan kaufmann series in networking). Morgan Kaufmann.
Assignment
Information Security Assignment Sample
Value: 15%
Due Date: 23-Apr-2021
Return Date: 18-May-2021
Length: 1000-1500 words
Group Assessment: No
Submission method options: Alternative submission method
TASK
This assessment relates to Topics 1 - 6 and consists of two tasks as follows:
Task 1 : Scenario Analysis (44 Marks)
1. Identify one real-life cybersecurity breach that may have occurred in the last 2 Years. Using the vulnerability-threat-control paradigm, discuss the breach (16 Marks).
Tip: You may use any one breach from the following link for assignment help.
2. Discuss the difference between cross site scripting (XSS) attack and cross site Request forgery (XSRF). Further, explain with justification, which attack is easier to defend against (16 Marks).
3. What is buffer overflow? Studies online (e.g. statcounter ) suggest Microsoft Windows has over 70% of the OS market share. For this reason, identify and discuss a feature in Microsoft Windows that prevents attackers from using buffer overflows to execute malware (12 marks).
Task 2 : Short Answer Questions (16 Marks)
1. Discuss the notion of "security through obscurity" and its implication on modern day computer security (8 marks).
2. Discuss at least two security advantages of a host running virtualisation (8 marks).
RATIONALE
SUBJECT LEARNING OUTCOMES
This assessment task will assess the following learning outcome/s:
• be able to justify security goals and the importance of maintaining the secure computing environment against digital threats.
• be able to examine malicious activities that may affect the security of a computer Program and justify the choice of various controls to mitigate threats.
• be able to compare and contrast the security mechanisms of a trusted operating system with those used in a general purpose operating system.
• be able to compare and contrast foundational security policies and models thatdeal with integrity and confidentiality.
GRADUATE LEARNING OUTCOMES
This task also contributes to the assessment of the following CSU Graduate Learning
Outcome/s:
• Academic Literacy and Numeracy (Knowledge) - Charles Sturt Graduates understand the use and structure of appropriate language in written, oral, visual, mathematical, and multi-modal communication.
• Academic Literacy and Numeracy (Skill) - Charles Sturt Graduates demonstrate the literacy and numeracy skills necessary to understand and interpret information and communicate effectively according to the context.
• Academic Literacy and Numeracy (Application) - Charles Sturt Graduates consider the context, purpose, and audience when gathering, interpreting, constructing, and presenting information.
Solution
Task 1
1. Identify one real-life cyber security breach that may have occurred in the last 2 years. Using the vulnerability-threat-control paradigm, discuss the breach
The world has been witnessing various cases of security breaches since the last decade. One major breach of the year 2019 was reported with regards to Facebook and its loss of confidential private data belonging to over 533 social media users. The founder of Facebook, Mark Zuckerburg could not provide the committed privacy and confidentiality to its millions of loyal users. Vulnerable data like the name, location data, phone number, emails, and other biological data were leaked. The investigators further found that the privacy controls security protocols implemented in this program were weak and had loopholes. As a result data of individuals from over 106 varied nations and 32million data records related to the US was the victim of a real security breach (Jackson, Vanteeva & Fearon, 2019, p. 1277). Serious doubts and questions were raised since Facebook conserved important data like emails and data of birth users, Serious doubts came as Facebook asked all its users to make a password reset be done with urgency.
The vulnerability Threat control paradigm is referred to analyze whether this real-life data breach case fulfills the requirements of computer security (Tamrin, Norman & Hamid, 2017, p. 131). CIA triad comprising of confidentiality, integrity and availability is considered as basic needs of computer security which Facebook failed to fulfill. Confidentiality was lost since user authorization was not there and still their data got leaked. Authorised Facebook users were deceived and were manipulated and hence integrity has been filed. The users were not safeguarded by the security system applied by Facebook and hence their information was not in their hands. This breaks the availability dimension of the CIA triad as well. It can hence be considered that the Facebook data breach incident has failed to provide privacy and security to the users.
2. Discuss the difference between cross site scripting (XSS) attack and cross site request forgery (XSRF). Further, explain with justification, which attack is easier to defend against
XSS or cross-site scripting attack is a web application-centric incidence of a security breach where data or content is vulnerable. Cybercriminal often follows the web programs which the client or users are using. Scripts especially JavaScript is induced in such web pages at the code end (Rodri?guez Germa?n E, Torres, Flores & Benavides, 2020, p. 166). When the potential victim hits these specific web site on their browser these script gets injected. It is an unethical activity where no permission is taken from the victim where they use the vulnerability of the website to exploit them.
CSRF or the cross-site request forgery on the other hand is a more server kind of computer security vulnerability caused by hackers. Cybercriminals at times will send requests in the form of an email communication where the victim will be urgently asked to click open a file or install a file on their system (Kour, 2020, p. 4561). Due to the urgency if this activity request is fulfilled then cookies are detected and interaction is carried out by a hacker. The cookies sit quietly and keep sending data of the co muter system comprised to the external hacker.
So, an XSS attack is where the user will be induced for performing any action. CSRF on the other hand is dangerous as it is associated with some subset activities which users are performing. This is more like a one-way kind of attack. XSS on the other hand is a two-way attack vulnerability.
When both of these attacks are compared it is found that XSS attacks can be defended more easily than CSRF attacks. This is because the security prediction of the ber criminal cannot be made easily for the latter. As result victimisation possible more than the first kind of attack where using ample protection mechanisms one can be protected.
3. What is buffer overflow? Studies online (e.g. statcounter) suggest Microsoft Windows has over 70% of the OS market share. For this reason, identify and discuss a feature in Microsoft Windows that prevents attackers from using buffer overflows to execute malware
When the volume of information to be stored is more than the usual capacity of the stye to store data inside buffer memory the event is termed a buffer overflow (Gao, Wang, Y., Wang, Yang, Z., & Li, 2020, p. 1406). In such a circumstance, efforts are made to conduct a program overwrite over data adjacent to the buffer memory site. This is also technically termed a buffer overrun.
Microsoft, for preventing any hacking incidents or intrusions has restricted such buffer overflow processes. The potentials that applications by Microsoft being exploited is a stack that is applied over the memory spaces. Here storage space is made available. The brand dominates the market and has over 76.56%of the market shares. This is possible as Microsoft makes use of DEP or Data execution prevention programs for the operating system design Windows XP and the SP2. Here the program is given autonomous power so that they can stop any malware to get carried out with the code where there is reach for non-executable memory spaces.
DEP feature in Microsoft is enabled so that any attack upcoming can be detected. The non-explicit memory is not executed. If the buffer overflow gets used up ht DEP protection is applied so the process is carried out without the program which will restrict the security bars automatically (Wang, Huang & Chen, 2019, p. 1). This is performed in two ways by Microsoft- address the space randomization process using ASLR or using the Data Execution Prevention method.
Task 2
1. Discuss the notion of “security through obscurity” and its implication on modern day computer security. All security engineer experts use their robust design, formats, and security mechanisms to be the primary tool to execute safety to their system. In this regards a concept of security through the notion of obscurity is used as the underlying principle for such a security execution by experts (Andrew, 2018, p. 1). In modern times, however, all computer systems and mechanisms are layered by their design. Often there are gaps and loopholes which are detected by the cyber criminals and they use them to attack or hack computer systems.
Such use of security approach using obscurity as the core principle is not a positive or effective one since it is about the protection of system and data. The security mechanism is hence effective only till w nth obscurity is not explored or discovered. Hence such an approach makes the system weak or vulnerable. A modern-day example can be given here. Imagine the owner of a precious residential house uses some of the best security locking systems to give protection to the door. To give effective safety and security jiggling is made through obscurity. However, sometimes tricky ways are used by cyber criminals to get insider information about codes which can then be used to crack open the lock. So as soon as the code is discovered the system becomes vulnerable.
2. Discuss at least two security advantages of a host running virtualization
Virtualization is one of the latest technologies which has revolutionized the way business enterprises conducted their operations. Small and medium scaled business organizations today use virtualized architecture to avail their security advantages (Gavrilovska, Rakovic & Ichkov, 2018, p. 67). In using virtualization, businesses can avoid the face to face communications. Hence the first security advantage is this. The face of an individual is a vulnerable biological data that is hidden along with their other identifying information such as location, contact number of pictures using virtualization. All kinds of personally identifiable information is kept secure due to this.
The second security advantage of virtualization is that it offers centralization of all managerial operations and functions. All the operations which a business performs can run over a controlled architecture as a result. All IT-related activities are kept protected. The authorized users can only get access to such a system. These two security befits make virtualization a highly popular architectural structure.
References
Andrew, M. (2018). No security through obscurity: changing circumvention law to protect our democracy against cyberattacks. Brooklyn Law Review, 83(4).
Gavrilovska, L., Rakovic, V., & Ichkov, A. (2018). Virtualization approach for machine-type communications in multi-rat environment. Wireless Personal Communications : An International Journal, 100(1), 67–79. https://doi.org/10.1007/s11277-018-5611-y
Gao, F.-J., Wang, Y., Wang, L.-Z., Yang, Z., & Li, X.-D. (2020). Automatic buffer overflow warning validation. Journal of Computer Science and Technology, 35(6), 1406–1427. https://doi.org/10.1007/s11390-020-0525-z
Jackson, S., Vanteeva, N., & Fearon, C. (2019). An investigation of the impact of data breach severity on the readability of mandatory data breach notification letters: evidence from u.s. firms. Journal of the Association for Information Science and Technology, 70(11), 1277–1289. https://doi.org/10.1002/asi.24188
Kour, P. (2020). A study on cross-site request forgery attack and its prevention measures. International Journal of Advanced Networking and Applications, 12(02), 4561–4566. https://doi.org/10.35444/IJANA.2020.12204
Rodri?guez Germa?n E, Torres, J. G., Flores, P., & Benavides, D. E. (2020). Cross-site scripting (xss) attacks and mitigation: a survey. Computer Networks, 166. https://doi.org/10.1016/j.comnet.2019.106960
Tamrin, S. I., Norman, A. A., & Hamid, S. (2017). Information systems security practices in social software applications. Aslib Journal of Information Management, 69(2), 131–157. https://doi.org/10.1108/AJIM-08-2016-0124
Wang, X., Huang, F., & Chen, H. (2019). Dtrace: fine-grained and efficient data integrity checking with hardware instruction tracing. Cybersecurity, 2(1), 1–15. https://doi.org/10.1186/s42400-018-0018-3
Coursework
DS7003 Advanced Decision Making: Predictive Analytics & Machine Learning Assignment Sample
Essential information
Welcome to this M-Level module on Advanced Decision Making. The module forms part of the MSc in Data Science and the Professional Doctorate in Data Science. This guide provides details of scheduled meetings, aims and learning outcomes, approaches to learning and teaching, assessment requirements, and recommended reading for this module. You will need to refer to it throughout the module. Further material may be distributed during the course of the module via Moodle (https://moodle.uel.ac.uk/).
You should consult the relevant Programme Handbook for details of the regulations governing your program.
The Data Science curriculum, for practical reasons, segments the learning process and preparing for research into a number of modules, and those modules into sessions. These sessions will necessarily overlap as their content can be treated from different perspectives and positions. Their content should be treated holistically rather than piecemeal.
Aims and learning outcomes
This module aims to develop a deep understanding of ways of making decisions that are based strongly on data and information. Particular focus will be on mathematical decision-making models including some use of computer-based support. Various case studies will be examined.
Learning outcomes for the module are for students for assignment help
1. Understand the design of decision-making models.
2. Understand the mathematical logic basis of decision-making.
3. Understand how to assign probabilities to uncertain events; assign utilities to possible consequences and make decisions that maximize expected utility.
4. Use of software-based decision-making tools.
5. Critically evaluate alternative decision models.
6. Conduct decision-making exercises.
7. Critically evaluate and analyze data.
8. Compose decision-making based reports.
The definitive description of the module is given in Annex 1.
Approaches to learning and teaching
This module is structured around 10 on-campus sessions over the one-week block.
This module employs a variety of approaches to learning and teaching, which include staff-led presentations, class and small-group discussions, debates, reflection, group exercises, journal-keeping and independent study. You are expected to spend time outside classes preparing for sessions by reading, thinking and engaging in other on- line activities as advised.
Important transferable skills for students intending to undertake or make a career in research include time management, communication skills and evaluation skills. This module places emphasis on developing these skills within the framework of completing the assignment. Strong emphasis is placed on your learning from experience. You must bring a laptop to each class for the practical exercises.
Reading
You are expected to read widely as part of your work for this module, and to spend approximately 15 hours per week in independent study and preparation for assessment. An indicative reading list is given in the Unit Specification Form in Annex 1 of this Guide and additional resources are made available through Moodle. These resources do have considerable overlap between the topics and in some cases repeat some of the knowledge. That is inevitable when looking at a rich literature. You are expected to identify further resources relevant to your particular interests and to the assignment through the Library’s on-line databases and from current affairs materials as Decision Making is very topical.
Attendance
Attendance at sessions is monitored. You should use your student ID card to touch in at the beginning of each session. You do not need to touch out.
Assessment
The assessment for this Module consists of one item: an analysis and review of decision-making using data set(s) of the student’s choosing using machine learning in R for classification, regression or time series of 5,000 words equivalence.
The piece of coursework should be submitted on-line using Moodle. Your work should first be submitted to Turnitin to guard against plagiarism and you can re- submit corrected work up to the due date and time that is specified for each piece of coursework. It is the student’s responsibility to ensure that coursework has been properly submitted on-line to the designated Moodle drop box. Late work may not have accepted for marking and could be treated as a non-submission. If there are justified extenuating circumstances, then these should be submitted on the requisite form according to the general academic regulations. The minimum pass mark for the module is 50%. Students who are unsuccessful in any M-level assessment can be re-assessed once without attendance and should they not be successful on the second take must re-take the module with attendance.
Solution
Introduction
Datasets these days offer several hidden useful information. Data mining is the field of extracting useful data with the help of different algorithms and techniques that covers classification, association, regression and association. It is noteworthy that health care industries have been majorly dependent on data mining tools and techniques. The patients’ risk factors can be predicted if a genuine dataset is examined over these data mining methods. Other than heart diseases, data mining is extensively used to predict other health conditions such as asthma, diabetes, breast cancer, etc. Many well-known studies have been published that proves the efficiency of algorithms such as support vector machine, logistic regression, naïve Bayesian classifier, neural networks and decision trees. The health care research in direction to predict underlying disease is widely in practice since few decades now (Jabbar, 2016).
Cardiovascular diseases are now becoming more chronic in last few years. Every year millions of people including all age groups die of severe heart diseases. The disease might not be detected at early stage due to which people have been dying as soon as the disease is diagnosed. However, early detection of heart disease can save patients’ lives as their risk factors are known before the time has passed. This prediction at early stage may help in minimizing mortality rates. The heart diseases are of various kinds that includes coronary heart disease, cardio myopathy, hypertensive heard disease, heart failure, etc. These conditions are caused due to diabetic conditions, hypertensions, high cholesterol levels in body, obesity, etc.
Data mining methods and techniques can be fruitful in early prognosis of disease that can calculate high risk factors by analyzing existing dataset. The data mining tools and algorithms are proven to be accurate enough to predict right information (Gandhi, 2015). The dataset used in this research on which analysis is done is collected from Cleveland Heart Clinic; the database is popularly known as Cleveland Heart Disease Database (CHDD) used by many researchers. The information about its key attributes is discussed later in the chapter.
The research report is organized as follows. The next section offers machine learning insights and details of categories of algorithms prevalent in machine learning. Later, literature is presented towards the researches being conducted to predict cardiovascular diseases by other researchers. Then, methodology is discussed about the work conducted in this research. It provides detailed description of how diseases are predicted by support vector machine and logistic regression. Additionally, both the techniques are tested for their accuracy and hence compared. The objectives of this research are two-fold: First, finding how accurate these two selected methods are for predicting heart disease. Second, comparison of two methods based on their accuracy.
Traditionally, statistical techniques were used to develop intelligent applications. The predictions were simply based on interpolation formulae as learned in high schools. However, in today’s AI applications, traditional interpolation formulae could fail; hence, new techniques are successfully developed to fulfill current AI needs and requirements. Most popular methods in artificial intelligence and machine learning are regression, clustering, classification, probability and decision trees. These methods contain several different algorithms to suit different class of problems to solve complex problems (Babu, 2017). Machine learning is further categorized as in figure 1.
Figure 1 Categories of Machine Learning (Babu, 2017)
The categories of machine learning are:
Supervised Learning: The very first found machine learning technique used first to predict residential pricing. The supervised learning, as the name suggests, supervises entire application working. Just as child is taught to walk, by holding hands, the supervised learning algorithm monitors each and every step of application to achieve best results. Regression and Classification are kinds of methods used in supervised learning.
Regression: The machine is trained first by providing results for the input value. The machine then learns the relationship between input and output values. Once the machine learns it, the value of output is predicted for input provided based on empirical relationship between previous inputs and their respected outputs.
Classification: The classification problem efficiently categorizes the pool of data into predefined classes. For example, if a box contains blue, red and green balls; the classification algorithm can sort and find the number of balls of each color in the box. The classification algorithm classifies objects of same kind into one category whose label is previously named. This technique of machine learning falls under supervised learning where group names are already defined. Objects are classified as per nature described.
Unsupervised Learning: This method doesn’t require any other agent to supervise it. Completely opposite to supervised learning, unsupervised learning technique never allows machine to train itself on the basis of known outputs from certain inputs. Rather, the algorithm forces machine to find all possible values of the given input. This is achieved by identifying the features mostly appearing in input.
Reinforcement Learning: The idea is to reward the machine whenever it achieves desired results. Consider at an instance, when training a dog to fetch a ball. If a ball thrown is fetched by dog, it is rewarded by the master. This helps dog to understand how to do the commanded task. This type of learning is termed as reinforcement. This algorithm is usually applied in games. The application should analyze the possible next moves after each next step. If the predicted next step is correct, the machine is rewarded else it is punished or penalized. This will help algorithm to identify right and wrong moves; hence the machine will learn right moves as the game proceeds. Thus, the accuracy towards winning keeps on increasing.
Deep Learning: To aid in analyzing big data, deep learning was introduced so that applications can be designed as human brains that can create artificial neural network.
Deep Reinforcement Learning: Similar to reinforcement learning, when deep learning application or machine works the same as expected, it is rewarded in deep reinforcement learning.
These algorithms are founded as listed from supervised learning to deep reinforcement learning. With need to solve each new complex problem, new machine learning method was introduced.
Literature Review
Researchers have been trying since decades the accurate way to predict heart diseases so that lives of millions of people can be saved. Authors have developed a system to detect heart diseases accurately by monitoring heart rate data collected from a survey (Wijaya, 2013). The tools act as a data feeder and retriever in the survey which is a pitfall. In other words, if tool isn’t available, data cannot be read. However, the correct prediction of severity of heart disease could increase person’s life span by developing healthy lifestyle. The system developed by authors (Gavhane, 2018) is less accurate as results obtained. The other researchers (Ul Haq et al., 2018) developed a system which was comparatively reliable that included usage of classification technique. The back propagation algorithm was used to predict heart diseases; and the results were promising (Xing et al., 2007). Used feature selection for gaining more accurate results. The authors developed a system to find heart diseases, cancer and diabetes from the dataset.
Apart from usage of feature selection and back propagation few researchers have developed systems that made good use of other algorithms such as support vector machine, neural network, regression, decision trees and several classifiers such as naïve bayes. The datasets were different and common for few authors but the techniques were unique. The datasets used were collected all around the globe; the results were different and accuracies differed in many ways as use of techniques were different. Xing et al. collected dataset of thousand patients wherein different parameters were included such as hypertension, smoking habits, age, gender, diabetic or not, etc. The authors developed three algorithms: SVM, ANN and decision trees. The accuracies calculated were 92.1%, 91.0% and 89.6% respectively.
Chen et al. developed a system to predict heart diseases with the help of algorithms like SVM, neural network, Bayes Calssifier, decision trees and logistic regression. The most accurate of all is support vector machine (90.5%) whereas the accuracy of logistic regression was the least (73.9%). Neural network, Bayes classifier and decision trees had accuracies 88.9%, 82.2%, 77.9% respectively.
Many researchers have selected different attributes of dataset for several machine learning techniques. It was observed that it does not provide a justified basis to compare the techniques for their accuracy. With this thing in consideration, Soni et al. selected those attributes that can affect largely to heart of patients that consist of gender, obesity, hypertension, smoking habits, drinking habits, salt intake, cholesterol level, diabetes, family history of the same disease, no physical exercises, etc. Similarly, Shouman et al. identified blood pressure as another risk factor that can be considered while predicting heart disease. Cleveland Heart Disease database is highly considered by researchers as it is one of the most trusted dataset for analysis. The very first research on this dataset was conducted in 1989 by Detrano et al. where logistic regression was implemented and accuracy of 77% was attained. This is worth noting that accuracy of models after their evolution is dramatically increasing and it is found to be above 90%. Many researchers have used combination of machine learning techniques to attain accuracy as high as possible.
Other than SVM and logistic regression, k-means clustering and c4.5 decision trees were implemented by Manikanthan and Latha to predict heart disease. The accuracy of the system was 92% which was considered as a promising approach. Nor Heiman et al. studied methods in decision tree algorithm to minimize errors. Dota et al. used decision tree algorithm to compare accuracies to detect quality of water. Rajeshwari et al chose some attributes that can help patients to find the list of medical tests that are of no need. Lakshmi et al used many data mining techniques such as c4.5, k-means, decision trees etc. and found their specificity. It was observed that PLS-DA shown promising results in prediction of heart disease. Taneja used Naïve Bayes classifier to choose attributes from dataset. He proved that data mining techniques for feature selection are equally important as that of prediction or classification itself. Sudhakar and Manimekalai comparatively presented many data mining techniques as a survey research paper. Ahmed and Hamman performed data mining for cardiovascular predictions using support vector machine and clustering techniques. They also performed association rules mining for attribute selection. Sugumaran et al performed data mining for fault detection using svm and classification.
Methodology
The research concentrates on implementation of logistic regression and support vector machines on Cleveland heart disease dataset in order to find and compare their accuracies.
Support Vector Machine
A machine learning model that helps in finding known patterns for classification and regression. SVM is mostly applied when the data can be classified into two groups. The hyper plane generated by SVM can be useful in partitioning similar kind of objects with other quite efficiently. It is considered that the distance between two classes should be maximum to prove that the model is good. To solve real world problems SVM is highly considered since it is a pure mathematical model and may provide best results. It is also better to SVM when a dataset consists of many attributes. The foremost task, an SVM does is mapping data into kernel space. Selection of kernel space can be quite challenging with SVM.
Logistic Regression
Logistic regression can predict the outcome with limited group categorical value dependent on a variable. In CHDD, the outcome should be heart disease detected or not. The outcomes are usually binary in logistic regressions. With binary, it means having two values at maximum. The probability of success is largely measured by logistic regression.
The system flowchart is presented below in figure 2. The Cleveland heart disease dataset is used via its link. The next step is data exploration and pre-processing. To accomplish this, features are selected first, in this dataset important parameters are first identified and selected for further processing. Support Vector Machine model is first applied and its accuracy is stored in an array. Later, Logistic Regression model is also applied and its accuracy is again stored in the same array. Finally, the accuracy of both the models applied is compared and results are presented. The experimental analysis is presented in next section.
Figure 2 Flowchart of Proposed Research
Data Exploration using R
Data Exploration is the initial and the most important step of data mining process. It not only helps in finding uncovered aspects but also offers details of the data under observation. It helps in building a system that can be accurate to its peak.
Data Exploration is a stepping stone for analysts to visualize dataset by applying statistical methods on dataset. The data and its nature are well understood by data exploration step. The size, type of attributes, format of attributes plays important roles in data exploration. The manual and automated, both ways are widely used as per data analysts ease. This step helps them to visualize important graphs and hence find correlation between attributes. The outlier detection and distribution of values of attributes can be performed by data exploration tools much efficiently than that of manual efforts. The datasets collected by other researchers are raw data and to find few important insights, it is necessary to perform data exploration. The data collection is a pillar to data exploration. To select correct data for analysis is again an important task. While selecting a dataset analyst must know what are the important attribute types to lookup.
Data exploration need is quite well justified. It is always observed that data in the form of pictures, graphs and any form of visualization is more easily grasped by viewers than that of numerical data in tabular form or in excel sheets. Hence, it is a tedious task for analysts to put millions of data rows and their corresponding attributes to frame in a graph so that it is well understood to the viewers.
Data visualization in R and its exploration is quite simple as it takes syntax to learn. It first starts with loading dataset chosen into allowable extensions such as csv, xlx, json and txt. The variables are converted into characters from numbers to aid the parsing in R. A dataset is then transposed from wide to narrow structure. Dataset is sorted accordingly and plots are created as per visualization requirements. Duplicate variables can be easily removed using R. Merging and joining dataset as well as count and sum functions are also easily available. Data Exploration in R is based on fixed syntax as presented next.
1. Reading a dataset

2. Transpose a dataset

3. Remove duplicate values

4. Create a histogram
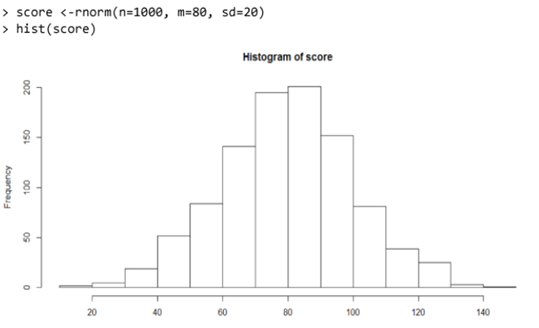
The operations provided here are just few from the pool of operations in R studio. There are numerous libraries one can import and use different function already defined in it.
Data Source
Dataset: Heart Disease Dataset from UCI Repository
Link: https://archive.ics.uci.edu/ml/datasets/Heart+Disease
The heart disease dataset is a collection of 303 records identified by 76 attributes. Out of which, goal attribute identifies if there is presence of heart disease in the underlying patient. It is represented by an integer value, where 0 indicates no heart disease and presence of heart disease is classified as values 1 to 4; low to the scales of severe.
14. #58 (num) (the predicted attribute)
Complete attribute documentation:
1 id: patient identification number
2 ccf: social security number (I replaced this with a dummy value of 0)
3 age: age in years
4 sex: sex (1 = male; 0 = female)
5 painloc: chest pain location (1 = substernal; 0 = otherwise)
6 painexer (1 = provoked by exertion; 0 = otherwise)
7 relrest (1 = relieved after rest; 0 = otherwise)
8 pncaden (sum of 5, 6, and 7)
9 cp: chest pain type
-- Value 1: typical angina
-- Value 2: atypical angina
-- Value 3: non-anginal pain
-- Value 4: asymptomatic
10 trestbps: resting blood pressure (in mm Hg on admission to the hospital)
11 htn
12 chol: serum cholestoral in mg/dl
13 smoke: I believe this is 1 = yes; 0 = no (is or is not a smoker)
14 cigs (cigarettes per day)
15 years (number of years as a smoker)
16 fbs: (fasting blood sugar > 120 mg/dl) (1 = true; 0 = false)
17 dm (1 = history of diabetes; 0 = no such history)
18 famhist: family history of coronary artery disease (1 = yes; 0 = no)
19 restecg: resting electrocardiographic results
-- Value 0: normal
-- Value 1: having ST-T wave abnormality (T wave inversions and/or ST elevation or depression of > 0.05 mV)
-- Value 2: showing probable or definite left ventricular hypertrophy by Estes' criteria
20 ekgmo (month of exercise ECG reading)
21 ekgday(day of exercise ECG reading)
22 ekgyr (year of exercise ECG reading)
23 dig (digitalis used furing exercise ECG: 1 = yes; 0 = no)
24 prop (Beta blocker used during exercise ECG: 1 = yes; 0 = no)
25 nitr (nitrates used during exercise ECG: 1 = yes; 0 = no)
26 pro (calcium channel blocker used during exercise ECG: 1 = yes; 0 = no)
27 diuretic (diuretic used used during exercise ECG: 1 = yes; 0 = no)
28 proto: exercise protocol
1 = Bruce
2 = Kottus
3 = McHenry
4 = fast Balke
5 = Balke
6 = Noughton
7 = bike 150 kpa min/min (Not sure if "kpa min/min" is what was written!)
8 = bike 125 kpa min/min
9 = bike 100 kpa min/min
10 = bike 75 kpa min/min
11 = bike 50 kpa min/min
12 = arm ergometer
29 thaldur: duration of exercise test in minutes
30 thaltime: time when ST measure depression was noted
31 met: mets achieved
32 thalach: maximum heart rate achieved
33 thalrest: resting heart rate
34 tpeakbps: peak exercise blood pressure (first of 2 parts)
35 tpeakbpd: peak exercise blood pressure (second of 2 parts)
36 dummy
37 trestbpd: resting blood pressure
38 exang: exercise induced angina (1 = yes; 0 = no)
39 xhypo: (1 = yes; 0 = no)
40 oldpeak = ST depression induced by exercise relative to rest
41 slope: the slope of the peak exercise ST segment
-- Value 1: upsloping
-- Value 2: flat
-- Value 3: downsloping
42 rldv5: height at rest
43 rldv5e: height at peak exercise
44 ca: number of major vessels (0-3) colored by flourosopy
45 restckm: irrelevant
46 exerckm: irrelevant
47 restef: rest raidonuclid (sp?) ejection fraction
48 restwm: rest wall (sp?) motion abnormality
0 = none
1 = mild or moderate
2 = moderate or severe
3 = akinesis or dyskmem (sp?)
49 exeref: exercise radinalid (sp?) ejection fraction
50 exerwm: exercise wall (sp?) motion
51 thal: 3 = normal; 6 = fixed defect; 7 = reversable defect
52 thalsev: not used
53 thalpul: not used
54 earlobe: not used
55 cmo: month of cardiac cath (sp?) (perhaps "call")
56 cday: day of cardiac cath (sp?)
57 cyr: year of cardiac cath (sp?)
58 num: diagnosis of heart disease (angiographic disease status)
-- Value 0: < 50% diameter narrowing
-- Value 1: > 50% diameter narrowing
(in any major vessel: attributes 59 through 68 are vessels)
59 lmt
60 ladprox
61 laddist
62 diag
63 cxmain
64 ramus
65 om1
66 om2
67 rcaprox
68 rcadist
69 lvx1: not used
70 lvx2: not used
71 lvx3: not used
72 lvx4: not used
73 lvf: not used
74 cathef: not used
75 junk: not used
76 name: last name of patient
Experimental Analysis
Comparisons
The metrics used to compare SVM and logistic regression is AUC and accuracy. As seen below, support vector machine performs better than logistic regression. Following is the snapshot of accuracy list of both the techniques used.
Some researchers have found that logistic regression performs better in most cases if selection of attribute is slightly different. However, in our prediction, support vector machine performed better. However, there is still need to finding another method that can provide better accuracy than SVM.
Conclusions
The research concentrated on mining data related to heart disease. The dataset is popular and hence highly trustworthy to conduct concrete research on. Only fourteen out of seventy-six attributes were selected to test models named support vector machine and logistic regression. This research explored data in R studio with the help of in built libraries for applying several models with utmost ease. Data mining has now gained huge importance due to curiosity of prediction for necessary information. Today’s world contains gigantic datasets built over the period of years. These datasets are future predictors for many hidden aspects. The models implemented in R shows that accuracy of support vector machine is better than logistic regression. However, the accuracy should be increased by implementing other data mining techniques such as decision trees or naïve bayes classifier, etc. The research report presents details related to machine learning domain along with data exploration in R. R studio is a user friendly platform with fixed syntax to explore data and find useful information from it.
References
Ahmed, A. & Hannan, S. (2012). Data mining techniques to find out heart diseases: An overview. International Journal of Innovative Technology and Exploring Engineering (IJITEE), Volume-1, Issue-4.
Babu, S. (2017). Heart disease diagnosis using data mining technique. International conference on electronics, communication and aerospace technology ICECA2017.
Chen, J. Xi, G. Xing, Y. Chen, J. & Wang, J. (2007). Predicting Syndrome by NEI Specifications: A Comparison of Five Data Mining Algorithms in Coronary Heart Disease. Life System Modeling and Simulation Lecture Notes in Computer Science, pp 129-135.
Detrano, R. Janosi, A. Steinbrunn, W. Pfisterer, M. Schmid, J. Sandhu, S. Guppy, K. Lee, S. & Froelicher, V. (1989). International application of a new probability algorithm for the diagnosis of coronary artery disease. The American Journal of Cardiology, pp 304-310.15.
Dota, M. Cugnasca, C. Savio, D. (2015). Comparative analysis of decision tree algorithms on quality of water contaminated with soil, Ciencia Rural, Santa Maria, v.45, n.2, p.267-273, ISSN 0103-8478.
Gandhi, M. (2015). Prediction in heart disease using techniques of data mining. International conference on futuristic trend in computational analysis and knowledge management (ABLAZE-2015).
Gavhane, A. (2018). Prediction of heart disease using machine learning, ISBN: 978-1-5386-0965-1.
Jabbar, M. (2016). Heart disease prediction system based on hidden Navie Bayes Classifier. International conference on circuits , controls, communications and computing (14C).
Lakshmi, K. Veera Krishna, M. and Prem Kumar, S. (2013). Performance Comparison of Data Mining Techniques for Predicting of Heart Disease Survivability. International Journal of Scientific and Research Publications, 3(6).
Mai Shouman, M. Turner, T. & Stocker, R. (2012). Using Data Mining Techniques In Heart Disease Diagnoses And Treatment. Electronics, Communications and Computers (JECECC), 2012 Japan-Egypt Conference March 2012, pp 173-177.
Manikantan, V. & Latha, S. (2013). Predicting the analysis of heart disease symptoms using medicinal data mining techniques. International Journal on Advanced Computer Theory and Engineering (IJACTE), ISSN (Print) : 2319 – 2526, 2(2).
Nor Haizan, W. Mohamed, M. & Omar, A. (2012). A comparative study of reduced error pruning method in decision tree algorithms. IEEE International conferance on control system, Computing and Engineering, 23 - 25, Penang, Malaysia.
Rajeswari, K. Vaithiyanathan, V & Pede, S. (2013). Feature Selection for Classification in Medical Data Mining. International Journal of emerging trends and technologies in Computer Science, 2(2).
Soni, J. Ansari, U. & Sharma, D. (2011). Predictive Data Mining for Medical Diagnosis: An
Overview of Heart Disease Prediction. International Journal of Computer Applications, doi 10.5120/2237-2860.
Sudhakar, K. and Manimekalai, M. (2014). Study of Heart Disease Prediction using Data Mining, International Journal of Advanced Research in Computer Science and Software Engineering, 4(1), ISSN: 2277 128X.
Sugumaran, V. Muralidharan, V. & Ramachandran, K. (2007). Feature selection using Decision Tree and classification through proximal support vector machine for fault diagnostics of roller bearing. mechanical systems and signal processing, 21 (2), Pages 930-942.
Taneja, A. (2013). Heart Disease Prediction System Using Data Mining Techniques. J. Comp. Sci. & Technol., 6(4), 457-466.
Ul Haq, A. Li, J. Memon, M. Nazir, S., & Sun, R. (2018). A Hybrid Intelligent System Framework for the Prediction of Heart Disease Using Machine Learning Algorithms.
Wijaya, R. (2013). Preliminary design of estimation heart disease by using machine learning ANN within one year. communication technology and electric vehicle technology , bandung-bali, Indonesia.
Xing, Y. Wang, J. & Gao, Z. (2007). Combination data mining methods with new medical data to predicting outcome of Coronary Heart Disease. Convergence Information Technology. International Conference November 2007, pp 868-872.
Essay
DAT7001 Data Handling and Decision Making Assignment Sample
Assignment Brief
As part of the formal assessment for the programme, you are required to submit a Data Handling and Decision Making essay. Please refer to your Student Handbook for full details of the programme assessment scheme and general information on preparing and submitting assignments.
Date for Submission: Please refer to the timetable on ilearn
(The submission portal on iLearn will close at 14:00 UK time on the date of submission)
Learning Outcomes (LO):
After completing the module, you should be able to:
1. Analyse methods of auditing data holdings and gap identification.
2. Critically analyse theoretical and core processes of data manipulation and mining.
3. Utilizes and evaluate basic statistical concepts.
4. Appreciate ethical issues and their importance to data handling and decision making.
5. Develop a practical ability with data analysis and data mining methods to analyse and interpret data sets.
6. Make recommendations based upon the findings from data analysis.
7. Graduate Attribute – Effective Communication
Communicate effectively both, verbally and in writing, using a range of media widely used in relevant professional context.
Maximum word count: 1,000 words
Please note that exceeding the word count by over 10% will result in a reduction in grade by
the same percentage that the word count is exceeded.
Assignment Part 1: Data Gap Analysis
Data gap analysis can be referred to as the process of inspecting an existing or planned big data infrastructure with the aim of identifying issues, risks and inefficiencies associated with the use of data in organization’s operations. Such analysis requires an integrated view on technical, managerial and legal aspects of organisational data. This activity represents a key initial step towards implementation of data-driven business decision-making.
For this assignment, you are required to demonstrate the data gap analysis for assignment help
You are encouraged to relate this assignment to your workplace, so that the outcomes can immediately be applied to improving its data analytics processes. However, if you have no immediate workplace to analyzed or its use for the assignment purposes is not possible, then you have an option of adopting another project (such as a commercial start-up, community project or social enterprise) which would take advantage of data driven decision-making. Either an existing or prospective project can be discussed. In the latter case, the data infrastructure might not exist yet, however, you have an opportunity to propose its design and analyze it for any potential gaps.
Please turn over for the questions
Task 1.1
Perform data gap analysis for an organization or project of your choice. Your response should include:
• Brief background to the organization or project in question.
• Identification of the key data sources and datasets available to the organization.
• Inspection of data integrity and current or potential gaps in data analytics and data protection.
Task 1.2
Using the findings of Task 1.1, recommend improvements to the organisational data analytics processes. These should be centered around the following:
• Reorganization of the current data-driven processes to streamline and enhance the data analytics and decision making.
• Roadmap to the development or enhancement of the big data infrastructure.
• Compliance aspects of the proposed changes in data analytics.
Task 1.3
Explain how the proposed big data analytics can be used in the organizational decision making. This includes the following:
• Identification of a range of business decisions that can be supported by the enhancements in data analytics proposed in Task 1.2.
• Formulation of a single decision of your choice out of those identified, in terms of the related business question to be solved, involved stakeholders and data available for its support. (You will then be required to analyze this decision systematically in Part 2 of this Assignment.)
Submission Guidance
Assignments submitted late will not be accepted and will be marked as a 0% fail.
Your assessment should be submitted as a single Word (MS Word) or PDF file. For more information, please see the “Guide to Submitting an Assignment” document available on the module page on iLearn.
You must ensure that the submitted assignment is all your own work and that all sources used are correctly attributed. Penalties apply to assignments which show evidence of academic unfair practice.
Solution
Task 1.1
The subsidiary company of Google is Alphabet Inc. which was renamed in 2015. Alphabet Inc. allowed the expansion of Google into domains outside of the internet search. Alphabet advertises Google's services to become a technology conglomerate. The company is working on a big breakthrough and providing super-fast internet services (CNN 2021). Alphabet invests in long-term technological trends. The company manages the data of a huge range of consumers, which aims to improve the security of data.
Alphabet manages the data of six subsidiaries of Google, where the information related to the browsing history of consumers, location data, and business intelligence data are sourced. The shares of Google are transferred to the Alphabet stock, where the information related to the new company trades are specific datasets. Alphabet also researches health data where the focus is mainly given up on the management of Google investment (Franek 2019). Around 40 subsidiaries are related to investment, where Google LLC is the core part. However, the company also manages the data related to stock prices, press releases, company news, contact information, and board member executives. The unprecedented mass of data of the company's consumers makes it more ambitious in resource management.
Investigation of a current potential gap in data analytics and data protection
Alphabet Inc. integrates the data of consumers for promoting security and privacy of data by managing the network integrity. In the track records of Alphabet Inc., an unfair and deceptive practice related to data privacy and data security has been discovered. It has highlighted a data gap between the FFC's evident lack of remedial security and data privacy authority and Google's evident security and data privacy recidivism (Cleland 2018). The data gap analysis shows that FTC does not enforce any authoritative power to deter Google Alphabet. Around 17 pieces of evidence of major business practices have been discovered to support the argument. The personal data of consumers show an evident gap where the information of consumers is not secured. The data gap shows that the company has seriously harmed consumer welfare.
Task 1.2
Reorganization of current data-driven processes
The company Google Alphabet Inc. needs to promote the security of data where FTC has to reinvestigate the privacy and reinforce data security authority from the Congress to identify the company's rampant recidivist deceptive privacy and security practices. To promote security to the consumer data, the company has to build strong resilience in the internet platforms. Proper implementation of the data analytics process for decision-making regarding the security and privacy of data is necessary (Karthiban and Raj 2019, p. 130). The company uses Web Index to match the potential queries and to produce results where the data from trusted sources are driven. However, the accuracy in the machine learning process helps the company to manage reliability. Google Alphabet Inc. can manage the security issues by promoting data analytics like AI or block chain technology which will help to manage the data security of consumers by protecting the data rights. Operationalizing through XOps to create business value can help better decision-making and make analytics an integral part of security. Data-driven creatives may help the company in the decision-making process. Big data analytics helps monitor data breaches to ensure data security (Tang, Alazab, and Luo 2017, p. 318). For managing the information security of consumers, the company has to speed up the recovery process of data breaching and automate the big data analytics process to prevent further data privacy issues. Operating data and analytics processes as a core business function and promoting engineered decision insights may help the company manage data security. However, the FTC has to track the record of the company's data management process to analyze the gap and support the company to maintain data privacy.
Roadmap to the development of big data infrastructure
Compliance aspects of proposed changes in data analytics
The data security compliance regulation related to the company's data gap issue may help the company to achieve security, integrity, and availability of sensitive data and information systems. The GDPR helps protect personal data with proper legal enforcement (Blix, Elshekeil, and Laoyookhong 2018). This can help the company to manage the proper security of consumer information. The regulatory compliance in the data analytics process helps in managing the storage mechanisms and governing the respective data and semantics. However, the regulatory compliances related to security management of the information of the consumers may help to resolve the evident gap. With specific compliance analytics, the company will enforce policy for protecting the data from misuse. The FTC will help in reinforcing the security compliances to manage the data gap.
Task 1.3
Identification of business decisions
Enhancement in the data analytics process in Google Alphabet may lead to changes in financial decisions. The organization has to plan for cost estimation for the implementation of data analytics. To improve the operational efficiencies, engineered decision intelligence will be taken in guidance. Data analytics will help in the decision-making process regarding security management (Rassam, Maarof, and Zainal 2017). In this case, the company can implement AI or block chain for maintaining the privacy of data of the consumers. However, the analytics will comply with the regulatory policies of data security management, which will help the company manage the existing data gap. However, security experts should be hired for managing the potential risks in consumer data management. The organization has to make changes in system management to promote proper access control and authentication of data. Implementation of the data analytics decision-making process will encourage the company to document relevant information regarding the system operation.
The selected decision for the organization
Implementation of data analytics tools for information security can be an effective solution for the organization. AI or block chain tool implementation in the system network will help to monitor the data and to maintain the privacy of customer information. Consumers are significant stakeholders of the organization. Security of the available data related to the stakeholders will be possible through data analytics tool implementation.
References
Blix, F., Elshekeil, S.A. and Laoyookhong, S., 2018. Designing GDPR Data Protection Principles in Systems Development. Journal of Internet Technology and Secured Transactions (JITST), [Online], 6(1).
Cleland, S., 2018. A Case Study of Alphabet-Google’s 2004-2018 Privacy Track Record of Evident Unfair and Deceptive Over-collection of Consumers’ Personal Data Exposes an Evident Gap in the FTC’s Remedial Authority to Protect Consumers. [online], Available from: https://www.ftc.gov/system/files/documents/public_comments/2018/07/ftc-2018-0052-d-0005-147574.pdf [Accessed 2 July 2021].
CNN, 2021. What is Google’s new Alphabet? - CNNMoney. [online] Available from: https://money.cnn.com/interactive/technology/what-is-googles-new-alphabet/index.html [Accessed 2 July 2021].
Franek, K., 2019. What Companies Google & Alphabet Own: Visuals & Full List. [online] Available from: https://www.kamilfranek.com/what-companies-alphabet-google-owns/ [Accessed 2 July 2021].
Karthiban, M.K. and Raj, J.S., 2019. Big data analytics for developing secure internet of everything. Journal of ISMAC, [Online], 1(02), 129-136.
Rossum, M.A., Maarof, M. and Zainal, A., 2017. Big Data Analytics Adoption for Cybersecurity: A Review of Current Solutions, Requirements, Challenges and Trends. Journal of Information Assurance & Security, [Online], 12(4).
Tang, M., Alazab, M. and Luo, Y., 2017. Big data for cybersecurity: Vulnerability disclosure trends and dependencies. IEEE Transactions on Big Data, [Online], 5(3), 317-329.
Assignment
MIS101 Information Systems for Business Assignment Sample
Assignment Brief
Length 1500 words (+/- 10%)
Learning Outcomes
The Subject Learning Outcomes demonstrated by successful completion of the task below include for assignment help
a) Identify and explain components of information system for business.
b) Demonstrate an understanding of computing related mathematics.
Submission Due - by 11:55pm AEST/AEDT Sunday end of Module 4.2 (Week 8)
Weighting - 40%
Total Marks - 100
Task Summary
Using your understanding of computer number system and logic, answer the questions provided.
Context
Computer systems only understand binary numbers. The CPU, the main component inside a computer system, makes logical decision based on binary numbers. In Modules 3 and 4, you learned about computing mathematics and logic. This assessment focuses on your understanding of the number system and logic in computers.
Task Instructions
Read the questions carefully and give clear and precise answers.
Question 1:
a) Choose a sentence of no more than 25 characters containing your name (Example: ‘Kyle is in high school.’ Identify the ASCII code for each character; identify its decimal representation and then convert it into its equivalent binary number. (10 marks).
b) Convert the binary sequence (identified in part ‘a’) back to characters (5 marks).
c) Show the hexadecimal representation of each character in the selected sentence (5 marks).
Question 2:
Select an everyday real-life problem that requires two inputs. Once selected, represent it using a truth table. Explain the possible outcomes. Represent your problem using a logic diagram (20 marks).
Question 3:
Use the internet to investigate and explain what data transfer rate or speed is (10 marks).
Question 4:
How is the concept of Set Theory applied to Relational Databases? Give two examples (10 marks).
Question 5:
Identify and explain at least two applications of hexadecimal numbers in modern computing (10 marks).
Question 6:
Consider the following scenario:
The three inputs which affect the outcome of a business are:
1. the management is good
2. employees are satisfied
3. people are hard-working
If the management is not good, the organization will be in loss. If management is good and employees are satisfied but they do not work hard, then the organization will be in loss. If the management is good but the employees are not satisfied, then the business will break-even. If all three conditions are satisfied, then the organization will be in profit.
Analyze the scenario and identify the inputs and outputs to a process which decides the success of a business. Show this in the form of a truth table and logic diagram (30 marks).
Referencing
It is essential that you use appropriate APA style for citing and referencing research. Please see more information on referencing here: http://library.laureate.net.au/research_skills/referencing
Submission Instructions
Please submit ONE Word document (.doc or .docx) via the Assessment 2 section found in the main navigation menu of the MIS101 Blackboard site.
Solution
Introduction
In the world of computing, mathematics is an important subject as this is helpful for the students to use abstract language, deal with algorithms, self-analysis of computational thinking, and accurate modeling of real-world solutions. Thus, the unit here introduces the mathematical paradigm in the context of computing. Here, the researcher shows different calculations.
Question 1
a) Sentence: Kyle is in high school
ASCII code for Each character: 075121108101 105115 105110 104105103104 115099104111111108
Decimal Representation: 75 121 108 101 32 105 115 32 105 110 32 104 105 103 104 32 115 99 104 111 111 108
Conversion to equivalent binary number: 01001011 01111001 01101100 01100101 00100000 01101001 01110011 00100000 01101001 01101110 00100000 01101000 01101001 01100111 01101000 00100000 01110011 01100011 01101000 01101111 01101111 01101100
b) Binary to character: Kyle is in high school
c) Hexadecimal representation: 4b796c6520697320696e2068696768207363686f6f6c
Question 2
Real-life problem
Premise: If an individual bought bread, then he/she went to the store
Premise: The individual bought bread
Conclusion: He/she went to the store
So, for this, the truth table will be represented as:
For the given problem, the logic problem will be represented as:
Question 3
A data transfer often talks about the movement of digital data from one place to another, from a hard drive to a USB flash drive at a specific point in time. It is commonly used for measuring how fast data is going to be transferred from one location to another. For example, ISP often provides an Internet Connection with a maximum rate of data transfer of only 1.5 Mbps. It is measured in terms of either bit per second or bytes per second. A bit is used for measuring speed, while Byte is used for measuring size (Comer, 2018).
The rate of data transfer can be tested using various online tools. Most of them are known as internet speed tests. These tools are mostly used in order to get the broadband speed promised by the Internet providers. Various speeds are measured, such as speed of downloading, uploading, and also latency. Download speed talks about the time taken to transfer a file from the Internet to the user’s home network or computer. Uploading speed is referring to as time is taken for uploading a file to the internet. At the same time, latency, also known as ping, depicts the delay in the transfer of data from a server to the user's computer.
A slow rate of data transfer is the result of the computer’s hard drive, so this can be fortunately increased. Some of the ways to enhance it are:
? Changing the file system used for formatting the drive from FAT32 to NTFS.
? Tweaking the settings of the system to perform better
? Turning off the compression of the disk
? Another method is the upgradation of USB 2.0 to USB 3.0 or new versions.
In the case of a hard drive, the data transfer rate is of two types: External rate of transfer and internal transfer rate. External is also known as curst data transfer rate or interface rate that means the speed at which the data is moving between the internal buffer and system memory. On the other hand, the internal transfer rate is also referred to as the maximum or minimum sustained rate of transfer (Bhati & Venkataram, 2017). This means the speed of data is often read and written to the hard disk. The external rate of transfer is faster than the internal just because it is purely electronic and hence not relying on the efficiency of actual physical elements.
Question 4
A set is the collection of objects. Objects in this assortment are additionally supposed to be the set components or individuals. The most important point of this is members must define it clearly and exactly. An explicit definition of the member is not able to identify the set. For example, months of the colder time of year season is indicating a set, yet a few months are not determining a set. Consequently, sets are frequently named with the assistance of capital letters (Rodionov & Zakharov, 2018). Set names are given in curly braces and separated with the help of commas. Such a representation is known as Roster or Tabular form. X= {December, January, February}
It can also be represented using a Venn Diagram.
According to the set theory, the union of two sets can be helpful to get a new set containing members of the union sets. The below example can represent this:
A= {Orange, Apple, Lemon, Avocado, Strawberry}
B= {Lemon, Avocado, Apricot, Grape}
The union will be hence depicted by A U B.
A U B= {Apple, Lemon, Avocado, Orange, Strawberry, Grapefruit, Apricot}
The Venn diagram will be hence:
In SQL Server, the UNION operator is concatenating the result sets obtained from two tables and hence eliminating the duplicated rows from the outcome. In fact, here, this is acting just like a union operator in the Set Theory. If, B and A sets are defined using SQL server’s tables then, in this context, first, create the table and then add the expressions similar to A and B.
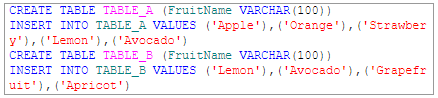
The union of these tables will result in:
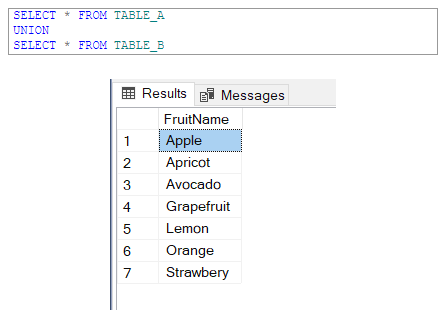
Change in the order of tables in the query will not result in any alteration.
On the other hand, the intersection of two sets is generating a set containing the common members of the intersected sets.
A∩ B = {Lemon, Avocado}
In SQL Server, the INTERSECT operator is implementing the logic of intersection in the Set Theory to tables. So, the intersection of both tables A and B can be given as:
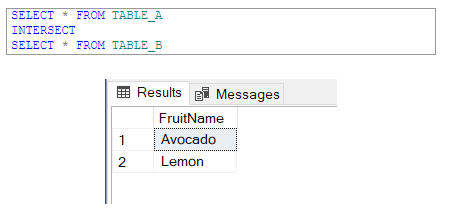
Question 5
Hexadecimal or hex with base 16 system is mainly used for simplifying the representation of binary. This hence means that an 8-bit binary number can be written with the help of two different hex digits, one for each nibble or group of 4-bits. Hexadecimal is utilized in the following manner:
? Defining the memory location: Hex has the potential to characterize every byte as two hex digits can only be compared to eight digits at the time of using binary.
? Defining colours on the web pages: Each primary colour, such as green, blue and red, is attributed by two hex digits (Massengale, 2019). The format that is used is #RRGGBB.
? Displaying an error message: Hex is used for defining the error location in the memory. This one is hence used by the programmers to find and fix the errors.
? Representing MAC addresses: There are 12-digit hex numbers in a MAC address. The format used is either in the form MM: MM: MM: SS: SS: SS or MMMM-MMSS-SSSS. The first 6-digits of the MAC address is hence showing the adapter manufacturer's ID, while the last 6-digits represent the adapter's serial number.
Question 6
For the given scenario, it can be observed that here three inputs are present they are: employees are satisfied, management is good, and people are working hard. From the scenario, it can be said that if the management is good and employees are highly satisfied with the work environment, then automatically, the companies can foster their business. However, if the management is good, but employees are less or not satisfied, then the organization will suffer a huge loss. If all the conditions are satisfied, then, obviously, the organization will be in profit. So, the overall scenario can be presented in the truth table. Once the truth table has been created, the logic diagram can also be created easily.
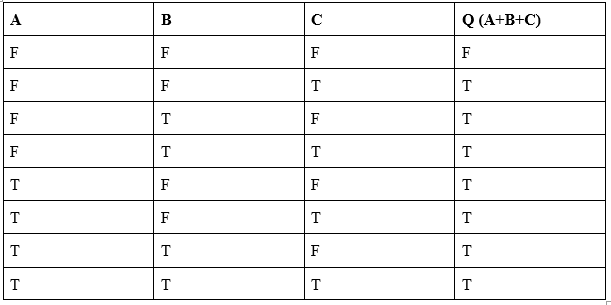
So, the logic gate for this truth table would be:

In this context, the "OR" operator has been applied. It is observed that if all the inputs are false, then the output will also be false. Similarly, when two false conditions are combined with one true value, then the result will be true itself. That means that if the management is not working well and employees are not satisfied but still working with great dedication, then also the organization is gaining a huge revenue because of high productivity level. Similarly, if all three inputs are false, then the firm automatically fails to provide the best service, and there will be a huge loss in revenue.
Conclusion
Comprehensively, it can be said that binary and ASCII codes are mostly used for transmitting data. These are codes to transmit data often used by smaller and less-powerful computers for representing both textual data and also non-input device commands. So, the unit discussed these concepts profoundly. The unit also consisted of some descriptive parts related to the computing world. The study also depicted the use of a truth table and logic gates for inferring a premise. This also discussed the relationship between set theory and relational databases. In this direction, the researcher used UNION and INTERSECTION operation.
References
Bhati, B. S., & Venkataram, P. (2017). Preserving data privacy during data transfer in manets. Wireless Personal Communications : An International Journal, 97(3), 4063–4086. Retrieved from: https://doi.org/10.1007/s11277-017-4713-2
Comer, D. (2018). The internet book : everything you need to know about computer networking and how the internet works (5th ed.). Chapman & Hall/CRC Retrieved from: https://lesa.on.worldcat.org/oclc/1052459938
Massengale, L. (2019). Digital systems design: numbering systems and logical operations. Momentum Press. Retrieved from: https://lesa.on.worldcat.org/oclc/1083457871
Rodionov, T. V., & Zakharov, V. K. (2018). Fundamentals of set and number theory (Ser. De gruyter studies in mathematics ser, v. 68/1). De Gruyter Retrieved from: https://lesa.on.worldcat.org/oclc/1023551253
Coursework
COMP1702 Big Data Assignment Sample
coursework Learning Outcomes:
1 Explain the concept of Big Data and its importance in a modern economy
2 Explain the core architecture and algorithms underpinning big data processing
3 Analyze and visualize large data sets using a range of statistical and big data technologies
4 Critically evaluate, select and employ appropriate tools and technologies for the development of big data applications
All material copied or amended from any source (e.g. internet, books) must be referenced correctly according to the reference style you are using.
Your work will be submitted for plagiarism checking. Any attempt to bypass our plagiarism detection systems will be treated as a severe Assessment Offence.
Coursework Submission Requirements
• An electronic copy of your work for this coursework must be fully uploaded on the Deadline Date of 29th Mar 2021 using the link on the coursework Moodle page for COMP1702.
• For this coursework submit all in PDF format. In general, any text in the document must not be an image (i.e. must not be scanned) and would normally be generated from other documents (e.g. MS Office using "Save As ... PDF"). An exception to this is handwritten mathematical notation, but when scanning do ensure the file size is not excessive.
• There are limits on the file size (see the relevant course Moodle page).
• Make sure that any files you upload are virus-free and not protected by a password or corrupted otherwise they will be treated as null submissions.
• Your work will not be printed in colour. Please ensure that any pages with colour are acceptable when printed in Black and White.
• You must NOT submit a paper copy of this coursework.
• All course works must be submitted as above. Under no circumstances can they be accepted by academic staff
The University website has details of the current Coursework Regulations, including details of penalties for late submission, procedures for Extenuating Circumstances, and penalties for Assessment Offences. See http://www2.gre.ac.uk/current- students/regs
Detailed Specification
You are expected to work individually and complete a coursework that addresses the following tasks. Note: You need to cite all sources you rely on with in-text style. References should be in Harvard format. You may include material discussed in the lectures or labs, but additional credit will be given for independent research.
PART A: Map Reduce Programming [300 words ±10% excluding java codes] (30 marks)
There is a text file (“papers.txt” is uploaded in Moodle) about computer science bibliography. Each line of this file describes the details of one paper in the following format: Authors|Title|Conference|Year. The different fields are separated by the “|” character, and the list of authors are separated by commas (“,”). An example line is given below: D Zhang, J Wang, D Cai, J Lu|Self-Taught Hashing for Fast Similarity Search|SIGIR|2010
You can assume that there are no duplicate records, and each distinct author or conference as a different name.
PART B: Big Data Project Analysis [2000 words ±10% excluding references] (70 marks)
Precision agriculture (PA) is the science of improving crop yields and assisting management decisions using high technology sensor and analysis tools. The AgrBIG company is a leading provider of agronomy services, technology and strategic advice. They plan to develop a big data system. The users can be farmers, research laboratories, policy makers, public administration, consulting or logistic companies, etc. The sources of data will be from various Sensors, Satellites, Drones, Social media, Market data, Online news feed, Logistic Corporate data, etc.
You need to design a big data project by solving the following tasks for the AgrBIG company:
Task1 (25 marks): Produce a Big Data Architecture for the AgrBIG company with the following components in detail for assignment help
- Data sources,
- Data extraction and cleaning,
- Data storage,
- Batch processing,
- Real time message ingestion,
- Analytical Data store
For each of the above, discuss various options and produce your recommendation which best meets the business requirement.
Task2 (10 marks): The AgrBIG company needs to store a large collection of plants, corps, diseases, symptoms, pests and their relationships. They also want to facilitate queries such as: "find all corn diseases which are directly or indirectly caused by Zinc deficiency". Please recommend a data store for that purpose and justify your choice.
Task3 (10 marks): MapReduce has become the standard for performing batch processing on big data analysis tasks. However, data analysists and researchers in the AgrBIG company found that MapReduce coding can be quite challenging to them for data analysis tasks. Please recommend an alternative way for those people who are more familiar with SQL language to do the data analysis tasks or business intelligence tasks on big data and justify your recommendation.
Task 4 (15 marks): The AgrBIG company needs near real time performance for some services such as soil moisture prediction service. It has been suggested the parallel distributed processing on a cluster should use MapReduce to process this requirement. Provide a detailed assessment of whether MapReduce is optimal to meet this requirement and If not, what would be the best approach.
Task 5 (10 marks): Design a detailed hosting strategy for this Big Data project and how this will meet the scalability, high availability requirements for this global business.
Assessment criteria
For a distinction (mark 70-79) the following is required:
1. An excellent/very good implementation of the coding task, all components are working and provide a very good result.
2. An excellent/very good research demonstrating a very good/ excellent understanding of big data concepts and techniques.
Note: In order to be eligible for a very high mark (80 and over) you will need to have:
Solution
Part A:
As the Map Reduce system in Hadoop mainly works on distributed server environment which helps in parallel execution of different processes and handle the communications among the different systems.
The model is a unique methodology of split-apply-join technique which helps in information retrieval. Mapping of the data is finished by the Mapper class and lessens the assignment is finished by Reducer class. On the other hand, MapReduce comprises of two stages – Map and Reduce.
As the name MapReduce recommends, the reducer stage happens after the mapper stage has been finished. Thus, the first is the guide work, where huge amount of data is perused and prepared to create key-value sets as middle of the results.
The yield of a Mapper or guide work (key-value sets for the process) is contribution to the Reducer. The reducer gets the key- value pair from different guide occupations.
At that point, the reducer totals those moderate information tuples (middle key-esteem pair) into a more modest arrangement of tuples or key-esteem sets which is the last yield. MapReduce expands on the perception that numerous data preparing errands have a similar essential construction: a calculation is applied over an enormous number of records (e.g., Web pages) to produce incomplete outcomes, which are then collected in some style. Normally, the per-record calculation and total capacity differ as per task, however the fundamental design stays fixed. Taking motivation from higher-request capacities in utilitarian programming, MapReduce gives a deliberation at the place of these two activities.
Following is the algorithm used for the program;
For Mapper
Input: ((word, datafilename), ( N,n, m))
consider D is known ()
Output ((word, datafilename), TF*IDF)
For Reducer
Just the considered identity function
Part B:
Task 1
Big Data Architecture is used by AgrBIG company in order to manage the business and the data related to the business can be analysed effectively. The architecture framework comes with different infrastructure solution for data storage, providing an opportunity to a business to hold a large amount of information and data (Ponsard et al., 2017). Data analytical tools are used in order to fetch the required result from a big set of data using the various components of big data architecture.
Data Sources
In order to ensure the effective running of the business and acquiring the desired outputs and profits, the company has to ensure that all the data that is to be operated or processed must be available to the company in time of requirement. The company has thus used different sources for utilising different data. The data sources come in different form from the company. Application data stores are used by the company in order to store the relational databases about different information about vendors and clients as well as the employees (Lai and Leu, 2017). Static files are produced by the company in order to run the applications, such as the server files, files associated with the website handling. Real-time data sources are also used by the company like devices which uses the technology of the Internet of Things.
Data extraction and Cleaning
Tokuç, Uran and Tekin (2019) discussed, the system has to include all data cleaning features in order to clear the junk data from the system for an effective running of the data tools that has been used by the management of the company. The company has to think of different approaches to ensure the cleaning of data is undertaken where the junk data has no requirement in the database. The data can be extracted from the system using any query language. Here, the company is dependent on NoSQL database for extracting information regarding different requirements of the business and associated stakeholders.
Data storage
For the process of data storage, the data is typically stored by AgrBIG company contains a huge number of information that is stored in the form of distributed files which contain a large volume of files and data that is stored in different formats. This huge volume of data can be stored in the storage called data lake. The data lake is considered to be the storage area used by the company in order to storage the vital information associated to the company and can be implemented for use anytime (Grover et al., 2018). The company is using Azure Data Lake Store for the storage of big data.
Batch Processing
As opined by Kim (2019), since the data used by the company comes in huge volume, they require to be provided with a solution of big data processing in order to filter the data and extracted in the time of requirement. Typically, long-running batch jobs are used to process the data files stored in big data. These data can be then prepared for the analysis of different jobs. The jobs related to analysis can include sourcing of files. processing the files and writing any new outputs on the files. U-SQL jobs is used in combination with Azure Data Lake Analytics in order to extract the required information. The company has also approached Map Reduce job for clustering the data using Java program.
Real-Time message ingestion
The solution of the data which is being extracted by the company if consists of real-time data sources then it has to implement the real-time message ingestion system in order to make the data for stream process. This is a way of simple storage of data where the incoming messages are handled and dropped into the folder which will be used for further processing. Different solution needs message ingestion according to eh requirements in order to act as buffer for the message an support the delivery of the message on forming semantics with queue.
Analytical Data store
Different kind of big data solution re now being prepared and used for analysis of data and the tools serves the data for processing in a sematic and structured format. Various analytic tools have been implemented in order to bring out the analysis through queries form the relation data warehouse. NoSQL technology or Hive database has been used for providing metadata abstraction features over the data files in the distributed storage of the system. The most traditional system being used by the business intelligence to implement the analytical storage of data through Azure Synapse analytics which is largely used by the company in order to provide a managed service in big data handling (Govindan et al., 2018). garbage company also uses cloud-based data warehousing for supporting interactive database management in order to serve the purpose of data analysis.
Task 2
garbage company has decided to implement large storage of bid data using a NoSQL database. This approach has been used by the company in order to handle a large volume of data which can be effectively extracted and used in higher speed and the scalability of the architecture being high (Eybers and Hattingh, 2017). In order to implement a scale-out architecture, NoSQL databases has been used by the company in order to communicate the queries even with cloud computing technologies. Moreover, it enables to process the data in large clusters and thus increases the capacity of the computers when added to the clusters.
Another reason for using the NoSQL database is to store the every unstructured and structured data with the help of some predefined schemas., These schemas can be easily used to transform into the data and can be loaded into the database. Few transformations are required in order to store retrieve information. In addition to that, the preference of choosing the NoSQL database by the AgrBIG company is that the database has the flexibility feature in order to be easily controlled by the developers and can be adaptable to holds different forms of data.
This technology has also features to update the data of the database easily by making transformation in the structure of the data. The value for rows and columns in the database can be updated with new values without disrupting the existing structure. The database comes with developer-friendly characteristics, which enables the developer to keep the control of the system and its associated structures of the data (Ekambaram et al., 2018). It thus helps to store the data where it can be closely observed when used in different application by the company. Moreover, the data in and data out is useful and easier though this technology used by the business.
Task 3
There are different methods that the company can use for data analysis tasks. The company has found that MapReduce is through an effective technology for the data analysis requirements of AgrBIG company, but the technology is posing different challenges in implementation. MapReduce uses different stages for the extraction of the data requirements. Though the technology is highly approached and effective in mapping a large set of data into cluster and creating several small elements of data by breaking them into tuples. Yet, the company prefers to use some other technology in order to implement the data processing. Hive can be used by AgrBIG company in order to run the parallel distributed system along with being familiar with the SQL language. This can be implemented by the company to run in parallel with MapReduce in order to distribute the data and sending these, mapper programs to the required location, locating the failures for handling. Hive is an alternative to MapReduce in order to reduce the line of the codes and making it easier to understand.
The coding approach of Hadoop comes with difficult functionality making it more complex for the business as it is time consuming. According to Bilal and Oyedele (2020), for advanced programming interfaces, the AgrBIG company can use Hive for the handling any large data. the technology also comes with special tools for the execution of data and manipulation of data. Hive also comprise of such technology which comes with different processing concepts for the selection, filtering and ordering of data according to provided syntax and has the flexibility to make conceptual adjustments Thus in most cases those who are familiar with SQL language prefers to have Hive over MapReduce as the data analysis tool for big data.
Task 4
Garbage company is concerned about implementing a scalable architecture that has the capacity to handle a large amount of distributed data in different servers across the cloud. The large data sets can be effectively handles and can be operated in parallel technology using MapReduce. Thus, this is chosen as the one of the best and optimal solution to the requirement of the business, which can handle the data effectively and process the huge amount of data at a very cost-effective solution. For real-time processing of data, the cost-effective approach used by MapReduce helps to meet the requirements of the business effectively as the technology allows the storage of data and processing of the data at a very affordable cost (Becker, 2017). The business of AgrBIG company has found that the programming through MapReduce has made an effective access to different sources of the data which helps to generate and extract values according to the requirements and thus flexible for the data processing and storage.
The business has also got advantages by MapReduce programming as it supports faster access to the distributed file system, which uses different mapping structure in order to locate data that is stored in clusters. The tools that MapReduce offers allows faster processing of big data. The essential feature for using MapReduce in order to recommend the technology as the optimal solution for the requirement of the business is the security which is the vital aspect of this application. Only approved users can gain the access to the data storage of the system and processing of the data.
MapReduce enables the AgrBIG company to provide the feature of parallel distributed processing through which the tasks can be divided in an effective manner and the execution can be done in parallel techniques. The parallel processing technique for the programming ensure the use of multiple process which can effectively handle the tasks by diving them and the programs can be computed and executed in faster approach (Walls and Barnard, 2020). Moreover, the data availability using this application is secured as the data is being forwarded to various node in the network. In case of failure of any of the node, data can be processed from other node which has the access of the data. This is offered by the fault tolerance feature of the application, which is very vital to meet the requirements of the business and make it more sustainable.
Task 5
Defining a big data strategy for hosting the requirements of the business it requires to synchronize the data for handling the objectives of the business in order to implement for big data. The strategy should be implemented in such a way that it can aligning the quality of the organisation long with approaching the performance goals focusing on different measurable outcomes. The strategy should be implemented with high scalability so that it possesses the decision making using data resources. Moreover, the data increases its volume with the expansion of the organisation, so it is required to choose the right data in order to find the solution to the various problems of the business. In the next approach, effective tools for handling the big data must be used by AgrBIG company in order to address the problems of the business. As stated by Ajah and Nek (2019), the Hadoop is being extensively used for an efficient handling of unstructured and structured data of the company. For the optimisation of the data, different analytical tools can be used by the company to meet the requirements and make the predictions based on the assumption of consumer behaviour. The entire process can ensure high availability of the information to meet the requirements of the business globally by synchronizing the entire flow of data with the help of public and private cloud provision which also comes with the feature of backups and data security. Thus, a hosting strategy for implementing Big Data project can ensure the management of organisation with the minimisation of risks and helps the project team to discover unexpected outcomes and examine the effects of the analysis.
Reference List
Ajah, I.A. and Nweke, H.F., (2019). Big data and business analytics: Trends, platforms, success factors and applications. Big Data and Cognitive Computing, 3(2), p.32. https://www.mdpi.com/2504-2289/3/2/32/pdf
Becker, D.K., (2017, December). Predicting outcomes for big data projects: Big Data Project Dynamics (BDPD): Research in progress. In 2017 IEEE International Conference on Big Data (Big Data) (pp. 2320-2330). IEEE. https://ieeexplore.ieee.org/abstract/document/8258186/
Bilal, M. and Oyedele, L.O., (2020). Big Data with deep learning for benchmarking profitability performance in project tendering. Expert Systems with Applications, 147, p.113194. https://uwe-repository.worktribe.com/preview/5307484/Manuscript.pdf
Ekambaram, A., Sørensen, A.Ø., Bull-Berg, H. and Olsson, N.O., (2018). The role of big data and knowledge management in improving projects and project-based organizations. Procedia computer science, 138, pp.851-858. https://www.sciencedirect.com/science/article/pii/S1877050918317587/pdf?md5=fb25e51566ae00860fc3831ce4088ce0&pid=1-s2.0-S1877050918317587-main.pdf
Eybers, S. and Hattingh, M.J., (2017, May). Critical success factor categories for big data: A preliminary analysis of the current academic landscape. In 2017 IST-Africa Week Conference (IST-Africa) (pp. 1-11). IEEE. https://www.academia.edu/download/55821724/Miolo_RBGN_ING-20-1_Art7.pdf
Govindan, K., Cheng, T.E., Mishra, N. and Shukla, N., (2018). Big data analytics and application for logistics and supply chain management. https://core.ac.uk/download/pdf/188718529.pdf
Grover, V., Chiang, R.H., Liang, T.P. and Zhang, D., (2018). Creating strategic business value from big data analytics: A research framework. Journal of Management Information Systems, 35(2), pp.388-423. https://files.transtutors.com/cdn/uploadassignments/2868103_1_bda-2018.pdf
Kim, S.H., (2019). Risk Factors Identification and Priority Analysis of Bigdata Project. The Journal of the Institute of Internet, Broadcasting and Communication, 19(2), pp.25-40. https://www.koreascience.or.kr/article/JAKO201914260900587.pdf
Lai, S.T. and Leu, F.Y., (2017, July). An iterative and incremental data preprocessing procedure for improving the risk of big data project. In International Conference on Innovative Mobile and Internet Services in Ubiquitous Computing (pp. 483-492). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-319-61542-4_46
Ponsard, C., Majchrowski, A., Mouton, S. and Touzani, M., (2017). Process Guidance for the Successful Deployment of a Big Data Project: Lessons Learned from Industrial Cases. In IoTBDS (pp. 350-355). https://www.scitepress.org/papers/2017/63574/63574.pdf
Tokuç, A.A., Uran, Z.E. and Tekin, A.T., (2019). Management of Big Data Projects: PMI Approach for Success. In Agile Approaches for Successfully Managing and Executing Projects in the Fourth Industrial Revolution (pp. 279-293). IGI Global. https://www.researchgate.net/profile/Ahmet_Tekin7/publication/331079533_Management_of_Big_Data_Projects/links/5c86857ba6fdcc068187e918/Management-of-Big-Data-Projects.pdf
Walls, C. and Barnard, B., (2020). Success Factors of Big Data to Achieve Organisational Performance: Theoretical Perspectives. Expert Journal of Business and Management, 8(1). https://business.expertjournals.com/23446781-801/
Dissertation
Character Embedded Based Deep Learning Approach For Malicious Url Detection
Learning Outcomes
The aim of this research is to enable you to undertake a sizeable piece of individual academic work in an area of your own interest relevant to, and to demonstrate technical skills acquired in, your programme of study.
This postgraduate work will include an advanced level of research, analysis, design, implementation and critical evaluation of your solution.
You must cover the following topics in practice by applying them to your chosen research project:
• Identification of a suitable research topic,
• Research methods,
• Literature surveys, searches and reviews, Dissertation
• Plagiarism and referencing,
• Effectively engaging with academic research both on a theoretical and practical point of view,
• Academic writing and presentation skills for matlab dissertation help
• The development and documentation, to a master level standard, of a large, non-trivial and genuine research project aligned with your Master of Science programme.
At the end of this module, you will be able to:
Knowledge
1. Demonstrate an advanced knowledge of one chosen and highly specific area within the scope of your Master of Science programme and to communicate this knowledge through both a written report (dissertation) and an oral assessment,
2. Demonstrate the knowledge of research methods appropriate for a master level course and to communicate this knowledge through both a written report (dissertation) and an oral assessment
The Contents of your Dissertation
It must include the following sections:
• Title page showing the title, student number, programme, year and semester of submission,
• Contents page(s),
• Acknowledgements (if you wish to acknowledge people that have helped you),
• Abstract,
• Body of the dissertation,
• List of references,
• Appendices (including implementation code).
Observe the following guidelines when writing your dissertation:
• Your dissertation must be word-processed. In particular, hand written submissions will NOT be accepted. You are also encouraged to use LATEX typesetting, which is best for producing high quality, well-formatted scientific publications. Overleaf (www.overleaf.com) is an online LATEX editor.
• Pages must be numbered but you will find paragraph numbers easier for cross referencing.
• Appendices should only contain supporting documentation which is relevant to the report in which they are included. Their size should be kept to a minimum.
• Material must be accurate and presented in a structured manner.
• The information contained within your dissertation should be presented in such a way as to allow both staff and students in the future to read, understand and learn from you.
• The word limit should be adhered to (see Section 21.). Indeed, this limit is set to force you to synthesize your thoughts. This ability is very important in industry as you must convey to your colleagues and managers the key ideas about your work in a clear and concise way. However, I point out that massively moving content from the body of your report to appendices is not a substitute for writing concisely.
• The code of your implementation must be submitted as appendices. It does NOT count towards the word limit.
This is a 60-credit course and its assessment is based on two elements:
• The writing of a 15,000-word dissertation (with a tolerance of ± 10% for the length of the final document),
• A presentation of the research work. This presentation will be in the form of a viva-voce where you will be required to present and defend your work.
Solution
Chapter 1
1.1 Introduction
Malicious URLs are the purpose of promoting scams as well as frauds and attacks. The infected URLs are actually detected by the antiviruses. There are various approaches to detecting malicious URLs which are mainly categorized by four parts such as classification based on contents, blacklists, classification based on URLs, and approach of feature engineering. Several linear and non-linear space transformations are used for the detection of malicious URLs; this actually improves the performance as well as support. The Internet is the basic part of daily life and the Uniform resource locator (URLs) are the main infrastructure for the entire online activities and discriminate the malware from benign problems. URL involves some of the complicated tasks such as data collection in a constant manner and feature extraction and pre-processing of data as well as classification. The online systems which are specialized and draw a huge amount of data are always challenging the traditional malware detection methods. The malicious URLs are now frequently used by criminals for several illegal activities such as phishing, financial activities, fake shopping, gaming, and gambling. Omnipresence smartphones are also the cause of illegal activities stimulated by the code of Quick response (QR) and encode the fake URLs in order to deceive the senior people. Detection of malicious URLs is focused on the improvement of the classifiers. The feature extraction and the feature selection process improves the efficiency of classifiers and integrates non-linear and linear space transformation processes in order to handle the large-scale URL dataset.
Deep learning embedded Data Analysis is in effect progressively utilized in digital protection issues and discovered to be helpful in situations where information volumes and heterogeneity make it bulky for manual appraisal by security specialists. In useful network protection situations including information-driven examination, acquiring information with comments (for example ground-truth names) is a difficult and known restricting component for some administered security examination tasks. Huge parts of the huge datasets commonly stay unlabeled, as the assignment of comment is broadly manual and requires an enormous measure of master mediation. In this paper, we propose a viable dynamic learning approach that can proficiently address this limit in a reasonable network protection issue of Phishing classification, whereby we utilize a human-machine community-oriented way to deal with plan a semi-regulated arrangement. An underlying classifier is learned on a limited quantity of the explained information which in an iterative way, is then slowly refreshed by shortlisting just important examples from the enormous pool of unlabeled information that is destined to impact the classifier execution quickly. Focused on Active Learning shows a critical guarantee to accomplish quicker intermingling regarding the grouping execution in a cluster learning structure and in this manner requiring much lesser exertion for a human explanation.
1.2 Background
The Malicious URLs are used by cybercriminals by some unsolicited scams, malware advertisements, and phishing methods. Detecting malicious URLs includes the approaches of signature matching and regular expression as well as blacklisting. The classic system of machine learning systems is actually used for the detection of malicious URLs. The state of art is used to evaluate and from the architectures and the features are essential for the embedding methods of malware URL detection. URLDetect or DURLD is used to encode the embedding which is done at the character level. In order to capture the different types of information encoded in the URL, use the architectures of deep learning in order to extract the features at the character level and estimate the URL probability. Currently, malicious features are not extracted appropriately and the current detection methods are currently based on the DCNN network in order to solve the problems. On the multilayer original network, another new folding layer is added and the pooling layer is being replaced by the K-max layer of pooling and using the dynamic convolution algorithm the middle layer in the feature mapping width. The internet users are actually tricked by using phishing techniques and spam by the hackers and the spammers. They are also using the Trojans and malware URLs to leak the sensitive information of the victims. In the traditional method, the detection of malicious URLs is adopted using methods based on the blacklist. This method actually has some of the advantages such as it improves the high data speed and reduces the rate of false positives and this is very easy for the realization. In recent times, the algorithm of domain generation for detecting the different malicious domains in order to detect the blacklist method of traditional methods (Cui et al. 2018, p. 23).
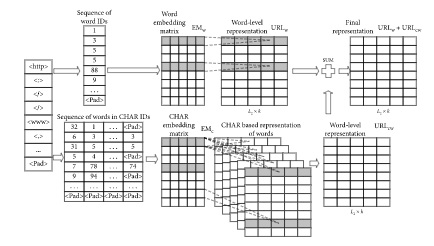
Figure 1: Method of word embedding
(Source: Verma and Das, 2017, p. 12)
The machine learning process is used to detect the model based on prediction and the statistical properties are classified as the benign URL. According to the model of vector embedding, the URL sequence is imputed in the proper vector and the subsequent process is being facilitated. This process is being initialized in a normal manner and the appropriate expression of the vector is being used for the training process. The advanced word embedding method is being used for character embedding. This data is extracted the phase information from the Unique resource locator and the extracted information is being extracted for the subsequent training process in order to obtain the proper expression vector and this is provided in the subsequent layer of convulsion. According to the method of dynamic conclusion, the input data is gathered from the extracted features. The procedure of this system includes folding, convulsion, and dynamic pooling which is suggested by the DCNN parameters for the current layer of convulsion. According to the DCNN training the output of the upper layer is being inputted in the next layer of the networks in order to convert the expression of the suitable vector. According to the method of the block extraction, the name of the domain, as well as the subdomain name, actually encodes the branch of the second data. In the embedding layer, the unique resource locator is actually used at the top level of the management (Patgiri et al. 2019, p. 21).
The powerlessness of the end client framework to recognize and eliminate the noxious URLs can place the real client in weak condition. Besides, the use of noxious URLs may prompt ill-conceived admittance to the client information by foe (Tekerek, 2021). The fundamental thought process in vindictive URL recognition is that they give an assault surface to the foe. It is essential to counter these exercises through some new approaches. In writing, there have been many separating components to identify the noxious URLs. Some of them are Black-Listing, Heuristic Classification, and so on These conventional instruments depend on catchphrase coordinating and URL linguistic structure coordinating. Subsequently, these traditional systems can't successfully manage the consistently advancing innovations and web-access methods. Besides, these methodologies additionally miss the mark in recognizing the advanced URLs like short URLs, dull web URLs. In this paper, we propose a novel characterization technique to address the difficulties looked at by the customary components in vindictive URL recognition. The proposed arrangement model is based on modern AI techniques that not just take care of the linguistic idea of the URL, yet in addition the semantic and lexical importance of these powerfully evolving URLs. The proposed approach is required to beat the current methods.
1.3 Problems analysis
In this section, the domain names, as well as the subdomain names, are extracted from the Unique resource locator and each URL has a fixed length which is actually being flattened in the flattened layer where the domain names, as well as subdomain names, are being marked. The common users need to use the advantages of the word embedding process which effectively express the rare words. The rare words can be represented accurately by the word embedding system in the URL. This method actually diminishes the scale of the present embedded matrix and thus memory space is also being reduced. This process is also converting the words which are new and the accurate vectors are not existing in the training sets and this helps to extract the character information. The attackers and the hackers are actually communicate using a control center through the DGA names which are malicious in nature and the structure of the network actually select a large amount of the URL data sets and the subdomains and domains in the top level are included at the dataset division (Sahoo et al. 2017, p. 23).
The deeply embedded learning process has been the most efficient way in determining the malicious websites causing potential threats to the users. These sites do not only contain damage-causing elements, but they can also get into a system and steal the data of a user and outsource it on the internet. If you notice at the address bar while using certain websites, they have very long URLs. These long texts indicate the subsidiary file directory of the file where it is present, clearly stating the parent folders and file name in the text. This deep learning process is easy to apply on such websites having long texts in the URL as it covers the maximum amount of data that the URL holds. But providing the same kind of security with short text URLs gets difficult (Cui, He, Yaoand Shi, 2018). These websites are more open to getting affected by such malicious websites. Therefore, the leaked data is mostly from websites having short URLs as the technology does not secure the subsidiary files and folders. Hence, the algorithm and working of the deeply embedded learning process need to modify in such a way that it covers each type of website with the best protocols.
1.4 Aim and Objectives
Aim
The preliminary aim of this research is to investigate character embedded-based deep learning approaches for malicious URL detection.
Objectives
- To determine the effects of multi-layer perception for determining malicious URL
- To determine the effects of artificial neural networks for determining malicious URL
- To determine the process of the deep embedded learning process for reducing malicious activities
- To recommend strategies for the machine learning process for eliminating malicious activities
1.5 Research Questions
- How to determine the effects of multi-layer perception for determining malicious URLs?
- How to determine the effects of artificial neural networks for determining malicious URLs?
- How to determine the process of deep embedded learning to reduce malicious activities?
- What are the recommended strategies for the machine learning process for eliminating malicious activities?
1.6 Rationale
Malicious URL is a well-known throat that is continuously surrounding the territory of cybersecurity. These URLs act as an effective tool that attackers use for propagating viruses and other types of malicious online codes. Reportedly, Malicious URLs are responsible for almost 60% of the cyber-attacks that take place in the modern-day (Bu and Cho, 2021). The constant attacks through malicious URLs are a burning issue that causes almost millions of losses for organizations and personal data losses for individuals. These malicious URLs can easily be delivered through text messages (Le et al. 2018). Email links, browsers and their pop-ups, online advertisement pages, etc. In most cases of cybersecurity casualties, these malicious URLs are directly linked with a shady website that has some downloadable embedded. These processes of downloads and downloaded materials can be viruses, spy-wares, worms, key-loggers, etc. which eventually corrupts the systems and sucks most of the important data out of it (Saxe and Berlin, 2017).
Nowadays, it has become a significant challenge for app developers and cyber security defenders to deal with these unwanted malicious viruses and mitigate them properly in order to protect the privacy of individuals and organizations. Previously the security protectors have significantly tried to use URL blacklisting and signature blacklisting in order to detect and defend the spread of malicious URLs (Vinayakumar et al. 2018). Although with the advancement of technology attackers have implemented new tools that can spread malicious URLs and it has become a constant huddle for cybersecurity professionals to deal with these problems. In order to improve the abstraction and timelessness of the malicious URL detection methods, professionals are developing python based machine learning techniques that can deal with this issue automatically by recognizing the malicious threats beforehand.
The issue of malicious URLs is becoming the most talked-about threat nowadays because on a daily basis worldwide companies and individuals are facing unwanted attacks from malicious attackers via malicious URLs. Reports from the FBI states that almost 3.5 billion records of data were lost in 2019 due to malicious attacks on their server. Also, according to some research, almost 84% of the worldwide email traffic is spam (Yang, Zhao, and Zeng, 2019). Some of the research work from IBM has confirmed that almost 14% of the malicious breaches surprisingly involve the process of phishing. Some of the related research has pointed out that almost 94% of the security attacks involve the process of malicious URLs and injecting malware through email (Yang, Zuo and Cui, 2019). Most of the common scams that involve malicious URLs generally involve phishing and spam. Phishing is a process of fraud that criminals generally use in order to deceive the victims by impersonating trusted people or organizations. The work process of Phishing involves receiving a malicious URL via email from a trusted individual or organization and after clicking on that particular URL most of the important data is hacked and compromised by the attackers. Nowadays it has become a process of spoofing some known addresses or names of individuals.
The emerging risk of malicious URLs and security casualties due to it has become a massive issue in today’s digital world. Security professionals face constant huddles dealing with this issue at the present time. In this scenario, developers need to take the process of a deep learning-based approach in order to mitigate the issues with these malicious URLs. In order to detect malicious URLs professionals can take character embedded-based deep learning approaches. Developing an effective machine learning system programmed with Python can be an efficient step for the developers in order to mitigate the issue of security attacks through Malicious URLs.
The research regarding the credibility of character embedded-based deep learning to detect malicious URLs can guide further researchers towards the way they should form their research. Additionally, this research can provide a wide range of scenarios that can efficiently describe multiple circumstances and parables of malicious URL attacks. The increase in the scam rates in recent years needs to be resolved with python-based embedded deep learning and this research attempts to identify the loophole in the existing system and tries to point out the issues regarding the harmful effect of malicious URLs.
1.7 Summary
The different sections of the introductory chapter provide the basics of the research efficiently where it introduces the credentials of malicious URLs and their extensive effect on the everyday security struggle of individuals and organizations. It efficiently points out the main aims and objectives of the research and clarifies what range will be covered by the researchers in the whole research paper. It also discusses the emerging issues of malicious URLs and how python based deep learning techniques can be fruitful and efficient to mitigate the security casualties caused by malicious URLs. Through the different parts of the introduction chapter, the researchers provide an insight into the whole territory that the research will cover and it also ensures that the issues with malicious URLs are resolved with an effective character embedded-based deep learning approach.
Chapter 2: Literature Review
2.1 Introduction
This literature part introduces the main detection control process based upon the blacklist. Hackers use spam or phishing for tricking customers into pressing on malicious URLs, which will be affected and implanted on any victims’ system or computers, and these victims’ personal sensitive data information would be hacked or leaked on social platforms. This type of malicious technology URLs detection could help each user to identify the malicious URLs and can prevent the users directly from attack by the malicious URLs. Traditionally, this research upon malicious URLs detection has adopted blacklist-based control methods for detecting malicious URLs. These methods have many unique benefits. The literature review has to point out which attackers could generate several malicious related domains as names by a simple seed for effectively evading the previous traditional system to detect this. Hence, nowadays, a domain control generation regarding algorithms or DGA could generate thousands of several malicious URL domain user names per day that could not be properly detected by the traditional method of blacklist-based effectively.
2.2 Conceptual framework
(Sources: Self-created)
2.3 Multilayer perceptron
Web-based applications are highly popular nowadays, be it online shopping, education, or web-based discussion forums. The organizations have vastly benefited from the employment of these applications. Also, most website developers rely on Content Management System (CMS) to build a website, which in turn uses lots of third-party plug-ins which have a lack of control. These CMS were created with a motive for people with less knowledge of computer programming, graphics imaging to build their website. However, they are patched for security threats, which becomes an easy way for hackers to steal valuable information from the website. This in turn exposes the website to cybersecurity risks such as Uniform Resource Locator (URL). These can lead to various risky activities like doing illegal activities on the client-side, further embedding malicious scripts into the web pages thereby exploiting the vulnerabilities at the end of the user. The study focuses on measuring the effective nature of identifying malicious URLs by using the multilayer Perception Technique. With the study, the researchers are trying to create a safe option for web developers to further improve the security of web-based applications.
Living with the 21st century, the world is moving towards obtaining so many technologies. The countries are at their best to produce and innovate the best of the technology to set up a benchmark in the entire world, and so does the UK. It is considered one of the most developed in terms of technology and is a civilized country. Since the developers have taken the country to a technological upfront, this makes the people much aware now of the innovated technologies and information systems. Modern or advanced technologies are developed to make the working of humans easier. People use modern technology to ease their work but there are people who try to deceive others and make fake and fraudulent technologies that are disguised as the real ones (SHOID, 2018). They do so with the intention to steal other’s personal data. This research is conducted with the objective to learn the approach for malicious URL detection. URL is termed as Uniform Resource Locator; it is an address of a given unique resource on the Web. So, what happens is that the people with wrong intentions or hackers try to create a malicious URL. This technique is termed mimicking websites.
The study lists the various artificial intelligence (AI) techniques used in the detection of malicious URLs that come in Decision Tree, Support Vector Machines, etc. The main reason for choosing Multilayer Perceptron (MLP) technique is because it is a "feed-forward artificial neural network model", primarily effective in identifying malicious URLs when the networks have a large dataset (Kumar, et al. 2017). Also, many others have stressed on the MLP technique having a high accuracy rate. The study has an elaborative explanation of the various techniques to identify malicious URLs, also giving an overview of studies on the particular topic. The research methodology consisted of the collection of 2.4 million URLs, where the data was pre-processed and divided into subsets. The result of the experiment was measured on the number of looping/epochs that are produced by the MLP system. Where the best performing URLs will be shown by a smaller number of looping/epochs and the bad ones by a greater number of looping/epochs. The dataset has been further divided into Matlab three smaller datasets which are the training dataset, validation dataset, and testing dataset. The training dataset trains the neural network by adjusting the weight and bias during the training stage. The validation dataset estimates how well the neural network model has been trained (Sahoo, Liu and Hoi, 2017).
After being trained and validated, the testing dataset evaluates the neural network. With the examples of figures, the study delineates the performance of training, validation, and testing in terms of mean squared error, where the iteration (epochs) moves forward. The study, however, seemed skeptical on suggesting the fastest training algorithm, as the training algorithm is influenced by many factors that include the complexity of the problem, the count of weights, the error goal, the number of data points in the training set. The vulnerabilities identified in Web applications; the most recognized ones are the problems caused by unchecked input. The attackers have to inject malicious data into web applications and manipulate applications using malicious data to exploit unchecked input. The study provided an extensive review on various techniques Naive Bayes, Random Forest, K-nearest neighbors, LogitBoost.The study used the Levenberg-Marquardt Algorithm (trainlm) as it was the fastest training function based on feedforward artificial neural network and the default training function as well. With the validation and test curves being quite similar, it meant that the neural network can predict the minimum error if compared with the real data training.
The study has however proved on the MLP system being able to detect, analyze and validate the malicious URLs, where the accuracy was found to be 90-99%. Achieving the objective and scope of the study by using data mining techniques in the detection and prediction of malicious URLs. Despite producing successful data, the study highlights the improvements: Gathering more information from experts for increasing accuracy leading to better reliability within the system (Le, et al. 2018). Further development of the system by enhancing knowledge in data mining along with improving neural network engines in the system.
For better accuracy, the system can be improved by using a hybrid technique where the study suggested combining the system with the Bayesian technique, decision tree, or support vector techniques.
The detection of malicious URLs has been addressed as a binary classification problem. The paper studies the performance of prominent classifiers, which includes Support Vector Machines, Multi-Layer Perceptrons, Decision Trees, Na¨?ve Bayes, Random Forest, and k-Nearest Neighbors. The study also adopted a public dataset that consisted of 2.4 million URLs as examples along with 3.2 million features. The study concluded that most of the classification methods have attained considerable, acceptable prediction rates without any domain expert, or advanced feature selection techniques as shown by the numerical simulations. Out of all the methods, the highest accuracy was attained by Multi-Layer Perceptron, and Random Forest, in particular, attained the highest accuracy. Highest scores for Random Forest in precision and recall. They indicate not only the production of the results in a balanced and unbiased prediction manner but also give out credibility. It enhances the method's ability to increase the identification of malicious URLs within reasonable boundaries. When only numerical features are used for training, the results of this paper indicate that for URL classification the classification methods must achieve competitive prediction accuracy rates (Wejinya and Bhatia, 2021).
2.4 Artificial neural network (ANN)
The study approaches the convolutional neural network algorithm for classification of URL, Logistic regression (LR), Support Vector Machine (SVM). The study, at first, gathered data, collected websites offering malicious links via browsing, and crawled on several malicious links from other websites. The Convolutional neural network algorithm was first used to detect malicious URLs as it was fast and quick. It also approached the blacklisting technique followed by features extraction with word2vec features and Term frequency-inverse document frequency features. The experiment could identify 75643 malicious URLs out of 344821 URLs. The algorithm has been able to attain an accuracy rate of about 96% in detecting malicious URLs. There is no doubt as to the importance of malicious URL detection for the safety of cyberspace. The study stresses deep learning as a probable and promising solution in the detection of malicious URLs for cybersecurity applications. The study compared the support vector machine algorithm on Term frequency-inverse document frequency along with the word vac feature based on the CNN algorithm and the logistic regression algorithm. While comparing the three aspects (precision, recall, fl-score) of Support Vector Machines (SVM),
Convolutional Neural Network (CNN), and Logical Regression (LR):
Term frequency-inverse document frequency of SVM can be used with the logical regression method, as the SVM of the aspects is higher than that of the logical regression algorithm. On the other hand, the convolution neural network (CNN) proved consistent on both Word2vac and on Term frequency-inverse document frequency.
Following the success of CNN in showing exemplar performance for text classification in many applications, be it speech recognition, natural language processing, speech recognition, etc., the study utilized CNN to learn a URL embedding for malicious URL detection (Joshi, et al. 2019). The URLNet understands a URL string as input applying CNNs to a URL's characters and words. The study also describes the approaches like blacklisting possessing limitations as they are highly exhaustive. The paper proposed a CNN-based neural network, URLNet for malicious URL detection. The study also stressed the various approaches adopted by other studies that had critical limitations, like the use of features with the added inability to detect sequential concepts in a URL string (Zhang, et al. 2020). The use of features further requires manual feature engineering, thereby leaving us unable to manage unseen features in test URLs, which seems to alleviate by the URLNet solution proposed by the study. The study applied Character CNNs and Word CNNs and optimized the network. The advanced word-embedding techniques, proposed by the study are supposed to help in dealing with rare words, a problem often encountered in malicious URL Detection tasks. This allowed URL Net in learning to embed and utilize sub word information from hidden words at test time and hence worked overall without the need for expert features.
The study's goal is to investigate the efficacy of the given URL attributes, demonstrating the utility of lexical analysis in detecting and classifying malicious URLs, with a focus on practicality in an industrial environment. This experimental study was primarily concerned with the identification and classification of different forms of URLs using lexical analysis through binary and multiclass classification, with a focus on comparing common deep learning models to conventional machine learning algorithms. Overall, the results of the two experiments showed improved output precision, with an improvement of 8-10% on average across all models, and the other showing a lower level of efficiency, with average accuracy. The study concludes that deep neural networks are somewhat less efficient than Random Forest while collecting the training and prediction times, concurring feature analysis. The less efficiency was concluded based on higher variance, feature count to match RF's performance, complexity, and time taken to train and predict at the time of deployment (Lakshmi and Thomas, 2019). An RF model can be employed to minimize the effort, as deploying the RF model can reduce the feature set to 5-10 features, is cost-effective, and will display efficient performance.
Whereas on the other side, despite being popular DNN frameworks, the employment of Keras-TensorFlow and Fast.ai over RF would require the need for more resources. The resources can be utilized in others domains within any organization. In a summary, it is quite succinct from the study that for any organization, in case of considering an alternation or a choice for its detection system, Random Forest is the most promising and efficient model for deployment.
The deep neural network models' findings suggest that further work is needed to explicitly demonstrate one's dominance over another (Naveen, Manamohana and Verma, 2019). A preference for one DNN model over the other in the current work will suggest the model's priorities: Fast-AI is superior in terms of accuracy at the expense of time, while the Keras-TensorFlow model is superior in terms of latency at the expense of accuracy. The feature analysis of the lexical-based ISCXURL-2016 dataset, as the work's final contribution, demonstrates the significance of the basic characteristics of these malicious URLs. The key conclusion drawn from this portion of the work is that the multiclassification problem needs more features than the binary classification problem.
Furthermore, the basic lexical features found inside URLs could be used to reduce the overhead cost of a deployed model, according to this analysis. Some of the study's limitations could spur further research. The paper suggests that it did not exhaustively investigate all of the network configurations and hyperparameters available for DNNs that could potentially boost their efficiency. While these enhancements can increase the recorded accuracy of succeeding RFs, they affect training and testing times, as well as the additional disadvantage of overfitting models, which reduces their real-world generalizability. The study further leaves a gap in its research as it did not deploy and examine the efficacy of the models with additional experiments; leaving it for future studies. The research paper believes that more research is required on this front to help bridge the gap between academic research and industrial implementations, to reduce the negative economic impacts of malicious URLs on businesses of all types.
2.5 Embedded learning process
The paper suggests the use of feature engineering and feature representation to be used and reformed to manage the URL variants. The study proposes DUD where raw URLs get encoded using character-level embedding. This paper presents a comparative analysis of deep learning-based character level embedding models for Malicious URL detection. The study took around 5 models, two on CNN, two on RNN, and the last one being the hybrid of CNN and LSTM. All the architectures of deep learning have a marginal difference if seen from the purview of accuracy. Coming to the models, where each model performed well and displayed a 93-98% Malicious URL detection rate. The experiment had a false positive rate of 0.001. This also means that out of 970 malicious URLs detected by deep learning-based character level embedding models, the model label only one good URL as malicious. The study suggests enhancing DeepURLDetect (DUD) by adding auxiliary modules which include registration services, website content, file paths, registry keys, and network reputation.
The paper performed the malicious URL detection approach on different deep neural network architectures. The study used Convolutional Neural Networks (CNN) and Recurrent Neural Networks (RNN) to differentiate Malicious and benign URLs. The training and evolution of the models were done on the ISCX-URL-2016 dataset. The results of the experiment showed the CNN model performing well having an acceptable rate of accuracy for the identification of Malicious URLs. The study mentions plan to bring up a hybrid deep learning model for the detection of Malicious URLs. A multi-spatial Convolutional Neural network was proposed by the study for an efficient detection sensor. After extensive evaluations, the detection rate achieved 86 .63% accuracy. A prototype, Raspberry Pi was used for enabling real-time detection.
2.6 Machine learning process
Many organizations with collaborations, bet it Google, Facebook and many start - ups work together in creating a safe system, preventing the users from falling into the trap of malicious URLs. Even though these organizations use exhaustive databases and manually refining a large number of URL sets regularly. However, this is not a feasible solution, as, despite high accuracy, human intervention is one of the major limitations. So, the study introduces the use of sophisticated machine learning techniques. The novel approach can be availed as a common platform for many internet users. The study shows the ability of a machine in judging the URLs based on the feature set. The feature set will be used to classify the URLs. The study claims its proposed method to bring improved results when traditional approaches get short in identifying Malicious URLs. The study further suggests improving the machine learning algorithm, which will give better results using the feature set. However, the features set will undergo evolution over time, hence effort is being made in creating robust features set in handling a large number of URLs. The study introduces the feature sets, composed of 18 features token count, largest path, average path token, largest token, etc. along with a generic framework. Using the framework at the network edge can help to protect the users of the digital space against cyber-attacks. The feature sets can be used with Support Vector Machine (SVM) for malicious URL detection.
The study focuses on using machine learning algorithms in the classification of URLs based on features and behavior (Astorino, et al. 2018). Algorithms like Support Vector Machine (SVM) and Random Forest (RF) are the supervisors in the detection of Malicious URLs. The extraction of features is done from static and dynamic which is claimed as new to the literature. The prime contribution to the research is of the newly proposed features. The study doesn't use special attributes nor does it create huge datasets for accuracy. The study concludes on application and implementation of the result in informing security technologies in information security systems, along with building a free tool for detection of Malicious URLs in web browsers.
The study combines attributes that are easy to calculate and big data processing technologies in ensuring the balance of two factors; which are the system's accuracy and processing time. The study suggests on the proposed system be comprehended as a friendly and optimized solution for Malicious URL detection. As per the study, going by statistics, URLs that increase the attacks are malicious URLs, phishing URLs, and botnet URLs. Some of the techniques that attack the system by using Malicious URLs are - Phishing, Social engineering, spam, and Drive-by Download.
The paper takes a machine learning solution combining URL lexical features, JavaScript source features along payload size. The study aims to create a real-time malware classifier in blocking out malicious URLs. For doing so, the study focusses on three sub-categories of web attacks: drive-by downloads, where the users unknowingly download malware; next comes Phishing where the intruders come up with websites posing it to be legitimate to steal user information while exploiting from JavaScript code that is generally found in the website source code. The paper could conduct a successful study whereby the construction of the SVM was taken to for the classification of malicious URLs. The study further proposes that testing, in the case of malicious URLs could be done on a wider array inculcating a sophisticated JavaScript feature extractor along with more of diving into network features. The study also mentioned using trained SVM, where Malicious URLs can be detected without any browsing device. Overall, it gives machine learning a potential approach for discovering cyber-attacks, attackers as wells as any malware URLs. The threat can also be mitigated by automatic URL detection by using a trained SVM. With it, a user can check the credibility of the URLs before using it for a real-time service, a pre-emptive service without creating an impact on the mobile experience.
URLs mostly malicious are generated on a day-to-day basis, and many of the techniques are used by researchers for detecting the malicious ones promptly. The most famous is the Blacklist method, often used for the easy identification of malicious URLs. The traditional method derives some limitations due to which identification of new ones becomes a bit difficult. Whereas Heuristic, an advanced technique, cannot be used for all types of attacks. Whereas the machine learning techniques undergo several phases and attain a considerate amount of accuracy in the detection of Malicious URLs. The paper gives a piece of extensive information, lists out the main methods which include blacklist, heuristic, and machine learning. The paper also discusses the Batch learning algorithm and online learning algorithm in the case of algorithms and phases for Malicious URL detection. The study describes the Feature extraction and representation phase as well. The study performs a detailed study of the various processes involved in the detection of malicious URLs. Increasing cybercrime cases have led to the weakening of cyberspace security and various ways are used in the detection of such kinds of attacks. Out of all the techniques, the machine learning technique is the most sought-after technique for such attacks. This particular paper intends to outline the various methods for malicious URL detection along with mentioning the pros and cons of machine learning over others.
2.7 malicious Web sites' URLs and others
Malicious Web pages are a key component of online illegal activity. Because of the risks of these pages, end-users have demanded protections to prevent them from visiting them. The lexical and host-based features of malicious Web sites' URLs are investigated in this report. The study demonstrates that this problem is well-suited to modern online learning algorithms. Online algorithms not only process large numbers of URLs faster than batch algorithms, but they also adapt to new features in the constantly changing distribution of malicious URLs more quickly. The paper created a real-time framework for collecting URL features, which we pair with a feed of labeled URLs on a real-time basis from a large Web mail provider.
Malicious Web pages continue to be a plague on the Internet, despite current defenses. The study mentions that by training an online classifier using the features and labels, detection of malicious Web pages can give 99 percent accuracy over a healthy dataset. The study also mentioned on organizations try to detect suspicious URLs by examining their lexical and host-based features to prevent end-users from accessing these pages.URL classifiers face a unique challenge in this domain because they must work in a complex environment where criminals are actively developing new tactics to counter our defenses. To win this competition, the need of algorithms is required that can adapt to new examples and features on the fly. The paper tested various methods for detecting malicious URLs to eventually implement a real-time system.
Experiments with a live feed of labeled examples exposed batch algorithms' shortcomings in this domain. Their precision tends to be constrained by the stored number of training examples in memory. The study looked into the issue of URL classification in an online environment after seeing this weakness in practice. On a balanced dataset, the paper discovered that the online algorithm performing the best (such as CW) produces highly accurate classifiers with error rates of about 1% (Kumi, Lim and Lee, 2021). The good performance of these classifiers, according to our findings, is in the face of new features through continuous retraining. The paper however hopes that this research will serve as a model for other machine learning applications in the future in the domain of computer security and digital space protection.
The digital space is often thought to be an efficient space to constantly become a threat, as it delivers attacks that include malware, phishing, and spamming. The study to block such attacks has delivered a machine learning method for the identification of malicious URLs and their attack types. The SVM detected malicious URLs while the attack types were recognized by the RAkEL and ML-kNN. A list of discriminative features namely link popularity, malicious SLD hit ratio, malicious link ratios, and malicious ASN ratios are attained from lexical, DNS, DNS fluxiness, network, webpage, link popularity properties of the associated URLs, which are highly effective as per the experiments. It is also efficient in identification and detection tasks. Achieving 98% accuracy in detecting malicious URLs and identifying the attack types, the paper further studies the effectiveness of each group on detection and identification discussing the discriminative features.
Feature engineering is a crucial step in detecting malicious URLs. In this paper, five space transformation models are used to create new features that free the linear and non-linear communications between points in malicious URLs data (decomposition on singular value, distance metric learning, Nyström methods, DML-NYS, and NYS-DML).
The proposed feature engineering models are successful and can dramatically boost the performance of certain classifiers in identifying malicious URLs, with experiments using 331,622 URL instances. The paper aims to identify malicious URLs, which require continuous data collection, feature collection and extraction, and model training. The integrated models combined the benefits of nonlinear, linear, unsupervised, and supervised models to concentrate on one aspect of space revision. The study mentions the future research path to look at how classifiers can be improved in terms of training time and accuracy based on URL characteristics.
Because of its widespread use, except for Naïve Bayes, the classifiers' highest TPR on the two textual-content datasets was 42.43 percent, while the highest TPR on the URL-based dataset was 86.40 percent (Patil and Patil, 2018). The detection rate of malicious URLs using a content-based approach was significantly lower than the URL-based approach used in this analysis. These findings indicate that separating malicious from benign websites solely based on their content is difficult, if not impossible. While transformer-based deep neural networks such as Bidirectional Encoder Representations from Transformers (BERT) and Net have made significant progress in recent years and be very effective on a variety of text mining tasks, they do not always apply well to the detection of malicious websites.
2.8 Summary
In the last part of the literature review, the basic summary of this branch to process data information is to expand the main input of this detection method. This paper proposes a malicious URL detection model based on a DCNN. It often adopts the word to embed based upon the basic character control embedding system for extracting features not manually or automatically with learning outcomes of the URL expression. Finally, they verify validity in that model through a proper series of contrast control experiments.
Chapter 3: Research Methodology
3.1 Introduction
Nowadays, the main methods to detect malicious URLs could be easily divided by the traditional controldetection drive method based upon blacklist with detection capacity methods based upon machine learning technique. Although the methods are efficient and simple, it could not properly detect any newly complex generated control malicious URLs, and also has been severed limitations. The malicious URLs detection methodology models are based upon the neural convolutional networks. Therefore, construction in the method mainly involves three main modules as vector convolution module, blockage extraction control module, and dynamic embedding module. The URLs are inputted directly into these embedding layers, or they utilize as word control embedding that is based upon characteristics embedding for transforming the basic URL from the vector embedding expression. Hence, this URL would be often input in the cover-up CNN just for the feature detection extraction.
3.2 Justification philosophy
The basic URL detection control process is justified by these sections. Firstly, domain user name, then subdomain device name with domain suffix name is often sequentially able to be extracted directly from the URL. Therefore, in this primary branch related to this detection method, it pads every URL to a particular length that each word is remarked within a significant number.
Justification
These whole URLs are represented by the sequence in numbers (Hain et al. 2017, p.161). Secondly, the main sequence is inputted to their embedding control layer to train together within a layer. This sequence would learn a specific vector convention expression process during their training control process. This overall data information stream output from embedding covered layers is subsequently outputted into the CNN. However, output control passes by the convolution detection layer, the folding purposes, and the pooling device layer of three successive rounds over the process.
3.3 Research approach
When it is trained in a totally connected URL layer, these features of the computer are often extracted by a neural convolutional network automatically and to extract artificially directly from an URL work field.
Justification
This detection methodology could effectively use critical data information of the named URL, including the top-level names domain and the domain of the national name, for achieving higher profile accuracy to recall (Bu, S.J. and Cho 2021, p.2689). Through the output of the SVM analysis, it can be analysed and understand that by predicting the test data set parameters. The malicious URLs detection methodology models are based upon the neural convolutional networks. Hence, accuracy is important, especially to the detection processes, because when the main accuracy is very low, nominal websites and pages might be estimated classified by malicious web and would be relocked.
Researchers of this thesis have to use proper machine learning tools and techniques for identifying malicious URLs. Therefore, these systems also require extracting the control of the main features manually, or attackers could design the features for avoiding identifying them.
Justification
It often has the highest speed, in a lower false-positive cyber rate, that’s it is too easy for users (Hamad et al. 2019, p. 4258). However, nowadays, a domain control generation regarding algorithms or DGA could generate thousands of several malicious URL domain user names per day that could not be properly detected by the traditional method of blacklist-based effectively. Faced with these issues in the recent complex networking environment, to design a more powerful and effective URL malicious detection model for becoming the research review focus.
The importance of gathering relevant data for or learning this specific methodology is predictable by the fact that its analysis will deliver fruitful information. There could be multiple aspects of taking the interviews but the most primary objective of carrying out an interview for such a thing is comprehensive and descriptive answers. The prospect of conducting a descriptive and comprehensive interview will deliver an influential amount of data for qualitative analysis. The qualitative analysis will consist of multiple elements and different angles of which the interviewer has not thought of. This will allow the analyst to segment the whole collected information in the comprehensive and market them in categories. Such kind of demarcation is extremely influential to identify what needs to be done and how it needs to be done. The interview will consist of a set of questions for getting the most appropriate methodology.
The participants of this interview can be analysts or cybersecurity experts who have substantial expertise and knowledge in this domain. There can be a set of questions that will dwell deeper into their experience with malicious URLs. The questions can be like telling about the experience with different kinds of malicious threats and how it is being carried out. In what ways the whole network in the digital market can be divided and which segment is most vulnerable. The types of tools analysts have incorporated previously to battle with such kinds of threats. Their familiarity with machine learning and how it can deliver this security. The current period of threat intelligence is associated with malicious URLs and their extent and what is the feature proposition in this arena. All the answers collected from more than 40 participants must be analysed strictly and finalized categorically.
The proposition of the Focus group is to identify a certain kind of group which has something in common and is largely affected by such kind of malicious activities. There is no denying the effects of malicious URLs in every possible domain of the digital world. But it is important to identify who are the most valuable domains and what are the intricacies associated with their domain and how they can be protected or resolved. The division of Focus groups can be parametrically decided based on the usage or exposure of the individuals. One focus group can be youth who are most largely influenced by E-Commerce activities. Another Focus group can be made on the basis of the age range in which the elderly people are most vulnerable.
Another Focus group can be an influential or well-known personality who is always on the verge of such threats. Under Focus groups can be individuals of the technical domain to identify what you think about such kinds of URLs and how they count them. All these focus groups must go through a group discussion for our individual campaign to curate the most suitable and appropriate pattern among their visualization and experience. In this methodology, there can be a couple of assignments such as a qualitative interview or quantitative survey which will provide the information in the form of experience or facts that can be used for other analyses of every domain of malicious URLs. These Focus groups provide a generalized view of malicious URLs and they are expected to not have much of technical background. The objective of the Focus group is to get collective information in a generalized way so that emotional, as well as psychological angles, can be comprehended.
There are so many case studies across the globe over the course of the last three decades where a particular scenario has been showcased. The powerful element of a case study is that it represents some kind of storyline or psychological processing of the fraud or criminal carrying out the particle malicious activity. These case studies provide a sense of generalized view in a multidimensional way which is to be comprehended by seeking the acquired or necessary information. Any type of information or processed facts can be utilized to define a new kind of angle in a particle attack. The case studies have built credibility based upon describing the whole scenario in a descriptive and sophisticated way.
The effectiveness of conducting research with a case study is that it is based on real-life scenarios and the most important element is it delivers the process of conducting the malicious activity (Story). The identification of the process and its psychological background is another challenge that has to be analysed so that a comprehensive and multidimensional campaign can be conducted to prevent these things from happening in the future. Case studies also portray the type of vulnerability possessed by the one who got adversely affected due to malicious attacks. The collected information from case studies and sorting information contained in it is further analysed to develop a quantitative parameter and predictable patterns. This is more of a profound approach in having things for developing documentation that contains a set of processes in a descriptive as well as instructive manner. The role of machine learning in this is to find keywords and collect them for testing them in a dataset.
This is more of an academic and theoretical perception of identifying and battling with unethical activities associated with malicious URLs. The association of keeping records goes beyond collecting data and information. It is meant to store the information in a very sophisticated and profound manner by documenting all the elements categorically and specifically. There can be multiple categories in which the collected information for malicious activities can be divided and stored. The process of doing so is also a matter of research to identify certain threats. The importance of record-keeping methodology is to build a strong case hold of identifying the intricate elements of URL characters and a certain pattern to identify the malicious content in it. Keeping recording is a responsibility that must be carried out with diligence so that none of the information can go to waste.
The importance of record-keeping research methodology is done to implement the positive effects of sharing and promoting research for the elements so that ethics can be maintained. There is much research that has already been conducted on character identification or you are a letter to vacation for and define its malicious content. All these research papers have been stored in a sophisticated manner which can be utilized through a partial window in order to get a strong base point for this research. The main proposition of methodology is to incorporate ethics and moral conduct in the research which is essentially required here for cybersecurity issues. It is meant to provide support for data analytics whenever required during technical analysis. There should be a keeper for looks after this and device information whenever necessary.
The process of observation begins with identifying the objective of the research which is here to identify the URL for its malicious content. Then the recording method is identified which can be anything here from the URL text to its landing page description or title, etc. All disconnected records based on human conduct of identifying the malicious content are recorded and questions are developed or in other ways, statements are being identified. This process is continued with every other encounter by observing all the elements and answering the questions specified before conducting this research. This methodology is completely based on human observation skills for or having intuition regarding any threat and approach being carried out to analyse and identify it. This process is slow and yet powerful because of its implications.
There can be many researchers across the domains who would adopt conducting observation for this research we identify malicious activities based on human skills. Incorporated questions allow the human mind to seek the attributes of whole digital information present before them. The process of observation in taking notes is the activity that is carried out in a sorted manner. These collected notes are analysed for behavioural elements of the malicious activities along with inferences associated with them. This behavioural analysis can be done by finding a set of patterns either directly or through data analysis. Every type of research comes to one point where it has a set of data that can be further that quickly as well as actually portrayed so that software based on the algorithm of probabilistic theory can find something which the human mind has missed.
3.10 Ethnographic research
The positional element of ethnography is associated with a behavioural analogy that can be aligned with the interaction of humans. In this case, the concept of economic geography can be related to an online culture where people are indulged in promotional and camping activities to cover their prospect of phishing and spamming. The conceptual and theoretical element in this kind of research is that it battles with the norms of technicality held by intellectuals. This means that a person with profound knowledge of online activities as well as the science of science opts to utilize it for delivering harm to normal people to get money or some kind of benefit. Since this kind of research can be changed across various domains but here it is specifically oriented with a psychological aspect.
The main question or objective behind this methodology is to identify the patterns of activities being carried out in the name of cover activities (Bhattacharjee, et al. 2019). The cover activities can include promotional campaigns or largely free gifts to the people. The method incorporated to analyse these is based upon seeking what kind of activities are going around in the market as well as how free stuff excites people to look over them. This also portrays a fact that certain kinds of malicious threats can be prevented by identifying such elements of attraction across different types of websites. Considering from the perspective of embedded learning and deep learning is that the backlinks as well as source code of certain web pages can be analysed to identify URLs that have targeted malicious activity. In this way, ethnographic research can facilitate a unique way of repression against malicious threats.
3.11 Summary
This could be quantified through the study that the different outputs based upon the heat maps work towards providing a better workspace and adhering to the laws and regulations. This could and needs to be inferred through the heat map that the different data septets of the map structure act towards providing a certain point of observation. The overall address needs to be confirmed through a proper guideline that works towards mitigating the different random parameters. The URL length and other parameters could be plotted in order to Number towards addressing the different parameters in relation to the respective variables and order. Through the random forecast, it can be addressed and identified by the different structural analyses. This needs to be addressed through a proper order of discussions. The output and random forecast classification work towards addressing the dataset that contains scattered data and determining the different classification of the overall data sets as addressed through the different parameters. Through the output of the SVM analysis, it can be analysed and understood that by predicting the test data set parameters could be set properly.
Chapter 4: Discussion
4.1 Phishing
Phishing is one of the types of cybercrime that adopts the way of contract to the target through emails. The objective of this crime is to get access to sensitive and confidential information of the targeted user by showcasing oneself as a reliable or legitimate individual or organization. Thus, collected information can cause harm to multiple levels such as loss of money, credible information, private details, identity theft, etc. It has a set of hyperlinks that takes the users to some other landing page or website whose sole purpose is to get more from the users. Such emails also contain some attachment that is sometimes senseless or contains a virus in it (Yuan, Chen, Tian and Pei, 2021). The primary identification of phishing is done by an unusual sender. The section of hyperlinks here is malicious URLs that are used to facilitate more harm to the user. The concept of phishing goes hand in hand with malicious URLs which is yet another objective to be analysed through data analysis.
4.2 Spamming
Spamming is another method of transmitting information from a criminal to the victim through lucrative offers. The proposition in spamming is the same as phishing. The only difference is an approach that varies for this one. There are various elements that spam can contain in terms of information and demanding economic data of the individual. The most effective element of phishing is that it contains graphics whereas spamming is mostly texts. The concept of spamming has also begun with mails but was generally used for text messages which were later broadened. The difference between phishing and spamming is that phishing demands the user’s information whereas spamming allures the person to visit a site to avail of some kind of information or offer. The intricacy of machine learning in this is to analyse the contents of the mail to identify the pattern for declaring it spam. There has been huge research on this by Google where they employed machine learning algorithms to declare a particular message as spam.
4.3 Malicious Content Detection
Malicious websites consider being a significant element in cyber-attacks found today. These harmful websites attack their host in two ways. The first one is the involvement of crafted content that exploits browser software vulnerabilities to achieve the users' files and use them accordingly for malicious ends, and the second one involves phishing that tricks users giving permissions to the attackers for the destruction. Both of these are discussed in detail before. These attacks are increasing very rapidly in today's world. Many peoples are getting attacked and end up losing their files, specifications, and businesses.
Detection of malicious content and blocking them involves multiple challenges. Firstly, the detection of such URLs must perform very quickly on the commodity hardware that operates in endpoints and firewalls of the user, so they cannot slow down the browsing experience of the user during the complete process. Secondly, the approaches made must be flexible to changes in syntactic and semiotic changes in malicious web content such that techniques of adversarial evasion like JavaScript obfuscation do not come under the detection radar. Finally, the detection approach must identify the small pieces of code and some specific characters in the URL that indicate the website is potentially dangerous. It is the most crucial point as many attackers enter via ad networks and comment feeds as tiny components into the users' computer. This paper will be focusing on the method of the methods in which the above-discussed steps can execute.
The methodology in the detection of malicious URLs using deep learning works in various ways. These ways are below:
Inspiration and Design Principles
The following intuitions listed below are involved in the building of the model for detecting harmful websites.
1) Malicious websites have a small portion of malicious code that infects the user. These small snippets are mainly JavaScript coded and embedded in a variable amount of Benign content (Vinayakumar, Soman and Poornachandran, 2018). For identifying the given document for threats, the program must examine the entire record at multiple spatial levels. It needs to scan because the size and range of this snippet are small, the length variance of the HTML document is large enough, which means that the document portion representing the malicious content is variable among the examples. It concludes that the identification of malicious URLs needs multiple repetitions as such small codes being variable need not detects in the first scan.
2) Specific parsing of the HTML documents, in reality, is the collection of HTML, CSS, JavaScript, and raw data is unacceptable as it complicates the implementation of the system, requires high computational overhead, and creates a hole in the detector. Attackers can breach to get into it and exploit the heart of the system.
3) JavaScript emulation, static analysis, or symbolic execution within HTML documents is undesirable. It is so because of the imposition of computational overhead and also because of the attacking hole; it opens up within the detector for the attackers.
From these ideas, the program must have the following design decisions that will help to resolve the maximum of the problems encountered.
1) Rather than parsing in detail, static analysis, graphic execution, or emulation of HTML document contents, the program can design to store a simple block of words. These words tokenize with the documents to perform minimal run tests for their assumptions. Every malicious URL contains a specific set of letters that links it to its original website. The program function is to search those keywords then the overall execution time can get decreased.
2) Instead of using the simple block of words representation declared over the entire document, the program can capture the multiple spatial scales locality that represents different levels of localization and aggregation, helping the program to find malicious contents in the URL at a very minute level where the overall might fail.
Approach for the method
The approach for this method involves a feature extraction process. It checks a series of characters in the HTML document and a Neural Network Model (NNM), which makes the classification decisions of the data within the webpage based on a shared-weight examination. The classification occurs at the hierarchical level of aggregation. The neural network contains two logical components for the execution of the program (Vanitha and Vinodhini, 2019).
• The first component: termed an inspector, aggregates information in the document to 1024 length by applying weights at spatial scales hierarchy.
• The second component: termed a master, uses the inspector outputs to make final decisions for the classification.
Backpropagation is used for optimizing the components of inspector and master in the network. Furthermore, the paper will focus on describing the function of these models in the overall functioning of the program.
4.4 Feature Extraction
The functioning of the program begins with the extraction of token words from the HTML webpage. The target webpage or document is tokenized using expression: ([A \xO 0- \x7F] + 1\ w+) that splits no alphanumeric words in the document. Then, the token divides into chunks of equal length 16 in a sequence. Here the word length defines as some tokens that include the last chunk gets fewer tokens if the document does not divide by 16.
Next, to create a bag of each chunk, a modified version of each chunk is used with 1024 bins. A technique is used to change the bin placement in the program that helps to feature both token and hash length. It results in a workflow where the files tokenize and divide into 16 equal length chunks of the token and then features the hash of each token multiplied by 1024 (number of bins). The 16*1024 quantity represents the texts extracted from the webpage divided into chunks, and each element in this chunk represents an aggregation over every 1/16 of the input document.
4.5 Inspector
When a feature representation is set for an HTML document, the design gets its input in the neural network. The first step is to create a hierarchical diagram of the sequential token of chunks in the computational flow. Here the sixteen token groups collapse into eight sequential token bags, eight token groups collapse into four groups, four collapses to two, and two token group collapses to one. The process helps to obtain multiple tokens groups representation that captures token occurrences at various spatial scales. The collapsing process occurs by averaging the windows of length two and step size two over the 16 token groups formed first. This process occurs repetitively until a single group of the token comes. Note, while averaging, the norm of each representation level in the token group is kept the same within the document. This is the reason why averaging is preferred over summing, as in summing, this norm will be changing each time the group changes.
When the hierarchical representation has been formed by the inspector, it starts hitting each node in the aggregation tree and computes an output vector with it (Bo, et al. 2021). The inspector has two fully connected layers with 1024 RELU units and considers a feed forwards neural network. The inspector regulates through layer normalization so that to guard against dropouts and vanishing gradients. The dropout rate used here is 0.2.
After visiting each node, for computing the inspector’s output of 1024-dimension, across the 31 outputs produced by 31 distinct chunks and each output containing 1024 output neurons, the maximum of each is taken. It results in the maximum output from each neuron in the final output layer of the inspector that gets all of its activations over the node in the hierarchy. Hence, this will make the output vector capture the patterns that will help to match the template of the malicious URLs features. Moreover, whenever they appear on the HTML webpage, it will help to point out such contents.
4.6 Master
After the computation of 1024-dimensional output by the inspector over the HTML webpage, these outputs are inputs into the master component. Like the inspector, the master is also a feed-forward neural network in design. But the master is with two layers of the logical fully-connected block. Here also, each fully connected layer precedes by the dropout and normalization of a layer. The dropout rate of the master is at 0.2. The overall construction of the master is similar to the construction of the inspector, with a difference that the output vector of the inspector is input for the master.
4.7 Summary
The final layer of the model is a composition of 26 sigmoid units that corresponds to 26 detection decisions the program makes for the malicious contents about the HTML webpage. Here, one sigmoid member is valuable in deciding whether the target HTML webpage is malicious or benign (Khan, 2019). The rest 25 sigmoid help determine other tags like whether the webpage is using a phishing document or exploitation for an instance. For training the models, each sigmoid output applies with binary cross-entropy loss and then the output of resulting parameters averages to calculate the parameter updates. Each of the sigmoid doesn't need to be helpful for the model. Many sigmoid in these results as bad for the model and are useless. The sole purpose of the model is to distinguish between the malicious content and the valuable content that serves at the end of the execution of this system.
Chapter 5: Analysis
5.1 Introduction
With the change in the centuries, new innovations have been witnessed in the world. People are getting advanced day by day by adapting the trends, and so does computers. The features of these machines are getting advanced after every innovation. If we go back to hundred years, the computer was just an electronic device used for storing and processing data. It was used for fast calculations. But as the grew, in 1959, machine learning was originated by Arthur Samuel, who was an American pioneer in the field of computer gaming and artificial intelligence. So, machine learning can be defined as the study of computer algorithms that gets improved automatically through experiences and by the use of data. In simple words, we can say that machine learning or MI is an application of artificial intelligence which provides the computer system an ability to learn automatically from experiences and also improve with every time without being specially programmed (Do Xuan, Nguyen and Nikolaevich). It can be seen as artificial intelligence but artificial intelligence or AI is a machine technology that behaves like humans, whereas machine learning or MI is a part or subset of artificial intelligence that allows the machine to learn something new from every experience. Here, computer algorithms mean steps or procedures taught to the machine which enable it to solve logical problems and mathematical problems. It is a well-defined sequence of instructions to be implemented in computers to solve the class of typical problems.
Among the mentioned uses of MI, machine learning or the embedded deep learning are best used for the detection of malicious content in Uniform Resource Locator or URL. Uniform Resource Locator or URL is defined as a unique locator or identifier used to locate a resource on the internet. It is referred to as a web address. A Uniform Resource Locator or URL consists of three parts, namely, Protocol, Domain, and Path. For example, if we assume ‘https://example.com/homepage’ this particular web address of a popular blogging site. In this, ‘https://’ is a protocol, ‘example.com’ is a domain and ‘homepage’ is a path. Thus, these three contents are together called URL or Uniform Resource Locator.
These URLs have made the work on the computer and internet easy for the users but with the positive side, it also consists of the negative side. These URLs become malicious by hackers which are not so easy to recognize. What happens is that the hackers create almost the same-looking websites or web addresses which have a very minute difference. The people who are not much aware of the malicious content fail to recognize the disguised website and share their true details with them. Thus, the hackers behind the disguised web address get the access to information of the user. They use it to steal data and to do illegal works or scams. For example, assume ‘https://favourite.com’ is a website of a photo-sharing site and the malicious website is made by the hacker like ‘https://fav0urite.com.’ These two websites are look-like and are difficult to predict. Thus, to predict the malicious content in Uniform Resource Locator the embedded deep learning plays a crucial role (Srinivasan, et al. 2021).
The detection of malicious Uniform Resource Locator contains the following stages or phases. These phases are:
1. Collection Stage: This is the first stage in the detection process of malicious Uniform Resource Locators with the help of MI or Machine Learning. So, in this stage, the collections, as well as the study of clean and malicious URLs, are done. After the collection of the URLs, labelling is done correctly and is then proceeded to attribute extractions.
2. Attribute Extraction Stage: Under this stage, the URL attribute extraction and selection are done in three following ways:
• Lexical Stage or features: This includes the length of the domain, the length of URL, the maximum token length, the length of the path, and the average token in the domain.
• Host-based Stage or features: Under this feature, the extraction is done from the host characteristics of Uniform Resource Locators. These indicate the location of malicious URLs and also identify the malicious servers.
• Content-based Stage or features: Under this, the extraction is acquired when the web page is downloaded. This feature works more than the other two features. The workload is heavy since a lot of extraction needs to be done at this stage.
3. Detection Stage: After the attribute extraction stage, the URLs are put to the classifier to classify whether the Uniform Resource Locator is clean or malicious.
Thus, the embedded deep learning or machine learning is best used to detect the malicious Uniform Resource Locators. It enhances the security against spam, malicious, and fraud websites.
5.2 Single type Detection
AI has been utilized in a few ways to deal with group malicious URLs. To recognize spam site pages through content examination. They utilized site-dependent heuristics, for example, words utilized in a page or title, what's more, part of the apparent substance. A process created a spam signature age structure called AutoRE to identify botnet-based spam messages. AutoRE utilizes URLs in messages as info and yields normal articulation marks that can identify botnet spam. This utilized measurable techniques to order phishing messages. They utilized a huge openly accessible corpus of genuine and phishing messages. Their classifiers analyze ten unique highlights, for example, the number of URLs in an email, the number of spaces, and the number of dabs in these URLs. It broke down the maliciousness of a huge assortment of website pages utilizing an AI calculation as a per-channel for VM-based examination. They embraced content-based highlights including the presence of muddled JavaScript and adventure locales pointing iframes. A method proposed a finder of malicious Web content utilizing AI. Specifically, we acquire a few page substance highlights from their highlights. This method proposed a phishing site classifier to refresh Google's phishing boycott naturally. They utilized a few highlights acquired from area data and page substance.
5.3 Multiple type Detection
The order model can distinguish spam and phishing URLs. They portrayed a strategy for URL order utilizing measurable techniques on lexical and host-based properties of malevolent URLs. Their strategy recognizes both spam and phishing yet can't recognize these two sorts of assault. Existing AI-based methodologies typically zero in on a solitary sort of malevolent conduct. They all use AI to tune their characterization models. Our strategy is likewise founded on AI, yet another also, more remarkable, and proficient grouping model is utilized. Also, our technique can recognize assault types of malicious URLs. These developments add to the predominant execution and capacity of our strategy. Other related work. Web spam or spamdexing points at acquiring an uncalled for high position from an inquiry motor by impacting the result of the web search tool's positioning calculations. Connection-based positioning calculations, which our connection prominence is like, are broadly utilized via web crawlers. Connection ranches are ordinarily utilized in Web spam to influence connect-based positioning calculations of web indexes, which can likewise influence our connection ubiquity (Jiang, et al. 2017). Investigates have proposed strategies to identify Web spams by utilizing proliferating trust or doubt through joins, identifying explosions of connecting movement as a dubious sign, coordinating connection and substance highlights, or different connection-based highlights including changed PageRank scores. A considerable lot of their procedures can be acquired to impede sidestepping join ubiquity highlights in our locator through interface ranches.
Unprotected Web applications are weak spots for programmers to assault an association's organization. Measurements show that 42% of Web applications are presented to dangers and programmers. Web demands that Web clients demand from Web applications are controlled by programmers to control Web workers. Web questions are identified to forestall controls of programmer assaults. Web assault discovery is amazingly fundamental in data conveyance over the previous many years. Peculiarity techniques dependent on AI are liked in Web application security. This current examination is expected to propose a peculiarity - based Web assault identification engineering in a Web application utilizing profound learning strategies. Many web applications experience the ill effects of different web assaults because of the absence of mindfulness concerning security. Hence, it is important to improve the unwavering quality of web applications by precisely recognizing malevolent URLs. In past investigations, watchword coordinating has consistently been utilized to identify malevolent URLs, however, this strategy isn't versatile. In this paper, factual investigations dependent on angle learning and highlight extraction utilizing a sigmoidal limit level are consolidated to propose another identification approach dependent on AI methods. In addition, the credulous Bayes, choice tree, and SVM classifiers are utilized to approve the exactness and proficiency of this technique. At last, the trial results show that this strategy has a decent recognition execution, with an exactness rate above 98.7%. In functional use, this framework has been sent on the web and is being utilized in huge scope discovery, breaking down roughly 2 TB of information consistently (Verma, and Das, 2017). The malicious URLs location is treated as a parallel arrangement issue and execution of a few notable classifiers are tried with test information. The calculations of Random Forests and backing Vector Machine (SVM) are concentrated specifically which accomplish a high precision. These calculations are utilized for preparing the dataset for the characterization of good and awful URLs. The dataset of URLs is separated into preparing and test information in 60:40, 70:30, and 80:20 proportions. The precision of Random Forests and SVMs is determined for a few emphases for each split proportion. As per the outcomes, the split proportion 80:20 is seen as a more precise split and the normal exactness of Random Forests is more than SVMs. SVM is seen to be more fluctuating than Random Forests in precision.
5.4 Data description
Figure 1: Code for data display
(Source: Self-created)
The panda’s package is used to develop the different python programming techniques. The data display is the first step to obtain the columns of the respective dataset which are analyzed. The dataset.csv dataset is used here to analyze the malicious URL detection using machine learning techniques.
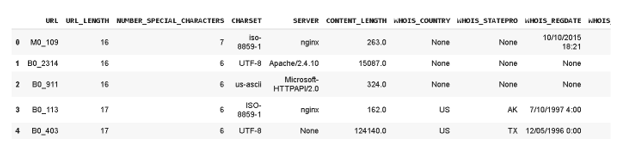
Figure 2: Output of data display
(Source: Self-created)
The output of the data display shows the variables of the dataset.csv dataset which represents the information regarding the malicious URLs which are to be detected (Rakotoasimbahoakaet al., 2019, p.469). The head command is used to show the attributes of the dataset in the python programming language. Therefore, the user can access the information of the dataset using the above-developed codes.
5.5 Histogram

Figure 3: Code for histogram
(Source: Self-created)
The histogram represents the range of the specific variable which is present in a dataset. In this report, the histogram of the URL_LENGTH is developed using python programming. The different plots of the ranges of URL length are shown in the output of the histogram.
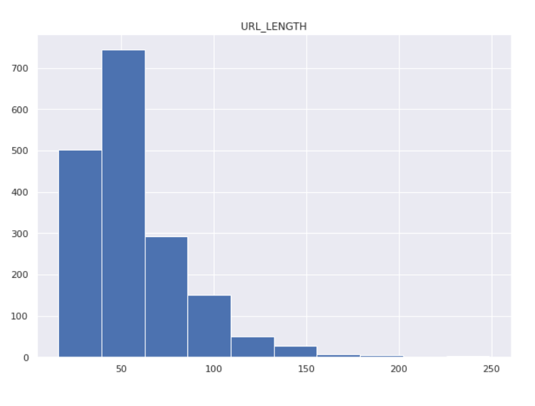
Figure 4: Output of Histogram
(Source: Self-created)
The output of the histogram shows the relation between the URL_LENGTH variable with the other variables in the dataset.csv dataset (Sahoo et al., 2017, p.158). The purpose of the histogram is to analyze the composition of the mentioned variable with different values as recorded in the dataset.
5.6 Heat map

Figure 5: Code for heat map
(Source: Self-created)
The heatmap measures the values which represent the various shades of the same color for each value. The dark shades of the chart show the higher values and the lighter shaded areas contain the lower values which are obtained from the dataset.
.png)
Figure 6: Output of heat map
(Source: Self-created)
The output of the heat map defines the graphical representation of the data that are used to represent different values. The heat maps are used to discover the variables in the dataset.csv dataset (Khan et al., 2020, p.996). The heat map is developed here to represent the different columns of the dataset.csv dataset using the map structure.
5.7 Scatter Plot

Figure 7: Code for scatter plot
(Source: Self-created)
The scatter plot shows the relation between the dependent and independent variables of the dataset.csv dataset. The purpose of the scatter plot is used to represent the special characters in the URLs which contain malicious information.
Figure 8: Output of scatter plot
(Source: Self-created)
The scatter plot observes the random variables in the malicious URL detection methods. The URL_LENGTH is plotted with respect to the NUMBER_SPECIAL_CAHARACTERS in the dataset.csv dataset. The scatter plot in the matplotlib library is used to sketch the scatter plot to determine the relationship between the two variables.
5.8 Random Forest

Figure 9: Code for random forest
(Source: Self-created)
The random forest is one kind of machine learning method which is used to measure the random variables present in the dataset (Kumar et al., 2017, p.98). The random forest is developed here to show the scatter plot based on all variables in the malicious URL detection dataset.
.png)
Figure 10: Output of random forest
(Source: Self-created)
The random forest classifier classifies the columns of the dataset using machine learning algorithms. The output of the random forest classification describes the sub-samples of the dataset which contains the scatters to determine the classification of the dataset.csv dataset.
5.9 SVM
.png)
Figure 11: Code for SVM
(Source: Self-created)
The support vector machine is a machine learning algorithm that measures the classification, regression, outlier detection based on the dataset. The support vector machine shows the expected scatter based on the variables of the malicious URL dataset (Joshi et al., 2019, p.889). The aim of SVM is to divide the dataset into different classes to perform the classification process.
.png)
Figure 12: Output of SVM
(Source: Self-created)
The output of the SVM analyses the trained and test samples of the dataset. The SVM classifies the predictors based on the variables of the dataset (Le et al., 2018, p.523). The scatter plot is developed by predicting the test set and then comparing the test set with the predicted value of the dataset.csv dataset.
5.10 Classification

Figure 13: Code for classification
(Source: Self-created)
The k classification is developed here to understand the number of nearest neighbors of the dataset.csv dataset. The number of nearest neighbors is the core deciding factor (Do Xuan et al., 2020, p.552). The k is the odd number that represents the number of classes in the neighbor clustering.
Figure 14: Output of classification
(Source: Self-created)
The output of the k classification shows the clustering of the different neighbors based on the dataset.csv dataset. The k nearest neighbors are used to measure the classification and regression analysis based on the given dataset. The
5.11 Support vector classifier

Figure 15: Code for SVM classifier
(Source: Self-created)
The support vector classifier determines the linear classifier with respect to a specific dataset. Therefore, the support vector classifier shows the model structure of the linear classification. The SVC is the command which is used to develop the support vector classifier using the malicious URL detection dataset. The support vector classifier improves the complexity of the classification which implements the generalization of the dataset variables.

Figure 16: Output of the svc
(Source: Self-created)
The output of SVM classification shows the size, weight of the dataset which is used here. The support vector classifier detects the malicious URL using the implementation of machine learning algorithms (Ferreira, 2019, p.114). Therefore, the support vector classifier represents the kernel trick to ensure the transformation of data using the transformation technology.
5.12 Support vector model

Figure 17: Implementation of the support vector model
(Source: Self-created)
The support vector model shows the implementation of the machine learning algorithm which measures the classification and regression challenges based on the malicious URL dataset. The support vector array shows the array structure of the result of the support vector machine (Sahoo et al., 2017, p.158). The purpose of the modeling is to determine the decision boundary through which the data can be divided in n-dimensional space.
Chapter 6: Recommendation
In this paper, we propose a technique utilizing machines figuring out how to recognize malevolent URLs of all the well-known assault types including phishing, spamming, and malware contamination, and recognize the assault types malignant URLs endeavor to dispatch. We have embraced a huge arrangement of discriminative highlights identified with printed designs, interface structures, content organization, DNS data, and organization traffic. A large number of these highlights are novel and exceptionally successful. As portrayed later in our trial considers, connect prevalence and certain lexical and DNS highlights are exceptionally discriminative in not just distinguishing noxious URLs yet additionally distinguishing assault types. Likewise, our strategy is hearty against known avoidance strategies such as redirection, interface control, and quick motion facilitating.
The set of recommendations can be divided into two sets. One of them can be on the user level and the other on the developer level. The task at the user level is quite simple which is to report spam for any URL content that seems malicious or contains such type of data. The tasks at the developer end are quite large and comprehensive. A developer can look forward to developing certain kinds of methodologies or ways through which they can develop software or a tool that can be embedded in the URL detection mechanism to identify its malicious content. There are numerous ways through which it can be done. The concepts of Machine learning applicable to this scenario can be based on supervised learning or non – supervised learning. The supervised learning will involve training a model based on collected URLs with malicious content or resource. Unsupervised learning will deliver an option for identifying it on a trial and test basis (Ferreira, 2019). Unsupervised learning cannot be applied to this scenario whereas supervised one can be utilized. The algorithms of supervised learning will be used to develop a deep learning algorithm that will analyze the characters and identify the pattern in it to declare certain URLs to be malicious or not. The process of development will be backed by a huge amount of test data and that’s why web applications such DNS or HTTP or web browsers will have these tools to identify the URLs with certain context. The main proposition behind using these methodologies is to implement the comprehensive method of applying different machine learning algorithms at different places to find possibilities for developing a tool that can detect such malicious URLs. The whole process should be done so intricately that nothing is left out and at the same time, the tool should be in learning mode to gather new data and detection parameters.
Chapter 7: Conclusion
Cyber-attackers have expanded the quantity of contaminated has by diverting clients of traded off famous sites toward sites that abuse weaknesses of a program and its modules. To forestall harm, identifying tainted hosts dependent on intermediary logs, which are by and large recorded on big business organizations, is acquiring consideration as opposed to restriction-based sifting on the grounds that making boycotts has gotten troublesome because of the short lifetime of malicious spaces and camouflage of endeavor code. Since data extricated from one URL is restricted, we center around a succession of URLs that incorporates relics of vindictive redirections. We propose a framework for distinguishing malevolent URL arrangements from intermediary logs with a low bogus positive rate. To clarify a powerful methodology of noxious URL arrangement recognition, we analyzed three methodologies: individual-based methodology, convolutional neural organization (CNN), and our recently evolved occasion de-noising CNN (EDCNN).
Therefore, highlighting designing in AI-based arrangements needs to advance with the new malignant URLs. As of late, profound learning is the most talked about because of the critical outcomes in different man-made consciousness (AI) undertakings in the field of picture preparing, discourse handling, characteristic language handling, and numerous others. They have the capacity to remove includes naturally by taking the crude info messages. To use this and to change the viability of profound learning calculations to the assignment of pernicious URL's location. All weaknesses are distinguished in Web applications, issues brought about by unchecked information are perceived similar to the most widely recognized. To abuse unchecked info, the aggressors, need to accomplish two objectives which are Inject malicious information into Web applications and Manipulate applications utilizing malevolent information. Web Applications getting requesting furthermore, a famous wellspring of diversion, correspondence, work and instruction since making life more helpful and adaptable. Web administrations additionally become so broadly uncovered that any current security weaknesses will most likely be uncovered and misused by programmers.
The process of detecting malicious URLs is not an easy task and it requires comprehensive efforts on multiple ends. The primary domain that has been specifically covered in this paper is Machine Learning and character recognition. This paper has gone through multiple algorithms and methodologies that can be considered a part of Machine Learning which can be utilized to detect malicious URLs. The paper has established a fundamental and obvious set of risks associated with a malicious URL and the necessity to battle and curb it. The important analogy associated with malicious URLs is that their harmful effect is unprecedented and opens door to multiple such occurrences in the future. That’s why it is important to consider the processes of detection to intricately define an overall strategy to detect malicious URLs. The concept of detection and restricting malicious URLs is an ever-growing and developing process. The main reason behind this is that hackers and spammers are consistently looking for new methodologies to conduct harmful processes for the user to make them vulnerable. The paper has covered all the important aspects of the Machine Learning domain to prevent attacks of malicious URLs. The set of recommendations has laid to follow a certain set of tasks associated with URL detection such as reporting spam to any such website or mail that has the intention to deliver harmful content.
The paper went through all the important terminologies and methodologies of algorithms–based tools that can be used for identifying and blocking malicious URLs. The research methodology employed in this paper is the Delphi method and the use of several other research papers is highly detectable. The necessity of preventing malicious URLs is extremely important for the sake of data security and privacy issues. This must be administered seriously in continuance to sustain the integrity of online activity without losing any kind of credibility.
References
1. Shibahara, T., Yamanishi, K., Takata, Y., Chiba, D., Akiyama, M., Yagi, T., Ohsita, Y. and Murata, M., 2017, May. Malicious URL sequence detection using event de-noising convolutional neural network. In 2017 IEEE International Conference on Communications (ICC) (pp. 1-7). IEEE. https://ieeexplore.ieee.org/abstract/document/7996831/
2. SHOID, S.M., 2018. Malicious URL classification system using multi-layer perceptron technique. Journal of Theoretical and Applied Information Technology, 96(19). http://www.jatit.org/volumes/Vol96No19/15Vol96No19.pdf
3. Choi, H., Zhu, B.B. and Lee, H., 2011. Detecting Malicious Web Links and Identifying Their Attack Types. WebApps, 11(11), p.218. http://gauss.ececs.uc.edu/Courses/c5155/pdf/webapps.pdf
4. Tekerek, A., 2021. A novel architecture for web-based attack detection using convolutional neural network. Computers & Security, 100, p.102096. https://www.sciencedirect.com/science/article/pii/S0167404820303692
5. Cui, B., He, S., Yao, X. and Shi, P., 2018. Malicious URL detection with feature extraction based on machine learning. International Journal of High Performance Computing and Networking, 12(2), pp.166-178. https://www.inderscienceonline.com/doi/abs/10.1504/IJHPCN.2018.094367
6. Patgiri, R., Katari, H., Kumar, R. and Sharma, D., 2019, January. Empirical study on malicious URL detection using machine learning. In International Conference on Distributed Computing and Internet Technology (pp. 380-388). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-030-05366-6_31
7. Tan, G., Zhang, P., Liu, Q., Liu, X., Zhu, C. and Dou, F., 2018, August. Adaptive malicious URL detection: Learning in the presence of concept drifts. In 2018 17th IEEE International Conference On Trust, Security and Privacy in Computing And Communications/12th IEEE International Conference On Big Data Science And Engineering (TrustCom/BigDataSE) (pp. 737-743). IEEE. https://ieeexplore.ieee.org/abstract/document/8455975
8. Kumar, R., Zhang, X., Tariq, H.A. and Khan, R.U., 2017, December. Malicious url detection using multi-layer filtering model. In 2017 14th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP) (pp. 97-100). IEEE. https://ieeexplore.ieee.org/abstract/document/8301457
9. Sahoo, D., Liu, C. and Hoi, S.C., 2017. Malicious URL detection using machine learning: A survey. arXiv preprint arXiv:1701.07179. https://arxiv.org/abs/1701.07179
10. Le, H., Pham, Q., Sahoo, D. and Hoi, S.C., 2018. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv preprint arXiv:1802.03162. https://arxiv.org/abs/1802.03162
11. Wejinya, G. and Bhatia, S., 2021. Machine Learning for Malicious URL Detection. In ICT Systems and Sustainability (pp. 463-472). Springer, Singapore. https://link.springer.com/chapter/10.1007/978-981-15-8289-9_45
12. Joshi, A., Lloyd, L., Westin, P. and Seethapathy, S., 2019. Using Lexical Features for Malicious URL Detection--A Machine Learning Approach. arXiv preprint arXiv:1910.06277. https://arxiv.org/abs/1910.06277
13. Naveen, I.N.V.D., Manamohana, K. and Versa, R., 2019. Detection of malicious URLs using machine learning techniques. International Journal of Innovative Technology and Exploring Engineering, 8(4S2), pp.389-393. https://manipal.pure.elsevier.com/en/publications/detection-of-malicious-urls-using-machine-learning-techniques
14. Ferreira, M., 2019. Malicious URL detection using machine learning algorithms. In Digital Privacy and Security Conference (p. 114). https://privacyandsecurityconference.pt/proceedings/2019/DPSC2019-paper11.pdf
15. Verma, R. and Das, A., 2017, March. What's in a url: Fast feature extraction and malicious url detection. In Proceedings of the 3rd ACM on International Workshop on Security and Privacy Analytics (pp. 55-63). https://dl.acm.org/doi/abs/10.1145/3041008.3041016
16. Jiang, J., Chen, J., Choo, K.K.R., Liu, C., Liu, K., Yu, M. and Wang, Y., 2017, October. A deep learning based online malicious URL and DNS detection scheme. In International Conference on Security and Privacy in Communication Systems (pp. 438-448). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-319-78813-5_22
17. Srinivasan, S., Vinayakumar, R., Arunachalam, A., Alazab, M. and Soman, K.P., 2021. DURLD: Malicious URL Detection Using Deep Learning-Based Character Level Representations. In Malware Analysis Using Artificial Intelligence and Deep Learning (pp. 535-554). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-030-62582-5_21
18. Do Xuan, C., Nguyen, H.D. and Nikolaevich, T.V., Malicious URL Detection based on Machine Learning. https://pdfs.semanticscholar.org/2589/5814fe70d994f7d673b6a6e2cc49f7f8d3b9.pdf
19. Khan, H.M.J., 2019. A MACHINE LEARNING BASED WEB SERVICE FOR MALICIOUS URL DETECTION IN A BROWSER (Doctoral dissertation, Purdue University Graduate School). https://hammer.purdue.edu/articles/thesis/A_MACHINE_LEARNING_BASED_WEB_SERVICE_FOR_MALICIOUS_URL_DETECTION_IN_A_BROWSER/11359691/1
20. Bo, W., Fang, Z.B., Wei, L.X., Cheng, Z.F. and Hua, Z.X., 2021. Malicious URLs detection based on a novel optimization algorithm. IEICE TRANSACTIONS on Information and Systems, 104(4), pp.513-516. https://search.ieice.org/bin/summary.php?id=e104-d_4_513
21. Vanitha, N. and Vinodhini, V., 2019. Malicious-URL Detection using Logistic Regression Technique. International Journal of Engineering and Management Research (IJEMR), 9(6), pp.108-113. https://www.indianjournals.com/ijor.aspx?target=ijor:ijemr&volume=9&issue=6&article=018
22. Vinayakumar, R., Soman, K.P. and Poornachandran, P., 2018. Evaluating deep learning approaches to characterize and classify malicious URL’s. Journal of Intelligent & Fuzzy Systems, 34(3), pp.1333-1343. https://content.iospress.com/articles/journal-of-intelligent-and-fuzzy-systems/ifs169429
23. Yuan, J., Chen, G., Tian, S. and Pei, X., 2021. Malicious URL Detection Based on a Parallel Neural Joint Model. IEEE Access, 9, pp.9464-9472. https://ieeexplore.ieee.org/abstract/document/9316171
24. Bhattacharjee, S.D., Talukder, A., Al-Shaer, E. and Doshi, P., 2017, July. Prioritized active learning for malicious URL detection using weighted text-based features. In 2017 IEEE International Conference on Intelligence and Security Informatics (ISI) (pp. 107-112). IEEE. https://ieeexplore.ieee.org/abstract/document/8004883
25. Story, A.W.A.U.S., Malicious URL detection via machine learning. https://geoipify.whoisxmlapi.com/storiesFilesPDF/malicious.url.machine.learning.pdf
26. Astorino, A., Chiarello, A., Gaudioso, M. and Piccolo, A., 2017. Malicious URL detection via spherical classification. Neural Computing and Applications, 28(1), pp.699-705. https://link.springer.com/article/10.1007/s00521-016-2374-9
27. Kumi, S., Lim, C. and Lee, S.G., 2021. Malicious URL Detection Based on Associative Classification. Entropy, 23(2), p.182. https://www.mdpi.com/1099-4300/23/2/182
28. Zhang, S., Zhang, H., Cao, Y., Jin, Q. and Hou, R., 2020. Defense Against Adversarial Attack in Malicious URL Detection. International Core Journal of Engineering, 6(10), pp.357-366. https://www.airitilibrary.com/Publication/alDetailedMesh?docid=P20190813001-202010-202009240001-202009240001-357-366
29. Lekshmi, A.R. and Thomas, S., 2019. Detecting malicious urls using machine learning techniques: A comparative literature review. International Research Journal of Engineering and Technology (IRJET), 6(06). https://d1wqtxts1xzle7.cloudfront.net/60339160/IRJET-V6I65420190819-80896-40px67.pdf?1566278320=&response-content-disposition=inline%3B+filename%3DIRJET_DETECTING_MALICIOUS_URLS_USING_MAC.pdf&Expires=1620469335&Signature=ghgtkQboBA38~WCrAAjExLjT5L3ZDBSE2jpls6zh3jg49QqgCiAyVq7UK4O6wmjr5BYU9QYUSJchdzWkL8Ov6llROtE6r0z92NEEhQGqGt1MagVkDL4G1F14~krYHnqyhrxXXt5IqhIy9koq9w40mTVEATBGnGCtmNbmJyuXDDIPyCe2Rm9ovdNVkaEm8eJvhY49finxPF1b5E56Xxjd9lLRT-0M19~zcQYdZiNjWAsJrrJZBYo0~cUsJmpnJVG6d2Xg-1AzMLW27ltWpkorabTU5~1Ms~N5QRIXiYrt3HUeqX1GaEC8KcUulV9-PK5pJOLumVEBskg6wJSM~Hb-UQ__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA
30. Patil, D.R. and Patil, J.B., 2018. Feature-based Malicious URL and Attack Type Detection Using Multi-class Classification. ISeCure, 10(2). https://www.sid.ir/FileServer/JE/5070420180207
31. Bu, S.J. and Cho, S.B., 2021. Deep Character-Level Anomaly Detection Based on a Convolutional Autoencoder for Zero-Day Phishing URL Detection. Electronics, 10(12), p.1492. https://www.mdpi.com/1157690
32. Cui, B., He, S., Yao, X. and Shi, P., 2018. Malicious URL detection with feature extraction based on machine learning. International Journal of High Performance Computing and Networking, 12(2), pp.166-178.https://www.inderscienceonline.com/doi/abs/10.1504/IJHPCN.2018.094367
33. Le, H., Pham, Q., Sahoo, D. and Hoi, S.C., 2018. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv preprint arXiv:1802.03162.https://arxiv.org/abs/1802.03162
34. Le, H., Pham, Q., Sahoo, D. and Hoi, S.C., 2018. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv preprint arXiv:1802.03162. https://arxiv.org/abs/1802.03162
35. Patgiri, R., Katari, H., Kumar, R. and Sharma, D., 2019, January. Empirical study on malicious url detection using machine learning. In International Conference on Distributed Computing and Internet Technology (pp. 380-388). Springer, Cham.https://link.springer.com/content/pdf/10.1007/978-3-030-05366-6_31.pdf
36. Sahoo, D., Liu, C. and Hoi, S.C., 2017. Malicious URL detection using machine learning: A survey. arXiv preprint arXiv:1701.07179.https://arxiv.org/abs/1701.07179
37. Saxe, J. and Berlin, K., 2017. eXpose: A character-level convolutional neural network with embeddings for detecting malicious URLs, file paths and registry keys. arXiv preprint arXiv:1702.08568. https://arxiv.org/abs/1702.08568
38. Verma, R. and Das, A., 2017, March. What's in a url: Fast feature extraction and malicious url detection. In Proceedings of the 3rd ACM on International Workshop on Security and Privacy Analytics (pp. 55-63).https://dl.acm.org/doi/abs/10.1145/3041008.3041016
39. Vinayakumar, R., Soman, K.P. and Poornachandran, P., 2018. Evaluating deep learning approaches to characterize and classify malicious URL’s. Journal of Intelligent & Fuzzy Systems, 34(3), pp.1333-1343. https://content.iospress.com/articles/journal-of-intelligent-and-fuzzy-systems/ifs169429
40. Yang, P., Zhao, G. and Zeng, P., 2019. Phishing website detection based on multidimensional features driven by deep learning. IEEE Access, 7, pp.15196-15209. https://ieeexplore.ieee.org/abstract/document/8610190/
41. Yang, W., Zuo, W. and Cui, B., 2019. Detecting malicious URLs via a keyword-based convolutional gated-recurrent-unit neural network. IEEE Access, 7, pp.29891-29900. https://ieeexplore.ieee.org/abstract/document/8629082/
42. Sahoo, D., Liu, C. and Hoi, S.C., 2017. Malicious URL detection using machine learning: A survey. arXiv preprint arXiv:1701.07179.
https://arxiv.org/abs/1701.07179
43. Ferreira, M., 2019. Malicious URL detection using machine learning algorithms. In Proc. Digit. Privacy Security Conf. (pp. 114-122).
https://privacyandsecurityconference.pt/proceedings/2019/DPSC2019-paper11.pdf
44. Do Xuan, C., Nguyen, H.D. and Nikolaevich, T.V., 2020. Malicious url detection based on machine learning.
https://pdfs.semanticscholar.org/2589/5814fe70d994f7d673b6a6e2cc49f7f8d3b9.pdf
45. Le, H., Pham, Q., Sahoo, D. and Hoi, S.C., 2018. URLNet: Learning a URL representation with deep learning for malicious URL detection. arXiv preprint arXiv:1802.03162.
https://arxiv.org/abs/1802.03162
46. Joshi, A., Lloyd, L., Westin, P. and Seethapathy, S., 2019. Using Lexical Features for Malicious URL Detection--A Machine Learning Approach. arXiv preprint arXiv:1910.06277.
https://arxiv.org/abs/1910.06277
47. Kumar, R., Zhang, X., Tariq, H.A. and Khan, R.U., 2017, December. Malicious URL detection using multi-layer filtering model. In 2017 14th International Computer Conference on Wavelet Active Media Technology and Information Processing (ICCWAMTIP) (pp. 97-100). IEEE.https://ieeexplore.ieee.org/abstract/document/8301457/
48. Khan, F., Ahamed, J., Kadry, S. and Ramasamy, L.K., 2020. Detecting malicious URLs using binary classification through addax boost algorithm. International Journal of Electrical & Computer Engineering (2088-8708), 10(1).
https://d1wqtxts1xzle7.cloudfront.net/64051690/44%2027sep%20%2029jun%2014apr%2019473%20ED%20%28edit%20lelli%20.pdf?1596070856=&response-content-disposition=inline%3B+filename%3DDetecting_malicious_URLs_using_binary_cl.pdf&Expires=1627026966&Signature=Fc86R-Fim4sTJXqv-T9~x76rKewY2Wz233XcezybbtWscGkvWzFU1iwJqXh0SVCdeDNVXiB0nFbzcg8kOsX3JnMBdR72Joh5AY6BiM5ttCfE5ExyOnMD7MBPKufRjvAkTpXDQ69oC78JIc1k5CQZjFPCZmU7PfuQ4P4M5zLWFHTBNZpZ3JMqDOghnvWCCjahLBU4DVqzFdDMjJX2dQU24zT0JCWQ2uRDm5jY3uZvhi0~whYNaAN0x0L7BBSpG-ruhXe8yQTyDccnlpLa6I89F9uDXSDkoOaPYmohrE7yRbOFr~G9Mx2EpbSkqWT8QLDHXtRldtFPzXEmfLuPirRuTA__&Key-Pair-Id=APKAJLOHF5GGSLRBV4ZA
49. Rakotoasimbahoaka, A., Randria, I. and Razafindrakoto, N.R., 2019. Malicious URL Detection by Combining Machine Learning and Deep Learning Models. Artificial Intelligence for Internet of Things, 1.
https://vit.ac.in/AIIoT/pages/Proceedings_AIIOT2019_VIT.pdf#page=5
50. Bu, S.J. and Cho, S.B., 2021. Deep Character-Level Anomaly Detection Based on a Convolutional Autoencoder for Zero-Day Phishing URL Detection. Electronics, 10(12), p.1492. https://www.mdpi.com/1157690
51. Lee, W.Y., Saxe, J. and Harang, R., 2019. SeqDroid: Obfuscated Android malware detection using stacked convolutional and recurrent neural networks. In Deep learning applications for cyber security (pp. 197-210). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-030-13057-2_9
52. Wei, B., Hamad, R.A., Yang, L., He, X., Wang, H., Gao, B. and Woo, W.L., 2019. A deep-learning-driven light-weight phishing detection sensor. Sensors, 19(19), p.4258. https://www.mdpi.com/544856
53. Bu, S.J. and Cho, S.B., 2021, June. Integrating Deep Learning with First-Order Logic Programmed Constraints for Zero-Day Phishing Attack Detection. In ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP) (pp. 2685-2689). IEEE. https://ieeexplore.ieee.org/abstract/document/9414850/
54. Hajian Nezhad, J., Vafaei Jahan, M., Tayarani-N, M. and Sadrnezhad, Z., 2017. Analyzing new features of infected web content in detection of malicious web pages. The ISC International Journal of Information Security, 9(2), pp.161-181. https://iranjournals.nlai.ir/handle/123456789/73428
Case Study
MIS300 Systems Analysis & Design Assignment Sample
MIS300 The Assignment Help Case Study
Online Restaurant Pre-order System
Rajesh’s Roti Kitchen has always done a roaring trade in tasty treats. Not only do people drive across the cityfor their roti but their sweet meats are highly prized, especially the burfi and jalebi. The Roti Kitchen has a CRM system and customer loyalty program with discounts and special offers, but at peak times it is too busy to sign the customer up at the till and staff make typos on mobile phone numbers and email addresses. Rajesh is seeking to develop an online ordering system (the system). He has seen several pre-order applications from established fast food chains and has some ideas about what he wants from this system. You have been engaged as the Business Analyst on this project. The system should allow Rajesh and his team to create, edit and remove menu items based on festivals and seasonal ingredient availability. Customers should be able to sign up, review the menu, place an order, and pay. Pre-ordering online will allow customers to take advantage of special offers and receive discounts. Customers should be able to access the system from a device of their choice, whether it be their PC at home, a tablet, or their phone. This will allow Rajesh to take the pressure off the queue and get more staff into the kitchen. Customers should be able to create, edit or remove items from their order up until completion of the order. At completion of the order, the system must generate on invoice and prompt the customer to a secure payment process, after which it confirms the order. Confirmation of the order must trigger an SMS to the customer’s phone indicating when the order will be ready for pick-up. Rajesh is very eager to have the capability to report on various aspects of his business and in particular would like to understand how popular various items are on the menu and whether there are times where some items are more popular than others.
For this assignment, students need to individually write a 1500-word business report in response to the provided case study. There are two components:
1. Conceptual questions about the role of business analysts and the tasks they undertake to support the systems analysis and design process.
2. Practical questions in response to the provided case study: MIS300 AssessmentCase Study. Please refer to the Task Instructions for details on how to complete this task. Context Requirements analysis is one of the primary roles of a business analyst; the business analyst helps stakeholders identify their needs. You will be expected to support users by eliciting their requirements of a system that is being built or modified and document these requirements in a way that is clear to stakeholders, ensuring user needs can be understood and met.
Task Instructions To complete this task, you must:
1. Carefully review the attached MIS300_ Assessment _Case Study.
2. Review your subject notes, essential readings and learning activities to ensure that you are well prepared for the assignment.
3. Create a report plan and identify all the key components required in your report. 4. Follow the outlined report structure: Note: The report is brief and therefore will not require an executive summary or abstract.
Title page: should include subject ID, subject name, assignment title, student’s name, student number and lecturer’s name.
Table of contents: include all key components of this assessment. Introduction (75–100 words): This serves as your statement of purpose. You will tell the reader what you are going to cover in your report. You will need to inform the reader about:
• your area of research and its context
• the key concepts you will be addressing
• what the reader can expect to find in the body of the report.
Body of the report (800–850 words):
Conceptual questions: • What is your understanding of the role of a business analyst?
• Why is requirements analysis important for the success of a system build or modification?
Practical tasks:
• Identify the stakeholders for this project
• Identify the actors in this system?
• Identify and list 2 major functional requirements for the system
Identify and list 4 non-functional requirements of the system. Include the reasons why you identified these particular requirements.
• Build a set of use case diagrams for the system using Lucidchart or any other diagramming app, such as app.diagrams.net.
• Based on the use case diagrams, develop and document two elaborated use cases. Each use case documentation must include: – use case name – ID – priority – actor – description – trigger – precondition – normal course – alternative courses – post conditions – exceptions. Layout: • The report should use Arial or Calibri 11-point font and should have 1.5 line spacing for ease of reading. A page number must be inserted on the bottom of each page.
• With the required diagrams, due attention should be given to pagination to avoid loss of meaning and continuity by unnecessarily splitting information over two pages. Diagrams must carry the appropriate captioning. Conclusion (75–100 words): summarise any findings or recommendations that the report puts forward regarding the concepts covered in the report.
SOLUTION
Introduction
According to Keller Andre? (2019), requirement analysis or requirement engineering is the process of defining user expectations for a new software being created or changed. It is also called requirements gathering or requirements capturing in software engineering. It identifies, analyses, and models the functionality of a prospective software system the requirements are modelled after analysis with the help of Unified Modeling Language Diagrams, Entity-Relationship Diagrams, Data Flow Diagrams, or formal methods. Through this case study, the researcher aims to analyze and discuss the techniques of systems analysis for enhancing the ability of Rajesh’s Kitchen to address their needs for the information systems. Also, the requirements for a variety of Rajesh’s kitchen’s information systems’ needs are being developed through this study.
Discussion
Conceptual Questions
Role of Business analysts
Business analysts mainly work with different organizations for getting assistance to improve the processes and systems. In other words, they hold a huge responsibility of bridging the gap between IT and business with the help of data analytics for assessing processes, determining the requirements and delivering recommendations driven by data. Moreover, on a regular basis, business analysts are responsible for knowing the change required in any business and finding out the implications of those changes (Gordon, 2017).
Thus, in the concerned case study, it has been observed that the role of a business analyst is quite essential. In order to introduce an online ordering system for Rajesh’s kitchen, the BA would analyze the structure of the business, involved processes and determine the key areas in which technology can help in adding value. Here, BA would work along with System analysts and hence find out the key challenges and their solutions (Paul & Lovelock, 2019). Furthermore, Business analysts would also help Rajesh to suggest the best technology and software tools for improving the operations of the business.
Importance of Requirement analysis
Requirement analysis is said to be an important aspect for organizations to determine the exact requirements of stakeholders. Meanwhile, it also helps the development team establish effective communication with the stakeholders in the easiest form. Therefore, it can be said that the main aim of such analysis is analyzing, validating, documenting and hence managing the requirements of the system. Requirements of high-quality are often documented, traceable, testable for identifying the opportunities within a business and hence facilitates the design for the same (Dick, Hull & Jackson, 2017).
In the concerned case study, requirements analysis will help Rajesh’s kitchen to introduce an online ordering system efficiently. Hence, it would be easier for Rajesh to identify the need of stakeholders in the entire lifecycle of an online ordering system.
Practical Tasks
Stakeholders for the project
?Figure 1: USE CASE for Online Ordering system
(Source: Created by the author)
Actors in this system
An actor in the system is responsible for specifying the role played by a user or other system interacting with the system. Hence, an actor can be a person, outside a system or sometimes an organization. In the given case study, the actors are customers, admin and payment gateways (Voirin, 2018). Customers here are responsible for creating an account, adding food items to the cart and then finally placing the order. Admin authenticates the entire operation carried out by the customer whereas payment gateways are responsible for making transactions.
Two major functional requirements
Two major functional requirements for the online food ordering system are registration and adding food items to the cart. Without registering the account, the user/customer may fail to order the food. Hence, at the initial stage, registration is important. Once, the process is over, the customer can add food items to the cart. Apart from these, other functional requirements are displaying the menu, modifying it, changing the order, reviewing the order before final processing and payment.
Four non-functional requirements
Four non-functional requirements are portability, reliability, availability and security. With the portability feature, the customer can use this application either on computer/PC/Laptops or mobiles (Garci?a-Lo?pez Dennys et al. 2020). Reliability will allow the system to behave consistently in a user-acceptable manner at the time of operating with the environment for which the system is mainly developed. Availability requirements allows the system to be available at all times. This means that customers can access the application with the help of a web browser. Security with help in ensuring the confidentiality of the user’s bank details.
Use Case Diagram
Here, a use case for the online food ordering system for Rajesh’s kitchen has been developed. With the help of this design, the researcher tried to show the interaction of various users with the proposed system. From the diagram, it can be observed that there are three actors actively involved in the system. Each one of them plays a significant role.
.png)
Figure 1: USE CASE for Online Ordering system
(Source: Created by the Author)
Use Case Documentation
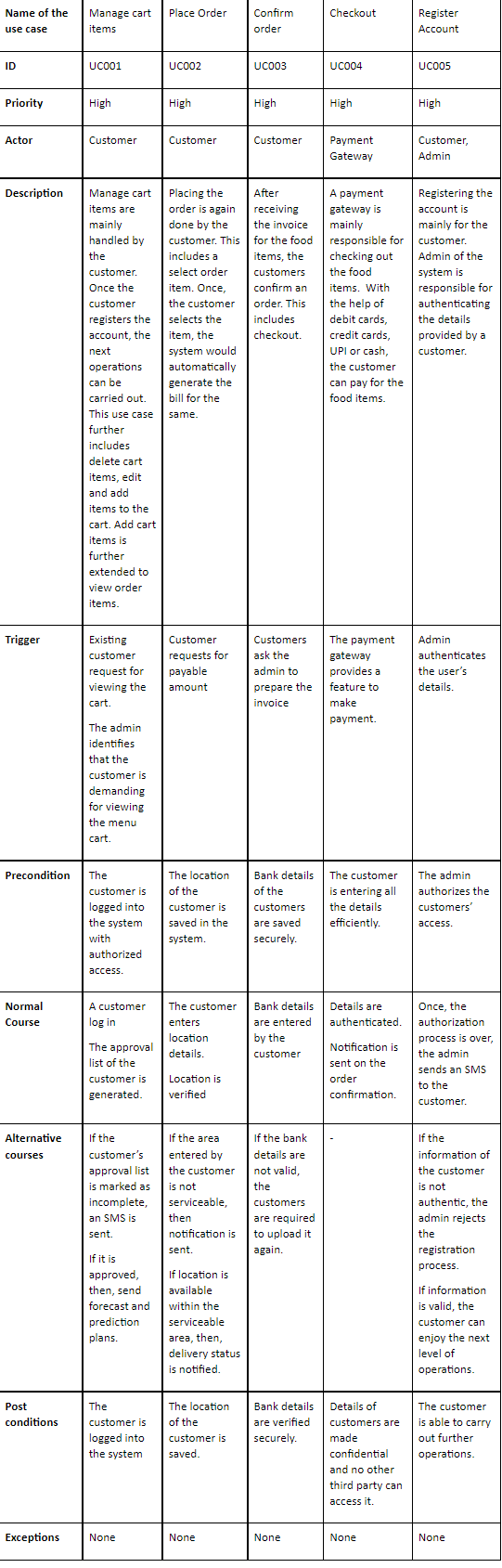
Table 2: Use Case Documentation
(Source: Created by the author)
Conclusion
From the comprehensive study, it can be concluded that requirement analysis has helped Rajesh’s kitchen to determine the actual requirements of the stakeholders of the organization. Moreover, it can be seen that requirement analysis enabled the development team of Rajesh’s kitchen to communicate with its stakeholders in a language they understand like charts, models, flow charts instead of text pages. The overall study focused on identification of stakeholders and their role in the system. In this study, the researcher designed a use case for showing the interaction of various users with the system. Moreover, the researcher also presented a brief documentation for the use case designed in this context.
References
Dick, J., Hull, E., & Jackson, K. (2017). Requirements engineering (4th ed.). Springer. Retrieved on 7th March 2021 from: https://doi.org/10.1007/978-3-319-61073-3
Garci?a-Lo?pez Dennys, Segura-Morales, M., & Loza-Aguirre, E. (2020). Improving the quality and quantity of functional and non?functional requirements obtained during requirements elicitation stage for the development of e?commerce mobile applications: an alternative reference process model. Iet Software, 14(2), 148–158. Retrieved on 7th March 2021 from:
Gordon, K. (2017). Modelling business information : entity relationship and class modelling for business analysts. BCS, The Chartered Institute for IT. Retrieved on 7th March 2021 from: https://lesa.on.worldcat.org/oclc/1004319314
https://doi.org/10.1049/iet-sen.2018.5443
Keller Andre? A. (2019). Multi-objective optimization in theory and practice ii : metaheuristic algorithms. Bentham Science. Retrieved on 7th March 2021 from: https://lesa.on.worldcat.org/oclc/1097974294
Paul, D., & Lovelock, C. (2019). Delivering business analysis : the ba service handbook. BCS Learning & Development Limited. Retrieved on 7th March 2021 from: https://lesa.on.worldcat.org/oclc/1119617420
Voirin, J.-L. (2018). Model-based system and architecture engineering with the arcadia method (Ser. Implementation of model based system engineering set). ISTE Press.Retrieved on 7th March 2021 from: https://lesa.on.worldcat.org/oclc/1013462528
Research
MIS500 Foundations of Information Systems Assignment Sample
Assignment Brief
Individual/Group - Individual
Length - 1500 words (+/- 10%
Learning Outcomes
The Subject Learning Outcomes demonstrated by successful completion of the task below include:
a) Effectively communicate and demonstrate understanding of the importance of ethical and professional standards in own career and professional future.
Submission - By 11:59 PM AEST Friday of Module 6.1 (Week 11)
Weighting - 35%
Total Marks - 35 marks
Task Summary
This assessment task requires you to reflect on your experiences in MIS500 this trimester by following a four-step process to gain insights into the work you have done and how it relates to your own career and life more broadly. In doing so, you will need to produce a weekly journal to record your learning and then as the trimester comes to a close reflect on these experiences and submit a final reflection of 1500 words (+/- 10%) that will include the weekly journal as an appendix.
Context
This is an individual assignment that tracks your growth as a student of Information Systems over the trimester. It is scaffolder around your weekly learning activities. Completing the activities and seeking input from your peers and the learning facilitator is essential for you to achieve a positive result in this subject. Before you start this assessment, be sure that you have completed the learning activities in all of the modules. This reflective report gives you the opportunity to communicate your understanding of how information systems relate to your career and future.
Task Instructions for assignment help
1. During Module 1 – 5, you were asking to produce a weekly journal to record your learnings each week. Based on these weekly journals, please write a 1500-word reflective report about your experience focusing on how this will support developing and planning your future career.
2. You are required to follow the four steps of Kolb’s learning cycle when writing the reflective report. You will keep a learning journal throughout the trimester. Each week as you complete the learning activities you record your experience in spreadsheet or word document.
Step 1
Concrete experience – Keep a learning journal
Step 2
Reflective observation – Summarise what happened
Step 3
Abstract conceptualization – Analyze what this means
Step 4
Active experimentation - New action
1. You are required to write this assessment in a report format using the following headings:
2. Introduction
3. Reflective Observation – Summarise what happened.
4. Abstract conceptualization – Analyze what this means for you and your career.
5. Active experimentation – What new action do you need to take to develop yourself and your career using the things you learned through your MIS 500 studies.
6. Conclusion
7. Appendix of learning journal (with evidence)
Referencing
Formal citation of sources is not required. However, specific reference to your own experiences must be made. It is essential that you use appropriate APA style for citing and referencing research if you do make reference other work. Please see more information on referencing here http://library.laureate.net.au/research_skills/referencing
Submission Instructions
Please submit ONE MSWord document (.doc or .docx) via the Assessment 3 section found in the main navigation menu of the subject’s Blackboard site. The Learning Facilitator will provide feedback via the Grade Centre in the LMS portal. Feedback can be viewed in My Grades.
Solution
Introduction
In this study, I have reflected on my learning experience related to MIS500 modules. I have described my learning experience based on Kolb’s learning cycle. This model explains that effective learning is a progressive process in which learners' knowledge develop based on the development of their understanding of a particular subject matter. Kolb's learning cycle has four phases, concrete learning, reflective observation, abstract conceptualisation and active experimentation. The learning process will help me to develop my career in the field of information technology.
Concrete Experience
Before the first module, I had little idea about the use of information systems in business. Thus, I was in the concrete experience stage of Kolb’s learning model, in which a learner has little idea about a concept. The first stage of Kolb’s model is concrete experience. In this stage, learners encounter new knowledge, concepts and ideas, or they reinterpret the ideas, concepts and knowledge that they already know (Hydrie et al., 2021). I learnt the use of information systems for making rational decisions in business is called business intelligence. I had no knowledge about business intelligence before the first module. Thus, it helped me to experience new knowledge about business intelligence. I started to think about how I can develop my career in the field of business career and the learning strategies that can help me to enhance my knowledge about the professional field.
The next modules helped me to deepen my understanding of business intelligence. I learnt that the emerging area of business intelligence is the result of a digital revolution across the world. Digital revolution refers to an increase in the number of users of tools and technologies of digital communication, such as smartphones and other types of computers, internet technology. The evidence for the digital revolution is the report "The Global State of Digital in October 2019.” The report mentions that there were around 155 billion unique users of mobile phones worldwide (Kemp, 2019). However, there were 479 billion internet users. The total number of social media users were 725 billion. The evidence has been obtained from module 1.2. Thus, there is high global penetration of digital technologies. The global penetration of digital technologies helped me to understand that I want to develop my career in the field of business intelligence. The digital revolution created thousands of career opportunities in the field. Business organisations need to use digital technologies to communicate with people or customers who use digital devices and technologies. Digital technologies are helping organisations in growth and international expansion (Hydrie et al., 2021). Businesses are expanding themselves with the help of digital technologies. Many businesses have transformed themselves from global to local with the help of digital technologies.
Reflective Observation
When I started to learn module 2, I learnt how business organisations use data to gain a competitive advantage over their competitors. In digital, the organisation which has relevant data can reach the targeted customers, improve their products and services and leverage different opportunities (Hydrie et al., 2021). Thus, data management and information management are vital for the success of an organisation. By collecting and managing data effectively, companies can obtain the knowledge that they require to achieve their business goals. I had reached the reflective observation stage by the time I learned this module because I started to reflect on new experiences by explaining why businesses need to digitise themselves. The reflection of observation is related to the second stage of Kolb’s model of learning. The reflective observation stage is related to the reflection on a new experience that a learner receives through his/her learning (Hydrie et al., 2021). It includes a comparison between the new knowledge or experience and existing knowledge or experience to identify a knowledge gap. This stage allowed me to know what I need to learn more to develop my career in the field of business intelligence or information system professional.
In the next modules, I tried to bridge the knowledge gap. In module 2.2, I learnt about the concepts of knowledge management and big data. Knowledge management is a collection of approaches that help to gather, share, create, use and manage related to management or information of an organisation (Arif et al., 2020). Knowledge management is crucial for organisations to gain meaningful insights from the collected data. However, big data refers to data in abundance which has high velocity and volume. Big data helps to identify important patterns related to events and processes and facilitates decision-making for business organisations.
These information systems are human resource information systems (HRIS), enterprise resource planning (ERP) systems and customer relationship management (CRM) systems Arif et al., 2020). This module played a vital role in shaping my knowledge by helping me to understand the practical use of information technology and information systems in business operations. I learnt how information systems help to describe and analyse the value chains of business organisations. A value chain of a business organisation is consist of main activities and supporting or auxiliary activities that help business organisations to carry out all their operations.
Module 3.1 also proved to bridge the knowledge gap. In this module, my knowledge reached to abstract conceptualisation stage of Kolb's learning model, which is related to the development of new ideas in a learner's mind or help him/her to modify existing ideas related to a concept. I started to use my learnings on how information systems can be used more effectively by business organisations. Thus, I tried to modify the knowledge related to existing applications of information systems in business.
Abstract Conceptualisation
Active conceptualisation is the stage of Kolb's learning cycle in which learners give a personal response to new experiences. In this stage, I started to think about how to use the new knowledge that I gained for the advancement of my career. I decided to learn more about ERP and CRM. If I learn about the two types of information systems, I can learn to develop them and help other organisations to learn their uses. It helped to shape my knowledge about area-specific information systems that can help organisations to meet the needs of the operations of their certain business operations. The two specific areas about which I gained knowledge in the module were ERP and CRM (Arif et al., 2020). ERP is an information system that helps to plan and manage the resources of a business organisation. It helps in managing to carry out supply chain operations. The main functions of an ERP are inventory planning and management, demand forecast and management of operations related to suppliers, wholesalers and retailers. However, CRM helps in managing relations with customers of business organisations (Hamdani & Susilawati, 2018). It helps to know and resolve customers’ grievances. CRM allows organisations to communicate with their customers to understand their needs and provide them with information about product and services offerings effectively. In module 4.2, I learnt how can help an organisation selects its business information system. The selection of a business information system by a business organisation depends on its business architecture (Hamdani & Susilawati, 2018). A business architecture refers to a holistic overview of operations, business capabilities, processes of value delivery and operational requirements. The information system that suits the business architecture of an organisation is most suitable for it. The price of information systems ascertained by vendors also influences the decisions of business organisations to use it.
Active Experiment
The active experiment is the stage in which learners decide what to do with the knowledge that they gained (Hydrie et al., 2021). I used the reflection technique to decide how to use my knowledge about information systems to develop my career. Harvard research in 2016 also explained the importance of reflection (Module 5.2). Reflecting on previous experiences helps individuals and organisations to recall what they learnt and find scopes of improvements in their existing skills and knowledge (Rigby, Sutherland & Noble, 2018). Thus, if business organisations reflect on their previous experiences related to IT operations, they can improve their knowledge about IT operations. Reflection can also help them to find a scope of improvements in their existing knowledge. As a result, they can improve their future IT strategies to achieve business goals. The improvements in the strategies can help them to ensure their future success. Thus, reflection can be an effective source of learning for organisations. The reflection of my learning helped me to know that I want to become a big data analyst because the requirements of big data analysis increasing in different fields, and I have effective knowledge about it. I will always follow ethics related to my profession to maintain professionalism because it is an ethical responsibility and professional conduct for IT professionals (McNamara et al., 2018).
Conclusion
In conclusion, my learning experience related to information systems helped me to know new concepts related to them. It helped me to bridge my knowledge gap about the use of information systems in business analytics. Based on my learning, I found that I have gained effective knowledge about big data analysis. Thus, I want to develop my career in the field of big data analysis.
References
Arif, D., Yucha, N., Setiawan, S., Oktarina, D., & Martah, V. (2020). Applications of Goods Mutation Control Form in Accounting Information System: A Case Study in Sumber Indah Perkasa Manufacturing, Indonesia. Journal of Asian Finance, Economics and Business, 7(8), 419-424. Retrieved from http://eprints.perbanas.ac.id/7166/
Di Stefano, G., Gino, F., Pisano, G. P., & Staats, B. R. (2016). Making experience count: The role of reflection in individual learning. Harvard Business School NOM Unit Working Paper, (14-093), 14-093. Retrieved from https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2414478
Hamdani, N. A., & Susilawati, W. (2018). Application of information system technology and learning organization to product innovation capability and its impact on business performance of leather tanning industry. Int. J. Eng. Techno, 7, 393-397. Retrieved from https://www.academia.edu/download/60118436/Application_of_Information20190725-106859-1v84mpn.pdf
Hydrie, M. Z. I., Naqvi, S. M. Z. H., Alam, S. N., & Jafry, S. I. A. (2021). Kolb’s Learning Style Inventory 4.0 and its association with traditional and problem based learning teaching methodologies in medical students. Pakistan Journal of Medical Sciences, 37(1), 146. Retrieved from https://www.ncbi.nlm.nih.gov/pmc/articles/pmc7794154/
Kemp, S. (2019, October 23). The Global State of Digital in October 2019. Retrieved from https://wearesocial.com/au/blog/2019/10/theglobal-state-of-digital-in-october-2019
McNamara, A., Smith, J., & Murphy-Hill, E. (2018, October). Does ACM’s code of ethics change ethical decision making in software development? In Proceedings of the 2018 26th ACM joint meeting on European software engineering conference and symposium on the foundations of software engineering (pp. 729-733). Retrieved from https://dl.acm.org/doi/abs/10.1145/3236024.3264833?casa_token=xu_JKZRcyBEAAAAA:GhNrkWmz5yEKg4TwJaWg6dfOBz8O1WWoUuOtwbJXbuo3TL623CitLoNeaEQiksit_hl5YrAcRQSQ
Rigby, D. K., Sutherland, J., & Noble, A. (2018). Agile at Scale. Harvard Business Review, 96(3), 88–96. Retrieved from http://search.ebscohost.com.ezproxy.laureate.net.au/login.aspx?direct=true&db=bsu&AN=129192576&site=ehost-live
Research
MIS607 Cybersecurity Assignment Sample
Assignment Brief
Assignment Title - MITIGATION PLAN FOR THREAT REPORT
Individual/Group - Individual
Length - 2500 words (+/- 10%)
Learning Outcomes:
The Subject Learning Outcomes demonstrated by successful completion of the task below include:
b) Explore and articulate cyber trends, threats and staying safe in cyberspace, plus protecting personal and company data.
c) Analyze issues associated with organizational data networks and security to recommend practical solutions towards their resolution.
d) Evaluate and communicate relevant technical and ethical considerations related to the design, deployment and/or the uses of secure technologies within various organizational contexts.
Submission - Due by 11:55pm AEST Sunday end of Module 6.1
Weighting - 45%
Total Marks - 100 marks
Task Summary
For this assessment, you are required to write a 2500 words mitigation plan for threat report based on knowledge you gained about threat types and key factors in Assessment 2. You are required to use the Assessment 2 case as context to write a report to address or alleviate problems faced by the business and to protect the customers. In doing so, you are required to demonstrate your ability to mitigate threat/risks identified in Assessment 2 through the strategy you recommend (STRIDE).
Context
Cybersecurity help organizations to mitigate threats/risks, reduce financial loss and safety violations, decrease unethical behaviour, improve customer satisfaction, and increase efficiency, as well as to maintain these improved results. Threats can be resolved by Risk Acceptance (doing nothing), Risk Transference (pass risk to an externality), Risk Avoidance (removing the feature/component that causes the risk) and Risk Mitigation (decrease the risk). This assessment gives you an opportunity to demonstrate your understanding of cybersecurity and your capability to explain Risk Mitigation strategies for such threats. Mitigations should be chosen according to the appropriate technology and resolution should be decided according to the risk level and cost of mitigation.
Task Instructions for assignment help
1. Read the Assessment 2 Case Scenario again to understand the concepts discussed in the case.
2. Review your subject notes to establish the relevant area of investigation that applies to the case. Re- read any relevant readings that have been recommended in the case area in modules. Plan how you will structure your ideas for the mitigation plan for threat report.
3. The mitigation plan for threat report should address the following:
• Setting priorities for risks/threats
• Analyze the case in terms of identified risk categories and scenarios
• Apply standard mitigations
• Discuss specific resolutions for improvement, and justify their significance
• Provide recommendations for mitigating risk based on an assessment of risk appetite, risk tolerance and current risk levels (Choose techniques to mitigate the threats)
• Make recommendations to the CEO on how to conduct risk management, key issues involving your process improvement model, including a road map, the identification of appropriate technologies for the identified techniques, communicating the strategy, and a suggested timeline.
4. The report should consist of the following structure:
A title page with subject code and name, assignment title, student’s name, student number, and lecturer’s name. The introduction that will also serve as your statement of purpose for the report. This means that you will tell the reader what you are going to cover in mitigation plan report. You will need to inform the reader of:
a) Your area of research and its context (how to mitigate or manage threats)
b) The key concepts you will be addressing
c) What the reader can expect to find in the body of the report
The body of the report will need to respond to the specific requirements of the case study. It is advised
that you use the case study to assist you in structuring the report. Set priorities for identified threats from assessment 2, analyze the case in terms of identified risk categories and discuss specific resolutions and recommendations for improvements in the body of the report.
The conclusion (will summarize any findings or recommendations that the report puts forward regarding the concepts covered in the report.
5. Format of the report
The report should use font Arial or Calibri 11 point, be line spaced at 1.5 for ease of reading, and have page numbers on the bottom of each page. If diagrams or tables are used, due attention should be given to pagination to avoid loss of meaning and continuity by unnecessarily splitting information over two pages. Diagrams must carry the appropriate captioning.
6. Referencing
There are requirements for referencing this report using APA referencing style for citing and referencing research. It is expected that you used 10 external references in the relevant subject area based on readings and further research. Please see more information on referencing here:https://library.torrens.edu.au/academic skills/apa/tool
7. You are strongly advised to read the rubric, which is an evaluation guide with criteria for grading the
assignment— this will give you a clear picture of what a successful report looks like.
Submission Instructions
Submit Assessment 3 via the Assessment link in the main navigation menu in MIS607 Cybersecurity. The Learning Facilitator will provide feedback via the Grade Centre in the LMS portal. Feedback can be viewed in My Grades.
Solution
Introduction
The purpose of this report is to prepare a mitigation plan for the identified threats from assessment-2 threat modelling report. The context of this report is based on the threat mitigation strategy, STRIDE which was recommended in the earlier assessment. In this threat report, it has been possible for me to address the key cybersecurity threats/risks faced by the Business & Communication (B&C) Insurance organisation and concept of risk acceptance, risk transference, risk avoidance, & risk mitigations. Moreover, in this report, recent cyber trends and relevant threats have been articulated and explored.
Readers can expect to learn about the risk mitigation strategies for critical cybersecurity threats through this assessment. Last, but not the least, this threat report helps the key stakeholders of B&C Insurance company to choose appropriate technology and resolution for the risk level. It also helps to understand the cost of mitigation and structured their own ideas for the same.
Threats Identification, Specific Resolution respond to the case study
Setting priorities for risks/threats
Table 1: Risk/Threat Prioritization (Source: Canfield & Fischhoff, 2018, p. 828)
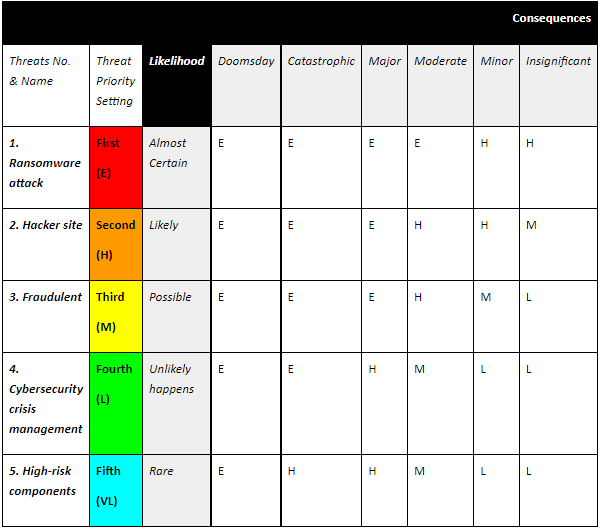
Analysis in terms of risk categories and scenarios
Table 2: Analysis of identified threats for particular scenario (Source: Canfield & Fischhoff, 2018, p. 830)
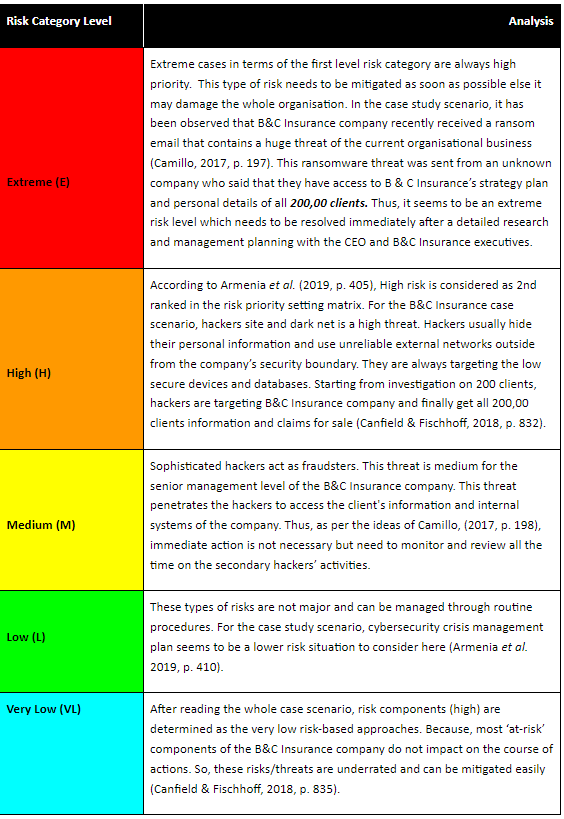
Standard Mitigations
After knowing the risk categories and relevant scenarios for this B&C Insurance case study organisation, it is necessary to identify and apply standard mitigation techniques as follows:
? Installing Firewalls to protect email/website
Firewalls are enabled to protect B&C Insurance company websites. It has been designed to create a buffer between IT systems and external networks so that it can monitor the network traffic, block anything that could damage the computers, systems, and private networks (Armenia et al. 2019, p. 405). Firewalls also prevent cyber criminals from breaking down into networks and block outgoing traffic that contains a virus.
? Installing antivirus software
Installing antivirus acts as an essential technological defence for the B&C Insurance company. Modern range of antiviruses generally provide protection against a range of malware (spam emails), key loggers, ransomware, adware, spyware, and so on (Ganin et al. 2020, p. 185).
? Patch management
For software updates, need to fix the vulnerability along with a patch management plan.
? Cybersecurity risk assessment
As per the International standard: ISO 27001, step-by-step guidance has been followed for cyber security risk assessment. It is a standard mutation applied to gain benefits (Zadeh, Jeyaraj & Biros, 2020, p. 5).
? Information security policy
It is the result of risk assessment which has been adopted by the organisation itself to prevent unauthorized access. Information security policy will review the effectiveness of the control.
? Sensitive data encryption
As suggested by Zheng & Albert, (2019, p. 2078), Under the General Data Protection Regulation (GDPR), encrypted data cannot be assessed by the criminal or hackers even if they break the systems. It only accessed by the authorized personnel i.e. CEO of the B&C Insurance with a decryption key.
? Remote working policy
Create a remote working policy for the B&C Insurance employees reshaped the organisational security services. It recommends two-factor authentication to any third-party services for personal use (Armenia et al. 2019, p. 410).
? Conduct vulnerability scans
Vulnerability scanning improves the overall cybersecurity effectiveness and security measurements.
? Create a different business continuity plan for B&C Insurance
It is also a standard mitigation that outlines the critical processes of an organisational operation in the event of a major disruption (Ganin et al. 2020, p. 188).
? Conducting penetration test
It is important to resist hacking on behalf of the B&C Insurance company. Automated scans enable the actors and leverage the weaknesses to gain a true insight. Penetration test is important to stop criminals, ethical hackers and implement defences (Zadeh, Jeyaraj & Biros, 2020, p. 12).
Specific Resolutions
After considering the cybersecurity threats for B&C Insurance company and discussing the standard mitigations, it has been possible for me to describe specific resolutions for improvement and justify their significance for the same. The following are the resolutions for B&C Insurance companies which can be implemented to ensure that the organisation does not become the victim of cyber-crime, hackers, or fraudsters (Zheng & Albert, 2019, p. 2080).
? Providing security training is a best resolution that aware the employees before clicking a malicious link or downloading fraudulent software.
? Updated strong anti-virus software is useful to protect internal organisational data (Armenia et al. 2019, p. 413).
? How to respond to the phishing threats from exploitation of software vulnerabilities has also to be considered.
? Strong password policy is a resolution to the threats and risks faced by the B&C Insurance company.
? As per the guidance of Ganin et al. (2020, p. 190), multi factor authentication is a resolution that allows B&C Insurance company to protect its compromised credentials. Attempting corporate applications, networks, and servers is also a resolution approach.
? Backing-up databases is also important. It could be the essential solution when the company lost almost its data after a cyber-attack (Zadeh, Jeyaraj & Biros, 2020, p. 20).
Recommendations for Risk Mitigation
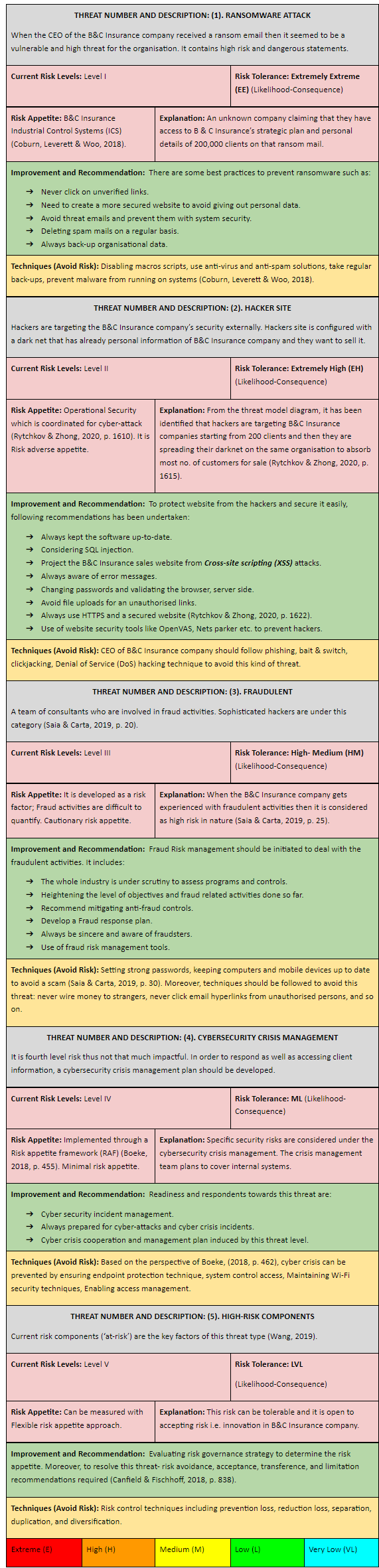
Table 3: Mitigating Risk Assessment (Source: Wang, 2019)
Risk Management Roadmap
In this stage, on the basis of risk categories and key issues involved to the threat model a risk management has been conducted. It is included in the following table.
Table 4: Risk Management approaches and relevant criterions (Source:
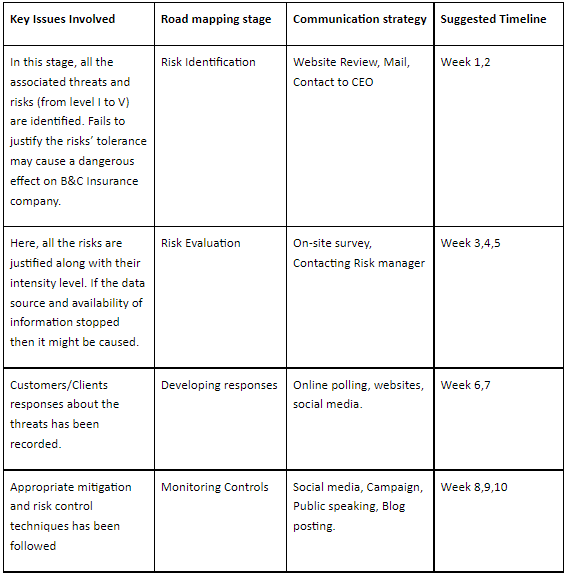
Figure 1: Risk Roadmap
(Source: Bahaloo-Horeh & Mousavi, 2020, p. 123186)
Identification of appropriate technologies
STRIDE elements are identified from assessment 2 which is an appropriate technique to diversify the threats. This technique is identified for the relevant threats and how to act against it.
? Spoofing is identified for Authentication security property.
? Tampering technique is for Integrity.
? Repudiation is a recommended threat key factor accessed by the CEO in a non-repudiation context (Laessoe, Jensen & Madeleine, 2017, 5).
? Information Disclosure might be considered for confidentiality.
? Denial of Service is considered for availability.
? Elevation of Privilege is an authorized technique involved in this case.
On the other hand, the DREAD model is a technique which is associated with risks/threats. NIST is also similar to these.
Conclusion
After discussing the threats, vulnerabilities in the B&C Insurance company, it is necessary to summarize those findings and outcomes that will be put forward in future cases. The course of actions must be recommended to mitigate potential threats in future are:
? Validating the threat and engaging the stakeholders.
? Conduct a proper risk management which may be beneficial and provide specific resolution to the existing threats.
? Beware of unreliable external networks, emails from the next time to prevent this kind of cybercrime scenario.
References
Armenia, S., Ferreira Franco, E., Nonino, F., Spagnoli, E., & Medaglia, C. M. (2019). Towards the definition of a dynamic and systemic assessment for cybersecurity risks. Systems Research and Behavioral Science, 36(4), 404–423. Retrieved on 18-Apr-2021 from, https://doi.org/10.1002/sres.2556
Bahaloo-Horeh, N., & Mousavi, S. M. (2020). Comprehensive characterization and environmental risk assessment of end-of-life automotive catalytic converters to arrange a sustainable roadmap for future recycling practices. Journal of Hazardous Materials, 400, 123186–123186. Retrieved on 19-Apr-2021 from, https://doi.org/10.1016/j.jhazmat.2020.123186
Boeke, S. (2018). National cyber crisis management: different European approaches. Governance, 31(3), 449–464. Retrieved on 19-Apr-2021 from, https://doi.org/10.1111/gove.12309
Camillo. (2017). Cybersecurity: risks and management of risks for global banks and financial institutions. Journal of Risk Management in Financial Institutions, 10(2), 196–200. Retrieved on 18-Apr-2021 from, https://lesa.on.worldcat.org/oclc/6998327984
Canfield, C. I., & Fischhoff, B. (2018). Setting priorities in behavioural interventions: an application to reducing phishing risk. Risk Analysis, 38(4), 826–838. Retrieved on 18-Apr-2021 from, https://doi.org/10.1111/risa.12917
Coburn, A., Leverett, E., & Woo, G. (2018). Solving cyber risk: protecting your company and society. John Wiley & Sons, Incorporated. Retrieved on 19-Apr-2021 from, https://lesa.on.worldcat.org/oclc/1080082434
Ganin, A. A., Quach, P., Panwar, M., Collier, Z. A., Keisler, J. M., Marchese, D., & Linkov, I. (2020). Multicriteria decision framework for cybersecurity risk assessment and management. Risk Analysis, 40(1), 183–199. Retrieved on 19-Apr-2021 from, https://doi.org/10.1111/risa.12891
Laessoe, U., Jensen, N. M. B., & Madeleine, P. (2017). Examination of the gait pattern based on adjusting and resulting components of the stride-to-stride variability: proof of concept. Bmc Research Notes, 10(1), 1–7. Retrieved on 19-Apr-2021 from, https://doi.org/10.1186/s13104-017-2623-8
Rytchkov, O., & Zhong, X. (2020). Information aggregation and p-hacking. Management Science, 66(4), 1605–1626. Retrieved on 19-Apr-2021 from, https://doi.org/10.1287/mnsc.2018.3259
Saia, R., & Carta, S. (2019). Evaluating the benefits of using proactive transformed-domain-based techniques in fraud detection tasks. Future Generation Computer Systems, 93, 18–32. Retrieved on 19-Apr-2021 from, https://doi.org/10.1016/j.future.2018.10.016
Wang, S. S. (2019). Integrated framework for information security investment and cyber insurance. Pacific-Basin Finance Journal, 57. Retrieved on 18-Apr-2021 from, https://doi.org/10.1016/j.pacfin.2019.101173
Zadeh, A. H., Jeyaraj, A., & Biros, D. (2020). Characterizing cybersecurity threats to organizations in support of risk mitigation decisions. E-Service Journal, 12(2), 1–34. Retrieved on 19-Apr-2021 from, https://lesa.on.worldcat.org/oclc/8978135163
Zheng, K., & Albert, L. A. (2019). A robust approach for mitigating risks in cyber supply chains. Risk Analysis, 39(9), 2076–2092. Retrieved on 19-Apr-2021 from, https://doi.org/10.1111/risa.13269
Research
MITS5001 IT Project Management Assessment 2 Sample
Assignment Brief
Objective(s)
This assessment item relates to the unit learning outcomes as in the unit descriptor. This assessment is designed to improve student presentation skills and to give students experience in researching a topic and writing a report relevant to the Unit of Study subject matter.
The following ULOs are assessed in this assessment.
LO2 Critically analyze project parameters and identify the key processes from the available project management book of knowledge in practical case scenarios.
LO5 Carry out research studies to provide expert judgement on the project progress and strategize contingency and fallback plans to ensure project deliverables are met as planned.
INSTRUCTIONS
For this component you will prepare a report or critique on an academic paper related to IT Project Management. The paper you select must be directly relevant to one of these major topics:
Project Life Cycles, Integration Management, Scope Management, Schedule Management, Cost Management, Quality Management, Resource Management, Communications Management, Risk Management, Procurement Management, Agile Project Management, Change Management, Earned Value Management, Resource Management and Stakeholder Management.
Your report should be limited to approx. 1500 words (not including references). Use 1.5 spacing with a 12 point Times New Roman font. Though your paper will largely be based on the chosen article, you can use other sources to support your discussion. Citation of sources is mandatory and must be in the IEEE style.
Your report or critique must include:
• Title Page: The title of the assessment, the name of the paper you are reviewing and its authors, and your name and student ID.
• Introduction: A statement of the purpose for your report and a brief outline of how you will discuss the selected article (one or two paragraphs). Make sure to identify the article being reviewed.
• Body of Report: Describe the intention and content of the article. If it is a research report, discuss the research method (survey, case study, observation, experiment, or other method) and findings. Comment on problems or issues highlighted by the authors. Discuss the conclusions of the article and how they are relevant to what you are studying this semester.
• Conclusion: A summary of the points you have made in the body of the paper. The conclusion should not introduce any ‘new’ material that was not discussed in the body of the paper. (One or two paragraphs)
• References: A list of sources used in your text. They should be listed alphabetically by (first) author’s family name. Follow the IEEE style.
• The footer must include your name, student ID, and page number
Submission Guidelines for assignment help
All submissions are to be submitted through turn-it-in. Drop-boxes linked to turn-it-in will be set up in the Unit of Study Moodle account. Assignments not submitted through these drop-boxes will not be considered.
Submissions must be made by the due date and time (which will be in the session detailed above) and determined by your Unit coordinator. Submissions made after the due date and time will be penalized at the rate of 10% per day (including weekend days).
Solution
Introduction
This report aims at finding out the importance of project management in terms of time, cost and quality assurance. The chosen article speaks about Agile Project Management technique, its advantage over traditional PMBOK (Project Management Body of Knowledge) when looking for innovation and change management. The use of agile technology and its effectiveness is discussed in the case study of a Brazilian Pharmaceutical Company’s IT Project. The disadvantages of using a traditional approach are analyzed, and the SCRUM framework is utilized for implanting Agile Technology in designing the new software.
Research Method
The research method used in the research paper is a qualitative exploratory research method. In this research, a case study of the pharmaceutical industry is considered [7]. The case study aims at investigating the current phenomenon where the context and phenomena are not categorized. The process of the case study includes data collection, both qualitative and quantitative.
Project Management knowledge areas
Project management knowledge areas are existing that includes risk management, change management, Human resources management, stakeholder management, quality management, time management, cost management, and many more. As per the [7] higher competition rate in the market forces various companies to consider change management in terms of project management in order to address those changes that can impact the company both positively as well as negatively. However, various studies are present which showcases other requirements for adopting the change management process during the conduction of project work. In the view of [1], the intention of the authorities of a company regarding internal change provokes companies to adopt change management principles in delivering prosperous project work. Often it is found that the requirements of project work cannot be addressed by project stakeholders by just considering the principles of project management. In this regard, it can be contradicted that the project manager of specific project work should consider a change management approach along with the project management approach in order to address the drawbacks of the ‘one-legged approach.’ On the other hand, [2] opined that the demand for global software development rise significantly due to which companies have to consider the aspects of Requirements Engineering and Change management for managing rich communication level among every stakeholder. Henceforth, it can be argued that the argument of [2], [1] and [7] is entirely different from each other. Lastly, from the concern of [4], it is found that the approach regarding Change management helps to increase the effectiveness of a project work significantly. Thus, it can be asserted that the change management approach is of utmost crucial and relevance in terms of accomplishing a project work properly. Although, every people have their own point of view regarding the utilization of change management principles.
Key Project parameter
The critical project parameters considered for any project include time, cost, quality and quantity of the products or deliverables. The project considered in the research paper was completed in 100 days (approximately about four months.) The total project cost was $US 145, 000, including the backlog changes [7]. The changes were incorporated after the completion of every Sprint, and the whole process ended in five Sprints. The information gathered, and knowledge gained in every Sprint was used to induce changes and proper decision making of the project. The traditional approach estimated seven months for completion, and the budget was Us $ 291, 000 [7]. The project team members were satisfied as the project’s testing was done in a real-time environment after subsequent phases. The changes were immediately incorporated and not waiting for the completion enhances the quantity as the products are delivered at every phase. Using SCRUM framework was helpful.
Project deliverables
A deliverable is tangible or intangible goods or services that need to be delivered. They can be documents, report, software product, a server upgrade or any other building blocks of the project [5]. The project deliverables were considered using the Product Backlogs and then estimating the items based on their priority which defines the requirement according to the Sprints of the project. The organization’s primary tangible deliverable was lowering down the need for stock as the expiration of medicines leads to loss. The XYZ project was designing an inventory module for considering the medicines with a shorter life span. It was necessary to apply filtration of medicine with batch numbers with shorter shelf life [7]. Arrange them by date, create a proper log, analyze the acquisition cost of storing and transport from inventory and total. The intangible products include the organizational reputation by meeting consumer demands and take decisions accordingly.
Project monitoring
The project was based on SCRUM framework where the stakeholders were the SCRUM team, the product owner and the Scrum master. The whole project was divided into Sprints, and the activities are described accordingly. Constant monitoring was done by meeting conducted by the Scrum Master where the report was taken from each member regarding their activities. The initial Sprint was to gather information regarding the stock of the existing drugs, their shelf life. The primary aim was to reduce damage and decrease the need for stock as the medicines were not allowed to be solved after their expiration date. The next Sprint was regarding speculation where Product Backlogs were created by the owner. From this stage, a Sprint backlog was created, which identified the product requirements that are required to be delivered in each subsequent stages of sprints. The Exploration phase covers the activities that were to be conducted in each Sprint. The meetings were held to ensure that the scope of the project is maintained. The next phase was the Adaptation Phase where the changes were incorporated according to the requirements gathered in previous stages. A retrospective approach is taken for considering the situation and how the requirements changed. But in later stages, more realistic decisions were taken.
Contingency Plan
Contingency plans are used to fight against any adverse incidences that may occur. The likelihood of risk is considered, and proactive measures are taken to combat the risk [6].
Table 1: Contingency plan
Source: (Developed by the author)
Research Findings
The research aimed to consider the positive aspects of using Agile Technology in SCRUM framework and its increased effectiveness as compared to the traditional approach. According to the research findings of the chosen paper, it is observed that a quantifiable benefit was observed in terms of time (80% increased performance as the project was completed in 100 days which was estimated to be seven months for traditional approach). In the case of cost, it got reduced by 50% [7]. The deliverables were produced after the first phase of the project life cycle, which motivated the employees as they could see the product even before the completion of the whole project. However, as per the consent of [3], every project manager needs to categorize the phases of a project work in short frequency that can provide the feeling of short-term wins to everyone associated with the project work.
However, the findings of the chosen research paper did not showcase the existence of such an aspect. Constant communication among the team members created the right working environment. The significant benefit was the project control in terms of scope. The results are analyzed, and changes were incorporated according to the requirements. According to [4], a communication plan must be deployed during the conduction of project work in order to cross-check the procedure of every step of that specific project work. However, the findings of [7] do not represent the utilization of such a communication plan. Aggregation was also initiated as the clients can instruct changes after using the products during the completion of the first phase [7]. Customer satisfaction is the major success as the change was initiated according to their demands. The major drawback of the research was to consider only a single case study of a Brazilian pharmaceutical company. It cannot be used as a generalized result, although exploratory research helped in gaining knowledge that can be used in real scenarios of business [7].
As per the above discussion, it can be argued that the project work was critically measured and delivered by the project team, although some gaps are present which could be addressed during the conduction of project work. Different authors represented different approaches for enriching the outcome of a project, which should be taken into account by authorities of project work in order to increase the effectiveness of the project. Hence, not only the aspects of Agile but also the principles of change management, appropriate communication need to considered by project stakeholders for managing change as well as to deliver a prosperous outcome by finishing the project work.
References
[1] G. O’Donovan, "Creating a culture of partnership between Project Management and Change Management", Project Management World Journal, vol. 7, no. 1, pp. 1-11, 2018. Available: https://pmworldlibrary.net/wp-content/uploads/2018/01/pmwj66-Jan2018-ODonovan-creating-culture-of-partnership-project-management-and-change-management.pdf. [Accessed 3 January 2021].
[2] M. Shafiq et al., "Effect of Project Management in Requirements Engineering and Requirements Change Management Processes for Global Software Development", IEEE Access, vol. 6, pp. 25747-25763, 2018. Available: 10.1109/access.2018.2834473 [Accessed 3 January 2021].
3] M. Fraser-Arnott, "Combining Project Management and Change Management for Project Success in Libraries", 2018. Available: https://doi.org/10.1108/S0732-067120180000038005 [Accessed 3 January 2021].
[4] F. Shirazi, H. Kazemipoor and R. Tavakkoli-Moghaddam, "Fuzzy decision analysis for project scope change management", Decision Science Letters, pp. 395-406, 2017. Available: 10.5267/j.dsl.2017.1.003 [Accessed 3 January 2021].
[5] D. Danda, "Greycampus", Greycampus.com, 2019. [Online]. Available: https://www.greycampus.com/blog/project-management/what-are-project-deliverables. [Accessed: 02- Jan- 2021].
[6] K. Hughes, "How to Make a Contingency Plan - ProjectManager.com", ProjectManager.com, 2018. [Online]. Available: https://www.projectmanager.com/blog/contingency-plan. [Accessed: 02- Jan- 2021].
[7] A. Terra, "Agile Project Management with Scrum: Case Study of a Brazilian Pharmaceutical Company IT Project", International Journal of Managing Projects in Business, vol. 10, no. 1, pp. 121-142, 2016. Available: https://www.emerald.com/insight/content/doi/10.1108/IJMPB-06-2016-0054/full/html. [Accessed 2 January 2021].
Research
MITS4004 - IT Networking and Communication Assignment 2 Sample
Assignment Brief
Due Date: Session 9
Weightage: 10%
Individual Assignment
This assessment item relates to the unit learning outcomes as in the unit descriptors.
L01: Identify the operation of the protocols that are used inside the Internet and use the seven-layer model to classify networking topology, protocol and security needs.
LO2: Evaluate LAN technology issues, including routing and flow control. Explain the difference between switches and routers. Build and troubleshoot Ethernet, Wi-Fi and Leased line networks. Connect networks with routers.
Scenario:
You are a Network and Security Engineer for the ABC Consulting Private Limited, which is a leading network and security provider for the small and medium scaled offices.
Task 1: Your task is to propose a network design for the small scaled company and sketch a basic logical network diagram of the office with 5 departments. You are free to assume:
• Name of the Office and Departments
• Networking Hardware’s such as routers, switches, hubs, modems wireless access points, firewalls etc.
Task 2: Using your expert knowledge on TCP/IP Model and its layers, sketch the TCP/IP protocols and identify at least one protocol used by each layer.
Task 3: At each level of the TCP/IP model, there are security vulnerabilities and therefore, security prevention measures that can be taken to ensure that enterprise applications are protected. As a network and security engineer, your task is to identify the security threats and propose a solution on each layer.
The report should be prepared in Microsoft word and uploaded on to the LMS. The word limit of the report is 2000 words. The report should be a properly constructed as an academic report. The report should include references in IEEE style.
Submission Guidelines for assignment help
The report should have a consistent, professional, and well-organized appearance.
1. Your report should include the following:
? The word limit of the report is 2000 words.
? The cover page must identify student names and the ID numbers, unit details, and the assignment details.
? The assignment must use 12-point font size and at least single line spacing with appropriate section headings.
? In-text referencing in IEEE style must be cited in the text of the report and listed appropriately at the end in a reference list.
2. The report must be submitted in soft (electronic) copy as a Microsoft Word document on the LMS in Turnitin drop box. Assignments submitted on the LMS will only be accepted.
3. Late penalty applies on late submission, 10% per day would be deducted.
4. The assignments will go through Turnitin and plagiarism penalty will be applied.
The report must be submitted in soft (electronic) copy as a Microsoft Word document via the upload link available on Moodle.
Solution
Introduction
The design of the network of the company has 5 departments. The office “GLORE” situated in the US is the small Scale which has 5 departments and the designing of the network is to be done for them. This plan of the organization for the organization should have 5 offices. The workplace "GLORE" arranged in the US is a limited scale which has 5 divisions and the planning of the organization is to be accomplished for them. The report comprises of the organization name GLORE with 5 divisions that are account, innovative work, advertising, client care, and IT.
Furthermore, the availability is finished utilizing a modem, switch, LAN, frameworks, stockpiling framework, centre point, an organization switch, printers, PCs, and so on. For the organization, the requirement LAN network is required as indicated by the need. The availability was used by the utilization of different organization media such as switches, centre, switch, stockpiling worker, firewall, connector, and so on. What's more, preceding to it the managing of the organization beginning initiating from ISP moving to the client. Next, we examined the TCP/IP convention suite and the conventions of the layer along with their graph. And then we considered the security weakness at TCP/IP distinctive layer of TCP/IP, and it enforced us and then we thought of the safety efforts and answers for those weaknesses. TCP/IP convention suite that is layered engineering where every layer has its conventions which are utilized to do the usefulness of that layer. Also, at each degree of TCP/IP observations of security weaknesses were seen and they need safety efforts and afterward new layers of the suite TCP/IP convention suite aren’t secure also it has weaknesses than to have sure about them. The utilization of various controls was run which will lesson the odds of the danger of information misfortune, data spilling, and numerous different issues looked in conventions downside. This report is made in the wake of experiencing the distinctive accessible examination materials and data accessible.
Organizational network design
The planning of the organization is to be accomplished for an occasion overseeing organization "GLORE Events" which has 5 divisions, and every office requires web access for their expert. For their concern of worker's prerequisites and also for the planning of the organization, we require the availability just as the equipment and programming for its arrangement. The association needs to be established and for the installation, the introduction was initiated for receiving of an association from Internet Service Provider(ISP).
ISP provides a source that is the utilization of Modem also afterward utilizing the LAN (Local Area Network). It provides arrangement to receive the admittance to the public organization and interfacing Router along with it that requires introduction in the organization. It also posts that utilizes links, we will append an organization switch with it. And then afterward frameworks of every division will be associated with that Switch and will have the option to operate it through the data and added to the stage to speak with different frameworks. From the earliest starting point the establishment for the association is needed from the Internet Service Provider that is ISP. At that point to receive the network modem is associated utilizing the NIC and the available links which were getting the signs also the utilization of LAN installed preceding to the modem and traced with firewall. Router is also associated which is giving the availability utilizing Wi-Fi and through Ethernet is associated with switch/center also.
Router is also associated with the capacity worker for the handling of the correspondence. Also, as the organization GLORE Events has 5 offices so the Switch is associated with 6 frameworks through the link.
One for every division and one concerning the principle office sort of a worker and now the plan of the fundamental rational network association: [6]
Figure 1 NETWORK LOGIC DIAGRAM
(Source: Self-developed)
The planning of the organization for the establishment of equipment is additionally thought of where the modem requires the installation where it was being designed and initiate it as a work. The five frameworks ought to be present at divisions of the organization and the switch ought to be set halfway such that in the event of any disappointment in any associations.
The framework can admittance to Wi-Fi also the individuals who expect the portability and don't lean toward the link and wires near them so they can without much of a stretch admittance to the availability.
The additional association that is the 6th ought to be put midway and ought to be utilized to teach the wide range of various frameworks.
In the same manner with a similar order can likewise be utilized as a reinforcement framework on the off chance that any of the frameworks isn't working or confronting any issue with the network. This sort of framework will make the moving simpler and as the situations are good then representatives will have the option to work productively thus it will be at last profit the organization.
TCP/IP model
As in an examination, it was indicated that correspondence between two frameworks is conceivable with the organization through convention suits. TCP/IP is one of the most generally utilized convention suite, additionally accessible without any problem. TCP/IP is the implementation of the OSI model (open system interconnection model). TCP/IP, the substitution of the convention isn't simple. TCP/IP convention is a structure of layers, and every layer posses with a particular use which is completed by the utilization of the convention. Every layer has conventions to complete its usefulness that is clung with the layer. TCP/IP convention suite consists of four layers:
Application layer: manages every layer ought to be independent and the tools that are of the first layer can secure the application information and probably not the data of TCP/IP as it is available in the next layers. The uppermost layer is an OSI and is distributed into 2 different layers and TCP/IP is the combination of 2 OSI layers. The protocols are Telnet, SMTP (Simple mail transfer protocol), HTTP (Hypertext transfer protocol), SNMP (Simple network management protocol), FTP (File transfer protocol).
Transport layer: it is the phase or layer which will ensure the information in one meeting of correspondence among the 2 communicators. As the Information Protocol data is raised in the organization phase and the layer isn't equipped for dealing with it. The layer that works as an intermediate and is properly oriented in the connection is also known as the connectionless or no connection layer. The protocols are UDP (User Datagram Protocol) and TCP (Transmission Control Protocol).
Organization layer: It is viewed as that the specific features of the organization layer could be shared by other layers and it will not create the hurdle as they are not specific with application explicit, which implies no change is needed in the insurance application. i.e. Another connectionless layer. The formation or transferring of the data is done in small units that have an address associated with them that is an IP address. The protocols are ISMP (Inter-Switch Message Protocol) and IP (Internet Protocol).
Datalink layer: The tools or managing are operated to the wide range of various layers and their controls committed circuits among the 2 communicators of an ISP. The management of data is done from the physical links and it is said that this gives the procedural and functional attributes to the data transferring. The protocols are ARP (Address Resolution Protocol), token ring, and Ethernet.
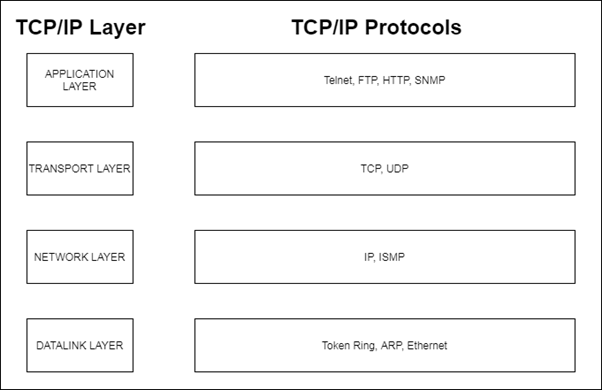
Figure 2 TCP/IP MODEL
(Source: self-developed)
Vulnerabilities
TCP/IP utilizes the location of the gadgets which are associated which fill the two or double that need to distinguishing the gadget also. As a result of this organization weakness is made and it will entirely noticeable and not contrasted with angry clients all through the globe. TCP/IP has 4 layers, as well as security concerns, that exist at every degree of the suite TCP/IP convention suite. TCP/IP information moves from the most elevated phase which is from the first Application layer and to the fourth layer which is named the Data link layer, at every next layer data is added. Along these lines, modes fitted on a more elevated phase cannot secure the previous phase, as the usefulness of the previous-level isn't distinguished from the preceding phase. Security controlling tools that are used at different layers and phase of TCP/IP convention suite available are: [1]
Application layer: manages of every phase ought to become independent and then the tools that are of the first layer phase can secure the first application information or data and probably not only the data of TCP/IP as this is available for the next layers of phase. The answer for being utilized for it ought to be level-based which can be utilized for quite a while, for instance, the utilization of Secure Multipurpose Internet Mail Extensions(S/MIME) that is continued because of the information that will be encoded in it. [2]
Transport layer: it is that of phase which will ensure the information in a meeting of correspondence among 2 communicators. Information Protocol data which was raised in any organization phase and also the layer isn't equipped for dealing with it. The layer is utilized to deal with the commotion of traffic created by the HTTP via the Transport Layer Security (TLS) convention. For utilizing Transport Layer Security (TLS) it is required that the application can uphold Transport Layer Security (TLS). In contrast with additional insurance to the first phase that is application layer utilizing or combining with the Transport Layer Security (TLS) is favored and considered safer. Transport Layer Security (TLS) will be utilized with SSL entryway VPNs.
Organization layer: displayed as that the specific features of the organization layer could be shared by other layers and it will not create the hurdle as they are not specific with application explicit, which implies no change is needed in the insurance application. In certain cases, the controlling is done by the Network layer of the IP Security (Internet Protocol security) is favored over different controls or the controls of different layers and the layers are transport and application layer. In this layer, information is ensured in parcels and the Internet
Protocol of every bundle is secured. [5]
Datalink layer: The tools or managing are operated to the wide range of various layers and their controls committed circuits among the 2 communicators of an ISP. The utilization of information encryptors is utilized to secure it. Although it does not provide help to the insurance from numerous lines thus it is viewed as basic in contrast with the different layer controls and it is simpler to execute. These conventions are utilized for the extra assurance for some particular connections that are least relied thus the utilization of these tools are finished. [3]
Conclusion
The entire report is on Network and beginning with the planning of the organization for an organization consists of 5 divisions. All the availability and connectivity and can be given by Local Area Network that is LAN since we have 3 kinds of organization that are WAN, LAN, and MAN.
Where LAN can be utilized for the structures or organization more than one spot for some clients yet MAN is used for intercity or state organization purposes and utilization of WAN is around the world. This report is set up in the wake of examining and experiencing sites and available books with network availability and their advantages.
At long last with which we thought of the answers for security weaknesses and portrayed the conventions and planned the organization for the organization GLORE Events. TCP/IP convention suite that is layered engineering where every layer has its conventions which are utilized to do the usefulness of that layer. Also, at each degree of TCP/IP, observations of weaknesses in security was seen. There is a need of safety efforts and afterward, new layers of the suite TCP/IP convention suite aren’t secure also it has weaknesses than to make sure about them. With the utilization of various controls was run which will lesson the odds of the danger of information misfortune, data spilling, and numerous different issues looked in conventions downside.
References
[1]
M. Ji, “Designing and Planning a Campus Wireless Local Area Network,” Theseus.fi, 2017, doi: URN:NBN:fi:amk-2017053011119. [Online]. Available: https://www.theseus.fi/handle/10024/130087. [Accessed: 12-Jan-2021]
[2]
M. Ji, “Designing and Planning a Campus Wireless Local Area Network,” Theseus.fi, 2017, doi: URN:NBN:fi:amk-2017053011119. [Online]. Available: https://www.theseus.fi/handle/10024/130087. [Accessed: 12-Jan-2021]
[3]
S. Francik, N. Pedryc, T. Hebda, and B. Brzychczyk, “Use of network planning methods in designing modernization of agri-food processing enterprise to improve organization of production: example of meat processing plant,” May 2018, doi: 10.22616/erdev2018.17.n426. [Online]. Available: http://www.tf.llu.lv/conference/proceedings2018/Papers/N426.pdf. [Accessed: 12-Jan-2021]
[4]
N. Zarbakhshnia, H. Soleimani, M. Goh, and S. S. Razavi, “A novel multi-objective model for green forward and reverse logistics network design,” Journal of Cleaner Production, vol. 208, pp. 1304–1316, Jan. 2019, doi: 10.1016/j.jclepro.2018.10.138. [Online]. Available: https://www.sciencedirect.com/science/article/abs/pii/S0959652618331548. [Accessed: 12-Jan-2021]
[5]
M. Mohammadi, S.-L. Jämsä-Jounela, and I. Harjunkoski, “Optimal planning of municipal solid waste management systems in an integrated supply chain network,” Computers & Chemical Engineering, vol. 123, pp. 155–169, Apr. 2019, doi: 10.1016/j.compchemeng.2018.12.022. [Online]. Available: https://www.sciencedirect.com/science/article/abs/pii/S0098135418302813. [Accessed: 12-Jan-2021]
[6]
B. Dey, K. Khalil, A. Kumar, and M. Bayoumi, “A Reversible-Logic based Architecture for Artificial Neural Network,” 2020 IEEE 63rd International Midwest Symposium on Circuits and Systems (MWSCAS), Aug. 2020, doi: 10.1109/mwscas48704.2020.9184662. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/9184662. [Accessed: 13-Jan-2021]
[7]
“US20200264901A1 - Configuring programmable logic region via programmable network - Google Patents,” Google.com, 14-Feb-2019. [Online]. Available: https://patents.google.com/patent/US20200264901A1/en. [Accessed: 13-Jan-2021]
[8]
“US20200336588A1 - Device logic enhancement for network-based robocall blocking - Google Patents,” Google.com, 19-Apr-2019. [Online]. Available: https://patents.google.com/patent/US20200336588A1/en. [Accessed: 13-Jan-2021]
[9]
“A comparative analysis of surface roughness in robot spray painting using nano paint by Taguchi – fuzzy logic-neural network methods,” Australian Journal of Mechanical Engineering, 2020. [Online]. Available: https://www.tandfonline.com/doi/abs/10.1080/14484846.2020.1842157. [Accessed: 13-Jan-2021]
Case Study
DATA4000 Introduction to Business Analytics Assignment Sample
Assignment Brief
Word Count - 2000 Words (+/-10%)
Weighting - 30 %
Total Marks - 30
Submission: via Turnitin
Due Date - Monday Week 5, 23:55pm AEDT
Your Task
Complete Parts A to C below by the due date. Consider the rubric at the end of the assignment guidance on structure and content.
Assessment Description
• You are to read case studies provided and answer questions in relation to the content, analytics theory and potential analytics professionals required for solving the business problems at hand.
• Learning outcomes 1 and 2 are addressed.
Assessment Instructions for assignment help
Part A: Case Study Analysis (700 words, 10 marks)
Instructions: Read the following two case studies. For each case study, briefly describe:
a) The industry to which analytics has been applied
b) A potential and meaningful business problem to be solved
c) The type of analytics used, and how it was used to address that potential and meaningful business problem
d) The main challenge(s) of using this type of analytics to achieve your business objective (from part b)
e) Recommendations regarding how to be assist stakeholders with adapting these applications
for their business.
1. Artificial Intelligence in Germany: Reinventing Engines of Growth
https://www.bernardmarr.com/default.asp?contentID=2141
2. GE Power: Big Data, Machine learning and ‘The Internet of Energy’
https://www.bernardmarr.com/default.asp?contentID=1226
Part B: The Role of Analytics in Solving Business Problems (500 words, 8 marks)
Instructions: Describe two different types of analytics (from Workshop 1) and evaluate how each could be used as part of a solution to a business problem with reference to ONE real-world case study of your own choosing. You will need to conduct independent research and consult resources provided in the subject.
Part C: Developing and Sourcing Analytics Capabilities (800 words, 12 marks)
Instructions: You are the Chief Analytics Officer for a large multinational corporation in the communications sector with operations that span South East Asia and Latin America. The organization is undergoing significant transformations; it is scaling back operations in existing low revenue segments and ramping up investments in next generation products and services - 5G, cloud computing and Software as a Service (SaaS). The business is keen to develop its data and analytics capabilities. This includes using technology for product innovation and for developing a large contingent of knowledge workers.
To prepare management for these changes, you have been asked review Accenture’s report
(see link below) and publish a short report of your own that addresses the following key points:
1. How do we best ingrain analytics into our decision-making processes?
2. How do we organize and coordinate analytics capabilities across the organization?
3. How should we source, train and deploy analytics talent?
To help you draft this report, you should review the following working paper from Accenture:
https://www.accenture.com/us-en/~/media/accenture/conversion-
assets/dotcom/documents/global/pdf/industries_2/accenture-building-analytics-driven-
organization.pdf
The report is prepared for senior management and the board of directors. It must reflect the needs of your organization and the sector you operate in (communications).
Solution
Part A: Case Study Analysis
A. The industry in which analytics has been used
The case studies concern themselves in two different aspects of analytics. The case study named 'Artificial Intelligence in Germany: Reinventing Engines of Growth' deals with the artificial intelligence analytic. Another case study named GE Power: Big Data, Machine learning, and 'The Internet of Energy' is related to block chain analytic. In the case study concerning artificial intelligence, several industries are introduced to use artificial intelligence analytics. Germany introduced AI in its traditional businesses at first. Company Otto, a giant E-commerce company, uses AI for analytics implementation (Marr 2020a). Another company Zalando, an E-tailer organization, uses AI for the performance management of the machines. Germany's largest railway infrastructure provider company Siemens AG uses AI for its railway infrastructure analysis (Marr 2020a).
Moreover, the automobile companies such as BMW and Daimler also use AI technology in their autonomous vehicles. Allianz Insurance company utilizes AI analytics (Marr 2020a). Also, Braun uses AI in its digital toothbrush making, where the AI technology will help to implement proper ways to brush the teeth. Media Conglomerate Bertelsmann hosted AI for solving data and AI challenges in business (Marr 2020a). Another case study related to block chain analytics targets the health care industry to solve the issues in operational management (Marr 2020b). MedRec uses block chains to improve electronic medical records, allowing patients' information to be accessed securely (Marr 2020b).
B. The potential and meaningful business problem to be solved
The possible and potential issues can be solved through strengthening AI research, using a competitive market to drive innovation for encouraging SMEs to use AI in business structure. The e-commerce company Otto has the problem of product returns in its online commerce market (Marr 2020a). Zalando has been facing the issue of fraudulence in the e-tailer system. Siemens AG wants to avoid the issues of delay in trains arrival. To promote reliability and accuracy is the target. BMW and Daimler are facing issues in traditional man-driven vehicles. For operational efficacy improvement, Allianz Insurance uses AI (Marr 2020a). Bruan targets healthy habit which is reasonably related to clinical activities to prevent teeth problems. Bertelsmann has faced challenges in business. The case study concerning block chain analytics corresponds to various issues related to health information. The case study shows around 140 million patient's records have been breached between 2015 to 2016 as per the report of the Protenus Breach Barometer (Marr 2020b). IT architecture is struggling to secure systems. It becomes an issue to generate and record data in disparate systems through any human. Medicare fraud is also an issue. They reduce the counterfeit drug application costs high to pharmaceutical companies, which have created a loss of $200 million (Marr 2020b). The issues such as waste of time, duplication in process, money, confusion, and life-threatening are related to MediRec.
C. The type of analytics used and how it was used to address that potential and meaningful business problem
Artificial intelligence and blockchains are the analytics used. Germany introduced AI to solve the operational issues related to products and services (Marr 2020a). The government wants to become one of the leaders of global technology. For that, business organisations in Germany focus on quality over quantity as the competition relating to AI technology is high in the global market. AI can benefit the citizens in Germany to experience a high level of IT security. For that, AI technology must be implemented legally and ethically. Otto uses algorithm processes in online activities to decrease product returns (Marr 2020a). Zalando uses AI to prevent fraud in the e-tailer system. The automobile vehicle companies BMW and Daimler use AI to produce autonomous vehicles to solve the prevalent issue. Bertelsmann uses AI to develop intelligent solutions to avoid possible issues in business (Marr 2020a). The teams focused on various tasks such as voice-controlled search functions, automated podcasts, listening recommendations. Higher privacy and security provision are agendas to use block chain analytics (Marr 2020b). Block chain infrastructure can be a possible solution to minimize the risk of patient record breaching. Block chain helps to disparate the systems for future treatment. Reducing the counterfeit drug application costs high to pharmaceutical companies can be managed through block chain (Marr 2020b). To deal with the issues such as waste of time, duplication in process, money, confusion, and life-threatening issue, MediRec applied block chain (Marr 2020b).
D. The main challenges in using the analytics to achieve business objective
The challenges concerning utilizing analytics such as artificial intelligence and block chain to achieve the business goal can be customer dissatisfaction, driver downtime, and reducing maintenance costs. Moreover, the issues regarding data security and privacy are a significant concern in both AI and Block chain. Artificial intelligence helps in securing the system from fraudulent transactions, but the barrier is to handle the system. For that, organisations need to hire IT experts, which will make the organisations bear additional costs. Kroger, while using artificial intelligence to Restock Krogers, can face significant challenges. Among them, data security while the transaction is a significant issue.
Furthermore, record tracking, sharing, assigning, and linking can be faced while using the blockchain analytic. For instance, Meta Capital has been facing challenges while implementing the blockchain technology in partnership channel with ConsenSys Config. Blockchain is used to reduce delay in banking sectors, but the cost of blockchain operation is high.
E. Recommendations regarding stakeholders’ assistance
Managing the business objective through using analytics needs to assist the stakeholders about application adaptation.
• Training regarding analytics such as artificial intelligence and blockchain is a must for the stakeholders.
• The stakeholders need to engage themselves with IT experts to know the system management through analytics.
• Discussion regarding the aim or objective with the stakeholders through meetings and conferences can be practical.
• The stakeholders need to know about the transformations after implementing the analytics in the system.
• Awareness must be created regarding the need for innovation to achieve organizational success.
• Training regarding privacy and security maintenance must be given to the stakeholders while operating through analytics.
Part B: The Role of Analytics in solving Business Problem
Analytics has immense contribution to business due to its ability in identifying problems and providing new opportunities to solve these problems. Analytics not only help in making business decisions but also in identifying opportunities to engage a more significant number of customers. In the case of Artificial intelligence, it is used to make a market survey and identify customer requirements by trend analysis. The critical business decisions regarding the product that needs to be more highlighted or updated and suggesting the products according to customer needs are made through artificial intelligence. Business analytics is also helpful in dealing with logistics issues where several shipping companies use analytics to keep track of their fleet. The sensor devices will help diagnose the problem in parts of the ship, which will reduce maintenance cost, driver downtime and customer dissatisfaction. Predictions related to internal problems within the organization can be solved through predictive analytics that helps in identifying the issues, predict what will happen in future through past data and make suggestions or recommendations accordingly (Michigan state university online 2020). Artificial Intelligence is making its mark in business organizations for dealing with issues like data security and fraudulent transactions for giving more safe and secured solutions in the business.
Nowadays, many online transactions occur through mobile phones using the internet, where personal data is shared constantly. Kroger using Artificial Intelligence in their initiative Restock Kroger where the shoppers are allowed to scan groceries through their smartphone using AI. They have also planned for an autonomous vehicle for delivery in partnership with Nuro, Silicon Valley Company. They are also planning to have robotics in their operations to design an automated warehouse where robots using Machine learning algorithm can select products for delivery from warehouses. Using smart shelves technology, customers will be given suggestions based on their choice and price demands. Machine learning will help in the deployment of several models without human interventions (Bernardmarr 2020). The data transfer process is speedy, and companies face a massive challenge in dealing with the security problem. Using Artificial Intelligence, the process of transaction scanning for potential fraud detection takes place at a fast rate, making the system more secure. Block chain technology is used in supply chain management where asset recording, tracking, sharing, assigning and linking makes it efficient, giving more transparency and better protection at every step. For example, Mata Capital has partnered with ConsenSys Config to leverage its assets by introducing security tokens using block chain technology. It has helped in better dealing with customer requirements, cost befits, more security in transactions, and business expansion to a new class of investors (Consensys 2020). block chain is used in several banking sectors to assist in cross-border transactions and reduce delay. The processing taking place in real-time ensures more security and restricts any securing them from any modifications. Data security is also a significant issue in the business where the personal data of customers and sensitive information of organizations are stored in large databases, which is prone to any security breach and malicious attack. Blockchain-enabled security systems are more effective as any attack has done to blockchain-based data storage will be fatal, and there is no way of tampering or stealing the data (Goodfirms 2021).
Part C: Developing and Sourcing Analytics Capabilities
1. As a chief analytics officer in the communication sector, it can be asserted that including analytics in the decision-making process is significant, which helps to manage the service changes. For infusing analytics in the decision-making process, CPG leaders addressed the business issues initially and then defined the data (Hernandez, Berkey & Bhattacharya 2013). After this process, they reengineer decisions for result analysis and insight. CPG focuses upon rare skill development for ingraining analytics into decision-making processes. The cross-functional process is also effective as it helps the business produces a greater return to analytics capabilities. It also enhances the price, promotion, and assortment efficiency. CPG enhances speed and end-to-end process assessment in decision making, which helps to infuse analytics in business decision making. In the decision-making process, changes for enhanced performance need fact-based discussion and action in brand marketing, field sales, supply chain, and sales planning. Reengineering the decision-making process in business will help to function the analytics-driven process in business. Analytics promote quicker decision-making abilities. Also, the organisations have to analyze their ability to manage the reengineering process. For example, P&G company uses data-driven culture and innovative tools like the business sphere to infuse analytics in the decision-making process (Hernandez, Berkey & Bhattacharya 2013).
Conducting an analytics diagnosis process will help to identify the type of insight needed and also determines who and when will develop the insight so that timely delivery can be possible. Organizational changes that enhance the value of Analytics and visibility are also required. Consistent and deliberate typing strategies and tactics will generate insights from Analytics. Analytics services aim to reach enterprise business goals which involve the prioritizing process.
2. Managing transformation in business due to technological inclusion needs to have organization and coordination analytics capabilities across the organization. The closest positioning to decision making and delivering the most value includes analytics insight development. Organisations construct and allocate resources based on business needs and maturity. Managing supply and demand for analytics services across the business is crucial. The fundamental organizational issues such as sponsorship, leadership, funding, and governance are addressed to extract value from analytics (Hernandez, Berkey & Bhattacharya 2013). For maintaining the balance of demand and supply, sponsorship helps to create benefits of analytics to whip up energy and confidence. The view of enterprise helps in making required decisions that benefit the organization. The ultimate objective of the sponsor is to accelerate adoption and buy-in within the organization. Sponsors need to be an astute leader in breaking the cultural barriers to disseminate data widely.
The leadership in organisations creates a considerable impact on the coordination of analytics capabilities. Analytics leaders encourage vision regarding the capabilities of them the organization in holding people accountable for the result. The leader has to build analytics capability in culture and improves the decision-making process. Funding comes from various sources or functions. In proportion, function puts on priority upon Analytics. The funding promotes the capabilities of analytics. It increases simultaneously with the proportion of analytics in the organization. Funding in organisations would signify the strategic value of Analytics which generates, preserving the point of migrating to a pay-to-play model (Hernandez, Berkey & Bhattacharya 2013). The pay-to-play model creates the ability for the functional executives for integrating Analytics insight development into business decisions. Due to the increment in adoption, resources become more appropriate.
Governance involves the ownership of analytics and the capability to manage demand and supply. Different roles and responsibilities correlate with the governance structure. The initial considerations involve the maturity of analytics capabilities, priorities of the organization, and the need to balance demand and supply. The centralizing model helps to grow demands for analytics. The Federated model also works when there is high demand in analytics, including the SWAT team to manage complex cross-functional decisions. (Hernandez, Berkey & Bhattacharya 2013) Governance reduced duplication KPIs establishment is done for the central and dispersed teams. Finally, Analytics resources provide capability development opportunities. Stakeholders' engagement in the analytics process is also significant for supply and demand management. Management of demand helps to identify, prioritise and service the highest value opportunities.
3. Sourcing, training, and deploying analytics talent includes several aspects regarding talent management. The seven components used to shape an appropriate operating model are sponsorship and governance, organizational structure and talent management, data of insights, capability development, Insight-driven decision, outcome measurements, and information and data management. Organisations for understanding the talent needs will use analytical skills. In that case, an analyst is needed who will understand the distribution network. CPG companies tend to have talent in descriptive Analytics (Hernandez, Berkey & Bhattacharya 2013). The company needs to generate predictive and prescriptive insights. Talent sourcing is another aspect that can be done in a variety of ways. The public-private partnership is effective in resourcing as universities like MIT invest in data science degree programs for talent sourcing. Even Google, Microsoft, and Amazon are supporting the programs related to Analytics for talent sourcing. Alternative arrangements can provide a dedicated capacity of analytics talent (Hernandez, Berkey & Bhattacharya 2013). Flexibility and capacity promote lower costs in comparison to the internal hiring process. Capacity development involves business skills to remain relevant with strategic management. It also includes executive-level skills. Ability to manipulate, find and interpret and manage the data help in developing capacity. Talent management requires a new approach beyond the standard career improvement. For instance, CGP needs to work hard to create a path that will retain the analytics talent.
References
Bernardmarr 2020, Kroger: How This U.S. Retail Giant Is Using AI And Robots To Prepare For The 4th Industrial Revolution, viewed 19 April 2021, <https://bernardmarr.com/default.asp?contentID=1537>.
Consensys 2020, Codefi Case Study Download: Mata Capital, viewed 19 April 2021, <https://pages.consensys.net/codefi-mata-capital-case-study>.
Goodfirms 2021, ‘Top 10 Problems that Blockchain Solves’, viewed 19 April 2021, <https://www.goodfirms.co/blog/problems-blockchain-solves#:~:text=One%20thing%20is%20certain%20now,charity%2C%20voting%2C%20and%20crowdfunding>.
Hernandez, J, Berkey, B & Bhattacharya, R 2013, Building-analytics-driven-organization. viewed 19 April 2021, <https://www.accenture.com/us-en/~/media/accenture/conversion-assets/dotcom/documents/global/pdf/industries_2/accenture-building-analytics-driven-organization.pdf>.
Marr, B 2020a, Artificial Intelligence In Germany, viewed 19 April 2021, <https://www.bernardmarr.com/default.asp?contentID=2141>.
Marr, B 2020b, This Is Why Blockchains Will Transform Healthcare, viewed 19 April 2021, <https://www.bernardmarr.com/default.asp?contentID=1226>.
Michigan state university online 2020, How Business Analytics Can Help Your Business, viewed 19 April 2021, <https://www.michiganstateuniversityonline.com/resources/business-analytics/how-business-analytics-can-help-your-business/>.
Research
MIS609 Data Management and Analytics Assignment Sample
Assignment Brief
Individual/Group - Individual
Length - 1500 words (+/- 10%)
Learning Outcomes:
The Subject Learning Outcomes demonstrated by successful completion of the task below include:
a) Demonstrate an understanding of the broad concepts of data management.
b) Demonstrate how to manage data within organizations, teams and projects. Investigate techniques on how to collect, store, clean and manipulate data.
c) Explore data management techniques and apply when and where applicable.
e) Effectively report and communicate findings to a business audience who are not necessarily IT professionals.
Submission - Due by 11:55pm AEST/AEDT Sunday end of Module 2.2.
Weighting - 25%
Total Marks – 100
Task Summary
For this assignment, you are required to write a 1500-word report proposing data management solutions for the organization presented in the case scenario.
Context
Module 1 and 2 explored the fundamentals of data management. This assignment gives you the opportunity to make use of these concepts and propose a data management solution (a pre proposal) for the organization presented in the case scenario. This assessment is largely inspired from Data Management Maturity (DMM)SM Model by CMMI (Capability Maturity Model Integration).
Task Instructions
1. For assignment help, please read the attached case scenario.
2. Write a 1500-word data management pre-proposal for the organization.
3. The pre-proposal should not only discuss the technical but also the managerial aspects (cost, manpower, resources, etc.). Please keep in mind that you are writing a pre-proposal and not a detailed proposal.
4. Please ensure that you remain objective when writing the pre-proposal.
5. You are strongly advised to read the rubric, which is an evaluation guide with criteria for grading your assignment. This will give you a clear picture of what a successful pre-proposal looks like.
Referencing
It is essential that you use appropriate APA style for citing and referencing research. Please see more information on referencing here: http://library.laureate.net.au/research_skills/referencing
Submission Instructions
Submit Assessment 1 via the Assessment link in the main navigation menu in MIS609 Data
Management and Analytics. The Learning Facilitator will provide feedback via the Grade Centre
in the LMS portal. Feedback can be viewed in My Grades.
Case Scenario
You are a Business Development Manager in a large Information System Support organization that provides data management solution for various clients in Australia. Your organization enjoys a very good repute for its services and is rated exceptionally well in the business community.
You are tasked by your supervisor, Vince Sutter, the president of the organization, and your direct supervisor, to write a service proposal for a new client. The new client of your organization is potentially a large private school that offers online schooling services to students who are at remote locations. This school has almost 2300 registered students from all over Australia from Year 1 to 10. Like your organization, this school also enjoys a very good reputation and is ranked as one of the best online schools based on the students’ and parents’ feedback.
John Brown, the school principal, is a forward-thinking man. He wants to ensure that the school should optimize its operations and keep improving in every way possible. Given the fact that the school has a large number of students and it is continually growing as a market leader, John Brown sees an opportunity for improvement. Brown now wishes that the school staff would focus more and more on learning and teaching, which is the core function of the school. To generate better focus, he and the school’s Board of Directors opt for managed services. They plan to outsource the school’s data management function to a reputed organization that is capable of managing the school’s data. Brown searches for a data management company and comes across your organization. He meets Vince Sutter and asks him to submit a pre-proposal for the school’s complete data management.
Solution
Introduction
The Business Development Manager holds the responsibility of preparing this pre-proposal report as they need to provide optimum data management solutions. This organisation is looking forward to working with the next potential client, which is a large private school well known for its actions so that online education in the distant locations of Australia can be included as well. This pre-proposal report is going to discuss both the technical aspects as well as the managerial aspects like cost, resources etc. This paper shall state the strategy which will help in management and communication of data to meet project objectives. The data of the school that the organisation will have to handle will also need effective ways of management and that will also be discussed in the report.
Aim and Objectives
The aim of this pre-proposal report is to find and analyse certain data management solutions and decide the most effective approach towards managing the data of the large private school, which is the next potential client of the organisation.
? To promote online education in the remote areas of Australia, and thus it is in the best interest of the organisation to get into business with the school as soon as possible.
? Both the Information System Support Organisation and the large private school have quite good reputations and thus keeping the reputations intact is also an objective for the parties and must be kept in mind while planning the project.
? To discuss in detail, the solution that is best suited to the needs of the school and will also have the objective to find out and analyse what improvements can be made in the selected solution.
Project background
The project will address the organisation’s need to find an effective data management solution for the data of the large private school. This will also require the organisation to have a solid project plan which will also be addressed in this pre-proposal. Both the organisation and the school have their reputations to uphold too, so it is of utmost importance that the project be mindful of the quality of the deliverables as well as the deadline.
The Information System Support Organisation must devise a concrete project plan so that the data management system can be efficiently implemented. The school has a total of 2300 registered students from various regions of Australia, and thus the organisation needs to keep in mind the quantity of data to handle and also need to be mindful of the regulations of the various regions (Lacy-Jones et al., 2017).
The project will also need to have a brief idea of what solution the organisation wants to implement before collecting and analysing data on various systems so that they can be compared to find the best suited system to the needs of the large private school (Yang, Zheng & Tang, 2017). For ensuring transparency in the project, the data management plan needs to provide the exact methods and avoid confusion while implementation of the project.
The project plan must aim at establishing and implementing an efficient and effective data management system which will be best suited for the purposes of the large private school. The project must also analyse what are the defects in the system that can be improved further so that the systems of data management can also be improved.
Methodology
(a) The data management strategy to be used would depend on the objectives of the school and would need strong data processes to be created. It will also require to search for the best technology and to establish governance on the collected data so that privacy can be protected. Finally, it should also include the proper training of the staff of the school so that they possess basic knowledge on how to use the implemented system (Chen, Lv & Song, 2019). Only after proper training has been done can the implemented system be properly executed.
(b) One of the main methods of data communication is through parallel transmission. The parallel transmission shall prove beneficial as it can transmit multiple bits of data simultaneously through different mediums.
(c) An estimate of ten people would form a specialized team which would manage the data of this school. This team would have the staff who had the experience of installing the system thus making it easier for them to communicate with the school (Babar et al., 2019). All the team members will report to the project manager, who will in turn report everything to the president of the organisation, Vince Sutter.
(d) The organisation will manage the general personal information (like names, emergency contact numbers, blood group, date of birth, etc.) of all the 2300 registered students as well as that of the staff of the school. The organisation intends to manage the entirety of the provided data by implementing an effective data management strategy as mentioned in the former part of this subheading.
(e) The school would need to provide resources like working computers and a working and strong enough network connection in the school for administrative and database related activities.
(h) The data management policy would be set by addressing the policy of operation with its focus on managing and governing the assets of the data collected. This policy will be implemented by forming a specific team within the organisation which is filled with people experts on the policy, so that they can effectively and efficiently implement the data management policy and so that they can also communicate the necessary details to the staff of the school.
(i) Tools like Talend Metadata Manager are best examples of ways to manage the metadata.
(j) Having an efficient structure of organisation, a precise definition of what to expect in the aspect of data quality, implementation of audit processes of data profiling and finally correcting errors will help the organisation to manage the quality of the data.
(k) Questions like whether the implemented system is being used to its maximum potential can be answered effectively by implementing a data management audit. The quality of the data can be assessed by comparing it against meta-data.
(l) The organisation also needs to have an open hotline and an online customer service for their client, i.e. the large private school so that they can state any other requirements or queries that they may have.
(m) Cloud model DAMA-DMBOK 2 can be regarded as one of the best techniques that would meet the needs of the school’s data management system.
(n) Legacy data would be taken care of by evaluating the inventory of the applications provided and by identifying the redundancies in them.
Results and analysis
(f) The project aims at delivering a fully working data management system capable of handling the information of all the 2300 students plus the staff of the school. The organisation will also aim to deliver an expert team to be present on the spot to check the safe delivery of the deliverables. One of the innovative ways for better data management operations is to offer a cloud environment (Jia et al., 2019).
(g) The organisation also aims to provide an expert team to guide and train the staff of the school so that they can become self-sufficient in the general data management operations.
(q) There are many threats involved in the data management process and has to be well managed by the expert system. There are risks involved with confidentiality and privacy that has to be managed by the experts in IT (Zheng et al., 2018). (o and p) The school will get benefits like the presence of experts to guide and instruct the staff of the school and to manage any risks that may occur otherwise. The school might also face certain challenges after the installation of the system. These challenges can be the risk of losing data, the risk of technical errors which can hinder the process of education which is the primary aim of the school.
Conclusion and Recommendations
In order to conclude this pre-proposal report, it is seen that the organisation needs to provide an efficient data management system to a large private school who are hoping to increase the rates of education in the remote areas of Australia through online education. It is also seen that to provide the data management system according to the requirements of the school will require the preparation of a detailed and properly analysed project plan (Mokhtar & Eltoweissy, 2017). The project plan needs to address data quality management, legacy data and various other issues.
As seen from this pre-proposal report, certain recommendations can be made like, although the data architecture and framework can be easily decided and confirmed for the needs of the school, there are always advances in technology, which need to be kept in mind and implemented in the data management system of the school as and when required.
Reference list
Babar, M., Arif, F., Jan, M. A., Tan, Z., & Khan, F. (2019). Urban data management system: towards big data analytics for internet of things based smart urban environment using customized hadoop. Future Generation Computer Systems, 96, 398–409. https://doi.org/10.1016/j.future.2019.02.035
Chen, J., Lv, Z., & Song, H. (2019). Design of personnel big data management system based on blockchain. Future Generation Computer Systems, 101, 1122–1129. https://doi.org/10.1016/j.future.2019.07.037
Jia, K., Guo, G., Xiao, J., Zhou, H., Wang, Z., & He, G. (2019). Data compression approach for the home energy management system. Applied Energy, 247, 643–656. https://doi.org/10.1016/j.apenergy.2019.04.078
Lacy-Jones, K., Hayward, P., Andrews, S., Gledhill, I., McAllister, M., Abrahamsson, B., … Pepin, X. (2017).
Biopharmaceutics data management system for anonymised data sharing and curation: first application with orbito imi project. Computer Methods and Programs in Biomedicine, 140, 29–44. https://doi.org/10.1016/j.cmpb.2016.11.006
Mokhtar, B., & Eltoweissy, M. (2017). Big data and semantics management system for computer networks. Ad Hoc Networks, 57, 32–51. https://doi.org/10.1016/j.adhoc.2016.06.013
Yang, Y., Zheng, X., & Tang, C. (2017). Lightweight distributed secure data management system for health internet of things. Journal of Network and Computer Applications, 89, 26–37. https://doi.org/10.1016/j.jnca.2016.11.017
Zheng, W., Liu, Q., Zhang, M., Wan, K., Hu, F., & Yu, K. (2018). J-text distributed data storage and management system. Fusion Engineering and Design, 129, 207–213. https://doi.org/10.1016/j.fusengdes.2018.02.058
Link followed for format of pre proposal:
https://ethz.ch/content/dam/ethz/main/education/finanzielles/files-de/Guidelines_Preproposal.pdf
Research
MITS5501 Software Quality, Change Management and Testing Assignment Sample
IT - Research Report Assignment 2
Assignment Brief
Objective(s)
This assessment item relates to the unit learning outcomes as in the unit descriptor. This assessment is designed to improve student presentation skills and to give students experience in researching a topic relevant to the Unit of Study subject matter.
INSTRUCTIONS
For assignment help, in assignment 1 you were required to do a 10-13 minutes’ presentation on a recent academic paper on on Software Quality, Software Change Management or Software Testing.
Assignment 2 requires writing a report or critique on the paper that you chose in Assignment 1 to Presentation and Participation component above.
Your report should be limited to approx. 1500 words (not including references). Use 1.5 spacing with a 12-point Times New Roman font. Though your paper will largely be based on the chosen article, you should use other sources to support your discussion or the chosen papers premises.
Citation of sources is mandatory and must be in the IEEE style.
Your report or critique must include:
Title Page: The title of the assessment, the name of the paper you are reporting on and its authors, and your name and student ID.
Introduction: Identification of the paper you are critiquing/ reviewing, a statement of the purpose for your report and a brief outline of how you will discuss the selected article (one or two paragraphs).
Body of Report: Describe the intention and content of the article. If it is a research report, discuss the research method (survey, case study, observation, experiment, or other method) and findings. Comment on problems or issues highlighted by the authors. Report on results discussed and discuss the conclusions of the article and how they are relevant to the topics of this Unit of Study.
Conclusion: A summary of the points you have made in the body of the paper. The conclusion should not introduce any ‘new’ material that was not discussed in the body of the paper. (One or two paragraphs)
References: A list of sources used in your text. They should be listed alphabetically by (first) author’s family name. Follow the IEEE style.
The footer must include your name, student ID, and page number.
Note: Reports submitted on papers that are not approved or not the approved paper registered for the student will not be graded and attract a zero (0) grades.
What to Submit
Submit your report to the Moodle drop-box for Assignment 2. Note that this will be a turn- it-in drop box and as such you will be provided with a similarity score. This will be taken into account when grading the assignment. Note that incidents of plagiarism will be penalized. If your similarity score is high you can re-submit your report, but resubmissions are only allowed up to the due date. If you submit your assignment after the due date
and time re-submissions will not be allowed.
Note: All work is due by the end of session 9. Late submissions will be penalized at the rate of 10% per day including weekends.
On Time Days Late _______Turn-it-in Similarity % _______
Solution
Introduction
The purpose of this report is to critically review the academic article identified in assessment-1. The chosen academic paper is on “AZ-model of software requirements and change management in global software development” which belongs to the course unit: “Software quality and Change Management”.
It has been possible for an individual researcher to discuss the selected article in following sections: Reviewing the Literature Survey; Critically reviewing the Proposed AZ-model; Undertaking a research method to collect data, information relevant to the topic; Discussion based upon the results and finally find the outcomes of the research report.
Literature Survey
This section is one of the major parts of this research report. Here, the researcher critically reviews the chosen academic paper and compares it with other similar papers.
Review of the Chosen Academic Paper
This paper indicates information about Requirements Change Management (RCM) and Global Software Development (GSD). Due to the lack of information communication, changes of customers’ demands, changes in management strategies might be required. With a centralised software development system, an organisation can improve its poor requirements management [7]. This literature is a proposed study of the AZ-model which has been explored through RCM & data collection process. Use of tools, technologies have been preferred here with various methods and tactics.
Comparison Literature I: Empirical investigation of barriers improvement in GSD
According to ([7]), this paper supports the chosen academic article and provides information for critical review. Capability Maturity Model Integration (CMMI) has been represented here with Initiating (I), Diagnosing (D), Establishing (E), Acting (A), and Learning (L)- IDEAL approach. During the research and review, Software Process Improvement Capability Determination (SPICE) has been recommended.
This research is a key context of supply chain management (SCM) which is a process improvement activity for GSD context. Planning, Conducting, and Reporting are the three phases of this research paper that added value to the software development model [7].
Comparison Literature II: Use of RE Tools in Global Software Engineering
As per the ideas of ([8]), this paper indicates requirements engineering (RE) tools for GSD. To support the literature survey of the chosen paper, this paper has been valued. In this study, the concept of Global Software Engineering (GSE) was also introduced. The objective of the paper is to support the chosen academic article with the concepts addressed in a different perspective. In the global software development market, the demand for changing the environment is high. Thus, evolving RE tools in GSD is an important aspect [2].
On the other hand, as per the International standard of software development, to achieve the effectiveness in requirements management, following steps to be followed which are: Change proposal, Review, Approval, Change notification. To change the market requirements as per the customers’ demand is a necessary and standard guideline for GSE [8].
Research Methodology
To continue with the research paper review, research methodology has been determined as a major section/part of the assessment [1]. In order to achieve the research problem and project objectives, it has been possible for the researcher to set research questions (RQs) and try to solve this by the end of this section.
? RQ1: How to propose the AZ-model of software requirements?
? RQ2: What is change management in GSD?
? RQ3: Which types of research methods seem suitable for this paper?
? RQ4: How to address the literature concept and analyse the data based on results?
To solve these RQs and propose the AZ-model of RCM in GSD, secondary data has been collected. The data are relevant to the research topic phase and sufficient to implement the AZ-model [2].
Collection of Data
Data collected in the form of questionnaire & survey [3]. Use of lightweight software development methodology in favour of heavyweight software development methodology has been proposed here. With the help of a project management research method, the AZ-model of RCM can be implemented. Moreover, Project manager is engaged to carry out development activities of the proposed AZ-model. Considering the Project management factor, it has been possible to set survey questions and answer accordingly.
Based on the perspective of ([7]), Software Development Methodology (SDM) refers to this AZ-model and is applied to collect data from survey respondents.
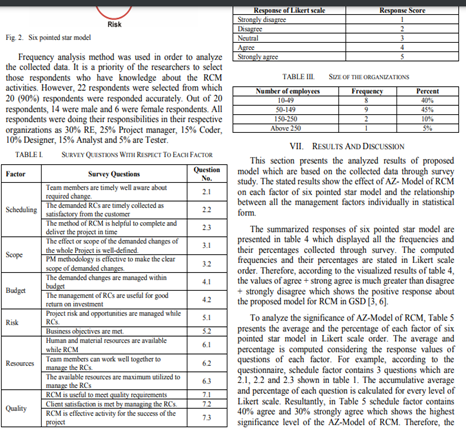
Figure 1: Sample Collected Data
Proposed Model
In this section, researchers are going to propose a model based on the empirical study and questionnaire survey [4]. Delay of one site effects in the proposed model implemented in six different areas of project management. Moreover, a six-pointed star model has been introduced here based on the guideline of Project Management Body of Knowledge (PMBoK).
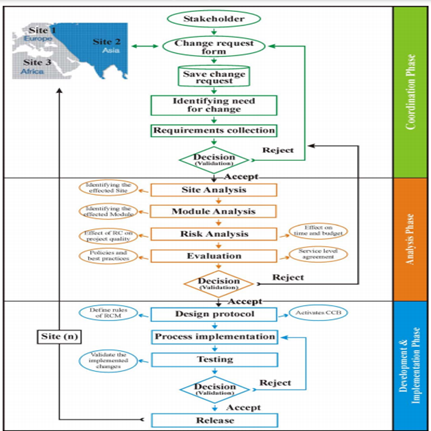
Figure 2: Proposed AZ-model of RCM
(Source: [7])
Findings and Analysis
From the collected database, it has been observed that, AZ-model can be implemented successfully if the GSD and PMBoK requirements have been fulfilled. The major findings of this academic paper are as follows:
? Workflow and Change Management
It is an important category that has been featured for global software development. In the case of GSD, high-awareness among the team is required for effective communication and model implementation [5]. However, multiple user access and collaborative life cycle management are the key approaches of software development and meeting change requirements. Regarding this, collaborative life cycle management and global stakeholder collaboration has been prioritised.
? System and Data Integration
In this case, the AZ-model framework can be implemented considering data import, data export and tool integration. System and data integration category focuses on the data collection & resources, RE and proposed AZ model [6].
? Shared Knowledge Management
The selected academic paper is useful for supporting stakeholders’ decisions, multiple user access and collaborative life cycle management. On the other end, for GSD it is necessary to introduce global stakeholders’ collaboration.
? Traceability
This is an important category featured by the GSD [1]. Flexible tracing, bi-directional tracing and traceability analysis are the key aspects of the AZ-model implementation and software development. Throughout the implemented software development lifecycle traceability seems to be a vital resource factor.
Issues addressed
While conducting systematic literature review (SLR) of the chosen article, several issues/barriers have been addressed [2]. Due to lack of organisational support and lower level of management, sometimes software development and change management has not been possible. Moreover, during the AZ-model implementation, non-availability of sufficient resources could be a major issue. Lack of client management support, lack of awareness towards the change management environment badly impacted on the GSD attributes.
Due to communication difficulties with the stakeholders the software requirements and change management may lead to misinterpretation [3]. Vital issues with the AZ-model implementation are popularly known as cross-cultural barriers among GSD organisations. Furthermore, an individual researcher faces lack of resources while reviewing this academic paper which is also a barrier. PMs were hesitant to allocate proper budget, financial support in terms of implementing the AZ-model.
Results and Discussions
This section shows the results of the proposed model and collected data in statistical form. Summarizing the data and relevant results of the six-pointed star model is the main objective of this part [4]. Researchers are prioritising the literature survey responses and evaluating the responses. To analyse the significance of the AZ-model, it is necessary to value the average, higher, and low percentage of the results from survey responses. Moreover, the evaluation criteria with the RE tool shows the performance features of the AZ-model. To analyse the results and discuss the relevant factors, a shared knowledge management and investigation method has been applied [7].
It has been possible for an individual researcher to identify and evaluate the outstanding score (CFI) from the collected database. However, in order to address the RQs, issues to be resolved on an immediate basis. On the other hand, while executing the GSD and change requirements for AZ-model, the survey data (positive/ negative/ neutral responses) are valued [5]. Significant differences observed during analysis of the results from the collected database. Categorizing the issues in a robust framework has also been valued for software process improvements. Demonstrating the Likert-scale value from the SLR exhibits in the form of results. Last, but not the least, from the proposed AZ-model and analysing the critical barriers researchers are able to modify the framework as per requirement [7].
Conclusion
After critically reviewing this academic article, how most of the software development organisations get facilities of AZ-model can be observed. Moreover, how this model can be useful in future work has also been understood from this academic paper. This paper demonstrates the key issues of AZ-model implementation and recommended for client & vendor management. How the RE tools become an advantage of GSD and AZ-model implementation has been analysed from this study [8].
In the future, global software management seems to be relevant for AZ-model implementation and featuring the gaps identified during the process improvement. Supporting features of GSD may be unsoundly obtained for the system integration part. Finally, not yet importantly, this paper provides ideas of traceability, software development, collaboration with the stakeholders and communicating with them for the next stage of change management in software industries.
References
[1] A.A. Khan, J. Keung, M. Niazi, S. Hussain and A. Ahmad, “Systematic literature review and empirical investigation of barriers to process improvement in global software development: Client–vendor perspective”, Information and Software Technology, vol. 87, pp.180-205, 2017. Accessed on: July 30, 2021. [Online]. Available: https://www.researchgate.net/profile/Arif-Khan23/publication/315382990_Systematic_Literature_Review_and_Empirical_Investigation_of_Barriers_to_Process_Improvement_in_Global_Software_Development_Client-_Vendor_Perspective/links/5b4d651ea6fdcc8dae246cc7/Systematic-Literature-Review-and-Empirical-Investigation-of-Barriers-to-Process-Improvement-in-Global-Software-Development-Client-Vendor-Perspective.pdf
[2] C. Djoweini, “The driven parameters of Software Development Projects”, 2019. Accessed on: July 31, 2021. [Online]. Available: https://www.diva-portal.org/smash/get/diva2:1371926/FULLTEXT01.pdf
[3] E. Serna, O. Bachiller and A. Serna, “Knowledge meaning and management in requirements engineering” International Journal of Information Management, vol. 37, no. 3, pp.155-161, 2017. Accessed on: July 31, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0268401216306582
[4] J. Band and M. Katoh, Interfaces on trial: Intellectual property and interoperability in the global software industry, Routledge, 2019. Accessed on: July 31, 2021. [Online]. Available: https://www.taylorfrancis.com/books/mono/10.4324/9780429046841/interfaces-trial-jonathan-band-masanobu-katoh
[5] K. Curcio, T. Navarro, A. Malucelli and S. Reineh, “Requirements engineering: A systematic mapping study in agile software development”, Journal of Systems and Software, vol. 139, pp.32-50, 2018, Accessed on: July 30, 2021. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0164121218300141
[6] M. El Bajta and A. Idri, “Identifying Software Cost Attributes of Software Project Management in Global Software Development: An Integrative Framework”, In Proceedings of the 13th International Conference on Intelligent Systems: Theories and Applications, pp. 1-5, 2020, September. Accessed on: July 30, 2021. [Online]. Available: https://dl.acm.org/doi/abs/10.1145/3419604.3419780
[7] M.A. Akbar, M. Shafiq, J. Ahmad, M. Mateen and M.T. Riaz, “AZ-Model of software requirements change management in global software development”, In 2018 International Conference on Computing, Electronic and Electrical Engineering (ICE Cube) (pp. 1-6), IEEE. 2018, November. Accessed on: July 28, 2021. [Online]. Available: https://www.researchgate.net/profile/Muhammad-Tanveer-Riaz/publication/330387529_AZ-Model_of_software_requirements_change_management_in_global_software_development/links/5cf4a8aa92851c4dd024128d/AZ-Model-of-software-requirements-change-management-in-global-software-development.pdf
[8] S. Yos and C. Chua, “Requirements engineering tools for global software engineering”, In Proc. 13th Int. Conf. Eval. Novel Approaches Softw. Eng.(ENASE), vol. 1, pp. 291-298, 2018, March. Accessed on: July 30, 2021. [Online]. Available: https://www.scitepress.org/Papers/2018/67601/67601.pdf
Research
MIS611 Information Systems Capstone Assignment Sample
Assessment Stakeholder Requirements Document
Task Summary
This capstone subject encompasses an authentic assessment strategy within a work integrated learning context that delivers a ’real life’ learning experience. You will receive a brief from a case organisation/client
which will form the basis for the three sequential assessments included in this subject. Assessment 1
Stakeholder Requirements Document is the first of three phases in which you, as a team will formulate a group
response to the case organisation/client’s brief.
1. First phase: Assessment 1: In the first phase, you as a team will determine the project approach and
framework, and the requirements of your case organisation/client and complete a 3000-word Stakeholder Requirements Document. Please see below for further details.
2. Second phase: Assessment 2: In the second phase, your group will develop and deliver a prototype solution for the case organisation/client (details as per the Assessment 2 brief).
3. Third phase: Assessment 3: In the third phase, your group will ‘demo’/ showcase your prototype solution to the case organisation/client (details as per the Assessment 3 brief).
You will be required to select a project management approach based on what you believe is the most suitable
approach for your client’s project. In doing so, you will make use of the tools and techniques that are aligned
with the chosen approach including the appropriate requirements lifecycle techniques. Part of this assessment
is also to briefly explain why the selected approach is the most appropriate to meet the needs of your client. In
alignment with your selected project approach and framework, you will need to detail and demonstrate the
requirements methods, tools and techniques that you are using with a justification as to why they have been
selected as the most appropriate.
Caveat: While this subject focuses on three phases of assessment, this does not preclude the selection of an
iterative framework. The structure of the assessment is not one of the characteristics which you should use to
define the selected approach. Also, note that the title of this report specifically does not references typical
document naming conventions within either the traditional ‘waterfall’ approach, nor the Agile approach to
offer you the freedom to make the selection you believe is the most appropriate response to the challenge.
Context
In the field of Information Systems (IS), there are several different frameworks with aligned tools and techniques that can be used to build solutions for organisations. Different frameworks are better suited to
different problems and solutions. For example, the traditional project management approach takes a linear
approach through a sequence of events, while an Agile approach is iterative.
IS leaders need to understand different philosophies and their approaches, their frameworks and the tools and
techniques which they employ. This is so that they can make discerning decisions when selecting approaches
to solve problems for the business. A key outcome of this series of sequential assessments will be for you to
demonstrate your skills in selecting an approach with reasoning and justification, and then follow through by
using the appropriate methods, tools and techniques as a simulation of a real solution delivery for a case
organisation/client.
Task Instructions
1. Team Formation and Registration
• Form teams of 5-6 members.
• The deadline for team registration is 11:45pm AEST Friday end of Module 1.2 (Week 2).
• To register your team, you are required to send your Learning Facilitator an email with “[MIS611] Team Registration” in the subject line. In the body of that email, please list the names and student ID numbers of all the members of your team.
• You are required to send the registration email to your facilitator before the registration deadline.
• After the registration deadline, those students who are not in a team will be allocated to a team by the Learning Facilitator.
2. Please read the case organisation/ client’s brief provided by the Learning Facilitator.
3. Write a 3000 words stakeholder requirements document outlining the project approach and framework, and the requirements of your case organisation/client.
4. Review your subject notes, from across the course, to establish the relevant area of investigation that applies to the case. Re-read any relevant readings for this subject. Plan how you will structure your ideas for your report and write a report plan before you start writing. You may like to start with MIS608 Agile Project Management and PROJ6000 Project Management.
5. Graphical representation of ideas and diagrams in the form of tables, graphs, diagrams and modelsare encouraged but must be anchored in the context of the material, explained, and justified for inclusion. No Executive Summary is required.
6. The stakeholder requirements document should consist of the following structure:
A title page with the subject code and subject name, assignment title, case organisation/client’s
name, student’s names and numbers and lecturer’s name.
A Table of Contents is mandatory for this assessment (Create the Table of Contents using MS Word’s
auto-generator. Instructions can be found here https://support.office.com/en-gb/article/Create- a-
table-of-contentsor-update-a-table-of-contents-eb275189-b93e-4559-8dd9-
c279457bfd72#__create_a_table).
Introduction: This must include background information about your case organisation/client as a business from quality sources, and any information about the S direction or strategies that you can gauge from the trade press or news articles. (375 words)
The brief: In this section you must describe and explain your interpretation of the case organisation/client’s brief to you. You are required to outline the following areas:
a. The problem area/scope of the project. (150 words)
b. The objectives of the project using SMART goals. (150 words)
c. The target audience for whom your solution is being defined. (225words)
d. Critical Success Factors. (75 words)
A description of the project: the approach that you will be taking and the associated framework with a justification as to what characteristics of this project informed your selection of this approach. (375 words)
A stakeholder map which identifies key stakeholders, assessing stakeholder interest and how the project will address those interests. (75 words)
The data collection strategy used to elicit requirements - both primary and secondary, quantitative, and qualitative methods and tools in alignment with the project approach. (750 words)
Appropriately documented functionality that will need to be developed in your solution prototype. These may be business and functional requirements, or user stories depending on your selected approach. (750 words)
A clear problem statement to guide the solution process. (35 words)
Next steps to be taken in progressing to your solution prototype. (40 words)
References according to the APA style. (Not part of your word count)
Appendices - if required. (Not part of your word count).
Introduction
The study has helped in understanding the ways in which money can be reinvented in 2050 in India and the target audience that has been considered is entire India. United Nations in conjunction with International Monetary Fund (IMF) have identified that by 2050 cash will not be available and IMF has thought of reinventing money for different countries (Auer, Cornelli& Frost, 2020). The study has focused on ways in which Central Bank Digital Currency (CBDC) can be implemented within India’s manufacturing industry such as automobile manufacturing. There are various ways through which CBDC can be implemented (De Lis& Sebastián, 2019). Central Bank Digital Currency (CBDC) has been referred to the virtual form of fiat currency and is considered as the digital token of a currency of a nation (Kumhof&Noone, 2018). The suggested product for development of cashless society is the designing of a mobile application through which the payment or transaction can be done digitally. It helps in making the payment in terms of digital currency that will be regulated and released by the central Bank of India. CBDC comes in the form of banknotes and coins along with being used for doing sales as well as purchasing goods. CBDCs are implied so as to present fiat currency and also according to convenience of the users. There will be presentation of security of digital along with having a well-regulated and reserve-backed circulation of the traditional banking system (Auer &Böhme,
2020). It has been observed that there are various types of Central Bank Digital Currencies (CBDCs) and they are Wholesale CBDCs in which the existing tier of banks as well as financial institutions goes for settling transactions.
Brief of the Study
Problem Statement
In the 21st century, cashless society is still a dream however, it is supported by the growth of reinvesting money. It has become difficult to access the transactions of capital in between manufacturing companies with speed (Thequint.com, 2021). There is also the threat of not been able to keep an account of the money being transferred in huge project deals in between manufacturing companies such as Tata, Bajaj. Another problem that will be solved by CBDC in India is that the reliance of the country on cash will be lowered. It has been observed that the Reserve bank of India (RBI) has thought of action plans through which CBDC is going to belaunched in phased manner (Thequint.com, 2021). It will help in solving the problems of getting efficient in international settlements and also achieve smooth functionalities. It will also help in protecting people from the volatile nature presented by cryptocurrencies. Thus, there are problems associated with uncertainties of cryptocurrencies which can be solved with the introduction of CBDC and also cashless society will take place (Thequint.com, 2021). CBDC can be considered as a virtual currency, however, is not comparable with the private virtual ones such as Ethereum or Bitcoin. In India, there is problem associated with dwindling usage of paper currency and there are various jurisdictions associated with physical cash usage (Yanagawa& Yamaoka2019). Central Banks have sought to mee the need of public for having digital currencies and reinvent money through making a cashless society. This problem can be overcome through the help of developing a mobile application through which the digital payment system can be initiated. It has to be linked with the bank account and mobile registration number.
Smart goals
Areas Goal 1: To reduce the dependency on cash
Goal 2: Decrease the settlement risks
Goal 3: To make the transactions using CBDC secure Specific This goal is specific with having a cashless society implemented through help of Central Bank Digital Currency (CBDC) This is specific since with help of CBDC in a country like India, transactions with foreign nations will be easily done This is specific as calibration of the privacy features of CBDC system can be done Measurable It is measurable by
estimating the total
number of usages of
CBDC and digital
currencies by the
population of India
It is measurable through
the help of counting the
reduction of risks that
happens
This is measurable by
estimating the efficiency
of the calibrated system
Attainable It is attainable through
the introduction of
either value-or cash-
based access and
Token-or account-
based access
It is attainable through
engaging in retail as
well as whole sale
CBDCs and also
introduce it within the
manufacturing hubs
It is attainable through
the introduction of a
calibrated privacy feature
and preserve privacy
through making the
transactions
pseudonymous
Relevant It is relevant since there
is huge pressure on
transactions using cash
It is relevant since there
are various foreign
companies with which
India does business
It is highly relevant as
disbursement happens
through third parties and
require security
Time Period By 2050 By 2050 as the project
of introduction of CBDC is happening in
phased manner
Target Audience
It is worth mentioning that all are living in a cashless society therefore it is our responsibility to contribute to the development of reinventing of money at a large platform. As per the views of Wasieleski & Weber (2017), the internal stakeholders include management, employees, shareholders, investors, and the company itself. Moreover, the management will be able to perform the manufacturing processes and other activities inside the organisation (Seiffert- Brockmann et al., 2018). The target audience consisted of the whole of India. The Digital
currencies issues by the CBDCs are also beneficial in decreasing the effort of Government functions along with ensuring the fact that distribution of benefits as well as tax collection becomes easy. Thus, with help of CBDC ai din going cashless entire India will be benefitted. An Empathy Map can be used to capture the behavior of the user and attitude towards the introduction of a new system or a product. Empathy Mapping has been observed to be beneficial at the beginning of the design process after the user research is done, however, has to be performed prior of getting the requirement as well as conceptualization done. There are certain categories in which an empathy map can be divided and they are what the user says, thinks, feels
and does. [refer to appendix 2] Persona Mapping: Persona Mapping is the process through which it is identified who are the clients and ways in which decisions are being made. The information obtained can be used in making more effective strategies. [refer to appendix 1] Critical Factors of Success
The critical factors of success are measured as follows:
? The proper identification of problem
? Development of the scope for cashless society
? Reinventment in money through CBDCs help to support the development of a cashless society which is beneficial for making the world a technologically developed place.
? The focus on serving for the good of the society and the employees by eliminating the risk of cyber-attacks as well as network vulnerabilities on the transaction of money through digitized system.
Description of the Project
The project is about developing a mobile application through which the CBDC system will ne initiated. The application will be the gateway for making the payment using digital currencies released by the Bank and Government of India. A CBDC or Central Bank Digital Currency system as a result or solution has been identified to be overcoming the issues. A CBDC is a legal tender that is issued by central Bank in digital form (Auer, Cornelli& Frost, 2020). It can be compared or is similar to fiat currency, however, the form is different. The project has been different from that of Bitcoin or any other private virtual currency as it has no issuer, however, in this case, this problem of lack of security is overcame as Central Bank of the country is the
issuer. The product prototype will be designed that will help the individuals in getting the access to digital currencies regulated by RBI. The reason behind taking participation in the project is that with help of introduction of CBDCs the implementation of the monetary policy and government functions become easy (De Lis& Sebastián, 2019). It has been identified to be automating the process of transactions that will take place in between financial institutions and wholesale CBDCs (Kumhof&Noone, 2018). The project will also consider the calibration of the CBDC system.
Therefore, the double diamond theory will be the most applicable and relevant theory.
According to the comment of Gunarathneet al., (2018), double diamond theory always provides a static structure to identify all the potential challenges with the help of four different phases. All those phrases are discovered, defined, developed and delivered. The first phase always helps to identify the exact problem. The second phase helps to determine which area should focus upon.
The third face helps to ensure the potential solutions to mitigate the challenge. The last phase
helps to implement the solution.
Figure 3: Framework of Double Diamond Theory (Source: medium, 2021)
? Discover
In the discover stage as it is stated that the problems are identified appropriately and then the solutions are defined in subsequent stages. It has been identified from the research done that there has been increase in pressure or increased dependency on cash in India. There is also theproblem of higher seigniorage due to the lower value or cost associated with transactionsKumhof&Noone, 2018). The settlement risk associated with transacting through capita is also high. It has to be minimized through the help of using cashless medium if
transactions and is possible through help of Central Bank Digital Currencies (CBDCs) in a country such as India. There is also requirement of meeting the requirements of Indian public regarding digital currencies by the Central Banks of India and this issue has increased with the increase in manifestations of private virtual currencies (Thequint.com, 2021). India has been the leasing the world in terms of digital payment innovations and the payment system has been observed to be available 24/7. Thus, the problem of increasing usage of paper currency needs to be solved with the help of using CBDCs and focus is on developing an electronic form of currency.
? Define
The prototype that will be developed will help the Indian society and the various business happening within it to go for transactions without the need of physical bank notes. The prototype that will be considered is that of making of Fiat money which are introduced by the financial institutions of India. It gets introduced in the form of banknotes and coins (Barontini& Holden, 2019). The CBDC that will be formed is the virtual form of the fiat money and also is going to have the back up support of Indian Government. The mobile application developed will be in synchronization and the digital currency can be used as long as the individual have equivalent cash or money in the bank. The prototype will be designing two variants of CBDCs and this consists of Value or cash-based access as well as Token or account-based access. The system of Value-or cash-based access will be made to pass onto the recipient through help of a pseudonymous digital wallet (Auer, Cornelli& Frost, 22020). Wallet will be made identifiable through the help of a public blockchain. Another prototype that can be designed is that of cash- based access for Indian population (Kochergin&Yangirova, 2019). The process gets initiated similar to that of the access provided by a financial institution account to its users. It has been observed that an intermediary is responsible for verification of the identity of the recipient and will also monitor the illicit activities
Stakeholders Map
Stakeholders Interest Engagement Strategy Indians High More involvement within the banking system and easy transfer of fund Employee High Accessing and utilizing all the components for keeping a track of the cashless transactions Investors Medium Maintaining all the legal and transaction ethics before
accessing the plan Shareholder Low Gather all the potential investors and influence them for corporate decision making regarding the reinvention of money Retailers, business persons and manufacturers
High They will be doing the payment using CBDCs and hence, business can be done with foreign companies
easily
Table 2: Stakeholders Map
(Source: Created by Author)
Data Collection Strategy
It is worth mentioning that the strategy of collecting data is the most crucial factor that has been taken into consideration but the results were performing the study. The strategy which has been selected for gathering the pertinent sources of data influences the factors of quality and authenticity of the report. According to the opinion of Vales (2020), there are major two sources with the help of which the data and information regarding the study can be collected and evaluated by the analyst. The researcher has to choose between these two Strategies for obtaining the relevant sources of information that can be used to make the study effective and informative. The primary strategy for collecting data has also been known as the gathering of raw data. Such
type of information and data has been collected by the research investigator for a specific study (Primary data collection, 2020). In this study, the focus of the research analysis is to obtain valuable information, data, and statistics that can define the importance of reinventing money for the development of cashless society for Tata Motors that can eliminate the negative impact of covid-19 on its manufacturing and business activities
Figure 4: Data Collection Strategy
(Source: Created by Author)
The primary strategy has also been divided into two types that are primary and quantitative primary qualitative. According to the words of Franzitta et al., (2020), it has been found that primary quantitative refers to the statistical evaluation of the data and information gathered by the researcher. Mostly the investigator performs a survey for doing the primary quantitative research. For the survey, the researcher designs a questionnaire that includes a number of questions that specifies the close-ended questions that are filled by the respondent that supports the research topic. Each of the respondents fills the question as per the best knowledge
experience. After the completion of gathering responses provided by the respondents, the researcher evaluates and analyses the result by various methods such as SPSS software or Excel sheet. As per the views of Wilson & Kim (2021), it is worth mentioning that for performing the primary qualitative study, the researcher mostly conducts an interview process which can help to gain information and knowledge regarding the research topic by interviewing the associated people with the research topic. In this study, the associated people are the employees, management, customer, investors, and shareholders.
Similarly, the secondary strategy for collecting the information and data focuses on addressing and evaluating the work of other researchers and investigators that work on a similar topic. As per the comment of Talbert (2019), this will help the researcher to understand the perspective of other analysts that can show their views regarding the importance of reinventing money. It has been identified that the secondary method of obtaining the data is more economical than the primary strategy. It has been said so because during the process of collecting the first handed information the investigator has to spend more time, effort, and money for collecting the data. It also includes the transportation cost and the survey, interview cost.
However, it has been found that for implementing the secondary strategy a researcher has to adopt the secondary qualitative study. As per the guidance of Haenssgen (2019), it has been observed that the secondary qualitative study is on developing relevant themes based on which the researcher can support their findings and evaluation in the study. After evaluating the benefits and rules of working of both the primary and secondary qualitative and quantitative data, the researcher will implement the secondary qualitative research for gathering valuable and authentic resources of the secondary database.
Documented Functionality
In this section, all the business and functional requirements that will help manufacturing companies to implement the cryptocurrency enabled cashless transaction is going to be discussed. All the potential functional requirements that the management of this organization will have to perform is to arrange some meetings with all the responsible employees and managers and discuss the comparison between the cashless modes of transactions (Auer&Böhme, 2020). It is worth mentioning that effective strategies should be implemented in order to identify the potential challenges that may impact the productivity and growth of cashless infrastructure (Kumhof& Noone,2018). After that identifying all the potential shareholders and
influencing them for this plan willbe the next functional requirement. According to the opinion of Marques et al., (2018), identifying all the investors with a proper determination regarding this plan will be one of the most important functional requirements of shareholders. There are certain examples of Central Bank Digital Currencies (CBDCs) that can be given and it has been observed that the Central Banks have initiated various pilot programs (Kumhof&Noone, 2018).
India can take inspiration from the fact that China has introduced digital yuan. Russia has also created the CryptoRuble and similar technology can be deployed within India to make the society cashless. India will require to have a digital version and the banks will be converting a part of their holdings into digital form. The digital monetary or the capital will be distributed to various business organizations and people of the country through help of mobile technology (De Lis& Sebastián, 2019). It can be observed that the largest difference in between cryptocurrencies and CBDC is that of the legal status as the later is more secured. Indian population will be benefitted as CBDC can be used as a payment mechanism and will be considered as an acceptable ledger system. In addition to this, CBDC will provide the advantage of being governed by Indian Government and is not anonymous.
There are two types of functionalities through which the CBDCs can be developed and they are Wholesale as well as Retail Central Bank Digital currencies. It can be stated that the Wholesale CBDCs uses the existing tier of banking as well as financial institutions so that transactions can be settled. This type of CBDC has been considered as traditional central bank reserves. The type of CBDC transaction that can be possible is that of interbank payment and transfer of capital takes places in between two financial institutions (De Lis& Sebastián, 2019). With help of CBDC, the process of cross-border transfer as well as automation is possible. There is also Retail CBDCs that involves transfer in between financial institution. The CBDC process that will be developed in India at first is that of retail one in which there is replacement of cash (Kumhof&Noone,2018). There must be caps imposed on the CBDC so that the banks are saved from having drainage of liquid fund. Digital tokens will be given to bearers and hence, identity verification will be conducted in an effective manner.
Conclusion
Thus, it can be concluded that this entire report has been formulated to describe a suitable reinvention plan of money by 2050. The target audience is the entire population of India and it has been observed that they will be benefitted with the help of CBDC as involvement within the banking system will get improved. It has been observed that with help of CBDC, the pressure on the use of physical notes will get decreased and also the drainage of liquid capital from banking sector will be removed. Furthermore, it can be stated with help of CBCD, there will be safer transaction of assets across borders and the system developed will be mainly token-based in the initial stage and then it can be developed in a hybrid model.
Reference List
Thequint.com, (2021), What is CBDC? Why Do We Need It in India?,https://www.thequint.com/explainers/explained-what-is-cbdc-why-do-we-need-it-in-india
Yanagawa, N., & Yamaoka, H. (2019). Digital Innovation, Data Revolution and Central Bank Digital Currency (No. 19-E-2). Bank of
Japan.https://theblockchaintest.com/uploads/resources/Bank%20of%20Japan%20-%20Central%20Bank%20Digital%20Currency%20-%202019%20-%20Feb.pdf
Auer, R. A., Cornelli, G., & Frost, J. (2020). Rise of the central bank digital currencies: drivers,approaches and technologies (No. 8655). CESifo Working Paper.https://www.econstor.eu/handle/10419/229473
De Lis, S. F., & Sebastián, J. (2019). Central Bank Digital Currencies and Distributed Ledger Technology. https://www.bbvaresearch.com/wp-content/uploads/2019/11/Banking-Lab-DLT-CBDCs_edi.pdf
Kumhof, M., &Noone, C. (2018). Central bank digital currencies-design principles and balance sheet implications. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3180713
Auer, R., &Böhme, R. (2020). The technology of retail central bank digital currency. BIS Quarterly Review, March. https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3561198
Barontini, C., & Holden, H. (2019). Proceeding with caution-a survey on central bank digital currency. Proceeding with Caution-A Survey on Central Bank Digital Currency (January 8, 2019). BIS Paper, (101).
https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3331590
Kochergin, D. A., &Yangirova, A. I. (2019). Central bank digital currencies: key characteristics and directions of influence on monetary and credit and payment systems. Finance: theory and practice, 23(4),8098.
https://financetp.fa.ru/jour/issue/download/51/23#page=75
Desmond Dawes, G., & Davidson, A. (2019). A framework for developing justice reinvestment plans for crime prevention and offender rehabilitation in Australia’s remote indigenous communities. Journal of offender rehabilitation,58(6),520543.https://researchonline.jcu.edu.au/58765/1/A%20framework%20for%20developing%20justice%20reinvestment%20plans%20for%20crime%20prevention%20and%20offender%20rehabilitation%20in%20Australia%20s%20remote%20indigenous%20communities.pdf
Franzitta, V., Longo, S., Sollazzo, G., Cellura, M., &Celauro, C. (2020). Primary data collection and environmental/energy audit of hot mix asphalt production. Energies, 13(8), 2045–2045.
https://lesa.on.worldcat.org/v2/oclc/8582369766
Gomes, P., Mendes, S. M., & Carvalho, J. (2017). Impact of pms on organizational performance and moderating effects of context. International Journal of Productivity and Performance Management, 66(4), 517–538.
https://doi.org/10.1108/IJPPM-03-2016-0057
Gunarathne, A. N., & Senaratne, S. (2018). Country readiness in adopting Integrated Reporting:
A Diamond Theory approach from an Asian Pacific economy. In Accounting for sustainability: Asia Pacific perspectives (pp. 39-66). Springer, Cham. https://link.springer.com/chapter/10.1007/978-3-319-70899-7_3
Haenssgen, M. J. (2019). Interdisciplinary qualitative research in global development : a concise guide (Ser. Emerald points). Emerald Publishing Limited. Retrieved October 4, 2021, from INSERT-MISSING-URL. https://lesa.on.worldcat.org/v2/oclc/1128408880
Marques, T., Nguyen, J., Fioreze, G., &Petreanu, L. (2018). The functional organization of cortical feedback inputs to primary visual cortex. Nature Neuroscience, 21(5), 757–764.https://doi.org/10.1038/s41593-018-0135-z
Primary data collection (netherlands-utrecht: research and development services and related consultancy services). (2020). Mena Report, (july 15 2020): Na.https://lesa.on.worldcat.org/v2/oclc/8628905727
Rubin, H. W., &Spaht, C. (2018). Quality Dollar Cost Averaging Investing Versus Quality Index Investing. Journal of Applied Business and Economics, 20(6), 193-200.http://na-businesspress.homestead.com/JABE/JABE20-6/RubinHW_20_6.pdf
Seiffert-Brockmann, J., Weitzl, W., &Henriks, M. (2018). Stakeholder engagement through gamification. Journal of Communication Management, 22(1), 67–78.https://lesa.on.worldcat.org/v2/oclc/7294428031
Sharma, D., & Swami, S. (2018). Information Security policies Requirement in Organization. International Journal on Future Revolution in Computer Science & Communication Engineering, 4(1), 431-432.
https://www.ijfrcsce.org/index.php/ijfrcsce/article/download/1036/1036
Talbert, E. (2019). Beyond data collection: ethical issues in minority research. Ethics & Behavior, 29(7), 531–546.https://lesa.on.worldcat.org/v2/oclc/8260802315
Tata motors: wheelspin. (2018). Financial Times, 10, 10–10. https://lesa.on.worldcat.org/v2/oclc/7908714374
Vales, M. (2020). Primary data collection for language description and documentation. Etudes Romanes De Brno, 41(1), 87–98. https://lesa.on.worldcat.org/v2/oclc/8650347961
Wasieleski, D. M., & Weber, J. (Eds.). (2017). Stakeholder management (First, Ser. Business and society 360). Emerald Publishing Limited. Retrieved October 4, 2021, from INSERT-MISSING-URL.https://lesa.on.worldcat.org/v2/oclc/988757040
Wilson, C., & Kim, E. S. (2021). Qualitative data collection: considerations for people with aphasia. Aphasiology, 35(3), 314–333. https://lesa.on.worldcat.org/v2/oclc/8929382816
Research
BDA601 Big Data and Analytics Assignment Sample
Task Summary
Critically analyse the online retail business case (see below) and write a 1,500-word online custom essay help report that: a) Identifies various sources of data to build an effective data pipeline; b) Identifies challenges in integrating the data from the sources and formulates a strategy to address those challenges; and c) Describes a design for a storage and retrieval system for the data lake that uses commercial and/or open-source big data tools. Please refer to the Task Instructions (below) for details on how to complete this task. Context A modern data-driven organisation must be able to collect and process large volumes of data and perform analytics at scale on that data. Thus, the establishment of a data pipeline is an essential first step in building a data-driven organisation. A data pipeline ingests data from various sources, integrates that data and stores that data in a ‘data lake’, making that data available to everyone in the organisation.
This Assessment prepares you to identify potential sources of data, address challenges in integrating data and design an efficient ‘data lake’ using the big data principles, practices and technologies covered in the learning materials. Case Study Big Retail is an online retail shop in Adelaide, Australia. Its website, at which its users can explore different products and promotions and place orders, has more than 100,000 visitors per month. During checkout, each customer has three options: 1) to login to an existing account; 2) to create a new account if they have not already registered; or 3) to checkout as a guest. Customers’ account information is maintained by both the sales and marketing departments in their separate databases. The sales department maintains records of the transactions in their database. The information technology (IT) department maintains the website. Every month, the marketing team releases a catalogue and promotions, which are made available on the website and emailed to the registered customers. The website is static; that is, all the customers see the same content, irrespective of their location, login status or purchase history. Recently, Big Retail has experienced a significant slump in sales, despite its having a cost advantage over its competitors. A significant reduction in the number of visitors to the website and the conversion rate (i.e., the percentage of visitors who ultimately buy something) has also been observed. To regain its market share and increase its sales, the management team at Big Retail has decided to adopt a data-driven strategy. Specifically, the management team wants to use big data analytics to enable a customised customer experience through targeted campaigns, a recommender system and product association. The first step in moving towards the data-driven approach is to establish a data pipeline. The essential purpose of the data pipeline is to ingest data from various sources, integrate the data and store the data in a ‘data lake’ that can be readily accessed by both the management team and the data scientists.
Task Instructions
Critically analyse the above case study and write a 1,500-word report. In your report, ensure that you:
• Identify the potential data sources that align with the objectives of the organisation’s datadriven strategy. You should consider both the internal and external data sources. For each data source identified, describe its characteristics. Make reasonable assumptions about the fields and format of the data for each of the sources;
• Identify the challenges that will arise in integrating the data from different sources and that must be resolved before the data are stored in the ‘data lake.’ Articulate the steps necessary to address these issues;
• Describe the ‘data lake’ that you designed to store the integrated data and make the data available for efficient retrieval by both the management team and data scientists. The system should be designed using a commercial and/or an open-source database, tools and frameworks. Demonstrate how the ‘data lake’ meets the big data storage and retrieval requirements; and Provide a schematic of the overall data pipeline. The schematic should clearly depict the data sources, data integration steps, the components of the ‘data lake’ and the interactions among all the entities.
Solution
Introduction
Retail industry has grown a lot in 2020-21, speciallyby the use of online store facility (Menidjel et al., 2021). Like the global retail market, Australian retail market has changed a lot. The market takes the online approach. Here customers are free to change their mind by simple mouse click. These makes this industry highly competitive.
Big Retail is a retail store situated in Adelaide,Australia. Historical data says, per month around 100000 customers visit their website and makes the purchases. The website is maintained by the IT department of Big Retail. The website is a static one. All the customers see the same content irrespective of their location and login status or purchase history. A visitor may login if he or she has an account,he or she can create an account or checkout as a guest user. These activities generate a huge amount of data every month. These raw data is unanalysed till now and a data-driven approach is not taken based on these collected data. Presently Big Retails are experiencing less sales and they are losing their revenue. Therefore, a data-driven approach has to be taken and a data pipeline needs to be made(Hussein& Kais,2021). By analysing the available dada, the possible solutions will come out and the revenue will reach its expected pick.
Data Source
The website of Big Retails is managed by the IT department of the company. Every day a large number of visitors comes in this website to see the product or to purchase. They provide their name, address, email id, phone number and other information. Customers follows a definite purchase pattern. Data are generated from this website every day.
Figure 1: Data Source
Source: Created by Author
Internal Data Source
Every month around 100000 visitors visit Big Retails website. These huge number of website visitor generate a large amount of data. These website visitor data are internal data. Internal data is information which is generate within the organisation. The operations, maintenance, HR, finance, sales and marketing information within the company is also internal data (Feng, Fan & Bednarz,2019). Customer analysis, sales analysis report, cost analysis, marketing report, budget of Big Retail are internal data.
a) Internal data are reliable. These data are collected from the organisations own system. Therefore, during analysis,we can rely on these data.
b) Internal data or often unique and can be separated. Every data has unique meaning.
c) These data are operational data. Special DBMS operation is already done on these data.
d) Internal data are well defined data. The value, occurrence and event of these data are well defined. We know the exact value of each data.
External Data Source
External data are the data which is outside the current database. External data is collected from the outside source. Marketing department of Big Retail often make some market analysis and feedback collection campaign. Marketing department also does several surveys. Data which are collected from these campaign and surveys are external data.
Characteristics
a) These data are not reliable. These data are collected from external sources
b) Data operations are needed on external data.
c) We cannot use external data in DBMS.
d) External data are not well defined.
Structured data source
Structure data are those data which reside in a specific file or record. Structure data is stored in RDBMS (Anadiotis et al., 2021). In Big Retail, the data which are collected from the website visitors are identified and make unique. These data then store in a file. This file is the source of structure data.
Semi-Structured Data Source
Semi-structured data sources are emails,address of the customers who visited the website of Big Retail,XMLs,zipped files and web pages collected from different sources (Anadiotis et al., 2021).
Unstructured Data Source
Unstructured data sources are, Media information, audio and video files, surveillance data, geological data, weather data (Anadiotis et al., 2021). In Big Retail, audio and video message, email message collected form the customers are the source of unstructured data.
Challenge of Integrating Data from Different Sources
The website of Big Retail is a busy one. Everyday a large number of customers visits the website. There are internal analysis data as well. The survey data are also there. There ae structured and unstructured dada as well. Data are coming from different sources. Integrating such huge amountof data is a big challenge.
Challenges
The challenge of integrating data from different source are many. Big Retail is a large organisation. It has different types of data. All data are not structured. First challenge is to get a structured data. The integration challenge is, the data are not there where we need it(Gorji& Siami, 2020). Sometimes, the data are there but it is late. Getting data on right time, in right place itself is a challenge. The next challenge is getting an unformatted data or ill-formatted data. We get the data, but it is not formatted well i.e. the format of the data is not correct. Often the data quality is very poor. These data cannot be integrated. And again, there are duplicates of data. Throughout our pipeline, the data are duplicated (Zipkin et al., 2021). The data has to be clear. There is no clear understanding of data. These data cannot be integrated. Poor quality, duplicated and unclear data often make the situation tougher.
Solutions
The solutions of data integration problems are not many. But there are few effective solutions. We need to automate the data as much as possible. Manual data operation has to be avoided (Kalayci et al., 2021).We should opt for smallest integration first. It is advised to avoid large integration. The simplest way is to use a system integration software which will allow to integrate large amount of data from different sources. Some data integration softwareis Zapier, IFTTT, Dell Boomi etc.
Data lake
Data lake is a storage repository which stores a last amount of raw data it its own format until it is taken (Nargesian et al., 2020).
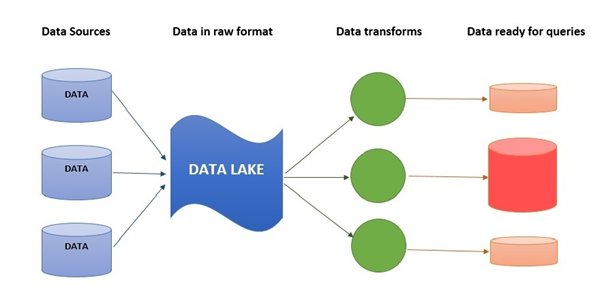
Figure 2: Data Lake
Source: Created by Author
Data lake does not use file or folder to store data, it stores data is its own flat architecture. Data lake is often a Hadoop oriented object storage. Data is first loaded in the Hadoop platform. After that, business analytics and data mining tools are used to get these data. Just like physical lake, it is a huge storage of data. The format of data is not a problem here.
Here, in Big Retail, data are coming from
1. website visitors,
2. active customers,
3. buyers,
4. feedback givers,
5. survey report,
6. sales reports
7. internal analytics report etc.
These data are structured as well as unstructured data. These data have different format. Some are integers, some are characters, some are binary data. These data are stores in data lake. Through the data pipeline these data cometothe data lake. Whenever the database administration of data scientist needs the data, some operations are done on that data and make the data available for use.
Schematic of the Overall Data Pipeline
The data pipeline is a set of actions that happen to the raw data to make them usable for the analytics purpose. There are series of data processing elements which are to be used on raw data.
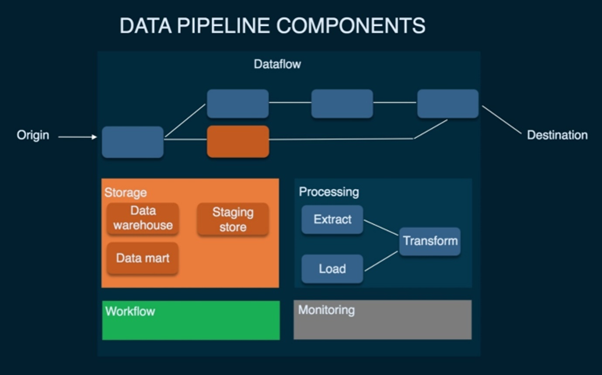
Figure 3: Data Pipeline Components
Source: (Giebler et al, 2019)
Big Retail business generate a massive amount of data which needs to be analysed to get the perfect business value and opt a business discission. Analysing data withing the system is not a wise idea. Moving data between systems requires many steps. Collecting data from one source, copping that data, upload the data to the cloud, reformatting the data, different operations on data and then joins it to other systems. This is a complex procedure. Data pipeline is the summation of all these above steps (Giebler et al, 2019).
Data from different source of Big Retails are collected first. Next part is uploading the data to the cloud. The using different software tool formatting of data is happening. Here the data goes to the data lake of Big Retail. In data lake, these data are received first and irrespective of its original format, it is stored in flat format(Quemy, 2019).
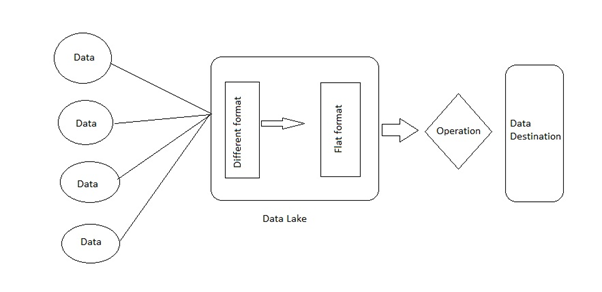
Figure 4: Data Pipeline
Source: Created by Author
Conclusion
The business scenario of today’s world is changing. Like other industry, retail in also facing a huge change due to the advancement of technology (Komagan, 2021). Big Retail of Adelaide, Australia needs to build this above-mentioned data pipeline and data lake. Being an online store, it is highly depending upon data and e-technology. It has been found that the data pipeline can help the store to get the data effectively. The proposed data lake will help to store data and can provide it when necessary. Using analytics tools, data analyst and data scientist can predict the business scenario and advice the management of Big Retail to take the necessary actions.
References
Anadiotis, A. C., Balalau, O., Conceicao, C., Galhardas, H., Haddad, M. Y., Manolescu, I., ... & You, J. (2021). Graph integration of structured, semistructured and unstructured data for data journalism. Information Systems, 101846.https://www.sciencedirect.com/science/article/abs/pii/S0306437921000806
Feng, T., Fan, F., & Bednarz, T. (2019, November). A Data-Driven Optimisation Approach to Urban Multi-Site Selection for Public Services and Retails. In The 17th International Conference on Virtual-Reality Continuum and its Applications in Industry (pp. 1-9).https://dl.acm.org/doi/abs/10.1145/3359997.3365686
Giebler, C., Gröger, C., Hoos, E., Schwarz, H., & Mitschang, B. (2019, November). Modeling data lakes with data vault: practical experiences, assessment, and lessons learned. In International Conference on Conceptual Modeling (pp. 63-77). Springer, Cham.https://link.springer.com/chapter/10.1007/978-3-030-33223-5_7
Gorji, M., & Siami, S. (2020). How sales promotion display affects customer shopping intentions in retails. International Journal of Retail & Distribution Management.https://www.emerald.com/insight/content/doi/10.1108/IJRDM-12-2019-0407/full/html
Hussein, R. S., & Kais, A. (2021). Multichannel behaviour in the retail industry: evidence from an emerging market. International Journal of Logistics Research and Applications, 24(3), 242-260.https://www.tandfonline.com/doi/abs/10.1080/13675567.2020.1749248
Kalayci, T. E., Kalayci, E. G., Lechner, G., Neuhuber, N., Spitzer, M., Westermeier, E., & Stocker, A. (2021). Triangulated investigation of trust in automated driving: Challenges and solution approaches for data integration. Journal of Industrial Information Integration, 21, 100186.https://www.sciencedirect.com/science/article/abs/pii/S2452414X20300613
Komagan, M. L. (2021). Impact of Service Environment for effective consumer behavior in Retails Industry with reference to Heritage Super Market. Turkish Journal of Computer and Mathematics Education (TURCOMAT), 12(3), 4357-4364.https://turcomat.org/index.php/turkbilmat/article/view/1727
Menidjel, C., Bilgihan, A., & Benhabib, A. (2021). Exploring the impact of personality traits on perceived relationship investment, relationship quality, and loyalty in the retail industry. The International Review of Retail, Distribution and Consumer Research, 31(1), 106-129.https://www.tandfonline.com/doi/abs/10.1080/09593969.2020.1781228
Nargesian, F., Pu, K. Q., Zhu, E., Ghadiri Bashardoost, B., & Miller, R. J. (2020, June). Organizing data lakes for navigation. In Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data (pp. 1939-1950).https://dl.acm.org/doi/abs/10.1145/3318464.3380605
Quemy, A. (2019). Data Pipeline Selection and Optimization. In DOLAP.https://www.aquemy.info/static/publications/quemy2019b.pdf
Zipkin, E. F., Zylstra, E. R., Wright, A. D., Saunders, S. P., Finley, A. O., Dietze, M. C., ... & Tingley, M. W. (2021). Addressing data integration challenges to link ecological processes across scales. Frontiers in Ecology and the Environment, 19(1), 30-38.https://esajournals.onlinelibrary.wiley.com/doi/full/10.1002/fee.2290
Case Study
MN621 Advanced Network Design Assignment Sample
Students are required to use an industry case study of your PBL exercise to complete the assignment. It is to note that this assignment consists of two parts a) Assignment 1a and b) Assignment 1b. You have to discuss your chosen case study with tutor in week 1 and 2. Make sure to design your own case study if possible to avoid Academic Misconduct.
Assignment 1A
1. Project Scope and Report Requirements
The project scope and requirement should have a detail explanation of the planning and designing of a network. It is recommended that bullet points are included whenever necessary. Use your Problem Based Learning (PBL) tutorial findings.
The Following is The Scope for Assignment 1a.
• Attach your chosen real world business case study with reference as an appendix A.
• Include points that you have gathered from your chosen case study on their existing network.
• Discuss in a tabular form how the information obtained will be useful in designing the network.
• Discuss the approach you will be taking (include bullet points whenever necessary) to redesign the network.
Assignment 1B
The Following is The Scope for Assignment 1b.
2. Response to Assignment 1a
• It is mandatory that students should demonstrate how they have incorporated the feedback given in assignment 1a. You may use a tabular form whenever necessary.
3. Network design and justification
• Draw a network design that you think will be useful in the future for the industry that you have visited. Network should include the following requirements:
o 3 routers
o 4 switches
o 10 PCs
o 4 VLANs.
• Suitable IP addressing scheme in tabular form (assume as many hosts as necessary for each department). Use your MIT student ID to come up with your own IP addressing scheme (to avoid Academic Misconduct). Justify the choice of IP address.
• Indicate where do you use static routing, dynamic routing protocols (name the protocols, RIP, EIGRP, OSPF, etc.), Access Control List (ACL) as per the network preferences. Justify your choices.
4. Network Configuration
Configure your network using Packet Tracer. Write a report on
• Packet Tracer Network diagram- Copy diagram from your simulator
• Switch configuration
• Router configuration
• Host configuration
• Access point and server configuration guidelines.
5. Timeline and Budget Estimation
This section should include the followings:
• Hardware requirements with the specification with costs
• Human resources and logistics
• Tentative timeline specifications.
Solution
1. Project Scope and Reporting Requirements
Crystal Point is a luxury building. It has 69 units, 24-hour security, a concierge, facility of fitness, & a year-round heated pool & all with 360-degree the mountains & city's views. Despite that, HOA (Homeowners Association) of Crystal Point discovered that one crucial amenity, Internet & Wi-Fi services, was falling short of residents' expectations. As a result of such problem, the residents receive an unsettling WIFI service, & the surveillance system is malfunctioning. As a result of these hassles, resident’s complaints are on the rise, as is the risk to security. Crystal Point needed a strong and dependable Internet & Wi-Fi solution since homeowners were complaining on a daily basis. Company wanted a high-end, Internet solution & fully managed Wi-Fi that was perceptibly superior in terms of dependability & quality than service provided by regular service provider.
The requirements of the crystal point are as follows:
• A network that could grow to handle rising demand from an increased number of people & devices
• Ensure secure & high-bandwidth internet connection is provided to the residents.
• Safe & secure connections in any area within the facility's footprint.
• A wireless & wired solution that was convenient to use.
Network configuration & system network up-gradation are critical for fixing the problem. For resolving the inadequate connectivity's issue, the system's each components, such as switches & host routers, must be upgraded. Changing the entire network system is not straightforward for the crystal point[1].To resolve all these issues, the solutions are as follows
• SmartZone controller was utilized for managing the APs & ease network management as well as set-up.
• Installed an R510 indoor AP in each condo unit.
• ICX switches were utilized to create a dependable wired & wireless network.
The benefits of redesign network are as follows:
• During boosting signal strength & wireless reliability, enhanced the several concurrent clients assisted per access points.
• Flexible & quick-to-respond service of customer.
• A complete controlled, actively controlled solution.
• Simplified network set-up and management, boosted security, minimized troubleshooting, & made updates simple Reliable, trouble-free Internet service fit for a high-end, luxury establishment
Useful Information To Redesign The Network
|
Current Status |
Status of network |
Bandwidth |
|
|
Email communication |
inadequate |
Up gradation needed (old) |
The AP's firmware is outdated. |
|
Voice chat for conference |
inadequate |
Up gradation needed (old) |
Old ADSL connection |
|
Video chat for conference |
inadequate |
Up gradation needed (old) |
Old ADSL connection |
|
Residence |
inadequate |
Up gradation needed (old) |
Old ADSL connection |
|
Working conditions |
inadequate |
Up gradation needed (old) |
Old ADSL connection |
|
Safety measures |
inadequate |
Up gradation needed (old) |
Don’t set a security policy. |
Approach To Redesign
The above issues in the network of crystal point are solved by Ruckus’ ICX switching & wireless access points (APs) through reconstructing the system network and for good performance:
• Using wireless access points (APs) & ICX switching of Ruckus, It allows giving residents of Crystal Point with consistent Wi-Fi reliability & greatly increased services.
• The Dual Path suggested a Cat6 & fibre infrastructure to provide Crystal Point residents with a much enhanced Internet experience.
• In each condo unit R510 AP & ICX switches installed, & a SmartZone 100 that manages & controls the Wi-Fi network makes up the solution.
• The SmartZone Wireless LAN controller & Ruckus ICX switches work together for making network management & setup easier, improve security, reduce troubleshooting, and make upgrades simple.
• Continuous Wi-Fi coverage is provided by the Ruckus R510. The exceptional RF (Radio Frequency) performance is provided by the APs provide.
• Automatic interference mitigation & a two-stream MIMO 2x2:2 are included in the Ruckus R510 APs, ensuring constant, predictable performance.
• The R510 is ideal for crowded device situations, with data rates up to 1200 Mbps.
References
[1] "Network Design and Management Overview", Copyright 2000–2014, [online] Available: http://www.bitpipe.com/netmgmt/netmgmt_overview.isn
[2] "Putting Technology to Work Providing Business Solutions", Valley Network Solutions, 2014, [online] Available: http://www.vns.net/services/infrastructure/index.htm.
[3] Cisco design model of a network, [online] Available: http://www.cisco.com/c/en/us/td/docs/solutions/Enterprise/Campus/Hcampus_DG/hacampusdg.html.
[4] J L Marzo, C Vaz de Carvalho, L Schoofs, R Van Steenberghe, S Knockaert, J Salonen, et al., "European Study Programme for Advanced Networking Technologies (ESPANT) EDULEARN" in , Barcelona, July 2009.
[5] CRYSTAL POINT. Luxury Living Condos Receives Top Technology Amenity 2012.
Case Study
MIS101 Information Systems for Business Assignment Sample
Question
Task Summary Using your understanding of the components of Information systems, propose a assignment help technical solution for another organization. Please refer to the Task Instructions for details on how to complete this task. Context In Module 1, you learned about Information Systems and its components. In Module 2, you learned about Information Technology and Data Management in relation to Information Systems. You now have the opportunity to apply these concepts and propose a solution for the scenario given to you by your Learning Facilitator.
Task Instructions Read the scenario in the file MIS101_Assessment_1_Scenario to complete the task of writing a technical proposal. Deliverables Required Write a technical proposal for the organization identified in the scenario. The proposal should only discuss the technical aspects of the project. Do not focus on the managerial aspects such as cost, human and technical resources, etc.
Important Notes
• You must ensure that the technical proposal essay help online is relevant to the scenario given.
• Your technical proposal should ideally answer the following questions (but not limited to):
1. What would be the hardware requirements?
2. What would be the software requirements?
3. What would the communication and network for the scenario look like?
4. What would be the data needs and the data storage needs?
5. What would be the structure of the data layout plan?
6. How would the technical proposal being put forth be beneficial for the management and other stakeholders?
7. How would the proposed solution improve operations?
8. What would the limitations of the proposed solution be?
9. Other questions When writing your technical proposal, make sure that you write in a systematic way (the questions above are not given in a systematic manner). Make use of the internet to find out the structure/format of a technical proposal. When writing the technical proposal, assume that this would be submitted to your potential customer (as identified in the scenario given to you).
MIS101 - Assessment Task 1 Scenario B: HealthWay is a privately-owned healthcare facility that has been in business for 10 years and has a good reputation. It is a small hospital that is equipped to treat 20 inpatients at one time. In addition to inpatient care, it provides medical care service to outpatients via clinics specialising in family medicine, gynaecology, and paediatrics. HealthWay’s mission is to provide quality and personalised medical care to the patients. The organisation relies on a traditional file management system for all its business operations and patient record keeping. The management feels that the current system affects the performance of the business and makes patient record maintenance a slow process, thus affecting the quality of patient care. Josh, the President of HealthWay, believes that it is time to review the business and introduce information systems in the organisation to improve overall performance and gain competitive advantage. Josh wants to automate and optimise business operations including human resources, accounting and finance, supply chain management, and administration (although it is not limited to just these areas). He also wants the patients’ data to be arranged in such a way that it can be easily accessed and updated by the hospital staff. As HealthWay is a growing business and expects an increase in the number of patients, Josh sees this as an opportunity for improvement. He also wants the system to help the management in decision-making and planning. He wants an information system that can support all core and support operations of the hospital. Josh has requested your organisation, KSoft, to provide a technical proposal to be further discussed with Healthway’s Chief Technology Officer.
Solution
1. Abstract
In business (e.g. healthcare), Management Information Systems (MIS) is introduced to support the organisational processes, intelligence, operations. To improve business operations related to IT, outpatients and impatiens via clinics, automated business operations in the healthcare organisation, information system is required. The criteria of a technical proposal are to identify the core technical problems first, then evaluating it or justifying it with the base requirements, and later providing proposed solutions for these. MIS tools helped to manage information and move data associated with the patients. MIS is a formal, sociotechnical, as well as organisational system designed to control performance of HealthWay business processes.
Keywords: MIS, Healthcare system, Data management, Proposed Solution, Technical requirements, Technical proposal, HealthWay.
2. Introduction
In this technical proposal, Information Technology (IT) and Data management with relation to Business Information systems is taken into consideration. Based on the case scenario of HealthWay privately-owned healthcare facility, it has been possible for me to propose solutions and meet the organisational needs. This technical proposal is prepared by KSoft organisation considering the HealthWay’s Chief Technical Officer's perspective. Here, a basic structure of technical proposal has been followed and all the technical aspects, factors related to this project have been elaborated with a systematic manner and submitted to HealthWay’s potential customers.
3. Statement of Need
3.1. Hardware Requirements
Based on the understanding of the case scenario, hardware requirements for HealthWay Information System (HIS) are:
• Keyboard (s)
• Monitor (s).
• Mouse (s)
• Central Processing Unit (CPU) as Microprocessor (Carvalho Joa?o et al., 2019, p. 390).
• Hard disk drive (HDD) to store patient’s data and records.
• Optical disc drives
• Expansion cards
• Motherboard
• Power supply unit to every healthcare departments’ system
• Main Memory (Random Access Memory- RAM).
As per the ideas of Beverungen, Matzner & Janiesch, 2017, p. 783), hardware requirements for HIS can also be managed by the Clinical management, Supplies management, Support services, patient management, and also by information management.
Figure 1: Inpatient & Outpatient requirements
(Source: Carvalho Joa?o et al., 2019, p. 393)
3.2. Software Requirements
In the case of the HealthWay Healthcare and Hospitality management system, to gather the patients’ data, software is required. Software is divided into two-part requirements: i). Functional, ii). Non-functional.
Under the functional requirements, Software Requirements Specification (SRS) is measured which is a complete configuration of different software requirements for registration process, report generation, database management etc (Beverungen, Matzner & Janiesch, 2017, p. 785). On the other hand, non-functional requirements of the HealthWay management system are for security, performance, reliability, and maintainability purposes.
3.3. Communication and Network scenario
On the basis of patients’ information and decision support tools, delivery of quality care, some technical factors are considered which are important for planning as well as implementation of healthcare communication networks:
• Transmission latency throughout the wide healthcare network.
• Ubiquity of network access (Carvalho Joa?o et al., 2019, p. 395)
• Bandwidth requirements and availability inside HealthWay
• Data security and confidentiality
• Continuous availability of the network.
3.4. Data & Data Storage Needs
As per the guidance of Daneshvar Kakhki & Gargeya, (2019, p. 5325), most of the HealthWay datasets are related to individual patients’ data, patients’ records, inpatients and outpatient’s data via clinics. Data storage options recommended for the same HealthWay organisation are:
• Cloud Computing is ideal to store healthcare information. Here, data stored online and considered for both security with latency and privacy for HealthWay.
• Storage Area Network (SAN) to the gynaecology, paediatrics, family medicine departments. SAN option is also applicable to measure the diagnostic data.
• External Storage Devices as Electronic Medical Records (EMR), External hard-disks or SSDs (Graybeal et al., 2018, p. 3276).
• Network Attached Storage System (NAS) stored humongous data churned out by HealthWay organisation. It is one of preferred storage options for HealthWay networks.
4. Evaluation
4.1. Data Layout Plan
With response to the raw data, and data storage, a layout plan has been recommended for the HealthWay information system. This data layout plan has been created by maintaining World Health Organisation (WHO) guidelines.
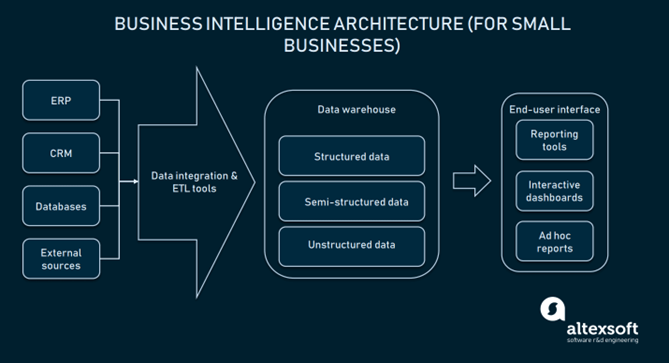
Figure 2: Basic Data structure of HealthWay Hospitality Management System (HMS)
(Source: Carvalho Joa?o et al., 2019, p. 398)
4.2. How it can be Beneficial for Stakeholders
This technical proposal put forth benefits for the HealthWay stakeholders and helps the higher managerial authority, Josh in following way:
• KSoft’s technical proposal is better for project planning, which often meets the dire need of the local communities.
• This proposal is recommended to solve the current healthcare issues.
• It builds with consensus (Beverungen, Matzner & Janiesch, 2017, p. 787).
• This technical proposal gives a plan for monitoring & evaluation
• It helps the researchers, experts to do more research and gives them ideas to move forward within the healthcare industry.
• Both Internal and External stakeholders are able to improve their business operations and marketing with HealthWay.
5. Solution
Understanding the scenario, this proposal provides technical solutions for all the major HealthWay attributes. This solution also created a link between the Case Scenario B and the technical proposal.
5.1. Proposed Solutions
Table 1: Detailed proposed solution for all the key aspects (Source: Jørgensen et al., 2019, p. 155)
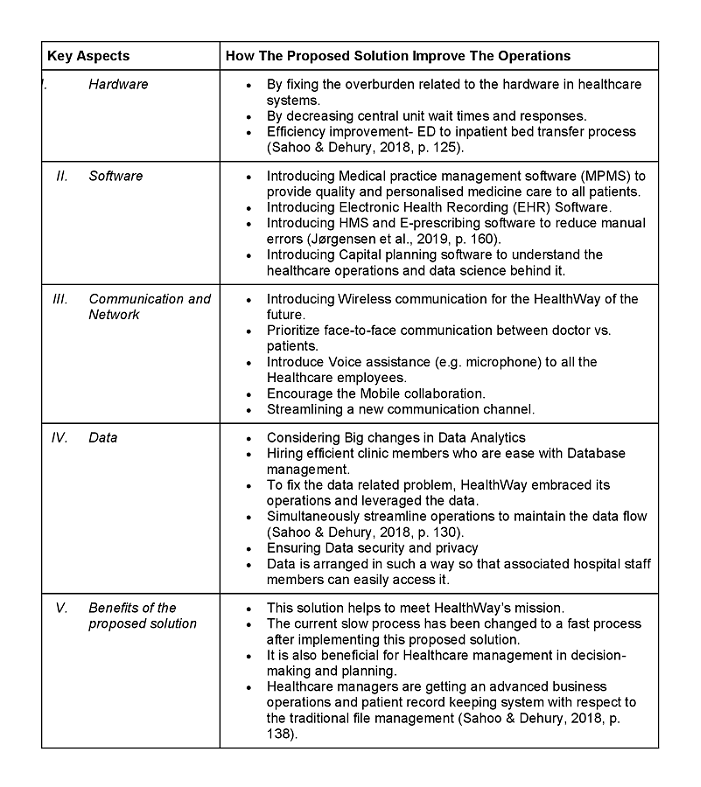
6. Conclusion
After addressing all the HealthWay requirements in a systematic manner, it can be concluded that the proposed solution recommended for the business scenario is appropriate and it provides further ideas to the learner.
6.1. Limitations
Limitations of the proposed solution would be:
• This technical proposal not focusing the managerial problems
• Solutions for cost breakdown, budgeting, human, and other technical resources have not been recommended here.
• This proposed solution is only limited to technical problems.
• Though it is an individual work but sometimes to find the exact solution for an appropriate MIS problem, more than one person is required.
7. References
Beverungen, D., Matzner, M., & Janiesch, C. (2017). Information systems for smart services. Information Systems and E-Business Management, 15(4), 781–787. https://doi.org/10.1007/s10257-017-0365-8
Carvalho Joa?o Vidal, Rocha A?lvaro, van de Wetering, R., & Abreu Anto?nio. (2019). A maturity model for hospital information systems. Journal of Business Research, 94, 388–399. https://lesa.on.worldcat.org/oclc/8089318423
Daneshvar Kakhki, M., & Gargeya, V. B. (2019). Information systems for supply chain management: a systematic literature analysis. International Journal of Production Research, 57(15-16), 5318–5339. https://doi.org/10.1080/00207543.2019.1570376
Graybeal, C., DeSantis, B., Duncan, B. L., Reese, R. J., Brandt, K., & Bohanske, R. T. (2018). Health-related quality of life and the physician-patient alliance: a preliminary investigation of ultra-brief, real-time measures for primary care. Quality of Life Research : An International Journal of Quality of Life Aspects of Treatment, Care and Rehabilitation - an Official Journal of the International Society of Quality of Life Research, 27(12), 3275–3279. https://doi.org/10.1007/s11136-018-1967-4
Jørgensen, R., Scarso, E., Edwards, K., & Ipsen, C. (2019). Communities of practice in healthcare: a framework for managing knowledge sharing in operations. Knowledge and Process Management, 26(2), 152–162. https://doi.org/10.1002/kpm.1590
Sahoo, P. K., & Dehury, C. K. (2018). Efficient data and cpu-intensive job scheduling algorithms for healthcare cloud. Computers and Electrical Engineering, 68, 119–139. https://doi.org/10.1016/j.compeleceng.2018.04.001
Case Study
MIS605 Systems Analysis and Design Assignment Sample
Scenario (The Case) Book reading is an extremely healthy activity. It has many benefits and above all, it is exciting, entertaining and a great way to release stress, anxiety and depression. These are not the only benefits. Above everything; book reading helps in mental stimulation; improvement of memory and it also helps in improving language skills. It also certainly allows an individual to help concentrate better. In short, the benefits are enormous. In recent times we have been introduced to technologies such as laptops, cell phones, tablets and other technologies but to date, the conventional book reading is something that people cherish and enjoy in its own way. It is believed that a “book has no substitute” and book readers from all over the world firmly agree to this. Cynthia, a young technopreneur and a book lover; plans to open an online lifestyle substitute business named ‘bookedbook.com’. This online business is Cynthia’s dream. Cynthia has formally registered her new company, everything is in place from a legal perspective and the company now has ample funds to develop an online website that would support Cynthia’s business idea. bookedbook.com would be an extremely interesting website. This website will require user registration. Children would also be able to register but their registration would be accompanied with some details of parents and their contacts. The website would only offer individual registrations and proof of ID would be a must when registering. bookedbook.com will offer quarterly, biannual and annual memberships. The whole idea is very simple. Registered book readers would be able to launch the books that they own and which they would want to give away to other registered members. A book launch would require complete details of the book. It would also require the user to provide the address where the book is available. Once the book details are provided by the subscriber (registered book reader) the company’s content manager would approve the book launch request. Once approved, the book would be available for all users for them to review and/or acquire. The review process would allow all users to provide feedback and comments about the book and would also allow users to rate the book. The acquisition process would allow book readers to acquire the book from the book owner. The users planning on acquiring the book, would make a request for book acquisition. This request would help facilitate book reader meetup and exchange books. Once the book would be acquired the book owner would have the option of removing the book. bookedbook.com will also allow users to interact with one another via messaging and chat rooms. Users will be given an option to decide the mode of communication that they would prefer. Off course all chat request, messages and acquisition request and all other messages are also provided to the user via email that is provided at the time of subscription. The website would also provide a portal to the administrator for data analytics. Cynthia is keen to observe and analyse every type of data that is obtained at this website. For example, she wants to know which book is being exchanged mostly, she wants complete customer analytics, book exchange analytics, analysis of book reviews and rating and other similar portals for data analysis. As soon as the user registration would expire, all book launch requests would be halted by the system and the users interested in acquiring the book(s) placed by the user whose registration is about to expire would be sent an email that these book(s) are no longer available. Users would be asked to renew their subscription 15 days before the registration expiry date to ensure continuity of services. Cynthia does not want this website to be a book exchange platform only. She also wants the website to provide a platform for all the users to arrange for an online and face to face meetup. She wants to ensure that any book meetup events that bookedbook.com plans should be available to its users. Users should be able to register for these events which may be paid or unpaid. She feels that these meetups would be a great source of fun for book lovers and also a source of marketing for the company. In order to ensure this website stays profitable Cynthia also wants this website to allow book authors from all around the world to advertise their books on bookedbook.com. This functionality, however, would not require book authors to register with bookedbook.com formally. Book authors would be able to just fill in a ‘book show request form’, provide their details, provide the details of their book and a credit/debit card number. They would also provide information about the time period for which they want their book to be advertised on the website. Advertisement requests would also be approved by the content manager. Once approved, the book authors would be charged and the advertisement would go live. The ad would be removed by the system automatically once it reaches the end date. bookedbook.com will only allow advertisement of up to 5 books at a time. All advertisement requests would be entertained by the system on a first come first serve basis. The advertisement functionality is also available for subscribers. In this case the fee for advertisement is very minimal. Cynthia wants this website to be upgradable and secure. She wants simple and modern interfaces and also wants a mobile application version of this website.
Assignment brief:
In response to the case study provided, identify the functional and the non-functional requirement for the required information system and then build a Use Case Diagram and document set of use cases. Context System analysis methods and skills are of fundamental importance for a Business Analyst. This online assignment help allows you to enhance your system analysis skills by capturing the business and then functional and non-functional requirement of a system. It helps you in identifying “what” the proposed system will do and “how”?
Instructions 1. Please read the attached MIS605_ Assessment 1_Case Study. Note that every piece of information provided in the following case serves a purpose. 2. Once you have completed reading the case study. Please answer the following questions for essay help online:
Question 1 (10 mark). Identify all the human and non-human actors within the system. Provide brief description against every actor.
Question 2 (30 marks). Using the information provided in the case study, build a Use Case Diagram using any diagramming software. Note: Please make assumptions where needed.
Question 3 (60 marks). Document all use cases (use case methods). All use cases identified in the Use Case Diagram in Question 2 must be elaborated in detail. Please document each use case using the following template: Use Case Number Use Case Type Base/Abstract (Extends or Includes) Use Case Name Priority Actor Involved Associated Data Sources Associated User Interfaces Pre-Condition(s) Post Condition(s) Detailed Description Normal Course of Events Using a Flow Chart Diagram Alternate Course(s)
SOLUTION
Question-1:
Human Actors:
Management: The management of the bookedbook.com will handle all the process that is going to happen inside the system or outside this. The management will solve the query of the users who will find any difficulty or have any doubts in the system. They are going to generate the subscription and giving approvals to the users to enter the system. The management will maintain the system for the user. The management will decide the price structure and schedule to design the system. The financial approval is must for the management from the client (Hopkins, 2017).
Authors: The author will have a chance to add their books in the system and they can sell their book through it. The author can also generate the advertisement for the books they want to get popular. The author has an interest in different types of book writing and they will be able to get a good book reader from the system so this is helpful for them.
Readers: The readers have an interest to read the different types of books. This system will give them many options to read the books or acquire the books they like. The readers can also exchange the books which they have completed and someone else will require. They will buy a membership from the system to make the book reading and exchanging easy.
Book Sellers: The book sellers are the one who has so many books with them or doing business of the book selling. The book sellers will add the available books and try to sell or exchange it with someone else. The readers who require the book will send the request for book acquiring or exchanging. The book sellers will also organize the event through the system so the readers can attend it and more selling can be possible of their book.
Publications: The publication will print the books for the writers who writes the book. The publication will do contract with the book writers and provide the printing of the books to the different book sellers. The publication house is required to the book writers or authors to let their book gets selling.
Non-human Actors:
Email notification: If the book seller or readers membership is about to get ended then the system should let them know by giving some kind of warning. This is possible by sending the email notifications to them. The email API will ask the system about the users details and send the mail directly to them.
Reminder: The book sellers will arrange the different events in the system. The book readers will take part in such events. Once the book reader registers themselves in the events then it is required to send them the reminder. The system will automatically generate the reminder for the book readers and send it to them through email or SMS(Bron, 2020).
Question-2:
Admin Use case:
Content Manager Use Case:
Book User Use Case:
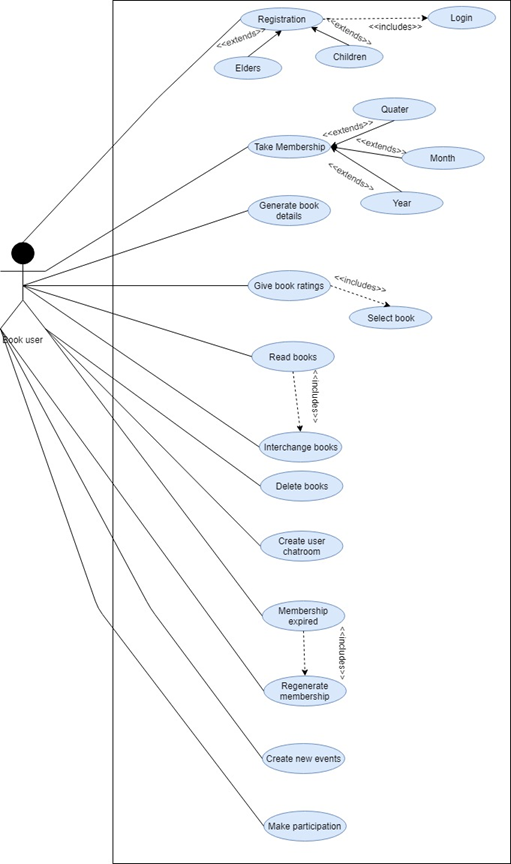
Author Use Case:
Question-3:
Sign in:
.png)
Provide Registration Access:

Enter Subscription Details:
.png)
Create Book Advertising:

Show Book Advertisement:

Generate Book Details:

Take Membership:

Create New Event:

References
Bron, J.Y., (2020). System requirements engineering : a SysML supported requirements engineering method. Hoboken,NJ: s.n.
Hopkins, M., (2017). Systems engineering : concepts, tools and applications. s.l.:Novinka.
Szabo, P. W., (2017). User experience mapping : get closer to your users and create better products for them. s.l.:Packt Publishing.
Research
MIS603 Microservices Architecture Assignment Sample
Question
Assessment Task This research paper should be approximately 2500 words (+/- 10%) excluding cover page, references and appendix. In this assessment, you need to present the different issues that have been previously documented on the topic using a variety of research articles and industry examples. Please make sure your discussion matches the stated purpose of the report and include the cases study throughout. Discuss and support any conclusions that can be reached using the evidence provided by the research articles you have found. Details about the different industry cases studies should NOT be a standalone section of the paper.
Context
Microservices is one of the most rapidly expanding architectural paradigms in commercial computing today. It delivers the fundamental benefits of integrating processes, optimization and Instructions delivering efficiency across many areas. These are core benefits expected in any implementation and the MSA is primarily configured to provide the functional business needs. On-the-one-hand, MSA can be leverage to provide further benefits for a business by facilitating:
• Innovation— reflecting the creation of novel or different services or businesses processes, or even disruptive business models.
• Augmented Reality — reflecting the situation where superimposing images and data on real objects allowing people to be better informed.
• Supply chain— reflecting how the MSA enables closer communication, engagement and interactivity amongst important external or internal entities.
On-the-other-hand culture is the totality of socially transmitted behaviour patterns, attitudes, values and beliefs, and it is these predominating values and behaviours that characterize the functioning of an individual, group or organisation. Organizational culture is what makes employees feel like they belong and what encourages them to work collectively to achieve organizational goals. Extant IS implementation studies have adopted culture theory to explain how organisations respond to implement a MSA system in their workplace, and how these responses lead to successful or failed implementations. As a professional, your role will require that you understand the benefits of MSA, especially in these three areas, which are significantly becoming the preferred strategy to achieve competitive advantage for many organisations. The purpose of this report is to engage you in building knowledge about how these benefits achieve in an organisational environment with a specific focus on how and why organisational culture can influence the successful implementation of an MSA within an organisation.
Task Instructions (the scenario)
You suppose to work for your selected organization (in assessment 2) and have read reports of other organisations leveraging the MSA application in three areas (innovation, augmented reality and supply chain). Accordingly, you need to prepare a research report for management on how the MSA application can be used to deliver benefits in these areas as well as how and why organisational culture can influence the successful implementation of an MSA. Use at least 2 different case study examples for showing the benefits can be achieved by organisations.
The report should consist of the following structure: A title page with subject code and name, assignment title, student’s name, student number, and lecturer’s name.
The introduction (250–300 words) that will also serve as your statement of purpose for the proposal—this means that you will tell the reader what you are going to cover in your proposal. You will need to inform the reader of:
a) Your area of research and its context
b) The key elements you will be addressing
c) What the reader can expect to find in the body of the report
The body of the report (1900–2000 words) will need to focus on these three areas (innovation, augmented reality and supply chain) also organisational culture to develop your research paper. Particularly, you need to prepare a research report for management on how the MSA application can be used to deliver benefits in different organisational environments- cultures.
The conclusion (250–300 words) will summarise any findings or recommendations that the report puts forward regarding the concepts covered in the report.
Answer
Introduction
MSA or microservice architecture is an architectural project management approach where the services or features are micro niche-based and specific in terms of usability as well. Nowadays, all the large and small organizations are implementing this architecture to minimize their cost. With several, real-life case studies the use and implementation of MSA can be clear in this report.
The key element is MSA and real-life organizations. The connection between these two elements is essential in this competitive market. There are also some issues with the system, which can be resolved easily with this project management approach.
The report consists of project management aspects and other essential factors. Companies are implementing this concept through their niche bae projects to lower their expenses. It eventually increases the profitability and sustainability of the business as well. System issues can be solved easily with more consumer engagement. System design and use will be specific and certain teams will also be there to support the consumers. In this way, the whole customer base will experience better design and features. This is the basic reason, that companies are planning and developing microservices. In this report, two real-life case studies are taken into consideration. Amazon, a web-based company, have developed two cloud based software, such as amazon music and amazon prime video. Through cloud computing technology they are providing different microservices. The implementation procedure and benefits are discussed ad well. This will eventually show the core features, aspects and significance of MSA or microservice architectural approach through three aspects mainly. innovation, augmented reality and supply chain will be majored or considered in these two organizations with detailed discussion and risk management as well (Wang et al., 2020).
MSA Project Management Approach
MSA project management approach is basically used in small and niche-based projects. Here, all the project components are planned and built into one focus feature. Several organizations like Amazon are using or implementing this approach to build and manage their new projects or products. In this way, the projects are also micro service-based. Every stakeholder can focus on one single project development and improvement. It is also easier for project manager to handle small amount of teams. In that way, he can engage or involve every team equally with the project. The project will be come successful. On other hand, the feedback sorting and organising team can also work on specific number of issues. In this way, the team can also be trained in specific ways. Whole project will experience better efficiency and improvement. Consumers of the system will also experience the results in form of better functionality and engagement.
This management approach has significant impact, several organisational cultures. These organisational cultures are the results of specific scenarios or systems. While implementation of MSA in Amazon products, these cultures have associated with different systems and policies. Three organisational culture scenarios are mentioned here with detailed discussion on MSA implementation.
MSA in Different Organisational Cultures
Several organisations like Amazon are using or implementing this methodology or project management approach. Implementation in two amazon cloud based products will be discussed in terms of innovation, augmented reality and supply chain. Starting from the implementation procedure to the benefits or significance will be mentioned in detail. Through this part of the report, organisational culture can also be derived. Three organisational cultures are discussed here through MSA implementation.
Each of these organisational culture scenarios are made of different systems. Amazon has taken different initiatives to change the workflow and working system inside the organisation. They have developed different workplace environments and work cultures to increase work efficiency and over-all productivity. In this way, different organisational cultures are implemented on employees and other major stakeholders. Implementation results are also very specific. Whole project management becomes efficient. On other hand, time accuracy is also another benefit of these cultures. All the three cultures, which are mentioned here, are discussed through MSA or micro service architectural project management approach.
Boldness
Boldness is an organisational culture scenario, where all the employees and stakeholders are influenced and motivated to be bold with the maintenance of all the products of s certain organization. MSA is an architectural approach, where a small cloud base project is focused. The organization provides a dedicated team and project manager as well. All these things pr elements allow the stakeholders and employees to be specific and particular in objective. There they can use their specific ideas and scope of development in the project. In this way, the whole project management team becomes bold along with the team manager as well. In this way, the whole project becomes better and efficient. Eventually, the profit growth comes at place and the organizational culture becomes bold and efficient as well. The internal and external structure of the organization goes through certain changes as well. This change in the supply chain is a basic characteristic of this microservice architectural or MSA project management approach. All the organization is segregated with different products here. The boldness of the company becomes higher here with this methodology (Pacheco, 2018).
Customer-Centricity
The organization targets a separate consumer base in different parts with different services and products. One single system is not handling every objective. In this way, MSA is implemented through an organization. Small projects and niche-based software are provided by the teams. In this way, all the products satisfy particular and specific needs of targeted consumers.
All the consumers will experience better and dedicated service from one dedicated team and project managers. The project also becomes better with time. The whole project becomes more customer-centric and specific. It also influences the customer experience. The consumer gets better design in the user interface or UI. A better support system is also provided here because every project gets separate support team management. Here, all the people are experienced and trained for this particular support system (Project Management Institute, 2017).
Here the augmented reality of MSA application or implementation becomes significant. Consumers are the key-stakeholder here, who are going to experience detailed systems and features according to their small needs and requirements as well. In the end, this whole customer-centricity can be well-defined and implemented by this MSA project management approach (Meyer, 2017).
Peculiarity
It is also another organizational culture or system, where new innovations take place. From the first place, the significance of MSA implementation is very clear here. The whole concept is based on innovating a new product feature or product component. Innovation comes the basic or primary characteristic of the MSA project management approach. In that case, this character or feature will definitely influence this part of organizational culture (Project Management Institute, 2019).
With this innovative approach, the project manager can achieve so many unexpected results and develop planning accordingly. Market research and analytical reports cannot always show the required features of the consumers. It is the work of the development team and other stakeholders to develop something innovative for a better user experience. With MSA, a dedicated team will work on a specific project, which will appreciate the potential of new innovations as well. It becomes easier to make new system policies or modifications (Atesmen, 2015).
Amazon Success Stories
Amazon is one of the largest companies in the world. All the people around the world, are experiencing amazon products for a better lifestyle and exciting features. Amazon is providing best cloud-based software with exciting usability for the last decade. These products are all based on MSA or microservice architectural, project management approach. All those projects are real-life business examples of MSA approach implementation. Those project management and development teams have implemented all the characteristics and features, of the MSA project management approach or methodology. Here two of those success stories will be discussed in detail for a better understanding of MSA implementation.
Amazon Prime Video
Amazon prime video is one of the most significant software, which includes one of the major profitability factors as well. This is basically a video streaming software or platform, where web series and movies around the world are uploaded. Some own production projects are also developed here. With prime membership of amazon, this prime video account is offered. People can experience the facilities through the application as well.
This product of the project is also developed with proper implementation of the MSA project management approach. All the primary features of the MSA approach is clearly discussed here through this specific project by amazon.
Firstly, the innovation is implemented particularly in this project. There are so many other video streaming platforms, apart from amazon, such as Netflix. In that case, the project management team has to plan and develop some unique strategies to make this platform profitable and beneficial for the consumers or viewers. The system provides a new collection of contents in the first place. On other hand, the prime membership structure also makes this significant. These modifications have helped this product to stand out in the competitive market. It shows the proper use of innovation here. Another exciting feature is provided as well, which is student membership. Student membership can be bought at lower rates at amazon prime video. That also played a significant role in amazon profitability and growth (Nikolakis et al., 2020).
Innovative cost distribution or plans categorization is also very specific here along with an innovative approach. Several screens are provided by Amazon, where more than one person can enjoy the platform and contents accordingly. It makes the system more exciting and attractive to different consumers around the world.
The next feature of the microservice architectural, project management approach is augmented reality. Here, the consumers are focused. This micro product or project is based on a specific and targeted audience. In that case, the team can modify and develop all the features and modifications accordingly. Amazon prime video has uploaded a separate collection of popular movies and web series for better expenditure. Eventually, consumers get the highest benefit. This is another factor of amazon prime video success and shows the significance of MSA implementation as well (Watts, 2019).
Lastly, the supply chain takes place. Here all the external and internal structures are considered along with team engagement and efficiency. In this case, also, this MSA approach is well-implemented. This approach changes the whole working culture or the environment of the system as well. Here, all the tea is dedicated to one software which is amazon prime video. That is the reason, why team engagement is more efficient. All the stakeholders of the system are well connected through communication and management. It is also easier for the project manager to handle a small and dedicated team (Nadareishvili et al., 2016).
Amazon Prime Music
Amazon prime music is also another cloud-based amazon product that basically presents a broad collection of songs to consumers around the world. Here all the consumers can hear the music with regular ads and exciting features. On other hand, with a subscription, they can also download the songs at a certain level. There are so many music streaming platforms as well, such as YouTube Music and Spotify. In that case, also, this software stands out in this competitive market through this MSA project management method or approach. All the features of this project management approach have built this system or product in a unique way of implementation and profitability.
Firstly, the innovation part takes place, which is the most relevant feature or characteristic of MSA or microservice architectural, project management approach. In this competitive market of music streaming platforms, amazon music also provides some extra features and offerings which holds the business. In this approach, it is easier to do because the whole team is dedicated to that single software or web-based product. In that case, the whole development and management teams focus on those certain developments. For that reason, consumers are also getting bigger benefits as well (Kerzner, 2013).
The second feature is called augmented reality. Here the consumers are the key stakeholder. All these features are implemented to improve the product or the service in a particular way. All the features become better with the system and updates. In this product also, everything is being built according to the customer needs and feedbacks. In the MSA approach, the design is also considered for better user experience and engagement. In this way, all the consumers can experience better facilities along with better project management. The support team is also dedicated to specific problems and technical issues, so the consumers get the solutions easily and efficiently. This whole part shows the significance of MSA implementation in the project of amazon prime music. With a subscription, all the consumers get better plans and experiences which make the whole thing more engaging as well.
Lastly, the supply chain takes place. This is the part, where all the internal and external structure changes of the organization are being discussed according to the MSA Approach. With this approach, the team members and various stakeholders become more engaged with each other and the communication becomes stronger. When all the people are working on a single niche, then it is also easier for the project manager to coordinate with all the segregated teams. In this way, involvement of implementation of MSA or microservice architectural, project management approach, company gets better profitability and growth matrix (McLarty, 2016).
Conclusion
This whole report is based on MSA or microservice architectural, project management method or approach. In this approach, certain things are being considered and those also influence any business model especially cloud-based business. With this approach, organizations can achieve a better success rate with broad cost-efficiency and fewer issues.
All the features and implementation procedures of this approach are discussed throughout the report. After that, all the essential work cultures are mentioned and discussed. This shows certain improvements, which are done by this particular approach. This can be beneficial for any kind of scenario, in different ways. On other hand, the features of the characteristics of MSA, are used differently in different scenarios or cultures. The way of implementation is also different here.
Lastly, the real-life business example has also been taken, which is amazon product-based. Amazon prime music and amazon prime video are the two cloud-based products, where amazon has used or implemented this MSA project management method. The whole project has become more successful and significant in this way. All the three characteristics of this approach, such as innovation, augmented reality and supply chain, are implemented in a proper and particular way. Here, both of the products are discussed in terms of that characteristic implementation ad well. All the factors are majored and evaluated accordingly. This report eventually shows the whole implemented structure of this project management approach. On other hand, how other several companies can implement and use this MSA, is explained here. This also presents all the significance of the system as well. On other hand, this report also present some factors, of this approach as well, which has a large impact on cloud based business model. Every aspect of the business model is also discussed. Organization can assess the business and current situation of the business through this report as well.
References
Atesmen, M. K. (2015). Project management case studies and lessons learned : stakeholder, scope, knowledge, schedule, resource and team management. CRC Press. https://lesa.on.worldcat.org/v2/oclc/895660999
Kerzner, H. (2013). Project management : case studies (Fourth). John Wiley & Sons. https://lesa.on.worldcat.org/v2/oclc/828724601
McLarty, M. (2016). Microservice architecture is agile software architecture. Javaworld, N/a. https://lesa.on.worldcat.org/v2/oclc/6858739262
Meyer, P. (2017). Amazon.com Inc.’s Organizational Culture Characteristics (An Analysis). http://panmore.com/amazon-com-inc-organizational-culture-characteristics-analysis
Nadareishvili, I., Mitra, R., McLarty, M., Amundsen, M. (2016). Microservice architecture : aligning principles, practices, and culture (First). O'Reilly Media. https://lesa.on.worldcat.org/v2/oclc/953834176
Nikolakis, N., Marguglio, A., Veneziano, G., Greco, P., Panicucci, S., Cerquitelli, T., Macii, E., Andolina, S., Alexopoulos, K. (2020). A microservice architecture for predictive analytics in manufacturing. Procedia Manufacturing, 51, 1091–1097. https://lesa.on.worldcat.org/v2/oclc/8709224754
Pacheco, V. F. (2018). Microservice patterns and best practices : explore patterns like cqrs and event sourcing to create scalable, maintainable, and testable microservices. Packt Publishing. https://lesa.on.worldcat.org/v2/oclc/1022785200
Project Management Institute. (2017). Project manager competency development framework (Third). Project Management Institute. https://lesa.on.worldcat.org/v2/oclc/974796222
Project Management Institute. (2019). Project management institute practice standard for work breakdown structures (Third). Project Management Institute. https://lesa.on.worldcat.org/v2/oclc/1107878459
Wang, R., Imran, M., Saleem, K. (2020). A microservice recommendation mechanism based on mobile architecture. Journal of Network and Computer Applications, 152. https://lesa.on.worldcat.org/v2/oclc/8520178287
Watts, A. (2019). Modern construction case studies : emerging innovation in building techniques (2nd ed.). Birkha?user. https://lesa.on.worldcat.org/v2/oclc/1110714056
Programming
MIS602 Data Modelling and Database Design Assessment Sample
Question
The following case study models a mobile phone company. The company has a number of phones that are sold by staff to various clients. Each phone comes with a plan and each plan has a number of features specific to that plan including:
• a call charge in cents per minute (this does not apply to all plans)
• a plan duration in months
• a break fee if the customer leaves the plan before the end of the plan duration
• a monthly data allowance in gigabytes
Assumptions that are made for the assignment are:
• mobile phones are locked to a plan for the length of the plan duration
Task Instructions
Please read and examine carefully the attached MIS602_Assessment 2_Data Implementation_ Case study and then derive the SQL queries to return the required information. Your focus should be providing the output as meaningful and presentable possible. Please note extra marks will be awarded for presentation and readability of SQL queries.
Please note all the SQL queries should be generated using MySQL server either using MySQL workbench or MySQL Command Line Client.
Provide SQL statements and the query output for the following:
1 Find all the customers whose surname or given name contains the string ‘IND’.
2 Find the total number of female staffs currently working in the company?
3 List all the staff who have resigned after 2018 who were living in any part of CARLTON.
4 List all the staff who gets a pay rate below-average pay rate?
5 Find the supervisor name of the youngest staff.
6 List the most popular plan. If there are more plans (ties), you should display both.
7 List the total number of plans sold by each staff including their name.
8 List the customer id, name, phone number and the details of the staff who sold the plan
to the customer?
9 List the all the staff (staffid and name) who are active not having any supervisor
assigned.
10 How many calls were made in total during the weekends of 2019?
11 The company is considering giving a 10% increase in payrate to all the staff joined before
2012.
(a) How many staff will be affected? Show your SQL query to justify your answer.
(b) What SQL will be needed to update the database to reflect the pay rate increase?
12 Which tower (Towerid, Location) was used by the customer 20006 to make his/her first
call.
13 List all the unique customers (CustomerId, name) having a same colour phone as
CustomerId 20008.
14 List the CustomerID, Customer name, phone number and the total duration customer
was on the phone during the month of August, 2019 from each phone number the
customer owns. Order the list from highest to the lowest duration.
15 i. Create a view that shows the popularity of the plans based on number of plans sold.
ii. Use this view in a query to determine the most popular plan.
16 List all the plans and total number of active phones on each plan.
17 Write an SQL query to join all the seven tables presented in this database taking at least
two columns from each table.
18 List the details of the youngest customer (CustomerId, name, dob, postcode) in postcode
3030 along with total time spent on calls in minutes. Assume call durations are in Seconds.
19 After evaluating all the tables, explain with reasons whether any of the tables violate the
conditions of 3rd Normal Form.
20 In not more 200 words, explain at least two ways to improve this database based on
what we have learned in 1st - 8 th Week.
Answer
Q1 Find all the customers whose surname or given name contains the string ‘IND’.
select * from customer where Surname like '%IND%' or Given like '%IND%';
Q2 Find the total number of female staffs currently working in the company?
select count(*) as 'Female Staff' from staff where Sex ='F';
Q3 List all the staff who have resigned after 2018 who were living in any part of CARLTON.
select * from staff where year(Resigned)>=2018 and Suburb like '%CARLTON%';
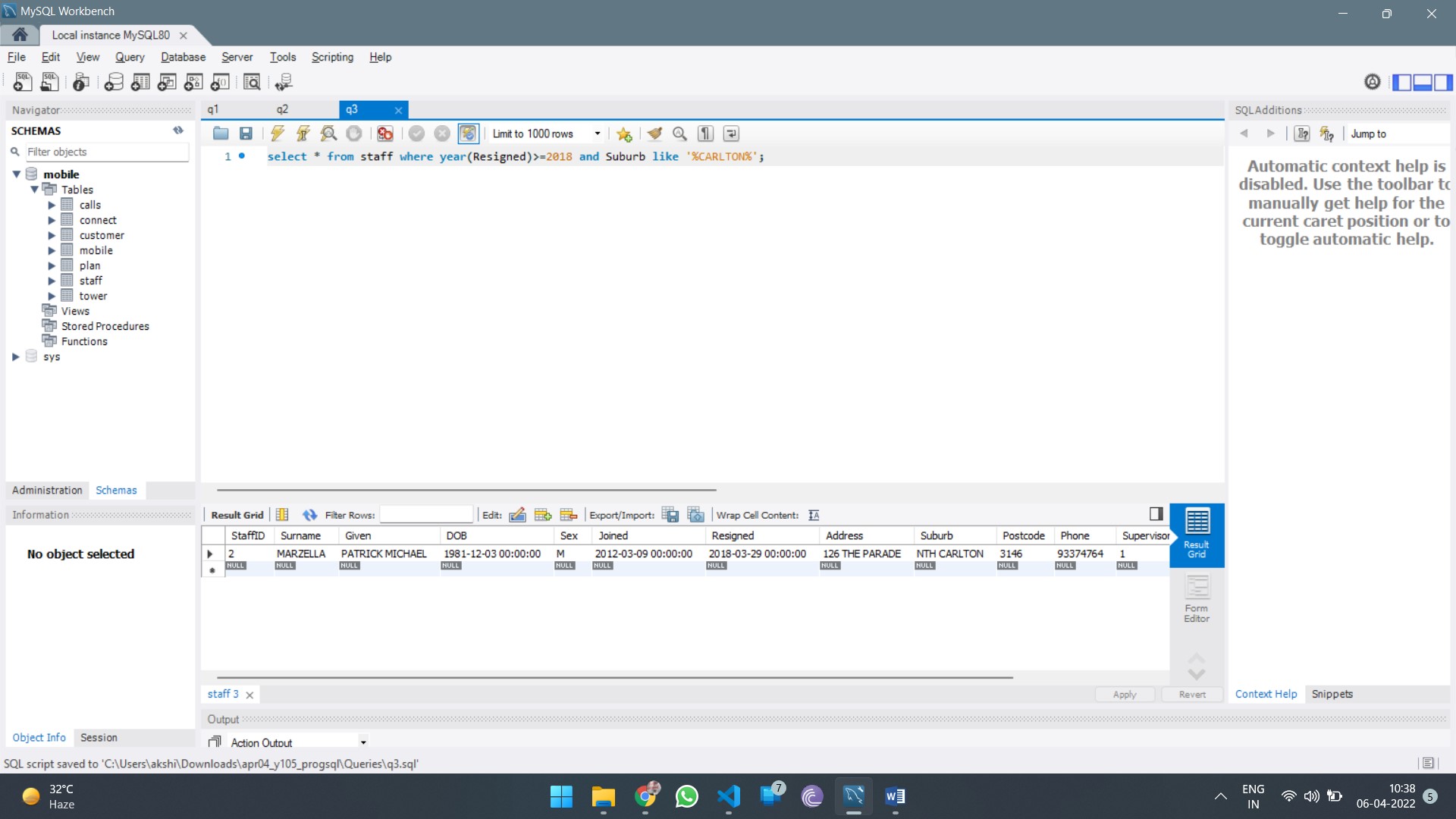
Q4 List all the staff who gets a pay rate below average pay rate?
select * from staff where RatePerHour <= (select avg(RatePerHour) from staff);
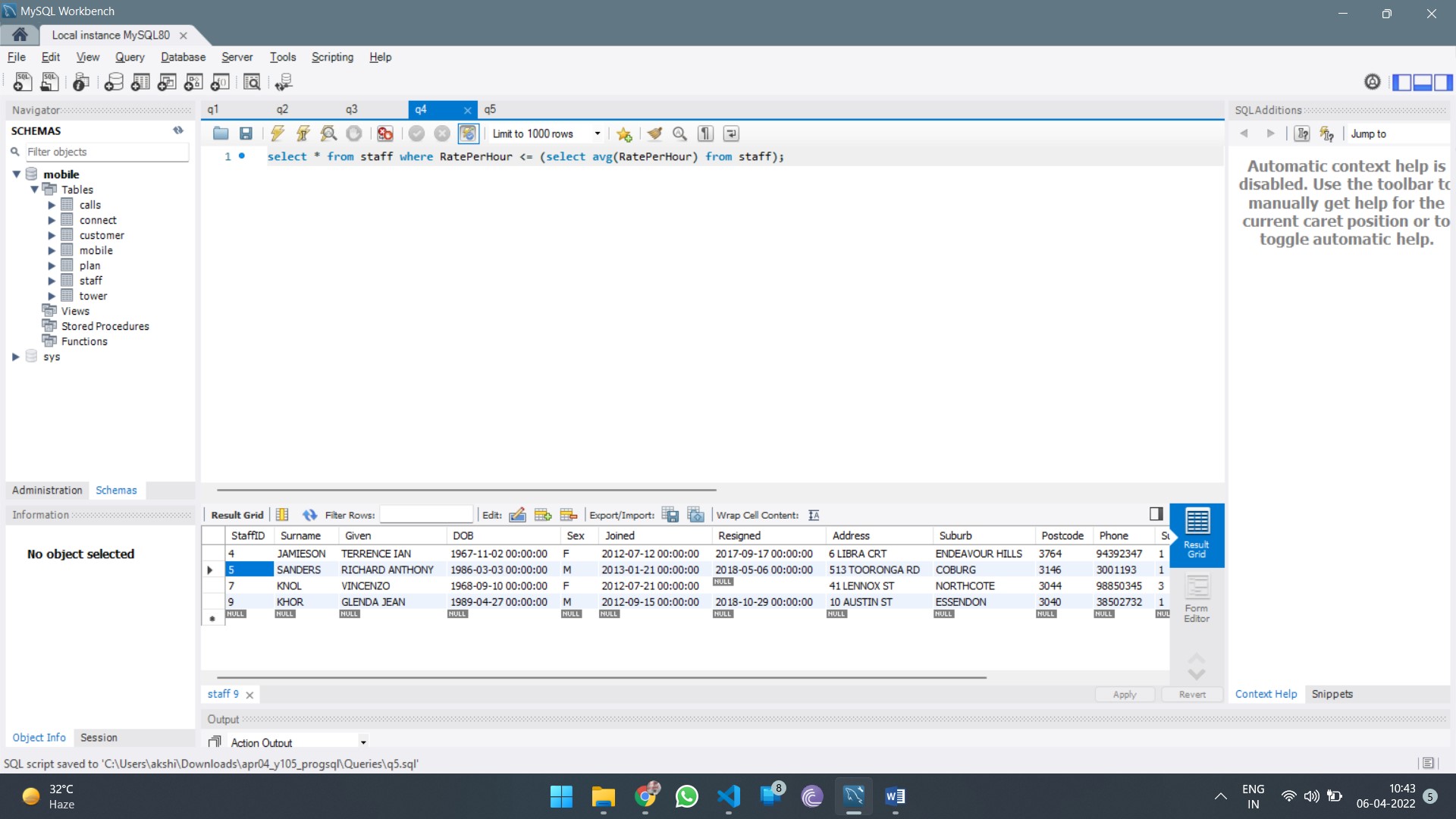
Q5 Find the supervisor name of the youngest staff.
select Given from staff order by DOB desc limit 1;
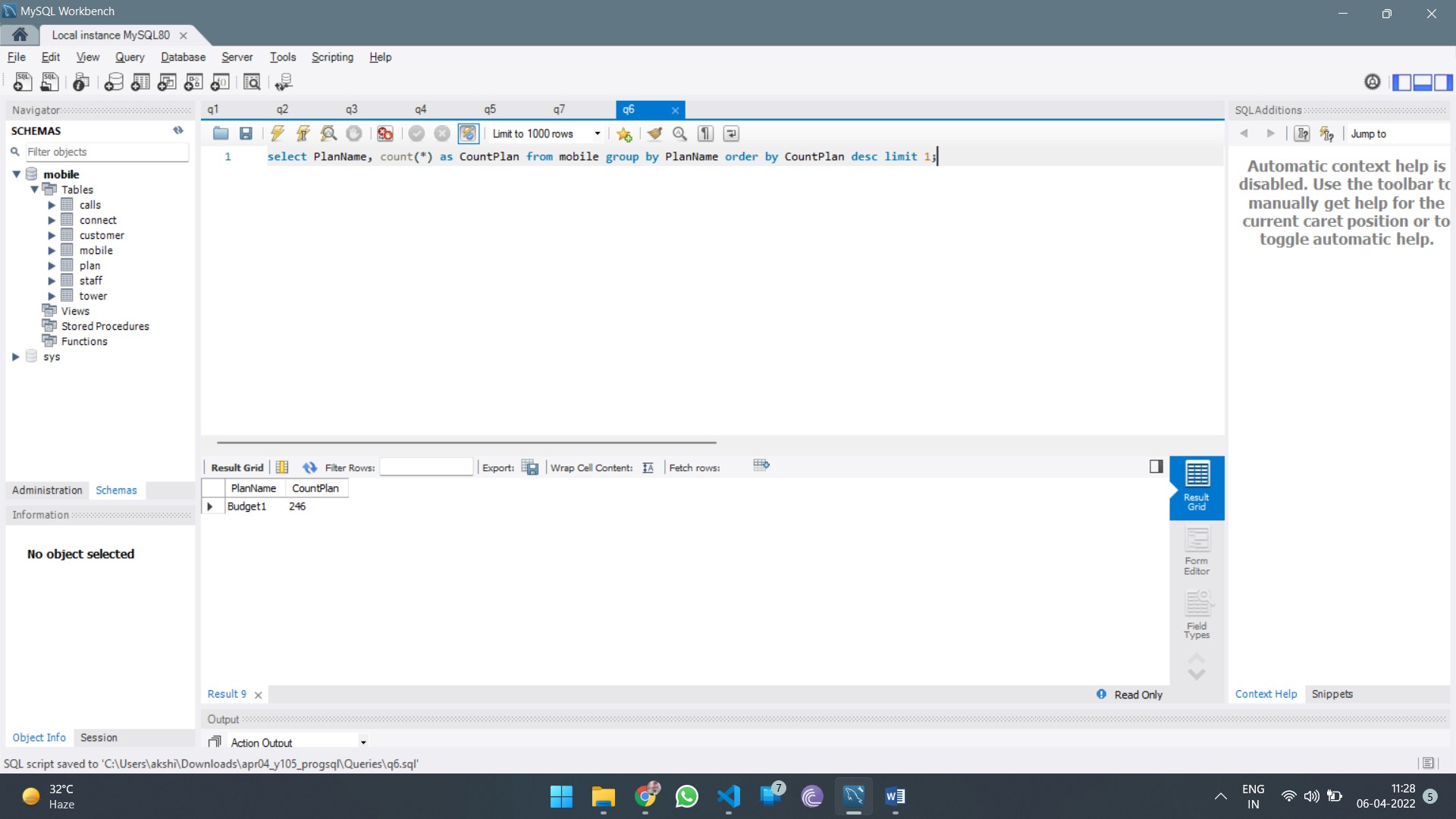
Q6 List the most popular plan. If there are more plans (ties), you should display both.
select PlanName, count(*) as CountPlan from mobile group by PlanName order by CountPlan desc limit 1;
.jpg)
Q7 List the total number of plans sold by each staff including their name.
select staff.Given, count(*) as 'Number of plans' from mobile left join staff on staff.StaffID = mobile.StaffID group by mobile.StaffID;
.jpg)
Q8 List the customer id, name, phone number and the details of the staff who sold the plan to the customer?
select c.CustomerID, c.Given, m.PhoneNumber, s.* from mobile as m left join customer as c on c.CustomerID = m.CustomerID left join staff as s on s.StaffID=m.StaffID;
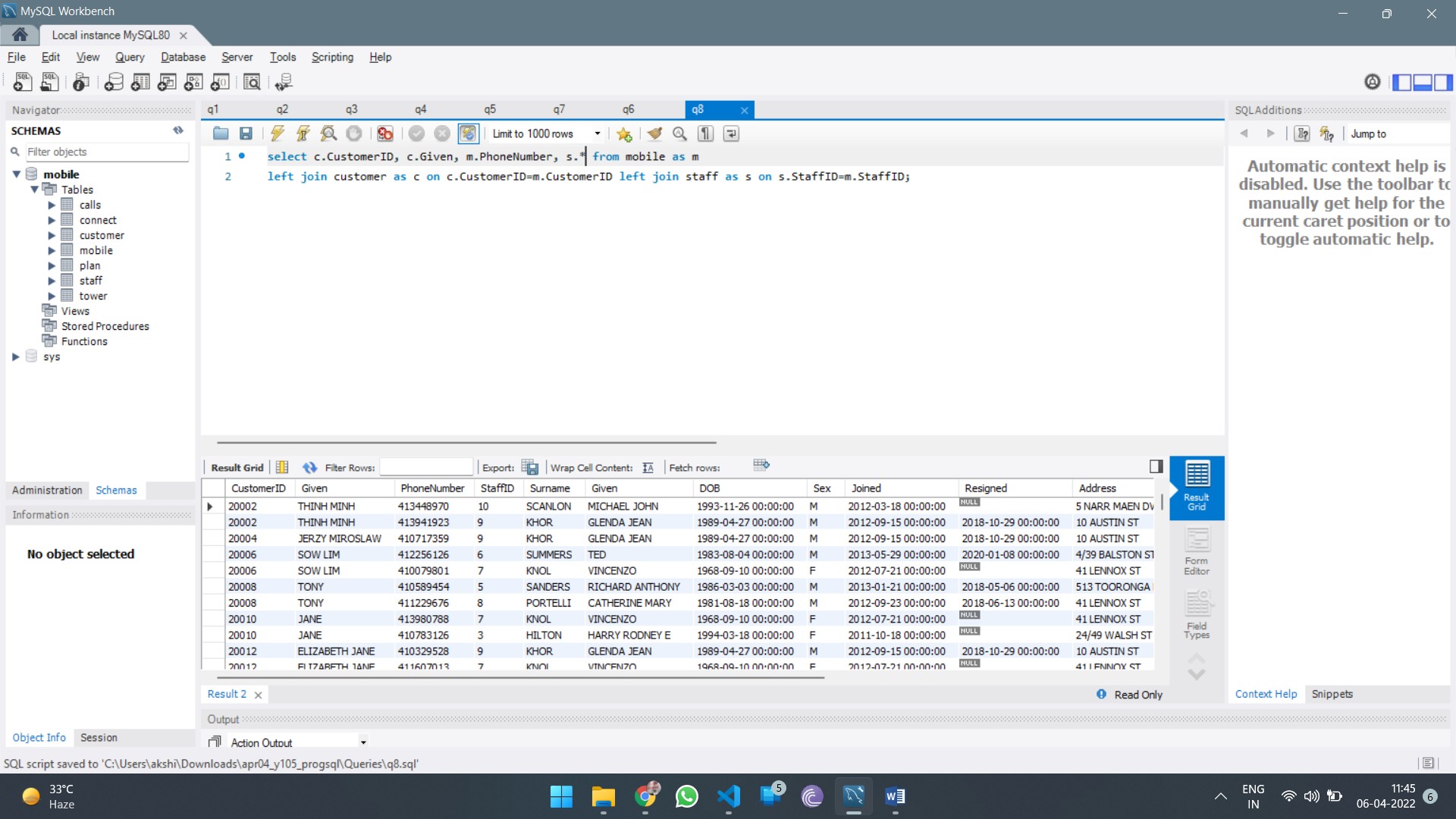
Q9 List the all the staff (staffid and name) who are active not having any supervisor assigned.
Select staffID, Given from staff where SupervisorID=0 and Resigned is null;
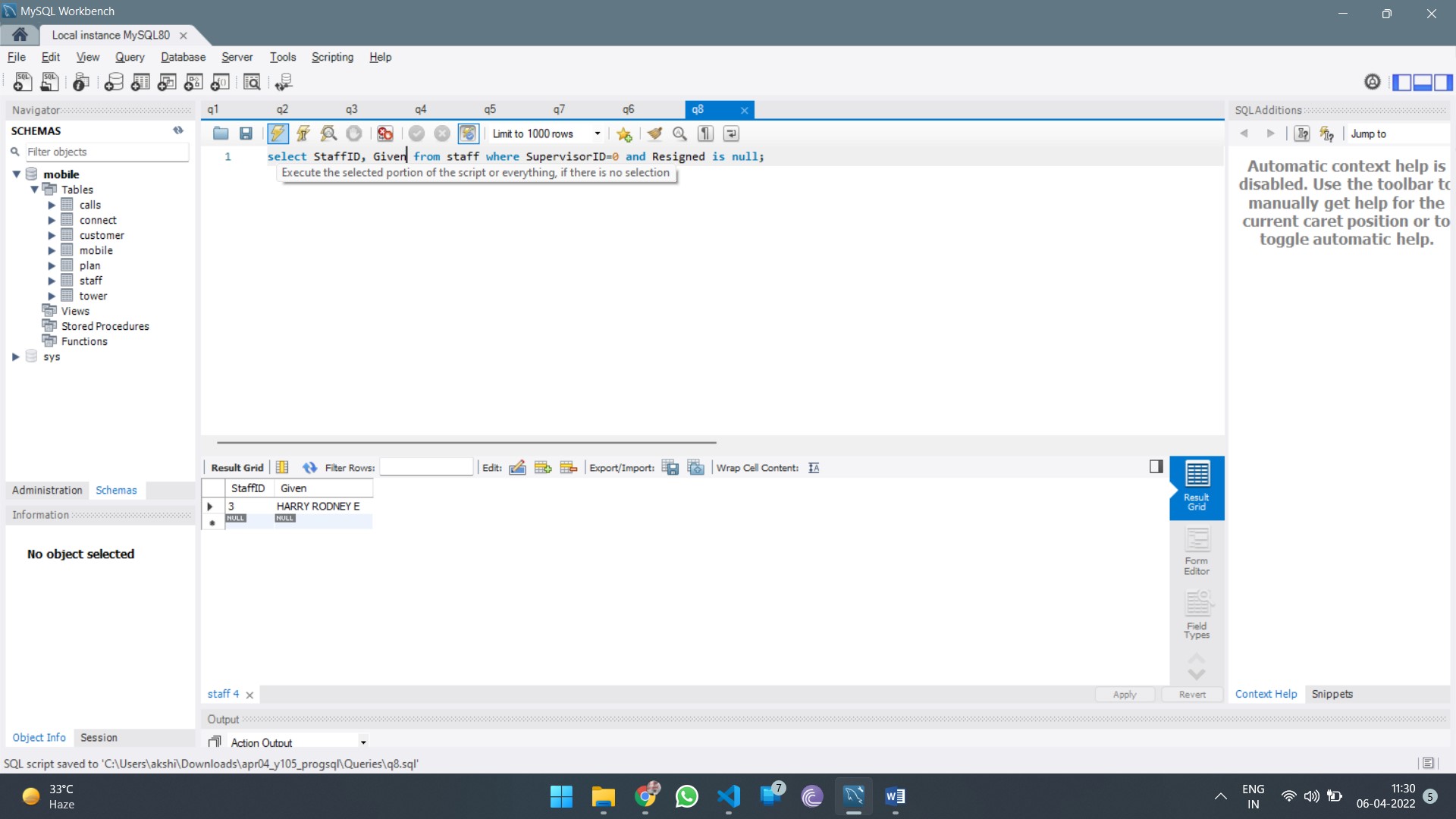
Q10 How many calls were made in total during the weekends of 2019?
select count(*) as 'Total calls' from calls where weekday(CallDate) in (5,6) and year(CallDate)=2019;
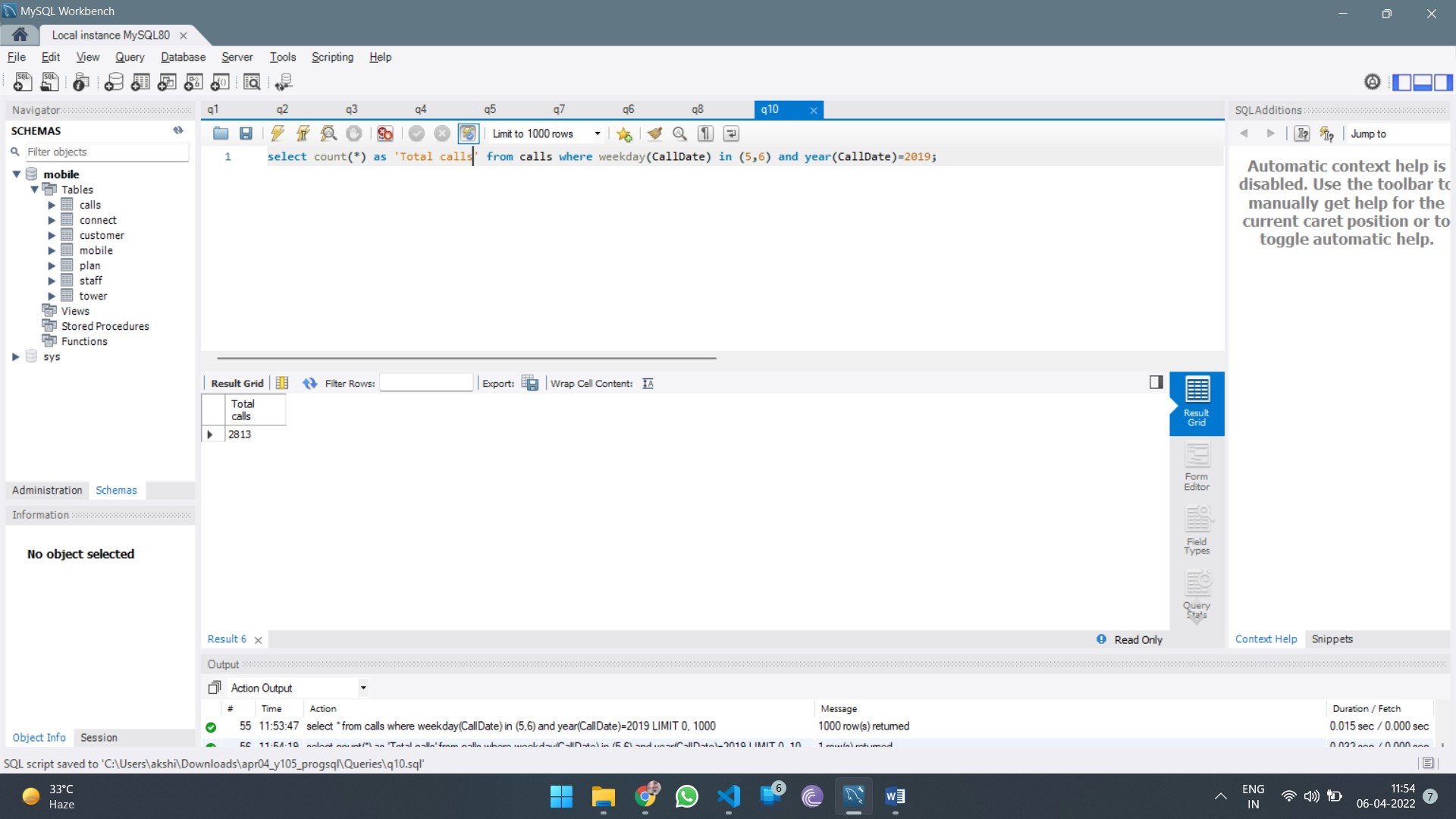
Q11a The company is considering giving a 10% increase in payrate to all the staff joined before 2012.
How many staff will be affected? Show your SQL query to justify your answer.
select count(*) as 'Total staff' from staff where year(Joined)<=2012;
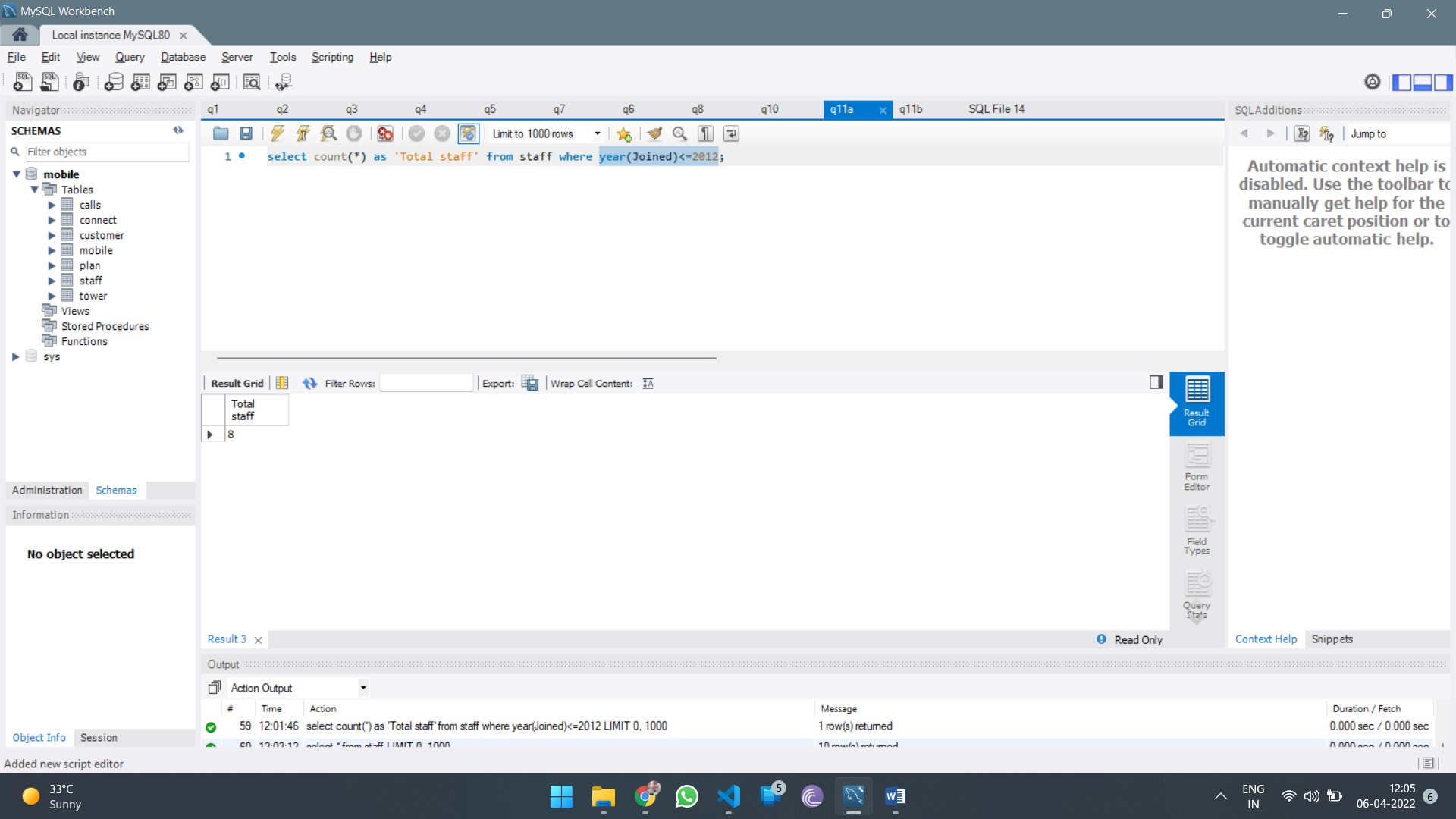
Q11b What SQL will be needed to update the database to reflect the pay rate increase?
update staff set RatePerHour = RatePerHour*1.10 where year(Joined)<=2012;
Q12 Which tower (Towerid, Location) was used by the customer 20006 to make his/her first call.
select t.TowerID, t.Location from mobile as m left join calls as c on c.MobileID=m.MobileID left join connect as cn on c.CallsID=cn.CallsID left join tower as t on t.TowerID=cn.TowerID where CustomerID=20006 order by c.CallDate desc limit 1;
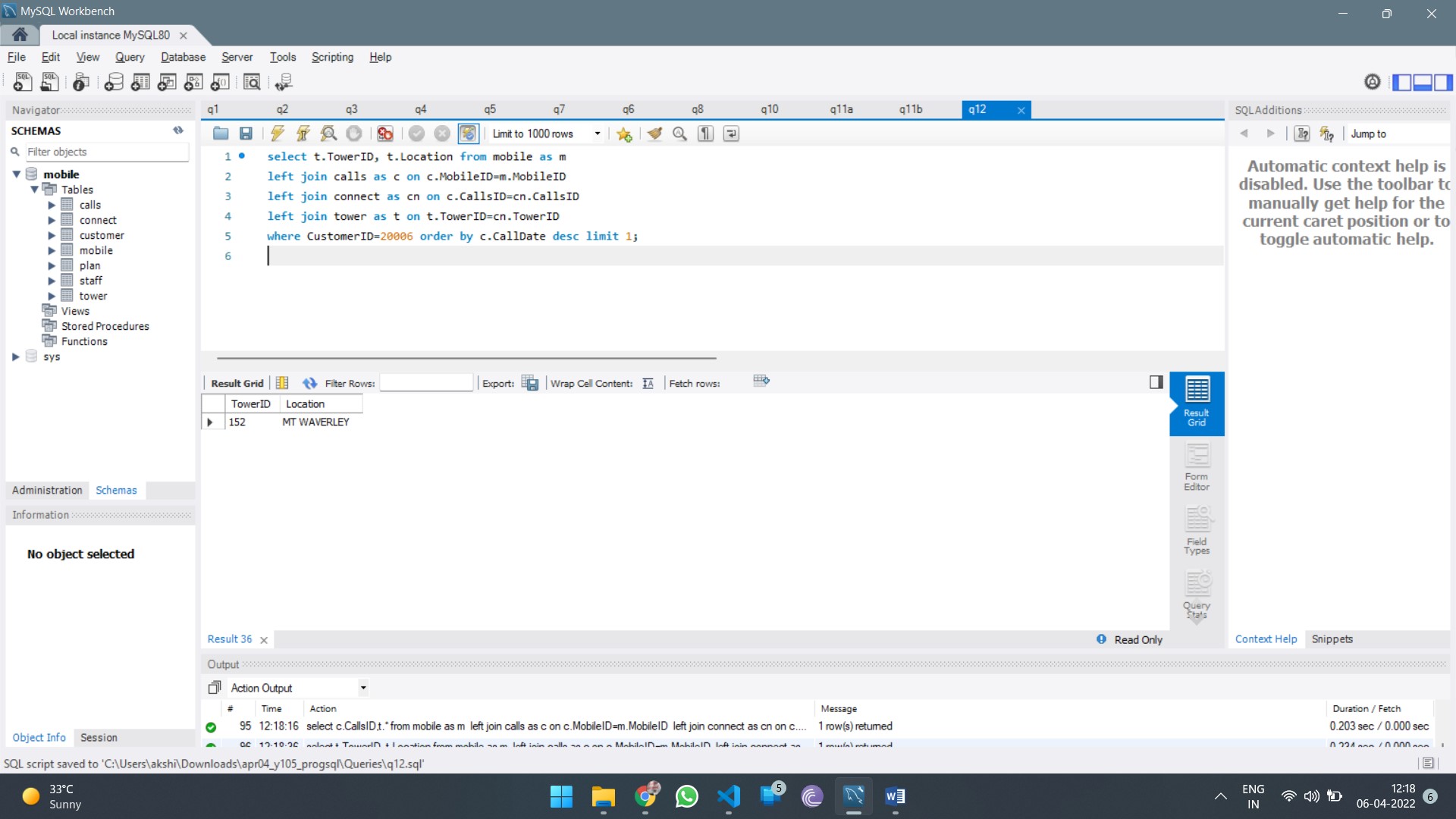
Q13 List all the unique customers (CustomerId, name) having a same colour phone as CustomerId 20008.
select distinct(m.CustomerID), c.Given from mobile as m left join customer as c on c.CustomerID=m.CustomerID where PhoneColour in (select PhoneColour from mobile where CustomerID=20008);
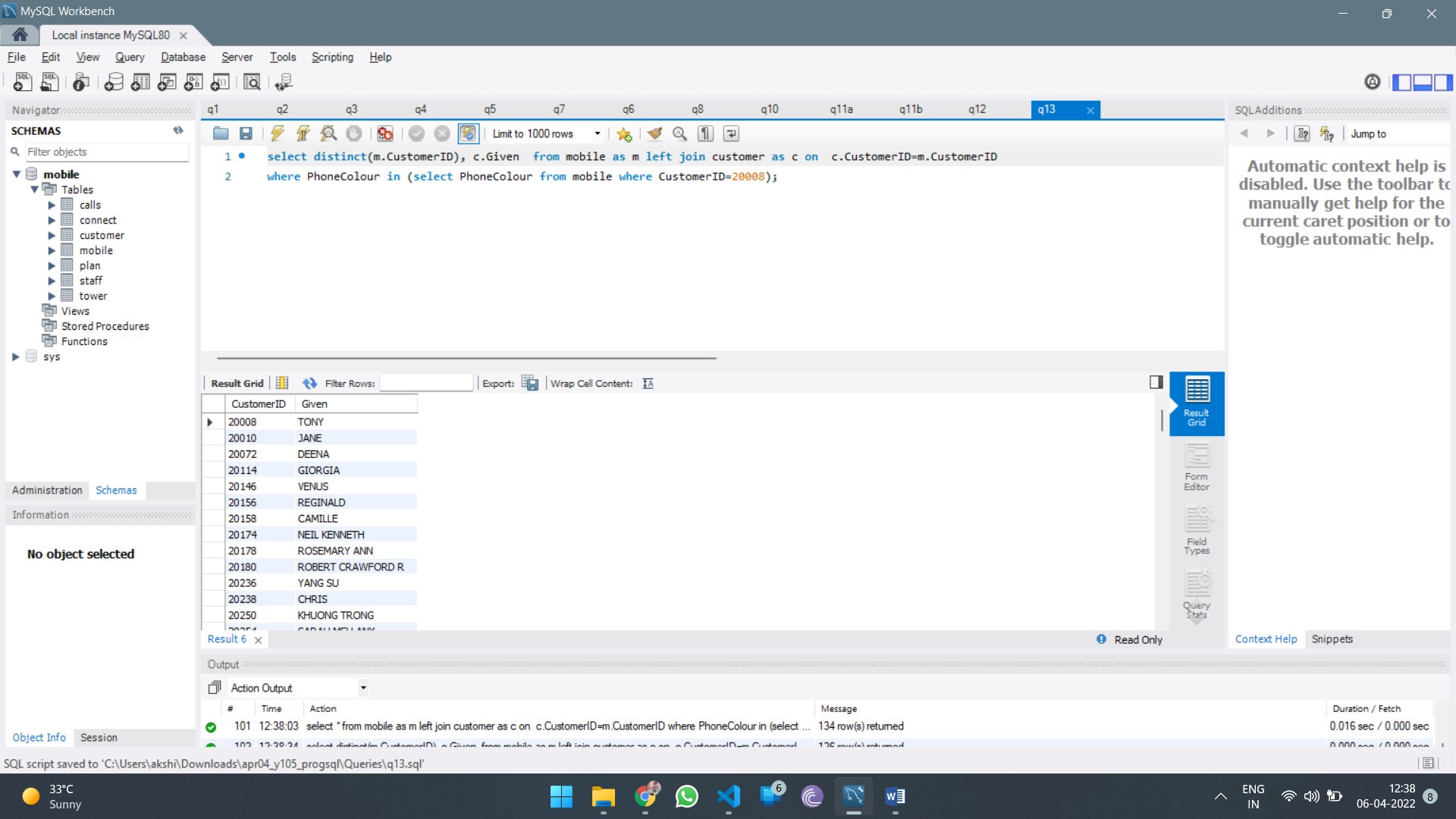
Q14 List the CustomerID, Customer name, phone number and the total duration customer was on the phone during the month of August, 2019 from each phone number the customer owns. Order the list from highest to the lowest duration.
select cs.CustomerID,cs.Given,m.PhoneNumber, sum(c.CallDuration) as TotalDuration from calls as c left join mobile as m on m.MobileID=c.MobileID left join customer as cs on cs.CustomerID=m.CustomerID where year(c.CallDate)=2019 and month(c.CallDate)=8 group by m.MobileID order by TotalDuration desc;
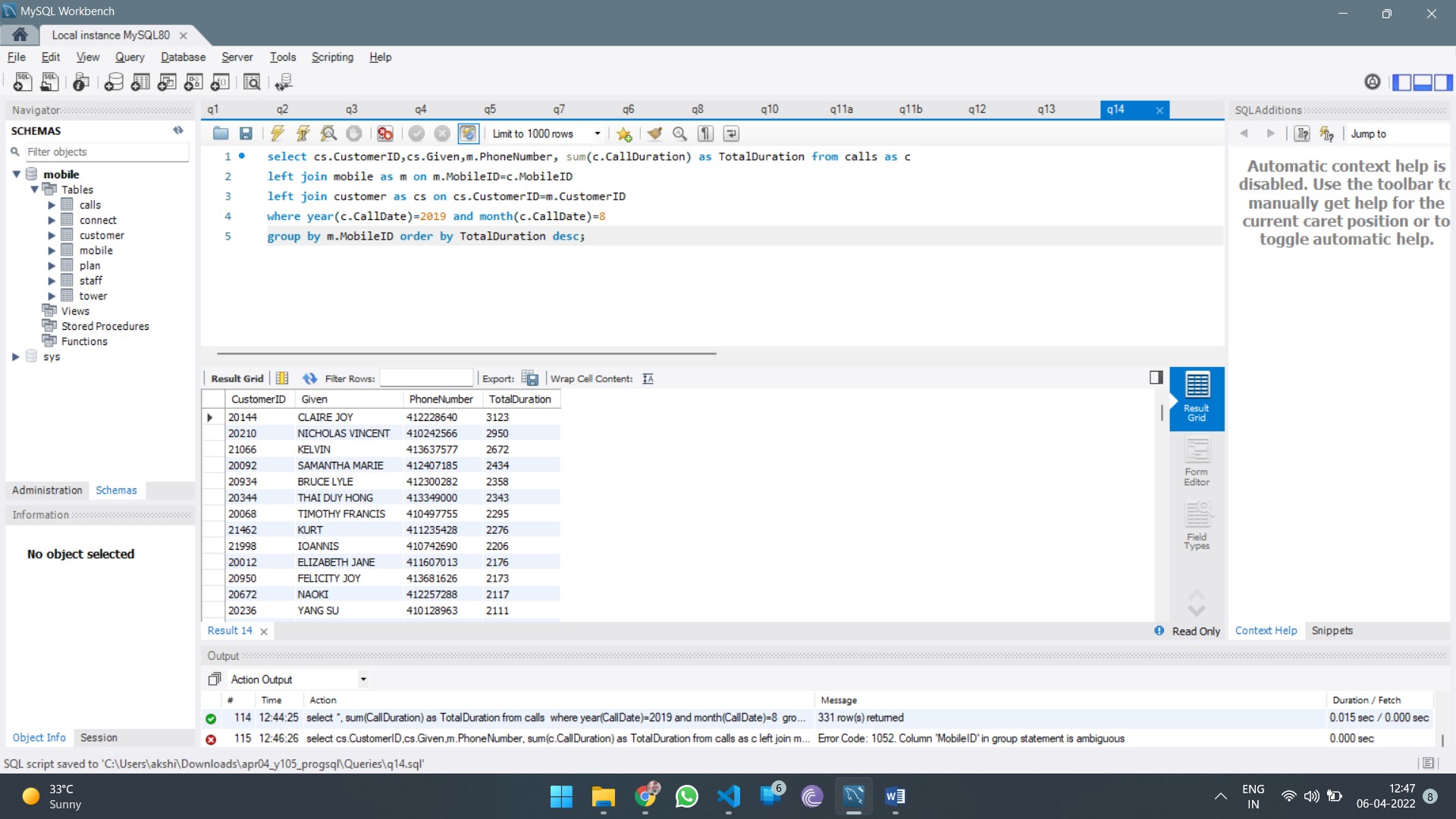
Q15a Create a view that shows the popularity of the plans based on number of plans sold.
create view popularity_of_plan as select PlanName, count(*) as TotalCount from mobile group by PlanName order by TotalCount desc;
Q15b Use this view in a query to determine the most popular plan.
select * from popularity_of_plan;
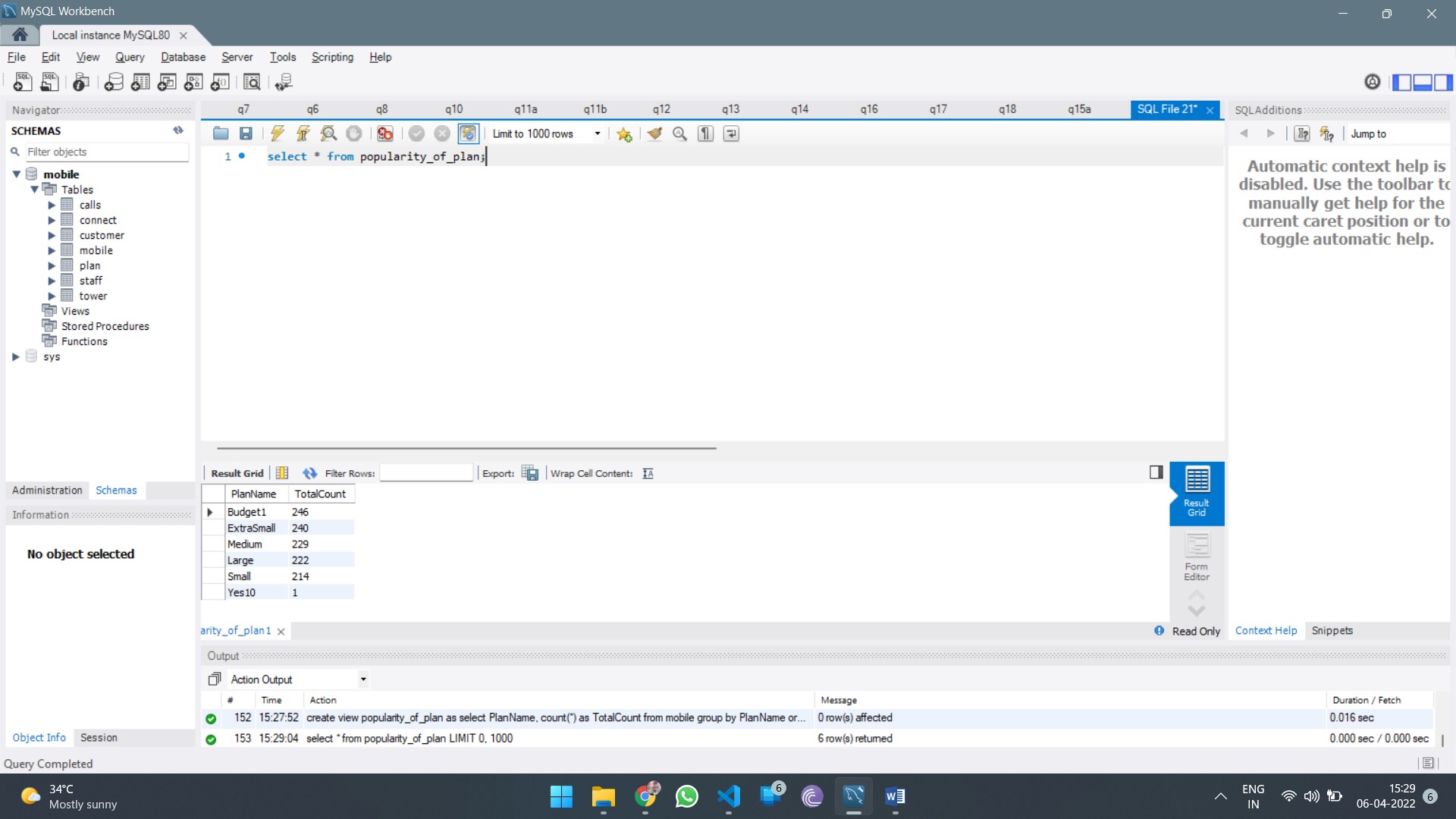
Q16 List all the plans and total number of active phones on each plan.
select PlanName, count(*) as 'Active phones' from mobile where Cancelled is null group by PlanName;
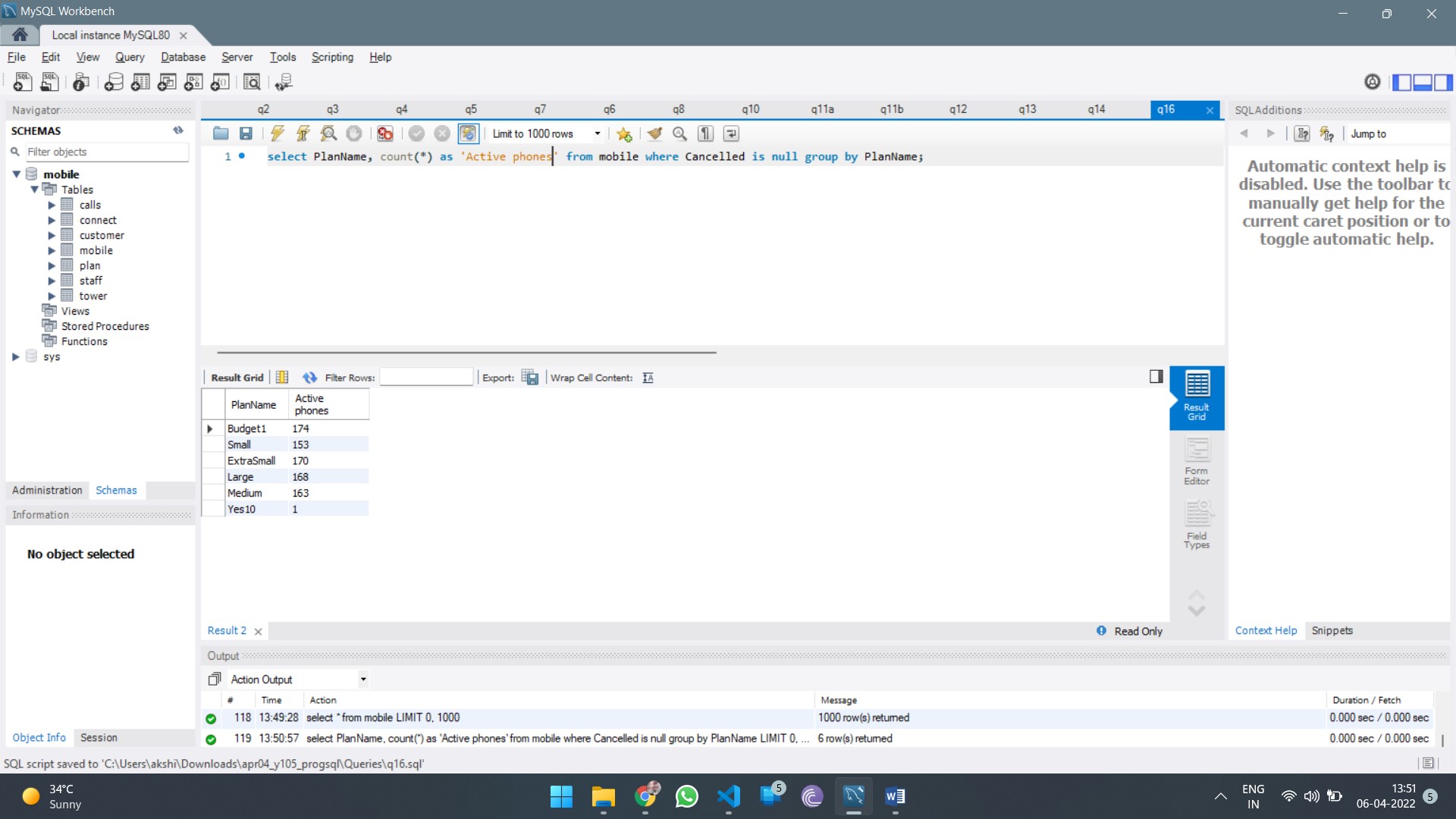
Q17 Write an SQL query to join all the seven tables presented in this database taking at least two columns from each table.
select cst.Given,cst.Sex, m.PhoneNumber, m.PhoneColour, s.RatePerHour,s.Joined, p.PlanName,p.CallCharge, cl.CallDuration,cl.CallTime, cn.ConnectID, cn.TowerID, t.Bandwidth, t.Location from customer as cst left join mobile as m on m.CustomerID=cst.CustomerID left join staff as s on s.StaffID=m.StaffID left join plan as p on p.PlanName=m.PlanName left join calls as cl on cl.MobileID=m.MobileID left join connect as cn on cn.CallsID=cl.CallsID left join tower as t on t.TowerID=cn.TowerID;
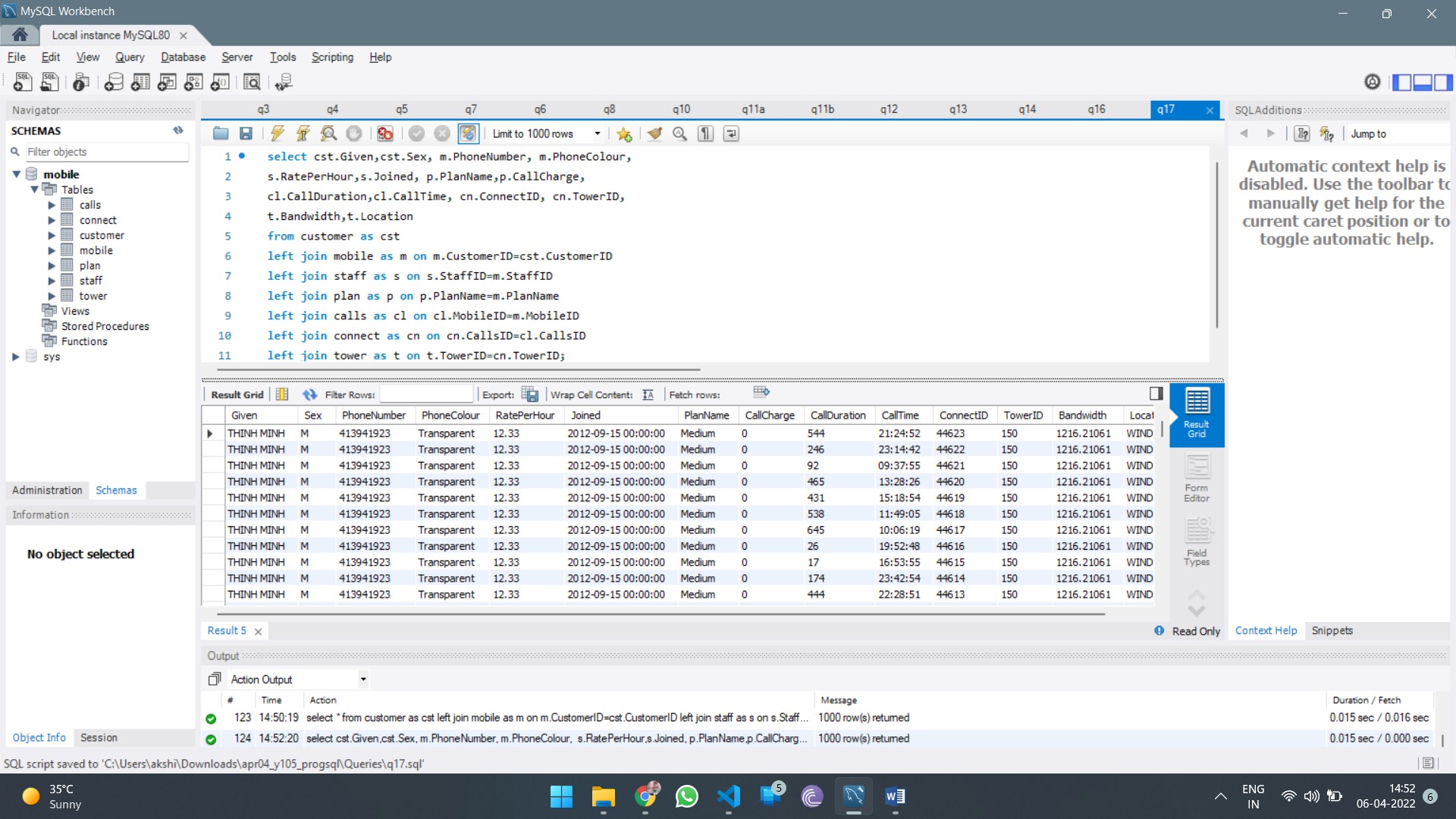
Q18 List the details of the youngest customer (CustomerId, name, dob, postcode) in postcode 3030 along with total time spent on calls in minutes. Assume call durations are in seconds.
select sum(CallDuration)/60 as 'Time Spend in calls' from calls where MobileID=(select mobile.MobileID from customer left join mobile on customer.CustomerID=mobile.CustomerID where Postcode=3030 order by DOB desc limit 1);
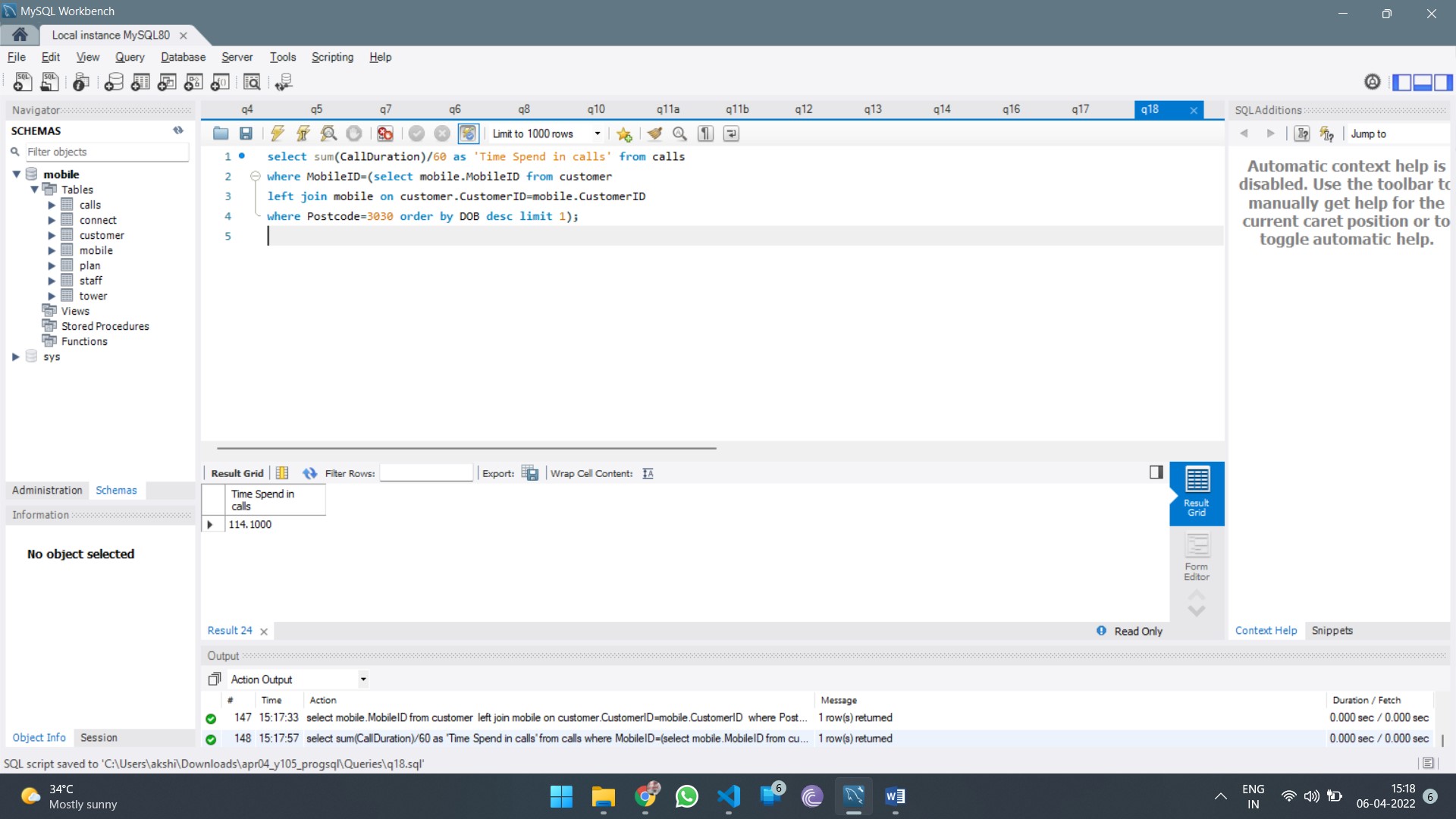
Q19 After evaluating all the tables, explain with reasons whether any of the tables violate the conditions of 3rd Normal Form.
Plan table has no unique identity if we want to change the name of the plan, we can’t change that because we are using primary key as plan name. We have to add primary key to plan table and use as foreign keys in other tables like mobile table.
Q20 In not more 200 words, explain at least two ways to improve this database based on what we have learned in 1st - 8 th Week.
We can combine surname field and given field as Name field in customer table and staff table. We don’t need date and time data type to DOB field, Joined field and Resigned field, use just date data type for those fields. Validate Phone field and Phonenumber field using only specific character in it. Remove data usage field from calls table. There is no use of data usage.

- Assignment - Child Care
- Assignment - Mathematics
- Assignment - Accounting
- Assignment - Auditing
- Assignment - Biology
- Assignment - Law
- Assignment - Management
- Assignment - Nursing
- Assignment - Finance
- Assignment - Computer Science and IT
- Assignment - Humanities
- Assignment - Economics
- Assignment - Statistics
- Assignment - Architecture
- Assignment - Engineering
- Assignment - cookery
- Assignment - Marketing
- Case Study - Chemistry
- Case Study - Accounting
- Case Study - Law
- Case Study - Management
- Case Study - Nursing
- Case Study - Finance
- Case Study - Computer Science and IT
- Case Study - Engineering
- Case Study - Economics
- Case Study - Biology
- Case Study - Auditing
- Case Study - Marketing
- Case Study - Project Management
- Coursework - Diploma
- Coursework - Accounting
- Coursework - Auditing
- Coursework - Biology
- Coursework - Management
- Coursework - Nursing
- Coursework - Finance
- Coursework - Computer Science and IT
- Coursework - Engineering
- Coursework - Humanities
- Coursework - Child Care
- Coursework - Project Management
- Coursework - Economics
- Coursework - Cookery
- Coursework - Law
- Dissertation - Accounting
- Dissertation - Auditing
- Dissertation - Biology
- Dissertation - Law
- Dissertation - Management
- Dissertation - Nursing
- Dissertation - Finance
- Dissertation - Computer Science and IT
- Dissertation - Humanities
- Dissertation - Economics
- Essay - Politics
- Essay - Childcare
- Essay - Accounting
- Essay - Biology
- Essay - Law
- Essay - Management
- Essay - Nursing
- Essay - Computer Science and IT
- Essay - Humanities
- Essay - Economics
- Essay - Auditing
- Essay - Engineering
- Essay - Architecture
- Essay - Finance
- Essay - Science
- Essay - Marketing
- Programming - Computer Science and IT
- Reports - Management
- Reports - Computer Science and IT
- Reports - Project Management
- Reports - Marketing
- Reports - Nursing
- Reports - Engineering
- Reports - Accounting
- Reports - Humanities
- Reports - Finance
- Reports - Architecture
- Reports - Biology
- Reports - Economics
- Reports - Childcare
- Reports - Law
- Research - Accounting
- Research - Auditing
- Research - Biology
- Research - Law
- Research - Management
- Research - Nursing
- Research - Finance
- Research - Computer Science and IT
- Research - Science
- Research - Engineering
- Research - Humanities
- Research - Economics
- Research - Project Management
- Research - Statistics
- Research - Architecture
- Research - Marketing
- Thesis Writing - Computer Science and IT
- Thesis Writing - Engineering
- Thesis Writing - Biology
- Thesis Writing - Finance
- Thesis Writing - Humanities
- Thesis Writing - Auditing
- Thesis Writing - Economics
- Thesis Writing - Law
- Thesis Writing - Nursing
- Thesis Writing - Accounting
- Thesis Writing - Architecture


.png)
~5.png)
.png)
~1.png)























































.png)






